

-
摘要: 近年来, 基于深度卷积神经网络的单图像超分辨率重建, 取得了显著的进展, 但是, 仍然存在诸如特征利用率低、网络参数量大和重建图像细节纹理模糊等问题. 我们提出了基于特征融合注意网络的单图像超分辨率方法, 网络模型主要包括特征融合子网络和特征注意子网络. 特征融合子网络可以更好地融合不同深度的特征信息, 以及增加跨通道的学习能力; 特征注意子网络则着重关注高频信息, 以增强边缘和纹理. 实验结果表明: 无论是主观视觉效果, 还是客观度量, 我们方法的超分辨率性能明显优于其他代表性的方法.Abstract: In recent years, single-image super-resolution (SISR) reconstruction based on deep convolutional neural networks has made significant progress, but there are still problems such as low feature utilization, large number of network parameters and blurred texture of the reconstructed image. We propose a new SISR network based on feature fusion attention mechanism, which mainly consists of a feature fusion sub-network and a feature attention sub-network. The feature fusion sub-network can better fuse feature information of different depths and increase the cross-channel learning ability; the feature attention sub-network focuses on high frequency information to enhance edges and textures. Experimental results demonstrate that the super-resolution performance of our method is significantly better than those of other representative methods in both subjective vision quality and objective metrics.
-
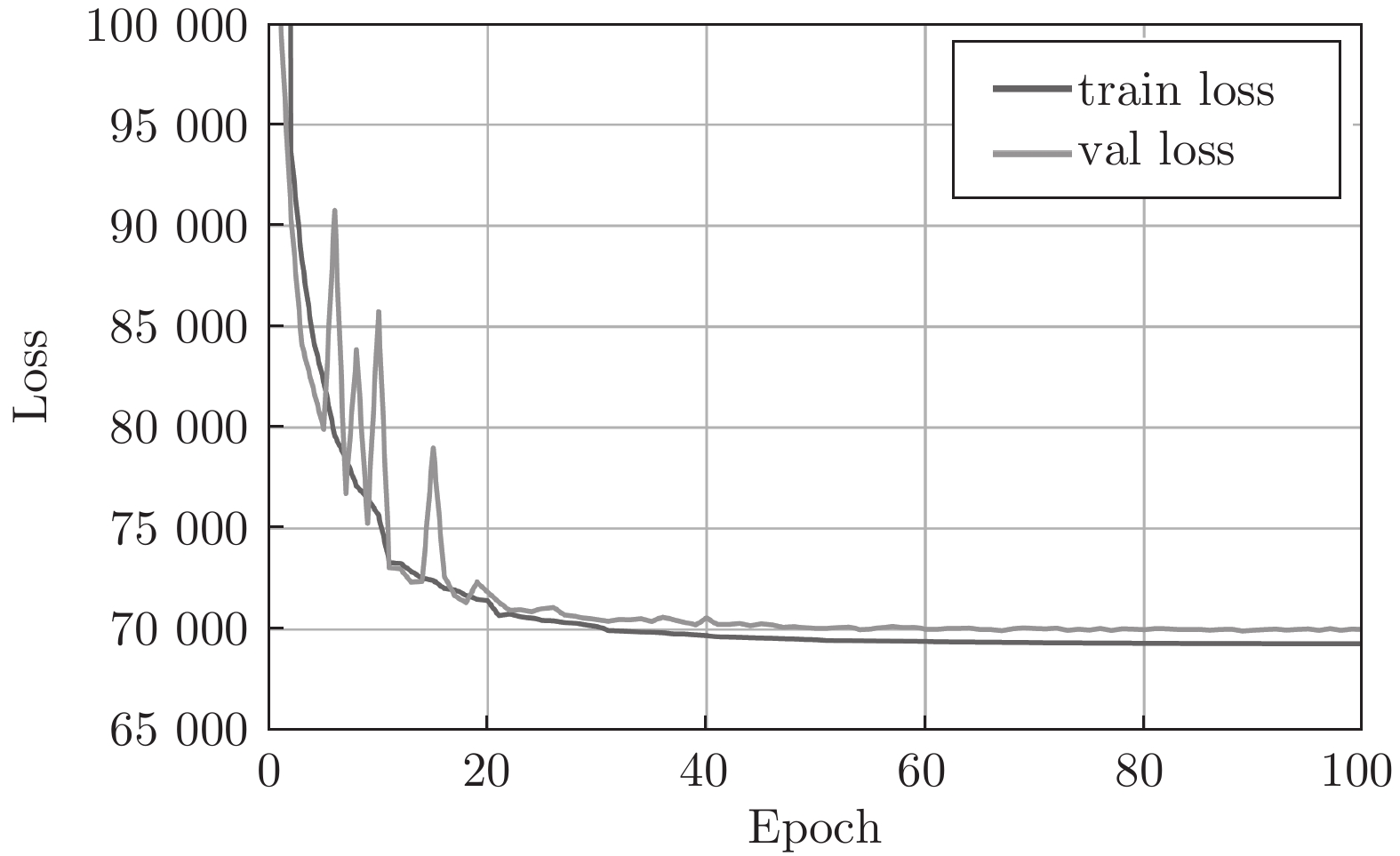
图 6 网络收敛曲线( “train loss” 是训练损失收敛曲线, “val loss” 是验证损失曲线)
Fig. 6 Network convergence curves ( “train loss” is the training loss convergence curve; “val loss” is the validation loss curve)

图 7 在Set5测试数据集上, 2个测试图像×4超分辨率结果对比
Fig. 7 A comparison of super-resolution results of two test images in Set5 for scale factor ×4

图 8 在Set14测试数据集上, 2个测试图像×4超分辨率结果对比
Fig. 8 A comparison of super-resolution results of two test images in Set14 for scale factor ×4

图 9 在BSD100测试数据集上, 2个测试图像×4超分辨率结果对比
Fig. 9 A comparison of super-resolution results of two test images in BSD100 for scale factor ×4

图 10 在BSD100测试数据集上, 2个测试图像×8超分辨率结果对比
Fig. 10 A comparison of super-resolution results of two test images in BSD100 for scale factor ×8
