

Relevance Vector Machine Based Remaining Useful Life Prediction for Traction Systems of High-speed Trains
-
摘要: 高速列车牵引系统在运行过程中总是受到诸多不确定因素的影响, 例如, 由于列车的负载、运行环境及元器件的老化引起的不确定性, 不确定因素不可避免地影响牵引系统剩余寿命的预测精度. 为了提高不确定情景下剩余寿命预测的准确性, 本文首先采用改进的相关向量机(Relevance vector machine, RVM)方法, 建立鲁棒性能良好的多步回归模型, 由于t分布比常用的高斯分布更具有鲁棒性, 通过权重和随机误差服从t分布而非高斯分布, 改进了相关向量机回归模型, 随后将超参数的先验一并融入似然函数, 通过最大化似然函数估计未知的超参数, 此外, 利用首达时间方法从概率角度对剩余寿命进行了预测, 最后通过牵引系统中电容器退化的案例, 与传统的相关向量机方法、自回归方法和支持向量机方法进行对比, 验证了所提算法的有效性.Abstract: Traction systems often suffer from many uncertainties during their running processes, such as the inevitable uncertainties caused by the change of loading, operation and usage conditions. In order to improve the accuracy of remaining useful life (RUL) prediction under the uncertain scenario, a robust multi-step regression model is established by the improved relevance vector machine (RVM) method, in which weights and random errors are t distributed rather than Gaussian distributed. Then, unknown hyperparameters are estimated by taking priors of the hyperparameters into consideration. Moreover, the RUL is predicted by the first hitting time (FHT) method in probability perspective. The proposed method is demonstrated by a case study of capacitors degradation in traction systems. The results show the effectiveness of the proposed method.
-
伴随人工智能与模式识别的迅猛发展, 从海量高维数据中提取能够有效表征事物或现象本质属性的特征是一件十分有意义的工作. 主成分分析(Principal component analysis, PCA)[1]是一种常见的特征提取与数据降维方法, 其目标是利用一组新的正交基向量去描述原始高维数据, 且满足在投影后的子空间中数据方差最大, 从而使得由投影方向构成的低维特征空间能够较好体现原高维数据的空间结构信息. 随后, 针对二维图像矩阵的特征提取, 相继提出了二维主成分分析(Two-dimensional PCA, 2DPCA)[2]、双向二维主成分分析(Two-directional 2DPCA, (2D)2PCA)[3]、行列顺序二维主成分分析(Sequential row-column 2DPCA, RC-2DPCA)[4]和对角线主成分分析(Diagonal PCA, Diagonal-PCA)[5]. RC2DPCA和(2D)2PCA分别在行列两个方向上实现了数据降维, 而Diagonal-PCA在对角线上进一步保留了数据行列间的相关性. 近年来, 相关PCA研究已在人脸识别[6]、语音识别[7]、字符识别[8]及姿势识别[9]等众多领域得到广泛应用.
上述提及的PCA方法均采用欧氏距离的平方作为目标函数的距离度量方式, 对噪声、离群数据或其他扰动较为敏感, 重构误差很大, 使得实际投影方向偏离了真实的投影方向, 进而影响到算法的鲁棒性. 针对鲁棒特征提取研究, 主要有两个思路: 1)将高维数据
$P \in {{\bf R}^{h \times w}}$ 分解成低秩结构矩阵$A$ 和含噪稀疏矩阵$E$ , 考虑到优化模型的凸松弛问题, 得到优化模型${\rm{min}}{\left\| A \right\|_*} + \lambda {\left\| E \right\|_1}\;\;{\rm s.t.}\;P = $ $ A + E$ , 其各种求解算法均需进行奇异值分解, 计算复杂度高. 在处理海量高维数据时, 其求解算法容易受到复杂度的制约[10-12]; 2)沿用PCA投影方差最大的思路, 在其目标函数中采用其他范数代替欧氏距离的平方进行距离度量, 使得算法具有鲁棒性.$L_{1}$ 范数被认为是基于投影距离进行鲁棒降维的最有效手段[13-14]. Kwak[15]提出了基于$L_{1}$ 范数的PCA-$L_{1}$ 方法, 试图在投影子空间中寻求基于$L_{1}$ 范数的最大投影距离, 并采用了贪婪迭代求解算法, 相较于欧氏距离平方的度量方式, 该方法具有较强的鲁棒性. Nie等[16]提出了基于PCA-$L_{1}$ 的非贪婪迭代求解算法, 且满足基于$L_{1}$ 范数的目标函数最优. 针对$L_{1}$ 范数在不同数据结构相关信息进行正则化时所遇到的稳定性问题, Lu等[17]提出了基于$L_{1}$ 范数的自适应正则化的PCA-$L_{1}$ /AR方法, 同时考虑了鲁棒性及数据的相关性. Wang[18]和Li等[19]针对块主成分分析(Block PCA, BPCA)分别提出了基于$L_{1}$ 范数的BPCA-$L_{1}$ 方法的贪婪求解和非贪婪求解算法. 为了更有效表征数据空间结构, 如同将PCA扩展到2DPCA[2]一样, Li等[20]和Wang等[21]则将PCA-$L_{1}$ 延伸到2DPCA-$L_{1}$ , 分别提出了2DPCA-$L_{1}$ 的贪婪求解和非贪婪求解算法. Wang等[22]结合2DPCA-$L_{1}$ 的鲁棒性和稀疏诱导回归模型, 提出了具有稀疏约束的2DPCA-$L_{1}$ -S方法. Pang等[23]和Zhao等[24]则进一步将PCA-$L_{1}$ 推广到基于$L_{1}$ 范数的鲁棒张量子空间学习. 考虑到$L_{1}$ 范数和$L_{2}$ 范数均为Lp范数的特例, 相继提出了PCA-Lp[25]、LpSPCA[26]和G2DPCA-Lp[27]. 所有的上述鲁棒降维方法均寻求在不同范数下样本投影距离最大的目标优化问题, 但其原始图像与重构图像之间的重构误差并未优化, 且失去了PCA和2DPCA原欧氏距离平方中$L_{2}$ 范数的旋转方差属性.为了更有效获得旋转方差属性, Li等[28]则用
${\rm{F}}$ 范数替代2DPCA的平方${\rm{F}}$ 范数, 作为距离度量方式构建目标函数. 与现有2DPCA-$L_{1}$ 相比, 基于${\rm{F}}$ 范数的2DPCA不仅对离群数据具有较强的鲁棒性, 还能很好揭示其旋转不变性的几何结构. Wang等[29]提出了${\rm{F}}$ 范数最小化的最优均值2DPCA(OMF-2DPCA), 空间属性维度的距离采用${\rm{F}}$ 范数度量, 而不同数据点求和则采用$L_{1}$ 范数度量. 上述方法利用${\rm{F}}$ 范数度量重构误差[29]或者子空间下投影距离[28], 其重构误差最小并不等效于投影距离最大, 因此, 需考虑同时将重构误差与数据投影距离两者集成到目标函数中. 为此, Gao等[30]提出了Angle-2DPCA方法, 采用${\rm{F}}$ 范数作为目标函数的距离度量方式, 通过最小化重构误差与投影距离的比率获得最优的投影矩阵, 实现了在投影距离最大的基础上使其重构误差尽可能小. 但Angle-2DPCA直接针对数据矩阵进行降维, 忽略了矩阵行列之间的异常信息, 其鲁棒性受到了一定程度的限制.本文借鉴前人研究成果, 提出一种基于广义余弦模型的二维主成分分析, 并给出其迭代贪婪的求解算法. 本文结构如下: 第1节对相关目标函数的优化问题进行分析, 给出了广义余弦模型的目标函数; 第2节提出GC2DPCA的求解算法并进行理论分析; 第3节在人工数据集及Yale、ORL及FERET人脸数据集上进行实验并加以分析; 第4节进行总结.
1. 问题提出
1.1 相关目标函数的优化问题
设原始数据矩阵维数为
$h \times w$ , 样本数为$N$ . PCA对矩阵向量化后, 重新构成向量化样本数据集表示为$p = \left\{ {{{\boldsymbol{p}}_i} \in {{\bf{R}}^{hw \times 1}},i = 1,2, \cdots ,N} \right\}$ . 为不失一般性, 假设所有向量化样本已被零均值化, 即满足$\dfrac{1}{N}\textstyle \sum\nolimits_{i = 1}^N$ ${{{\boldsymbol{p}}_i}} = 0$ . PCA寻求由前$k$ $(k \ll hw)$ 个主成分(Principal component, PC)所组成的投影矩阵$V$ , 使得上述向量数据集p在该子空间中的投影方差尽可能最大, 可通过求解以下目标函数得到$$ \mathop {\arg \max }\limits_{{V^{\rm T}}V = {I_{k \times k}}} \sum\limits_{i = 1}^N {\left\| {{V^{\rm T}}{{\boldsymbol{p}}_i}} \right\|_2^2} $$ (1) 其中,
${\left\| \cdot \right\|_2}$ 为向量的2范数,$V = \left[ {{{{\boldsymbol{v}}_1}},{{{\boldsymbol{v}}_2}}, \cdots ,{{{\boldsymbol{v}}_k}}} \right] \in $ $ {{\bf R}^{hw \times k}}$ ,${I_{k \times k}} \in {{\bf{R}}^{k \times k}}$ 代表单位矩阵. 式(1)可通过特征值分解算法得到$k$ 维线性子空间的标准正交基.2DPCA[2]无需向量化, 直接针对数据矩阵进行降维, 保留了矩阵本身的行列结构信息. 假设零均值后矩阵样本集为
$P = \left\{ {P_i} \in {{\bf{R}}^{h \times w}},i = 1, 2, \cdots ,\right.$ $\left.N \right\}$ , 则2DPCA的目标函数为$$ \mathop {\arg \max }\limits_{{V^{\rm T}}V = {I_{k \times k}}} \sum\limits_{i = 1}^N {\left\| {{P_i}V} \right\|_{\rm{F}}^2 = \mathop {\arg \max }\limits_{{V^{\rm T}}V = {I_{k \times k}}} \sum\limits_{i = 1}^N {\sum\limits_{j = 1}^h {\left\| {{\boldsymbol{P}}_{ij}V} \right\|_2^2} } } $$ (2) 其中,
${\left\| \cdot \right\|_{\rm{F}}}$ 代表矩阵的F范数(也称$L_{2}$ 范数),$V = \left[ {{{\boldsymbol{v}}_1},{{\boldsymbol{v}}_2},\cdots,{{\boldsymbol{v}}_k}} \right] \in {{\bf R}^{w \times k}}$ 表示由前$k\;(k \ll h)$ 个PC构成的投影矩阵,${\boldsymbol{P}}_{ij} \in {{\bf{R}}^{1 \times w}}$ 表示第$i$ 个矩阵样本的第$j$ 行. 在${\rm{F}}$ 范数下重构误差与投影距离之间满足$$ \sum\limits_{i = 1}^N {\left\| {{E_i}} \right\|_{\rm{F}}^2} + \sum\limits_{i = 1}^N {\left\| {{P_i}V} \right\|_{\rm{F}}^2} = \sum\limits_{i = 1}^N {\left\| {{P_i}} \right\|_{\rm{F}}^2} $$ (3) 其中,
${E_i} = {P_i} - {P_i}V{V^{\rm{T}}}$ 表示第$i$ 个样本的重构误差. 式(2)同样满足所有样本的重构误差之和最小, 则有$$ \mathop {\arg \min }\limits_{{V^{\rm T}}V = {I_{k \times k}}} \sum\limits_{i = 1}^N {\left\| {{E_i}} \right\|_{\rm{F}}^2} $$ (4) 式(2)或式(4)最优解均可通过求解协方差矩阵
$\sum\nolimits_{i = 1}^N {P_i^{\rm{T}}{P_i}}$ 前$k$ 个最大特征值所对应的单位正交特征向量得到. 式(2)说明2DPCA实质是将数据矩阵的每一行用作训练样本, 并利用欧氏距离的平方度量所有样本行向量的投影方差.PCA-L1[15]为寻求一个投影矩阵
$V \in {{\bf R}^{hw \times k}}$ 以满足如下目标函数$$ \mathop {\arg \max }\limits_{{V^{\rm T}}V = {I_{k \times k}}} \sum\limits_{i = 1}^N {{{\left\| {{V^{\rm T}}{{\boldsymbol{p}}_i}} \right\|}_1}} $$ (5) 其中,
${\left\| \cdot \right\|_1}$ 为向量的1范数. 而2DPCA-$L_{1}$ [20]的目标函数则可表示为$$ \mathop {\arg \max }\limits_{{V^{\rm T}}V = {I_{k \times k}}} \sum\limits_{i = 1}^N {{{\left\| {{P_i}V} \right\|}_{{L_1}}} = \mathop {\arg \max }\limits_{{V^{\rm T}}V = {I_{k \times k}}} \sum\limits_{i = 1}^N {\sum\limits_{j = 1}^h {{{\left\| {{\boldsymbol{P}}_{ij}V} \right\|}_1}} } } $$ (6) 其中,
${\left\| \cdot \right\|_{{L_1}}}$ 为矩阵的$L_{1}$ 范数. 与2DPCA不同的是, 在$L_{1}$ 范数度量下存在如下不等式$$ \sum\limits_{i = 1}^N {{{\left\| {{E_i}} \right\|}_{{L_1}}}} + \sum\limits_{i = 1}^N {{{\left\| {{P_i}V} \right\|}_{{L_1}}}} \ne \sum\limits_{i = 1}^N {{{\left\| {{P_i}} \right\|}_{{L_1}}}} $$ (7) 则符合目标函数(6)的解, 其重构误差之和
