

-
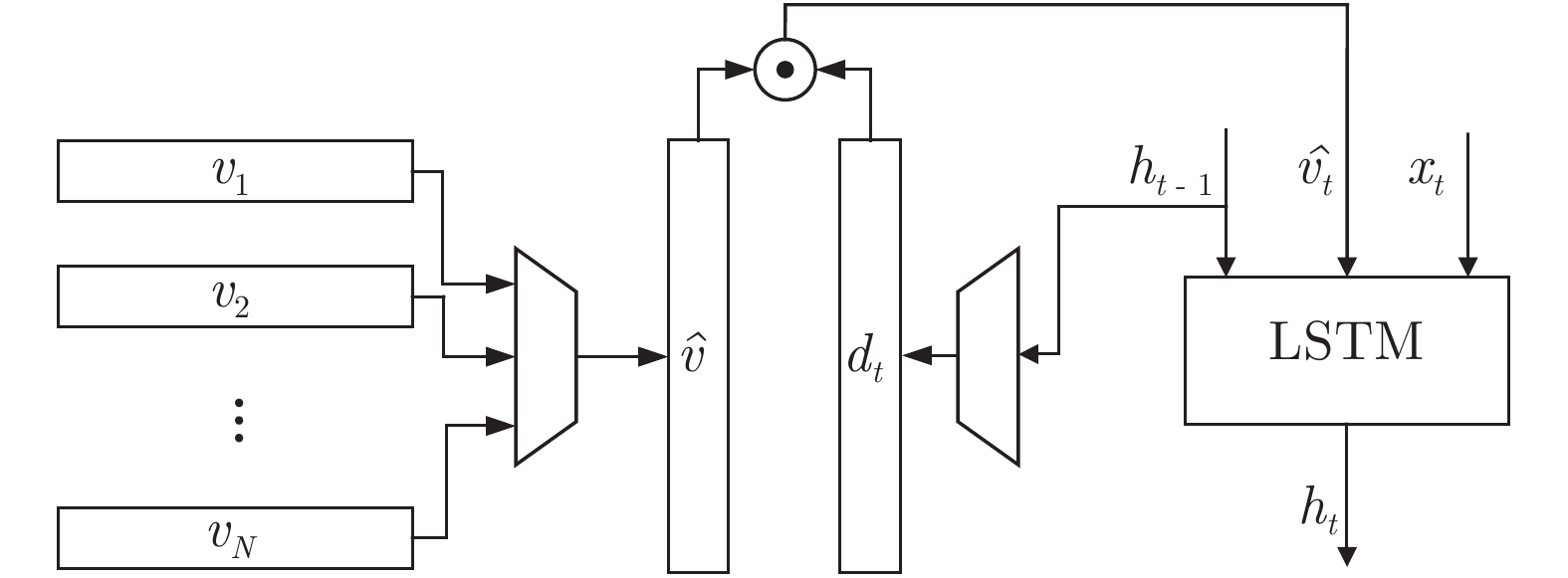
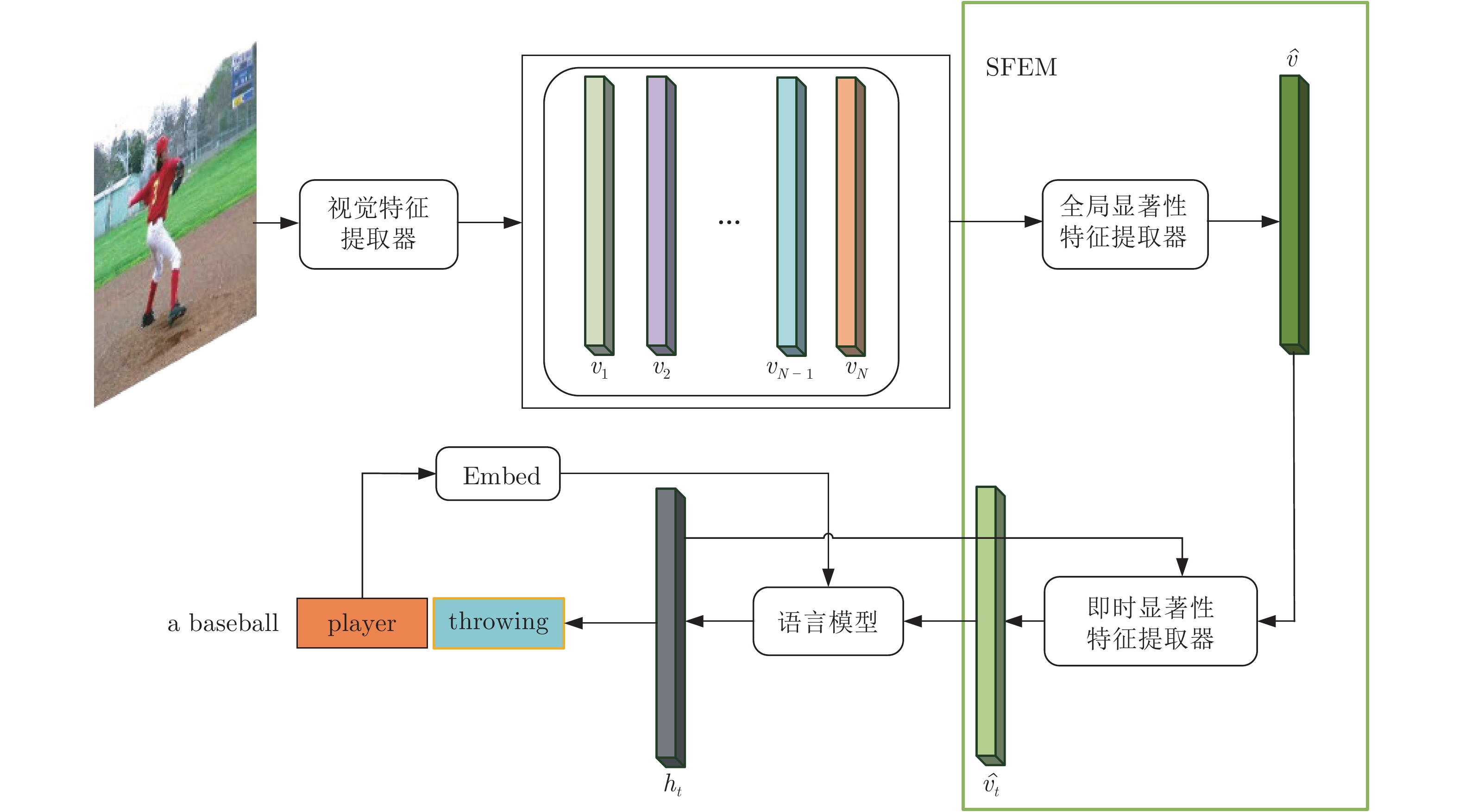
摘要: 图像描述(Image captioning)是一个融合了计算机视觉和自然语言处理这两个领域的研究方向, 本文为图像描述设计了一种新颖的显著性特征提取机制(Salient feature extraction mechanism, SFEM), 能够在语言模型预测每一个单词之前快速地向语言模型提供最有价值的视觉特征来指导单词预测, 有效解决了现有方法对视觉特征选择不准确以及时间性能不理想的问题. SFEM包含全局显著性特征提取器和即时显著性特征提取器这两个部分: 全局显著性特征提取器能够从多个局部视觉向量中提取出显著性视觉特征, 并整合这些特征到全局显著性视觉向量中; 即时显著性特征提取器能够根据语言模型的需要, 从全局显著性视觉向量中提取出预测每一个单词所需的显著性视觉特征. 本文在MS COCO (Microsoft common objects in context)数据集上对SFEM进行了评估, 实验结果表明SFEM能够显著提升基准模型 (baseline)生成图像描述的准确性, 并且SFEM在生成图像描述的准确性方面明显优于广泛使用的空间注意力模型, 在时间性能上也大幅领先空间注意力模型.Abstract: Image captioning is a research direction that combines computer vision and natural language processing. In this paper, a novel saliency feature extraction mechanism (SFEM) is designed to solve several key problems existing in current methods. It can quickly provide the most valuable visual features to the language model before which predict word. And it effectively solves the problems that the existing methods are inaccurate in selecting visual features and time-consuming. SFEM consists of global salient feature extractor and instant salient feature extractor: global salient Feature extractor extracts salient visual features from multiple local visual vectors and integrate these features into a global salient visual vector; the instant salient feature extractor can extract the saliency visual features required at each moment from the global saliency visual vector according to the needs of the language model. We evaluated SFEM on the MS COCO (Microsoft common objects in context) dataset. Experiments show that our SFEM can significantly improve the accuracy of baseline in caption generating. And SFEM is significantly better than the widely used spatial attention model in both the accuracy of generating caption and time performance.
