

Feature Correlation-based Ground Fault Diagnosis Method for Main Circuit of Traction System
-
摘要:
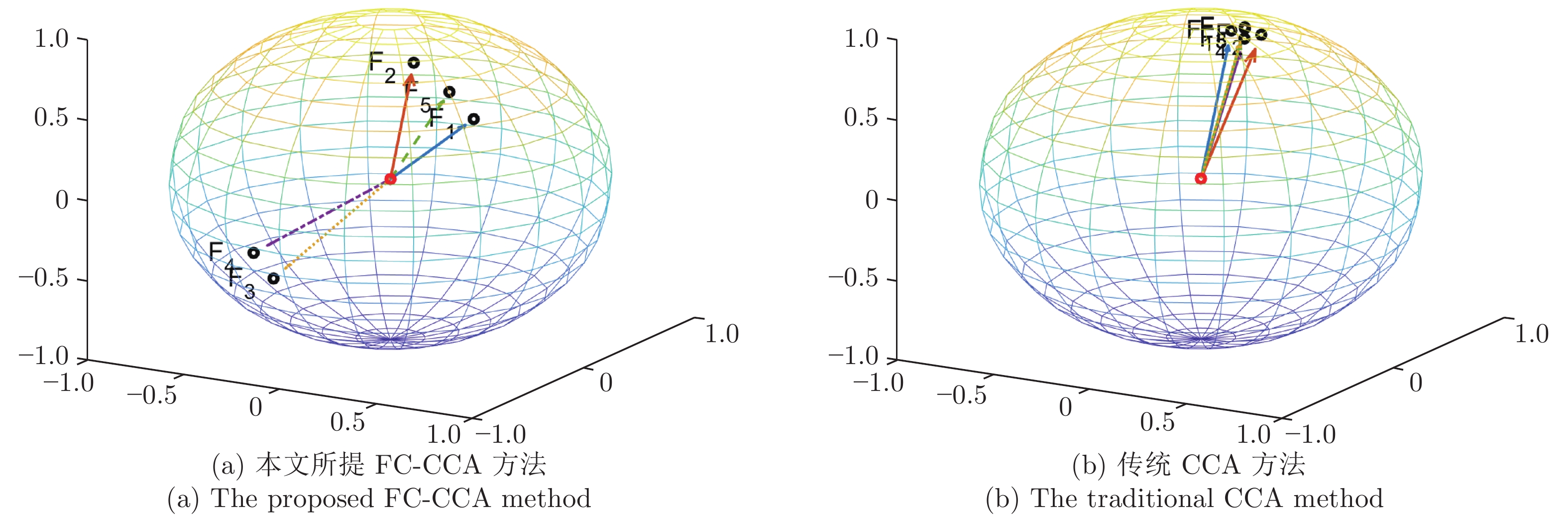
本文针对目前机车、动车牵引系统中主回路接地故障的精确定位问题, 提出了一种基于特征相关性的故障诊断方法. 该方法通过在线计算与故障关联的特征变量, 提取相关故障特征指标, 并考虑各故障特征指标间的相关性, 利用典型相关分析得到残差, 以实现快速故障检测. 进一步, 构建基于残差方向的故障隔离方法, 实现准确地故障定位. 现场实验表明, 与传统基于相关性的故障诊断方法以及实际工程应用方法相比, 在存在较大测量噪声与暂态工况变化时, 本文所提方法能实现更好的故障检测与隔离性能, 具有良好的应用价值.
Abstract:A fault diagnosis method based on feature correlation is proposed in this paper to accurately locate the main circuit ground fault in the traction system of electrical locomotive and electric multiple unit (EMU). The characteristic variables and fault features associated with faults are calculated online, and canonical correlation analysis (CCA) is carried out to generate residual signal based on the correlation among the fault features to achieve fast fault detection. Accurate fault location is achieved based on the residual signal direction method. Field tests show that, compared with traditional CCA-based and on-board fault detection method, the proposed method has better fault detection and isolation performance in the presence of large measurement noise and transient condition changes and is also applicable to practice.