$\mathop {\arg \min }\nolimits_{{V^{\rm T}}V = {I_{k \times k}}} \sum\nolimits_{i = 1}^N {{{\left\| {{E_i}} \right\|}_{{L_1}}}}$ 并不一定最小. 因此, 基于$L_{1}$ 范数的方法虽具有一定的抑制噪声能力, 但其重构误差并没有得到有效控制.Angle-2DPCA[30]通过最小化重构误差与投影距离的比率获得最优投影矩阵, 基于
${\rm{F}}$ 范数的目标函数为$$ \begin{split} &{\mathop {\arg \min }\limits_{{V^{\rm T}}V = {I_{k \times k}}} \sum\limits_{i = 1}^N {\frac{{{{\left\| {{E_i}} \right\|}_{\rm{F}}}}}{{{{\left\| {{P_i}V} \right\|}_{\rm{F}}}}}} {\rm{ = }}}\\ &\qquad{\mathop {\arg \min }\limits_{{V^{\rm T}}V = {I_{k \times k}}} \sum\limits_{i = 1}^N {\frac{{{{\left\| {{P_i} - {P_i}V{V^{\rm T}}} \right\|}_{\rm{F}}}}}{{{{\left\| {{P_i}V} \right\|}_{\rm{F}}}}}}} \end{split} $$ (8) 相较于2DPCA, Angle-2DPCA不仅减弱了远距离离群点的影响, 而且在优化投影距离最大的基础上兼顾了重构误差的影响.
从前述分析可知, 范数的距离度量方式和目标函数均影响到各个算法的鲁棒性. 从距离度量方式考虑,
$L_{2}$ 范数的相关算法寻求数据投影方差最大的优化目标, 容易放大离群点的作用, 导致求得的PC失真, 鲁棒性较差.$L_{1}$ 范数对数据投影的绝对值进行优化, 相比于$L_{2}$ 范数的投影方差, 降低了对离群点的敏感性.${\rm{F}}$ 范数因存在不等式${\left\| {{E_i}} \right\|_{\rm{F}}}\;+$ ${\left\| {{P_i}V} \right\|_{\rm{F}}} \ne {\left\| {{P_i}} \right\|_{\rm{F}}}$ , 相关算法[28-29]将重构误差作为目标函数的优化问题, 但并未考虑投影距离最大化, 反之也亦然. 从目标函数的两个方面考虑, 基于${\rm{F}}$ 范数的Angle-2DPCA算法[30]将重构误差与投影距离的比率作为目标函数, 有利于解决两个目标的优化问题. 但从数据${\left\| {{P_i}} \right\|_{\rm{F}}}$ 投影角度考虑, 进一步分析目标函数(8), 优化重构误差${\left\| {{E_i}} \right\|_{\rm{F}}}$ 与投影距离${\left\| {{P_i}V} \right\|_{\rm{F}}}$ 的比率实质上是一个正切模型. 其目标函数中的分子与分母均置于${\rm{F}}$ 范数度量下, 且均受到同一投影矩阵V的制约. 因此, Angle-2DPCA的重构误差与投影距离很难实现同时优化.1.2 广义余弦模型
传统
$L_{2}$ 范数的平方会放大离群数据的主导作用, 其鲁棒性较差;$L_{1}$ 范数虽能降低离群数据的敏感性, 但无法有效控制数据投影后的重构误差. 此外, Angle-2DPCA直接针对数据矩阵进行鲁棒降维, 不利于抑制数据矩阵行列之间的异常值, 算法的鲁棒性受到一定限制. 鉴于这些问题, 受Angle-2DPCA[30]的目标函数启发, 本文构造一个基于广义余弦模型的目标函数, 在满足数据投影距离最大的基础上使得其重构误差较小.假设零均值化后矩阵样本集为
$P$ , 则基于余弦模型的目标函数定义为$$ \mathop {\arg \max }\limits_{{{{\boldsymbol{v}}}^{\rm T}}{{\boldsymbol{v}}} = 1} \sum\limits_{i = 1}^N {\sum\limits_{j = 1}^h {\left| {\cos \left( {{\theta _{ij}}} \right)} \right|} } {\rm{ = }}\mathop {\arg \max }\limits_{{{{\boldsymbol{v}}}^{\rm T}}{{\boldsymbol{v}}} = 1} \sum\limits_{i = 1}^N {\sum\limits_{j = 1}^h {\frac{{\left| {{\boldsymbol{P}}_{ij}{{\boldsymbol{v}}}} \right|}}{{{{\left\| {{\boldsymbol{P}}_{ij}} \right\|}_2}}}} } $$ (9) 其中,
${{\boldsymbol{v}}} \in {{\bf{R}}^{w \times 1}}$ 表示$V$ 中前$k$ 个PC中任意一个,${\theta _{ij}}$ 表示第$i$ 个样本的第$j$ 行${\boldsymbol{P}}_{ij}$ 与${{\boldsymbol{v}}}$ 的夹角,$\left| {{\boldsymbol{P}}_{ij}{{\boldsymbol{v}}}} \right|$ 为数据的投影距离, 也可写为${\left\| {{\boldsymbol{P}}_{ij}{{\boldsymbol{v}}}} \right\|_2}$ .为了调整行向量
${\boldsymbol{P}}_{ij}$ 的距离度量方式, 将式(9)推广延伸得到广义余弦模型为$$\begin{split} &{\mathop {\arg \max }\limits_{{{{\boldsymbol{v}}}^{\rm T}}{{\boldsymbol{v}}} = 1} \sum\limits_{i = 1}^N {\sum\limits_{j = 1}^h {\left| {\cos \left( {{\theta _{ij}}} \right)} \right|} } = }\\ &\qquad{\mathop {\arg \max }\limits_{{{{\boldsymbol{v}}}^{\rm T}}{{\boldsymbol{v}}} = 1} \sum\limits_{i = 1}^N {\sum\limits_{j = 1}^h {\frac{{\left| {{\boldsymbol{P}}_{ij}{{\boldsymbol{v}}}} \right|}}{{{{\left\| {{\boldsymbol{P}}_{ij}} \right\|}_2}}}} } \mathop \Rightarrow \limits^{{\rm{generalization}}}}\\ &\qquad\mathop {\arg \max }\limits_{{{{\boldsymbol{v}}}^{\rm T}}{{\boldsymbol{v}}} = 1} \sum\limits_{i = 1}^N {\sum\limits_{j = 1}^h {\frac{{\left| {{\boldsymbol{P}}_{ij}{{\boldsymbol{v}}}} \right|}}{{\left\| {{\boldsymbol{P}}_{ij}}\right\|_2^S}}} } \end{split}$$ (10) 其中,
$\left\| \cdot \right\|_2^S$ 为向量2范数${\left\| \cdot \right\|_2}$ 的$S$ 次幂,$S$ 为可调幂参数$(S\ge0)$ . 特别地, 当$S = 0$ 时, 式(10)为2DPCA-$L_{1}$ 的目标函数, 因此, 2DPCA-$L_{1}$ 可作为GC2DPCA 的一个特例; 当$S = 1$ 时, 即为式(9)函数, 表示为常规余弦模型. 式(10)是通过极大化行向量${\boldsymbol{P}}_{ij}$ 的投影距离$\left| {{\boldsymbol{P}}_{ij}{{\boldsymbol{v}}}} \right|$ 与其可调幂的2范数$\left\| {{\boldsymbol{P}}_{ij}} \right\|_2^S$ 的比值来解决目标函数的优化问题.化简式(10), 可得
$$ \begin{split} &{\mathop {\arg \max }\limits_{{{{\boldsymbol{v}}}^{\rm T}}{{\boldsymbol{v}}} = 1} \sum\limits_{i = 1}^N {\sum\limits_{j = 1}^h {\frac{{\left| {{\boldsymbol{P}}_{ij}{{\boldsymbol{v}}}} \right|}}{{\left\| {{\boldsymbol{P}}_{ij}} \right\|_2^S}}} }}=\\ &\qquad{\mathop {\arg \max }\limits_{{{{\boldsymbol{v}}}^{\rm T}}{{\boldsymbol{v}}} = 1} \sum\limits_{i = 1}^N {\sum\limits_{j = 1}^h {\left| {\frac{{{\boldsymbol{P}}_{ij}}}{{\left\| {{\boldsymbol{P}}_{ij}} \right\|_2^S}}{{\boldsymbol{v}}}} \right|} }}=\\ &\qquad{\mathop {\arg \max }\limits_{{{{\boldsymbol{v}}}^{\rm T}}{{\boldsymbol{v}}} = 1} \sum\limits_{i = 1}^N {\sum\limits_{j = 1}^h {\left| {{l_{ij}}{\boldsymbol{P}}_{ij}{{\boldsymbol{v}}}} \right|} }} \end{split}$$ (11) 其中,
${l_{ij}} = \left\| {{\boldsymbol{P}}_{ij}} \right\|_2^{ - S}$ , 表示为行向量${\boldsymbol{P}}_{ij}$ 的权重系数. 因此, 通常把式(11)作为广义余弦模型的目标函数, 其优化问题理解为带权重${l_{ij}}$ 的数据${\boldsymbol{P}}_{ij}$ 在${\boldsymbol{v}}$ 方向上投影距离最大的问题, 其广义余弦模型如图1所示. 此外, 考虑重构误差满足${{\boldsymbol{E}}_{ij}} = {\boldsymbol{P}}_{ij} - {\boldsymbol{P}}_{ij}{\boldsymbol{v}}{{{\boldsymbol{v}}}^{\rm{T}}}$ , 则有$\Vert {{\boldsymbol{P}}_{ij}{{\boldsymbol{v}}}{{\boldsymbol{v}}^{\rm{T}}}} \Vert_2^2 + \left\| {{{\boldsymbol{E}}_{ij}}} \right\|_2^2 = \left\| {{\boldsymbol{P}}_{ij}} \right\|_2^2$ , 推导式(10)可得$$ \begin{split} &{\mathop {\arg \max }\limits_{{{{\boldsymbol{v}}}^{\rm T}}{{\boldsymbol{v}}} = 1} \sum\limits_{i = 1}^N {\sum\limits_{j = 1}^h {\frac{{\left| {{\boldsymbol{P}}_{ij}{{\boldsymbol{v}}}} \right|}}{{\left\| {{\boldsymbol{P}}_{ij}} \right\|_2^S}}} }}=\\ &\qquad{\mathop {\arg \max }\limits_{{{{\boldsymbol{v}}}^{\rm T}}{{\boldsymbol{v}}} = 1} \sum\limits_{i = 1}^N {\sum\limits_{j = 1}^h {\frac{{{{\left\| {{\boldsymbol{P}}_{ij}{{\boldsymbol{v}}}{{{\boldsymbol{v}}}^{\rm T}}} \right\|}_2}}}{{\left\| {{\boldsymbol{P}}_{ij}} \right\|_2^S}}} }}=\\ &\qquad{\mathop {\arg \max }\limits_{{{{\boldsymbol{v}}}^{\rm T}}{{\boldsymbol{v}}} = 1} \sum\limits_{i = 1}^N {\sum\limits_{j = 1}^h {\left\| {{\boldsymbol{P}}_{ij}} \right\|_2^{1 - S}\frac{{{{\left\| {{\boldsymbol{P}}_{ij}{{\boldsymbol{v}}}{{{\boldsymbol{v}}}^{\rm T}}} \right\|}_2}}}{{{{\left\| {{\boldsymbol{P}}_{ij}} \right\|}_2}}}} }}=\\ &\qquad{\mathop {\arg \max }\limits_{{{{\boldsymbol{v}}}^{\rm T}}{{\boldsymbol{v}}} = 1} \sum\limits_{i = 1}^N {\sum\limits_{j = 1}^h {\left\| {{\boldsymbol{P}}_{ij}} \right\|_2^{1 - S}\sqrt {1 - \frac{{\left\| {{{\boldsymbol{E}}_{ij}}} \right\|_2^2}}{{\left\| {{\boldsymbol{P}}_{ij}} \right\|_2^2}}} } }}=\\ &\qquad{\mathop {\arg \max }\limits_{{{{\boldsymbol{v}}}^{\rm T}}{{\boldsymbol{v}}} = 1} \sum\limits_{i = 1}^N {\sum\limits_{j = 1}^h {{l_{ij}}\sqrt {\left\| {{\boldsymbol{P}}_{ij}} \right\|_2^2 - \left\| {{{\boldsymbol{E}}_{ij}}} \right\|_2^2} } }} \end{split} $$ (12) 对于已知确定的样本和参数
$S$ 值, 式(12)中的${l_{ij}}$ 和$\left\| {{\boldsymbol{P}}_{ij}} \right\|_2^2$ 均是固定不变的数值, 因此, 在式(10)或式(11)投影距离达到最优的同时, 其重构误差${\left\| {{{\boldsymbol{E}}_{ij}}}\right\|_2}$ 也通过式(12)间接得到有效控制.广义余弦模型与Angle-2DPCA的目标函数形式一样, 均为比值形式. Angle-2DPCA的重构误差与投影距离中均呈现同一投影矩阵
