

A Road Extraction Method for High Resolution Remote Sensing Images
-
摘要: 针对空间异质性导致的道路几何纹理特征突出性下降问题, 提出一种高分辨率遥感影像道路提取方法. 首先设定跟踪模型, 依据人工输入点, 自适应提取道路中心点和道路宽度, 设计迭代内插、双向迭代两种跟踪方式以及矩形跟踪模板; 然后提出多描述子道路匹配模型, 针对道路几何纹理特征突出性不足问题, 基于道路区域地物边缘与道路方向一致的语义关系, 通过线段峰值约束的思想, 提出一种多尺度线段方向直方图(Multi-scale line segment orientation histogram, MSLSOH)描述子, 以此对跟踪方向进行预测; 针对道路几何纹理特征均质性下降问题, 从道路区域与道路非道路混合区域纹理差异性出发, 组合三角形构成扇形描述子, 突出道路影像纹理特征, 以此不仅可对预测跟踪点进行验证, 而且也可在结构信息缺失的情况下对道路进行跟踪; 最后选取不同类型、不同分辨率、不同场景的高分辨率遥感影像, 通过与其他方法的实验对比, 表明该方法能够解决道路提取过程中几何纹理特征突出性下降问题, 具有准确率高和自动化程度高的优势.Abstract: In order to solve the problem of road geometric texture feature prominence decline caused by spatial heterogeneity, a road extraction method for high resolution remote sensing images is proposed in this paper. This method first sets a tracking model, adaptively extracts road center point and road width according to manual input points, thereby designing two tracking methods (interpolation and bidirectional iteration), and a rectangular tracking template. Secondly, a multi-descriptor road matching model is proposed: Facing with the lack of prominent geometric features of roads, based on the semantic relationship between the edges of the objects in the road area and the direction of the road, a MSLSOH (Multi-scale line segment orientation histogram) descriptor is proposed to predict the matching tracking direction through the idea of line segment peak constraint. And then, for the problem of the homogeneity reduction of road texture features, from the difference of texture between road area and road non-road mixed area, a sector descriptor composed of multiple triangles was designed to highlighting the road image texture features, so that not only the predicted tracking points can be verified, but also tracking roads in the absence of structural information. Finally, high resolution remote sensing images of different types, resolutions and scenes are selected. Compared with other methods, the experimental results show that this method can solve the problem of decreasing the prominence of geometric texture features in the process of road extraction, and has the advantages of high accuracy and high degree of automation.
-
图像分类是指根据图片中的信息将图片划分到某一类别, 因此对图像进行特征信息提取是图像分类的重要研究内容. 传统的图像分类主要采用机器学习方法来提取特征, 随着深度学习的不断发展, 各种深度学习算法逐渐应用到图像分类当中. 2012年, AlexNet[1]神经网络在图像分类效果上超越了传统方法, 在AlexNet之后, 涌现出一系列改进的卷积神经网络(Convolutional neural network, CNN)模型[2-4], 不断地提高分类精度.
然而, CNN的模型也存在一些缺陷. 首先, CNN的池化层会导致大量有价值的特征信息丢失, 从而对分类精度产生影响. 其次, 由于CNN对位置信息不敏感, 这将导致CNN对物体之间的空间关系的识别能力不强[5]. 随后提出的胶囊网络[6]则能够较好地处理上述问题, 具体地, 胶囊网络摒弃了CNN的池化层, 保留了大量的图片信息, 这使得胶囊网络运用较少的训练数据就能达到理想的效果. 此外, 胶囊网络是部分对整体的预测, 在预测的过程中能够较好地保留特征的姿态, 如位置、大小、方向等信息, 这使得胶囊网络不仅能够进行更加精确的分类, 还能够有效地识别出经过仿射变换等一系列空间变换的图像.
近年来, 胶囊网络成为图像领域的一大研究热点. Sabour等[6]首先提出胶囊网络并且应用到图像分类任务, 作者基于公共数据集研究了胶囊网络的图像识别能力, 实验结果表明胶囊网络在图像分类的问题上可以成功地超越CNN. 然而, 由于胶囊网络在计算和内存负载方面的代价较高, 所以该胶囊网络的结构相对较浅, 主要适用于简单数据集, 在处理复杂数据时表现不佳. 随后, Deliege等[7]提出一种名为HitNet的深度学习网络, 该网络的核心思想是使用由胶囊组成的“Hit-or-Miss”层, 假定给定类的所有图像都具有各类特有的特征, 当给定一个输入图像, 强制HitNet瞄准真实类的胶囊所在的特定空间的中心, 而其他类的胶囊则被发送到远离各自特征空间中心的地方. 虽然该方法的收敛速度有大幅度提升, 但是复杂数据集上的精度有所降低. 针对该问题, 文献[8]提出多种改进的胶囊网络, 例如堆叠更多胶囊层、增加初始胶囊的数量、增加卷积层的层数或者更换其他激活函数等. 然而, 在复杂数据集上, 改进的胶囊网络在分类精度上没有明显的提升. 文献[9]中将原始胶囊网络中用向量表示的胶囊替换为矩阵表示, 同时将动态路由中的聚类算法思想换成高斯混合模型(Gaussian mixture model, GMM). 实验结果表明该模型仅在smallNORB数据集上有较小的提升, 复杂数据集上的效果依然不尽如人意.
在注意力胶囊网络的研究方面, 相对于注意力卷积神经网络丰富的研究成果而言, 还有待进一步深入开展. 文献[10]在胶囊网络的卷积层中, 针对低层特征添加空间注意力机制, 虽然有效提取了特征之间的空间位置信息, 但缺乏对高层特征所描述的重要语义信息的特别关注, 同时也没有充分考虑低层胶囊对高层胶囊的影响. 文献[11]通过采用注意力路由来调整训练参数的大小进而改变不同空间位置上胶囊的权重, 虽然在一定程度上增加了对重要胶囊的关注, 但没有充分考虑从低层胶囊到高层胶囊的预测过程中低层胶囊的影响.
由上述分析可见, 尽管胶囊网络是近年来模式识别领域的一大研究热点, 已经取得一些研究成果, 但目前仍处于起步阶段, 有很多尚待完善之处, 例如特征提取不充分、在复杂数据集上的分类效果较差等. 针对以上问题, 本文提出了一种改进的胶囊网络模型, 主要贡献如下:
1)提出一种多阶段注意力胶囊网络的新模型, 该模型分别在卷积层和动态路由层中引入了注意力机制, 这使得模型的参数可以根据与给定任务相关的图像区域进行更新. 注意力机制考虑了特征之间的相关性, 保证能够学习到更多和任务相关的重要特征, 从而提升了效率.
2)为充分提取特征信息以及特征之间的空间位置信息, 在卷积层中引入注意力机制. 具体地: 对于高层特征, 重点考虑其包含的高度抽象语义, 因此采用通道注意力(Channel attention, CA)机制; 对于低层特征, 重点考虑特征之间的空间位置信息, 因此采用空间注意力(Spatial attention, SA)机制.
3)为提高对仿射变换图像的鲁棒性, 提出基于向量的注意力(Vector attention, VA)机制并且应用到胶囊网络动态路由层中的低级胶囊中, 充分考虑初始胶囊(即低级胶囊)之间的相关性, 从而加大对任务相关的初始胶囊的关注, 为高级胶囊的准确预测提供帮助.
