

No Reference Video Quality Objective Assessment Based on Multilayer BP Neural Network
-
摘要: 机器学习在视频质量评价(Video quality assessment, VQA)模型回归方面具有较大的优势, 能够较大地提高构建模型的精度. 基于此, 设计了合理的多层BP神经网络, 并以提取的失真视频的内容特征、编解码失真特征、传输失真特征及其视觉感知效应特征参数为输入, 通过构建的数据库中的样本对其进行训练学习, 构建了一个无参考VQA模型. 在模型构建中, 首先采用图像的亮度和色度及其视觉感知、图像的灰度梯度期望值、图像的模糊程度、局部对比度、运动矢量及其视觉感知、场景切换特征、比特率、初始时延、单次中断时延、中断频率和中断平均时长共11个特征, 来描述影响视频质量的4个主要方面, 并对建立的两个视频数据库中的大量视频样本, 提取其特征参数; 再以该特征参数作为输入, 对设计的多层BP神经网络进行训练, 从而构建VQA模型; 最后, 对所提模型进行测试, 同时与14种现有的VQA模型进行对比分析, 研究其精度、复杂性和泛化性能. 实验结果表明: 所提模型的精度明显高于其14种现有模型的精度, 其最低高出幅度为4.34 %; 且优于该14种模型的泛化性能, 同时复杂性处于该15种模型中的中间水平. 综合分析所提模型的精度、泛化性能和复杂性表明, 所提模型是一种较好的基于机器学习的VQA模型.Abstract: Machine learning has a great advantage in the regression of video quality assessment (VQA) model and can greatly improve the accuracy of built model. To this end, a reasonable BP neural network is designed, and taking the feature values of the distorted video contents, code and decode distortion, transmission distortion, and visual perception effect as inputs, a no reference VQA model is constructed by training them with the samples of the built video databases. In modeling, firstly, 11 features are used to describe the four main factors that affect video quality, which are the brightness and chroma of image and their visual perception, the gray gradient expectation of image, the blur degree of image, the local contrast, the motion vectors and their visual perception, the scene switching feature, the bitrate, the initial delay, the single interrupt delay, the interrupt frequency and the average time of interrupt. And the feature parameters of a large number of video samples in the two video databases established are extracted. Then by using these feature parameters as inputs, the BP