

Black-box Adversarial Attack on License Plate Recognition System
-
摘要:
深度神经网络(Deep neural network, DNN)作为最常用的深度学习方法之一, 广泛应用于各个领域. 然而, DNN容易受到对抗攻击的威胁, 因此通过对抗攻击来检测应用系统中DNN的漏洞至关重要. 针对车牌识别系统进行漏洞检测, 在完全未知模型内部结构信息的前提下展开黑盒攻击, 发现商用车牌识别系统存在安全漏洞. 提出基于精英策略的非支配排序遗传算法(NSGA-II)的车牌识别黑盒攻击方法, 仅获得输出类标及对应置信度, 即可产生对环境变化较为鲁棒的对抗样本, 而且该算法将扰动控制为纯黑色块, 可用淤泥块代替, 具有较强的迷惑性. 为验证本方法在真实场景的攻击可复现性, 分别在实验室和真实环境中对车牌识别系统展开攻击, 并且将对抗样本用于开源的商业软件中进行测试, 验证了攻击的迁移性.
Abstract:Deep neural network (DNN) is one of the most commonly used deep learning methods and is widely used in various fields. However, DNN is vulnerable to adversarial attacks, so it is crucial to detect the vulnerabilities of DNN in the application system by adversarial attacks. In this paper, the vulnerability detection of the license plate recognition system is carried out. Under the premise of completely unknown internal structure information of the model, a black-box adversarial attack is launched, and security vulnerabilities in commercial license plate recognition system are found. The paper first proposes a black-box attack method for license plate recognition based on NSGA-II. Only by obtaining the output class label and corresponding confidence can produce a robust attack against environmental changes, and the algorithm controls the perturbation as a pure black block, which can be replaced by a silt block and has strong confusion. In order to verify the reproducibility of the attack of this method in real scenes, the license plate recognition system was attacked in the laboratory and the real environment, and the adversarial examples were tested in open source commercial software to verify the transferability of the attack.
-
Key words:
- Deep learning /
- license plate recognition /
- adversarial attack /
- black-box attack /
- physical attack
-
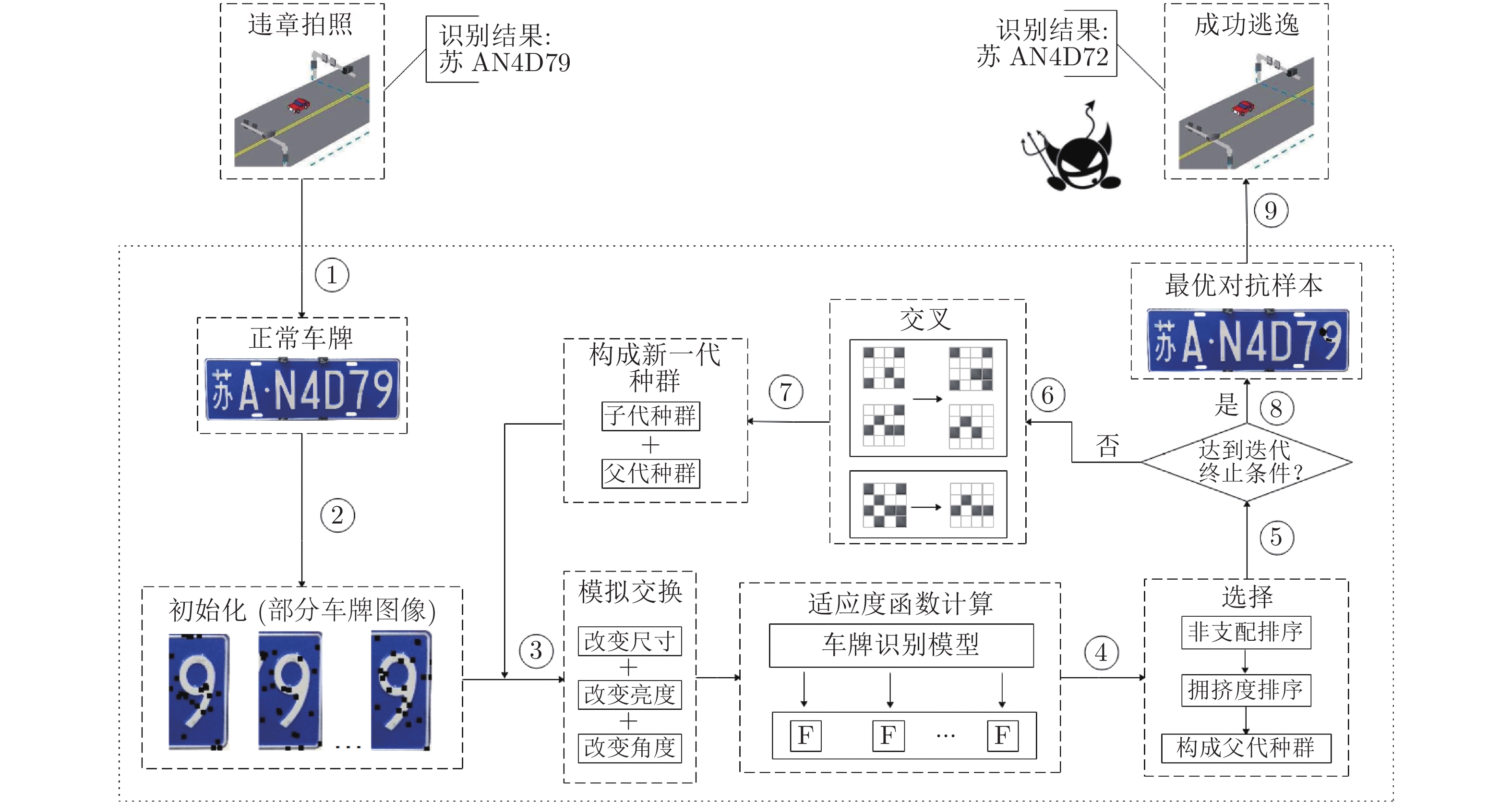
图 1 车牌识别系统的黑盒攻击方法整体框图
