

The State of the Art and Prospects of Lip Reading
-
摘要: 唇读, 也称视觉语言识别, 旨在通过说话者嘴唇运动的视觉信息, 解码出其所说文本内容. 唇读是计算机视觉和模式识别领域的一个重要问题, 在公共安防、医疗、国防军事和影视娱乐等领域有着广泛的应用价值. 近年来, 深度学习技术极大地推动了唇读研究进展. 本文首先阐述了唇读研究的内容和意义, 并深入剖析了唇读研究面临的难点与挑战; 然后介绍了目前唇读研究的现状与发展水平, 对近期主流唇读方法进行了梳理、归类和评述, 包括传统方法和近期的基于深度学习的方法; 最后, 探讨唇读研究潜在的问题和可能的研究方向. 以期引起大家对唇读问题的关注与兴趣, 并推动与此相关问题的研究进展.Abstract: Lip reading, also known as visual speech recognition, aims to infer the content of a speech through the motion of the speaker´s mouth. Lip reading is an important issue in the field of computer vision and pattern recognition. It has a wide range of applications in the fields of public security, medical, defense military and professional filming. In recent years, deep learning technology has greatly promoted the progress of lip reading research. Starting from the definition of lip reading problem, this paper first expounds the content and significance of lip reading research, and deeply analyzes the difficulties and challenges of lip reading research. Then, the recent achievements of lip reading research are introduced, and the current mainstream lip reading methods are combed, categorized and reviewed as well, including traditional methods and recent methods based on deep learning. Finally, the potential problems and possible research directions of lip reading research are discussed to arouse the attention and interest of this research, and promote the research progress of related issues.
-

图 2 唇读难点示例. (a)第一行为单词place的实例, 第二行为单词please的实例, 唇形变化难以区分, 图片来自GRID数据集; (b)上下两行分别为单词wind在不同上下文环境下的不同读法/wind/与/waind/实例, 唇形变化差异较大; (c)上下两行分别为两位说话人说同一个单词after的实例, 唇形变化存在差异, 图片来自LRS3-TED数据集; (d)说话人在说话过程中头部姿态实时变化实例. 上述对比实例均采用相同的视频时长和采样间隔.
Fig. 2 Challenging examples of lip reading. (a) The upper line is an instance of the word place, the lower line is an instance of the word please; (b) The upper and lower lines are respectively different pronunciation of word wind in different contexts; (c) The upper and lower lines respectively tell the same word after, with big difference in lip motion; (d) An example of a real-time change in the head posture of the speaker during the speech. The above comparison examples all use the same video duration and sampling interval.
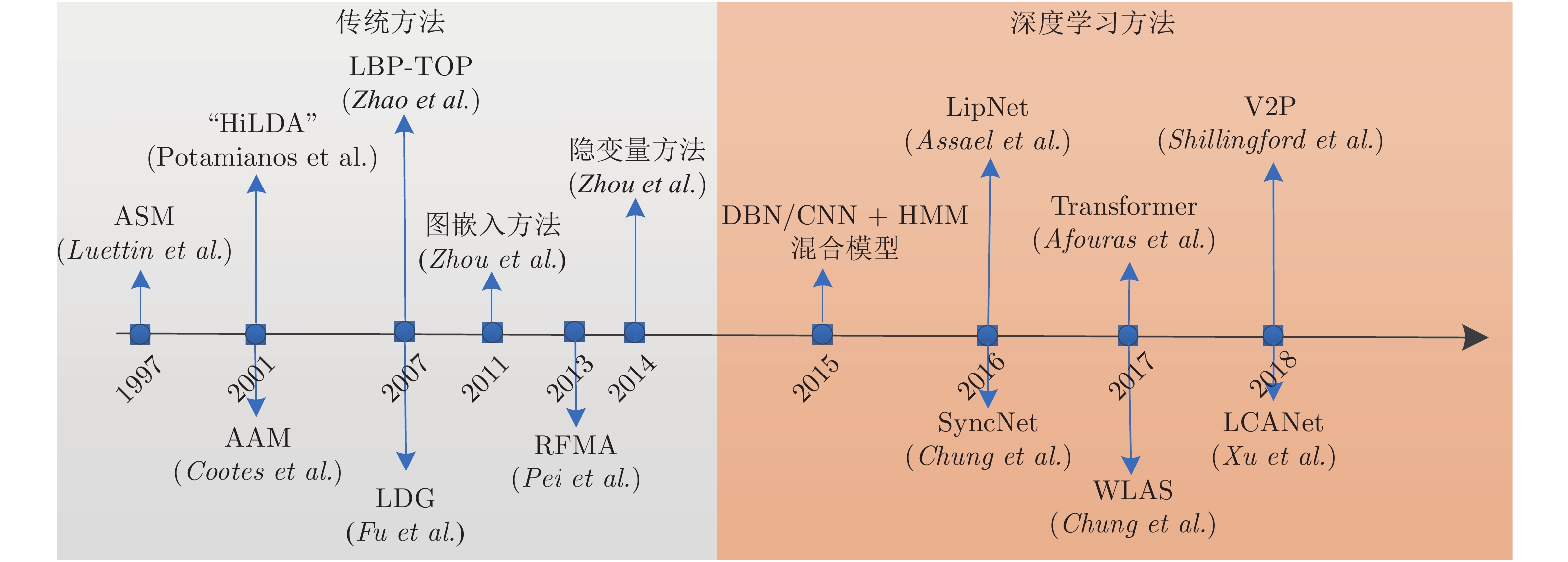
图 4 唇读研究过程中代表性方法. 传统特征提取方法: 主动形状模型ASM[51], 主动表观模型AAM[39], HiLDA[38], LBP-TOP[52], 局部判别图模型[40], 图嵌入方法[53], 随机森林流形对齐RFMA[41], 隐变量方法[54]; 深度学习方法: DBN/CNN+HMM混合模型[42-48], SyncNet[55], LipNet[49], WLAS[10], Transformer[50], LCANet[56], V2P[15].
Fig. 4 Representative methods in the process of lip reading research. Traditional feature extraction methods:ASM[51], AAM[39], HiLDA[38], LBP-TOP[52], LDG[40], Graph Embedding[53], RFMA[41], Hidden variable method[54]; Deep learning based methods: DBN/CNN+HMM hybrid model[42-48], SyncNet[55], LipNet[49], WLAS[10], Transformer[50], LCANet[56], V2P[15].

