

-
摘要:
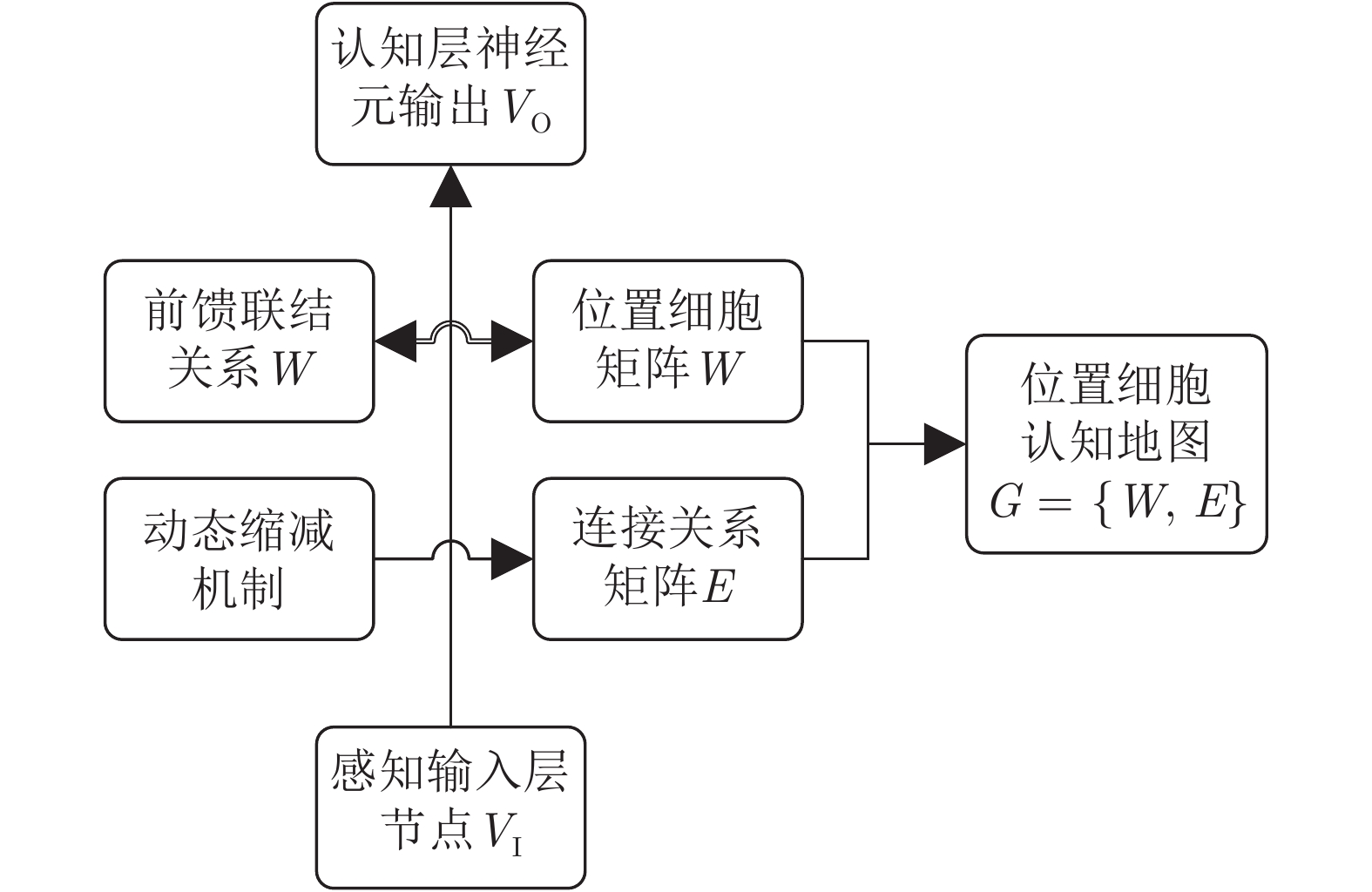
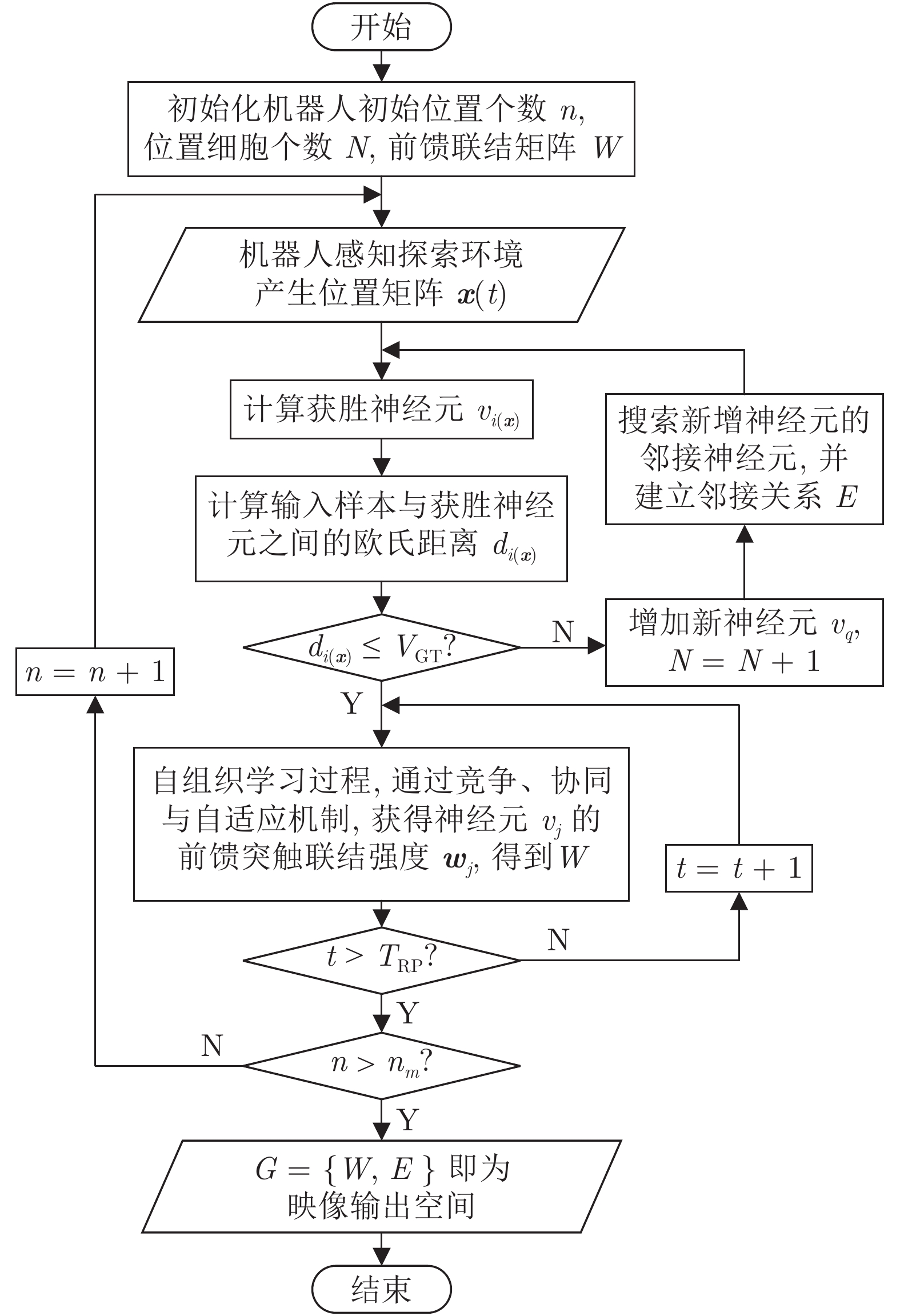
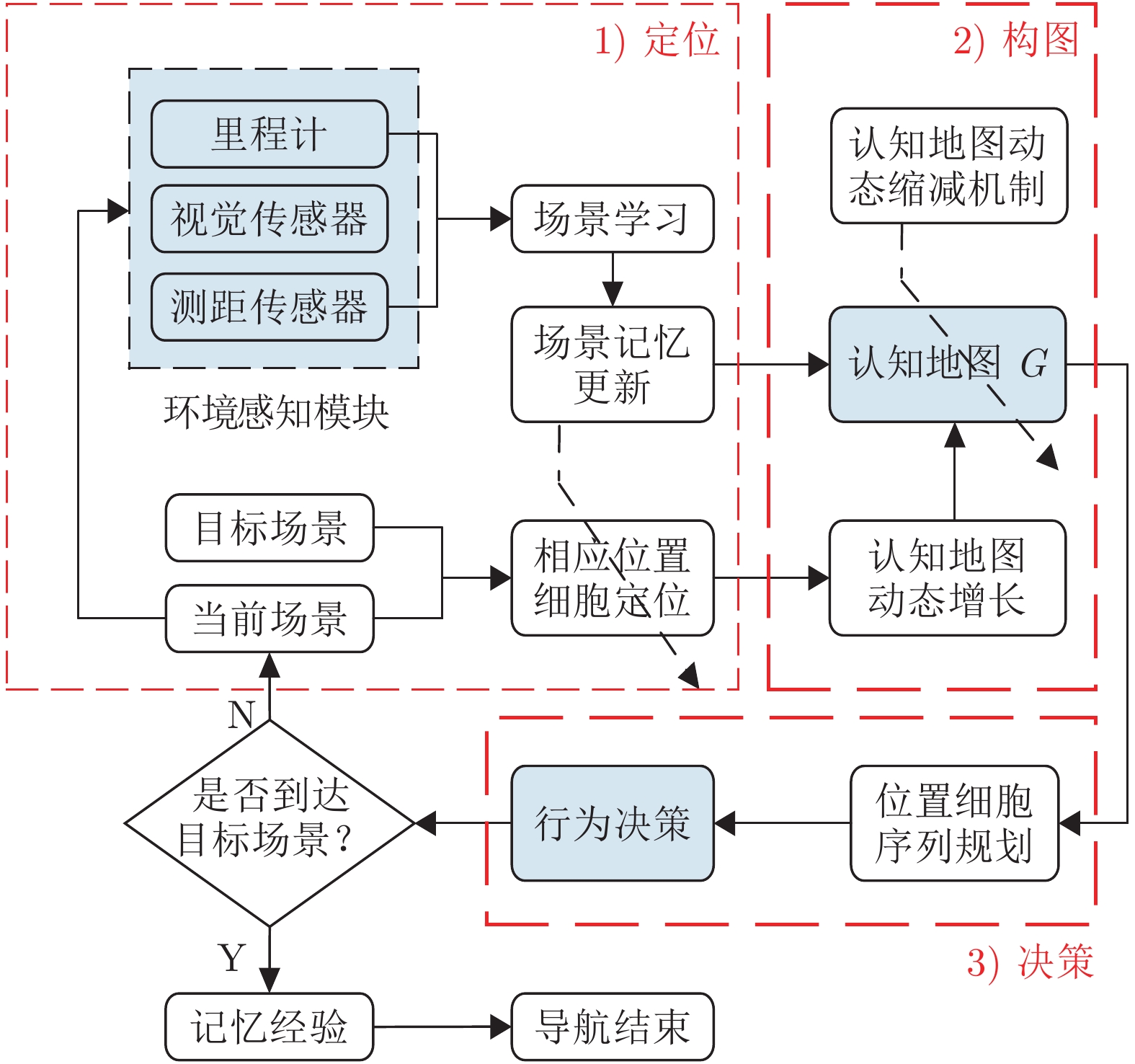
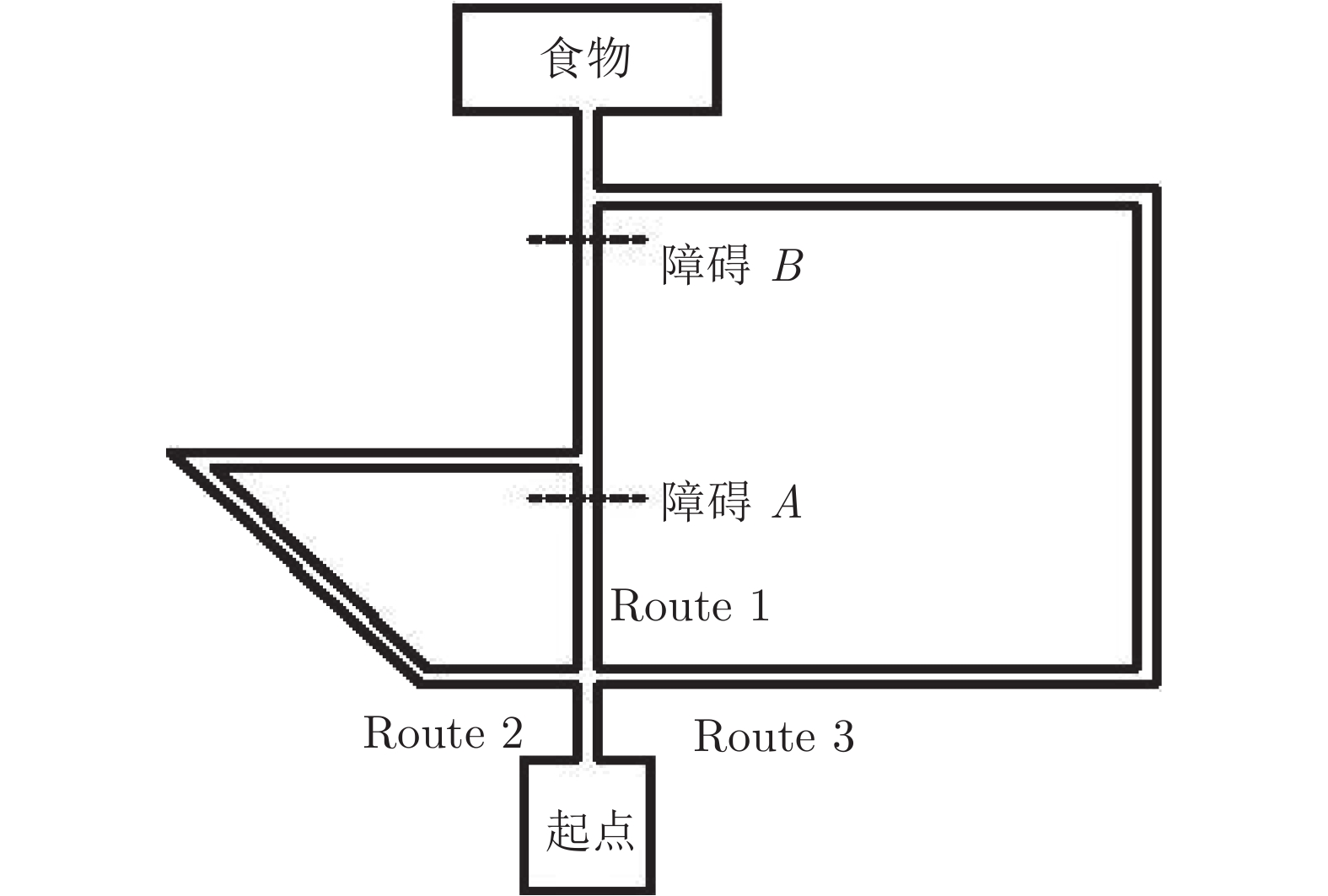
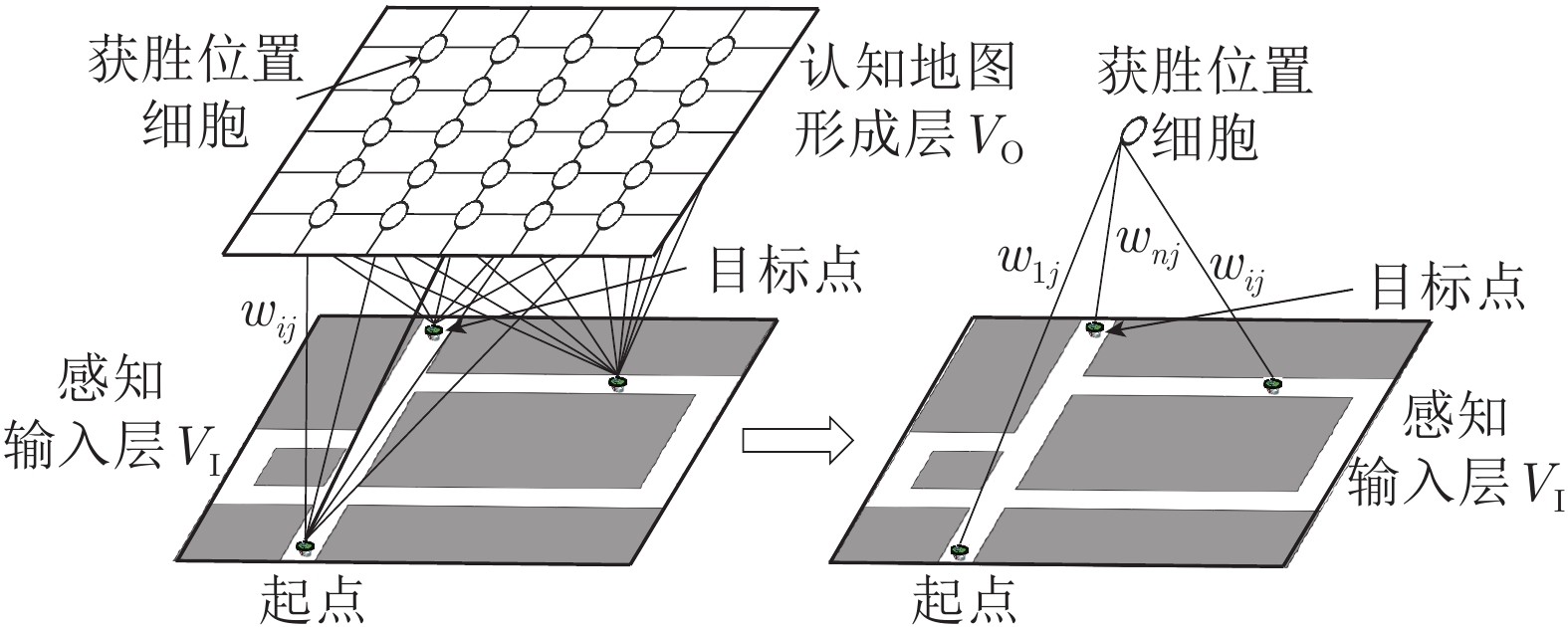
针对移动机器人环境认知问题, 受老鼠海马体位置细胞在特定位置放电的启发, 构建动态增减位置细胞认知地图模型(Dynamic growing and pruning place cells-based cognitive map model, DGP-PCCMM), 使机器人在与环境交互的过程中自组织构建认知地图, 进行环境认知. 初始时刻, 认知地图由初始点处激活的位置细胞构成; 随着与环境的交互, 逐渐得到不同位置点处激活的位置细胞, 并建立其之间的连接关系, 实现认知地图的动态增长; 如果机器人在已访问区域发现新的障碍物, 利用动态缩减机制对认知地图进行更新. 此外, 提出一种位置细胞序列规划算法, 该算法以所构建的认知地图作为输入, 进行位置细胞序列规划, 实现机器人导航. 为验证模型的正确性和有效性, 对Tolman的经典老鼠绕道实验进行再现. 实验结果表明, 本文模型能使机器人在与环境交互的过程中动态构建并更新认知地图, 能初步完成对Tolman老鼠绕道实验的再现. 此外, 进行了与四叉树栅格地图、动态窗口法的对比实验和与其他认知地图模型的讨论分析. 结果表明了本文方法在所构建地图的简洁性、完整性和对动态障碍适应性方面的优势.
