

-
摘要: 如何有效挖掘多视角数据内部的一致性以及差异性是构建多视角模糊聚类算法的两个重要问题. 本文在Co-FKM算法框架上, 提出了基于低秩约束的熵加权多视角模糊聚类算法(Entropy-weighting multi-view fuzzy C-means with low rank constraint, LR-MVEWFCM). 一方面, 从视角之间的一致性出发, 引入核范数对多个视角之间的模糊隶属度矩阵进行低秩约束; 另一方面, 基于香农熵理论引入视角权重自适应调整策略, 使算法根据各视角的重要程度来处理视角间的差异性. 本文使用交替方向乘子法(Alternating direction method of multipliers, ADMM)进行目标函数的优化. 最后, 人工模拟数据集和UCI (University of California Irvine)数据集上进行的实验结果验证了该方法的有效性.Abstract: Effective mining both internal consistency and diversity of multi-view data is important to develop multi-view fuzzy clustering algorithms. In this paper, we propose a novel multi-view fuzzy clustering algorithm called entropy-weighting multi-view fuzzy c-means with low-rank constraint (LR-MVEWFCM). On the one hand, we introduce the nuclear norm as the low-rank constraint of the fuzzy membership matrix. On the other hand, the adaptive adjustment strategy of view weight is introduced to control the differences among views according to the importance of each view. The learning criterion can be optimized by the alternating direction method of multipliers (ADMM). Experimental results on both artificial and UCI (University of California Irvine) datasets show the effectiveness of the proposed method.
-
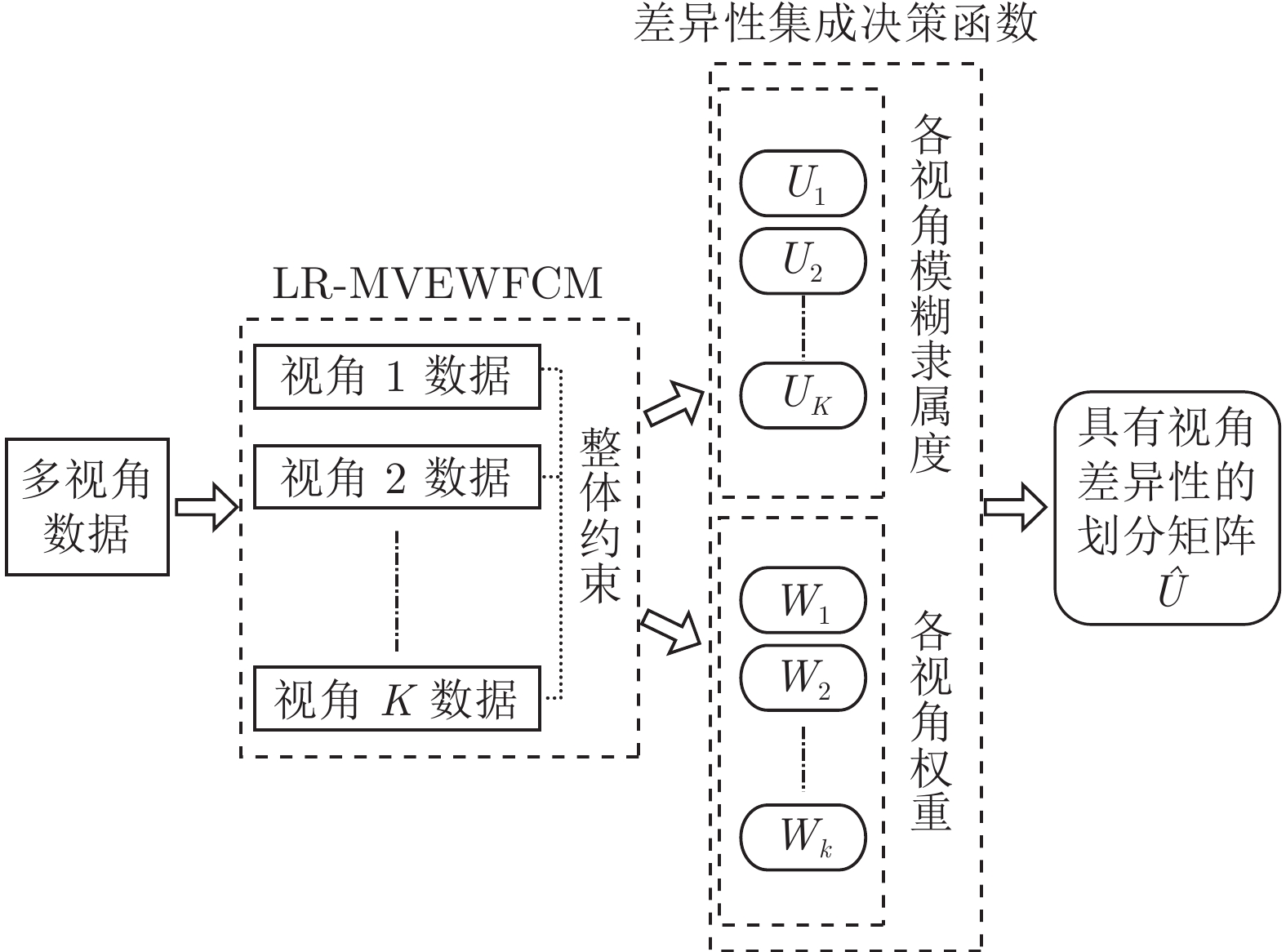
图 2 LR-MVEWFCM算法处理多视角聚类任务工作流程
Fig. 2 LR-MVEWFCM algorithm for multi-view clustering task

图 4 低秩约束对算法性能的影响(横坐标为数据集编号, 纵坐标为聚类性能指标)
Fig. 4 The influence of low rank constraints on the performance of the algorithm (the X-coordinate is the data set number and the Y-coordinate is the clustering performance index)
表 1 参数定义和设置
Table 1 Parameter setting in the experiments
算法 算法说明 参数设置 FCM 经典的单视角模糊聚类算法 模糊指数$m=\frac{\min (N, D-1)}{\min (N, D-1)-2}$,
其中, $N$表示样本数, $D$表示样本维数CombKM 组合${\rm{K}}\text{-}{\rm{means}}$算法 — Co-FKM 多视角协同划分的模糊聚类算法 模糊指数$m=\frac{\min (N, D-1)}{\min (N, D-1)-2}$, 协同学习系数$\eta{}\in{}\frac{K-1}{K}$,
其中, $K$为视角数, 步长$\rho{}=0.01$Co-Clustering 基于样本与特征空间的协同聚类算法 正则化系数$\lambda \in\left\{10^{-3}, 10^{-2}, \cdots, 10^{3}\right\}$,
正则化系数$\mu \in\left\{10^{-3}, 10^{-2}, \cdots, 10^{3}\right\}$LR-MVEWFCM 基于低秩约束的熵加权多视角模糊聚类算法 视角权重平衡因子$\lambda{}\in{}\left\{{10}^{-5}, {10}^{-4}, \cdots{}, {10}^5\right\}$, 低秩约束正则项系数$\theta{}\in{}\left\{{10}^{-3}, 10^{-2}, \cdots{}, {10}^3\right\}$, 模糊指数$m=2$ MVEWFCM LR-MVEWFCM 算法中低秩约束正则项系数$\theta{}=0$ 视角权重平衡因子$\lambda{}\in{}\left\{{10}^{-5}, {10}^{-4}, \cdots{}, {10}^5\right\}$, 模糊指数$m=2$  下载: 导出CSV
