

-
摘要: 深度确定性策略梯度(Deep deterministic policy gradient, DDPG)方法在连续控制任务中取得了良好的性能表现. 为进一步提高深度确定性策略梯度方法中经验回放机制的效率, 提出分类经验回放方法, 并采用两种方式对经验样本分类: 基于时序差分误差样本分类的深度确定性策略梯度方法(DDPG with temporal difference-error classification, TDC-DDPG)和基于立即奖赏样本分类的深度确定性策略梯度方法(DDPG with reward classification, RC-DDPG).在TDC-DDPG和RC-DDPG方法中, 分别使用两个经验缓冲池, 对产生的经验样本按照重要性程度分类存储, 网络模型训练时通过选取较多重要性程度高的样本加快模型学习. 在连续控制任务中对分类经验回放方法进行测试, 实验结果表明, 与随机选取经验样本的深度确定性策略梯度方法相比, TDC-DDPG和RC-DDPG方法具有更好的性能.Abstract: The deep deterministic policy gradient (DDPG) algorithm achieves good performance in continuous control tasks. In order to further improve the efficiency of the experience replay mechanism in the DDPG algorithm, a method of classifying the experience replay is proposed, where transitions are classified in two branches: deep deterministic policy gradient with temporal difference-error classification (TDC-DDPG) and deep deterministic policy gradient with reward classification (RC-DDPG). In both methods, two replay buffers are introduced respectively to classify the transitions according to the degree of importance. Learning can be speeded up in network model training period by selecting a greater number of transitions with higher importance. The classification experience replay method has been tested in a series of continuous control tasks and experimental results show that the TDC-DDPG and RC-DDPG methods have better performance than the DDPG method with random selection of transitions.