4)传统胶囊网络由于网络架构较浅, 不能充分提取有效特征, 因而在如CIFAR10这样的复杂数据集上效果不好. 针对该问题, 本文提出的多阶段注意力的胶囊网络具有更深的网络架构, 在复杂数据集上也能获得比较满意的结果. 大量的实验结果表明, 改进的胶囊网络模型能够在不同数据集中得到更加准确的分类结果, 明显优于几类常用的胶囊网络模型. 并且, 所提出的胶囊网络在图像重构方面也表现良好.
1. 胶囊网络
最近崛起的胶囊网络代表了在神经网络方面的巨大突破. 胶囊网络主要包含三种不同类型的网络层: 卷积层、初始胶囊层和分类胶囊层[6], 如图1所示. 与CNN相比, 胶囊网络主要包含以下两大优点: 1)摒弃了CNN中的池化层, 在初始胶囊层和分类胶囊层之间添加动态路由层, 以便于在低层胶囊中选择合适的低层胶囊对高层胶囊进行准确的预测. 对于每个高层胶囊来说, 胶囊网络可以增加或者减少低层胶囊和高层胶囊之间的连接强度. 因此, 胶囊网络能够保持图像内部目标之间的相关性. 2)将CNN中用标量表示的特征替换为用向量表示的胶囊特征. 胶囊是一组神经元, 可以捕捉图像的各种属性, 如位置、大小、纹理等. 同时, 分类胶囊层输出的胶囊经压缩后可以较好地表示输入图像中出现对象的概率, 进而为图像分类任务的完成提供有效的帮助.
2. 注意力机制
注意力机制能够帮助模型聚焦于图像中与任务相关的区域, 从而提升模型的性能. 除此之外, 注意力机制还能够学习到对象之间更深层次的关联以及不同区域之间的依赖. 目前注意力机制已经成功地应用到各个领域中, 包括机器翻译[12-14]、家庭活动识别[15]、图像字幕[16-18]、显著性检测[19]、视觉问题回答[20-21]、行为检测[22-23]、文本分类[24]、图像分类[25]、自然语言处理[26]等. 在图像分类中, 注意力机制大致分为SA机制和CA机制. SA机制主要用于捕获特征之间的位置关系, 提出基于空间的注意力机制模型主要有Non-local[27]和CBAM (Convolutional block attention module)[28]. CA机制主要用于获得不同通道间特征之间的相关性, 提出基于通道的注意力机制模型主要有SENet[29]. 本文除了在特征提取部分分别采用SA和CA机制外, 还在动态路由部分提出一种VA机制, 通过给与任务相关的胶囊分配更多的权重来加大对重要胶囊的关注.
3. 本文模型
在本文中, 提出了一种多阶段注意力的胶囊网络, 并且在图像分类上进行了应用. 该网络包括三个注意力机制模块, 分别为SA模块[27]、CA模块[29]和动态路由中低级胶囊层的VA模块. 其中SA机制模块和CA机制模块分别加在低层特征和高层特征中, 并且将低层特征和高层特征进行融合, 既保留了低层特征的位置信息和细节信息等, 又得到了高层特征的语义信息. 这使得胶囊网络不仅能够得到有效特征, 同时特征中保留的位置信息也有助于胶囊网络对真实的类进行分类. 动态路由层中的VA模块则加在低层胶囊和高层胶囊之间, 动态路由中包括低层胶囊对高层胶囊的预测, 所以注意力机制可以更多地考虑低层胶囊中与分类任务相关的低层胶囊, 加大与分类任务相关的低层胶囊的权重, 进而增加低层胶囊对高层胶囊预测的准确性, 最终提高分类精度. 总体网络模型如图2所示.
3.1 特征提取
标准CNN使用的是卷积池化的组合操作, 并且一般在卷积的时候使用的是大小相同的卷积核, 由此得到特征的感受野大小是相同的. 本文在卷积的过程中使用大小不同的卷积核来提取特征, 进而增加特征的多样性.
首先, 本文对输入的图片进行四层卷积, 然后将其中的前两层特征进行融合作为低层特征; 后两层特征进行融合作为高层特征. 随后分别对低层特征和高层特征使用多卷积(Multiple convolution, MC)操作, 即分别使用两个不同大小的卷积核对特征进行卷积, 获得不同大小的感受野, 经过测试后本文使用的是$3 \times 3$和$5 \times 5$大小的卷积核. 最后将得到的两个特征进行融合(对应元素相加), 并输出融合后的特征.
3.2 注意力模块
神经网络中随着卷积层数的增加, 得到的特征的语义性也会越来越高级. 现有的方法大多是没有区分地集中多尺度特征, 这将导致信息冗余, 从而降低模型的性能. 针对该问题, 本文根据不同层次的特征的特点, 对高级特征采用CA机制[29], 对低层特征采用SA机制[27], 进而选择有效特征. 此外, 对高层特征不使用SA机制, 因为高层特征包含高级的抽象语义, 不需要过滤空间信息; 而对于低层特征, 不使用CA机制, 因为低层特征的不同通道上几乎没有语义上的区别. 同时本文在动态路由层中添加向量注意力机制, 增加和分类任务相关的低层胶囊的权重, 进而提高分类效率.
3.2.1 通道注意力机制模块
在CNN中, 不同通道上的特征代表着不同的语义信息. 低层特征中不同通道之间的语义性没有太大的差别, 而高层特征中不仅拥有丰富的语义信息, 不同通道之间的语义性也有较大的差异. 本文在融合后的高层特征中加入CA模块[29]来给每个通道上的特征分配不同的权重, 加大与分类任务相关的通道特征的权重, 进而增加与分类任务相关的特征的关注, 提高分类效率.
具体地, 将融合后的高层特征${f^h} \in {\bf{R}}^{W \times H \times C}$展开为${f^h} = [f_{\rm{1}}^h{\rm{,}}f_{\rm{2}}^h,\cdots,f_C^h{\rm{]}}$, 其中, $f_i^h \in {\bf{R}}^{W \times H}$代表高层特征${f^h}$中第$i$个通道上的特征, $C$代表高层特征的通道数. 首先, 对每个通道上的特征$f_i^h$采用平均池化(Average pooling), 进而得到基于通道特征的向量${{\boldsymbol{v}}^{{h}}} \in {\bf{R}}^C$. 紧接着, 将得到的向量输入两个连续的全连接层(Full connection, FC)来捕捉特征通道间的依赖关系(如图3(a)所示), 其中$ K $为降维参数, 用于降低FC的参数量, 两个全连接层中的ReLU激活函数既可以限制模型的复杂性, 又可以增加模型的非线性拟合能力. 然后, 通过式(1)的sigmoid运算将已经映射到的特征进行归一化处理, 即
$$ CA={F_{{\rm{se}}}}{\rm{(}}{{\boldsymbol{v}}^{{h}}}{{,W}}) = \sigma (f{c_2}(\delta (f{c_1}({{\boldsymbol{v}}^{{h}}},{W_1})),{W_2})) $$ (1) 其中, $F_{\rm{se}}$表示通道注意力机制操作, $W$为CA机制模块的参数, $\sigma $为sigmoid操作, $fc$代表FC操作, $\delta $代表ReLU激活函数. 最后, 使用CA模块对输入${f^h}$的不同通道特征进行加权得到${\hat f^h}$:
$$ {\hat f^h} = CA \cdot {f^h} $$ (2) 3.2.2 空间注意力机制模块
CNN中低层特征的语义性较低, 所以一般情况下图像分类模型都会选择增加网络的层数来得到更高的语义信息, 进而使用高层特征来进行分类. 虽然低层特征的语义性较低, 但是低层特征包含更多的位置和细节信息, 这些信息正是高层特征不具有的. 在低层特征中加入SA机制[27]可以选择性地考虑空间位置, 通过分配不同的权重来更多地关注和分类任务相关的区域, 如边缘信息、纹理等.