图 5 线性变换特征提取方法一般流程
Fig. 5 The workflow of linear transformation feature extraction method
表 1 传统时空特征提取算法优缺点总结
Table 1 A summary of advantages and disadvantages of traditional spatiotemporal feature extraction methods
时空特征提取方法 代表性方法 优势 不足 基于表观的 全局图像线性变换[38,57,60-63],
图嵌入与流形[40-41, 53-54,65],
LBP-TOP[52,66], HOG[67], 光流[29, 68]···1) 特征提取速度快;
2) 无需复杂的人工建模.1) 对唇部区域提取精度要求高;
2) 对环境变化、姿态变化、噪声敏感;
3) 不同讲话者之间泛化性能较差.基于形状的 轮廓描述[69-72],
AFs[73], 形状模型[74-75]···1) 具有良好的可解释性;
2) 不同讲话者之间泛化性能较好;
3) 能有效去除冗余信息.1) 会造成部分有用信息丢失;
2) 需要大量的人工标注;
3) 对于姿态变化非常敏感.形状表观融合的 形状+表观特征串联[76-77],
形状表观模型[39]···1) 特征表达能力较强;
2) 不同讲话者之间泛化性能较好.1) 模型复杂,运算量大;
2) 需要大量的人工标注. 下载: 导出CSV
下载: 导出CSV
表 3 单词、短语和语句识别数据集, 其中(s)代表不同语句的数量. 下载地址为: MIRACL-VC[171], LRW[172], LRW-1000[173], GRID[174], OuluVS[175], VIDTIMIT[176], LILiR[177], MOBIO[178], TCD-TIMIT[179], LRS[180], VLRF[181]
Table 3 Word, phrase and sentence lip reading datasets and their download link: MIRACL-VC[171], LRW[172], LRW-1000[173], GRID[174], OuluVS[175], VIDTIMIT[176], LILiR[177], MOBIO[178], TCD-TIMIT[179], LRS[180], VLRF[181]
数据集 语种 识别任务 词汇量 话语数目 说话人数目 姿态 分辨率 谷歌引用 发布年份 IBMViaVoice 英语 语句 10 500 24 325 290 0 704 × 480, 30 fps 299 2000 VIDTIMIT 英语 语句 346 (s) 430 43 0 512 × 384, 25 fps 51 2002 AVICAR 英语 语句 1 317 10 000 100 −15 $\sim$ 15720 × 480, 30 fps 170 2004 AV-TIMIT 英语 语句 450 (s) 4 660 233 0 720 × 480, 30 fps 127 2004 GRID 英语 短语 51 34 000 34 0 720 × 576, 25 fps 700 2006 IV2 法语 语句 15 (s) 4 500 300 0,90 780 × 576, 25 fps 19 2008 UWB-07-ICAV 捷克语 语句 7 550 (s) 10 000 50 0 720 × 576, 50 fps 16 2008 OuluVS 英语 短语 10 (s) 1 000 20 0 720 × 576, 25 fps 211 2009 WAPUSK20 英语 短语 52 2 000 20 0 640 × 480, 32 fps 16 2010 LILiR 英语 语句 1 000 2 400 12 0, 30, 45, 60, 90 720 × 576, 25 fps 67 2010 BL 法语 语句 238 (s) 4 046 17 0, 90 720 × 576, 25 fps 12 2011 UNMC-VIER 英语 语句 11 (s) 4 551 123 0, 90 708 × 640, 25 fps 8 2011 MOBIO 英语 语句 30 186 152 0 640 × 480, 16 fps 175 2012 MIRACL-VC 英语 单词 10 1 500 15 0 640 × 480, 15 fps 22 2014 短语 10 (s) 1 500 Austalk 英语 单词 966 966 000 1 000 0 640 × 480 11 2014 语句 59 (s) 59 000 MODALITY 英语 单词 182 (s) 231 35 0 1 920 × 1 080, 100 fps 23 2015 RM-3000 英语 语句 1 000 3 000 1 0 360 × 640, 60 fps 7 2015 IBM AV-ASR 英语 语句 10 400 262 0 704 × 480, 30 fps 103 2015 TCD-TIMIT 英语 语句 5 954 (s) 6 913 62 0, 30 1920 × 1080, 30 fps 59 2015 OuluVS2 英语 短语 10 1 590 53 0, 30, 45, 60, 90 1920 × 1080, 30 fps 46 2015 语句 530 (s) 530 LRW 英语 单词 500 550 000 1 000+ 0 $\sim$ 30256 × 256, 25 fps 115 2016 HAVRUS 俄语 语句 1 530 (s) 4 000 20 0 640 × 480, 200 fps 13 2016 LRS2-BBC 英语 语句 62 769 144 482 1 000+ 0 $\sim$ 30160 × 160, 25 fps 172 2017 VLRF 西班牙语 语句 1 374 10 200a 24 0 1 280 × 720, 50 fps 6 2017 LRS3-TED 英语 语句 70 000 151 819 1 000+ −90 $\sim$ 90224 × 224, 25 fps 2 2018 LRW-1000 中文 单词 1 000 745 187 2 000+ −90 $\sim$ 901 920 × 1 080, 25 fps 0 2018 LSVSR 英语 语句 127 055 2 934 899 1 000+ −30 $\sim$ 30128 × 128, 23 ~ 30 fps 16 2018
下载: 导出CSV
表 2 字母、数字识别数据集. 下载地址为: AVLetters[152], AVICAR[153], XM2VTS[154], BANCA[155], CUAVE[156], VALID[157], CENSREC-1-AV[158], Austalk[159], OuluVS2[160]
Table 2 Alphabet and digit lip reading datasets and their download link: AVLetters[152], AVICAR[153], XM2VTS[154], BANCA[155], CUAVE[156], VALID[157], CENSREC-1-AV[158], Austalk[159], OuluVS2[160]
数据集 语种 识别任务 类别数目 话语数目 说话人数目 姿态 分辨率 谷歌引用 发布年份 AVLetters 英语 字母 26 780 10 0 376 × 288, 25 fps 507 1998 XM2VTS 英语 数字 10 885 295 0 720 × 576, 25 fps 1 617 1999 BANCA 多语种 数字 10 29 952 208 0 720 × 576, 25 fps 530 2003 AVICAR 英语 字母 26 26 000 100 −15 $\sim$ 15720 × 480, 30 fps 170 2004 数字 13 23 000 CUAVE 英语 数字 10 7 000+ 36 −90, 0, 90 720 × 480, 30 fps 292 2002 VALID 英语 数字 10 530 106 0 720 × 576, 25 fps 38 2005 AVLetters2 英语 字母 26 910 5 0 1 920 × 1 080, 50 fps 62 2008 IBMSR 英语 数字 10 1 661 38 −90, 0, 90 368 × 240, 30 fps 17 2008 CENSREC-1-AV 日语 数字 10 5 197 93 0 720 × 480, 30 fps 25 2010 QuLips 英语 数字 10 3 600 2 −90 $\sim$ 90720 × 576, 25 fps 21 2010 Austalk 英语 数字 10 24 000 1 000 0 640 × 480 11 2014 OuluVS2 英语 数字 10 159 53 0 $\sim$ 901 920 × 1 080, 30 fps 46 2015
下载: 导出CSV
表 4 不同数据集下代表性方法比较
Table 4 Comparison of representative methods under different datasets
数据集 识别任务 参考文献 模型 主要实验条件 识别率 前端特征提取 后端分类器 音频信号 讲话者依赖 外部语言模型 最小识别单元 AVLetters 字母 [41] RFMA × √ × 字母 69.60 % [48] RTMRBM SVM √ √ × 字母 66.00 % [42] ST-PCA Autoencoder × × × 字母 64.40 % [52] LBP-TOP SVM × √ × 字母 62.80 % × × 43.50 % [193] DBNF+DCT LSTM × √ × 字母 58.10 % CUAVE 数字 [102] AAM HMM √ × × 数字 83.00 % [91] HOG+MBH SVM × × × 数字 70.10 % √ × 90.00 % [194] DBNF DNN-HMM × × × 音素 64.90 % [60] DCT HMM √ × × 数字 60.40 % LRW 单词 [128] 3D-CNN+ResNet BiLSTM × × × 单词 83.00 % [131] 3D-CNN+ResNet BiGRU × × × 单词 82.00 % √ × 98.00 % [10] CNN LSTM+Attention × × × 单词 76.20 % [9] CNN × × × 单词 61.10 % GRID 短语 [56] 3D-CNN+highway BiGRU+Attention × √ × 字符 97.10 % [10] CNN LSTM+Attention × √ × 单词 97.00 % [134] Feed-forward LSTM × √ × 单词 84.70 % √ 95.90 % [49] 3D-CNN BiGRU × × × 字符 93.40 % [126] HOG SVM × √ × 单词 71.20 % LRS3-TED 语句 [151] 3D-CNN+ResNet Transformer+seq2seq × × √ 字符 41.10 % Transformer +CTC 33.70 % [15] 3DCNN BiLSTM+CTC × × √ 音素 44.90 %
下载: 导出CSV
-
[1] McGurk H, MacDonald J. Hearing lips and seeing voices. Nature, 1976, 264(5588): 746−748 doi: 10.1038/264746a0 [2] Potamianos G, Neti C, Gravier G, Garg A, Senior A W. Recent advances in the automatic recognition of audiovisual speech. Proceedings of the IEEE, 2003, 91(9): 1306−1326 doi: 10.1109/JPROC.2003.817150 [3] Calvert G A, Bullmore E T, Brammer M J, Campbell R, Williams S C R, McGuire P K, et al. Activation of auditory cortex during silent lipreading. Science, 1997, 276(5312): 593−596 doi: 10.1126/science.276.5312.593 [4] Deafness and hearing loss [online] available:https://www.who.int/news-room/fact-sheets/detail/deafness-and-hearing-loss, July 1, 2019 [5] Tye-Murray N, Sommers M S, Spehar B. Audiovisual integration and lipreading abilities of older adults with normal and impaired hearing. Ear and Hearing, 2007, 28(5): 656−668 doi: 10.1097/AUD.0b013e31812f7185 [6] Akhtar Z, Micheloni C, Foresti G L. Biometric liveness detection: Challenges and research opportunities. IEEE Security and Privacy, 2015, 13(5): 63−72 doi: 10.1109/MSP.2015.116 [7] Rekik A, Ben-Hamadou A, Mahdi W. Human machine interaction via visual speech spotting. In: Proceedings of the 2015 International Conference on Advanced Concepts for Intelligent Vision Systems. Catania, Italy: Springer, 2015. 