

Improving Semi-supervised Neural Machine Translation With Variational Information Bottleneck
-
摘要: 变分方法是机器翻译领域的有效方法, 其性能较依赖于数据量规模. 然而在低资源环境下, 平行语料资源匮乏, 不能满足变分方法对数据量的需求, 因此导致基于变分的模型翻译效果并不理想. 针对该问题, 本文提出基于变分信息瓶颈的半监督神经机器翻译方法, 所提方法的具体思路为: 首先在小规模平行语料的基础上, 通过引入跨层注意力机制充分利用神经网络各层特征信息, 训练得到基础翻译模型; 随后, 利用基础翻译模型, 使用回译方法从单语语料生成含噪声的大规模伪平行语料, 对两种平行语料进行合并形成组合语料, 使其在规模上能够满足变分方法对数据量的需求; 最后, 为了减少组合语料中的噪声, 利用变分信息瓶颈方法在源与目标之间添加中间表征, 通过训练使该表征具有放行重要信息、阻止非重要信息流过的能力, 从而达到去除噪声的效果. 多个数据集上的实验结果表明, 本文所提方法能够显著地提高译文质量, 是一种适用于低资源场景的半监督神经机器翻译方法.Abstract: Variational approach is effective in the field of machine translation, its performance is highly dependent on the scale of the data. However, in low-resource setting, parallel corpus is