

-
摘要: 并行主成分提取算法在信号特征提取中具有十分重要的作用, 采用加权规则将主子空间(Principal subspace, PS)提取算法转变为并行主成分提取算法是很有效的方式, 但研究加权规则对状态矩阵影响的理论分析非常少. 对加权规则影响的分析不仅可以提供加权规则下的主成分提取算法动力学的详细认知, 而且对于其他子空间跟踪算法转变为并行主成分提取算法的可实现性给出判断条件. 本文通过比较Oja的主子空间跟踪算法和加权Oja并行主成分提取算法, 通过两种算法的差异分析了加权规则对算法提取矩阵方向的影响. 首先, 针对二维输入信号, 研究了提取两个主成分时加权规则的信息准则对状态矩阵方向的作用方式. 进而, 针对大于二维输入信号的情况, 给出加权规则影响多个主成分提取方式的讨论. 最后, MATLAB仿真验证了所提出理论的有效性.Abstract: The parallel principal component extraction algorithms play an important role in signal feature extraction. It is very effective and very useful to modify the principal subspace (PS) extraction algorithms into parallel principal components extraction algorithms by using weighted rules, but so far, few people theoretically analyze the variation of the state matrix under the extraction algorithm of weighted rules. The analysis of this variation can not only provide detailed knowledge of the dynamics of the principal component extraction algorithms under weighted rules, but also give the realization conditions for transferring subspace extraction algorithms into parallel principal components extraction algorithm. In this paper, by comparing the difference between Oja principal subspace extraction algorithm and weighted Oja parallel principal components extraction algorithm, the influence of weighted rules on the extraction direction is analyzed. Firstly, for the case of extracting two principal components, the influence of the information criterion under the weighted rule on the direction of the state matrix is studied. Furthermore, for the case of extracting more than two principal components, a discussion is given on the manner where the weighted rules are applied. Finally, the MATLAB simulation verifies the validity of the proposed theory.
-

图 1 Oja信息准则和加权Oja信息准则在
$\theta$ 变化情况下的数值变化Fig. 1 Curves of the information criterion Oja and weighted Oja algorithms on
$\theta$ 
图 2 Oja信息准则和加权Oja信息准则在
$\theta = \dfrac{\pi}{2}$ 处的投影Fig. 2 Projection of the information criterion Oja and weighted Oja algorithms when
$\theta = \dfrac{\pi}{2}$ 
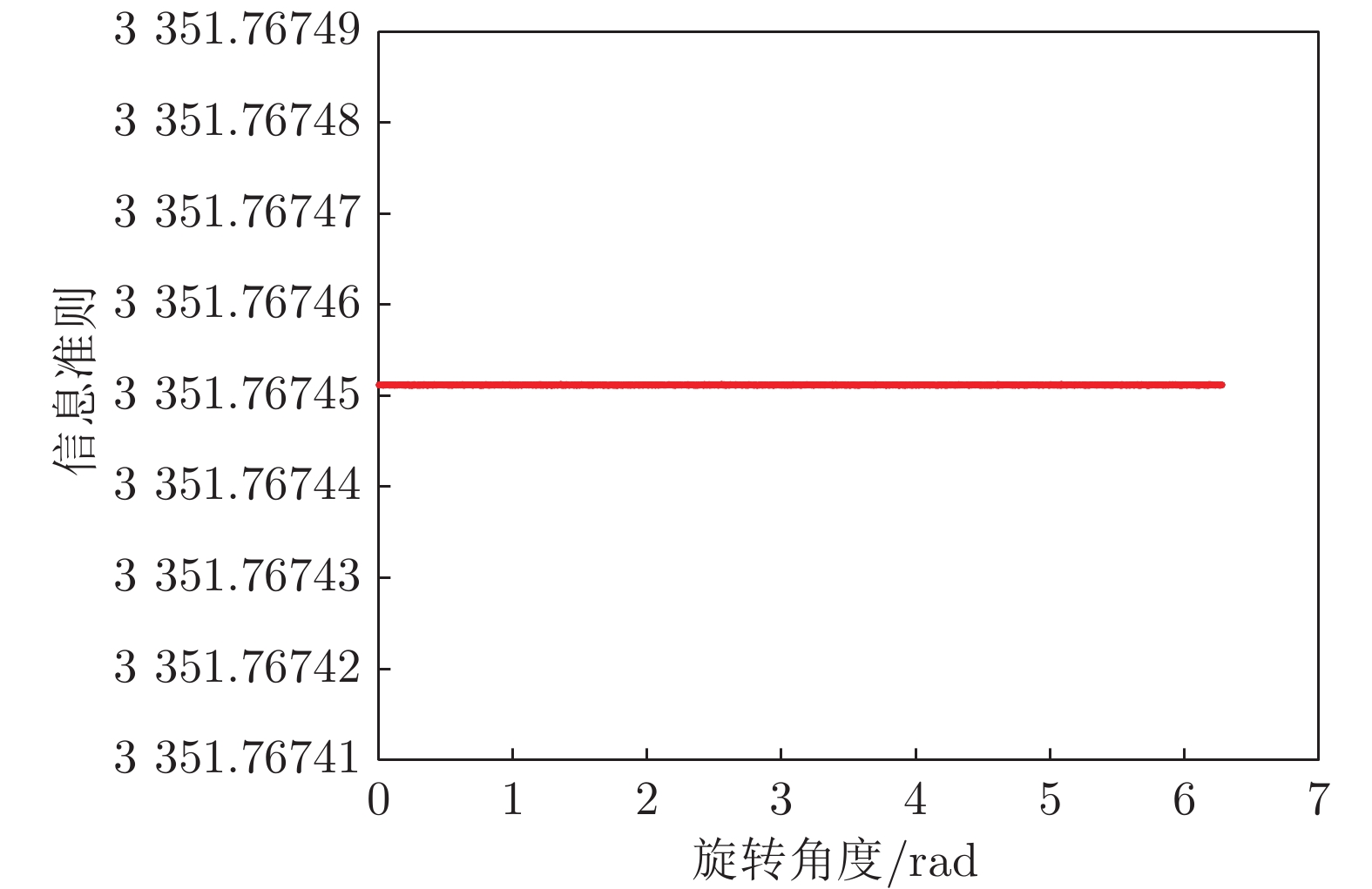
图 4 加权Oja信息准则在
$\theta$ 变化情况下的数值变化Fig. 4 Curves of weighted Oja information criterion on
$\theta$ 
图 5 Miao信息准则和Ouyang信息准则在
$\theta$ 变化情况下的数值变化Fig. 5 Curves of the information criterion Miao and Ouyang algorithms on
$\theta$ 
图 6 Miao信息准则和Ouyang信息准则在