SA机制模型如图3(b)所示, 设融合后的低层特征为${f^l} \in {\bf{R}}^{{W^1} \times {H^1} \times {C^1}}$, 其中, $H $、$W $和$C $分别为特征高度、宽度和通道的数量. 我们将其定义为$x \in {\bf{R}}^{{N^1} \times {C^1}}$, $v(x),k(x),q(x)$分别为从低层特征${f^l}$中提取出的特征的特征提取器. 其中, $v(x)$和${f^l}$具有相同的通道数$({C^1})$, 这里综合考虑实验精度和速度后选取通道数为256, $k(x),q(x)$用于计算注意力机制分布图的位置模块, $k({x_i})$和$q({x_j})$分别为输入特征映射中的第$i$和第$j$个位置. 与$v(x)$相比, $k({x_i})$和$q({x_j})$的通道数减少到${C^1}/8$, 这使得能够过滤掉输入通道中的噪声, 进而保留与注意力机制相关的特征. 在SA机制模块中, 使用$1 \times 1$大小的卷积核和non-local算法, 通过对图像特征的所有位置进行加权求和, 帮助模型建立位置特征之间的长距离依赖关系, 使得模型即使在浅层网络中依然能够捕获全局的感受野. 这里non-local算法定义为
$$ {\theta _{ij}}(x) = k^{\rm{T}}{({x_i})}q({x_j}) $$ (3) 其中, $k({x_i}) = {W_k}{x_i}$, $q({x_j}) = {W_q}{x_j}$, ${W_k} \in {\bf{R}}^{{C^1} \times {C^1}}$, ${W_q} \in {\bf{R}}^{{C^1} \times {C^1}}$为学习到的权重矩阵. 接下来, 我们对${\theta _{ij}}$进行如下所示的softmax归一化:
$$ {\alpha _{ij}} = \frac{{{\rm{exp}}({\theta _{ij}})}}{{\sum\limits_{i = 1}^N {{\rm{exp}}({\theta _{ij}})} }} $$ (4) 得到注意力机制权重分布图. 为了得到最终的注意力机制特征图, 将${\alpha _{ij}}$和$v({x_i})$进行矩阵乘法, 即
$$ {\beta _j} = \sum\limits_{i = 1}^N {{\alpha _{ij}}} v({x_i}) $$ (5) 其中, $v({x_i}) = {W_h}{x_i}$是第三个特征提取器, 其通道数为${C^1}$. 与${W_q}$和${W_k}$相似, ${W_h}$也是一个学习过的权重矩阵. 通过这个矩阵乘法, $\beta $中的每个位置都是图像特征中所有位置的一个加权和, 将以上所有运算归为SA模块, 可以得到最终的输出, 即
$$ {\hat f^l} = SA \cdot {f^l} + {f^l} $$ (6) 3.2.3 向量注意力机制模块
胶囊网络中的动态路由是低层胶囊对高层胶囊的预测. 一方面由于胶囊网络在预测的过程中对每个低层胶囊都是等价处理的, 所以会导致低层胶囊中的一些冗余信息包括背景也以等价的形式参与训练, 致使训练效率下降; 另一方面低层胶囊对高层胶囊单独进行预测, 每个胶囊在训练过程中都忽略了其他胶囊对自身的影响. 我们在动态路由层中加入向量注意力机制, 可以对低层胶囊先进行一次筛选, 降低与分类任务无关或者关联较小的胶囊的权重, 提高与分类任务相关的胶囊权重.
如图4所示, 设低层特征为$U \in {\bf{R}}^{{H^2} \times {W^2} \times {C^2} \times {L^2}}$, ${\boldsymbol{f}} = [{{\boldsymbol{f}}_1},{{\boldsymbol{f}}_{{2}}},{{\boldsymbol{f}}_{{3}}},\cdots,{{\boldsymbol{f}}_{{{{N}}^{{2}}}}}]$, 其中${{\boldsymbol{f}}_s}$表示第$s$个低层胶囊, ${N^2}$表示低层胶囊的个数. 将其沿着向量方向进行压缩, 得到${N^2}$$ ({N^2} = {H^2} \times {W^2} \times {C^2})$个$1 \times {L^2}$大小的低层胶囊, 定义为
$$ {z_s} = {F_{{\rm{ap}}}}(f) = \frac{1}{{{L^2}}}\sum\limits_{i = 1}^{{L^2}} {{f_s}} (i) $$ (7) 其中, $z \in {\bf{R}}^{{N^2}}$代表压缩后的特征, ${z_s}$表示压缩第$s$个胶囊后的标量, $F_{\rm{ap}}$代表胶囊压缩操作, ${L^2}$表示胶囊的长度.
为了利用压缩操作中聚集的信息, 接下来进行第二个操作, 用于捕获低层胶囊之间的依赖关系, 即
$$ o = {F_{{\rm{fc}}}}(z,{W^2}) = \sigma ({W_2}^2,\delta ({W_1}^2z)) $$ (8) 其中, $F_{\rm{fc}} $表示两层全连接层, $\delta $代表ReLU激活函数, $\sigma $代表sigmoid激活函数, ${W_1}^2 \in {\bf{R}}^{\frac{{{C^2}}}{r} \times {C^2}}$, ${W_2}^2 \in {\bf{R}}^{{C^2} \times \frac{{{C^2}}}{r}}$, $r $为降维参数, 用于降低两层全连接层的参数量. 首先将压缩后的胶囊特征放入两层FC中, 进而实现以下四种功能: 1)两层FC能够捕获低层胶囊之间的线性关系; 2) ReLU激活函数能够增加模型的非线性拟合能力; 3)减少隐藏层的参数量, 降低模型的复杂度; 4)对输出使用sigmoid激活函数将参数归一化, 方便后续处理. 最后将输出$o$和输入的低层胶囊$f$相乘, 即
$$ {\hat {\boldsymbol{f}}_{{N^2}}} = {F_{{\rm{scale}}}}({\boldsymbol{f}},{o_{{N^2}}}) = {\boldsymbol{f}} \cdot {o_{{N^2}}} $$ (9) 其中, $F_{\rm{scale}} $代表逐胶囊相乘, $\hat {\boldsymbol{f}} = [{\hat {\boldsymbol{f}}_1},{\hat {\boldsymbol{f}}_2},\cdots ,{\hat {\boldsymbol{f}}_{{N^2}}}]$表示添加注意力机制后输出的初始胶囊. 将上述过程用VA表示, 则有
$$ \hat {\boldsymbol{f}} = VA \cdot {\boldsymbol{f}} $$ (10) 3.3 动态路由层
将添加了注意力机制的初始胶囊${\hat {\boldsymbol{f}}_{{i}}}$送入动态路由层. 设${\tilde {\boldsymbol{f}}_{{j}}}$为胶囊$j$的输出向量, 向量的长度表示特定对象位于图像中给定位置的概率, 因而其取值范围应在0到1之间. 为保证这一条件成立, 运用一个压缩函数来保存对象的位置信息. 短向量可以压缩到接近0, 长向量则可以延伸至接近1, 压缩函数定义为
$$ {\tilde {\boldsymbol{f}}_{{j}}} = \frac{{{{\left\| {\sum\limits_i {c_i}_j{W^3_{ij}}{{\hat {\boldsymbol{f}}}_i}} \right\|}^2}}}{{\left( {1 + \left\| {\sum\limits _i {c_{ij}}{W^3_{ij}}{{\hat {\boldsymbol{f}}}_i}} \right\|} \right)}}\frac{\sum\limits _i{c_i}_j{W^3_{ij}}{{\hat {\boldsymbol{f}}}_i} }{{{{\left\| {\sum\limits_i {c_{ij}}{W^3_{ij}}\hat {\boldsymbol{f}}} \right\|}_i}}} $$ (11) 其中, ${W^3_{ij}}$是低层胶囊和高层胶囊中的权重矩阵, ${c_{ij}}$是第$i$个低层胶囊与所有第$j$个高层胶囊之间的耦合系数, 由如下定义的迭代动态路由过程确定, 即
$$ {c_{ij}} = \frac{{{\rm{exp}}({b_{ij}})}}{{\sum\limits_j {\rm{exp}}({b_{ij}})}} $$ (12) 其中, ${b_{ij}}$是第$i$个低层胶囊和第$j$个高层胶囊耦合的先验概率.
