

Asymmetric Cross-domain Transfer Learning of Person Re-identification Based on the Many-to-many Generative Adversarial Network
-
摘要: 无监督跨域迁移学习是行人再识别中一个非常重要的任务. 给定一个有标注的源域和一个没有标注的目标域, 无监督跨域迁移的关键点在于尽可能地把源域的知识迁移到目标域. 然而, 目前的跨域迁移方法忽略了域内各视角分布的差异性, 导致迁移效果不好. 针对这个缺陷, 本文提出了一个基于多视角的非对称跨域迁移学习的新问题. 为了实现这种非对称跨域迁移, 提出了一种基于多对多生成对抗网络(Many-to-many generative adversarial network, M2M-GAN)的迁移方法. 该方法嵌入了指定的源域视角标记和目标域视角标记作为引导信息, 并增加了视角分类器用于鉴别不同的视角分布, 从而使模型能自动针对不同的源域视角和目标域视角组合采取不同的迁移方式. 在行人再识别基准数据集Market1501、DukeMTMC-reID和MSMT17上, 实验验证了本文的方法能有效提升迁移效果, 达到更高的无监督跨域行人再识别准确率.Abstract: Unsupervised cross-domain transfer learning is an extremely important task in person re-identification (ReID). Given a labeled source domain and an unlabeled target domain, the key to the unsupervised cross-domain transfer learning is to transfer the knowledge from the source domain to the target domain as much as possible. However, current cross-domain transfer learning methods cannot obtain desired performance because they ignore the distribution differences between different views within domains. Therefore, we propose a new problem of view-based asymmetric cross-domain transfer learning for ReID. To address this problem, we propose a novel transfer learning method based on the many-to-many generative adversarial network (M2M-GAN). The M2M-GAN embeds source view labels and target view labels as the guide information, and adds view classifiers to identify different view distributions, so that the model can automatically adopt different transferring ways according to different source views or target views. Experiments on three ReID benchmark datasets Market1501, DukeMTMC-reID and MSMT17 verify that the proposed method can improve the performance of transfer learning and achieve higher recognition rate of unsupervised cross-domain ReID.1) 收稿日期 2019-04-16 录用日期 2019-09-02 Manuscript received April 16, 2019; accepted September 2, 2019 国家自然科学基金(61573387, 62076258), 广东省重点研发项目(2017B030306018), 广东省海洋经济发展项目(粤自然资合[2021] 34)资助 Supported by National Natural Science Foundation of China (61573387, 62076258), Key Research Projects in Guangdong Province (2017B030306018), and Contract of Department of Natural Resources of Guangdong Province ([2021] 34) 本文责任编委 刘青山 Recommended by Associate Editor LIU Qing-Shan 1. 