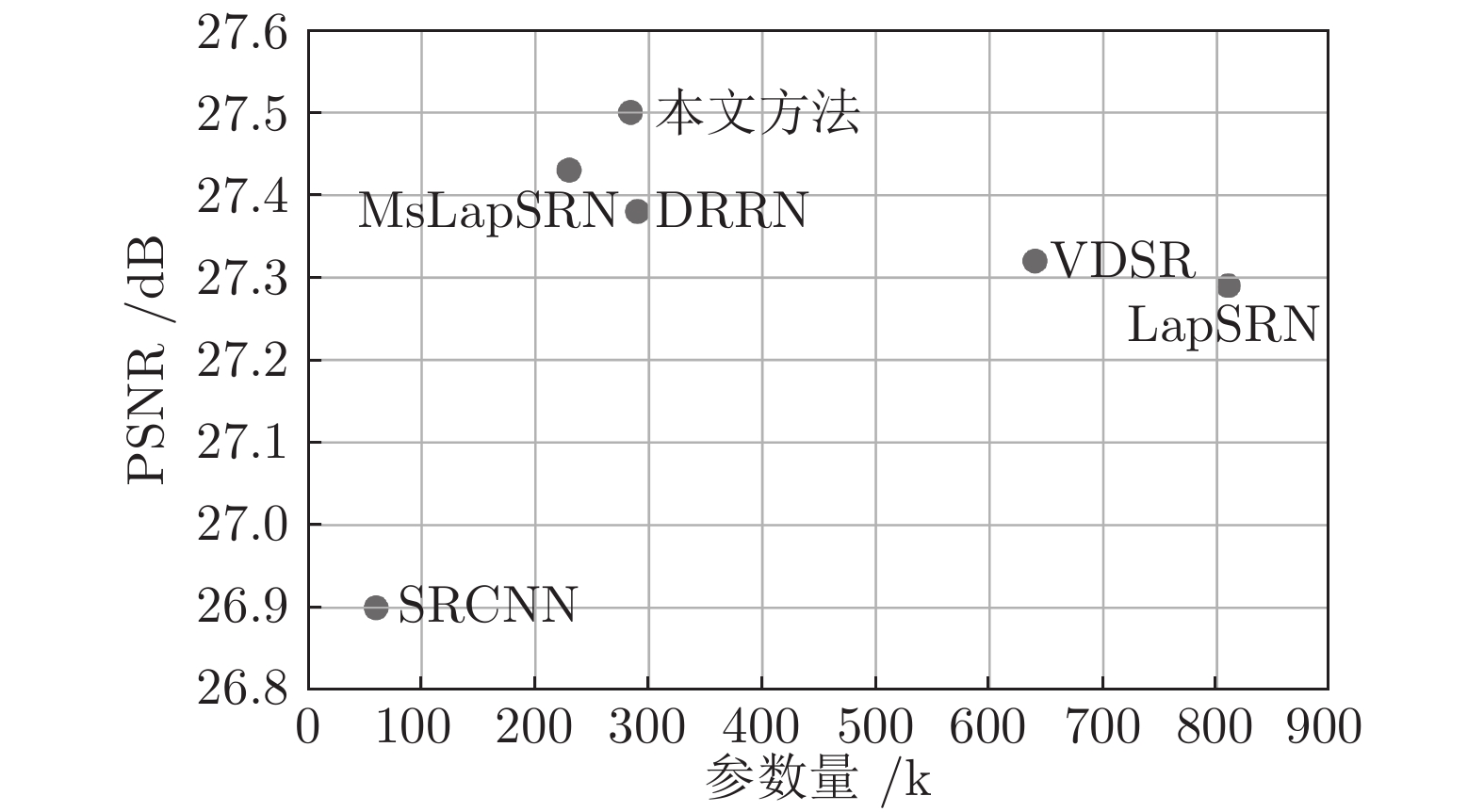
图 11 6个基于深度CNN的方法, 在BSD100数据集上×4超分辨率的平均PSNR和参数量对比
Fig. 11 Number of parameters and average PSNR of six methods based on depth CNN, on the BSD100 for scale factor ×4
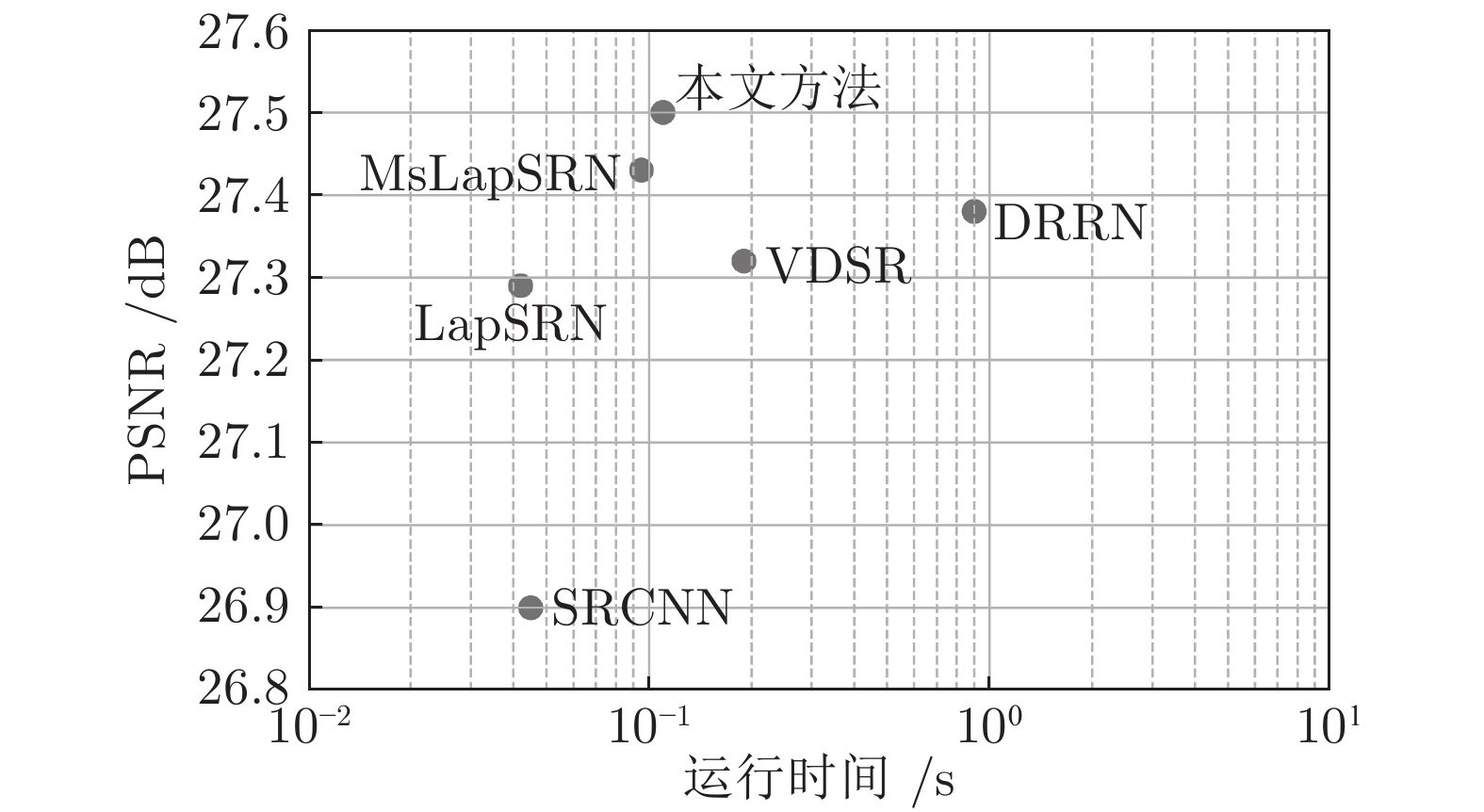
图 12 6个基于深度CNN的方法, 在BSD100数据集上×4超分辨率的平均运行时间对比
Fig. 12 A comparison of running times of six methods based on depth CNN, on the BSD100 for scale factor ×4
表 1 每一级超分辨率子网络的参数设置
Table 1 Parameter setting of each level of super-resolution sub-network
网络组件名称 组件内容及
滤波器尺寸输入尺寸 输出尺寸 维度转换层 Conv 3×3 H×W×3 H×W×64 递归卷积块×5 Conv 3×3 H×W×64 H×W×64 LReLU H×W×64 H×W×64 多通道特征融合层×8 Conv 1×1 H×W×64 H×W×64 全局特征融合层 Conv 1×1 H×W×512 H×W×64 Conv 1×1 H×W×64 H×W×64 特征注意网络 MaxPool 7×7 H×W×64 H×W×64 Conv 3×3 H×W×64 H×W×32 LReLU H×W×32 H×W×32 Conv 3×3 H×W×32 H×W×32 LReLU H×W×32 H×W×32 Conv 3×3 H×W×32 H×W×64 特征上采样层 ConvT 4×4 H×W×64 2H×2W×64 Conv 3×3 2H×2W×64 2H×2W×3 LR图像上采样层 ConvT 4×4 H×W×3 2H×2W×3  下载: 导出CSV
下载: 导出CSV
表 2 不同变种的网络模型×4超分辨率, 在Set5、Set14数据集上的平均峰值信噪比(dB)及参数量
Table 2 Average PSNR (dB) and number of parameters of different super-resolution network models for scale factor ×4, on Set5 and Set14 datasets
特征融合
子网络特征注意
子网络递归结构 参数量 (k) Set5 Set14 × × × 1 566 31.55 28.21 × × √ 222 31.54 28.21 × √ √ 232 31.65 28.27 √ × √ 274 31.79 28.33 √ √ × 1 628 31.83 28.38 √ √ √ 284 31.85 28.39
下载: 导出CSV
表 3 在Set5、Set14和BSD100测试数据集上, 各种超分辨率方法的 ×2、×4和 ×8超分辨率的平均 PSNR (dB)和SSIM
Table 3 Average PSNR (dB)/SSIMs of various SISR methods for scale factor ×2, ×4, and ×8 on Set5, Set14 and BSD100
测试集 放大倍数 Bicubic[28]
PSRN/SSIMSelfEx[29]
PSRN/SSIMSRCNN[8]
PSRN/SSIMLapSRN[12]
PSRN/SSIMVDSR[10]
PSRN/SSIMDRRN[11]
PSRN/SSIMMsLapSRN[13]
PSRN/SSIM本文方法