下载: 导出CSV
表 2 模拟数据集特征组成
Table 2 Characteristic composition of simulated dataset
视角 包含特征 视角 1 $x,y$ 视角 2 $y,z$ 视角 3 $x,z$
下载: 导出CSV
表 3 模拟数据实验算法性能对比
Table 3 Performance comparison of the proposed algorithms on simulated dataset
编号 包含特征 NMI RI 1 视角1 1.0000 ± 0.0000 1.0000 ± 0.0000 2 视角2 0.7453 ± 0.0075 0.8796 ± 0.0081 3 视角3 0.8750 ± 0.0081 0.9555 ± 0.0006 4 视角1, 视角2 1.0000 ± 0.0000 1.0000 ± 0.0000 5 视角1, 视角3 1.0000 ± 0.0000 1.0000 ± 0.0000 6 视角2, 视角3 0.9104 ± 0.0396 0.9634 ± 0.0192 7 视角2, 视角3 1.0000 ± 0.0000 1.0000 ± 0.0000
下载: 导出CSV
表 4 模拟数据集7上各算法的性能比较
Table 4 Performance comparison of the proposed algorithms on simulated dataset 7
数据集 指标 Co-Clustering CombKM FCM Co-FKM LR-MVEWFCM A NMI-mean 1.0000 0.9305 1.0000 1.0000 1.0000 NMI-std 0.0000 0.1464 0.0000 0.0000 0.0000 RI-mean 1.0000 0.9445 1.0000 1.0000 1.0000 RI-std 0.0000 0.1171 0.0000 0.0000 0.0000
下载: 导出CSV
表 5 基于UCI数据集构造的多视角数据
Table 5 Multi-view data constructded based on UCI dataset
编号 原数据集 说明 视角特征 样本 视角 类别 8 IS Shape 9 2 310 2 7 RGB 9 9 Iris Sepal长度 2 150 2 3 Sepal宽度 Petal长度 2 Petal宽度 10 Balance 天平左臂重量 2 625 2 3 天平左臂长度 天平右臂重量 2 天平右臂长度 11 Iris Sepal长度 1 150 4 3 Sepal宽度 1 Petal长度 1 Petal宽度 1 12 Balance 天平左臂重量 1 625 4 3 天平左臂长度 1 天平右臂重量 1 天平右臂长度 1 13 Ionosphere 每个特征单独
作为一个视角1 351 34 2 14 Wine 每个特征单独
作为一个视角1 178 13 3
下载: 导出CSV
表 6 5种聚类方法的NMI值比较结果
Table 6 Comparison of NMI performance of five clustering methods
编号 Co-Clustering CombKM FCM Co-FKM LR-MVEWFCM 均值 P-value 均值 P-value 均值 P-value 均值 P-value 均值 8 0.5771 ±
0.00230.0019 0.5259 ±
0.05510.2056 0.5567 ±
0.01840.0044 0.5881 ±
0.01093.76×10−4 0.5828 ±
0.00449 0.7582 ±
7.4015 ×10−172.03×10−24 0.7251 ±
0.06982.32×10−7 0.7578 ±
0.06981.93×10−24 0.8317 ±
0.00648.88×10−16 0.9029 ±
0.005710 0.2455 ±
0.05590.0165 0.1562 ±
0.07493.47×10−5 0.1813 ±
0.11720.0061 0.2756 ±
0.03090.1037 0.3030 ±
0.040211 0.7582 ±
1.1703×10−162.28×10−16 0.7468 ±
0.00795.12×10−16 0.7578 ±
1.1703×10−165.04×10−16 0.8244 ±
1.1102×10−162.16×10−16 0.8768 ±
0.009712 0.2603 ±
0.06850.3825 0.1543 ±
0.07634.61×10−4 0.2264 ±
0.11270.1573 0.2283 ±
0.02940.0146 0.2863 ±
0.061113 0.1385 ±
0.00852.51×10−9 0.1349 ±
2.9257×10−172.35×10−13 0.1299 ±
0.09842.60×10−10 0.2097 ±
0.03290.0483 0.2608 ±
0.025114 0.4288 ±
1.1703×10−161.26×10−08 0.4215 ±
0.00957.97×10−09 0.4334 ±
5.8514×10−172.39×10−08 0.5295 ±
0.03010.4376 0.5413 ±
