

Unsupervised Cross-domain Object Detection Based on Progressive Multi-source Transfer
-
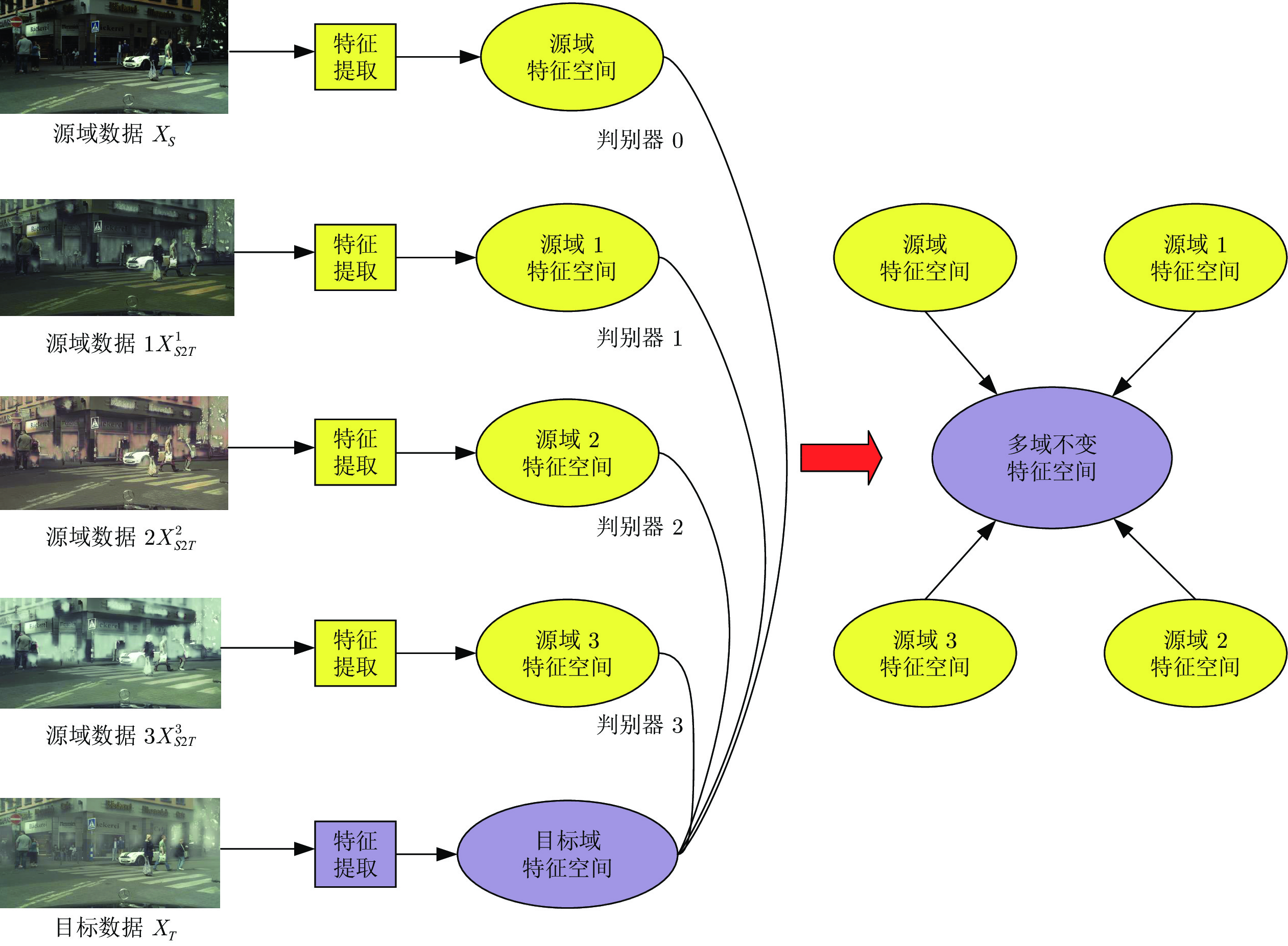
摘要: 针对目标检测任务中获取人工标注训练样本的困难, 提出一种在像素级与特征级渐进完成域自适应的无监督跨域目标检测方法. 现有的像素级域自适应方法中, 存在翻译图像风格单一、内容结构不一致的问题. 因此, 将输入图像分解为域不变的内容空间及域特有的属性空间, 综合不同空间表示进行多样性的图像翻译, 同时保留图像的空间语义结构以实现标注信息的迁移. 此外, 对特征级域自适应而言, 为缓解单源域引起的源域偏向问题, 将得到的带有标注的多样性翻译图像作为多源域训练集, 设计基于多领域的对抗判别模块, 从而获取多个领域不变的特征表示. 最后, 采用自训练方案迭代生成目标域训练集伪标签, 以进一步提升模型在目标域上的检测效果. 在Cityscapes & Foggy Cityscapes与VOC07 & Clipart1k数据集上的实验结果表明, 相比现有的无监督跨域检测算法, 该检测框架具更优越的迁移检测性能.Abstract: To address the difficulty of collecting manually labeled training samples for object detection tasks, this paper proposes an unsupervised cross-domain object detection method that gradually adapts the model at pixel level and feature level. The existing pixel-level domain adaptive methods generate translated images with a single style and inconsistent content structure. To solve this problem, this paper embeds the input images into domain-invariant content space and domain-specific attribute space, then cooperates different space representations to synthesize diverse translated images that preserve the spatial semantic information to enable label transfer. In addition, for feature-level domain adaptation, to alleviate the source-bias problem caused by single source domain, we treat the generated diverse labeled images as source domain data and design a multi-domain discriminator to get multi-domain-invariant representations. Finally, To further enhance the detection performance on the target domain, we propose a self-training framework to alternatively generate pseudo labels on target training data. The exploratory experiment results from the Cityscapes & Foggy Cityscapes dataset and VOC07 & Clipart1k dataset demonstrate that compared with the current unsupervised cross-domain detection methods, the proposed detection framework achieves better transferability.
