

-
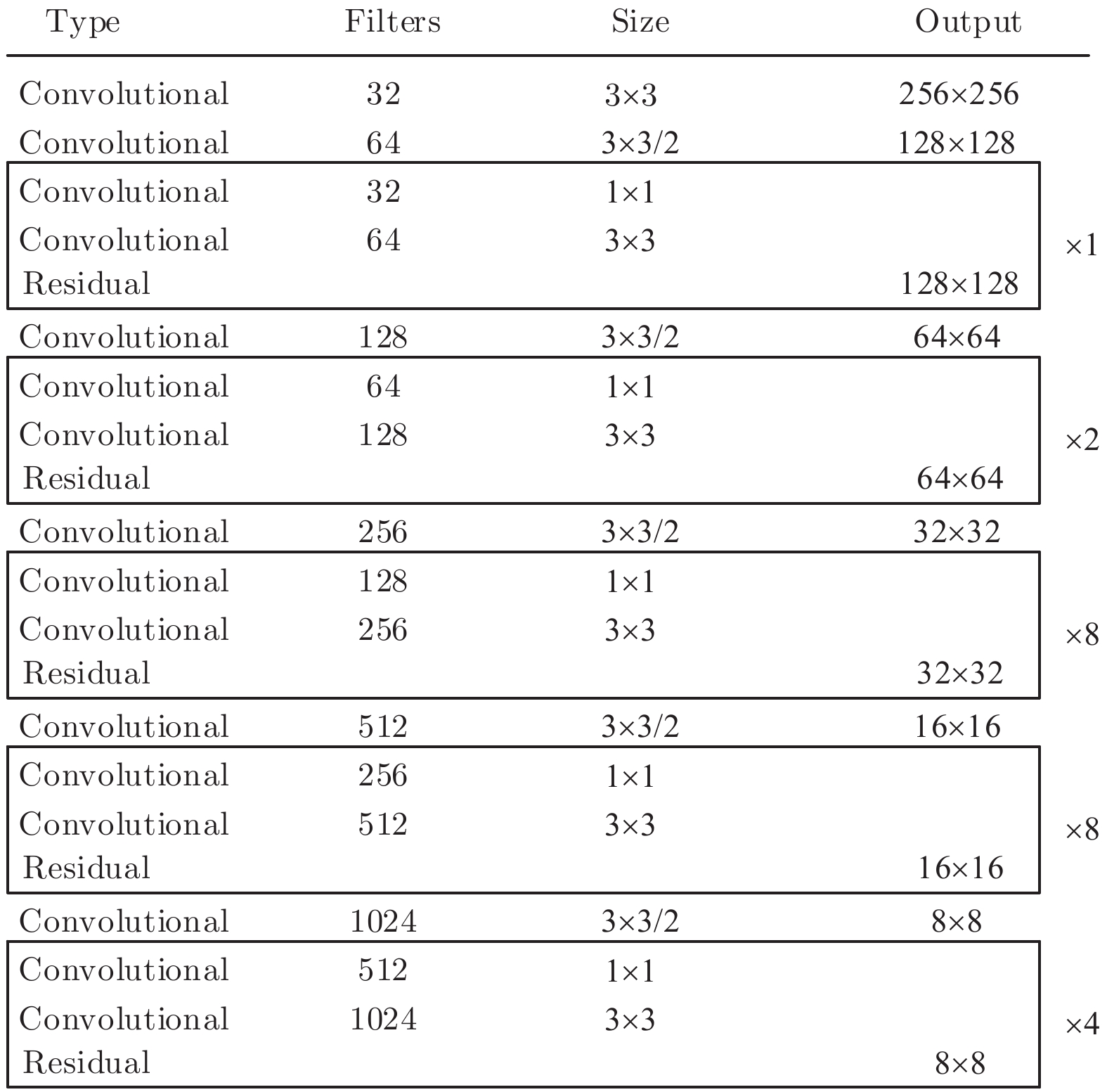
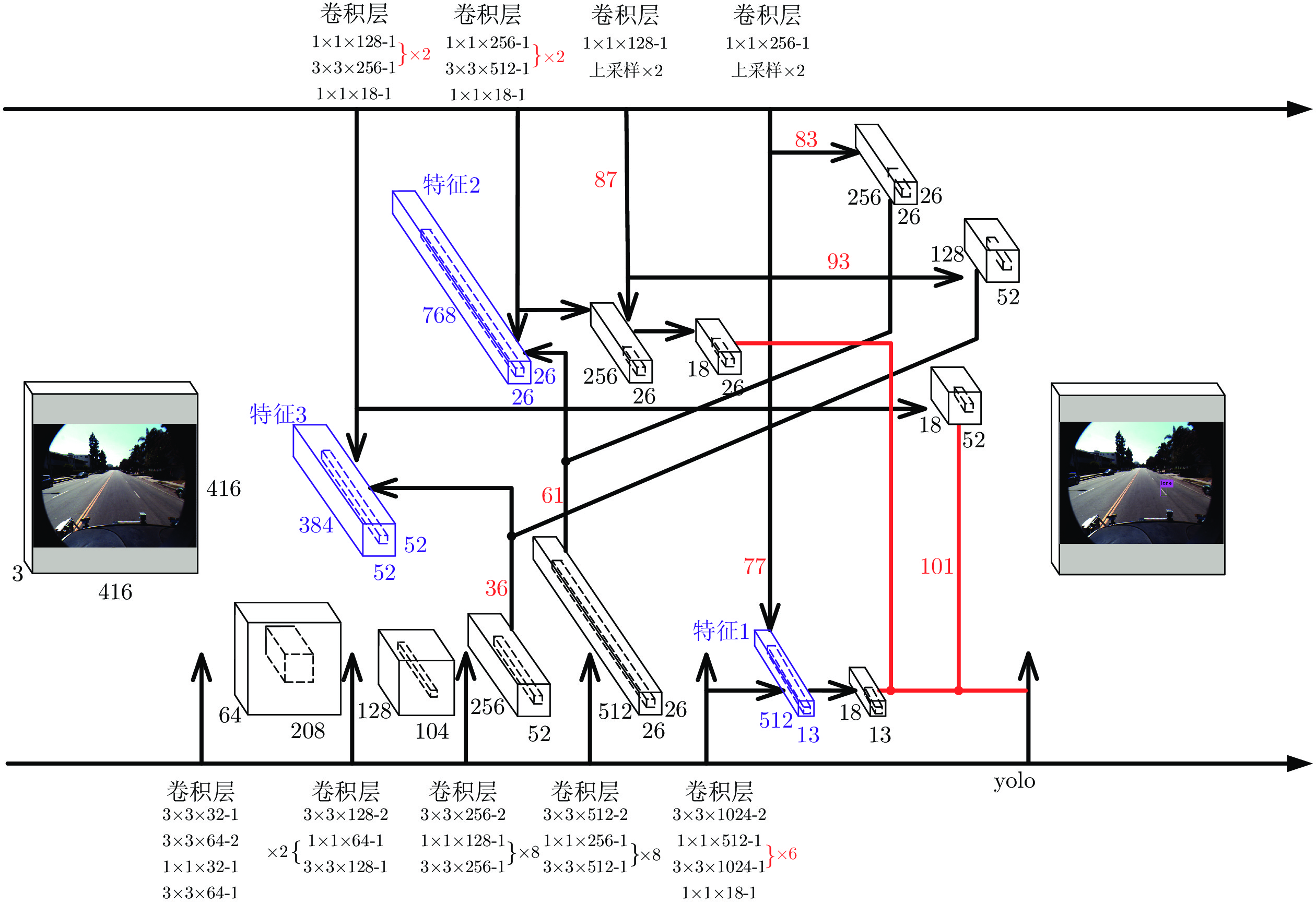
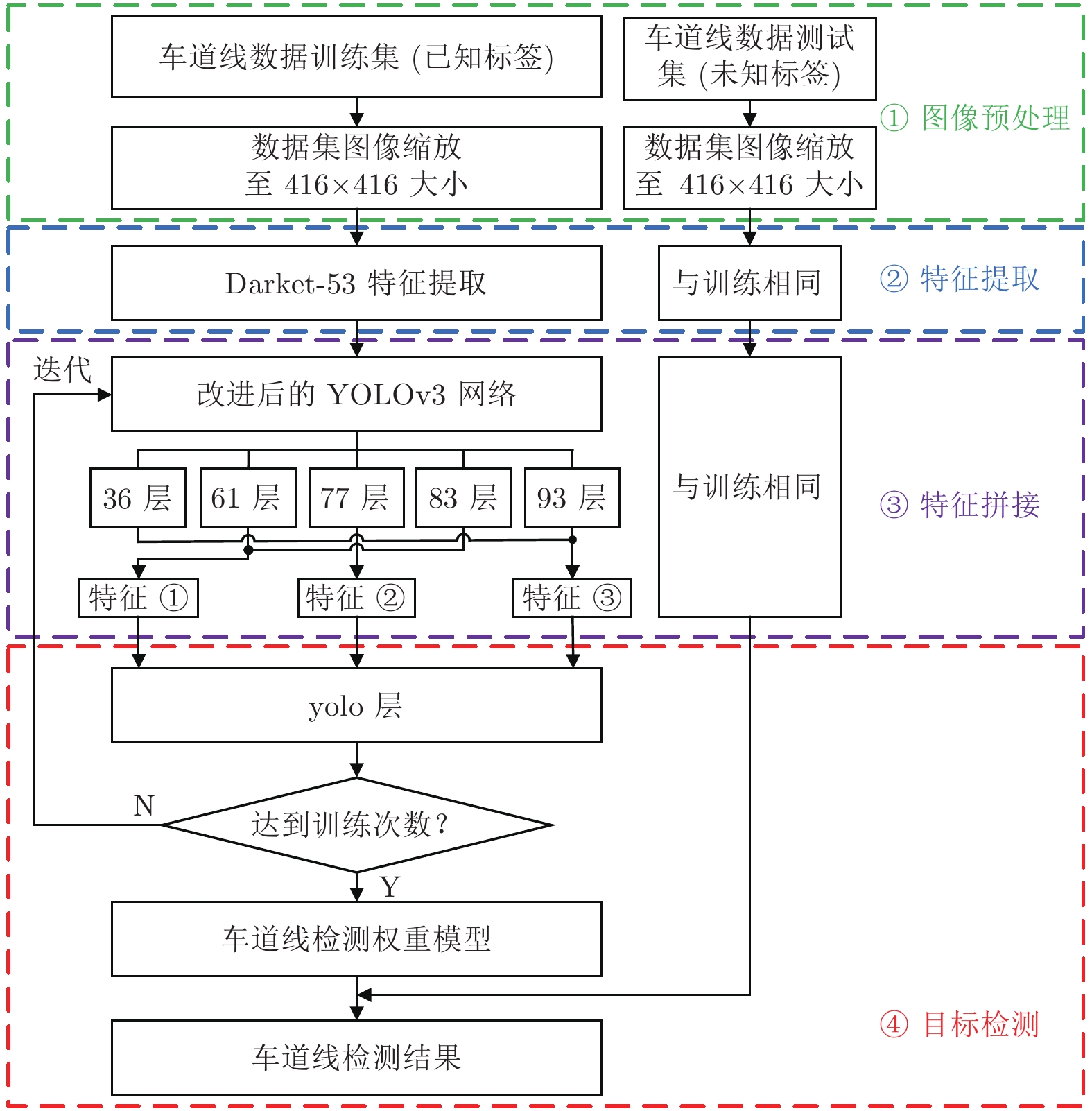
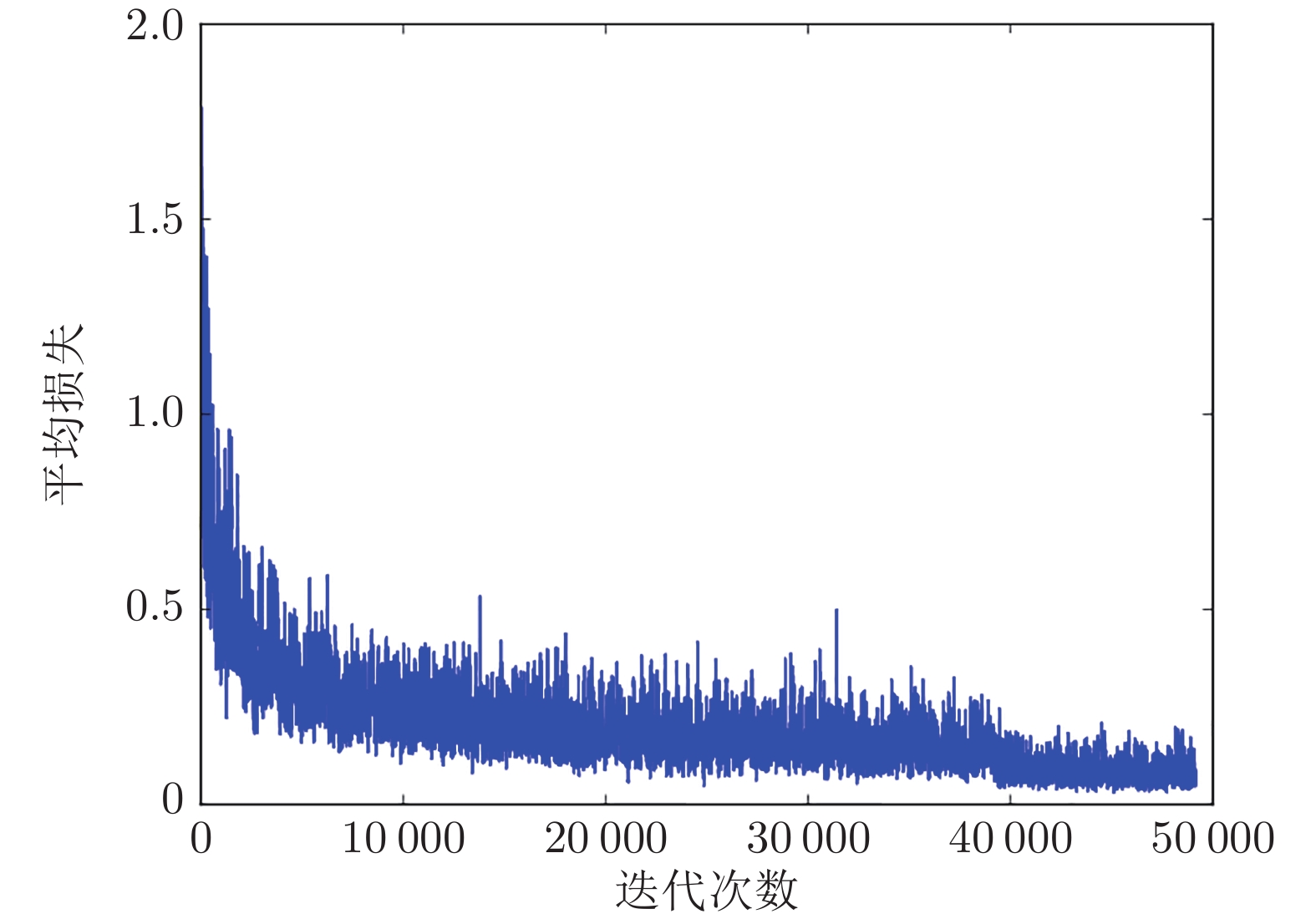
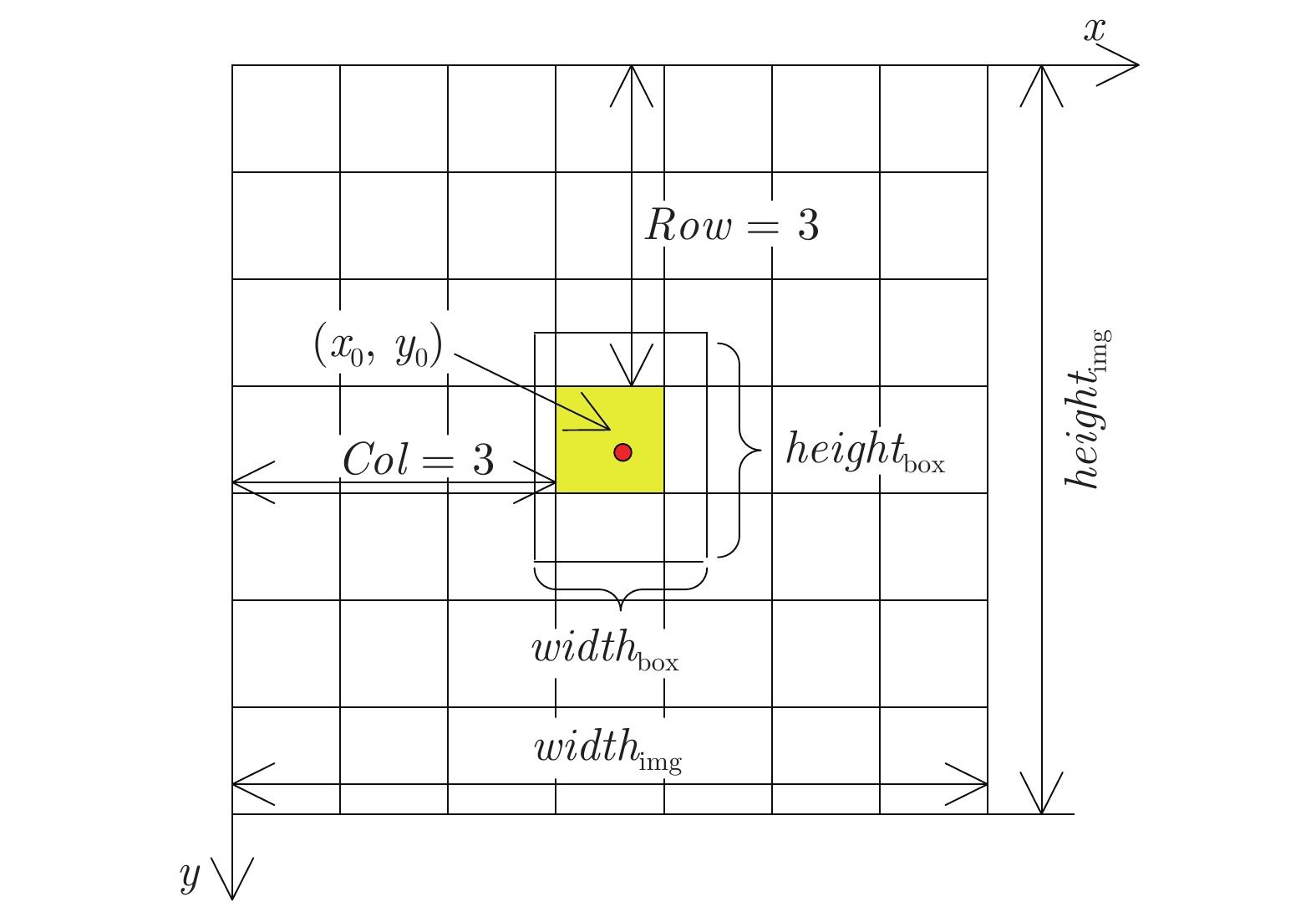
摘要: 针对YOLOv3算法在检测公路车道线时存在准确率低和漏检概率高的问题, 提出一种改进YOLOv3网络结构的公路车道线检测方法.该方法首先将图像划分为多个网格, 利用K-means++聚类算法, 根据公路车道线宽高固有特点, 确定目标先验框数量和对应宽高值; 其次根据聚类结果优化网络Anchor参数, 使训练网络在车道线检测方面具有一定的针对性; 