

Text Detection in Natural Scene Images Based on Enhanced Receptive Field and Fully Convolution Network
-
摘要: 自然场景图像质量易受光照及采集设备的影响, 且其背景复杂, 图像中文字颜色、尺度、排列方向多变, 因此, 自然场景文字检测具有很大的挑战性. 本文提出一种基于全卷积网络的端对端文字检测器, 集中精力在网络结构和损失函数的设计, 通过设计感受野模块并引入 Focalloss、GIoUloss 进行像素点分类和文字包围框回归, 从而获得更加稳定且准确的多方向文字检测器. 实验结果表明本文方法与现有先进方法相比, 无论是在多方向场景文字数据集还是水平场景文字数据集均取得了具有可比性的成绩.Abstract: The quality of natural scene images is influenced easily by the shooting environment and conditions, and scene image background is relatively complex and has a strong interference for detection, besides, text in scene images may have different colors, fonts, sizes, directions, languages and so on, all these situations make natural scene text detection be still a challenging research topic. This paper proposes an end-to-end text detector based on fully convolution network. We focus on the design of the network structure and the loss function, through adding the enhanced receptive field module and introducing Focalloss, GIoUloss for pixels classification and text boxes regression respectively, we gain a more stable accurate multi-oriented text detector. Our method provides promising performance compared to the recent state-of-the art methods on both the multi-oriented scene text dataset and horizontal text dataset.
-
Key words:
- Receptive field enhanced module /
- Focalloss /
- GIoUloss /
- full convolution network
-
表 1 ICDAR2015测试集检测结果对比
Table 1 Qualitative comparison on ICDAR2015 dataset
方法 召回率 (R) 精确度 (P) F 值 CNN MSER[22] 0.34 0.35 0.35 Islam 等[25] 0.64 0.78 0.70 AJOU[26] 0.47 0.47 0.47 NJU[22] 0.36 0.70 0.48 StradVision2[22] 0.37 0.77 0.50 Zhang 等[23] 0.43 0.71 0.54 Tian 等[27] 0.52 0.74 0.61 Yao 等[28] 0.59 0.72 0.65 Liu 等[29] 0.682 0.732 0.706 Shi 等[24] 0.768 0.731 0.750 East PVANET[15] 0.7135 0.8086 0.7571 East PVANET2x[15] 0.735 0.836 0.782 EAST PVANET2x MS[15] 0.783 0.833 0.807 TextBoxes++[30] 0.767 0.872 0.817 RRD[8] 0.79 0.8569 0.822 TextSnake[6] 0.804 0.849 0.826 TextBoxes++ MS[30] 0.785 0.878 0.829 Lv 等[7] 0.895 0.797 0.843 本文方法 0.789 0.854 0.82  下载: 导出CSV
