

Relevance Vector Machine Based Remaining Useful Life Prediction for Traction Systems of High-speed Trains
-
摘要: 高速列车牵引系统在运行过程中总是受到诸多不确定因素的影响, 例如, 由于列车的负载、运行环境及元器件的老化引起的不确定性, 不确定因素不可避免地影响牵引系统剩余寿命的预测精度. 为了提高不确定情景下剩余寿命预测的准确性, 本文首先采用改进的相关向量机(Relevance vector machine, RVM)方法, 建立鲁棒性能良好的多步回归模型, 由于t分布比常用的高斯分布更具有鲁棒性, 通过权重和随机误差服从t分布而非高斯分布, 改进了相关向量机回归模型, 随后将超参数的先验一并融入似然函数, 通过最大化似然函数估计未知的超参数, 此外, 利用首达时间方法从概率角度对剩余寿命进行了预测, 最后通过牵引系统中电容器退化的案例, 与传统的相关向量机方法、自回归方法和支持向量机方法进行对比, 验证了所提算法的有效性.Abstract: Traction systems often suffer from many uncertainties during their running processes, such as the inevitable uncertainties caused by the change of loading, operation and usage conditions. In order to improve the accuracy of remaining useful life (RUL) prediction under the uncertain scenario, a robust multi-step regression model is established by the improved relevance vector machine (RVM) method, in which weights and random errors are t distributed rather than Gaussian distributed. Then, unknown hyperparameters are estimated by taking priors of the hyperparameters into consideration. Moreover, the RUL is predicted by the first hitting time (FHT) method in probability perspective. The proposed method is demonstrated by a case study of capacitors degradation in traction systems. The results show the effectiveness of the proposed method.
-
基于信息系统的知识获取是机器学习、人工智能研究的重要方面, 而规则提取又是知识获取的主要内容之一[1]. 形式背景$ (G,M,I) $是一个由对象集$ G $, 属性集$ M $及$ G $与$ M $间的二元关系$ I $组成的三元组. 在基于形式背景进行规则提取时, 规则是通过内涵属性集合之间的关系描述且通过对应的外延对象集合之间的包含(或近似包含)关系来反映, 其形式是一个如$ A \to B $的表达式, 其中$ A $和$ B $是属性集合, 其含义是形式背景中具有属性$ A $的对象也具有属性$ B $[2-3].
为了从逻辑角度刻画蕴涵规则, 通常在更广泛意义下讨论蕴涵规则$ A \to B $, $ A $和$ B $分别是条件属性集和决策属性集, 此时的蕴涵规则被称为决策蕴涵规则, 简称决策蕴涵[3-4]. Zhai等[5-6]在抽象的条件属性和决策属性集上引进决策蕴涵, 从逻辑语义和逻辑语构2个方面对决策蕴涵进行了探讨[6], 他们还在Pavelka模糊逻辑意义下提出并讨论了模糊决策蕴涵. 贾楠等[7]分析了这种一般决策蕴涵的推理规则, 并讨论了推理规则集的完备性和无冗余性. 为适应智能决策的需要, 王琪等[8]研究了含参模糊决策蕴涵. 张少霞等[9]讨论了基于逻辑公式的逻辑型决策蕴涵, 使得决策知识的表示更加丰富. 抽象集合上的决策蕴涵讨论固然可以丰富决策蕴涵的理论, 但实际数据分析中在讨论决策蕴涵时更加关注信息系统上、特别是形式背景中的决策蕴涵$ A \to B $, 此时$ A $和$ B $分别是决策形式背景的条件属性集和决策属性集. 形式背景上的决策蕴涵还包括概念规则和粒规则2个特殊类型. Zhang等[10]对决策形式背景中的决策蕴涵、概念规则、粒规则的特征和彼此间的关系进行了研究, 借助决策蕴涵逻辑分析了概念规则和粒规则中的信息损失及其信息丢失背后的原因. 为有效进行多粒度意义下的数据分析, 李金海等[11-12]讨论了多粒度意义下的决策蕴涵性质, 实现了跨粒度重组数据的决策蕴涵生成.
传统上, 人们习惯于应用二值逻辑及其推理以探究事物之间的确定因果关系和获取确定性新知识[13]. 但是, 正如亚马逊的推荐系统[14]和谷歌的流感预测[15]等现实案例所展示, 对于大数据环境下的数据分析和应用, 人们更加关注事物之间的相关关系分析, 寻找数据之间的近似因果关系一样受到人们的关注和重视[16]. 也正是因为这个原因, 人们不断尝试创新各种方法以探索事物之间的近似因果关系, 并依托这种近似因果关系从现有知识获取新知识[17]. 推理是寻找事物之间因果关系, 从已有知识获取新知识的重要方法, 是数理逻辑的主要研究内容. 人们一般认为模糊逻辑及其推理应用是探究事物之间近似因果关系及获取不确定性知识的手段和方法[18-19]. 然而, 正如文献[18]所指出, 借助于全蕴涵三I推理思想[19], 经典二值逻辑系统中存在着与模糊推理相同的求解机制, 从而基于经典二值逻辑也可以进行近似推理的探讨.
决策蕴涵、概念规则都是信息系统上知识的表现形式, 决策蕴涵、概念规则推理是知识推理的一个重要方面. 因此, 将经典二值逻辑框架下的近似推理模式应用于决策蕴涵、概念规则, 讨论决策蕴涵、概念规则的推理模式及性质, 依据形式背景上的现有决策蕴涵、概念规则, 通过近似推理方法寻找新的决策蕴涵、概念规则是有意义的. 从知识发现的角度看, 基于现有数据集上的决策蕴涵、概念规则等知识, 采用近似推理的方法获取更大数据集上的决策蕴涵、概念规则等新的知识是非常有价值的.
本文应用经典二值逻辑中的分离规则(Modus ponens, MP)、逆分离规则(Modus tonens, MT)近似推理来探讨形式背景上的决策蕴涵和概念规则的近似推理的特征, 并提出实现方法. 首先, 讨论决策蕴涵的属性逻辑语义的性质. 其次, 在经典二值逻辑框架下分析基于全蕴涵三I推理思想的决策蕴涵和概念规则的MP、MT近似推理模式的特征, 证明决策蕴涵的MP、MT近似推理结论是决策蕴涵, 概念规则的MP、MT近似推理的结论是概念规则. 引进属性逻辑公式间的伪距离, 并在逻辑伪距离空间中分析对象参数变化对决策蕴涵的MP、MT近似推理结论的影响. 最后, 提出2个利用MP、MT近似推理来生成拟决策蕴涵的算法, 对2个算法的复杂性进行分析, 并通过数值实验对本文提出方法的有效性进行验证.
1. 形式概念和属性逻辑概述
本节概述下文要用到的形式概念分析和属性逻辑的知识.
定义1[3]. 一个形式背景是一个三元组$ K = (G,M,I) $, 其中$ G $为对象集合, $ M $为属性集合, $ I $是$ G $到$ M $的二元关系, $ gIm $表示对象$ g $具有属性$ m $.
通常称不包含空行、空列、满行和满列的形式背景为正则形式背景[20]. 本文只讨论正则形式背景.
定义2[3]. 在形式背景$ K = (G,M,I) $中, 对$ A \subseteq G $, 记$ \alpha^I(A) = \{m \in M | \forall g \in A, gIm\} $ ($ A $中对象共同具有属性的集合); 对$ B \subseteq M $, 记$\beta^I(B) = \{g \in G | \forall m \in B, gIm\}$ (具有$ B $中所有属性的对象集合); $ \alpha^I $, $ \beta^I $分别称为$ K $的属性映射和对象映射.
定义3[3]. 在形式背景$ K = (G,M,I) $中, 对$A \subseteq G$, $ B \subseteq M $, 如果$ \alpha^I(A) = B $, $ \beta^I(B) = A $, 则称$C = (A, B)$是一个概念, 并称$ A $是概念$ C $的外延, $ B $是概念$ C $的内涵. 形式背景$ K $的全体概念记为$ C(K) $.
命题1[3]. 对$ A, A_1, A_2 \subseteq G $, $ B, B_1, B_2 \subseteq M $.
1) $\alpha^I(A_1) \subseteq \alpha^I(A_2) \Rightarrow \alpha^I(A_2) \subseteq \alpha^I(A_1)$, $\beta^I(B_1) \subseteq \beta^I(B_2) \Rightarrow \beta^I(B_2) \subseteq \beta^I(B_1)$;
2) $ A \subseteq \beta^I(\alpha^I(A)) $, $B \subseteq \alpha^I(\beta^I (B))$;
3) $ A \subseteq \beta^I(B) $当且仅当$ B \subseteq \alpha^I(A) $;
4) $ \alpha^I(A_1 \cup A_2) = \alpha^I(A_1) \cap \alpha^I(A_2) $, $\beta^I(A_1 \cup A_2) = \beta^I(A_1) \cap \alpha^I(A_2)$;
5) $ \alpha^I(A_1 \cap A_2) \supseteq \alpha^I(A_1) \cup \alpha^I(A_2) $, $\beta^I(A_1 \cap A_2) \supseteq \beta^I(A_1) \cup \alpha^I(A_2)$;
6) $(\beta^I(\alpha^I(A))、 \alpha^I(A))、 (\beta^I (B) $ 和 $\alpha^I(\beta^I (B))) $都是概念.
定义4[21]. 设$ K = (G,M,I) $是一个形式背景, $\neg、 \wedge\;和\; \to$是逻辑联结词. 称$ a \in M $为一个原子属性公式, 全部原子属性公式生成的$ (\neg, \wedge, \to) $自由代数记为$ \Gamma(K) $, 称$ \Gamma(K) $中的元素为基于形式背景$ K $的属性逻辑公式 (简称属性公式).
$ \Gamma(K) $中的元素可以通过以下方式[21]得到:
1)$ M \subseteq \Gamma(K) $;
2)若$ \varphi \in \Gamma(K) $, 则$ \neg \in \Gamma(K) $;
3)若$ \varphi, \psi \in \Gamma(K) $, 则$ \varphi \wedge \psi, \varphi \to \psi \in \Gamma(K) $;
4)$ \gamma \in \Gamma(K) $当且仅当$ \gamma $可经过以上3步有限次所产生.
本文讨论的决策蕴涵的前件和后件都是属性合取公式, 对于$ B \subseteq M $, 由$ B $中的属性合取公式为$ \varphi = \wedge_{b \in B} $. 在不会引起混淆时, 时常不区分属性集$ B $及$ B $中属性组成的合取公式. 同时, 为了表述简便, 也经常使用逻辑联结词$\varphi \vee \psi = \neg (\neg \varphi \;\wedge \neg \psi)$.
对逻辑公式进行赋值是研究二值逻辑、模糊逻辑等逻辑系统语义的基本手段[18], 但现有文献对决策逻辑[1]及决策蕴涵的逻辑研究较少有从赋值出发来进行[6]. 本文作者在基于软集的决策分析[22]和基于形式背景的属性逻辑[21, 23]的研究中, 已经尝试从属性公式赋值的角度来对相关内容进行讨论.
设$ K = (G,M,I) $是形式背景. 对每个$uu \in G$, $ u $自然地决定了一个映射 $ v^{(0)}_{u}: M \to \{0,1\} $, $ v^{(0)}_{u}(a) = I(u, a) $. 由于$ \Gamma(K) $是由原子属性公式集$ M $生成的$(\neg、 \wedge、 \to)$型自由代数, 故$ v^{(0)}_{u} $可唯一延拓成$ \Gamma(K) $上的一个映射$ v_{u} $, $ v_{u} $在$ M $上的限制正是$ v^{(0)}_{u} $, 称映射$ v_{u} $为属性公式集的一个K-赋值, 全体K-赋值之集记为$ \Omega_K = \{v_{u}: u \in G\} $. 显然, $ G $到$\Omega_K$之间有一一对应$\pi: G \to \Omega_K$, $ \pi(u) = v_{u} $. 对每个$ a \in M $, $ a $决定了一个定义在 $ G $上的函数 $ \overline{a} $, $\overline{a}: G \to \{0,1\}$, $ \overline{a} (u) \;=\; I(a, u) $. 同样, 一个由 $ t $个原子属性公式$a_{i_{1}},\cdots,a_{i_{t}}$组成的属性公式$\varphi = \varphi (a_{i_{1}}, \cdots, a_{i_{t}})$也决定了 $ G $ 上的函数 $\overline{\varphi}(u)\; =\; \overline{\varphi} (\overline{a}_{i_{1}}(u),\cdots, \overline{a}_{i_{t}}(u))$, $ \overline{\varphi} $作用于$\overline{a}_{i_{1}},\cdots,\overline{a}_{i_{t}}$的方式如同$ \varphi $作用于$a_{i_{1}},\cdots,a_{i_{t}}$的方式一样. 例如, $ \varphi = \neg a_1 \vee a_2 \to a_3 $, 则$ \overline{\varphi}(u) = (1- \overline{a}_1(u)) \vee \overline{a}_2(u) \to \overline{a}_3(u) $.
另一方面, 按照经典二值逻辑系统的赋值方法, 由映射$ v^{M}_{u}: M \to \{0,1\} $所决定的公式集$ \Gamma(K) $上的映射$ v: \Gamma(K) \to \{0,1\} $为$ \Gamma(K) $的赋值, 对$ \varphi \in \Gamma(K) $, $ v(\varphi) $称为逻辑公式$ \varphi $的值. $ \Gamma(K) $的全部赋值之集记为$\Omega$. 一般地, $\Omega_K$为$\Omega$的子集.
例1. 一个形式背景$ K = (G,M,I) $见表1, 其中对象集$ G = \{u_1, u_2, u_3, u_4, u_5, u_6, u_7\} $, 属性集$ M = \{a_1, a_2, a_3, a_4, a_5, a_6\} $.
表 1 形式背景$K=(G,M,I)$Table 1 A formal context $K=(G,M,I)$$G$ $a_1$ $a_2$ $a_3$ $a_4$ $a_5$ $u_1$ 1 1 0 0 1 $u_2$ 0 0 1 1 0 $u_3$ 1 0 1 0 0 $u_4$ 0 1 0 1 0 $u_5$ 0 1 0 1 1 $u_6$ 1 0 1 0 1 根据K-赋值的产生方法, $\Omega_K$有7个赋值. 而按照二值逻辑赋值方法, $\Omega$有$ 2^{5} = 32 $个赋值. 一般地, $ \Omega_K $为 $\Omega$的真子集, 比如赋值 $ v_{0}: v_{0}(a_1) = 0 $, $ v_{0}(a_2) = 0 $, $ v_{0}(a_3) = 0 $, $ v_{0}(a_4) = 0 $, $ v_{0}(a_5) = 0 $; $v_{1}: v_{1}(a_1) \,=\, 1$, $v_{1}(a_2) \,= \,1$, $v_{1}(a_3)\, =\, 1$, $v_{1}(a_4) \,= \,0$, $v_{1}(a_5) = 0$; $v_0、 v_1$在 $\Omega$中, 而不在 $\Omega_K$中.
由于全体K-赋值集$\Omega_K$为全体赋值集$\Omega$的真子集, 因此, 本文的K-赋值也可作为文献[24]所讨论的数理逻辑部分赋值理论的具体实例.
在形式背景中, $ I(u,a) = 1 $表明一个对象$ u $具有属性$ a $, 此时有$ \overline{a}(u) = 1 $. 一般地, 如果$ \overline{\varphi}(u) = 1 $, 则表明对象$ u $具有属性公式$ \varphi $中的全部属性, 此时也称对象$ u $满足公式$ \varphi $. 对于$ \varphi \in \Gamma(K) $, 称满足$ \varphi $的对象之集$ \{u \in G | \overline{\varphi}(u) = 1\} $为$ \varphi $的K-语义, 本文记$ \varphi $的K-语义为$ ||\varphi||_{K} $, 在不会引起混乱时, 也可将下标$ K $省略. 属性公式的K-语义有以下命题2.
命题2[21]. 设$ K = (G,M,I) $是一个形式背景, 则对任何$ \varphi, \psi \in \Gamma(K) $, 下式成立:
1) $ ||\neg \varphi|| = G - ||\varphi|| $;
2) $ ||\varphi \vee \psi|| = ||\varphi|| \cup ||\psi|| $;
3) $ ||\varphi \wedge \psi|| = ||\varphi|| \cap ||\psi|| $;
4) $ ||\varphi \to \psi|| = (G-||\varphi||) \cup ||\psi|| $.