$\theta = \dfrac{\pi}{2}$ 处的投影Fig. 6 Projection of the information criterion Miao and Ouyang algorithms when
$\theta = \dfrac{\pi}{2}$ 
图 7 Miao信息准则在
$\theta$ 变化情况下的数值变化Fig. 7 Curves of Miao information criterion on
$\theta$ 
图 8 Ouyang信息准则在
$\theta$ 变化情况下的数值变化Fig. 8 Curves of Ouyang information criterion on
$\theta$ -
[1] Gersho A, Gray R M. Vector Quantization and Signal Compression. Boston, MA: KLuwer, 1992. [2] Oja E. Subspace Methods of Pattern Recognition. Letchworth, UK: Research Studies Press, 1992. [3] 潘宗序, 禹晶, 肖创柏, 等. 基于光谱相似性的高光谱图像超分辨率算法. 自动化学报, 2014, 40(12): 2797−2807.Pan Zong-Xu, Yu Jing, Xiao Chuang-Bai, et al. Spectral similarity-based super resolution for hyperspectral images. Acta Automatica Sinica, 2014, 40(12): 2797−2807. [4] 肖进胜, 朱力, 赵博强, 等. 基于主成分分析的分块视频噪声估计. 自动化学报, 2018, 44(09): 1618−1625.Xiao Jin-sheng, Zhu li, Zhao Bo-qiang, et al. Block-based video noise estimation algorithm via principal component analysis Acta Automatica Sinica, 2018, 44(09): 1618−1625. [5] 周平, 张丽, 李温鹏, 等. 集成自编码与PCA 的高炉多元铁水质量随机权神经网络建模. 自动化学报, 2018, 44(10): 1700−1811.Zhou Ping, Zhang Li, Li Wen-Peng, et al. Autoencoder and PCA based RVFLNs modeling for multivariate molten iron quality in blast furnace ironmaking Acta Automatica Sinica, 2018, 44(10): 1700−1811. [6] Kong Xiangyu, Hu Changhua, Han Chongzhao. A dual purpose principal and minor subspace gradient flow. IEEE Transaction on Signal Processing, 2012, 60(1): 197−210. doi: 10.1109/TSP.2011.2169060 [7] Oja Erkki. Neural networks, principal components, and subspaces. International Journal of Neural Systems, 1989, 01(01): 61−68. doi: 10.1142/S0129065789000475 [8] Williams R J. Feature Discovery Through Error-Correction Learning. San Diego, California: Institute of Cognetive Science, University of California, 1985. [9] Lei Xu. Least mean square error reconstruction principle for self-organizing neural-nets. Neural Networks, 1993, 6(5): 627−648. doi: 10.1016/S0893-6080(05)80107-8 [10] Yang bin. Projection approximation subspace tracking. IEEE Transaction on Signal Processing, 1995, 43(1): 95−107. doi: 10.1109/78.365290 [11] Kong Xiangyu, Hu Changhua, Ma Hongguang, Han Chongzhao. A unified self-stabilizing neural network algorithm for principal and minor components extraction. IEEE Transactions on Neural Networks and Learning Systems, 2012, 23(2): 185−198. doi: 10.1109/TNNLS.2011.2178564 [12] Kenji Kakimoto, Masao Yamagishi, Isao