3.4 图像重构
胶囊网络还有一个典型特征是能够进行较好的图像重构, 其实现架构如图5所示.
为了在训练过程中得到一幅重构的图像, 先使用${c_{ij}}$中对应的耦合系数最高的向量${\tilde {\boldsymbol{f}}_{{j}}}$, 然后使用两个完全连接的ReLU提供正确的${\tilde {\boldsymbol{f}}_{{j}}}$. 重构的损失函数定义为
$$ {L_R}(I,\hat I) = \left\| {I - \hat I} \right\|_2^2 $$ (13) 其中, $I$是原始输入图像, $\hat I$是重构图像. ${L_R}(I,\hat I)$需要根据选择的${\tilde {\boldsymbol{f}}_{{j}}}$和输入来重构图像, 这使得胶囊网络在学习的过程中会尽量选择对重构图像有用的特征, 进而降低重构损失. 将重构损失函数添加到间隔损失函数${L_M}$中, 则有
$$ \begin{split} {L_M} =\;& \sum\limits_K {\left( {{T_K}{\rm{max}}{{\left( {0,{m^ + } - \left\| {{{\tilde f}_K}} \right\|} \right)}^2}} \right)}\; + \\ & \sum\limits_K {\left( {\lambda \left( {1 - {T_K}} \right){\rm{max}}{{\left( {0,\left\| {{{\tilde f}_K}} \right\| - {m^ - }} \right)}^2}} \right)} \end{split} $$ (14) 其中, ${T_K}$表示对应的样本标签, 若输入图像中的对象属于类别K, 则${T_K} = 1$, max是最大值函数, 参数$\lambda = 0.5$. 参照文献[6], 令${m^ + } = 0.9$, ${m^ - } = 0.1$, 使用总损失函数${L_T}$对模型进行评估, 即
$$ {L_T} = {L_M} + \varepsilon {I_{{\rm{size}}}}{L_R} $$ (15) 其中, $\varepsilon = 0.000\;5$是每个通道像素值的正则化因子, 保证了在训练过程中重构损失${L_R}$不高于${L_M}$, ${I_{{\rm{size}}}} = {H^4} \times {W^4} \times {C^4}$是输入值的数量.
4. 实验结果
4.1 实验数据
本文借助于MNIST、Fashion-MNIST、CIFAR-10、SVHN和smallNORB五个数据集来验证提出模型的有效性. MNIST是一个包含数字0 ~ 9的手写体数字数据集, 大小为$28 \times 28$像素的黑白图片, 包含
60000 幅训练样本和10000 幅测试样本; Fashion-MNIST与MNIST相似, 但是种类为10种衣物; CIFAR-10是包含10类RGB、大小为$32 \times 32$像素图片的真实世界对象的数据集, 包括交通工具和动物, 含有50000 幅训练样本和10000 幅测试样本; SVHN包含从谷歌街景中房屋数字号码截取的经过裁剪的RGB图像, 大小为$32 \times 32$像素, 与MNIST一样为数字样本, 但是因为有不同的颜色和样式, 单个样本中还包含多个数字, 所以更加复杂, 其拥有73257 幅训练样本,26032 幅测试样本; smallNORB是一个包含5类样本不同角度图片的数据集, 单个样本为$96 \times 96$像素大小的灰度图片, 本文使用24300 幅图片作为训练集,24300 幅图片作为测试集.4.2 消融实验
本文对原始的胶囊网络做了很多改进, 主要包括添加卷积层中的注意力机制模块来提取有效特征; 添加动态路由层中的向量注意力机制模块来提高分类的准确率; 采用交叉验证来说明添加注意力机制模块的有效性. 实验结果如表1和图6所示, 其中, (SA + CA)为卷积层中的注意力机制, (VA)为动态路由层中的向量注意力机制.
表 1 不同改进模块在五个数据集上的分类错误率(%)Table 1 Classification error rates of different improvement modules on five datasets (%)模型 MNIST Fashion-MNIST CIFAR-10 SVHN smallNORB Baseline 0.38 7.11 21.21 5.12 5.62 Baseline + (SA + CA) 0.32 5.54 11.69 4.61 5.07 Baseline + VA 0.28 5.53 14.65 4.99 5.21 Baseline + (SA + CA + VA) 0.22 4.63 9.99 4.08 4.89  图 6 不同改进模块在五个数据集上的迭代曲线Fig. 6 Iteration curves of different improvement modules on five datasets
图 6 不同改进模块在五个数据集上的迭代曲线Fig. 6 Iteration curves of different improvement modules on five datasets实验结果表明, 传统的胶囊网络[6]虽然在MNIST上具有非常好的分类精度, 但是在复杂数据集, 如CIFAR-10上的分类效果较差, 而增加注意力机制后的胶囊网络不仅可以提升简单数据集的精度, 在复杂数据集上的实验效果也大大超过原始的胶囊网络. 对于MNIST、Fashion-MNIST、CIFAR-10、SVHN和smallNORB这五个数据集, 本文的模型比原始的胶囊网络分别提高了0.16%、2.48%、11.22%、1.04%和0.73%.
4.3 分类对比实验
本文使用交叉验证证明了提出模型的有效性, 同时与几个常用胶囊网络, 包括Prem Nair et al.'s CapsNet[5], HitNet[7], Matrix Capsule EM-routing[9], SACN[10], AR-CapsNet[11], DCNet[30], MS-CapsNet[31], VB-routing[32], Aff-CapsNets[33]在五个公共数据集上进行了分类对比实验, 实验结果如表2所示.