limited, which cannot meet the demand of variational approach on data, resulting in suboptimal translation effect. To address this problem, we propose a semi-supervised neural machine translation approach based on variational information bottleneck. The central ideas are as follows: 1) cross-layer attention mechanism is introduced to train the basic translation model; 2) the trained basic translation model is used on the basis of small-scale parallel corpus, then get large-scale noisy pseudo-parallel corpus by back-translation with the input of monolingual corpus. Finally, pseudo-parallel and parallel corpora are merged into combinatorial corpora; 3) variational information bottleneck is used to reduce data noise and eliminate information redundancy in the combinatorial corpus. Experiment results on multiple language pairs show that the model we proposed can effectively improve the quality of translation.
-
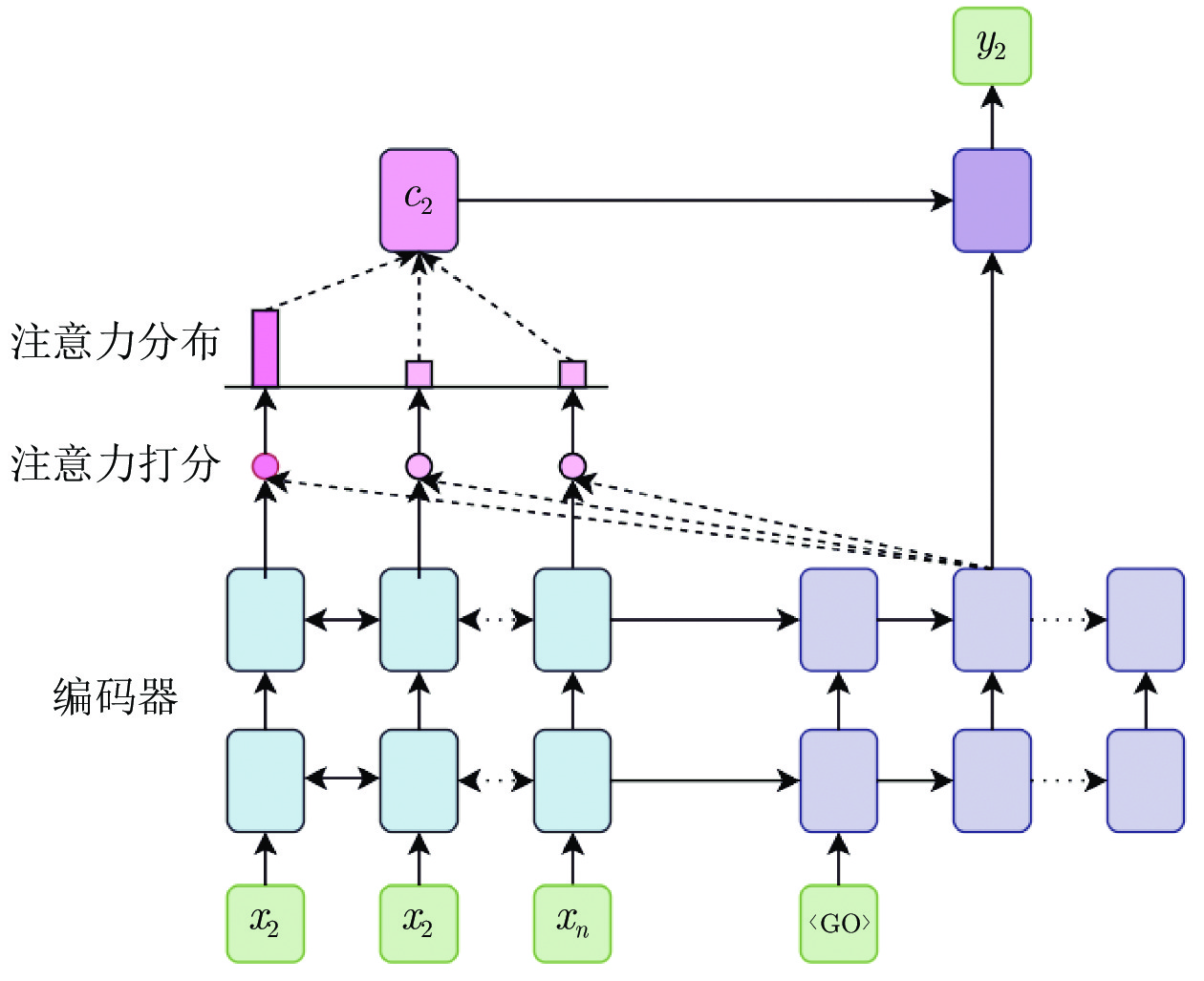
图 1 传统作用于最高层网络的注意力机制融入
Fig. 1 Model with traditional attention mechanism based on top-layer merge
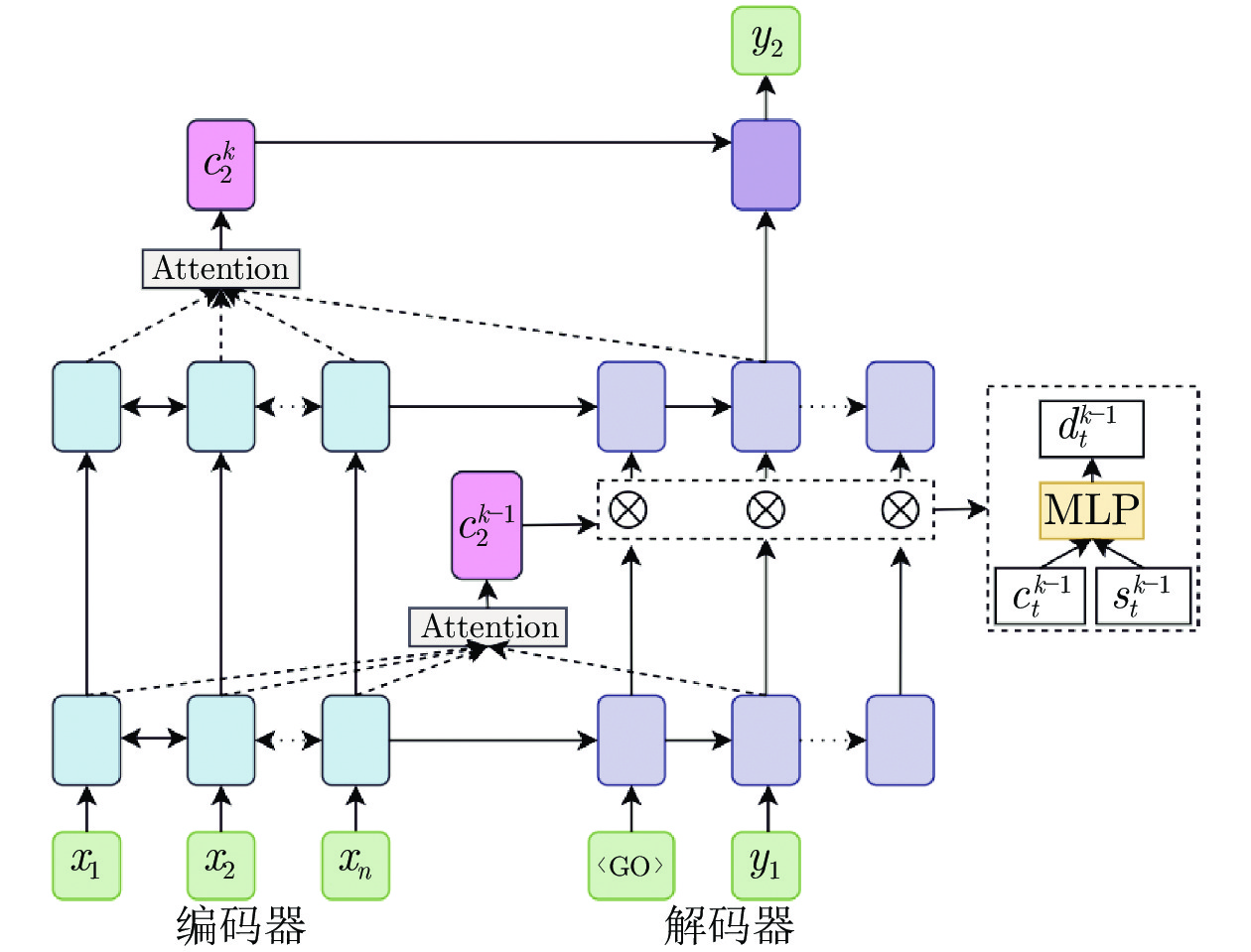
图 2 层内融合方式的层级注意力机制融入
Fig. 2 Model with hierarchical attention mechanism based on inner-layer merge

图 3 跨层融合方式的层级注意力机制融入
Fig. 3 Model with hierarchical attention mechanism based on cross-layer merge
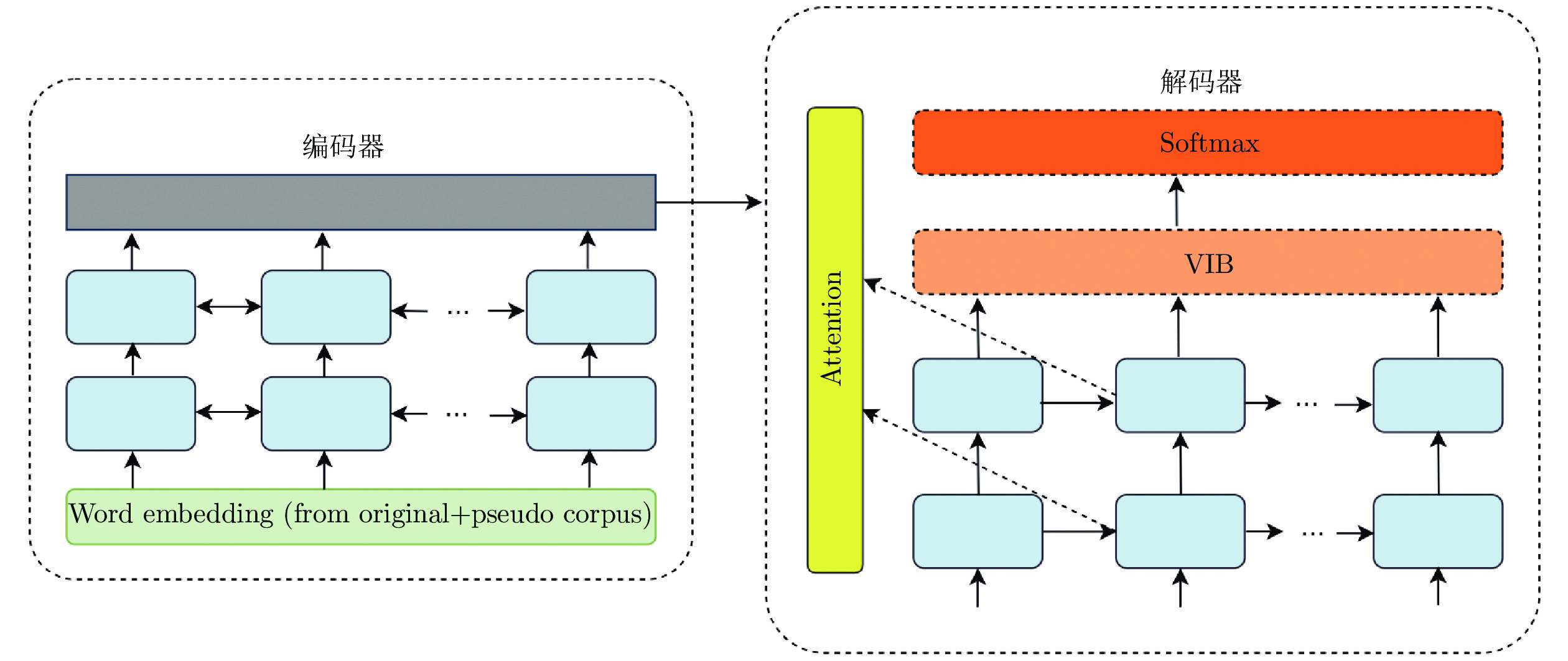
图 4 融入变分信息瓶颈后的神经机器翻译模型
Fig. 4 NMT model after integrating variational information bottleneck