-
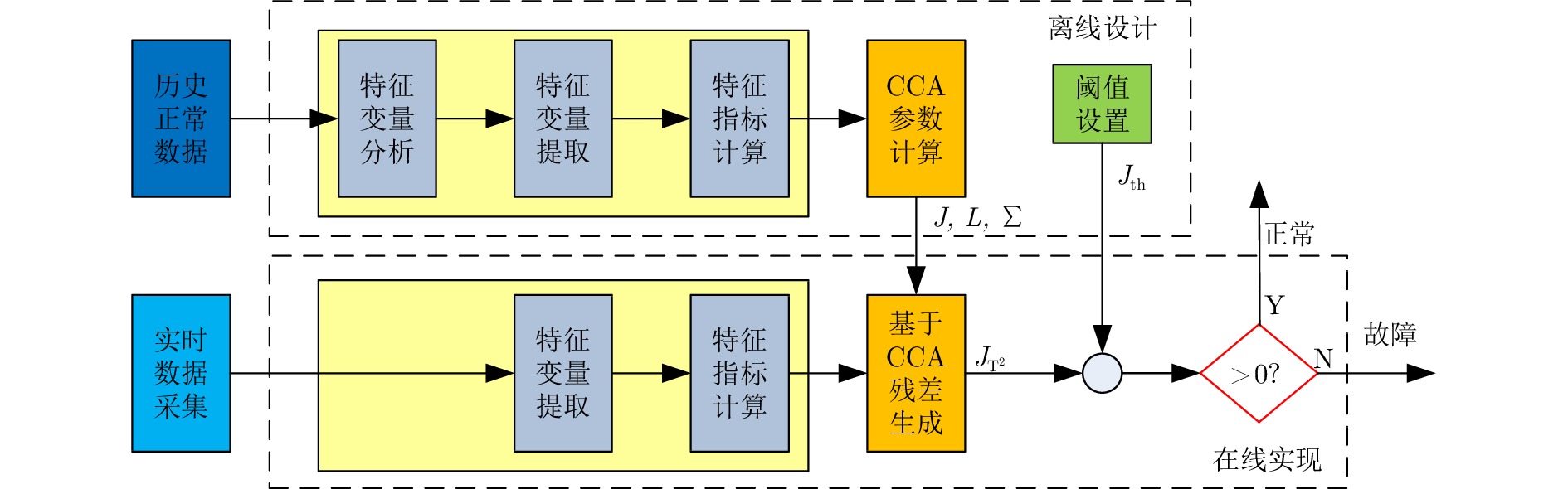
图 3 基于特征相关性的故障检测算法流程图
Fig. 3 Flowchart of the feature correlation-based fault detection algorithm
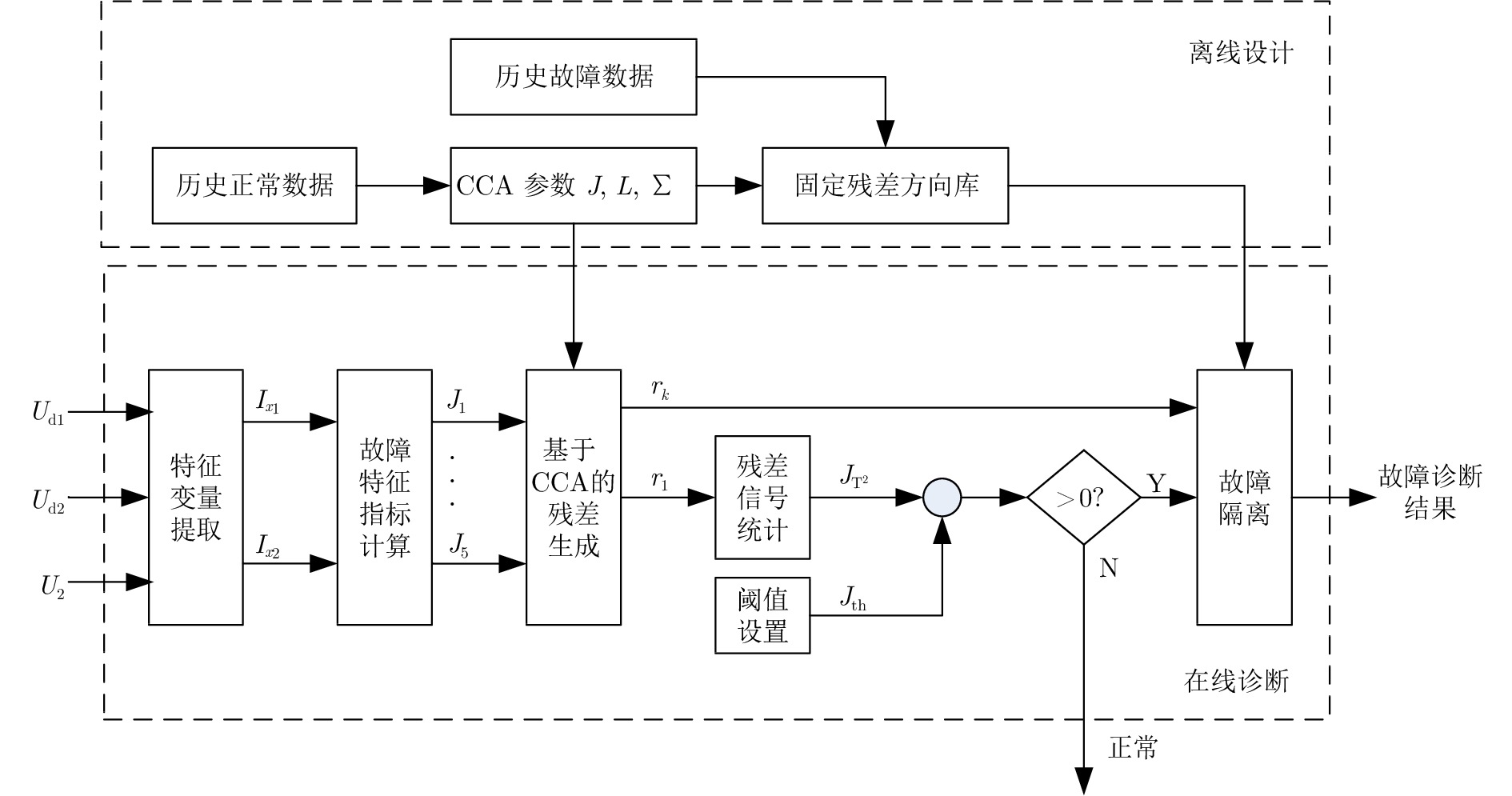
图 4 基于特征相关性的牵引主回路接地故障诊断算法原理框图
Fig. 4 Diagram of the feature correlation-based fault diagnosis algorithm for main circuit of the traction system
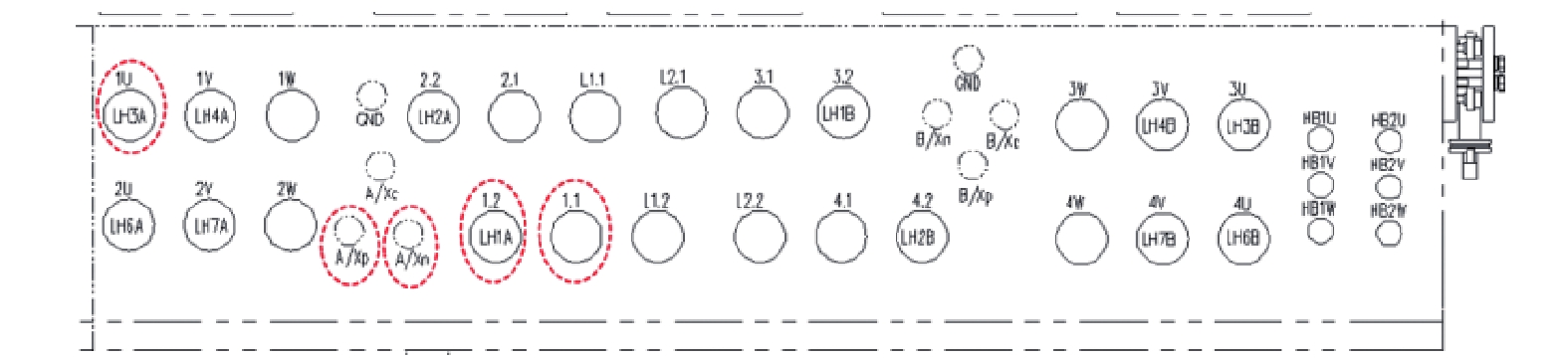
图 6 牵引变流器对外连接端子布置图
Fig. 6 Layout diagram of connection terminals under traction converter cabinet
表 2 不同接地故障类型时故障特征变量
$ I_{x1} $ 变化规律Table 2 The change rules of
$ I_{x1} $ with different ground faults under working condition C5故障类型 $ I_{x1} $变化规律 $ I_{x1} $相关指标 F1 其值在−0.5$ {\bar U_{s1}} $与0.5$ {\bar U_{s1}} $间变化, 均值, 方差, 最大值, 最大峰值 F2 且频率与四象限模块开关频率相同 F3 其值约为−0.5$ {\bar U_{s1}} $ F4 其值约为0.5$ {\bar U_{s1}} $ F5 其值在−0.5$ {\bar U_{s1}} $与0.5$ {\bar U_{s1}} $间变化,
且频率与逆变模块开关频率相同 下载: 导出CSV
下载: 导出CSV
表 3 不同接地故障类型时故障特征变量
$ I_{x2} $ 变化规律(工况5)Table 3 The change rules of
$ I_{x2} $ with different ground faults under work condition C5故障类型 $ I_{x2} $变化规律 $ I_{x2} $相关时域指标 F1 $ I_{x2} $均值小于一定门槛值 (负值) F2 $ I_{x2} $均值大于一定门槛值 (正值) 均值 F5 $ I_{x2} $均值约为 0
下载: 导出CSV
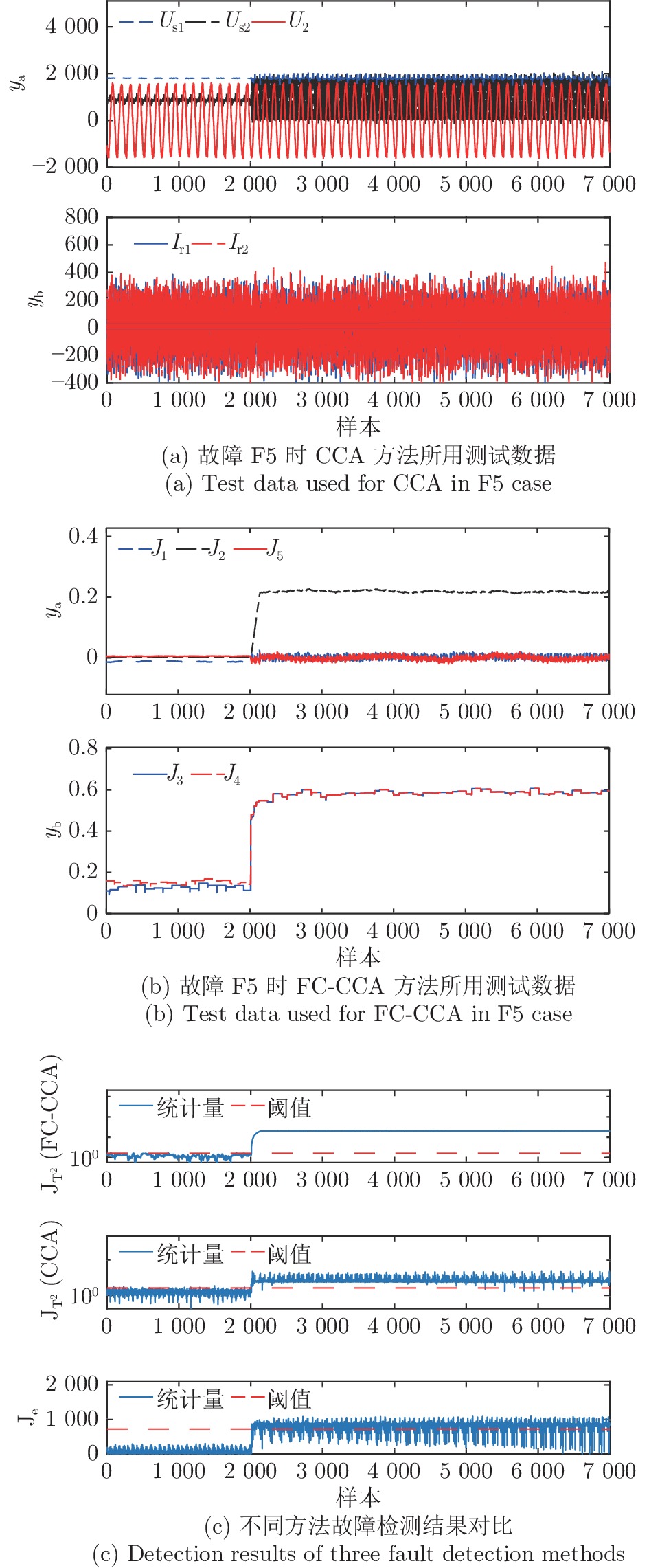
表 4 算法对比验证所采用数据
Table 4 Test data for comparing and verifying algorithms
序号 y 本文所提的FC-CCA方法 基于原始数据的CCA方法 指标/变量 含义 指标/变量 含义 1 $ y_a $ $ J_1 $ $ I_{x1} $均值 $ U_{s1} $ 中间直流电压 2 $ y_a $ $ J_2 $ $ I_{x1} $方差 $ U_{s2} $ 半中间电压 3 $ y_a $ $ J_5 $ $ I_{x2} $均值 $ U_2 $ 牵引变压器次边电压 4 $ y_b $ $ J_3 $ $ I_{x1} $最大值 $ I_{r1} $ 四象限一输入电流 5 $ y_b $ $ J_4 $ $ I_{x1} $最大峰值 $ I_{r2} $ 四象限二输入电流
下载: 导出CSV