表 2 不同模型在五个数据集上的分类错误率(%)Table 2 Classification error rates of different models on five datasets (%)模型 MNIST Fashion-MNIST CIFAR-10 SVHN smallNORB Prem Nair et al.'s CapsNet[5] 0.50 10.20 31.47 8.94 — HitNet[7] 0.32 7.70 26.70 5.50 — Matrix Capsule EM-routing[9] 0.70 5.97 16.79 9.64 5.20 SACN[10] 0.50 5.98 16.65 5.01 7.79 AR-CapsNet[11] 0.54 — 12.71 — — DCNet[30] 0.25 5.36 17.37 4.42 5.57 MS-CapsNet[31] — 6.01 18.81 — — VB-routing[32] — 5.20 11.20 4.75 1.60 Aff-CapsNets[33] 0.46 7.47 23.72 7.85 — 本文模型 0.22 4.63 9.99 4.08 4.89 由表2可得, 本文提出的模型在五个数据集上的分类错误率都低于其他的胶囊网络模型, 在MNIST、Fashion-MNIST、CIFAR-10、SVHN和smallNORB这五个数据集上的分类错误率分别为0.22%, 4.63%, 9.99%, 4.08%, 4.89%, 实验结果证明了本文模型的先进性.
4.4 鲁棒性对比实验
为了验证模型的鲁棒性, 本文将MNIST数据集的测试集在[−25°, −15°, 0°, 15°, 25°]之间进行随机旋转, 旋转结果如图7所示, 然后将训练好的模型在旋转过后的测试集上进行验证. 同时, 本文还与文献[6]和文献[9]提出的CapsNet和EM-routing, 以及与本文模型具有相同层数的CNN进行鲁棒性对比实验, 对比结果如表3和图8所示. 由表3可得, CNN在处理旋转图像时的分类精度降低了4.78%, 文献[6]的胶囊网络降低了1.73%, EM-routing的降低了2.22%, 而本文提出的模型在旋转数据集上精度只降低了0.41%. 实验结果不仅证明了胶囊网络与CNN相比, 对仿射变换图像具有更强的鲁棒性, 同时验证了本文提出的胶囊网络在鲁棒性方面是传统胶囊网络的进一步提升和改善.
表 3 不同模型的鲁棒性对比实验(%)Table 3 Robustness comparison test of different models (%)4.5 重构对比实验
模型重构的结果也是衡量模型的评判标准, 通过可视化模型产生的重构结果, 可以更加直观地对不同模型进行对比. 在图9 ~ 13中, 本文分别展示了100个真实图像、原始胶囊网络重构出的100个图像和本文模型重构出的100个图像. 通过获取100个图像中的部分样本进而将原始的胶囊网络与本文提出的模型进行比较, 图9 ~ 13中, 子图(a)代表100个真实图像的部分图像; 子图(b)代表原始的胶囊网络重构的100个图像中的部分图像; 子图(c)代表本文模型重构的100个图像中的部分图像.
 图 9 比较MNIST数据集中的真实图像、传统胶囊网络的重构图像以及本文模型的重构图像Fig. 9 Comparison of the real images from the MNIST dataset, the reconstructions from a conventional capsule network, and the reconstructions from our model
图 9 比较MNIST数据集中的真实图像、传统胶囊网络的重构图像以及本文模型的重构图像Fig. 9 Comparison of the real images from the MNIST dataset, the reconstructions from a conventional capsule network, and the reconstructions from our model 图 10 比较Fashion-MNIST 数据集中的真实图像、传统胶囊网络的重构图像以及本文模型的重构图像Fig. 10 Comparison of the real images from the Fashion-MNIST dataset, the reconstructions from a conventional capsule network, and the reconstructions from our model
图 10 比较Fashion-MNIST 数据集中的真实图像、传统胶囊网络的重构图像以及本文模型的重构图像Fig. 10 Comparison of the real images from the Fashion-MNIST dataset, the reconstructions from a conventional capsule network, and the reconstructions from our model 图 11 比较CIFAR-10 数据集中的真实图像、传统胶囊网络的重构图像以及本文模型的重构图像Fig. 11 Comparison of the real images from the CIFAR-10 dataset, the reconstructions from a conventional capsule network, and the reconstructions from our model
图 11 比较CIFAR-10 数据集中的真实图像、传统胶囊网络的重构图像以及本文模型的重构图像Fig. 11 Comparison of the real images from the CIFAR-10 dataset, the reconstructions from a conventional capsule network, and the reconstructions from our model 图 12 比较SVHN 数据集中的真实图像、传统胶囊网络的重构图像以及本文模型的重构图像Fig. 12 Comparison of the real images from the SVHN dataset, the reconstructions from a conventional capsule network, and the reconstructions from our model
图 12 比较SVHN 数据集中的真实图像、传统胶囊网络的重构图像以及本文模型的重构图像Fig. 12 Comparison of the real images from the SVHN dataset, the reconstructions from a conventional capsule network, and the reconstructions from our model 图 13 比较smallNORB数据集中的真实图像、传统胶囊网络的重构图像以及本文模型的重构图像Fig. 13 Comparison of the real images from the smallNORB dataset, the reconstructions from a conventional capsule network, and the reconstructions from our model
图 13 比较smallNORB数据集中的真实图像、传统胶囊网络的重构图像以及本文模型的重构图像Fig. 13 Comparison of the real images from the smallNORB dataset, the reconstructions from a conventional capsule network, and the reconstructions from our modelMNIST的重构图相比于真实图片的数字边缘更宽, 类似于图像膨胀的效果, 可以将数字之间断开的部分进行连接. 由图7可得, 原始的胶囊网络在重构的时候容易将数字2重构成数字7, 而本文的模型则能够正确地重构出与真实图片相对应的结果; Fashion-MNIST中无论是原始的胶囊网络还是本文模型, 重构结果都与原图十分相似, 但仔细观察可以发现, 本文模型能够重构出原始图像中衣服上的褶皱, 而原始的胶囊网络则不能. 对比重构图和原图易见, 重构图像中并没有捕捉到精细的特征, 如衣服的标志和鞋子上的图案, 这可能与原始胶囊模型重构的网络太浅有关; CIFAR-10的重构图几乎难以辨认, 但是仔细观察还是能够发现本文的模型在色彩的重构方面强于原始的胶囊网络; SVHN中原始的胶囊网络将数字0重构成了数字6, 而本文的模型则能够正确地重构; 在smallNORB数据集的重构中, 能够很明显地看到本文模型重构的图片在清晰度上远远高于初始胶囊网络的重构图. 以上实验结果充分说明了本文模型的有效性.
4.6 仿射图像重构对比实验
为了进一步验证本文提出的多阶段注意力胶囊网络针对仿射变换图像的重构性能, 我们将MINST数据集上的原始图片分别旋转+25°和−25°生成仿射变换图像, 如图14所示. 然后分别使用文献[10]的CapsNet和本文模型进行测试并输出重构图片如图15和图16所示, 同时采用均方误差(Mean square error, MSE)损失函数来计算模型重构图片与真实图片的差值, 实验结果如图17所示. 由对比重构实验结果可见, 本文提出的多层注意力胶囊网络在仿射变换图像的重构上效果更好, 具有更好的鲁棒性.