中山大学计算机学院 广州 510006 2. 广州新华学院 广州 510520 3. 广东省信息安全技术重点实验室 广州 510006 4. 机器智能与先进计算教育部重点实验室 广州 5100062) 1. School of Computer Science and Engineering, Sun Yat-senUniversity, Guangzhou 510006 2. Guangzhou Xinhua University, Guangzhou 510520 3. Guangdong Province Key Laboratory of Computational Science, Guangzhou 510006 4. Key Laboratory of Machine Intelligence and Advanced Computing, Ministry of Education, Guangzhou 510006
-

图 2 本文提出的多视角对多视角迁移方式与现有迁移方式的比较
Fig. 2 Comparison of our M2M transferring way and the existing methods
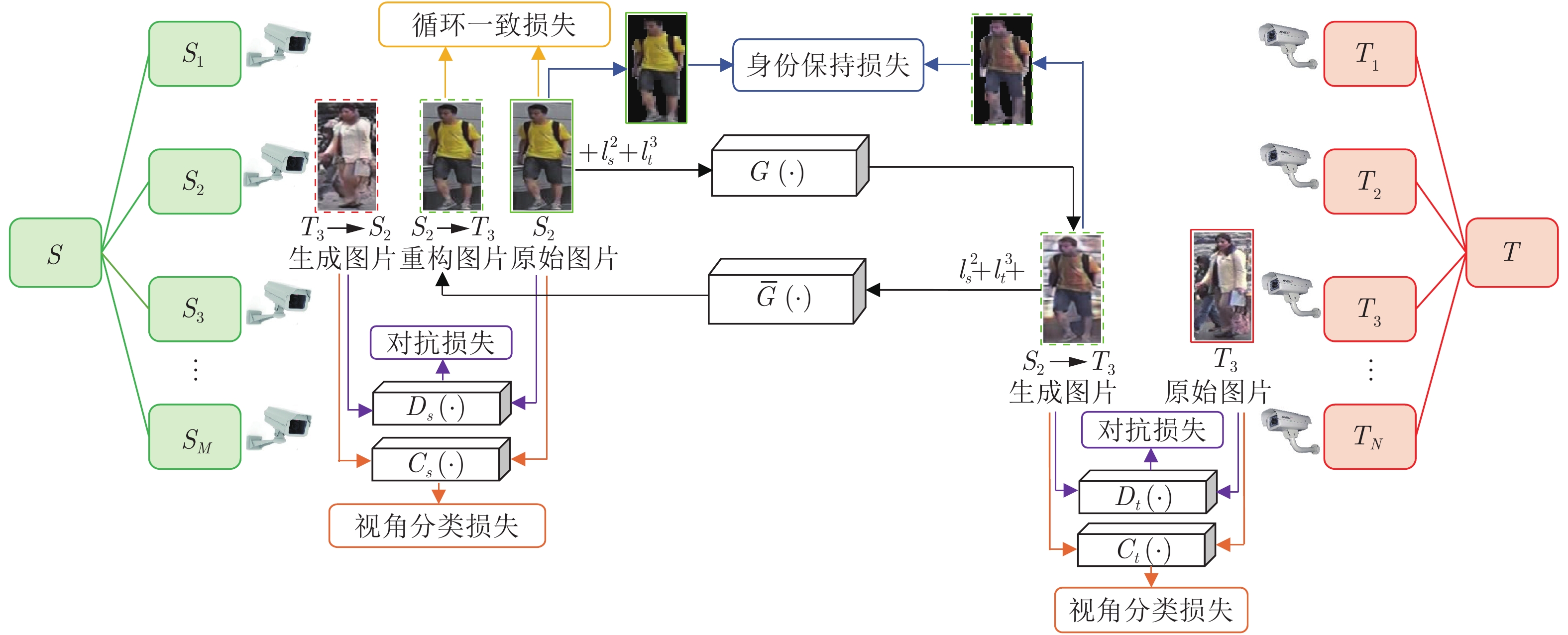
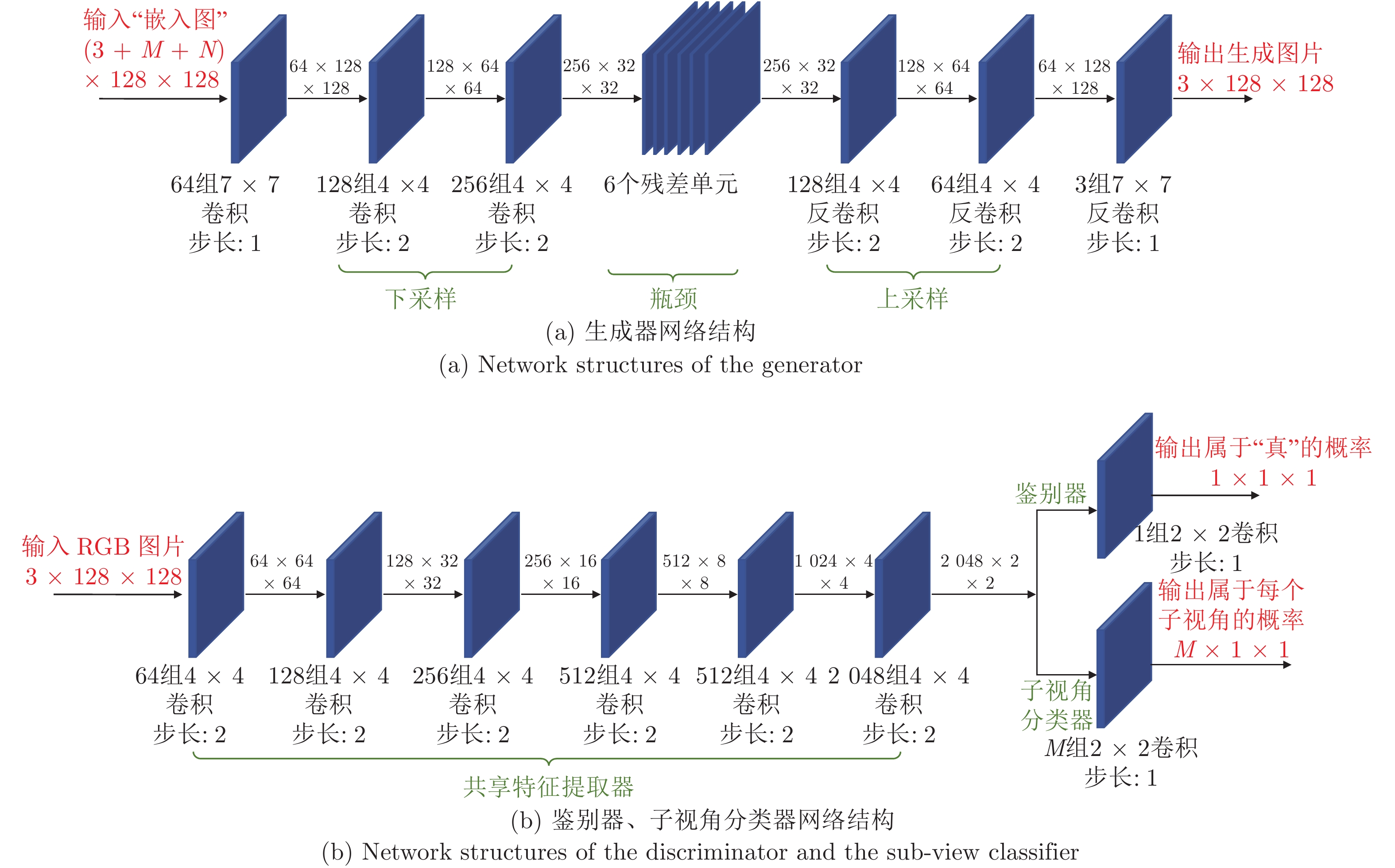
图 3 多对多生成对抗网络框架(省略了目标域
$ \rightarrow $ 源域的生成过程、循环一致损失和身份保持损失)Fig. 3 Framework of our M2M-GAN (The generation process, the cycle consistency loss, and the identity preserve loss of target domain
$ \rightarrow $ source domain are omitted)
图 7 其他数据集迁移到Market数据集的可视化例子
Fig. 7 Visual examples of translations from otherdatasets to the Market1501 dataset

图 8 其他数据集迁移到DukeMTMC-reID数据集的可视化例子
Fig. 8 Visual examples of translations from otherdatasets to the DukeMTMC-reID dataset

图 9 其他数据集迁移到MSMT17数据集的可视化例子
Fig. 9 Visual examples of translations from other datasets to the MSMT17 dataset
表 2 不同方法在Market1501数据集上的训练时间和模型参数量
Table 2 Training time and model parameters ofdifferent methods on the Market1501 dataset
方法 训练时间 模型参数量 Rank1 (%) CycleGAN 16 h 106.3 M 47.4 $M \times N$ CycleGAN 14 h$ \times 8 \times 6$ 106.3 M$ \times 8 \times 6$ 58.0 M2M-GAN (本文) 17 h 106.6 M 59.1  下载: 导出CSV
下载: 导出CSV
表 6 不同方法在DukeMTMC-reID数据集上的训练时间和模型参数量
Table 6 Training time and model parameters ofdifferent methods on the DukeMTMC-reID dataset
方法 训练时间 模型参数量 Rank1 (%) CycleGAN 16 h 106.3 M 43.1 $M \times N$ CycleGAN 14 h$ \times 6 \times 8$ 106.3 M$ \times 6 \times 8$ 49.9 M2M-GAN (本文) 17 h 106.6 M 52.0
下载: 导出CSV
表 1 不同风格迁移方法在Market1501数据集上的识别率(%)
Table 1 Matching rates of different style translation methods on the Market1501 dataset (%)
方法 (源域数据集) DukeMTMC-reID MSMT17 Rank1 mAP Rank1 mAP Pre-training 50.4 23.6 51.5 25.5 CycleGAN 47.4 21.5 46.1 21.1 M2M-GAN (本文) 59.1 29.6 57.9 28.8
下载: 导出CSV
表 3 不同模块在Market1501数据集上的准确率分析(%)
Table 3 Accuracy of different modules on the Market1501 dataset (%)
视角嵌入
模块视角分类
模块身份保持
