

Image Semantic Segmentation Method Based on Context and Shallow Space Encoder-decoder Network
-
摘要: 当前图像语义分割研究基本围绕如何提取有效的语义上下文信息和还原空间细节信息两个因素来设计更有效算法. 现有的语义分割模型, 有的采用全卷积网络结构以获取有效的语义上下文信息, 而忽视了网络浅层的空间细节信息; 有的采用U型结构, 通过复杂的网络连接利用编码端的空间细节信息, 但没有获取高质量的语义上下文特征. 针对此问题, 本文提出了一种新的基于上下文和浅层空间编解码网络的语义分割解决方案. 在编码端, 采用二分支策略, 其中上下文分支设计了一个新的语义上下文模块来获取高质量的语义上下文信息, 而空间分支设计成反U型结构, 并结合链式反置残差模块, 在保留空间细节信息的同时提升语义信息. 在解码端, 本文设计了优化模块对融合后的上下文信息与空间信息进一步优化. 所提出的方法在3个基准数据集CamVid、SUN RGB-D和Cityscapes上取得了有竞争力的结果.Abstract: Recently, the research on image semantic segmentation basically focuses on how to extract effective semantic context information and restore spatial information in order to get more efficient algorithms. Some models use a fully convolutional network structure to obtain effective semantic context information. This kind of framework does not use the spatial details in the shallow layers of the networks. To effectively restore the spatial details for the decoder, some researches utilize the U-shape structure of complex network connections. But they could not obtain high-quality semantic context features. To better combine context information and space information, a novel semantic segmentation framework is proposed in this paper. A two-branch strategy is adopted on the encoder. One branch is called contextual branch, which is constructed with a proposed semantic context module to obtain high-quality semantic context information. And the other branch is spatial branch, which is designed as an inverse U-shaped structure with the proposed chain-reverse residual module to enhance semantic information and preserve spatial details. Moreover, a refinement module is proposed to add to the decoder to further refine the fusion features of context information and spatial information. The proposed approach achieves competitive results on the CamVid, SUN RGB-D and Cityscapes benchmarks.
-
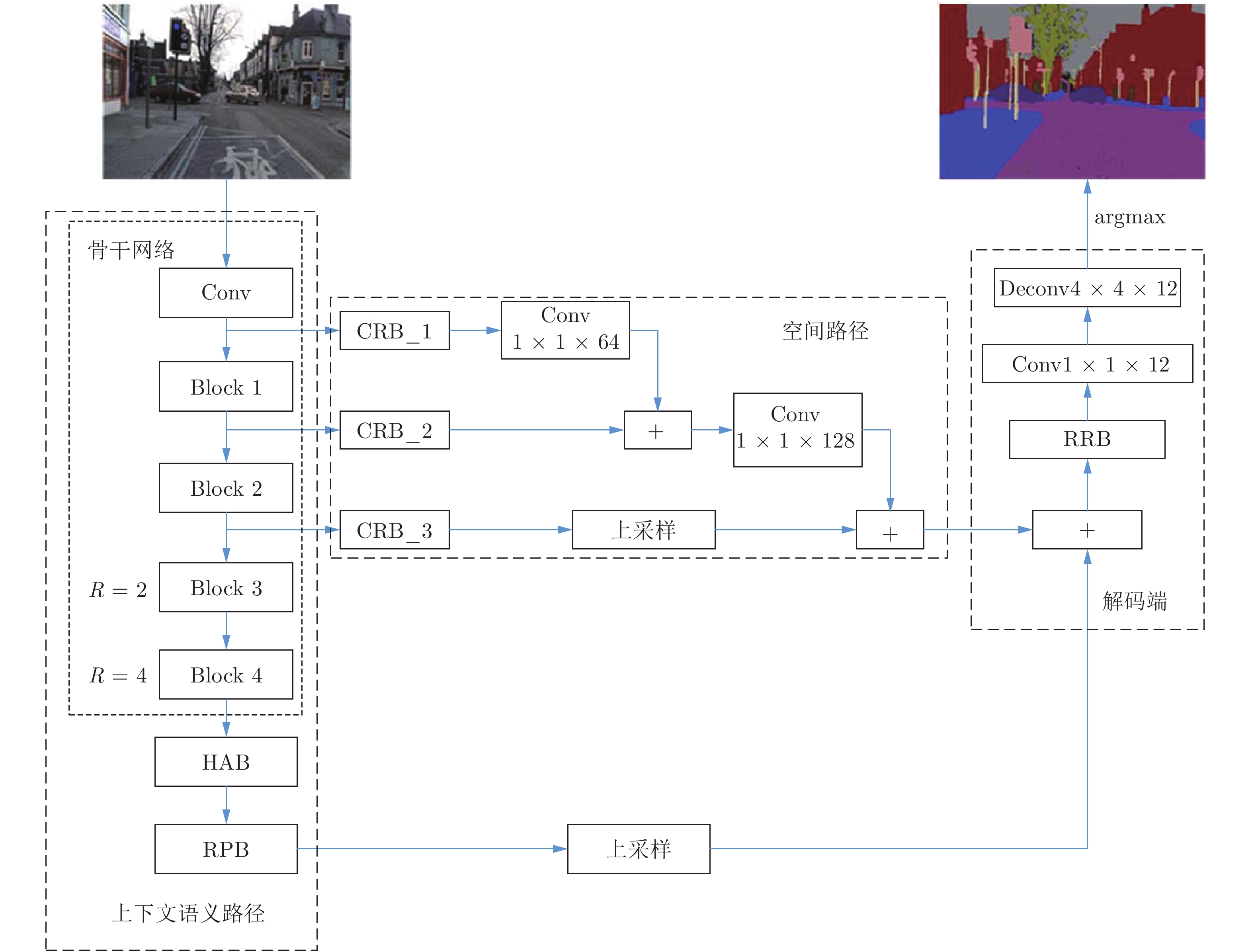
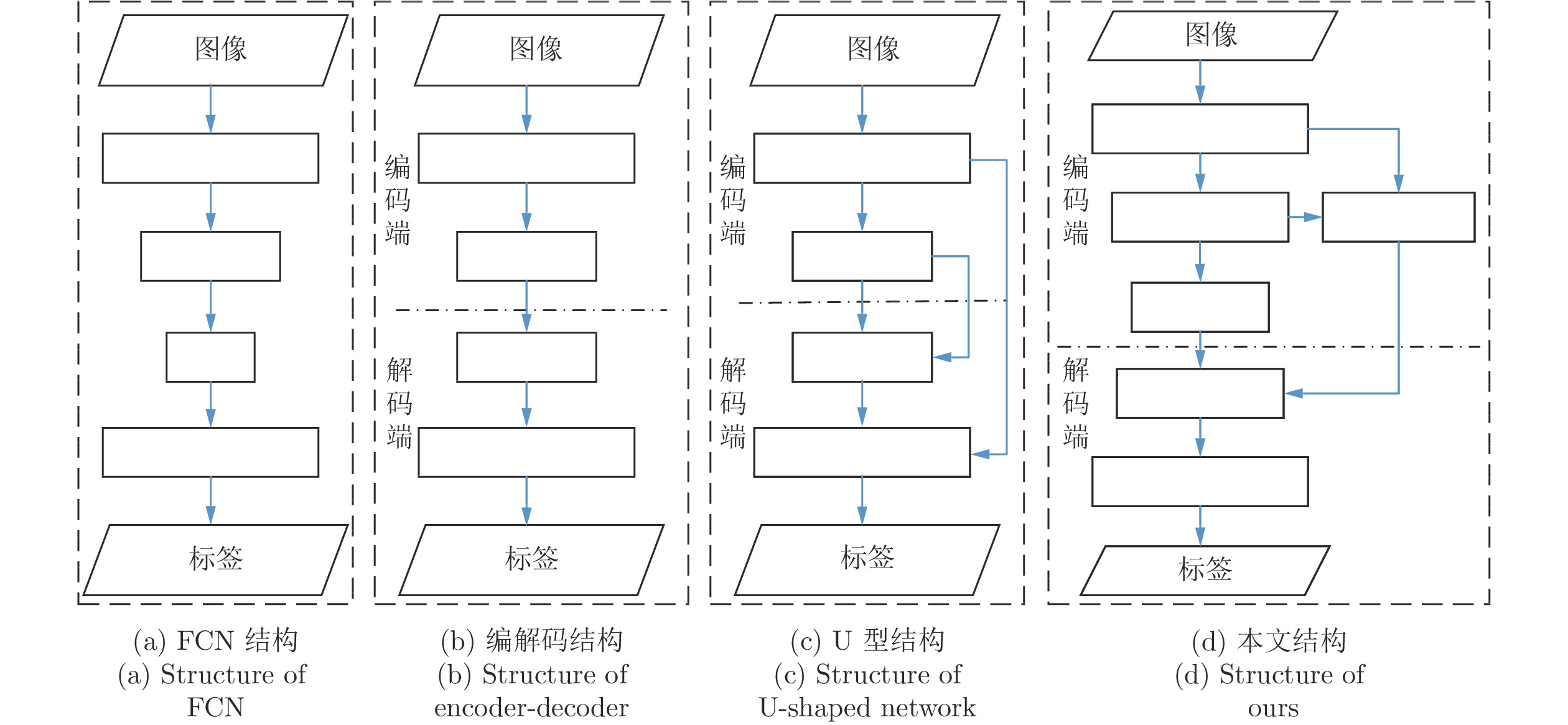
图 2 本文网络框架(HAB: 混合扩张卷积模块; RPB: 残差金字塔特征提取模块; CRB: 链式残差模块;RRB: 残差循环卷积模块; Deconv: 转置卷积; R: 扩张率)