表 5 不同故障类型时测量值变化情况说明
Table 5 Description of changes in measured in different fault types
故障类型 可检测工况 C3 C4 C5 F1 √ √ √ F2 √ √ √ F3 √ √ √ F4 √ √ √ F5 × × √
下载: 导出CSV
表 6 不同故障类型时FDR与CIR结果对比
Table 6 Comparison results of FDR and CIR in different fault types
故障代号 故障检测率(FDR) 正确隔离率(CIR) FC-CCA
方法CCA
方法传统工程
方法FC-CCA
方法CCA
方法传统工程
方法F1 100% 99.99% 64.09% 100% 27.48% 0% F2 100% 100% 79.74% 100% 14.44% 0% F3 100% 100% 100% 100% 61.12% 0% F4 100% 100% 79.03% 100% 21.93% 0% F5 99.84% 99.68% 94.16% 99.32% 1.42% 0%
下载: 导出CSV
-
[1] 2018年中国轨道交通行业分析报告—市场运营态势与发展前景预测. 中国报告网, http://baogao.chinabaogao.com/yunshufuzhusheshi/342590342590.html. [2] Dong H. R, Ning B, Cai B. G, Hou Z. Automatic train control system development and simulation for high-speed railways. IEEE Circuits & Systems Magazine, 2010, 10(2): 6−18 [3] 周东华, 纪洪泉, 何潇. 高速列车信息控制系统的故障诊断技术. 自动化学报, 2018, 44(7): 1153−1164Zhou Dong-Hua, Ji Hong-Quan, He Xiao. Fault diagnosis techniques for the information control system of high-speed trains. Acta Automatica Sinica, 2018, 44(7): 1153−1164 [4] 杨超, 彭涛, 阳春华, 陈志文, 桂卫华. 高速列车牵引传动系统故障测试与验证仿真平台研究综述. 自动化学报, 2019, 47(12): 2218−2232Yang Chao, Peng Tao, Yang Chun-Hua, Chen Zhi-Wen, Gui Wei-Hua. Review of fault testing and its validation simulation platform for traction drive system of high-speed trains. Acta Automatica Sinica, 2019, 47(12): 2218−2232 [5] Chen H. T, Jiang B. A review of fault detection and diagnosis for the traction system in high-speed trains. IEEE Transactions on Intelligent Transportation Systems, 2019: 1−16 [6] 陶宏伟, 彭涛, 杨超, 阳春华, 陈志文, 桂卫华. 