

-
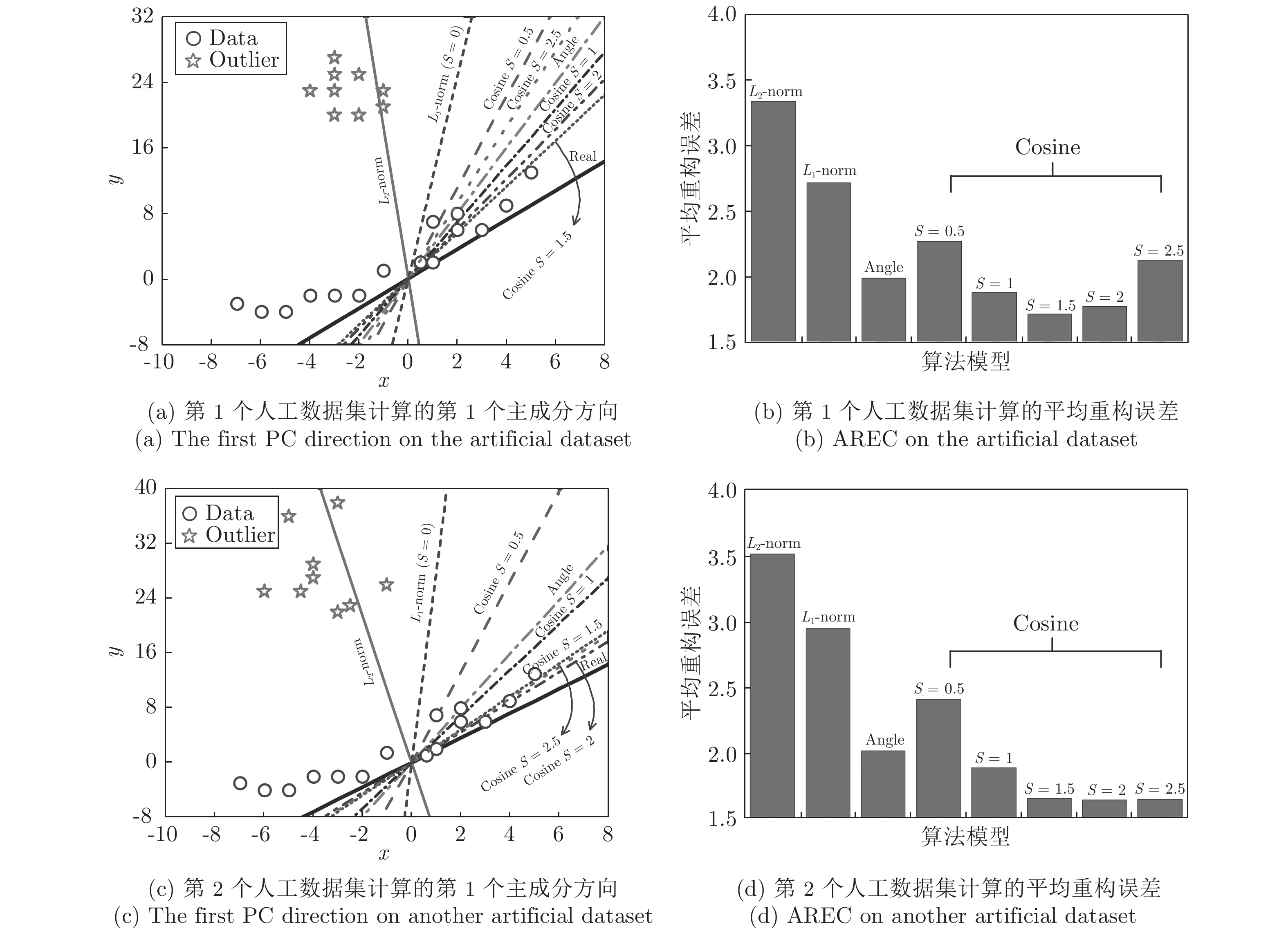
摘要: 主成分分析(Principal component analysis, PCA) 是一种广泛应用的特征提取与数据降维方法, 其目标函数采用L2范数距离度量方式, 对离群数据及噪声敏感. 而L1范数虽然能抑制离群数据的影响, 但其重构误差并不能得到有效控制. 针对上述问题, 综合考虑投影距离最大及重构误差较小的目标优化问题, 提出一种广义余弦模型的目标函数. 通过极大化矩阵行向量的投影距离与其可调幂的2范数之间的比值, 使得其在数据降维的同时提高了鲁棒性. 在此基础上提出广义余弦二维主成分分析(Generalized cosine two dimensional PCA, GC2DPCA), 给出了其迭代贪婪的求解算法, 并对其收敛性及正交性进行理论证明. 通过选择不同的可调幂参数, GC2DPCA可应用于广泛的含离群数据的鲁棒降维. 人工数据集及多个人脸数据集的实验结果表明, 本文算法在重构误差、相关性及分类率等性能方面均得到了提升, 具有较强的抗噪能力.Abstract: Principal component analysis (PCA) is a widely used feature extraction and dimensionality reduction method, which employs L2-norm distance metric and is sensitive to outliers and noise. Although L1-norm distance metric can suppress outliers, the reconstruction error in the objective function cannot be effectively controlled. To solve these problems, a new objective function based on the generalized cosine model is first proposed by considering the maximum projection distance and the smaller reconstruction error. By maximizing the ratio between the projection distance of row vectors and the 2-norm with the adjustable power, the robustness is improved while reducing dimensions. Then, the generalized cosine two-dimensional PCA (GC2DPCA) is presented by using the model and can be solved by an iterative greedy algorithm. The convergence and orthogonality of the algorithm can be proved theoretically. By choosing a different adjustable power parameter, GC2DPCA can be widely used in robust dimensionality reduction with outliers. The experimental results on artificial synthetic datasets and several face datasets show that the proposed algorithm not only improves the performances of reconstruction error, orthogonal correlation and classification rate, but also has strong anti-noise ability.