下载: 导出CSV
表 2 MSRA-TD500测试集检测结果对比
Table 2 Qualitative comparison on MSRA-TD500 dataset
方法 召回率 (R) 精确度 (P) F 值 Epshtein 等[31] 0.25 0.25 0.25 TD-ICDAR[21] 0.52 0.53 0.50 Zhang 等[23] 0.43 0.71 0.54 TD-Mixture[21] 0.63 0.63 0.60 Yao 等[28] 0.59 0.72 0.65 Kang 等[32] 0.62 0.71 0.66 Yin 等[33] 0.62 0.81 0.71 East PVANET[15] 0.6713 0.8356 0.7445 EAST PVANET2x[15] 0.6743 0.8728 0.7608 TextSnake[6] 0.739 0.832 0.783 本文方法 0.689 0.925 0.79
下载: 导出CSV
表 3 ICDAR2013测试集检测结果对比
Table 3 Qualitative comparison on ICDAR2013 dataset
方法 召回率 (R) 精确度 (P) F 值 Fasttext[34] 0.69 0.84 0.77 MMser[35] 0.70 0.86 0.77 Lu 等[36] 0.70 0.89 0.78 TextFlow[37] 0.76 0.85 0.80 TextBoxes [38] 0.74 0.86 0.80 TextBoxes++[30] 0.74 0.86 0.80 RRD[8] 0.75 0.88 0.81 He 等[39] 0.73 0.93 0.82 FCN[23] 0.78 0.88 0.83 Qin 等[40] 0.79 0.89 0.83 Tian 等[41] 0.84 0.84 0.84 TextBoxes MS[38] 0.83 0.88 0.85 Lv 等[7] 0.933 0.794 0.858 TextBoxes++ MS[30] 0.84 0.91 0.88 EAST PVANET2x[15] 0.8267 0.9264 0.8737 Tang 等[42] 0.87 0.92 0.90 本文方法 0.858 0.931 0.893
下载: 导出CSV
表 4 多种文字检测方法在ICDAR2015上的精度和速度对比结果
Table 4 Comparison of accuracy and speed on ICDAR2015 dataset
方法 测试图片尺寸
(像素)设备 帧率
(帧/s)F 值 Zhang 等[23] MS TitanX 0.476 0.54 Tian 等[27] ss-600 GPU 7.14 0.61 Yao 等[28] 480 p K40m 1.61 0.65 Shi 等[24] 768 × 768 TitanX 8.9 0.750 EAST PVANET[15] 720 p TitanX 16.8 0.757 EAST PVANET2x[15] 720 p TitanX 13.2 0.782 TextBoxes++[30] 1024 × 1024 TitanX 11.6 0.817 RRD[8] 1024 × 1024 TitanX 6.5 0.822 TextSnake[6] 1280 × 768 TitanX 1.1 0.826 TextBoxes++ MS[30] MS TitanX 2.3 0.829 Lv 等[7] 512 × 512 TitanX 1 0.843 本文方法 720 p TitanX 12.5 0.82
下载: 导出CSV
表 5 本文方法各组件在ICDAR2015数据集上的作用效果
Table 5 Effectiveness of various designs on ICDAR2015 dataset
ResNet50 感受野增强模块 Focalloss GIoUloss 召回率 (R) 精确度 (P) F 值 × × × × 0.735 0.836 0.782 √ × × × 0.764 0.833 0.797 √ √ × × 0.766 0.845 0.802 √ √ √ × 0.776 0.853 0.813 √ √ √ √ 0.789 0.854 0.82
下载: 导出CSV
-