566−574 [8] Suwajanakorn S, Seitz S M, Kemelmacher-Shlizerman I. Synthesizing obama: Learning lip sync from audio. ACM Transactions on Graphics, 2017, 36(4): Article No.95 [9] Chung J S, Zisserman A. Lip reading in the wild. In: Proceedings of the 2016 Asian Conference on Computer Vision. Taiwan, China: Springer, 2016. 87−103 [10] Chung J S, Senior A, Vinyals O, Zisserman A. Lip reading sentences in the wild. In: Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition. Honolulu, USA: IEEE, 2017. 3444−3453 [11] Chen L, Li Z, K Maddox R K, Duan Z, Xu C. Lip movements generation at a glance. In: Proceedings of the 2018 European Conference on Computer Vision. Munich, Germany: Springer, 2018. 538−553 [12] Gabbay A, Shamir A, Peleg S. Visual speech enhancement. arXiv preprint arXiv: 1711.08789, 2017 [13] 黄雅婷, 石晶, 许家铭, 徐波. 鸡尾酒会问题与相关听觉模型的研究现状与展望. 自动化学报, 2019, 45(2): 234−251Huang Ya-Ting, Shi Jing, Xu Jia-Ming, Xu Bo. Research advances and perspectives on the cocktail party problem and related auditory models. Acta Automatica Sinica, 2019, 45(2): 234−251 [14] Akbari H, Arora H, Cao L L, Mesgarani N. Lip2AudSpec: Speech reconstruction from silent lip movements video. In: Proceedings of the 2018 IEEE International Conference on Acoustics, Speech and Signal Processing. Calgary, Canada: IEEE, 2018. 2516−2520 [15] Shillingford B, Assael Y, Hoffman M W, Paine T, Hughes C, Prabhu U, et al. Large-scale visual speech recognition. arXiv preprint arXiv: 1807.05162, 2018 [16] Mandarin Audio-Visual Speech Recognition Challenge [online] available: http://vipl.ict.ac.cn/homepage/mavsr/index.html, July 1, 2019 [17] Potamianos G, Neti C, Luettin J, Matthews I. Audio-visual automatic speech recognition: An overview. Issues in Visual and Audio-Visual Speech Processing. Cambridge: MIT Press, 2004. 1−30 [18] Zhou Z H, Zhao G Y, Hong X P, Pietikainen M. A review of recent advances in visual speech decoding. Image and Vision Computing, 2014, 32(9): 590−605 doi: 10.1016/j.imavis.2014.06.004 [19] Fernandez-Lopez A, Sukno F M. Survey on automatic lip-reading in the era of deep learning. Image and Vision Computing, 2018, 78: 53−72 doi: 10.1016/j.imavis.2018.07.002 [20] 姚鸿勋, 高文, 王瑞, 郎咸波. 视觉语言-唇读综述. 电子学报, 2001, 29(2): 239−246 doi: 10.3321/j.issn:0372-2112.2001.02.025Yao Hong-Xun, Gao Wen, Wang Rui, Lang Xian-Bo. A survey of lipreading-one of visual languages. Acta Electronica Sinica, 2001, 29(2): 239−246 doi: 10.3321/j.issn:0372-2112.2001.02.025 [21] Cox S J, Harvey R W, Lan Y, et al. The challenge of multispeaker lip-reading. In: Proceedings of AVSP. 2008: 179−184 [22] Messer K, Matas J, Kittler J, et al. XM2VTSDB: The extended M2VTS database. In: Proceedings of the Second International Conference on Audio and Video-based Biometric Person Authentication. 1999, 964: 965−966 [23] Bailly-Bailliére E, Bengio S, Bimbot F, Hamouz M, Kittler J, Mariéthoz J, et al. The BANCA database and evaluation protocol. In: Proceedings of the 2003 International Conference on Audio- and Video-based Biometric Person Authentication. Guildford, United Kingdom: Springer, 2003. 625−638 [24] Ortega A, Sukno F, Lleida E, Frangi A F, Miguel A, Buera L, et al. AV@CAR: A Spanish multichannel multimodal corpus for in-vehicle automatic audio-visual speech recognition. In: Proceedings of the 4th International Conference on Language Resources and Evaluation. Lisbon, Portugal: European Language Resources Association, 2004. 763−766 [25] Lee B, Hasegawa-Johnson M, Goudeseune C, Kamdar S, Borys S, Liu M, et al. AVICAR: Audio-visual speech corpus in a car environment. In: Proceedings of the 8th International Conference on Spoken Language Processing. Jeju Island, South Korea: International Speech Communication Association, 2004. 2489−2492 [26] Twaddell W F. On defining the phoneme. Language, 1935, 11(1): 5−62 [27] Woodward M F, Barber C G. Phoneme perception in lipreading. Journal of Speech and Hearing Research, 1960, 3(3): 212−222 doi: 10.1044/jshr.0303.212 [28] Fisher C G. Confusions among visually perceived consonants. Journal of Speech and Hearing Research, 1968, 11(4): 796−804 doi: 10.1044/jshr.1104.796 [29] Cappelletta L, Harte N. Viseme definitions comparison for visual-only speech recognition. In: Proceedings of the 19th European Signal Processing Conference. Barcelona, Spain: IEEE, 2011. 2109−2113 [30] Wu Y, Ji Q. Facial landmark detection: A literature survey. International Journal of Computer Vision, 2019, 127(2): 115−142 doi: 10.1007/s11263-018-1097-z [31] Chrysos G G, Antonakos E, Snape P, Asthana A, Zafeiriou S. A comprehensive performance evaluation of deformable face tracking "in-the-wild". International Journal of Computer Vision, 2018, 126(2-4): 198−232 doi: 10.1007/s11263-017-0999-5 [32] Koumparoulis A, Potamianos G, Mroueh Y, et al. Exploring ROI size in deep learning based lipreading. In: Proceedings of AVSP. 2017: 64−69 [33] Deller J R Jr, Hansen J H L, Proakis J G. Discrete-Time Processing of Speech Signals. New York: Macmillan Pub. Co, 1993. [34] Rabiner L R, Juang B H. Fundamentals of Speech Recognition. Englewood Cliffs: Prentice Hall, 1993. [35] Young S, Evermann G, Gales M J F, Hain T, Kershaw D, Liu X Y, et al. The HTK Book. Cambridge: Cambridge University Engineering Department, 2002. [36] Povey D, Ghoshal A, Boulianne G, Burget L, Glembek O, Goel N, et al. The Kaldi speech recognition toolkit. In: IEEE 2011 Workshop on Automatic Speech Recognition and Understanding. Hilton Waikoloa Village, Big Island, Hawaii, US: IEEE, 2011. [37] Matthews I, Cootes T F, Bangham J A, Cox S, Harvey R. Extraction of visual features for lipreading. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2002, 24(2): 198−213 doi: 10.1109/34.982900 [38] Potamianos G, Graf H P, Cosatto E. An image transform approach for HMM based automatic lipreading. In: Proceedings of 1998 International Conference on Image Processing. Chicago, USA: IEEE, 1998. 173−177 [39] Cootes T F, Edwards G J, Taylor C J. Active appearance models. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2001, 23(6): 681−685 doi: 10.1109/34.927467 [40] Fu Y, Zhou X, Liu M, Hasegawa-Johnson M, Huang T S. Lipreading by locality discriminant graph. In: Proceedings of 2007 IEEE International Conference on Image Processing. San Antonio, USA: IEEE, 2007. III−325−III−328 [41] Pei Y R, Kim T K, Zha H B. Unsupervised random forest manifold alignment for lipreading. In: Proceedings of 2013 IEEE International Conference on Computer Vision. Sydney, Australia: IEEE, 2013. 