 图 14 MINST数据集原图和仿射变换图Fig. 14 Original image and affine transformations images of MINST dataset
图 14 MINST数据集原图和仿射变换图Fig. 14 Original image and affine transformations images of MINST dataset 图 15 图14(b)的重构实验对比图Fig. 15 Comparison of reconstructions to Fig. 14(b)
图 15 图14(b)的重构实验对比图Fig. 15 Comparison of reconstructions to Fig. 14(b) 图 16 图14(c)的重构实验对比图Fig. 16 Comparison of reconstructions to Fig. 14(c)
图 16 图14(c)的重构实验对比图Fig. 16 Comparison of reconstructions to Fig. 14(c)
5. 结束语
本文提出的多阶段注意力胶囊网络模型能够有效地解决原始胶囊网络特征提取不充分, 在复杂数据集上表现欠佳的问题. 在特征提取过程中, 我们通过在卷积层中对低层特征采用SA机制, 对高层特征采用CA机制来捕捉有效特征; 在计算效率方面, 我们在动态路由中添加VA机制来更多地考虑和分类任务相关的胶囊; 此外, 胶囊网络能够较好地学习特征间的空间相关性, 从而解决CNN特征间的空间关系难以捕获的问题. 通过实验可以看出, 本文的模型无论在简单数据集还是复杂数据集上都明显优于其他的胶囊网络模型. 未来的工作将专注于更加复杂的数据集以及模型中注意力机制模块的优化, 同时改进图像重构的模型, 得到还原度更高的重构图像, 进而用于模型训练.
-
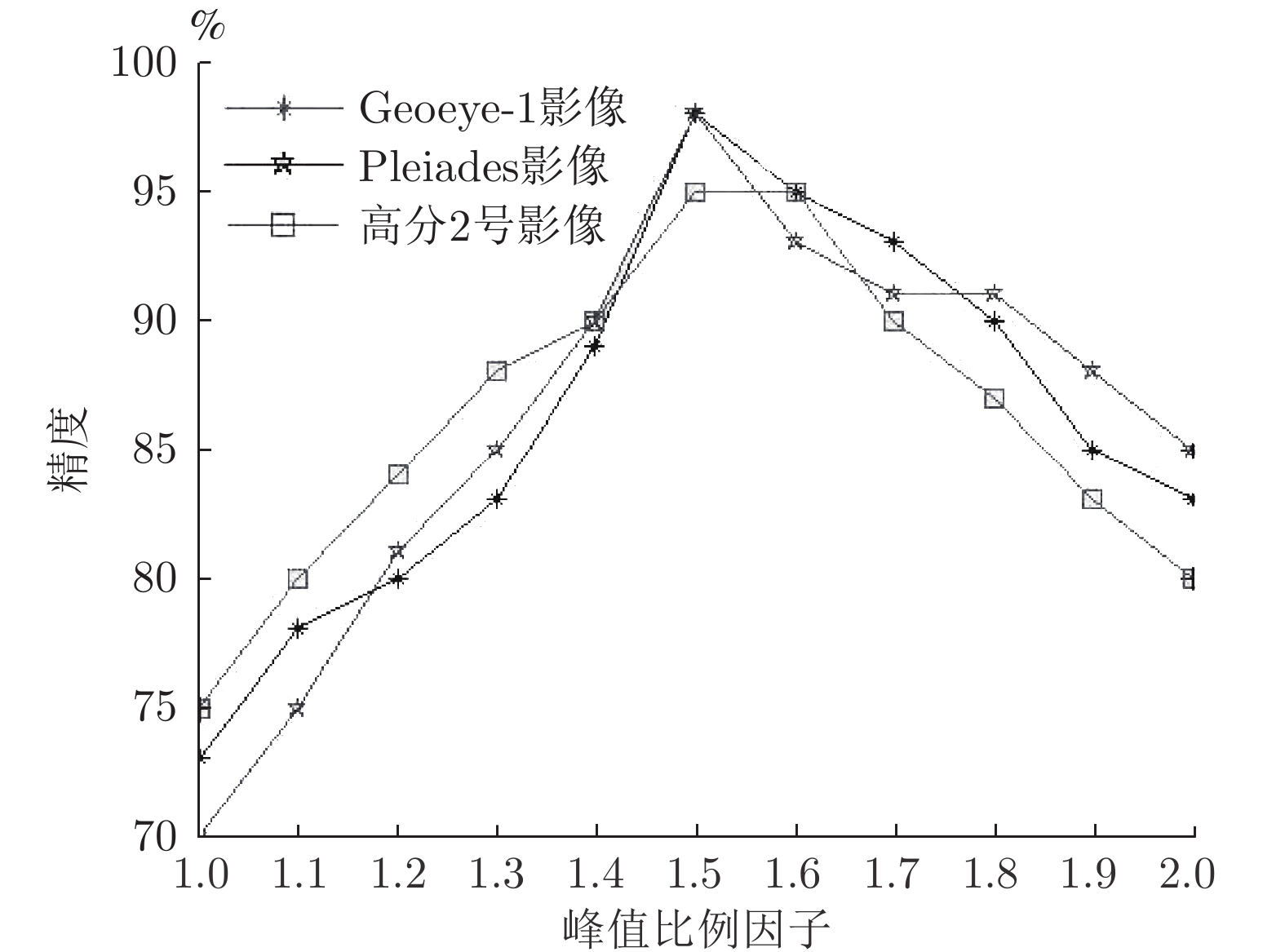
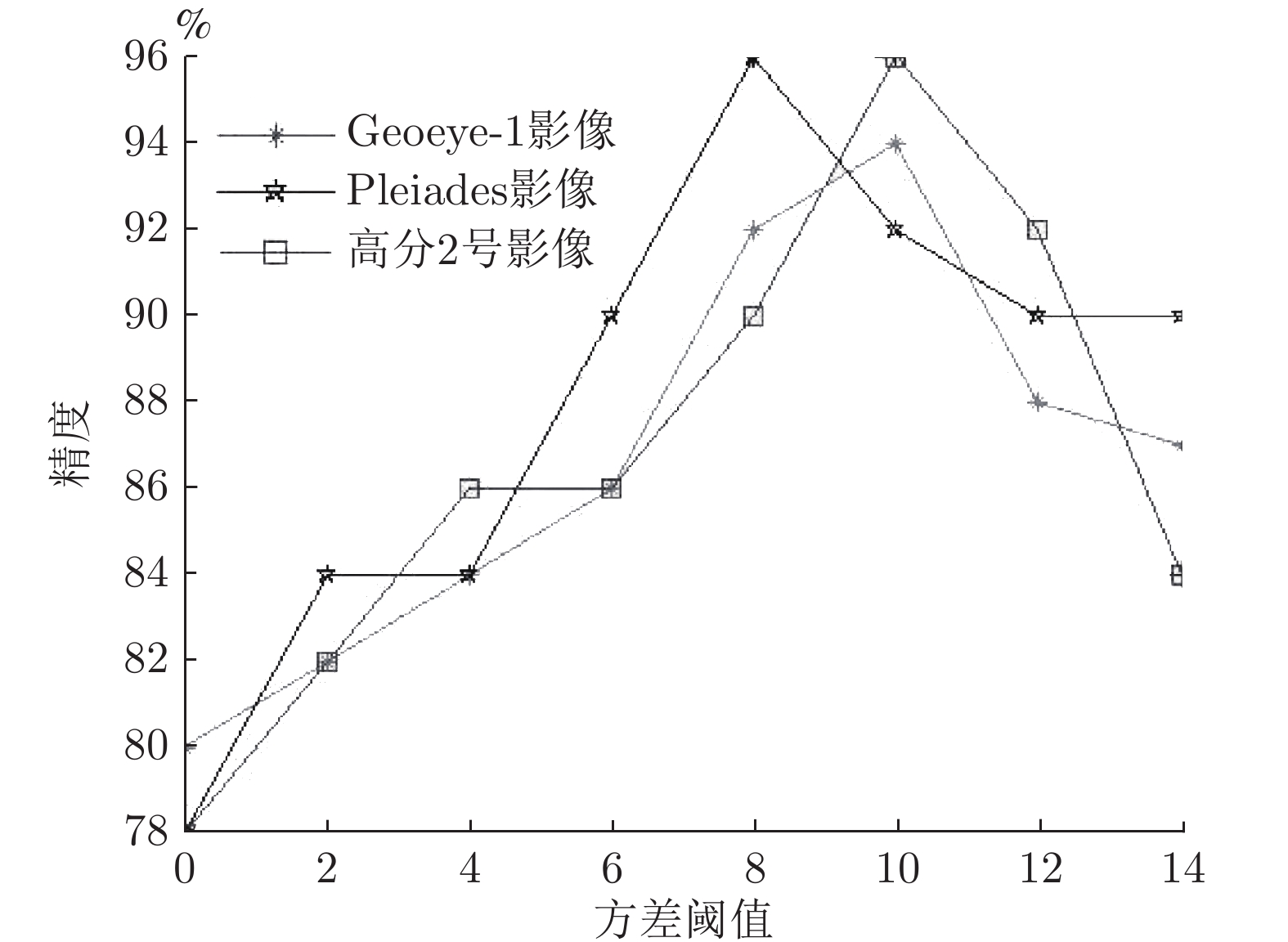
表 1 不同道路提取方法对比
Table 1 Comparison of different methods for road extraction
评价参数 本文方法 Erdas 算法 T 型模板算法 圆型模板算法 实验一 实验二 实验三 实验一 实验二 实验三 实验一 实验二 实验三 实验一 实验二 实验三 完整度 (%) 99.7 99.7 99.6 99.8 99.6 99.7 94.7 99.2 97.4 99.4 99.7 99.1 正确率 (%) 99.5 96.4 99.4 99.6 99.7 99.8 96.4 88.5 99.1 99.5 96.3 98.7 提取质量 (%) 99.2 96.0 99.1 99.4 99.3 99.5 90.8 87.9 96.5 98.9 96.0 97.8 种子点数 (个) 22 6 24 199 62 107 70 34 110 61 13 46 运行时间 (s) 348 102 374 803 259 457 416 152 553 279 116 231  下载: 导出CSV
下载: 导出CSV
-
[1] 曹帆之, 朱述龙, 朱宝山, 李润生, 孟伟灿. 均值漂移与卡尔曼滤波相结合的遥感影像道路中心线追踪算法. 测绘学报, 2016, 45(2): 205−212 doi: 10.11947/j.AGCS.2016.20140610Cao Fan-Zhi, Zhu Shu-Long, Zhu Bao-Shan, Li Run-Sheng, Meng Wei-Can. Tracking road centerlines from remotely sensed imagery using mean shift and Kalman filtering. Acta Geodaetica et Cartographica Sinica, 2016, 45(2): 205−212 doi: 10.11947/j.AGCS.2016.20140610 [2] 戴激光, 杜阳, 方鑫鑫, 王杨, 苗志鹏. 多特征约束的高分辨率光学遥感影像道路提取. 遥感学报, 2018, 22(5): 777−791Dai Ji-Guang, Du Yang, Fang Xin-Xin, Wang Yang, Miao Zhi-Peng. Road extraction method for high resolution optical remote sensing images with multiple feature constraints. Journal of Remote Sensing, 2018, 22(5): 777−791 [3] Vosselman G, De Knecht J. Road tracing by profile matching and kaiman filtering. Automatic Extraction of Man-made Objects from Aerial and Space Images. Basel: Birkhäuser, 1995. 265−274 [4] Blaschke T, Hay G J, Weng Q H, Resch B. Collective sensing: Integrating geospatial technologies to understand urban systems–An overview. Remote Sensing, 2011, 3(8): 1743−1776 doi: 10.3390/rs3081743 [5] Blaschke T, Hay G J, Kelly M, Lang S, Hofmann P, Addink E, et al. Geographic object-based image analysis-towards a new paradigm. ISPRS Journal of Photogrammetry and Remote Sensing, 2014, 87: 180−191 doi: 10.1016/j.isprsjprs.2013.09.014 [6] Talbot H, Appleton B. Efficient complete and incomplete path openings and closings. Image and Vision Computing, 2007, 25(4): 416−425 doi: 10.1016/j.imavis.2006.07.021 [7] Schubert H, Van De Gronde J J, Roerdink J B T M. Efficient computation of greyscale path openings. Mathematical Morphology - Theory and Applications, 2016, 1: 189−202 [8] 戴激光, 苗志鹏, 葛连茂, 王晓桐, 朱婷婷. 结合路径形态学的高分遥感影像道路提取方法. 