PSRN/SSIMSet5 2 33.66/0.929 36.49/0.953 36.66/0.954 37.52/0.959 37.53/0.959 37.74/0.959 37.78/0.960 37.91/0.969 Set14 2 30.24/0.868 32.22/0.903 32.42/0.906 33.08/0.913 33.05/0.913 33.23/0.914 33.28/0.915 33.42/0.925 BSD100 2 29.56/0.841 31.18/0.885 31.36/0.887 31.80/0.895 31.90/0.896 32.05/0.897 32.05/0.898 32.19/0.904 Set5 4 28.42/0.810 30.31/0.861 30.48/0.862 31.54/0.885 31.35/0.883 31.68/0.888 31.74/0.889 31.85/0.908 Set14 4 26.00/0.702 27.40/0.751 27.49/0.753 28.19/0.772 28.02/0.768 28.21/0.772 28.26/0.774 28.39/0.789 BSD100 4 25.96/0.667 26.84/0.710 26.90/0.711 27.29/0.727 27.32/0.726 27.38/0.728 27.43/0.731 27.50/0.748 Set5 8 24.40/0.658 25.49/0.703 25.33/0.690 26.15/0.738 25.93/0.724 26.18/0.738 26.34/0.752 26.40/0.755 Set14 8 23.10/0.566 23.92/0.601 23.76/0.591 24.35/0.620 24.26/0.614 24.42/0.622 24.57/0.629 24.60/0.631 BSD100 8 23.67/0.548 24.19/0.568 24.13/0.566 24.54/0.586 24.49/0.583 24.59/0.587 24.65/0.591 24.72/0.602
下载: 导出CSV
-
[1] Oktay O, Bai W J, Lee M, Guerrero R, Kamnitsas K, Caballero J, et al. Multi-input cardiac image super-resolution using convolutional neural networks. In: Proceedings of the 19th International Conference on Medical Image Computing and Computer-assisted Intervention. Athens, Greece: Springer, 2016. 246−254 [2] Luo Y M, Zhou L G, Wang S, Wang Z Y. Video satellite imagery super resolution via convolutional neural networks. IEEE Geoscience and Remote Sensing Letters, 2017, 14(12): 2398-2402 doi: 10.1109/LGRS.2017.2766204 [3] Rasti P, Uiboupin T, Escalera S, Anbarjafari G. Convolutional neural network super resolution for face recognition in surveillance monitoring. In: Proceedings of the 9th International Conference on Articulated Motion and Deformable Objects. Palma de Mallorca, Spain: Springer, 2016. 175−184 [4] Harris J L. Diffraction and resolving power. Journal of the Optical Society of America, 1964, 54(7): 931-936 doi: 10.1364/JOSA.54.000931 [5] 陆志芳, 钟宝江. 基于预测梯度的图像插值算法. 自动化学报, 2018, 44(6): 1072-1085 doi: 10.16383/j.aas.2017.c160793Lu Zhi-Fang, Zhong Bao-Jiang. Image interpolation with predicted gradients. Acta Automatica Sinica, 2018, 44(6): 1072-1085 doi: 10.16383/j.aas.2017.c160793 [6] 熊娇娇, 卢红阳, 张明辉, 刘且根. 