命题3[21]. 设$\Sigma = \{v_{u_{1}}, \cdots, v_{u_{l}}\} \subset \Omega_K$, $\{r_{1}, \cdots, r_{l}\}$是一个0 ~ 1序列, 则存在属性公式$ \varphi \in \Gamma(K) $满足$v_{u_{i}}(\varphi) = r_i, i = 1, \cdots, l$.
在经典二值逻辑的确定性推理中, 有2个基本的推理规则: MP和MT, 这2个规则同样适应属性逻辑的推理. 但在人工智能的研究中同样也关注近似推理, 即对知识的近似获取同样感兴趣. 因此, 人们也经常需要如下适应于近似推理的广义MP[17-18]:
$$ \left\{ \begin{array}{ll} \text{已 知} \qquad\quad \varphi \to \psi \quad \\ \underline{\text{且给定} \qquad \varphi^{\ast}\quad\quad } \qquad \qquad \qquad \\ \text{求} \qquad\qquad\qquad \psi^{\ast} \end{array} \right. $$ (1) 式中, $ \varphi,\psi,\varphi^{\ast},\psi^{\ast} \in \Gamma(K) $.
在确定推理中, 上述广义MP式(1)是无解的. 在实际应用中, 虽然不能找到其精确解, 但可以寻求上述广义MP式(1)的近似解. 根据全蕴涵三I推理思想, 所求的近似解$ \psi^{\ast} $要得到小前提$ \varphi^{\ast} $的最大支持, 还要得到大前提$ \varphi \to \psi $的最大支持, 即$ \psi^{\ast} $应该使得对于所讨论范围内的对象, 蕴涵公式$(\varphi \to \psi) \to (\varphi^{\ast} \to \psi^{\ast})$能取得最大值1. 因此, 给出如下广义MP解的定义.
定义5[17]. 设$ \varphi,\psi,\varphi^{\ast} \in \Gamma(K) $, $\Sigma、 \Delta$为$ G $的2个子集. 基于形式背景的近似推理的广义MP式(1)的$( \Sigma, \Delta)$解是满足以下条件的属性公式$ \psi^{\ast} $:
1) $\forall x \in \Delta, \forall y \in \Sigma$,
$(\overline{\varphi}(y) \to \overline{\psi}(x)) \to (\overline{\varphi^{\ast}} (y) \to \overline{\psi^{\ast}}(x)) = 1.$
2)如果有$\gamma \in \Gamma(K)$满足$\forall x \in \Delta, \forall y \in \Sigma$,
$ (\overline{\varphi}(y) \to \overline{\psi}(x)) \to (\overline{\varphi^{\ast}}(y) \to \overline{\gamma}(x)) = 1 $, 则$\forall x \in \Delta$, $ \overline{\psi^{\ast}}(x) \leq \overline{\gamma}(x) $.
定理1[17]. 设$\varphi,\psi,\varphi^{\ast} \in \Gamma(K)$, $\Sigma$和$ \Delta $是$ G $的2个子集. 基于形式背景的广义MP式(1)的解$ \psi^{\ast} $满足:
$$ \overline{\psi^{\ast}}(x) = [\overline{\varphi^{\ast}}(y) \wedge (\overline{\varphi}(y) \to \overline{\psi}(x))], x \in \Delta $$ (2) 式中, $ \wedge$表示函数取小运算.
注1. 由于$ \overline{\varphi}(y) \to \overline{\psi}(x) = (1 - \overline{\varphi}(y)) \wedge \overline{\psi}(x) $, 因此式(2)可改写为:
$$ \overline{\psi^{\ast}}(x) = \mathop\vee\limits_{y \in \Sigma} [\overline{\varphi^{\ast}}(y) \wedge (1-\overline{\varphi}(y))] \vee [\overline{\psi}(x) \wedge\mathop \vee\limits_{y \in \Sigma} \overline{\varphi^{\ast}}(y)] $$ 式中, $\vee$表示函数取大运算.
从而有以下4种特殊情形:
1)如果有$y_0 \in \Sigma$, 使得$\overline{\varphi^{\ast}}(y_0) \wedge (1-\overline{\varphi}(y_0)) = 1$, 则$\forall x \in \Delta$, $ \overline{\psi^{\ast}}(x) = 1 $.
2)如果对任何$y \in \Sigma$, 有$ \overline{\varphi^{\ast}}(y) = 0 $, 则$\forall x \in \Delta$, $ \overline{\psi^{\ast}}(x) = 0 $.
3)如果有$y_0 \in \Sigma$, 使得$ \overline{\varphi^{\ast}}(y) = 1 $, 且$||\varphi^{\ast}|| \subseteq ||\varphi||$, 则$\forall x \in \Delta$, $ \overline{\psi^{\ast}}(x) = \overline{\psi}(x) $.
4)如果$ \varphi = \varphi^{\ast} $, 则由式(2)有$ \psi = \varphi^{\ast} $, 从而广义MP的确是经典MP的推广.
对于如下多规则MP近似推理问题[17]:
$$ \left\{ \begin{array}{ll} \text{已 知} \qquad \quad \varphi_1 \to \psi_1 \quad \\ \qquad \qquad \qquad \cdots \\ \qquad \qquad \quad \varphi_n \to \psi_n \quad \qquad \qquad \\ \underline{\text{且给定} \qquad \varphi^{\ast}\quad\quad } \\ \text{求} \qquad\qquad\qquad \psi^{\ast} \end{array} \right. $$ (3) 如果采用先推理后聚合的推理过程, 聚合算子取合取算子, 则其推理结论的属性公式函数为[17]:
$$ \overline{\psi^{\ast}}(x) = \mathop\wedge^{n}\limits_{i = 1} \mathop\vee\limits_{y \in \Sigma} [\overline{\varphi^{\ast}}(y) \wedge (\overline{\varphi}_{i}(y) \to \overline{\psi}_{i}(x))], x \in \Delta $$ (4) 类似于二值逻辑推理的MT, 考虑如下基于形式背景的近似推理的广义MT[17]:
$$ \left\{ \begin{array}{ll} \text{已 知} \qquad\quad \varphi \to \psi \quad \\ \underline{\text{且给定} \qquad \qquad \psi^{\ast} } \qquad \qquad \\ \text{求} \qquad\qquad \varphi^{\ast} \end{array} \right. $$ (5) 式中, $\varphi,\psi,\varphi^{\ast},\psi^{\ast} \in \Gamma(K)$.
定义6[17]. 设$\varphi,\psi,\psi^{\ast} \in \Gamma(K)$, $\Sigma、\Delta$是$ G $的2个子集. 基于形式背景的近似推理的广义MT式(3)的$( \Sigma, \Delta)$解是满足以下条件的属性公式$ \varphi^{\ast} $:
1)$\forall x \in \Delta,\;\forall y \in \Sigma$,
$(\overline{\varphi}(y) \to \overline{\psi}(x)) \to (\overline{\varphi^{\ast}} (y) \to \overline{\psi^{\ast}}(x)) = 1 .$
2)如果有$\chi \in \Gamma(K)$满足$\forall x \in \Delta, \forall y \in \Sigma$,
$(\overline{\varphi}(y) \to \overline{\psi}(x)) \to (\overline{\varphi^{\ast}}(y) \to \overline{\gamma}(x)) = 1$则$\forall y \in \Sigma$, $ \overline{\psi^{\ast}}(y) \geq \overline{\chi}(y) $.
定理2[17]. 设$\varphi,\psi,\psi^{\ast} \in \Gamma(K)$, $\Sigma、 \Delta$是$ G $的2个子集. 基于形式背景的广义MT式(3)的解$ \varphi^{\ast} $满足:
$$ \overline{\varphi^{\ast}}(y) = \mathop\wedge\limits_{x \in \Delta} [(\overline{\varphi}(y) \to \overline{\psi}(x)) \to \overline{\psi^{\ast}}(x)], y \in \Sigma $$ (6) 注2. 由于$ \overline{\varphi}(y) \to \overline{\psi}(x) = (1 - \overline{\varphi}(y)) \wedge \overline{\psi}(x) $, 因此式(6)可改写为:
$$ \overline{\varphi^{\ast}}(y) = \mathop\wedge\limits_{x \in \Delta} [\overline{\psi^{\ast}}(x) \vee (1-\overline{\psi}(x))] \wedge [\overline{\varphi}(x) \vee \mathop\wedge\limits_{x \in \Delta} \overline{\psi^{\ast}}(x)] $$ 从而有以下3种特殊的情形:
1)如果有$x_0 \in \Delta$, 使得$ \overline{\psi^{\ast}}(x) \vee (1-\overline{\psi}(x)) = 0 $, 则$\forall y \in \Sigma$, $ \overline{\varphi^{\ast}}(x) = 0 $.
2)如果对任何$x \in \Delta$, 有$ \overline{\psi^{\ast}}(y) = 1 $, 则$\forall y \in \Sigma$, $ \overline{\varphi^{\ast}}(x) = 1 $.
3)如果有$x_0 \in \Delta$, 使得$ \overline{\psi^{\ast}}(y) = 0 $, 且$||\psi|| \subseteq ||\psi^{\ast}||$, 则$\forall y \in \Sigma$, $ \overline{\varphi^{\ast}}(y) = \overline{\varphi}(y) $.
对于如下多规则MT近似推理问题[17]:
$$ \left\{ \begin{array}{ll} \text{已 知} \qquad\quad \varphi_1 \to \psi_1 \quad \\ \qquad \qquad \qquad \cdots \\ \qquad \qquad \quad \varphi_n \to \psi_n \quad \qquad \qquad \\ \underline{\text{且给定} \qquad \qquad \psi^{\ast} } \\ \text{求} \qquad\qquad \psi^{\ast} \end{array} \right. $$ (7) 如果采用先推理后聚合的推理过程, 聚合算子取合取算子, 则其推理结论的属性公式函数为[17]:
$$ \overline{\psi^{\ast}}(y) = \mathop\wedge^{n}\limits_{i = 1} \mathop\wedge\limits_{x \in \Delta} [(\overline{\varphi}_{i}(y) \to \overline{\psi}_{i}(x)) \to \overline{\psi^{\ast}}(x)], y \in \Sigma $$ (8) 2. 决策蕴涵的属性逻辑语义分析
为了方便展开决策蕴涵的逻辑推理, 本节利用属性逻辑的K-赋值, 对决策蕴涵进行属性逻辑的语义分析.
定义 7[5]. 称形式背景$ K_1 = (G,C,I) $和$K_2 = (G,D,J)$的并置$ K = (G,C,D,I,J) $为决策形式背景, 并分别称$ C $和$ D $为条件属性集和决策属性集. 若$ A \subseteq C, B \subseteq D $, 且有$ ||\wedge_{a \in A} a|| \subseteq ||\wedge_{b \in B} b|| $, 称属性公式$ \wedge_{a \in A} a \to \wedge_{b \in B} b $为决策蕴涵, 称$ \wedge_{a \in A} a $为决策蕴涵前件(或前提), $ \wedge_{b \in B} b $为决策蕴涵后件(或结论). 如果$A, B$还分别是条件概念和决策概念的内涵属性集, 称决策蕴涵$ \wedge_{a \in A} a \to \wedge_{b \in B} b $为概念规则. 记决策形式背景$ K $的全体决策蕴涵之集为$ K_D $, 全体概念规则之集为$ K_C $.
为了不引起混淆, 也经常简记$ ||\wedge_{a \in A} a|| $为$ ||A|| $, $ \wedge_{a \in A} a \to \wedge_{b \in B} b $为$ A \to B $.
从形式上看, 文献[5-6]讨论的抽象集合上的决策蕴涵$ A \to B $是一个由逻辑联结词$ \to $将2个属性合取公式联结起来的属性公式. 但是, 由于数据分析讨论决策蕴涵时常常是在信息系统或决策形式背景上进行的, 而且还要将概念规则和粒规则纳入决策蕴涵的范畴来统一讨论, 因此基于决策形式背景上的决策蕴涵$ A \to B $比一般抽象属性集上的决策蕴涵多了一个限制条件$ ||\wedge_{a \in A} a|| \subseteq ||\wedge_{b \in B} b|| $[4, 10-11].
定义8[5]. 设$ (G,C,D,I,J) $是决策形式背景.
1)对于属性集$ T \subseteq C \cup D $和决策蕴涵$ A \to B $, 若$ A \varsubsetneq T \cap C $或$ B \subseteq T \cap D $, 称$ T $满足$ A \to B $ (或称$ T $是$ A \to B $的模型), 记为$ T \models A \to B $. 设$ L \subseteq K_D $, 若$ T $满足$ L $中的任意一个决策蕴涵, 称$ T $是$ L $的一个模型, 记为$ T \models L $.
2)若对任意$ T \subseteq C \cup D $, $ T \models L $蕴涵$T \models A \to B$, 称$ A \to B $为$ L $的语义结论, 记为$L \models A \to B$.
从逻辑观点看, 一个决策蕴涵是通过蕴涵联结词将条件属性合取公式和决策属性合取公式连接起来的属性逻辑公式, 定义8和语义结论等术语是命题逻辑中的相应术语在决策蕴涵中的本质特征刻画. 因此, 在引进属性逻辑语言后, 可以借用命题逻辑中的赋值方法对决策蕴涵、概念规则等进行讨论.
利用前面引入的K-赋值, 以下给出决策蕴涵的K-语义结论定义.
定义9. 设$ K = (G,C,D,I,J) $是决策形式背景, $ A \to B \in K_D $, $ L \subseteq K_D $, $ v $是K-赋值. 记$ v(L) = \wedge_{A_1 \to B_1 \in L} v(A_1 \to B_1) $, 如果对任何K-赋值$v \in \Omega_K$, 都有$ v(L) = 1 $蕴涵$ v(A \to B) = 1 $, 称$ A \to B $为 $ L $的K-语义结论, 记为$ L \models_K A \to B $.
从逻辑语义角度看, 决策蕴涵集的语义结论是从全部模型$ L $的角度来讨论, 而K-语义结论只从形式背景对象集所决定的K-赋值来考虑. 之间的关系正是计量逻辑学中基于全部赋值和部分赋值推理的关系在决策蕴涵的具体体现[13, 24].
命题4. 设$ K = (G,C,D,I,J) $是决策形式背景, $ A \to B \in K_D $.
1)$ T \subseteq C \cup D $是$ A \to B $的模型当且仅当对赋值$v_T \in \Omega$, 有$ v_T (A \to B) = 1 $, $ v_T $是由$ T $决定的赋值.
2)如果$v \in \Omega_K$, 使得$ v(A \to B) = 1 $, 则$ T_0 = \{m | m \in C \cup D, v(m) = 1\} $是$ A \to B $的模型.
证明. 1)设$ T \subseteq C \cup D $是$ A \to B $的模型, $ v_T $是由$ T $所决定的赋值, 即$ T $中的原子属性公式赋值为1, $ C \cup D -T $中的原子属性公式赋值为0. 则当$ A \varsubsetneq T \cap C $时, 有$ a \in A $使$ v_T (a) = 0 $, 于是$v_T (A \to B) = v_T (A) \to v_T (B) = 1$. 而当$ B \subseteq T \cap D $时, 对任何$ b \in B $有$ v_T (b) = 1 $, 此时同样有$v_T (A \to B) = v_T (A) \to v_T (B) = 1$. 因此总有$ v_T (A \to B) = 1 $.
反之, 假设$ T $不是$ A \to B $的模型. 若令 $T = \{m | m \in C \cup D, v(m) = 1\}$, 则可断定 $ T $是$ A \to B $的模型, 即$ A \varsubsetneq T \cap C $或$ B \subseteq T \cap D $. 否则, 如果$A \subseteq T \cap C$且$ B \varsubsetneq T \cap D $, 则有$ v_T (A) = 1 $且$ v_T (B) = 0 $, 从而$ v_T (A \to B) = 0 $. 与已知矛盾.
2)如果$ T_0 $不是$ A \to B $的模型, 则$ A \subseteq T_0 \cap C $且$ B \varsubsetneq T \cap D $. 从而$ \forall a \in A, a \in T_0 \cap C $, 且$\exists b \in B, b \notin T_0 \cap D$, 于是$ v(A) = 1, v(B) = 0 $. 因此$v(A \to B) = 0$, 与已知$ v(A \to B) = 1 $矛盾. 所以$ T_0 $是$ A \to B $的模型.