-
Key words:
- Image captioning /
- salient feature extract /
- language model /
- encoder /
- decoder
-
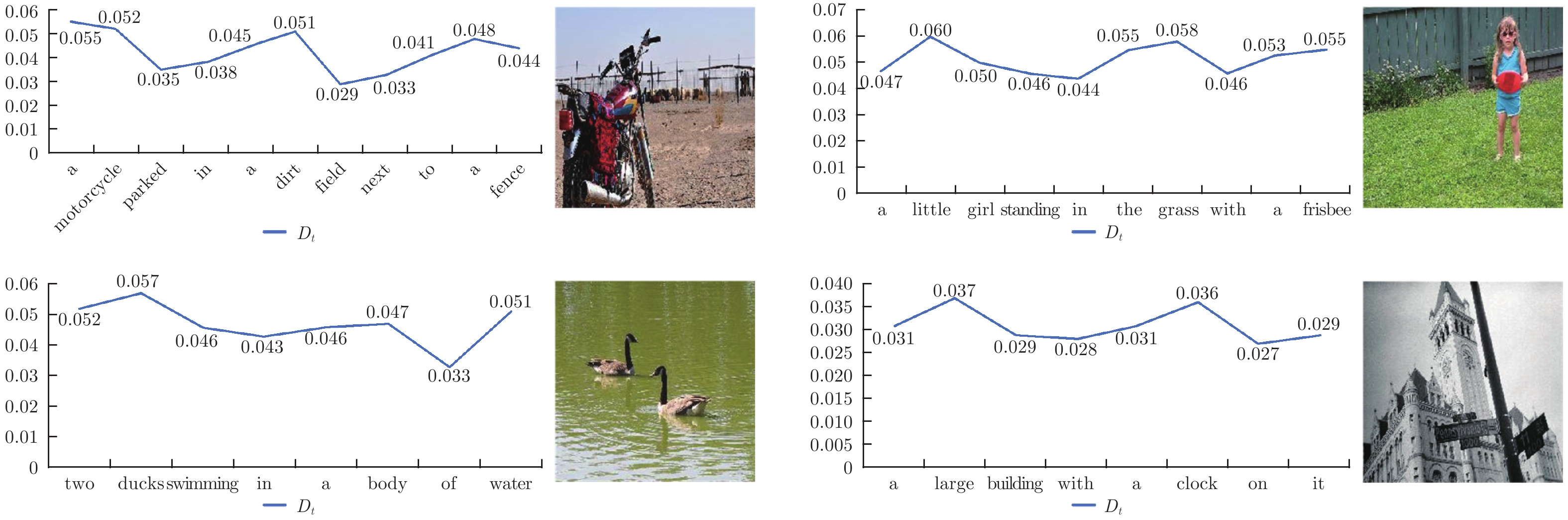
图 5 即时显著性特征随预测单词的变化
Fig. 5 The change of instant salient features with predicted words
表 1
$\bar{D_{t}}$ 值最高的20个单词Table 1 The top-20 words with
$\bar{D_{t}}$ value单词 $\overline{D}_{t}$ 单词 $\overline{D}_{t}$ 单词 $\overline{D}_{t}$ hood 0.0592 ducks 0.0565 doughnut 0.0546 cats 0.0589 pug 0.0564 baby 0.0546 teddy 0.0576 rug 0.0561 bird 0.0545 little 0.0573 hummingbird 0.0556 pen 0.0543 duck 0.0571 pasta 0.0549 motorcycle 0.0543 bananas 0.0569 horse 0.0547 colorful 0.0542 seagull 0.0565 panda 0.0546 — —  下载: 导出CSV
下载: 导出CSV
表 2 Encoder-Decoder + SFEM在MS COCO数据集上的表现(%)
Table 2 The performance of Encoder-Decoder + SFEM on MS COCO dataset (%)
下载: 导出CSV
表 3 Up-Down + SFEM在MS COCO数据集上的表现(%)
Table 3 The performance of Up-Down + SFEM on MS COCO dataset (%)
下载: 导出CSV
表 4 本模型和空间注意力模型的时间性能对比(帧/s)
Table 4 Time performance comparison between our model and the spatial attention model (frame/s)
下载: 导出CSV
表 5 各个模块单次执行平均花费时间(s)
Table 5 The average time spent by each module in a single execution (s)
下载: 导出CSV
表 7 组合模型在MS COCO数据集上的表现(%)
Table 7 Performance of the combined model on MS COCO dataset (%)
下载: 导出CSV
-
[1] Kulkarni G, Premraj V, Ordonez V, Dhar S, Li S M, Choi Y, et al. BabyTalk: Understanding and generating simple image descriptions. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2013, 35(12): 2891-2903 doi: 10.1109/TPAMI.2012.162 [2] Mao J H, Xu W, Yang Y, Wang J, Yuille A L. Deep captioning with multimodal recurrent neural networks (m-RNN). In: Proceedings of the 3rd International Conference on Learning Representations. San Diego, USA: ICLR, 2015. [3] 汤鹏杰, 王瀚漓, 许恺晟. LSTM逐层多目标优化及多层概率融合的图像描述. 自动化学报, 2018, 44(7): 1237-1249Tang Peng-Jie, Wang Han-Li, Xu Kai-Sheng. Multi-objective layer-wise optimization and multi-level probability fusion for image description generation using LSTM. Acta Automatica Sinica, 2018, 44(7): 1237-1249 [4] Cho K, Van Merriënboer B, Gulcehre C, Bahdanau D, Bougares F, Schwenk H, et al. Learning phrase representations using RNN encoder-decoder for statistical machine translation [Online], available: https://arxiv.org/pdf/1406.1078v3.pdf, September 3, 2014 [5] Bahdanau D, Cho K, Bengio Y. Neural machine translation by jointly learning to align and translate. In: Proceedings of the 3rd International Conference on Learning Representations. San Diego, USA: ICLR, 2015. [6] Sutskever I, Vinyals O, Le Q V. Sequence to sequence learning with neural networks. In: Proceedings of the 27th International Conference on Neural Information Processing Systems. Montreal, Canada: NIPS, 2014. [7] Vinyals O, Toshev A, Bengio S, Erhan D. Show and tell: A neural image caption generator. In: Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). Boston, USA: IEEE, 2015. 