$V$ . 在${\rm{F}}$ 范数的距离度量方式下, 其重构误差与投影距离相互受到牵制. 因此, Angle-2DPCA最终无法真正实现投影距离最大与重构误差较小的双目标优化. 而广义余弦模型仅在投影距离中呈现投影向量${{\boldsymbol{v}}}$ , 其重构误差最小与投影距离最大的目标优化能力得以加强. 其次, 从带权重${l_{ij}}$ 的数据优化问题考虑, 若${{\boldsymbol{P}}_{ij}}$ 是离群数据, 则${\left\| {{\boldsymbol{P}}_{ij}} \right\|_2}$ 会较大, 权重系数${l_{ij}}$ 会相当小. 因此, 其提取的PC也就更逼近真实PC, 离群数据得到抑制. 此外, 从受离群数据干扰的百分比R考虑,${R_{{{\rm{GC2DPCA}}}}} \le {R_{{{\rm{Angle {\text{-}} 2DPCA}}}}}$ , 广义余弦模型采用行向量的优化方式可以减少受污染样本干扰的百分比, 其鲁棒性也能得以进一步增强.2. GC2DPCA算法
设数据矩阵零均值后构成样本集
$P = \left\{ {P_i} \in \right. $ $ \left.{{\bf{R}}^{h \times w}},i = 1,2, \cdots ,N \right\}$ . 对于投影矩阵$V$ 中前$k$ 个PC的任意一个${{\boldsymbol{v}}}$ , 综合式(10)和式(11), 考虑求解如下目标函数的优化问题$$ \mathop {\arg \max }\limits_{{{{\boldsymbol{v}}}^{\rm T}}{{\boldsymbol{v}}} = 1} \sum\limits_{i = 1}^N {\sum\limits_{j = 1}^h {\left| {{l_{ij}}{\boldsymbol{P}}_{ij}{{\boldsymbol{v}}}} \right|} } ,\;\; {{l_{ij}} = \left\| {{\boldsymbol{P}}_{ij}} \right\|_2^{{\rm{ - }}S}, S \ge 0} $$ (13) 对于该问题求解, 采用迭代贪婪算法实现.
2.1 第一个主成分求解算法
针对投影矩阵
$V$ 中的第一个主成分${{\boldsymbol{v}}_1}$ 的目标函数式表示为$$ \phi \left( {{{\boldsymbol{v}}_1}} \right) = \sum\limits_{i = 1}^N {\sum\limits_{j = 1}^h {\left| {{l_{ij}}{\boldsymbol{P}}_{ij}{{\boldsymbol{v}}_1}} \right|} } $$ (14) 为了去掉绝对值, 引入符号函数
${f_{ij}}(t)$ 为$$ {f_{ij}}(t) = \left\{ \begin{aligned} &1, &{\rm{ }}{l_{ij}}{\boldsymbol{P}}_{ij}{{\boldsymbol{v}}_1}(t) \ge 0{\rm{ }}\\ & - 1, &{l_{ij}}{\boldsymbol{P}}_{ij}{{\boldsymbol{v}}_1}(t) < 0 \end{aligned} \right. $$ (15) 其中,
$t$ 为迭代步数.将式(15)代入式(14), 可得
$$ \phi \left( {{{\boldsymbol{v}}_1}(t)} \right) = \sum\limits_{i = 1}^N {\sum\limits_{j = 1}^h {{f_{ij}}(t){l_{ij}}{\boldsymbol{P}}_{ij}{{\boldsymbol{v}}_1}(t)} } $$ (16) 为了使得目标函数(13)最优, 其迭代求解算法如下:
算法 1. GC2DPCA第一个主成分求解算法
输入. 数据行向量样本
${\boldsymbol{P}}_{ij} \in {{\bf{R}}^{1\times w}}$ , 且$i = 1, $ $2, \cdots ,N,$ $j = 1,2, \cdots ,h$ , 参数$S$ .输出.
${{\boldsymbol{v}}_1} \in {{\bf{R}}^{w \times 1}}$ .步骤 1. 数据样本更新, 计算样本行向量
${\boldsymbol{P}}_{ij}$ 的权重系数${l_{ij}} = \left\| {{\boldsymbol{P}}_{ij}}\right\|_2^{{-}S}$ 后,${\boldsymbol{P}}_{ij}$ 更新为${l_{ij}}{\boldsymbol{P}}_{ij}$ .步骤 2. 初始化第一个主成分, 取任意
${{\boldsymbol{v}}_1}(1) \in $ $ {{\bf{R}}^{w \times 1}}$ , 且满足${{\boldsymbol{v}}_1^{\rm{T}}}(1){{\boldsymbol{v}}_1}(1) = 1$ 即可.步骤 3. 利用符号函数翻转迭代, 在第
$t$ 步迭代过程中将${l_{ij}}{\boldsymbol{P}}_{ij}$ 更新为${f_{ij}}\left( t \right){l_{ij}}{\boldsymbol{P}}_{ij}$ , 其中,${f_{ij}}\left( t \right)$ 可通过式(15)得到.步骤 4.
${{\boldsymbol{v}}_1}(t + 1)$ 通过式(17)得到$$ {\boldsymbol{v}}_1^{\rm{T}}\left( {t + 1} \right) = \frac{{\displaystyle\sum\limits_{i = 1}^N {\displaystyle\sum\limits_{j = 1}^h {{f_{ij}}\left( t \right){l_{ij}}{\boldsymbol{P}}_{ij}} } }}{{{{\left\| {\displaystyle\sum\limits_{i = 1}^N {\displaystyle\sum\limits_{j = 1}^h {{f_{ij}}\left( t \right){l_{ij}}{\boldsymbol{P}}_{ij}} } } \right\|}_2}}} $$ (17) 若
${{\boldsymbol{v}}_1}\left( {t + 1} \right) = {{\boldsymbol{v}}_1}\left( t \right)$ , 则停止循环迭代; 若${\boldsymbol{v}}_1 \left( t +\right. $ $\left. 1 \right) \ne {{\boldsymbol{v}}_1}\left( t \right)$ , 则返回步骤3.定理 1. 算法1中目标优化问题(13)的求解迭代过程收敛.
证明. 分两步证明
$\phi \left( {{{\boldsymbol{v}}_1}\left( {t + 1} \right)} \right) \ge \phi \left( {{{\boldsymbol{v}}_1}\left( t \right)} \right)$ , 先证不等式$\sum\nolimits_{i = 1}^N {\sum\nolimits_{j = 1}^h {{f_{ij}}\left( {t\; +\; 1} \right){l_{ij}}{\boldsymbol{P}}_{ij}{{\boldsymbol{v}}_1}\left( {t\; + \;1} \right)} } \ge$ $\sum\nolimits_{i = 1}^N {\sum\nolimits_{j = 1}^h {{f_{ij}}\left( t \right){l_{ij}}{\boldsymbol{P}}_{ij}{{\boldsymbol{v}}_1}\left( {t + 1} \right)} }$ . 由前面所述, 必有${f_{ij}}\left( {t + 1} \right){l_{ij}}{\boldsymbol{P}}_{ij}{{\boldsymbol{v}}_1}\left( {t + 1} \right) \ge 0$ , 下面分两种情形讨论.1)当
${f_{ij}}\left( t \right) = 1$ 时, 有$$ \left\{\begin{aligned} &{f_{ij}}\left( {t + 1} \right){l_{ij}}{\boldsymbol{P}}_{ij}{{\boldsymbol{v}}_1}\left( {t + 1} \right) = \\ &\quad{f_{ij}}\left( t \right){l_{ij}}{\boldsymbol{P}}_{ij}{{\boldsymbol{v}}_1}\left( {t + 1} \right),\\ &\qquad\qquad\qquad{ }若\,\, {l_{ij}}{\boldsymbol{P}}_{ij}{{\boldsymbol{v}}_1}\left( {t + 1} \right) \ge 0\\ &{f_{ij}}\left( {t + 1} \right){l_{ij}}{\boldsymbol{P}}_{ij}{{\boldsymbol{v}}_1}\left( {t + 1} \right) > \\ &\quad{f_{ij}}\left( t \right){l_{ij}}{\boldsymbol{P}}_{ij}{{\boldsymbol{v}}_1}\left( {t + 1} \right),\\ &\qquad \qquad\qquad{}若 \,\, {l_{ij}}{\boldsymbol{P}}_{ij}{{\boldsymbol{v}}_1}\left( {t + 1} \right) < 0\end{aligned} \right. $$ 则
$$ {f_{ij}}\left( {t + 1} \right){l_{ij}}{\boldsymbol{P}}_{ij}{{\boldsymbol{v}}_1}\left( {t + 1} \right) \ge {f_{ij}}\left( t \right){l_{ij}}{\boldsymbol{P}}_{ij}{{\boldsymbol{v}}_1}( t +1) $$ 2)当
${f_{ij}}\left( t \right) = - 1$ 时, 有$$ \left\{ \begin{aligned} &{f_{ij}}\left( {t + 1} \right){l_{ij}}{\boldsymbol{P}}_{ij}{{\boldsymbol{v}}_1}\left( {t + 1} \right) > \\ & \quad {f_{ij}}\left( t \right){l_{ij}}{\boldsymbol{P}}_{ij}{{\boldsymbol{v}}_1}\left( {t + 1} \right),\\ & \qquad\qquad\qquad { 若} \,\, {l_{ij}}{\boldsymbol{P}}_{ij}{{\boldsymbol{v}}_1}\left( {t + 1} \right) \ge 0\\ & {f_{ij}}\left( {t + 1} \right){l_{ij}}{\boldsymbol{P}}_{ij}{{\boldsymbol{v}}_1}\left( {t + 1} \right) =\\ & \quad {f_{ij}}\left( t \right){l_{ij}}{\boldsymbol{P}}_{ij}{{\boldsymbol{v}}_1}\left( {t + 1} \right) ,\\ & \qquad\qquad\qquad{若 }\,\, {l_{ij}}{\boldsymbol{P}}_{ij}{{\boldsymbol{v}}_1}\left( {t + 1} \right) < 0 \end{aligned} \right.$$ 则
$$ {f_{ij}}\left( {t + 1} \right){l_{ij}}{\boldsymbol{P}}_{ij}{{\boldsymbol{v}}_1}\left( {t + 1} \right) \ge {f_{ij}}\left( t \right){l_{ij}}{\boldsymbol{P}}_{ij}{{\boldsymbol{v}}_1}( t +1) $$ 因此, 由前述可得
${f_{ij}}\left( {t + 1} \right){l_{ij}}{\boldsymbol{P}}_{ij}{{\boldsymbol{v}}_1}\left( {t + 1} \right) \ge $ $ {f_{ij}}\left( t \right){l_{ij}}{\boldsymbol{P}}_{ij}{{\boldsymbol{v}}_1}\left( {t + 1} \right)$ . 显然, 可得到所有样本行向量之和满足$\sum\nolimits_{i = 1}^N {\sum\nolimits_{j = 1}^h {{f_{ij}}\left( {t + 1} \right){l_{ij}}{\boldsymbol{P}}_{ij}{{\boldsymbol{v}}_1}\left( {t + 1} \right)} } \ge $ $ \sum\nolimits_{i = 1}^N {\sum\nolimits_{j = 1}^h {{f_{ij}}\left( t \right){l_{ij}}{\boldsymbol{P}}_{ij}{{\boldsymbol{v}}_1}\left( {t + 1} \right)} } $ .再证不等式
$\sum\nolimits_{i = 1}^N {\sum\nolimits_{j = 1}^h {{f_{ij}}\left( t \right){l_{ij}}{\boldsymbol{P}}_{ij}{{\boldsymbol{v}}_1}\left( {t + 1} \right)} } \ge $ $ \sum\nolimits_{i = 1}^N {\sum\nolimits_{j = 1}^h {{f_{ij}}\left( t \right){l_{ij}}{\boldsymbol{P}}_{ij}{{\boldsymbol{v}}_1}\left( t \right)} } $ .证明推导过程如下:
$$ \begin{split}&\sum\limits_{i = 1}^N {\sum\limits_{j = 1}^h {{f_{ij}}(t){l_{ij}}{\boldsymbol{P}}_{ij}{{\boldsymbol{v}}_1}(t + 1)} } =\\ &\quad \left[ {\sum\limits_{i = 1}^N {\sum\limits_{j = 1}^h {{f_{ij}}(t){l_{ij}}{\boldsymbol{P}}_{ij}} } } \right]\left[ {\frac{{\sum\limits_{i = 1}^N {\sum\limits_{j = 1}^h {{f_{ij}}(t){l_{ij}}{\boldsymbol{P}}_{ij}^{\rm T}} } }}{{{{\left\| {\sum\limits_{i = 1}^N {\sum\limits_{j = 1}^h {{f_{ij}}(t){l_{ij}}{\boldsymbol{P}}_{ij}^{\rm T}} } } \right\|}_2}}}} \right]= \\ &\quad {\left\| {\sum\limits_{i = 1}^N {\sum\limits_{j = 1}^h {{f_{ij}}(t){l_{ij}}{\boldsymbol{P}}_{ij}^{\rm T}} } } \right\|_2}\ge\\ &\quad {\left\| {\sum\limits_{i = 1}^N {\sum\limits_{j = 1}^h {{f_{ij}}(t){l_{ij}}{\boldsymbol{P}}_{ij}^{\rm T}} } } \right\|_2} \times \\ &\quad \cos \left( {\sum\limits_{i = 1}^N {\sum\limits_{j = 1}^h {{f_{ij}}(t){l_{ij}}{\boldsymbol{P}}_{ij}^{\rm T}} } ,\sum\limits_{i = 1}^N {\sum\limits_{j = 1}^h {{f_{ij}}(t - 1){l_{ij}}{\boldsymbol{P}}_{ij}^{\rm T}} } } \right) = \\ & \quad {\left\| {\sum\limits_{i = 1}^N {\sum\limits_{j = 1}^h {{f_{ij}}(t){l_{ij}}{\boldsymbol{P}}_{ij}^{\rm T}} } } \right\|_2} \times \\ &\quad \frac{{{{\left( {\sum\limits_{i = 1}^N {\sum\limits_{j = 1}^h {{f_{ij}}(t){l_{ij}}{\boldsymbol{P}}_{ij}^{\rm T}} } } \right)}^{\rm T}}\left( {\sum\limits_{i = 1}^N {\sum\limits_{j = 1}^h {{f_{ij}}(t - 1){l_{ij}}{\boldsymbol{P}}_{ij}^{\rm T}} } } \right)}}{{{{\left\| {\sum\limits_{i = 1}^N {\sum\limits_{j = 1}^h {{f_{ij}}(t){l_{ij}}{\boldsymbol{P}}_{ij}^{\rm T}} } } \right\|}_2}{{\left\| {\sum\limits_{i = 1}^N {\sum\limits_{j = 1}^h {{f_{ij}}(t - 1){l_{ij}}{\boldsymbol{P}}_{ij}^{\rm T}} } } \right\|}_2}}}=\\ &\quad {\left( {\displaystyle\sum\limits_{i = 1}^N {\displaystyle\sum\limits_{j = 1}^h {{f_{ij}}(t){l_{ij}}{\boldsymbol{P}}_{ij}^{\rm T}} } } \right)^{\rm T}} \times \\ &\quad\frac{{\displaystyle\sum\limits_{i = 1}^N {\displaystyle\sum\limits_{j = 1}^h {{f_{ij}}(t - 1){l_{ij}}{\boldsymbol{P}}_{ij}^{\rm T}} } }}{{{{\left\| {\displaystyle\sum\limits_{i = 1}^N {\displaystyle\sum\limits_{j = 1}^h {{f_{ij}}(t - 1){l_{ij}}{\boldsymbol{P}}_{ij}^{\rm T}} } } \right\|}_2}}}=\\ &\quad \sum\limits_{i = 1}^N {\sum\limits_{j = 1}^h {{f_{ij}}(t){l_{ij}}{\boldsymbol{P}}_{ij}{{\boldsymbol{v}}_1}(t)} }\end{split} $$ 因此, 得到
$\sum\nolimits_{i = 1}^N \;{\sum\nolimits_{j = 1}^h {{f_{ij}}\left( t \right){l_{ij}}{\boldsymbol{P}}_{ij}{{\boldsymbol{v}}_1}\left( {t\; + \;1} \right)} } \ge$ $ \sum\nolimits_{i = 1}^N {\sum\nolimits_{j = 1}^h {{f_{ij}}\left( t \right){l_{ij}}{\boldsymbol{P}}_{ij}{{\boldsymbol{v}}_1}\left( t \right)} } $ .综上,
$\sum\nolimits_{i = 1}^N {\sum\nolimits_{j = 1}^h {{f_{ij}}\left( {t\; + \;1} \right){l_{ij}}{\boldsymbol{P}}_{ij}{{\boldsymbol{v}}_1}\left( {t \;+\; 1} \right)} } \ge$ $ \sum\nolimits_{i = 1}^N {\sum\nolimits_{j = 1}^h {{f_{ij}}\left( t \right){l_{ij}}{\boldsymbol{P}}_{ij}{{\boldsymbol{v}}_1}\left( t \right)} } $ 得以证明. 因此, 可得出算法1的迭代过程是非降的. 考虑到数据集中的样本数量$N$ 和样本数据一般为有限值, 则函数$\phi \left( {{{\boldsymbol{v}}_1}} \right)$ 必存在上界. 因此, 算法1迭代过程收敛. □本质上, 算法1中步骤3和步骤4是不断调整所有
${f_{ij}}$ , 从而可使得${{\boldsymbol{v}}_1} = \dfrac{{\sum\nolimits_{i = 1}^N {\sum\nolimits_{j = 1}^h {{f_{ij}}{l_{ij}}{\boldsymbol{P}}_{ij}} } }}{{{{\left\| {\sum\nolimits_{i =1}^N {\sum\nolimits_{j = 1}^h {{f_{ij}}{l_{ij}}{\boldsymbol{P}}_{ij}} } }\right\|}_2}}}$ 与所有${f_{ij}}{l_{ij}}{\boldsymbol{P}}_{ij}$ 在空间上的夹角总满足小于等于${90^ \circ }$ . 不断迭代到收敛, 其求和项全为正, 即$\phi \left( {{{\boldsymbol{v}}_1}} \right) = \sum\nolimits_{i = 1}^N {\sum\nolimits_{j = 1}^h {\left| {{l_{ij}}{\boldsymbol{P}}_{ij}{{\boldsymbol{v}}_1}} \right|} } \; =\; \sum\nolimits_{i = 1}^N {\sum\nolimits_{j = 1}^h {{f_{ij}}{l_{ij}}{\boldsymbol{P}}_{ij}{{\boldsymbol{v}}_1}} }$ 达到最优.本文是在参数S已知确定的情况下, 对
${{\boldsymbol{v}}}$ 进行优化. 若参数S为未知变量, 则上述目标函数的优化问题变为$\mathop {\arg \max }\nolimits_{{{{\boldsymbol{v}}}^{\rm{T}}}{{\boldsymbol{v}}} = 1} \phi \left( {S,{{\boldsymbol{v}}}} \right)$ , 而二元函数$\phi \left( {S,{{\boldsymbol{v}}}} \right)$ 为$\sum\nolimits_{i = 1}^N \;{\sum\nolimits_{j = 1}^h \;{\dfrac{{\left| {{\boldsymbol{P}}_{ij}{{\boldsymbol{v}}}} \right|}}{{\left\| {{\boldsymbol{P}}_{ij}} \right\|_2^S}}} }$ . 可构造函数$L = \sum\nolimits_{i = 1}^N \sum\nolimits_{j = 1}^h$ $ {\dfrac{{\left| {{\boldsymbol{P}}_{ij}{{\boldsymbol{v}}}} \right|}}{{\left\| {{\boldsymbol{P}}_{ij}} \right\|_2^S}}} - \lambda \left( {{{{\boldsymbol{v}}}^{\rm{T}}}{{\boldsymbol{v}}} - 1} \right)$ , 分别求解$L$ 对$S, v,\lambda $ 三者的偏导均为0, 则符号函数${f_{ij}}$ 本质上与参数S关联耦合, 导致难以求得参数S的最优解. 因此, 本文仅研究在确定参数S值下的目标优化问题.2.2 其余主成分求解算法
求解其余主成分依然利用贪婪求解算法, 为了保证投影矩阵中的每个PC与其他PC是正交的, 对其余PC所对应的数据样本进行更新, 则更新迭代式为
$$ {\boldsymbol{P}}_{ij}^k = {\boldsymbol{P}}_{ij}^{k - 1} - {\boldsymbol{P}}_{ij}^{k - 1}{{\boldsymbol{v}}_{k-1}}{\boldsymbol{v}}_{k-1}^{\rm T} $$ (18) 其中,
${{\boldsymbol{v}}_{k-1}},\; {k = 2,3, \cdots ,d}$ , 为投影矩阵$V$ 的第$k-1$ 个高阶PC,${\boldsymbol{P}}_{ij}^k$ 和${\boldsymbol{P}}_{ij}^{k - 1}$ 分别是第k个和第$k -1 $ 个高阶PC对应的数据样本.同理, 为使目标函数(13)最优, 其余主成分迭代求解算法如下:
算法 2. GC2DPCA的其余主成分求解算法
输入.
${\boldsymbol{P}}_{ij}^k$ , 参数$S$ .输出.
${{\boldsymbol{v}}_k} \in {{\bf{R}}^{w \times 1}},\; {k = 2, \cdots ,d}$ .步骤 1. 高阶样本数据更新, 计算高阶行向量
${\boldsymbol{P}}_{ij}^k$ 的权重$l_{ij}^k = \| {{\boldsymbol{P}}_{ij}^k}\|_2^{{-}S}$ 后, 将${\boldsymbol{P}}_{ij}^k$ 更新为$l_{ij}^k{\boldsymbol{P}}_{ij}^k$ .步骤 2. 初始化高阶主成分, 取任意
${{\boldsymbol{v}}_k} \in {{\bf R}^{w \times 1}}$ , 满足${\boldsymbol{v}}_k^{\rm{T}}{{\boldsymbol{v}}_k} = 1$ 即可.步骤 3. 循环迭代, 运用算法1中步骤3和步骤4循环迭代, 直到
${{\boldsymbol{v}}_k}\left( {t + 1} \right) = {{\boldsymbol{v}}_k}\left( t \right)$ .利用算法2可以求得其余高阶主成分, 将求得的各个高阶主成分按顺序排列, 可得到前
$k$ 个主成分组成的投影矩阵为$V = \left[ {{{\boldsymbol{v}}_1},{{\boldsymbol{v}}_2}, \cdots ,{{\boldsymbol{v}}_k}} \right]$ .定理 2. 第
$k$ 个高阶主成分和前$k - 1$ 个主成分之间是正交的.证明. 设
$a,b \in {\bf{Z}}$ 介于$1 \sim d$ 之间, 且$a \ne b$ . 要证${\boldsymbol{v}}_a^{\rm{T}}{{\boldsymbol{v}}_b} \;= \;0$ , 则可证明${\boldsymbol{P}}_{ij}^a{{\boldsymbol{v}}_b}\; =\; 0$ , 因为${\boldsymbol{v}}_a^{\rm{T}}\; =$ $\dfrac{{\sum\nolimits_{i = 1}^N {\sum\nolimits_{j = 1}^h {f_{ij}^al_{ij}^a{\boldsymbol{P}}_{ij}^a} } }}{{{{\left\| {\sum\nolimits_{i = 1}^N {\sum\nolimits_{j = 1}^h {f_{ij}^al_{ij}^a{\boldsymbol{P}}_{ij}^a} } } \right\|}_2}}}$ . 下面利用第二类数学归纳法证明:1)当
$k = 2$ 时,${\boldsymbol{P}}_{ij}^2{{\boldsymbol{v}}_1} = \left( {{\boldsymbol{P}}_{ij} - {\boldsymbol{P}}_{ij}{{\boldsymbol{v}}_1}{\boldsymbol{v}}_1^{\rm{T}}} \right){{\boldsymbol{v}}_1} =$ $0 $ , 则${\boldsymbol{v}}_2^{\rm{T}}{{\boldsymbol{v}}_1} = 0$ . 因此,$k= 2$ 时结论成立.2)当
$k = 3$ 时, 有$$ \left\{ \begin{aligned} {\boldsymbol{P}}_{ij}^3{{\boldsymbol{v}}_2} =& \left( {{\boldsymbol{P}}_{ij}^2 -{\boldsymbol{P}}_{ij}^2{{\boldsymbol{v}}_2}{\boldsymbol{v}}_2^{\rm{T}}} \right){{\boldsymbol{v}}_2} = 0\\ {\boldsymbol{P}}_{ij}^3{{\boldsymbol{v}}_1} =& \left( {{\boldsymbol{P}}_{ij} - {\boldsymbol{P}}_{ij}{{\boldsymbol{v}}_1}{\boldsymbol{v}}_1^{\rm{T}} - {\boldsymbol{P}}_{ij}{{\boldsymbol{v}}_2}{\boldsymbol{v}}_2^{\rm{T}}} \right){{\boldsymbol{v}}_1} =\\& \ {\boldsymbol{P}}_{ij}{{\boldsymbol{v}}_1} - {\boldsymbol{P}}_{ij}{{\boldsymbol{v}}_1} - 0 = 0 \end{aligned} \right. $$ 则
$\left\{ \begin{aligned} &{\boldsymbol{v}}_3^{\rm{T}}{{\boldsymbol{v}}_2} = 0\\ &{\boldsymbol{v}}_3^{\rm{T}}{{\boldsymbol{v}}_1} = 0 \end{aligned} \right. .$ 因此, k = 3时结论成立.3)假设
$k = x\;\left( {3 < x \le w - 1,x \in {\bf{Z}}} \right)$ 时结论成立, 即有${\boldsymbol{v}}_x^{\rm{T}}{{\boldsymbol{v}}_y} = 0\;\left( {1 \le y \le x - 1,y \in {\bf{Z}}} \right)$ .4)当
