

Recognizing Action Using Multi-center Subspace Learning-based Spatial-temporal Information Fusion
-
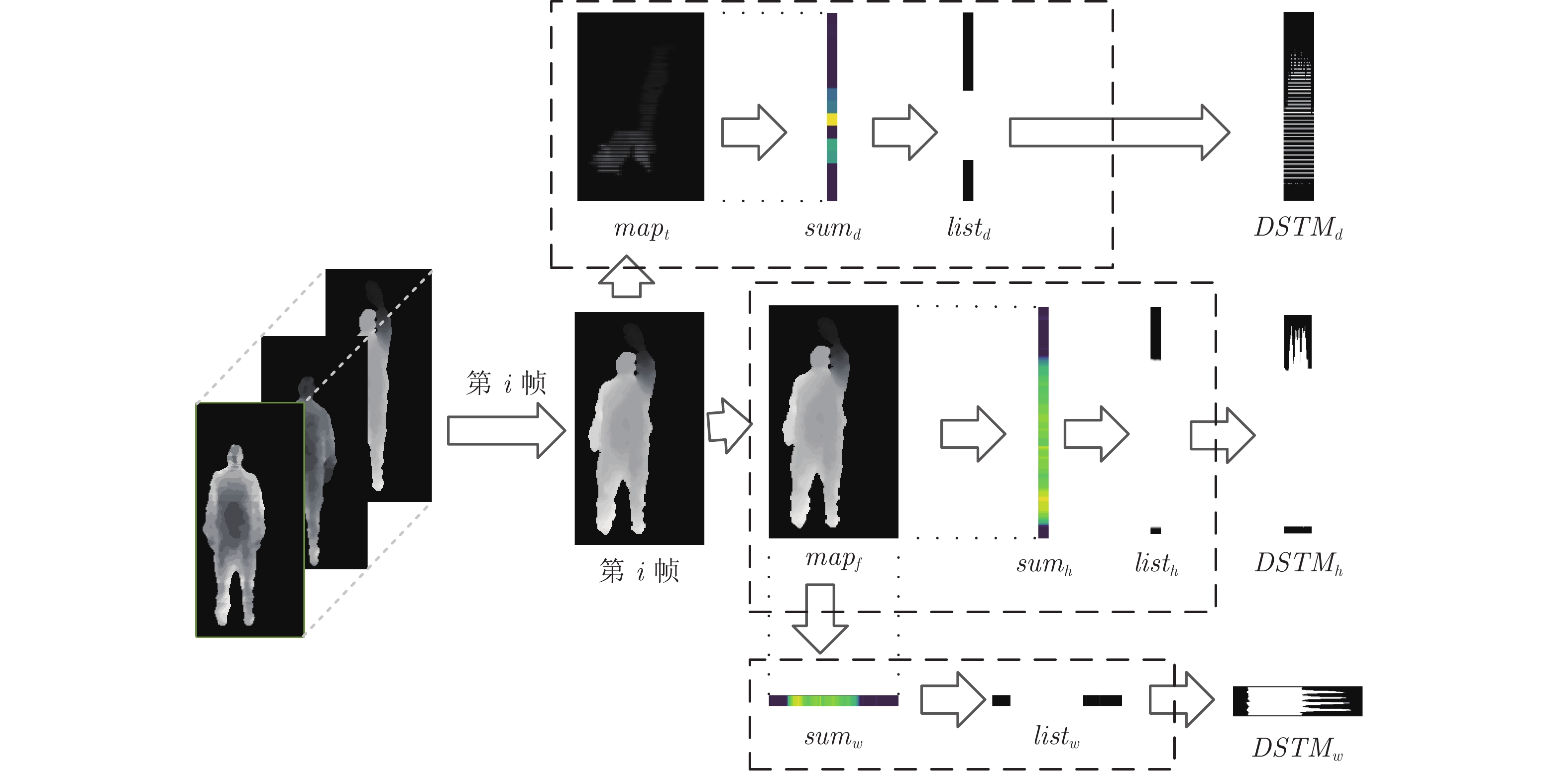
摘要: 基于深度序列的人体行为识别, 一般通过提取特征图来提高识别精度, 但这类特征图通常存在时序信息缺失的问题. 针对上述问题, 本文提出了一种新的深度图序列表示方式, 即深度时空图(Depth space time maps, DSTM). DSTM降低了特征图的冗余度, 弥补了时序信息缺失的问题. 本文通过融合空间信息占优的深度运动图(Depth motion maps, DMM) 与时序信息占优的DSTM, 进行高精度的人体行为研究, 并提出了多聚点子空间学习(Multi-center subspace learning, MCSL)的多模态数据融合算法. 该算法为各类数据构建多个投影聚点, 以此增大样本的类间距离, 降低了投影目标区域维度. 本文在MSR-Action3D数据集和UTD-MHAD数据集上进行人体行为识别. 最后实验结果表明, 本文方法相较于现有人体行为识别方法有着较高的识别率.Abstract: Human action recognitions from depth map sequences improve the recognition accuracy by extracting feature maps. A new representation of depth map sequences called depth space time map (DSTM) is proposed in this paper for overcoming the lack of temporal information in the feature maps. DSTM reduces the redundancy of action features. We conduct high-precision human action recognitions by fusing depth motion maps (DMM) and DSTM based on a new multi-modal data fusion algorithm called multi-center subspace learning (MCSL). The algorithm constructs multiple projection centers for each class data to expand the samples inter-class distance and reduce the projection target area dimension. Experiments conducted on MSR-Action3D and UTD-MHAD depth database show the effectiveness of the proposed method.
-
表 1 MSR数据库中的人体行为
Table 1 Human actions in MSR
动作 样本数 动作 样本数 高挥手 (A01) 27 双手挥 (A11) 30 水平挥手 (A02) 26 侧边拳击 (A12) 30 锤 (A03) 27 弯曲 (A13) 27 手抓 (A04) 25 向前踢 (A14) 29 打拳 (A05 26 侧踢 (A15) 20 高抛 (A06) 26 慢跑 (A16) 30 画叉 (A07) 27 网球挥拍 (A17) 30 画勾 (A08) 30 发网球 (A18) 30 画圆 (A09) 30 高尔夫挥杆 (A19) 30 拍手 (A10) 30 捡起扔 (A20) 27  下载: 导出CSV
下载: 导出CSV
表 2 UTD数据库中的人体行为
Table 2 Human actions in UTD
动作 样本数 动作 样本数 向左滑动 (B01) 32 挥网球 (B15) 32 向右滑动 (B02) 32 手臂卷曲 (B16) 32 挥手 (B03) 32 网球发球 (B17) 32 鼓掌 (B04) 32 推 (B18) 32 扔 (B05) 32 敲 (B19) 32 双手交叉 (B06) 32 抓 (B20) 32 拍篮球 (B07) 32 捡起扔 (B21) 32 画叉 (B08) 31 慢跑 (B22) 31 画圆 (B09) 32 走 (B23) 32 持续画圆 (B10) 32 坐下 (B24) 32 画三角 (B11) 32 站起来 (B25) 32 打保龄球 (B12) 32 弓步 (B26) 32 冲拳 (B13) 32 蹲 (B27) 32 挥羽毛球 (B14) 32
下载: 导出CSV
表 3 MSR-Action3D 数据分组
Table 3 MSR-Action3D data grouping
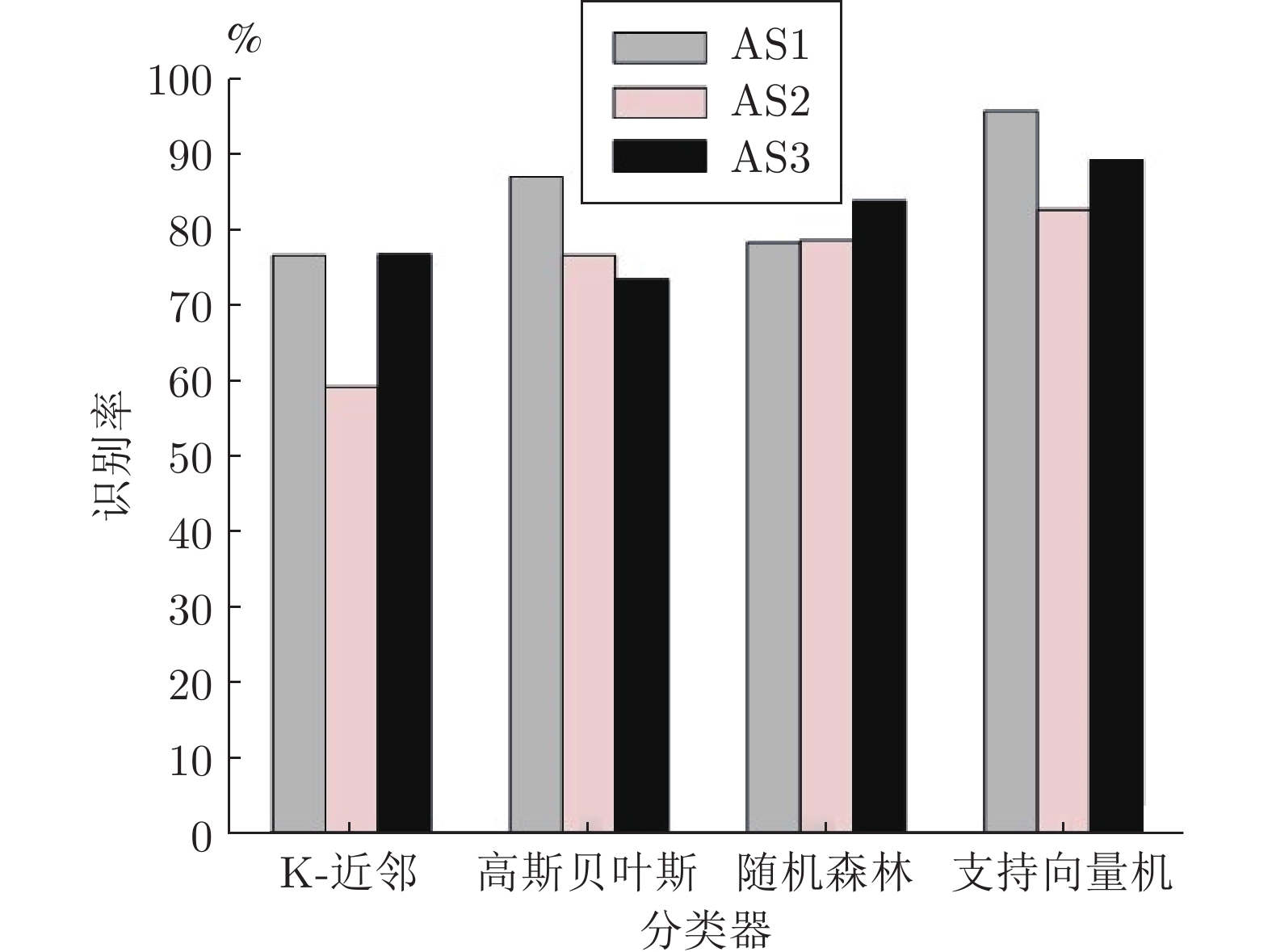