-
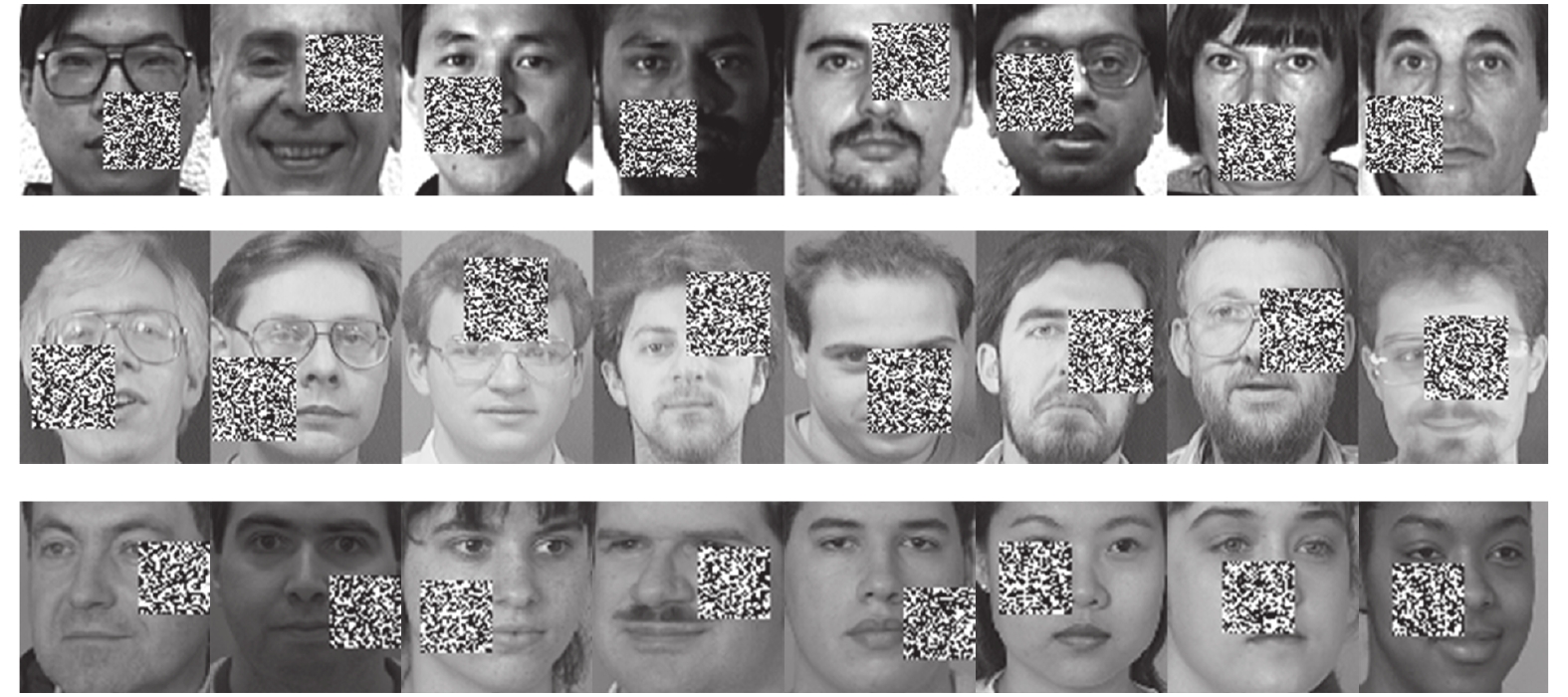
表 1 Yale数据集下平均分类率 (40%遮盖噪声) (%)
Table 1 Average classification rate under Yale dataset (40% occluded noise) (%)
NPC PCA PCA-$L_1$ 2DPCA 2DPCA-$L_1$ 2DPCA-
$L_1$(non-greedy)Angle-
2DPCAGC2DPCA
S = 0.5GC2DPCA
S = 1GC2DPCA
S = 1.5GC2DPCA
S = 210 78.9 77.8 84.4 84.4 72.9 73.3 84.2 84.7 84.7 84.9 20 75.3 76.4 82.2 83.1 74.2 70.9 83.3 83.3 83.3 83.3 30 72.0 73.1 79.3 80.0 74.2 73.1 80.7 80.2 80.2 80.2 40 71.6 71.6 76.2 77.1 73.8 74.0 77.8 78.0 77.8 78.0 50 72.0 71.8 74.4 75.1 74.2 75.8 75.3 75.8 76.2 76.0  下载: 导出CSV
下载: 导出CSV
表 2 ORL数据集下平均分类率 (40%遮盖噪声) (%)
Table 2 Average classification rate under ORL dataset (40% occluded noise) (%)
NPC PCA PCA-$L_1$ 2DPCA 2DPCA-$L_1$ 2DPCA-
$L_1$(non-greedy)Angle-
2DPCAGC2DPCA
S = 0.5GC2DPCA
S = 1GC2DPCA
S = 1.5GC2DPCA
S = 210 79.9 79.3 88.1 88.1 77.2 80.3 88.3 88.5 88.6 88.5 20 81.2 80.4 85.9 85.9 82 80.6 86.3 86.4 86.4 86.4 30 81.6 82.3 85.1 85.5 84.8 83.3 85.5 85.6 85.7 85.7 40 81.9 82.8 85.4 85.5 85.7 85.4 85.5 85.5 85.5 85.5 50 81.7 83.2 85.6 85.5 85.6 85.5 85.4 85.6 85.6 85.6
下载: 导出CSV
表 3 FERET数据集下平均分类率 (40%遮盖噪声) (%)
Table 3 Average classification rate under FERET dataset (40% occluded noise) (%)
NPC PCA PCA-$L_1$ 2DPCA 2DPCA-$L_1$ 2DPCA-
$L_1$(non-greedy)Angle-
2DPCAGC2DPCA
S = 0.5GC2DPCA
S = 1GC2DPCA
S = 1.5GC2DPCA
S = 210 50.5 52.5 58.0 58.5 47.8 51.0 59.0 59.8 60.0 60.0 20 50.0 51.0 52.5 53.5 50.8 51.3 54.0 54.3 54.5 54.3 30 51.3 51.3 51.5 50.8 51.8 52.8 50.8 51.8 51.8 51.8 40 48.8 49.8 51.3 50.8 50.5 50.5 50.8 50.8 50.8 50.8 50 48.0 49.5 51.3 50.8 50.8 50.8 50.0 50.0 50.0 50.0