模块Rank1 mAP $ \times $ $ \times $ $ \times $ 35.7 12.5 $ \times $ $ \times $ ${\surd}$ 47.4 21.5 ${\surd}$ $ \times $ ${\surd}$ 48.0 22.0 $ \times $ ${\surd}$ ${\surd}$ 48.6 22.1 ${\surd}$ ${\surd}$ ${\surd}$ 59.1 29.6
下载: 导出CSV
表 4 不同无监督方法在Market1501数据集上的识别率(%) (源数据集为DukeMTMC-reID数据集)
Table 4 Matching rates of different unsupervised methods on the Market1501 dataset (%) (The source dataset is the DukeMTMC-reID dataset)
下载: 导出CSV
表 5 不同风格迁移方法在DukeMTMC-reID数据集上的识别率(%)
Table 5 Matching rates of different style translation methods on the DukeMTMC-reID dataset (%)
方法 (源域数据集) Market1501 MSMT17 Rank1 mAP Rank1 mAP Pre-training 38.1 21.4 53.5 32.5 CycleGAN 43.1 24.1 51.1 30.0 M2M-GAN (本文) 52.0 29.8 61.1 37.5
下载: 导出CSV
表 7 不同模块在DukeMTMC-reID数据集上的准确率分析(%)
Table 7 Accuracy of different modules on theDukeMTMC-reID dataset (%)
视角嵌入
模块视角分类
模块身份保持
模块Rank1 mAP $ \times $ $ \times $ $ \times $ 31.8 12.6 $ \times $ $ \times $ ${\surd}$ 43.1 24.1 ${\surd}$ $ \times $ ${\surd}$ 45.0 25.3 $ \times $ ${\surd}$ ${\surd}$ 43.5 24.1 ${\surd}$ ${\surd}$ ${\surd}$ 52.0 29.8
下载: 导出CSV
表 8 不同无监督方法在DukeMTMC-reID数据集上的识别率(%) (源数据集为Market1501数据集)
Table 8 Matching rates of different unsupervised methods on the DukeMTMC-reID dataset (%) (The source dataset is the Market1501 dataset)
下载: 导出CSV
表 9 不同风格迁移方法在MSTM17数据集上的识别率(%)
Table 9 Matching rates of different styletranslation methods on the MSTM17 dataset (%)
方法 (源域数据集) Market1501 DukeMTMC-reID Rank1 mAP Rank1 mAP Pre-training 14.2 4.5 20.2 6.7 CycleGAN 22.7 7.6 24.7 7.8 M2M-GAN (本文) 31.9 10.8 36.8 11.9
下载: 导出CSV
-
[1] 李幼蛟, 卓力, 张菁, 李嘉锋, 张辉. 行人再识别技术综述. 自动化学报, 2018, 44(9): 1554-1568Li You-Jiao, Zhuo Li, Zhang Jing, Li Jia-Feng, Zhang Hui. A survey of person re-identification. Acta Automatica Sinica, 2018, 44(9): 1554-1568 [2] 齐美彬, 檀胜顺, 王运侠, 刘皓, 蒋建国. 基于多特征子空间与核学习的行人再识别. 自动化学报, 2016, 42(2): 299-308Qi Mei-Bin, Tan Sheng-Shun, Wang Yun-Xia, Liu Hao, Jiang Jian-Guo. Multi-feature subspace and kernel learning for person re-identification. Acta Automatica Sinica, 2016, 42(2): 299-308 [3] 刘一敏, 蒋建国, 齐美彬, 刘皓, 周华捷. 融合生成对抗网络和姿态估计的视频行人再识别方法. 