

-
摘要: 在机器学习领域中, 梯度下降算法是求解最优化问题最重要、最基础的方法. 随着数据规模的不断扩大, 传统的梯度下降算法已不能有效地解决大规模机器学习问题. 随机梯度下降算法在迭代过程中随机选择一个或几个样本的梯度来替代总体梯度, 以达到降低计算复杂度的目的. 近年来, 随机梯度下降算法已成为机器学习特别是深度学习研究的焦点. 随着对搜索方向和步长的不断探索, 涌现出随机梯度下降算法的众多改进版本, 本文对这些算法的主要研究进展进行了综述. 将随机梯度下降算法的改进策略大致分为动量、方差缩减、增量梯度和自适应学习率等四种. 其中, 前三种主要是校正梯度或搜索方向, 第四种对参数变量的不同分量自适应地设计步长. 着重介绍了各种策略下随机梯度下降算法的核心思想、原理, 探讨了不同算法之间的区别与联系. 将主要的随机梯度下降算法应用到逻辑回归和深度卷积神经网络等机器学习任务中, 并定量地比较了这些算法的实际性能. 文末总结了本文的主要研究工作, 并展望了随机梯度下降算法的未来发展方向.Abstract: In the field of machine learning, gradient descent algorithm is the most significant and fundamental method to solve optimization problems. With the continuous expansion of the scale of data, the traditional gradient descent algorithms can not effectively solve the problems of large-scale machine learning. Stochastic gradient descent algorithm selects one or several sample gradients randomly to represent the overall gradients in the iteration process, so as to reduce the computational complexity. In recent years, stochastic gradient descent algorithm has become the research focus of machine learning, especially deep learning. With the constant exploration of search directions and step sizes, numerous improved versions of the stochastic gradient descent algorithm have emerged. This paper reviews the main research advances of these improved versions. The improved strategies of stochastic gradient descent algorithm are roughly divided into four categories, including momentum, variance reduction, incremental gradient and adaptive learning rate. The first three categories mainly correct gradient or search direction and the fourth designs adaptively step sizes for different components of parameter variables. For the stochastic gradient descent algorithms under different strategies, the core ideas and principles are analyzed emphatically, and the difference and connection between different algorithms are investigated. Several main stochastic gradient descent algorithms are applied to machine learning tasks such as logistic regression and deep convolutional neural networks, and the actual performance of these algorithms is numerically compared. At the end of the paper, the main research work of this paper is summarized, and the future development direction of the stochastic gradient descent algorithms is prospected.1) 收稿日期 2019-03-28 录用日期 2019-07-30 Manuscript received March 28, 2019; accepted July 30, 2019 国家自然科学基金 (61876220, 61876221), 中国博士后科学基金 (2017M613087) 资助 Supported by National Natural Science Foundation of China (61876220, 61876221) and China Postdoctoral Science Foundation (2017M613087) 本文责任编委 王鼎 Recommended by Associate Editor WANG Ding 1. 西安建筑科技大学理学院 西安 710055 2. 省部共建西部绿色建筑国家重点实验室 西安 710055 3. 西安电子科技大学人工智能学院智能感知与图像理解教育部重点实验室 西安 7100714. 西安电子科技大学计算机科学与技术学院 西安 7100712) 1. School of Science, Xi' an University of Architecture and Technology, Xi' an 710055 2. State Key Laboratory of Green Building in Western China, Xi' an University of Architecture and Technology, Xi' an 710055 3. Key Laboratory of Intelligent Perception and Image Understanding of Ministry of Education of China, School of Artiflcial Intelligence, Xidian University, Xi' an710071 4. School of Computer Science and Technology, Xidian University, Xi' an 710071
-
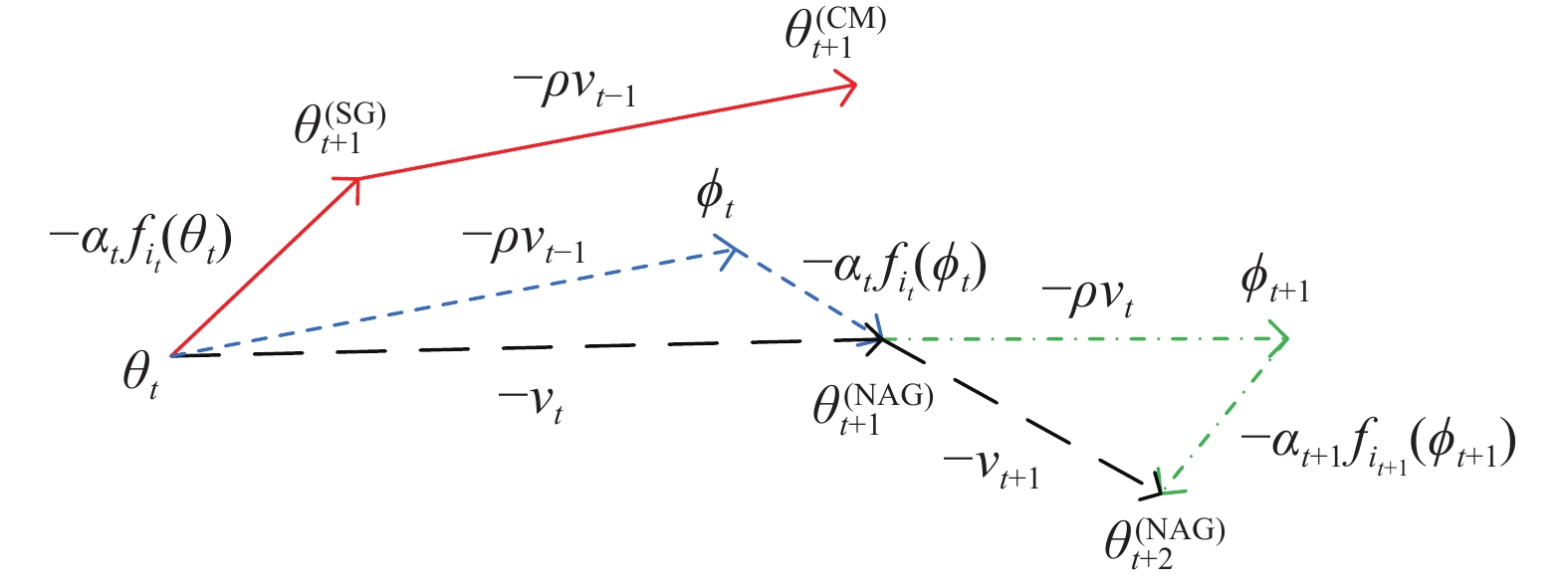
图 3 SGD、CM和NAG的参数更新示意图
Fig. 3 Schematic diagram of parameters update of SGD, CM and NAG
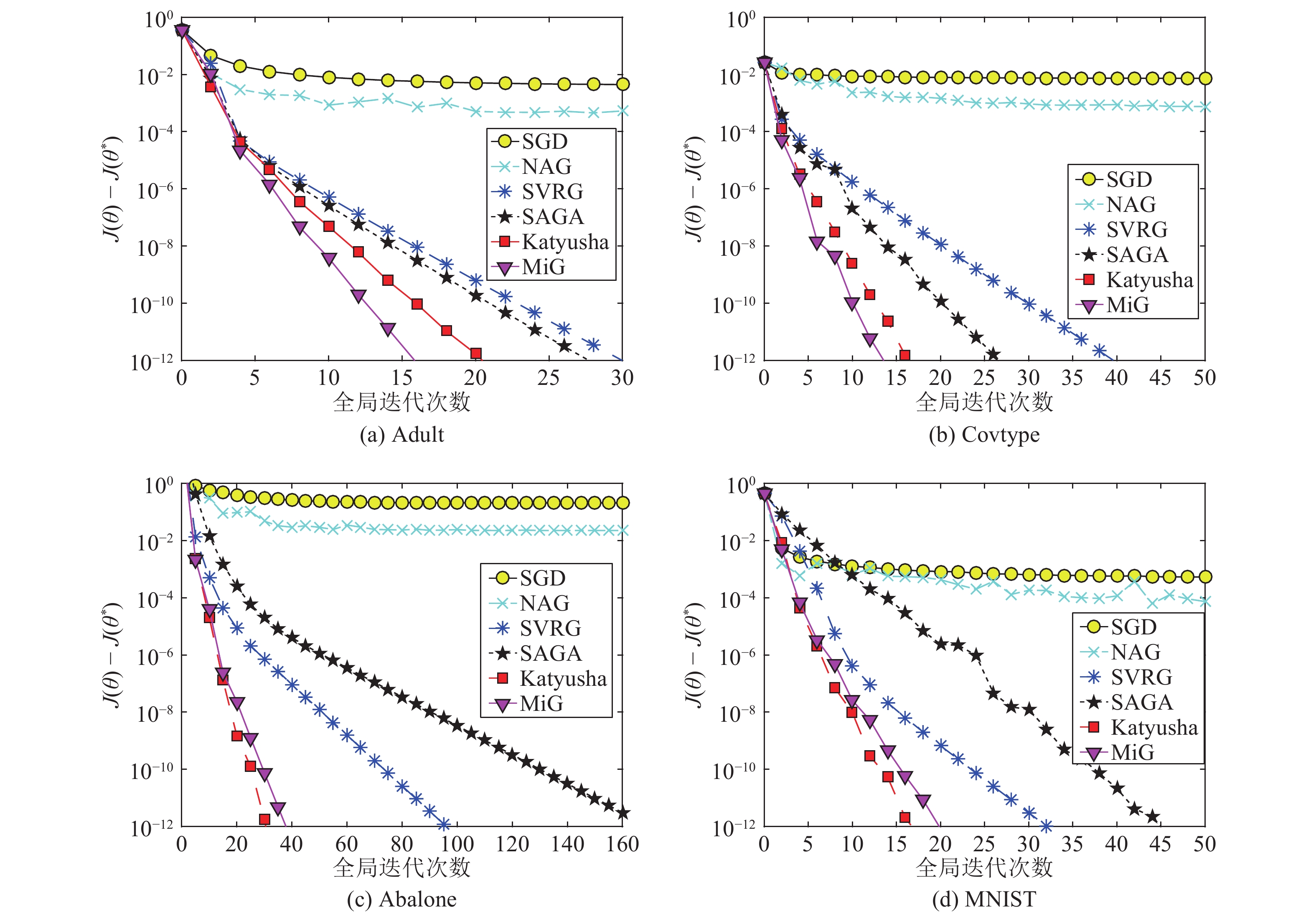
图 6 随机梯度下降算法的迭代效率对比
