

An Identification Method of High-speed Railway Sign Based on Convolutional Neural Network
-
摘要: 轨道交通在我国综合交通运输体系中占有重要的地位, 随着人工智能的发展, 智能感知轨道交通周围环境的信息也变得越来越引人注目. 本文结合深度学习与图像处理的方法, 设计并实现了一种基于卷积神经网络的高铁轨道周边路牌数字识别的智能系统, 该系统通过在高铁驾驶室内安装摄像头的方式采集运行前方的视频, 并通过目标识别、语义分割等深度学习算法自动定位并识别路牌内的数字, 从而解决了之前人工处理的繁琐和低效率.本算法整体系统由三个子模块构成, 分别为目标检测模块、语义分割模块以及数字识别模块, 其中目标检测模块基于SSD (Single shot MultiBox dector)模型, 并对其进行了改进, 使其更适用于轨道交通中的小目标识别; 语义分割模块使用了全卷积的方式, 对目标检测的结果进一步处理, 准确得到路牌中的数字区域; 数字识别模块的设计参考了著名的识别MNIST数据集的手写体识别系统, 并针对路牌中数字的特点做了相应的改进, 实现了对每个数字的准确识别. 实验结果表明, 本系统可适应白天、夜间情况下轨道交通的路况, 识别的综合准确率为80.45 %, 其中, 白天的平均识别准确率为87.98 %, 夜间的平均识别准确率为72.92 %.Abstract: Rail transit plays an important role in China's comprehensive transportation system.Intelligent perception of environmental information around rail traffic is also becoming more and more attractive. Combining the methods of deep learning and image processing, the paper designs and implements an intelligent system that is based on convolutional neural network for identification of rail digital signs around high-speed rail. The system not only collects videos by installing a camera in the high-speed rail cab but also automatically locates and identifies the numbers in the railway sign by the depth learning algorithm such as object detection and semantic segmentation, which can solve the cumbersome and inefficient manual