-
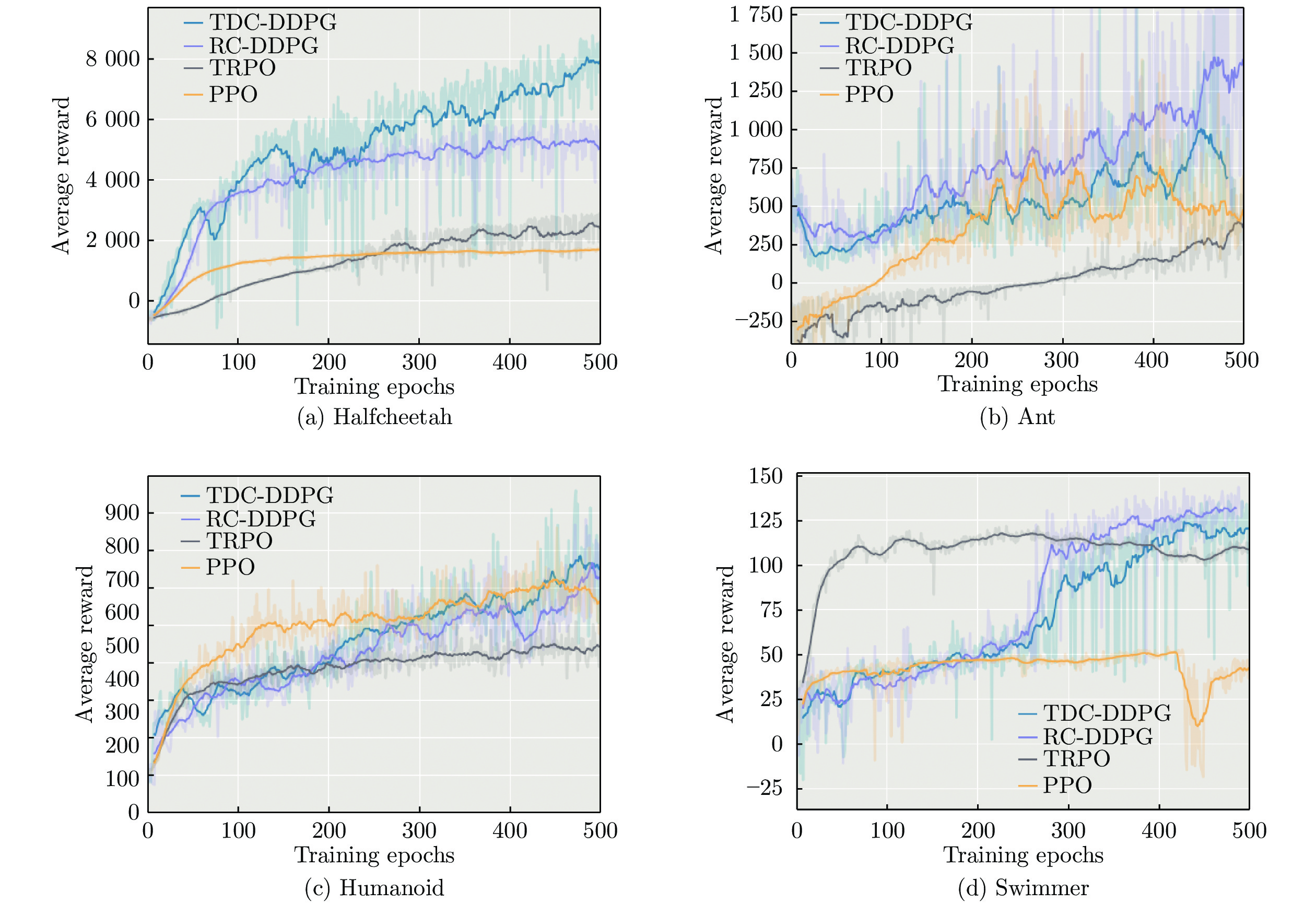
图 3 CER-DDPG与最新策略梯度算法的实验对比
Fig. 3 Experimental comparison of CER-DDPG with the latest policy gradient algorithm
表 1 连续动作任务中实验数据
Table 1 Experimental data in continuous action tasks
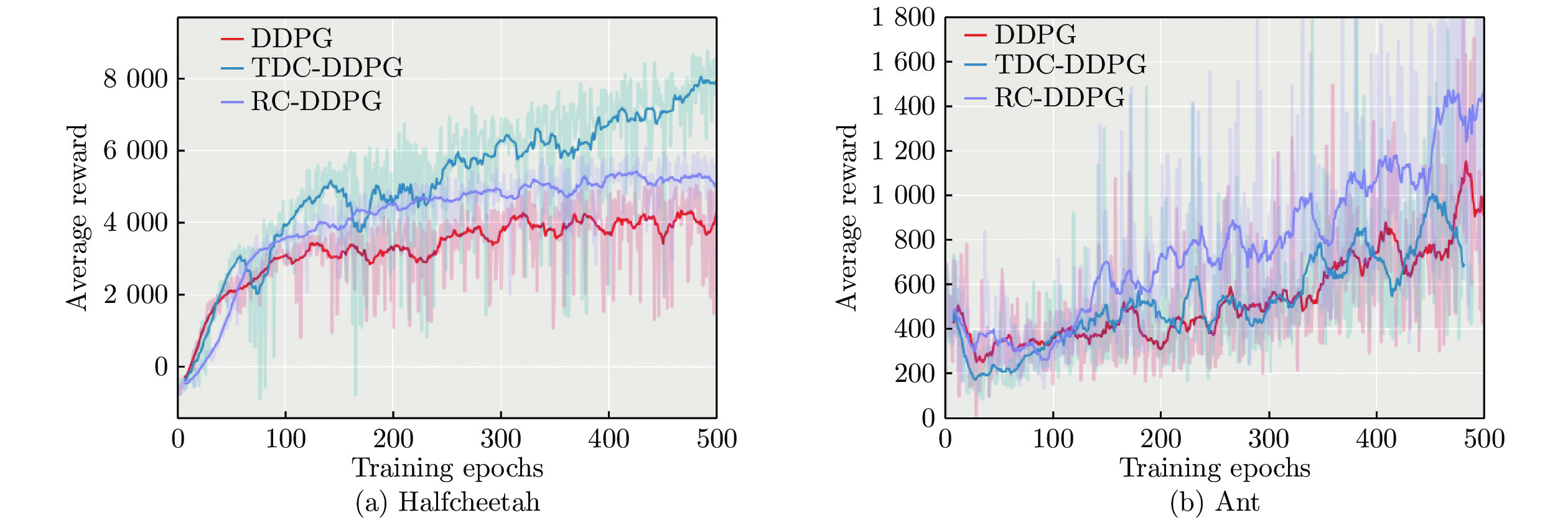
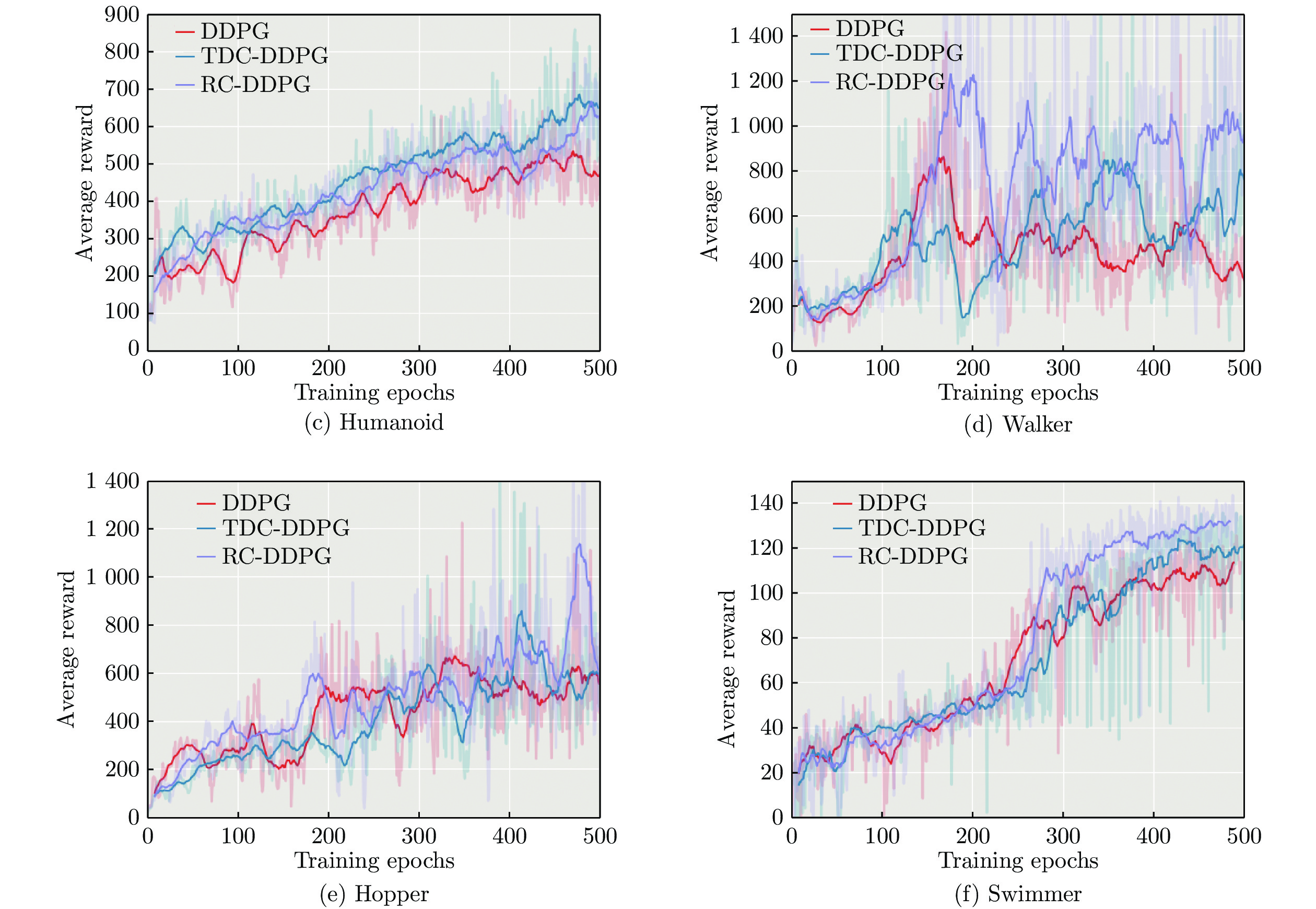
任务名称 算法 平均奖赏 最高奖赏 标准差 HalfCheetah DDPG 3 360.32 5 335.23 1 246.40 TDC-DDPG 5 349.64 9 220.27 2 368.13 RC-DDPG 3 979.64 6 553.49 1 580.21 Ant DDPG 551.87 1 908.30 307.86 TDC-DDPG 521.42 1 863.99 296.91 RC-DDPG 772.37 2 971.63 460.05 Humanoid DDPG 404.36 822.11 114.38 TDC-DDPG 462.65 858.34 108.20 RC-DDPG 440.30 835.75 100.31 Walker DDPG 506.10 1 416.00 243.02 TDC-DDPG 521.58 1 919.15 252.95 RC-DDPG 700.57 3 292.62 484.65 Hopper DDPG 422.10 1 224.68 180.04 TDC-DDPG 432.64 1 689.48 223.61 RC-DDPG 513.45 2 050.72 257.82 Swimmer DDPG 34.06 63.16 16.74 TDC-DDPG 44.18 69.40 19.77 RC-DDPG 38.44 71.70 21.59  下载: 导出CSV
下载: 导出CSV
-
[1] 张耀中, 胡小方, 周跃, 段书凯.基于多层忆阻脉冲神经网络的强化学习及应用.自动化学报, 2019, 45(08): 1536-1547.Zhang Yao-Zhong, Hu Xiao-Fang, Zhou Yue, Duan Shu-Kai. A novel reinforcement learning algorithm based on multilayer memristive spiking neural network with applications. Acta Automatic Sinica, 