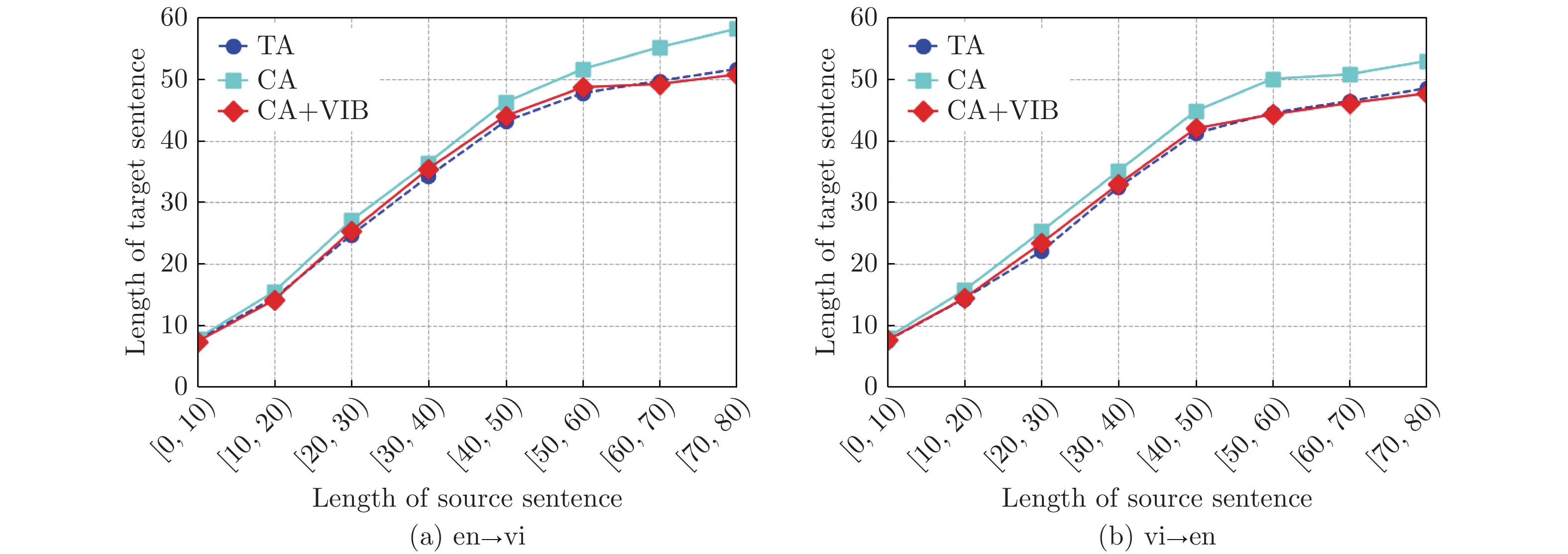
图 6 英−越翻译任务的译文长度评测
Fig. 6 Translation length evaluation of English-Vietnamese translation task
表 1 语料组合结构示例
Table 1 Examples of the combined corpus structure
语料类别 源语言语料 目标语言语料 原始语料 $ {D}_{a} $ $ {D}_{b} $ 单语语料 $ {D}_{x} $ — 伪平行语料 $ {D}_{x} $ $ {D}_{y} $ 组合语料 $ {D}_{b}+{D}_{y} $ $ {D}_{a}+{D}_{x} $  下载: 导出CSV
下载: 导出CSV
表 2 平行语料的构成
Table 2 The composition of parallel corpus
语料类型 数据集 语言对 训练集 验证集 测试集 小规模平行语料 IWSLT15 ${\rm{en} }\leftrightarrow {\rm{vi} }$ 133 K 1553 1268 IWSLT15 ${\rm{en}}\leftrightarrow {\rm{zh}} $ 209 K 887 1261 IWSLT15 ${\rm{en}}\leftrightarrow {\rm{de}} $ 172 K 887 1565 大规模平行语料 WMT14 ${\rm{en}}\leftrightarrow {\rm{de}} $ 4.5 M 3003 3000 注: en: 英语, vi: 越南语, zh: 中文, de: 德语.