129−136 [42] Ngiam J, Khosla A, Kim M, Nam J, Lee H, Ng A Y. Multimodal deep learning. In: Proceeding of the 28th International Conference on Machine Learning. Washington, USA: ACM, 2011. 689−696 [43] Salakhutdinov R, Mnih A, Hinton G. Restricted Boltzmann machines for collaborative filtering. In: Proceedings of the 24th International Conference on Machine Learning. Corvallis, USA: ACM, 2007. 791−798 [44] Huang J, Kingsbury B. Audio-visual deep learning for noise robust speech recognition. In: Proceedings of 2013 IEEE International Conference on Acoustics, Speech and Signal Processing. Vancouver, Canada: IEEE, 2013. 7596−7599 [45] Ninomiya H, Kitaoka N, Tamura S, et al. Integration of deep bottleneck features for audio-visual speech recognition. In: Proceedings of the 16th Annual Conference of the International Speech Communication Association. 2015. [46] Sui C, Bennamoun M, Togneri R. Listening with your eyes: Towards a practical visual speech recognition system using deep Boltzmann machines. In: Proceedings of the IEEE International Conference on Computer Vision. Santiago, Chile: IEEE, 2015. 154−162 [47] Noda K, Yamaguchi Y, Nakadai K, Okuno H G, Ogata T. Audio-visual speech recognition using deep learning. Applied Intelligence, 2015, 42(4): 722−737 doi: 10.1007/s10489-014-0629-7 [48] Hu D, Li X L, Lu X Q. Temporal multimodal learning in audiovisual speech recognition. In: Proceedings of 2016 IEEE Conference on Computer Vision and Pattern Recognition. Las Vegas, USA: IEEE, 2016. 3574−3582 [49] Assael Y M, Shillingford B, Whiteson S, De Freitas N. LipNet: End-to-end sentence-level lipreading. arXiv preprint arXiv:1611.01599, 2016 [50] Afouras T, Chung J S, Zisserman A. Deep lip reading: A comparison of models and an online application. arXiv preprint arXiv:1806.06053, 2018 [51] Luettin J, Thacker N A. Speechreading using probabilistic models. Computer Vision and Image Understanding, 1997, 65(2): 163−178 doi: 10.1006/cviu.1996.0570 [52] Zhao G Y, Barnard M, Pietikäinen M. Lipreading with local spatiotemporal descriptors. IEEE Transactions on Multimedia, 2009, 11(7): 1254−1265 doi: 10.1109/TMM.2009.2030637 [53] Zhou Z H, Zhao G Y, Pietikäinen M. Towards a practical lipreading system. In: Proceedings of IEEE Conference on Computer Vision and Pattern Recognition. Providence, RI, USA: IEEE, 2011. 137−144 [54] Zhou Z H, Hong X P, Zhao G Y, Pietikäinen M. A compact representation of visual speech data using latent variables. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2014, 36(1): 1 [55] Chung J S, Zisserman A. Out of time: Automated lip sync in the wild. In: Proceedings of Asian Conference on Computer Vision. Taiwan, China: Springer, 2016. 251−263 [56] Xu K, Li D W, Cassimatis N, Wang X L. LCANet: End-to-end lipreading with cascaded attention-CTC. In: Proceedings of the 13th IEEE International Conference on Automatic Face & Gesture Recognition. Xi'an, China: IEEE, 2018.−548−555 [57] Lucey P J, Potamianos G, Sridharan S. A unified approach to multi-pose audio-visual ASR. In: Proceedings of the 8th Annual Conference of the International Speech Communication Association. Antwerp, Belgium: Causal Productions Pty Ltd., 2007. 650−653 [58] Almajai I, Cox S, Harvey R, Lan Y X. Improved speaker independent lip reading using speaker adaptive training and deep neural networks. In: Proceedings of 2016 IEEE International Conference on Acoustics, Speech and Signal Processing. Shanghai, China: IEEE, 2016. 2722−2726 [59] Seymour R, Stewart D, Ming J. Comparison of image transform-based features for visual speech recognition in clean and corrupted videos. EURASIP Journal on Image and Video Processing, 2007, 2008(1): Article No.810362 [60] Estellers V, Gurban M, Thiran J P. On dynamic stream weighting for audio-visual speech recognition. IEEE Transactions on Audio, Speech, and Language Processing, 2012, 20(4): 1145−1157 doi: 10.1109/TASL.2011.2172427 [61] Potamianos G, Neti C, Iyengar G, Senior A W, Verma A. A cascade visual front end for speaker independent automatic speechreading. International Journal of Speech Technology, 2001, 4(3−4): 193−208 [62] Lucey P J, Sridharan S, Dean D B. Continuous pose-invariant lipreading. In: Proceedings of the 9th Annual Conference of the International Speech Communication Association (Interspeech 2008) incorporating the 12th Australasian International Conference on Speech Science and Technology (SST 2008). Brisbane Australia: International Speech Communication Association, 2008. 2679−2682 [63] Lucey P J, Potamianos G, Sridharan S. Patch-based analysis of visual speech from multiple views. In: Proceedings of the International Conference on Auditory-Visual Speech Processing 2008. Moreton Island, Australia: AVISA, 2008. 69−74 [64] Tim Sheerman-Chase, Eng-Jon Ong, Richard Bowden. Cultural Factors in the Regression of Non-verbal Communication Perception. In Workshop on Human Interaction in Computer Vision, Barcelona, 2011 [65] Zhou Z H, Zhao G Y, Pietikäinen M. Lipreading: A graph embedding approach. In: Proceedings of the 20th International Conference on Pattern Recognition. Istanbul, Turkey: IEEE, 2010. 523−526 [66] Zhao G Y, Pietikäinen M. Dynamic texture recognition using local binary patterns with an application to facial expressions. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2007, 29(6): 915−928 doi: 10.1109/TPAMI.2007.1110 [67] Dalal N, Triggs B. Histograms of oriented gradients for human detection. In: Proceedings of 2005 IEEE Computer Society Conference on Computer Vision and Pattern Recognition. San Diego, USA: IEEE, 2005. 886−893 [68] Mase K, Pentland A. Automatic lipreading by optical-flow analysis. Systems and Computers in Japan, 1991, 22(6): 67−76 doi: 10.1002/scj.4690220607 [69] Aleksic P S, Williams J J, Wu Z L, Katsaggelos A K. Audio-visual speech recognition using MPEG-4 compliant visual features. EURASIP Journal on Advances in Signal Processing, 2002, 2002(1): Article No. 150948 [70] Brooke N M. Using the visual component in automatic speech recognition. In: Proceedings of the 4th International Conference on Spoken Language Processing. Philadelphia, USA: IEEE, 1996. 1656−1659 [71] Cetingul H E, Yemez Y, Erzin E, Tekalp A M. Discriminative analysis of lip motion features for speaker identification and speech-reading. IEEE Transactions on Image Processing, 2006, 15(10): 2879−2891 doi: 10.1109/TIP.2006.877528 [72] Nefian A V, Liang L H, Pi X B, Liu X X, Murphy K. Dynamic Bayesian networks for audio-visual speech recognition. EURASIP Journal on Advances in Signal Processing, 2002, 2002(11): Article No.783042 doi: 10.1155/S1110865702206083 [73] Kirchhoff K. Robust speech recognition using articulatory information Elektronische Ressource. 