

-
摘要: 研究了控制信号被恶意篡改的信息物理系统的安全控制问题. 首先, 提出一种改进果蝇优化核极限学习机算法(Kernel extreme learning machine with improved fruit fly optimization algorithm, IFOA-KELM)对攻击信号进行重构. 然后, 将所得重构信号作为系统扰动加以补偿, 进而设计模型预测控制策略, 并给出了使被控系统是输入到状态稳定的条件. 另外, 本文从攻击者角度建立优化模型得到最优攻击策略用以生成足够的受攻击数据, 基于此数据, 来训练改进果蝇优化核极限学习机算法. 最后, 使用弹簧−质量−阻尼系统进行仿真, 验证了改进果蝇优化极限学习机算法和所提安全控制策略的有效性.Abstract: This paper investigates the security control problem of cyber-physical systems whose control signals are maliciously tampered. Firstly, a kernel extreme learning machine with improved fruit fly optimization (IFOA-KELM) algorithm is proposed to reconstruct the attack signal. Secondly, with the reconstructed signal treated as disturbance, a model predictive control strategy is designed to secure the system, and a condition that guarantees the input-to-state stability of the attacked system is given. In addition, to train the proposed algorithm, enough data of the system attacked with an optimal strategy is generated. This strategy is obtained by solving an optimization problem from the attacker' s perspective. Finally, a numerical example of the spring-mass-damping system is illustrated to verify the effectiveness of the IFOA-KELM algorithm and the proposed control strategy.
-
信息物理系统(Cyber-physical systems, CPSs)是计算单元与物理对象在网络空间中高度集成交互形成的智能系统[1-2]. CPSs广泛应用于水净化与分配[3-4]、智能电网[5]、智能交通[6]和国防军事[7]等重要领域. 然而, 网络的开放性使得CPSs极易受到攻击, 这对人们的经济和生活产生了巨大危害[8-9]. 如: 2019年3月全球最大铝生产商挪威海德鲁公司的勒索病毒攻击事件, 2019年1月委内瑞拉水电站的网络攻击事件, 2017 年美国制药公司默克的勒索病毒攻击事件, 2014年美国波士顿儿童医院的大规模分布式拒绝服务攻击事件等. 因此, 研究CPSs安全相关的理论和技术刻不容缓.
常见的研究CPSs安全问题的方法有: Lyapunov方法[10-11]、最优化方法[12-13]、博弈论方法[14]等. 近年来, 人工智能、云计算等技术的发展, 为解决CPSs的安全问题提供了新的途径和方法. 不过, 值得注意的是, 现有的大部分研究成果主要着重于攻击的检测和识别, 如: Vu等[15]利用K-最近邻算法对网络状态进行分类以主动检测分布式拒绝服务攻击; Kumar和Devaraj[16]先采用基于互信息的特征选择方法选取网络的重要特征, 再将它们作为反向传播神经网络(Back-propagation neural network, BPNN)的输入用以识别系统中各种类型的入侵事件; Nawaz等[17]和Esmalifalak等[18]利用支持向量机(Support vector machine, SVM)算法检测智能电网中的虚假数据注入攻击; Kiss等[19]利用高斯混合模型算法对田纳西 − 伊士曼过程中的传感器测量值进行聚类, 并选取轮廓系数作为评价指标有效识别攻击; Inoue等[3]基于由SWaT系统产生的时间序列数据(包括正常和攻击数据)对比了深度神经网络(Deep neural network, DNN)和支持向量机(SVM)两种算法的攻击检测效果, 整体而言DNN要优于SVM. 然而, 对于某些情况仅仅做到攻击检测与识别是不够的, 还需要考虑对攻击信号进行重构进而设计出合适的安全控制器, 以削弱甚至消除攻击对系统造成的影响和危害.
本文利用机器学习技术对攻击信号进行重构, 本质上是对从受攻击CPS中采集到的数据进行拟合回归进而获取攻击策略的过程. 常见的机器学习回归方法有: BPNN、高斯过程(Gaussian process, GP)、极限学习机(Exteme learning machine, ELM)、最小二乘支持向量机(Least square support vector machine, LS-SVM)等. 文献[20]为了提高非线性系统控制器的控制精度, 分别利用BPNN、ELM和LS-SVM对系统的未建模动态部分以及线性化误差进行精确估计和补偿, 并从算法的训练时长和测试误差角度对三种算法进行了对比, 结果表明训练ELM用时最短, LS-SVM拟合精度最高. 为了改善上述算法各自存在的弊端, 在原始算法基础上出现了不同的变体, 如: 为了改善BPNN存在的训练速度慢、参数寻优难、过拟合、局部最优以及隐含层节点数人为指定等问题, 文献[21]利用引入了自适应学习率和动量项的粒子群优化BP神经网络(Particle swarm optimization BP neural network, PSO-BP)预测网络流量; 为了提高ELM的稳健性和非线性逼近能力, Huang等[22]提出了核极限学习机(Kernel extreme learning machine, KELM), 并通过实验验证了KELM比LS-SVM具有更强的泛化能力.
基于以上考虑, 本文利用KELM重构攻击信号, 但是考虑到KELM同样具有参数敏感性问题, 于是选择具有结构简单、调整参数少、计算量小、收敛速度快等优点的果蝇优化算法(Fruit fly optimization algorithm, FOA)对KELM进行优化. 然而, 基础的FOA存在容易陷入局部最优解的问题, 因此本文对FOA进行改进, 最终利用基于改进的果蝇优化算法(Improved fruit fly optimization algorithm, IFOA)的KELM对攻击信号进行重构, 将攻击信号视作系统扰动并利用重构的攻击信号对其进行补偿, 对补偿后的系统使用模型预测控制(Model predictive control, MPC)策略, 并给出了使系统是输入到状态稳定(Input-to-state stable, ISS)的条件. 此外, 为了验证所提算法的有效性, 本文从攻击者角度建立了优化模型用以生成攻击数据. 最终, 通过数值仿真验证了IFOA-KELM相较于FOA-KELM、PSO-BP和LS-SVM的优越性以及安全控制策略的有效性.
符号说明.
$ {\bf R}^{n} $ 表示$ n $ 维欧几里得空间;$ I_n $ 表示$ n $ 阶单位阵;$A > 0\;(A\geq0)$ 表示矩阵$ A $ 是正定矩阵(半正定矩阵); 对于列向量$ { x} $ 和矩阵$ P>0 $ ,$ \|{ x}\| $ 表示$ { x} $ 的$ 2 $ 范数,$ \|{ x}\|_{P} = \sqrt{{ x}^{\rm T}P{ x}} $ 表示$ { x} $ 的加权范数.1. 问题描述
本文考虑执行器受到攻击或控制信号遭受篡改的CPS, 具体如图1所示.
图1中的物理对象是线性时不变系统, 它的状态方程可表示为
$$ { x}(k+1) = A{ x}(k)+B{ u}(k) $$ (1) 其中,
$ { x}(k)\in{\bf R} ^{n} $ 和$ { u}(k) = K{ x}(k)\in{\bf R}^{m} $ 分别为$ k $ 时刻的系统状态变量和控制输入,$ A $ ,$ B $ 和$ K $ 分别为相应的系统矩阵, 输入矩阵和状态反馈增益矩阵.假设攻击者根据系统的状态和控制输入设计攻击策略, 则可将受攻击后系统的状态方程表示为
$$ \begin{split} { x}_{c}(k+1) =\;& A{ x}_{c}(k)+B{ u}_{c}(k)+B_a{ a}(k) =\\ & A{ x}_{c}(k)+B{ u}_{c}(k)+a({ x}_{c}(k),{ u}_{c}(k))= \\& A{ x}_{c}(k)+BK{ x}_{c}(k)+\\ & a({ x}_{c}(k),K{ x}_{c}(k)) \\[-10pt] \end{split} $$ (2) 其中,
$ { x}_{c}(k) $ 和$ { u}_{c}(k) $ 分别为受攻击后系统的状态变量和控制输入, 矩阵$ B_a $ 描述了攻击对系统产生的影响,$ { a}(k) $ 表示攻击信号, 函数$a({ x}_{c}(k),K{ x}_{c}(k)) = $ $ B_a{ a}(k)$ 为待设计的攻击者策略.为了获得足够的标记数据用于训练机器学习算法, 我们从攻击者角度出发, 建立系统的优化模型.
令
$ A_{1} = A+BK $ , 对于攻击者而言, 系统的状态方程可表示为$$ { x}_{c}(k+1) = A_{1}{ x}_{c}(k)+B_a{ a}(k) \\ $$ (3) 攻击者的目标往往是用较少代价使得系统状态尽量偏离其期望的轨迹, 因此可以用如下优化问题来描述攻击者的攻击目标
$$ {\rm max}\ J = \sum\limits_{k = 0}^{\infty}\left[{ e}^{\rm T}(k)Q{ e}(k)-{ a}^{\rm T}(k)R{ a}(k)\right] $$ (4) 其中,
$ { e}(k) = { x}_{c}(k)-{ x}(k) $ 表示系统的状态误差,$ Q\geq0 $ 和$ R\geq0 $ 分别为状态误差和攻击信号的加权矩阵.为了方便求解上述优化问题, 定义如下变量
$$ \begin{array}{l} {\bar{ x}}(k) = \left[ {\begin{array}{*{20}{c}} { x}_{c}(k) \\ { x}(k) \end{array}} \right], \;{\bar{ u}}(k) = \left[ {\begin{array}{*{20}{c}} { a}(k) \\ 0 \end{array}} \right]\\ \bar{A} = \left[ {\begin{array}{*{20}{c}} A_{1} & 0 \\ 0 & A_{1} \end{array}} \right],\; \bar{B} = \left[ {\begin{array}{*{20}{c}} B_a & 0 \\ 0 & 0 \end{array}} \right] \end{array}$$ 根据式(1)和式(3)可以得到
$$ {\bar{ x}}(k+1) = \bar{A}{\bar{ x}}(k)+\bar{B}{\bar{ u}}(k) $$ (5) 并且可将优化问题(4)转化为
$$ {\rm min}\ J = \sum\limits_{k = 0}^{\infty}\left[{\bar{ x}}^{\rm T}(k)\bar{Q}{\bar{ x}}(k)+{\bar{ u}}^{\rm T}(k)\bar{R}{\bar{ u}}(k)\right] $$ (6) 其中,
$\bar{Q} = \left[ {\begin{aligned} -Q \;\;\; Q\;\; \\ \;Q \;\;\;-Q \end{aligned}} \right]\leq0$ ,$\bar{R} = \left[ {\begin{aligned} R \;\; 0 \\ 0 \;\; R \end{aligned}} \right]\geq0$ .由式(6)可求得最优反馈攻击策略
