

A Survey on Multi-source Person Re-identification
-
摘要: 行人重识别是近年来计算机视觉领域的热点问题, 经过多年的发展, 基于可见光图像的一般行人重识别技术已经趋近成熟. 然而, 目前的研究多基于一个相对理想的假设, 即行人图像都是在光照充足的条件下拍摄的高分辨率图像. 因此虽然大多数的研究都能取得较为满意的效果, 但在实际环境中并不适用. 多源数据行人重识别即利用多种行人信息进行行人匹配的问题. 除了需要解决一般行人重识别所面临的问题外, 多源数据行人重识别技术还需要解决不同类型行人信息与一般行人图片相互匹配时的差异问题, 如低分辨率图像、红外图像、深度图像、文本信息和素描图像等. 因此, 与一般行人重识别方法相比, 多源数据行人重识别研究更具实用性, 同时也更具有挑战性. 本文首先介绍了一般行人重识别的发展现状和所面临的问题, 然后比较了多源数据行人重识别与一般行人重识别的区别, 并根据不同数据类型总结了5 类多源数据行人重识别问题, 分别从方法、数据集两个方面对现有工作做了归纳和分析. 与一般行人重识别技术相比, 多源数据行人重识别的优点是可以充分利用各类数据学习跨模态和类型的特征转换. 最后, 本文讨论了多源数据行人重识别未来的发展.Abstract: Person re-identification (Re-ID) has been a popular and well-investigated topic in computer vision community. However, current researches have a relatively ideal assumption that person images are captured under a sufficient light condition and with high-resolution. Although most researches can achieve very exciting performances, they are not suitable for practical applications. Since practical conditions are a little complicated, and there are multiple sources to represent persons' appearance. In this paper, we focus on the multi-source person Re-ID, which refers to the problem of using multiple sources of data for person re-identification. Compared with general person Re-ID methods, multi-source person Re-ID researches are more practical, yet more challenging in reality. We need to face challenges caused by domain gap among different data sources, such as low-resolution images, infrared images, depth images, text information and sketch images. In this paper, we start with a brief introduction of general person Re-ID. The differences between general and multi-source person Re-ID are then compared. Five types of multi-source person Re-ID are further analyzed and summarized. From these discussions, it will become evident that several advantages exist in multi-source person Re-ID over general person Re-ID methods, as the former can make full use of data sources to learn cross-modality feature transformation. Finally, the future trends of multi-source person Re-ID are discussed.
-

图 2 多源数据行人重识别类型
Fig. 2 Scope of multi-source data person re-identification studied in this survey
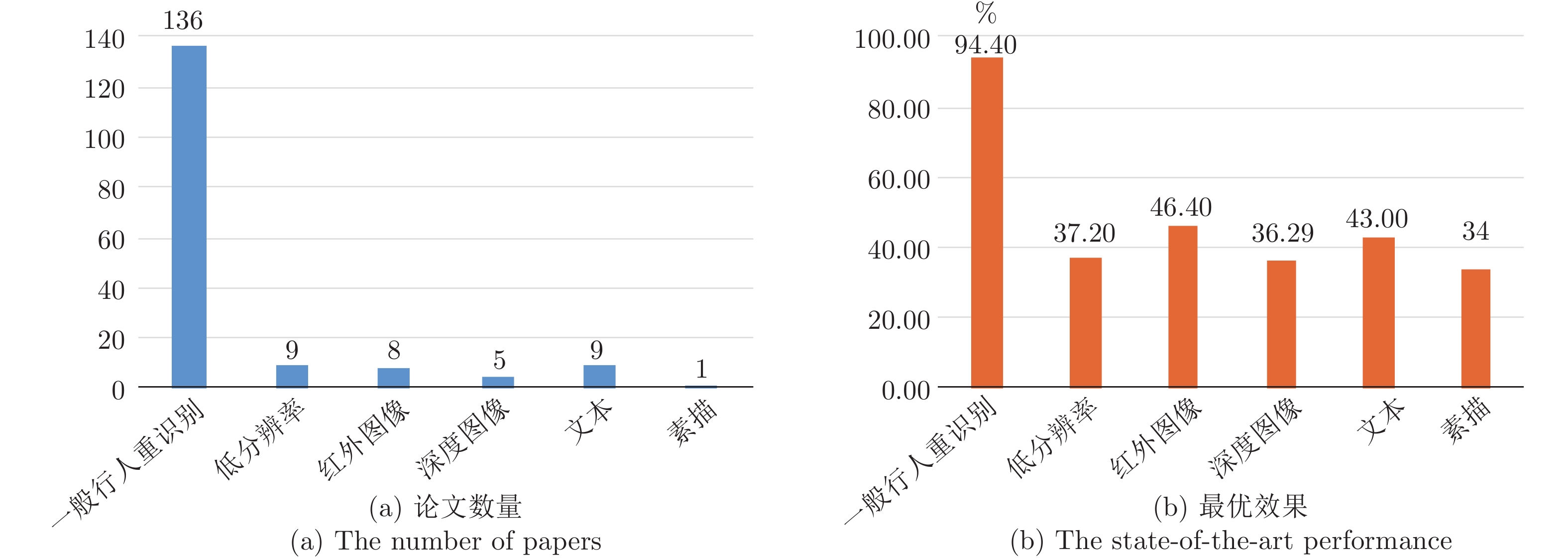
图 3 一般行人重识别与多源数据行人重识别论文数量和最优效果对比
Fig. 3 The state-of-the-art performance and number of papers between general Re-ID and multi-source data Re-ID
表 1 一般行人重识别与多源数据行人重识别的对比
Table 1 Comparison of general Re-ID and multi-source data Re-ID