0.0364
下载: 导出CSV
表 7 5种聚类方法的RI值比较结果
Table 7 Comparison of RI performance of five clustering methods
编号 Co-Clustering CombKM FCM Co-FKM LR-MVEWFCM 均值 P-value 均值 P-value 均值 P-value 均值 P-value 均值 8 0.8392 ±
0.00101.3475 ×10−14 0.8112 ±
0.03691.95×10−7 0.8390 ±
0.01150.0032 0.8571 ±
0.00190.0048 0.8508 ±
0.00139 0.8797 ±
0.00141.72×10−26 0.8481 ±
0.06672.56×10−5 0.8859 ±
1.1703×10−166.49×10−26 0.9358 ±
0.00373.29×10−14 0.9665 ±
0.002610 0.6515 ±
0.02313.13×10−4 0.6059 ±
0.03401.37×10−6 0.6186 ±
0.06240.0016 0.6772 ±
0.02270.0761 0.6958 ±
0.021511 0.8797 ±
0.00141.25×10−18 0.8755 ±
0.00295.99×10−12 0.8859 ±
0.02432.33×10−18 0.9267 ±
2.3406×10−165.19×10−18 0.9527 ±
0.004112 0.6511 ±
0.02790.0156 0.6024 ±
0.03222.24×10−5 0.6509 ±
0.06520.1139 0.6511 ±
0.01890.008 0.6902 ±
0.037013 0.5877 ±
0.00301.35×10−12 0.5888 ±
0.02922.10×10−14 0.5818 ±
1.1703×10−164.6351 ×10−13 0.6508 ±
0.01470.0358 0.6855 ±
0.011514 0.7187 ±
1.1703×10−163.82×10−6 0.7056 ±
0.01681.69×10−6 0.7099 ±
1.1703×10−168.45×10−7 0.7850 ±
0.01620.5905 0.7917 ±
0.0353
下载: 导出CSV
-
[1] Xu C, Tao D, Xu C. Multi-view Learning with Incomplete Views[J]. IEEE Transactions on Image Processing, 2015, 24(12): 5812-5825 doi: 10.1109/TIP.2015.2490539 [2] Brefeld U. Multi-view learning with dependent views. In: Proceedings of the 30th Annual ACM Symposium on Applied Computing, Salamanca, Spain: ACM, 2015. 865−870 [3] Muslea I, Minton S, Knoblock C A. Active Learning with Multiple Views[J]. Journal of Artificial Intelligence Research, 2006, 27(1): 203-233 [4] Zhang C, Adeli E, Wu Z, et al. Infant brain development prediction with latent partial multi-view representation learning[J]. IEEE Transactions on Medical Imaging, 2018, 38(4): 909-918 [5] Bickel S, Scheffer T. Multi-view clustering. In: Proceedings of the 4th IEEE International Conference on Data Mining (ICDM'04), Brighton, UK: IEEE, 2004. 19−26 [6] Wang Y, Chen L. Multi-view fuzzy clustering with minimax optimization for effective clustering of data from multiple sources[J]. Expert Systems with Applications, 2017, 72: 457-466 doi: 10.1016/j.eswa.2016.10.006 [7] 王骏, 王士同, 邓赵红. 聚类分析研究中的若干问题[J]. 