$$ {\bar{ u}}(k) = -(\bar{R}+\bar{B}^{\rm T}\bar{P}\bar{B})^{-1}\bar{B}^{\rm T}\bar{P}\bar{A}{\bar{ x}}(k) $$ (7) 其中,
$ \bar{P} $ 通过求解下面的代数Ricatti方程得到$$ \bar{P}-\!\bar{Q}-\!\bar{A}^{\rm T}\bar{P}\bar{A}\!+\!\bar{A}^{\rm T}\bar{P}\bar{B}(\bar{R}\!+\!\bar{B}^{\rm T}\bar{P}\bar{B})^{-1}\bar{B}^{\rm T}\bar{P}\bar{A}\! = \!0 $$ (8) 然而, 由于
$ \bar{Q}\leq0 $ , 优化问题(6)不是传统的线性二次型调节器问题, 式(8)不一定有唯一正定解, 本文考虑获得式(8)的一个特解.令
$\bar{P}\! = \!\left[ {\begin{aligned} P_{11}\;\;P_{12} \\ P_{21}\;\;P_{22} \end{aligned}} \right]$ ,$ P_{11} $ 是$ n $ 阶方阵, 并将$ \bar{P} $ 代入式(7)得$$ {\overline{ u}} (k) = \left[ {\begin{array}{*{20}{c}} {{ a}(k)}\\ 0 \end{array}} \right] = - \left[ {\begin{array}{*{20}{c}} { \psi} \\ 0 \end{array}} \right] $$ (9) 其中,
${ \psi} = (R+B_a^{\rm T}P_{11}B_a)^{-1}B_a^{\rm T}P_{11}A_{1}{ x}_{c}(k)+ (R+$ $B_a^{\rm T}P_{11}B_a)^{-1}B_a^{\rm T}P_{12}A_{1}{ x}(k) ,$ $ { x}(k) $ 是系统在不受攻击情况下的状态.考虑到攻击策略一般不依赖于受攻击前的系统状态
$ { x}(k) $ , 故令$ P_{12} = 0 $ . 若满足$$ \begin{split} & A_{1}^{\rm T}P_{11}B_a(R+B_a^{\rm T}P_{11}B_a)^{-1}B_a^{\rm T}\;+\\ & \qquad P_{11}+Q-A_{1}^{\rm T}P_{11}A_{1} = 0 \end{split} $$ (10) $$ \begin{split}& A_{1}^{\rm T}P_{21}B_a(R+B_a^{\rm T}P_{11}B_a)^{-1}B_a^{\rm T}\;+\\ &\qquad P_{21}-Q-A_{1}^{\rm T}P_{21}A_{1} = 0 \end{split} $$ (11) $$ P_{22}+Q-A_{1}^{\rm T}P_{22}A_{1} = 0 \hspace{42pt}$$ (12) 那么,
$\bar P\! = \left[ {\begin{aligned} {{P_{11}}}\;\;\;0\;\;\\ {{P_{21}}}\;\;{{P_{22}}} \end{aligned}} \right]$ 可以使得式(8)成立. 通过求解式(10)~(12)获得矩阵$ P_{11} $ , 即可得到最优反馈攻击策略$$ { a}(k) = -(R+B_a^{\rm T}P_{11}B_a)^{-1}B_a^{\rm T}P_{11}A_{1}{ x}_{c}(k) $$ (13) 结合式(3)和式(13)可以生成一系列的攻击数据以供训练机器学习算法.
2. 攻击信号重构算法
本节利用IFOA-KELM算法对攻击信号进行重构.
2.1 核极限学习机
ELM是一种前馈神经网络[23], 如图2所示, 它由输入层、隐藏层和输出层共三层构成.
假设存在
$ N $ 个不同的训练样本$\{({{x}}_{k},{{t}}_{k})\}_{k = 1}^{N},$ 其中,$ {{x}}_{k} = [x_{k1},x_{k2},\cdots,x_{kp}]^{\rm{T}}\in{\bf R}^{p} $ 为输入矢量,$ {{t}}_{k} = $ $[t_{k1},t_{k2},\cdots,t_{kl}]^{\rm{T}}\in{\bf R}^{l}$ 为期望输出矢量,$ {{y}}_{k} = [y_{k1}, $ $y_{k2},\cdots,y_{kl}]^{\rm{T}}\in{\bf R}^{l}\;$ 为输出矢量. 将第$ i $ 个隐层神经元与输入层之间的连接权重记作${{w}}_i = [\omega_{i1},\omega_{i2},\cdots,\omega_{ip}]^{\rm{T}},$ 并记${{w}} = [{{w}}_1,{{w}}_2,\cdots,{{w}}_q]^{\rm T}.$ 将第$ i $ 个隐层神经元的阈值记作$ b_i $ . 隐藏层神经元的激活函数为$ \hat{g}(\cdot) $ . 将第$ i $ 个隐层神经元与输出层之间的连接权重记作${{\beta}}_i = [\beta_{i1},\beta_{i2},\cdots,\beta_{il}]^{\rm{T}} ,$ 并记$\;{{\beta}} = [{{\beta}}_1,{{\beta}}_2,\cdots,{{\beta}}_q]^{\rm T}.\;$ ELM的期望目标为$ \displaystyle \sum \nolimits_{k = 1}^{N}\|{{y}}_{k}-{{t}}_{k}\| = 0, $ 因此$$ \sum\limits_{i = 1}^{q}{{\beta}}_{i}\hat{g}({{w}}_{i}^{\rm T}{{x}}_{k}+b_{i}) = {{t}}_{k} $$ (14) 将上式表示成矩阵形式
$$ {{H\beta}} = {{T}}$$ (15) 其中,
$$ \begin{split} {{T}} =\;& [{{t}}_{1},{{t}}_{2},\cdots,{{t}}_{N}]^{\rm{T}}\\ {{H}} =\;& [{{h}}^{\rm T}({{x}}_{1}),\cdots,{{h}}^{\rm T} ({{x}}_{N})]^{\rm T}= \\ & \left[\begin{array}{*{20}{c}} \hat{g}({{w}}_{1}^{\rm T}{{x}}_{1}+b_{1})&\cdots &\hat{g}({{w}}_{q}^{\rm T}{{x}}_{1}+b_{q})\\ \vdots & \ddots &\vdots\\ \hat{g}({{w}}_{1}^{\rm T}{{x}}_{N}+b_{1})&\cdots &\hat{g}({{w}}_{q}^{\rm T}{{x}}_{N}+b_{q}) \end{array}\right] \end{split} $$ 训练ELM本质上是为了得到
$ {{\beta}} $ , 而根据式(15)可得$$ {{\beta}} = {{H^{\dagger}T}} $$ (16) 其中,
${{H}^{\dagger}} = {{H}}^{\rm T}\Big({{H}}{{H}}^{\rm T}+\dfrac{{{I_N}}}{C}\Big)^{-1} ,$ $ C $ 为惩罚系数.在ELM训练过程中,
$ {{w}}_{i} $ 和$ b_{i} $ 是随机给定的, 这可能会导致ELM的稳健性和泛化能力变差, 为了解决上述问题, 将隐藏层神经元的随机映射用核映射来代替, 即得到KELM[24]. 现将KELM中采用的核函数定义为$$ \begin{split}&{{\Omega}}_{{\rm{ELM}}} = {{HH}}^{\rm T} \\ & \Omega_{{\rm{ELM}}m,n} = {{h}}({{x}}_{m}){{h}}^{\rm{T}}({{x}}_{n}) = {\cal K}({{x}}_{m},{{x}}_{n}) \end{split} $$ (17) 于是, KELM的输出
$ { y} $ 可表示为$$ \begin{split} { y} =\;& {{h}}\left({{x}}){{\beta}} = {{h}}({{x}}\right){{H}}^{\rm T}({{H}}{{H}}^{\rm T}+\frac{{{I_N}}}{C})^{-1}{{T}}=\\ & \left[\begin{array}{*{20}{c}}{\cal K}({{x}},{{x}}_{1})\\{\cal K}({{x}},{{x}}_{2})\\\vdots\\{\cal K}({{x}},{{x}}_{N})\end{array}\right]^{\rm T}\left({{\Omega}}_{{\rm{ELM}}}+\frac{{{I_N}}}{C}\right)^{-1}{{T}} \end{split}$$ (18) 注 1. 根据Mercer定理[25], 本文选用高斯核函数作为核函数, 即
${\cal K}({ x}_{a},{ x}_{b}) = {\rm{e}}^{-\frac{\|{ x}_{a}-{ x}_{b}\|^2}{2\sigma^2}} ,$ 其中$ \sigma $ 是带宽.由式(18)可知, KELM中需要调整的参数只有两个: 核函数参数
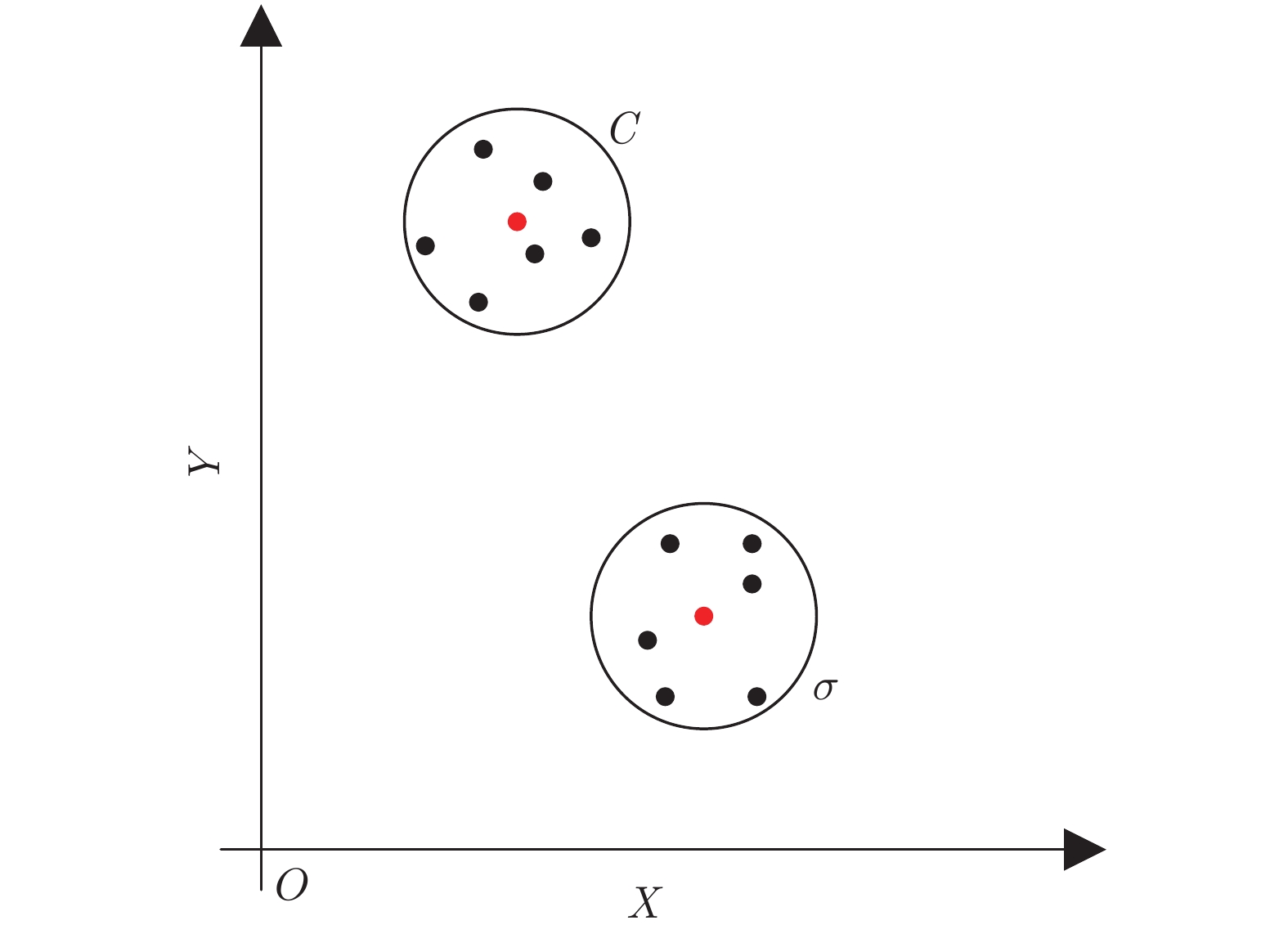
$ \sigma $ 和惩罚因子$ C $ , 它们对于KELM的性能起着至关重要的作用. 因此, 如图3所示, 本文利用FOA择优选取$ \sigma $ 和$ C, $ 并将两个果蝇群体分别称作$ \sigma $ 群体和$ C $ 群体.2.2 果蝇优化算法
FOA[26]源于果蝇的觅食行为, 它和粒子群优化算法[27]、鲨鱼优化算法[28]、细菌群体趋药性算法[29]类似也属于群体智能优化算法的一种. 果蝇具有优于其他物种的嗅觉器官和视觉器官, 它们的觅食原理如下: 首先借助嗅觉器官搜集空气中弥散的各种气味, 然后发觉目标大致方位并飞往附近区域, 最后利用敏锐的视觉定位目标和群体聚集的具体位置. FOA具体实现步骤如下:
步骤 1. 初始化果蝇群体大小, FOA最大迭代次数以及果蝇群体位置.
步骤 2. 每个果蝇个体按照随机给定的方向和范围搜寻目标位置.
步骤 3. 由于果蝇个体事先不知道目标所在的位置, 因此以原点作为参考点, 计算个体到原点的距离, 并将该距离的倒数作为个体味道浓度判定值.
步骤 4. 将味道浓度判定值代入适应度函数求得个体的适应度值.
步骤 5. 确定具有最优适应度值的个体所在位置, 以供其他个体借助视觉飞向此位置.
步骤 6. 重复执行步骤2 ~ 5, 直至迭代次数超限, 结束算法.
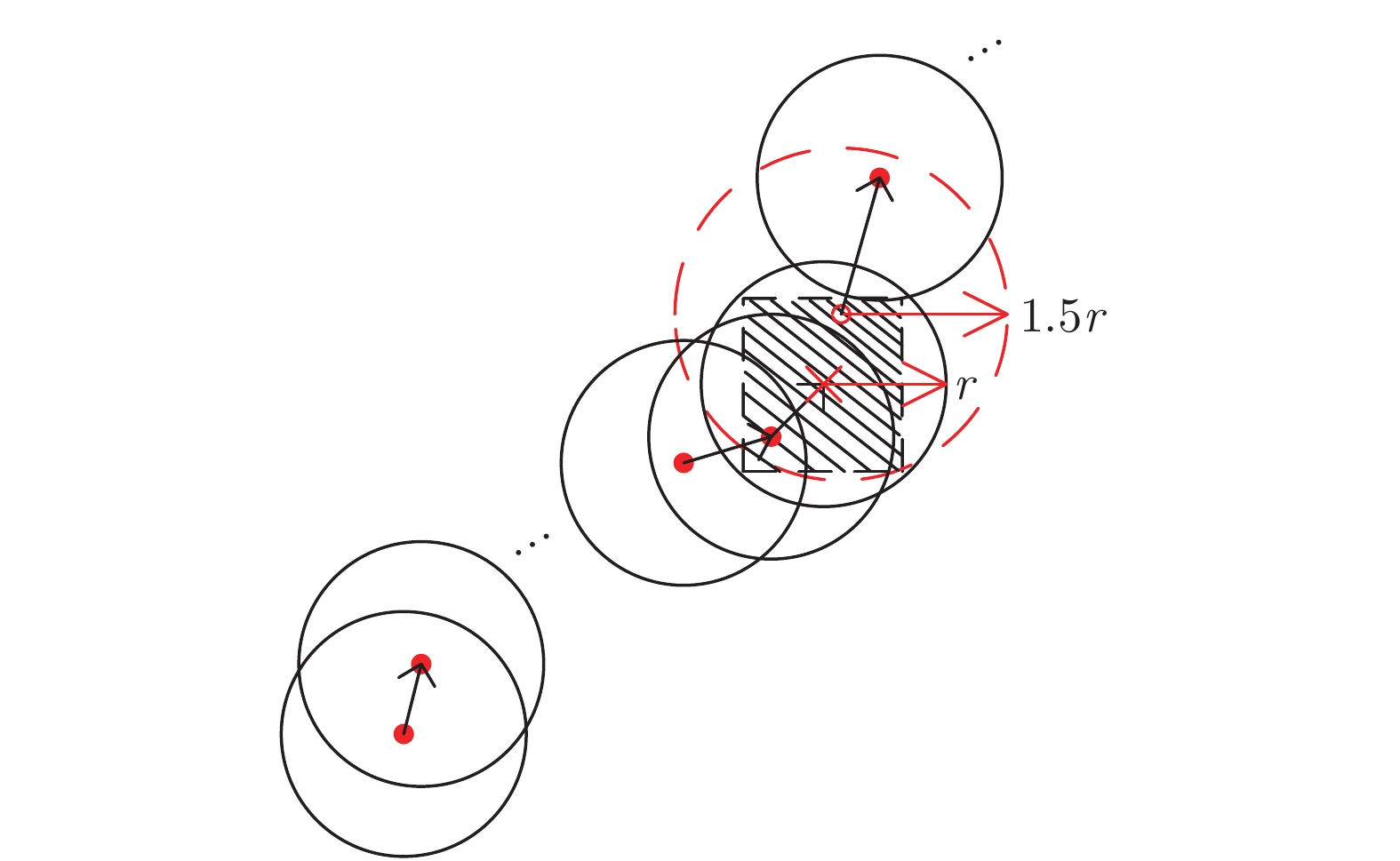
上述基本的FOA容易陷入局部最优解, 对此本文对其进行改进. 理论上, 可以通过将每次迭代寻优过程中果蝇群体的初始位置随机“小范围”地置于另一新位置以及增大果蝇个体寻优范围的方式帮助寻优过程有效地跳出局部死循环. 值得注意的是, 这里的“小范围”需要保证经上一次迭代得到的最优个体位置在本次迭代个体寻优范围内, 进而使本次迭代能够得到比上次更优的结果. 最终, 得到IFOA.
2.3 基于IFOA-KELM的攻击信号重构算法
利用IFOA先对KELM中核函数参数
$ \sigma $ 和惩罚因子$ C $ 两个参数的初始值进行优化, 再进行KELM的训练. 具体的IFOA-KELM算法步骤如下:步骤 1. 初始化果蝇群体大小
$ particlesize, $ FOA最大迭代次数$Max\_num ,$ 两个果蝇群体位置${{X}}\_{{axis}} = $ $ [X\_axis_1,X\_axis_2] $ 和$ {{Y}}\_{{axis}} = $ $[Y\_ axis_1, Y\_axis_2]$ 以及最优适应度值$Smellbest.$ 步骤 2. 设定果蝇个体初始寻优半径为
$(r_{1},r_{2}),$ 并随机给定果蝇个体搜寻方向$(2\times Random-1)\in$ $[-1,1) $ 以确定个体接下来飞向的位置$$ \left\{\begin{aligned}& X_{i1}= X\_axis_1+r_{1}\;×\;(2\;×\;Random-1)\\ & Y_{i1}= Y\_axis_1+r_{1}\;×\;(2\;×\;Random-1)\\ & X_{i2}= X\_axis_2+r_{2}\;×\;(2\;×\;Random-1)\\ & Y_{i2}= Y\_axis_2+r_{2}\;×\;(2\;×\;Random-1)\\ \end{aligned}\right. $$ (19) 其中,