-
Key words:
- Transfer learning /
- domain adaptation /
- object detection /
- multi-source domain /
- self training
-

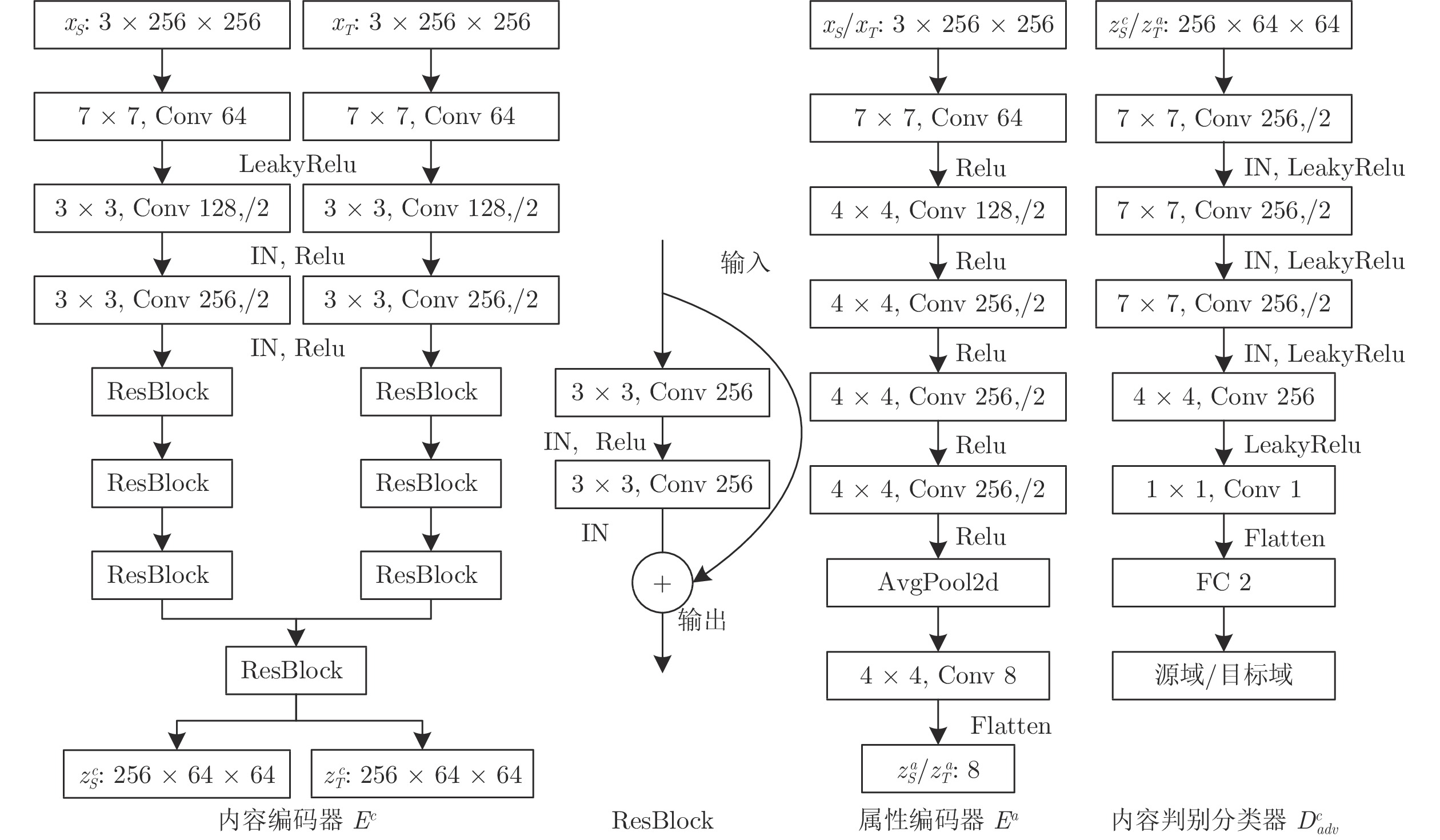
图 4 分解表示所采用模块网络结构
Fig. 4 Modular network structures used in the disentangled representation framework

图 5 图像翻译中采用的生成器与判别器网络结构
Fig. 5 Network structures of the generator and the discriminator used in image-to-image translation
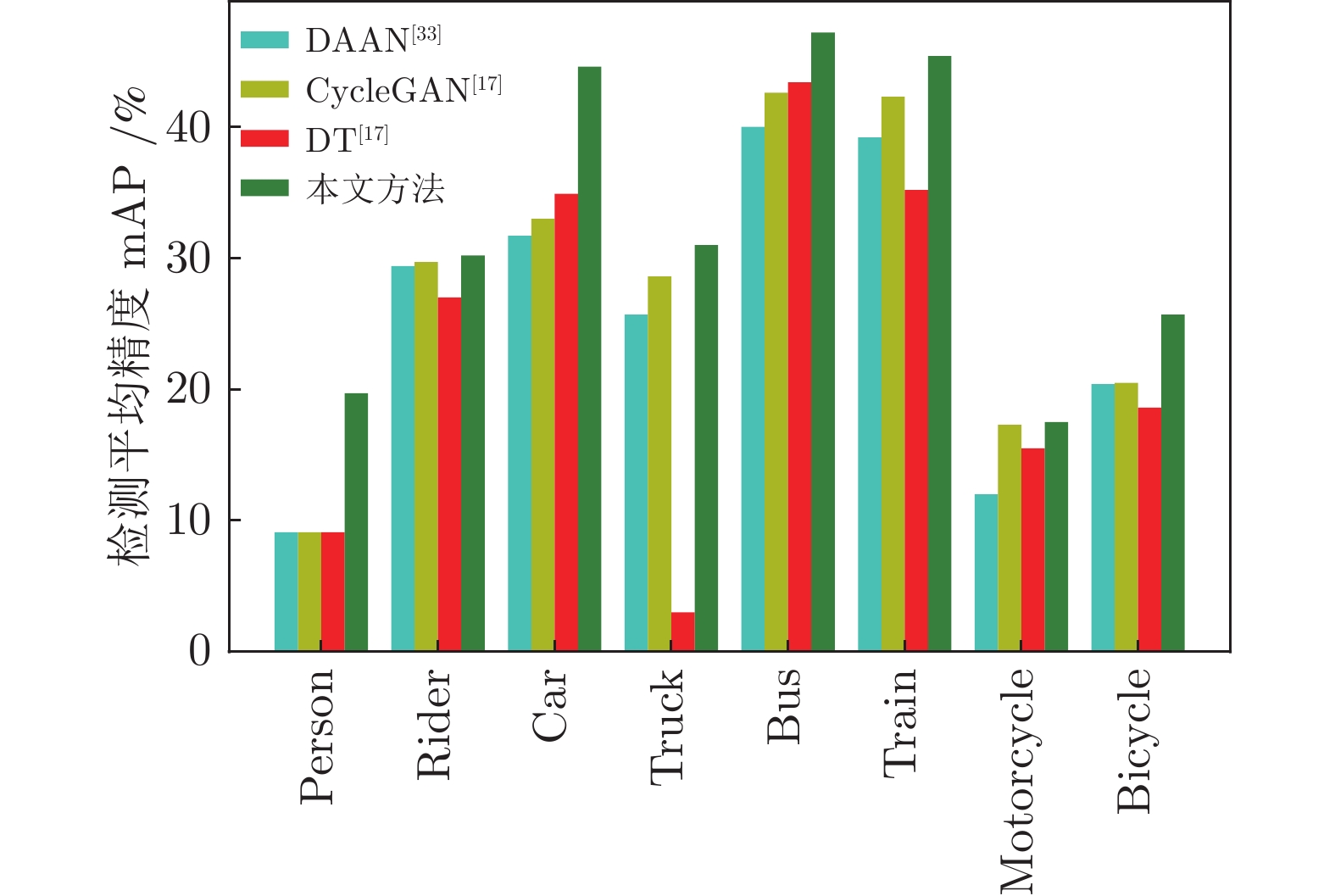
图 7 在Cityscapes
$ \rightarrow $ Foggy Cityscapes实验中不同方法在所有8个类别上的mAP表现Fig. 7 Percategory mAP performance of different approaches over all the 8 categories on the experimentCityscapes
$ \rightarrow $ Foggy Cityscapes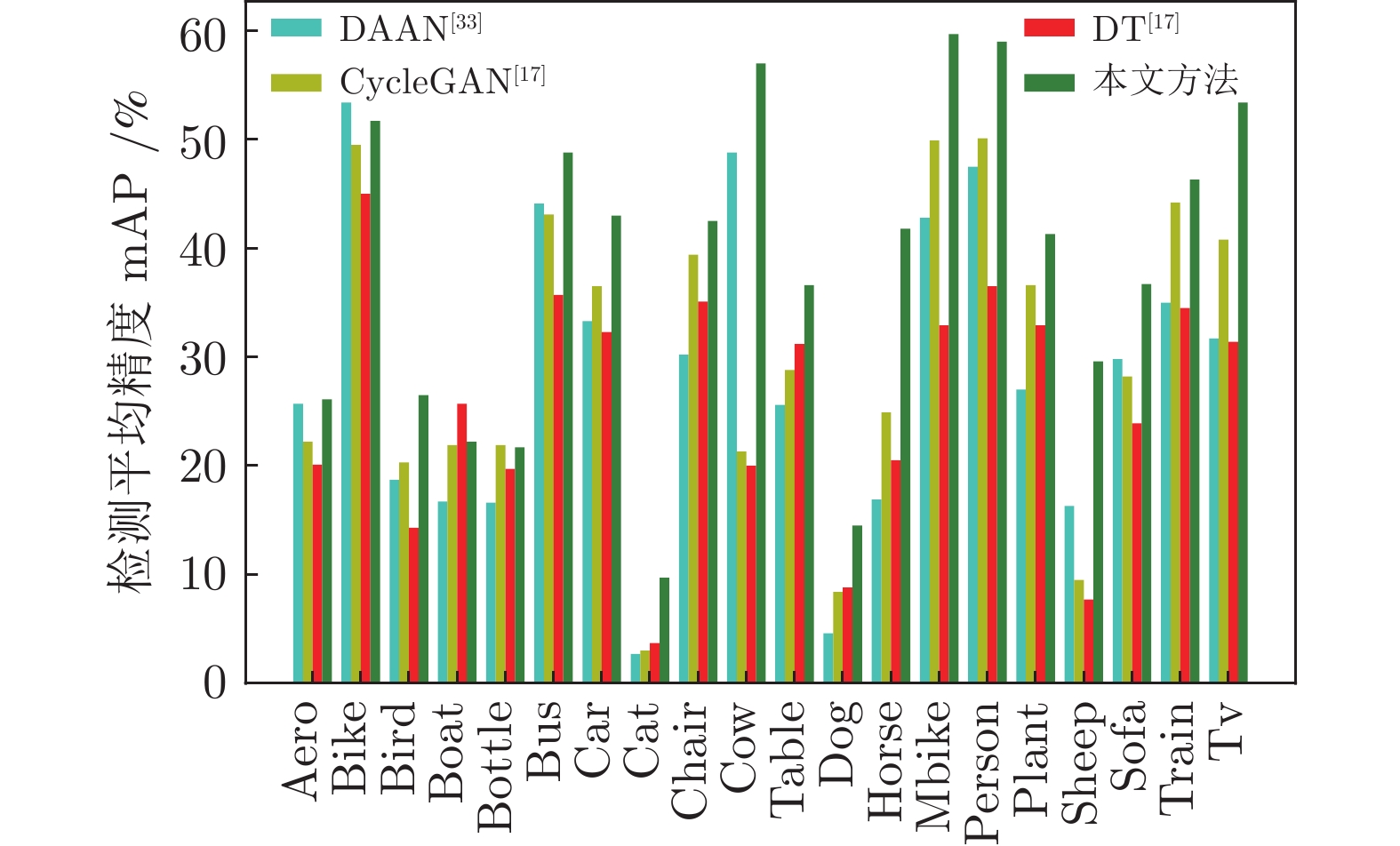
图 8 在VOC07
$ \rightarrow $ Clipart1k实验中不同方法在所有20个类别上的mAP表现Fig. 8 Percategory mAP performance of differentapproaches over all the 20 categories on the experiment VOC07
$ \rightarrow $ Clipart1k
图 9 多种方法在Cityscapes
$ \rightarrow $ Foggy Cityscapes实验中检测结果对比Fig. 9 Comparison of different detection methods in the Cityscapes
$ \rightarrow $ Foggy Cityscapes experiment
图 10 不同方法在VOC07
$\rightarrow$ Clipart1k实验中检测结果对比Fig. 10 Comparison of different detection methods in the VOC07
$ \rightarrow $ Clipart1k experiment表 1 不同目标检测方法mAP性能对比 (%)
Table 1 Comparison of different detection methods on performance of mAP (%)
 下载: 导出CSV
下载: 导出CSV
表 2 在 Cityscapes
$ \rightarrow $ Foggy Cityscapes 实验中基于Faster R-CNN 的不同跨域检测方法性能对比 (%)Table 2 Comparison of different cross-domain detection methods based on Faster R-CNN detector in Cityscapes