基于梯度域的卷积稀疏编码磁共振成像重建. 自动化学报, 2017, 43(10): 1841-1849 doi: 10.16383/j.aas.2017.e160135Xiong Jiao-Jiao, Lu Hong-Yang, Zhang Ming-Hui, Liu Qie-Gen. Convolutional sparse coding in gradient domain for MRI reconstruction. Acta Automatica Sinica, 2017, 43(10): 1841-1849 doi: 10.16383/j.aas.2017.e160135 [7] 孙京, 袁强强, 李冀玮, 周春平, 沈焕锋. 亮度—梯度联合约束的车牌图像超分辨率重建. 中国图象图形学报, 2018, 23(6): 802-813 doi: 10.11834/jig.170489Sun Jing, Yuan Qiang-Qiang, Li Ji-Wei, Zhou Chun-Ping, Shen Huan-Feng. License plate image super-resolution based on intensity-gradient prior combination. Journal of Image and Graphics, 2018, 23(6): 802-813 doi: 10.11834/jig.170489 [8] Dong C, Loy C C, He K M, Tang X O. Learning a deep convolutional network for image super-resolution. In: Proceedings of the 13th European Conference on Computer Vision (ECCV). Zurich, Switzerland: Springer, 2014. 184−199 [9] Dong C, Loy C C, Tang X O. Accelerating the super-resolution convolutional neural network. In: Proceedings of the 14th European Conference on Computer Vision (ECCV). Amsterdam, the Netherlands: Springer, 2016. 391−407 [10] Kim J, Lee J K, Lee K M. Accurate image super-resolution using very deep convolutional networks. In: Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). Las Vegas, USA: IEEE, 2016. 1646−1654 [11] Tai Y, Yang J, Liu X M. Image super-resolution via deep recursive residual network. In: Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). Honolulu, USA: IEEE, 2017. 2790−2798 [12] Lai W S, Huang J B, Ahuja N, Yang M H. Deep Laplacian pyramid networks for fast and accurate super-resolution. In: Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). Honolulu, USA: IEEE, 2017. 5835−5843 [13] Lai W S, Huang J B, Ahuja N, Yang M H. Fast and accurate image super-resolution with deep laplacian pyramid networks. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2019, 41(11): 2599-2613 doi: 10.1109/TPAMI.2018.2865304 [14] He K M, Zhang X Y, Ren S Q, Sun J. Deep residual learning for image recognition. In: Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). Las Vegas, USA: IEEE, 2016. 770−778 [15] Koch C, Ullman S. Shifts in selective visual attention: Towards the underlying neural circuitry. Matters of Intelligence: Conceptual Structures in Cognitive Neuroscience. Dordrecht: Springer, 1987. 115−141 [16] Mnih V, Heess N, Graves A, Kavukcuoglu K. Recurrent models of visual attention. In: Proceedings of the 27th International Conference on Neural Information Processing Systems. Montreal, Canada: MIT Press, 2014. 2204−2212 [17] Wang F, Jiang M Q, Qian C, Yang S, Li C, Zhang H G, et al. Residual attention network for image classification. In: Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). Honolulu, USA: IEEE, 2017. 6450−6458 [18] Zhang Q S, Wu Y N, Zhu S C. Interpretable convolutional neural networks. In: Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Salt Lake City, USA: IEEE, 2017. 8827−8836 [19] Zhang Y L, Li K P, Li K, Wang L C, Zhong B N, Fu Y. Image super-resolution using very deep residual channel attention networks. In: Proceedings of the 15th European Conference on Computer Vision (ECCV). Munich, Germany: Springer, 2018. 294−310 [20] Yang J C, Wright J, Huang T S, Ma Y. Image super-resolution via sparse representation. IEEE Transactions on Image Processing, 2010, 19(11): 2861-2873 doi: 10.1109/TIP.2010.2050625 [21] Martin D, Fowlkes C, Tal D, Malik J. A database of human segmented natural images and its application to evaluating segmentation algorithms and measuring ecological statistics. In: Proceedings of the 8th IEEE International Conference on Computer Vision. Vancouver, Canada: IEEE, 2002. 416−423 [22] Bevilacqua M, Roumy A, Guillemot C, Morel M L M. Neighbor embedding based single-image super-resolution using semi-nonnegative matrix factorization. In: Proceedings of the 2012 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). Kyoto, Japan: IEEE, 2012. 