$ i $ 表示第$ i $ 组果蝇个体, 由$ C $ 群体中的一个个体和$ \sigma $ 群体中的一个个体组成.$ (X_{i1},Y_{i1}) $ 表示$ C $ 群体中第$ i $ 个个体的位置,$ (X_{i2},Y_{i2}) $ 表示$ \sigma $ 群体中第$ i $ 个个体的位置,$ Random $ 是一个$ [0,1) $ 范围服从均匀分布的随机数,$ i = 1,2,\cdots,particlesize .$ 步骤 3. 计算第
$ i $ 组果蝇个体分别与$ (0,0) $ 之间的距离$ { D}_{i} = [D_{i1},D_{i2}] $ , 其中,$$ \left\{\begin{aligned} & D_{i1} = \sqrt{X_{i1}^2+Y_{i1}^2} \\& D_{i2} = \sqrt{X_{i2}^2+Y_{i2}^2} \end{aligned}\right. $$ 以及相应的味道浓度判定值
$ { S}_{i} = [S_{i1},S_{i2}], $ 其中,$$ \left\{\begin{aligned}& S_{i1} = \frac{1}{{D}_{i1}}\\& S_{i2} = \frac{1}{{D}_{i2}} \end{aligned}\right. $$ 步骤 4. 将味道浓度判定值
$ { S}_{i} $ 代入如下适应度函数以得到适应度值$ Smell_i $ $$ Smell_i = \frac{1}{2N}\sum\limits_{k = 1}^{N}\sum\limits_{r = 1}^{l}(y_{r}^{i}-t_{r}^{i}) $$ (20) 其中,
$ N $ 为训练样本数.步骤 5. 确定具有最优适应度值的果蝇个体组
$$ [bestSmell,bestIndex] = {\rm min}({{Smell}}) $$ (21) 其中,
$ {{Smell}} = [Smell_1,\cdots,Smell_{particlesize}] $ , bestSmell表示最优适应度值,$ bestIndex $ 表示得到最优适应度值的果蝇个体组号.步骤 6. 判断
$ bestSmell<Smellbest $ 是否成立, 若成立, 按照式(22)更新最优适应度值$ Smellbest $ 及与之对应的最优个体位置坐标$ ({{Xbest}}, $ $ {{Ybest}}), $ 并将果蝇个体寻优半径置为初始值$ r ,$ 此外, 将最优味道浓度值${ S}_{{\rm{bestIndex}}}$ 记录至数组$ {{SS}} $ $$ \left\{\begin{aligned}& Smellbest = bestSmell\\ &{{X}}\_{{axis}} = {{Xbest}} = { X}_{{\rm{bestIndex}}}\\ &{{Y}}\_{{axis}} = {{Ybest}} = { Y}_{{\rm{bestIndex}}}\\ &{{SS}} = { S}_{{\rm{bestIndex}}} \end{aligned}\right. $$ (22) 其中,
$ { X}_i = [X_{i1},X_{i2}] $ ,$ { Y}_i = [Y_{i1},Y_{i2}] $ .否则, 按照式(23)更新下次迭代的初始果蝇群体位置
${{X}}\_{{axis}},$ $ {{Y}}\_{{axis}} $ 和果蝇个体寻优半径$ r $ $$ \left\{\begin{aligned}& {{X}}\_{{axis}} = {{Xbest}}+\frac{\sqrt{2}}{2}\;×\;(2\;×\;Random-1)\;×\;{{r}}\\ & {{Y}}\_{{axis}}= {{Ybest}}+\frac{\sqrt{2}}{2}\;×\;(2\;×\;Random-1)\;×\;{{r}}\\ & {{r}} \leftarrow 1.5\;×\;{{r}} \end{aligned}\right. $$ (23) 其中,
$ {{r}} = [r_1,r_2] $ .将本次迭代产生的最优个体位置作为下次迭代的初始果蝇群体位置, 即满足
$ {{X}}\_{{axis}} = {{Xbest}} $ 和$ {{Y}}\_{{axis}} = {{{Ybest}}} $ .步骤 7. 重复步骤2 ~ 6, 为了防止KELM过拟合, 需要满足
$ Smellbest $ 不超过给定值$ \theta ;$ 此外, 当前迭代次数不得超过$ Max\_num .$ 否则, 跳出循环, 并将$ SS $ 的最后记录用于训练KELM.步骤 8. 利用训练好的KELM对需要测试的样本数据进行预测, 算法结束.
注 2. 由式(20)可知, 适应度值实为KELM算法的均方误差损失项, 如果一味地追求训练集上误差损失最小化, 则会导致所训练的算法过分拟合训练集, 从而导致所训练算法在测试集上表现变差. 所以, 需要针对
$ Smellbest $ 给出合适的下界$ \theta $ 以防止IFOA-KELM算法过拟合. 这里合适的$ \theta $ 值需要通过反复试验来获取.以单个果蝇群体为例, 具体的IFOA寻优过程如图4所示. 其中, “
$ \times $ ”代表局部最优解, 阴影区域表示最优位置坐标变化范围. 由图4可看出, 当寻优过程陷入局部最优解时, 会通过移动最优位置坐标以及放大搜索半径的方式设法跳出局部最优解.基于上述IFOA-KELM算法得到重构的攻击信号
$ g({ x}_{c}(k),K{ x}_{c}(k)). $ 注 3. 径向基函数
$ g({ x}_{c}(k),K{ x}_{c}(k)) $ 满足Lipschitz条件.将
$ g({ x}_{c}(k),K{ x}_{c}(k)) $ 与真实攻击信号$a({ x}_{c}(k), $ $ K{ x}_{c}(k)) $ 之间的偏差记为$ { \omega}(k), $ 由前馈神经网络的万能逼近特性[30]得$$ \begin{split} \|{ \omega}(k)\| =\;& \|a({ x}_{c}(k),K{ x}_{c}(k))-\\ & g({ x}_{c}(k),K{ x}_{c}(k))\| \leq\gamma \end{split} $$ (24) 其中,
$ \gamma>0 $ 为偏差上界.为保证受攻击系统的安全运行, 将系统(2)的状态反馈控制策略更新为
$ { u}(k) $ , 此时系统的状态方程可表示为$$ \begin{split} { x}_{c}(k+1) =\;& A{ x}_{c}(k)+B{ u}(k)+a({ x}_{c}(k),K{ x}_{c}(k)) =\\ & f^{*}({ x}_{c}(k),{ u}(k)) \\[-10pt] \end{split}$$ (25) 利用
$ g({ x}_{c}(k),K{ x}_{c}(k)) $ 替代式(25)中的真实攻击信号$ a({ x}_{c}(k),K{ x}_{c}(k)) $ 得到标称模型$$ \begin{split} { x}_{c}(k+1) =\;& A{ x}_{c}(k)+B{ u}(k)+g({ x}_{c}(k),K{ x}_{c}(k))= \\ & f({ x}_{c}(k),{ u}(k)) \\[-10pt] \end{split} $$ (26) 显然,
$ f({ x},{ u}) $ 满足Lipschitz条件, 并设$ f({ x},{ u}) $ 关于$ { x} $ 的Lipschitz常数为$ L_{f}\in(0,\infty). $ 由式(24)可知,
$ f^{*}({ x}_{c}(k),{ u}(k)) $ 与$ f({ x}_{c}(k),{ u}(k)) $ 满足$$\begin{split}& \|f^{*}({ x}_{c}(k),{ u}(k))-f({ x}_{c}(k),{ u}(k))\| = \|{ \omega}(k)\| \leq \gamma \end{split} $$ (27) 因此, 可将式(25)看作是包含有界外部扰动的不确定系统. 由式(24)可知, 所得受攻击系统的标称模型与真实受攻击系统模型之间存在一定的误差, 此时如果继续使用状态反馈控制策略, 仅仅改变控制律的状态反馈增益矩阵, 不能够很好地应对该误差进而保证被控系统的稳定性. 而MPC具有良好的内在鲁棒性, 并且可以结合合适的收缩约束条件很好地处理这一问题. 因此, 在得到式(26)之后, 假设攻击者不再更新其攻击策略, 使用MPC策略对受攻击系统进行控制以保证系统安全运行.
3. 模型预测控制器
模型预测控制是一种基于模型的开环最优控制策略[31-32], 通过在线求解有限时域优化控制问题计算预测状态和未来的控制输入.
为了获取使得受攻击系统安全运行的控制信号
$ { u}(k) ,$ 本文求解如下有限时域MPC优化问题$$ \begin{array}{l} \min\limits_{{ u}_{M}(k)}\; J_{H_{p}}({ x}_{c}(k),{ U}_{M}(k))\\ {\rm{\; s.t.\; }}\;\;\;\;{ x}_{c}(k\!+j\!+1|k)\! = \!f({ x}_{c}(k\!+j|k),{ u}_{M}(k+j|k))\\ \; \; \; \; \; \; \; \; \; \; \; \; \; \; \; \; \; \; \; \; \; \; \; \; \; \; \; \; \; \; \; \; \; \; \; \; \; \; \; j\in[0,H_{p}-1]\\ \; \; \; \; \; \; \; \; \;\;\;{ x}_{c}(k+H_{p}|k)\in\Omega\\[-10pt] \end{array}$$ (28) 其中, 决策变量
$ { u}_{M}(k+j|k) $ 定义了模型预测控制器在$ k $ 时刻预测的$ k+j $ 时刻控制输入, 因此$ { U}_{M}(k) = $ $ \{{ u}_{M}(k|k),\cdots,{ u}_{M}(k+H_{p}-1|k)\} $ 表示系统在未来预测时域$ H_{p} $ 内的控制输入序列;$ { x}_{c}(k+j|k) $ 表示在$ { U}_{M}(k) $ 作用下标称系统$ k+j $ 时刻的预测状态;$ \Omega $ 表示终端状态约束集. 将优化问题(28)的最优解表示为$\hat{{ U}}_{M}(k) = \{\hat{{ u}}_{M}(k|k),\cdots, \hat{{ u}}_{M}(k+H_{p}-1|k)\},$ 相应的预测状态为$\hat{{ X}}_{M}(k) = \{\hat{{ x}}_c(k|k),\cdots, \hat{{ x}}_c(k+ $ $ H_p|k)\},$ 其中$ \hat{{ x}}_c(k|k) = { x}_{c}(k) = { x}_c(k|k), $ 与此相对应的最优成本记为$ \hat{J}_{H_p}(k) $ . 系统在$ k $ 时刻的实际输入为$ { u}_{M}(k) = $ $\hat{{ u}}_{M}(k|k).$ 现将成本函数$J_{H_{p}}({ x}_{c}(k), $ $ { U}_{M}(k))$ 定义为$$ \begin{split} J_{H_{p}}&({ x}_{c}(k),{ U}_{M}(k)) = \! \sum\limits_{j = 0}^{H_{p}-1}\!\!L({ x}_{c}(k\!\!+\!j|k),\\ &{ u}_{M}(k\!+\!j|k))+V({ x}_{c}(k+H_{p}|k)) \end{split}$$ (29) 其中,
$ L({ x},{ u}) $ 为阶段成本函数,$ V({ x}_{c}(k+H_{p}|k) $ 为终端成本函数.引理1[33]. 基于标称模型的最优预测状态
$\hat{{ x}}_{c}(k+j|k)\;(j\geq1)$ 与真实状态${ x}_{c}(k+j)\;(j\geq1)$ 之间的偏差满足以下关系$$ \|\hat{ x}_{c}(k+j|k)-{ x}_{c}(k+j)\|\leq \frac{L_{f}^j-1}{L_{f}-1}\gamma $$ (30) 针对阶段成本函数及终端集, 本文给出如下假设:
假设1. 假设阶段成本函数