$ \rightarrow $ Foggy Cityscapes (%)方法 Person Rider Car Truck Bus Train Motorcycle Bicycle mAP 基线方法 (Faster R-CNN) 24.7 31.7 33.0 11.5 24.4 9.5 15.9 28.9 22.5 域自适应 Faster R-CNN[19] 25.0 31.0 40.5 22.1 35.3 20.2 20.0 27.1 27.6 DT[17] 25.4 39.3 42.4 24.9 40.4 23.1 25.9 30.4 31.5 选择性跨域对齐[21] 33.5 38.0 48.5 26.5 39.0 23.3 28.0 33.6 33.8 多对抗超快速区域卷积网络[23] 28.2 39.5 43.9 23.8 39.9 33.3 29.2 33.9 34.0 强弱分布对齐[20] 29.9 42.3 43.5 24.5 36.2 32.6 30.0 35.3 34.3 域自适应表示学习[18] 30.8 40.5 44.3 27.2 38.4 34.5 28.4 32.2 34.6 一致性教师客体关系[22] 30.6 41.4 44.0 21.9 38.6 40.6 28.3 35.6 35.1 多层域自适应[24] 33.2 44.2 44.8 28.2 41.8 28.7 30.5 36.5 36.0 加噪标签[26] 35.1 42.1 49.2 30.1 45.3 26.9 26.8 36.0 36.5 像素级 + 多域特征对齐 (联合训练) 32.3 42.5 49.1 26.5 44.6 32.8 31.5 35.6 36.9 像素级对齐 33.1 43.0 49.4 28.0 43.3 35.2 35.4 36.3 38.0 多域特征对齐 33.0 43.8 48.5 26.7 45.2 44.6 30.8 37.0 38.7 像素级 + 多域特征对齐 + 自训练 35.7 45.6 51.7 31.0 47.0 41.4 30.3 36.7 39.9 全监督 35.4 47.1 52.4 29.6 42.7 46.3 33.8 38.4 40.7
下载: 导出CSV
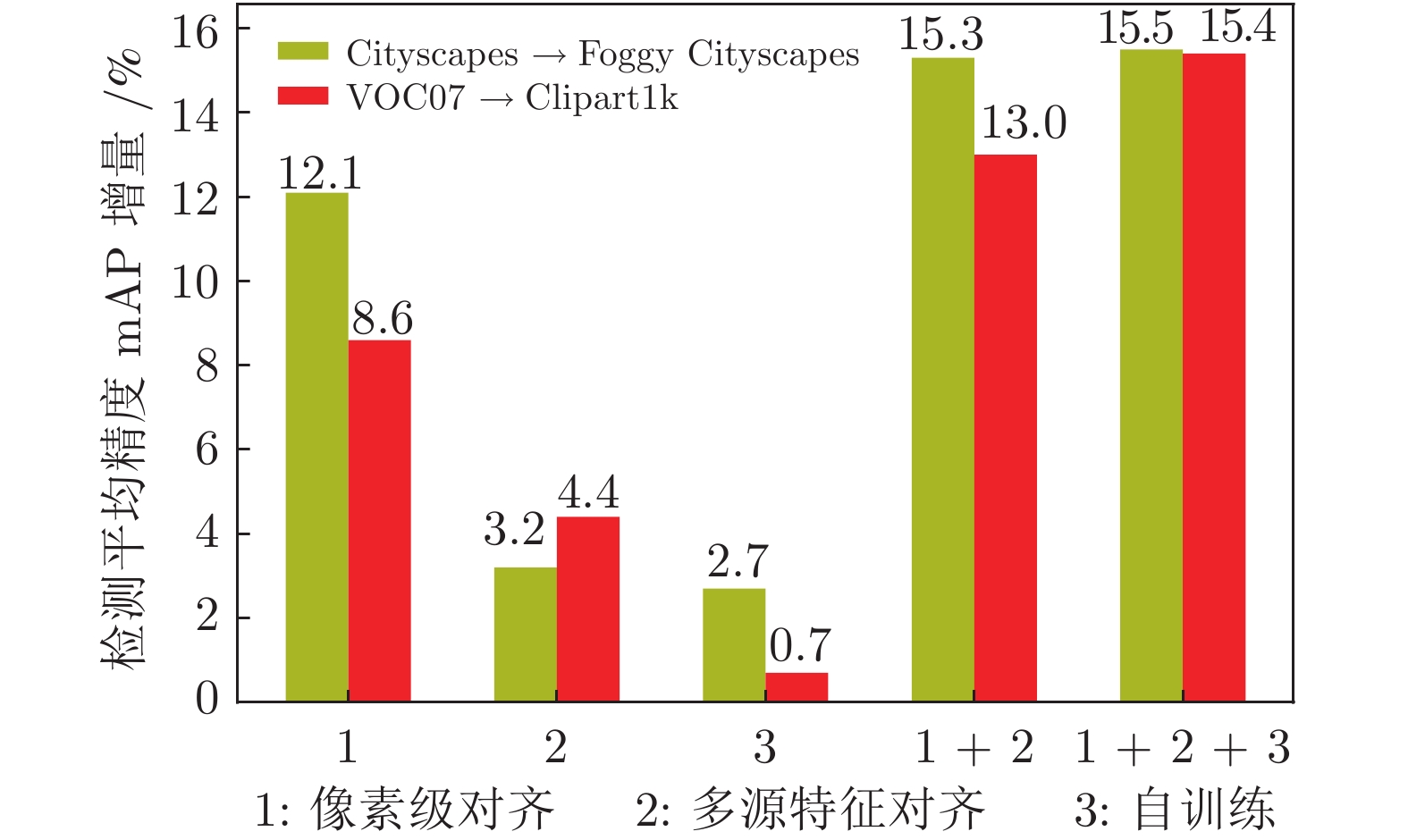
表 3 在Cityscapes
$\rightarrow $ Foggy Cityscapes实验中源域数量$M$ 对检测性能的影响 (%)Table 3 Impact of the number of source domains
$M$ on the detection performance in Cityscapes$\rightarrow $ Foggy Cityscapes (%)M 0 1 2 3 像素级对齐 mAP 17.4 27.3 28.9 29.5 多源域特征对齐 mAP 17.4 29.6 30.3 32.7
下载: 导出CSV
表 4 Cityscapes
$\rightarrow $ Foggy Cityscapes实验中属性特征对检测性能的影响 (%)Table 4 Impact of attribute features on the detection performance in Cityscapes
$ \rightarrow$ Foggy Cityscapes (%)方法 框架 mAP 像素级对齐 (随机属性) SSD 29.0 像素级对齐 SSD 29.5 多源域特征对齐 (随机属性) SSD 31.6 多源域特征对齐 SSD 32.7 像素级对齐 (随机属性) Faster R-CNN 34.7 像素级对齐 Faster R-CNN 38.0 多源域特征对齐 (随机属性) Faster R-CNN 36.5 多源域特征对齐 Faster R-CNN 38.7
下载: 导出CSV
表 5 在VOC07