processing. The total system of the algorithm consists of three sub-modules: the object detection module is based on the single shot MultiBox dector (SSD) model and improves it to be more suitable to detect the small target in the rail transit; the semantic segmentation module uses the full convolution method to further process the result of the object detection module and then get accurate digital region in the rail sign; the design of the digital identification module referred to the famous handwriting recognition system that recognizes the MNIST dataset. Besides,it improved the characteristics of the numbers in the railway signs and achieved the accurate identification of each number. The experimental results show that the system can adapt to the conditions of various rail transits, including: day and night. The comprehensive accuracy of recognition is 80.45 %. Furthermore,the average accuracy of the daytime is 87.98 %, and the average accuracy of the night is 72.92 %.1) 收稿日期 2019-03-19 录用日期 2019-08-08 Manuscript received March 19, 2019; accepted August 8, 2019 本文责任编委 阳春华 Recommended by Associate Editor YANG Chun-Hua 1. 东北大学信息科学与工程学院 沈阳 110000 2. 友和利德科技有限公司 沈阳 110000 3. 沈阳产品质量监督检验院 沈阳 110000 1. College of Information Science and Engineering, Northeastern2) University, Shenyang 110000 2. UUValue Technology Co., Ltd, Shenyang 110000 3. Shenyang Product Quality Supervision and Inspection Institute, Shenyang 110000