$ L({ x},{ u}) $ 满足$ L(0,0) = $ $0 \;$ 并且是Lipschitz连续的, 记$ L({ x},{ u}) $ 相对$ { x} $ 的Lipschitz常数为$ L_{c}\in(0,\infty) ;$ 另外, 存在常数$ \varphi>0 $ 和$ \sigma\geq1 $ 使得$ L({ x},{ u})\geq \varphi\|({ x},{ u})\|^{\sigma} $ 成立, 即$$ |L({ x}_{1},{ u})-L({ x}_{2},{ u})|\leq L_{c}\|{ x}_{1}-{ x}_{2}\| $$ (31) 假设2. 定义
$ \Phi $ 是对于标称系统(26)的一个正不变集, 且$ \Omega\!\subseteq\!\Phi $ . 存在局部控制器${ u}_{M}(k)\!\; = \!\;h({ x}_{c}(k))$ 以及相关Lyapunov函数使得1) 对于
${ x}_{c}(k)\;\in\;\Phi,\;$ $V(f({ x}_{c}\,(k),\;h({ x}_{c}\,(k))))\;-$ $V({ x}_{c}(k))\leq-L({ x}_{c}(k),h({ x}_{c}(k))) .$ 2) 终端成本函数
$ V({ x},{ u}) $ 在$ \Phi $ 内是Lipschitz连续的, 相对$ { x} $ 的Lipschitz常数记为$ L_{v}, $ 即$$ \begin{array}{l} |V({ x}_{1},{ u})-V({ x}_{2},{ u})|\leq L_{v}\|{ x}_{1}-{ x}_{2}\|\\ \;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\forall { x}_{1},{ x}_{2}\in\Phi \end{array}$$ 其中,
$ \Phi = \{{ x}\in{\bf R}^{n}:V({ x})\leq\alpha\} $ .假设3. 集合
$ \Omega\! = \!\{{ x}\!\in\!{\bf R}^{n}\!:\!V({ x})\!\leq\!\alpha_{v}\} $ 满足$ \forall { x}\!\in\! $ $\Phi,$ $f({ x},h({ x}))\in\Omega.$ 引理2[33]. 假设
$ k $ 时刻优化问题(28)存在最优解$\hat{{ U}}_{M}(k) = \{\hat{{ u}}_{M}(k|k),\hat{{ u}}_{M}(k+1|k),\cdots,\hat{{ u}}_{M}(k+ H_{p}\;-$ $1|k)\} $ , 据此构造$ k+1 $ 时刻的解$\tilde{{ U}}_M(k+1) = \{\hat{{ u}}_{M}(k+$ $ 1|k),\cdots,\hat{{ u}}_{M}(k+H_{p}-1|k),h(\tilde{{ x}}(k+H_p|k+1)\} $ , 即$$ \begin{array}{l} \tilde{{ u}}_{M}(k+j+1)\nonumber=\\ \qquad\left\{\!\! \begin{array}{l}\hat{{ u}}_{M}(k+j+1|k),\;\;\;\;\;\;\;\;\; j\in[0,H_{p}-2]\\h(\tilde{{ x}}(k+j+1|k+1)),\ j=H_{p}-1\end{array} \right. \end{array}$$ 则由标称模型(26)得到的
$ k+1 $ 时刻预测状态序列为$\tilde{{ X}}_{M}\;(k+1) = \{\tilde{{ x}}_c\;(k+1|k+1),\;\tilde{{ x}}_c(k+ 2|k+$ $1),\cdots,\tilde{{ x}}_c(k+H_p+1|k+1)\} $ , 其中$ \tilde{{ x}}_c(k+1| k+1) \!=$ ${ x}_c(k+1|k+1).$ 此时, 预测状态$ \tilde{{ x}}_{c}(k+H_{p}|k+1) $ 和$ \hat{{ x}}_{c}(k+H_{p}|k) $ 的偏差满足$$ \|\tilde{{ x}}_{c}(k+H_{p}|k+1)-\hat{{ x}}_{c}(k+H_{p}|k)\|\leq L_{f}^{H_{p}-1}\gamma $$ (32) 定理1. 当闭环系统(25)的参数满足假设1 ~ 3以及
$ \gamma\leq\dfrac{\alpha-\alpha_{v}}{L_{v} L_{f}^{N-1}} $ 时, 优化问题(28)是迭代可行的, 并且闭环系统(25)是ISS的.证明.
1) 可行性. 由假设2和引理2得
$$ \begin{split} V(\tilde{{ x}}_{c}(k\!+\!H_{p}|k\!+\!1)) \!\leq\;&\! V(\hat{{ x}}_{c}(k\!+\!H_{p}|k))+L_vL_{f}^{H_{p}\!-\!1}\!\gamma \notag \leq\\ & \alpha_v\!+\!L_vL_{f}^{H_{p}\!-\!1}\!\gamma \notag \leq \alpha \end{split}$$ 因此,
$ \tilde{{ x}}_{c}(k+H_{p}|k+1)\in\Phi $ . 再由假设3可知, 存在局部控制器$ h(\tilde{{ x}}_{c}(k+H_{p}|k+1)) $ 使得$\tilde{{ x}}_{c}(k+H_{p}+ $ $ 1|k+1)\in\Omega $ . 于是, 优化问题(28)是迭代可行的.2) 稳定性. 由假设1 ~ 3以及引理1和引理2得
$$\begin{split} \hat{J}_{H_p}&(k+1)-\hat{J}_{H_p}(k)\leq \\ & \sum\limits_{i = 0}^{H_p-1}\{L(\tilde{ x}(k+i+1|k\!+\!1),\tilde{ u}(k+i+1|k+1)) -\\ & L(\hat{ x}(k+i|k),\hat{ u}(k+i|k))\}+\\ & V(\tilde{ x}(k+H_p+1|k+1))-V(\hat{ x}(k+H_p|k))=\\ & \sum\limits_{i = 0}^{H_p-2}\{L(\tilde{ x}(k+i+1|k+1),\tilde{ u}(k+i+1|k+1)) -\\ & L(\hat{ x}(k+i+1|k),\hat{ u}(k+i+1|k))\}+\\ & L(\tilde{ x}(k+H_p|k+1),h(\tilde{ x}(k+H_p|k)))-\\ & L({ x}(k|k),{ u}(k|k))+V(\tilde{ x}(k+H_p+1|k+1))-\\ & V(\hat{ x}(k+H_p|k))\leq\\ & L_c\frac{1\!\!-\!\!L_f^{H_p\!-\!1}}{1\!-\!L_f}\gamma \!+\!L(\tilde{ x}(k\!+\!H_p|k\!+\!1),h(\tilde{ x}(k\!+\!H_p|k)))\;\!+\!\!\\ & V(\tilde{ x}(k+H_p+1|k+1))-V(\tilde{ x}(k+H_p|k+1)) + \\ & L_vL_f^{H_p-1}\gamma-L({ x}(k|k),{ u}(k|k))\leq\\ & L_c\frac{1-L_f^{H_p-1}}{1-L_f}\gamma \!+\! L_vL_f^{H_p-1}\gamma \!-\!L({ x}(k|k),{ u}(k|k))=\\ & L_Z\times\gamma-\varphi\|{ x(k)}\|^{\sigma} \end{split} $$ 其中,
$L_Z = L_c\dfrac{1-L_f^{H_p-1}}{1-L_f} + L_vL_f^{H_p-1}.$ 因此, 闭环系统(25)是ISS的. □4. 数值仿真及结果分析
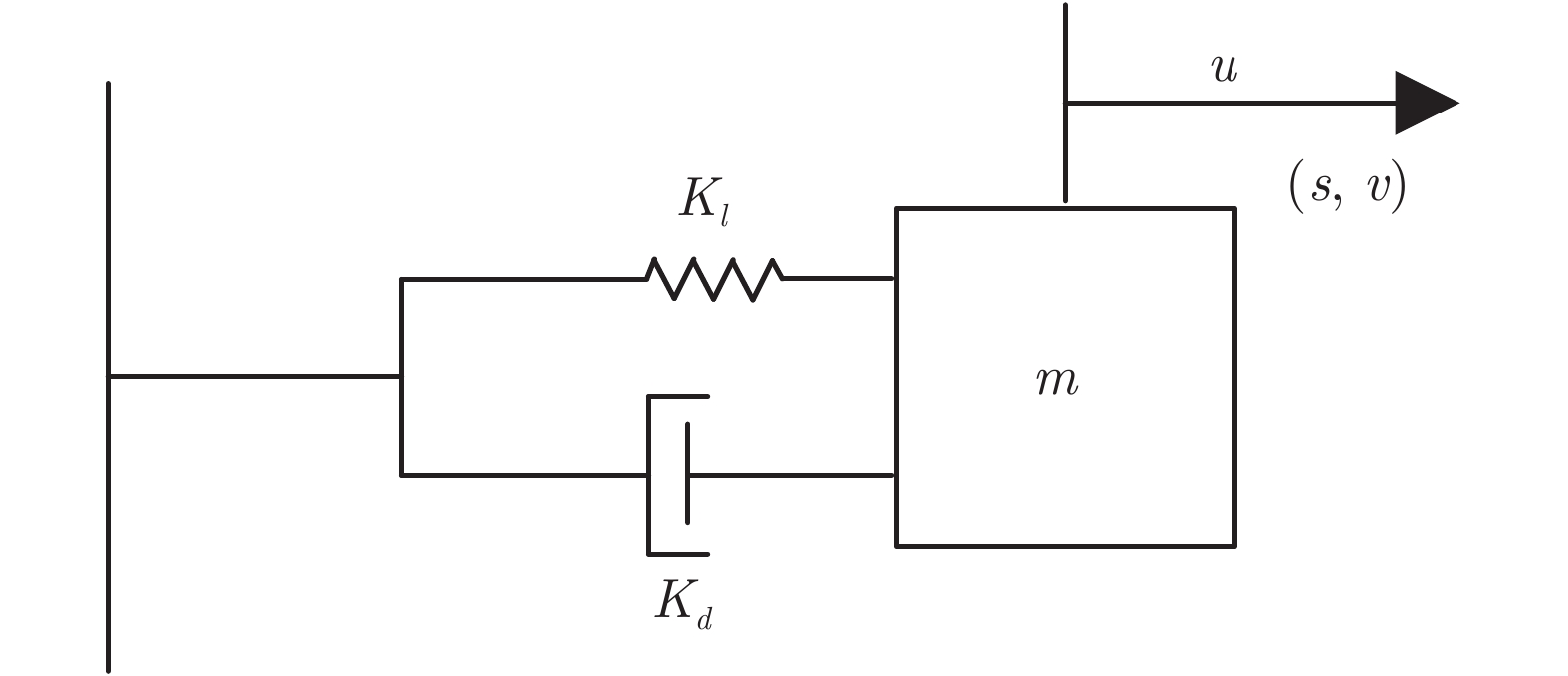
本节将通过数值算例验证本文提出的基于机器学习的安全控制策略的有效性. 考虑如图5所示的弹簧−质量−阻尼系统. 其中,
$ m $ 表示物体的质量,$ u $ 表示作用在物体上的力,$ s $ 表示物体的位移,$ v $ 表示物体的运动速度,$ K_{l} $ 表示弹簧的弹性系数,$ K_{d} $ 表示阻尼器的阻尼系数.未受攻击的系统模型为
$$ \left\{ \begin{aligned} &{ x}(k\!+\!1) \!=\!\!\left[\!\! {\begin{array}{*{20}{c}}0.9819 & 0.1716\\-0.1716 & 0.7245\end{array}} \!\!\right]\!{ x}(k)\!+\!\!\left[\!\! {\begin{array}{*{20}{c}}0.0181\\0.1716\end{array}} \!\!\right]\!u(k)\!\\ &u(k) =\left[ {\begin{array}{*{20}{c}}-0.1613&-1.1854\end{array}} \right]{ x}(k) \end{aligned} \right. $$ (33) 其中,
${ x}(k) = [s^{\rm T}(k),v^{\rm T}(k)]^{\rm T}.$ 假设攻击者按照设计的最优攻击策略(3)和(13)对系统(33)进行攻击, 其中,
$B_a = I_2 .$ 令$Q\!= $ $ \left[ \!\!{\begin{aligned}\;\;\;1.2786 \;\; -0.4926\\-0.4926 \;\; 3.2637\;\;\end{aligned}} \right]$ ,$R\! = \!1,$ 由式(10) ~ (12)得到$$ P_{11}=\left[ {\begin{array}{*{20}{c}}-20.1258 & -5.9459\\-5.9459 & -8.3562\end{array}} \right] $$ 将
$ P_{11} $ 代入式(13)得到受攻击后的系统模型$$ \left\{ \begin{aligned} &{ x}_{c}(k\!+\!1) \!=\!\left[ {\begin{array}{*{20}{c}}0.9790 & 0.1502\\-0.1993 & 0.5210\end{array}} \right]\!{ x}_{c}(k)\!+\!{ a}(k)\\ &{ a}(k)\!=\!\left[ {\begin{array}{*{20}{c}}0.0267&0.0257\\0.2532&0.2443\end{array}} \right]\!{ x}_{c}(k) \end{aligned} \right.$$ (34) 设系统的初始状态为
${ x}_{0} = [0.8,0]^{\rm T} ,\;$ 则系统在受到攻击前后的状态变化曲线如图6所示. 从图中可以看出, 受攻击后的系统状态发散.通过随机选取16组不同的初始状态生成如图7所示的1 600组数据
$({ x}_{c}(k),{ a}(k)).$ 将$ { x}_{c}(k) $ 作为输入样本,$ { a}(k) $ 作为期望输出进行IFOA-KELM的训练, 经IFOA优化得到的KELM初始化参数为$C_{{\rm{best}}}\! = \!10\;469, \sigma_{{\rm{best}}}\! = \!8.5945 .$ 基于最优攻击信号
${ a}(k)\!=\!\left[ {\begin{aligned}0.0267\;\;0.0257\\0.2532\;\;0.2443\end{aligned}} \right]{ x}_{c}(k)$ 随机生成400组数据分别对所训练的IFOA-KELM、FOA-KELM、PSO-BP和LS-SVM进行测试, 得到重构的攻击信号与真实攻击信号之间的绝对误差, 如图8 ~ 11所示.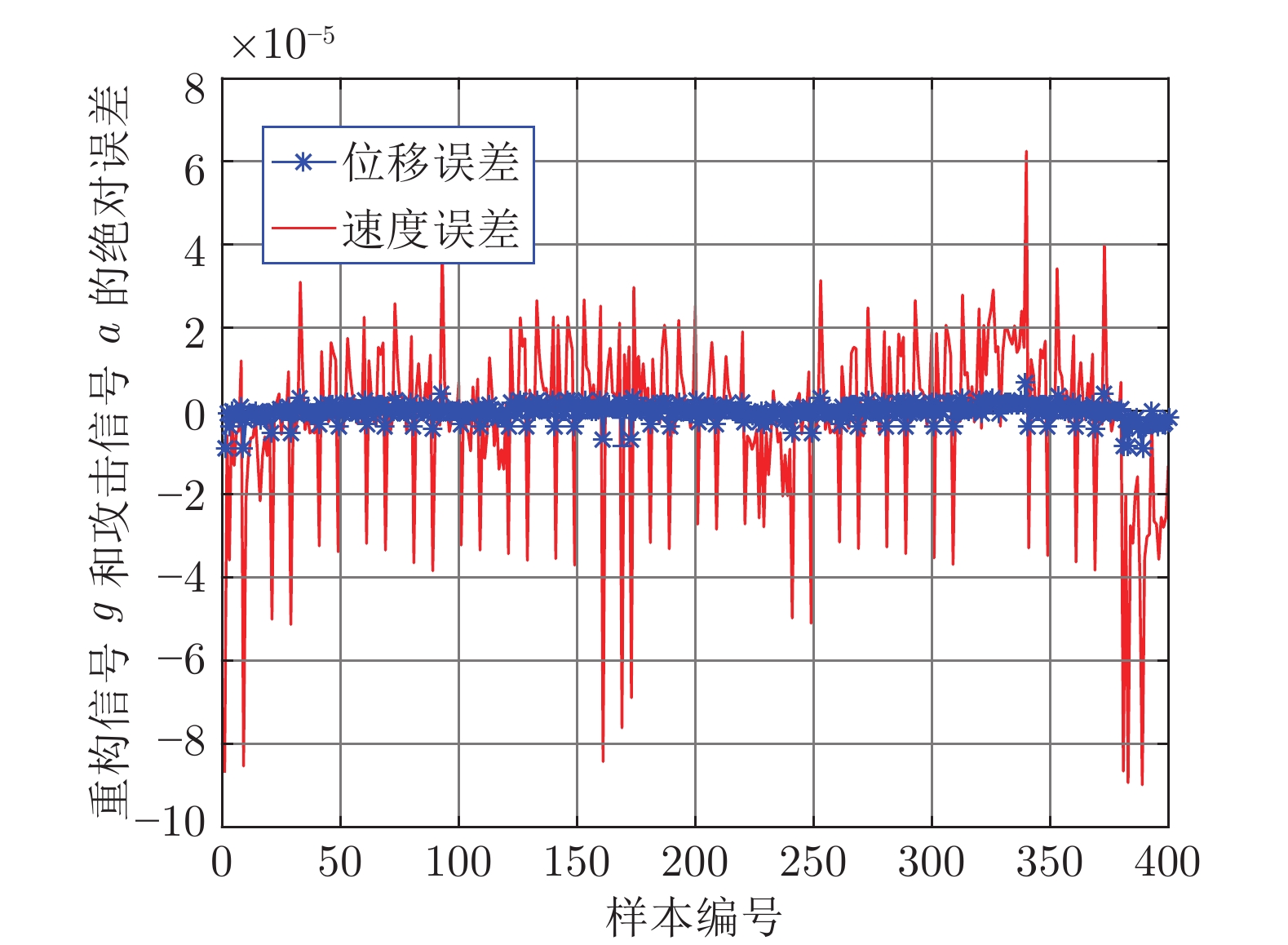 图 8 IFOA-KELM测试样本绝对误差Fig. 8 The error between the real attack and the attack learned by IFOA-KELM