下载: 导出CSV
表 4 Yale数据集下平均分类率 (60%遮盖噪声) (%)
Table 4 Average classification rate under Yale dataset (60% occluded noise) (%)
NPC PCA PCA-$L_1$ 2DPCA 2DPCA-$L_1$ 2DPCA-
$L_1$(non-greedy)Angle-
2DPCAGC2DPCA
S = 0.5GC2DPCA
S = 1GC2DPCA
S = 1.5GC2DPCA
S = 210 61.8 58.7 72.4 73.6 62.4 59.3 73.6 74.4 74.4 74.4 20 60.4 60.0 63.3 65.3 62.9 59.1 66.4 67.6 67.8 67.8 30 60.7 61.3 62.2 62.7 62.4 61.1 63.6 63.6 63.6 63.6 40 61.1 61.6 62.2 62.7 62.2 62.9 62.2 62.4 62.2 62.4 50 60.7 62.0 62.2 62.7 62.4 62.7 62.4 62.4 62.4 62.4
下载: 导出CSV
表 5 ORL数据集平均分类率 (60%遮盖噪声) (%)
Table 5 Average classification rate under ORL dataset (60% occluded noise) (%)
NPC PCA PCA-$L_1$ 2DPCA 2DPCA-$L_1$ 2DPCA-
$L_1$(non-greedy)Angle-
2DPCAGC2DPCA
S = 0.5GC2DPCA
S = 1GC2DPCA
S = 1.5GC2DPCA
S = 210 66.0 65.0 73.6 74.4 72.1 67.0 74.6 74.7 74.6 74.7 20 68.1 67.7 73.4 74.2 71.3 70.8 74.1 74.3 74.3 74.2 30 68.7 69.4 73.7 74.2 72.4 72.9 74.4 74.4 74.3 74.4 40 69.0 70.0 74.4 74.4 73.5 75.0 74.5 74.4 74.3 74.4 50 69.2 70.2 74.1 74.4 74.2 74.4 74.3 74.5 74.4 74.4
下载: 导出CSV
表 6 FERET数据集平均分类率 (60%遮盖噪声) (%)
Table 6 Average classification rate under FERET dataset (60% occluded noise) (%)
NPC PCA PCA-$L_1$ 2DPCA 2DPCA-$L_1$ 2DPCA-
$L_1$(non-greedy)Angle-
2DPCAGC2DPCA
S = 0.5GC2DPCA
S = 1GC2DPCA
S = 1.5GC2DPCA
S = 210 43.8 43.5 50.0 47.8 40.0 40.3 48.8 50.5 50.3 50.0 20 43.8 44.3 48.5 45.0 44.8 45.0 44.8 45.3 45.8 46.0 30 44.0 43.8 46.8 45.0 44.8 45.3 45.0 45.0 45.5 45.5 40 41.5 44.3 45.3 45.0 44.0 44.3 45.0 45.3 45.3 45.3 50 42.0 42.0 44.8 45.0 45.0 45.3 45.3 45.0 45.0 45.0
下载: 导出CSV
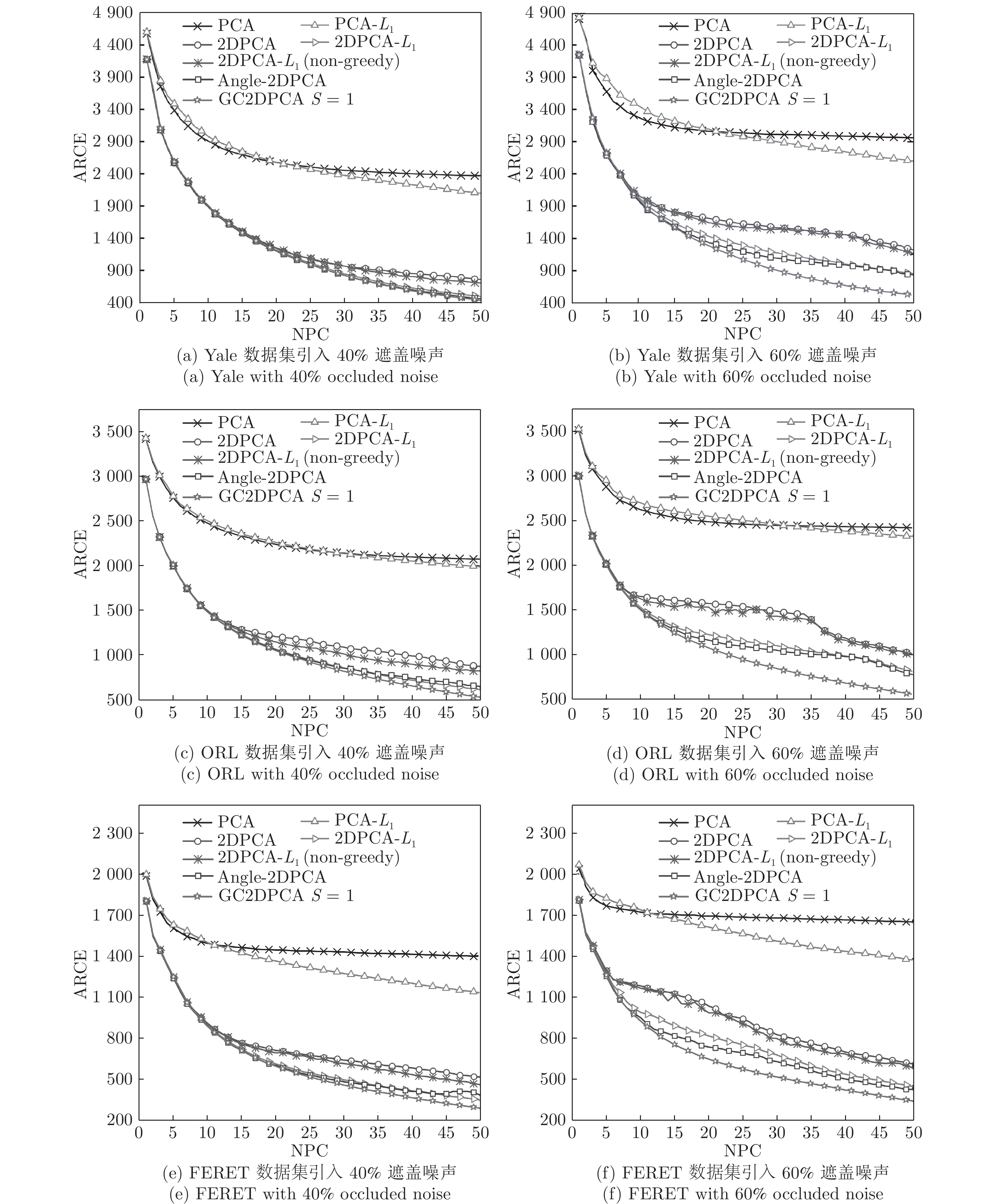
表 7 时间复杂度分析
Table 7 Time complexity analysis