Fig. 1 The main block diagram of the proposed method against license plate recognition system
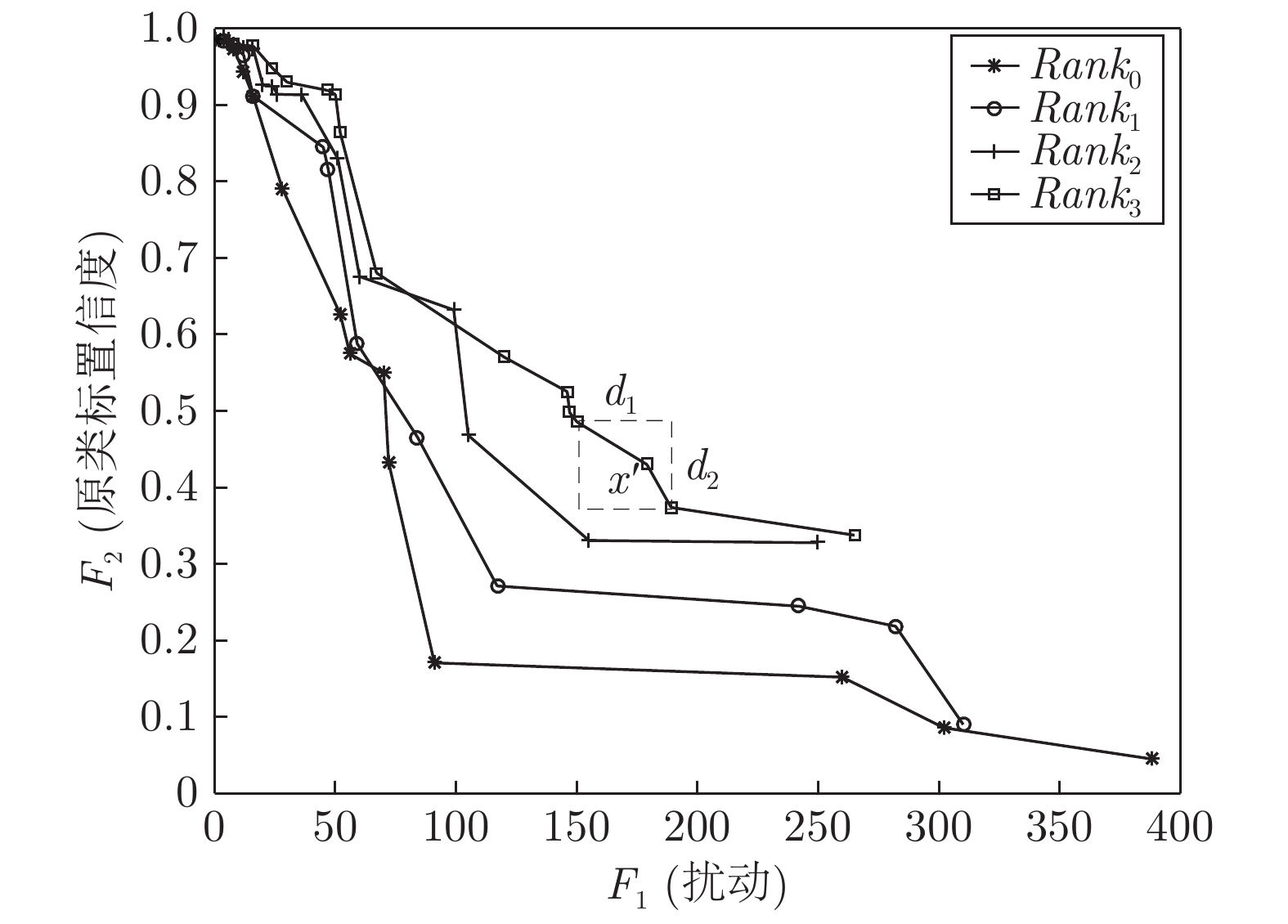
图 4 车牌样本第10次迭代非支配排序结果
Fig. 4 License plate example in 10th iteration non-dominated sorting result

图 8 不同攻击算法攻击同一张车牌样本的不同位置的对抗样本图
Fig. 8 Adversarial examples graph of different attack algorithms attacking different positions of the same license plate sample
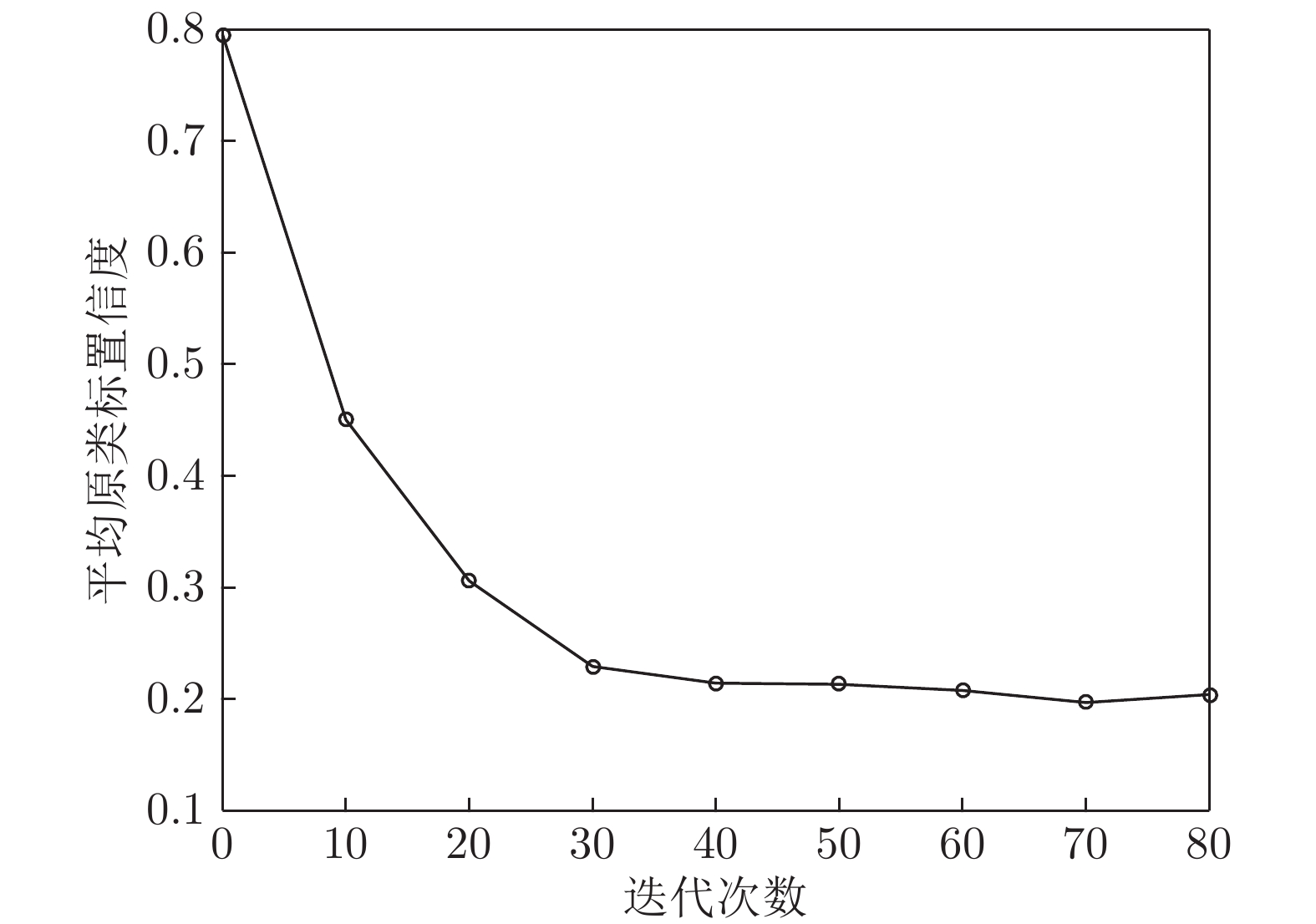
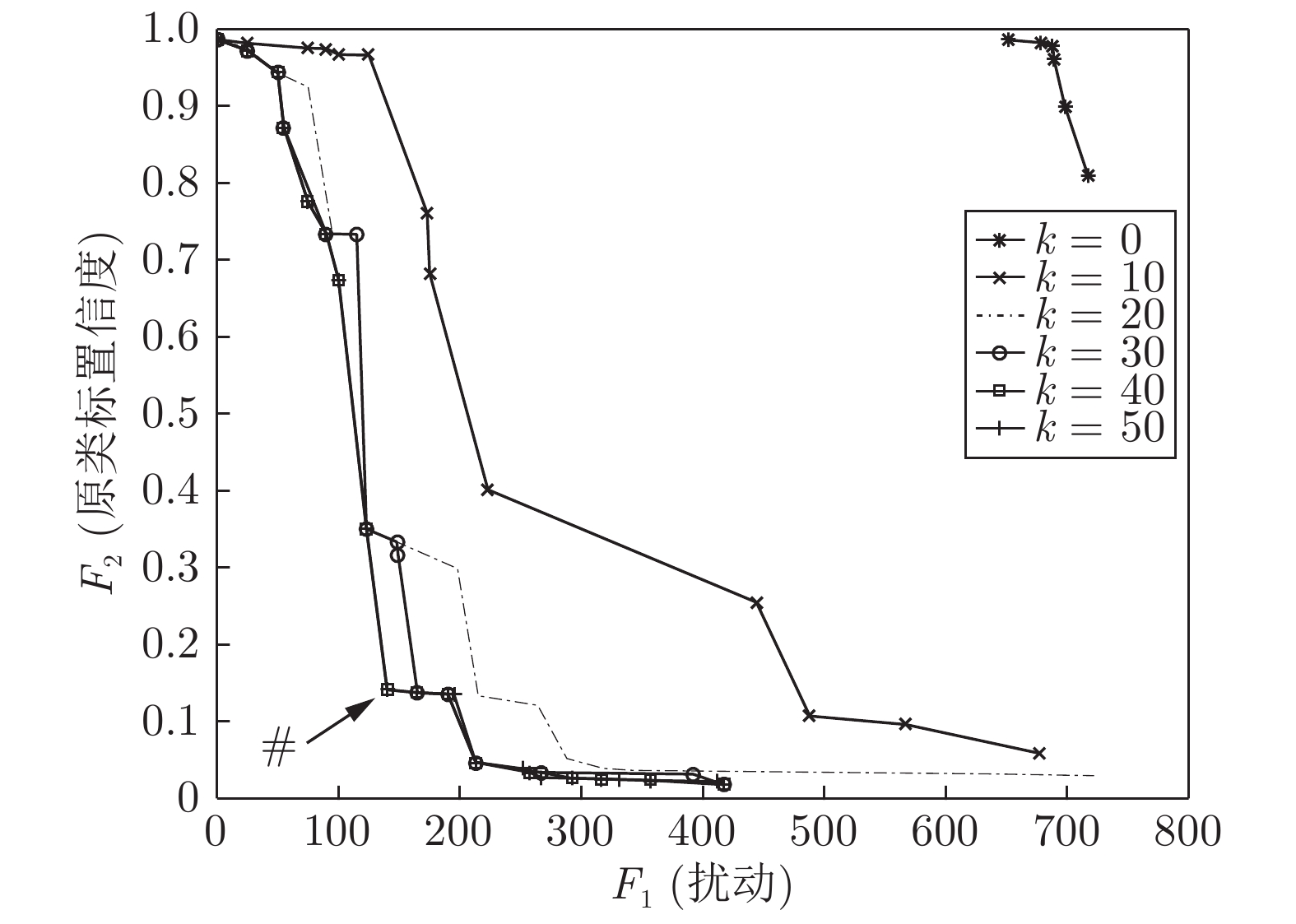
图 9 平均原类标置信度随迭代次数变化曲线图
Fig. 9 Curve of the original class standard confidence varying with the number of iterations
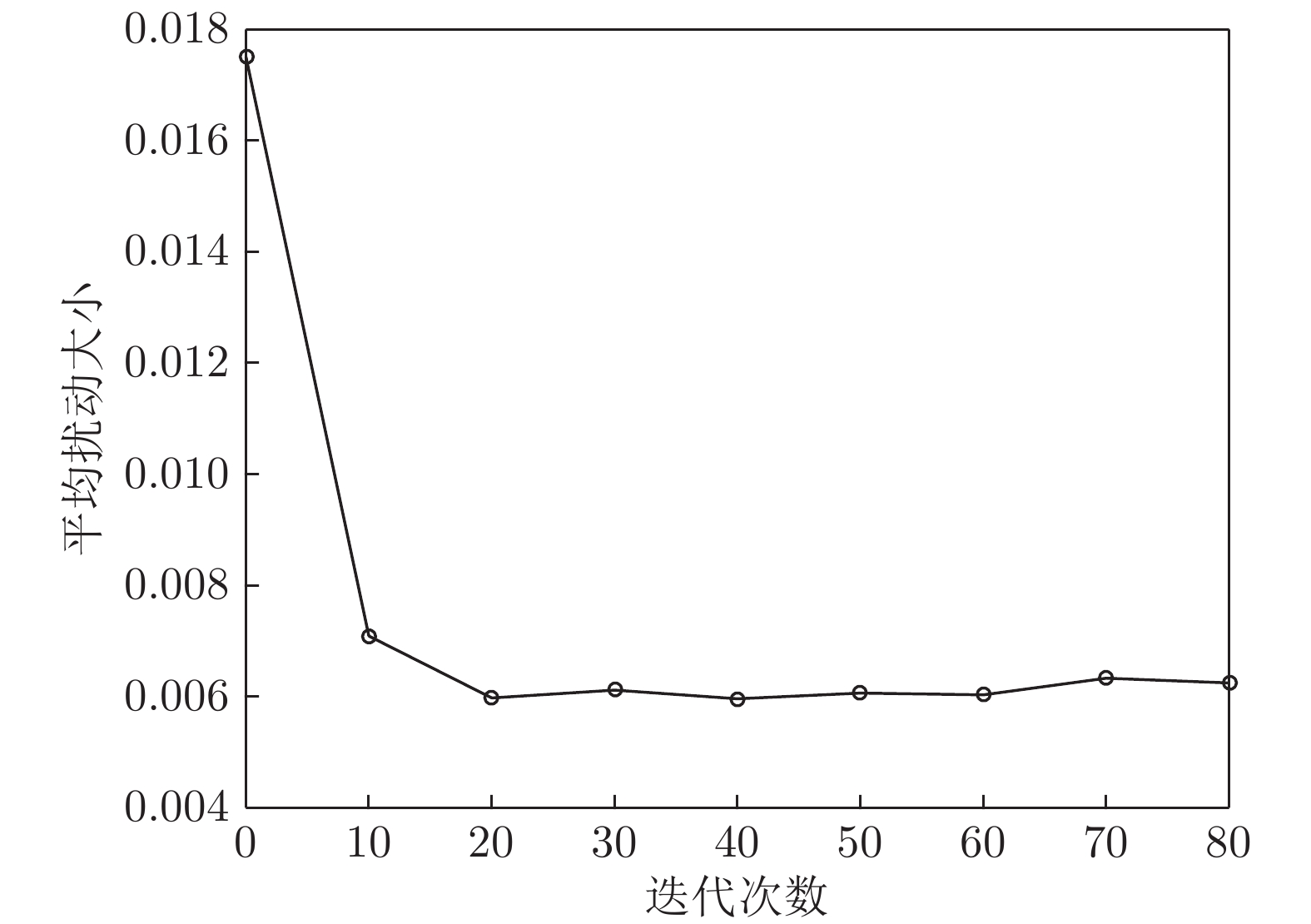
图 10 平均扰动大小随迭代次数变化曲线图
Fig. 10 Curve of the perturbation varying with the number of iterations
表 1 三种模型的识别准确率
Table 1 Recognition accuracy of the three models
模型名称 训练准确率 测试准确率 HyperLPR 96.7% 96.3% EasyPR 85.4% 84.1% PaddlePaddle - OCR车牌识别 87.9% 86.5%  下载: 导出CSV
下载: 导出CSV
表 2 车牌图像攻击算法对比结果
Table 2 Comparison results of plate images attack algorithms
攻击算法 攻击成功率 ${\tilde L_2}$ ${\tilde L_0}$ 访问次数 白盒 FGSM 89.3% 0.067 0.937 32 2-norm 92.8% 0.051 0.923 3 黑盒 ZOO 85.7% 0.087 0.953 74356 AutoZOO 87.1% 0.069 0.938 4256 本文算法 98.6% 0.035 0.004 1743
下载: 导出CSV
表 3 不同环境模拟策略在不同模拟环境下的攻击成功率
Table 3 The attack success rate of different simulation strategies in different simulation environments
环境因素 攻击成功率 (%) 平均成功
率 (%)0 1 2 3 4 5 6 7 8 9 原始对抗样本 固定1 100 96 100 100 100 100 100 100 100 100 99.6 固定2 100 94 96 98 94 100 100 96 100 100 98.0 随机变换 100 94 98 100 94 100 100 98 100 100 98.4 尺寸 (× 0.5) 固定1 100 80 90 92 90 94 98 90 96 100 93.8 光线 (+ 30) 固定2 98 76 90 84 88 92 94 86 92 98 90.4 角度 (右 30 度) 随机变换 100 76 92 92 90 94 96 88 92 98 92.8 尺寸 (× 2) 固定1 100 80 90 92 92 94 98 90 96 100 93.6 光线 (– 30) 固定2 100 78 90 86 86 88 92 82 90 96 89.2 角度 (左 30 度) 随机变换 100 78 92 90 88 90 96 84 92 96 91.4 尺寸 (× 0.3) 固定1 92 76 80 86 82 84 88 84 90 88 85.0 光线 (+ 50) 固定2 98 82 92 92 90 94 96 90 