

-
摘要: 为提高神经网络对语音信号时域波形的直接处理能力, 提出了一种基于RefineNet的端到端语音增强方法. 本文构建了一个时频分析神经网络, 模拟语音信号处理中的短时傅里叶变换, 利用RefineNet网络学习含噪语音到纯净语音的特征映射. 在模型训练阶段, 用多目标联合优化的训练策略将语音增强的评价指标短时客观可懂度(Short-time objective intelligibility, STOI)与信源失真比(Source to distortion ratio, SDR)融入到训练的损失函数. 在与具有代表性的传统方法和端到端的深度学习方法的对比实验中, 本文提出的算法在客观评价指标上均取得了最好的增强效果, 并且在未知噪声和低信噪比条件下表现出更好的抗噪性.Abstract: In order to improve the direct processing ability of the neural network to the time domain waveform of speech signal, this paper proposes an end-to-end speech enhancement method based on RefineNet. To simulate the short-time Fourier transform, a time-frequency analysis neural network is used in speech signal processing and the RefineNet is used to learn the feature mapping of noisy speech to clean speech. The speech enhancement evaluation metric short-time objective intelligibility (STOI) and source to distortion ratio (SDR) are integrated into the training loss function in the model training phase by using the multi-objective joint optimization training strategy. Experiments show that the proposed method consistently outperforms conventional methods and end-to-end deep learning methods on objective evaluation metric and has better noise immunity under unseen noise and low SNR conditions than other methods.
-
Key words:
- Speech enhancement /
- end-to-end /
- RefineNet /
- multi-objective joint optimization /
- deep neural network
-
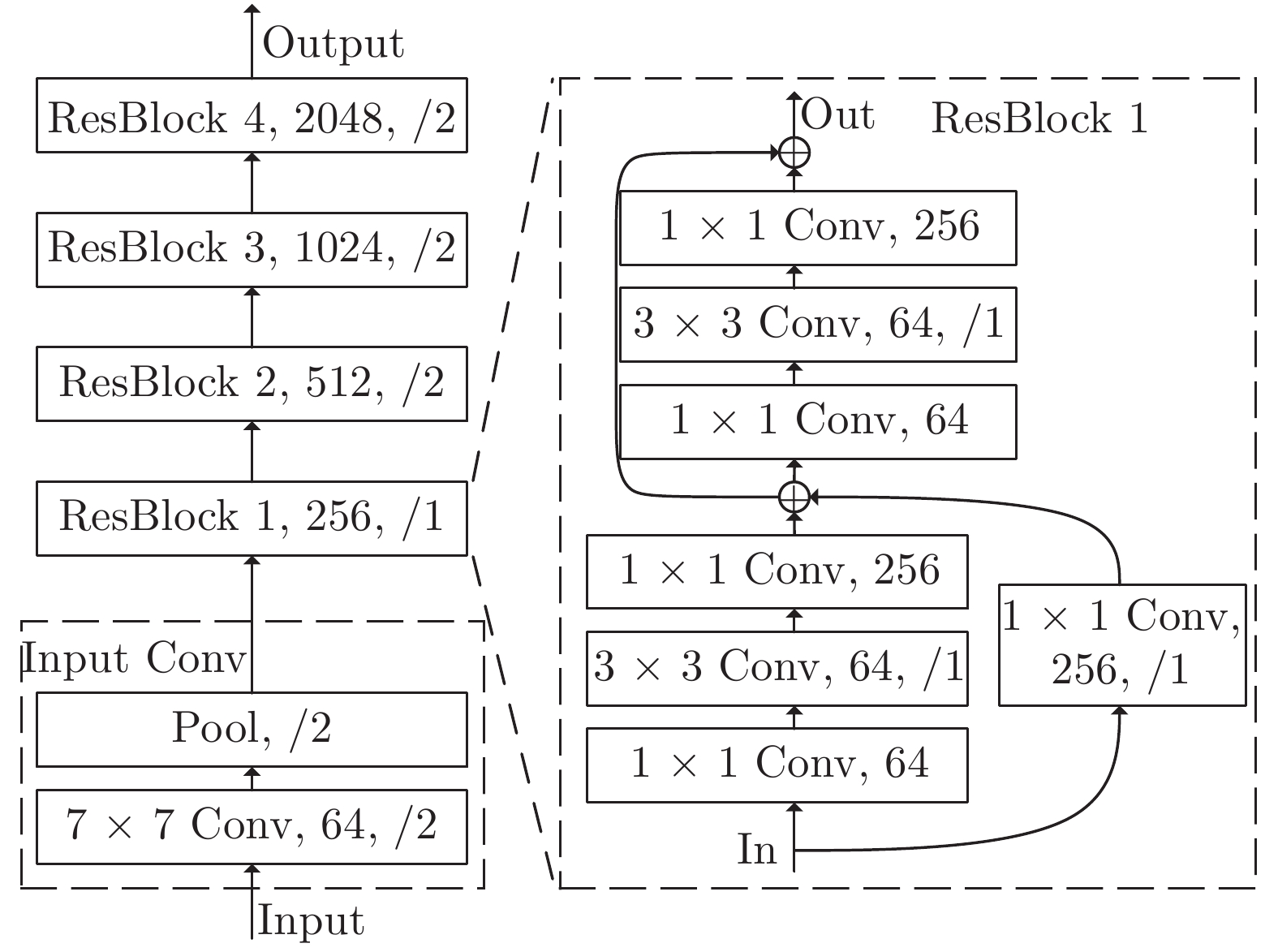
图 2 ResNet模型结构图(Conv后用, 分隔的分别是卷积层的输出通道数、步长, 若未指明步长, 默认为1)
Fig. 2 The diagram for ResNet architecture
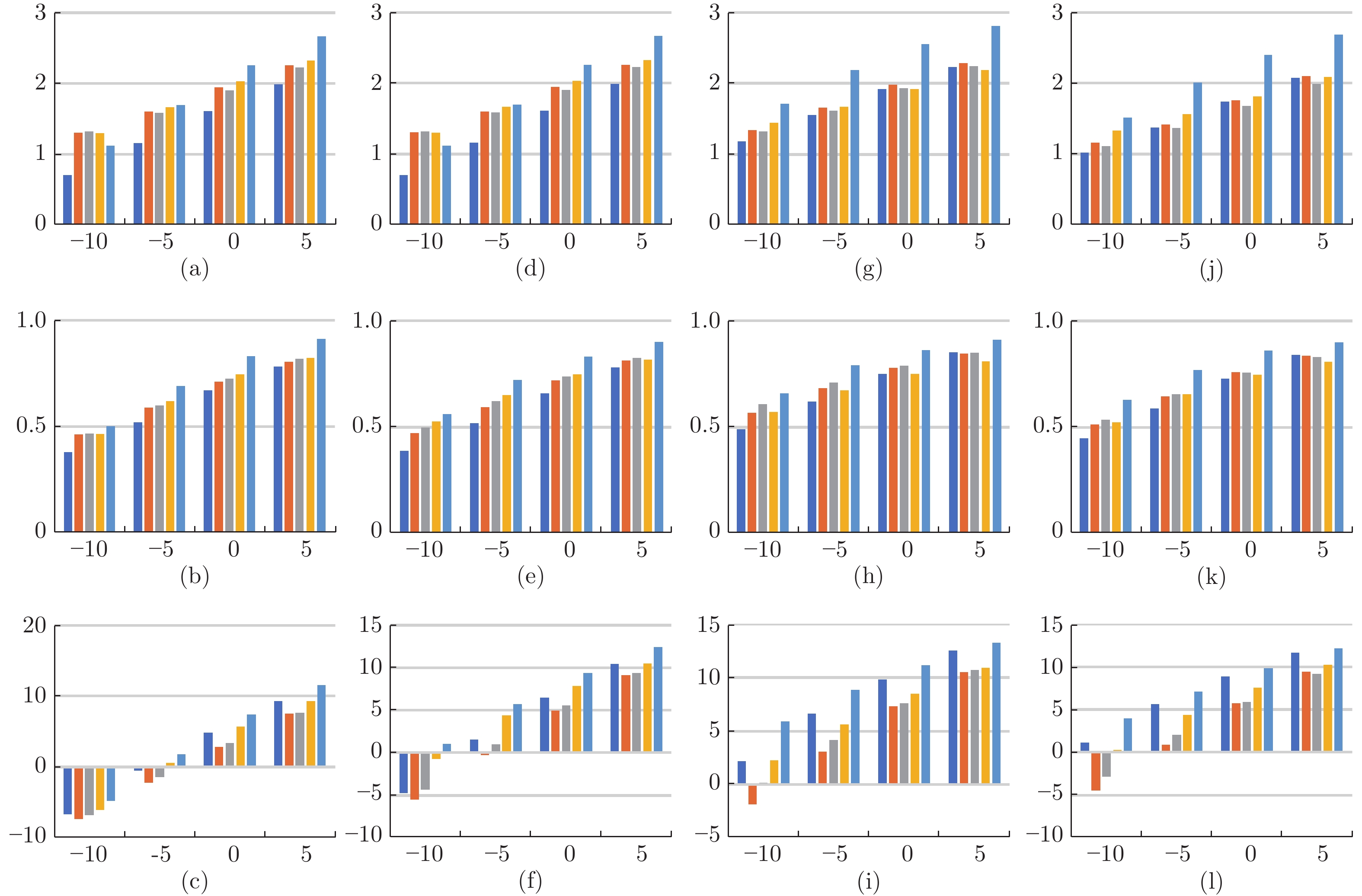
图 4 不同噪声不同信噪比下实验结果图(从第一行到第三行评价指标分别为PESQ、STOI与SDR, 图(a) ~ (c)、图(d) ~ (f)、图(g) ~ (i)、图(j) ~ (l)分别为Babble, Factory1, White, HFChannel噪声下的结果;每簇信噪比中的柱状图从左至右依次对应Log-MMSE, CNN-SE, WaveUNet, AET以及RNSE)
Fig. 4 Experimental results under different noise and SNR

图 5 0 dB的Babble噪声下的语音增强语谱图示例
Fig. 5 An example of spectrogram of enhanced speech under Babble noise at 0 dB SNR
表 1 可见噪声的测试结果