[1] Liu W, Anguelov D, Erhan D, Szegedy C, Reed S, Fu C Y, et al. SSD: Single shot multibox detector. In: Proceedings of the 14th European Conference on Computer Vision. Amsterdam, the Netherlands: Springer, 2016. 21−37 [2] Ren S Q, He K M, Girshick R, Sun J. Faster R-CNN: Towards real-time object detection with region proposal networks. In: Proceedings of the 2015 Advances in Neural Information Processing Systems. NIPS, 2015. 91−99 [3] He W H, Zhang X Y, Yin F, Liu C L. Deep direct regression for multi-oriented scene text detection. In: Proceedings of the 2017 IEEE International Conference on Computer Vision. Venice, Italy: IEEE, 2017. 745−753 [4] Deng D, Liu H F, Li X L, Cai D. Pixellink: Detecting scene text via instance segmentation. In: Proceedings of the 32nd AAAI Conference on Artificial Intelligence. New Orleans, LA, USA: AAAI, 2018. 6773−6780 [5] Yan S, Feng W, Zhao P, Liu C L. Progressive scale expansion network with octave convolution for arbitrary shape scene text detection. In: Proceedings of the 2019 Asian Conference on Pattern Recognition. Springer, Cham, 2019. 663−676 [6] Long S B, Ruan J Q, Zhang W J, He X, Wu W H, Yao C. TextSnake: A flexible representation for detecting text of arbitrary shapes. In: Proceedings of the 15th European Conference on Computer Vision (ECCV). Munich, Germany: Springer, 2018. 19−35 [7] Lv P Y, Yao C, Wu W H, Yan S C, Bai X. Multi-oriented scene text detection via corner localization and region segmentation. In: Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Salt Lake City, USA: IEEE, 2018. 7553−7563 [8] Liao M H, Zhu Z, Shi B G, Xia G S, Bai X. Rotation-sensitive regression for oriented scene text detection. In: Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Salt Lake City, USA: IEEE, 2018. 5909−5918 [9] Lyu P Y, Liao M H, Yao C, Wu W H, Bai X. Mask textspotter: An end-to-end trainable neural network for spotting text with arbitrary shapes. In: Proceedings of the 15th European Conference on Computer Vision (ECCV). Munich, Germany: Springer, 2018. 71−88 [10] Lin T Y, Goyal P, Girshick R, He K M, Dollar P. Focal loss for dense object detection. In: Proceedings of the 2017 IEEE International Conference on Computer Vision. Venice, Italy: IEEE, 2017. 