$k = x + 1$ 时, 承接3)中结论, 有$$ \left\{ \begin{aligned} &{\boldsymbol{P}}_{ij}^{x + 1}{{\boldsymbol{v}}_x} = \left( {{\boldsymbol{P}}_{ij}^x - {\boldsymbol{P}}_{ij}^x{{\boldsymbol{v}}_x}{\boldsymbol{v}}_x^{\rm T}} \right){{\boldsymbol{v}}_x} = 0\\ &{\boldsymbol{P}}_{ij}^{x + 1}{{\boldsymbol{v}}_{x-1}} = \\ & \qquad \left( {{\boldsymbol{P}}_{ij}^{x - 1} - {\boldsymbol{P}}_{ij}^{x - 1}{{\boldsymbol{v}}_{x-1}}{\boldsymbol{v}}_{x-1}^{\rm T} - {\boldsymbol{P}}_{ij}^{x - 1}{{\boldsymbol{v}}_x}{\boldsymbol{v}}_x^{\rm T}} \right)\times\\ & \qquad {{\boldsymbol{v}}_{x-1}} = 0\\ &\qquad \qquad \qquad \vdots \\ & {\boldsymbol{P}}_{ij}^{x + 1}{{\boldsymbol{v}}_1} = {\boldsymbol{P}}_{ij}{{\boldsymbol{v}}_1} - {\boldsymbol{P}}_{ij}{{\boldsymbol{v}}_1} - 0 -\cdots - 0 = 0 \end{aligned} \right. $$ 则得到
$\left\{ \begin{aligned} & {\boldsymbol{v}}_{x+1}^{\rm{T}}{{\boldsymbol{v}}_x} = 0\\ & {\boldsymbol{v}}_{x+1}^{\rm{T}}{{\boldsymbol{v}}_{x-1}} = 0\\& \qquad \qquad \vdots \\ & {\boldsymbol{v}}_{x+1}^{\rm{T}}{{\boldsymbol{v}}_1} = 0 \end{aligned} \right.$ 因此,
$k = x + 1$ 时结论成立.综上, 第
$k$ 个高阶主成分和前$k-1$ 个主成分之间是正交的. □定理2同样说明任意两个主成分之间是相互正交的. 不妨设
$1 \le a < b \le d$ ,$a,b \in {\bf{Z}}$ , 利用定理2,${v_b}$ 与前$b - 1$ 个主成分正交, 则${v_b}$ 必定与${v_a}$ 正交.如同PCA-
$L_{1}$ 和2DPCA-$L_{1}$ 的贪婪求解算法[15, 20]一样, GC2DPCA不能确保得到全局最优解. 这种贪婪求解算法能够保证各个PC之间在满足正交的同时, 使得每一个PC均依赖于提出的广义余弦模型. 在求解各个PC时离群数据能够得到抑制, 其重构误差也能间接得到控制. 此外, 贪婪算法使得各个PC之间满足如式(18)的迭代关系. 当提取PC数增加时, 之前计算的PC得以保留. 通过迭代, 可进一步计算更高阶PC.3. 实验结果与分析
为验证本文算法的有效性及鲁棒性, 采用人工数据集、Yale、ORL及FERET人脸数据集分别进行实验, 并对PCA、PCA-
$L_{1}$ [15]、2DPCA[2]、2DPCA-$L_{1}$ [20]、2DPCA-$L_{1}$ (non-greedy)[21]、Angle-2DPCA[30]以及本文所提的GC2DPCA算法进行实验对比分析. 鲁棒性实验主要用于判定各算法目标函数中的重构误差损失情形, 而相关性实验用于判定各算法在满足投影距离最大时求得PC的真实程度, 分类率实验则将求得的PC用于判定分类识别效果, 时间复杂度实验用于判定各个求解PC算法的复杂程度. 实验软件环境为Windows7、Microsoft Visual Studio 2010和OpenCV 2.4.10, 采用Intel i5-5200U (2.2 GHz)处理器, 8 GB内存的硬件环境.3.1 鲁棒性实验与分析
考虑上述数据集已进行零均值化, 以平均重构误差(Average reconstruction error, ARCE)为性能指标, 进行鲁棒性实验与对比分析.
当数据矩阵需先向量化时:
$$ \begin{split} {\rm{ARCE}} =\;& \frac{1}{{{N_I}}}\sum\limits_{i = 1}^{{N_I}} {{{\left\| {{{\boldsymbol{p}}_i} - V{V^{\rm T}}{{\boldsymbol{p}}_i}} \right\|}_2}} = \\ & \frac{1}{{{N_I}}}\sum\limits_{i = 1}^{{N_I}} {{{\left\| {{{\boldsymbol{p}}_i} - \sum\limits_{j = 1}^k {{{\boldsymbol{v}}_j}{\boldsymbol{v}}_j^{\rm T}} {{\boldsymbol{p}}_i}} \right\|}_2}} \end{split} $$ (19) 当数据矩阵无需向量化时:
$$ \begin{split} {\rm{ARCE}} =\;& \frac{1}{{{N_I}}}\sum\limits_{i = 1}^{{N_I}} {{{\left\| {{P_i} - {P_i}V{V^{\rm T}}} \right\|}_{\rm{F}}}} = \\ &\frac{1}{{{N_I}}}\sum\limits_{i = 1}^{{N_I}} {{{\left\| {{P_i} - \sum\limits_{j = 1}^k {{P_i}{{\boldsymbol{v}}_j}{\boldsymbol{v}}_j^{\rm T}} } \right\|}_{\rm{F}}}} \end{split} $$ (20) 其中,
${N_I}$ 表示未受到噪声干扰的样本数量.3.1.1 人工数据集
分别构建如图2(a)和图2(c)所示的二维人工数据集(已被零均值), 数据集表示为
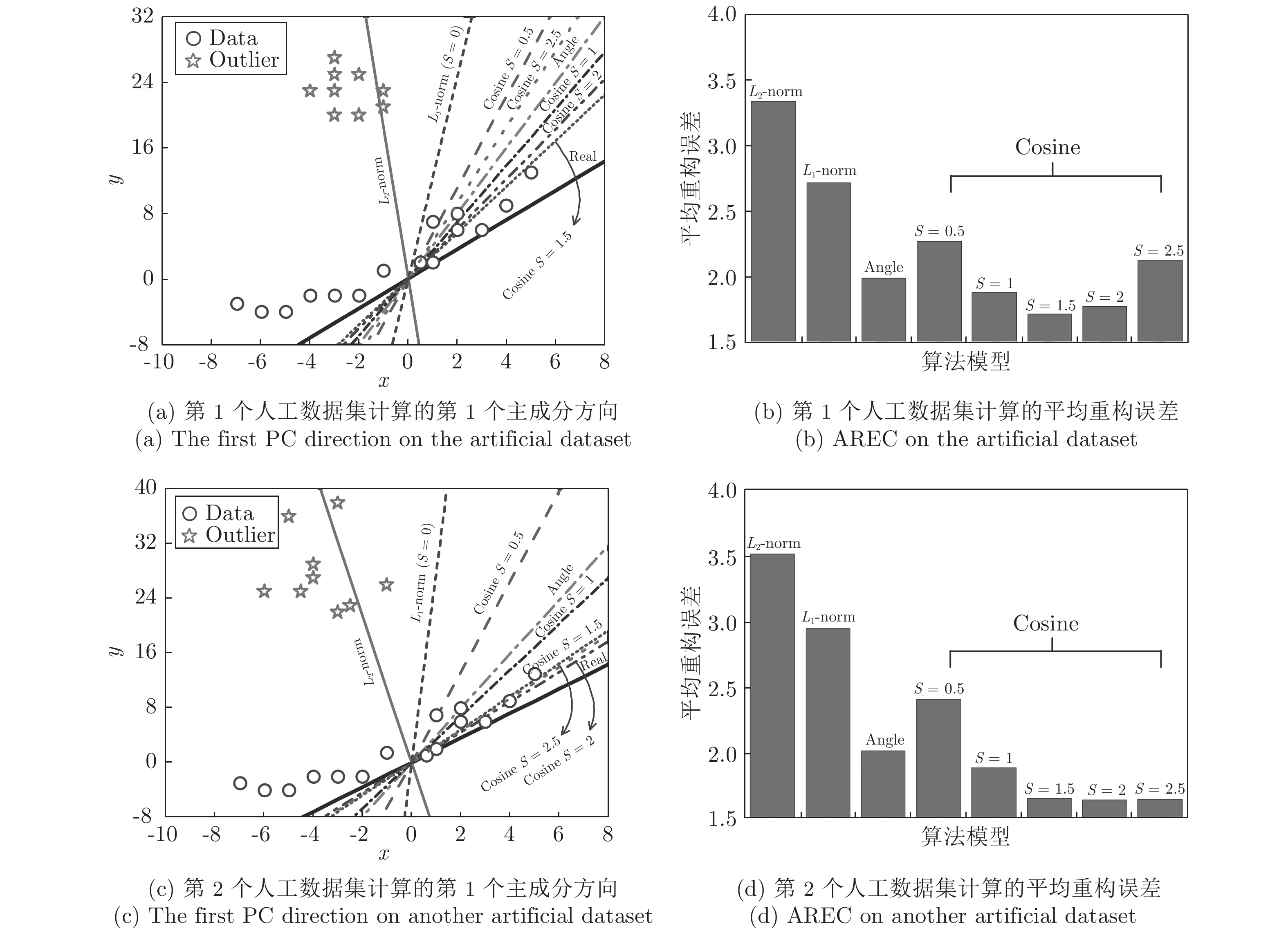
${\xi _i} = \left\{ \left( {{x_i},{y_i}} \right), \right.$ $\left.i = 1,2, \cdots ,24 \right\}$ . 其中, 五角星代表离群数据点, 圆圈代表纯净数据点, Real表示排除离群数据点后利用$L_{2}$ 范数度量方式提取的第一个PC的方向, Angle为Angle-2DPCA[30]中的比率度量方式. 受离群数据点的影响, 通过各个算法提取的第一个PC方向与Real的接近程度来判断其鲁棒性.从图2(a)可以看出, 基于
$L_{2}$ 范数的度量方式提取的第一个PC方向受离群数据点影响最大, 而$L_{1}$ 范数更靠近Real方向, 因此, 与$L_{2}$ 范数相比,$L_{1}$ 范数对噪声相对不敏感. Angle度量方式更接近Real方向, 具有较强的鲁棒性. 随着广义余弦模型参数S的变化, 其鲁棒性顺序依次为Cosine S = 1.5 > Cosine S = 2 > Cosine S = 1 > Angle > Cosine S = 2.5 > Cosine S = 0.5 >$L_{1}$ -norm >$L_{2}$ -norm. 利用上述度量方式提取的第一个PC再重构原始数据, 借助式(19)计算得到其相应的ARCE分别如图2(b)和图2(d)所示. 从图2(b)可以看出,$L_{2}$ 范数度量方式下其重构数据能力最差, 其ARCE最大.$L_{1}$ 范数和Angle的ARCE均有不同程度下降, 当Cosine S = 1.5时, 其ARCE最小. 因此, 随着参数S的变化, 广义余弦模型重构数据能力优于其他距离度量方式, 且随着参数S的逐步增加, 其ARCE先减少到最优值, 然后再逐步增加, 其ARCE变化规律与图2(a)所示的鲁棒性分析一致. 进一步分析参数S对鲁棒性的影响规律, 从图2(c)和图2(d)可以看出, 当Cosine S = 2时, 其ARCE最小, 鲁棒性最优, 并且变化规律与图2(a)和图2(b)分析完全一致. 通过大量的重复实验可以得到, 随着参数S的增加, 广义余弦模型总存在一个相对最优值(对应ARCE最小), 其ARCE规律是先逐步减少到某一个最优值, 然后再逐步增大. 在实际应用过程中, 可根据上述变化规律寻求相对合理的参数S.3.1.2 Yale、ORL及FERET人脸数据集
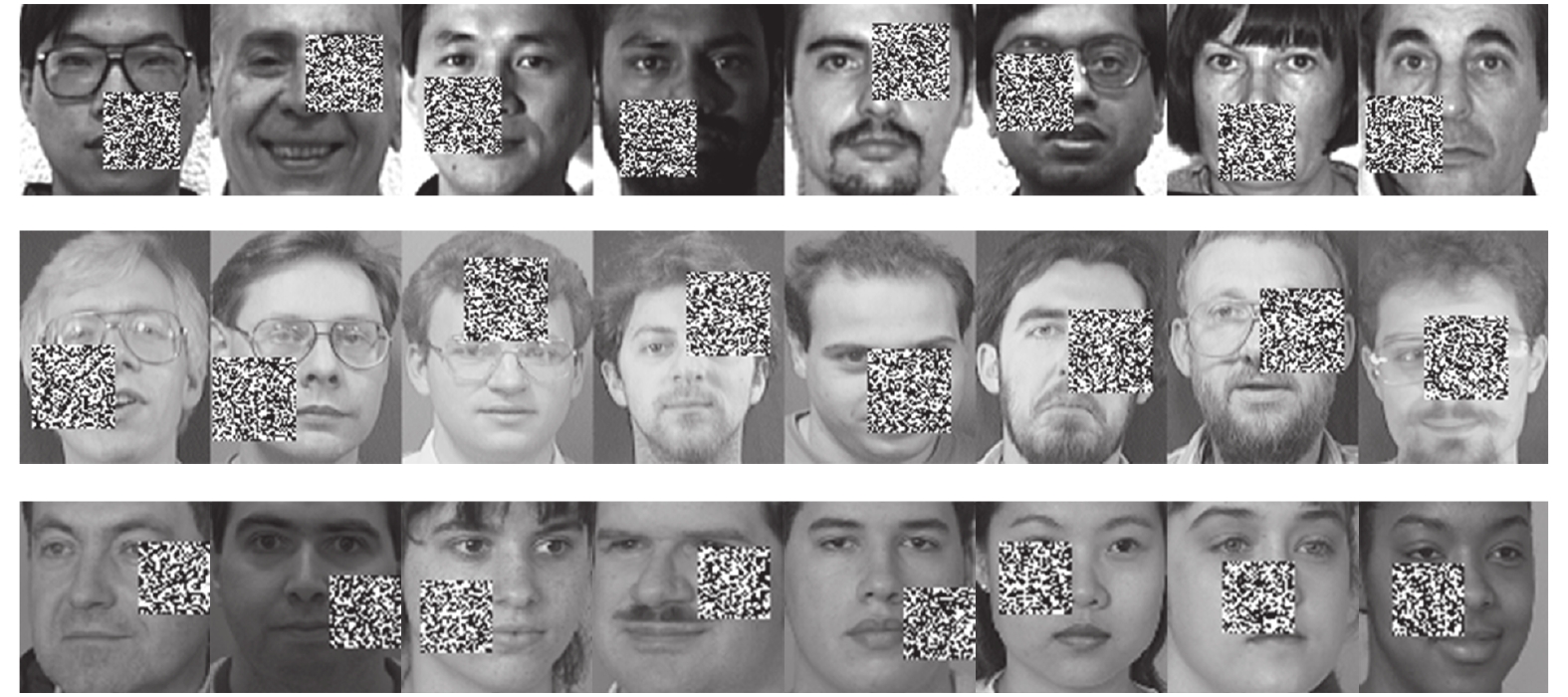
Yale数据集包含15个人脸图像, 每人11幅共165幅, 分辨率为
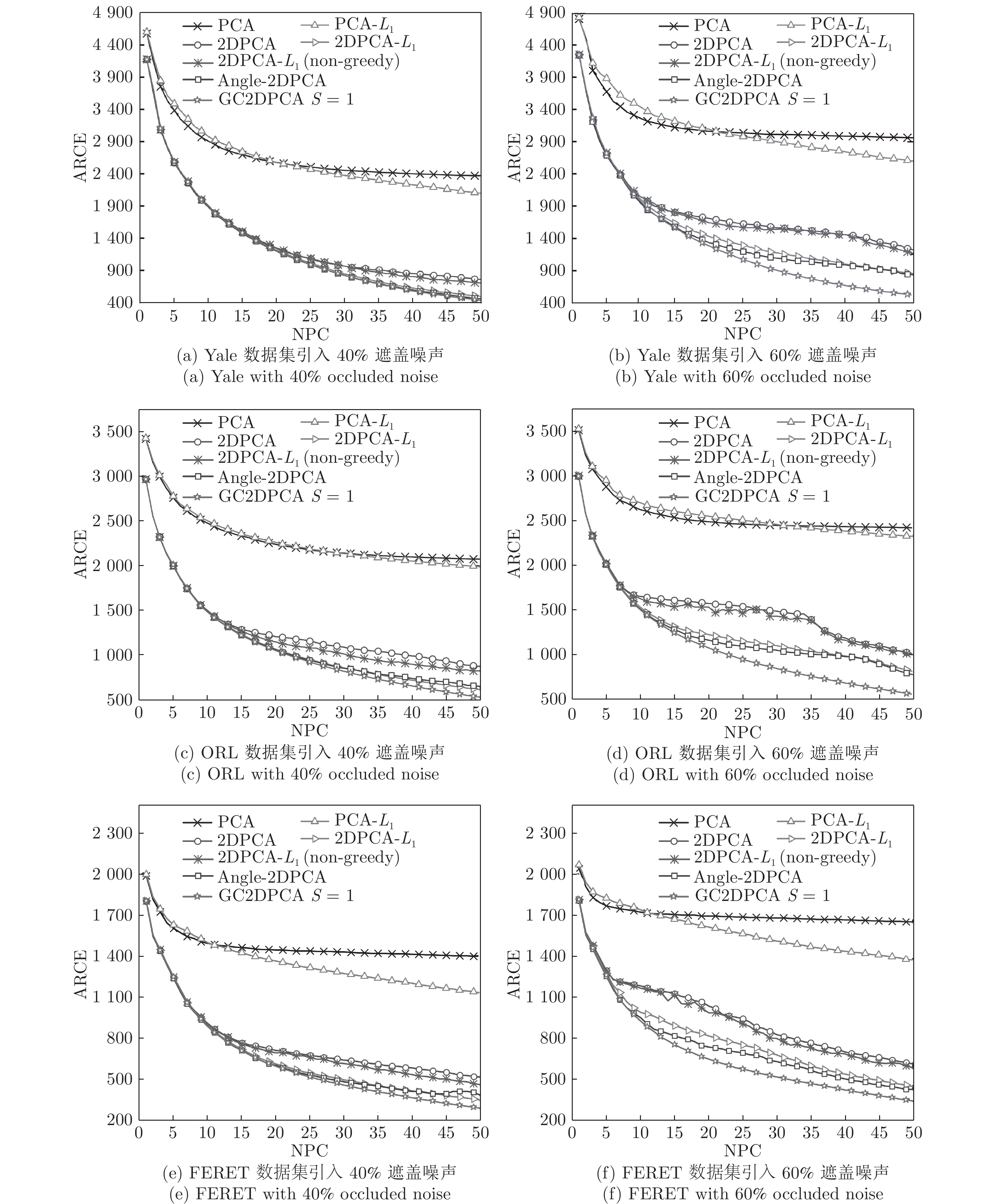
$100 \times 100$ 像素. ORL数据集由40个人脸图像组成, 每人10幅共400幅, 分辨率为$112 \times 92$ 像素. FERET数据集有20人, 每人7幅共140幅, 分辨率为$80 \times 80$ 像素. 图3展示了Yale、ORL及FERET三个数据集的部分图像. 为了测试GC2DPCA算法的鲁棒性, 采取文献[26]的方式对数据集进行加噪: 1)遮盖噪声(Occluded noise). 在40%遮盖噪声下, 从Yale、ORL及FERET数据集中分别随机抽取总样本数的40%, 在抽取的图像样本上对应加入$40 \times 40$ 像素、$40 \times 40 $ 像素和$30 \times 30$ 像素的杂点噪声进行覆盖. 在60%遮盖噪声下, 从3个数据集抽取60%图像样本上分别加入$60 \times 60$ 像素、$60 \times 60$ 像素和$45 \times 45$ 像素的杂点噪声进行覆盖. 上述遮盖噪声位置随机且不超越图像边界, 分别如图4和图5所示; 2)哑噪声(Dummy noise). 在整个数据集中额外增加总样本数的40%和60%杂点噪声样本, 其分辨率与原数据集样本一致, 如图6所示.将具有40%和60%遮盖噪声的Yale、ORL和FERET人脸数据集投影到不同的主成分个数(Number of principal components, NPC)所组成的投影子空间上, 利用式(19)及式(20)计算各个算法对应的ARCE如图7所示. 从图7(a) ~ 7(f)中可以得出如下结论: 1)各个算法随着NPC的增加, 其ARCE均呈现逐步下降趋势且逐渐趋于平缓, 因此, 其降维的子空间维数将对ARCE影响很大. 2) PCA和PCA-
$L_{1}$ 因向量化而增加了数据维数, 其ARCE相比其他二维算法均偏大. 随着NPC的增加,$L_{1}$ 范数使得PCA-$L_{1}$ 的最终鲁棒性要略优于PCA. 3)对于2DPCA、2DPCA-$L_{1}$ 、2DPCA-$L_{1}$ (non-greedy)及Angle-2DPCA均为二维算法, 直接针对图像矩阵进行特征提取, 相比一维算法其ARCE均大为减小. 2DPCA和2DPCA-$L_{1}$ (non-greedy)两个算法ARCE差异不明显, 且不受数据集及遮盖噪声影响. 2DPCA-$L_{1}$ 与2DPCA-$L_{1}$ (non-greedy)相比, 其ARCE具有明显优势, 且不受数据集的影响. 随着噪声的增加, 2DPCA-$L_{1}$ 其贪婪求解算法优势更趋明显. 而Angle-2DPCA的ARCE与2DPCA-$L_{1}$ 较为接近. 在遮盖噪声下, 可知${R_{{\rm{GC2DPCA}}}} < {R_{{\rm{Angle}} {\text{-}} {\rm{2DPCA}}}}$ , 因此, GC2DPCA也优于Angle-2DPCA. 4)相比上述其他算法, GC2DPCA的ARCE具有较为明显的优势, 且不受数据集的影响. 当加入60%遮盖噪声后, GC2DPCA的ARCE在两个不同数据集下, 与其他算法相比下降优势更趋明显, 并且其ARCE几乎不变, 而其他算法均有不同程度的增大. 通过多次重复实验可得到, 参数S改变对GC2DPCA的ARCE略有变化, 且参数S对ARCE影响规律与人工数据集的变化规律一致, 图7各个子图为显示简洁仅呈现GC2DPCA S = 1的情形. 因此, 针对遮盖噪声, 本文所提算法GC2DPCA的鲁棒性均优于其他算法, 并且加大噪声, 其优势也愈加明显.引入不同哑噪声之后, 各个算法对应的ARCE如图8所示. 可以看出, GC2DPCA的鲁棒性可以得到与遮盖噪声实验的类似结论. 1)当NPC小于5时, PCA的ARCE下降较快, 当NPC大于10时, PCA-
$L_{1}$ 比PCA的鲁棒效果十分明显, 而PCA几乎趋于常值. 2) 2DPCA-$L_{1}$ (non-greedy)在面对哑噪声时已经不如2DPCA, 并且在图8(d)和图8(f)中其趋势不稳定, 振动较大. 3)其余算法ARCE曲线走势与遮盖噪声实验中类似, 进一步验证前述分析结论, 不同的是GC2DPCA与Angle-2DPCA在不同数据集及不同哑噪声下几乎完全重叠. 4)加大哑噪声后, 各个算法的ARCE变化很小.以上带遮盖噪声和哑噪声的人脸数据集上的鲁棒性实验结果表明, 相比经典的PCA和PCA-
$L_{1}$ , 本文所提算法优势十分明显; 与2DPCA、2DPCA-$L_{1}$ 、2DPCA-$L_{1}$ (non-greedy)相比, 降低了ARCE, 提升了鲁棒性能; 与Angle-2DPCA相比, 在大遮盖噪声下具有较为明显优势. 而在哑噪声下, 两者其样本污染情况一致, 因均兼顾到数据的重构误差, 则GC2DPCA与Angle-2DPCA的ARCE几乎完全相同.3.2 相关性实验与分析
为验证各算法提取的PC与真实PC之间的相关性, 用内积矩阵定义相关性, 表示为
$$ Z = V_{{\rm{true}}}^{\rm T}{V_{{\rm{test}}}} $$ (21) 其中,
${V_{{\rm{true}}}}$ 表示用$L_{2}$ 范数计算纯净样本数据得到的PC所构成的投影矩阵,${V_{{\rm{test}}}}$ 为各个算法针对含噪数据计算得到的PC构成的投影矩阵. 显然,$Z$ 越接近单位矩阵, 说明${V_{{\rm{test}}}}$ 越接近${V_{{\rm{true}}}}$ . 选用Yale数据集的60%遮盖噪声进行相关性实验. 各个算法实验结果如图9所示, x轴和y轴分别代表${V_{{\rm{true}}}}$ 和${V_{{\rm{test}}}}$ 中对应的NPC, z轴表示PC之间内积的绝对值. 因此, 通过直观观察三维图中z值来判定算法的相关性. 如对角线上的z值越接近1, 而对角线以外区域越接近0, 则表示内积矩阵Z相关性越高, 求解的PC也就越接近真实的PC.从图9可以看出, PCA提取的主成分大部分偏离了真实值, 对角线上仅有第一个PC约为0.85, 对角线上其余PC均在0.5以下. 而PCA-
$L_{1}$ 也不太理想, 对角线上的PC与PCA近似, 对角线外其他区域与PCA相比多了一些小凸峰, 无法接近0, 因此PCA-$L_{1}$ 相关性不如PCA. 2DPCA对角线上前10个主成分相关性几乎为1, 对角线上其余PC锐减至0.6以下, 而对角线外其他区域凸峰严重, 几乎逼近0.4. 在2DPCA-$L_{1}$ 中, 与2DPCA相比凸峰有向对角线方向收敛的趋势, 其相关性得到一定程度的提升. 而在GC2DPCA中, 随$S$ 参数逐渐增加, 凸峰逐渐收敛到对角线上, 当$S = 1.5$ 时最优, 对角线上主成分相关性均在0.6之上, 而在对角线外其他区域几乎接近于0, 因此, GC2DPCA提取的主成分更接近真实值, 且相互正交. 可以看到, 与前述算法不同的是, 2DPCA-$L_{1}$ (non-greedy)和Angle-2DPCA呈现一种杂乱的态势, 这是由于这两个算法提取得到投影矩阵$V$ 中的各个主成分之间无顺序优先之分, 它们对$V$ 中所有主成分是同时进行优化的. 这两个算法在调整主成分数量时, 需重新计算之前得到的所有主成分, 这也是2DPCA-$L_{1}$ (non-greedy)和Angle-2DPCA的不利之处. 而图9中其他算法均是在原始数据减去之前计算主成分分量之后再进行迭代计算, 其相关性均优于2DPCA-$L_{1}$ (non-greedy)和Angle-2DPCA. 因此, 本文提出的GC2DPCA在相关性方面均远优于其他算法.3.3 分类率实验与分析