-
关键词:
- 移动机器人 /
- 环境认知 /
- 海马体位置细胞 /
- 导航 /
- Tolman老鼠绕道实验
Abstract:Aiming at environmental cognition problem of mobile robot, inspired by the activation of hippocampal place cells in particular regions, a dynamic growing and pruning place cells-based cognitive map model (DGP-PCCMM) is established, which enables robot to construct the cognitive map self-organizingly by interacting with the environment and to implement environmental cognition. In the beginning, cognitive map consists of the activated place cell responding to current region; With the interaction with the environment, the responding activated place cells at different regions are gradually obtained, and the relationship among them is established, thus realizing the dynamic growing of the cognitive map; If new obstacles are discovered in the visited area, the cognitive map is updated using dynamic pruning mechanism. Besides, a sequence planning algorithm of place cells is proposed to realize robot navigation, which uses the constructed cognitive map as input. To verify the correctness and validity of the model, the classical Tolman detour task was reproduced. Results show that the model can enable robot to construct and update the cognitive map dynamically in the process of interacting with the environment, and to complete the reproduction of the Tolman detour task substantially. In addition, comparative experiments with occupancy grids, dynamic window approach and discussion about other cognitive map models are carried out, and results show the advantages of the proposed methods in the aspects of simplicity, completeness of the constructed cognitive maps and adaptability to dynamic obstacles.
-
Key words:
- Mobile robot /