96 98 93.4 角度 (右 50 度) 随机变换 96 80 90 88 86 90 94 92 92 94 90.8 尺寸 (× 3) 固定1 90 74 80 86 82 82 90 82 88 88 84.2 光线 (– 50) 固定2 98 80 90 92 90 92 96 92 94 98 92.8 角度 (左 50 度) 随机变换 96 78 88 88 84 92 92 92 94 94 90.6 尺寸 (× 0.7) 固定1 92 76 80 88 84 82 90 82 92 90 85.6 光线 (+ 20) 固定2 94 76 86 90 86 84 92 86 90 92 88.4 角度 (右 42 度) 随机变换 96 78 90 92 90 92 94 90 94 96 92.2 尺寸 (× 1.3) 固定1 92 76 78 86 82 84 90 82 88 84 84.2 光线 (– 75) 固定2 92 74 82 86 82 86 92 88 90 90 88.0 角度 (左 15 度) 随机变换 94 76 88 90 86 92 92 90 92 94 91.0 各种环境平均攻击成功率 固定1 95.1 79.7 85.4 90.0 87.4 88.6 93.4 87.1 92.9 92.9 89.3 固定2 97.1 79.4 89.4 89.4 88.0 90.9 94.6 88.3 93.1 96.0 90.8 随机变换 97.4 79.7 90.6 90.6 88.3 92.6 94.9 90.0 93.7 96.0 91.6
下载: 导出CSV
表 4 车牌对抗样本识别结果及其置信度、扰动等展示
Table 4 License plate against sample identification results and their confidence, disturbance display
环境因素 识别结果 (固定1/固定2/随机变换) 









原始对抗样本 C/C/Q H/5/5 Z/Z/Z 5/5/2 J/6/Z 3/3/3 3/5/5 T/T/Z G/S/S 2/2/2 平均置信度: 0.92/0.87/0.86 尺寸 (× 0.5)
光线 (+ 30)
角度 (右 30 度)C/C/Q H/5/5 Z/Z/3 5/5/2 J/X/Z 3/3/3 3/3/3 T/1/Z G/S/S 2/2/2 平均置信度: 0.90/0.86/0.83 尺寸 (× 2)
光线 (– 30)
角度 (左 30 度)C/C/Q H/7/5 Z/Z/Z 5/5/2 J/6/Z 3/3/3 3/5/5 T/T/Z G/S/G 2/2/2 平均置信度: 0.89/0.83/0.86 尺寸 (× 0.3)
光线 (+ 50)
角度 (右 50 度)C/C/Q 1/5/1 2/Z/X 5/5/5 4/6/X 3/3/3 3/5/5 T/T/Z G/S/S 2/2/2 平均置信度: 0.84/0.90/0.85 尺寸 (× 3)
光线 (– 50)
角度 (左 50 度)C/C/Q 1/5/7 Z/Z/Z 5/5/2 J/6/4 3/3/3 3/5/5 1/T/1 G/S/S 2/2/2 平均置信度: 0.84/0.88/0.86 尺寸 (× 0.7)
光线 (+ 20)
角度 (右 42 度)C/C/Q H/1/5 Z/Z/Z 5/5/2 J/6/Z 3/3/3 5/5/5 T/T/Z G/S/S 2/2/2 平均置信度: 0.81/0.87/0.85 尺寸 (× 1.3)
光线 (– 75)
角度 (左 15 度)C/C/0 1/1/7 Z/2/Z 5/5/5 4/6/Z 3/3/3 3/5/5 7/T/Z S/G/S 2/2/2 平均置信度: 0.87/0.82/0.83
下载: 导出CSV
表 5 实验室环境的车牌对抗攻击
Table 5 License plate adversarial attack in the laboratory environment
环境因素 0度, 1 m, 白天 0度, 1 m, 夜晚 0度, 5 m, 白天 0度, 5 m, 夜晚 20度, 1 m, 白天 20度, 1 m, 夜晚 物理对抗样本 