最后将经过Darknet-53网络提取的特征进行拼接, 改进YOLOv3算法卷积层结构, 使用GPU进行多尺度训练得到最优的权重模型, 从而对图像中的车道线目标进行检测,并选取置信度最高的边界框进行标记.使用Caltech Lanes数据库中的图像信息进行对比试验, 实验结果表明, 改进的YOLOv3算法在公路车道线检测中平均准确率(Mean average precision, mAP)为95%, 检测速度可达50帧/s, 较YOLOv3原始算法mAP值提升了11%, 且明显高于其他车道线检测方法.Abstract: Aiming at the problem that the YOLOv3 algorithm has low accuracy, high probability of missed detection when detecting road lane lines, a road lane detection method for improving YOLOv3 network structure is proposed. At first, the method divides the image into multiple grids, and uses the K-means++ clustering algorithm to determine the number of target priori boxes and the corresponding value according to the inherent characteristics of the road lane line width and height. Then, according to the clustering result, the network anchor parameter is optimized to make the training network have certain pertinence in lane line detection. At last, the features extracted by the Darknet-53 are spliced, the network structure of the YOLOv3 algorithm is improved, and the GPU is used for multi-scale training to obtain the optimal weight model, thereby detecting the lane line target in the image and selecting the bounding box with the highest confidence to mark. Using the image information in the Caltech Lanes database for comparison experiments, the experimental results show that the improved YOLOv3 algorithm's mean average precision is 95% in road lane detection, the improved detection speed can be achieved 50 frame/s, which is 11% higher than the original algorithm and significantly higher than other lane detection methods.