AS1 AS2 AS3 A02 A01 A06 A03 A04 A14 A05 A07 A15 A06 A08 A16 A10 A09 A17 A13 A11 A18 A18 A14 A19 A20 A12 A20
下载: 导出CSV
表 4 MSR数据库上不同特征的识别率(%)
Table 4 Different of feature action recognition on MSR (%)
方法 测试 1 测试 2 测试 3 AS1 AS2 AS3 均值 AS1 AS2 AS3 均值 AS1 AS2 AS3 均值 MEI-HOG 69.79 77.63 79.72 75.71 84.00 89.58 93.24 88.94 86.95 86.95 95.45 89.78 MEI-LBP 57.05 56.58 64.19 59.27 66.66 69.79 78.37 71.61 69.56 73.91 77.27 73.58 DSTM-HOG 83.22 71.71 87.83 80.92 94.66 84.37 88.23 89.80 91.30 82.61 95.95 89.95 DSTM-LBP 84.56 71.71 87.83 81.37 88.00 82.29 95.94 88.74 86.96 82.61 95.45 88.34 MHI-HOG 69.79 72.36 70.95 71.03 88.00 84.37 89.19 87.19 95.65 82.60 95.45 91.23 MHI-LBP 51.67 60.52 54.05 55.41 73.33 70.83 78.37 74.18 82.60 65.21 72.72 73.51 DMM-HOG 88.00 87.78 87.16 87.65 94.66 87.78 100.00 94.15 100.00 88.23 95.45 94.56 DMM-LBP 89.52 87.78 93.20 90.17 93.11 85.19 100.00 92.77 94.03 88.98 92.38 91.80
下载: 导出CSV
表 5 UTD数据库上不同特征的识别率(%)
Table 5 Different of feature action recognition on UTD (%)
方法 测试 1 测试 2 测试 3 MEI-HOG 69.51 65.42 68.20 MEI-LBP 45.12 51.97 52.61 DSTM-HOG 71.08 80.28 89.54 DSTM-LBP 68.81 80.97 86.06 MHI-HOG 56.44 66.58 73.14 MHI-LBP 49.82 53.82 57.40 DMM-HOG 78.39 75.40 87.94 DMM-LBP 68.98 74.94 86.75
下载: 导出CSV
表 6 DMM和DSTM对比实验结果(%)
Table 6 Experimental results of DMM and DSTM (%)
方法 D1 D2 DSTM 62.83 81.53 DMM 32.17 63.93
下载: 导出CSV
表 7 DMM和DSTM平均处理时间(s)
Table 7 Average processing time of DMM and DSTM (s)
方法 D1 D2 DSTM 2.1059 3.4376 DMM 5.6014 8.6583
下载: 导出CSV
表 8
$ \mathrm{MSR}\text{-}\mathrm{Action} 3 \mathrm{D}^{1} $ 上的实验结果Table 8 Experimental results on
$ \mathrm{MSR}\text{-}\mathrm{Action} 3 \mathrm{D}^{1} $
下载: 导出CSV
表 9
$\mathrm{MSR}\text{-}\mathrm{Action} 3 \mathrm{D}^{2}$ 上的实验结果Table 9 Experimental results on
$\mathrm{MSR}\text{-}\mathrm{Action} 3 \mathrm{D}^{2}$
下载: 导出CSV
-
[1] Yousefi S, Narui H, Dayal S, Ermon S, Valaee S. A survey on behavior recognition using WiFi channel state information. IEEE Communications Magazine, 2017, 55(10): 98−104 doi: 10.1109/MCOM.2017.1700082 [2] Ben Mabrouk A, Zagrouba E. Abnormal behavior recognition for intelligent video surveillance systems: A review. Expert Systems with Applications, 2018, 91: 480−491 doi: 10.1016/j.eswa.2017.09.029 [3] Fang C C, Mou T C, Sun S W, Chang P C. Machine-learning based fitness behavior recognition from camera and sensor modalities. In: Proceedings of the 2018 IEEE International Conference on Artificial Intelligence and Virtual Reality (AIVR). Taichung, China: IEEE, 2018. 