□ 由命题4的1)可知, $ T $是$ L \subseteq K_D $的模型当且仅当对任何的$ A_1 \to B_1 \in K_D $, 有$ v_T (A_1 \to B_1) = 1 $. $L \models A \to B$当且仅当如果对任何的$ A_1 \to B_1 $和$ v \in \Omega $, 有$ v(A_1 \to B_1) = 1 $, 则一定也有$v(A \to B) = 1$. 由于K-赋值$ \Omega_K $只是全部模型$ T \subseteq C \cup D $所决定赋值集$ \Omega $的真子集, 因此如果$ L \models A \to B $, 则$ L \models_K A \to B $. 反之, 即使对任何K-赋值$ v \in \Omega_K $, 当对任何$ A_1 \to B_1 \in L $, $ v(A_1 \to B_1) = 1 $时, 都有$ v(A \in B) = 1 $, 也不一定能断定$ L \models A \to B $. 因此, 命题4的2)只能用来判定$ A \to B $不是$ L $的语义结论. 即如果有$ K $-赋值$ v_0 \in \Omega_K $, 使得$ \forall A_1 \to B_1 \in L $, $v_0(A_1 \to B_1) = 1$, 但$ v_0(A \to B) = 0 $, 这时就可以断言$ A \to B $不是$ L $的语义结论. 本文例2也说明了这一点.
例2. 一个决策形式背景$ K = (G,C,D,I,J) $见表2, 对象集$ G = \{u_1, u_2, u_3, u_4\} $, 条件属性集$ C = \{a_1, a_2, a_3, a_4\} $, 决策属性集$ D = \{d_1, d_2, d_3\} $.
表 2 决策形式背景$K=(G,C,D,I,J)$Table 2 A formal decision context $K=(G,C,D,I,J)$$G$ $a_1$ $a_2$ $a_3$ $a_4$ $d_1$ $d_2$ $d_3$ $u_1$ 1 1 1 1 1 0 1 $u_2$ 0 0 1 0 0 1 0 $u_3$ 1 0 0 0 0 1 1 $u_4$ 0 1 1 0 1 0 0 $ L = \{a_1 \wedge a_2 \wedge a_3 \to d_1 \wedge d_3\} $, 显然对任何K-赋值$ v \in \Omega_K $, 当$ v(a_1 \wedge a_2 \wedge a_3 \to d_1 \wedge d_3) = 1 $时, 有$ v(a_1 \wedge a_2 \to d_1 \wedge d_3) = 1 $, 即$L \models_{K} a_1 \wedge a_2 \to d_1 \wedge d_3$. 若取$ T = \{a_1, a_2, a_4, d_1, d_2\} $, 显然有$v_{T} (a_1 \wedge a_2 \;\wedge a_3 \to d_1 \wedge d_3) = 1$的模型, 但$ T $却不是$a_1 \wedge a_2 \to d_1\; \wedge d_3$的模型, 于是$ a_1 \wedge a_2 \to d_1 \wedge d_3 $不是$ L $的语义结论.
命题5. 设$ K = (G,C,D,I,J) $是决策形式背景. 对$ A \subseteq C, B \subseteq D $, 有:
1) $ A \to \alpha^{J} (\beta^{I}(A)) $是决策蕴涵;
2) $ A \to B $是决策蕴涵当且仅当$B \subseteq \alpha^{J} (\beta^{I}(A))$.
证明. 1)显然有$ \alpha^{J} (\beta^{I}(A)) \subseteq D $, 且$||A|| = \beta^{I}(A) \subseteq \beta^{I} (\alpha^{J} (\beta^{I}(A))) = ||\alpha^{J} (\beta^{I}(A))||.$ 所以 $ A \to \alpha^{J} (\beta^{I}(A)) $是决策蕴涵.
2)若$ A \to B $是决策蕴涵, 则 $||A|| = \beta^{I}(A) \subseteq ||B|| = \beta^{J}(B)$. 因此$ B \subseteq \alpha^{J} (\beta^{J}(B)) \subseteq \alpha^{J} (\beta^{I}(A)) $.
反之, 如果$ B \subseteq \alpha^{J} (\beta^{I}(A)) $, 则$||A|| = \beta^{I}(A) \subseteq \beta^{J} (\alpha^{J} (\beta^{I}(A))) \subseteq \beta^{J}(B) = ||B||.$ 所以 $ A \to B $是决策蕴涵.
□ 命题6. 设$ K = (G,C,D,I,J) $是决策形式背景, $ A \to B \in K_D $, $ L \subseteq K_D $. 则$ A \to B $不是$ L $的K-语义结论当且仅当存在$ d \in B $使得$ A \to d $不是$ L $的K-语义结论.
证明. 如果$ A \to B $不是$ L $的K-语义结论, 则存在K-赋值$ v_0 \in \Omega_K $, 虽然$ \forall A_1 \to B_1 \in L $, $ v_0(A_1 \to B_1) = 1 $, 但$ v_0(A \to B) = 0 $, 即$ v_0(A) > v_0(B) $. 于是存在$ d \in B $, 使得$ v_0(A) = 1 $, 而$ v_0(d) = 0 $. 所以$ A \to d $不是$ L $的K-语义结论.
反之, 若存在$ d \in B $使得$ A \to d $不是$ L $的K-语义结论, 则有K-赋值$ v_0 \in \Omega_K $, 使得$ \forall A_1 \to B_1 \in L $, $ v_0(A_1 \to B_1) = 1 $, 但$ v_0(A \to d) = 0 $意味着$ v_0(A) = 1 $, $ v_0(d) = 0 $. 于是$ v_0(A) = 1 > 0 = v_0(d) \geq v_0(B) $, 即$ v_0(A \to d) = 0 $. 所以$ A \to B $不是$ L $的K-语义结论.
□ 3. 决策蕴涵和概念规则的近似推理模式
第1节给出的形式背景上的广义MP、广义MT的前提和结论所涉及的公式是一般的属性公式, 且通常是在给定的对象范围内$( \Sigma, \Delta)$探讨推理规则的解. 由于本文是在决策形式背景上来讨论决策蕴涵推理, 而决策蕴涵中的前件和后件分别是条件原子属性公式和决策原子属性合取公式, 且通常是通过全部的对象集合之间的包含关系来反映. 因此, 本节在分析决策蕴涵的MP近似推理、MT近似推理的特征时, 推理的对象范围参数$( \Sigma, \Delta)$是全部对象集$ G $.
3.1 决策蕴涵和概念规则的MP近似推理模式
本节讨论决策形式背景上基于广义MP的决策蕴涵的近似推理 (以下简称决策蕴涵的MP近似推理)的特征.
定理3. 设$L = \{\varphi_{i} \to \psi_{i} | i = 1, \cdots, n\}$是决策形式背景$ K = (G,C,D,I,J) $的决策蕴涵集, $ \varphi^{\ast} $是条件属性合取公式, $ f $是由$L = \{\varphi_{i} \to \psi_{i} | i = 1, \cdots, n\}$和$ \varphi^{\ast} $的MP近似推理得到的解函数:
$$ f(x) =\mathop \wedge^{n}\limits_{i = 1} \mathop\vee\limits_{y \in G} [\overline{\varphi^{\ast}}(y) \wedge (\overline{\varphi}_{i}(y) \to \overline{\psi}_{i}(x))], x \in G $$ 如果记$ W = \{x \in G | f(x) = 1\} $, $\alpha^{J}(W) = \{d \in D | \forall x \in W, xJd\}$. 当$ \alpha^{J}(W) $非空时, 令$ \psi^{\ast} = \wedge_{d \in \alpha^{J}(W)} d $, 则$ \varphi^{\ast} \to \psi^{\ast} $是决策蕴涵.
证明. 如果$ ||\varphi^{\ast}|| $是空集, $ \varphi^{\ast} \to \psi^{\ast} $当然是决策蕴涵. 因此, 不妨设$ ||\varphi^{\ast}|| $非空, 并设$ x_0 \in ||\varphi^{\ast}|| $, 有$ \overline{\varphi^{\ast}} (x_0) = 1 $. 设:
$$ f_i (x) = \mathop\vee\limits_{y \in G} [\overline{\varphi^{\ast}}(y) \wedge (\overline{\varphi}_{i}(y) \to \overline{\psi}_{i}(x))], i = 1, \cdots, n $$ 根据注1, 在$ \overline{\varphi^{\ast}} (x_0) = 1 $的条件下, 只有当$ ||\varphi^{\ast}|| \subseteq ||\varphi_{i}|| $时, 才有$ f_i (x) = \overline{\psi}_{i} (x) $; 否则, $ f_i (x) $恒等于1. 不妨设在决策蕴涵集$ L $的前件属性公式集$\{\varphi_{1}, \cdots, \varphi_{n}\}$中有$ i_k $个属性公式$\varphi_{i_1}, \cdots, \varphi_{i_k}$满足条件$ ||\varphi^{\ast}|| \subseteq ||\varphi_{i_1}||, \cdots $, $ ||\varphi^{\ast}|| \subseteq ||\varphi_{i_k}|| $. 从而:
$$ f(x) = \mathop\wedge^{n}\limits_{i = 1} f_{i} (x) = \overline{\psi}_{i_1}(x) \wedge \cdots \wedge \overline{\psi}_{i_k}(x), x \in G $$ 如果记$ W = \{x \in G | f(x) = 1\} $, $\alpha^{J}(W) = \{d \in D | \forall x \in W, xJd\}$, 当$ \alpha^{J}(W) $非空时, 令$ \psi^{\ast} = \wedge_{d \in \alpha^{J}(W)} d $,则对$ x \in G $:
$$ \overline{\psi^{\ast}} (x) = \mathop\wedge\limits_{d \in \alpha^{J}(W)} \overline{d}(x) \geq f(x) = \overline{\psi}_{i_1}(x) \wedge \cdots \wedge \overline{\psi}_{i_k}(x) $$ 上式说明, 当$ \overline{\varphi^{\ast}} (x_0) = 1 $时, 有$\overline{\varphi}_{i_1} (x_0) = 1, \cdots$, $\overline{\varphi}_{i_k} (x_0) = 1$. 又由于$ \varphi_{i_1} \to \psi_{i_1}, \cdots $, $ \varphi_{i_k} \to \psi_{i_k} $是决策蕴涵, 故有$ ||\varphi_{i_1}|| \subseteq ||\psi_{i_1}||, \cdots $, $ ||\varphi_{i_k}|| \subseteq ||\psi_{i_k}|| $. 从而$ \overline{\psi}_{i_1} (x_0) = 1, \cdots $, $ \overline{\psi}_{i_k} (x_0) = 1 $. 因此:
$$ \overline{\psi^{\ast}} (x_0) \geq f(x_0) = \overline{\psi}_{i_1}(x_0) \wedge \cdots \wedge \overline{\psi}_{i_k}(x_0) = 1 $$ 即$ ||\varphi^{\ast}|| \subseteq ||\psi^{\ast}|| $. 所以$ \varphi^{\ast} \to \psi^{\ast} $是决策蕴涵.
□ 下面探讨基于现有决策蕴涵经过MP近似推理生成新的决策蕴涵的模式1.
模式1. 决策蕴涵的MP近似推理生成模式
前提. 决策蕴涵集$L = \{\varphi_{i} \to \psi_{i} | i = 1, \cdots, n\}$, 条件属性合取公式$\varphi^{\ast}$.
结论. 决策蕴涵$ \varphi^{\ast} \to \psi^{\ast} $.
1)计算属性公式函数$\overline{\varphi^{\ast}}, \overline{\varphi}_{i}, \overline{\psi}_{i}, i = 1, \cdots, n .$
2)计算MP近似推理解函数:
$$ f(x) = \mathop\wedge^{n}\limits_{i = 1}\mathop \vee\limits_{y \in G} [\overline{\varphi^{\ast}}(y) \wedge (\overline{\varphi}_{i}(y) \to \overline{\psi}_{i}(x))], x \in G $$ 3) 计算$ W = \{x \in G | f(x) = 1\} $, $\alpha^{J}(W) = \{d \in D | \forall x \in W, xJd\}.$
4)生成决策蕴涵$ \varphi^{\ast} \to \wedge_{d \in \alpha^{J}(W)} d $.
5)对任何$ B \subseteq \alpha^{J}(W) $, 生成决策蕴涵$ \varphi^{\ast} \to \wedge_{d \in B} d $.
例3. 一个决策形式背景$ K = (G,C,D,I,J) $见表3, 对象集$G = \{u_1, u_2, u_3, u_4, u_5, u_6, u_7\}$, 条件属性集$ C = \{a_1, a_2, a_3, a_4, a_5, a_6\} $, 决策属性集$ D = \{d_1, d_2, d_3\} $.
表 3 决策形式背景$K=(G,C,D,I,J)$Table 3 A formal decision context $K=(G,C,D,I,J)$$G$ $a_1$ $a_2$ $a_3$ $a_4$ $a_5$ $a_6$ $d_1$ $d_2$ $d_3$ $u_1$ 1 1 0 0 1 1 1 0 1 $u_2$ 0 0 1 1 1 1 1 1 0 $u_3$ 1 0 1 0 0 1 0 0 1 $u_4$ 0 1 0 1 0 1 1 0 0 $u_5$ 0 1 0 1 1 1 1 1 0 $u_6$ 1 0 1 0 1 1 0 1 1 $u_7$ 0 1 1 1 0 0 1 1 1 给定2个决策蕴涵$ a_1 \wedge a_2 \to d_1 \wedge d_3 $, $a_1 \wedge a_6 \to d_3$和条件属性公式$ a_1 \wedge a_2 \wedge a_6 $, 根据决策蕴涵生成模式1, MP近似推理得到如下非平凡决策蕴涵$ a_1 \wedge a_2 \wedge a_6 \to d_1 \wedge d_3 $, $ a_1 \wedge a_2 \wedge a_6 \to d_1 $, $a_1 \wedge a_2\; \wedge a_6 \to d_3$.
按照决策蕴涵的定义, 对于由原子属性公式构成的蕴涵公式, 当$ ||\varphi|| $是空集时, $ \varphi \to \psi $一定是决策蕴涵, 但这类决策蕴涵在实际知识获取中作用不是很大, 且极大地增大了决策蕴涵的个数. 因此, 决策蕴涵的MP近似推理生成模式1没有考虑生成这类平凡的决策蕴涵. 定理3和决策蕴涵生成模式1给出的决策蕴涵的MP近似推理是基于广义MP的, 是从逻辑角度来考虑的. 注意到, 广义MP的小前提是条件属性公式, 大前提是决策蕴涵, 而决策蕴涵的前件和后件分别是由条件属性和决策属性的合取构成的属性公式. 从知识发现的角度看, 属性合取公式本质上描述了知识的内涵, 因此决策蕴涵的MP近似推理的实质是一种从条件形式背景上的知识来获取决策形式背景上的知识的知识推理方法. 如果将条件属性理解为原因, 决策属性理解为结果, 则决策蕴涵的MP近似推理遵循的是一种“由因及果”的知识推理模式.
当$ \varphi^{\ast} \to \psi^{\ast} $是决策蕴涵时, 对任何由$ \psi^{\ast} $中部分原子属性公式组成的合取公式$ \gamma $, $ \varphi^{\ast} \to \gamma $都是决策蕴涵. 显然$ \varphi^{\ast} \to \wedge_{d \in \alpha^{J}(||\varphi^{\ast}||))} d $是决策蕴涵且含有最多的决策属性. 由定理3的证明过程可知, $ f(x) $和$ \varphi^{\ast} (x) $不一定总相等, 从而$ \alpha^{J}(W) $和$ \alpha^{J}(||\varphi^{\ast}||) $不一定相同. 因此, 对给定的$ \varphi^{\ast} $, 通过MP近似推理得到的决策蕴涵$ \varphi^{\ast} \to \wedge_{d \in \alpha^{J}(W)} d $不一定就是决策蕴涵$\varphi^{\ast} \to \wedge_{d \in \alpha^{J}(||\varphi^{\ast}||)} d$. 这是因为由MP近似推理得到的决策蕴涵$\varphi^{\ast} \to \wedge_{d \in \alpha^{J}(W)} d$还受到了大前提 $ \varphi^{\ast} \to \gamma $的约束. 定理3的证明过程表明了$\varphi^{\ast} \;\to \wedge_{d \in \alpha^{J}(W)} d$是得到给定前提$ \varphi^{\ast} $和$\{\varphi_{i} \to \psi_{i} | i = 1, \cdots, n\}$最大支持的含有最多决策属性的决策蕴涵.
定理4. 在定理3条件下, 有$\{\varphi_{1} \to \psi_{1}, \cdots, \varphi_{n} \to \psi_{n}\} \models_{K} \varphi^{\ast} \to \psi^{\ast}$.