自动化学报, 2020, 46(3): 576-584Liu Yi-Min, Jiang Jian-Guo, Qi Mei-Bin, Liu Hao, Zhou Hua-Jie. Video-based person re-identification method based on GAN and pose estimation. Acta Automatica Sinica, 2020, 46(3): 576-584 [4] Wang G C, Lai J H, Xie X H. P2SNet: Can an image match a video for person re-identification in an end-to-end way? IEEE Transactions on Circuits and Systems for Video Technology, 2018, 28(10): 2777-2787 doi: 10.1109/TCSVT.2017.2748698 [5] Feng Z X, Lai J H, Xie X H. Learning view-specific deep networks for person re-identification. IEEE Transactions on Image Processing, 2018, 27(7): 3472-3483 doi: 10.1109/TIP.2018.2818438 [6] Zhuo J X, Chen Z Y, Lai J H, Wang G C. Occluded person re-identification. In: Proceedings of the 2018 IEEE International Conference on Multimedia and Expo. San Diego, USA: IEEE, 2018. 1−6 [7] Chen Y C, Zhu X T, Zheng W S, Lai J H. Person re-identification by camera correlation aware feature augmentation. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2018, 40(2): 392-408 doi: 10.1109/TPAMI.2017.2666805 [8] Gong S G, Cristani M, Yan S C, Loy C C. Person Re-identification. London: Springer, 2014. 139−160 [9] Chen Y C, Zheng W S, Lai J H, Pong C Y. An asymmetric distance model for cross-view feature mapping in person reidentification. IEEE Transactions on Circuits and Systems for Video Technology, 2017, 27(8): 1661-1675 doi: 10.1109/TCSVT.2016.2515309 [10] Chen Y C, Zheng W S, Lai J H. Mirror representation for modeling view-specific transform in person re-identification. In: Proceedings of the 24th International Conference on Artificial Intelligence. Buenos Aires, Argentina: AAAI Press, 2015. 3402−3408 [11] Zheng W S, Li X, Xiang T, Liao S C, Lai J H, Gong S G. Partial person re-identification. In: Proceedings of the 2015 IEEE International Conference on Computer Vision. Santiago, Chile: IEEE, 2015. 4678−4686 [12] Liao S C, Hu Y, Zhu X Y, Li S Z. Person re-identification by local maximal occurrence representation and metric learning. In: Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition. Boston, USA: IEEE, 2015. 2197−2206 [13] Wu A C, Zheng W S, Lai J H. Robust depth-based person re-identification. IEEE Transactions on Image Processing, 2017, 26(6): 2588-2603 doi: 10.1109/TIP.2017.2675201 [14] Köstinger M, Hirzer M, Wohlhart P, Roth P M, Bischof H. Large scale metric learning from equivalence constraints. In: Proceedings of the 2012 IEEE Conference on Computer Vision and Pattern Recognition. Providence, USA: IEEE, 2012. 