

-
摘要: 针对YOLOv3算法在检测公路车道线时存在准确率低和漏检概率高的问题, 提出一种改进YOLOv3网络结构的公路车道线检测方法.该方法首先将图像划分为多个网格, 利用K-means++聚类算法, 根据公路车道线宽高固有特点, 确定目标先验框数量和对应宽高值; 其次根据聚类结果优化网络Anchor参数, 使训练网络在车道线检测方面具有一定的针对性; 最后将经过Darknet-53网络提取的特征进行拼接, 改进YOLOv3算法卷积层结构, 使用GPU进行多尺度训练得到最优的权重模型, 从而对图像中的车道线目标进行检测,并选取置信度最高的边界框进行标记.使用Caltech Lanes数据库中的图像信息进行对比试验, 实验结果表明, 改进的YOLOv3算法在公路车道线检测中平均准确率(Mean average precision, mAP)为95%, 检测速度可达50帧/s, 较YOLOv3原始算法mAP值提升了11%, 且明显高于其他车道线检测方法.Abstract: Aiming at the problem that the YOLOv3 algorithm has low accuracy, high probability of missed detection when detecting road lane lines, a road lane detection method for improving YOLOv3 network structure is proposed. At first, the method divides the image into multiple grids, and uses the K-means++ clustering algorithm to determine the number of target priori boxes and the corresponding value according to the inherent characteristics of the road lane line width and height. Then, according to the clustering result, the network anchor parameter is optimized to make the training network have certain pertinence in lane line detection. At last, the features extracted by the Darknet-53 are spliced, the network structure of the YOLOv3 algorithm is improved, and the GPU is used for multi-scale training to obtain the optimal weight model, thereby detecting the lane line target in the image and selecting the bounding box with the highest confidence to mark. Using the image information in the Caltech Lanes database for comparison experiments, the experimental results show that the improved YOLOv3 algorithm's mean average precision is 95% in road lane detection, the improved detection speed can be achieved 50 frame/s, which is 11% higher than the original algorithm and significantly higher than other lane detection methods.
-
Key words:
- Lane detection /
- deep learning /
- YOLOv3 /
- K-means++ /
- computer vision
-
图像密集描述是基于自然语言处理和计算机视觉两大研究领域的任务, 是一个由图像到语言的跨模态课题. 其主要工作是为图像生成多条细节描述语句, 描述对象从整幅图像扩展到图中局部物体细节. 近年来, 该任务颇受研究者关注. 一方面, 它具有实际的应用场景[1], 如人机交互[2]、导盲等; 另一方面, 它促进了众多研究任务的进一步发展, 如目标检测[3-4]、图像分割[5]、图像检索[6]和视觉问答[7]等.
作为图像描述的精细化任务, 图像密集描述实现了计算机对图像的细粒度解读. 同时, 该任务沿用了图像描述的一般网络架构. 受机器翻译[8]启发, 目前的图像描述网络[9-11]大多为编码器−解码器(Encoder-decoder, ED)框架, 因此图像密集描述任务也大多基于该传统结构. 该框架首先将卷积神经网络(Convolutional neural network, CNN)作为编码器来提取图像视觉信息[12], 得到一个全局视觉向量, 然后输入到基于长短期记忆网络(Long-short term memory, LSTM)[13]的解码器中, 最后逐步输出相应的描述文本单词.
基于上述编码−解码框架, 为实现图像区域密集描述, Karpathy等[14]试图在区域上运行图像描述模型, 但无法在同一模型中同时实现检测和描述. 在此基础上, Johnson等[15]实现了模型的端到端训练, 并首次提出了图像密集描述概念. 该工作为同时进行检测定位和语言描述提出了一种全卷积定位网络架构, 通过单一高效的前向传递机制处理图像, 不需要外部提供区域建议, 并且可实现端到端的优化. 虽然全卷积定位网络架构可实现端到端密集描述, 但仍存在两个问题:
1)模型送入解码器的视觉信息仅为感兴趣区域的深层特征向量, 忽略了浅层网络视觉信息和感兴趣区域间的上下文信息, 从而导致语言模型预测出的单词缺乏场景信息的指导, 所生成的描述文本缺乏细节信息, 甚至可能偏离图像真实内容.