下载: 导出CSV
表 3 实验使用的单语语料的构成, 其中越南语使用本文构建的单语语料
Table 3 The composition of monolingual corpus, in which Vietnamese was collected by ourselves
翻译任务 语言 数据集 句数 (M) 单语语料 $ {\rm{en} }\leftrightarrow {\rm{vi} } $ en GIGAWORD 22.3 vi None 1 $ {\rm{en} }\leftrightarrow {\rm{zh} } $ en GIGAWORD 22.3 zh GIGAWORD 18.7 ${\rm{en} }\leftrightarrow {\rm{de}}\;{\rm{(IWSLT15)} }$ en WMT14 18 de WMT14 17.3 ${\rm{en} }\leftrightarrow {\rm{de}}\;{\rm{(WMT14)} }$ en WMT14 18 de WMT14 17.3
下载: 导出CSV
表 4 BLEU值评测结果(%)
Table 4 Evaluation results of BLEU (%)
模型 BLEU en→vi vi→en en→zh zh→en en→de
(IWSLT15)de→en
(IWSLT15)en→de
(WMT14)de→en
(WMT14)RNNSearch 26.55 24.47 21.18 19.15 25.03 28.51 26.62 29.20 RNNSearch+CA 27.04 24.95 21.64 19.59 25.39 28.94 27.06 29.58 RNNSearch+VIB 27.35 25.12 21.94 19.84 25.77 29.31 27.27 29.89 RNNSearch+CA+VIB 27.83* 25.61* 22.39 20.27 26.14* 29.66* 27.61* 30.22* $\triangle $ +1.28 +1.14 +1.21 +1.12 +1.11 +1.15 +0.99 +1.02 Transformer 29.20 26.73 23.69 21.61 27.48 30.66 28.74 31.29 Transformer+CA 29.53 27.00 23.95 21.82 27.74 30.98 28.93 31.51 Transformer+VIB 29.96 27.38 24.30 22.13 28.04 31.24 29.16 31.75 Transformer+CA+VIB 30.17* 27.56* 24.43 22.32 28.11* 31.35* 29.25* 31.89* $\triangle $ +0.97 +0.83 +0.74 +0.71 +0.63 +0.69 +0.51 +0.60 注: $\triangle $表示融入CA+VIB后相较基准系统的BLEU值提升, * 表示利用bootstrap resampling[37] 进行了显著性检验 ($ p<0.05 $)
下载: 导出CSV
表 6 RIBES值评测结果(%)
Table 6 Evaluation results of RIBES (%)
翻译方向 基础翻译模型 单语
语料基准
模型跨层注意力 跨层注意力+
变分信息瓶颈en→vi vi→en vi 74.38 75.07 75.83 vi→en en→vi en 74.29 74.70 75.64 en→zh zh→en zh 72.87 73.33 73.83 zh→en en→zh en 71.81 72.25 72.55 en→de
(IWSLT15)de→en de 79.81 80.14 80.96 de→en
(IWSLT15)en→de en 78.48 78.88 79.61 en→de
(WMT14)de→en de 80.15 80.40 81.29 de→en
(WMT14)en→de en 79.33 79.52 80.07
下载: 导出CSV
表 5 与其他半监督方法的比较(en-de)
Table 5 Comparison between our work and different semi-supervised NMT approach (en-de)
模型 翻译方向 基础翻译模型 单语语料 BLEU Zhang et al. (2018) en→de de→en de 23.60 de→en en→de en 27.98 this work en→de de→en de 24.73 de→en en→de en 28.65
下载: 导出CSV
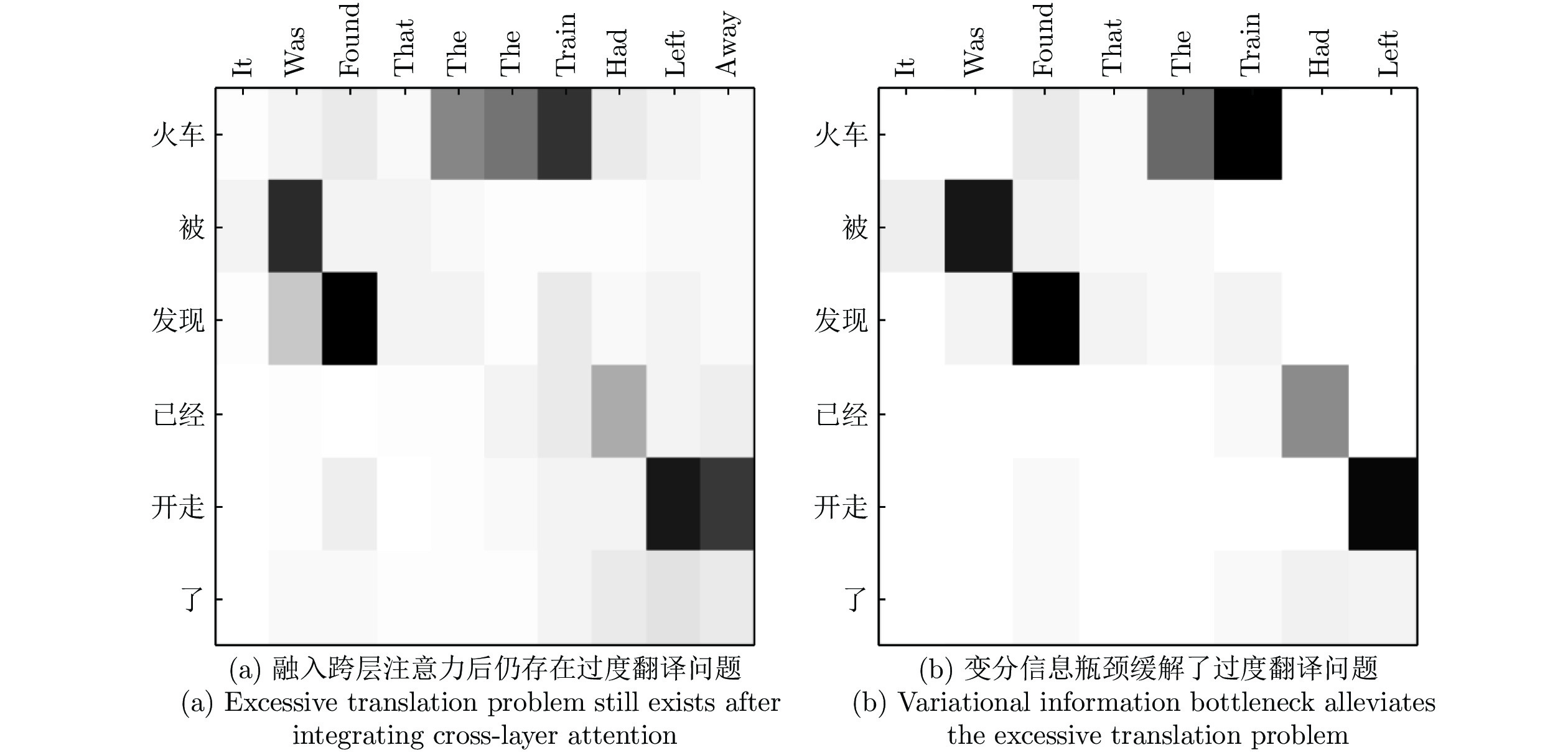
表 7 中−英翻译实例
Table 7 Chinese-English translation examples
源句 参考译文 真实译文 火车被发现
已经开走了It was found that the train had already left [TA] Found that the
the train had gone[CA] It was found that the the train had left away [CA+VIB] It was found that the train had left
下载: 导出CSV
-
[1] Sutskever I, Vinyals O, Le Q V. Sequence to sequence learning with neural networks. In: Proceedings of the 27th International Conference on Neural Information Processing Systems. Montreal, Canada: MIT Press, 2014. 3104−3112 [2] Bahdanau D, Cho K, Bengio Y. Neural machine translation by jointly learning to align and translate. In: Proceedings of the 3rd International Conference on Learning Representations (ICLR). San Diego, USA, 2015. 1−15 [3] 蒋宏飞, 李生, 张民, 赵铁军, 杨沐昀. 基于同步树序列替换文法的统计机器翻译模型. 