一般行人重识别 多源数据行人重识别 定义 给定一个监控行人图像, 检索跨设备下的该行人图像的技术 给定一个监控行人的跨类型或模态信息/图像, 检索跨设备跨模态下的该行人图像的技术 数据类型 单一类型的图像 多类型的图像/视频、文本、语言、素描等数据信息 方法 针对输入图像提取稳定、鲁棒且能描述和区分不同行人的特征信息, 计算特征相似性, 根据相似性大小排序 使用特定于类型/域的网络提取该类型/域的特征信息, 通过共享网络生成特征, 使用合适的损失函数进行训练并与普通网络相连确保重识别工作的有效性 数据集 单一的可见光图像、二分类属性数据集 多种图像、多种信息、多属性数据集 解决重点和难点 低分辨率、视角和姿势变化、光照变化、遮挡和视觉模糊性问题 模态变化以及一般行人重识别需要克服的问题  下载: 导出CSV
下载: 导出CSV
表 2 多源数据行人重识别工作中的代表性方法
Table 2 A summary of representational methods in multi-source data Re-ID
方法 模态 年份 会议/期刊 方法类别 数据集 度量学习 特征模型 统一模态 JUDEA[7] 高−低分辨率图像 2015 ICCV 度量学习 ⑩⑪⑫ √ × × SLD2L[9] 2015 CVPR 字典学习 ⑪⑬⑭ × √ × SALR-REID[8] 2016 IJCAI 子空间学习 ⑩⑮⑯ √ √ × SING[14] 2018 AAAI 超分辨率 ⑰⑱⑲ × √ √ CSR-GAN[15] 2018 IJCAI 超分辨率 ⑩⑮⑯ × √ √ DSPDL[11] 2018 AAAI 字典学习 ⑪⑭⑳ × √ × Zhuang[18] 2018 CVPR 深度对偶学习 ㉑㉒㉓ √ × √ Wu[22] 红外−可见光图像 2017 ICCV 深度零填充 ㉔ × √ × TONE[24] 2018 AAAI 度量学习 ㉕ √ √ × Ye[23] 2018 IJCAI 特征学习 ㉔㉕ √ √ × cmGAN[25] 2018 IJCAI 特征嵌入 ㉔ × √ × D2RL[26] 2019 CVPR 图像生成 ㉔㉕ × √ √ Barbosa[27] 深度−可见光图像 2012 ECCV 度量学习 ㉖ √ × × Wu[30] 2017 TIP 子空间学习 ㉖㉗㉘ √ √ × Hafner[31] 2018 CVPR 模态转移 ㉗㉚ × √ √ Ye[40] 文本−可见光图像 2015 ACM 度量学习 ①④㉛ √ × × Shi[35] 2015 CVPR 属性识别 ①⑤㉛ √ × × APR[37] 2017 CVPR 属性识别 ⑦⑧ √ × × GNA-RNN[42] 2017 CVPR 密切关系学习 ㉜ × √ × CNN-LSTM[41] 2017 ICCV 特征学习 ㉜ × √ × MTL-LORAE[39] 2018 PAMI 特征学习 ①③④⑨ √ √ × Pang[45] 素描−可见光图像 2018 ACM MM 特征学习 ㉝ × √ ×
下载: 导出CSV
表 3 常用的一般行人重识别数据集与跨模态行人重识别数据集
Table 3 A summary of general Re-ID dataset and multi-source data Re-ID datase
类别 数据集名称 发布时间 数据集类型 人数 相机数量 数据集大小 一般行人数据集 ①VIPeR[51] 2008 真实数据集 632 2 1 264幅 RGB 图像 ②3DPES[52] 2011 192 8 1 011 幅 RGB 图像 ③i-LIDS[50] 2009 119 2 476 幅 RGB 图像 ④PRID2011[53] 2011 934 2 1 134 幅 RGB 图像 ⑤CUHK01[48] 2012 971 2 3 884幅 RGB 图像 ⑥CUHK03[6] 2014 1 467 10 13 164幅 RGB 图像 ⑦Market-1501[54] 2015 1 501 6 32 217 幅 RGB 图像 ⑧DukeMT MC-REID[55] 2017 1 812 8 36 441 幅 RGB 图像 ⑨SAIVT-SoftBio[56] 2012 152 8 64 472 幅 RGB 图像 低分辨率行人数据集 ⑩CAVIAR[57] 2011 真实数据集 72 2 720 幅高分辨率图像 500 幅低分辨率图像 ⑪LR-VIPeR[7, 9-11] 2015 模拟数据集 632 2 1 264 幅 RGB 图像 ⑫LR-3DPES[7] 2015 192 8 1 011 幅 RGB 图像 ⑬LR-PRID2011[9, 15] 2015 100 2 200 幅 RGB 图像 ⑭LR-i-LDIS[9, 11] 2015 119 2 238 幅 RGB 图像 ⑮SALR-VIPeR[8, 15] 2016 632 2 1 264 幅 RGB 图像 ⑯SALR-PRID[8, 15] 2016 450 2 900 幅 RGB 图像 ⑰MLR-VIPeR[14] 2018 632 2 1 264 幅 RGB 图像 ⑱MLR-SYSU[14] 2018 502 2 3 012 幅 RGB 图像 ⑲MLR-CUHK03[14] 2018 1 467 2 14 000 幅 RGB 图像 ⑳LR-CUHK01[11] 2018 971 2 1 942 幅 RGB 图像 ㉑LR-CUHK03[18] 2018 1 467 10 13 164 幅 RGB 图像 ㉒LR-Market-1501[18] 2018 1 501 6 32 217 幅 RGB 图像 ㉓LR-DukeMTMC-REID[18] 2018 1 812 8 36 441 幅 RGB 图像 红外行人数据集 ㉔SYSU-MM01[22] 2017 真实数据集 491 6 287 628 幅 RGB 图像 15 792幅红外图像 ㉕RegDB[58] 2017 412 2 4 120 幅 RGB 图像 4 120 幅红外图像 深度图像行人数据集 ㉖PAVIS[27] 2012 真实数据集 79 − 316 组视频序列 ㉗BIWI RGBD-ID[28] 2014 50 − 22 038 幅 RGB-D 图像 ㉘IAS-Lab RGBD-ID[28] 2014 11 − 33 个视频序列 ㉙Kinect REID[59] 2016 71 − 483 个视频序列 ㉚RobotPKU RGBD-ID[60] 2017 90 − 16 512 幅 RGB-D 图像 文本行人数据集 ㉛PETA[34] 2014 真实数据集 8 705 − 19 000 幅图像 66 类文字标签 ㉜CUHK-PEDES[42] 2017 13 003 − 40 206 幅图像 80 412 个句子描述 素描行人数据集 ㉝Sketch Re-ID[45] 2018 真实数据集 200 2 400 幅 RGB 图像 200 幅素描