2)对于单一图像的某个区域而言, 描述文本的生成过程即为一次图像描述. 图像描述中, 由于网络仅使用单一LSTM来预测每个单词, 故解码器未能较好地捕捉到物体间的空间位置关系[16], 从而造成描述文本的句式简单, 表述不够丰富.
为解决上下文场景信息缺失问题, Yang等[17]基于联合推理和上下文融合思想提出了一种多区域联合推理模型. 该模型将图像特征和区域特征进行集成, 实现了较为准确的密集描述. 但是提出的上下文信息过于粗糙, 且尚不完整. Yin等[18]通过相邻区域与目标区域间的多尺度信息传播, 提出一种上下文信息传递模块. 该模块引入了局部、邻居和全局信息, 从而获取较细粒度的上下文信息. 此外, Li等[19]通过目标检测技术揭示了描述区域与目标间的密切关系, 提出一种互补上下文学习架构, 也可实现上下文信息的细粒度获取. 在图像密集描述任务的最新进展中, Shao等[20]提出一种基于Transformer的图像密集描述网络, 打破了传统的编码−解码框架, 致力于改进LSTM网络和关注信息丰富区域. 上述工作在一定程度上解决了上下文场景信息的缺失问题, 但尚未有研究能解决浅层特征信息利用不完全和区域内空间位置信息获取不完备的问题.