Fig. 6 Comparison of iterative efficiency of stochastic gradient descent algorithms

图 7 随机梯度下降算法的时间效率对比
Fig. 7 Comparison of time efficiency of stochastic gradient descent algorithms
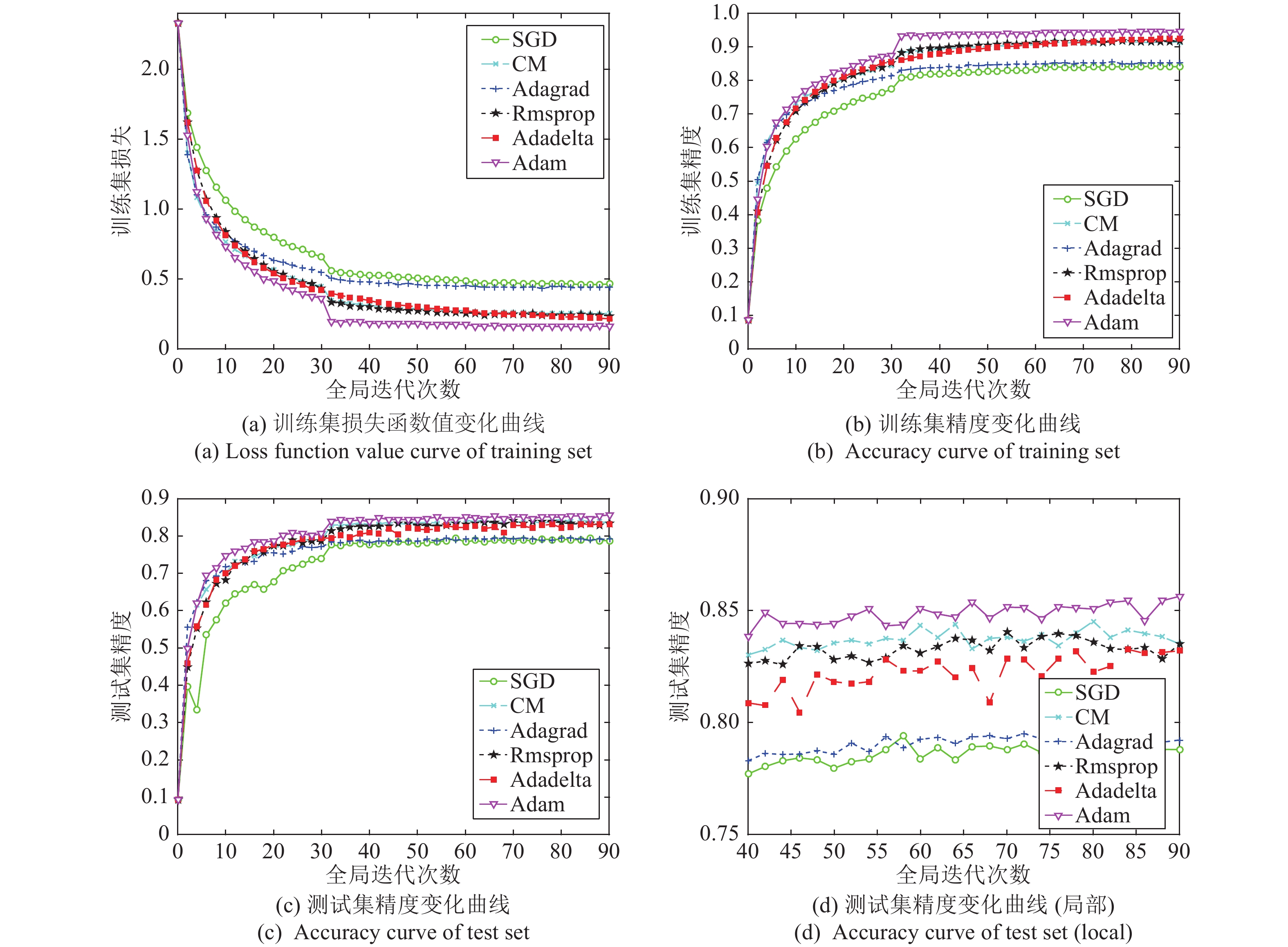
图 8 自适应学习率的随机梯度下降算法性能比较
Fig. 8 Performance comparison of stochastic gradient descent algorithms with adaptive learning rates
表 1 CM与NAG的更新公式比较
Table 1 Comparison of update formulas between CM and NAG
CM NAG (写法1) NAG (写法2) 梯度 ${\boldsymbol{g} }_{t}=\nablaf_{i_t}({\boldsymbol{\theta}}_{t})$ ${\boldsymbol{g} }_{t}=\nabla f_{i_{t} }({\boldsymbol{\theta}}_{t}-\rho {\boldsymbol{v} }_{t-1})$ ${\boldsymbol{g}}_{t}=\nabla f_{i_t}({\boldsymbol{\theta}}_{t})$ 动量 ${\boldsymbol{v}}_{t}=\alpha_{t} {\boldsymbol{g}}_{t}+\rho {\boldsymbol{v}}_{t-1}$ ${\boldsymbol{v}}_{t}=\alpha_{t} {\boldsymbol{g}}_{t}+\rho {\boldsymbol{v}}_{t-1}$ ${{\boldsymbol{v}}_t} = {\alpha _t}{{\boldsymbol{g}}_t} + \rho {{\boldsymbol{v}}_{t - 1} }$
${ {\bar {\boldsymbol{v} } }_t} = {\alpha _t}{{\boldsymbol{g}}_t} + \rho { {\boldsymbol{v} }_t} \;\;$参数
迭代${\boldsymbol{\theta }}_{t + 1} = {\boldsymbol{\theta}} _{t} - {\boldsymbol{v}} _{t}$ ${\boldsymbol{\theta}} _{t + 1} = {\boldsymbol{\theta}} _{t} - {\boldsymbol{v}} _{t}$ ${\boldsymbol{\theta}} _{t + 1} ={\boldsymbol{ \theta }}_{t} - \overline{{\boldsymbol{v}}} _{t}$  下载: 导出CSV
下载: 导出CSV
表 3 SVRG与增量算法参数更新公式对比
Table 3 Comparison of parameters updating formulas among SVRG and incremental algorithms
算法名称 参数更新公式 SVRG $\scriptstyle{{\boldsymbol{\theta}} _{t + 1} = {\boldsymbol{\theta}} _{t} - \alpha _{t} \left(\nabla f _{i _{t} } \left( {\boldsymbol{\theta}} _{t}\right) - \nabla f _{i _{t} }(\tilde{{\boldsymbol{\theta}}})+\frac{1}{n}\sum_{i=1}^{n}\nabla f_{i}(\tilde{{\boldsymbol{\theta}}})\right)}$ SAG $\scriptstyle{ {\boldsymbol{\theta} } _{t + 1} = {\boldsymbol{\theta} } _{t} - \frac{\alpha _{t} }{n} \left( \nabla f _{i _{t} } \left( {\boldsymbol{\theta} } _{t} \right) - \nabla f _{i _{t} } \left( {\boldsymbol{\psi}} _{t} ^{i _{t} } \right) + \sum _{i = 1} ^{n} \nabla f _{i} \left( {\boldsymbol{\psi}} _{t} ^{i} \right) \right)}$ SAGA $\scriptstyle{{\boldsymbol{\theta}} _{t + 1} = {\boldsymbol{\theta}} _{t} - \alpha _{t} \left( \nabla f _{i _{t} } \left({\boldsymbol{ \theta}} _{t} \right) - \nabla f _{i _{t} } \left( {\boldsymbol{\psi}} _{t} ^{i _{t} } \right) + \frac{1}{n} \sum _{i = 1} ^{n} \nabla f _{i} \left( {\boldsymbol{\psi}} _{t} ^{i} \right) \right)}$ Point-
SAGA$\scriptstyle{{\boldsymbol{\theta }}_{t + 1} = {\boldsymbol{\theta }}_{t} - \alpha _{t} \left( \nabla f _{i _{t} } \left( {\boldsymbol{\theta}} _{t + 1} \right) - \nabla f _{i _{t} } \left({\boldsymbol{ \psi }}_{t} ^{i _{t} } \right) + \frac{1}{n} \sum _{i = 1} ^{n} \nabla f _{i} \left({\boldsymbol{ \psi}} _{t} ^{i} \right) \right)}$
下载: 导出CSV
表 4 随机梯度下降算法的复杂度与收敛速度
Table 4 Complexity and convergence speed of stochastic gradient descent algorithms
算法名称 复杂度 (强凸) 复杂度 (凸) 收敛速度 (强凸) 收敛速度 (凸) 第1代 SGD[43] ${\rm{O} } \left( ( \kappa / \varepsilon ) \log \frac {1} {\varepsilon} \right)$ ${\rm{O} }\left( 1 / \varepsilon ^ {2} \right)$ ${\rm{O} }( 1 / T )$ ${\rm{O}}( 1 / \sqrt {T} )$ NAG[26] ${\rm{O} }\left( n \sqrt {\kappa} \log \frac {1} {\varepsilon} \right)$ — ${\rm{O} } \big( \rho ^ {T} \big)$ ${\rm{O} }\big(1 / T ^ {2}\big)$ 第2代 SVRG[28] ${\rm{O} }\left( ( n + \kappa ) \log \frac {1} {\varepsilon} \right)$ — ${\rm{O} } \big( \rho ^ {T} \big)$ — Prox-SVRG[29] ${\rm{O} } \left( ( n + \kappa ) \log \frac {1} {\varepsilon} \right)$ — ${\rm{O} } \big( \rho ^ {T} \big)$ — SAG[32] ${\rm{O} }\left( ( n + \kappa ) \log \frac {1} {\varepsilon} \right)$ — ${\rm{O} } \big( \rho ^ {T}\big)$ ${\rm{O}} ( 1 / T )$ SAGA[33] ${\rm{O} }\left( ( n + \kappa ) \log \frac {1} {\varepsilon} \right)$ ${\rm{O}} ( n / \varepsilon )$ ${\rm{O} }\big( \rho ^ {T} \big)$ ${\rm{O}}( 1 / T )$ 第3代 Katyusha[30] ${\rm{O} } \left( ( n + \sqrt {n \kappa} ) \log \frac {1} {\varepsilon} \right)$ ${\rm{O}}( n + \sqrt {n / \varepsilon} )$ ${\rm{O} }\big( \rho ^ {T} \big)$ ${\rm{O} } \left( 1 / T ^ {2} \right)$ Point-SAGA[34] ${\rm{O} } \left( ( n + \sqrt {n \kappa} ) \log \frac {1} {\varepsilon} \right)$ — ${\rm{O} }\big( \rho ^ {T} \big)$ — MiG[31] ${\rm{O} }\left( ( n + \sqrt {n \kappa} ) \log \frac {1} {\varepsilon} \right)$ ${\rm{O}}( n + \sqrt {n / \varepsilon} )$ ${\rm{O} } \big( \rho ^ {T} \big)$ ${\rm{O} } \left( 1 / T ^ {2} \right)$
下载: 导出CSV
表 5 数据集描述
Table 5 Description of datasets
数据集 样本总数 样本特征 占用内存 Adult 32562 123 734 KB Covtype 581012 54 52 MB Abalone 4177 8 71 KB MNIST 60000 784 12 MB
下载: 导出CSV
表 6 3种机器学习任务的优化模型
Table 6 Optimization models for 3 machine learning tasks
模型名称 模型公式 $\ell _{2}$逻辑
回归$\min\limits _{{\boldsymbol{\theta}} \in {\bf{R} } ^{d} }J ( {\boldsymbol{\theta}} ) = \frac{1}{n}\sum\nolimits _{i = 1}^{n}\log \left( 1 + \exp \left( - y _{i}{\boldsymbol{x}} _{i}^{\mathrm{T} }{\boldsymbol{\theta}} \right) \right) + \frac{\lambda _{2} }{2}\| {\boldsymbol{\theta}} \| _{2}^{2}$ 岭回归 $\min\limits _{{\boldsymbol{\theta }}\in {\bf{R} } ^{d} }J ( {\boldsymbol{\theta }}) = \frac{1}{2 n}\sum\nolimits _{i = 1}^{n}\left( {\boldsymbol{x}} _{i}^{\mathrm{T} }{\boldsymbol{\theta}} - y _{i}\right) ^{2}+ \frac{\lambda _{2} }{2}\| {\boldsymbol{\theta}} \| _{2}^{2}$ Lasso $\min\limits _{{\boldsymbol{\theta }}\in {\bf{R} } ^{d} }J ( {\boldsymbol{\theta}} ) = \frac{1}{2 n}\sum\nolimits _{i = 1}^{n}\left( {\boldsymbol{x}} _{i}^{\mathrm{T} }{\boldsymbol{\theta}} - y _{i}\right) ^{2}+ \lambda _{1}\| {\boldsymbol{\theta}} \| _{1}$
下载: 导出CSV
表 7 数据集对应的优化模型与正则参数
Table 7 Optimization model and regularization parameter for each dataset
编号 数据集 优化模型 正则参数 (a) Adult $\ell _{2}$ 逻辑回归 $\lambda _{2} = 10 ^{- 5}$ (b) Covtype $\ell _{2}$ 逻辑回归 $\lambda _{2} = 10 ^{- 6}$ (c) Abalone Lasso $\lambda _{1} = 10 ^{- 4}$ (d) MNIST 岭回归 $\lambda _{2} = 10 ^{- 5}$
下载: 导出CSV
-
[1] Jordan M I, Mitchell T M. Machine learning: Trends, perspectives, and prospects. Science, 2015, 349(6245): 255−260 doi: 10.1126/science.aaa8415 [2] 林懿伦, 戴星原, 李力, 王晓, 王飞跃. 人工智能研究的新前线: 生成式对抗网络. 自动化学报, 2018, 44(5): 775−792Lin Yi-Lun, Dai Xing-Yuan, Li Li, Wang Xiao, Wang Fei-Yue. The new frontier of AI research: Generative adversarial networks. Acta Automatica Sinica, 2018, 44(5): 775−792 [3] LeCun Y, Bengio Y, Hinton G. Deep learning. Nature, 2015, 521(7553): 436−444 doi: 10.1038/nature14539 [4] Bottou L, Curtis F E, Nocedal J. Optimization methods for large-scale machine learning. SIAM Review, 2018, 60(2): 223−311 doi: 10.1137/16M1080173 [5] 焦李成, 赵进, 杨淑媛, 刘芳. 深度学习、优化与识别. 北京: 清华大学出版社, 2017.Jiao Li-Cheng, Zhao Jin, Yang Shu-Yuan, Liu Fang. Deep Learning, Optimization and Recognition. Beijing: Tsinghua University Press, 2017. [6] Robbins H, Monro S. A stochastic approximation method. The Annals of Mathematical Statistics, 1951, 22(3): 400−407 doi: 10.1214/aoms/1177729586 [7] Amari S. A theory of adaptive pattern classifiers. IEEE Transactions on Electronic Computers, 1967, EC-16(3): 299−307 doi: 10.1109/PGEC.1967.264666 [8] Bottou L. Online algorithms and stochastic approximations. Online Learning and Neural Networks. Cambridge, UK: Cambridge University Press, 1998. [9] 焦李成, 杨淑媛, 刘芳, 王士刚, 冯志玺. 