-

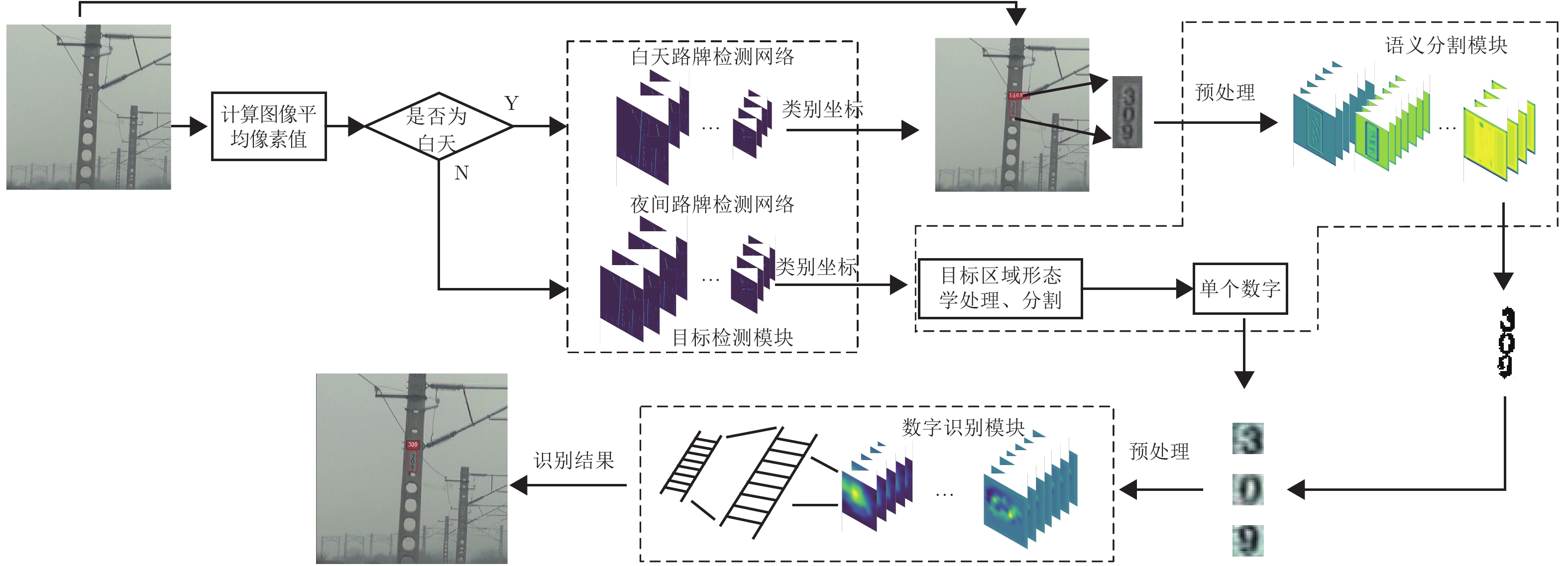
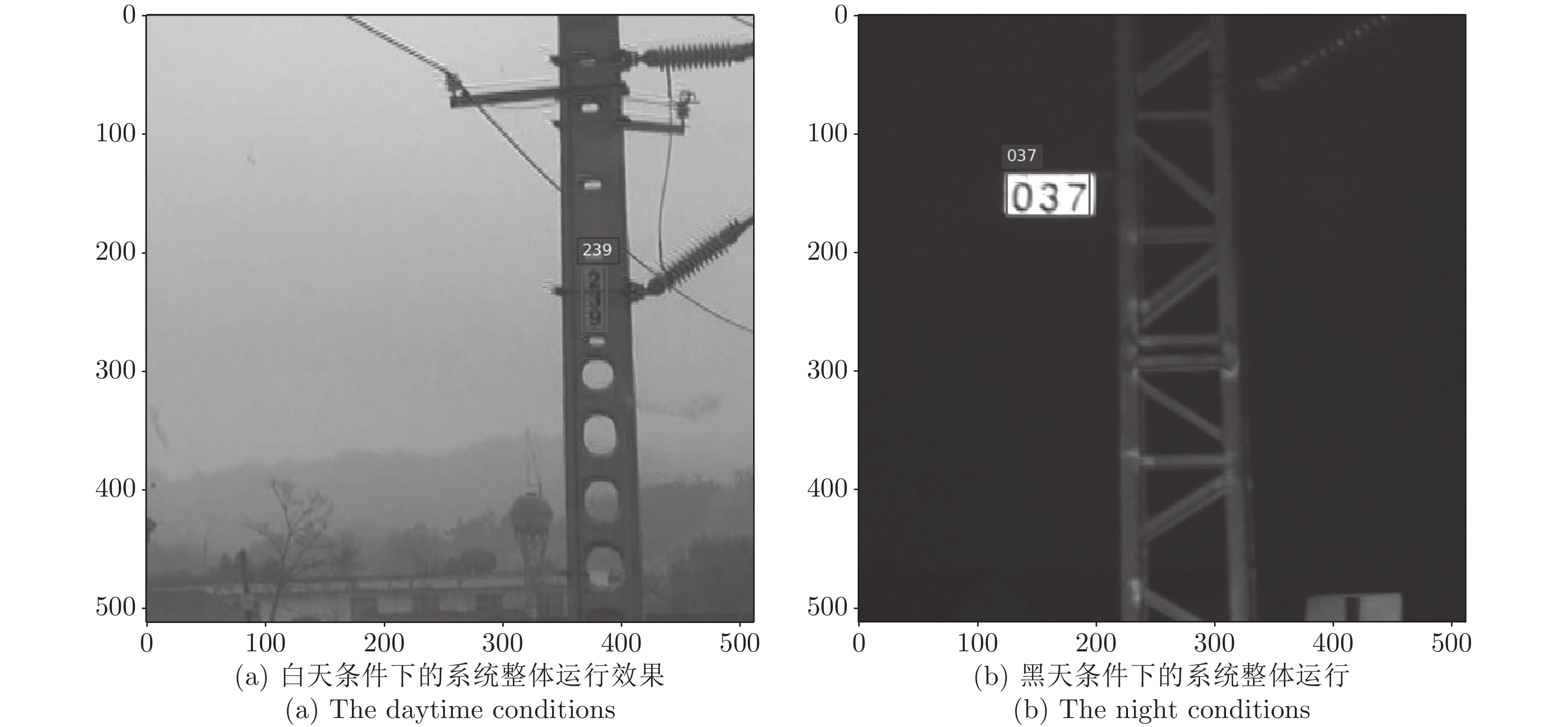
图 1 高铁运行过程中, 驾驶室内摄像头所拍摄的视频图像路牌内包含数字, 其范围为000
$\sim $ 999Fig. 1 The image captured by the camera in the cab, the number range is 000
$\sim $ 999
图 5 路牌检测模块的训练数据集示例图
Fig. 5 Example image of the training data set of the road sign detection module

图 7 白天条件下语义分割模块单独数字分割过程
Fig. 7 Semantic segmentation module separate digital segmentation process under daytime conditions

图 8 夜间条件下路牌中数字区域的二值化过程
Fig. 8 Binary process of digital regions in rail signs under night conditions
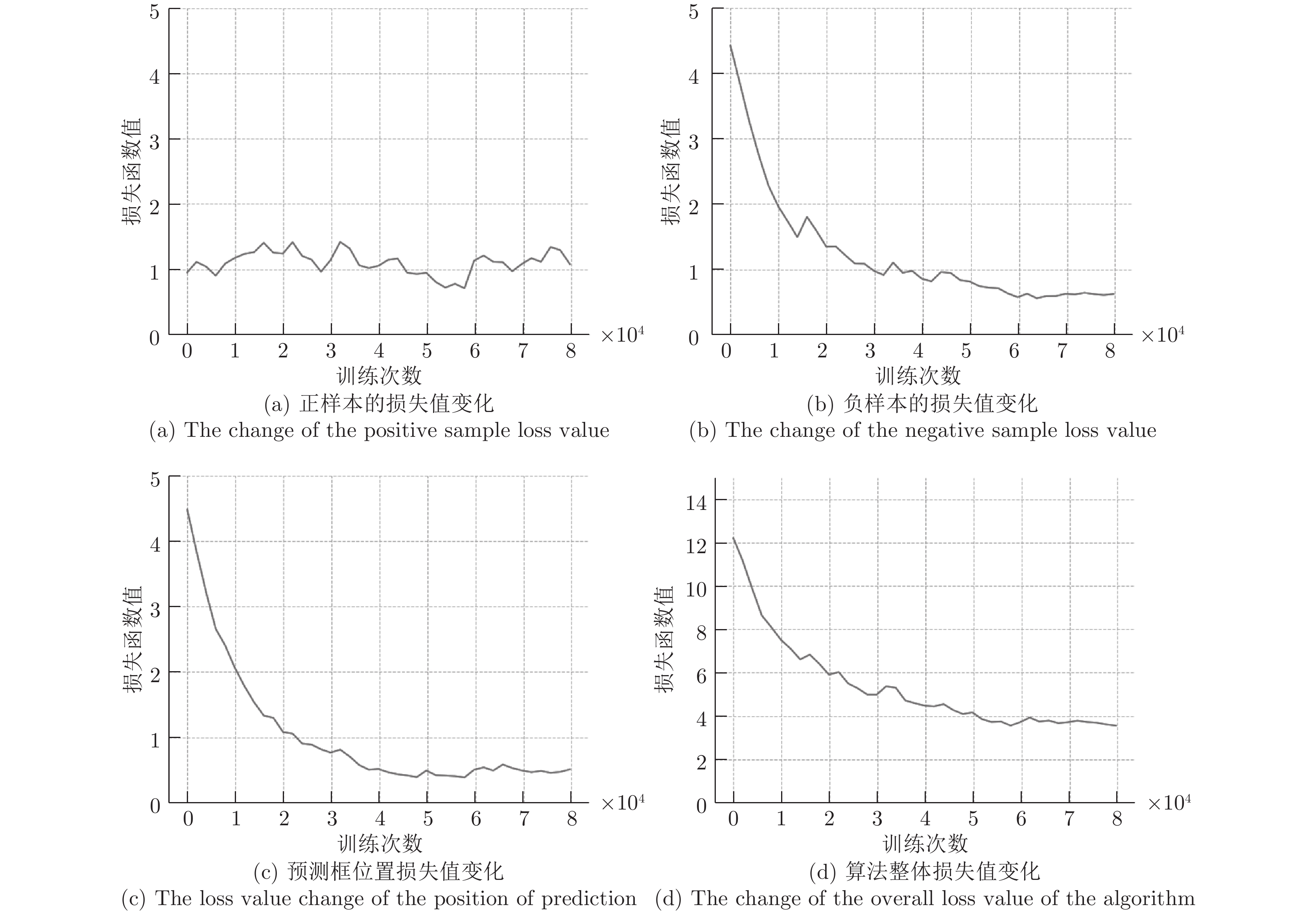
图 10 白天条件下路牌检测模块训练损失值变化图
Fig. 10 The rail sign detection module training loss value change graph under the daytime conditions
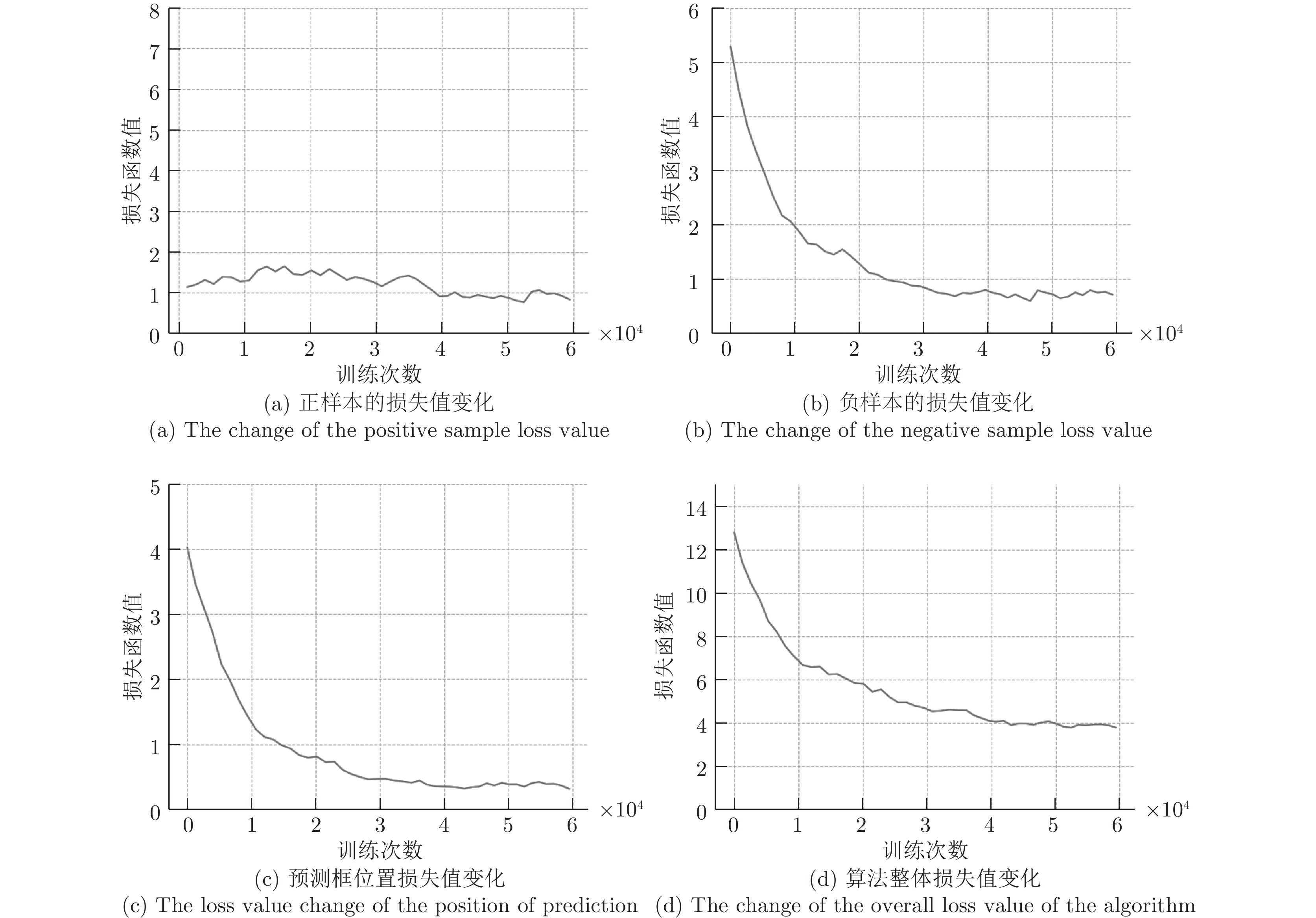
图 11 黑天条件下路牌检测模块训练损失值变化图
Fig. 11 The rail sign detection module training loss value change graph under the dark conditions

图 14 语义分割网络损失函数变化图
Fig. 14 Semantic segmentation network loss function curve in the training

图 16 单个数字区域的结果图
Fig. 16 Regions of each digital number obtained by semantic segmentation algorithm

图 17 数字识别网络损失函数变化图
Fig. 17 Digital recognition network loss function curve in the training
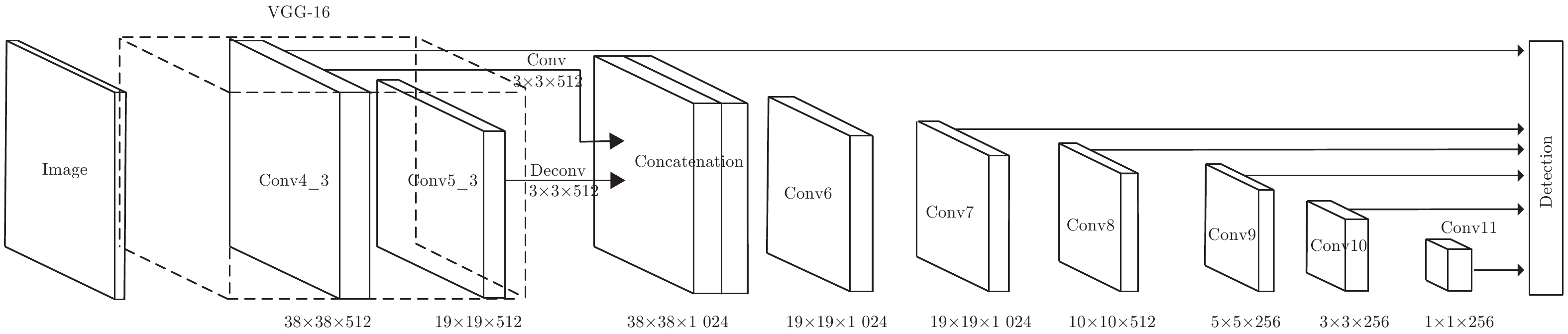
表 1 特征融合SSD算法训练超参数
Table 1 The hyperparameter of feature fusion SSD algorithm
