

-
摘要: 针对一类具有模型不确定性和外部扰动的时变非线性系统, 基于模型参考控制方法, 设计了具有固定时间收敛特性的终端滑模控制器. 首先, 提出一种带有输入饱和限幅和补偿信号滤波的模型参考控制结构; 然后针对广义误差信号, 采用新型终端滑模面设计了补偿控制器, 较好地平衡靠近和远离平衡点的收敛速度. 基于李雅普诺夫方法证明了闭环系统的稳定性和固定时间收敛特性, 并给出了收敛时间上界. 最后将该方法应用到含有极限环的非线性系统跟踪控制中, 仿真结果验证了该方法的有效性.Abstract: Based on model reference method, a nonsingular terminal sliding-mode control method with fixed time convergence is proposed for a class of time-varying nonlinear systems with model uncertainties and external disturbances. Firstly, a model reference controller structure considering input saturation and compensation signal filtering is proposed. Then a sliding mode controller based on a novel nonlinear terminal sliding mode manifold is constructed for generalized errors, which balances the convergence speed near and away from the equilibrium point. The fixed time convergence and stability of closed-loop system are proved with the Lyapunov method, and the upper bound of convergence time is obtained. Finally, the method proposed is applied to tracking control of nonlinear systems with limit cycle.The simulation results verify its effectiveness.
-
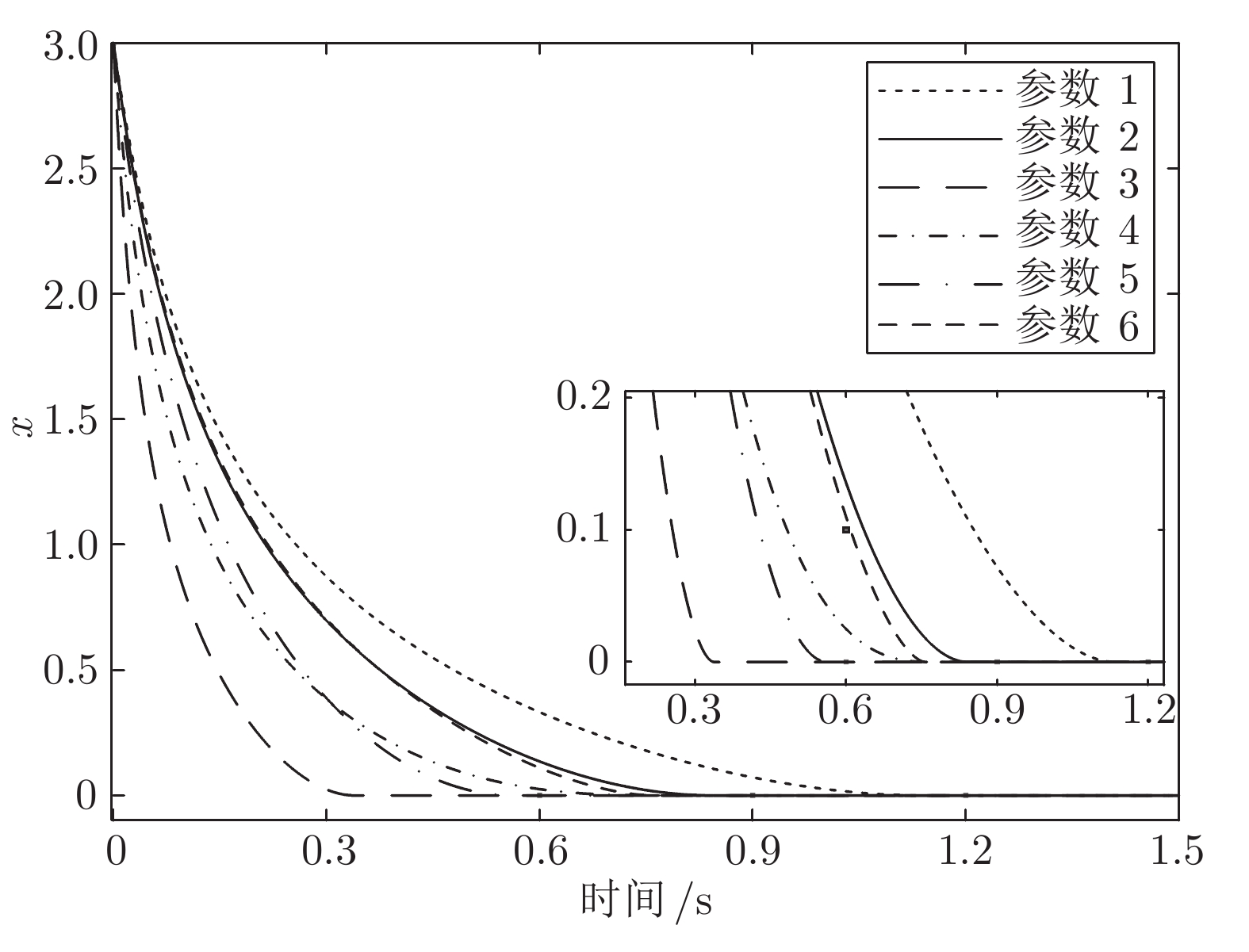
表 1 标量系统参数和收敛时间 (s)
Table 1 Coefficients and convergence time (s) of the scalar system
参数 $\beta $ $q $ $\alpha $ $p $ $T $ 1 1 5/9 0 5/9 1.08 2 1 5/9 1 5/9 0.80 3 3 5/9 1 5/9 0.34 4 1 3/9 1 5/9 0.68 5 1 5/9 3 5/9 0.56 6 1 5/9 1 3/9 0.75  下载: 导出CSV
下载: 导出CSV
表 2 模型A的气动数据
Table 2 Aerodynamic coefficients for Model A
$\alpha\;{\rm{(rad)}}$ $\hat a_0$ $ \hat a_1 $ $ \hat a_2 $ $ \hat a_3 $ $ \hat a_4 $ 0.4363 0.00543 −0.01426 0.41336 −0.00465 0.00263 0.4800 0.00594 −0.01765 0.38793 −0.00487 0.01689 0.5236 0.00657 −0.02040 0.38008 −0.00537 0.02596 0.5672 0.00732 −0.03104 0.53884 −0.00623 0.04189 0.6109 0.00794 −0.03137 0.53455 −0.00751 0.05144 0.6545 0.00914 −0.00246 0.00105 −0.01059 0.03736 0.6981 0.00902 −0.01881 0.62351 −0.01187 0.06119 0.7418 0.00999 −0.03219 1.51180 −0.02862 0.06867 0.7854 0.01135 −0.03712 2.42520 −0.08113 0.02935
下载: 导出CSV
表 3 模型C的气动数据
Table 3 Aerodynamic coefficients for Model C
$\alpha\;{\rm{(rad)}}$ $\hat a_0$ $ \hat a_1 $ $ \hat a_2 $ $ \hat a_3 $ $ \hat a_4 $ 0.4363 0.00615 −0.02644 0.82603 −0.00940 0.04934 0.4800 0.00310 −0.00057 1.00250 −0.01157 −1.19080 0.5236 0.00523 −0.00406 0.09998 −0.00167 −0.00183 0.5672 0.00729 −0.01260 0.33063 −0.00506 −0.00378 0.6109 0.00591 −0.03024 1.07030 −0.00285 −0.03726 0.6545 −0.00406 −0.00588 1.0840 0.03646 −0.15374 0.6981 0.00574 −0.00771 −0.03172 −0.01095 0.16302 0.7418 −0.0040 −0.03261 2.3447 0.13848 0.90542 0.7854 −0.00089 −0.02071 0.8361 0.13752 2.8685