-
Key words:
- Lane detection /
- deep learning /
- YOLOv3 /
- K-means++ /
- computer vision
-

图 9 测试集图像在不同网络结构中的检测准确率
Fig. 9 The detection accuracy of test images in different network structures
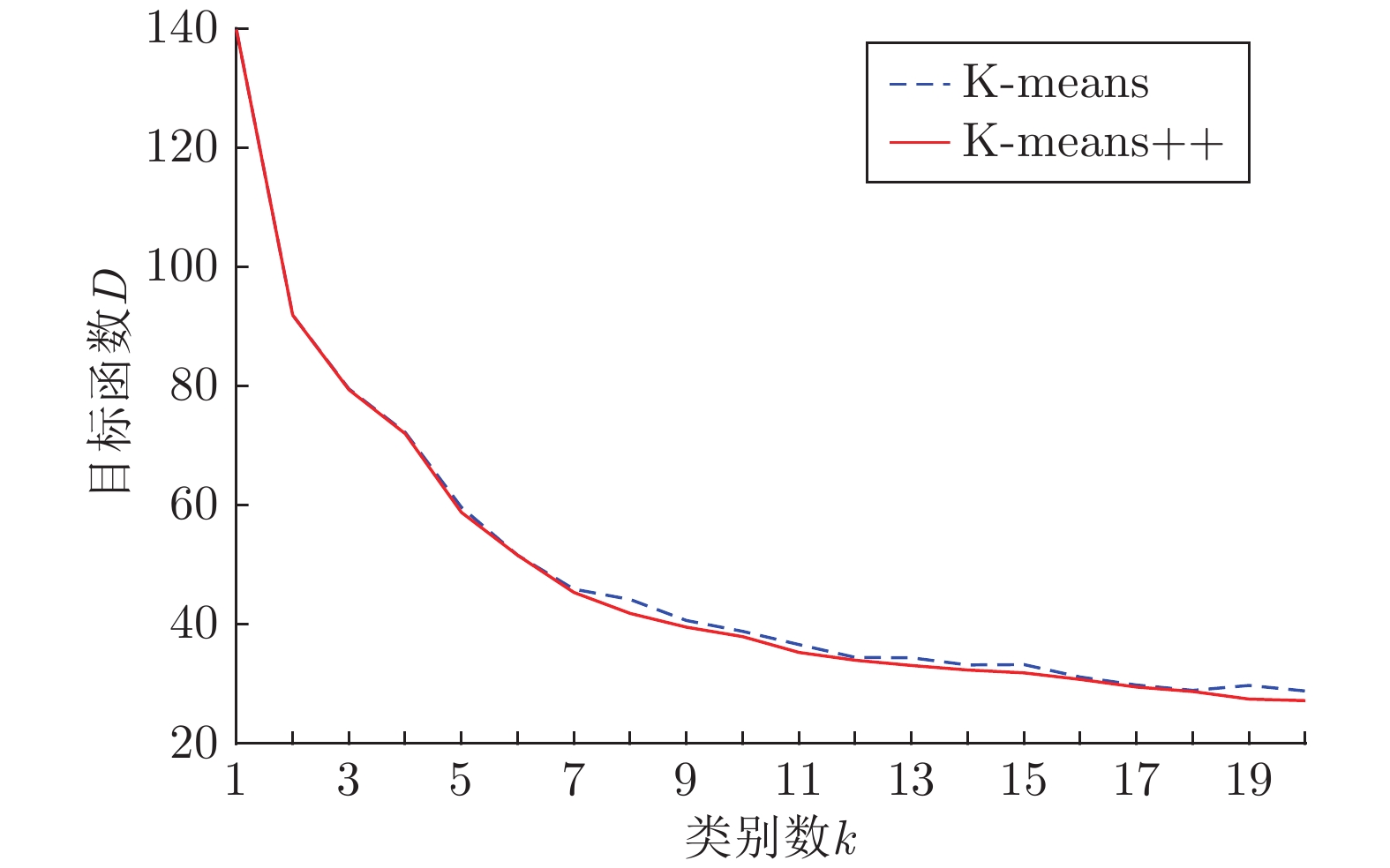
表 1 不同
$k$ 值对应的先验框宽高Table 1 The width and height of priori boxes corresponding to different
$k$ values$k$ = 7 $k$ = 8 $k$ = 9 $k$ = 10 $k$ = 11 (6, 9) (6, 9) (6, 9) (5, 12) (5, 7) (10, 15) (8, 12) (9, 14) (5, 17) (7, 11) (13, 21) (11, 17) (12, 18) (7, 11) (10, 14) (19, 30) (15, 24) (15, 24) (10, 14) (10, 18) (27, 44) (20, 32) (20, 32) (11, 18) (13, 20) (36, 60) (26, 43) (26, 43) (15, 24) (16, 25) (141, 10) (36, 69) (32, 51) (20, 32) (21, 32) — (141, 10) (40, 69) (27, 44) (26, 43) — — (141, 10) (36, 60) (32, 51) — — — (141, 10) (40, 70) — — — — (141, 10)  下载: 导出CSV
下载: 导出CSV
-
[1] 张慧, 王坤峰, 王飞跃. 深度学习在目标视觉检测中的应用进展与展望. 自动化学报, 2017, 43(08): 1289-1305Zhang Hui, Wang Kun-Feng, Wang Fei-Yue. Advances and perspectives on applications of deep learning in visual object detection. Acta Automatica Sinica, 2017, 43(08): 1289-1305 [2] 尹宏鹏, 陈波, 柴毅, 刘兆栋. 基于视觉的目标检测与跟踪综述. 自动化学报, 2016, 42(10): 1466-1489Yin Hong-Peng, Chen Bo, Chai Yi, Liu Zhao-Dong. Vision-based object detection and tracking: a review. Acta Automatica Sinica, 2016, 42(10): 1466-1489 [3] 《中国公路学报》编辑部. 中国汽车工程学术研究综述. 中国公路学报, 2017, 30(06): 1-197 doi: 10.3969/j.issn.1001-7372.2017.06.001Editorial department of china journal of highway and transport. Review on China's automotive engineering research progress. China Journal of Highway and Transport, 2017, 30(06): 1-197 doi: 10.3969/j.issn.1001-7372.2017.06.001 [4] 田娟秀, 刘国才, 谷珊珊, 鞠忠建, 刘劲光, 顾冬冬. 医学图像分析深度学习方法研究与挑战. 自动化学报, 2018, 44(03): 401-424Tian Juan-Xiu, Liu Guo-Cai, Gu Shan-Shan, Ju Zhong-Jian, Liu Jin-Guang, Gu Dong-Dong. Deep learning in medical image analysis and its challenges. Acta Automatica Sinica, 2018, 44(03): 401-424 [5] 李文英, 曹斌, 曹春水, 黄永祯. 一种基于深度学习的青铜器铭文识别方法. 自动化学报, 2018, 44(11): 2023-2030Li Wen-Ying, Cao Bing, Cao Chun-Shui, Huang Yong-Zhen. A deep learning based method for bronze inscription recognition. Acta Automatica Sinica, 2018, 44(11): 2023-2030 [6] 唐智威. 基于视觉的无人驾驶汽车研究综述. 