正常车牌识别结果 苏 AN4D79 苏 AN4D79 苏 AN4D79 苏 AN4D79 苏 AN4D79 苏 AN4D79 正常车牌识别置信度 0.9751 0.9741 0.9242 0.9214 0.9578 0.9501 对抗样本识别结果 苏 AH4072 苏 AH4072 苏 AH4072 苏 AH4072 苏 AH4072 苏 AH4072 对抗样本识别置信度 0.9041 0.8862 0.8248 0.8310 0.8045 0.8424
下载: 导出CSV
表 6 初始扰动信息的影响
Table 6 Influences of initial perturbation information
面积比值 数量 形状 攻击成功率 最终扰动 迭代次数 1: 50 10 R 100% 0.0062 33 C 100% 0.0059 32 R+C 100% 0.0063 35 30 R 100% 0.0054 36 C 100% 0.0052 35 R+C 100% 0.0054 34 50 R 100% 0.0042 42 C 100% 0.0043 40 R+C 100% 0.0043 44 1: 80 10 R 100% 0.0058 34 C 100% 0.0054 33 R+C 100% 0.0055 34 30 R 100% 0.0043 34 C 100% 0.0041 32 R+C 100% 0.0042 35 50 R 96% 0.0037 48 C 94% 0.0036 48 R+C 96% 0.0032 46 1: 120 10 R 100% 0.0042 32 C 100% 0.0045 31 R+C 98% 0.0042 31 30 R 98% 0.0035 36 C 96% 0.0033 36 R+C 96% 0.0033 35 50 R 87% 0.0027 56 C 86% 0.0025 58 R+C 87% 0.0024 58
下载: 导出CSV
表 7 交叉概率敏感性分析
Table 7 Cross-probability sensitivity analysis
交叉概率 迭代次数 原类标置信度 扰动大小$({\tilde L_0})$ 0.2 75 0.153 0.0048 0.4 53 0.138 0.0046 0.6 42 0.113 0.0048 0.8 34 0.126 0.0043 1 32 0.140 0.0045
下载: 导出CSV
表 8 躲避公路探头抓拍
Table 8 Avoiding road probe capture




HyperLPR 云 AG7C35 HyperLPR 新 AG7C65 HyperLPR 浙 AG7C65 百度AI 浙 AC7C35 百度AI 浙 AG7C35 百度AI 浙 AG7C35 OpenALPR 浙 A67C65 OpenALPR 浙 A67C55 OpenALPR 浙 A07C35
下载: 导出CSV
表 10 冒充出入库车辆
Table 10 Posing as a warehousing vehicle



立方 浙 AP0F20 立方 浙 AP0F20 百度AI 浙 AF0F20 百度AI 浙 AT0F20 OpenALPR 浙 A10F20 OpenALPR 浙 A10F20
下载: 导出CSV
表 9 躲避车牌尾号限行
Table 9 Avoiding license plate tail number limit




HyperLPR 苏 A14D72 HyperLPR 苏 AH4D72 HyperLPR 苏 AH4D72 百度AI 苏 AH4D72 百度AI 苏 AH4D79 百度AI 苏 AH4D72 OpenALPR 苏 AM4D78 OpenALPR 苏 AM4D79 OpenALPR 苏 AM4D72
下载: 导出CSV
-