算法 时间复杂度 PCA ${{\rm{O}}}({Nh}^{2}{w}^{2}+{h}^{3}{w}^{2}) $ PCA-$L_1$ ${ {\rm{O} } }({Nhwk}{t}_{{\rm{PCA}}\text{-}L_{1} })$ 2DPCA ${{\rm{O}}}({Nh}^{2}{w}+{h}^{3}) $ 2DPCA-$L_1$ ${ {\rm{O} } }({Nhwk} {t}_{{\rm{2DPCA}}\text{-}L_{1} })$ 2DPCA-$L_1$(non-greedy) ${{\rm{O}}}[({Nhw}^{2}+{wk}^{2}+{w}^{2}{k})$
${t}_{{\rm{2DPCA}}\text{-}L_{1}({\rm{non}}\text{-}{\rm{greedy}})}]$Angle-2DPCA ${ {\rm{O} } }[({Nhw}^{2}+{wk}^{2}+{w}^{2}{k}){t}_{{\rm{Angle2DPCA}}}]$ GC2DPCA ${ {\rm{O} } }({Nhwkt}_{{\rm{GC2DPCA}}})$
下载: 导出CSV
表 8 各个算法所需时间对比(s)
Table 8 Comparison of the required time by each algorithm (s)
样本数 PCA PCA-$L_1$ 2DPCA 2DPCA-$L_1$ 2DPCA-$L_1$ (non-greedy) Angle-2DPCA GC2DPCA 20 0.855 0.576 0.310 2.861 9.672 5.585 2.637 40 1.643 0.882 0.363 5.834 17.550 7.753 5.413 60 3.072 1.326 0.452 8.611 28.096 16.567 9.049 80 4.733 1.940 0.507 17.800 35.896 14.040 14.883 100 6.732 2.226 0.620 22.449 88.671 40.092 18.517
下载: 导出CSV
-
[1] Jolliffe I T, Cadima J. Principal component analysis: a review and recent developments. Philosophical Transactions of the Royal Society A: Mathematical, Physical and Engineering Sciences, 2016, 374(2065): 20150202. DOI: 10.1098/rsta.2015.0202 [2] Yang J, Zhang D D, Frangi A F, Yang J Y. Two-Dimensional PCA: a new approach to appearance-based face representation and recognition. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2004, 26(1):131-137 doi: 10.1109/TPAMI.2004.1261097 [3] Ji Y, Xie H B. Myoelectric signal classification based on S transform and two-directional two-dimensional principal component analysis. Transactions of the Institute of Measurement and Control, 2018, 40(7): 2387-2395 doi: 10.1177/0142331217704035 [4] Yang W, Sun C, Ricanek K. Sequential row-column 2DPCA for