Fig. 2 The network framework of our method (HAB: hybrid atrous convolution block; RPB: residual pyramid feature block; CRB: chain inverted residual block; RRB: residual recurrent convolution block; Deconv: transposed convolution; R: atrous rate)
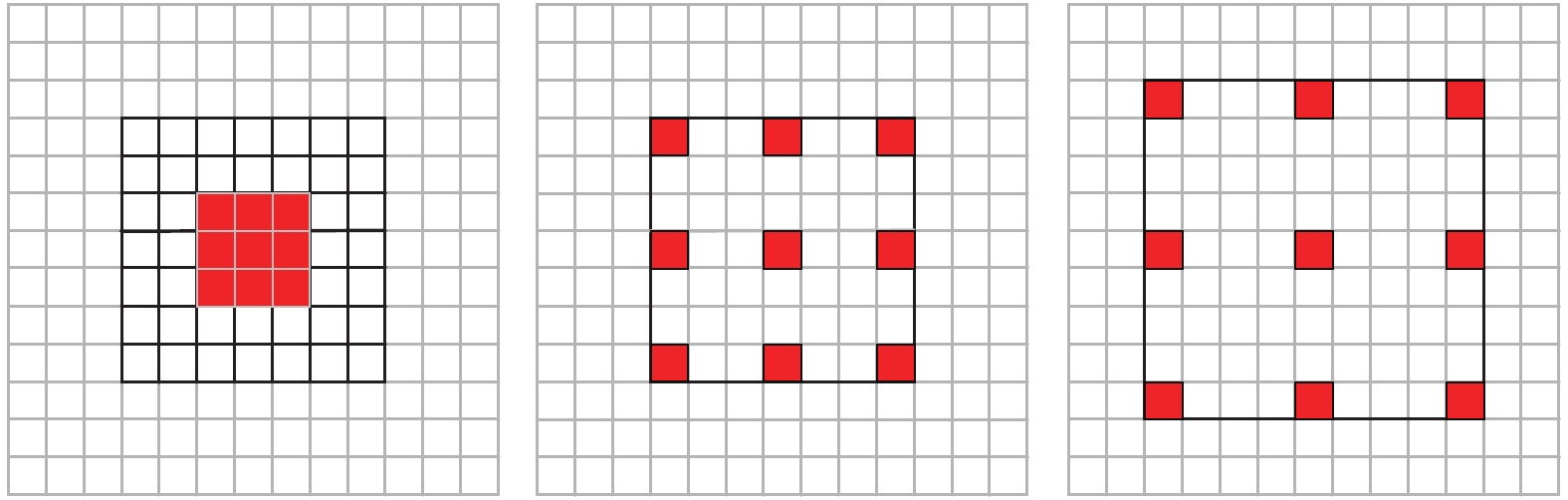
图 4 3种不同扩张率的扩张卷积, 从左到右分别为r = 1, 3, 4
Fig. 4 Illustrations of the atrous convolution with three different atrous rates, r = 1, 3, 4


图 10 本文方法在SUN RGB-D测试集上的定性结果
Fig. 10 Qualitative results of our method on the SUN RGB-D test set

图 11 本文方法在Cityscapes验证集上的定性结果
Fig. 11 Qualitative results of our method on the Cityscapes val set
表 1 本文方法与其他方法在CamVid测试集上的MIoU比较(%)
Table 1 Comparison of MIoU between our method and the state-of-the-art methods on the CamVid test set (%)
方法 Tree Sky Building Car Sign Road Pedestrian Fence Pole Sidewalk Bicyclist MIoU FCN-8[1] − − − − − − − − − − − 52.0 DeconvNet[8] − − − − − − − − − − − 48.9 SegNet[12] 52.0 87.0 68.7 58.5 13.4 86.2 25.3 17.9 16.0 60.5 24.8 50.2 ENet[7] 77.8 95.1 74.7 82.4 51.0 95.1 67.2 51.7 35.4 86.7 34.1 51.3 Dilation[2] 76.2 89.9 82.6 84.0 46.9 92.2 56.3 35.8 23.4 75.3 55.5 65.29 LRN[10] 73.6 76.4 78.6 75.2 40.1 91.7 43.5 41.0 30.4 80.1 46.5 61.7 FC-DenseNet103[11] 77.3 93.0 83.0 77.3 43.9 94.5 59.6 37.1 37.8 82.2 50.5 66.9 G-FRNet[18] 76.8 92.1 82.5 81.8 43.0 94.5 54.6 47.1 33.4 82.3 59.4 68.0 BiSeNet (xception)[14] 74.4 91.9 82.2 80.8 42.8 93.3 53.8 49.7 31.9 81.4 54.0 65.6 CGNet[23] − − − − − − − − − − − 65.6 本文方法 75.8 92.4 81.9 82.2 43.3 94.3 59.0 42.3 37.3 80.2 61.3 68.26  下载: 导出CSV
下载: 导出CSV
表 2 在CamVid数据集上的性能比较
Table 2 Performance comparisons of our method and the state-of-the-art methods on the CamVid dataset
下载: 导出CSV
表 3 本文方法与其他方法在SUN RGB-D测试集上的MIoU比较 (%)
Table 3 Comparison of MIoU between our method and the state-of-the-art methods on the SUN RGB-D test set (%)
下载: 导出CSV
表 4 本文方法与其他方法在Cityscapes测试集上的比较
Table 4 Comparisons of our method with the state-of-the-art methods on the Cityscapes test set
下载: 导出CSV
表 5 混合扩张卷积和残差金字塔特征提取模块对性能的影响 (HAB: 混合扩张卷积模块; RPB: 残差金字塔特征提取模块)