Yamada. Smoothing of adaptive eigenvector extraction in nested orthogonal complement structure with minimum disturbance principle. Multidimensional systems and signal processing, 2018, 29(1): 433−465. doi: 10.1007/s11045-017-0528-2 [13] Ouyang Shan, Bao Zheng, Liao Guisheng. Robust recursive least squares learning algorithm for principal component analysis. IEEE Transaction on Neural Networks, 2000, 11(1): 215−221. doi: 10.1109/72.822524 [14] Gao Yingbin, Kong Xiangyu, Zhang Huihui, Hou li’ an. A weighted information criterion for multiple minor components and its adaptive extraction algorithms. Neural Networks, 2017, 89: 1−10. doi: 10.1016/j.neunet.2017.02.006 [15] Gao Yingbin, Kong Xiangyu, Hu Changhua, Li Hongzeng, Hou Lian. A generalized information criterion for generalized minor component extraction. IEEE transactions on signal processing, 2017, 65(4): 974−959. [16] Toshihisa Tanaka, Generalized weighted rules for principal components tracking. IEEE transactions on signal processing, 2005, 53(4): 1243−1253. doi: 10.1109/TSP.2005.843698 [17] Kushner H J, Clark D S. Stochastic Approximation Methods for Constrained and Unconstrained Systems. New York, NY: Springer-Verlag, 1978. [18] Oja Erkki, Ogawa H, Wangviwattana J. Principal component analysis by homogeneous neural networks―Part I: Weighted subspace criterion. IEICE Transactions on Information Systems, 1992, 75(3): 366−375. [19] Zhang Yi, Ye Mao, Lv Jiancheng, Tan Kok Kiong. Convergence analysis of a deterministic discrete time system of Oja’s PCA learning algorithm. IEEE Transaction on Neural Networks, 2005, 16(6): 1318−1328. doi: 10.1109/TNN.2005.852236 [20] Miao Yongfeng, Hua Yingbo. Fast subspace tracking and neural network learning by a novel information criterion. IEEE transactions on signal processing, 1998, 46(8): 1967−1979. [21] Ouyang Shan, Bao Zheng. Fast Principal Component Extraction by a Weighted Information Criterion. IEEE transactions on signal processing, 2002, 50(8): 1994−2002. doi: 10.1109/TSP.2002.800395 [22] 方蔚涛, 马鹏, 成正斌, 等. 二维投影非负矩阵分解算法及其在人脸识别中的应用. 自动化学报, 2012, 38(9): 1503−1512.Fang Wei-Tao, Ma Peng, Cheng Zheng-Bin, et al. 2-dimensional projective non-negative matrix factorization and its application to face recognition. Acta Automatica Sinica, 2012, 38(9): 1503−1512. -



 下载:
下载:
















计量
- 文章访问数: 820
- HTML全文浏览量: 266
- PDF下载量: 186
- 被引次数: 0