face recognition. Neural Computing and Applications, 2012, 21(7): 1729-1735 doi: 10.1007/s00521-011-0676-5 [5] Zhang D, Zhou Z H, Chen S. Diagonal principal component analysis for face recognition. Pattern Recognition, 2006, 39(1): 140-142 doi: 10.1016/j.patcog.2005.08.002 [6] Wang H, Hu J, Deng W. Face feature extraction: a complete review. IEEE Access, 2018, 6: 6001-6039 doi: 10.1109/ACCESS.2017.2784842 [7] Tirumala S S, Shahamiri S R, Garhwal A S, Wang R. Speaker identification features extraction methods: a systematic review. Expert Systems with Applications, 2017, 90: 250-271 doi: 10.1016/j.eswa.2017.08.015 [8] Soora N R, Deshpande P S. Review of feature extraction techniques for character recognition. IETE Journal of Research, 2018, 64(2): 280-295 doi: 10.1080/03772063.2017.1351323 [9] Neiva D H, Zanchettin C. Gesture recognition: a review focusing on sign language in a mobile context. Expert Systems with Applications, 2018, 103: 159-183 doi: 10.1016/j.eswa.2018.01.051 [10] 史加荣, 周水生, 郑秀云. 多线性鲁棒主成分分析. 电子学报, 2014, 42(08): 1480-1486 doi: 10.3969/j.issn.0372-2112.2014.08.004Shi Jia-Rong, Zhou Shui-Sheng, Zheng Xiu-Yun. Multilinear robust principal component analysis. Acta Electronica Sinica, 2014, 42(08): 1480-1486 doi: 10.3969/j.issn.0372-2112.2014.08.004 [11] Namrata V, Thierry B, Sajid J, Praneeth N. Robust subspace learning: robust PCA, robust subspace tracking, and robust subspace recovery. IEEE Signal Processing Magazine, 2018, 35(4): 32-55 doi: 10.1109/MSP.2018.2826566 [12] Menon V, Kalyant S. Structured and unstructured outlier identification for robust PCA: a fast parameter free algorithm. IEEE Transactions on Signal Processing, 2019, 67(9): 