249−250 [4] Chen C, Liu K, Jafari R, Kehtarnavaz N. Home-based senior fitness test measurement system using collaborative inertial and depth sensors. In: Proceedings of the 36th Annual International Conference of the IEEE Engineering in Medicine and Biology Society. Chicago, USA: IEEE, 2014. 4135−4138 [5] Laver K E, Lange B, George S, Deutsch J E, Saposnik G, Crotty M. Virtual reality for stroke rehabilitation. Cochrane Database of Systematic Reviews, 2017, 11(11): Article No. CD008349 [6] Sun J, Wu X, Yan S C, Cheong L F, Chua T S, Li J T. Hierarchical spatio-temporal context modeling for action recognition. In: Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition. Miami, USA: IEEE, 2009. 2004−2011 [7] 胡建芳, 王熊辉, 郑伟诗, 赖剑煌. RGB-D行为识别研究进展及展望. 自动化学报, 2019, 45(5): 829−840 doi: 10.16383/j.aas.c180436Hu Jian-Fang, Wang Xiong-Hui, Zheng Wei-Shi, Lai Jian-Huang. RGB-D action recognition: Recent advances and future perspectives. Acta Automatica Sinica, 2019, 45(5): 829−840 doi: 10.16383/j.aas.c180436 [8] Bobick A F, Davis J W. The recognition of human movement using temporal templates. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2001, 23(3): 257−267 doi: 10.1109/34.910878 [9] 苏本跃, 蒋京, 汤庆丰, 盛敏. 基于函数型数据分析方法的人体动态行为识别. 自动化学报, 2017, 43(5): 866−876 doi: 10.16383/j.aas.2017.c160120Su Ben-Yue, Jiang Jing, Tang Qing-Feng, Sheng Min. Human dynamic action recognition based on functional data analysis. Acta Automatica Sinica, 2017, 43(5): 866−876 doi: 10.16383/j.aas.2017.c160120 [10] Anderson D, Luke R H, Keller J M, Skubic M, Rantz M J, Aud M A. Modeling human activity from voxel person using fuzzy logic. IEEE Transactions on Fuzzy Systems, 2009, 17(1): 39−49 doi: 10.1109/TFUZZ.2008.2004498 [11] Wu Y X, Jia Z, Ming Y, Sun J J, Cao L J. Human behavior recognition based on 3D features and hidden Markov models. Signal, Image and Video Processing, 2016, 10(3): 495−502 doi: 10.1007/s11760-015-0756-6 [12] Wang J, Liu Z C, Chorowski J, Chen Z Y, Wu Y. Robust 3D action recognition with random occupancy patterns. In: Proceedings of the 12th European Conference on Computer Vision. Florence, Italy: Springer, 2012. 