自动化学报, 2009, 35(10): 1317−1326 doi: 10.3724/SP.J.1004.2009.01317Jiang Hong-Fei, Li Sheng, Zhang Min, Zhao Tie-Jun, Yang Mu-Yun. Synchronous tree sequence substitution grammar for statistical machine translation. Acta Automatica Sinica, 2009, 35(10): 1317−1326 doi: 10.3724/SP.J.1004.2009.01317 [4] 李亚超, 熊德意, 张民. 神经机器翻译综述. 计算机学报, 2018, 41(12): 2734−2755 doi: 10.11897/SP.J.1016.2018.02734Li Ya-Chao, Xiong De-Yi, Zhang Min. A survey of neural machine translation. Chinese Journal of Computers, 2018, 41(12): 2734−2755 doi: 10.11897/SP.J.1016.2018.02734 [5] Kingma D P, Rezende D J, Mohamed S, Welling M. Semi-supervised learning with deep generative models. In: Proceedings of the 27th International Conference on Neural Information Processing Systems. Montreal, Canada: MIT Press, 2014. 3581−3589 [6] Kingma D P, Welling M. Auto-encoding variational bayes. In: Proceedings of the 2nd International Conference on Learning Representations (ICLR). Banff, Canada, 2014. [7] Zhang B, Xiong D Y, Su J S, Duan H, Zhang M. Variational neural machine translation. In: Proceedings of the 2016 Conference on Empirical Methods in Natural Language Processing (EMNLP 2016). Austin, USA: Association for Computational Linguistics, 2016. 521−530 [8] Sennrich R, Haddow B, Birch A. Improving neural machine translation models with monolingual data. In: Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics. Berlin, Germany: Association for Computational Linguistics, 2016. 86−96 [9] Socher R, Pennington J, Huang E H, Ng A Y, Manning C D. Semi-supervised recursive autoencoders for predicting sentiment distributions. In: Proceedings of the 2011 Conference on Empirical Methods in Natural Language Processing (EMNLP). Edinburgh, UK: Association for Computational Linguistics, 2011. 151−161 [10] Ammar W, Dyer C, Smith N A. Conditional random field autoencoders for unsupervised structured prediction. In: Proceedings of the 27th International Conference on Neural Information Processing Systems. Montreal, Canada: MIT Press, 2014. 3311−3319 [11] Belinkov Y, Durrani N, Dalvi F, Sajjad H, Glass J. What do neural machine translation models learn about morphology? In: Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics. Vancouver, Canada: Association for Computational Linguistics, 2017. 861−872 [12] Alemi A A, Fischer I, Dillon J V, Murphy K. Deep variational information bottleneck. In: Proceedings of the 5th International Conference on Learning Representations (ICLR). Toulon, France: OpenReview.net, 2017. [13] Nguyen T T, Choi J. Layer-wise learning of stochastic neural networks with information bottleneck. arXiv: 1712.01272, 2017. [14] Yang Z C, Yang D Y, Dyer C, He X D, Smola A, Hovy E. Hierarchical attention networks for document classification. In: Proceedings of the 2016 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies. San Diego, USA: Association for Computational Linguistics, 2016. 1480−1489 [15] Pappas N, Popescu-Belis A. Multilingual hierarchical attention networks for document classification. In: Proceedings of the 8th International Joint Conference on Natural Language Processing. Taipei, China: Asian Federation of Natural Language Processing, 2017. 