分类率实验采用K-最近邻分类算法(K-nearest neighbor, KNN), 并选取
${{K}} = 1$ 时进行分类. 所有实验数据样本均经过零均值处理, 其中训练样本和测试样本零均值化所采用的均值来源于训练样本的均值. 在Yale和ORL数据集每个人脸图像中, 随机抽取其中5幅用作训练样本, 其余用作测试样本. 在FERET数据集中, 每人随机抽取3幅用作训练样本, 其余为测试样本. 在3个数据集中训练样本中随机抽取40%样本添加遮盖噪声. 考虑到噪声的随机性, 重复5次随机遮盖噪声进行分类率实验, 得到平均分类率分别如表1 ~ 3所示.表 1 Yale数据集下平均分类率 (40%遮盖噪声) (%)Table 1 Average classification rate under Yale dataset (40% occluded noise) (%)NPC PCA PCA-$L_1$ 2DPCA 2DPCA-$L_1$ 2DPCA-
$L_1$(non-greedy)Angle-
2DPCAGC2DPCA
S = 0.5GC2DPCA
S = 1GC2DPCA
S = 1.5GC2DPCA
S = 210 78.9 77.8 84.4 84.4 72.9 73.3 84.2 84.7 84.7 84.9 20 75.3 76.4 82.2 83.1 74.2 70.9 83.3 83.3 83.3 83.3 30 72.0 73.1 79.3 80.0 74.2 73.1 80.7 80.2 80.2 80.2 40 71.6 71.6 76.2 77.1 73.8 74.0 77.8 78.0 77.8 78.0 50 72.0 71.8 74.4 75.1 74.2 75.8 75.3 75.8 76.2 76.0 表 2 ORL数据集下平均分类率 (40%遮盖噪声) (%)Table 2 Average classification rate under ORL dataset (40% occluded noise) (%)NPC PCA PCA-$L_1$ 2DPCA 2DPCA-$L_1$ 2DPCA-
$L_1$(non-greedy)Angle-
2DPCAGC2DPCA
S = 0.5GC2DPCA
S = 1GC2DPCA
S = 1.5GC2DPCA
S = 210 79.9 79.3 88.1 88.1 77.2 80.3 88.3 88.5 88.6 88.5 20 81.2 80.4 85.9 85.9 82 80.6 86.3 86.4 86.4 86.4 30 81.6 82.3 85.1 85.5 84.8 83.3 85.5 85.6 85.7 85.7 40 81.9 82.8 85.4 85.5 85.7 85.4 85.5 85.5 85.5 85.5 50 81.7 83.2 85.6 85.5 85.6 85.5 85.4 85.6 85.6 85.6 表 3 FERET数据集下平均分类率 (40%遮盖噪声) (%)Table 3 Average classification rate under FERET dataset (40% occluded noise) (%)NPC PCA PCA-$L_1$ 2DPCA 2DPCA-$L_1$ 2DPCA-
$L_1$(non-greedy)Angle-
2DPCAGC2DPCA
S = 0.5GC2DPCA
S = 1GC2DPCA
S = 1.5GC2DPCA
S = 210 50.5 52.5 58.0 58.5 47.8 51.0 59.0 59.8 60.0 60.0 20 50.0 51.0 52.5 53.5 50.8 51.3 54.0 54.3 54.5 54.3 30 51.3 51.3 51.5 50.8 51.8 52.8 50.8 51.8 51.8 51.8 40 48.8 49.8 51.3 50.8 50.5 50.5 50.8 50.8 50.8 50.8 50 48.0 49.5 51.3 50.8 50.8 50.8 50.0 50.0 50.0 50.0 从表1 ~ 3可以看出, 从求解算法看, 2DPCA-
$L_{1}$ (non-greedy)和Angle-2DPCA均为非贪婪算法, 随着NPC的增加, 其平均分类率逐渐增加, 这是由于这两个算法求得的主成分随NPC增加而逐步得到优化, 与前述相关性分析结论一致. 而对于其他贪婪算法, 随着NPC的增加, 各个算法平均分类率均有所下降. 这是由于NPC越多, 包含的噪声成分也就越多, 其分类率也就相应下降. 从算法的维数看, 一维算法(包括PCA和PCA-$L_{1}$ )普遍低于其他二维算法, 与文献[2]和[18]实验结果一致, 这是由于二维算法提取了更多的图像模式特征, 并且损失图像的行列结构信息偏少. 从距离度量方式看,$L_{1}$ 范数相关算法(PCA-$L_{1}$ 和2DPCA-$L_{1}$ )大部分情形分类率要略高于$L_{2}$ 范数相对应的算法(PCA和2DPCA), 这是由于$L_{1}$ 范数度量方式具有一定的抗噪能力和分类优越性. 基于${\rm{F}}$ 范数的Angle-2DPCA算法与基于$L_{1}$ 范数的算法2DPCA-$L_{1}$ 相比, 分类率并无优势. 而本文提出的GC2DPCA相比其他算法, 具有较为明显的分类优势. 随着参数S的增加, GC2DPCA算法的分类率略有提升, 但分类率并不明显. 同样, 在Yale、ORL数据集以及FERET中分别加入60%的遮盖噪声, 得到平均分类率如表4 ~ 6所示. 可以看出, 平均分类率总体趋势与添加少量噪声情形近似, 但在大量噪声下所有算法的平均分类率均相应有所下降, 这是由于在人为增加噪声时, 使得投影距离减少所致. 此外, GC2DPCA的平均分类率具有较为明显的优势. 从表1 ~ 6中的参数S对GC2DPCA算法分类率的影响可以看出, 随着参数S的增加, 也存在一个近似最优的分类结果. 如表2所示, S = 1.5时呈现最优分类率. 若增加噪声数据, 如表5所示, 近似最优分类率的S值有前移迹象. 从表1 ~ 6中均可观察到此情况. 因此, 当噪声增加到可与原始数据相抗衡时, 如增加S值可以更大程度地抑制噪声, 但在某种程度上也抑制了真正有用的数据. 因此, 在大噪声的情况下可以选择略小的S值进行测试. 另外, GC2DPCA在提取少量PC的情况下分类率较高, NPC越多引入噪声数量也越多, 因此, 在实际应用中可根据数据的维数选择较小的NPC进行鲁棒降维.表 4 Yale数据集下平均分类率 (60%遮盖噪声) (%)Table 4 Average classification rate under Yale dataset (60% occluded noise) (%)NPC PCA PCA-$L_1$ 2DPCA 2DPCA-$L_1$ 2DPCA-
$L_1$(non-greedy)Angle-
2DPCAGC2DPCA
S = 0.5GC2DPCA
S = 1GC2DPCA
S = 1.5GC2DPCA
S = 210 61.8 58.7 72.4 73.6 62.4 59.3 73.6 74.4 74.4 74.4 20 60.4 60.0 63.3 65.3 62.9 59.1 66.4 67.6 67.8 67.8 30 60.7 61.3 62.2 62.7 62.4 61.1 63.6 63.6 63.6 63.6 40 61.1 61.6 62.2 62.7 62.2 62.9 62.2 62.4 62.2 62.4 50 60.7 62.0 62.2 62.7 62.4 62.7 62.4 62.4 62.4 62.4 表 5 ORL数据集平均分类率 (60%遮盖噪声) (%)Table 5 Average classification rate under ORL dataset (60% occluded noise) (%)NPC PCA PCA-$L_1$ 2DPCA 2DPCA-$L_1$ 2DPCA-
$L_1$(non-greedy)Angle-
2DPCAGC2DPCA
S = 0.5GC2DPCA
S = 1GC2DPCA
S = 1.5GC2DPCA
S = 210 66.0 65.0 73.6 74.4 72.1 67.0 74.6 74.7 74.6 74.7 20 68.1 67.7 73.4 74.2 71.3 70.8 74.1 74.3 74.3 74.2 30 68.7 69.4 73.7 74.2 72.4 72.9 74.4 74.4 74.3 74.4 40 69.0 70.0 74.4 74.4 73.5 75.0 74.5 74.4 74.3 74.4 50 69.2 70.2 74.1 74.4 74.2 74.4 74.3 74.5 74.4 74.4 表 6 FERET数据集平均分类率 (60%遮盖噪声) (%)Table 6 Average classification rate under FERET dataset (60% occluded noise) (%)NPC PCA PCA-$L_1$ 2DPCA 2DPCA-$L_1$ 2DPCA-
$L_1$(non-greedy)Angle-
2DPCAGC2DPCA
S = 0.5GC2DPCA
S = 1GC2DPCA
S = 1.5GC2DPCA
S = 210 43.8 43.5 50.0 47.8 40.0 40.3 48.8 50.5 50.3 50.0 20 43.8 44.3 48.5 45.0 44.8 45.0 44.8 45.3 45.8 46.0 30 44.0 43.8 46.8 45.0 44.8 45.3 45.0 45.0 45.5 45.5 40 41.5 44.3 45.3 45.0 44.0 44.3 45.0 45.3 45.3 45.3 50 42.0 42.0 44.8 45.0 45.0 45.3 45.3 45.0 45.0 45.0 3.4 时间复杂度实验与分析
参考上述所提及相关算法对应的文献, 得到各个算法的时间复杂度如表7所示. 其中, t为迭代步数. PCA-
$L_{1}$ 、2DPCA-$L_{1}$ 、2DPCA-$L_{1}$ (non-greedy)和GC2DPCA的迭代步数与样本数正相关, 并且${t_{{\rm{PCA}} {\text{-}} {L_1}}}小于{t_{{\rm{2DPCA}} {\text{-}} {L_1}}} 、$ ${t_{{\rm{2DPCA}} {\text{-}} {L_1}({\rm{non}} {\text{-}} {\rm{greedy}})}}$ 和${t_{{\rm{GC2DPCA}}}}$ . PCA-$L_{1}$ 理论上比PCA运算快, 但2DPCA-$L_{1}$ 因${t_{2{\rm{DPCA }}{\text{-}}{L_1}}} \propto Nh$ , 反而会比2DPCA运算速度慢. 2DPCA-$L_{1}$ 与GC2DPCA复杂度一致. 2DPCA-$L_{1}$ (non-greedy)和Angle-2DPCA求解过程包含奇异值分解, 相应增加了算法的运算时间. Angle-2DPCA算法收敛的原因在文献[30]中未加以解释, 具体运算时间可在实验中间接得到.表 7 时间复杂度分析Table 7 Time complexity analysis算法 时间复杂度 PCA ${{\rm{O}}}({Nh}^{2}{w}^{2}+{h}^{3}{w}^{2}) $ PCA-$L_1$ ${ {\rm{O} } }({Nhwk}{t}_{{\rm{PCA}}\text{-}L_{1} })$ 2DPCA ${{\rm{O}}}({Nh}^{2}{w}+{h}^{3}) $ 2DPCA-$L_1$ ${ {\rm{O} } }({Nhwk} {t}_{{\rm{2DPCA}}\text{-}L_{1} })$ 2DPCA-$L_1$(non-greedy) ${{\rm{O}}}[({Nhw}^{2}+{wk}^{2}+{w}^{2}{k})$
${t}_{{\rm{2DPCA}}\text{-}L_{1}({\rm{non}}\text{-}{\rm{greedy}})}]$Angle-2DPCA ${ {\rm{O} } }[({Nhw}^{2}+{wk}^{2}+{w}^{2}{k}){t}_{{\rm{Angle2DPCA}}}]$ GC2DPCA ${ {\rm{O} } }({Nhwkt}_{{\rm{GC2DPCA}}})$ 实验选用Yale数据集的60%遮盖噪声进行实验, 提取的NPC设为10, 分析各个算法提取PC所需时间随样本数的变化. 此处, GC2DPCA其参数S与时间复杂度无关, 可设定S = 1.
各个算法所需时间如表8所示, 可以看出, 2DPCA相比于PCA降低了数据维数, 所需时间比PCA低. 鲁棒算法PCA-
$L_{1}$ 的运行时间最快, 因为其迭代样本数N较少. 2DPCA-$L_{1}$ 与GC2DPCA接近, 但是余弦模型的引入抑制了离群噪声数据, 使得PC方向往真实方向偏转较快, 时间上略优于2DPCA-$L_{1}$ . Angle-2DPCA低于2DPCA-$L_{1}$ (non-greedy), 但它们每次迭代均需奇异值分解, 因此, Angle-2DPCA与2DPCA-$L_{1}$ (non-greedy)所需时间均高于GC2DPCA.表 8 各个算法所需时间对比(s)Table 8 Comparison of the required time by each algorithm (s)样本数 PCA PCA-$L_1$ 2DPCA 2DPCA-$L_1$ 2DPCA-$L_1$ (non-greedy) Angle-2DPCA GC2DPCA 20 0.855 0.576 0.310 2.861 9.672 5.585 2.637 40 1.643 0.882 0.363 5.834 17.550 7.753 5.413 60 3.072 1.326 0.452 8.611 28.096 16.567 9.049 80 4.733 1.940 0.507 17.800 35.896 14.040 14.883 100 6.732 2.226 0.620 22.449 88.671 40.092 18.517 4. 结束语
本文提出了一种基于广义余弦模型的GC2DPCA及其贪婪求解算法. 广义余弦模型的引入使得样本中混入较多噪声数据时, 算法依然能够呈现较好的鲁棒性, 且其对于不同的遮盖噪声和哑噪声均具有一定的适应性. GC2DPCA算法求解过程简单、易实现, 理论层面证明了算法的收敛性及提取的主成分之间的正交性. 其次, 通过选择不同的
$S$ 参数, 可应用于更广泛的含离群数据的鲁棒降维, 并在实验层面得到了$S$ 参数对算法的影响规律. 将GC2DPCA与PCA算法、PCA-$L_{1}$ 算法、2DPCA算法、2DPCA-$L_{1}$ 算法、2DPCA-L1 (non-greedy)算法及Angle-2DPCA算法在平均重构误差、相关性、分类率及时间复杂度等方面进行比较, 本文算法在人工数据集、Yale、ORL以及FERET人脸数据集上的实验结果均具有更优的性能. 然而, 本文的算法并不能实现样本的增量迭代求解, 将影响到算法的增量学习能力. 因此, 探索GC2DPCA算法的增量求解形式值得进一步研究. -
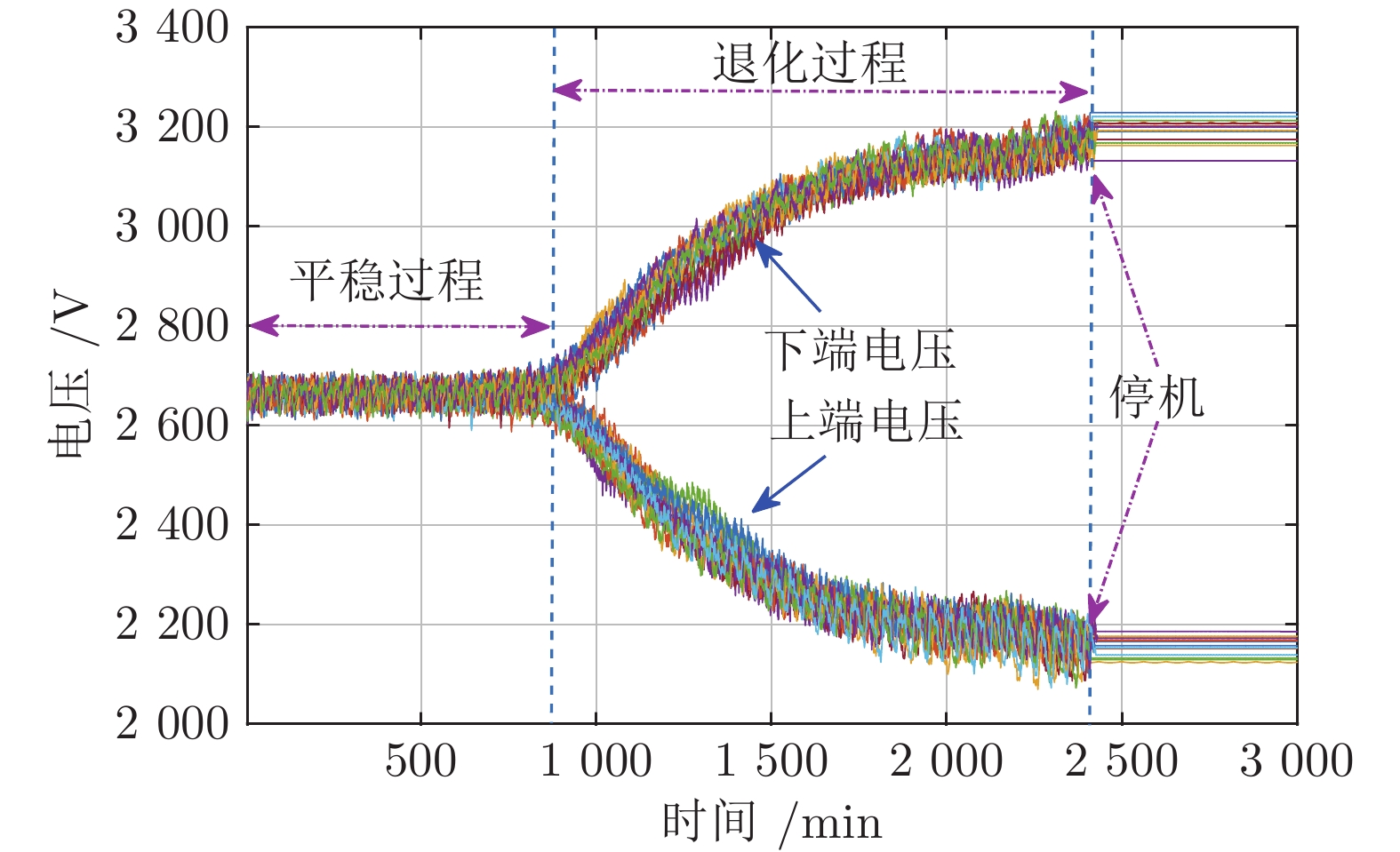
图 2 上下端电压从平稳过程到退化过程直至停机的演变趋势
Fig. 2 The voltages evolution from the stationary process to the degradation process