下载: 导出CSV
-
[1] Fukushima H, Muro K, Matsuno F. Sliding-mode control for transformation to an inverted pendulum mode of a mobile robot with wheel-arms. IEEE Transactions on Industrial Electronics, 2015, 62(7): 4257-4266 doi: 10.1109/TIE.2014.2384475 [2] Rios H, Falcon R, Gonzalez O A, Dzul A. Continuous sliding-mode control strategies for quadrotor robust tracking: real-time application. IEEE Transactions on Industrial Electronics, 2019, 66(2): 1264-1272 doi: 10.1109/TIE.2018.2831191 [3] Yan Z, Jin C X, Utkin V I. Sensorless sliding-mode control of induction motors. IEEE Transactions on Industrial Electronics, 2000, 47(6): 1286-1297 doi: 10.1109/41.887957 [4] Liu Xiang-Jie, Wang Cheng-Cheng, Han Yao-Zhen. Second-order sliding mode control of DFIG based variable speedwind turbine for maximum power point tracking. Acta Automatica Sinica, 2017, 43(8): 1434-1442 [5] 杨赟杰, 朱纪洪, 和阳. 近似时间最优的舵机多模位置控制策略. 控制理论与应用, 2018, 35(4): 468-474 doi: 10.7641/CTA.2017.70087YANG Yun-Jie, ZHU Ji-Hong, HE Yang. Multi-mode position control strategy with approximate time-optimal for actuator. Control Theory & Applications, 2018, 35(4): 468-474(in Chinese) doi: 10.7641/CTA.2017.70087 [6] Sira-Ramlrez H. On the dynamical sliding mode control of nonlinear systems. International Journal of Control, 1993, 57(5): 1039-1061 doi: 10.1080/00207179308934429 [7] 李雪冰, 马莉, 丁世宏. 一类新的二阶滑模控制方法及其在倒立摆控制中的应用. 自动化学报, 2015, 41(1): 193-202Li Xue-Bing, Ma Li, Ding Shi-Hong. A new second-order sliding mode control and its application to inverted pendulum. Acta Automatica Sinica, 2015, 41(1): 193-202(in Chinese) [8] Bhat S P, Bernstein D S. Finite-time stability of continuous autonomous systems. SIAM Journal on Control and Optimization, 2000, 38(3): 751-766 doi: 10.1137/S0363012997321358 [9] Polyakov A. Nonlinear feedback design for fixed-time stabilization of linear control systems. IEEE Transactions on Automatic Control, 2012, 57(8): 2106-2110 doi: 10.1109/TAC.2011.2179869 [10] Polyakov A, Efimov D, Perruquetti W. Finite-time and fixed-time stabilization: Implicit Lyapunov function approach. Automatica, 2015, 51: 332-340 doi: 10.1016/j.automatica.2014.10.082 [11] Feng Y, Yu X, Man Z. Non-singular terminal sliding mode control of rigid manipulators. Automatica, 2002, 38(12): 2159-2167 doi: 10.1016/S0005-1098(02)00147-4 [12] Yang L, Yang J. Nonsingular fast terminal sliding-mode control for nonlinear dynamical systems. International