超参数 取值 Iteration 5 000 Learn rate 0.00099 Learn rate decay factor 0.98 Weight decay 0.0005 Batch size 16 Optimizer SGD  下载: 导出CSV
下载: 导出CSV
表 2 不同结构下分割准确率及速度
Table 2 Segmentation accuracy and speed in different structures
网络层数 重叠率 (%) 速度 (s/张) 5 81.15 0.006 6 82.19 0.010 7 81.38 0.017 8 81.8 0.019 9 82.02 0.020
下载: 导出CSV
表 3 语义分割网络卷积核大小
Table 3 The kernel size of semantic segmentation network convolution
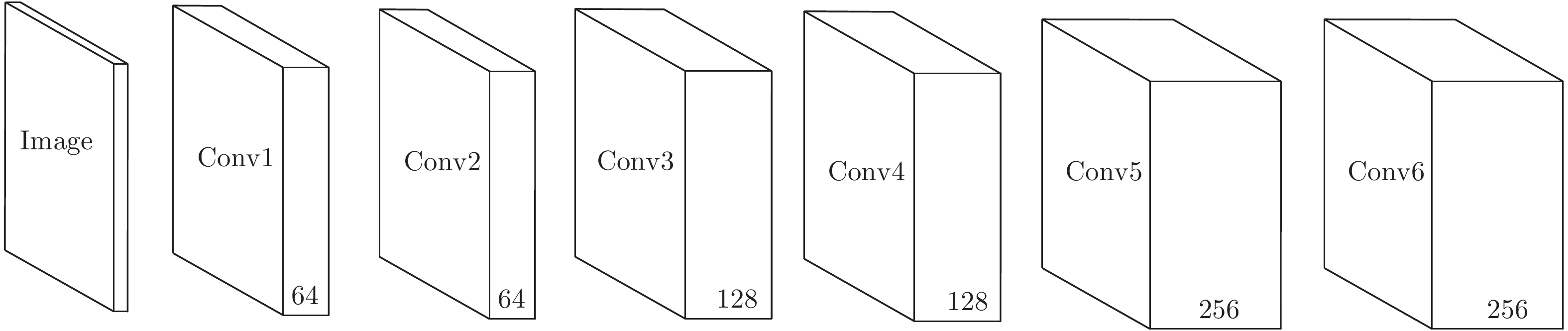
网络层 卷积核大小 输出大小 Input − $72\times72$ Conv1 3×3 $72\times72\times64$ Conv2 3×3 $72\times72\times64$ Conv3 3×3 $72\times72\times128$ Conv4 3×3 $72\times72\times128$ Conv5 3×3 $72\times72\times256$ Conv6 3×3 $72\times72\times256$
下载: 导出CSV
表 4 语义分割算法训练超参数
Table 4 The hyperparameter semantic segmentation algorithm
超参数 取值 Iteration 100 000 Learn rate 0.0001 Learn rate decay factor 0.98 Batch size 2 Optimizer SGD
下载: 导出CSV
表 5 数字识别算法训练超参数
Table 5 The hyperparameter of digital recognition algorithm
超参数 取值 Iteration 80 000 Learn rate 0.001 Learn rate decay factor 0.99 Batch size 8 Optimizer SGD
下载: 导出CSV
表 6 服务器配置
Table 6 Server configuration
设备 配置 系统 Ubuntu16.04 内存 64 GB GPU Tesla K40 显存 12 GB
下载: 导出CSV
表 7 不同网络结构下的测试结果
Table 7 Test results in different training datasets
网络结构 测试集 mAP (%) 特征融合 SSD 白天 + 黑天 80.10 浅层特征 SSD (VGG-2) 白天 + 黑天 76.23 浅层特征 SSD (VGG-3) 白天 + 黑天 79.01 浅层特征 SSD (VGG-4) 白天 + 黑天 79.89
下载: 导出CSV
表 8 不同训练集下的测试结果