- environmental cognition /
- hippocampal place cells /
- navigation /
- Tolman detour task
-
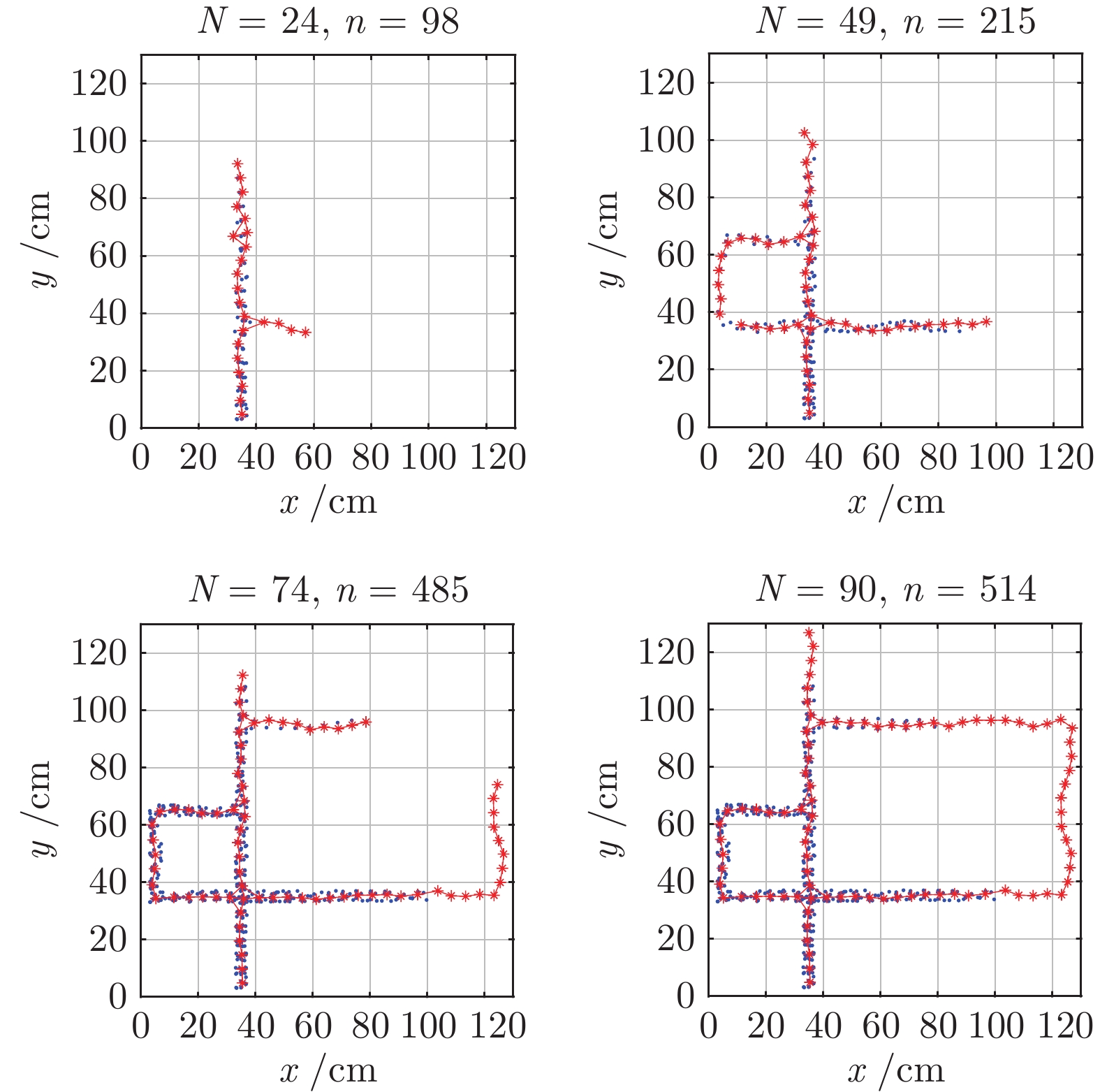
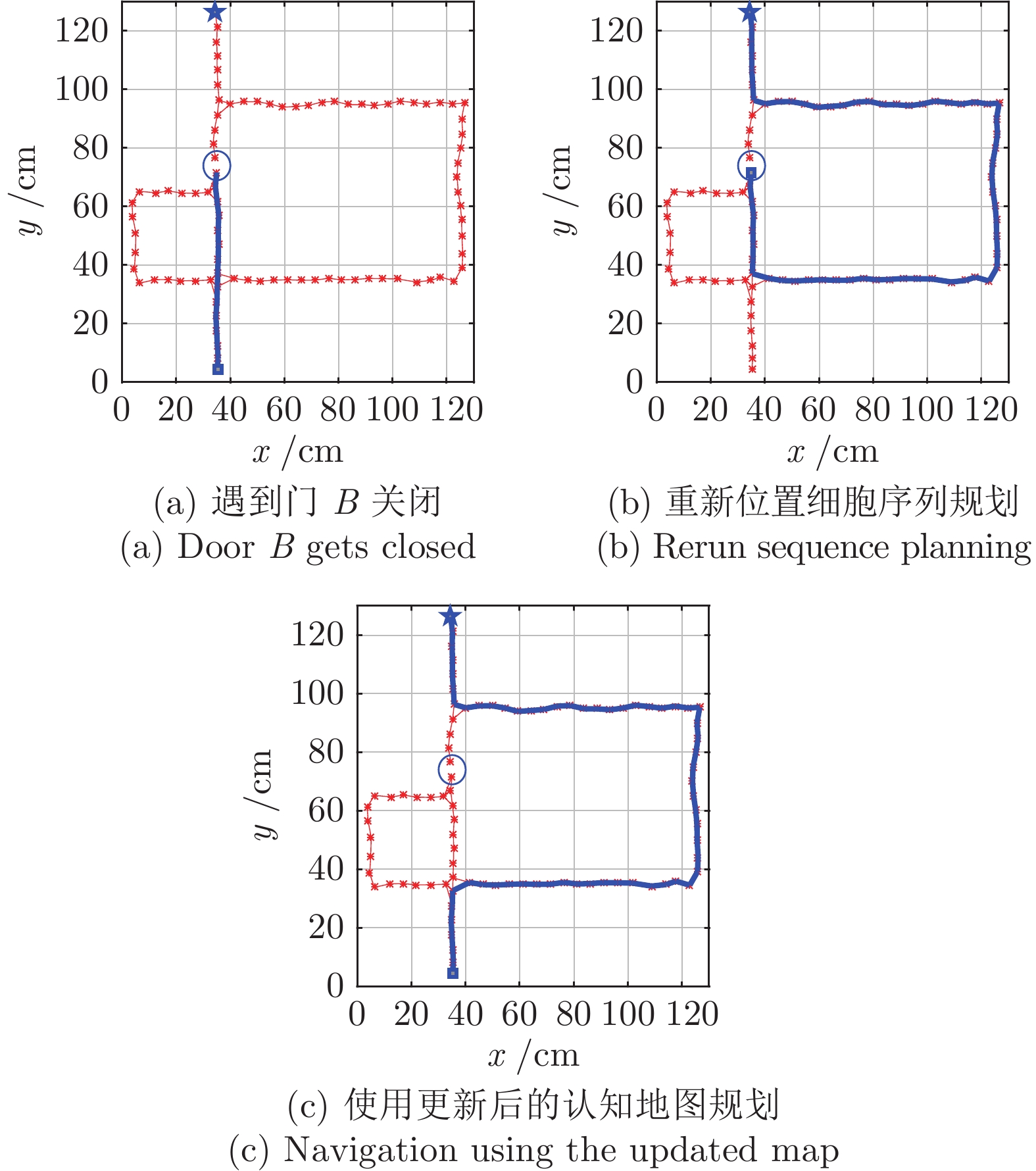
图 9 认知地图构建过程(
$ n_m $ = 1 000)Fig. 9 The formation process of cognitive map (
$ n_m $ = 1 000)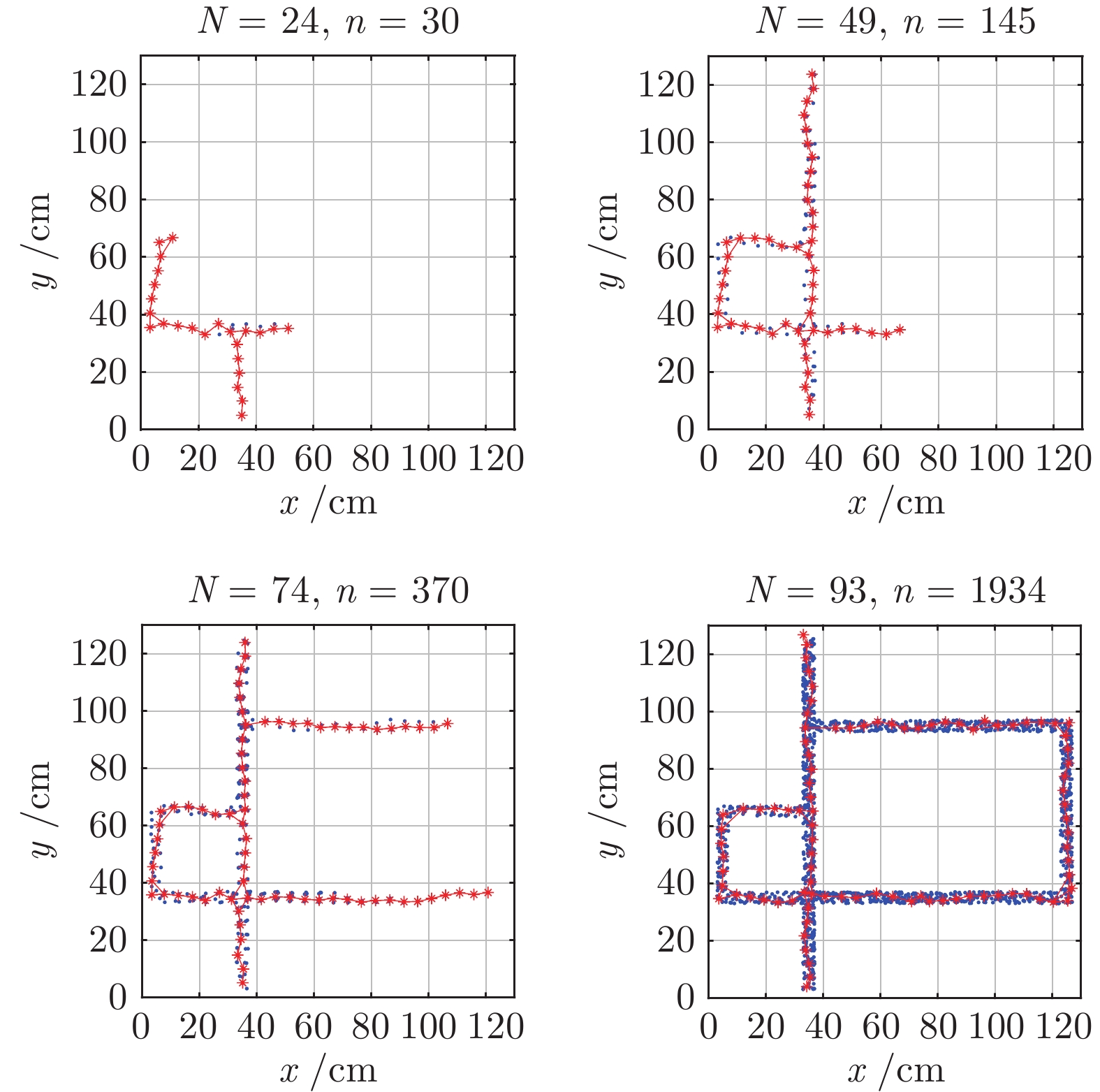
图 10 认知地图构建过程(
$ n_m $ = 2 000)Fig. 10 The formation process of cognitive map (
$ n_m $ = 2 000)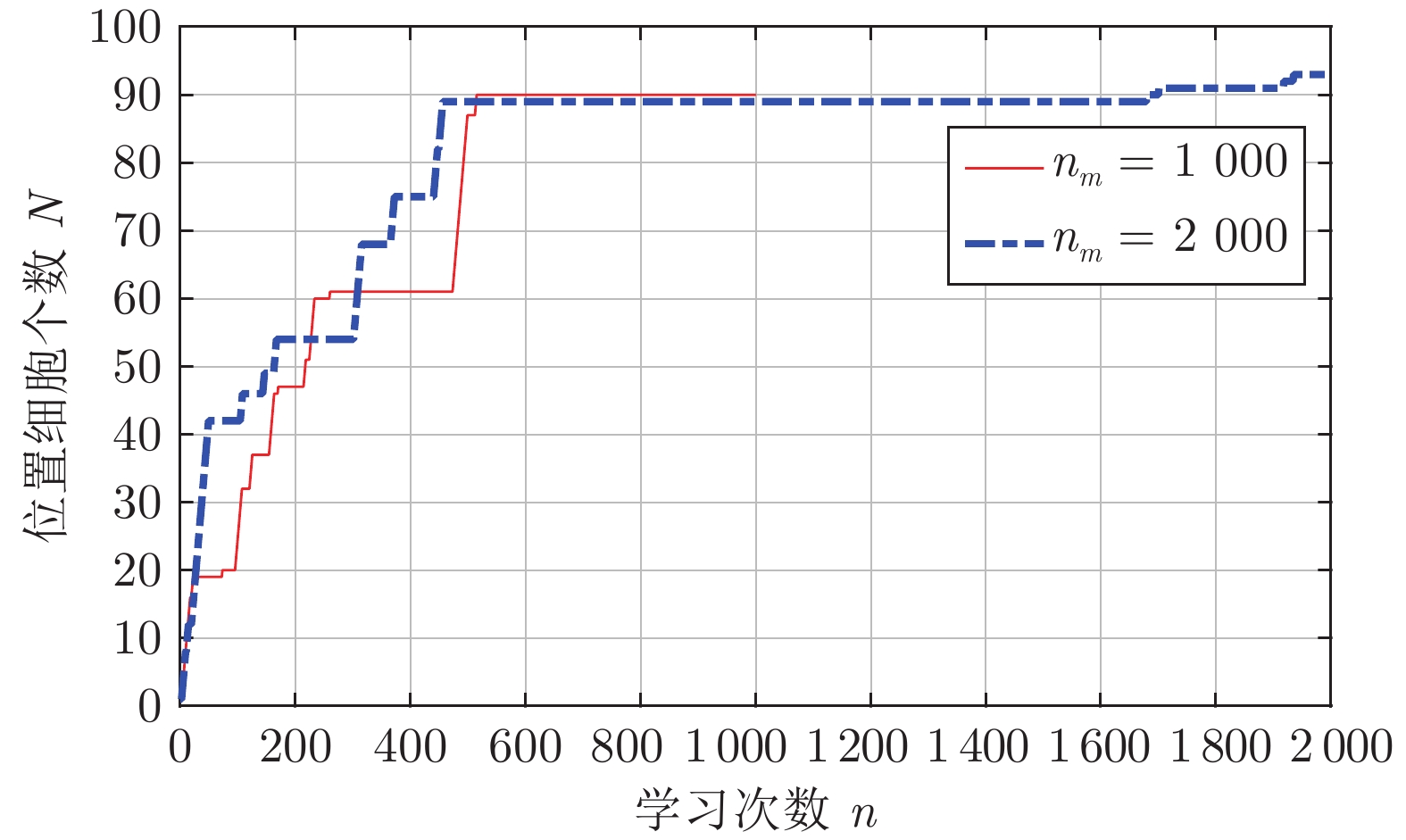
图 11 位置细胞个数随学习次数变化情况
Fig. 11 The number of place cells changing with the number of learning times
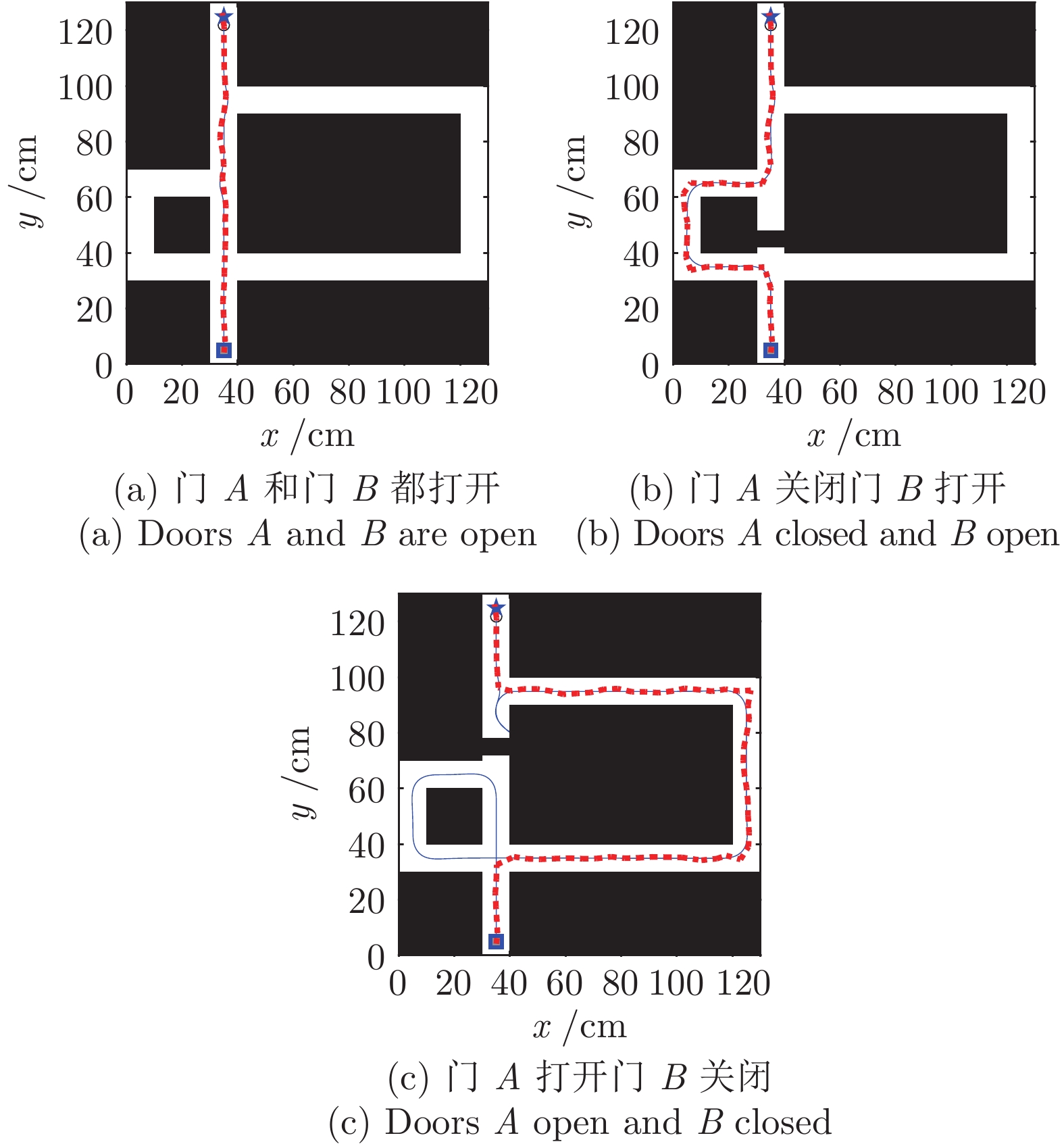
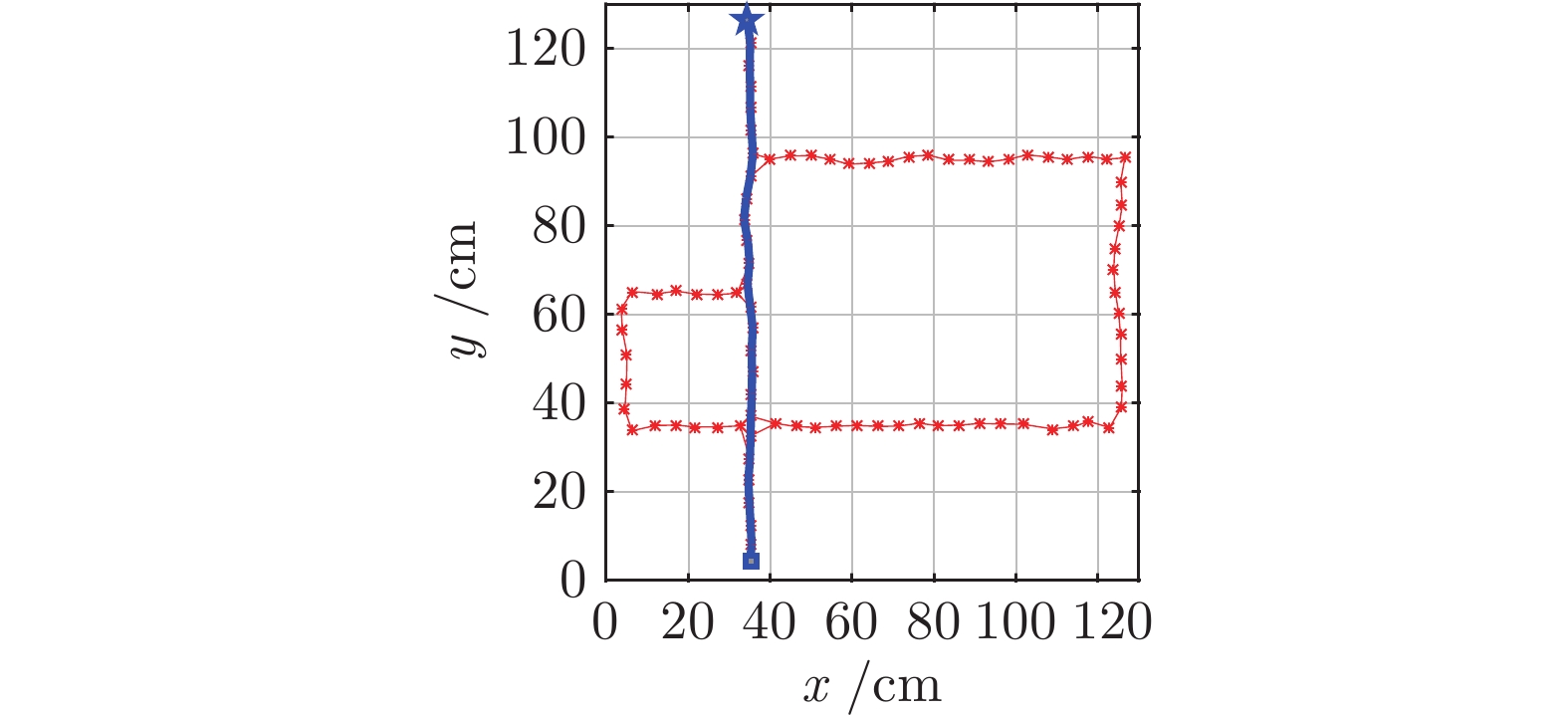
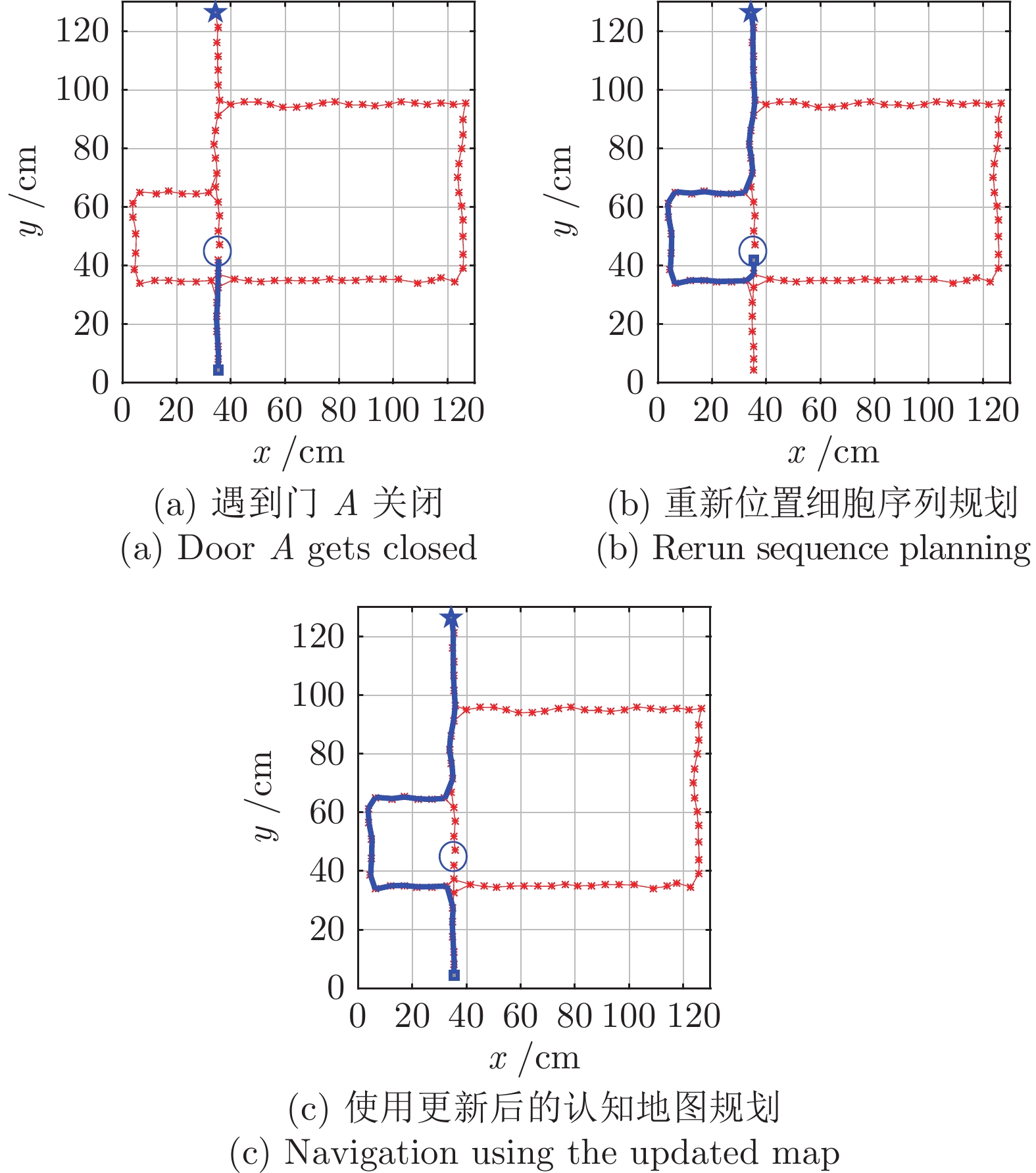
图 18 动态窗口法和本文方法导航结果对比图
Fig. 18 Comparation of navigation results between dynamic window approach and DGP-PCCMM
表 1 DGP-PCCMM初始参数设置
Table 1 Initial simulation parameters for DGP-PCCMM
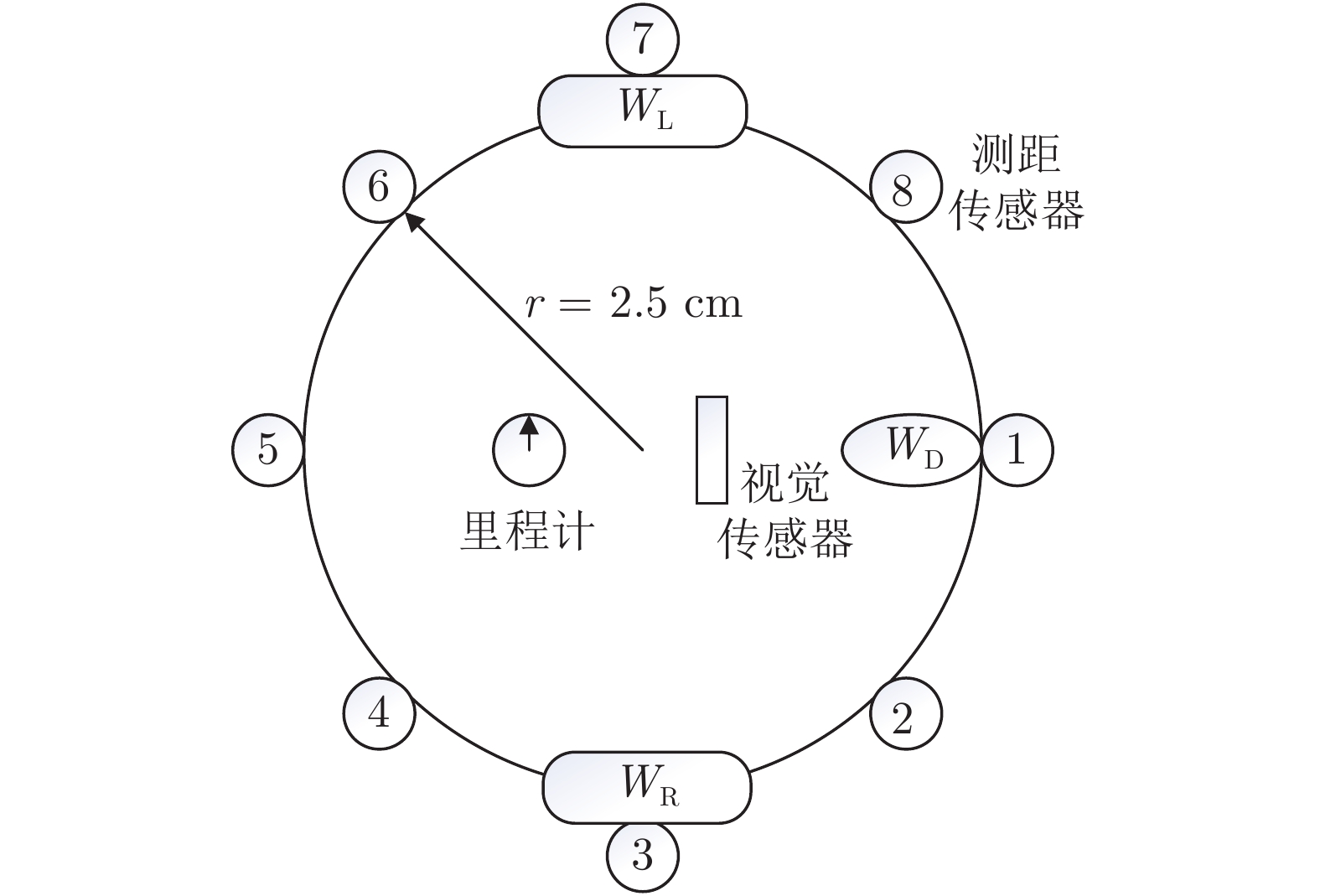
参数 值 参数 值 参数 值 $ t $ 0 $ n_2 $ 3.2 $ T_{\rm{RP}} $ 3 $ N $ 0 $ n_{m} $ 1 000 $ n_{\rm{init}} $ 1 $ V_{\rm{GT}} $ 4.5 $ \sigma_0 $ 0.01 $ r $ 0.025 m $ n_1 $ 1.8 $ \alpha_0 $ 0.01 $ d_{\rm{step}} $ 0.05 m  下载: 导出CSV
下载: 导出CSV
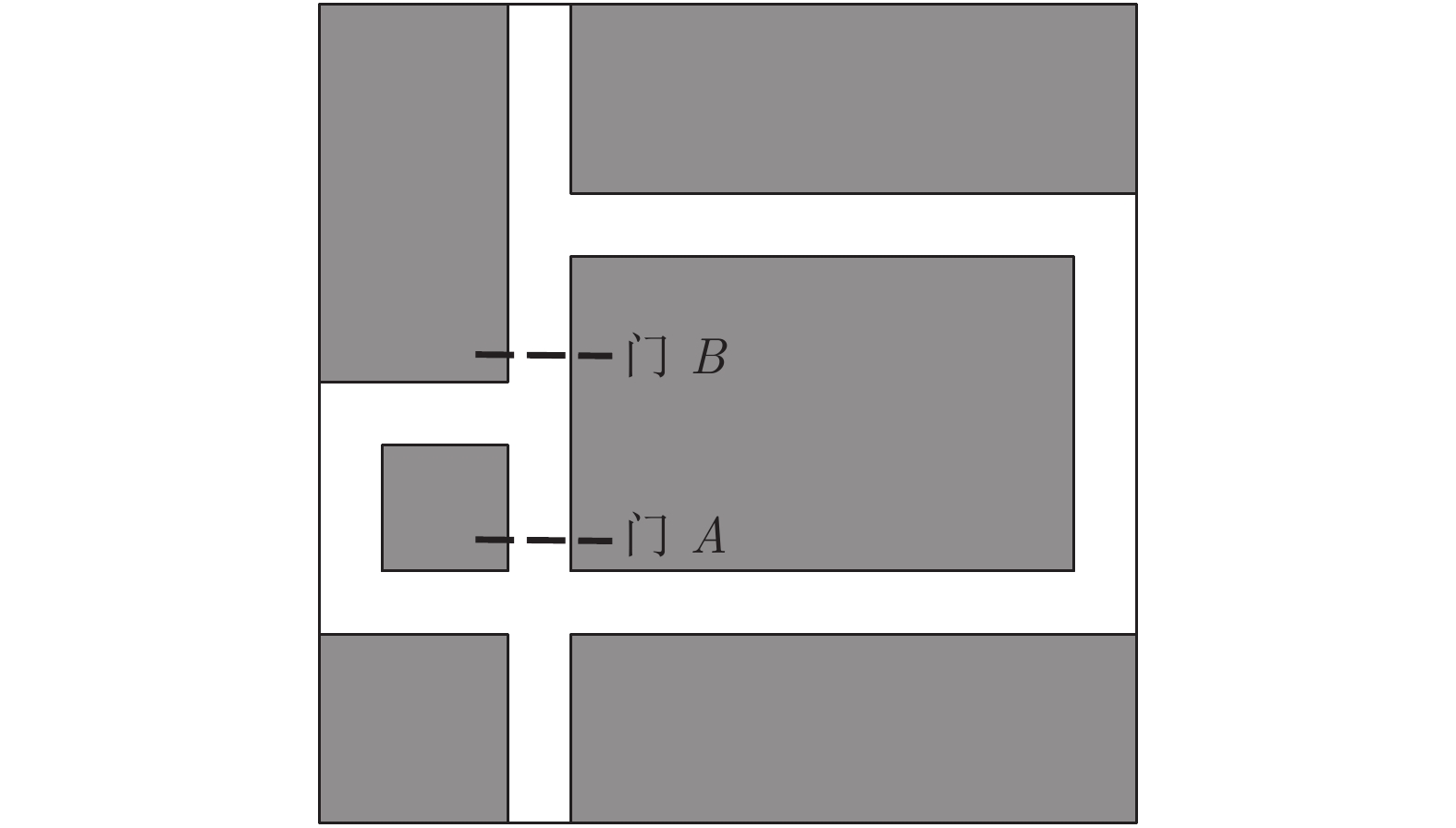
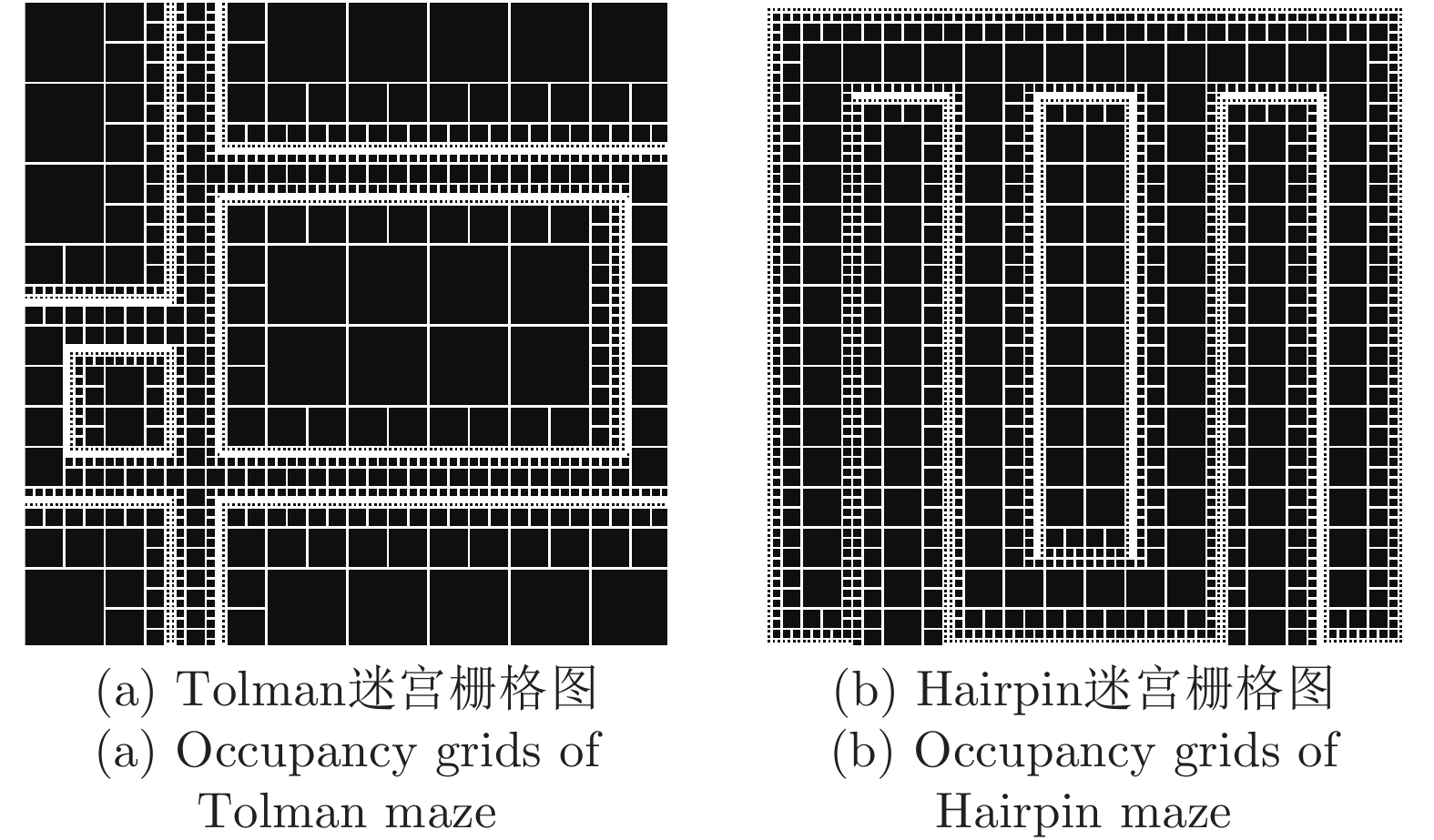
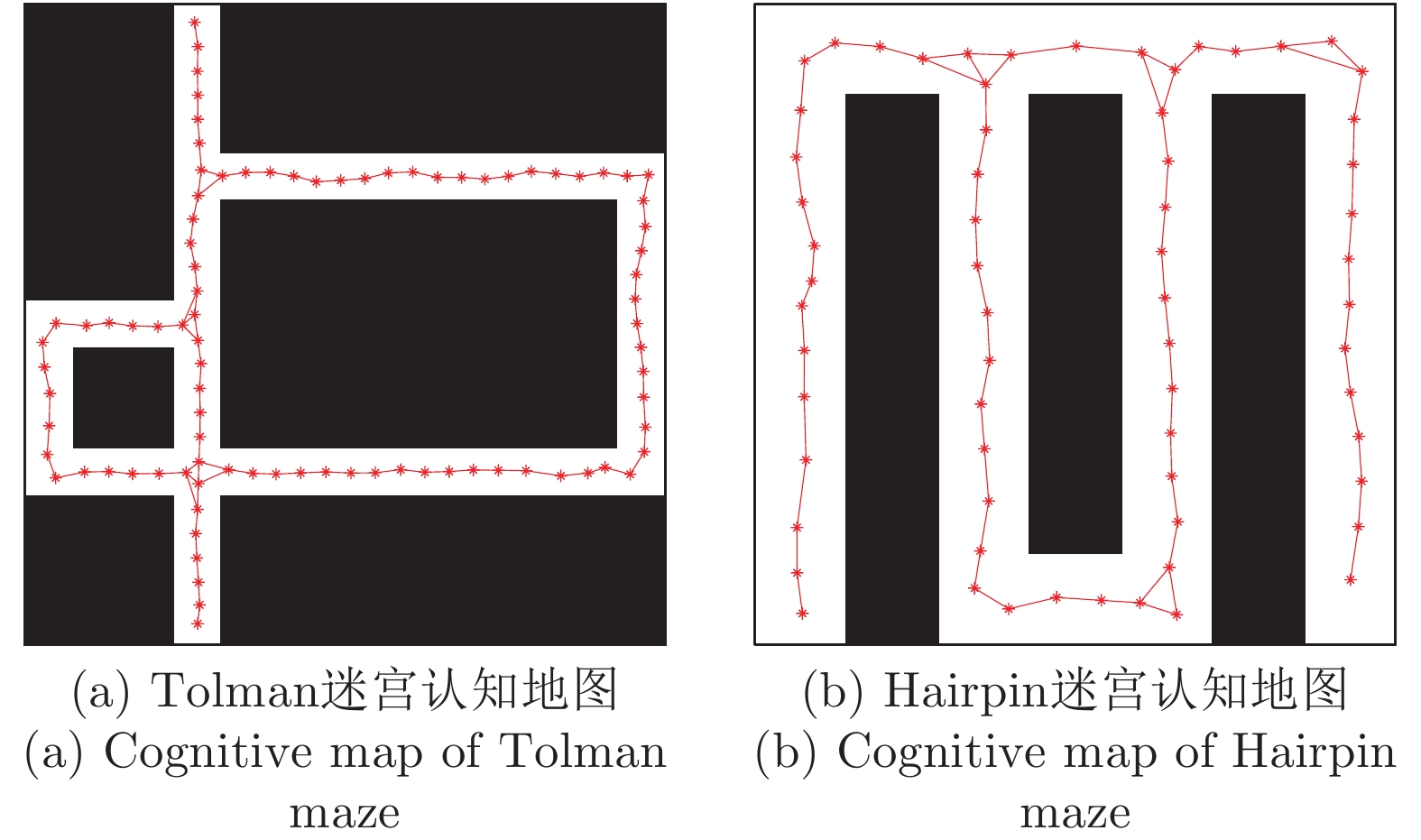
表 2 本文与四叉树栅格对比
Table 2 Comparison between occupancy grids based on quadtree and DGP-PCCMM
性能指标 占用栅格或位置
细胞个数有无仿生性 对动态变化
的适应性四叉树栅格 > 256 (Hairpin);
> 196 (Tolman)无 较弱 本文认知地图 65 (Hairpin);
90 (Tolman)有 较好
下载: 导出CSV
表 3 本文与动态窗口法对比
Table 3 Comparison between dynamic window approach and our method
性能指标环境 运行时间 (s) 导航路线长度 (cm) T1 T2 T3 T1 T2 T3 动态窗口法 141.4 188.6 717.9 121.3 171.2 418.6 本文认知地图 24.5 35.7 60.2 122.6 178.6 301.2
下载: 导出CSV
-