[1] Goodfellow I J, Bengio Y, Courville A. Deep Learning. Cambridge: MIT Press, 2016. 24−45 [2] Chen J Y, Zheng H B, Lin X, Wu Y Y, Su M M. A novel image segmentation method based on fast density clustering algorithm. Engineering Applications of Artificial Intelligence, 2018, 73: 92−110 doi: 10.1016/j.engappai.2018.04.023 [3] Sutskever I, Vinyals O, Le Q V. Sequence to sequence learning with neural networks. In: Proceedings of the 27th International Conference on Neural Information Processing Systems. Montreal, Quebec, Canada: MIT Press, 2014. 3104−3112 [4] 代伟, 柴天佑. 数据驱动的复杂磨矿过程运行优化控制方法. 自动化学报, 2014, 40(9): 2005−2014Dai Wei, Chai Tian-You. Data-driven optimal operational control of complex grinding processes. Acta Automatica Sinica, 2014, 40(9): 2005−2014 [5] Chen J Y, Zheng H B, Xiong H, Wu Y Y, Lin X, Ying S Y, et al. DGEPN-GCEN2V: A new framework for mining GGI and its application in biomarker detection. Science China Information Sciences, 2019, 62(9): Article No. 199104 doi: 10.1007/s11432-018-9704-7 [6] 姚乃明, 郭清沛, 乔逢春, 陈辉, 王宏安. 基于生成式对抗网络的鲁棒人脸表情识别. 自动化学报, 2018, 44(5): 865−877Yao Nai-Ming, Guo Qing-Pei, Qiao Feng-Chun, Chen Hui, Wang Hong-An. Robust facial expression recognition with generative adversarial networks. Acta Automatica Sinica, 2018, 44(5): 865−877 [7] 袁文浩, 孙文珠, 夏斌, 欧世峰. 利用深度卷积神经网络提高未知噪声下的语音增强性能. 自动化学报, 2018, 44(4): 751−759Yuan Wen-Hao, Sun Wen-Zhu, Xia Bin, Ou Shi-Feng. Improving speech enhancement in unseen noise using deep convolutional neural network. Acta Automatica Sinica, 2018, 44(4): 751−759 [8] Szegedy C, Zaremba W, Sutskever I, Bruna J, Erhan D, Goodfellow I J, et al. Intriguing properties of neural networks. In: Proceedings of the 2nd International Conference on Learning Representations (ICLR 2014). Banff, AB, Canada: ICLR, 2014. [9] Moosavi-Dezfooli S M, Fawzi A, Fawzi O, Frossard P. Universal adversarial perturbations. In: Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition. Honolulu, USA: IEEE, 2017. 