证明. 由定理3可知, $ \varphi^{\ast} \to \psi^{\ast} $是决策蕴涵. 由于$ G $ ~ $ \Omega_K $间存在一一对应$\pi: G \to \Omega_K$, $ \pi(x) = v_x $. 对$ x \in G $决定的$v_x \in \Omega_K$, 如果$v_x (\varphi_{1} \to \psi_{1}) = 1, \cdots, v_x (\varphi_{n} \to \psi_{n}) = 1$, 则$v_x (\varphi_{1}) \leq v_x (\psi_{1}), \cdots, v_x (\varphi_{n}) \leq v_x (\psi_{n})$. 即$\overline{\varphi}_{1}(x) \leq \overline{\psi}_{1}(x), \cdots, \overline{\varphi}_{n}(x) \leq \overline{\psi}_{n}(x)$. 因此:
$$ \begin{split} f(x) =\;& \mathop\wedge^{n}\limits_{i = 1} \mathop\vee\limits_{y \in G} [\overline{\varphi^{\ast}}(y) \wedge (\overline{\varphi}_{i}(y) \to \overline{\psi}_{i}(x))] \;\geq \\ & \mathop\wedge^{n}\limits_{i = 1} [\overline{\varphi^{\ast}}(x) \wedge (\overline{\varphi}_{i}(x) \to \overline{\psi}_{i}(x))] \end{split}$$ $ \forall x \in G $, 如果记$ W = \{x \in G | f(x) = 1\} $, $\alpha^{J}(W) = \{d \in D | \forall x \in W, xJd\}$, $ \psi^{\ast} = \wedge_{d \in \alpha^{J}(W)} d $. 则$ \overline{\psi^{\ast}}(x) = \wedge_{d \in \alpha^{J}(W)} \overline{d}(x) \geq f(x) \geq \overline{\varphi^{\ast}}(x) $. 从而对任何$v_x \in \Omega_K$, $ v_x (\varphi^{\ast}) \leq v_x (\psi^{\ast}) $, $ v_x(\varphi^{\ast} \to \psi^{\ast}) = 1 $. 所以$\{\varphi_{1} \;\to \psi_{1}, \cdots, \varphi_{n} \to \psi_{n}\} \models_{K} \varphi^{\ast} \to \psi^{\ast}$.
□ 定义10. 对于给定的属性公式$\varphi_{1}, \cdots, \varphi_{k}$, 称属性公式集$\varphi_{1}, \cdots, \varphi_{k}$不相容是指$ \forall x \in G $, $\overline{\varphi}_{1} (x) \;\wedge \cdots \wedge \overline{\varphi}_{k} (x) = 0$; 否则, 称为相容.
命题7. 设$ \varphi \to \psi $是决策形式背景$K = (G, C, D,I,J)$的决策蕴涵, $ \varphi^{\ast} $是与$ \varphi $不相容的条件属性公式, 则由$ \varphi \to \psi $和$ \varphi^{\ast} $经过MP近似推理可以得到前件为$ \varphi^{\ast} $的全部决策蕴涵.
证明. $ \varphi \to \psi $和$ \varphi^{\ast} $的MP近似推理的解函数为:
$$ f(x) =\mathop \vee\limits_{y \in G} [\overline{\varphi^{\ast}}(y) \wedge (1-\overline{\varphi}(y))] \vee [\overline{\psi}(x) \wedge\mathop \vee\limits_{y \in G} \overline{\varphi^{\ast}}(y)] $$ 由于$ \varphi^{\ast} $与$ \varphi $不相容, 故$ \forall x \in G $, $\overline{\varphi^{\ast}} (x) \wedge \overline{\varphi} (x) = 0$. 于是$ \forall x \in G $, $ f(x) = 1 $. 由定理3的证明可知, 对任何$ W \subseteq G = \{x \in G | f(x) = 1\} $, $ \psi^{\ast} = \wedge_{d \in \alpha^{J}(W)} d $, $ \varphi^{\ast} \to \psi^{\ast} $是决策蕴涵.
□ 命题7表明, 一个与决策蕴涵前提不相容的条件属性公式$ \varphi^{\ast} $, 与决策蕴涵一起可以MP近似推理得出前提为$ \varphi^{\ast} $的全部决策蕴涵.
命题8. 在定理3的条件下, 有$\{\varphi_{1} \to \psi_{1}, \varphi_{2} \;\to \psi_{2}\} \models_K \varphi_{1} \wedge \varphi_{2} \to \psi_{1} \wedge \psi_{2}$.
证明. 由定理3, $\{\varphi_{1} \to \psi_{1}, \varphi_{2} \to \psi_{2}\} \models_K \varphi_{1} \;\wedge \varphi_{2} \to \psi^{\ast}$, $ \psi^{\ast} $是由$ \{\varphi_{1} \to \psi_{1}, \varphi_{2} \to \psi_{2}\} $和 $\varphi_{1} \wedge \varphi_{2}$的MP近似推理的结论. 因此:
$$ \begin{split} f(x) =\;& \mathop\wedge^{2}_{i = 1} \mathop\vee\limits_{y \in G} [\overline{\varphi_{1} \wedge \varphi_{2}} (y) \wedge (\overline{\varphi}_{i}(y) \to \overline{\psi}_{i}(x))] \;= \\ & \overline{\psi}_{1} (x) \wedge \overline{\psi}_{2} (x) \end{split}$$ $ W = \{x \in G | \overline{\psi}_{1} (x) \wedge \overline{\psi}_{2} (x) = 1\} $, 又由于$\alpha^{J}(W) \;= \{d \in D | \forall x \in W, xJd\}$, 故结论$ \psi^{\ast} = \wedge_{d \in \alpha^{J}(W)} d $包含$ \psi_{1} \wedge \psi_{2} $的全部原子属性公式. 所以$ \{\varphi_{1} \to \psi_{1} $, $ \varphi_{2} \to \psi_{2}\} \models_K \varphi_{1} \wedge \varphi_{2} \to \psi_{1} \wedge \psi_{2} $.
□ 定理5. 设$L = \{\varphi_{i} \to \psi_{i} | i = 1, \cdots, n\}$是决策形式背景$ K = (G,C,D,I,J) $的概念规则集, $ \varphi^{\ast} $是条件概念的内涵属性公式, $ f $是由$L = \{\varphi_{i} \to \psi_{i} | i = 1, \cdots, n\}$和$ \varphi^{\ast} $的MP近似推理得到的解函数:
$$ f(x) = \mathop\wedge^{n}\limits_{i = 1} \mathop\vee\limits_{y \in G} [\overline{\varphi^{\ast}}(y) \wedge (\overline{\varphi}_{i}(y) \to \overline{\psi}_{i}(x))], x \in G $$ 若记$ W = \{x \in G | f(x) = 1\} $, $\alpha^{J}(W) = \{d \in D | \forall x \in W, xJd\}$. 当$ \alpha^{J}(W) $非空时, 令$ \psi^{\ast} = \wedge_{d \in \alpha^{J}(W)} d $, 则$ \varphi^{\ast} \to \psi^{\ast} $是概念规则.
证明. 由定理3可知, $ \varphi^{\ast} \to \psi^{\ast} $是决策蕴涵. 显然有$ (||\psi^{\ast}||, \alpha^{J}(W)) $是决策概念, 即$ \psi^{\ast} $是决策概念的内涵属性公式. 与定理3的证明类似, 可以证明$ ||\varphi^{\ast}|| \subseteq ||\psi^{\ast}|| $, $ \varphi^{\ast} \to \psi^{\ast} $是概念规则.
□ 由定理5, 在基于MP近似推理的决策蕴涵生成模式中, 用概念规则代替决策蕴涵, 条件概念属性公式代替条件属性公式, 可以得到相应的基于MP近似推理的概念规则生成方法.
例4 (续例3). $ a_2 \wedge a_4 \to d_1 $, $ a_3 \wedge a_4 \to d_2 $是两条概念规则, $a_2 \wedge a_3 \wedge a_4$是条件概念内涵属性公式, 利用决策蕴涵生成模式1, 得到概念规则: $a_2 \;\wedge a_3 \wedge a_4 \to d_1$, $a_2 \wedge a_3 \wedge a_4 \to d_2$, $ a_2 \wedge a_3 \wedge a_4 \to d_3 $, $ a_2 \wedge a_3 \wedge a_4 \to d_1 \wedge d_2 $, $a_2 \wedge a_3 \wedge a_4 \to d_2 \wedge d_3$, $a_2 \;\wedge a_3 \wedge a_4 \to d_1 \wedge d_3$, $ a_2 \wedge a_3 \wedge a_4 \to d_1 \wedge d_2 \wedge d_3 $.
以上结论表明, 本文给出的MP近似推理方法是一种保持决策蕴涵和概念规则不变的推理模式, 即决策蕴涵和概念规则集在MP近似推理模式下是封闭的.
3.2 决策蕴涵和概念规则的MT近似推理模式
本节讨论决策形式背景上基于广义MT的近似推理(以下简称MT近似推理)的特征.
定理6. 设$L = \{\varphi_{i} \to \psi_{i} | i = 1, \cdots, n\}$是决策形式背景$ K = (G,C,D,I,J) $的决策蕴涵集, $ \psi^{\ast} $是决策属性合取公式, 由$L = \{\varphi_{i} \to \psi_{i} | i = 1, \cdots, n\}$和$ \psi^{\ast} $的MT近似推理得到的解函数为:
$$ g(y) = \mathop\wedge^{n}\limits_{i = 1}\mathop \wedge\limits_{x \in G} [(\overline{\varphi}_{i}(y) \to \overline{\psi}_{i}(x)) \to \overline{\varphi^{\ast}}(x)], y \in G $$ 若记$ V = \{y \in G | g(y) = 1\} $, $\alpha^{I}(V) = \{c \in C | \forall y \in V, yIc\}$. 当$ \alpha^{I}(V) $非空时, 令$ \varphi^{\ast} = \wedge_{c \in \alpha^{I}(V)} c $, 则$ \varphi^{\ast} \to \psi^{\ast} $是决策蕴涵.
证明. 设$ y_0 \notin ||\psi^{\ast}|| $, 即$ \psi^{\ast} (y_0) = 0 $. 如果记:
$$ \begin{split} g_i (y) = \;&\mathop\wedge\limits_{x \in G} [(\overline{\varphi}_{i}(y) \to \overline{\psi}_{i}(x)) \to \wedge \overline{\varphi^{\ast}}(x)],\\ & i = 1, \cdots, n \end{split}$$ 由注2, 在$ \psi^{\ast} (y_0) = 0 $的条件下, 只有满足$||\psi_{i}|| \subseteq ||\psi^{\ast}||$时, 才会有$ g_i (y) = \overline{\varphi}_{i}(y) $; 否则, $ g_i (y) $在$ G $上恒为0. 不妨设决策蕴涵集$ L $的后件属性公式集$\{\psi_{1}, \cdots, \psi_{n}\}$中有$ i_l $个属性公式$\psi_{i_1}, \cdots, \psi_{i_l}$满足条件$||\psi_{1}|| \subseteq ||\psi^{\ast}||, \cdots,$ $ ||\psi_{l}|| \subseteq ||\psi^{\ast}|| $. 从而有:
$$ g(y) = \mathop\wedge^{n}\limits_{i = 1} g_{i} (y) = \overline{\varphi}_{i_1}(y) \wedge \cdots \wedge \overline{\varphi}_{i_l}(y), y \in G $$ 记$ V = \{y \in G | g(y) = 1\} $, $\alpha^{I}(V) = \{c \in C | \forall y \in V, yIc\}$. 当$ \alpha^{I}(V) $非空时, 令$ \varphi^{\ast} = \wedge_{c \in \alpha^{I}(V)} c $, 注意到都是原子属性公式的合取, 于是有:
$$ \overline{\psi^{\ast}} (y) =\mathop \wedge\limits_{c \in \alpha^{I}(V)} \overline{c}(y) = g(y) = \overline{\varphi}_{i_1}(y) \wedge \cdots \wedge \overline{\varphi}_{i_l}(y) $$ $ \forall y \in G $. 由于$\varphi_{i_1} \to \psi_{i_1}, \cdots,$ $ \varphi_{i_l} \to \psi_{i_l} $是决策蕴涵, 故有$||\varphi_{i_1}|| \subseteq ||\psi_{i_1}||, \cdots ,$ $ ||\varphi_{i_l}|| \subseteq ||\psi_{i_l}|| $. 又由$ \overline{\psi^{\ast}} (y_0) = 0 $, 知$ \overline{\psi}_{1} (y_0) = 0, \cdots $, $ \overline{\psi}_{l} (y_0) = 0 $, 从而$\overline{\varphi}_{1} (y_0) = 0, \cdots ,$ $ \overline{\varphi}_{l} (y_0) = 0 $. 故$\overline{\psi^{\ast}} (y_0) = \overline{\varphi}_{i_1}(y_0) \wedge \cdots \wedge \;\overline{\varphi}_{i_l}(y_0) = 0$, 即$ y_0 \notin ||\varphi^{\ast}|| $. 因此$ ||\varphi^{\ast}|| \subseteq ||\psi^{\ast}|| $. 所以$ \varphi^{\ast} \to \psi^{\ast} $是决策蕴涵.
□ 定理6给出的决策蕴涵的MT近似推理是基于广义MT的. 从知识发现的思维过程看, 广义MT有着与MP相反的思维模式. 因此, 决策蕴涵的MT近似推理本质上应属于“由果溯因”的知识推理模式.
命题9. 在定理6的条件下, 有$\{\varphi_{1} \to \psi_{1}, \cdots ,$ $ \varphi_{n} \to \psi_{n}\} \models_{K} \varphi^{\ast} \to \psi^{\ast} $.
证明. 由定理6知$ \varphi^{\ast} \to \psi^{\ast} $是决策蕴涵. 由于$ G $和$\Omega_K$之间有一一对应$\pi: G \to \Omega_K$, $ \pi(y) = v_y $. 对$ y \in G $决定的$v_y \in \Omega_K$, 如果$v_y (\varphi_{1} \to \psi_{1}) = 1, \cdots, v_y (\varphi_{n} \to \psi_{n}) = 1$, 则$v_y (\varphi_{1}) \leq v_y(\psi_{1}), \cdots, v_y (\varphi_{n}) \leq v_y(\psi_{n})$. 即$\overline{\varphi}_{1}(y) \leq \overline{\psi}_{1}(y), \cdots, \overline{\varphi}_{n}(y) \leq \overline{\psi}_{n}(y)$. 因此:
$$ \begin{split} g(y) = \;&\mathop\wedge^{n}\limits_{i = 1} \mathop\wedge\limits_{x \in G} [(\overline{\varphi}_{i}(y) \to \overline{\psi}_{i}(x)) \to \overline{\varphi^{\ast}}(x)]\; \leq \\ &\mathop \wedge^{n}\limits_{i = 1} [(\overline{\varphi}_{i}(y) \to \overline{\psi}_{i}(y)) \to \overline{\varphi^{\ast}}(y)] = \overline{\psi^{\ast}}(y) \end{split}$$ $ \forall y \in G $, $ V = \{y \in G | g(y) = 1\} $, $\alpha^{I}(V) = \{c \in C | \forall y \in V, yIc\}$, $ \varphi^{\ast} = \wedge_{c \in \alpha^{I}(V)} c $, 于是$\overline{\psi^{\ast}}(y) \geq g(y) = \wedge_{c \in \alpha^{I}(V)} \overline{c}(y) = \overline{\varphi^{\ast}}(y)$. 故$\forall v_y \in \Omega_K$, $ v_y (\varphi^{\ast}) \leq v_y (\psi^{\ast}) $, $ v_y (\varphi^{\ast} \to \psi^{\ast}) = 1 $. 所以$\{\varphi_{1} \to \psi_{1}, \cdots, \varphi_{n} \to\psi_{n}\} \models_{K}$ $ \varphi^{\ast} \to \psi^{\ast}$.
□ 定理7. 设$L = \{\varphi_{i} \to \psi_{i} | i = 1, \cdots, n\}$是决策形式背景$ K = (G,C,D,I,J) $的概念规则集, $ \psi^{\ast} $是决策概念内涵属性合取公式, $ g $是由$L = \{\varphi_{i} \to \psi_{i} | i = 1, \cdots, n\}$和$ \psi^{\ast} $的MT近似推理得到的解函数:
$$ g(y) = \mathop\wedge^{n}\limits_{i = 1}\mathop \wedge\limits_{x \in G} [(\overline{\varphi}_{i}(y) \to \overline{\psi}_{i}(x)) \to \overline{\varphi^{\ast}}(x)], y \in G $$ 若记$ V = \{y \in G | g(y) = 1\} $, $\alpha^{I}(V) = \{c \in C | \forall y \in V, yIc\}$. 当$ \alpha^{I}(V) $非空时, 令$ \varphi^{\ast} = \wedge_{c \in \alpha^{I}(V)} c $, 则$ \varphi^{\ast} \to \psi^{\ast} $是概念规则.