2019, 45(08): 1536-1547. [2] Dorpinghaus M, Roldan E, Neri I, Meyr H, Julicher F. An information theoretic analysis of sequential decision-making. Mathematics, 2017, 39(6): 429-437. [3] Yu Xi-Li. Deep reinforcement learning: an overview. Machine Learning, 2017, 12(2): 231-316. [4] 秦蕊, 曾帅, 李娟娟, 袁勇.基于深度强化学习的平行企业资源计划.自动化学报, 2017, 43(09): 1588-1596.Qin Rui, Zeng Shuai, Li Juan-Juan, Yuan Yong. Parallel enterprises resource planning based on deep reinforcement learning. Acta Automatic Sinica, 2017, 43(9): 1588-1596. [5] Mnih V, Kavukcuoglu K, Silver D, Graves A, Antonoglou A, Wierstra D, et al. Playing atari with deep reinforcement learning. In: Proceedings of the Workshops at the 26th Neural Information Processing Systems 2013. Lake Tahoe, USA: MIT Press, 2013. 201−220 [6] Mnih V, Kavukcuoglu K, Silver D, Andrei A, Rusu, Veness J. Human-level control through deep reinforcement learning. Nature, 2015, 518(7540): 529-533. doi: 10.1038/nature14236 [7] Schaul T, Quan J, Antonoglou I, Silver D. Prioritized experience replay. In: Proceedings of the 4th International Conference on Learning Representations. San Juan, PuertoRico, USA: ICLR, 2016. 322−355 [8] 高阳, 陈世福, 陆鑫.强化学习研究综述.自动化学报, 2004, 30(1): 86-100.Gao Yang, Chen Shi-Fu, Lu Xin. Research on reinforcement learning: a review. Acta Automatic Sinica, 2004, 30(1): 86-100. [9] Ertel W. Reinforcement Learning. London: Springer-Verlag, 2017. 