图 3 上下端电压在支撑电容器退化过程中的平均幅值
Fig. 3 The mean amplitude of the upper and lower voltages during the capacitors' degradation
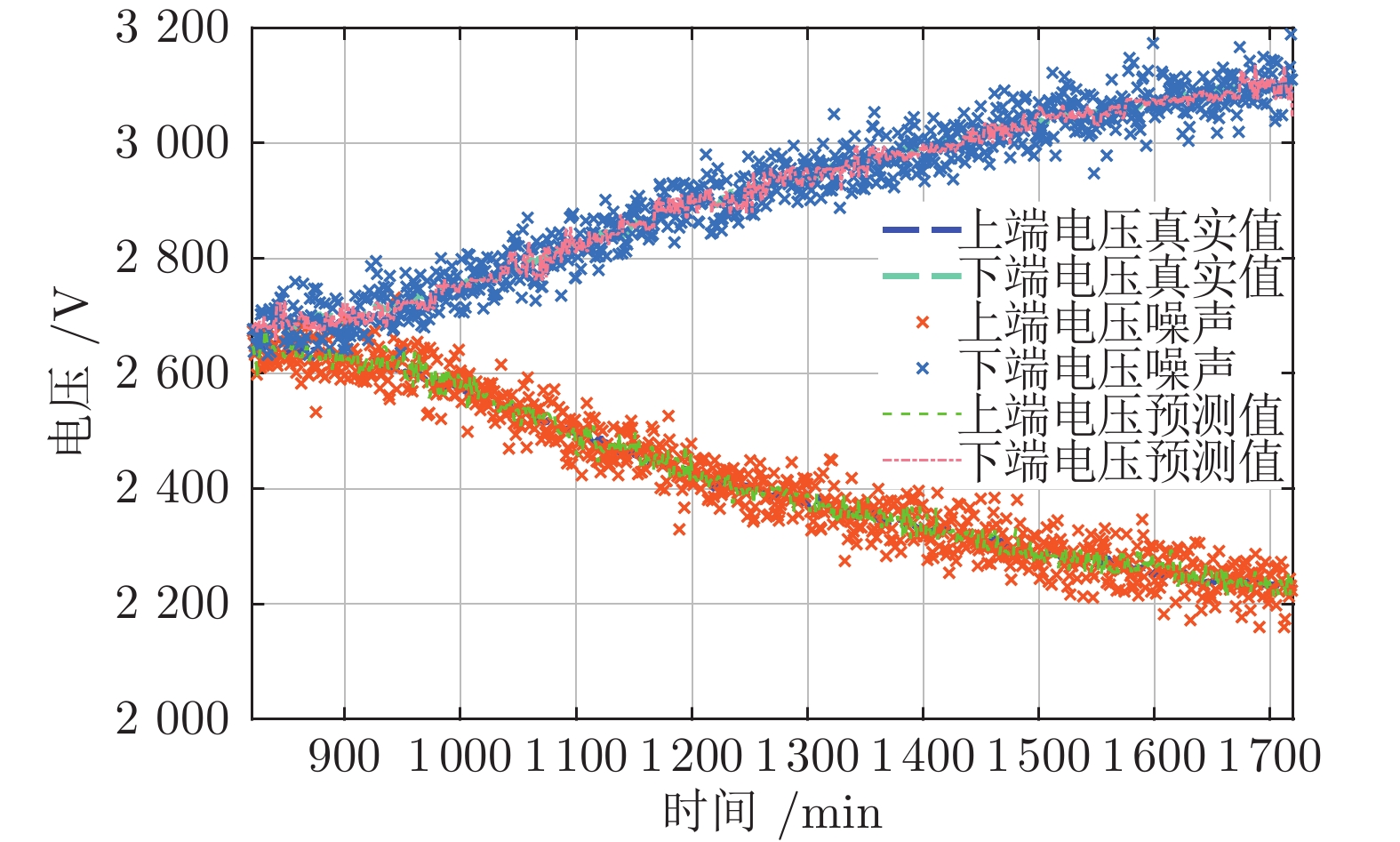
图 4 建模过程中的预测值与真实值进行比较
Fig. 4 The comparison between predicted values and the actual values in the modeling process
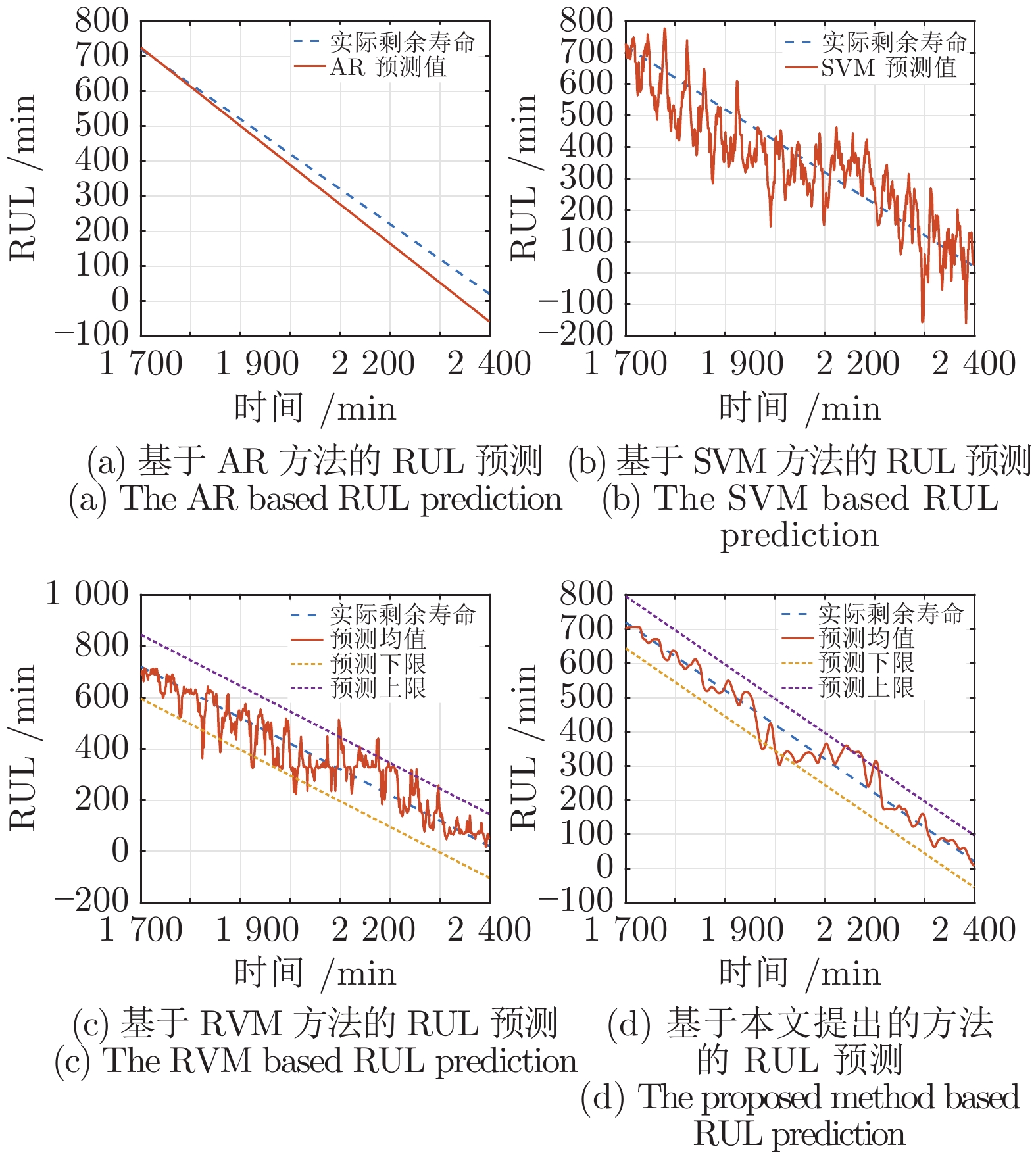
图 5 剩余寿命预测值与真实值对比图
Fig. 5 The RUL comparison between the predicted values and the actual values
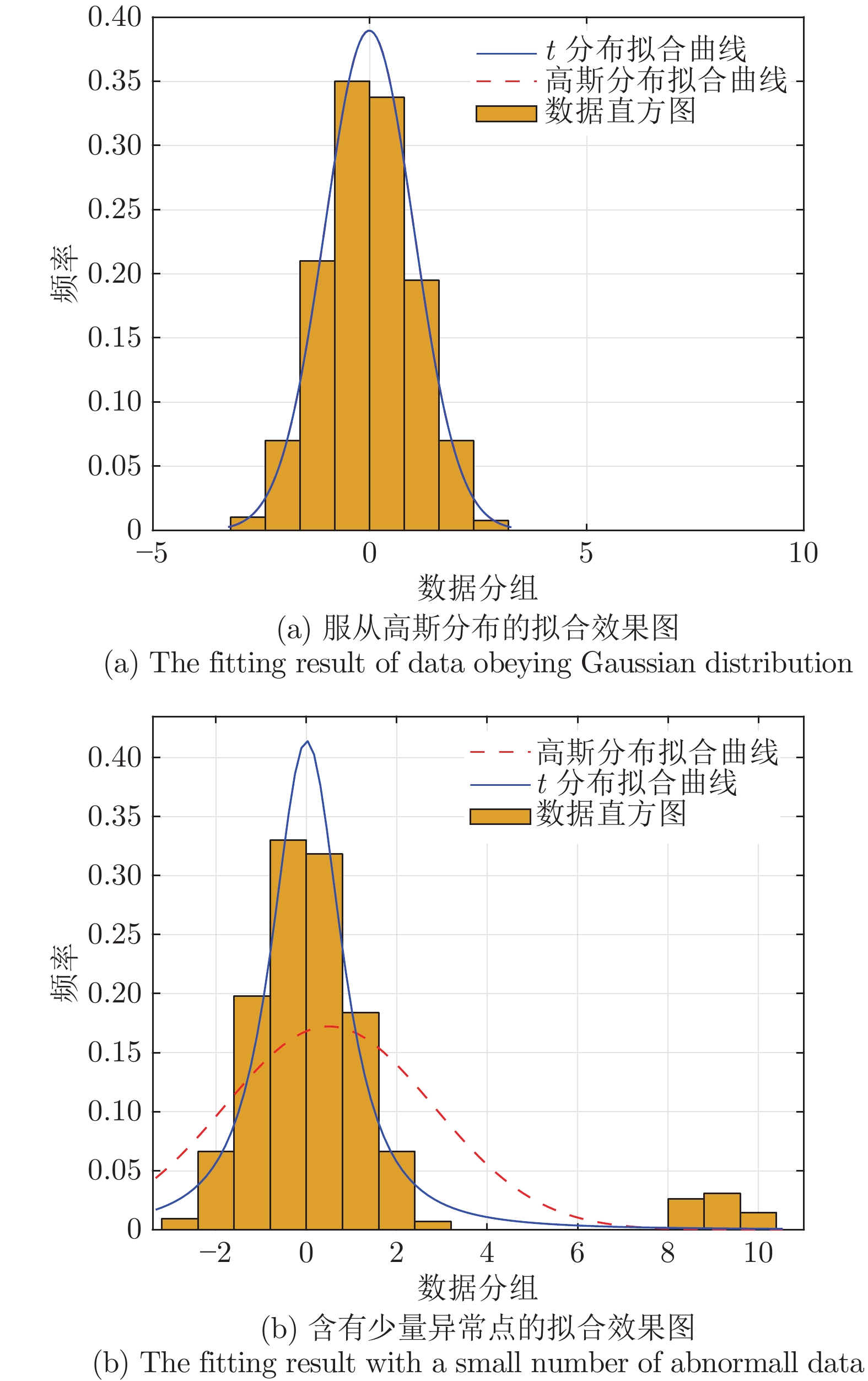
图 6 高斯分布与
$ t $ 分布拟合效果对比图Fig. 6 The fitting comparison between the Gaussian distribution and the
$ t $ distribution表 1 退化趋势模型中的参数取值
Table 1 The parameter values in the degradation model
SVM RVM 改进RVM 核函数 径向基 高斯 高斯 $ \alpha_i $ / $ 1.0\times 10^{12} $ $ 1.2\times 10^{-6} $ $ \beta $ / $ 2.47\times 10^{-4} $ $ 6.62\times 10^{-4} $  下载: 导出CSV
下载: 导出CSV
表 2 剩余寿命均方根误差(RMSE)及相对平均偏差(RAD)比较
Table 2 The RMSE and RAD comparison of RUL between different methods
AR SVM RVM 改进RVM RMSE (min) 1.6860 3.5654 2.3905 1.4586 RAD (%) 29.6802 35.8900 20.3468 11.3533
下载: 导出CSV
-
[1] 姜斌, 吴云凯, 陆宁云, 冒泽慧. 高速列车牵引系统故障诊断与预测技术综述. 控制与决策, 2018, 33(5): 841−8551 Jiang Bin, Wu Yun-Kai, Lu Ning-Yun, Mao Ze-Hui. Review of fault diagnosis and prognosis techniques for high-speed railway traction system. Control and Decision, 2018, 33(5): 841−855 [2] 2 Shang J, Chen M Y, Ji H Q, Zhou D H. Recursive transformed component statistical analysis for incipient fault detection. Automatica, 2017, 80: 313−327 doi: 10.1016/j.automatica.2017.02.028 [3] 3 Lei Y G, Qiao Z J, Xu X F, Liu J, Niu S T. An underdamped stochastic resonance method with stable-state matching for incipient fault diagnosis of rolling element bearings. Mechanical Systems and Signal Processing, 2017, 94: 148−164 doi: 10.1016/j.ymssp.2017.02.041 [4] 周东华, 纪洪泉, 何潇. 高速列车信息控制系统的故障诊断技术. 自动化学报, 2018, 44(7): 1153−11644 Zhou Dong-Hua, Ji Hong-Quan, He Xiao. Fault diagnosis techniques for the information control system of high-speed trains. Acta Automatica Sinica, 2018, 44(7): 1153−1164 [5] 5 Tobon-Mejia D A, Medjaher K, Zerhouni N, Tripot, G. A data-driven failure prognostics method based on mixture of Gaussians hidden Markov models. IEEE Transactions on Reliability, 2012, 61(2): 491−503 doi: 10.1109/TR.2012.2194177 [6] 6 Haque M S, Choi S, Baek J. Auxiliary particle filtering-based estimation of remaining useful life of IGBT. IEEE Transactions on Industrial Electronics, 2018, 65(3): 2693−2703 doi: 10.1109/TIE.2017.2740856 [7] 7 Tseng S T, Balakrishnan N, Tsai C C. Optimal step-stress accelerated degradation test plan for gamma degradation processes. IEEE Transactions on Reliability, 2009, 58(4): 611−618 doi: 10.1109/TR.2009.2033734 [8] 8 Zhai Q, Ye Z S. RUL prediction of deteriorating products using an adaptive wiener process model. IEEE Transactions on Industrial Informatics, 2017, 13(6): 2911−2921 doi: 10.1109/TII.2017.2684821 [9] 9 Si X S, Wang W B, Hu C H, Zhou D H. Remaining useful life estimation-a review on the statistical data driven approaches. European Journal of Operational Research, 2011, 213(1): 1−14 doi: 10.1016/j.ejor.2010.11.018 [10] 10 Lu N Y, Yao Y, Gao F R. Two-dimensional dynamic PCA for batch process monitoring. AIChE Journal, 2005, 51(12): 3300−3304 doi: 10.1002/aic.10568 [11] 11 Zhao C H, Gao F R. Online fault prognosis with relative deviation analysis and vector autoregressive modeling. Chemical Engineering Science, 2015, 138(22): 531−543 [12] 12 Zhao C H, Gao F R. Critical-to-fault-degradation variable analysis and direction extraction for online fault prognostic. IEEE Transactions on Control Systems Technology, 2017, 25(3): 842−854 doi: 10.1109/TCST.2016.2576018 [13] 13 Li Y, Lu N Y, Wang X L, Jiang B. Islanding fault detection based on data-driven approach with active developed reactive power variation. Neurocomputing, 2019, 337(14): 97−109 [14] 14 Pham H T, Yang B S, Nguyen T T. Machine performance degradation assessment and remaining useful life prediction using proportional hazard model and support vector machine. Mechanical Systems and Signal Processing, 2012, 32: 320−330 doi: 10.1016/j.ymssp.2012.02.015 [15] 15 Huang H Z, Wang H K, Li Y F, Zhang L L, Liu Z L. Support vector machine based estimation of remaining useful life: current research status and future trends. Journal of Mechanical Science and Technology, 2015, 29(1): 151−163 doi: 10.1007/s12206-014-1222-z [16] 16 Tipping M E. Sparse bayesian learning and the relevance vector machine. Journal of Machine Learning Research, 2001, 1(3): 211−44 [17] 17 Yu H Y, Wu Z H, Chen D W, Ma X L. Probabilistic prediction of bus headway using relevance vector machine regression. IEEE Transactions on Intelligent Transportation Systems, 2017, 18(7): 1772−1781 doi: 10.1109/TITS.2016.2620483 [18] 18 Wu Y M, Breaz E, Gao F, Miraoui A. A modified relevance vector machine for PEM fuel-cell stack aging prediction. IEEE Transactions on Industry Applications, 2016, 52(3): 2573−2581 doi: 10.1109/TIA.2016.2524402 [19] 19 Saha B, Goebel K, Poll S, Christophersen J. Prognostics methods for battery health monitoring using a Bayesian framework. IEEE Transactions on Instrumentation and Measurement, 2009, 58(2): 291−296 doi: 10.1109/TIM.2008.2005965 [20] 20 Widodo A, Kim, E Y, Son J D, Yang B S, Tan A C, Gu D S, Choid B K, Mathew J. Fault diagnosis of low speed bearing based on relevance vector machine and support vector machine. Expert Systems with Applications, 2009, 36(3): 7252−7261 doi: 10.1016/j.eswa.2008.09.033 [21] 21 Zio E, Di Maio F. Fatigue crack growth estimation by relevance vector machine. Expert Systems with Applications, 2012, 39(12): 10681−10692 doi: 10.1016/j.eswa.2012.02.199 [22] 22 Widodo A, Yang B S. Application of relevance vector machine and survival probability to machine degradation assessment. Expert Systems with Applications, 2011, 38(3): 2592−2599 doi: 10.1016/j.eswa.2010.08.049 [23] Wang X L, Jiang B, Lu N Y. Adaptive relevant vector machine based RUL prediction under uncertain conditions. ISA Transactions, 2018, DOI: 10.1016/j.isatra. 2018.11.024 [24] 24 Yang C H, Yang C, Peng T, Yang X Y, Gui W H. A fault-injection strategy for traction drive control systems. IEEE Transactions on Industrial Electronics, 2017, 64(7): 5719−5727 doi: 10.1109/TIE.2017.2674610 [25] 25 Yang X Y, Yang C H, Peng T, Chen Z W, Liu B, Gui W H. Hardware-in-the-loop fault injection for traction control system. IEEE Journal of Emerging and Selected Topics in Power Electronics, 2018, 6(2): 696−706 doi: 10.1109/JESTPE.2018.2794339 期刊类型引用(8)
1. 葛泉波,程惠茹,张明川,郑瑞娟,朱军龙,吴庆涛. 基于PCA和ICA模式融合的非高斯特征检测识别. 自动化学报. 2024(01): 169-180 .  本站查看
本站查看2. 邢楷,单耀,王克南,樊林林,邹阳. 耦合主成分分析下煤矿矿井突水水源识别方法. 能源与环保. 2024(04): 38-43 . 百度学术3. 李伟,雷鹏,黄天尘,张晓利,叶鸥. 基于MLP-DBN模型的构造煤分布预测策略分析. 能源与环保. 2024(04): 118-123 . 百度学术4. 吕弢,陈璟,薛善烨. 离散制造中基于多源多模数据的产品指标联合分析. 空天防御. 2024(05): 110-119+126 . 百度学术5. 毕鹏飞,胡志远,陈璇,杜雪. 双灵活度量自适应加权2DPCA在水下光学图像识别中的应用. 电子与信息学报. 2024(11): 4188-4197 . 百度学术6. 裴正中,赵旭俊. 基于同构化角度的离群检测方法. 计算机工程与设计. 2024(12): 3622-3630 . 百度学术7. 陈璇,毕鹏飞,胡志远. 任意三角形结构2DPCA在水下光学图像识别中的应用. 电子测量与仪器学报. 2024(12): 43-53 . 百度学术8. 吴磊,康英伟. 基于深度强化学习的湿法脱硫系统运行优化. 系统科学与数学. 2022(05): 1067-1087 . 百度学术其他类型引用(5)
-