Table 1 The performance of baseline systems compared to the proposed RNSE approach in seen noise condition
指标 模型 可见噪声 −10 −5 0 5 PESQ (a) 1.11 1.46 1.79 2.10 (b) 1.65 1.92 2.24 2.51 (c) 1.66 1.92 2.23 2.50 (d) 1.70 2.00 2.25 2.48 (e) 2.11 2.46 2.73 2.93 STOI (a) 0.58 0.68 0.77 0.85 (b) 0.64 0.72 0.80 0.86 (c) 0.66 0.74 0.81 0.86 (d) 0.63 0.72 0.79 0.84 (e) 0.77 0.85 0.90 0.93 SDR (a) −6.67 −1.72 3.07 7.58 (b) −2.24 2.02 6.35 9.76 (c) −0.61 3.30 7.25 10.38 (d) 1.43 5.76 8.67 10.87 (e) 7.01 9.96 12.16 13.98 注: (a) Log-MMSE, (b) CNN-SE, (c) WaveUnet, (d) AET, (e) RNSE  下载: 导出CSV
下载: 导出CSV
表 2 不可见噪声的测试结果
Table 2 The performance of baseline systems compared to the proposed RNSE approach in unseen noise condition
指标 模型 不可见噪声 −10 −5 0 5 PESQ (a) 1.33 1.70 2.04 2.35 (b) 1.48 1.77 2.09 2.39 (c) 1.49 1.76 2.08 2.36 (d) 1.58 1.87 2.15 2.39 (e) 1.80 2.24 2.61 2.88 STOI (a) 0.52 0.63 0.74 0.83 (b) 0.56 0.66 0.76 0.83 (c) 0.59 0.69 0.78 0.85 (d) 0.57 0.69 0.77 0.83 (e) 0.67 0.79 0.87 0.92 SDR (a) −0.17 4.77 8.69 12.03 (b) −2.97 1.96 6.34 9.81 (c) −1.28 3.25 7.05 10.22 (d) 1.50 5.65 8.66 10.99 (e) 4.86 8.45 11.39 13.78 注: (a) Log-MMSE, (b) CNN-SE, (c) WaveUnet, (d) AET, (e) RNSE
下载: 导出CSV
-
[1] 刘文举, 聂帅, 梁山, 张学良. 基于深度学习语音分离技术的研究现状与进展. 自动化学报, 2016, 42(6): 819-833Liu Wen-Ju, Nie Shuai, Liang Shan, Zhang Xue-Liang. Deep learning based speech separation technology and its developments. Acta Automatica Sinica, 2016, 42(6): 819-833 (in Chinese) [2] Wang D, Chen J. Supervised speech separation based on deep learning: An overview. IEEE/ACM Transactions on Audio, Speech and Language Processing, 2018, 26(10): 1702-1726 doi: 10.1109/TASLP.2018.2842159 [3] Lecun Y, Bengio Y, Hinton G. Deep learning. Nature, 2015, 521(7553): 436-444 doi: 10.1038/nature14539 [4] Wang Y, Wang D. Towards scaling up classification-based speech separation. IEEE Trans Audio Speech Lang Process, 2013, 21(7): 10 [5] Narayanan A, Wang D. Ideal ratio mask estimation using deep neural networks for robust speech recognition. In: Proceedings of the 38th IEEE International Conference on Acoustics, Speech and Signal Processing. Vancouver, Canada: IEEE, 2013. 