2288−2295 [15] Prosser B, Zheng W S, Gong S G, Xiang T. Person re-identification by support vector ranking. In: Proceedings of the British Machine Vision Conference. Aberystwyth, UK: British Machine Vision Association, 2010. 1−11 [16] Zheng L, Bie Z, Sun Y F, Wang J D, Su C, Wang S J, et al. Mars: A video benchmark for large-scale person re-identification. In: Proceedings of the 14th European Conference on Computer Vision. Amsterdam, the Netherlands: Springer, 2016. 868−884 [17] Yi D, Lei Z, Liao S C, Li S Z. Deep metric learning for person re-identification. In: Proceedings of the 22nd International Conference on Pattern Recognition. Stockholm, Sweden: IEEE, 2014. 34−39 [18] Cheng D, Gong Y H, Zhou S P, Wang J J, Zheng N N. Person re-identification by multi-channel parts-based CNN with improved triplet loss function. In: Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition. Las Vegas, USA: IEEE, 2016. 1335−1344 [19] Zheng Z D, Zheng L, Yang Y. Pedestrian alignment network for large-scale person re-identification. IEEE Transactions on Circuits and Systems for Video Technology, 2019, 29(10): 3037-3045 doi: 10.1109/TCSVT.2018.2873599 [20] Zhao L M, Li X, Zhuang Y T, Wang J D. Deeply-learned part-aligned representations for person re-identification. In: Proceedings of the 2017 IEEE International Conference on Computer Vision. Venice, Italy: IEEE, 2017. 3239−3248 [21] Luo H, Jiang W, Zhang X, Fan X, Qian J J, Zhang C. AlignedReID++: Dynamically matching local information for person re-identification. Pattern Recognition, 2019, 94: 53-61 doi: 10.1016/j.patcog.2019.05.028 [22] Zhong Z, Zheng L, Zheng Z D, Li S Z, Yang Y. Camera style adaptation for person re-identification. In: Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Salt Lake City, USA: IEEE, 2018. 5157−5166 [23] Su C, Li J N, Zhang S L, Xing J L, Gao W, Tian Q. Pose-driven deep convolutional model for person re-identification. In: Proceedings of the 2017 IEEE International Conference on Computer Vision. Venice, Italy: IEEE, 2017. 3980−3989 [24] Su C, Yang F, Zhang S L, Tian Q, Davis L S, Gao W. Multi-task learning with low rank attribute embedding for person re-identification. In: Proceedings of the 2015 IEEE International Conference on Computer Vision. Santiago, Chile: IEEE, 2015. 3739−3747 [25] Song C F, Huang Y, Ouyang W L, Wang L. Mask-guided contrastive attention model for person re-identification. In: Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Salt Lake City, USA: IEEE, 2018. 