下载: 导出CSV
表 4 几种多源数据行人重识别方法在常用的行人数据集上的识别结果
Table 4 Comparison of state-of-the-art methods on infra-red person re-identification dataset
数据集 算法 年份 Rank1 (%) Rank5 (%) Rank10 (%) 低分辨率 VIPeR SLD2L[9] 2015 16.86 41.22 58.06 MVSLD2L[10] 2017 20.79 45.08 61.24 DSPDL[11] 2018 28.51 61.08 76.11 CAVIAR JUDEA[7] 2015 22.12 59.56 80.48 SLD2L[9] 2015 18.40 44.80 61.20 SING[14] 2018 33.50 72.70 89 红外 SYSU-MM01 Wu等[22] 2017 24.43 − 75.86 Ye等[23] 2018 17.01 − 55.43 CMGAN[25] 2018 37.00 − 80.94 RegDB Ye等[23] 2018 33.47 − 58.42 TONE[24] 2018 16.87 − 34.03 深度图像 BIWI RGBD-ID Wu等[30] 2017 39.38 72.13 − Hafner[31] 2018 36.29 77.77 94.44 PAVIS Wu等[30] 2017 71.74 88.46 − Ren等[63] 2017 76.70 87.50 96.10 素描 SKETCH Re-ID Pang等[45] 2018 34 56.30 72.50 文本 VIPeR Shi等[35] 2015 41.60 71.90 86.20 SSDAL[38] 2016 43.50 71.80 81.50 MTL-LORAE[39] 2018 42.30 42.30 81.6 PRID SSDAL[38] 2016 22.60 48.70 57.80 MTL-LORAE[39] 2018 18 37.40 50.10 Top1 Top10 文本 CUHK-PEDES CNN-LSTM[41] 2017 25.94 60.48 GNA-RNN[42] 2017 19.05 53.64
下载: 导出CSV
-
[1] 宋婉茹, 赵晴晴, 陈昌红, 干宗良, 刘峰. 行人重识别研究综述. 智能系统学报, 2017, 12(6): 770−780Song Wan-Ru, Zhao Qing-Qing, Chen Chang-Hong, Gan Zong-Liang, Liu Feng. Survey on pedestrian re-identification research. CAAI Transactions on Intelligent Systems, 2017, 12(6): 770−780 [2] 李幼蛟, 卓力, 张菁, 李嘉锋, 张辉. 行人再识别技术综述. 自动化学报, 2018, 44(9): 1554−1568Li You-Jiao, Zhuo Li, Zhang Jing, Li Jia-Feng, Zhang Hui. A survey of person re-identification. Acta Automatica Sinica, 2018, 44(9): 1554−1568 [3] 郑伟诗, 吴岸聪. 非对称行人重识别: 跨摄像机持续行人追踪. 中国科学: 信息科学, 2018, 48(5): 545−563Zheng Wei-Shi, Wu An-Cong. Asymmetric person re-identification: cross-view person tracking in a large camera network. Scientia Sinica Informationis, 2018, 48(5): 545−563 [4] 王正. 条件复杂化行人重识别关键技术研究[博士学位论文]. 武汉大学, 中国, 2017.Wang Zheng. Person Re-identification in Complicated Conditions [Ph.D. dissertation], Wuhan University, China, 2017. [5] Zhu X, Jing X Y, You X, Zuo W, Shan S, Zheng W S. Image to video person re-identification by learning heterogeneous dictionary pair with feature projection matrix. IEEE Transactions on Information Forensics and Security, 2018, 13(3): 717−732 doi: 10.1109/TIFS.2017.2765524 [6] Li W, Zhao R, Xiao T, Wang X G. DeepReID: deep filter pairing neural network for person re-identification. In: Proceedings of the 27th IEEE International Conference of Computer Vision and Pattern Recognition. Columbus, USA: IEEE, 2014. 