Table 5 The influence of HAB and RPB on performance (HAB: hybrid atrous convolution block; RPB: residual pyramid feature block)
HAB RPB MIoU (%) × × 66.57 √ × 66.22 × √ 67.51 √ √ 68.26
下载: 导出CSV
表 6 混合扩张卷积模块对性能的影响 (HAB: 混合扩张卷积模块; RPB: 残差金字塔特征提取模块)
Table 6 The influence of HAB on performance (HAB: hybrid atrous convolution block; RPB: residual pyramid feature block)
HAB RPB HAB各分支扩张率 MIoU (%) √ × 2, 3, 4 66.22 √ × 1 67.84 √ √ 1 68.16 √ √ 2, 3, 4 68.26
下载: 导出CSV
表 7 混合扩张卷积模块与残差金字塔特征提取模块的结构顺序对性能的影响 (HAB: 混合扩张卷积模块; RPB: 残差金字塔特征提取模块)
Table 7 The influence of the structural order of HAB and RPB on performance (HAB: hybrid atrous convolution block; RPB: residual pyramid feature block)
方法 MIoU (%) HAB+HAB 67.29 RPB+RPB 66.95 RPB+HAB 68.29 本文 (HAB+RPB) 68.26
下载: 导出CSV
表 8 不同空间路径对性能的影响 (CRB: 链式反置残差模块; SP: 空间路径; LFP: 浅层特征作为空间路径; HFP: 高层特征作为空间路径; RUP: 反U型空间路径)
Table 8 The influence of different spatial paths on performance (CRB: chain inverted residual block; SP: spatial path; LFP: low-level feature as spatial path; HFP: high-level feature as spatial path; RUP: reverse u-shaped spatial path)
方法 MIoU (%) No SP 63.51 LFP 66.06 HFP 67.49 RUP 66.79 RUP+CRB 68.26
下载: 导出CSV
表 9 链式反置残差模块不同链长对性能的影响
Table 9 The influence of CRB chain length on performance
方法 MIoU (%) 各路径链长均为 1 67.20 各路径链长均为 3 67.25 本文 (分别为 3, 2, 1) 68.26
下载: 导出CSV
表 10 残差循环卷积模块对性能的影响
Table 10 The influence of RRB on performance
方法 MIoU (%) 使用优化模块 68.26 不使用优化模块 67.50
下载: 导出CSV
-
[1] Long J, Shelhamer E, Darrell T. Fully convolutional networks for semantic segmentation. IEEE Transactions on Pattern Analysis and Machine Intelligence. 2017, 39(4): 640-651 doi: 10.1109/TPAMI.2016.2572683 [2] Yu F, Koltun V. Multi-scale context aggregation by dilated convolutions. In: Proceedings of the 4th International Conference on Learning Representations (ICLR). San Juan, Puerto Rico, USA: Conference Track Proceedings, 2016. [3] Yu F, Koltun V, Funkhouser T. Dilated residual networks. In: Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). Honolulu, Hawaii, USA: IEEE, 2017. 