图 8 IFOA-KELM测试样本绝对误差Fig. 8 The error between the real attack and the attack learned by IFOA-KELM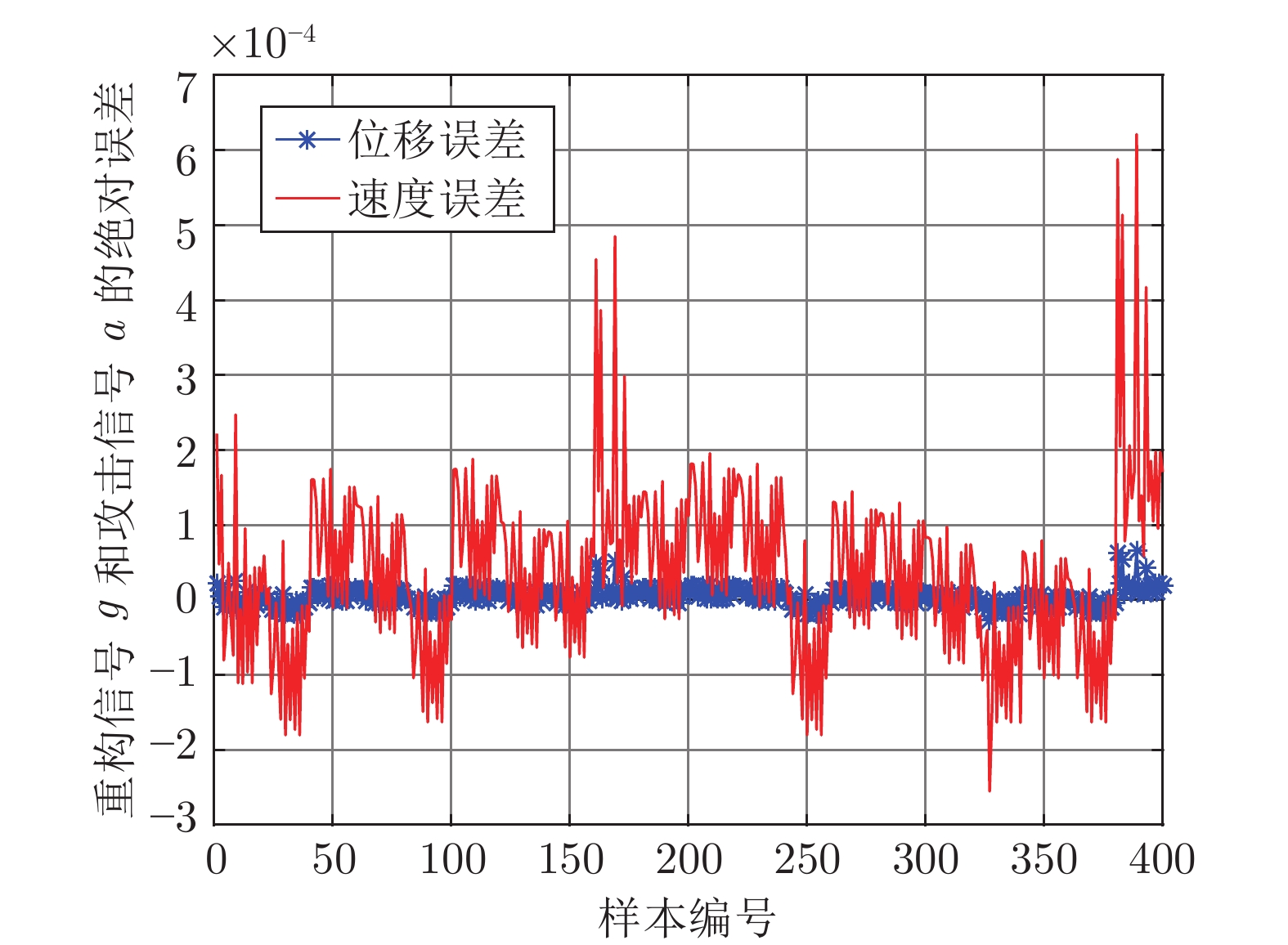 图 11 LSSVM测试样本绝对误差Fig. 11 The error between the real attack and the attack learned by LSSVM
图 11 LSSVM测试样本绝对误差Fig. 11 The error between the real attack and the attack learned by LSSVM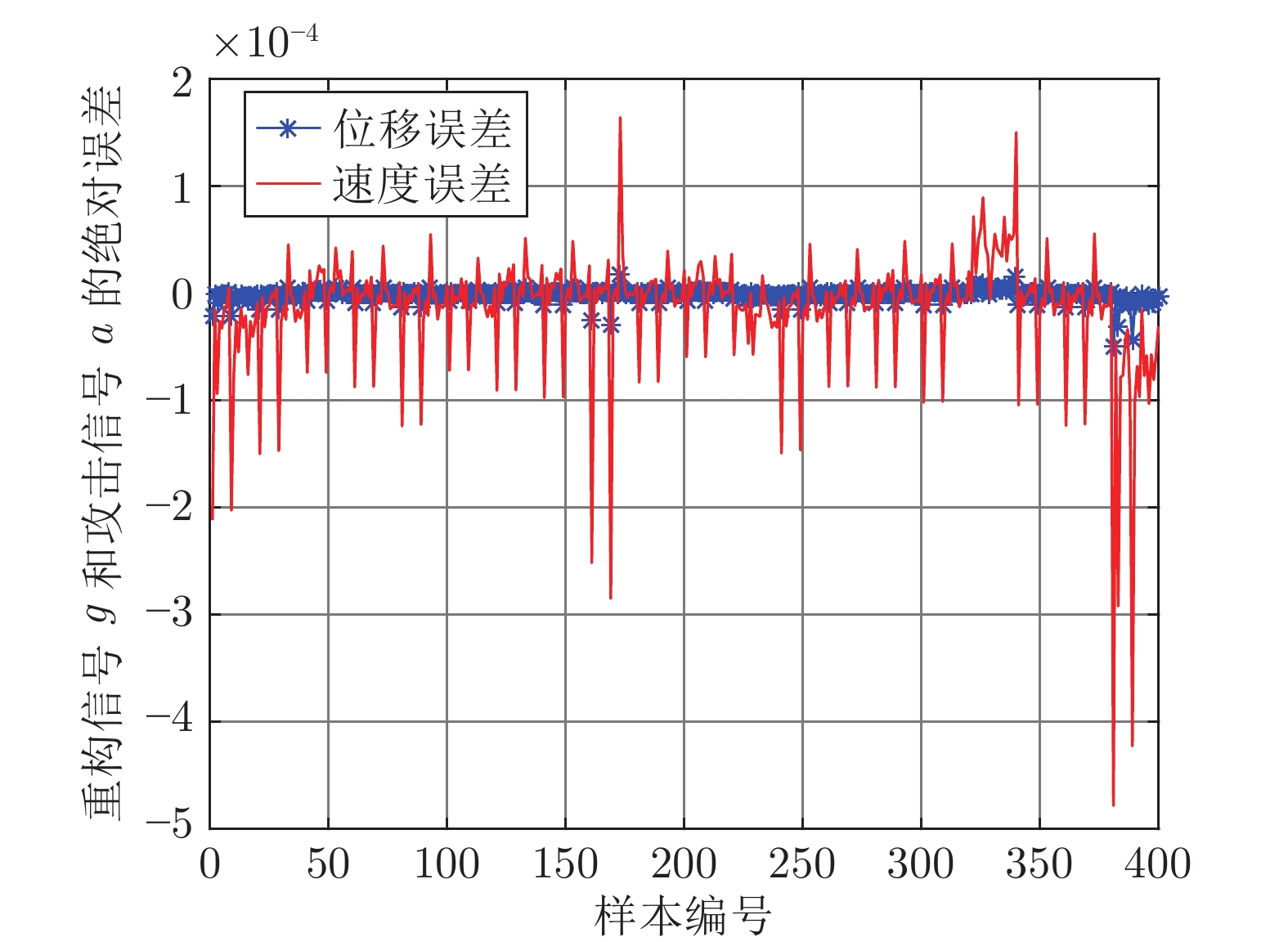 图 9 FOA-KELM测试样本绝对误差Fig. 9 The error between the real attack and the attack learned by FOA-KELM
图 9 FOA-KELM测试样本绝对误差Fig. 9 The error between the real attack and the attack learned by FOA-KELM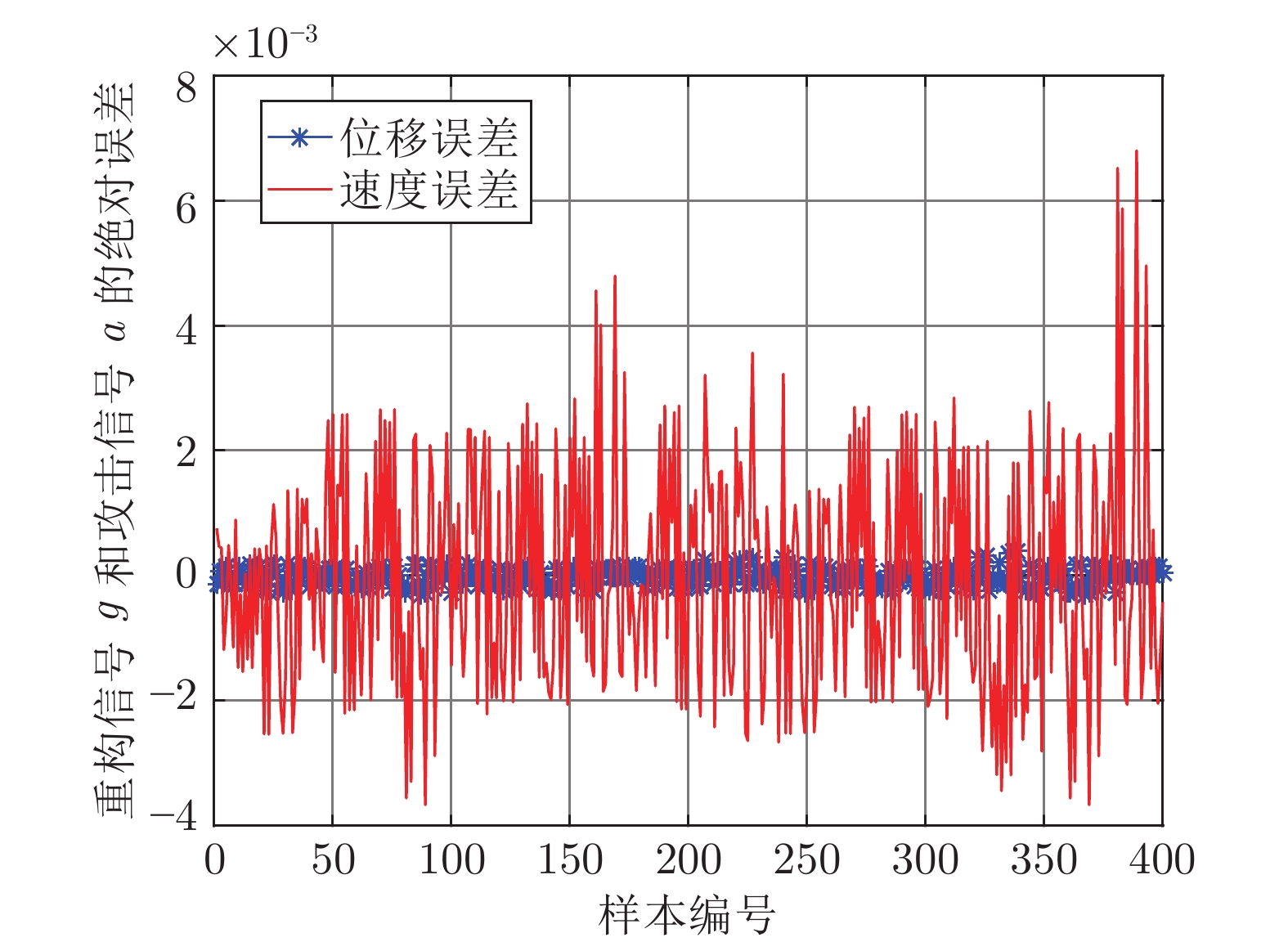 图 10 PSO-BP测试样本绝对误差Fig. 10 The error between the real attack and the attack learned by PSO-BP
图 10 PSO-BP测试样本绝对误差Fig. 10 The error between the real attack and the attack learned by PSO-BP对比发现, IFOA-KELM的学习效果要优于FOA-KELM、PSO-BP和LS-SVM. 因此, 本文选用IFOA-KELM对攻击信号进行重构, 且
$ \gamma = 10^{-4} $ .为了对比IFOA-KELM与FOA-KELM的初始参数值优化性能, 将IFOA与FOA同样迭代50次后得到二者的最优适应度值变化曲线, 如图12所示.
由图12可以看出, FOA-KELM的初始参数优化过程容易陷入局部最优解, 收敛速度更慢; 而IFOA-KELM的初始参数优化过程能够及时跳出局部最优解, 继续寻找最优解, 收敛速度更快. 此外, 经过实验发现, 当
$ Smellbest<10^{-11} $ 时, 利用IFOA得到的最优参数$ C $ 和$ \sigma $ 训练的KELM会产生过拟合, 因此IFOA-KELM算法中的$ \theta $ 取$ 10^{-11}. $ 为了保证受攻击系统的安全性, 将系统的控制方式改为MPC. 系统标称模型(26)的Lipschitz常数为
$ L_{f} = 1.0539. $ 根据式(29), 将MPC的阶段成本函数取为$ L({ x},{ u}) = \|{ x}\|_{\bar{Q}}+\|{ u}\|_{\bar{R}} $ , 其中$ \bar{Q} = 0.5I_{2} $ ,$\bar{R} = 0.1,\;$ 则阶段成本函数$ L({ x},{ u}) $ 的Lipschitz常数为$L_{c} = 0.5 ; \;$ 将终端成本函数取为$ V({ x}) = \sqrt{{ x}^{\rm T}P{ x}}, $ 其中,$P=\left[ {\begin{aligned}4.6958\;\;1.4098\\1.4098\;\;1.3978\end{aligned}} \right] > 0,$ 并由此得到$ L_{v} = $ $2.2839 . \;$ 选取$\alpha = 0.3 ,$ $\alpha_{v} = 0.2,$ 分别对应正不变集$\Phi\! = \!\{{ x}\!\in\!{\bf R}^{n}\!:\!V({ x})\!\leq \!0.3\} , \;$ 终端状态约束集$\Omega\! = \!\{{ x}\!\in\! $ $ {\bf R}^{n}\!:\!V({ x})\!\leq\! 0.2\} $ . 当系统运行进入到终端域$ \Omega $ 时, 采用局部状态反馈控制器$ u_{M}(k) = h({ x}_{c}(k)) = [-2.9281\;$ $-1.8531]{ x}_{c}(k) . \;$ 此时, 条件$ \gamma\leq\dfrac{\alpha-\alpha_{v}}{L_{v} L_{f}^{N-1}} = 0.03 $ 成立. 因此, 根据定理1可知, 闭环系统是ISS的. 对受攻击后的系统分别使用原有控制策略和MPC策略进行控制, 系统的状态变化曲线如图13所示.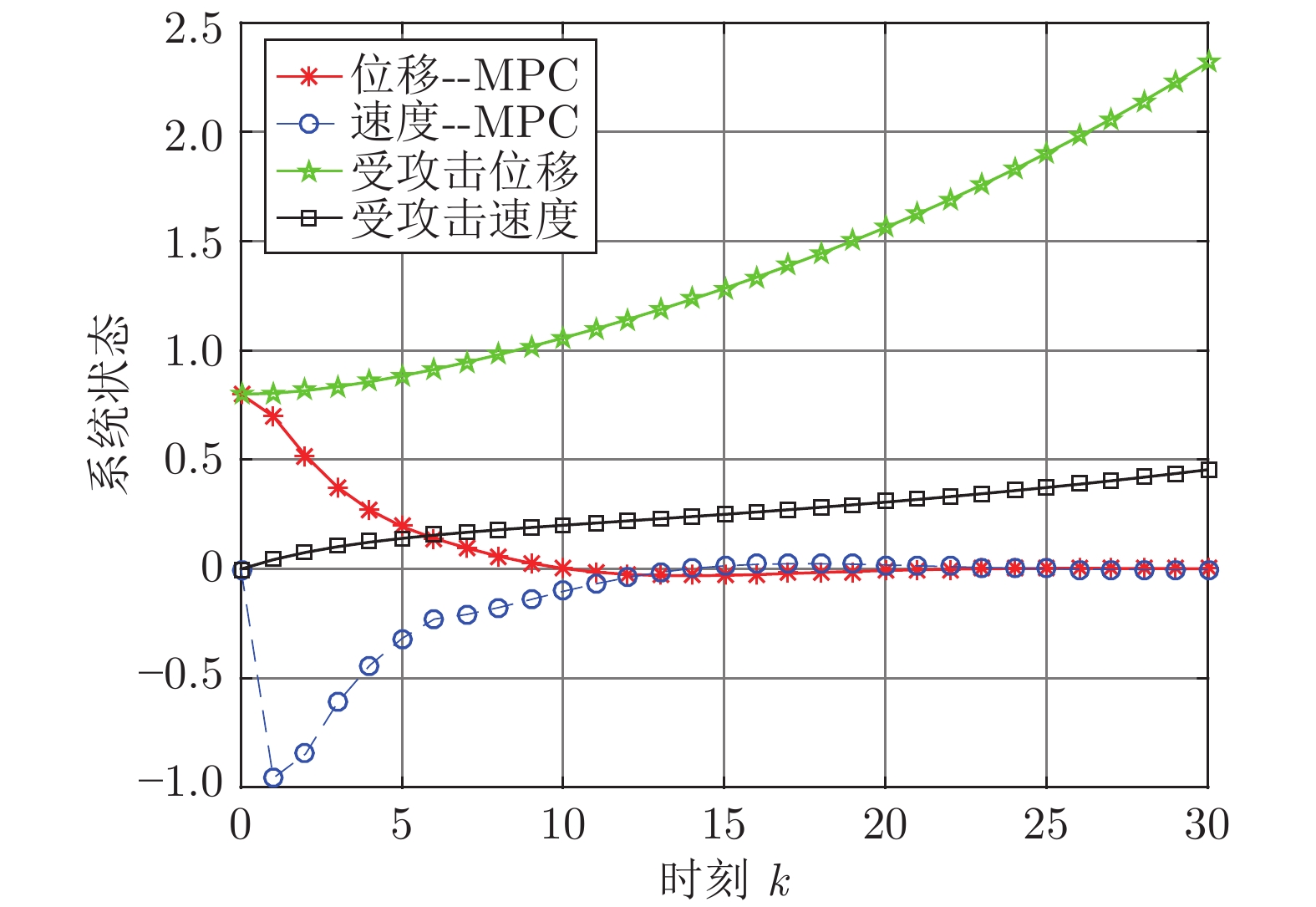 图 13 受攻击系统引入MPC前后的状态轨迹Fig. 13 The state trajectory of the attacked system with MPC and without MPC
图 13 受攻击系统引入MPC前后的状态轨迹Fig. 13 The state trajectory of the attacked system with MPC and without MPC在MPC策略中, 系统受到的真实攻击信号
$ a({ x}_{c}(k),K{ x}_{c}(k)) $ 与经IFOA-KELM重构的攻击信号$ g({ x}_{c}(k),K{ x}_{c}(k)) $ 之间的绝对误差如图14所示.5. 结论
本文针对受攻击的信息物理系统设计了一种基于机器学习的安全控制方法. 首先, 提出了一种IFOA-KELM算法对攻击信号进行重构. 然后, 对受攻击系统设计MPC策略, 并给出了使被控系统输入到状态稳定的条件. 此外, 从攻击者角度建立了优化模型, 得到最优攻击策略以生成足够的受攻击数据. 最后, 利用以弹簧 − 质量 − 阻尼系统作为物理对象的CPS进行数值仿真, 将IFOA-KELM、FOA-KELM、LS-SVM和PSO-BP的攻击信号重构效果进行对比. 仿真结果表明IFOA-KELM的初始参数优化阶段能够有效解决FOA-KELM初始参数优化阶段容易陷入局部最优的问题, 加快整个寻优过程的收敛速度, 并且IFOA-KELM相较其他三种算法能够获得更好的拟合效果; 此外, 还验证了本文所提安全控制策略的有效性.
另外, 本文所提的基于机器学习的攻击信号重构算法和MPC算法均需要较大的计算资源. 因此, 本文接下来将考虑利用云计算实现上述算法, 并进一步考虑云控制系统[34]的安全问题.
-
图 8 IFOA-KELM测试样本绝对误差
Fig. 8 The error between the real attack and the attack learned by IFOA-KELM
图 11 LSSVM测试样本绝对误差
Fig. 11 The error between the real attack and the attack learned by LSSVM
图 9 FOA-KELM测试样本绝对误差
Fig. 9 The error between the real attack and the attack learned by FOA-KELM
图 10 PSO-BP测试样本绝对误差
Fig. 10 The error between the real attack and the attack learned by PSO-BP
图 13 受攻击系统引入MPC前后的状态轨迹
Fig. 13 The state trajectory of the attacked system with MPC and without MPC
-
[1] Lee J, Bagheri B, Kao H A. A cyber-physical systems architecture for industry 4.0-based manufacturing systems. Manufacturing Letters, 2015, 3: 18−23 doi: 10.1016/j.mfglet.2014.12.001 [2] 李洪阳, 魏慕恒, 黄洁, 邱伯华, 赵晔, 骆文城, 何晓, 何潇. 信息物理系统技术综述. 自动化学报, 2019, 45(1): 37−50Li Hong-Yang, Wei Mu-Heng, Huang Jie, Qiu Bo-Hua, Zhao Ye, Luo Wen-Cheng, He Xiao, He Xiao. Survey on cyber-physical systems. Acta Automatica Sinica, 2019, 45(1): 37−50 [3] Inoue J, Yamagata Y, Chen Y, Poskitt C, Sun J. Anomaly detection for a water treatment system using unsupervised machine learning. In: Proceedings of the 2017 IEEE International Conference on Data Mining Workshops. New Orleans, LA, USA: IEEE, 2017. 1058−1065 [4] Li D, Chen D C, Goh J, Ng S K. Anomaly detection with generative adversarial networks for multivariate time series. arXiv: 1809.04758, 2018. [5] He H B, Yan J. Cyber-physical attacks and defences in the smart grid: A survey. IET Cyber-Physical Systems: Theory and Applications, 2016, 1(1): 13−27 [6] 夏元清, 闫策, 王笑京, 宋向辉. 智能交通信息物理融合云控制系统. 自动化学报, 2019, 45(1): 132−142Xia Yuan-Qing, Yan Ce, Wang Xiao-Jing, Song Xiang-Hui. Intelligent transportation cyber-physical cloud control systems. Acta Automatica Sinica, 2019, 45(1): 132−142 [7] Wang H J, Zhao H T, Zhang J, Ma D T. Survey on unmanned aerial vehicle networks: A cyber physical system perspective. arXiv: 1812.06821, 2018. [8] 刘烃, 田决, 王稼舟, 吴宏宇, 孙利民, 周亚东, 沈超, 管晓宏. 信息物理融合系统综合安全威胁与防御研究. 