1999. [74] Cootes T F, Taylor C J, Cooper D H, Graham J. Active shape models-their training and application. Computer Vision and Image Understanding, 1995, 61(1): 38−59 doi: 10.1006/cviu.1995.1004 [75] Luettin J, Thacker N A, Beet S W. Speechreading using shape and intensity information. In: Proceedings of the 4th International Conference on Spoken Language Processing. Philadelphia, USA: IEEE, 1996. 58−61 [76] Dupont S, Luettin J. Audio-visual speech modeling for continuous speech recognition. IEEE Transactions on Multimedia, 2000, 2(3): 141−151 doi: 10.1109/6046.865479 [77] Chan M T. HMM-based audio-visual speech recognition integrating geometric- and appearance-based visual features. In: Proceedings of the 4th Workshop on Multimedia Signal Processing. Cannes, France: IEEE, 2001. 9−14 [78] Roweis S T, Sau L K. Nonlinear dimensionality reduction by locally linear embedding. Science, 2000, 290(5500): 2323−2326 doi: 10.1126/science.290.5500.2323 [79] Tenenbaum J B, de Silva V, Langford J C. A global geometric framework for nonlinear dimensionality reduction. Science, 2000, 290(5500): 2319−2323 doi: 10.1126/science.290.5500.2319 [80] Yan S C, Xu D, Zhang B Y, Zhang H J, Yang Q, Lin S. Graph embedding and extensions: A general framework for dimensionality reduction. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2007, 29(1): 40−51 doi: 10.1109/TPAMI.2007.250598 [81] Fu Y, Yan S C, Huang T S. Classification and feature extraction by simplexization. IEEE Transactions on Information Forensics and Security, 2008, 3(1): 91−100 doi: 10.1109/TIFS.2007.916280 [82] Ojala T, Pietikäinen M, Harwood D. A comparative study of texture measures with classification based on featured distributions. Pattern Recognition, 1996, 29(1): 51−59 doi: 10.1016/0031-3203(95)00067-4 [83] Ojala T, Pietikäinen M, Mäenpää T. Multiresolution gray-scale and rotation invariant texture classification with local binary patterns. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2002, 24(7): 971−987 doi: 10.1109/TPAMI.2002.1017623 [84] 刘丽, 赵凌君, 郭承玉, 王亮, 汤俊. 图像纹理分类方法研究进展和展望. 自动化学报, 2018, 44(4): 584−607Liu Li, Zhao Ling-Jun, Guo Cheng-Yu, Wang Liang, Tang Jun. Texture classification: State-of-the-art methods and prospects. Acta Automatica Sinica, 2018, 44(4): 584−607 [85] Pietikäinen M, Hadid A, Zhao G, Ahonen T. Computer Vision Using Local Binary Patterns. London: Springer, 2011. [86] Liu L, Chen J, Fieguth P, Zhao G Y, Chellappa R, Pietikäinen M. From BoW to CNN: Two decades of texture representation for texture classification. International Journal of Computer Vision, 2019, 127(1): 74−109 doi: 10.1007/s11263-018-1125-z [87] 刘丽, 谢毓湘, 魏迎梅, 老松杨. 局部二进制模式方法综述. 中国图象图形学报, 2014, 19(12): 1696−1720 doi: 10.11834/jig.20141202Liu Li, Xie Yu-Xiang, Wei Ying-Mei, Lao Song-Yang. Survey of Local Binary Pattern method. Journal of Image and Graphics, 2014, 19(12): 1696−1720 doi: 10.11834/jig.20141202 [88] Horn B K P, Schunck B G. Determining optical flow. Artificial Intelligence, 1981, 17(1-3): 185−203 doi: 10.1016/0004-3702(81)90024-2 [89] Bouguet J Y. Pyramidal implementation of the affine Lucas Kanade feature tracker description of the algorithm. Intel Corporation, 2001, 5: 1−9 [90] Lucas B D, Kanade T. An iterative image registration technique with an application to stereo vision. In: Proceedings of the 7th International Joint Conference on Artificial Intelligence. San Francisco, CA, United States: Morgan Kaufmann Publishers Inc., 1981. 674−679 [91] Rekik A, Ben-Hamadou A, Mahdi W. An adaptive approach for lip-reading using image and depth data. Multimedia Tools and Applications, 2016, 75(14): 8609−8636 doi: 10.1007/s11042-015-2774-3 [92] Shaikh A A, Kumar D K, Yau W C, Azemin M Z C, Gubbi J. Lip reading using optical flow and support vector machines. In: Proceedings of the 3rd International Congress on Image and Signal Processing. Yantai, China: IEEE, 2010. 327−330 [93] Goldschen A J, Garcia O N, Petajan E. Continuous optical automatic speech recognition by lipreading. In: Proceedings of the 28th Asilomar Conference on Signals, Systems and Computers. Pacific Grove, CA, USA: IEEE, 1994. 572−577 [94] King S, Frankel J, Livescu K, McDermott E, Richmond K, Wester M. Speech production knowledge in automatic speech recognition. The Journal of the Acoustical Society of America, 2007, 121(2): 723−742 doi: 10.1121/1.2404622 [95] Kirchhoff K, Fink G A, Sagerer G. Combining acoustic and articulatory feature information for robust speech recognition. Speech Communication, 2002, 37(3−4): 303−319 doi: 10.1016/S0167-6393(01)00020-6 [96] Livescu K, Cetin O, Hasegawa-Johnson M, King S, Bartels C, Borges N, et al. Articulatory feature-based methods for acoustic and audio-visual speech recognition: Summary from the 2006 JHU Summer Workshop. In: Proceedings of the 2007 IEEE International Conference on Acoustics, Speech and Signal Processing. Honolulu, USA: IEEE. 2007. IV−621−IV−624 [97] Saenko K, Livescu K, Glass J, Darrell T. Production domain modeling of pronunciation for visual speech recognition. In: Proceeding of the 2005 IEEE International Conference on Acoustics, Speech, and Signal Processing. Philadelphia, USA: IEEE. 2005. v/473−v/476 [98] Saenko K, Livescu K, Glass J, Darrell T. Multistream articulatory feature-based models for visual speech recognition. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2009, 31(9): 1700−1707 doi: 10.1109/TPAMI.2008.303 [99] Saenko K, Livescu K, Siracusa M, Wilson K, Glass J, Darrell T. Visual speech recognition with loosely synchronized feature streams. In: Proceeding of the 10th IEEE International Conference on Computer Vision. Beijing, China: IEEE. 2005. 1424−1431 [100] Papcun G, Hochberg J, Thomas T R, Laroche F, Zacks J, Levy S. Inferring articulation and recognizing gestures from acoustics with a neural network trained on x-ray microbeam data. The Journal of the Acoustical Society of America, 1992, 92(2): 688−700 doi: 10.1121/1.403994 [101] Matthews I, Potamianos G, Neti C, Luettin J. A comparison of model and transform-based visual features for audio-visual LVCSR. In: Proceedings of the 2001 IEEE International Conference on Multimedia and Expo. Tokyo, Japan: IEEE, 2001. 