2439-2452 doi: 10.1109/TSP.2019.2905826 [13] Wang W Q, Aggarwal V, Aeron S. Principal component analysis with tensor train subspace. Pattern Recognition Letters, 2019, 122: 86-91 doi: 10.1016/j.patrec.2019.02.024 [14] Markopoulos P P, Chachlakis D G, Papalexakis E E. The exact solution to rank-1 L1-norm TUCKER2 decomposition. IEEE Signal Processing Letters, 2018, 25(4): 511-515 doi: 10.1109/LSP.2018.2790901 [15] Kwak N. Principal component analysis based on L1-norm maximization. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2008, 30(9): 1672-1680 doi: 10.1109/TPAMI.2008.114 [16] Nie F P, Huang H, Ding C, Luo D, Wang H. Robust principal component analysis with non-greedy L1-norm maximization. In: Proceedings of the 22nd International Joint Conference on Artificial Intelligence. Barcelona, Spain: AAAI, 2011. 1433−1438 [17] Lu G F, Zou J, Wang Y, Wang Z. L1-norm-based principal component analysis with adaptive regularization. Pattern Recognition, 2016, 60: 901-907 doi: 10.1016/j.patcog.2016.07.014 [18] Wang H. Block principal component analysis with L1-norm for image analysis. Pattern Recognition Letters, 2012, 33(5): 537-542 doi: 10.1016/j.patrec.2011.11.029 [19] Bing N L, Qiang Y, Rong W, Xiang K, Meng W, Li X. Block principal component analysis with nongreedy L1-norm maximization. IEEE Transactions on Cybernetics, 2016, 46(11): 2543-2547 doi: 10.1109/TCYB.2015.2479645 [20] Li X, Pang Y, Yuan Y. L1-norm-based 2DPCA. IEEE Transactions on Systems, Man, and Cybernetics, Part B (Cybernetics), 2010, 40(4): 1170-1175 doi: 10.1109/TSMCB.2009.2035629 [21] Wang R, Nie F, Yang X, Gao F, Yao M. Robust 2DPCA With non-greedy L1-norm maximization for image analysis[J]. IEEE