神经网络七十年: 回顾与展望. 计算机学报, 2016, 39(8): 1697−1717Jiao Li-Cheng, Yang Shu-Yuan, Liu Fang, Wang Shi-Gang, Feng Zhi-Xi. Seventy years beyond neural networks: Retrospect and prospect. Chinese Journal of Computers, 2016, 39(8): 1697−1717 [10] Kasiviswanathan S P, Jin H X. Efficient private empirical risk minimization for high-dimensional learning. In: Proceedings of the 33rd International Conference on Machine Learning. New York, USA: JMLR, 2016. 488−497 [11] Krizhevsky A, Sutskever I, Hinton G E. ImageNet classification with deep convolutional neural networks. In: Proceedings of the 25th International Conference on Neural Information Processing Systems. Red Hook, NY, United States: Curran Associates Inc., 2012. 1097−1105 [12] Sutskever I, Martens J, Dahl G, Hinton G. On the importance of initialization and momentum in deep learning. In: Proceedings of the 30th International Conference on Machine Learning. Atlanta, USA: ACM, 2013. III-1139−III-1147 [13] Shamir O. Fast stochastic algorithms for SVD and PCA: Convergence properties and convexity. In: Proceeding ofs the 33rd International Conference on Machine Learning. New York, USA: JMLR, 2016. 248−256 [14] Shamir O. Convergence of stochastic gradient descent for PCA. In: Proceedings of the 33rd International Conference on Machine Learning. New York, USA: JMLR, 2016. 257−265 [15] Garber D, Hazan E, Jin C, Kakade S M, Musco C, Netrapalli P, et al. Faster eigenvector computation via shift-and-invert preconditioning. In: Proceedings of the 33rd International Conference on Machine Learning. New York, USA: JMLR, 2016. 2626−2634 [16] Allen-Zhu Z, Li Y Z. Doubly accelerated methods for faster CCA and generalized eigendecomposition. In: Proceedings of the 34th International Conference on Machine Learning. Sydney, Australia: JMLR, 2017. 98−106 [17] Kasai H. Stochastic variance reduced multiplicative update for nonnegative matrix factorization. In: Proceedings of the 44th IEEE International Conference on Acoustics, Speech, and Signal Processing. Alberta, Canada: IEEE, 2018. 6338−6342 [18] Zhang X, Wang L X, Gu Q Q. Stochastic variance-reduced gradient descent for low-rank matrix recovery from linear measurements [Online], available: https://arxiv.org/pdf/1701.00481.pdf, January 16, 2017 [19] Ouyang H, He N, Tran L Q, Gray A. Stochastic alternating direction method of multipliers. In: Proceedings of the 30th International Conference on Machine Learning. Atlanta, USA: JMLR, 2013. I-80−I-88 [20] Liu Y Y, Shang F H, Cheng J. Accelerated variance reduced stochastic ADMM. In: Proceedings of the 31st AAAI Conference on Artificial Intelligence. California, USA: AAAI Press, 2017. 2287−2293 [21] Qu C, Li Y, Xu H. Linear convergence of SVRG in statistical estimation [Online], available: https://arxiv.org/pdf/1611.01957.pdf, July 27, 2017 [22] Paquette C, Lin H Z, Drusvyatskiy D, Mairal J, Harchaoui Z. Catalyst acceleration for gradient-based non-convex optimization [Online], available: https://arxiv.org/pdf/1703.10993.pdf, December 31, 2018 [23] Duchi J C, Ruan F. Stochastic methods for composite optimization problems [Online], available: https://arxiv.org/pdf/1703.08570.pdf, September 21, 2018 [24] Schmidt M, Babanezhad R, Ahmed M O, Defazio A, Clifton A, Sarkar A. Non-uniform stochastic average gradient method for training conditional random fields. In: Proceedings of the 18th International Conference on Artificial Intelligence and Statistics. California, USA: JMLR, 2015. 