1015−1025 [16] Zhang Y, Wang Y H, Liao J Z, Xiao W D. A hierarchical attention Seq2seq model with CopyNet for text summarization. In: Proceedings of the 2018 International Conference on Robots and Intelligent System (ICRIS). Changsha, China: IEEE, 2018. 316−320 [17] Miculicich L, Ram D, Pappas N, Henderson J. Document-level neural machine translation with hierarchical attention networks. In: Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing. Brussels, Belgium: Association for Computational Linguistics, 2018. 2947−2954 [18] Zhang B, Xiong D Y, Su J S. Neural machine translation with deep attention. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2020, 42(1): 154−163 doi: 10.1109/TPAMI.2018.2876404 [19] Ueffing N, Haffari G, Sarkar A. Semi-supervised model adaptation for statistical machine translation. Machine Translation, 2007, 21(2): 77−94 doi: 10.1007/s10590-008-9036-3 [20] Bertoldi N, Federico M. Domain adaptation for statistical machine translation with monolingual resources. In: Proceedings of the 4th Workshop on Statistical Machine Translation. Athens, Greece: Association for Computational Linguistics, 2009. 182−189 [21] Klementiev A, Irvine A, Callison-Burch C, Yarowsky D. Toward statistical machine translation without parallel corpora. In: Proceedings of the 13th Conference of the European Chapter of the Association for Computational Linguistics. Avignon, France: Association for Computational Linguistics, 2012. 130−140 [22] Zhang J J, Zong C Q. Learning a phrase-based translation model from monolingual data with application to domain adaptation. In: Proceedings of the 51st Annual Meeting of the Association for Computational Linguistics. Sofia, Bulgaria: Association for Computational Linguistics, 2013. 1425−1434 [23] Ravi S, Knight K. Deciphering foreign language. In: Proceedings of the 49th Annual Meeting of the Association for Computational Linguistics: Human Language Technologies. Portland, USA: Association for Computational Linguistics, 2011. 12−21 [24] Dou Q, Vaswani A, Knight K. Beyond parallel data: Joint word alignment and decipherment improves machine translation. In: Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP). Doha, Qatar: Association for Computational Linguistics, 2014. 557−565 [25] Cheng Y, Xu W, He Z J, He W, Wu H, Sun M S, et al. Semi-supervised learning for neural machine translation. In: Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics. Berlin, Germany: Association for Computational Linguistics, 2016. 1965−1974 [26] Skorokhodov I, Rykachevskiy A, Emelyanenko D, Slotin S, Ponkratov A. Semi-supervised neural machine translation with language models. In: Proceedings of the 2018 AMTA Workshop on Technologies for MT of Low Resource Languages (LoResMT 2018). Boston, USA: Association for Machine Translation in the Americas, 2018. 