825−828 [102] Papandreou G, Katsamanis A, Pitsikalis V, Maragos P. Adaptive multimodal fusion by uncertainty compensation with application to audiovisual speech recognition. IEEE Transactions on Audio, Speech, and Language Processing, 2009, 17(3): 423−435 doi: 10.1109/TASL.2008.2011515 [103] Hilder S, Harvey R W, Theobald B J. Comparison of human and machine-based lip-reading. In: Proceedings of the 2009 AVSP. 2009: 86−89 [104] Lan Y X, Theobald B J, Harvey R. View independent computer lip-reading. In: Proceedings of the 2012 IEEE International Conference on Multimedia and Expo. Melbourne, Australia: IEEE, 2012. 432−437 [105] Lan Y X, Harvey R, Theobald B J. Insights into machine lip reading. In: Proceedings of the 2012 IEEE International Conference on Acoustics, Speech and Signal Processing. Kyoto, Japan: IEEE, 2012. 4825−4828 [106] Bear H L, Harvey R. Decoding visemes: Improving machine lip-reading. In: Proceedings of the 2016 IEEE International Conference on Acoustics, Speech and Signal Processing. Shanghai, China: IEEE, 2016. 2009−2013 [107] LeCun Y, Bengio Y, Hinton G. Deep learning. Nature, 2015, 521(7553): 436−444 doi: 10.1038/nature14539 [108] Hinton G E, Salakhutdinov R R. Reducing the dimensionality of data with neural networks. Science, 2006, 313(5786): 504−507 doi: 10.1126/science.1127647 [109] Hong X P, Yao H X, Wan Y Q, Chen R. A PCA based visual DCT feature extraction method for lip-reading. In: Proceedings of the 2006 International Conference on Intelligent Information Hiding and Multimedia. Pasadena, USA: IEEE, 2006. 321−326 [110] Krizhevsky A, Sutskever I, Hinton G E. ImageNet classification with deep convolutional neural networks. In: Proceedings of the 25th International Conference on Neural Information Processing Systems. Red Hook, NY, United States: Curran Associates Inc., 2012. 1097−1105 [111] Simonyan K, Zisserman A. Very deep convolutional networks for large-scale image recognition. arXiv preprint arXiv: 1409.1556, 2014 [112] Szegedy C, Liu W, Jia Y Q, Sermanet P, Reed S, Anguelov D, et al. Going deeper with convolutions. In: Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition. Boston, USA: IEEE, 2015. 1−9 [113] He K M, Zhang X Y, Ren S Q, Sun J. Deep residual learning for image recognition. In: Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition. Las Vegas, USA: IEEE, 2016. 770−778 [114] Huang G, Liu Z, Van Der Maaten L, Weinberger K Q. Densely connected convolutional networks. In: Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition. Hawaii, USA: IEEE, 2017. 2261−2269 [115] Hu J, Shen L, Sun G. Squeeze-and-excitation networks. In: Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Salt Lake City, Utah, USA: IEEE, 2018. 7132−7141 [116] Liu L, Ouyang W L, Wang X G, Fieguth P, Chen J, Liu X W, et al. Deep learning for generic object detection: A survey. arXiv preprint arXiv: 1809.02165, 2018 [117] Long J, Shelhamer E, Darrell T. Fully convolutional networks for semantic segmentation. In: Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition. Boston, USA: IEEE, 2015. 3431−3440 [118] Graves A, Mohamed A, Hinton G. Speech recognition with deep recurrent neural networks. In: Proceedings of the 2013 IEEE international Conference on Acoustics, Speech and Signal Processing. Vancouver, Canada: IEEE, 2013. 6645−6649 [119] Noda K, Yamaguchi Y, Nakadai K, Okuno H G, Ogata T. Lipreading using convolutional neural network. In: Proceedings of the 15th Annual Conference of the International Speech Communication Association. Singapore: ISCA, 2014. 1149−1153 [120] Ji S W, Xu W, Yang M, Yu K. 3D convolutional neural networks for human action recognition. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2013, 35(1): 221−231 doi: 10.1109/TPAMI.2012.59 [121] Herath S, Harandi M, Porikli F. Going deeper into action recognition: A survey. Image and Vision Computing, 2017, 60: 4−21 doi: 10.1016/j.imavis.2017.01.010 [122] Mroueh Y, Marcheret E, Goel V. Deep multimodal learning for audio-visual speech recognition. In: Proceedings of the 2015 IEEE International Conference on Acoustics, Speech and Signal Processing. Queensland, Australia: IEEE, 2015. 2130−2134 [123] Thangthai K, Harvey R W, Cox S J, et al. Improving lip-reading performance for robust audiovisual speech recognition using DNNs. In: Proceedings of the 2015 AVSP. 2015: 127−131. [124] Gers F A, Schmidhuber J, Cummins F. Learning to forget: Continual prediction with LSTM. Neural Computation, 2000, 12(10): 2451−2471 doi: 10.1162/089976600300015015 [125] Chung J, Gulcehre C, Cho K, Bengio Y. Empirical evaluation of gated recurrent neural networks on sequence modeling. arXiv preprint arXiv: 1412.3555, 2014 [126] Wand M, Koutník J, Schmidhuber J. Lipreading with long short-term memory. In: Proceedings of the 2016 IEEE International Conference on Acoustics, Speech and Signal Processing. Shanghai, China: IEEE, 2016. 6115−6119 [127] Garg A, Noyola J, Bagadia S. Lip reading using CNN and LSTM, Technical Report, CS231n Project Report, Stanford University, USA, 2016. [128] Stafylakis T, Tzimiropoulos G. Combining residual networks with LSTMs for lipreading. arXiv preprint arXiv: 1703.04105, 2017 [129] Graves A, Fernández S, Gomez F, Schmidhuber J. Connectionist temporal classification: Labelling unsegmented sequence data with recurrent neural networks. In: Proceedings of the 23rd International Conference on Machine Learning. New York: ACM, 2006. 369−376 [130] Miao Y, Gowayyed M, Metze F. EESEN: End-to-end speech recognition using deep RNN models and WFST-based decoding. In: Proceedings of the 2015 IEEE Workshop on Automatic Speech Recognition and Understanding. Arizona, USA: IEEE, 2015. 167−174 [131] Petridis S, Stafylakis T, Ma P, Cai F P, Tzimiropoulos G, Pantic M. End-to-end audiovisual speech recognition. In: Proceedings of the 2018 IEEE International Conference on Acoustics, Speech and Signal Processing. Calgary, Canada: IEEE, 2018. 6548−6552 [132] Fung I, Mak B. End-to-end low-resource lip-reading with Maxout Cnn and Lstm. In: Proceedings of the 2018 IEEE International Conference on Acoustics, Speech and Signal Processing. Calgary, Canada: IEEE, 2018. 2511−2515 [133] Wand M, Schmidhuber J. Improving speaker-independent lipreading with domain-adversarial training. arXiv preprint arXiv: 1708.01565, 2017 [134] Wand M, Schmidhuber J, Vu N T. Investigations on end-to-end audiovisual fusion. In: Proceedings of the 2018 IEEE International Conference on Acoustics, Speech and Signal Processing. Calgary, Canada: IEEE, 2018. 