遥感信息, 2019, 34(1): 28−35 doi: 10.3969/j.issn.1000-3177.2019.01.005Dai Ji-Guang, Miao Zhi-Peng, Ge Lian-Mao, Wang Xiao-Tong, Zhu Ting-Ting. Road extraction method based on path morphology for high resolution remote sensing imagery. Remote Sensing Information, 2019, 34(1): 28−35 doi: 10.3969/j.issn.1000-3177.2019.01.005 [9] Hu X Y, Zhang Z X, Zhang J Q. An approach of semiautomated road extraction from aerial image based on template matching and neural network. In: Proceedings of the 19th International Archives of Photogrammetry and Remote Sensing. Amsterdam, Netherlands: Amsterdam University, 2000. 994−999 [10] Leninisha S, Vani K. Water flow based geometric active deformable model for road network. ISPRS Journal of Photogrammetry and Remote Sensing, 2015, 102: 140−147 doi: 10.1016/j.isprsjprs.2015.01.013 [11] 孙晨阳, 周廷刚, 陈圣波, 沈敬伟, 王骏飞, 杨桦. 基于矩形模板匹配的线状地物半自动提取方法研究. 西南大学学报(自然科学版), 2015, 37(7): 155−160Sun Chen-Yang, Zhou Ting-Gang, Chen Sheng-Bo, Shen Jing-Wei, Wang Jun-Fei, Yang Hua. Research of a semi-automatic extraction method for linear features based on rectangular template matching. Journal of Southwest University (Natural Science Edition), 2015, 37(7): 155−160 [12] 林祥国, 张继贤, 李海涛, 杨景辉. 基于T型模板匹配半自动提取高分辨率遥感影像带状道路. 武汉大学学报·信息科学版, 2009, 34(3): 293−296Lin Xiang-Guo, Zhang Ji-Xian, Li Hai-Tao, Yang Jing-Hui. Semi-automatic extraction of ribbon road from high resolution remotely sensed imagery by a T-shaped template matching. Geomatics and Information Science of Wuhan University, 2009, 34(3): 293−296 [13] Xu C Y, Prince J L. Gradient vector flow: A new external force for snakes. In: Proceedings of the 1997 IEEE Computer Society Conference on Computer Vision and Pattern Recognition. San Juan, USA: IEEE, 1997. 66−71 [14] Li C M, Kao C Y, Gore J C, Ding Z H. Minimization of region-scalable fitting energy for image segmentation. IEEE Transactions on Image Processing, 2008, 17(10): 1940−1949 doi: 10.1109/TIP.2008.2002304 [15] 唐伟, 赵书河. 基于GVF和Snake模型的高分辨率遥感图像四元数空间道路提取. 遥感学报, 2011, 15(5): 1040−1052 doi: 10.11834/jrs.2011239Tang Wei, Zhao Shu-He. Road extraction in quaternion space from high spatial resolution remotely sensed images basing on GVF Snake model. Journal of Remote Sensing, 2011, 15(5): 1040−1052 doi: 10.11834/jrs.2011239 [16] Nakaguro Y, Makhanov S S, Dailey M N. Numerical experiments with cooperating multiple quadratic snakes for road extraction. International Journal of Geographical Information Science, 2011, 25(5): 765−783 doi: 10.1080/13658816.2010.498377 [17] Sethian J A. A fast marching level set method for monotonically advancing fronts. Proceedings of the National Academy of Sciences of the United States of America, 1996, 93(4): 1591−1595 doi: 10.1073/pnas.93.4.1591 [18] 吴学文, 徐涵秋. 一种基于水平集方法提取高分辨率遥感影像中主要道路信息的算法. 宇航学报, 2010, 31(5): 1495−1502 doi: 10.3873/j.issn.1000-1328.2010.05.038Wu Xue-Wen, Xu Han-Qiu. Level set method major roads information extract from high-resolution remote-sensing imagery. Journal of Astronautics, 2010, 31(5): 1495−1502 doi: 10.3873/j.issn.1000-1328.2010.05.038 [19] 龚健雅, 季顺平. 摄影测量与深度学习. 