7092−7096 [6] Williamson D S, Wang Y, Wang D. Complex ratio masking for monaural speech separation. IEEE/ACM Transactions on Audio, Speech and Language Processing, 2016, 24(3): 483-492 doi: 10.1109/TASLP.2015.2512042 [7] Xu Y, Du J, Dai L-R, Lee C-H. A regression approach to speech enhancement based on deep neural networks. IEEE/ACM Transactions on Audio, Speech, and Language Processing, 2015, 23(1): 7-19 doi: 10.1109/TASLP.2014.2364452 [8] Park S R, Lee J W. A fully convolutional neural network for speech enhancement. In: Proceedings of the 18th Annual Conference of the International Speech Communication Association. Stockholm, Sweden: ISCA, 2017. 1993−1997 [9] Qian K, Zhang Y, Chang S, Yang X. Speech enhancement using bayesian Wavenet. In: Proceedings of the 18th Annual Conference of the International Speech Communication Association. Stockholm, Sweden: ISCA, 2017. 2013−2017 [10] Oord A v d, Dieleman S, Zen H, Simonyan K. WaveNet: A generative model for raw audio. In: Proceedings of the 9th ISCA Speech Synthesis Workshop. Sunnyvale, USA: ISCA, 2016. 125−125 [11] Rethage D, Pons J, Serra X. A wavenet for speech denoising. In: Proceedings of the 43rd IEEE International Conference on Acoustics, Speech and Signal Processing. Calgary, Canada: IEEE, 2018. 5069−5073 [12] Pascual S, Bonafonte A, Serrà J. SEGAN: Speech enhancement generative adversarial network. In: Proceedings of the 18th Annual Conference of the International Speech Communication Association. Stockholm, Sweden: ISCA, 2017. 3642−3646 [13] Goodfellow I J, Pouget-Abadie J, Mirza M, Xu B. Generative adversarial nets. In: Proceedings of the 28th International Conference on Neural Information Processing Systems. Montreal, Canada: Curran Associates, 2014. 