Table 8 Test results in different training datasets
训练集 测试集 算法 mAP (%) 白天 白天 特征融合 SSD 81.29 黑天 黑天 特征融合 SSD 83.57 白天 + 黑天 白天 特征融合 SSD 80.12 白天 + 黑天 黑天 特征融合 SSD 79.30
下载: 导出CSV
表 9 不同训练集与分割方法下的分割效果
Table 9 Segmentation effects under different training sets and segmentation methods
使用方法 训练集 测试集 mAP (%) 速度 (s/张) 深度学习 白天+黑天 白天 83.67 0.001 深度学习 白天 白天 82.19 0.001 深度学习 白天+黑天 黑天 83.07 0.001 阈值分割+形态学 黑天 黑天 85.39 0.0001
下载: 导出CSV
表 10 系统准确率统计(%)
Table 10 Statistics of each system accuracy rate (%)
使用方法 准确率 目标检测 + 语义分割 + 数字识别
(白天)73 目标检测 + 语义分割 + 数字识别 + 后处理
(位置关系) (白天)78 目标检测 + 语义分割 + 数字识别 + 后处理
(位置关系 + 逻辑关系) (白天)87.98 目标检测 + 语义分割 + 数字识别
(黑天)58.33 目标检测 + 语义分割 + 数字识别 + 后处理
(位置关系 + 逻辑关系) (黑天)72.92
下载: 导出CSV
-
[1] 李泽新. 人工智能在智能交通中的应用. 科技传播, 2018, 10(19): 104−105 doi: 10.3969/j.issn.1674-6708.2018.19.0601 Li Ze-Xin. Application of artificial intelligence in intelligent transportation. Public Communication of Science and Technology, 2018, 10(19): 104−105 doi: 10.3969/j.issn.1674-6708.2018.19.060 [2] 冯江华. 轨道交通装备技术演进与智能化发展. 控制与信息技术, 2019, 1(1): 1−62 Feng Jiang-Hua. Technical evolution and intelligent development of rail transit equipments. Control and Information Technology, 2019, 1(1): 1−6 [3] Girshick R, Donahue J, Darrell T, Malik J. Rich feature hierarchies for accurate object detection and semantic segmentation. In: Proceedings of the 2014 IEEE Conference on Computer Vision and Pattern Recognition, Columbus, USA: IEEE, 2014. 