[1] 曹风魁, 庄严, 闫飞, 杨奇峰, 王伟. 移动机器人长期自主环境适应研究进展和展望. 自动化学报, 2020, 46(2): 205−221Cao Feng-Kui, Zhuang Yan, Yan Fei, Yang Qi-Feng, Wang Wei. Long-term autonomous environment adaptation of mobile robots: state-of-the-art methods and prospects. Acta Automatica Sinica, 2020, 46(2): 205−221 [2] 朱博, 高翔, 赵燕喃. 机器人室内语义建图中的场所感知方法综述. 自动化学报, 2017, 43(4): 493−508Zhu Bo, Gao Xiang, Zhao Yan-Nan. Place perception for robot indoor semantic mapping: A survey. Acta Automatica Sinica, 2017, 43(4): 493−508 [3] Collett M, Chittka L, Collett T S. Spatial memory in insect navigation. Current Biology, 2013, 23(17): R789−R800 doi: 10.1016/j.cub.2013.07.020 [4] Ruan X, Wu X. The skinner automaton: A psychological model formalizing the theory of operant conditioning. Science China-Technological Sciences, 2013, 56(11): 2745−2761 doi: 10.1007/s11431-013-5369-0 [5] Milford M, Schulz R. Principles of goal-directed spatial robot navigation in biomimetic models. Philosophical Transactions of Royal Society B, 2014, 369: 1−13 [6] Frohnwieser A, Murray J C, Pike T W, Wilkinson A. Using robots to understand animal cognition. Journal of the Experimental Analysis of Behavior, 2016, 105(1): 14−22 doi: 10.1002/jeab.193 [7] 秦方博, 徐德. 机器人操作技能模型综述. 自动化学报, 2019, 45(8): 1401−1418Qin Fang-Bo, Xu De. Review of robot manipulation skill models. Acta Automatica Sinica, 2019, 45(8): 1401−1418 [8] Tang H J, Huang W W, Narayanamoorthy A, Yan R. Cognitive memory and mapping in a brain-like system for robotic navigation. Neural Networks, 2017, 87: 27−37 doi: 10.1016/j.neunet.2016.08.015 [9] Gianelli S, Harland B, Fellous J. A new rat-compatible robotic framework for spatial navigation behavioral experiments. Journal of Neuroscience Methods, 2018, 294: 40−50 doi: 10.1016/j.jneumeth.2017.10.021 [10] 黄秉宪. 关于人工智能中的脑模型研究. 