2999−3007 [11] Rezatofighi H, Tsoi N, Gwak J, Sadeghian A, Reid I, Savarese S. Generalized intersection over union: A metric and a loss for bounding box regression. In: Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Long Beach, USA: IEEE, 2019. 658−666 [12] Lin T Y, Dollar P, Girshick R, He K M, Hariharan B, Belongie S. Feature pyramid networks for object detection. In: Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition. Honolulu, USA: IEEE, 2017. 936−944 [13] Krizhevsky A, Sutskever I, Hinton G E. ImageNet classification with deep convolutional neural networks. Communications of the ACM, 2017, 60(6): 84-90 doi: 10.1145/3065386 [14] He K M, Zhang X Y, Ren S Q, Sun J. Deep residual learning for image recognition. In: Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition. Las Vegas, USA: IEEE, 2016. 770−778 [15] Zhou X Y, Yao C, Wen H, Wang Y Z, Zhou S C, He W R, et al. EAST: An efficient and accurate scene text detector. In: Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition. Honolulu, USA: IEEE, 2017. 2642−2651 [16] Liu S T, Huang D, Wang Y H. Receptive field block net for accurate and fast object detection. In: Proceedings of the 15th European Conference on Computer Vision (ECCV). Munich, Germany: Springer, 2018. 404−419 [17] Szegedy C, Ioffe S, Vanhoucke V, Alemi A A. Inception-v4, Inception-ResNet and the impact of residual connections on learning. In: Proceedings of the 31st AAAI Conference on Artificial Intelligence. San Francisco, USA: AAAI, 2017. 4278−4284 [18] Yu F, Koltun V. Multi-scale context aggregation by dilated convolutions. arXiv: 1511.07122, 2015. [19] Karatzas D, Shafait F, Uchida S, Iwamura M, Bigorda L G I, Mestre S R, et al. ICDAR 2013 robust reading competition. In: Proceedings of the 12th International Conference on Document Analysis and Recognition. Washington, USA: IEEE, 2013. 