472−480 [4] Chen L C, Papandreou G, Kokkinos I, Murphy K, Yuille A L. Deeplab: Semantic image segmentation with deep convolutional nets, atrous convolution and fully connected CRFS. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2018, 40(4): 834-848 doi: 10.1109/TPAMI.2017.2699184 [5] Zhao H S, Shi J P, Qi X J, Wang X G, Jia J Y. Pyramid scene parsing network. In: Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). Honolulu, Hawaii, USA: IEEE, 2017. 2881−2890 [6] Chen L C, Papandreou G, Schroff F, Adam H. Rethinking atrous convolution for semantic image segmentation. [Online], available: https://arxiv.org/abs/1706.05587v1, Jun 17, 2017 [7] Paszke A, Chaurasia A, Kim S, Culurciello E. Enet: A deep neural network architecture for real-time semantic segmentation. [Online], available: https://arxiv.org/abs/1606.02147, Jun 7, 2016 [8] Noh H, Hong S, Han B. Learning deconvolution network for semantic segmentation. In: Proceedings of the 2015 IEEE International Conference on Computer Vision (ICCV). Santiago, Chile: IEEE, 2015. 1520−1528 [9] 黄庭鸿, 聂卓赟, 王庆国, 李帅, 晏来成, 郭东生. 基于区块自适应特征融合的图像实时语义分割. 自动化学报, 2021, 47(5): 1137−1148Huang Ting-Hong, Nie Zhuo-Yun, Wang Qing-Guo, Li Shuai, Yan Lai-Cheng, Guo Dong-Sheng. Real-time image semantic segmentation based on block adaptive feature fusion. Acta Automatica Sinica, 2021, 47(5): 1137−1148 [10] Islam M A, Naha S, Rochan M, Bruce N, Wang Y. Label refinement network for coarse-to-fine semantic segmentation. [Online], available: https://arxiv.org/abs/1703.00551v1, Mar 1, 2017 [11] Jégou S, Drozdzal M, Vazquez D, Romero A, Bengio Y. The one hundred layers tiramisu: Fully convolutional densenets for semantic segmentation. In: Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition Workshops (CVPRW). Honolulu, Hawaii, USA: IEEE, 2017. 11−19 [12] Badrinarayanan V, Kendall A, Cipolla R. SegNet: a deep convolutional encoder-decoder architecture for scene segmentation. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2017, 39(12): 2481-2495 doi: 10.1109/TPAMI.2016.2644615 [13] Zeiler M D, Fergus R. Visualizing and understanding convolutional networks. In: Proceedings of the 2014 European Conference on Computer Vision (ECCV). Zürich, Switzerland: Springer, 2014. 818−833 [14] Yu C Q, Wang J B, Peng C, Gao C X, Yu G, Sang N. Bisenet: Bilateral segmentation network for real-time semantic segmentation. In: Proceedings of the 2018 European Conference on Computer Vision (ECCV). Munich, Germany: Springer, 2018. 325−341 [15] Sandler M, Howard A, Zhu M, Zhmoginov A, Chen L C. Mobilenetv2: Inverted residuals and linear bottlenecks. In: Proceedings of the 2018 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). Salt lake, Utah, USA: IEEE, 2018. 4510−4520 [16] Alom M Z, Hasan M, Yakopcic C, Taha T M, Asari V K. Recurrent residual convolutional neural network based on U-net (R2U-Net) for medical image segmentation. [Online], available: https://arxiv.org/abs/1802.06955v1, Feb 20, 2018 [17] Chaurasia A, Culurciello E. Linknet: Exploiting encoder representations for efficient semantic segmentation. In: Proceedings of the 2017 IEEE Visual Communications and Image Processing (VCIP). Saint Petersburg, Florida, USA: IEEE, 2017. 1−4 [18] Amirul Islam M, Rochan M, Bruce N D, Wang Y. Gated feedback refinement network for dense image labeling. In: Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). Honolulu, Hawaii, USA: IEEE, 2017. 3751−3759 [19] Poudel R P, Bonde U, Liwicki S, Zach C. Contextnet: Exploring context and detail for semantic segmentation in real-time. In: Proceedings of the 2018 British Machine Vision Conference (BMVC). Northumbria University, Newcastle, UK: BMVA, 2018. 146 [20] Poudel R P, Liwicki S, Cipolla R. Fast-SCNN: Fast semantic segmentation network. [Online], available: https://arxiv.org/abs/1902.04502, Feb 12, 2019 [21] He K M, Zhang X Y, Ren S Q, Sun J. Deep residual learning for image recognition. In: Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). Las Vegas, USA: IEEE, 2016. 