自动化学报, 1979, 5(2): 157−166Huang Bing-xian. On brain model in artificial intelligence. Acta Automatica Sinica, 1979, 5(2): 157−166 [11] Tolman E C. Cognitive maps in rats and men. Psychological Review, 1948, 55(4): 189−208 doi: 10.1037/h0061626 [12] O'Keefe J, Dostrovsky J. The hippocampus as a spatial map. Preliminary evidence from unit activity in the freely-moving rat. Brain Research, 1971, 34(1): 171−175 doi: 10.1016/0006-8993(71)90358-1 [13] Mehta M R. From synaptic plasticity to spatial maps and sequence learning. Hippocampus, 2015, 25(6): 756−762 doi: 10.1002/hipo.22472 [14] Alme C B, Miao C, Jezek K, Treves A, Moser E, Moser M B. Place cells in the hippocampus: eleven maps for eleven rooms. Proceedings of the National Academy of Sciences, 2014, 111(52): 18428−18435 doi: 10.1073/pnas.1421056111 [15] 于乃功, 苑云鹤, 李倜, 蒋晓军, 罗子维. 一种基于海马认知机理的仿生机器人认知地图构建方法. 自动化学报, 2018, 44(1): 52−73Yu Nai-Gong, Yuan Yun-He, Li Ti, Jiang Xiao-Jun, Luo Zi-Wei. A cognitive map building algorithm by means of cognitive mechanism of hippocampus. Acta Automatica Sinica, 2018, 44(1): 52−73 [16] 邹强, 丛明, 刘冬, 杜宇, 崔瑛雪. 基于生物认知的移动机器人路径规划方法. 机器人, 2018, 40(6): 894−902Zou Qiang, Cong Ming, Liu Dong, Du Yu, Cui Ying-Xue. Path planning of mobile robots based on biological cognition. Robot, 2018, 40(6): 894−902 [17] Kabadayi C, Bobrowicz K, Osvath M. The detour paradigm in animal cognition. Animal Cognition, 2018, 21(1): 21−35 doi: 10.1007/s10071-017-1152-0 [18] Fakhari P, Khodadadi A, Busemeyer J R. The detour problem in a stochastic environment: Tolman revisited. Cognitive Psychology, 2018, 101: 29−49 doi: 10.1016/j.cogpsych.2017.12.002 [19] Schmajuk N A, Buhusi C V. Spatial and temporal cognitive mapping: a neural network