为提高图像区域描述的准确性, 本文提出一种基于多重注意结构的图像密集描述生成方法 —MAS-ED (Multi-attention structure-encoder decoder). 该方法通过构建多尺度特征环路融合(Multi-scale feature loop fusion, MFLF)机制, 为解码器提供多尺度有效融合特征, 增加比较细节的几何信息; 并设计多分支空间分步注意力(Multi-branch spatial step attention, MSSA)解码器, 通过提取目标间的空间维度信息, 以加强文本中目标间的位置关系描述. 模型训练过程中, MFLF机制和MSSA解码器之间交替优化、相互促进. 实验结果表明, 本文的MAS-ED方法在Visual Genome数据集上获得了具有竞争力的结果.
1. 基于多重注意结构的密集描述
1.1 算法模型
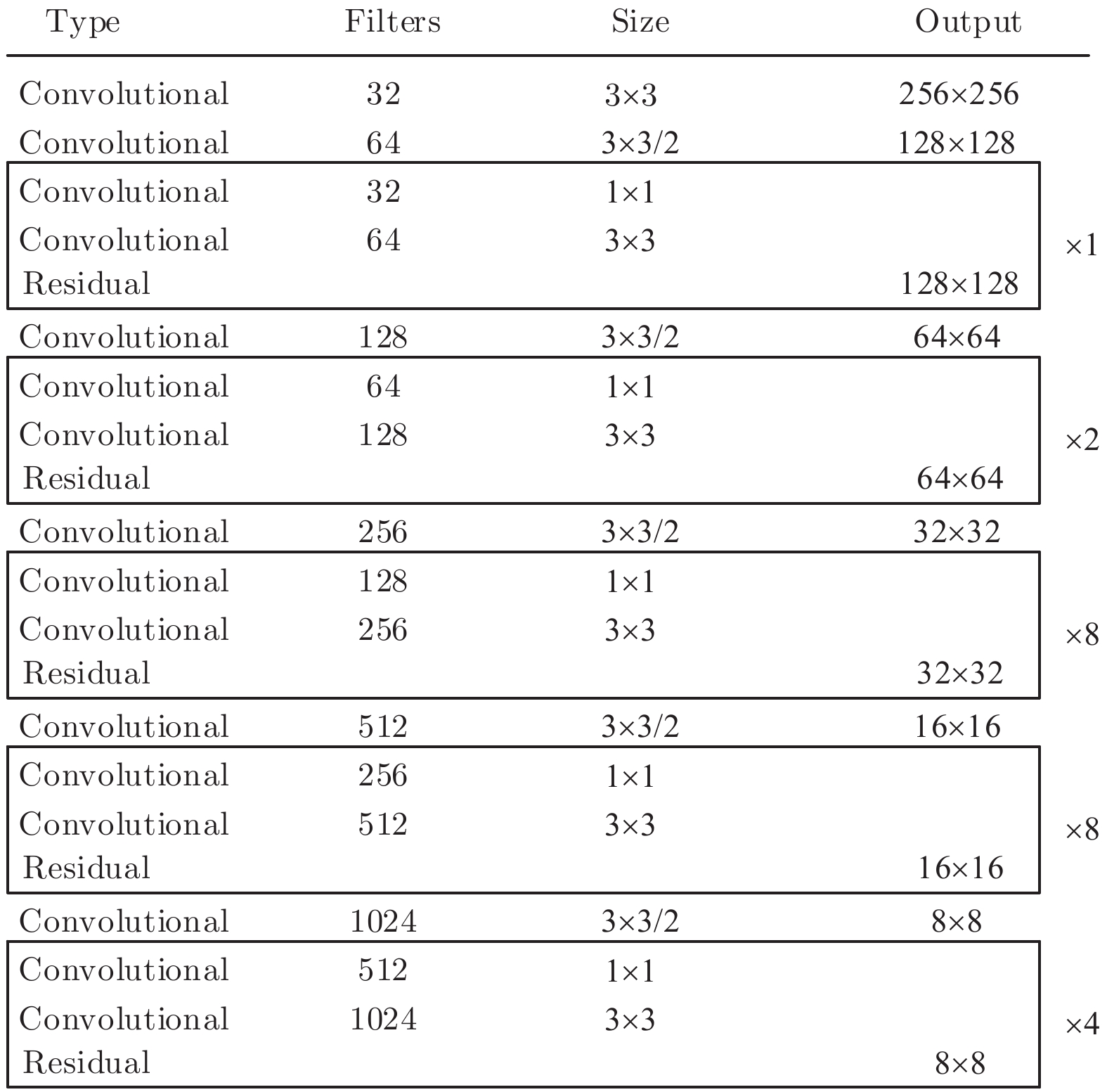