819−828 [25] Qian N. On the momentum term in gradient descent learning algorithms. Neural Networks, 1999, 12(1): 145−151 doi: 10.1016/S0893-6080(98)00116-6 [26] Nesterov Y. A method for solving a convex programming problem with convergence rate O(1/k2). Soviet Mathematics Doklady, 1983, 27(2): 372−376 (请联系作者确认修改是否正确) [27] Botev A, Lever G, Barber D. Nesterov's accelerated gradient and momentum as approximations to regularised update descent. In: Proceedings of the 30th International Joint Conference on Neural Networks. Alaska, USA: IEEE, 2017.1899−1903 [28] Johnson R, Zhang T. Accelerating stochastic gradient descent using predictive variance reduction. In: Proceedings of the 26th International Conference on Neural Information Processing Systems. Red Hook, NY, United States: Curran Associates Inc., 2013. 315−323 [29] Xiao L, Zhang T. A proximal stochastic gradient method with progressive variance reduction. SIAM Journal on Optimization, 2014, 24(4): 2057−2075 doi: 10.1137/140961791 [30] Allen-Zhu Z. Katyusha: The first direct acceleration of stochastic gradient methods. Journal of Machine Learning Research, 2018, 18: 1−51 [31] Zhou K W, Shang F H, Cheng J. A simple stochastic variance reduced algorithm with fast convergence rates [Online], available: https://arxiv.org/pdf/1806.11027.pdf, July 28, 2018 [32] Schmidt M, Le Roux N, Bach F. Minimizing finite sums with the stochastic average gradient. Mathematical Programming, 2017, 162(1−2): 83−112 doi: 10.1007/s10107-016-1030-6 [33] Defazio A, Bach F, Lacoste-Julien S. SAGA: A fast incremental gradient method with support for non-strongly convex composite objectives. In: Proceedings of the 27th International Conference on Neural Information Processing Systems. Cambridge, MA, United States: MIT Press, 2014. 1646−1654 [34] Defazio A. A simple practical accelerated method for finite sums. In: Proceedings of the 29th Conference on Neural Information Processing Systems. Barcelona, Spain: MIT Press, 2016. 676−684 [35] Goodfellow I, Bengio Y, Courville A. Deep Learning. Cambridge: MIT Press, 2016. 267−309 [36] Duchi J, Hazan E, Singer Y. Adaptive subgradient methods for online learning and stochastic optimization. Journal of Machine Learning Research, 2011, 12: 2121−2159 [37] Zeiler D M. ADADELTA: An adaptive learning rate method [Online], available: https://arxiv.org/pdf/1212.5701.pdf, December 22, 2012 [38] Kingma D, Ba J. Adam: A method for stochastic optimization. In: Proceedings of the 3rd International Conference on Learning Representations. San Diego, USA: Workshop Track, 2015. 1−13 [39] Dozat T. Incorporating Nesterov momentum into Adam. In: Proceedings of the 4th International Conference on Learning Representations. San Juan, Puerto Rico, USA: Workshop Track, 2016. [40] Ruder S. An overview of gradient descent optimization algorithms [Online], available: https://arxiv.org/pdf/1609.04747.pdf, June 15, 2017 [41] Nesterov Y. Smooth convex optimization. Introductory Lectures on Convex Optimization: A Basic Course. Boston, MA: Springer, 2004. 51−110 [42] Nesterov Y. Gradient methods for minimizing composite functions. Mathematical Programming, 2013, 140(1): 125−161 doi: 10.1007/s10107-012-0629-5 [43] Bottou L. Large-scale machine learning with stochastic gradient descent. In: Proceedings of the 19th International Conference on Computational Statistics. Paris, France: Physica-Verlag HD, 2010. 