Journal of Robust & Nonlinear Control, 2011, 21(16): 1865-1879 [13] Zuo Z. Non-singular fixed-time terminal sliding mode control of non-linear systems. IET Control Theory & Applications, 2014, 9(4):545-552. [14] Li H, Cai Y. On SFTSM control with fixed-time convergence. IET Control Theory & Applications, 2017, 11(6): 766-773 [15] Corradini M L, Cristofaro A. Nonsingular terminal sliding-mode control of nonlinear planar systems with global fixed-time stability guarantees. Automatica, 2018, 95: 561-565 doi: 10.1016/j.automatica.2018.06.032 [16] Levant A. Higher-order sliding modes, differentiation and output-feedback control. International Journal of Control, 2003, 76(9-10): 924-941 doi: 10.1080/0020717031000099029 [17] Andrieu V, Praly L, Astolfi A. Homogeneous Approximation, Recursive Observer Design, and Output Feedback. SIAM Journal on Control and Optimization, 2008, 47(4): 1814-1850 doi: 10.1137/060675861 [18] Tian B L, Lu H C, Zuo Z Y, Zong Q, Multivariable finite-time output feedback trajectory tracking control of quadrotor helicopters. International Journal of Robust and Nonlinear Control, 2018, 28(1): 281-295 doi: 10.1002/rnc.3869 [19] Levant A, Yu X H. Sliding-mode-based differentiation and filtering. IEEE Transactions on Automatic Control, 2018, 63(9): 3061-3067 doi: 10.1109/TAC.2018.2797218 [20] Hua C C, Wang K, Chen J N, You X. Tracking differentiator and extended state observer-based nonsingular fast terminal sliding mode attitude control for a quadrotor. Nonlinear Dynamics, 2018, 94(1): 343-354 doi: 10.1007/s11071-018-4362-3 [21] Zhang L, Wei C, Jing L, Cui N. Fixed-time sliding mode attitude tracking control for a subfarine-launched missile with multiple disturbances. Nonlinear Dynamics, 2018, 93(4): 2543-2563 doi: 10.1007/s11071-018-4341-8 [22] Zuo Z Y, Han Q L, Ning B, Ge X H, Zhang X M. An overview of recent advances in fixed-time cooperative control of multiagent systems. IEEE Transactions on Industrial Informatics, 2018, 14(6): 2322-2334 doi: 10.1109/TII.2018.2817248 [23] Ni J K, Liu L, Liu C X, Hu X Y, Li S L. Fast fixed-time nonsingular terminal sliding mode control and its application to chaos suppression in power system. IEEE Transactions on Circuits and Systems Ii-Express Briefs, 2017, 64(2): 151-155 doi: 10.1109/TCSII.2016.2551539 [24] Li S H, Zhou M M, Yu X H. Design and implementation of terminal sliding mode control method for pmsm speed regulation system. IEEE Transactions on Industrial Informatics, 2013, 9(4): 1879-1891 doi: 10.1109/TII.2012.2226896 [25] 柴天佑, 岳恒. 