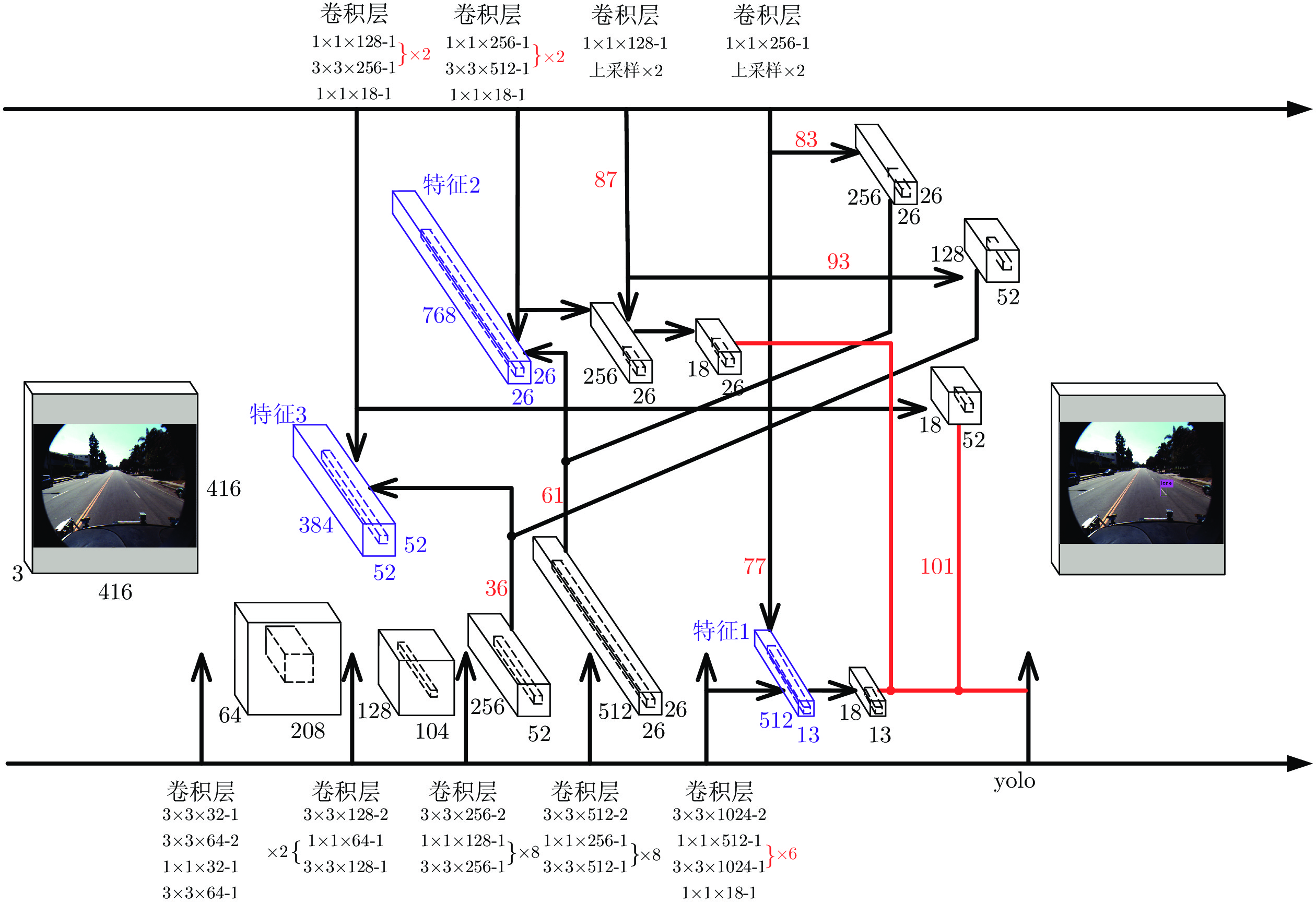
本文提出的基于多重注意结构的密集描述生成方法网络框架如图1所示. 模型是一个端到端的网络模型. 据图1可知, MAS-ED模型是基于残差网络和LSTM网络的编码−解码架构, 总体可分解为以下几个阶段.
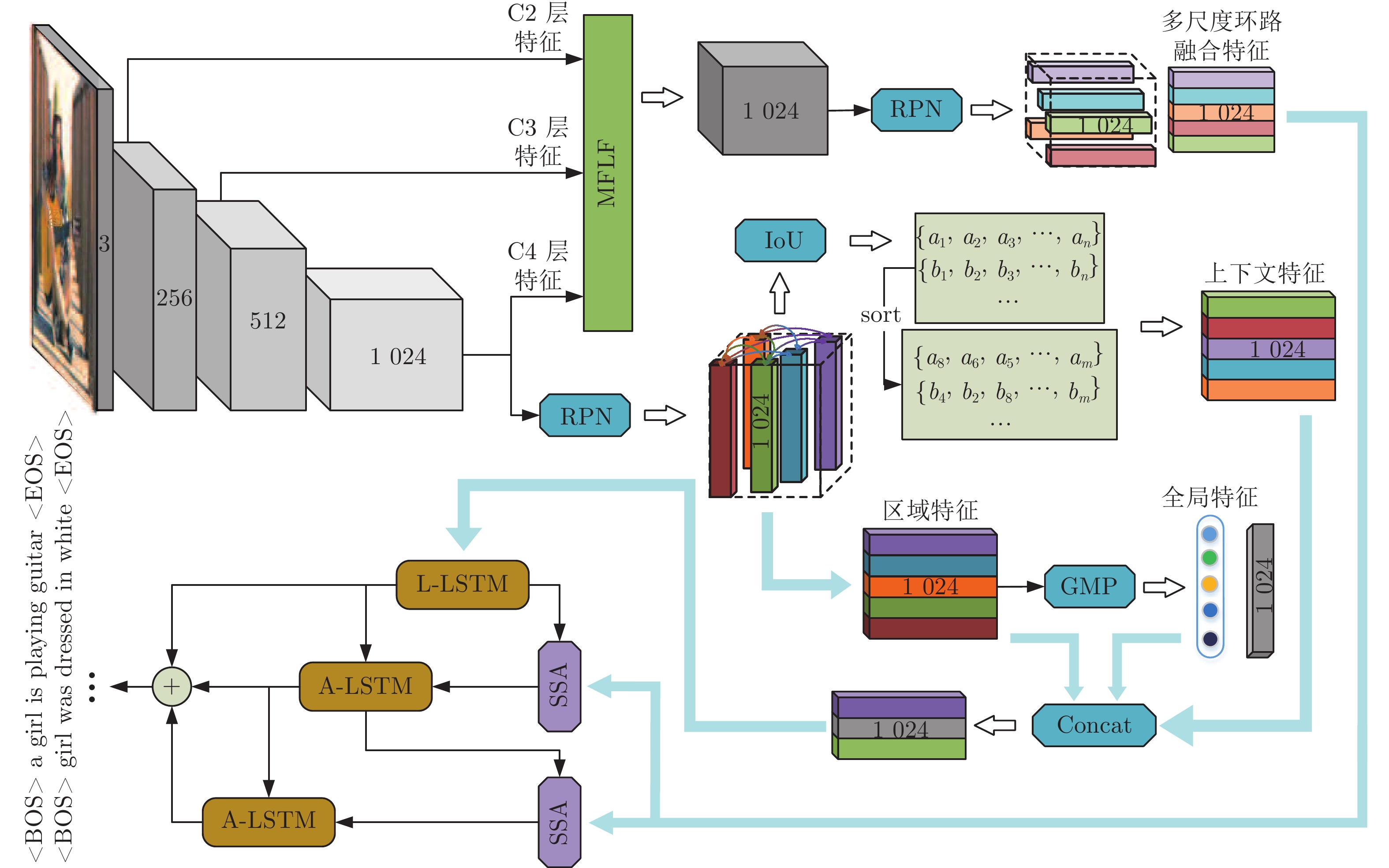 图 1 基于多重注意结构的图像密集描述生成方法Fig. 1 Dense captioning method based on multi-attention structure
图 1 基于多重注意结构的图像密集描述生成方法Fig. 1 Dense captioning method based on multi-attention structure1)区域视觉特征获取. 选用在ImageNet数据集上预训练过的ResNet-152网络作为特征提取器, 用来获取含有整幅图像视觉信息的全局视觉向量, 然后将其送入区域建议网络(Region proposal network, RPN), 得到高质量的区域建议候选框.
2)上下文信息处理. 通过交并比(Intersection over union, IoU)计算两个区域图像块间的交并比分数, 并进行排序. 将分值最高的相邻图像块特征作为当前图像块的上下文特征. 全局特征的获取由全局池化层(Global pooling layer, GAP)来完成.
3)多尺度环路融合特征提取. MFLF机制会从残差网络的各Block层视觉特征中提取各向量上包含的几何信息和语义信息, 然后将其中显著性视觉信息编码进一个和Block层视觉特征维度相同的特征向量中. 最后将该向量送入RPN层, 以得到含有几何细节和语义信息丰富的多尺度环路融合特征.
4)空间位置信息提取. 空间分步注意力(Spatial step attention, SSA)模块会根据上一解码器当前的隐含层状态, 动态决定从多尺度环路融合特征中获取哪些位置信息, 同时决定位置信息在当前单词预测时刻的参与比例, 从而向语言模型提供对预测本时刻单词最有用的位置关系特征.