neural network is trained to construct our VQA model. Finally, the proposed model is tested and compared with 14 existing VQA models to study its accuracy, complexity and generalization performance. The experimental results show that the accuracy of the proposed model is significantly higher than those of 14 existing models, and the lowest increase was 4.34%. And in the generalization performance, it is better than 14 models. Moreover, the complexity of the proposed model is at the intermediate in the 15 VQA methods. Comprehensively analyzing the accuracy, generalization performance and complexity of the proposed model, it is shown that it is a good VQA model based on machine learning.
-
Key words:
- Video quality evaluation /
- neural networks /
- delay /
- video contents
1) 收稿日期 2019-07-19 录用日期 2019-09-24 Manuscript received July 19, 2019; accepted September 24, 2019 国家自然科学基金(61301237), 江苏省自然科学基金面上项目(BK20201468), 南京工程学院高层次引进人才基金(YKJ201981)和西安交通大学博士后基金(2018M633512)资助 Supported by National Natural Science Foundation of China (61301237), Natural Science Foundation of Jiangsu Province, China (BK20201468), Scientific Research Foundation for Advanced Talents, Nanjing Institute of Technology (YKJ201981),2) and Postdoctoral Science Foundation of Xi' an Jiaotong University (2018M633512) 本文责任编委 黄庆明 Recommended by Associate Editor HUANG Qing-Ming 1. 南京工程学院计算机工程学院 南京 211167 2. 西安交通大学电子与信息工程学院 西安 710049 1. School of Computer Engineering, Nanjing Institute of Technology, Nanjing 211167 2. School of Electronic and Information Engineering, Xi' an Jiaotong University, Xi' an 710049 -
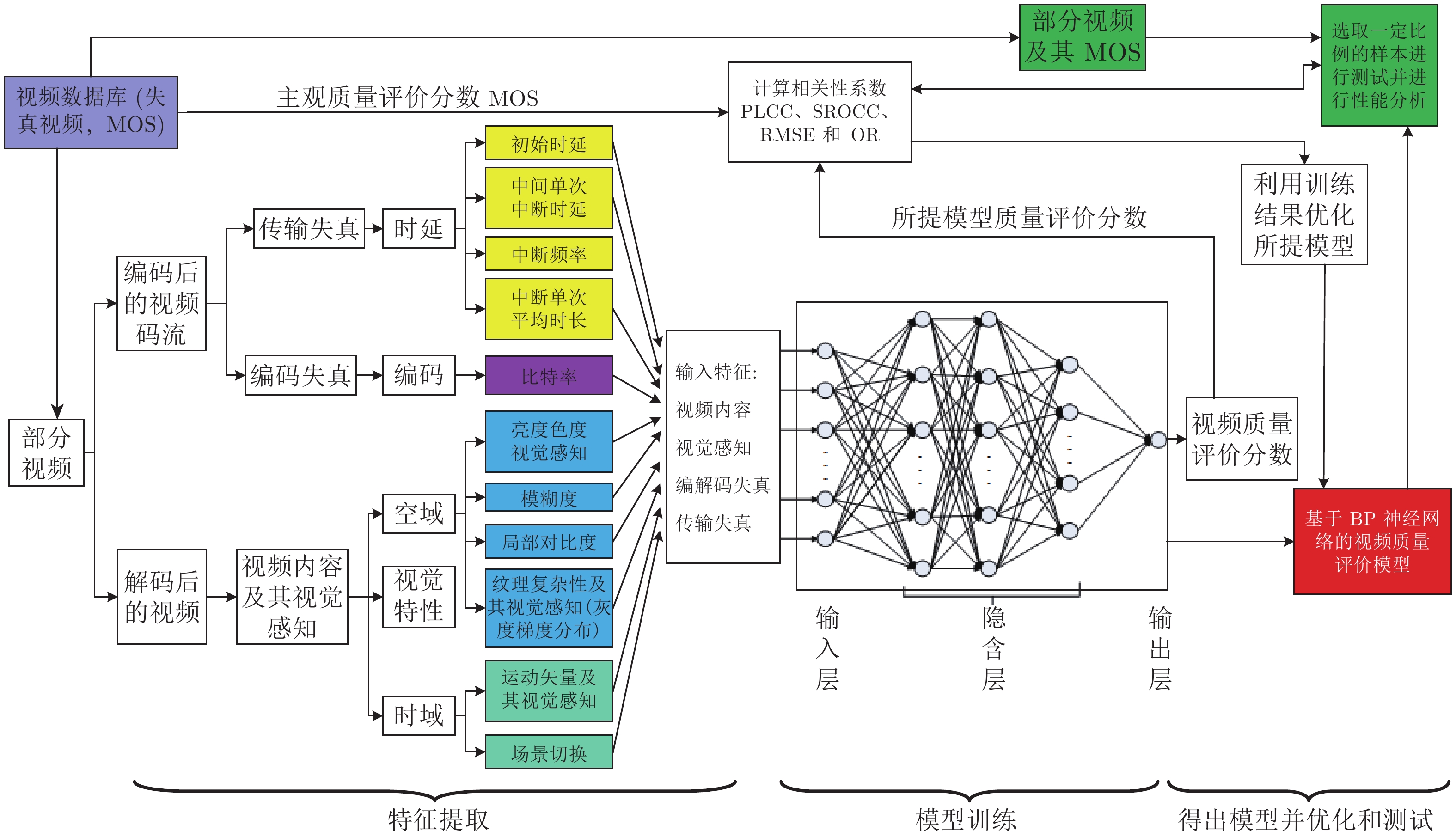
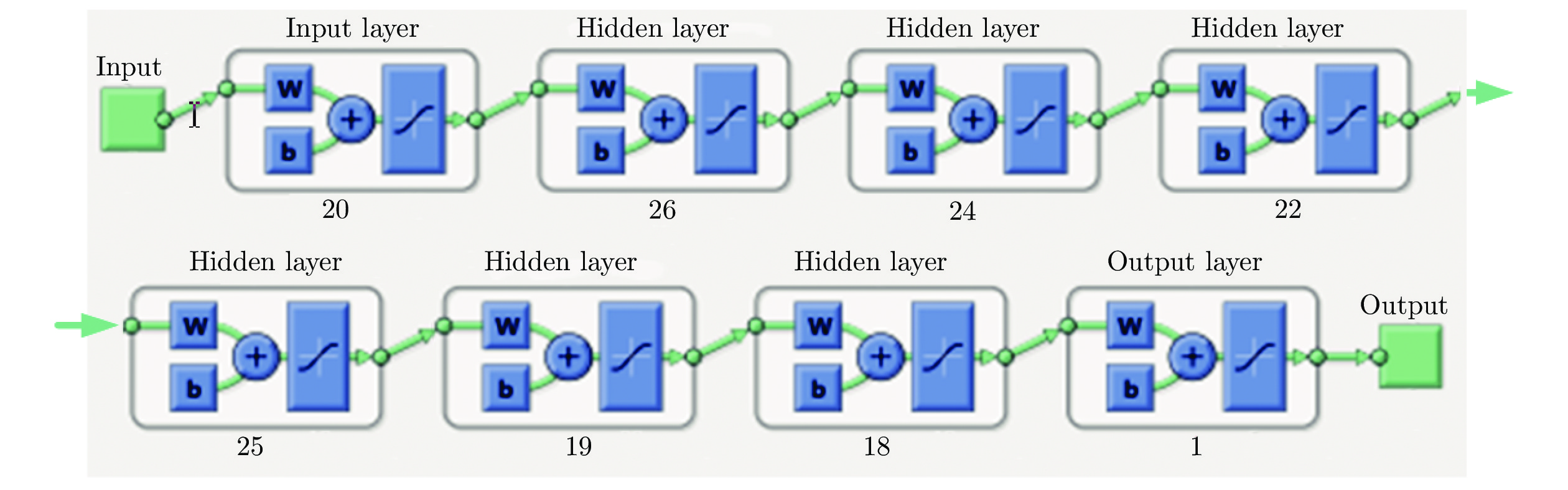
图 1 基于多层BP神经网络的无参考视频质量客观评价方法流程图