approach. Trends in Cognitive Sciences, 1997, 1(3): 109−114 doi: 10.1016/S1364-6613(97)89057-2 [20] Martinet L E, Sheynikhovich D, Benchenane K, Arleo A. Spatial learning and action planning in a prefrontal cortical network model. Plos Computational Biology, 2011, 7(5): e1002045 doi: 10.1371/journal.pcbi.1002045 [21] Gao Y, Song H. A motor learning model based on the basal ganglia in operant conditioning. In: Proceedings of the 26th Chinese Control and Decision Conference. Changsha, China: IEEE, 2014. 5236−5241 [22] Alvernhe A, Save E, Poucet B. Local remapping of place cell firing in the Tolman detour task. European Journal of Neuroscience, 2011, 33(9): 1696−1705 doi: 10.1111/j.1460-9568.2011.07653.x [23] Ruan X G, Gao Y Y, Song H J, Chen J. A new dynamic self-organizing method for mobile robot environment mapping. Journal of Intelligent Learning Systems and Applications, 2011, 3: 249−256 doi: 10.4236/jilsa.2011.34028 [24] Vasighi M, Amini H. A directed batch growing approach to enhance the topology preservation of self-organizing map. Applied Soft Computing, 2017, 55: 424−435 doi: 10.1016/j.asoc.2017.02.015 [25] Madl T, Chen K, Montaldi D, Trappl R. Computational cognitive models of spatial memory in navigation space: A review. Neural Networks, 2015, 65: 18−43 doi: 10.1016/j.neunet.2015.01.002 [26] Ciancia F. Tolman and Honzik (1930) revisited or the mazes of psychology (1930−1980). The Psychological Record, 1991, 41: 461−472 [27] Thrun S. Robotic mapping: A survey. Exploring Artificial Intelligence in the New Millennium, 2002, 1: 1−35 [28] 周彦, 李雅芳, 王冬丽, 裴廷睿. 视觉同时定位与地图创建综述. 