177−186 [44] Hinton G, Srivastava N, Swersky K. Neural networks for machine learning: Lecture 6a overview of mini-batch gradient descent [Online], available: https://www.cs.toronto.edu/~tijmen/csc321/slides/lecture_slides_lec6.pdf, 2012. [45] Li M, Zhang T, Chen Y Q, Smola A J. Efficient mini-batch training for stochastic optimization. In: Proceedings of the 20th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining. New York, USA: ACM, 2014. 661−670 [46] Bach F. Linearly-convergent stochastic gradient algorithms [Online], available: http://homepages.laas.fr/henrion/aime@cz18/bach.pdf, February 22, 2018 [47] Dekel O, Gilad-Bachrach R, Shamir O, Xiao L. Optimal distributed online prediction using mini-batches. Journal of Machine Learning Research, 2012, 13(6): 165−202 [48] 李飞, 高晓光, 万开方. 基于权值动量的RBM加速学习算法研究. 自动化学报, 2017, 43(7): 1142−1159Li Fei, Gao Xiao-Guang, Wan Kai-Fang. Research on RBM accelerating learning algorithm with weight momentum. Acta Automatica Sinica, 2017, 43(7): 1142−1159 [49] 朱小辉, 陶卿, 邵言剑, 储德军. 一种减小方差求解非光滑问题的随机优化算法. 软件学报, 2015, 26(11): 2752−2761Zhu Xiao-Hui, Tao Qing, Shao Yan-Jian, Chu De-Jun. Stochastic optimization algorithm with variance reduction for solving non-smooth problems. Journal of Software, 2015, 26(11): 2752−2761 [50] Atchadé Y F, Fort G, Moulines E. On perturbed proximal gradient algorithms [Online], available: https://arxiv.org/pdf/1402.2365.pdf, November 19, 2016 [51] Parikh N, Boyd S. Proximal algorithms. Foundations and Trends® in Optimization, 2014, 1(3): 127−239 (找不到®的代码, 请联系作者确认) [52] Nitanda A. Stochastic proximal gradient descent with acceleration techniques. In: Proceedings of the 27th International Conference on Neural Information Processing Systems. Cambridge, MA, United States: MIT Press, 2014. 1574−1582 [53] Shang F H, Zhou K W, Liu H Y, Cheng J, Tsang I W, Zhang L J, et al. VR-SGD: A simple stochastic variance reduction method for machine learning. IEEE Transactions on Knowledge and Data Engineering, 2020, 32(1): 188−202 doi: 10.1109/TKDE.2018.2878765 [54] Shalev-Shwartz S, Zhang T. Stochastic dual coordinate ascent methods for regularized loss minimization. Journal of Machine Learning Research, 2013, 14(1): 567−599 [55] Zhang Y C, Xiao L. Stochastic primal-dual coordinate method for regularized empirical risk minimization. Journal of Machine Learning Research, 2017, 18: 1−42 [56] Gürbüzbalaban M, Ozdaglar A, Parrilo P A. On the convergence rate of incremental aggregated gradient algorithms. SIAM Journal on Optimization, 2017, 27(2): 1035−1048 doi: 10.1137/15M1049695 [57] Tseng P, Yun S. Incrementally updated gradient methods for constrained and regularized optimization. Journal of Optimization Theory and Applications, 2014, 160(3): 832−853 doi: 10.1007/s10957-013-0409-2 [58] Poon C, Liang J W, Schönlieb C B. Local convergence properties of SAGA/Prox-SVRG and acceleration [Online], available: https://arxiv.org/pdf/1802.02554.pdf, November 1, 2018 [59] Rockafellar R T. Monotone operators and the proximal point algorithm. SIAM Journal on Control and Optimization, 1976, 14(5): 877−898 doi: 10.1137/0314056 [60] Dean J, Corrado G S, Monga R, Chen K, Devin M, Le Q V, et al. Large scale distributed deep networks. In: Proceedings of the 25th International Conference on Neural Information Processing Systems. Red Hook, NY, United States: Curran Associates Inc., 2012. 