Fig. 1 Flow chart of no reference video quality objective evaluation method based on multilayer BP neural network
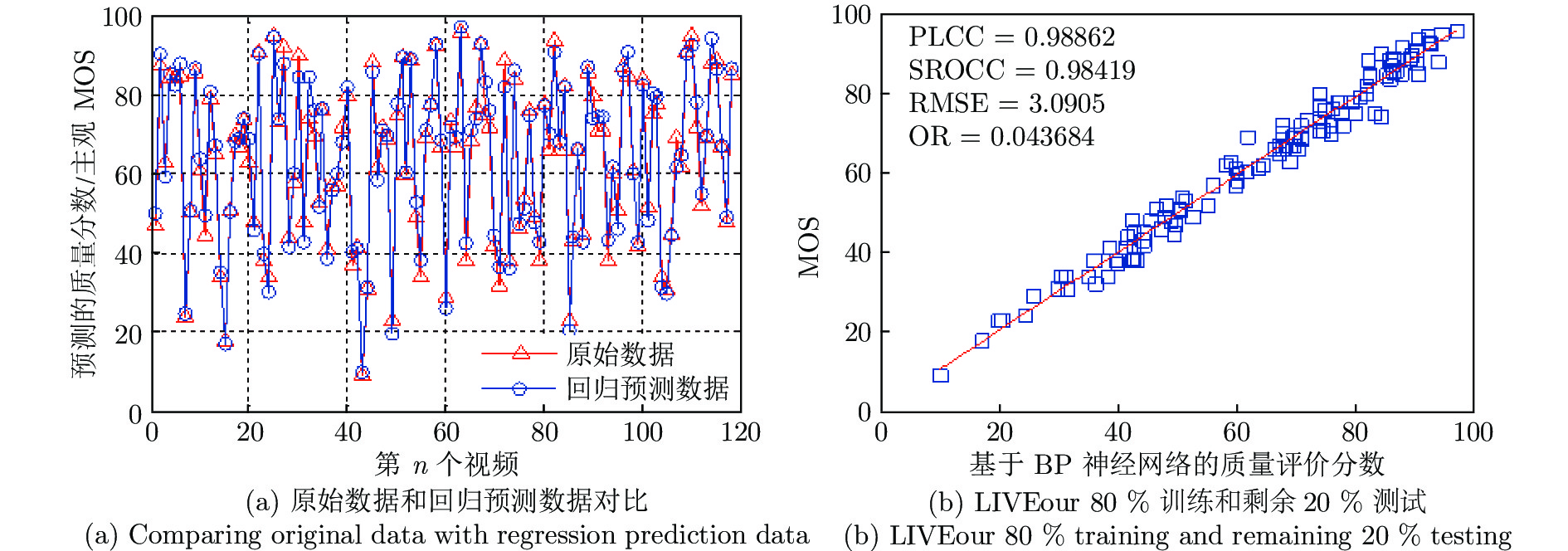
图 3 LIVEour数据库中(80 %训练, 20 %测试)实验结果
Fig. 3 Experimental results in LIVEour database (80 % training, 20 % testing)

图 4 VIPSLour数据库中(80 %训练, 20 %测试)实验结果
Fig. 4 Experimental results in VIPSLour database (80 % training, 20 % testing)
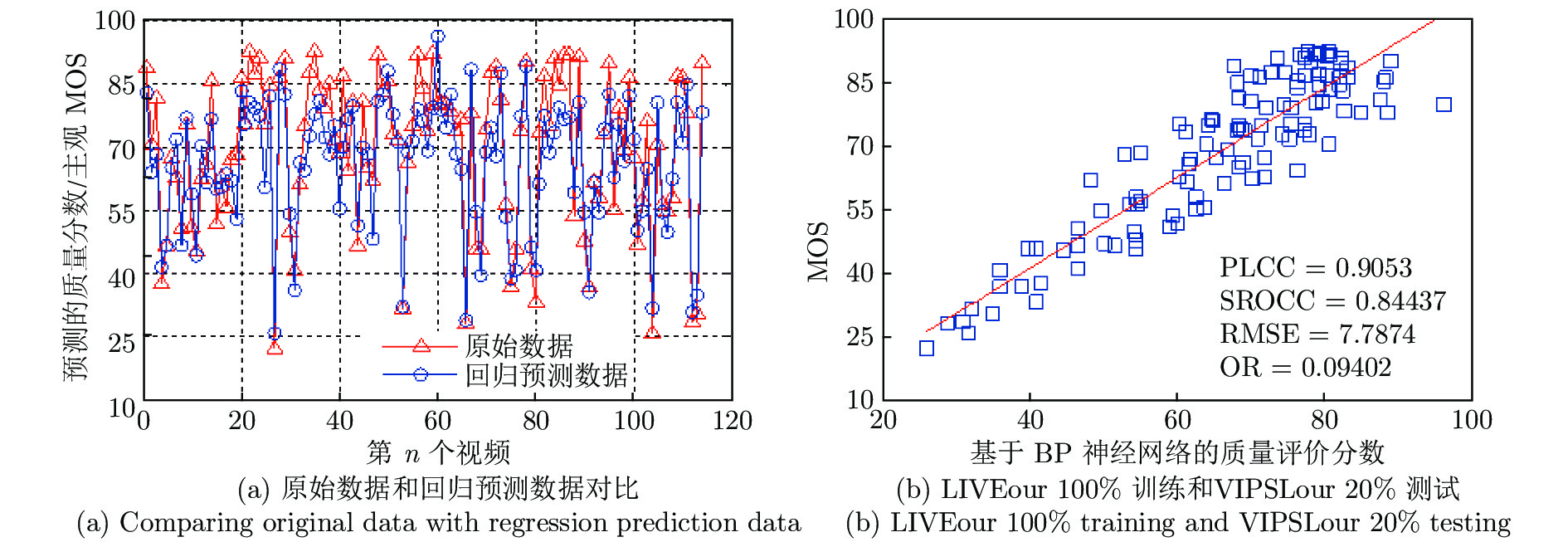
图 5 LIVEour 100 %训练和VIPSLour 20 %测试的实验结果
Fig. 5 Experimental results from training by 100 % samples in LIVEour and testing 20 % samples in VIPSLour
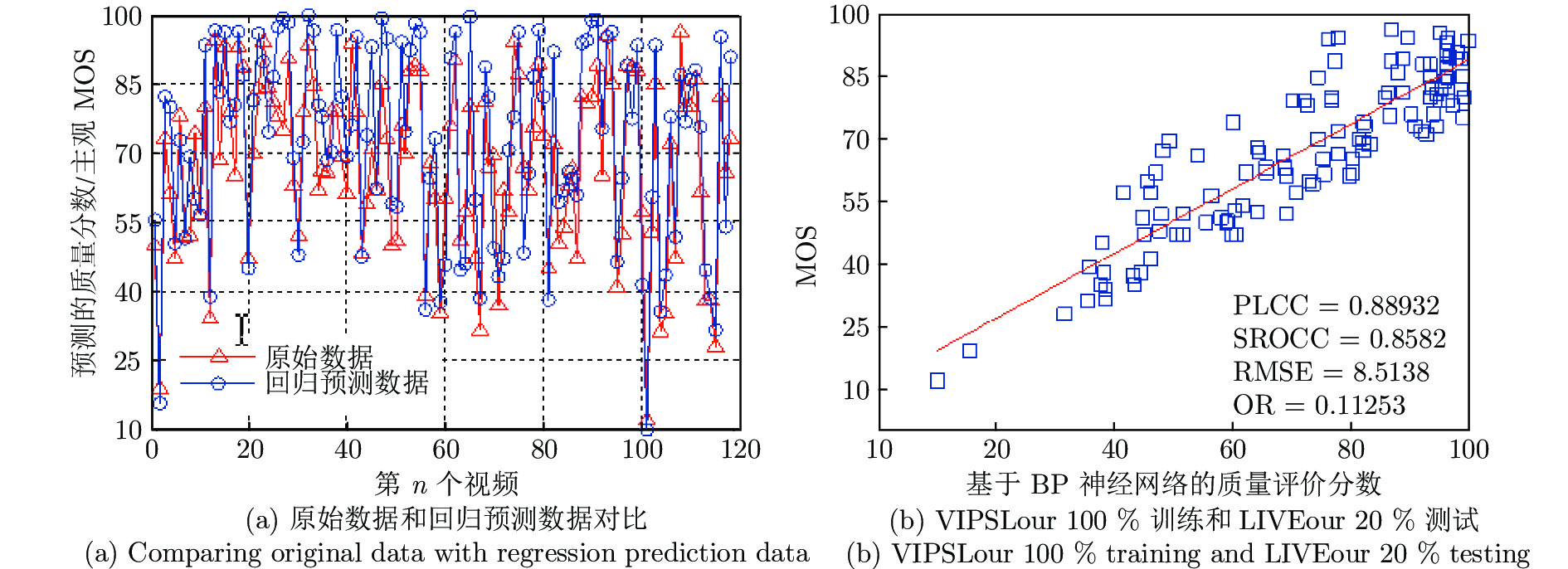
图 6 VIPSLour中训练(100 %样本) LIVEour中测试(20 %样本)的实验结果
Fig. 6 Experimental results from training by 100 % samples in VIPSLour database and testing 20 % samples in LIVEour database
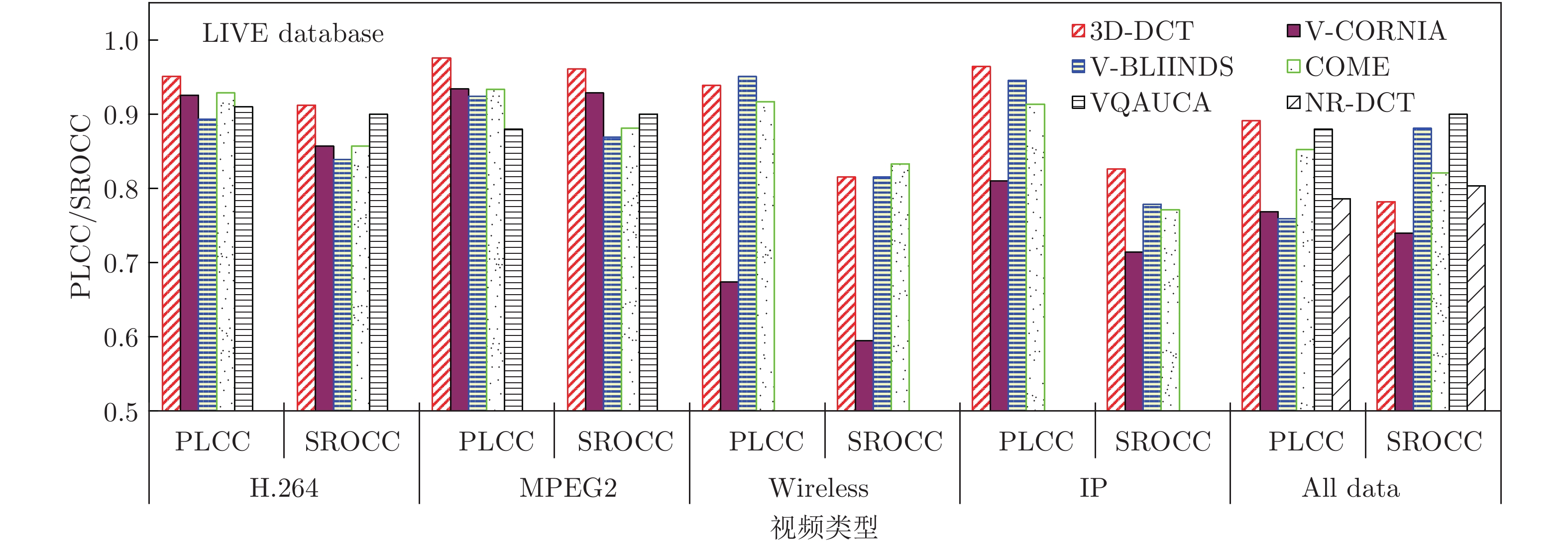
图 7 采用现有6种基于机器学习的VQA模型评价结果的PLCC和SROCC
Fig. 7 PLCC and SROCC of VQA results with 6 existing models based on machine learning
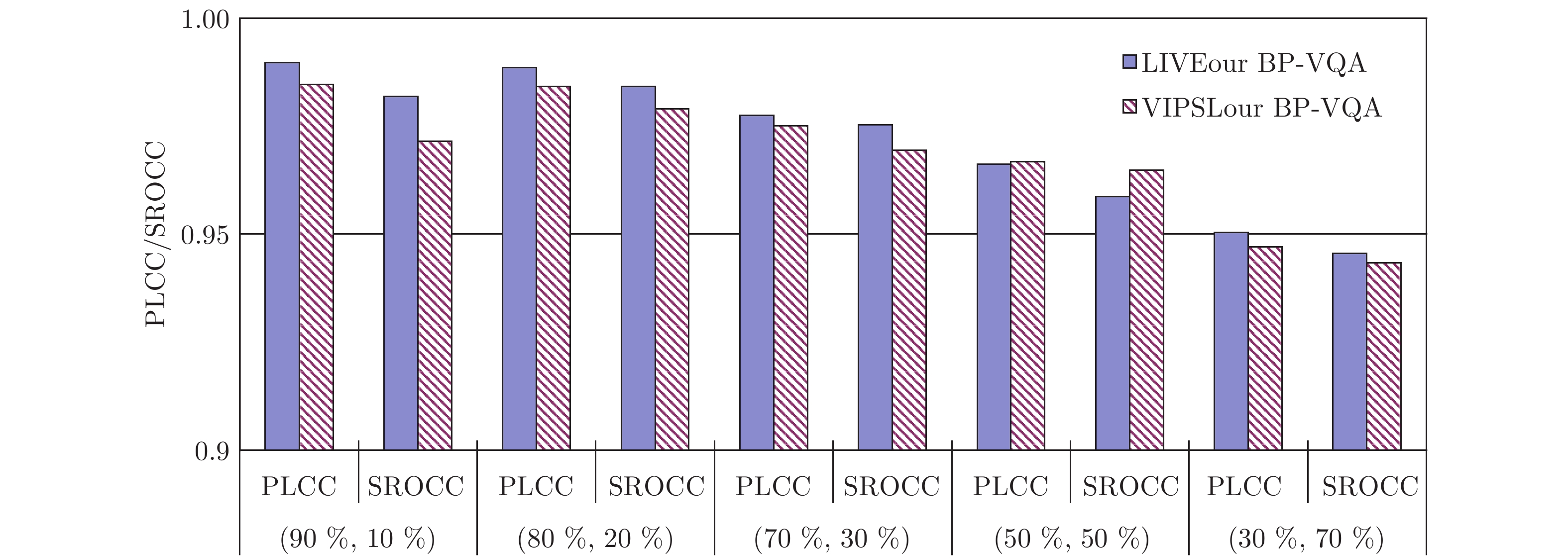
图 8 不同训练和测试样本比例下采用所提BP-VQA模型评价结果的PLCC和SROCC
Fig. 8 PLCC and SROCC from applying the proposed BP-VQA model to evaluate video quality under different training and test sample ratios
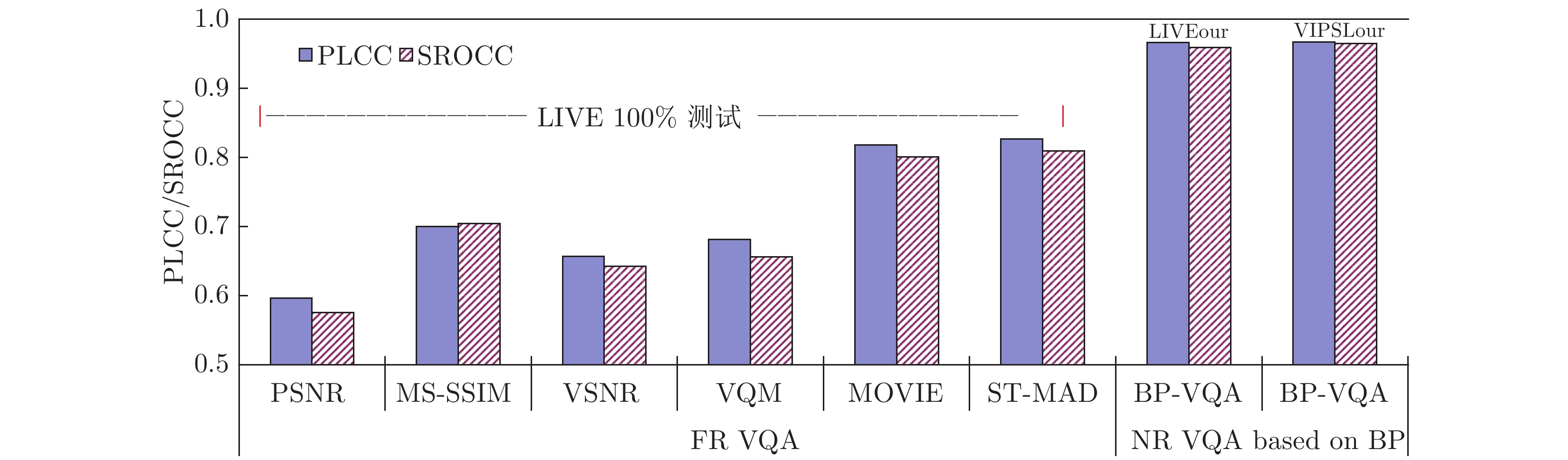
图 9 所提BP-VQA模型与6种现有FR-VQA模型的精度对比
Fig. 9 Accuracy comparison between the proposed BP-VQA model and six existing FR-VQA models
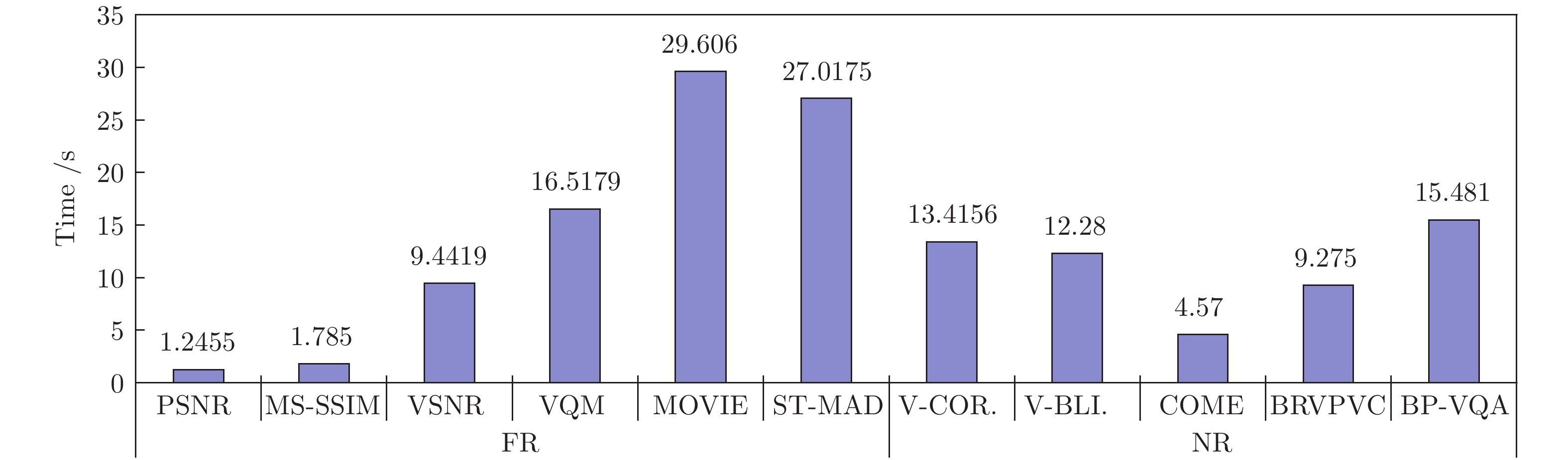
图 10 所提模型与10种现有VQA模型的运算耗时对比
Fig. 10 Comparisons of the computational time between the proposed model and 10 existing VQA models
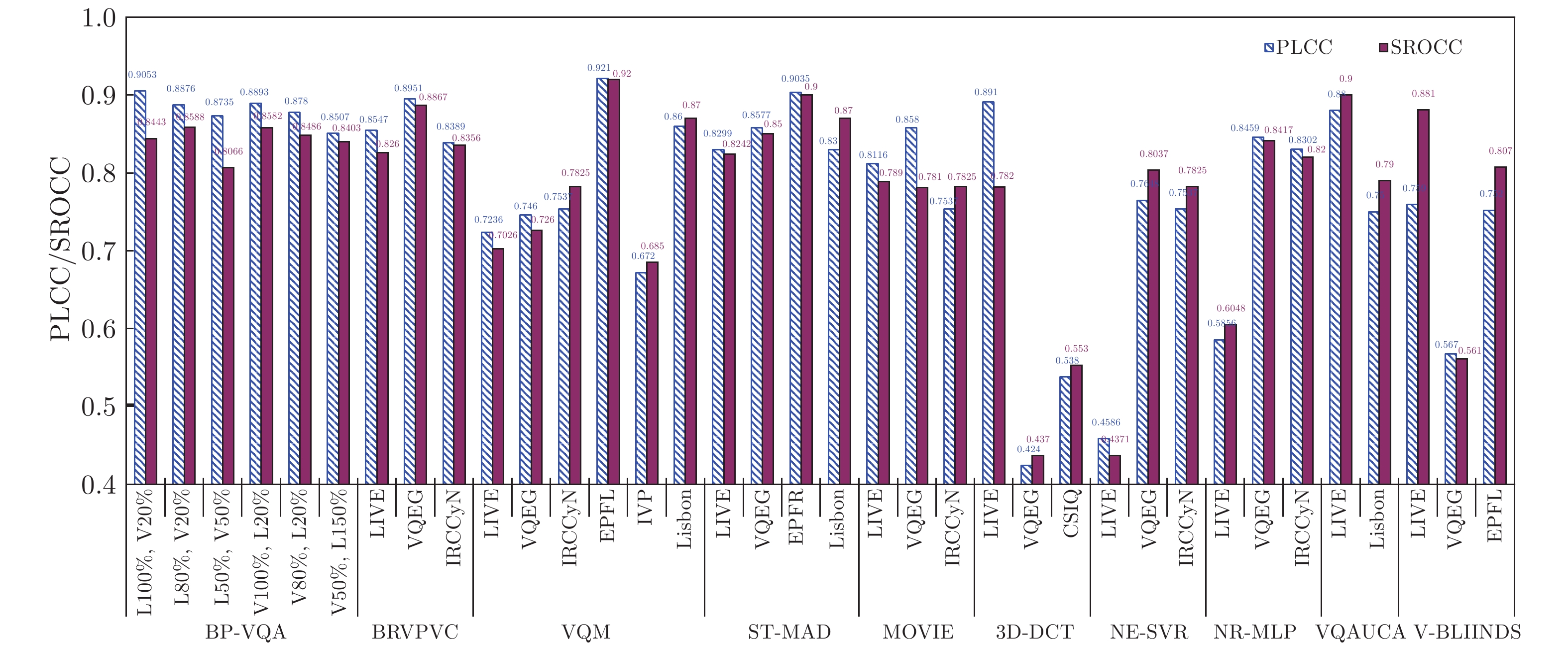
图 11 所提模型与8种现有模型的泛化性能对比
Fig. 11 Comparison of generalization performance between the proposed model and 8 existing models
表 1 所提视频特征及其参数描述
Table 1 Video features and description of their parameters
