

Local Enhancement Reconstruction Algorithm Based on Multi-hypothesis Prediction in Compressed Video Sensing
-
摘要: 在基于多假设预测的视频压缩感知重构中, 不同图像块对应的假设集匹配程度差异较大, 因此重构难度差异明显. 本文提出多假设局部增强重构算法(Local enhancement reconstruction algorithm based on multi-hypothesis prediction, MH-LE), 利用帧间相关性对图像块进行分类后针对运动图像块提出像素域双路匹配策略, 通过强化图像块基本特征来提高相似块匹配效果, 获取更高质量的假设集; 同时将结构相似度评价标准引入假设块权值分配过程, 提高预测精度. 仿真结果表明, 所提算法的重构质量明显优于其他多假设预测重构算法. 和基于组稀疏的重构算法相比, 所提算法具有更快的重构速度, 在大部分的采样率条件下具有更高的重构质量.Abstract: In multi-hypothesis prediction-based compressed video sensing reconstruction algorithms, the matching degrees of the hypothesis set corresponding to different image blocks are quite different, so the reconstruction difficulty of different blocks is obviously different. In this paper, a local enhancement reconstruction algorithm based on multi-hypothesis (MH-LE) is proposed. Image blocks are classified into two categories and a pixel domain dual channel matching strategy is proposed for moving image blocks, where the basic features of the image blocks are enhanced to improve the matching effectivity of similar blocks and obtain a higher quality hypothesis set. Besides, the structural similarity evaluation criteria are introduced into the matching block weight assignment process to improve prediction accuracy. The simulation results show that the reconstruction quality of the proposed algorithm is superior to other multi-hypothesis prediction-based reconstruction algorithms. Compared with the group sparsity-based reconstruction algorithms, the proposed algorithm possesses faster reconstruction speed and higher reconstruction quality at most sampling rates.
-
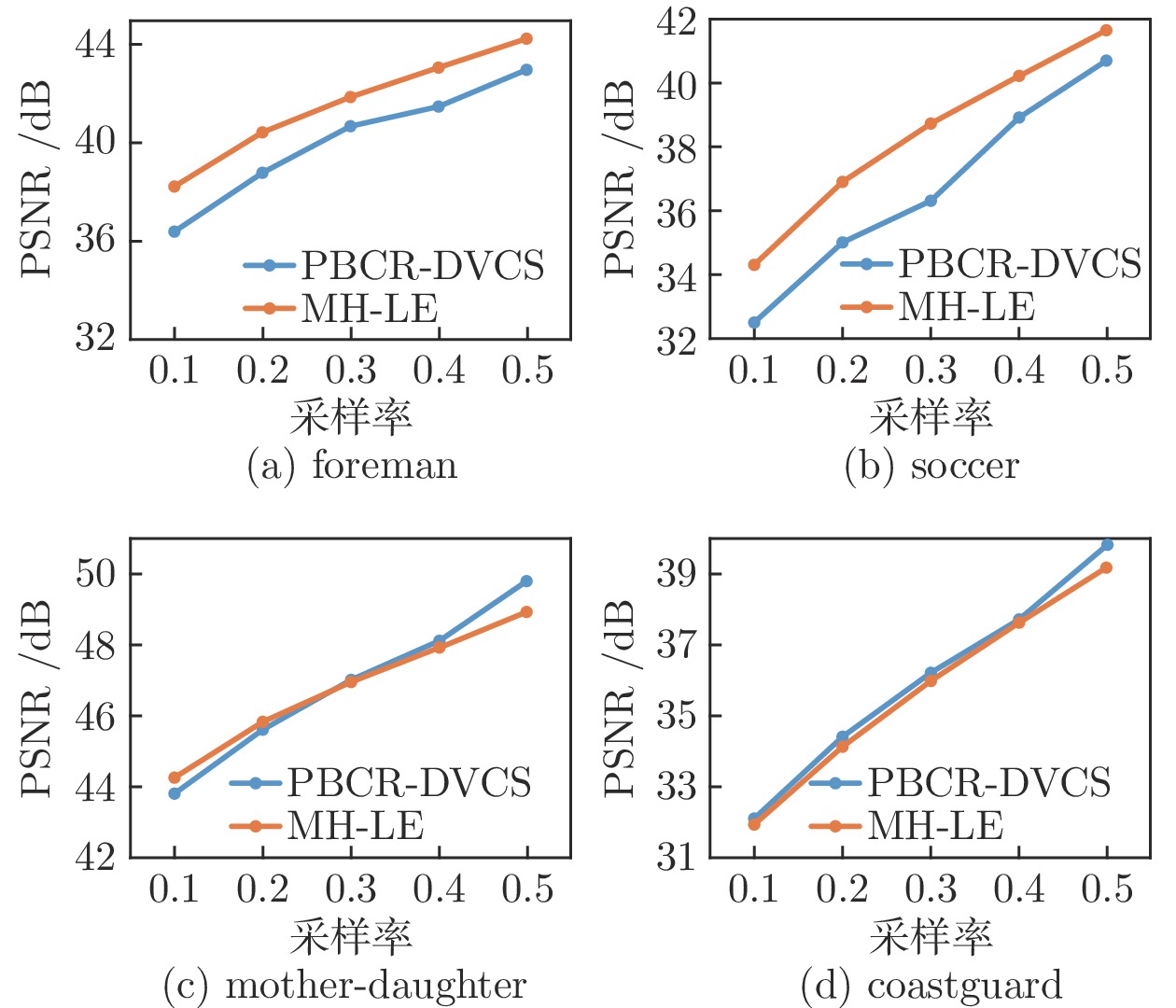
图 4 MH-LE与PBCR-DCVS重构PSNR对比
Fig. 4 Reconstruction PSNR performance comparison between MH-LE and PBCR-DCVS

图 5 foreman第8帧重构视觉效果图
Fig. 5 Visual quality comparison of various algorithms recovery on the 8th frame of foreman
表 1 各采样率下算法重构PSNR对比
Table 1 Reconstruction PSNR performance comparison of various algorithms at different sampling rates
采样率 重构算法 视频序列 foreman hall coastguard suzie salesman soccer 0.1 RRS 31.10 26.73 25.96 34.39 31.18 29.31 2sMHR 33.25 32.88 28.91 37.82 35.32 29.32 SSIM-InterF-GSR 34.63 33.87 29.09 36.68 34.39 29.51 MH-LE 35.60 35.57 30.67 38.18 37.09 30.32 0.2 RRS 35.78 33.45 30.32 37.94 37.15 32.29 2sMHR 36.17 34.76 30.82 40.06 36.56 32.42 SSIM-InterF-GSR 37.71 37.34 31.70 39.55 36.52 34.60 MH-LE 38.79 37.82 32.61 40.61 38.59 33.75 0.3 RRS 37.91 38.56 32.57 39.60 38.07 34.05 2sMHR 38.38 36.21 32.44 41.63 37.38 34.81 SSIM-InterF-GSR 39.57 39.29 33.25 41.36 37.80 37.17 MH-LE 40.87 39.54 34.26 42.28 39.50 36.16 平均值 RRS 34.93 32.91 29.61 37.31 35.47 31.88 2sMHR 35.93 34.61 30.72 39.84 36.42 32.18 SSIM-InterF-GSR 37.21 36.83 31.34 39.19 36.23 33.76 MH-LE 38.42 37.64 32.50 40.35 38.39 33.41  下载: 导出CSV