测绘学报, 2018, 47(6): 693−704 doi: 10.11947/j.AGCS.2018.20170640Gong Jian-Ya, Ji Shun-Ping. Photogrammetry and deep learning. Acta Geodaetica et Cartographica Sinica, 2018, 47(6): 693−704 doi: 10.11947/j.AGCS.2018.20170640 [20] Alshehhi R, Marpu P R. Hierarchical graph-based segmentation for extracting road networks from high-resolution satellite images. ISPRS Journal of Photogrammetry and Remote Sensing, 2017, 126: 245−260 doi: 10.1016/j.isprsjprs.2017.02.008 [21] Cheng G L, Wang Y, Xu S B, Wang H Z, Xiang S M, Pan C H. Automatic road detection and centerline extraction via cascaded end-to-end convolutional neural network. IEEE Transactions on Geoscience and Remote Sensing, 2017, 55(6): 3322−3337 doi: 10.1109/TGRS.2017.2669341 [22] Zhang Z X, Liu Q J, Wang Y H. Road extraction by deep residual U-Net. IEEE Geoscience and Remote Sensing Letters, 2018, 15(5): 749−753 doi: 10.1109/LGRS.2018.2802944 [23] 刘如意, 宋建锋, 权义宁, 许鹏飞, 雪晴, 杨云, 等. 一种自动的高分辨率遥感影像道路提取方法. 西安电子科技大学学报(自然科学版), 2017, 44(1): 100−105Liu Ru-Yi, Song Jian-Feng, Quan Yi-Ning, Xu Peng-Fei, Xue Qing, Yang Yun, et al. Automatic road extraction method for high-resolution remote sensing images. Journal of Xidian University, 2017, 44(1): 100−105 [24] Cardim G P, Da Silva E A, Dias M A, Bravo I, Gardel A. Statistical evaluation and analysis of road extraction methodologies using a unique dataset from remote sensing. Remote Sensing, 2018, 10(4): Article No. 620 [25] 戴激光, 张力, 李晋威, 方鑫鑫. 一种链码跟踪与相位验证相结合的直线提取方法. 测绘学报, 2017, 46(2): 218−227 doi: 10.11947/j.AGCS.2017.20160303Dai Ji-Guang, Zhang Li, Li Jin-Wei, Fang Xin-Xin. A line extraction method for chain code tracking with phase verification. Acta Geodaetica et Cartographica Sinica, 2017, 46(2): 218−227 doi: 10.11947/j.AGCS.2017.20160303 [26] 谭仁龙, 万幼川, 袁芳, 李刚. 基于圆形模板的高分辨率遥感影像道路半自动提取. 测绘通报, 2014(10): 63−66Tan Ren-Long, Wan You-Chuan, Yuan Fang, Li Gang. Semi-automatic road extraction of high resolution remote sensing images based on circular template. Bulletin of Surveying and Mapping, 2014(10): 63−66 [27] 胡翔云, 张祖勋, 张剑清. 航空影像上线状地物的半自动提取. 中国图象图形学报, 2002, 7(2): 137−140 doi: 10.3969/j.issn.1006-8961.2002.02.008Hu Xiang-Yun, Zhang Zu-Xun, Zhang Jian-Qing. Semiautomatic extraction of linear object form aerial image. Journal of Image and Graphics, 2002, 7(2): 137−140 doi: 10.3969/j.issn.1006-8961.2002.02.008 [28] Miao Z L, Wang B, Shi W Z, Zhang H. A semi-automatic method for road centerline extraction from VHR images. IEEE Geoscience and Remote Sensing Letters, 2014, 11(11): 1856−1860 doi: 10.1109/LGRS.2014.2312000 [29] Yang Y, Zhu C Q. Extracting road centrelines from high-resolution satellite images using active window line segment matching and improved SSDA. International Journal of Remote Sensing, 2010, 31(9): 2457−2469 doi: 10.1080/01431160903019288 [30] 余洁, 余峰, 张晶, 刘振宇. 结合区域生长与道路基元的高分辨率遥感影像道路提取. 武汉大学学报·信息科学版, 2013, 38(7): 761−764Yu Jie, Yu Feng, Zhang Jing, Liu Zhen-Yu. High resolution remote sensing image road extraction combining region growing and road-unit. Geomatics and Information Science of Wuhan University, 2013, 38(7): 761−764 [31] 连仁包, 王卫星, 李娟. 自适应圆形模板及显著图的高分辨遥感图像道路提取. 测绘学报, 2018, 47(7): 950−958 doi: 10.11947/j.AGCS.2018.20170596Lian Ren-Bao, Wang Wei-Xing, Li Juan. Road extraction from high-resolution remote sensing images based on adaptive circular template and saliency map. Acta Geodaetica et Cartographica Sinica, 2018, 47(7): 950−958 doi: 10.11947/j.AGCS.2018.20170596 [32] Wiedemann C, Ebner H. Automatic completion and evaluation of road networks. In: Proceedings of the 19th International Archives of Photogrammetry and Remote Sensing. Amsterdam: ISPRS, 2000. 979−986 -


 下载:
下载:












计量
- 文章访问数: 1109
- HTML全文浏览量: 421
- PDF下载量: 261
- 被引次数: 0