信息描述 特征 特征名称 参数值描述 空域信息及其感知 特征 1 图像局部对比度 对比度平均值 对比度最大值 特征 2 亮度色度视觉感知 亮度色度感知平均值 亮度色度感知最大值 特征 3 图像模糊度 模糊度平均值 模糊度最大值 特征 4 图像灰度梯度分布及其视觉感知 (内容复杂性视觉感知) 结合 HVS 的灰度梯度期望平均值 结合 HVS 的灰度梯度期望值的最大值 每次中断时前 3 帧的结合 HVS 的灰度梯度期望平均值 时域信息及其感知 特征 5 运动信息及其感知 结合 MCSFst 的运动矢量平均值 结合 MCSFst 的运动矢量最大值 特征 6 场景切换 复杂性变化对比感知平均值 复杂性变化对比感知最大值 编解码 特征 7 码率 比特率 传输时延 特征 8 初始时延 初始中断 (缓冲) 时延时长 特征 9 中间中断时延 中间单次中断 (缓冲) 时延时长 特征 10 平均中断时长 多次中断平均中断时长 特征 11 中断频率 单位时间中断次数  下载: 导出CSV
下载: 导出CSV
表 2 计算的4个相关性参数值
Table 2 Calculated results of four correlation parameters
样本数据库 PLCC SROCC RMSE OR LIVEour (80 % 训练、20 % 测试) 0.9886 0.9842 3.0905 0.0437 VIPSLour (80 % 训练、20 % 测试) 0.9842 0.97899 3.4389 0.04463
下载: 导出CSV
表 3 计算的4个相关性参数值
Table 3 Calculated results of four correlation parameters
样本说明 (100 %训练, 20 % 测试) PLCC SROCC RMSE OR LIVEour 训练和 VIPSLour 测试 0.9053 0.8443 7.7874 0.0940 VIPSLour 训练和 LIVEour 测试 0.8893 0.8582 8.5138 0.1125
下载: 导出CSV
表 4 计算的4个相关性参数值
Table 4 Calculated results of four correlation parameters
样本说明 PLCC SROCC RMSE OR LIVEour 中 90 % 训练和 10 % 测试 0.9897 0.9819 2.8792 0.03375 LIVEour 中 70 % 训练和 30 % 测试 0.9775 0.9753 4.6518 0.07064 LIVEour 中 50 % 训练和 50 % 测试 0.9663 0.9587 5.5681 0.07566 LIVEour 中 30 % 训练和 70 % 测试 0.9504 0.9456 6.3464 0.08892 VIPSLour 中 90 % 训练和 10 % 测试 0.9847 0.9715 3.4695 0.04362 VIPSLour 中 70 % 训练和 30 % 测试 0.9751 0.9694 4.3601 0.05401 VIPSLour 中 50 % 训练和 50 % 测试 0.9668 0.9648 5.1316 0.06715 VIPSLour 中 30 % 训练和 70 % 测试 0.9471 0.9434 6.3954 0.07859
下载: 导出CSV
表 5 计算的4个相关性参数值
Table 5 Calculated results of four correlation parameters
样本 (训练、测试) 比例说明 PLCC SROCC RMSE OR LIVEour 80 % 和 VIPSL 20 % 0.8876 0.8588 8.4442 0.1116 LIVEour 50 % 和 VIPSL 50 % 0.8735 0.8066 8.4322 0.0970 VIPSLour 80 % 和 LIVE 20 % 0.8780 0.8486 9.3577 0.1267 VIPSLour 50 % 和 LIVE 50 % 0.8507 0.8403 10.7100 0.1449
下载: 导出CSV
表 6 所提BP-VQA模型与3种NR-VQA模型的精度对比