$ \rightarrow$ Clipart1k实验中参数$ \lambda $ 的敏感性分析 (%)Table 5 Sensitivity analysis of
$ \lambda $ in VOC07$\rightarrow $ Clipart1k (%)$\lambda$ 0.1 0.5 1.0 1.5 2.0 mAP 34.0 36.1 36.3 36.1 35.7
下载: 导出CSV
表 6 在VOC07
$ \rightarrow$ Clipart1k实验中阈值$ \theta $ 的敏感性分析 (%)Table 6 Sensitivity analysis of
$ \theta $ in VOC07$\rightarrow $ Clipart1k (%)$ \theta $ 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 第 1 轮 mAP 37.8 38.3 38.1 37.8 37.7 37.2 36.2 35.7 35.0 第 2 轮 mAP − − 38.0 38.3 38.4 38.6 38.6 38.3 38.4 第 3 轮 mAP − − − − − − 38.6 38.3 38.4
下载: 导出CSV
-
[1] Liu L, Ouyang W L, Wang X A, Paul W. F, Jie C, Liu X W, et al. Deep learning for generic object detection: A survey. arXiv preprint, 2018, arXiv: 1809.02165 [2] 张慧, 王坤峰, 王飞跃. 深度学习在目标视觉检测中的应用进展与展望. 自动化学报, 2017, 43(8): 1289−1305Zhang Hui, Wang Kun-Feng, Wang Fei-Yue. Advances andperspectives on applications of deep learning in visual objectdetection. Acta Automatica Sinica, 2017, 43(8): 1289−1305 [3] Krizhevsky A, Sutskever I, Hinton G E. ImageNet classification with deep convolutional neural networks. In: Proceedings of the 25th International Conference on Neural Information Processing Systems (NIPS), Lake Tahoe, USA: IEEE, 2012. 1097−1105 [4] Girshick R, Donahue J, Darrell T, Malik J. Rich feature hierarchies for accurate object detection and semantic segmentation. In: Proceedings of the 2014 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Columbus, USA: IEEE, 2014. 580−587 [5] Girshick R. Fast R-CNN. In: Proceedings of the 2015 IEEE International Conference on Computer Vision (ICCV), Santiago, Chile: 2015. 1440−1448 [6] Ren S Q, He K M, Girshick R, Sun J. Faster R-CNN: Towards real-time object detection with region proposal networks, In: Proceedings of the 28th International Conference on Neural Information Processing Systems (NIPS), Montreal, Canada: IEEE, 2015. 