自动化学报, 2019, 45(1): 5−24Liu Ting, Tian Jue, Wang Jia-Zhou, Wu Hong-Yu, Sun Li-Min, Zhou Ya-Dong, Shen Chao, Guan Xiao-Hong. Integrated security threats and defense of cyber-physical systems. Acta Automatica Sinica, 2019, 45(1): 5−24 [9] Wolf M, Serpanos D. Safety and security in cyber-physical systems and internet-of-things systems. Proceedings of the IEEE, 2018, 106(1): 9−20 doi: 10.1109/JPROC.2017.2781198 [10] De Persis C, Tesi P. Input-to-state stabilizing control under denial-of-service. IEEE Transactions on Automatic Control, 2015, 60(11): 2930−2944 doi: 10.1109/TAC.2015.2416924 [11] Liu K, Guo H, Zhang Q R, Xia Y Q. Distributed secure filtering for discrete-time systems under Round-Robin protocol and deception attacks. IEEE Transactions on Cybernetics, 2020, 50(8): 3571−3580 doi: 10.1109/TCYB.2019.2897366 [12] Peng L H, Shi L, Cao X, Sun C Y. Optimal attack energy allocation against remote state estimation. IEEE Transactions on Automatic Control, 2018, 63(7): 2199−2205 doi: 10.1109/TAC.2017.2775344 [13] Zhang Q R, Liu K, Xia Y Q, Ma A Y. Optimal stealthy deception attack against cyber-physical systems. IEEE Transactions on Cybernetics, 2020, 50(9): 3963−3972 doi: 10.1109/TCYB.2019.2912622 [14] Zhu Q Y, Basar T. Game-theoretic methods for robustness, security, and resilience of cyberphysical control systems: Games-in-games principle for optimal cross-layer resilient control systems. IEEE Control Systems Magazine, 2015, 35(1): 46−65 doi: 10.1109/MCS.2014.2364710 [15] Vu N H, Choi Y S, Choi M. DDoS attack detection using K-nearest neighbor classifier method. In: Proceedings of the 4th IASTED International Conference on Telehealth/Assistive Technologies. Baltimore, Maryland, USA, 2008. 248−253 [16] Kumar P G, Devaraj D. Intrusion detection using artificial neural network with reduced input features. ICTACT Journal on Soft Computing, 2010: 30−36 [17] Nawaz R, Shahid M A, Qureshi I M, Mehmood M H. Machine learning based false data injection in smart grid. In: Proceedings of the 1st International Conference on Power, Energy and Smart Grid. Mirpur, Azad Kashmir, Pakistan, 2018. 1−6 [18] Esmalifalak M, Liu L, Nguyen N, Zheng R. Detecting stealthy false data injection using machine learning in smart grid. IEEE Systems Journal, 2017, 11(3): 1644−1652 doi: 10.1109/JSYST.2014.2341597 [19] Kiss I, Genge B, Haller P. A clustering-based approach to detect cyber attacks in process control systems. In: Proceedings of the 13th International Conference on Industrial Informatics. Cambridge, United Kingdom, 2015. 142−148 [20] Yan Z, Wang J. Model predictive control of nonlinear systems with unmodeled dynamics based on feedforward and recurrent neural networks. IEEE Transactions on Industrial Informatics, 2012, 8(4): 746−756 doi: 10.1109/TII.2012.2205582 [21] 封鹏. 基于PSO-BP神经网络的网络流量预测算法的研究与应用[硕士学位论文], 东北大学, 中国, 2015.Feng Peng. Research and Application of Network Traffic Prediction Algorithm Based on PSO-BP Neural Network [Master thesis], Northeastern University, China, 2015. [22] Huang G B, Zhou H M, Ding X J, Zhang R. Extreme learning machine for regression and multiclass classification. IEEE Transactions on Systems, Man, and Cybernetics, Part B (Cybernetics), 2012, 42(2): 513−529 doi: 10.1109/TSMCB.2011.2168604 [23] Huang G B, Zhu Q Y, Siew C K. Extreme learning machine: A new learning scheme of feedforward neural networks. In: Proceedings of the 2004 IEEE International Joint Conference on Neural Networks. Budapest, Hungary: IEEE, 2004. 985−990 [24] Huang G B, Siew C K. Extreme learning machine with randomly assigned RBF kernels. International Journal of Information Technology, 2005, 11(1): 16−24 [25] Minh H Q, Niyogi P, Yao Y. Mercer' s theorem, feature maps, and smoothing. In: Proceedings of the 2006 International Conference on Computational Learning Theory. Berlin, Heidelberg, Germary: Springer, 2006. 154−168 [26] Pan W T. A new fruit fly optimization algorithm: Taking the financial distress model as an example. Knowledge-Based Systems, 2012, 26: 69−74 doi: 10.1016/j.knosys.2011.07.001 [27] Kennedy J, Eberhart R. Particle swarm optimization. In: Proceedings of the 1995 IEEE International Conference on Neural Networks. Perth, Australia, 1995. 1942−1948 [28] 魏立新, 赵默林, 范锐, 周红星. 基于改进鲨鱼优化算法的自抗扰控制参数整定. 控制与决策, 2019, 34(4): 816−820Wei Li-Xin, Zhao Mo-Lin, Fan Rui, Zhou Hong-Xing. Parameter tuning of active disturbance rejection control based on ameliorated shark smell optimization algorithm. Control and Decision, 2019, 34(4): 816−820 [29] Muller S D, Marchetto J, Airaghi S, Kournoutsakos P. Optimizationbased on bacterial chemotaxis. IEEE Transactions on Evolutionary Computation, 2002, 6(1): 16−29 doi: 10.1109/4235.985689 [30] Guliyev N, Ismailov V. On the approximation by single hidden layer feedforward neural networks with fixed weights. Neural Networks, 2018, 98: 296−304 doi: 10.1016/j.neunet.2017.12.007 [31] 戴荔. 分布式随机模型预测控制方法研究[博士学位论文], 北京理工大学, 中国, 2016.Dai Li. Distributed Stochastic Model Predictive Control [Ph.D. dissertation], Beijing Institute of Technology, China, 2016. [32] Liu K, Ma A Y, Xia Y Q, Sun Z Q, Johansson K H. Network scheduling and control co-design for multi-loop MPC. IEEE Transactions on Automatic Control, 2019, 64(12): 5238−5245 doi: 10.1109/TAC.2019.2910724 [33] Marruedo D L, Alamo T, Camacho E F. Input-to-state stable MPC for constrained discrete-time nonlinear systems with bounded additive uncertainties. In: Proceedings of the 41st IEEE Conference on Decision and Control. Las Vegas, Nevada, USA, 2002. 4619−4624 [34] 夏元清. 云控制系统及其面临的挑战. 自动化学报, 2016, 42(1): 1−12Xia Yuan-Qing. Cloud control systems and their challenges. Acta Automatica Sinica, 2016, 42(1): 1−12 期刊类型引用(8)
1. 宁梓淯,李萌,李燕,高宇,任重贵. 基于深度学习的广域网教育信息安全访问自动化控制系统设计. 电子设计工程. 2025(06): 100-103+108 .  百度学术
百度学术2. 杨挺,许哲铭,赵英杰,翟峰. 数字化新型电力系统攻击与防御方法研究综述. 电力系统自动化. 2024(06): 112-126 . 百度学术3. 贺宁,范昭,马凯. FDI攻击下移动机器人弹性预测镇定控制研究. 北京理工大学学报. 2024(07): 722-730 . 百度学术4. 刘坤,曾恩,刘博涵,李俊达,李江荣. 基于多变量时序数据的对抗攻击与防御方法. 北京工业大学学报. 2023(04): 415-423 . 百度学术5. 顾仁龙,曾鸿孟,徐超,胡琳,周憧. 基于机器学习的云原生结构数据攻击检测系统设计. 电子设计工程. 2023(14): 62-65+70 . 百度学术6. 罗香,冯元珍. DoS攻击下二阶多智能体系统二分跟踪一致性. 计算机工程与应用. 2023(12): 77-83 . 百度学术7. 游秀,许俊茹,贾新春. DoS攻击下信息物理系统的分布式协同控制. 控制工程. 2022(06): 971-976 . 百度学术8. 冯健,王健安. 基于观测器的多智能体系统安全一致性控制. 控制工程. 2022(06): 977-987 . 百度学术其他类型引用(9)
-