Table 6 Accuracy comparison between the proposed BP-VQA model and three existing NR-VQA models
数据库 Metric LIVE database LIVEour BP-VQA VIPSLour BP-VQA NVSM C-VQA BRVPVC PLCC 0.732 0.7927 0.8547 0.9663 0.9668 SROCC 0.703 0.772 0.826 0.9587 0.9648
下载: 导出CSV
-
[1] Vega M T, Perra C, Turck F D, Liotta A. A review of predictive quality of experience management in video streaming services. IEEE Transactions on Broadcasting, 2018, 64(2): 432–445 doi: 10.1109/TBC.2018.2822869 [2] James N, Pablo S G, Jose M A C, Wang Q. 5G-QoE: QoE modelling for Ultra-HD video streaming in 5G networks. IEEE Transactions on Broadcasting, 2018, 64(2): 621-634 doi: 10.1109/TBC.2018.2816786 [3] Demóstenes Z R, Renata L R, Eduardo A C, Julia A, Graca B. Video quality assessment in video streaming services considering user preference for video content. IEEE Transactions on Consumer Electronics, 2014, 60(3): 436-444 doi: 10.1109/TCE.2014.6937328 [4] 南栋, 毕笃彦, 马时平, 凡遵林, 何林远. 基于分类学习的去雾后图像质量评价算法. 自动化学报, 2016, 42(2): 270-278Nan D, Bi D Y, Ma S P, Fan Z L, He L Y. A quality assessment method with classified-learning for dehazed images. Acta Automatica Sinica, 2016, 42(2): 270-278 [5] 高新波. 视觉信息质量评价方法. 西安: 西安电子科技大学出版社, 2011.72−85Gao Xin-Bo. Quality Assessment Methods for Visual Imformation. Xi'an: Xi'an Electronic Science & Technology University Press, 2011.72−85 [6] 冯欣, 杨丹, 张凌. 基于视觉注意力变化的网络丢包视频质量评估. 自动化学报, 2011, 37(11): 1322-1331Feng X, Yang D, Zhang L. Saliency Variation Based Quality Assessment for Packet-loss-impaired Videos. Acta Automatica Sinica, 2011, 37(11): 1322-1331 [7] Chandler D M, Hemami S S. VSNR: A wavelet-based visual signal-to-noise ratio for natural images. IEEE Transactions on Image Processing, 2007, 16(9): 2284-2298 doi: 10.1109/TIP.2007.901820 [8] Wang