证明. 显然有$ (||\varphi^{\ast}||, \alpha^{I}(V)) $是条件概念, 即$ \varphi^{\ast} $是条件概念的内涵属性公式. 与定理6的证明类似, 可证明$ ||\varphi^{\ast}|| \subseteq ||\psi^{\ast}|| $, $ \varphi^{\ast} \to \psi^{\ast} $是概念规则.
□ 由定理5和定理7可知, 决策蕴涵和概念规则集在MT近似推理模式下也是封闭的.
应用定理6的结论, 可以得到下述基于MT近似推理的决策蕴涵和概念规则生成模式2.
模式2. 决策蕴涵的MT近似推理生成模式
前提. 决策蕴涵集$L = \{\varphi_{i} \to \psi_{i} | i = 1, \cdots, n\}$, 决策属性合取公式$ \psi^{\ast} $.
结论. 决策蕴涵$ \varphi^{\ast} \to \psi^{\ast} $.
1)计算属性公式函数$\overline{\psi^{\ast}}, \overline{\varphi}_{i}, \overline{\psi}_{i}, i = 1, \cdots, n$;
2)计算MT近似推理解函数:
$$ g(y) = \mathop\wedge^{n}\limits_{i = 1}\mathop \wedge\limits_{x \in G} [(\overline{\varphi}_{i}(y) \to \overline{\psi}_{i}(x)) \to \overline{\varphi^{\ast}}(x)], y \in G . $$ 3)计算$ V \;=\; \{y \in G | g(y) = 1\} $, $\alpha^{I}(V) = \{c \in C | \forall y \in V, yIc\}$;
4)生成决策蕴涵$ \wedge_{c \in \alpha^{I}(V)} c \to \psi^{\ast} $;
5)对任何$ A \supseteq \alpha^{I}(A) $, 生成决策蕴涵$\wedge_{c \in A} c \to \psi^{\ast}$.
由定理7, 在基于MT近似推理的决策蕴涵生成模式中, 用概念规则代替决策蕴涵, 决策概念内涵属性公式代替决策属性公式, 可以得到相应的基于MT近似推理的概念规则生成方法.
例5 (续例3). 对于给定的2条概念规则$(a_2 \;\wedge a_4 \wedge a_5 \wedge a_6 \to d_1 \wedge d_2$, $a_1 \wedge a_3 \wedge a_5 \wedge a_6 \to d_1 \wedge d_3)$和决策概念内涵属性公式$ d_2 $, 利用决策蕴涵生成模式2, 经过MT近似推理得到概念规则$a_1 \wedge a_2 \;\wedge a_3 \wedge a_4 \wedge a_5 \wedge a_6 \to d_2$.
4. 近似推理生成决策蕴涵的有效性分析
第3节分析了决策形式背景全体对象集上的决策蕴涵的MP、MT近似推理的特征, 给出了利用MP、MT近似推理生成决策蕴涵的方法. 在人工智能环境下, 在应用MP、MT近似推理进行知识获取时, 经常需要基于部分数据集上的现有决策蕴涵经过MP、MT近似推理动态地挖掘更大数据集上的决策蕴涵, 即遇到更多的是数据对象动态变化时的决策蕴涵挖掘. 另一方面, 利用少量的决策蕴涵借助MP、MT近似推理模式产生更多的决策蕴涵, 这正是知识推理的目的. 如何评价近似推理的好坏, 即如何评价近似推理结论的有效性, 目前还没有见到公认的标准. 本节引入属性逻辑伪距离, 对MP、MT近似推理结论的有效性进行刻画, 进而提出基础数据对象集动态变化时应用MP、MT近似推理来获取决策蕴涵的算法.
例6 (续例3). 给定决策蕴涵$a_1 \wedge a_2 \to d_1 \wedge d_3$、 $ a_1 \wedge a_6 \to d_3 $和条件属性公式$ a_2 \wedge a_6 $.
如果近似推理的基础数据对象集是整个对象集, MP近似推理得到的解函数为$ f(x) = 1, x \in G $, 这时MP近似推理的结论是空集. 如果推理范围限定为${ \Sigma} = \{u_1, u_2, u_3, u_6, u_7\}$, MP近似推理得到的解函数为$ f(x) = \overline{d_1 \wedge \ d_3}(x), x \in G $, 从而可得属性公式$ a_2 \wedge a_6 \to d_1 \wedge d_3 $. 注意到, 在整个对象集$ G $上, 它不是决策蕴涵, 但如果限定在对象集$ \Sigma $上, 则它是决策蕴涵. 本文称限定在部分对象集上是决策蕴涵的属性公式为拟决策蕴涵.
定义11. 设$ K = (G,M,I) $是形式背景, 属性公式$ \varphi,\psi \in \Gamma (K) $, ${ \Sigma} \subseteq G$. 定义$ \varphi $在${ \Sigma}$上的真度为:
$$ \tau_{ \Sigma} (\varphi) = \int_{ \Sigma} \overline{\varphi} (x) \text{d} P $$ 式中, $ P $是$ G $上的概率测度. 属性公式$ \varphi,\psi $的${ \Sigma}\text{-} 伪$距离定义为:
$$ \rho_{ \Sigma} (\varphi, \gamma) = 1- \tau_{ \Sigma} ((\varphi \to \psi) \wedge (\psi \to \varphi)) $$ 当$ P $是$ G $上的均匀概率测度 (计数测度) 时, 定义11中定义的真度可表示为:
$$ \tau_{ \Sigma} (\varphi) = \frac{1}{m} \sum^{m}\limits_{i = 1} \overline{\varphi} (x_i) $$ 式中, $ m $为对象集${ \Sigma}$的元素个数.
由于$ \varphi $是一些属性的合取, 按照决策逻辑思想, $ \overline{\varphi} (x) = 1 $意味着支持“$ x $支持$ \varphi $”, 即对象$ x $具有$ \varphi $中的全部属性, 因此真度$\tau_{ \Sigma}$可以被理解为一种“投票模型”. 由于在实际数据处理中形式背景通常是用表格表示的, 这时对象$ x $的概率$ P(x) $其实就是与$ x $有相同属性值的对象数与全体对象个数的比值, 而公式$ \varphi $的真度$\tau_{ \Sigma} (\varphi)$其实就是${ \Sigma}$上具有$ \varphi $中全部属性的对象的概率和. 当$ P $是$ G $上的计数测度时, $\tau_{ \Sigma} (\varphi)$是$\Sigma $上具有$ \varphi $中全部属性的对象个数与$\Sigma $中全体对象个数的比值.
命题10. 设$ \varphi,\psi \in \Gamma (K) $, ${ \Sigma} \subseteq G$. 则:
$$ \begin{split} \rho_{ \Sigma} (\varphi) =\;& \int_{ \Sigma} |\overline{\varphi} (x) - \overline{\psi} (x)| \text{d}P \;= \\ & \frac{1}{m} \sum^{m}\limits_{i = 1} |\overline{\varphi} (x_i) - \overline{\psi} (x_i)| \end{split} $$ 证明.
$$ \begin{split} &\rho_{ \Sigma} (\varphi, \psi) = 1- \tau_{ \Sigma} ((\varphi \to \psi) \wedge (\psi \to \varphi))\; = \\ &\quad 1- \int_{ \Sigma} (\overline{\varphi \to \psi} (x) \wedge \overline{\psi \to \varphi} (x)) \text{d}P \;= \\ &\quad 1- \int_{ \Sigma} (\overline{\varphi} (x) \to \overline{\psi} (x) \wedge \overline{\psi} (x) \to \overline{\varphi} (x)) \text{d}P \;= \\ &\quad 1- \int_{ \Sigma} (1- \overline{\varphi} (x) + \overline{\psi} (x)) \;\wedge\\ &\quad (1- \overline{\psi} (x) + \overline{\varphi} (x)) \text{d}P \;= \\ &\quad\int_{ \Sigma} [1- (1- \overline{\varphi} (x) + \overline{\psi} (x)) \;\wedge \\ &\quad(1- \overline{\psi} (x) + \overline{\varphi} (x))] \text{d}P \;= \\ &\quad\int_{ \Sigma} |\overline{\varphi} (x) - \overline{\psi} (x)| \text{d}P \end{split} $$ □ 设$ F \subseteq \Gamma (K) $, ${ \Sigma} \subseteq G$, 称$ \gamma \in \Gamma (K) $是$ F $的$\Sigma$-语义结论是指$\Sigma$对所决定的任何赋值$v_x \in v_{ \Sigma}$, 如果$ v_x (F) = \wedge \{v_x (\varphi) | \varphi \in F\} = 1 $, 则有$ v_x (\gamma) = 1 $. $ F $的全体$\Sigma$-语义结论之集记为$D_{ \Sigma}(F)$.
定义12. 设$ K = (G,M,I) $是形式背景, $ F \subseteq \Gamma (K) $, $ \varphi \in \Gamma (K) $, $\Sigma \subseteq G$, $ \varepsilon >0 $. 如果${\rm{div}}(F) = \text{inf} \{\rho_{ \Sigma}(\varphi, \gamma) | \gamma \in D_{ \Sigma}(F)\}$, 则称$ \varphi $为$ F $的误差小于$ \varepsilon $的结论, 记为$ \varphi \in D_{\varepsilon}(F) $.
定理8. 设$ K = (G,M,I) $是形式背景, $ F \subseteq \Gamma (K) $, $ \varphi \in \Gamma (K) $, $\Sigma \subseteq G$, $ \varepsilon >0 $. 则$ \varphi \in D_{\varepsilon}(F) $当且仅当$\text{sup}\{\tau_{ \Sigma} (\gamma \to \varphi) | \gamma \in D_{ \Sigma}(F)\} > 1-\varepsilon$.
证明. 设$ \varphi \in D_{\varepsilon}(F) $, 则存在属性公式$\gamma_{0} \in D_{ \Sigma}(F)$使得$\rho_{ \Sigma} (\varphi, \gamma_0) < \varepsilon$. 则:
$$ \begin{split} \rho_{ \Sigma} (\varphi, \gamma_0) =\;& 1- \tau_{ \Sigma} ((\varphi \to \gamma_0) \wedge (\gamma_0 \to \varphi))\; \geq \\ &1- \tau_{ \Sigma} (\gamma_0 \to \varphi) \end{split}$$ 因此
$$ \begin{split}&1-\text{sup}\{\tau_{ \Sigma} (\gamma \to \varphi) | \gamma \in D_{ \Sigma}(F)\}\; \leq \\ &\qquad 1-\tau_{ \Sigma} (\gamma_0 \to \varphi) | \gamma \in D_{ \Sigma}(F)< \varepsilon \end{split}$$ 所以, $\text{sup}\{\tau_{ \Sigma} (\gamma \to \varphi) | \gamma \in D_{ \Sigma}(F)\} > 1-\varepsilon$.
反之, 如果$\text{sup}\{\tau_{ \Sigma} (\gamma \to \varphi) | \gamma \in D_{ \Sigma}(F)\} > 1-\varepsilon$, 则$\text{inf}\{1-\tau_{ \Sigma} (\gamma \to \varphi) | \gamma \in D_{ \Sigma}(F)\} < \varepsilon .$易证:
$$ (\varphi \to \varphi \vee \gamma) \wedge (\varphi \vee \gamma \to \varphi) \approx \gamma \to \varphi $$ 则:
$$ \begin{split} \rho_{ \Sigma} (\varphi, \varphi \vee \gamma) = \;&1- \tau_{ \Sigma} ((\varphi \to \varphi \vee \gamma) \wedge (\varphi \vee \gamma \to \varphi))= \\ & 1- \tau_{ \Sigma} (\gamma \to \varphi) \qquad \end{split}$$ 故$\text{inf} \{\rho_{ \Sigma}(\varphi, \varphi \vee \gamma) | \gamma \in D_{ \Sigma}(F)\} < \varepsilon$. 于是存在$\gamma \in D_{ \Sigma}(F)$使得$\rho_{ \Sigma}(\varphi, \varphi \vee \gamma) < \varepsilon$. 又由$\gamma \in D_{ \Sigma}(F)$有$\varphi \vee \gamma \in D_{ \Sigma}(F)$. 因此:
$$ \text{inf} \{\rho_{ \Sigma}(\varphi, \gamma) | \gamma \in D_{ \Sigma}(F)\} \leq \rho_{ \Sigma}(\varphi, \varphi \vee \gamma)<\varepsilon $$ 所以, $ \varphi \in D_{\varepsilon}(F) $.
□ 定理9. 设${ \Sigma} \subset { \Delta} \subseteq G$, $ \psi^{\ast} $是$ \{\varphi_{i} \to \psi_{i} | $ $i = 1, \cdots, n\}$和$ \varphi^{\ast} $的MP近似推理结论, 则$ \psi^{\ast} $是$ L $的后件属性公式集$F = \{\psi_1, \cdots,\psi_n\}$的误差小于$(| \Delta|-| \Sigma|)/{| \Delta|}$的结论, 其中$| \Delta|$表示$\Delta$的元素个数.
证明. $\{\varphi_{i} \to \psi_{i} | i = 1, \cdots, n\}$和$ \varphi^{\ast} $的MP近似推理的$( \Sigma, \Delta)$解函数为:
$$ f(x) =\mathop \wedge^{n}\limits_{i = 1} \mathop\vee\limits_{y \in \Sigma} [\overline{\varphi^{\ast}}(y) \wedge (\overline{\varphi}_{i}(y) \to \overline{\psi}_{i}(x))], x \in \Delta $$ (9) 设$||\varphi^{\ast}||_{\Delta} \cap \Sigma \subseteq ||\varphi_{i_1}||_{\Delta} \cap \Sigma, \cdots,$ $||\varphi^{\ast}||_{\Delta} \cap \Sigma \;\subseteq ||\varphi_{i_k}||_{\Delta} \cap \Sigma$. 从而$f(x) = \overline{\psi}_{i_1}(x) \wedge \cdots \wedge \overline{\psi}_{i_k}(x), x \;\in \Delta .$令$ \gamma = \psi_{i_1} \wedge \cdots \wedge \psi_{i_k} $, 显然有$\gamma \in D_{ \Sigma}(F)$. 又记$W = \{x \in { \Delta} | f(x) = 1\}$, $ \psi^{\ast} = \wedge_{d \in \alpha^{J}(W)} d $. 由式(9)和决策蕴涵生成模式1可知, $\forall x \in \Sigma$, $\overline{\varphi^{\ast}} (x) = \wedge_{d \in \alpha^{J}(W)} \overline{d}(x) \geq f(x) = \overline{\psi}_{i_1}(x) \wedge \cdots \wedge \overline{\psi}_{i_k}(x) , $ 即 $ \forall x \in \Sigma $, $ \overline{\gamma \to \psi^{\ast}} (x) = 1 $. 所以:
$$ \tau_{ \Delta} (\gamma \to \psi^{\ast}) = \int_{\Delta} \overline{\gamma \to \psi^{\ast}} (x) \text{d}P \geq \qquad $$ $$\qquad \qquad \frac{| \Sigma|}{| \Delta|} = 1-\frac{| \Delta|-| \Sigma|}{| \Delta|} $$ □ 命题11. 设${ \Sigma} \subset \Delta_1 \subset \Delta_2$, $ \{\varphi_{i} \to \psi_{i} | $ $i = 1, \cdots, n\}$和$ \varphi^{\ast} $的MP近似推理的$({ \Sigma}, \Delta_1)$, $({ \Sigma}, \Delta_2)$结论分别是$ \psi^{\ast}_{1} $和$ \psi^{\ast}_{2} $. 则$ \psi^{\ast}_{2} $比$ \psi^{\ast}_{1} $包含有更多的原子属性公式, 且$ \psi^{\ast}_{2} $和$F = \{\psi_1, \cdots, \psi_n\}$的距离小于$ \psi^{\ast}_{1} $和$F = \{\psi_1, \cdots, \psi_n\}$的距离.