152−159 [7] Li X, Zheng W, Wang X, Xiang T, Gong S. Multi-scale learning for low-resolution person re-identification. In: Proceedings of the 28th IEEE International Conference on Computer Vision. Santiago, Chile: IEEE, 2015. 3765−3773 [8] Wang Z, Hu R M, Yu Y, Jiang J J, Chao L, Wang J Q. Scale-adaptive low-resolution person re-identification via learning a discriminating surface. In: Proceedings of the 2016 International Joint Conference on Artificial Intelligence. New York, USA, 2016. 2669−2675 [9] Jing X Y, Zhu X K, Wu F, You X G, Liu Q L, Yue D, et al. Super-resolution person re-identification with semi-coupled low-rank discriminant dictionary learning. In: Proceedings of the 28th IEEE Conference on Computer Vision and Pattern Recognition. Boston, USA: IEEE, 2015. 695−704 [10] Jing X Y, Zhu X K, Wu F, Hu R M, You X G, Wang Y H, et al. Super-resolution person re-identification with semi-coupled low-rank discriminant dictionary learning. IEEE Transactions Image Process, 2017, 26(3): 1363−1378 doi: 10.1109/TIP.2017.2651364 [11] Li K, Ding Z M, Li S, Fu Y. Discriminative semi-coupled projective dictionary learning for low-resolution person re-identification. In: Proceedings of the 32nd AAAI Conference on Artificial Intelligence. Louisiana, USA: IEEE, 2018. 2331−2338 [12] Wang S Y, Ding Z M, Fu Y. Coupled marginalized auto-encoders for cross-domain multi-view learning. In: Proceedings of the 2016 International Joint Conference on Artificial Intelligence. New York, USA, 2016. 2125−2131 [13] Liao S C, Li S Z. Efficient psd constrained asymmetric metric learning for person re-identification. In: Proceedings of the 2015 IEEE International Conference on Computer Vision. Santiago, Chile: IEEE, 2015. 3685−3693 [14] Jiao J N, Zheng W S, Wu A C, Zhu X T, Gong S G. Deep low-resolution person re-identification. In: Proceedings of the 32nd AAAI Conference on Artificial Intelligence. Louisiana, USA: IEEE, 2018. 6967−6974 [15] Wang Z, Ye M, Yang F, Bai X, Satoh S I. Cascaded SR-GAN for scale-adaptive low resolution person re-identification. In: Proceedings of the 2018 International Joint Conferences on Artificial Intelligence. Stockholm, Sweden, 2018. 3891−3897 [16] Wang Y, Wang L Q, You Y R, Zou X, Chen V, Li S, et al. Resource aware person re-identification across multiple resolutions. In: Proceedings of the 31st IEEE Conference on Computer Vision and Pattern Recognition. Salt Lake City, USA: IEEE, 2018. 