872−885 [13] Zhang H L, Zhong P, He J L, Xia C X. Combining depth-skeleton feature with sparse coding for action recognition. Neurocomputing, 2017, 230: 417−426 doi: 10.1016/j.neucom.2016.12.041 [14] Zhang S C, Chen E Q, Qi C, Liang C W. Action recognition based on sub-action motion history image and static history image. MATEC Web of Conferences, 2016, 56: Article No. 02006 [15] Liu Z, Zhang C Y, Tian Y L. 3D-based Deep Convolutional Neural Network for action recognition with depth sequences. Image and Vision Computing, 2016, 55: 93−100 doi: 10.1016/j.imavis.2016.04.004 [16] Xu Y, Hou Z J, Liang J Z, Chen C, Jia L, Song Y. Action recognition using weighted fusion of depth images and skeleton$'$s key frames. Multimedia Tools and Applications, 2019, 78(17): 25063−25078 doi: 10.1007/s11042-019-7593-5 [17] Wang P C, Li W Q, Li C K, Hou Y H. Action recognition based on joint trajectory maps with convolutional neural networks. Knowledge-Based Systems, 2018, 158: 43−53 doi: 10.1016/j.knosys.2018.05.029 [18] Kamel A, Sheng B, Yang P, Li P, Shen R M, Feng D D. Deep convolutional neural networks for human action recognition using depth maps and postures. IEEE Transactions on Systems, Man, and Cybernetics: Systems, 2019, 49(9): 1806−1819 doi: 10.1109/TSMC.2018.2850149 [19] Li C K, Hou Y H, Wang P C, Li W Q. Joint distance maps based action recognition with convolutional neural networks. IEEE Signal Processing Letters, 2017, 24(5): 624−628 doi: 10.1109/LSP.2017.2678539 [20] Yang X D, Zhang C Y, Tian Y L. Recognizing actions using depth motion maps-based histograms of oriented gradients. In: Proceedings of the 20th ACM International Conference on Multimedia. Nara, Japan: ACM, 2012. 1057−1060 [21] Li A N, Shan S G, Chen X L, Gao W. Face recognition based on non-corresponding region matching. In: Proceedings of the 2011 International Conference on Computer Vision. Barcelona, Spain: IEEE, 2011. 