91−99 [7] Redmon J, Farhadi A. YOLOv3: An incremental improvement. arXiv preprint, 2018, arXiv: 1804.02767 [8] Liu W, Anguelov D, Erhan D, Szegedy C, Reed E, Fu C Y, et al. SSD: Single shot multi-box detector. In: Proceedings of the 14th European Conference on Computer Vision (ECCV). Amsterdam, Netherlands: Springer International Publishing, 2016. 21−37 [9] Cordts M, Omran M, Ramos S, Rehfeld T, Enzweiler N, Benenson R, et al. The Cityscapes dataset for semantic urban scene understanding. In: Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, USA: IEEE Computer Society, 2016. 3213−3223 [10] Sakaridis C, Dai D X, Gool L V. Semantic foggy scene understanding with synthetic data. International Journal of Computer Vision(IJCV). 2018, 126(9): 973−992 doi: 10.1007/s11263-018-1072-8 [11] Li D, Huang J B, Li Y L, Wang S J, Yang M H. Weakly supervised object localization with progressive domain adaptation. In: Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition. Amsterdam, Netherland: 2016. 3512− 3520 [12] Bilen H, Vedaldi A. Weakly supervised deep detection networks. In: Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition. Amsterdam, Netherland: 2016. 2846− 2854 [13] 张雪松, 庄严, 闫飞, 王伟. 基于迁移学习的类别级物体识别与检测研究与进展. 自动化学报, 2019, 45(7):1224−1243Zhang Xue-Song, Zhuang Yan, Yan Fei, Wang Wei. Status and development of transfer learning basedcategory-level object recognition and detection. Acta Automatica Sinica, 2019, 45(7): 1224−1243 [14] Sun B C, Feng J S, Saenko K. Return of frustratingly easy domain adaptation. In: Proceedings of the 2016 Thirtieth AAAI Conference on Artificial Intelligence, Phoenix, Arizona, USA: AAAI Press, 2016. 