自适应控制, 北京: 清华大学出版社, 2016, 127−165Chai Tian-You,Yue Heng. Adaptive Control. Beijing: Tsinghua University Press, 2016, 127−165 [26] Hovakimyan N, Cao C, Kharisov E, Xargay E, Gregory I M. L1 adaptive control for safety-critical systems. IEEE Control Systems Magazine, 2011, 31(5): 54-104 doi: 10.1109/MCS.2011.941961 [27] 钟宜生. 基于信号补偿的鲁棒控制方法. 清华大学学报(自然科学版), 2003, 43(4): 536-542 doi: 10.3321/j.issn:1000-0054.2003.04.027Zhong Yi-Sheng,Robust control based on signal compensation. Journal of Tsinghua University(Science and Technology), 2003, 43(4): 536-542(in Chinese) doi: 10.3321/j.issn:1000-0054.2003.04.027 [28] Patino H D, Liu D. Neural network-based model reference adaptive control system. IEEE Transactions on Systems, Man, and Cybernetics, Part B (Cybernetics), 2000, 30(1): 198-204 doi: 10.1109/3477.826961 [29] Wang W, Nonami K, Ohira Y. Model reference sliding mode control of small helicopter xrb based on vision. International Journal of Advanced Robotic Systems, 2008, 5(3): 235-242 [30] Zhang D, Wei B. A review on model reference adaptive control of robotic manipulators. Annual Reviews in Control, 2017, 43: 188-198 doi: 10.1016/j.arcontrol.2017.02.002 [31] Rotondo D, Cristofaro A, Gryte K, Johansen T A. LPV model reference control for fixed-wing UAVs. In: Proceedings of the 20th World Congress of the International Federation of Automatic Control. Toulouse, France: IFAC, 2017, 50(1): 11559-11564 [32] Ucar A. Model-reference control of chaotic systems. Chaos Solitons & Fractals, 2007, 31(3): 712-717 [33] Capello E, Guglieri G, Sartori D. Performance evaluation of an L1 adaptive controller for wing-body rock suppression. Journal of Guidance, Control, and Dynamics, 2012, 35(6): 1702-1708 doi: 10.2514/1.57595 [34] Luo J, Cao C. L 1 adaptive control with sliding-mode based adaptive law. Control Theory and Technology, 2015, 13(3): 221-229 doi: 10.1007/s11768-015-3116-8 [35] Isidori A. Nonlinear Control Systems. Lodon: Springer Science and Business Media, 2013. [36] Kori D K, Kolhe J P, Talole S E. Extended state observer based robust control of wing rock motion. Aerospace Science and Technology, 2014, 33(1): 107-117 doi: 10.1016/j.ast.2014.01.008 [37] Lee K W, Singh S N. Immersion and invariance-based adaptive wing rock control with nonlinear terminal manifold. Nonlinear Dynamics, 2017, 88(2): 955-972 doi: 10.1007/s11071-016-3287-y -

 下载:
下载:



图(10) / 表(3)
计量
- 文章访问数: 2279
- HTML全文浏览量: 1068
- PDF下载量: 713
- 被引次数: 0