3041−3045 [135] Srivastava R K, Greff K, Schmidhuber J. Training very deep networks. In: Proceedings of the 28th International Conference on Neural Information Processing Systems. Cambridge, MA United States: MIT Press, 2015. 2377−2385 [136] Sutskever I, Vinyals O, Le Q V. Sequence to sequence learning with neural networks. In: Proceedings of the 27th International Conference on Neural Information Processing Systems. Cambridge, MA: MIT Press, 2014. 3104−3112 [137] Bahdanau D, Cho K, Bengio Y. Neural machine translation by jointly learning to align and translate. arXiv preprint arXiv: 1409.0473, 2014 [138] Chaudhari S, Polatkan G, Ramanath R, Mithal V. An attentive survey of attention models. arXiv preprint arXiv: 1904.02874, 2019 [139] Wang F, Tax D M J. Survey on the attention based RNN model and its applications in computer vision. arXiv preprint arXiv: 1601.06823, 2016 [140] Chung J S, Zisserman A. Lip reading in profile. In: Proceedings of the British Machine Vision Conference. Guildford: BMVA Press, 2017. 155.1−155.11 [141] Russakovsky O, Deng J, Su H, Krause J, Satheesh S, Ma S, et al. ImageNet large scale visual recognition challenge. International Journal of Computer Vision, 2015, 115(3): 211−252 doi: 10.1007/s11263-015-0816-y [142] Saitoh T, Zhou Z H, Zhao G Y, Pietikäinen M. Concatenated frame image based cnn for visual speech recognition. In: Proceedings of the 2016 Asian Conference on Computer Vision. Taiwan, China: Springer, 2016. 277−289 [143] Lin M, Chen Q, Yan S C. Network in network. arXiv preprint arXiv: 1312.4400, 2013 [144] Petridis S, Li Z W, Pantic M. End-to-end visual speech recognition with LSTMs. In: Proceedings of the 2017 IEEE International Conference on Acoustics, Speech and Signal Processing. New Orleans, USA: IEEE, 2017. 2592−2596 [145] Petridis S, Wang Y J, Li Z W, Pantic M. End-to-end audiovisual fusion with LSTMS. arXiv preprint arXiv: 1709.04343, 2017 [146] Petridis S, Wang Y J, Li Z W, Pantic M. End-to-end multi-view lipreading. arXiv preprint arXiv: 1709.00443, 2017 [147] Petridis S, Shen J, Cetin D, Pantic M. Visual-only recognition of normal, whispered and silent speech. In: Proceedings of the 2018 IEEE International Conference on Acoustics, Speech and Signal Processing. Calgary, Canada: IEEE, 2018. 6219−6223 [148] Moon S, Kim S, Wang H H. Multimodal transfer deep learning with applications in audio-visual recognition. arXiv preprint arXiv: 1412.3121, 2014 [149] Chollet F. Xception: Deep learning with depthwise separable convolutions. In: Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition. Honolulu, Hawaii, USA: IEEE, 2017. 1800−1807 [150] Vaswani A, Shazeer N, Parmar N, Uszkoreit J, Jones L, Gomez A N, et al. Attention is all you need. In: Proceedings of the 31st International Conference on Neural Information Processing Systems. New York, United States: Curran Associates Inc., 2017. 6000−6010 [151] Afouras T, Chung J S, Senior A, et al. Deep audio-visual speech recognition. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2018.DOI: 10.1109/TPAMI.2018.2889052 [152] AV Letters Database [Online], available: http://www2.cmp.uea.ac.uk/~bjt/avletters/, October 27, 2020 [153] AVICAR Project: Audio-Visual Speech Recognition in a Car [Online], available: http://www.isle.illinois.edu/sst/AVICAR/#information, October 27, 2020 [154] The Extended M2VTS Database [Online], available: http://www.ee.surrey.ac.uk/CVSSP/xm2vtsdb/, October 27, 2020 [155] The BANCA Database [Online], available: http://www.ee.surrey.ac.uk/CVSSP/banca/, October 27, 2020 [156] CUAVE Group Set [Online], available: http://people.csail.mit.edu/siracusa/avdata/, October 27, 2020 [157] VALID: Visual quality Assessment for Light field Images Dataset [Online], available: https://www.epfl.ch/labs/mmspg/downloads/valid/, October 27, 2020 [158] Speech Resources Consortium [Online], available: http://research.nii.ac.jp/src/en/data.html, October 27, 2020 [159] AusTalk [Online], available: https://austalk.edu.au/about/corpus/, October 27, 2020 [160] OULUVS2: A MULTI-VIEW AUDIOVISUAL DATABASE [Online], available: http://www.ee.oulu.fi/research/imag/OuluVS2/, October 27, 2020 [161] Patterson E K, Gurbuz S, Tufekci Z, Gowdy J N. CUAVE: A new audio-visual database for multimodal human-computer interface research. In: Proceedings of the 2002 IEEE International Conference on Acoustics, Speech, and Signal Processing. Orlando, Florida, USA: IEEE, 2002. II−2017−II−2020 [162] Fox N A, O'Mullane B A, Reilly R B. VALID: A new practical audio-visual database, and comparative results. In: Proceedings of the 2005 International Conference on Audio-and Video-Based Biometric Person Authentication. Berlin, Germany: Springer, 2005. 777−786 [163] Anina I, Zhou Z H, Zhao G Y, Pietikäinen M. OuluVS2: A multi-view audiovisual database for non-rigid mouth motion analysis. In: Proceedings of the 11th IEEE International Conference and Workshops on Automatic Face and Gesture Recognition. Ljubljana, Slovenia: IEEE, 2015. 1−5 [164] Estival D, Cassidy S, Cox F, et al. AusTalk: an audio-visual corpus of Australian English. In: Proceedings of the 2014 LREC 2014. [165] Tamura S, Miyajima C, Kitaoka N, et al. CENSREC-1-AV: An audio-visual corpus for noisy bimodal speech recognition. In: Proceedings of the Auditory-Visual Speech Processing 2010. 2010. [166] Pass A, Zhang J G, Stewart D. An investigation into features for multi-view lipreading. In: Proceedings of the 2010 IEEE International Conference on Image Processing. Hong Kong, China: IEEE, 2010. 2417−2420 [167] Neti C, Potamianos G, Luettin J, et al. Audio visual speech recognition. IDIAP, 2000. [168] Sanderson C. The vidtimit database. IDIAP, 2002. [169] Jankowski C, Kalyanswamy A, Basson S, Spitz J. NTIMIT: A phonetically balanced, continuous speech, telephone bandwidth speech database. In: Proceedings of the 1990 International Conference on Acoustics, Speech, and Signal Processing. Albuquerque, New Mexico, USA: IEEE, 1990. 109−112 [170] Hazen T J, Saenko K, La C H, Glass J R. A segment-based audio-visual speech recognizer: Data collection, development, and initial experiments. In: Proceedings of the 6th International Conference on Multimodal Interfaces. State College, PA, USA: ACM, 2004. 