1−10 [17] He K M, Zhang X Y, Ren S Q, Jian S. Deep residual learning for image recognition. In: Proceedings of the 29th IEEE Conference on Computer Vision and Pattern Recognition. Las Vegas, USA: IEEE, 2016. 770−778 [18] Zhuang Z J, Ai H Z, Chen L, Shang C. Cross-resolution person re-identification with deep antithetical learnin. In: Proceedings of the 31st IEEE Conference on Computer Vision and Pattern Recognition. Salt Lake City, USA: IEEE, 2018. 1−16 [19] Kai J L, Arens M. Local feature based person reidentification in infrared image sequences. In: Proceedings of the 7th IEEE International Conference on Advanced Video and Signal Based Surveillance. Boston, USA: IEEE, 2010. 448−455 [20] Møgelmose A, Bahnsen C, Moeslund T B, Clapes A, Escalera S. Tri-modal person re-identification with RGB, depth and thermal features. In: Proceedings of the 26th IEEE Conference on Computer Vision and Pattern Recognition Workshops. Portland, USA: IEEE, 2013. 301−307 [21] Bay H, Ess A, Tuytelaars T, Gool L V. Speeded-up robust features. Computer Vision and Image Understanding, 2008, 110(3): 346−359 doi: 10.1016/j.cviu.2007.09.014 [22] Wu A C, Zheng W S, Yu H X, Gong S G, Lai J H. RGB-infrared cross-modality person re-identification. In: Proceedings of the 2017 IEEE International Conference on Computer Vision. Venice, Italy: IEEE, 2017. 5390−5399 [23] Ye M, Wang Z, Lan X Y, Yuen P C. Visible thermal person re-identification via dual-constrained top-ranking. In: Proceedings of the 2018 International Joint Conferences on Artificial Intelligence. Stockholm, Sweden, 2018. 1092−1099 [24] Ye M, Lan X Y, Li J W, Yuen P C. Hierarchical discriminative learning for visible thermal person re-identification. In: Proceedings of the 32nd AAAI Conference on Artificial Intelligence. Louisiana, USA: AAAI, 2018. 7501−7508 [25] Dai P Y, Ji R R, Wang H B, Wu Q, Huang Y Y. Cross-modality person re-identification with generative adversarial training. In: Proceedings of the 2018 International Joint Conference on Artificial Intelligence. Stockholm, Sweden, 2018. 677−683 [26] Wang Z X, Wang Z, Zheng Y Q, Chuang Y-Y, Satoh S I. Learning to reduce dual-level discrepancy for infrared-visible person re-identification. In: Proceedings of the 2019 IEEE Conference on Computer Vision and Pattern Recognition. Long Beach, California, USA: IEEE, 2019. 618−626 [27] Barbosa I B, Cristani M, Bue A D, Bazzani L, Murino V. Re-identification with RGB-D sensors. In: Proceedings of the 12th International Conference on Computer Vision. Florence, Italy: ECCV, 2012. 