3156−3164 [8] 张雪松, 庄严, 闫飞, 王伟. 基于迁移学习的类别级物体识别与检测研究与进展. 自动化学报, 2019, 45(7): 1224-1243Zhang Xue-Song, Zhuang Yan, Yan Fei, Wang Wei. Status and development of transfer learning based category-level object recognition and detection. Acta Automatica Sinica, 2019, 45(7): 1224-1243 [9] You Q Z, Jin H L, Wang Z W, Fang C, Luo J B. Image captioning with semantic attention. In: Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). Las Vegas, USA: IEEE, 2016. 4651−4659 [10] Hochreiter S, Schmidhuber J. Long short-term memory. Neural Computation, 1997, 9(8): 1735-1780 doi: 10.1162/neco.1997.9.8.1735 [11] Jia X, Gavves E, Fernando B, Tuytelaars T. Guiding the long-short term memory model for image caption generation. In: Proceedings of the 2015 IEEE International Conference on Computer Vision (ICCV). Santiago, Chile: IEEE, 2015. 2407−2415 [12] Wu Q, Shen C H, Liu L Q, Dick A, Van Den Hengel A. What value do explicit high level concepts have in vision to language problems? In: Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). Las Vegas, USA: IEEE, 2016. 203−212 [13] Yang Z L, Yuan Y, Wu Y X, Cohen W W, Salakhutdinov R R. Review networks for caption generation. In: Proceedings of the 30th International Conference on Neural Information Processing Systems. Barcelona, Spain: NIPS, 2016. [14] 奚雪峰, 周国栋. 面向自然语言处理的深度学习研究. 自动化学报, 2016, 42(10): 1445-1465Xi Xue-Feng, Zhou Guo-Dong. A survey on deep learning for natural language processing. Acta Automatica Sinica, 2016, 42(10): 1445-1465 [15] 侯丽微, 胡珀, 曹雯琳. 主题关键词信息融合的中文生成式自动摘要研究. 自动化学报, 2019, 45(3): 530-539Hou Li-Wei, Hu Po, Cao Wen-Lin. Automatic Chinese abstractive summarization with topical keywords fusion. Acta Automatica Sinica, 2019, 45(3): 530-539 [16] Xu K, Ba J, Kiros R, Cho K, Courville A, Salakhudinov R, et al. Show, attend and tell: Neural image caption generation with visual attention. In: Proceedings of the 32nd International Conference on Machine Learning. Lille, France: JMLR.org, 2015. 2048−2057 [17] Lu J S, Xiong C M, Parikh D, Socher R. Knowing when to look: Adaptive attention via a visual sentinel for image captioning. In: Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). Honolulu, USA: IEEE, 2017. 3242−3250 [18] Chen L, Zhang H W, Xiao J, Nie L Q, Shao J, Liu W, et al. SCA-CNN: Spatial and channel-wise attention in convolutional networks for image captioning. In: Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). Honolulu, USA: IEEE, 2017. 6298−6306 [19] Chen X P, Ma L, Jiang W H, Yao J, Liu W. Regularizing RNNs for caption generation by reconstructing the past with the present. In: Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Salt Lake City, USA: IEEE, 2018. 