12−16 [10] Peters J, Bagnell J A, Sammut C. Policy gradient methods. Encyclopedia of Machine Learning, 2010, 5(11): 774-776. [11] Sutton R S, Barto A G. Reinforcement learning: An introduction. Cambridge, USA: MIT Press, 2018. [12] Thomas P S, Brunskill E. Policy gradient methods for reinforcement learning with function approximation and action-dependent baselines. Artificial Intelligence, 2018, 16(4): 23-25. [13] Silver D, Lever G, Heess N, Degris T, Wierstra D, Riedmillerm M. Deterministic policy gradient algorithms. In: Proceedings of the 31st International Conference on Machine Learning. New York, USA: ACM, 2014. 387−395 [14] Lillicrap T P, Hunt J J, Pritzel A, Heess N, Erez T, Tassa Y. Continuous control with deep reinforcement learning. Computer Science, 2015, 8(6): A187. [15] Atherton L A, Dupret D, Mellor J R. Memory trace replay: the shaping of memory consolidation by neuromodulation. Trends in Neurosciences, 2015, 38(9): 560-570. doi: 10.1016/j.tins.2015.07.004 [16] Olafsdottir H, Barry C, Saleem AB, Hassabis D, Spiers HJ. Hippocampal place cells construct reward related sequences through unexplored space. Elife, 2015, 4: e06063. doi: 10.7554/eLife.06063 -

 下载:
下载:

图(4) / 表(1)
计量
- 文章访问数: 1038
- HTML全文浏览量: 524
- PDF下载量: 218
- 被引次数: 0