Z, Bovik A C, Sheikh H R, Simoncelli E P. Image quality assessment: from error visibility to structural similarity. IEEE Transactions on Image Processing, 2004, 13(4): 600-612 doi: 10.1109/TIP.2003.819861 [9] Pinson M H, Wolf S. New standardized method for objectively measuring video quality. IEEE Transactions on Broadcasting, 2004, 50 (3): 312-322 doi: 10.1109/TBC.2004.834028 [10] Vu P V, Vu C T, Chandler D M. A spatiotemporal most-apparent-distortion model for video quality assessment. In: Proceedings of the 2011 IEEE International Conference on Image Processing (ICIP). Brussels, Belgium: IEEE, 2011. 2505–2508 [11] Seshadrinathan K, Bovik A C. Motion tuned spatio-temporal quality assessment of natural videos. IEEE Transactions on Image Processing, 2010, 19(2): 335-350 doi: 10.1109/TIP.2009.2034992 [12] Uzair M, Dony R D. No-Reference transmission distortion modelling for H. 264/AVC-coded video. IEEE Transactions on Signal and Information Processing over Networks, 2015, 1(3): 209-221 doi: 10.1109/TSIPN.2015.2476695 [13] Menor D P A, Mello C A B, Zanchettin C. Objective video quality assessment based on neural networks. Procedia Computer Science, 2016, 96(1): 1551-1559 [14] Jacob S, Søren F, Korhonen J. No-reference video quality assessment using codec analysis. IEEE Transactions on Circuits & Systems for Video Technology, 2015, 25(10): 1637-1650 [15] Xu J, Ye P, Liu Y, Doermann D. No-reference video quality assessment via feature learning. In: Proceedings of the 2014 IEEE International Conference on Image Processing (ICIP). Paris, France: IEEE, 2014. 