制造业自动化, 2016, 38(8): 134-136 doi: 10.3969/j.issn.1009-0134.2016.08.032Tang Zhi-Wei. A review of driverless cars based on vision. Manufacturing Automation, 2016, 38(8): 134-136 doi: 10.3969/j.issn.1009-0134.2016.08.032 [7] He B, Ai R, Yan Y. Accurate and robust lane detection based on dual-view convolution neutral network. In: Proceedings of the 2016 Intelligent Vehicles Symposium. Gothen, Sweden: IEEE, 2016. 1041−1046 [8] Li J, Mei X, Prokhorov D, Tao D. Deep neural network for structural prediction and lane detection in traffic scene. Neural Networks and Learning Systems, 2017, 28(3): 690-703 doi: 10.1109/TNNLS.2016.2522428 [9] 陈无畏, 胡振国, 汪洪波, 魏振亚, 谢有浩. 基于可拓决策和人工势场法的车道偏离辅助系统研究. 机械工程学报, 2018, 54(16): 134-143 doi: 10.3901/JME.2018.16.134Chen Wu-Wei, Hu Zhen-Guo, Wang Hong-Bo, Wei Zhen-Ya, Xie You-Hao. Study on extension decision and artificial potential field based lane departure assistance system. Journal of Mechanical Engineering, 2018, 54(16): 134-143 doi: 10.3901/JME.2018.16.134 [10] 冯学强, 张良旭, 刘志宗. 无人驾驶汽车的发展综述. 山东工业技术, 2015, 2015(05): 51Feng Xue-Qiang, Zhang Liang-Xu, Liu Zhi-Zong. Overview of the development of driverless cars. Shandong Industrial Technology, 2015, 2015(05): 51 [11] 余天洪, 王荣本, 顾柏园, 郭烈. 基于机器视觉的智能车辆前方道路边界及车道标识识别方法综述. 公路交通科技, 2006, 2006(01): 139-142+158 doi: 10.3969/j.issn.1002-0268.2006.01.034Yu Tian-Hong, Wang Rong-Ben, Gu Bai Yuan, Guo Lie. Survey on the vision-based recognition methods of intelligent vehicle road boundaries and lane markings. Journal of Highway and Transportation, 2006, 2006(01): 139-142+158 doi: 10.3969/j.issn.1002-0268.2006.01.034 [12] Aly M. Real time detection of lane markers in urban streets. In: Proceedings of the 2008 Intelligent Vehicles Symposium. Eindhoven, the Netherlands: IEEE, 2008. 7−12 [13] Turchetto R, Manduchi R. Visual curb localization for autonomous navigation. In: Proceedings of the 2003 International Conference on Intelligent Robots and Systems. Las Vegas, USA: IEEE, 2003. 1336−1342 [14] Dang H S, Guo C J. Structure lane detection based on saliency feature of color and direction. In: Proceedings of the 2014 International Conference on Advances in Materials Science and Information Technologies in Industry. Xi'an, China: Science, 2014. 2876−2879 [15] Du X X, Tan K K, Htet K K K. Vision-based lane line detection for autonomous vehicle navigation and guidance. In: Proceedings of the 10th Asian Control Conference. Kota Kinabalu, Malaysia: IEEE, 2015. 1−5 [16] 李彦冬, 郝宗波, 雷航. 卷积神经网络研究综述. 