1223−1231 [61] Pennington J, Socher R, Manning C. GloVe: Global vectors for word representation. In: Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing. Doha, Qatar: ACL, 2014. 1532−1543 [62] Chen Z Y, Xu Y, Chen E H, Yang T B. SADAGRAD: Strongly adaptive stochastic gradient methods. In: Proceedings of the 35th International Conference on Machine Learning. Stockholm, Swedish: ACM, 2018. 913−921 [63] Tieleman T, Hinton G. Lecture 6.5-rmsprop: Divide the gradient by a running average of its recent magnitude. COURSERA: Neural Networks for Machine Learning, 2012, 4(2): 26−30 [64] Carlini N, Wagner D. Towards evaluating the robustness of neural networks. In: Proceedings of the 2017 IEEE Symposium on Security and Privacy. San Jose, USA: IEEE, 2017. 39−57 [65] Zhang K, Zuo W M, Chen Y J, Meng D Y, Zhang L. Beyond a gaussian denoiser: Residual learning of deep CNN for image denoising. IEEE Transactions on Image Processing, 2017, 26(7): 3142−3155 doi: 10.1109/TIP.2017.2662206 [66] Hubara I, Courbariaux M, Soudry D, Yaniv R E. Binarized neural networks. In: Proceedings of the 30th International Conference on Neural Information Processing Systems. Red Hook, NY, United States: Curran Associates Inc., 2016. 4114−4122 [67] Luo L C, Huang W H, Zeng Q, Nie Z Q, Sun X. Learning personalized end-to-end goal-oriented dialog. In: Proceedings of the 33rd AAAI Conference on Artificial Intelligence. Honolulu, Hawaii, USA: AAAI, 2019. [68] Wilson A C, Roelofs R, Stern M, Srebro N, Recht B. The marginal value of adaptive gradient methods in machine learning. In: Proceedings of the 31st Conference on Neural Information Processing Systems. Long Beach, USA: MIT Press, 2017. 4148−4158 [69] Reddi S J, Kale S, Kumar S. On the convergence of adam and beyond. In: Proceedings of the 6th International Conference on Learning Representations. Vancouver, Canada: Workshop Track, 2018. [70] Luo L C, Xiong Y H, Liu Y, Sun X. Adaptive gradient methods with dynamic bound of learning rate. In: Proceedings of the 7th International Conference on Learning Representations. New Orleans, USA: Workshop Track, 2019. [71] He K M, Zhang X Y, Ren S Q, Sun J. Deep residual learning for image recognition. In: Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition. Las Vegas, USA: IEEE, 2016. 770−778 [72] 谢佩, 游科友, 洪奕光, 谢立华. 网络化分布式凸优化算法研究进展. 控制理论与应用, 2018, 35(7): 918−927 doi: 10.7641/CTA.2018.80205Xie Pei, You Ke-You, Hong Yi-Guang, Xie Li-Hua. A survey of distributed convex optimization algorithms over networks. Control Theory and Applications, 2018, 35(7): 918−927 doi: 10.7641/CTA.2018.80205 [73] 亢良伊, 王建飞, 刘杰, 叶丹. 可扩展机器学习的并行与分布式优化算法综述. 软件学报, 2018, 29(1): 109−130Kang Liang-Yi, Wang Jian-Fei, Liu Jie, Ye Dan. Survey on parallel and distributed optimization algorithms for scalable machine learning. Journal of Software, 2018, 29(1): 109−130 [74] Zinkevich M A, Weimer M, Smola A, Li L H. Parallelized stochastic gradient descent. In: Proceedings of the 23rd International Conference on Neural Information Processing Systems. Red Hook, NY, United States: Curran Associates Inc., 2010. 2595−2603 [75] Niu F, Recht B, Re C, Wright S J. HOGWILD!: A lock-free approach to parallelizing stochastic gradient descent. In: Proceedings of the 24th International Conference on Neural Information Processing Systems. Red Hook, NY, United States: Curran Associates Inc., 2011. 693−701 [76] 陈振宏, 兰艳艳, 郭嘉丰, 程学旗. 基于差异合并的分布式随机梯度下降算法. 