1484−1493 [20] Karatzas D, Gomez-Bigorda L, Nicolaou A, Ghosh S, Bagdanov A, Iwamura M, et al. ICDAR 2015 competition on robust reading. In: Proceedings of the 13th International Conference on Document Analysis and Recognition. Tunis, Tunisia: IEEE, 2015. 1156−1160 [21] Yao C, Bai X, Liu W Y, Ma Yi, Tu Z W. Detecting texts of arbitrary orientations in natural images. In: Proceedings of the 2012 IEEE Conference on Computer Vision and Pattern Recognition. Providence, USA: IEEE, 2012. 1083−1090 [22] Yao C, Bai X, Liu W Y. A unified framework for multioriented text detection and recognition. IEEE Transactions on Image Processing, 2014, 23(11): 4737-4749 doi: 10.1109/TIP.2014.2353813 [23] Zhang Z, Zhang C Q, Shen W, Yao C, Liu W Y, Bai X. Multi-oriented text detection with fully convolutional networks. In: Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). Las Vegas, USA: IEEE, 2016. 4159−4167 [24] Shi B G, Bai X, Belongie S. Detecting oriented text in natural images by linking segments. In: Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition. Honolulu, USA: IEEE 2017. 3482−3490 [25] Islam M R, Mondal C, Azam M K, Islam A S M. Text detection and recognition using enhanced MSER detection and a novel OCR technique. In: Proceedings of the 5th International Conference on Informatics, Electronics and Vision (ICIEV). Dhaka, Bangladesh: IEEE, 2016. 15−20 [26] Gupta A, Vedaldi A, Zisserman A. Synthetic data for text localisation in natural images. In: Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition. Las Vegas, NV, USA: IEEE, 2016. 2315−2324 [27] Tian Z, Huang W L, He T, He P, Qiao Y. Detecting text in natural image with connectionist text proposal network. In: Proceedings of the 14th European Conference on Computer Vision. Amsterdam, the Netherlands: Springer, 2016. 56−72 [28] Yao C, Bai X, Sang N, Zhou X Y, Zhou S C, Cao Z M. Scene text detection via holistic, multi-channel prediction. arXiv: 1606.09002, 2016. [29] Liu Y L, Jin L W. Deep matching prior network: Toward tighter multi-oriented text detection. In: Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition. Honolulu, USA: 2017. 