高速列车牵引整流器多类故障联合诊断方法. 自动化学报, 2019, 45(12): 2294−2302Tao Hong-Wei, Peng Tao, Yang Chao, Yang Chun-Hua, Chen Zhi-Wen, Gui Wei-Hua. Joint fault diagnosis method of multiclass faults for traction rectififier in high-speed train. Acta Automatica Sinica, 2019, 45(12): 2294−2302 [7] 刘强, 方彤, 董一凝, 秦泗钊. 基于动态建模与重构的列车轴承故障检测和定位. 自动化学报, 2019, 45(12): 2233−2241Liu Qiang, Fang Tong, Dong Yi-Ning, Qin S. Joe. Dynamic modeling and reconstruction based fault detection and location of train bearings. Acta Automatica Sinica, 2019, 45(12): 2233−2241 [8] 田光兴, 郝凤荣, 代兴军. HXD3系列电力机车接地方式及接地故障检测环节探析. 铁道机车与动车, 2016, 5: 27−33 doi: 10.3969/j.issn.1003-1820.2016.02.009Tian Guang-Xing, Hao Feng-Rong, Dai Xing-Jun. Discussion on grounding mode and ground fault detection circuit of HXD3 serial electric locomotive. Railway Locomotive and Motor Car, 2016, 5: 27−33 doi: 10.3969/j.issn.1003-1820.2016.02.009 [9] El-Sherif N. Ground fault protection − all you need to know. IEEE Transactions on Industry Applications, 2017, 53(6): 6047−6056 doi: 10.1109/TIA.2017.2746558 [10] RumMdkarn J, Ngaopitakkul A. Behavior analysis of winding to ground fault in transformer using high and low frequency components from discrete wavelet transform. In: Proceedings of International conference on applied system innovation, Sapporo, Japan, 2017: 13−17 [11] Gruhn T, Glenney J, Savostianik M. Type B ground-fault protection on adjustable frequency drives. IEEE Transactions on Industry Applications, 2017, 54(1): 934−939 [12] Wei L, Liu Z, Kerkman R. J, Skibinski