证明. $ \{\varphi_{i} \to \psi_{i} | $ $i = 1, \cdots, n\}$和$ \varphi^{\ast} $的MP近似推理的$({ \Sigma}, \Delta_1)$, $({ \Sigma}, \Delta_2)$解函数分别为$ f_1 (x) $和$ f_2 (x) $:
$$ \begin{split}& f_1(x) =\mathop \wedge^{n}\limits_{i = 1} \mathop\vee\limits_{y \in \Sigma} [\overline{\varphi^{\ast}}(y) \wedge (\overline{\varphi}_{i}(y) \to \overline{\psi}_{i}(x))], x \in \Delta_1 \\ & f_2(x) =\mathop \wedge^{n}\limits_{i = 1} \mathop\vee\limits_{y \in \Sigma} [\overline{\varphi^{\ast}}(y) \wedge (\overline{\varphi}_{i}(y) \to \overline{\psi}_{i}(x))], x \in \Delta_2 \end{split} $$ 显然$ \forall x \in \Delta_1, f_1(x) = f_2(x) $. 不妨设在决策蕴涵集$ L $的前件属性公式集$\{\varphi_1, \cdots, \varphi_n\}$中有$ i_k $个前件属性公式$\varphi_{i_1}, \cdots, \varphi_{i_k}$满足条件$||\varphi^{\ast}||_{\Delta} \cap { \Sigma} \subseteq ||\varphi_{i_1}||_{\Delta}\; \cap { \Sigma}, \cdots$, $||\varphi^{\ast}||_{ \Delta} \cap { \Sigma} \subseteq ||\varphi_{i_k}||_{\Delta} \cap { \Sigma}$. 因此, 类似于定理3的证明, 不妨设:
$$ \begin{split} &f_1(x) = \overline{\psi}_{i_1}(x) \wedge \cdots \wedge \overline{\psi}_{i_k}(x), x \in \Delta_1 \\ & f_2(x) = \overline{\psi}_{i_1}(x) \wedge \cdots \wedge \overline{\psi}_{i_k}(x), x \in \Delta_2 \end{split} $$ 记$ \gamma = \psi_{i_1} \wedge \cdots \wedge \psi_{i_k} $, $ W_1 = \{x \in \Delta_1 | f(x) = 1\} $, $ \psi^{\ast}_{1} = \wedge_{d \in \alpha^{J}(W_1)} d $, $ W_2 = \{x \in \Delta_2 | f(x) = 1\} $, $\psi^{\ast}_{2} \;= \wedge_{d \in \alpha^{J}(W_2)} d$. 显然$ W_1 \subseteq W_2 $, 从而$ \psi^{\ast}_{1} $比$ \psi^{\ast}_{2} $包含有更多的决策原子属性公式, 于是$\forall x \in \Delta_2, \overline{\psi^{\ast}_{1}} (x)\; \leq \overline{\psi^{\ast}_{2}} (x)$. 因此由伪距离的定义知, $ \psi^{\ast}_{2} $与$ \gamma $间的伪距离比$ \psi^{\ast}_{1} $与$ \gamma $间的伪距离要小.
□ 由命题11, 当${ \Sigma} \subset \Delta_1 \subset \Delta_2$时, $ \{\varphi_{i} \to \psi_{i} | $ $i = 1, \cdots, n\}$和$ \varphi^{\ast} $的MP近似推理的$({ \Sigma}, \Delta_1)$结论$ \psi^{\ast}_{1} $比$({ \Sigma}, \Delta_2)$结论$ \psi^{\ast}_{2} $有更小的精确度.
定理10. 设$\Sigma \subset \Delta \subseteq G$, $ \varphi^{\ast} $是$ \{\varphi_{i} \to \psi_{i} | $ $i = 1, \cdots, n\}$和$ \psi^{\ast} $的MT近似推理结论. 则$ \varphi^{\ast} $是$ L $的前件属性公式集$F = \{\varphi_1, \cdots, \varphi_n\}$的误差小于$(| \Delta|\;- | \Sigma|)/{| \Delta|}$的结论.
证明. $L = \{\varphi_{i} \to \psi_{i} | i = 1, \cdots, n\}$和$ \psi^{\ast} $的多规则MT近似推理的$( \Sigma, \Delta)$解函数为:
$$ g(y) = \mathop\wedge^{n}\limits_{i = 1} \mathop\wedge\limits_{x \in \Sigma} [(\overline{\varphi}_{i}(y) \to \overline{\psi}_{i}(x)) \to \overline{\varphi^{\ast}}(x)], y \in \Delta $$ (10) 设$||\varphi_{i_1}||_{\Delta} \cap \Sigma \subseteq ||\varphi^{\ast}||_{\Delta} \cap \Sigma, \cdots,$ $||\varphi_{i_l}||_{\Delta} \cap \Sigma \;\subseteq ||\varphi^{\ast}||_{\Delta} \cap \Sigma$. 从而$f(x) = \overline{\varphi}_{i_1}(x) \wedge \cdots \wedge \overline{\varphi}_{i_l}(x), x \in \Delta .$令$ \gamma = \varphi_{i_1} \wedge \cdots \wedge \varphi_{i_l} $, 显然有$\gamma \in D_{ \Sigma}(F)$. 又记$V = \{y \in { \Delta} | g(y) = 1\}$, $ \varphi^{\ast} = \wedge_{c \in \alpha^{I}(V)} c $. 由式(9)和决策蕴涵生成模式2可知:
$$ \overline{\varphi^{\ast}} (y) = \wedge_{c \in \alpha^{I}(V)} \overline{c}(y) \geq g(y) = \overline{\varphi}_{i_1}(x) \wedge \cdots \wedge \overline{\varphi}_{i_l}(x) $$ $\forall y \in \Sigma$, 则$\forall y \in \Sigma$, $ \overline{\gamma \to \varphi^{\ast}} (y) = 1 $. 所以:
$$ \begin{split} \tau_{ \Delta} (\gamma \to \varphi^{\ast}) =\;& \int_{\Delta} \overline{\gamma \to \varphi^{\ast}} (y) \text{d}P \;\geq \\ &\frac{| \Sigma|}{| \Delta|} = 1-\frac{| \Delta|-| \Sigma|}{| \Delta|} \end{split} $$ □ 由定理10、命题11的证明, 可证明如下结论成立.
命题12. 设${ \Sigma} \subset \Delta_1 \subset \Delta_2$, $ \{\varphi_{i} \to \psi_{i} | $ $i = 1, \cdots, n\}$和$ \psi^{\ast} $的MT近似推理的$({ \Sigma}, \Delta_1)$, $({ \Sigma}, \Delta_2)$结论分别是$ \varphi^{\ast}_{1} $和$ \varphi^{\ast}_{2} $, 则$ \varphi^{\ast}_{2} $比$ \varphi^{\ast}_{1} $包含更多的原子属性公式, 且$ \varphi^{\ast}_{2} $和$F = \{\varphi_1, \cdots, \varphi_n\}$的距离小于$ \varphi^{\ast}_{1} $和$F = \{\varphi_1, \cdots, \varphi_n\}$的距离.
由例6可知, $ \{\varphi_{i} \to \psi_{i} | $ $i = 1, \cdots, n\}$和$ \varphi^{\ast} $在部分对象集$\Sigma \subset \Delta$的具有局部意义的MP近似推理结论$ \psi^{\ast} $不一定使得$ \psi^{\ast} \to \varphi^{\ast} $是整个对象集$ G $上的决策蕴涵. 由定理9、定理10、命题11和命题12可知, 利用MP、MT近似推理提取局部意义的决策蕴涵(以下称为拟决策蕴涵)生成算法1和算法2.
算法1. MP近似推理生成拟决策蕴涵算法
输入. $L = \{\varphi_{i} \to \psi_{i} | i = 1, \cdots, n\}$, 条件属性合取公式$ \varphi^{\ast} $, 部分决策形式背景$K = ({ \Delta},C,D,I,J)$, 对象集${ \Sigma} \subseteq { \Delta}$.
输出. 拟决策蕴涵$ \varphi^{\ast} \to \psi^{\ast} $.
1) 计算$||\varphi^{\ast}||_{ \Sigma}$, $||\varphi_{i}||_{ \Sigma}$, $i = 1, \cdots, n$, 其中$||\varphi^{\ast}||_{ \Sigma} = \{u \in \Sigma | \forall a \in \varphi^{\ast}, I(u,c) = 1\}$;
2) 找出满足条件$||\varphi^{\ast}||_{ \Sigma} \subseteq ||\varphi_{i}||_{ \Sigma}$的前件属性公式$\varphi_{i_1}, \cdots, \varphi_{i_k}$, 相应的后件属性公式为$\psi_{i_1}, \cdots, \psi_{i_k}$;
3) 如果没有满足条件2), 推理问题无解; 否则, 令$ \gamma = \psi_{i_1} \wedge \cdots \wedge \psi_{i_k} $;
4) 计算$W = \{u \in \Delta | \forall d \in { \Sigma},\ J(u,d) = 1\}$, $\alpha^{J}(W) = \{d \in D | \forall u \in W, uJd\}$.
5)令$ \psi^{\ast} = \wedge_{d \in \alpha^{J}(W)} d $, 计算属性公式$ \gamma $和$ \psi^{\ast} $的伪距离;
6)获取拟决策蕴涵$ \varphi^{\ast} \to \psi^{\ast} $.
算法1的时间复杂度分析如下:
1)计算$||\varphi^{\ast}||_{ \Sigma}$, $||\varphi_{i}||_{ \Sigma}$, $i = 1, \cdots, n$的时间复杂度为$\mathrm{O}((n+1)|C|| \Sigma|)$, $ n $为$ L $中的决策蕴涵个数, $ |C| $是条件属性集$ C $的元素个数, $ | \Sigma| $是对象集$ \Sigma $的元素个数.
2)找出满足条件$||\varphi^{\ast}||_{ \Sigma} \subseteq ||\varphi_{i}||_{ \Sigma}$的前件属性公式$\varphi_{i_1}, \cdots, \varphi_{i_k}$的时间复杂度为$ \mathrm{O}(n| \Sigma|) $.
3)计算$ W $的时间复杂度为$\mathrm{O}(|D|| \Delta|)$; 计算$ \alpha^{J}(W) $的时间复杂度也是$\mathrm{O}(|D|| \Delta|)$, $ |D| $是决策属性集$ D $的元素个数, $| \Delta|$是对象集$\Delta$的元素个数.
4)计算$ \psi^{\ast} = \wedge_{d \in \alpha^{J}(W)} d $的时间复杂度为$ \mathrm{O}(|D|) $, 计算$ \gamma $和$ \psi^{\ast} $的伪距离需要先计算属性公式函数$ \overline{\gamma} $和$ \overline{\psi^{\ast}} $, 其时间复杂度为$\mathrm{O}(2|D|| \Delta|)$, 计算$ \gamma $和$ \psi^{\ast} $的伪距离时间复杂度为$\mathrm{O}(| \Delta|)$, 所以算法1中步骤5)的时间复杂度为$\mathrm{O}(2|D|| \Delta|)$.
由于$\Sigma \subseteq \Delta$且$| \Sigma|$与$| \Delta|$相差不是很大, 所以MP近似推理生成一个拟决策蕴涵算法的时间复杂度为$\mathrm{O}((n+1)|C \cup D|| \Delta|)$.
算法2. MT近似推理生成拟决策蕴涵算法
输入. $L = \{\varphi_{i} \to \psi_{i} | i = 1, \cdots, n\}$, 决策属性合取公式$ \psi^{\ast} $, 部分决策形式背景$K = ({ \Delta},C,D,I,J)$, 对象集${ \Sigma} \subseteq { \Delta}$.
输出. 拟决策蕴涵$ \varphi^{\ast} \to \psi^{\ast} $.
1) 计算$||\psi^{\ast}||_{ \Sigma}$, $||\psi_{i}||_{ \Sigma}$, $i = 1, \cdots, n$, 其中$||\psi^{\ast}||_{ \Sigma} = \{u \in \Sigma | \forall a \in \psi^{\ast}, J(u,d) = 1\}$;
2) 找出满足条件$||\psi_{i}||_{ \Sigma} \subseteq ||\psi^{\ast}||_{ \Sigma}$的后件属性公式$\psi_{i_1}, \cdots, \psi_{i_l}$, 相应的前件属性公式为$\varphi_{i_1}, \cdots, \varphi_{i_l}$;
3) 如果没有满足式(2)中条件的公式, 推理问题无解; 否则, 令$ \lambda = \varphi_{i_1} \wedge \cdots \wedge \varphi_{i_l} $;
4) 计算$V = \{u \in { \Delta} | \forall c \in \lambda,\ I(u,c) = 1\}$, $\alpha^{I}(V) = \{c \in C | \forall u \in V, uIc\}$;
5)令$ \varphi^{\ast} = \wedge_{c \in \alpha^{I}(V)} c $, 计算属性公式$ \lambda $和$ \varphi^{\ast} $的伪距离;
6)获取拟决策蕴涵$ \varphi^{\ast} \to \psi^{\ast} $.
类似于MP近似推理生成拟决策蕴涵算法的时间复杂度分析, MT近似推理生成拟决策蕴涵算法的时间复杂度也是$\mathrm{O}((n+1)|C \cup D|| \Delta|)$.
5. 数值实验与讨论
本节参考文献[25], 通过3个数值实验验证本文算法的有效性. 由于MT近似推理生成拟决策蕴涵算法与MP近似推理生成拟决策蕴涵算法的推理机制、步骤和计算表达式类似, 因此只就MP近似推理生成拟决策蕴涵算法进行实验. 基于定理9和命题11的证明过程, 算法的有效性通过MP近似推理结论$ \psi^{\ast}_{\Delta} $与相应大前提的后件合取公式$\gamma = \psi_{i_1} \wedge \cdots \wedge \psi_{i_k}$的伪距离$\rho_{ \Delta}(\gamma, \psi^{\ast}_{\Delta})$、后件属性公式合取式对MP近似推理结论的平均支持度$\tau_{\Delta}(\gamma, \psi^{\ast}_{\Delta})$、MP近似推理获取拟决策蕴涵的时间成本来评价.
实验环境为Win7 64位 Intel (R) 3.4 GHz, 4 GB内存. 实验1用来测试MP近似推理生成拟决策蕴涵个数及与相应后件公式的伪距离. 实验数据设置为条件属性个数20, 决策属性个数10, 对象个数
2000 , 分成4个数据组, 每组500个数据, 数据的属性值(包括条件属性和决策属性) 随机生成, 数据填充比强度${|I|} / ({|G| |M|} )$为20%. 每组前400个数据为基础数据集$\Sigma$, MP近似推理的大前提是由$\Sigma$产生的决策蕴涵集$ L = \{\varphi_{u} \to \psi_{u} | u \in \Sigma\} $, $\varphi_{u} (c) = I(c, u), c \in C$是对象$ u $决定的条件属性公式, 决策属性公式$\psi_{u} (d) = \wedge_{x \in \Sigma} [\beta^{I} (\varphi_{u}) (x) \to J(x,d)] , d \in D$, 后100个数据中的对象$ u $决定的条件属性公式$ \varphi^{\ast}_{u} $作为MP近似推理的小前提, 并用来测试算法1的效果.各组后100个数据经过MP近似推理生成的拟决策蕴涵个数见表4.
表 4 生成的拟决策蕴涵个数Table 4 The number of generated quasi-decision implications数据组别 生成的拟决策蕴涵个数 数据组1 62 数据组2 58 数据组3 74 数据组4 71 各组数据经过MP近似推理产生的拟决策蕴涵的后件$\psi^{\ast}_{ \Delta}$与相应后件合取公式$\gamma = \psi_{i_1} \wedge \cdots \wedge \psi_{i_k}$的最大伪距离和最小伪距离见表5.
表 5 生成的拟决策蕴涵后件与后件合取公式的伪距离Table 5 The pseudo-metric between the consequent of generated quasi-decision implications and the consequent conjunctive数据组别 最大伪距离 最小伪距离 数据组1 0.195 0.147 数据组2 0.189 0.160 数据组3 0.197 0.152 数据组4 0.194 0.161 实验1基于400个实验基础数据, 通过近似推理获得新增加100个数据所确定的拟决策蕴涵. 实验结果显示经过MP近似推理产生的拟决策蕴涵的后件与相应后件合取公式的伪距离有点大. 但在实际知识推理中, 往往依据大量的数据通过近似推理发现少量新增数据所隐含的新知识. 由定理9可知, 当待获取新知识的新增数据个数与基础数据集的数据个数的比值${(| \Delta|-| \Sigma|)} / {| \Delta|}$较小时, MP近似推理产生的拟决策蕴涵的后件与相应后件合取公式的伪距离也比较小. 实验2和实验3也都有效地支持了这个理论分析.