491–495 [16] Lin X, Ma H, Luo L, Chen Y. No–reference video quality assessment in the compressed domain. IEEE Transactions on Consumer Electronics, 2012, 58(2): 505–512 doi: 10.1109/TCE.2012.6227454 [17] Zhu K, Li C, Asari V, Saupe D. No-reference video quality assessment based on artifact measurement and statistical analysis. IEEE Transactions on Circuits and Systems for Video Technology, 2015, 25(4): 533-546 doi: 10.1109/TCSVT.2014.2363737 [18] Saad M A, Bovik A C, Charrier C. Blind prediction of natural video quality. IEEE Transactions on Image Processing, 2014, 23(3): 1352-1365 doi: 10.1109/TIP.2014.2299154 [19] Galea C, Farrugia R A. A no-reference video quality metric using a natural video statistical model. In: Proceedings of the 2015 International Conference on Computer as a Tool (EUROCON). Salamanca, Spain: IEEE, 2015. 1–6 [20] Li X, Guo Q, Lu X. Spatiotemporal statistics for video quality assessment. IEEE Transactions on Image Processing, 2016, 25(7): 3329–3342 doi: 10.1109/TIP.2016.2568752 [21] Wang C, Su L, Zhang W. COME for no-reference video quality assessment. In: Proceedings of the 2018 IEEE Conference on Multimedia Information Processing and Retrieval (MIPR). Miami, FL, USA: IEEE, 2018. 232–237 [22] Song J, Yang F, Zhou Y, Gao S. Parametric planning model for video quality evaluation of IPTV services combining channel and video characteristics. IEEE Transactions Multimedia, 2017, 19(5): 1015–1029 doi: 10.1109/TMM.2016.2638621 [23] Nadenau M. Integration of human color vision models into high quality image compression [Ph. D. dissertation], École Polytechnique Fédérale de Lausanne, Switzerland, 2000 [24] Barten P. Evaluation of subjective image quality with the square-root integral method. Journal of the Optical Society of America A, 1990, 7 (10): 2024-2031 doi: 10.1364/JOSAA.7.002024 [25] 王鸿南, 钟文, 汪静, 夏德深. 图像清晰度评价方法研究. 