2672−2680 [14] Wang K, Gou C, Duan Y, Lin Y. Generative adversarial networks: introduction and outlook. IEEE/CAA Journal of Automatica Sinica, 2017, 4(4): 588-598 doi: 10.1109/JAS.2017.7510583 [15] Fu S W, Tsao Y, Lu X, Kawai H. Raw waveform-based speech enhancement by fully convolutional networks. In: Proceedings of the 9th Asia-Pacific Signal and Information Processing Association Annual Summit and Conference. Kuala Lumpur, Malaysia: IEEE, 2017. 006−012 [16] Fu S-W, Wang T W, Tsao Y, Lu X G. End-to-End waveform utterance enhancement for direct evaluation metrics optimization by fully convolutional neural networks. IEEE/ACM Transactions on Audio, Speech and Language Processing, 2018, 26(9): 1570-1584 doi: 10.1109/TASLP.2018.2821903 [17] Dieleman S, Schrauwen B. End-to-end learning for music audio. In: Proceedings of the 39th IEEE International Conference on Acoustics, Speech and Signal Processing. Florence, Italy: IEEE, 2014. 6964−6968 [18] Sainath T N, Weiss R J, Senior A, Wilson K W. Learning the speech front-end with raw waveform CLDNNs. In: Proceedings of the 16th Annual Conference of the International Speech Communication Association. Dresden, Germany: ISCA, 2015. 1−5 [19] Venkataramani S, Casebeer J, Smaragdis P. End-to-end source separation with adaptive front-ends. In: Proceedings of the 52nd Asilomar Conference on Signals, Systems, and Computers. Pacific Grove, USA: IEEE, 2018. 684−688 [20] Hui L, Cai M, Guo C, He L. Convolutional maxout neural networks for speech separation. In: Proceedings of the 15th IEEE International Symposium on Signal Processing and Information Technology. Abu Dhabi, United Arab Emirates: IEEE, 2015. 24−27 [21] Grais E M, Plumbley M D. Single channel audio source separation using convolutional denoising autoencoders. In: Proceedings of the 5th IEEE Global Conference on Signal and Information Processing. Montreal, Canada: IEEE, 2017. 1265−1269 [22] Kounovsky T, Malek J. Single channel speech enhancement using convolutional neural network. In: Proceedings of the 15th IEEE International Workshop of Electronics, Control, Measurement, Signals and their Application to Mechatronics. Donostia-San Sebastian, Spain: IEEE, 2017. 