7995−8003 [20] Anderson P, He X D, Buehler C, Teney D, Johnson M, Gould S, et al. Bottom-up and top-down attention for image captioning and visual question answering. In: Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Salt Lake City, USA: IEEE, 2018. 6077−6086 [21] Lu J S, Yang J W, Batra D, Parikh D. Neural baby talk. In: Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Salt Lake City, USA: IEEE, 2018. 7219−7228 [22] Lin T Y, Maire M, Belongie S, Hays J, Perona P, Ramanan D, et al. Microsoft COCO: Common objects in context. In: Proceedings of the 13th European Conference on Computer Vision. Zurich, Switzerland: Springer, 2014. 740−755 [23] Karpathy A, L F F. Deep visual-semantic alignments for generating image descriptions. In: Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). Boston, USA: IEEE, 2015. 3128−3137 [24] Papineni K, Roukos S, Ward T, Zhu W J. BLEU: A method for automatic evaluation of machine translation. In: Proceedings of the 40th Annual Meeting on Association for Computational Linguistics. Philadelphia, USA: ACL, 2002. 311−318 [25] Banerjee S, Lavie A. METEOR: An automatic metric for MT evaluation with improved correlation with human judgments. In: Proceedings of the ACL Workshop on Intrinsic and Extrinsic Evaluation Measures for Machine Translation and/or Summarization. Ann Arbor, USA: ACL, 2005. 65−72 [26] Vedantam R, Zitnick C L, Parikh D. CIDEr: Consensus-based image description evaluation. In: Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). Boston, USA: IEEE, 2015. 4566−4575 [27] Lin C Y. ROUGE: A package for automatic evaluation of summaries. In: Proceedings of the Workshop on Text Summarization Branches Out, Post-Conference Workshop of ACL 2004. Barcelona, Spain: Association for Computational Linguistics, 2004. [28] Anderson P, Fernando B, Johnson M, Gould S. SPICE: Semantic propositional image caption evaluation. In: Proceedings of the 14th European Conference on Computer Vision. Amsterdam, the Netherlands: Springer, 2016. [29] Ren S Q, He K M, Girshick R, Sun J. Faster R-CNN: Towards real-time object detection with region proposal networks. In: Proceedings of the 28th International Conference on Neural Information Processing Systems. Montreal, Canada: NIPS, 2015. 91−99 [30] Krishna R, Zhu Y K, Groth O, Johnson J, Hata K, Kravitz J, et al. Visual genome: Connecting language and vision using crowdsourced dense image annotations. International Journal of Computer Vision, 2017, 123(1): 32-73 doi: 10.1007/s11263-016-0981-7 [31] Rennie S J, Marcheret E, Mroueh Y, Ross J, Goel V. Self-critical sequence training for image captioning. In: Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). Honolulu, USA: IEEE, 2017. 1179−1195 -

 下载:
下载:






计量
- 文章访问数: 1201
- HTML全文浏览量: 986
- PDF下载量: 314
- 被引次数: 0