433−442 [28] Matteo M, Alberto B, Andrea F, Luc V G, Menegatti E. 3D reconstruction of freely moving persons for reidentification with a depth sensor. In: Proceedings of the 2014 IEEE International Conference on Robotics and Automation. Hong Kong, China: IEEE, 2014. 4512−4519 [29] Haque A, Alahi A, Li F F. Recurrent attention models for depth-based person identification. In: Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition. Las Vegas, USA: IEEE, 2016. 1229−1238 [30] Wu A C, Zheng W S, Lai J H. Robust depth-based person re-identification. IEEE Transactions on Image Processing, 2017: 2588−2603 [31] Hafner F, Bhuiyan A, Kooij J F P, Granger E. A cross-modal distillation network for person re-identification in rgb-depth. In: Proceedings of the 31st IEEE Conference on Computer Vision and Pattern Recognition. Salt Lake City, USA: IEEE, 2018. 1−18 [32] Gupta S, Hoffman J, Malik J. Cross modal distillation for supervision transfer. In: Proceedings of the 29th IEEE Conference on Computer Vision and Pattern Recognition. Las Vegas, USA: IEEE, 2016. 2827−2836 [33] Jason T, Jeanette B G, Daniel B, Michael C, Heather Z. Person attribute search for large-area video surveillance. In: Proceedings of the 2012 IEEE International Conference on Technologies for Homeland Security. Boston, USA: IEEE, 2012. 55−61 [34] Deng Y B, Luo P, Loy C C, Tang X O. Pedestrian attribute recognition at far distance. In: Proceedings of the 22nd ACM International Conference on Multimedia. Orlando, USA: ACM MM, 2014. 789−792 [35] Shi Z Y, Hospedales T M, Xiang T. Transferring a semantic representation for person re-identification and search. In: Proceedings of the 28th IEEE Conference on Computer Vision and Pattern Recognition, Boston, USA: IEEE, 2015. 4184−4193 [36] Wang Z, Hu R M, Yu Y, Liang C, Huang W X. Multi-level fusion for person re-identification with incomplete marks. In: Proceedings of the 23rd ACM International Conference on Multimedia. Brisbane, Australia: ACM MM, 2015. 1267−1270 [37] Lin Y T, Liang Z, Zheng Z D, Yu W, Yi Y. Improving person re-identification by attribute and identity learning. In: Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition, Hawaii, USA: IEEE, 2017: 1−10 [38] Su C, Zhang S L, Xing J L, Wen G, Qi T. Deep attributes driven multi-camera person re-identification. In: Proceedings of the 2016 European Conference on Computer Vision. Amsterdam, the Netherlands, 2016. 475−491 [39] Su C, Yang F, Zhang S L, Tian Q, Davis L S, Gao W. Multi-task learning with low rank attribute embedding for multi-camera person re-identification. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2018, 40(5): 1167−1181 doi: 10.1109/TPAMI.2017.2679002 [40] Ye M, Liang C, Wang Z, Leng Q M, Chen J, Liu J. Specific person retrieval via incomplete text description. In: Proceedings of the 5th ACM on International Conference on Multimedia Retrieval. Shanghai, China: ACM, 2015. 547−550 [41] Li S, Xiao T, Li H S, Yang W, Wang X G. Identity-aware textual-visual matching with latent co-attention. In: Proceedings of the 2017 IEEE International Conference on Computer Vision. Venice, Italy: IEEE, 2017. 1890−1899 [42] Li S, Xiao T, Li H S, Zhou B L, Yue D Y, Wang X G. Person search with natural language description. In: Proceedings of the 30th IEEE Conference on Computer Vision and Pattern Recognition. Hawaii, USA: IEEE, 2017. 5187−5196 [43] Galoogahi H K, Sim T. Face photo retrieval by sketch example. In: Proceedings of the 20th ACM International Conference on Multimedia. Nara, Japan: ACM, 2012. 949−952 [44] Zhang W, Wang X G, Tang X O. Coupled information-theoretic encoding for face photo-sketch recognition. In: Proceedings of the 24th IEEE Conference on Computer Vision and Pattern Recognition. Providence, RI, USA: IEEE, 2011. 513−520 [45] Pang L, Wang Y W, Song Y Z, Huang T J, Tian Y H. Cross-domain adversarial feature learning for sketch re-identification. In: Proceedings of the 2018 ACM Multimedia Conference on Multimedia Conferenc. Seoul, Korea: ACM, 2018. 609−617 [46] Yu Q, Liu F, Song Y Z, Xiang T, Hospedales T M, Chen C L. Sketch me that shoe. In: Proceedings of the 29th IEEE Conference on Computer Vision and Pattern Recognition. Las Vegas, USA: IEEE, 2016. 799−807 [47] Gray D, Brennan S, Tao H. Evaluating appearance models for recognition, reacquisition, and tracking. In: Proceedings of the 10th International Workshop on Performance Evaluation for Tracking and Surveillance. Rio de Janeiro, Brazil: IEEE, 2007. 1−7 [48] Li W, Zhao R, Wang X G. Human reidentification with transferred metric learning. In: Proceedings of the 2012 Asian Conference on Computer Vision. Daejeon, Korea, 2012. 31−44 [49] Roth P M, Martin H, Köstinger M, Beleznai C, Bischof H. Mahalanobis distance learning for person re-identification. Person Re-Identification, 2014: 247−267 [50] Zheng W S, Gong S G, Tao X. Associating groups of people. In: Proceedings of the 2009 British Machine Vision Conference. London, UK, 2009: 1−11 [51] Gray D, Hai T. Viewpoint invariant pedestrian recognition with an ensemble of localized features. In: Proceedings of the 10th European Conference on Computer Vision. Marseille, France, 2008. 262−275 [52] Baltieri D, Vezzani R, Cucchiara R. 3Dpes: 3D people dataset for surveillance and forensics. In: Proceedings of the 2011 ACM Joint ACM Workshop on Human Gesture and Behavior Understanding. Scottsdale, USA: ACM, 2011. 