计算机学报, 2015, 38(10): 2054−2063) doi: 10.11897/SP.J.1016.2015.02054Chen Zhen-Hong, Lan Yan-Yan, Guo Jia-Feng, Cheng Xue-Qi. Distributed stochastic gradient descent with discriminative aggregating. Chinese Journal of Computers, 2015, 38(10): 2054−2063 doi: 10.11897/SP.J.1016.2015.02054 [77] Zhao S Y, Li W J. Fast asynchronous parallel stochastic gradient descent: A lock-free approach with convergence guarantee. In: Proceedings of the 30th AAAI Conference on Artificial Intelligence. Phoenix, USA: AAAI Press, 2016. 2379−2385 [78] De S, Goldstein T. Efficient distributed SGD with variance reduction. In: Proceedings of the 16th IEEE International Conference on Data Mining. Barcelona, Spain: IEEE, 2016. 111−120 [79] Bach F, Moulines E. Non-asymptotic analysis of stochastic approximation algorithms for machine learning. In: Proceedings of the 24th International Conference on Neural Information Processing Systems. Red Hook, NY, United States: Curran Associates Inc., 2011. 451−459 [80] Babichev D, Bach F. Constant step size stochastic gradient descent for probabilistic modeling [Online], available: https://arxiv.org/pdf/1804.05567.pdf, November 21, 2018 [81] Andrychowicz M, Denil M, Colmenarejo S G, Hoffman M W, Pfau D, Schaul T, et al. Learning to learn by gradient descent by gradient descent. In: Proceedings of the 30th Neural Information Processing Systems. Barcelona, Spain: MIT Press, 2016. 3981−3989 [82] Allen-Zhu Z. Katyusha X: Practical momentum method for stochastic sum-of-nonconvex optimization [Online], available: https://arxiv.org/pdf/1802.03866.pdf, February 12, 2018 [83] Allen-Zhu Z, Hazan E. Variance reduction for faster non-convex optimization. In: Proceedings of the 33rd International Conference on Machine Learning. New York, USA: JMLR, 2016. 699−707 [84] Lei L, Ju C, Chen J, Jordan M. Non-convex finite-sum optimization via SCSG methods. In: Proceedings of the 31st International Conference on Neural Information Processing Systems. Red Hook, NY, United States: Curran Associates Inc., 2017. 2345−2355 [85] Allen-Zhu Z. Natasha 2: Faster non-convex optimization than SGD. In: Proceedings of the 32nd International Conference on Neural Information Processing Systems. Red Hook, NY, United States: Curran Associates Inc., 2018. 2680−2691 [86] Li Q W, Zhou Y, Liang Y B, Varshney P K. Convergence analysis of proximal gradient with momentum for nonconvex optimization. In: Proceedings of the 34th International Conference on Machine Learning. Sydney, Australia: JMLR, 2017. 2111−2119 [87] Zhou D R, Xu P, Gu Q Q. Stochastic nested variance reduced gradient descent for nonconvex optimization. In: Proceedings of the 32nd Conference on Neural Information Processing Systems. Montreal, Canada: MIT Press, 2018. 3921−3932 [88] Jin C, Ge R, Netrapalli P, Kakade S M, Jordan M I. How to escape saddle points efficiently. In: Proceedings of the 34th International Conference on Machine Learning. Sydney, Australia: JMLR, 2017. 1724−1732 [89] Reddi S J, Sra S, Póczos B, Smola A J. Proximal stochastic methods for nonsmooth nonconvex finite-sum optimization. In: Proceedings of the 30th International Conference on Neural Information Processing Systems. Red Hook, NY, United States: Curran Associates Inc., 2016. 1153−1161 [90] Li Z Z, Li J. A simple proximal stochastic gradient method for nonsmooth nonconvex optimization. In: Proceedings of the 32nd Conference on Neural Information Processing Systems. Montreal, Canada: MIT Press, 2018. 5569−5579 -

 下载:
下载:



计量
- 文章访问数: 4733
- HTML全文浏览量: 2772
- PDF下载量: 1420
- 被引次数: 0