1289−1292 [23] Zeyde R, Elad M, Protter M. On single image scale-up using sparse-representations. In: Proceedings of the 7th International Conference on Curves and Surfaces. Avignon, France: Springer, 2010. 711−730 [24] Arbeláez P, Maire M, Fowlkes C, Malik J. Contour detection and hierarchical image segmentation. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2011, 33(5): 898-916 doi: 10.1109/TPAMI.2010.161 [25] Timofte R, Agustsson E, van Gool L, Yang M H, Zhang L, Lim B, et al. NTIRE 2017 challenge on single image super-resolution: Methods and results. In: Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition Workshops (CVPRW). Honolulu, USA: IEEE, 2017. 1110−1121 [26] Kingma D P, Ba J. Adam: A method for stochastic optimization. In: Proceedings of the 3rd International Conference on Learning Representations (ICLR). San Diego, USA, 2015. [27] He K M, Zhang X Y, Ren S Q, Sun J. Delving deep into rectifiers: Surpassing human-level performance on ImageNet classification. In: Proceedings of the 2015 IEEE International Conference on Computer Vision (ICCV). Santiago, Chile: IEEE, 2015. 1026−1034 [28] Wang Z, Bovik A C, Sheikh H R, Simoncelli E P. Image quality assessment: From error visibility to structural similarity. IEEE Transactions on Image Processing, 2004, 13(4): 600-612 doi: 10.1109/TIP.2003.819861 [29] Keys R G. Cubic convolution interpolation for digital image processing. IEEE Transactions on Acoustics, Speech, and Signal Processing, 1981, 29(6): 1153-1160 doi: 10.1109/TASSP.1981.1163711 [30] Huang J B, Singh A, Ahuja N. Single image super-resolution from transformed self-exemplars. In: Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). Boston, USA: IEEE, 2015. 5197−5206 -

 下载:
下载:





计量
- 文章访问数: 1251
- HTML全文浏览量: 652
- PDF下载量: 331
- 被引次数: 0