智能系统学报, 2018, 13(1): 97−106Zhou Yan, Li Ya-Fang, Wang Dong-Li, Pei Ting-Rui. A survey of VSLAM. CAAI Transactions on Intelligent Systems, 2018, 13(1): 97−106 [29] Barrera A, Cáceres A, Weitzenfeld A, Amaya V R. Comparative experimental studies on spatial memory and learning in rats and robots. Journal of Intelligent and Robotic Systems, 2011, 63: 361−397 doi: 10.1007/s10846-010-9467-y [30] 郭利进, 师五喜, 李颖, 李福祥. 基于四叉树的自适应栅格地图创建算法. 控制与决策, 2011, 26(11): 1690−1694Guo Li-Jin, Shi Wu-Xi, Li Ying, Li Fu-Yang. Mapping algorithm using adaptive size of occupancy grids based on quadtree. Control and Decision, 2011, 26(11): 1690−1694 [31] Chersi F, Burgess N. The cognitive architecture of spatial navigation: hippocampal and striatal contributions. Neuron, 2015, 88(1): 64−77 doi: 10.1016/j.neuron.2015.09.021 [32] 许凯波, 鲁海燕, 黄洋, 胡士娟. 基于双层蚁群算法和动态环境的机器人路径规划方法. 电子学报, 2019, 47(10): 2166−2176 doi: 10.3969/j.issn.0372-2112.2019.10.019Xu Kai-Bo, Lu Hai-Yan, Huang Yang, Hu Shi-Juan. Robot path planning based on double-layer ant colony optimization algorithm and dynamic environment. Acta Electronica Sinica, 2019, 47(10): 2166−2176 doi: 10.3969/j.issn.0372-2112.2019.10.019 [33] 王永雄, 田永永, 李璇, 李梁华. 穿越稠密障碍物的自适应动态窗口法. 控制与决策, 2019, 34(5): 927−936Wang Yong-Xiong, Tian Yong-Yong, Li Xuan, Li Liang-Hua. Self-adaptive dynamic window approach in dense obstacles. Control and Decision, 2019, 34(5): 927−936 [34] Fox D, Burgard W, Thrun S. The dynamic window approach to collision avoidance. Robotics and Automation Magazine, 1997, 4(1): 23−33 doi: 10.1109/100.580977 [35] Erdem U M, Hasselmo M. A goal directed spatial navigation model using forward trajectory planning based on grid cells. European Journal of Neuroscience, 2012, 35(6): 916−931 doi: 10.1111/j.1460-9568.2012.08015.x -

 下载:
下载:








计量
- 文章访问数: 1709
- HTML全文浏览量: 1314
- PDF下载量: 277
- 被引次数: 0