3454−3461 [30] Liao M H, Shi B G, Bai X. TextBoxes++: A single-shot oriented scene text detector. IEEE Transactions on Image Processing, 2018, 27(8): 3676-3690 doi: 10.1109/TIP.2018.2825107 [31] Epshtein B, Ofek E, Wexler Y. Detecting text in natural scenes with stroke width transform. In: Proceedings of the 2010 IEEE Computer Society Conference on Computer Vision and Pattern Recognition. San Francisco, USA: IEEE, 2010. 2963−2970 [32] Kang L, Li Y, Doermann D. Orientation robust text line detection in natural images. In: Proceedings of the 2014 IEEE Conference on Computer Vision and Pattern Recognition. Columbus, OH, USA: IEEE, 2014. 4034−4041 [33] Yin X C, Pei W Y, Zhang J, Hao H W. Multi-orientation scene text detection with adaptive clustering. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2015, 37(9): 1930-1937 doi: 10.1109/TPAMI.2014.2388210 [34] Buta M, Neumann L, Matas J. FASText: Efficient unconstrained scene text detector. In: Proceedings of the 2015 IEEE International Conference on Computer Vision (ICCV). Santiago, Chile: IEEE, 2015. 1206−1214 [35] Zamberletti A, Noce L, Gallo I. Text localization based on fast feature pyramids and multi-resolution maximally stable extremal regions. In: Proceedings of the 2015 Asian Conference on Computer Vision. Singapore, Singapore: Springer, 2014. 91−105 [36] Lu S J, Chen T, Tian S X, Lim J H, Tan C L. Scene text extraction based on edges and support vector regression. International Journal on Document Analysis and Recognition (IJDAR), 2015, 18(2): 125-135 doi: 10.1007/s10032-015-0237-z [37] Tian S X, Pan Y F, Huang C, Lu S J, Yu Kai, Tan C L. Text flow: A unified text detection system in natural scene images. In: Proceedings of the 2015 IEEE International Conference on Computer Vision. Santiago, Chile: 2015. 4651−4659 [38] Liao M H, Shi B G, Bai X, Wang X G, Liu W Y. Textboxes: A fast text detector with a single deep neural network. In: Proceedings of the 31st AAAI Conference on Artificial Intelligence. San Francisco, USA: AAAI, 2017. 