2058−2065 [15] Long M S, Cao Y, Wang J M, Jordan M. Learning transferable features with deep adaptation networks. In: Proceedings of the 32nd International Conference on Machine Learning. Lille, France: 2015. 97−105 [16] Peng X C, Usman B, Saito K, Kaushik N, Hoffman J, Saenko K. Syn2Real: A new benchmark for synthetic-to-real visual domain adaptation. arXiv preprint, 2018, arXiv: 1806.09755 [17] Inoue N, Furuta R, Yamasak T, Aizawa K. Cross-Domain weakly-supervised object detection through progressive domain adaptation. In: Proceedings of the 2018 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, USA: 2018. 5001−5009 [18] Kim T, Jeong M K, Kim S, Choi S, Kim C. Diversify and match: A domain adaptive representation learning paradigm for object detection. In: Proceedings of the 2019 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, USA: 2019. 12456−12465 [19] Chen Y H, Li W, Sakaridis C, Dai D X, Gool L V. Domain adaptive faster R-CNN for object detection in the wild. In: Proceedings of the 2018 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, USA: 2018. 3339− 3348 [20] Saito K, Ushiku Y, Harada T, Saenko K. Strong-weak distribution alignment for adaptive object detection. In: Proceedings of the 2019 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, USA: 2019. 6956−6965 [21] Zhu X G, Pang J M, Yang C Y, Shi J P, Lin D H. Adapting object detectors via selective cross-domain alignment. In: Proceedings of the 2019 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, USA: 2019. 687−696 [22] Cai Q, Pan Y W, Ngo C W, Tian X M, Duan L Y, Yao T. Exploring object relation in mean teacher for cross-domain detection. In: Proceedings of the 2019 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, USA: 2019. 