37−44 [27] Artetxe M, Labaka G, Agirre E, Cho K. Unsupervised neural machine translation. In: Proceedings of the 6th International Conference on Learning Representations (ICLR 2018). Vancouver, Canada: OpenReview.net, 2018. [28] Lample G, Ott M, Conneau A, Denoyer L, Ranzato M A. Phrase-based and neural unsupervised machine translation. In: Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing. Brussels, Belgium: Association for Computational Linguistics, 2018. 5039−5049 [29] Burlot F, Yvon F. Using monolingual data in neural machine translation: A systematic study. In: Proceedings of the 3rd Conference on Machine Translation: Research Papers. Brussels, Belgium: Association for Computational Linguistics, 2018. 144−155 [30] Tishby N, Pereira F C, Bialek W. The information bottleneck method. arXiv: physics/0004057, 2000. [31] Eikema B, Aziz W. Auto-encoding variational neural machine translation. In: Proceedings of the 4th Workshop on Representation Learning for NLP (RepL4NLP-2019). Florence, Italy: Association for Computational Linguistics, 2019. 124−141 [32] Su J S, Wu S, Xiong D Y, Lu Y J, Han X P, Zhang B. Variational recurrent neural machine translation. In: Proceedings of the 32nd AAAI Conference on Artificial Intelligence. New Orleans, USA: AAAI, 2018. 5488−5495 [33] Kingma D P, Ba L J. Adam: A method for stochastic optimization. In: Proceedings of the 3rd International Conference on Learning Representations (ICLR 2015). San Diego, USA, 2014. [34] Sennrich R, Zhang B. Revisiting low-resource neural machine translation: A case study. In: Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics (ACL2019). Florence, Italy: Association for Computational Linguistics, 2019. 211−221 [35] Papineni K, Roukos S, Ward T, Zhu W J. BLEU: A method for automatic evaluation of machine translation. In: Proceedings of the 40th Annual Meeting of the Association for Computational Linguistics (ACL). Philadelphia, USA: Association for Computational Linguistics, 2002. 311−318 [36] Isozaki H, Hirao T, Duh K, Sudoh K, Tsukada H. Automatic evaluation of translation quality for distant language pairs. In: Proceedings of the 2010 Conference on Empirical Methods in Natural Language Processing. Cambridge, USA: Association for Computational Linguistics, 2010. 944−952 [37] Koehn P. Statistical significance tests for machine translation evaluation. In: Proceedings of the 2004 Conference on Empirical Methods in Natural Language Processing (EMNLP2004). Barcelona, Spain: Association for Computational Linguistics, 2004. 388−395 [38] Zhang Z R, Liu S J, Li M, Zhou M, Chen E H. Joint training for neural machine translation models with monolingual data. In: Proceedings of the 32nd AAAI Conference on Artificial Intelligence and the 30th Innovative Applications of Artificial Intelligence Conference and the 8th AAAI Symposium on Educational Advances in Artificial Intelligence. New Orleans, USA: AAAI Press, 2018. Article No. 69 -

 下载:
下载:




计量
- 文章访问数: 1610
- HTML全文浏览量: 724
- PDF下载量: 222
- 被引次数: 0