770−778 [22] Deng J, Dong W, Socher R, Li J A, Li K, Li F F. Imagenet: A large-scale hierarchical image database. In: Proceedings of the 2009 IEEE conference on Computer Vision and Pattern Recognition (CVPR), Florida, USA: IEEE, 2009. 248−255 [23] Wu T Y, Tang S, Zhang R, Zhang Y D. CGNet: A light-weight context guided network for semantic segmentation. [Online], available: https://arxiv.org/abs/1811.08201v1, Nov 20, 2018 [24] Szegedy C, Ioffe S, Vanhoucke V, Alemi A A. Inception-v4, inception-resnet and the impact of residual connections on learning. In: Proceedings of the 31st AAAI Conference on Artificial Intelligence (AAAI). San Francisco, California, USA: AAAI, 2017. 4278−4284 [25] Ioffe S, Szegedy C. Batch normalization: Accelerating deep network training by reducing internal covariate shift. In: Proceedings of the 2015 International Conference on Machine Learning (ICML). Lille, France: PMLR, 2015. 448−456 [26] Brostow G J, Fauqueur J, Cipolla R. Semantic object classes in video: A high-definition ground truth database. Pattern Recognition Letters, 2009, 30(2): 88-97 doi: 10.1016/j.patrec.2008.04.005 [27] Song S R, Lichtenberg S P, Xiao J X. Sun RGB-D: A RGB-D scene understanding benchmark suite. In: Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). Boston, Massachusetts, USA: IEEE, 2015. 567−576 [28] Cordts M, Omran M, Ramos S, Rehfeld T, Enzweiler M, Benenson R, et al. The cityscapes dataset for semantic urban scene understanding. In: Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition. Las Vegas, NV, USA: IEEE, 2016. 3213−3223 [29] He K M, Zhang X Y, Ren S Q, Sun J. Delving deep into rectifiers: Surpassing human-level performance on ImageNet classification. In: Proceedings of the 2015 IEEE International Conference on Computer Vision (ICCV). Santiago, Chile, USA: IEEE, 2015. 1026−1034 [30] Kingma D P, Ba J. Adam: A method for stochastic optimization. In: Proceedings of the 4th International Conference on Learning Representations ICLR). San Diego, CA, USA: Conference Track Proceedings, 2015. -

 下载:
下载:



计量
- 文章访问数: 1156
- HTML全文浏览量: 499
- PDF下载量: 285
- 被引次数: 0