1179−1188 [26] Kalayeh M M, Basaran E, Gökmen M, Kamasak M E, Shah M. Human semantic parsing for person re-identification. In: Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Salt Lake City, USA: IEEE, 2018. 1062−1071 [27] Wang G C, Lai J H, Huang P G, Xie X H. Spatial-temporal person re-identification. In: Proceedings of the 33rd AAAI Conference on Artificial Intelligence. Hawaii, USA: AAAI, 2019. 8933−8940 [28] Yu H X, Wu A C, Zheng W S. Cross-view asymmetric metric learning for unsupervised person re-identification. In: Proceedings of the 2017 IEEE International Conference on Computer Vision. Venice, Italy: IEEE, 2017. 994−1002 [29] Fan H H, Zheng L, Yan C G, Yang Y. Unsupervised person re-identification: Clustering and fine-tuning. ACM Transactions on Multimedia Computing, Communications, and Applications, 2018, 14(4): Article No. 83 [30] Lin Y T, Dong X Y, Zheng L, Yan Y, Yang Y. A bottom-up clustering approach to unsupervised person re-identification. In: Proceedings of the 33rd AAAI Conference on Artificial Intelligence. Hawaii, USA: AAAI, 2019. 8738−8745 [31] Ganin Y, Ustinova E, Ajakan H, Germain P, Larochelle H, Laviolette F, et al. Domain-adversarial training of neural networks. The Journal of Machine Learning Research, 2016, 17(1): 2096-2030 [32] Ma A J, Li J W, Yuen P C, Li P. Cross-domain person reidentification using domain adaptation ranking SVMs. IEEE Transactions on Image Processing, 2015, 24(5): 1599-1613 doi: 10.1109/TIP.2015.2395715 [33] Deng W J, Zheng L, Ye Q X, Kang G L, Yang Y, Jiao J B. Image-image domain adaptation with preserved self-similarity and domain-dissimilarity for person re-identification. In: Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Salt Lake City, USA: IEEE, 2018. 994−1003 [34] Wei L H, Zhang S L, Gao W, Tian Q. Person transfer GAN to bridge domain gap for person re-identification. In: Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Salt Lake City, USA: IEEE, 2018. 79−88 [35] Goodfellow I J, Pouget-Abadie J, Mirza M, Xu B, Warde-Farley D, Ozair S, et al. Generative adversarial nets. In: Proceedings of the 27th Conference on Neural Information Processing Systems. Quebec, Canada: NIPS, 2014. 