86−94 [10] Akhtar N, Mian A. Threat of adversarial attacks on deep learning in computer vision: A survey. IEEE Access, 2018, 6: 14410−14430 doi: 10.1109/ACCESS.2018.2807385 [11] Zeng X H, Liu C X, Wang Y S, Qiu W C, Xie L X, Tai Y W, et al. Adversarial attacks beyond the image space. In: Proceedings of the 2019 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). California, USA: IEEE, 2019. 4302−4311 [12] Deb K, Agarwal S, Pratap A, Meyarivan T. A fast and elitist multiobjective genetic algorithm: NSGA-II. IEEE Transactions on Evolutionary Computation, 2002, 6(2): 182−197 doi: 10.1109/4235.996017 [13] Goodfellow I J, Shlens J, Szegedy C. Explaining and harnessing adversarial examples. In: Proceedings of the 3rd International Conference on Learning Representations (ICLR 2015). San Diego, CA, USA: ICLR, 2015. [14] Kurakin A, Goodfellow I J, Bengio S. Adversarial examples in the physical world. In: Proceedings of the 5th International Conference on Learning Representations (ICLR 2017). Toulon, France: ICLR, 2017. [15] Moosavi-Dezfooli S M, Fawzi A, Frossard P. Deepfool: A simple and accurate method to fool deep neural networks. In: Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition. Las Vegas, USA: IEEE, 2016. 2574−2582 [16] Carlini N, Wagner D. Towards evaluating the robustness of neural networks. In: Proceedings of the 2017 IEEE Symposium on Security and Privacy. San Jose, USA: IEEE, 2017. 39−57 [17] Papernot N, McDaniel P, Jha S, Fredrikson M, Celik Z B, Swami A. The limitations of deep learning in adversarial settings. In: Proceedings of the 2016 IEEE European Symposium on Security and Privacy. Saarbrucken, Germany: IEEE, 2016. 372−387 [18] Lyu C, Huang K Z, Liang H N. A unified gradient regularization family for adversarial examples. In: Proceedings of the 2015 IEEE International Conference on Data Mining. Atlantic City, USA: IEEE, 2015. 