1060−1067 [22] Haghighat M, Abdel-Mottaleb M, Alhalabi W. Discriminant correlation analysis: Real-time feature level fusion for multimodal biometric recognition. IEEE Transactions on Information Forensics and Security, 2016, 11(9): 1984−1996 doi: 10.1109/TIFS.2016.2569061 [23] Rosipal R, Krämer N. Overview and recent advances in partial least squares. In: Proceedings of the 2006 International Statistical and Optimization Perspectives Workshop “Subspace, Latent Structure and Feature Selection”. Bohinj, Slovenia: Springer, 2006. 34−51 [24] Liu H P, Sun F C. Material identification using tactile perception: A semantics-regularized dictionary learning method. IEEE/ASME Transactions on Mechatronics, 2018, 23(3): 1050−1058 doi: 10.1109/TMECH.2017.2775208 [25] Zhuang Y T, Yang Y, Wu F. Mining semantic correlation of heterogeneous multimedia data for cross-media retrieval. IEEE Transactions on Multimedia, 2008, 10(2): 221−229 doi: 10.1109/TMM.2007.911822 [26] Sharma A, Kumar A, Daume H, Jacobs D W. Generalized multiview analysis: A discriminative latent space. In: Proceedings of the 2012 IEEE Conference on Computer Vision and Pattern Recognition. Providence, USA: IEEE, 2012. 2160−2167 [27] Wang K Y, He R, Wang L, Wang W, Tan T N. Joint feature selection and subspace learning for cross-modal retrieval. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2016, 38(10): 2010−2023 doi: 10.1109/TPAMI.2015.2505311 [28] Nie F, Huang H, Cai X, Ding C. Efficient and robust feature selection via joint $\ell_{2,1} $-norms minimization. In: Proceedings of the 23rd International Conference on Neural Information Processing Systems. Vancouver British, Canada: Curran Associates Inc., 2010. 1813−1821 [29] He R, Tan T N, Wang L, Zheng W S. $l_{2,1} $ regularized correntropy for robust feature selection. In: Proceedings of the 2012 IEEE Conference on Computer Vision and Pattern Recognition. Providence, USA: IEEE, 2012. 2504−2511 [30] 朱红蕾, 朱昶胜, 徐志刚. 人体行为识别数据集研究进展. 自动化学报, 2018, 44(6): 978-1004 doi: 10.16383/j.aas.2018.c170043Zhu Hong-Lei, Zhu Chang-Sheng, Xu Zhi-Gang. Research advances on human activity recognition datasets. Acta Automatica Sinica, 2018, 44(6): 978−1004 doi: 10.16383/j.aas.2018.c170043 [31] Shotton J, Fitzgibbon A, Cook M, Sharp T, Finocchio M, Moore R, et al. Real-time human pose recognition in parts from single depth images. In: Proceedings of the 2011 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). Colorado Springs, USA: IEEE, 2011. 