下载: 导出CSV
表 2 不同算法下每帧平均所需重构时间(s)
Table 2 Running time comparison with various algorithms for reconstructing a video frame at different sampling rates (s)
采样率 重构算法 视频序列 suzie hall foreman soccer 0.1 RRS 103.8 110.3 115.2 104.3 SSIM-InterF-GSR 168.9 177.5 167.2 184.2 2sMHR 6.9 7.1 7.2 7.3 MH-LE 13.5 15.2 23.3 60.7 0.2 RRS 98.5 125.0 106.4 99.6 SSIM-InterF-GSR 174.3 188.2 166.2 182.5 2sMHR 7.1 7.3 7.4 7.7 MH-LE 14.8 15.5 25.1 67.2 0.3 RRS 99.0 123.7 103.5 100.7 SSIM-InterF-GSR 171.4 173.4 169.3 176.4 2sMHR 7.3 7.4 7.4 7.6 MH-LE 15.1 14.6 24.8 86.2
下载: 导出CSV
-
[1] Donoho D L. Compressed sensing. IEEE Transactions on Information Theory, 2006, 52(4): 1289-1306 doi: 10.1109/TIT.2006.871582 [2] Gan L. Block compressed sensing of natural images. In: Proceedings of the 2017 International Conference on Digital Signal Processing. Cardiff, UK: IEEE, 2007. 403−406 [3] Mun S K, Fowler J E. Block compressed sensing of images using directional transforms. In: Proceedings of the 2019 International Conference on Image Processing. Cairo, Egypt: IEEE, 2009. 3021−3024 [4] Zhang J, Zhao D, Gao W. Group-based sparse representation for image restoration. IEEE Transactions on Image Processing, 2014, 23(8): 3336-3351 doi: 10.1109/TIP.2014.2323127 [5] Zhang J, Ghanem B. ISTA-Net: Interpretable optimization-inspired deep network for image compressive sensing. In: Proceedings of the 2018 IEEE Conference on Computer Vision and Pattern Recognition. Salt Lake City, USA: IEEE, 2018. 1828−1837 [6] Shi W Z, Jiang F, Zhang S P, Zhao D B. Deep networks for compressed image sensing. In: Proceedings of the 2017 IEEE International Conference on Multimedia and Expo. Hong Kong, China: IEEE, 2017. 877−882 [7] Tramel E W, Fowler J E. Video compressed sensing with multihypothesis. In: Proceedings of the 2011 Data Compression Conference. Snowbird, USA: IEEE, 2011. 193−202 [8] Azghani M, Karimi M, Marvasti F. Multi-hypothesis compressed video sensing technique. IEEE Transactions on Circuits & Systems for Video Technology, 2016, 26(4): 627-635 [9] Jian C, Ning W, Fei X, et al. Distributed compressed video sensing based on the optimization of hypothesis set update technique. Multimedia Tools & Applications, 2016, 74(14): 1-20 [10] Chen J, Chen Y, Qin D, et al. An elastic net-based hybrid hypothesis method for compressed video sensing. Multimedia Tools & Applications, 2015, 74(6): 2085-2108 [11] Kuo Y, Wu K, Chen J. A scheme for distributed compressed video sensing based on hypothesis set optimization techniques. Multidimensional Systems and Signal Processing, 2017, 28(1): 129-148 doi: 10.1007/s11045-015-0337-4 [12] 欧伟枫, 杨春玲, 戴超. 