实验2用来测试对象集$\Sigma、 \Delta$的变化对MP近似推理生成拟决策蕴涵的个数及与相应后件合取公式的伪距离的影响. 实验数据设置为条件属性为20个, 决策属性为10个, 实验基础数据对象集$\Sigma$的元素个数$| \Sigma|$为
1000 , 近似推理新增对象以10个为1组的频率, 逐步增加到100个, 从而$\Delta$的元素个数$| \Delta|$动态地逐步增加到1010 ,1020 , $\cdots,$1100 , 相应的数据组分别被命名为数据组1, 数据组$2,\cdots,$数据组10, 数据填充比强度与实验1相同, 为20%.基于基础数据对象集$\Sigma$产生的MP近似推理的决策蕴涵集$ L $和逐次新增加数据中的对象$ u $所决定的条件属性公式$ \varphi_{u} $进行MP近似推理. MP近似推理生成的拟决策蕴涵的个数以及生成的拟决策蕴涵的后件与相应后件合取公式$\gamma = \psi_{i_1} \wedge \cdots \wedge \psi_{i_k}$的最小伪距离见表6.
表 6 测试数据变化生成的拟决策蕴涵表Table 6 A table of generated quasi-decision implication as test data changes数据组别 拟决策蕴涵个数 最小伪距离 数据组1 3 0.0082 数据组2 5 0.0157 数据组3 8 0.0256 数据组4 12 0.0324 数据组5 16 0.0418 数据组6 21 0.0527 数据组7 25 0.0619 数据组8 29 0.0718 数据组9 34 0.0821 数据组10 39 0.0913 由表5和表6可以看出, 在基础数据集确定前提下, 从新增加数据所生成的拟决策蕴涵个数以及生成的拟决策蕴涵的后件与相应的后件合取公式$ \gamma = \psi_{i_1} \wedge \cdots \wedge \psi_{i_k} $的最小伪距离都随着测试数据的增加而增加, 增加趋势基本是线性的. 这与定理9、命题11的理论分析结论相吻合.
实验3用来测试在同一个数据集上、采用不同方式获取拟决策蕴涵时的时间成本比较. 实验3的实验数据取值方式和数据填充比强度同实验1. 基础数据对象集$\Sigma$的元素个数$| \Sigma|$为
2000个 , MP近似推理的新增数据对象以100个为1组的频率, 逐步增加到500个, 从而$\Delta$的元素个数$| \Delta|$动态地逐次增加到$2\,100, 2\,200,\cdots ,2\,500$, 相应的数据组分别被命名为数据组1, 数据组$2,\cdots,$数据组5.根据命题5中步骤1), 由包含
2000 个对象的基础数据集$\Sigma$中的每个对象$ u $产生决策蕴涵(对象$ u $决策蕴涵产生的过程同实验1), 以如此产生的全部决策蕴涵集$L = \{\varphi_{u} \to \psi_{u} | u \in \Sigma\}$作为MP近似推理的大前提. MP近似推理的小前提是各数据组中新增加对象$u \in \Delta - \Sigma$所决定的条件属性公式$ \varphi^{\ast}_{u} $. MP近似推理的对象范围参数$\Sigma$为2000 个对象组成的基础数据集, 参数$\Delta$分别为在$\Sigma$上逐次加入新数据得到的数据组1, 数据组$2,\cdots,$数据组5. 运用算法1, 分别由$ L $和$ \varphi^{\ast}_{u} $进行MP近似推理生成以$ \varphi^{\ast}_{u} $为前件的拟决策蕴涵. 采用2种方式获取$\Delta\; - \Sigma$上的新增决策蕴涵: 方式1)是由各数据组的新增加对象$u \in \Delta - \Sigma$所决定的条件属性公式$ \varphi^{\ast}_{u} $和$ L $直接在$\Delta$上进行MP近似推理以获取$\Delta$上的拟决策蕴涵, 即通过:$$ \begin{split} &f_{\Delta u}(x) = \mathop\wedge\limits^{n}_{i = 1} \mathop\vee\limits_{y \in \Delta} [\overline{\varphi^{\ast}}(y) \wedge (\overline{\varphi}_{i}(y) \to \overline{\psi}_{i}(x))], x \in \Delta \\ &W_u = \{x \in \Delta | f_{\Delta u}(x) = 1\}, \psi^{\ast}_{\Delta u} = \wedge_{d \in \alpha^{J}(W_u)} d \end{split}$$ 获取$\Delta$上的决策蕴涵$\varphi^{\ast}_{u} \to \psi^{\ast}_{\Delta u}$.
方式2)是先由基础数据集$\Sigma$产生决策蕴涵集$L = \{\varphi_{u} \to \psi_{u} | u \in \Sigma\}$, 再运用MP近似推理算法1获取$\Delta$上的拟决策蕴涵 (以下称这种获取方式为增量获取方式). 算法效率是通过$ L $中的决策蕴涵后件对MP近似推理结论的平均支持度$\tau_{ \Delta}(\psi_{1} \wedge\;\cdots \wedge \;\psi_{n} \to \psi^{\ast}_{\Delta})$以及获取$\Delta$上拟决策蕴涵所用时间成本来刻画. 采用2种不同方式获取拟决策蕴涵时, 拟决策蕴涵集$ L $的后件对MP近似推理结论的平均支持度$\tau_{\Delta}(\psi_{1} \wedge \cdots \wedge \psi_{n} \to \psi^{\ast}_{ \Delta})$和时间成本对比如表7所示.
表 7 后件集对结论的支持度和获取拟决策蕴涵时间成本对比Table 7 Comparison of the support degree of consequent set to the conclusion and time consumption of obtaining quasi-decision implications数据组别 $L$的后件集对结论支持度$\tau_{\Delta}$ 方式1)总时间成本(s) 方式2)总时间成本 (s) 增量获取所用时间成本(s) 数据组1 0.933 0.204 0.223 0.103 数据组2 0.923 0.283 0.304 0.147 数据组3 0.914 0.361 0.389 0.198 数据组4 0.903 0.450 0.484 0.258 数据组5 0.893 0.539 0.258 0.326 由表7可以看出, 对给定的基础数据集$ \Sigma $, 随着数据集$ \Delta $的数据个数的增加, 决策蕴涵集$ L $的后件公式集对MP近似推理结论的支持度会减少, 其变化幅度不是很显著, 当MP近似推理的参数数据集$ \Sigma $与$ \Delta $的数据个数比 ${| \Sigma|} / {| \Delta|}$较大时, 实际支持度$ \tau_{\Delta} $比 ${| \Sigma|} / {| \Delta|}$要小很多, 定理9中的比值 ${| \Sigma|} / {| \Delta|}$只是支持度$ \tau_{ \Delta} $的下界. 2种方式总时间成本随着实验数据的增加而增加, 增加的趋势基本上是线性的. 与方式1)相比, 方式2)获取决策蕴涵的总时间成本可能要多些. 但如果是在已有$ \Sigma $上的决策蕴涵的基础上来获取$ \Delta $上的新增决策蕴涵, 方式2)充分利用了$ \Sigma $上的已有决策蕴涵, 减少了获取决策蕴涵$ L = \{\varphi_{u} \to \psi_{u} | u \in \Sigma\} $的时间成本, 扣除获取$ \Sigma $上的决策蕴涵的时间成本后, 增量获取决策蕴涵所用时间成本就要少很多.
方式2)是基于已有决策蕴涵借助近似推理模式产生新的更多决策蕴涵, 体现了人工智能时代通过学习来获取新知识的思想方法, 是知识推理的有效手段. 但如何评价近似推理好坏, 目前还没有公认的标准. 本文引入的“决策蕴涵后件对MP近似推理结论的平均支持度”和“决策蕴涵前件对MT近似推理结论的伪距离”都是通过公式的真度来定义的. 按照文献[18]的支持度理论, 一个由条件联结词连接的蕴涵公式的真度本质上刻画了前件公式对后件公式的支持度, 上述评价标准实际上刻画了推理大前提中的知识对近似推理得到的结论知识的支持程度, 因此, 它们应是一个比较有效的知识推理评价标准. 由实验1 ~ 实验3可知, 本文提出的应用MP和MT近似推理生成拟决策蕴涵的方法具有较好效果.
本文提出的近似推理方法的一个应用是针对有缺失值的不完全决策形式背景的属性值补齐. 这时对象范围参数选择为包含缺失值的对象集, 对象范围选择不包含缺失值的对象集, 进而根据缺失值是条件属性值还是决策属性值, 选择应用MP或MT近似推理来补齐有缺失值的不完全决策形式背景, 进而实现不完全决策形式背景上的决策蕴涵和概念规则等知识的获取.
6. 结束语
本文从数据分析需求的角度讨论决策蕴涵, 利用属性逻辑的K-赋值对决策蕴涵进行属性逻辑语义刻画, 在此基础上研究决策蕴涵、概念规则的近似推理. 分析经典二值逻辑框架下基于全蕴涵三I推理思想的决策蕴涵和概念规则的MP、MT近似推理模式的特征, 证明决策蕴涵的MP、MT近似推理结论是决策蕴涵, 概念规则的MP、MT近似推理结论是概念规则, 引进属性逻辑伪距离, 分析人工智能环境下通过MP、MT近似推理生成拟决策蕴涵的模式和效果. 提出若干基于现有决策蕴涵、概念规则通过MP、MT近似推理产生新的决策蕴涵、概念规则、拟决策蕴涵的模式和方法, 并通过实际例子和数值实验来说明这些模式的应用和效果. 人工智能环境下的机器学习是一种基于现有知识通过一定的规则获取新知识的过程. 本文提出的基于现有决策蕴涵、概念规则通过近似推理来产生新的决策蕴涵及概念规则的方法正是依据这个思想来进行的. 本文提出的方法是一种获取决策蕴涵、概念规则的新方法, 为人工智能、大数据环境下的知识发现、知识推理提供了新的途径. 未来工作包括以下2个方面:
1)决策蕴涵和概念规则的近似推理机制的逻辑语构方面也是值得探讨的.
2)将本文提出的形式背景上的近似推理模式推广到模糊形式背景, 研究模糊形式背景中模糊决策蕴涵和模糊概念规则的近似推理机制及方法.
-
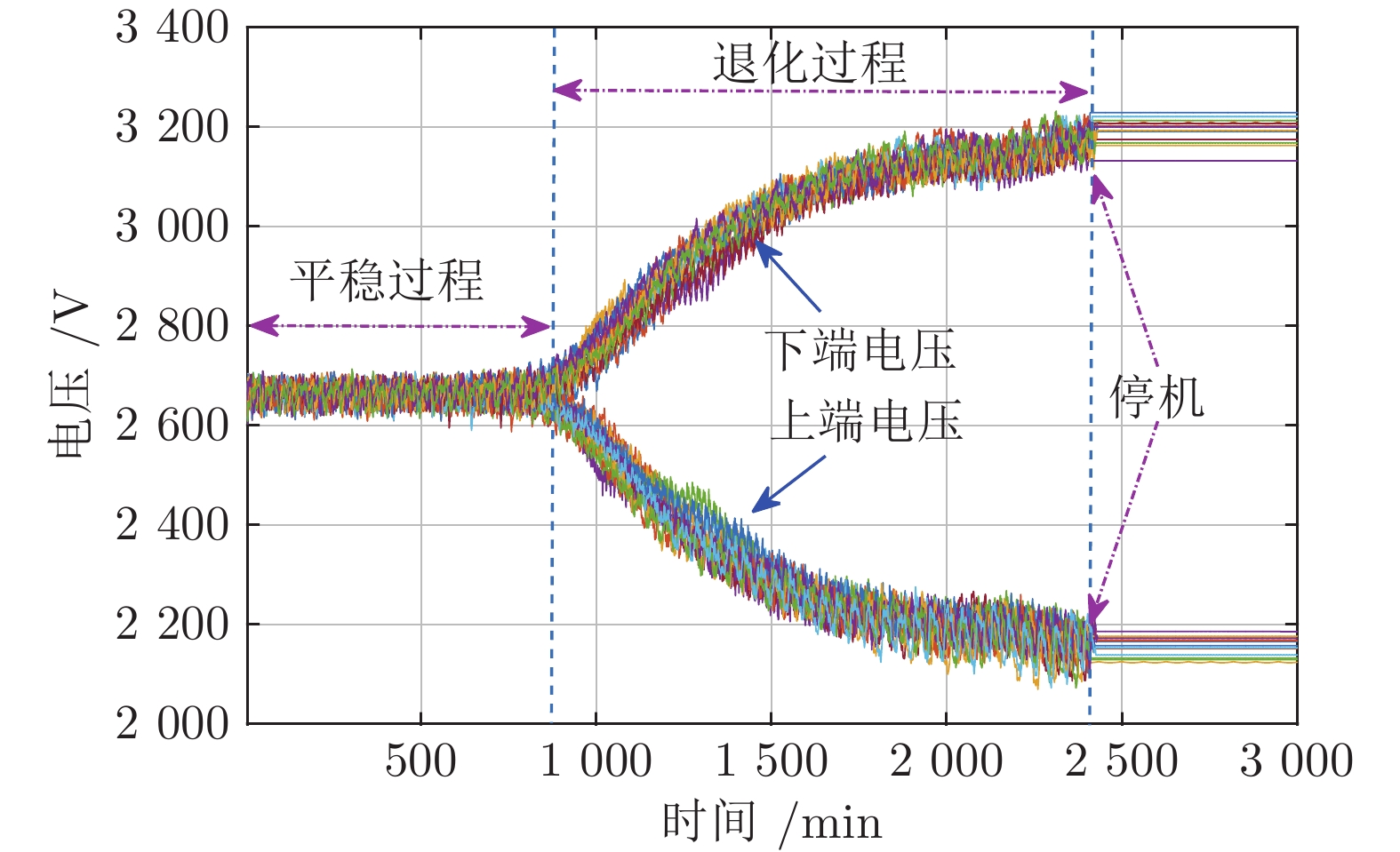
图 2 上下端电压从平稳过程到退化过程直至停机的演变趋势
Fig. 2 The voltages evolution from the stationary process to the degradation process

图 3 上下端电压在支撑电容器退化过程中的平均幅值
Fig. 3 The mean amplitude of the upper and lower voltages during the capacitors' degradation
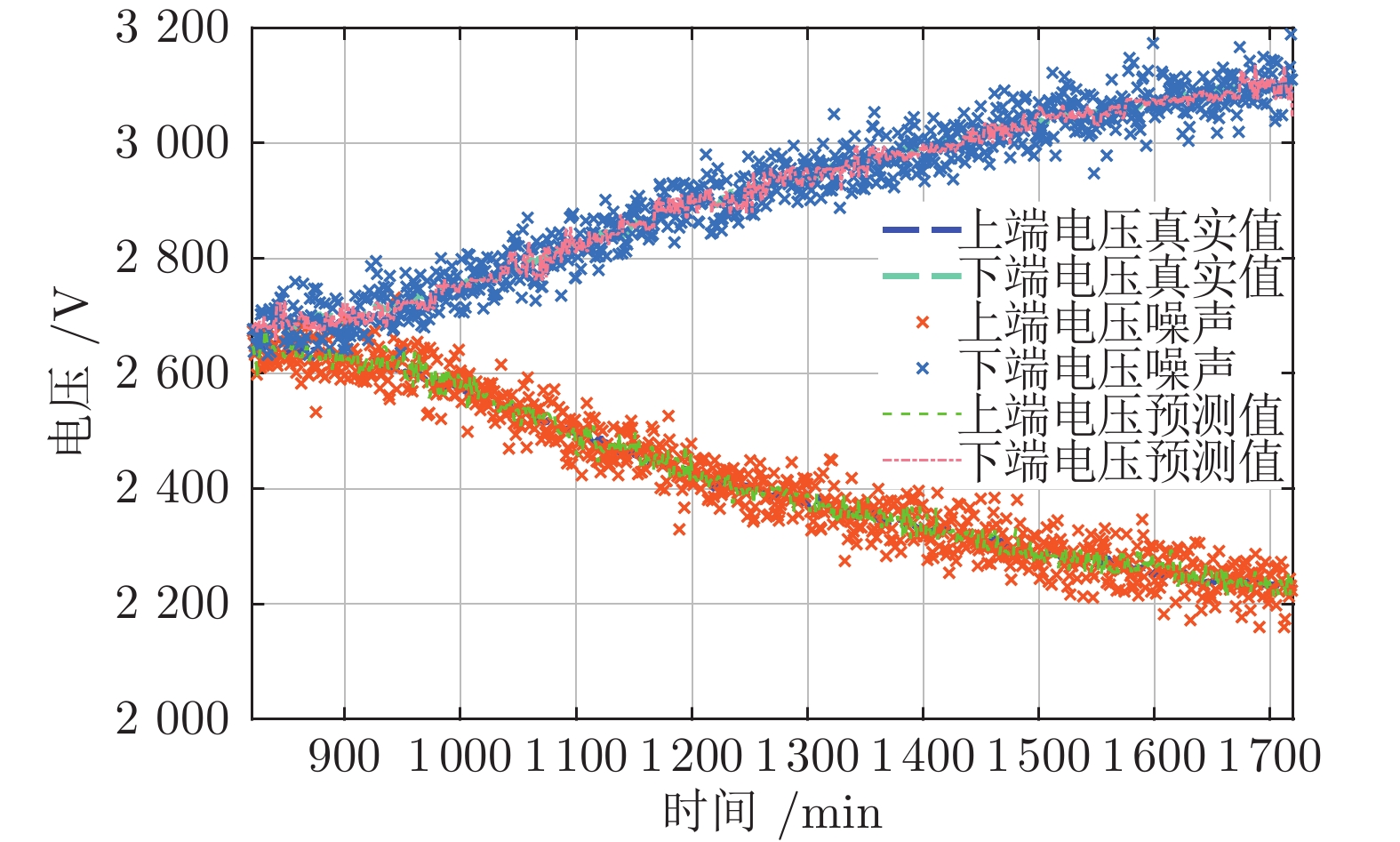
图 4 建模过程中的预测值与真实值进行比较
Fig. 4 The comparison between predicted values and the actual values in the modeling process
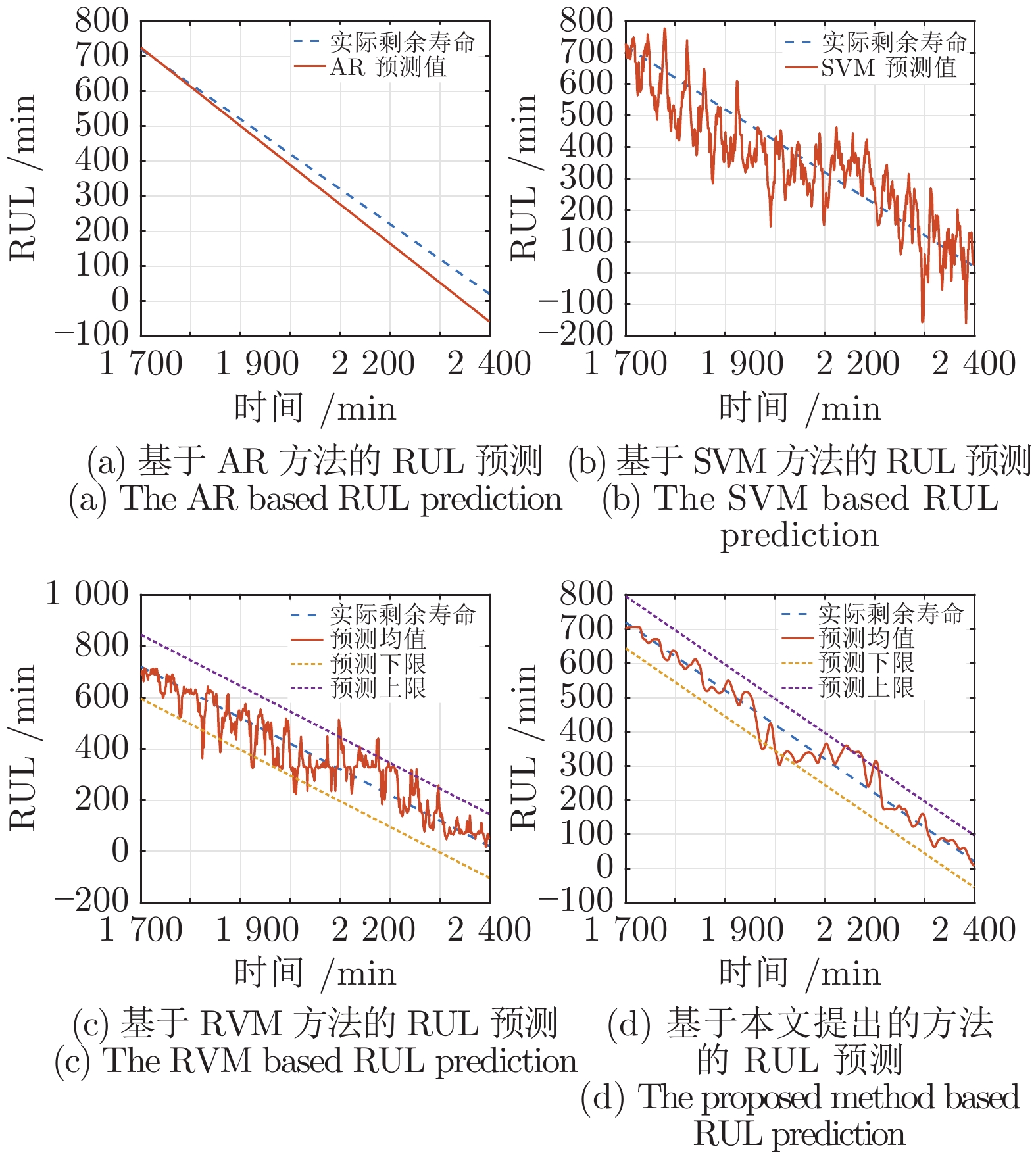
图 5 剩余寿命预测值与真实值对比图
Fig. 5 The RUL comparison between the predicted values and the actual values
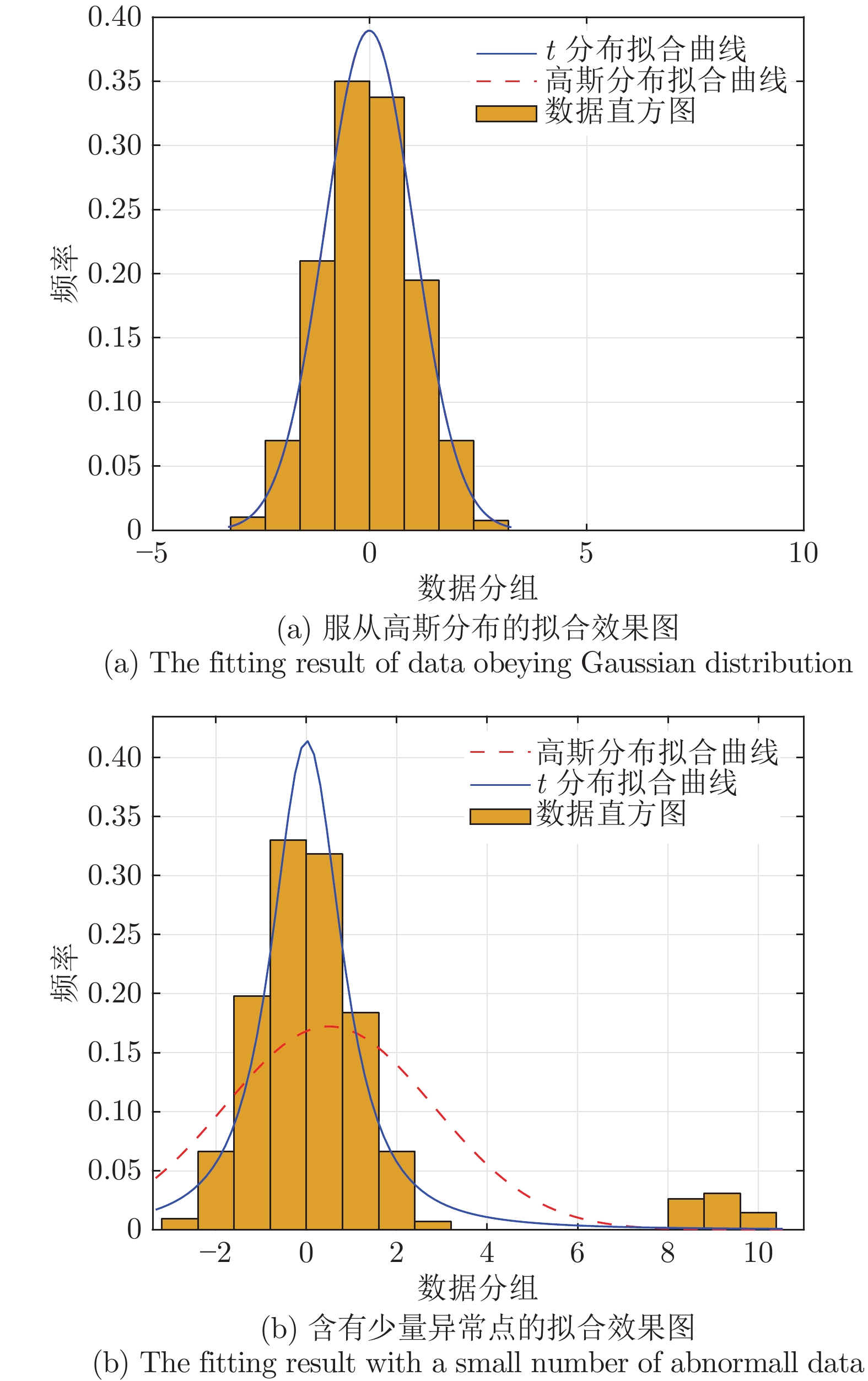
图 6 高斯分布与
$ t $ 分布拟合效果对比图Fig. 6 The fitting comparison between the Gaussian distribution and the
$ t $ distribution表 1 退化趋势模型中的参数取值
Table 1 The parameter values in the degradation model
SVM RVM 改进RVM 核函数 径向基 高斯 高斯 $ \alpha_i $ / $ 1.0\times 10^{12} $ $ 1.2\times 10^{-6} $ $ \beta $ / $ 2.47\times 10^{-4} $ $ 6.62\times 10^{-4} $  下载: 导出CSV
下载: 导出CSV
表 2 剩余寿命均方根误差(RMSE)及相对平均偏差(RAD)比较
Table 2 The RMSE and RAD comparison of RUL between different methods