59−64 [53] Hirzer M, Beleznai C, Roth P M, Bischof H. Person re-identification by descriptive and discriminative classification. In: Proceedings of the 2011 Scandinavian Conference on Image Analysis. Ystad, Sweden, 2011. 91−102 [54] Zheng L, Shen L Y, Tian L, Wang S J, Wang J D, Tian Q. Scalable person re-identification: A benchmark. In: Proceedings of the 2015 IEEE International Conference on Computer Vision. Santiago, Chile: IEEE, 2015. 2380−7504 [55] Zheng Z D, Zheng L, Yang Y. Unlabeled samples generated by gan improve the person re-identification baseline in vitro. In: Proceedings of the 2017 IEEE International Conference on Computer Vision. Honolulu, USA: IEEE, 2017. 3774−3782 [56] Bialkowski A, Denman S, Sridharan S, Fookes C, Lucey P. A database for person re-identification in multi-camera surveillance networks. In: Proceedings of the 2012 International Conference on Digital Image Computing Techniques and Applications. Fremantle, Australia, 2012. 1−8 [57] Dong S C, Cristani M, Stoppa M, Bazzani L, Murino V. Custom pictorial structures for re-identification. In: Proceedings of the 2011 British Machine Vision Conference. Dundee, Scotland, 2011. 1−11 [58] Nguyen D T, Hong H G, Kim K W, Park. K R. Person recognition system based on a combination of body images from visible light and thermal cameras. Sensors, 2017, 17(3): 605−633 doi: 10.3390/s17030605 [59] Pala F, Satta R, Fumera G, Roli F. Multimodal person reidentification using RGB-D cameras. IEEE Transactions on Circuits and Systems for Video Technology, 2016, 26(4): 788−799 doi: 10.1109/TCSVT.2015.2424056 [60] Hong L, Liang H, Ma L Q. Online RGB-D person re-identification based on metric model update. CAAI Transactions on Intelligence Technology, 2017, 2(1): 48−55 doi: 10.1016/j.trit.2017.04.001 [61] Joost V D W, Cordelia S, Jakob V, Diane L. Learning color names for real-world applications. IEEE Transactions on Image Processing, 2009, 18(7): 1512−1523 doi: 10.1109/TIP.2009.2019809 [62] Zhu J Q, Liao S C, Lei Z, Yi D, Li S. Pedestrian attribute classification in surveillance: Database and evaluation. In: Proceedings of the 2013 IEEE International Conference on Computer Vision Workshops. Sydney, Australia: IEEE, 2013. 331−338 [63] Ren L L, Lu J W, Feng J J, Zhou J. Multi-modal uniform deep learning for RGB-D person re-identification. Pattern Recognition, 2017, 72: 446−457 doi: 10.1016/j.patcog.2017.06.037 -

 下载:
下载:



计量
- 文章访问数: 4028
- HTML全文浏览量: 1406
- PDF下载量: 866
- 被引次数: 0