1−5 [23] Lin G, Milan A, Shen C, Reid I. Refinenet: multi-path refinement networks for high-resolution semantic segmentation. In: Proceedings of the 30th IEEE Conference on Computer Vision and Pattern Recognition. Honolulu, USA: IEEE, 2017. 5168−5177 [24] He K, Zhang X, Ren S, Sun J. Identity mappings in deep residual networks. In: Proceedings of the 14th European Conference on Computer Vision. Amsterdam, The Netherlands: Springer, 2016. 630−645 [25] Zhao Y, Xu B, Giri R, Zhang T. Perceptually guided speech enhancement using deep neural networks. In: Proceedings of the 43rd IEEE International Conference on Acoustics, Speech and Signal Processing. Calgary, Canada: IEEE, 2018. 5074−5078 [26] He K, Zhang X, Ren S, Sun J. Deep residual learning for image recognition. In: Proceedings of the 29th IEEE Conference on Computer Vision and Pattern Recognition. Las Vegas, USA: IEEE, 2016. 770−778 [27] Bertsekas D P. Nondifferentiable optimization via approximation [M]. Nondifferentiable optimization. Springer. 1975: 1-25 [28] Hendriks R C, Heusdens R, Jensen J. MMSE based noise PSD tracking with low complexity. In: Proceedings of the 35th IEEE International Conference on Acoustics, Speech and Signal Processing. Dallas, USA: IEEE, 2010. 4266−4269 [29] Zhao Z, Liu H, Fingscheidt T. Convolutional neural networks to enhance coded speech. IEEE/ACM Transactions on Audio, Speech, and Language Processing, 2019, 27(4): 663-678 doi: 10.1109/TASLP.2018.2887337 [30] Ronneberger O, Fischer P, Brox T. U-net: Convolutional networks for biomedical image segmentation. In: Proceedings of the 18th International Conference on Medical image computing and computer-assisted intervention. Munich, Germany: Springer, 2015. 234−241 [31] Stoller D, Ewert S, Dixon S. Wave-u-net: A multi-scale neural network for end-to-end audio source separation. In: Proceedings of the 19th International Society for Music Information Retrieval Conference. Paris, France, 2018. 334−340 -

 下载:
下载:


计量
- 文章访问数: 999
- HTML全文浏览量: 1031
- PDF下载量: 232
- 被引次数: 0