中国图象图形学报, 2018, 9(7): 828-831Wang H N, Zhong W, Wang J, Xia D S. Research of measurement for digital image definition. Journal of Image and Graphics, 2018, 9(7): 828-831 [26] Kelly D H. Motion and vision II Stabilized spatio-temporal threshold surface. Journal of the Optical Society of America, 1979, 69(10): 1340-1349 doi: 10.1364/JOSA.69.001340 [27] Sheikh H R., Wang Z, Bovik A C. LIVE image and video quality assessment database [Online], available: http://live.ece.utexas.edu/research/quality, May 20, 2018 [28] Gao X B, Li J, Deng C. VIPSL image & video database [Online], available: http://see.xidian.edu.cn/vipsl/index.html, June 5, 2018 [29] 唐贤伦, 杜一铭, 刘雨微, 李佳歆, 马艺玮. 基于条件深度卷积生成对抗网络的图像识别方法. 自动化学报, 2018, 44(5): 855-864Tang X L, Du Y M, Liu Yw, Li J X, Ma Y W. Image recognition with conditional deep convolutional generative adversarial networks. Acta Automatica Sinica, 2018, 44(5): 855-864 [30] Yao J C, Liu G Z. Bitrate-based no-reference video quality assessment combining the visual perception of video contents. IEEE Transactions on Broadcasting, 2019, 65(3): 546-557 doi: 10.1109/TBC.2018.2878360 [31] Zhu K, Li C, Asari V, Saupe D. No-reference video quality assessment based on artifact measurement and statistical analysis. IEEE Transactions on Circuits and Systems for Video Technology, 2015, 25(4): 533-546 [32] Li X, Guo Q, Lu X. Spatiotemporal statistics for video quality assessment. IEEE Transactions on Image Processing, 2016, 25(7): 3329–3342 [33] Blu T, Cham WK, Ngan KN. IVP video quality database [Online] , available: http://ivp.ee.cuhk.edu.hk/, July 12, 2018 [34] Brandão T, Roque L, Queluz M P. IST–Tech. University of Lisbon subjective video database [Online], available: http://amalia.img.lx.it.pt/~tgsb/H264_test/, July 15, 2018 -

 下载:
下载:

计量
- 文章访问数: 1644
- HTML全文浏览量: 746
- PDF下载量: 227
- 被引次数: 0