301−309 [19] Su J W, Vargas D V, Sakurai K. One pixel attack for fooling deep neural networks. IEEE Transactions on Evolutionary Computation, 2019, 23(5): 828−841 doi: 10.1109/TEVC.2019.2890858 [20] Brendel W, Rauber J, Bethge M. Decision-based adversarial attacks: Reliable attacks against black-box machine learning models. In: Proceedings of the 6th International Conference on Learning Representations (ICLR 2018). Vancouver, BC, Canada: ICLR, 2018. [21] Chen P Y, Zhang H, Sharma Y, Yi J F, Hsieh C J. Zoo: Zeroth order optimization based black-box attacks to deep neural networks without training substitute models. In: Proceedings of the 10th ACM Workshop on Artificial Intelligence and Security. Dallas, USA: ACM, 2017. 15−26 [22] Tu C C, Ting P S, Chen P Y, Liu S J, Zhang H, Yi J F, et al. Autozoom: Autoencoder-based zeroth order optimization method for attacking black-box neural networks. In: Proceedings of the 33rd AAAI Conference on Artificial Intelligence. Hawaii, USA: AAAI, 2019. 742−749 [23] Chen J B, Jordan M I. Boundary attack++: Query-efficient decision-based adversarial attack. arXiv: 1904.02144, 2019. [24] Chen J Y, Su M M, Shen S J, Xiong H, Zheng H B. POBA-GA: Perturbation optimized black-box adversarial attacks via genetic algorithm. Computers & Security, 2019, 85: 89−106 [25] Bhagoji A N, He W, Li B. Exploring the space of black-box attacks on deep neural networks. arXiv: 1712.09491, 2017. [26] Chen S T, Cornelius C, Martin J, Chau D H. ShapeShifter: Robust physical adversarial attack on faster R-CNN object detector. In: Proceedings of Joint European Conference on Machine Learning and Knowledge Discovery in Databases. Dublin, Ireland: Springer, 2019. 52−68 [27] Ren S Q, He K M, Girshick R, Sun J. Faster R-CNN: Towards real-time object detection with region proposal networks. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2017, 39(6): 1137−1149 [28] Eykholt K, Evtimov I, Fernandes E, Li B, Rahmati A, Tramer F, et al. Physical adversarial examples for object detectors. In: Proceedings of the 12th USENIX Workshop on Offensive Technologies. Baltimore, MD, USA: USENIX Association, 2018. [29] Redmon J, Farhadi A. YOLO9000: Better, faster, stronger. In: Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition. Honolulu, USA: IEEE, 2017. 