控制与决策, 2012, 27(3): 321-328Wang J, Wang S T, Deng Z H. Survey on challenges in clustering analysis research. Control and Decision, 2012, 27(3): 321-328 [8] Pedrycz W. Collaborative fuzzy clustering[J]. Pattern Recognition Letters, 2002, 23(14): 1675-1686 doi: 10.1016/S0167-8655(02)00130-7 [9] Cleuziou G, Exbrayat M, Martin L, Sublemontier J H. CoFKM: A centralized method for multiple-view clustering. In: Proceedings of the 9th IEEE International Conference on Data Mining, Miami, FL, USA: IEEE, 2009. 752−757 [10] Jiang Y, Chung F L, Wang S, et al. Collaborative fuzzy clustering from multiple weighted views[J]. IEEE Trans Cybern, 2015, 45(4): 688-701 doi: 10.1109/TCYB.2014.2334595 [11] Bettoumi S, Jlassi C, Arous N. Collaborative multi-view k-means clustering[J]. Soft Computing, 2019, 23(3): 937-945 [12] Zhang G Y, Wang C D, Huang D, et al. TW-Co-k-means: two-level weighted collaborative k-means for multi-view clustering[J]. Knowledge-Based Systems, 2018, 150: 127-138 doi: 10.1016/j.knosys.2018.03.009 [13] Cao X C, Zhang C Q, Fu H Z, Liu S, Zhang H. Diversity-induced multi-view subspace clustering. In: Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA: IEEE, 2015. 586−594 [14] Zhang C Q, Fu H Z, Liu S, Liu G C, Cao X C. Low-rank tensor constrained multiview subspace clustering. In: Proceedings of the 2015 IEEE International Conference on Computer Visio, Santiago, Chile: IEEE, 2015. 1582−1590 [15] Boyd S, Parikh N, Chu E, et al. Distributed optimization and statistical learning via the alternating direction method of multipliers[J]. Foundations and Trends in Machine learning, 2011, 3(1): 1-122 [16] Liu G, Lin Z, Yan S, et al. Robust Recovery of Subspace Structures by Low-Rank Representation[J]. In: Proceedings of IEEE Transactions on Pattern Analysis and Machine Intelligence, 2013, 35(1): 171-184 doi: 10.1109/TPAMI.2012.88 [17] Bezdek J C, Ehrlich R, Full W. FCM: The fuzzy c -means clustering algorithm[J]. Computers Geosciences, 1984, 10(2): 191-203 [18] Abavisani M, Patel V M. Multimodal sparse and low-rank subspace clustering[J]. Information Fusion, 2018, 39: 168-177 doi: 10.1016/j.inffus.2017.05.002 [19] Gu Q Q, Zhou J. Learning the shared subspace for multi-task clustering and transductive transfer classification. In: Proceedings of the 9th IEEE International Conference on Data Mining, Miami beach, FL, USA: IEEE, 2009. 159−168 [20] Gu Q Q, Zhou J. Co-clustering on manifolds. In: Proceedings of the 15th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Paris, France: ACM, 2009. 359−368 -

 下载:
下载:



计量
- 文章访问数: 867
- HTML全文浏览量: 236
- PDF下载量: 217
- 被引次数: 0