AR SVM RVM 改进RVM RMSE (min) 1.6860 3.5654 2.3905 1.4586 RAD (%) 29.6802 35.8900 20.3468 11.3533
下载: 导出CSV
-
[1] 姜斌, 吴云凯, 陆宁云, 冒泽慧. 高速列车牵引系统故障诊断与预测技术综述. 控制与决策, 2018, 33(5): 841−8551 Jiang Bin, Wu Yun-Kai, Lu Ning-Yun, Mao Ze-Hui. Review of fault diagnosis and prognosis techniques for high-speed railway traction system. Control and Decision, 2018, 33(5): 841−855 [2] 2 Shang J, Chen M Y, Ji H Q, Zhou D H. Recursive transformed component statistical analysis for incipient fault detection. Automatica, 2017, 80: 313−327 doi: 10.1016/j.automatica.2017.02.028 [3] 3 Lei Y G, Qiao Z J, Xu X F, Liu J, Niu S T. An underdamped stochastic resonance method with stable-state matching for incipient fault diagnosis of rolling element bearings. Mechanical Systems and Signal Processing, 2017, 94: 148−164 doi: 10.1016/j.ymssp.2017.02.041 [4] 周东华, 纪洪泉, 何潇. 高速列车信息控制系统的故障诊断技术. 自动化学报, 2018, 44(7): 1153−11644 Zhou Dong-Hua, Ji Hong-Quan, He Xiao. Fault diagnosis techniques for the information control system of high-speed trains. Acta Automatica Sinica, 2018, 44(7): 1153−1164 [5] 5 Tobon-Mejia D A, Medjaher K, Zerhouni N, Tripot, G. A data-driven failure prognostics method based on mixture of Gaussians hidden Markov models. IEEE Transactions on Reliability, 2012, 61(2): 491−503 doi: 10.1109/TR.2012.2194177 [6] 6 Haque M S, Choi S, Baek J. Auxiliary particle filtering-based estimation of remaining useful life of IGBT. IEEE Transactions on Industrial Electronics, 2018, 65(3): 2693−2703 doi: 10.1109/TIE.2017.2740856 [7] 7 Tseng S T, Balakrishnan N, Tsai C C. Optimal step-stress accelerated degradation test plan for gamma degradation processes. IEEE Transactions on Reliability, 2009, 58(4): 611−618 doi: 10.1109/TR.2009.2033734 [8] 8 Zhai Q, Ye Z S. RUL prediction of deteriorating products using an adaptive wiener process model. IEEE Transactions on Industrial Informatics, 2017, 13(6): 2911−2921 doi: 10.1109/TII.2017.2684821 [9] 9 Si X S, Wang W B, Hu C H, Zhou D H. Remaining useful life estimation-a review on the statistical data driven approaches. European Journal of Operational Research, 2011, 213(1): 1−14 doi: 10.1016/j.ejor.2010.11.018 [10] 10 Lu N Y, Yao Y, Gao F R. Two-dimensional dynamic PCA for batch process monitoring. AIChE Journal, 2005, 51(12): 3300−3304 doi: 10.1002/aic.10568 [11] 11 Zhao C H, Gao F R. Online fault prognosis with relative deviation analysis and vector autoregressive modeling. Chemical Engineering Science, 2015, 138(22): 531−543 [12] 12 Zhao C H, Gao F R. Critical-to-fault-degradation variable analysis and direction extraction for online fault prognostic. IEEE Transactions on Control Systems Technology, 2017, 25(3): 842−854 doi: 10.1109/TCST.2016.2576018 [13] 13 Li Y, Lu N Y, Wang X L, Jiang B. Islanding fault detection based on data-driven approach with active developed reactive power variation. Neurocomputing, 2019, 337(14): 97−109 [14] 14 Pham H T, Yang B S, Nguyen T T. Machine performance degradation assessment and remaining useful life prediction using proportional hazard model and support vector machine. Mechanical Systems and Signal Processing, 2012, 32: 320−330 doi: 10.1016/j.ymssp.2012.02.015 [15] 15 Huang H Z, Wang H K, Li Y F, Zhang L L, Liu Z L. Support vector machine based estimation of remaining useful life: current research status and future trends. Journal of Mechanical Science and Technology, 2015, 29(1): 151−163 doi: 10.1007/s12206-014-1222-z [16] 16 Tipping M E. Sparse bayesian learning and the relevance vector machine. Journal of Machine Learning Research, 2001, 1(3): 211−44 [17] 17 Yu H Y, Wu Z H, Chen D W, Ma X L. Probabilistic prediction of bus headway using relevance vector machine regression. IEEE Transactions on Intelligent Transportation Systems, 2017, 18(7): 1772−1781 doi: 10.1109/TITS.2016.2620483 [18] 18 Wu Y M, Breaz E, Gao F, Miraoui A. A modified relevance vector machine for PEM fuel-cell stack aging prediction. IEEE Transactions on Industry Applications, 2016, 52(3): 2573−2581 doi: 10.1109/TIA.2016.2524402 [19] 19 Saha B, Goebel K, Poll S, Christophersen J. Prognostics methods for battery health monitoring using a Bayesian framework. IEEE Transactions on Instrumentation and Measurement, 2009, 58(2): 291−296 doi: 10.1109/TIM.2008.2005965 [20] 20 Widodo A, Kim, E Y, Son J D, Yang B S, Tan A C, Gu D S, Choid B K, Mathew J. Fault diagnosis of low speed bearing based on relevance vector machine and support vector machine. Expert Systems with Applications, 2009, 36(3): 7252−7261 doi: 10.1016/j.eswa.2008.09.033 [21] 21 Zio E, Di Maio F. Fatigue crack growth estimation by relevance vector machine. Expert Systems with Applications, 2012, 39(12): 10681−10692 doi: 10.1016/j.eswa.2012.02.199 [22] 22 Widodo A, Yang B S. Application of relevance vector machine and survival probability to machine degradation assessment. Expert Systems with Applications, 2011, 38(3): 2592−2599 doi: 10.1016/j.eswa.2010.08.049 [23] Wang X L, Jiang B, Lu N Y. Adaptive relevant vector machine based RUL prediction under uncertain conditions. ISA Transactions, 2018, DOI: 10.1016/j.isatra. 2018.11.024 [24] 24 Yang C H, Yang C, Peng T, Yang X Y, Gui W H. A fault-injection strategy for traction drive control systems. IEEE Transactions on Industrial Electronics, 2017, 64(7): 5719−5727 doi: 10.1109/TIE.2017.2674610 [25] 25 Yang X Y, Yang C H, Peng T, Chen Z W, Liu B, Gui W H. Hardware-in-the-loop fault injection for traction control system. IEEE Journal of Emerging and Selected Topics in Power Electronics, 2018, 6(2): 696−706 doi: 10.1109/JESTPE.2018.2794339 -

 下载:
下载:



计量
- 文章访问数: 2191
- HTML全文浏览量: 639
- PDF下载量: 312
- 被引次数: 0