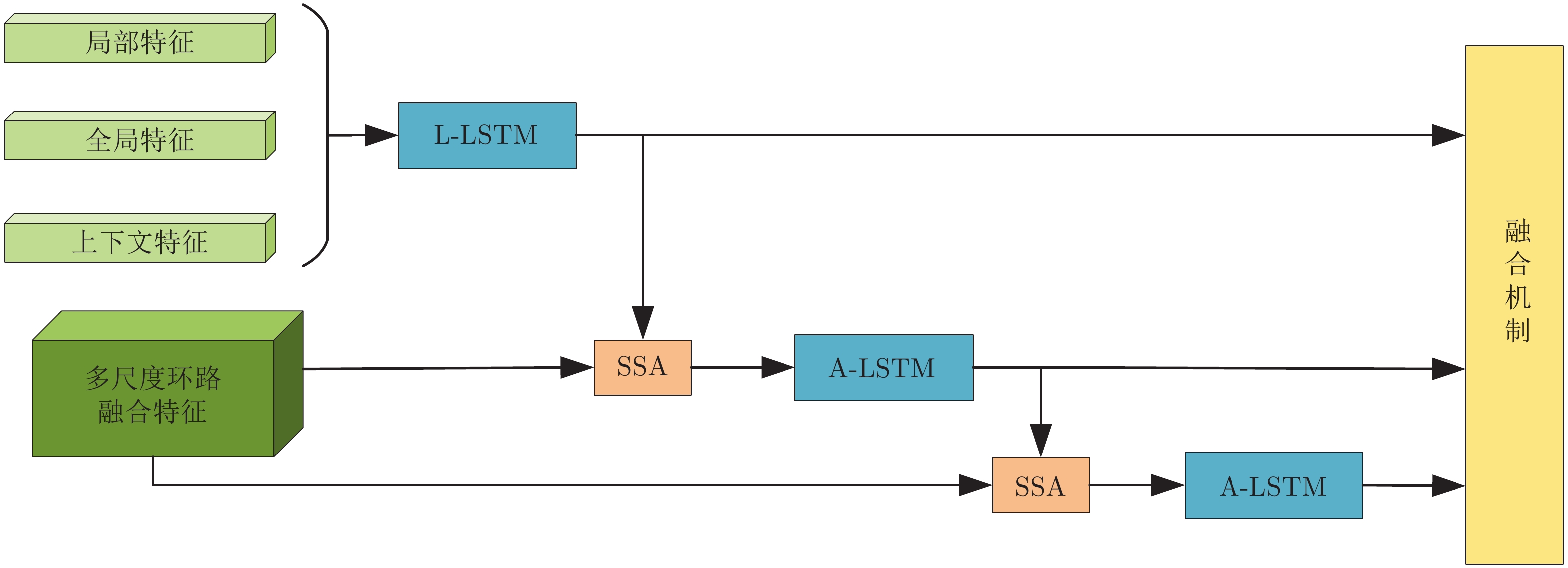
5)单词预测. 本文采用表示物体间空间位置关系的注意力特征来引导LSTM网络的单词序列建模过程. 图1中L-LSTM表示Language-LSTM, 输入的视觉特征由区域特征、上下文特征和全局特征组成; A-LSTM表示Attention-LSTM, 输入的视觉特征是注意力引导的多尺度环路融合特征. 为使空间位置信息更好地融入到解码器的输出中, 本文将SSA模块和三个LSTM网络组成图1所示结构, 以形成选择和融合的反馈连接, 并称为多分支空间分步注意力(MSSA)解码器.