1297−1304 [32] Chen C, Jafari R, Kehtarnavaz N. UTD-MHAD: A multimodal dataset for human action recognition utilizing a depth camera and a wearable inertial sensor. In: Proceedings of the 2015 IEEE International Conference on Image Processing (ICIP). Quebec City, Canada: IEEE, 2015. 168−172 [33] Chen C, Jafari R, Kehtarnavaz N. Action recognition from depth sequences using depth motion maps-based local binary patterns. In: Proceedings of the 2015 IEEE Winter Conference on Applications of Computer Vision. Waikoloa, USA: IEEE, 2015. 1092−1099 [34] Koniusz P, Cherian A, Porikli F. Tensor representations via kernel linearization for action recognition from 3D skeletons. In: Proceedings of the 14th European Conference on Computer Vision. Amsterdam, The Netherlands: Springer, 2016. 37−53 [35] Ben Tanfous A, Drira H, Ben Amor B. Coding Kendall′s shape trajectories for 3D action recognition. In: Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Salt Lake City, USA: IEEE, 2018. 2840−2849 [36] Vemulapalli R, Chellappa R. Rolling rotations for recognizing human actions from 3D skeletal data. In: Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition. Las Vegas, USA: IEEE, 2016. 4471−4479 [37] Wang L, Huynh D Q, Koniusz P. A comparative review of recent kinect-based action recognition algorithms. IEEE Transactions on Image Processing, 2019, 29: 15-28 [38] Rahmani H, Mian A. 3D action recognition from novel viewpoints. In: Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). Las Vegas: IEEE, 2016. 1506−1515 [39] Ben Tanfous A, Drira H, Ben Amor B. Sparse coding of shape trajectories for facial expression and action recognition. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2020, 42(10): 2594-2607 doi: 10.1109/TPAMI.2019.2932979 [40] Ben Amor B, Su J Y, Srivastava A. Action recognition using rate-invariant analysis of skeletal shape trajectories. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2016, 38(1): 1−13 -

 下载:
下载:








计量
- 文章访问数: 1408
- HTML全文浏览量: 310
- PDF下载量: 185
- 被引次数: 0