4161−4167 [39] He T, Huang W L, Qiao Y, Yao J. Text-attentional convolutional neural network for scene text detection. IEEE Transactions on Image Processing, 2016, 25(6): 2529-2541 doi: 10.1109/TIP.2016.2547588 [40] Qin S Y, Manduchi R. A fast and robust text spotter. In: Proceedings of the 2016 IEEE Winter Conference on Applications of Computer Vision. Lake Placid, USA: IEEE, 2016. 1−8 [41] Tian C N, Xia Y, Zhang X N, Gao X B. Natural scene text detection with MC-MR candidate extraction and coarse-to-fine filtering. Neurocomputing, 2017, 260: 112-122 doi: 10.1016/j.neucom.2017.03.078 [42] Tang Y B, Wu X Q. Scene text detection and segmentation based on cascaded convolution neural networks. IEEE Transactions on Image Processing, 2017, 26(3): 1509-1520 doi: 10.1109/TIP.2017.2656474 [43] 李文英, 曹斌, 曹春水, 黄永祯. 一种基于深度学习的青铜器铭文识别方法. 自动化学报, 2018, 44(11): 2023-2030Li Wen-Ying, Cao Bin, Cao Chun-Shui, Huang Yong-Zhen. A deep learning based method for bronze inscription recognition. Acta Automatica Sinica, 2018, 44(11): 2023-2030 [44] 王润民, 桑农, 丁丁, 陈杰, 叶齐祥, 高常鑫, 等. 自然场景图像中的文本检测综述. 自动化学报, 2018, 44(12): 2113-2141Wang Run-Min, Sang Nong, Ding Ding, Chen Jie, Ye Qi-Xiang, Gao Chang-Xin, et al. Text detection in natural scene image: A survey. Acta Automatica Sinica, 2018, 44(12): 2113-2141 [45] 金连文, 钟卓耀, 杨钊, 杨维信, 谢泽澄, 孙俊. 深度学习在手写汉字识别中的应用综述. 自动化学报, 2016, 42(8): 1125-1141Jin Lian-Wen, Zhong Zhuo-Yao, Yang Zhao, Yang Wei-Xin, Xie Ze-Cheng, Sun Jun. Applications of deep learning for handwritten Chinese character recognition: A review. Acta Automatica Sinica, 2016, 42(8): 1125-1141 [46] Wang W H, Xie E Z, Li X, Hou W B, Lu T, Yu G, Shao S. Shape robust text detection with progressive scale expansion network. In: Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). Long Beach, USA: IEEE, 2018. 9328−9337 -

 下载:
下载:
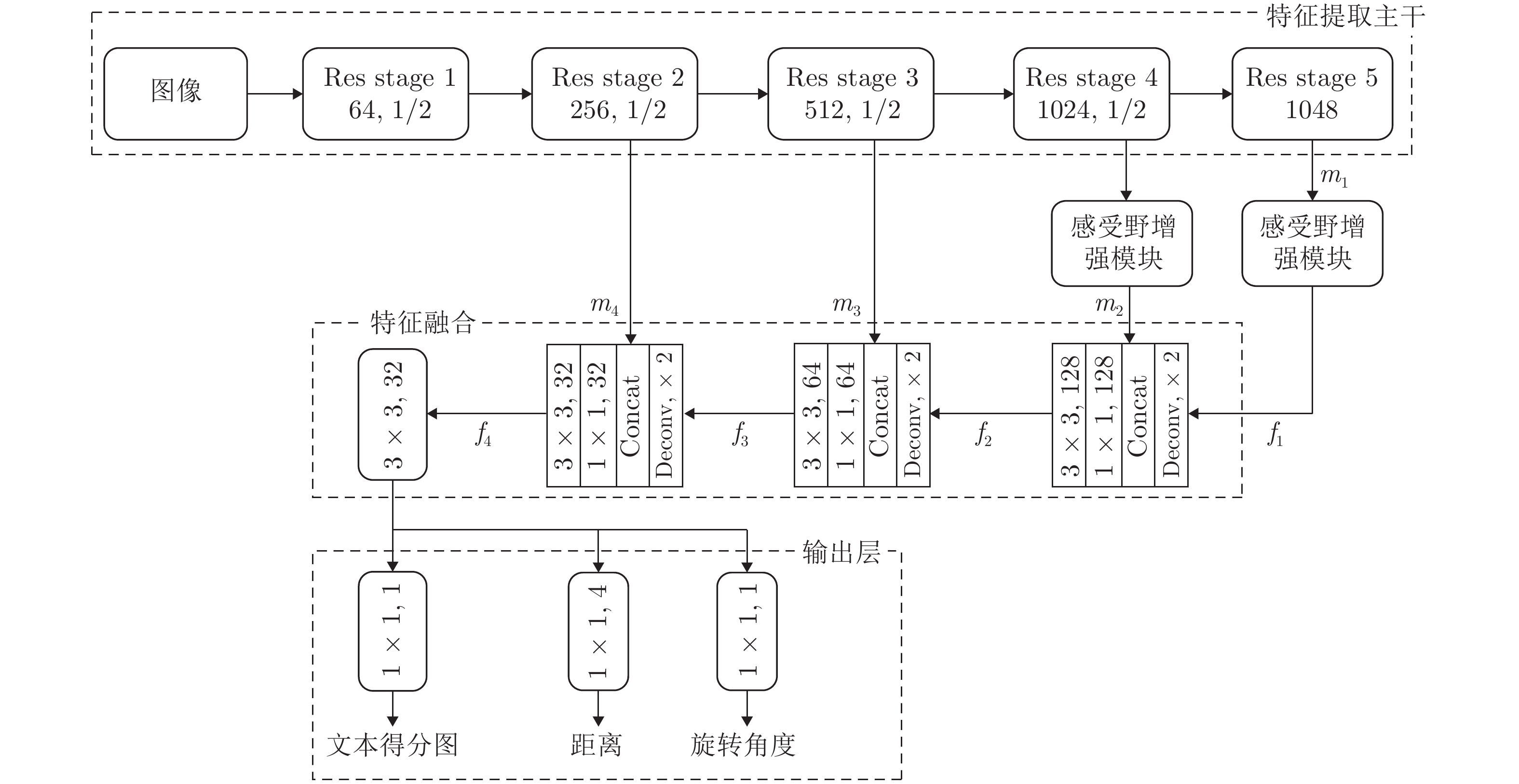
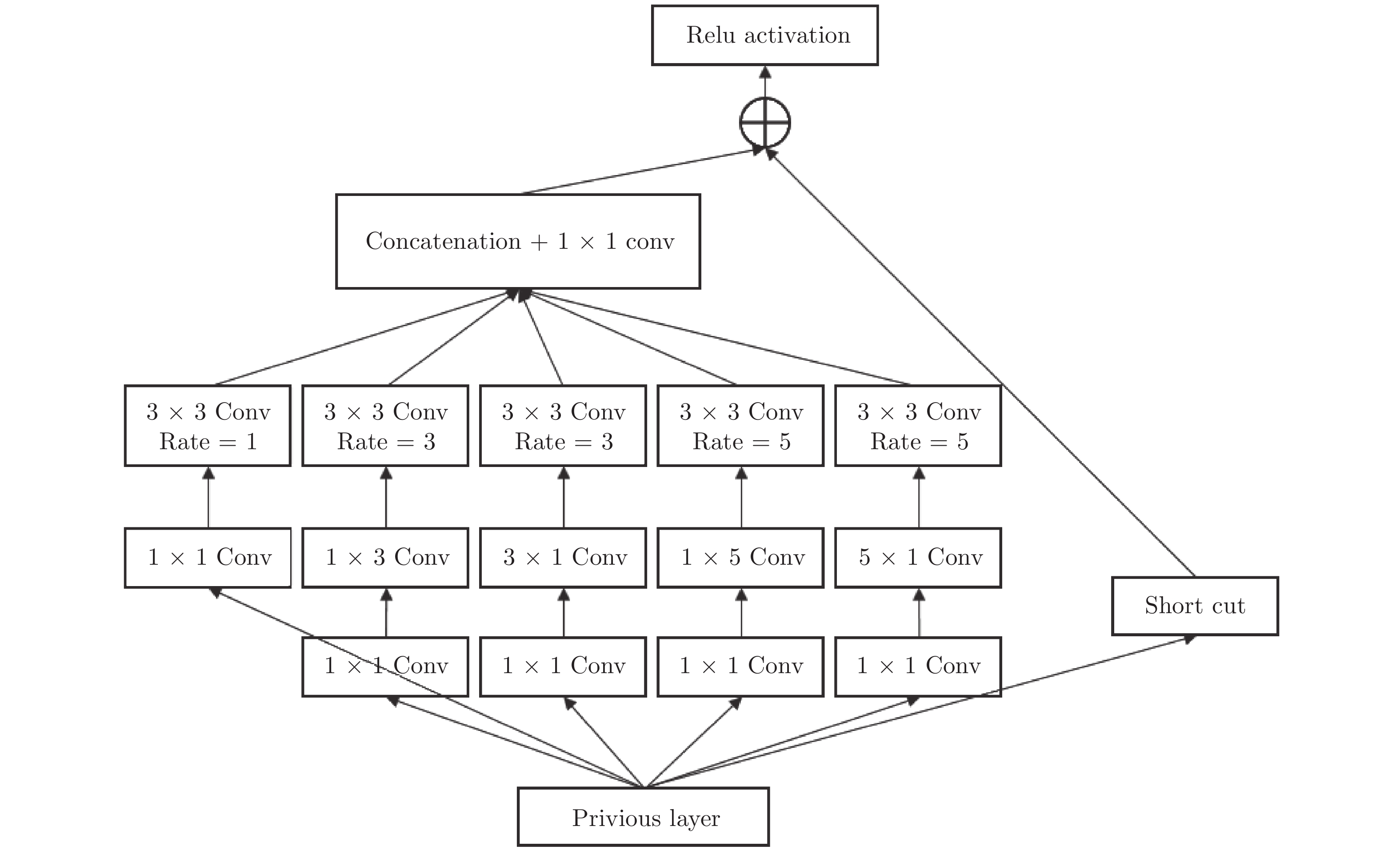
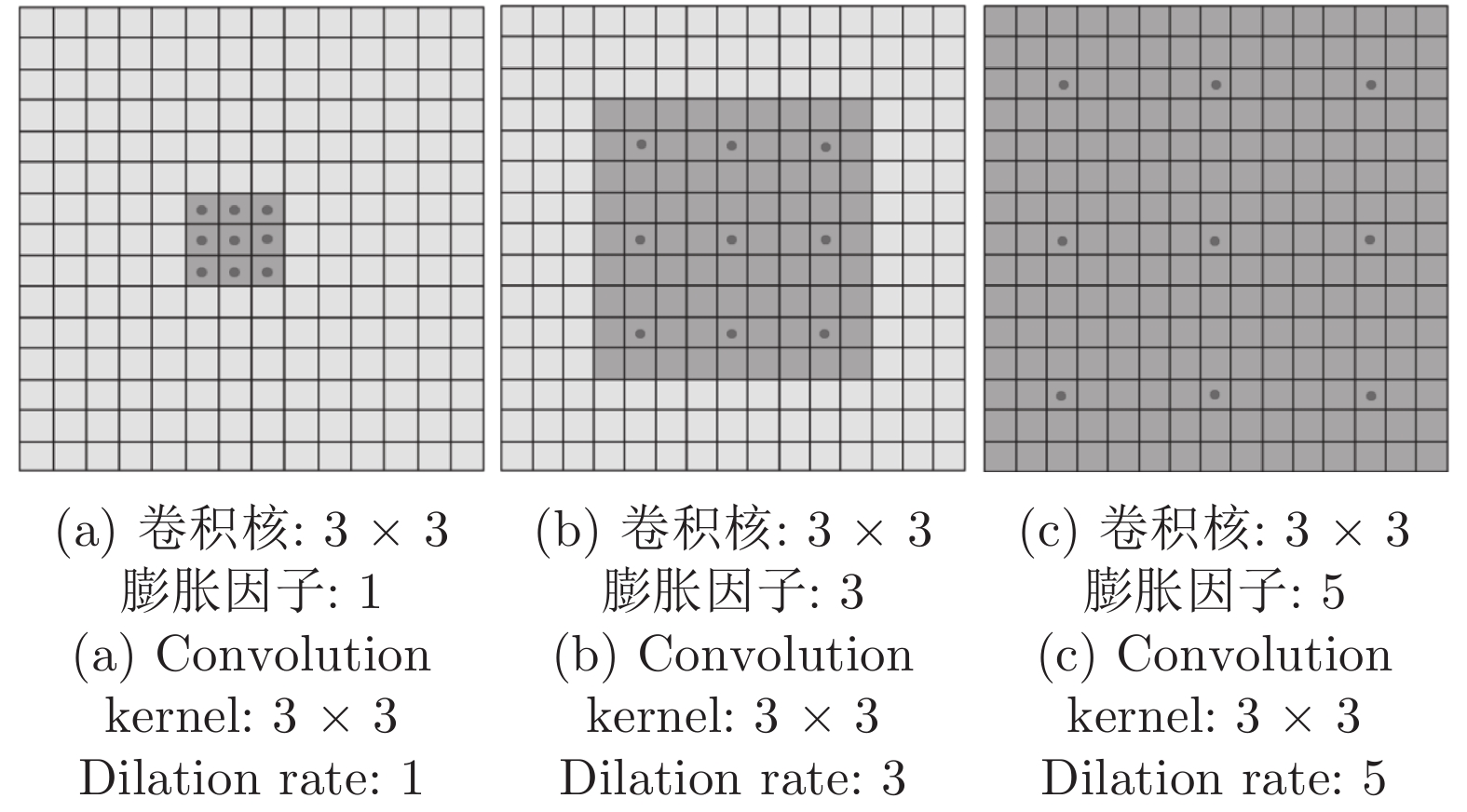





计量
- 文章访问数: 818
- HTML全文浏览量: 606
- PDF下载量: 203
- 被引次数: 0