G. L. Identifying ground-fault locations: Using adjustable speed drives in high-resistance grounded systems. IEEE Industry Applications Magazine, 2013, 19(2): 47−55 [13] Hu J, Wei L, McGuire J, Liu Z. Ground fault location self-diagnosis in high resistance grounding drive systems. In: Proceedings of IEEE Energy Conversion Congress and Exposition, Pittsburgh, PA, USA, 2014: 3179−3185 [14] Hu J, Wei L, McGuire J, Liu Z. Flux linkage detection based ground fault identification and system diagnosis in high-resistance grounding systems. IEEE Transactions on Industry Applications, 2016, 53(3): 2967−2975 [15] 李伟, 郭晓燕, 张波. “和谐”系列电力机车传动系统接地检测比较. 机车电传动, 2010, 6: 67−69Li Wei, Guo Xiao-Yan, Zhang Bo. Comparisons of HXD serial locomotives drive system grounding detection. Electric Drive for Locomotives, 2010, 6: 67−69 [16] 徐培刚, 彭军华, 罗铁军. HXD1C型机车主回路接地故障分析. 机车电传动, 2013, 36: 103−107Xu Pei-Gang, Peng Jun-Hua, Luo Tie-Jun. Analysis on main circuit ground fault of HXD1C locomotive. Electric Drive for Locomotives, 2013, 36: 103−107 [17] 陈立胜, 颜罡. 交流传动电力机车主电路接地故障的检测、定位及对策分析. 电力机车与城轨车辆, 2013, 36(3): 84−86Chen Li-Sheng, Yan Gang. Location and countermeasure analysis of main circuit grounding fault of AC drive electric locomotive. Electric Locomotives & Mass Transit Vehicles, 2013, 36(3): 84−86 [18] 李耘笼, 刘可安. DJJ2型动力车主接地故障分析. 