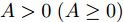
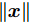
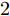
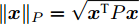
 下载:
下载:
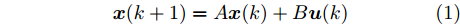
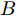
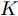
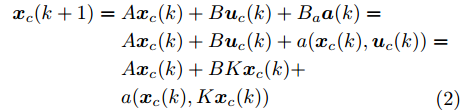
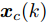
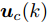
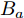
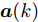
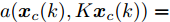
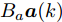
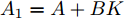
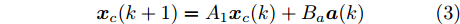
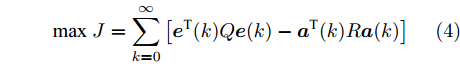
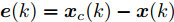
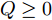
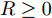
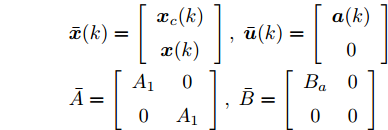
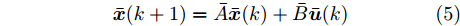
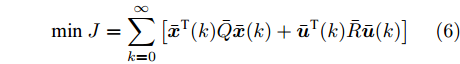
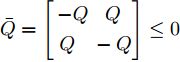
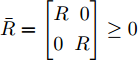
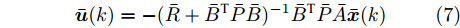
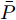
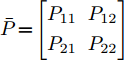
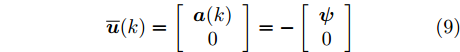
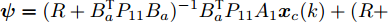
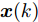
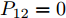
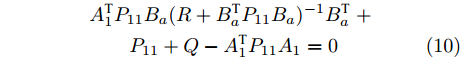
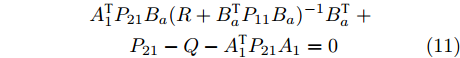
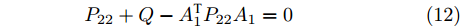
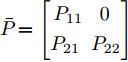
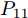
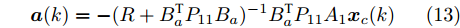