计算机应用, 2016, 36(09): 2508-2515Li Yan-Dong, Hao Zong-Bo, Lei Hang. Survey of convolutional neural network. Journal of Computer Applications, 2016, 36(09): 2508-2515 [17] 李茂晖, 吴传平, 鲍艳, 房卓群. 论YOLO算法在机器视觉中应用原理. 教育现代化, 2018, 5(41): 174-176Li Mao-Hui, Wu Chuan-Ping, Bao Yan, Fang Zhuo-Qun. On the application principle of YOLO algorithm in machine vision. Journal of Computer Applications, 2018, 5(41): 174-176 [18] Girshick R, Donahue J, Darrell T, Malik J. Rich feature hierarchies for accurate object detection and semantic segmentation. In: Proceedings of the 2014 Conference on Computer Vision and Pattern Recognition. Columbus, OH, USA: IEEE, 2014. 580−587 [19] Girshick R. Fast R-CNN. In: Proceedings of the 2015 International Conference on Computer Vision. Santiago, Chile: IEEE, 2015. 1440−1448 [20] Ren S, He K, Girshick R, Sun J. Faster R-CNN: towards real-time object detection with region proposal networks. Pattern Analysis and Machine Intelligence, 2017, 39(60): 1137-1149 [21] Kim J, Lee M. Robust lane detection based on convolutional neural network and random sample consensus. In: Proceedings of the 2014 International Conference on Neural Information Progressing. Springer, Cham: 2014. 454−461 [22] Redmon J, Divvala S, Girshick R, Farhadi A. You only look once: Unified, real-time object detection. In: Proceedings of the 2016 Conference on Computer Vision and Pattern Recognition. Las Vegas, NV, USA: IEEE, 2016. 779−788 [23] Redmon J, Farhadi A. YOLO9000: Better, faster, stronger. In: Proceedings of the 2017 Conference on Computer Vision and Pattern Recognition. Honolulu, HI, USA: IEEE, 2017. 6517−6525 [24] 魏湧明, 全吉成, 侯宇青阳. 基于YOLO v2的无人机航拍图像定位研究. 激光与光电子学进展, 2017, 54(11): 101-110Wei Yong-Ming, Quan Ji-Cheng, Hou Yu-Qing-Yang. Aerial image location of unmanned aerial vehicle based on YOLO v2. Laser and Optoelectronics Progress, 2017, 54(11): 101-110 [25] Lee S, Kim J, Yoon J S, Shin S, Bailo O, Kim N, et al. VPGNet: Vanishing point guide network for lane and road marking detection and recognition. In: Proceedings of the 2017 International Conference on Computer Vision. Venice, Italy: IEEE, 2017. 1965−1973 [26] Redmon J, Farhadi A. YOLOv3: An incremental improvement. In: Proceedings of the 2018 Conference on Computer Vision and Pattern Recognition. Salt Lake City, USA: 2018. 1−4 -

 下载:
下载:







图(9) / 表(2)
计量
- 文章访问数: 2182
- HTML全文浏览量: 1386
- PDF下载量: 660
- 被引次数: 0