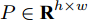
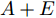
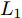
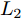

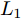
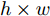
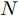
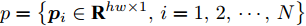
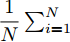
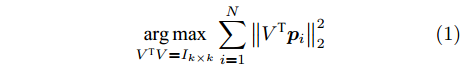
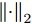
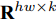
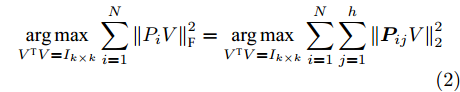
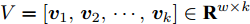
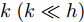
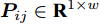

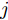

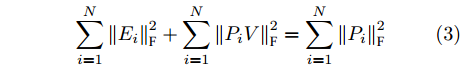
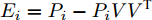

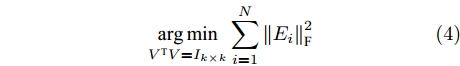
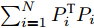
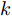
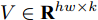
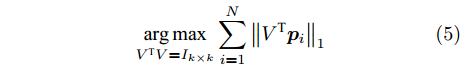
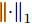
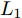
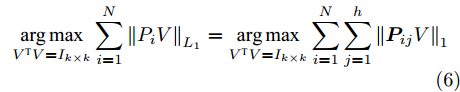
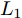
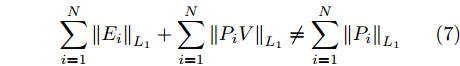
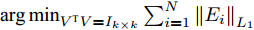

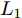

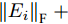
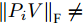
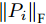
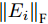
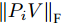
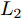
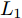
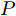
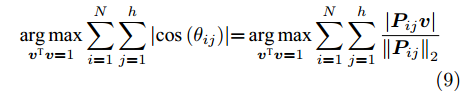
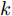
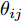

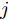
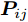
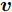
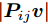
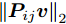
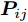
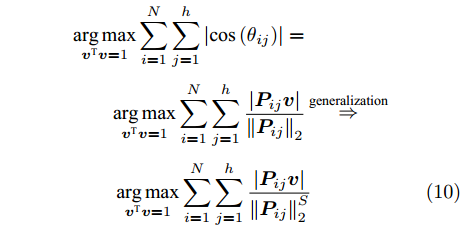
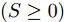
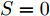
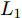
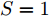
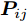
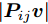
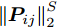
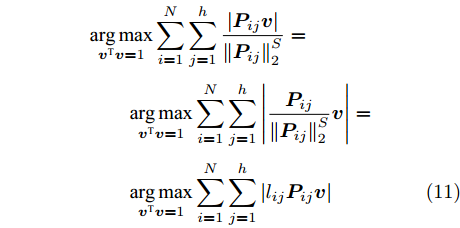
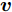
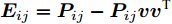
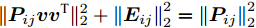

 下载:
下载:
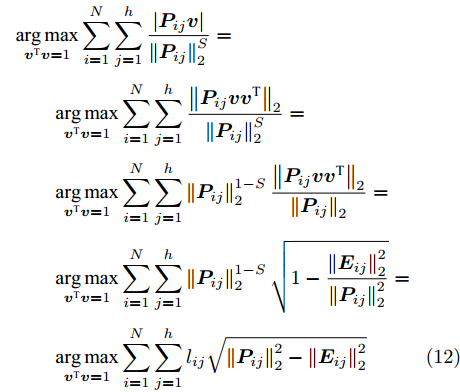
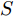
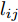
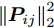
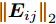

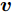
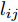
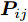
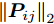
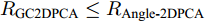
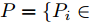
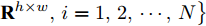
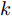
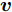
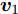
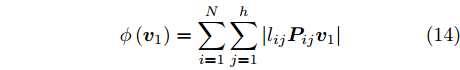
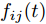
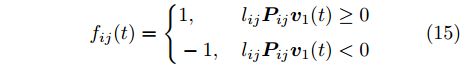
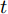
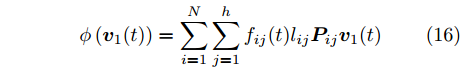
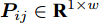
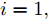

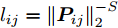
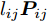
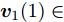
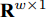
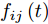
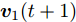
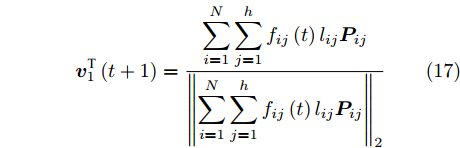
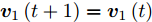
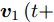
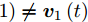
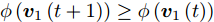
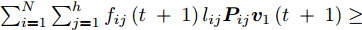
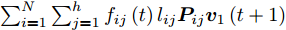
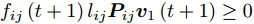
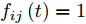

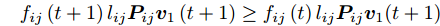
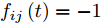

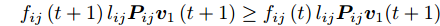
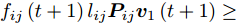
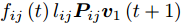
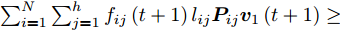
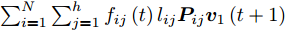
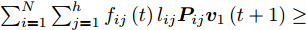
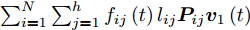
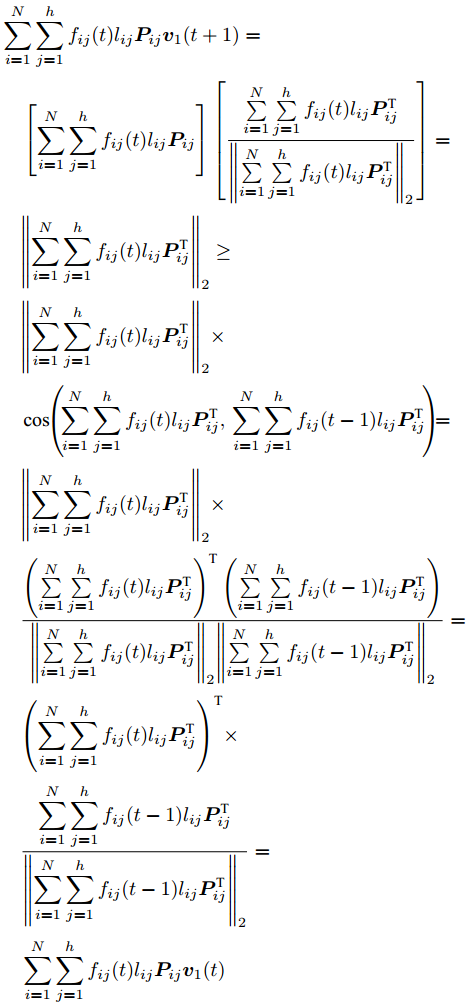
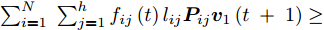
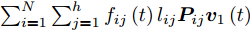
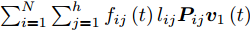
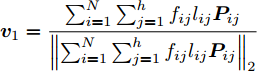
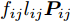
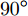
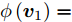
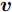
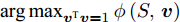
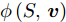
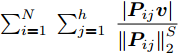
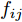

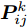
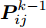

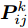

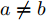
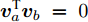
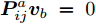
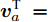
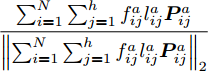

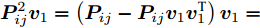


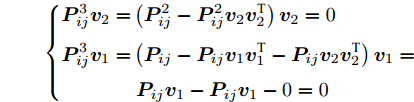
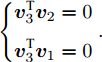
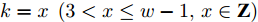
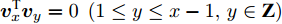
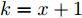
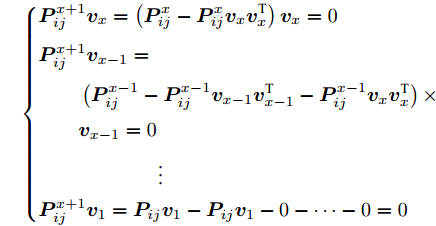
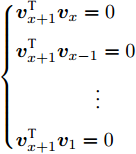
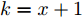
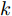

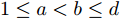
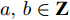

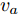
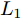
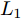
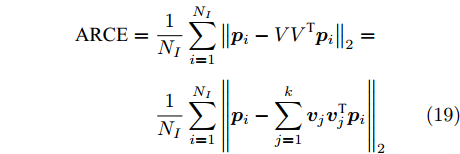
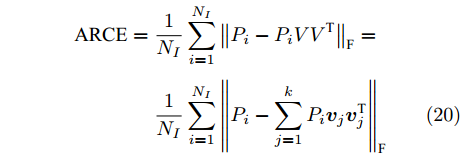
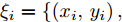
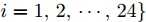
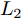
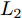
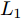
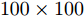
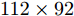
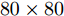
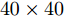
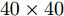
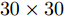
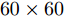
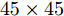



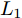
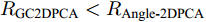
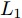

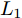
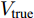
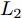
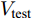
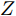

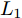

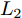

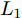
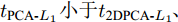
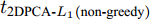
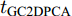
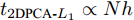
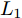



计量
- 文章访问数: 2191
- HTML全文浏览量: 640
- PDF下载量: 312
- 被引次数: 13