235−242 [171] MIRACL-VC1 [Online], available: https://sites.google.com/site/achrafbenhamadou/-datasets/miracl-vc1, October 27, 2020 [172] The Oxford-BBC Lip Reading in the Wild (LRW) Dataset [Online], available: http://www.robots.ox.ac.uk/~vgg/data/lip_reading/lrw1.html, October 27, 2020 [173] LRW-1000: Lip Reading database [Online], available: http://vipl.ict.ac.cn/view_database.php?id=14, October 27, 2020 [174] The GRID audiovisual sentence corpus [Online], available: http://spandh.dcs.shef.ac.uk/gridcorpus/, October 27, 2020 [175] OuluVS database [Online], available: https://www.oulu.fi/cmvs/node/41315, October 27, 2020 [176] VidTIMIT Audio-Video Dataset [Online], available: http://conradsanderson.id.au/vidtimit/#downloads, October 27, 2020 [177] LiLiR [Online], available: http://www.ee.surrey.ac.uk/Projects/LILiR/datasets.html, October 27, 2020 [178] MOBIO [Online], available: https://www.idiap.ch/dataset/mobio, October 27, 2020 [179] TCD-TIMIT [Online], available: https://sigmedia.tcd.ie/TCDTIMIT/, October 27, 2020 [180] Lip Reading Datasets [Online], available: http://www.robots.ox.ac.uk/~vgg/data/lip_reading/, October 27, 2020 [181] Visual Lip Reading Feasibility (VRLF) [Online], available: https://datasets.bifrost.ai/info/845, October 27, 2020 [182] Rekik A, Ben-Hamadou A, Mahdi W. A new visual speech recognition approach for RGB-D cameras. In: Proceedings of the 2014 International Conference Image Analysis and Recognition. Vilamoura, Portugal: Springer, 2014. 21−28 [183] McCool C, Marcel S, Hadid A, Pietikäinen M, Matejka P, Cernockỳ J, et al. Bi-modal person recognition on a mobile phone: Using mobile phone data. In: Proceedings of the 2012 IEEE International Conference on Multimedia and Expo Workshops. Melbourne, Australia: IEEE, 2012. 635−640 [184] Howell D. Confusion Modelling for Lip-Reading [Ph. D. dissertation], University of East Anglia, Norwich, 2015 [185] Harte N, Gillen E. TCD-TIMIT: An audio-visual corpus of continuous speech. IEEE Transactions on Multimedia, 2015, 17(5): 603−615 doi: 10.1109/TMM.2015.2407694 [186] Verkhodanova V, Ronzhin A, Kipyatkova I, Ivanko D, Karpov A, Zelezny M. HAVRUS corpus: High-speed recordings of audio-visual Russian speech. In: Proceedings of the 2016 International Conference on Speech and Computer. Budapest, Hungary: Springer, 2016. 338−345 [187] Fernandez-Lopez A, Martinez O, Sukno F M. Towards estimating the upper bound of visual-speech recognition: The visual lip-reading feasibility database. In: Proceedings of the 12th IEEE International Conference on Automatic Face & Gesture Recognition. Washington, USA: IEEE, 2017. 208−215 [188] Cooke M, Barker J, Cunningham S, Shao X. An audio-visual corpus for speech perception and automatic speech recognition. The Journal of the Acoustical Society of America, 2006, 120(5): 2421−2424 doi: 10.1121/1.2229005 [189] Vorwerk A, Wang X, Kolossa D, et al. WAPUSK20-A Database for Robust Audiovisual Speech Recognition. In: Proceedings of the 2010 LREC. 2010. [190] Czyzewski A, Kostek B, Bratoszewski P, Kotus J, Szykulski M. An audio-visual corpus for multimodal automatic speech recognition. Journal of Intelligent Information Systems, 2017, 49(2): 167−192 doi: 10.1007/s10844-016-0438-z [191] Afouras T, Chung J S, Zisserman A. LRS3-TED: A large-scale dataset for visual speech recognition. arXiv preprint arXiv: 1809.00496, 2018 [192] Yang S, Zhang Y H, Feng D L, Yang M M, Wang C H, Xiao J Y, et al. LRW-1000: A naturally-distributed large-scale benchmark for lip reading in the wild. In: Proceedings of the 14th IEEE International Conference on Automatic Face and Gesture Recognition. Lille, France: IEEE, 2019. 1−8 [193] Petridis S, Pantic M. Deep complementary bottleneck features for visual speech recognition. In: Proceedings of the 2016 IEEE International Conference on Acoustics, Speech and Signal Processing. Shanghai, China: IEEE, 2016. 2304−2308 [194] Rahmani M H, Almasganj F. Lip-reading via a DNN-HMM hybrid system using combination of the image-based and model-based features. In: Proceedings of the 3rd International Conference on Pattern Recognition and Image Analysis. Shahrekord, Iran: IEEE, 2017. 195−199 [195] Dosovitskiy A, Fischer P, Ilg E, Häusser P, Hazirbas C, Golkov V, et al. FlowNet: Learning optical flow with convolutional networks. In: Proceedings of the 2015 IEEE International Conference on Computer Vision. Santiago, Chile: IEEE, 2015. 2758−2766 [196] Ilg E, Mayer N, Saikia T, Keuper M, Dosovitskiy A, Brox T. FlowNet 2.0: Evolution of optical flow estimation with deep networks. In: Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition. Hawaii, USA: IEEE, 2017. 1647−1655 [197] Simonyan K, Zisserman A. Two-stream convolutional networks for action recognition in videos. In: Proceedings of the 27th International Conference on Neural Information Processing Systems. Cambridge, MA, United States: MIT Press, 2014. 568−576 [198] Feichtenhofer C, Pinz A, Zisserman A. Convolutional two-stream network fusion for video action recognition. In: Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition. Las Vegas, USA: IEEE, 2016. 1933−1941 [199] Jaderberg M, Simonyan K, Zisserman A, Kavukcuoglu K. Spatial transformer networks. In: Proceedings of the 28th International Conference on Neural Information Processing Systems. Cambridge, MA, United States: MIT Press, 2015. 2017−2025 [200] Bhagavatula C, Zhu C C, Luu K, Savvides M. Faster than real-time facial alignment: A 3D spatial transformer network approach in unconstrained poses. In: Proceedings of the 2017 IEEE International Conference on Computer Vision. Venice, Italy: IEEE, 2017. 4000−4009 [201] Baltrušaitis T, Ahuja C, Morency L P. Multimodal machine learning: A survey and taxonomy. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2019, 41(2): 423−443 doi: 10.1109/TPAMI.2018.2798607 [202] Loizou P C. Speech Enhancement: Theory and Practice. Boca Raton, FL: CRC Press, 2013. [203] Hou J C, Wang S S, Lai Y H, Tsao Y, Chang H W, Wang H M. Audio-visual speech enhancement based on multimodal deep convolutional neural network. arXiv preprint arXiv: 1703.10893, 2017 [204] Ephrat A, Halperin T, Peleg S. Improved speech reconstruction from silent video. In: Proceedings of the 2017 IEEE International Conference on Computer Vision Workshops. Venice, Italy: IEEE, 2017. 455−462 [205] Gabbay A, Shamir A, Peleg S. Visual speech enhancement. arXiv preprint arXiv: 1711.08789, 2017. -

 下载:
下载:





















计量
- 文章访问数: 5354
- HTML全文浏览量: 2335
- PDF下载量: 436
- 被引次数: 0