11457−11466 [23] He Z W, Zhang L. Multi-adversarial faster-RCNN for unrestricted object detection. In: Proceedings of the 2019 IEEE International Conference on Computer Vision Workshops, Seoul, South Korea: 2019. 6667−6676 [24] Xie R C, Yu F, Wang J C, Wang Y Z, Zhang L. Multi-level domain adaptive learning for cross-domain detection. In: Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision Workshops. Seoul, South Korea: 2019. 3213−3219 [25] Wang T, Zhang Y P, Yuan L, Feng J S. Few-shot adaptive faster R-CNN. In: Proceedings of the 2019 IEEE Conference on Computer Vision and Pattern Recognition. Long Beach, USA: 2019. 7173−7182 [26] Khodabandeh M, Vahdat A, Ranjbar M, Macready W G. A robust learning approach to domain adaptive object detection. In: Proceedings of the 2019 IEEE International Conference on Computer Vision Workshops. Seoul, South Korea: 2019. 480−490 [27] Wang X D, Cai Z W, Gao D S, Vasconcelos N. Towards universal object detection by domain attention. In: Proceedings of the 2019 IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, USA: 2019. 7289−7298 [28] Zhu J Y, Park T, Isola P, Efros A. Unpaired Image-to-Image translation using cycle-consistent adversarial networks. In: Proceedings of the 2017 IEEE International Conference on Computer Vision. Venice, Italy: 2017. 2242−2251 [29] Goodfellow I J, Pouget-Abadie J, Mehdi M, Bing X, David W F, Sherjil O, et al. Generative adversarial nets. In: Proceedings of the 27th International Conference on Neural Information Processing Systems, Montreal, Canada: 2014. 