2672−2680 [36] Zhu J Y, Park T, Isola P, Efros A A. Unpaired image-to-image translation using cycle-consistent adversarial networks. In: Proceedings of the 2017 IEEE International Conference on Computer Vision. Venice, Italy: IEEE, 2017. 2242−2251 [37] Lin T Y, Maire M, Belongie S, Hays J, Perona P, Ramanan D, et al. Microsoft COCO: Common objects in context. In: Proceedings of the 13th European Conference on Computer Vision. Zurich, Switzerland: Springer, 2014. 740−755 [38] He K M, Gkioxari G, Dollár P, Girshick R. Mask R-CNN. In: Proceedings of the 2017 IEEE International Conference on Computer Vision. Venice, Italy: IEEE, 2017. 2980−2988 [39] Zheng L, Shen L Y, Tian L, Wang S J, Wang J D, Tian Q. Scalable person re-identification: A benchmark. In: Proceedings of the 2015 IEEE International Conference on Computer Vision. Santiago, Chile: IEEE, 2015. 1116−1124 [40] Zheng Z D, Zheng L, Yang Y. Unlabeled samples generated by GAN improve the person re-identification baseline in vitro. In: Proceedings of the 2017 IEEE International Conference on Computer Vision. Venice, Italy: IEEE, 2017. 3774−3782 [41] Kingma D P, Ba J. Adam: A method for stochastic optimization. In: Proceedings of the 3rd International Conference on Learning Representations. San Diego, USA: ICLR, 2014. 1−13 [42] He K M, Zhang X Y, Ren S Q, Sun J. Deep residual learning for image recognition. In: Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition. Las Vegas, USA: IEEE, 2016. 770−778 [43] Wang J Y, Zhu X T, Gong S G, Li W. Transferable joint attribute-identity deep learning for unsupervised person re-identification. In: Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Salt Lake City, USA: IEEE, 2018. 2275−2284 [44] Li Y J, Yang F E, Liu Y C, Yeh Y Y, Du X F, Wang Y C F. Adaptation and re-identification network: An unsupervised deep transfer learning approach to person re-identification. In: Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops. Salt Lake City, USA: IEEE, 2018. 172−178 [45] Peng P X, Xiang T, Wang Y W, Pontil M, Gong S G, Huang T J, et al. Unsupervised cross-dataset transfer learning for person re-identification. In: Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition. Las Vegas, USA: IEEE, 2016. 1306−1315 -

 下载:
下载:





计量
- 文章访问数: 1549
- HTML全文浏览量: 493
- PDF下载量: 310
- 被引次数: 0