一种视频压缩感知中两级多假设重构及实现方法. 电子与信息学报, 2017, 39(7): 1688-1696Ou Wei-Feng, Yang Chun-Ling, Dai Chao. A two-stage multi-hypothesis reconstruction and two implementation schemes for compressed video sensing. Journal of Electronics & Information Technology, 2017, 39(7): 1688-1696 [13] Zheng S, Chen J, Kuo Y H. An improved distributed compressed video sensing scheme in reconstruction algorithm. Multimedia Tools and Applications, 2018, 77(7): 8711-8728 doi: 10.1007/s11042-017-4765-z [14] Chen Z, Ma S, Jian Z, et al. Video compressive sensing reconstruction via reweighted residual sparsity. IEEE Transactions on Circuits & Systems for Video Technology, 2017, 27(6): 1182-1195 [15] 和志杰, 杨春玲, 汤瑞东. 视频压缩感知中基于结构相似的帧间组稀疏表示重构算法研究. 电子学报, 2018, 46(3): 544-533 doi: 10.3969/j.issn.0372-2112.2018.03.005He Zhi-Jie, Yang Chun-Ling, Tang Rui-Dong. Research on structural similarity based inter-frame group sparse representation for compressed video sensing. Journal of Electronics, 2018, 46(3): 544-553 doi: 10.3969/j.issn.0372-2112.2018.03.005 [16] Baraniuk R G, Goldstein T, Sankaranarayanan A C, et al. Compressive video sensing: algorithms, architectures, and applications. IEEE Signal Processing Magazine, 2017, 34(1): 52-66 doi: 10.1109/MSP.2016.2602099 [17] Xu K, Ren F B. CSVideoNet: A real-time end-to-end learning framework for high-frame-rate video compressive sensing. In: Proceedings of the 2018 IEEE Winter Conference on Applications of Computer Vision. Lake Tahoe, USA: IEEE, 2018. 1680−1688 [18] Zou H, Hastie T. Regularization and variable selection via the elastic net. Journal of the Royal Statistical Society, 2005, 67(2): 301-320 doi: 10.1111/j.1467-9868.2005.00503.x [19] 杨春玲, 欧伟枫. CVS中基于多参考帧的最优多假设预测算法. 华南理工大学学报(自然科学版), 2016, 44(1): 1-8 doi: 10.3969/j.issn.1000-565X.2016.01.001Yang Chun-Ling, Ou Wei-Feng. Multi-reference frames-based optimal multi-hypothesis prediction algorithm for compressed video sensing. Journal of South China University of Technology (Natural Science Edition), 2016, 44(1): 1-8 doi: 10.3969/j.issn.1000-565X.2016.01.001 [20] Tomasi C, Manduchi R. Bilateral filtering for gray and color images. In: Proceedings of the 6th International Conference on Computer Vision. Bombay, India: IEEE, 1998. 839−846 [21] Sjöstrand K, Ersbøll B. SpaSM. A MATLAB toolbox for sparse statistical modeling [Online], available: http://www2.imm.dtu.dk/projects/spasm/, October 30, 2019 -

 下载:
下载:



计量
- 文章访问数: 612
- HTML全文浏览量: 444
- PDF下载量: 154
- 被引次数: 0