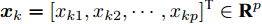

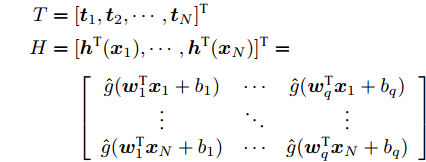
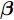
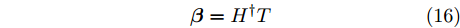
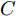
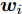
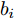
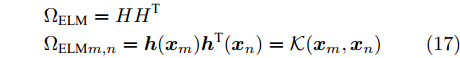
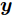
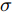
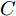
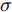
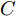
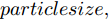
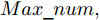
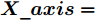
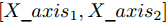
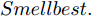
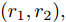
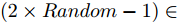
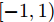
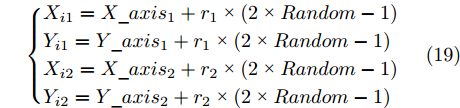

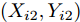

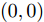
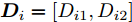
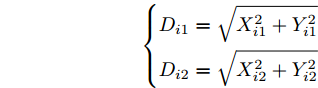
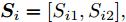

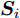
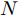
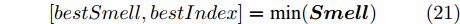
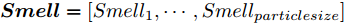
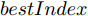
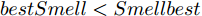
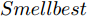
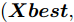
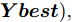
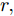

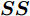
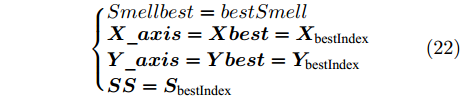
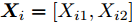
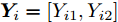
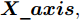
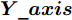
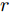
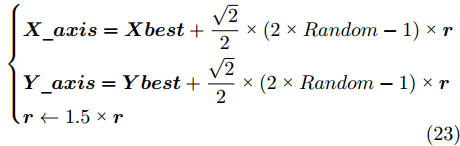
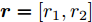
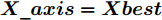

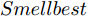
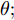
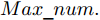
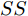
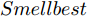
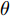

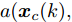
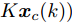
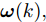
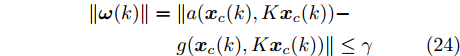
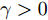
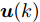
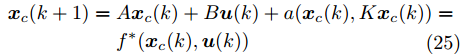
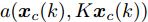
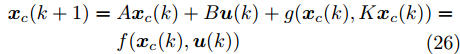
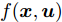
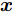
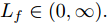
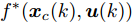
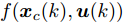
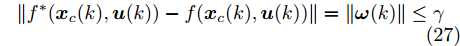
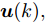
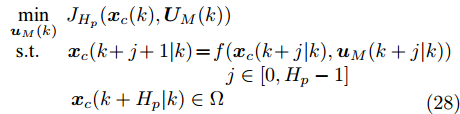
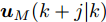
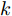
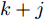
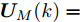
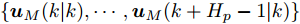
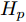
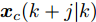
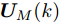
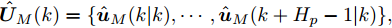
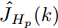
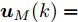
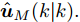
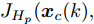
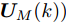
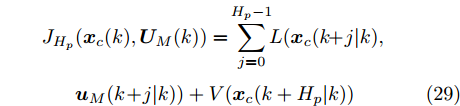
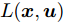
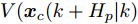
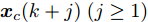
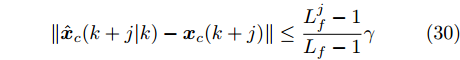
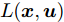
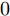
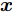
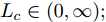
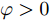
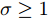
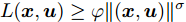
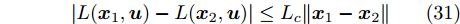
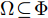
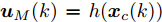
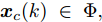
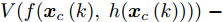
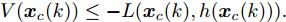
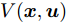
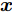
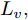
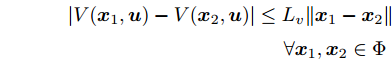
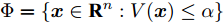
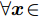
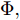
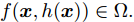
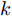
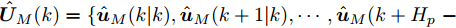
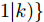
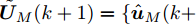
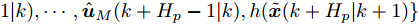
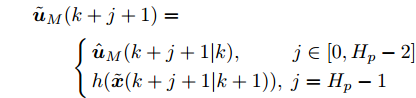
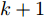
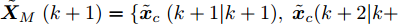
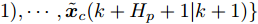
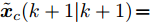
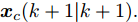
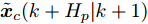
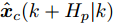
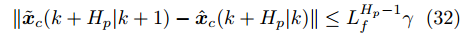
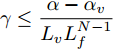
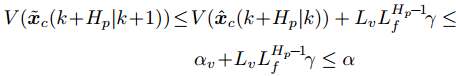
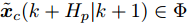
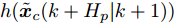
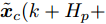
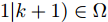
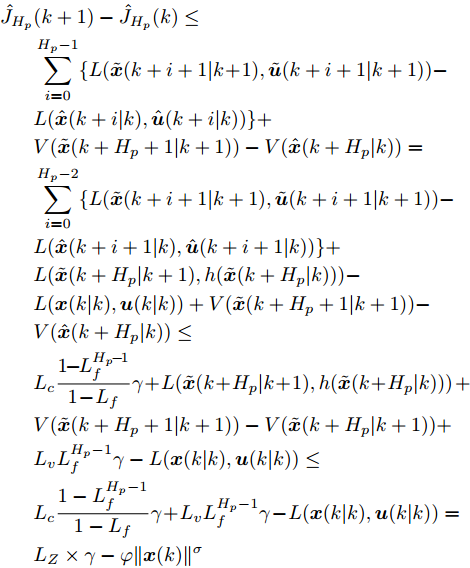
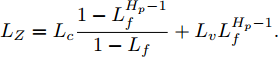

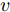
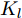
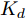
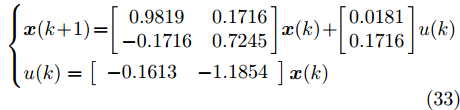
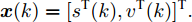

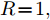
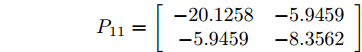
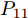
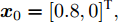

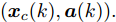
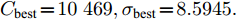

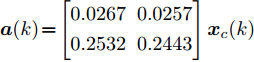
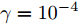

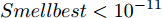
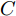
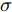
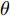
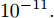
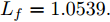
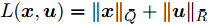
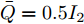
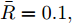
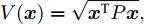
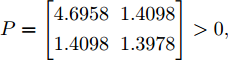
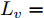
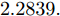
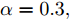
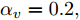
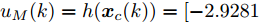
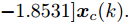
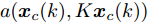
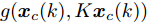

 下载:
下载:

计量
- 文章访问数: 2289
- HTML全文浏览量: 617
- PDF下载量: 846
- 被引次数: 17