Transactions on Cybernetics, 2015, 45(5): 1108-1112 [22] Wang H, Wang J. 2DPCA with L1-norm for simultaneously robust and sparse modelling. Neural Networks, 2013, 46: 190-198 doi: 10.1016/j.neunet.2013.06.002 [23] Pang Y, Li X, Yuan Y. Robust tensor analysis with L1-norm. IEEE Transactions on Circuits and Systems for Video Technology, 2010, 20(2): 172-178 doi: 10.1109/TCSVT.2009.2020337 [24] Zhao L, Jia W, Wang R, Yu Q. Robust tensor analysis with non-greedy L1-norm maximization. Radioengineering, 2016, 25(1): 200-207 doi: 10.13164/re.2016.0200 [25] Kwak N. Principal component analysis by Lp-norm maximization. IEEE Transactions on Cybernetics, 2014, 44(5): 594-609 doi: 10.1109/TCYB.2013.2262936 [26] 李春娜, 陈伟杰, 邵元海. 鲁棒的稀疏Lp-模主成分分析. 自动化学报, 2017, 43(01): 142-151Li Chun-Na, Chen Wei-Jie, Shao Yuan-Hai. Robust sparse Lp-norm principal component analysis. Acta Automatica Sinica, 2017, 43(01): 142-151 [27] Wang J. Generalized 2-D principal component analysis by Lp-norm for image analysis. IEEE Transactions on Cybernetics, 2016, 46(3): 792-803 doi: 10.1109/TCYB.2015.2416274 [28] Li T, Li M, Gao Q, Xie D. F-norm distance metric based robust 2DPCA and face recognition. Neural Networks, 2017, 94: 204-211 doi: 10.1016/j.neunet.2017.07.011 [29] Wang Q, Gao Q, Gao X, Nie F. Optimal mean two-dimensional principal component analysis with F-norm minimization. Pattern Rrecognition, 2017, 68: 286-294 doi: 10.1016/j.patcog.2017.03.026 [30] Gao Q, Ma L, Liu Y, Gao X, Nie F. Angle 2DPCA: a new formulation for 2DPCA. IEEE Transactions on Cybernetics, 2018, 48(5): 1672-1678 doi: 10.1109/TCYB.2017.2712740 -

 下载:
下载:







计量
- 文章访问数: 774
- HTML全文浏览量: 230
- PDF下载量: 176
- 被引次数: 0