6517−6525 [30] Thys S, Ranst W V, Goedemé T. Fooling automated surveillance cameras: Adversarial patches to attack person detection. In: Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops. Long Beach, USA: IEEE, 2019. 49−55 [31] Sharif M, Bhagavatula S, Bauer L, Reiter M K. Accessorize to a crime: Real and stealthy attacks on state-of-the-art face recognition. In: Proceedings of the 2016 ACM SIGSAC Conference on Computer and Communications Security. Vienna, Austria: ACM, 2016. 1528−1540 [32] Eykholt K, Evtimov I, Fernandes E, Li B, Rahmati A, Xiao C W, et al. Robust physical-world attacks on deep learning visual classification. In: Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Salt Lake City, USA: IEEE, 2018. 1625−1634 [33] Sitawarin C, Bhagoji A N, Mosenia A, Mittal P, Chiang M. Rogue signs: Deceiving traffic sign recognition with malicious ads and logos. arXiv: 1801.02780, 2018. [34] Athalye A, Engstrom L, Ilyas A, Kwok K. Synthesizing robust adversarial examples. In: Proceedings of the 35th International Conference on Machine Learning. Stockholm, Sweden: PMLR, 2018. 284−293 [35] Li J C, Schmidt F, Kolter Z. Adversarial camera stickers: A physical camera-based attack on deep learning systems. In: Proceedings of the 36th International Conference on Machine Learning. Long Beach, USA: PMLR, 2019. 3896−3904 [36] Xu Z B, Yang W, Meng A J, Lu N X, Huang H, Ying C C, et al. Towards end-to-end license plate detection and recognition: A large dataset and baseline. In: Proceedings of the 15th European Conference on Computer Vision. Munich, Germany: Springer, 2018. 261−277 -

 下载:
下载:



计量
- 文章访问数: 2246
- HTML全文浏览量: 1384
- PDF下载量: 352
- 被引次数: 0