电力机车与城轨车辆, 2005, 28(2): 54−55Li Geng-Long, Liu Ke-An. Ground fault analysis on main circuit for power car with type DJJ2. Electric Locomotives & Mass Transit Vehicles, 2005, 28(2): 54−55 [19] Liu Y, Liu B, Zhao X, Xie M. A mixture of variational canonical correlation analysis for nonlinear and quality-relevant process monitoring. IEEE Transactions on Industrial Electronics, 2018, 65(8): 6478−6486 doi: 10.1109/TIE.2017.2786253 [20] Chen Z. W, Ding S. X, Peng T, Yang C. H, Gui W. H. Fault detection for non-Gaussian processes using generalized correlation analysis and randomized algorithms. IEEE Transactions on Industrial Electronics, 2018, 65(2): 1559−1567 doi: 10.1109/TIE.2017.2733501 [21] Zhang K, Peng K. X, Ding S. X, Chen Z. W, Yang X. A correlation-based distributed fault detection method and its application to a hot tandem rolling mill process. IEEE Transactions on Industrial Electronics, 2019, 67(3): 2380−2390 doi: 10.1109/TIE.2019.2901565 [22] Chen Z. W, Li X. M, Yang C, Peng T, Yang C. H, Karimi H, Gui W. H. A data-driven ground fault detection and isolation method for main circuit in railway electrical traction system. ISA Transactions, 2019, 87: 264−271 doi: 10.1016/j.isatra.2018.11.031 [23] Anderson T. An Introduction to Multivariate Statistical Analysis. Second Edition. New York: John Wiley and Sons, LTD: 1984 [24] Gustafsson F. Statistical signal processing approaches to fault detection. Annual Reviews in Control, 2006, 31(1): 41−54 [25] He Z. M, Chen Z. W, Zhou H. Y, Wang D. Y, Xing Y, Wang J. Q. A visualization approach for unknown fault diagnosis. Chemometrics and Intelligent Laboratory Systems, 2018, 172: 80−89 doi: 10.1016/j.chemolab.2017.11.013 -

 下载:
下载:









计量
- 文章访问数: 1670
- HTML全文浏览量: 730
- PDF下载量: 269
- 被引次数: 0