580−587 [4] 4 Uijlings J, van de Sande K, Gevers T, Smeulders A. Selective search for object recognition. International Journal of Computer Vision, 2013, 104(2): 154−171 doi: 10.1007/s11263-013-0620-5 [5] 5 He K M, Zhang X Y, Ren S Q, Sun J. Spatial pyramid pooling in deep convolutional networks for visual recognition. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2015, 37(9): 1904−1916 doi: 10.1109/TPAMI.2015.2389824 [6] Girshick R. Fast R-CNN. In: Proceedings of the 2015 IEEE International Conference on Computer Vision, Santiago, Chile: IEEE, 2015. 1440−1448 [7] Redmon J, Divvala S, Girshick R, Farhadi A. You only look once: unified, real-time object detection. In: Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition, Nevada, USA: IEEE, 2016. 779−788 [8] Redmon J, Farhadi A. YOLO9000: better, faster, stronger. In: Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition. Honolulu, USA: IEEE, 2017. 6517−6525 [9] Viola P, Jones M. Object detection using a boosted cascade of simple features. In: Proceedings of the 2001 IEEE Computer Society Conference on Computer Vision and Pattern Recognition. Kauai, USA: IEEE, 2001. 1−1 [10] Dalal N, Triggs B. Histograms of oriented gradients for human detection. In: Proceedings of the 2005 IEEE Computer Society Conference on Computer Vision and Pattern Recognition. SanDiego, USA: IEEE, 2005. 