2672−2680 [30] Simonyan K, Zisserman A. Very deep convolutional networks for large-scale image recognition. arXiv preprint, 2014, arXiv: 1409.1556 [31] Lee H Y, Tseng H Y, Huang J B, Singh M, Yang M H. Diverse image-to-image translation via disentangled representations. In: Proceedings of the Proceedings of the 2018 European Conference on Computer Vision. Munich, Germany: 2018. 36−52 [32] Ulyanov D, Vedaldi D, Lempitsky V. Improved texture networks: Maximizing quality and diversity in feed-forward stylization and texture synthesis. In: Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition. Honolulu, USA: 2017. 4105−4113 [33] Ganin Y, Ustinova E, Ajakan H, Germain P, Larochelle H, Laviolette F, et al. Domain-adversarial training of neural networks. In: Proceedings of the 2017 Domain Adaptation in Computer Vision Applications. Cham, Switzerland: 2017. 189−209 [34] Zhao H, Zhang S H, Wu G H, Moura J, Costeira J P, Gordon G J. Adversarial multiple source domain adaptation. In: Proceedings of the 31st International Conference on Neural Information Processing Systems. Montreal, Canada: 2018. 8568−8579 [35] Ioffe S, Szegedy C. Batch normalization: Accelerating deep network training by reducing internal covariate shift. In: Proceedings of the 32nd International Conference on Machine Learning. Lille, France: 2015. 448−456 [36] Everingham M, Gool L J, Williams C, Winn J, Zisserman A. Semantic the pascal visual object classes (VOC) Challenge. International Journal of Computer Vision(IJCV). 2010, 88(2): 303−338 doi: 10.1007/s11263-009-0275-4 [37] Diederik P K, Jimmy B. Adam: A method for stochastic optimization. arXiv preprint, 2014, arXiv: 1412.6980 -

 下载:
下载:



























计量
- 文章访问数: 1976
- HTML全文浏览量: 491
- PDF下载量: 352
- 被引次数: 0