886−893 [11] 11 Girshick R, McAllester D, Ramanan D. Object detection with discriminatively trained part — based models. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2010, 32(9): 1627−1645 doi: 10.1109/TPAMI.2009.167 [12] 12 Shelhamer E, Long J, Darrell T. Fully convolutional networks for semantic segmentation. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2014, 39(4): 640−651 [13] Liu W, Dragomir A, Dumitru E, Christian S, Scott R, Fu C Y, et al. SSD: single shot multiBox detector. In: Proceedings of the 2016 European Conference on Computer Vision. Amsterdam, The Netherlands: ECCV, 2016. 21−37 [14] Simonyan K, Zisserman A. Very deep convolutional networks for large-scale image recognition. In: Proceedings of the 2015 International Conference on Learning Representations. San Diego, USA: ICLR, 2015. [15] 15 Ren S Q, He K M, Girshick R, Sun J. Faster R-CNN: towards real-time object detection with region proposal networks. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2017, 39(6): 1137−1149 doi: 10.1109/TPAMI.2016.2577031 [16] Neubeck A, Van G. Efficient non maximum suppression. In: Proceedings of the 18th International Conference on Pattern Recognition. Hong Kong, China: IEEE, 2006. 850−855 -



 下载:
下载:












计量
- 文章访问数: 2863
- HTML全文浏览量: 1454
- PDF下载量: 580
- 被引次数: 0