1.2 多尺度特征环路融合机制
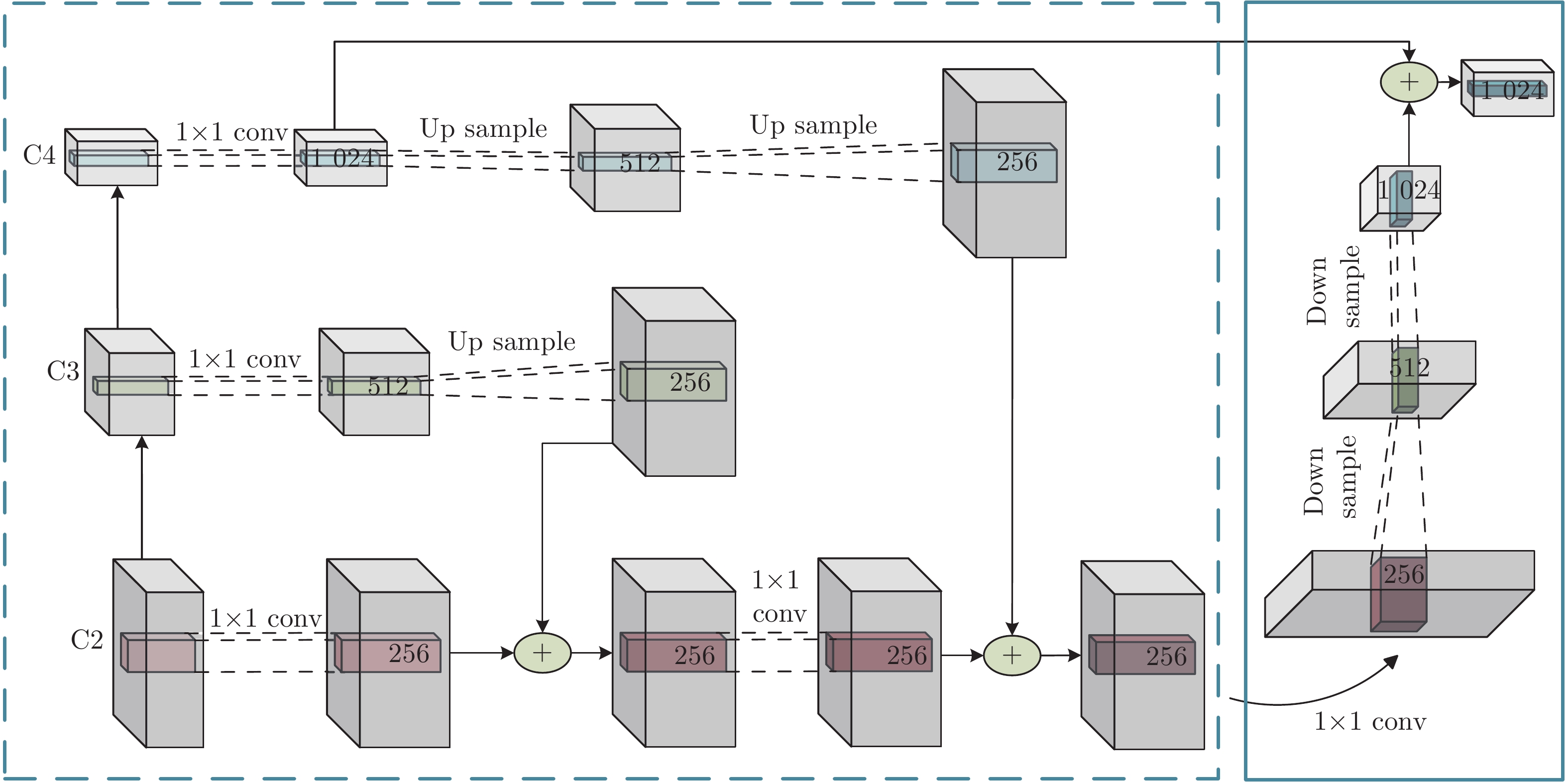
图像密集描述兼具标签密度大和复杂性高两大难点, 其任务网络模型较为庞大. 现有研究方法仅将深层网络特征用于文本生成, 而浅层网络特征并未有效利用. 虽然深层网络特征语义信息表征能力强, 但其特征图分辨率低, 几何信息含量少. 而浅层网络特征的特征图分辨率高, 几何信息表征能力强. 故本文在增加少许网络参数量和计算量的情况下, 提出一种多尺度特征环路融合机制, 即MFLF机制, 将同一网络的深层和浅层特征进行多尺度融合, 使模型可更完备地提取出图中含有的几何信息和语义信息. 其结构如图2所示.
受到特征金字塔算法[21]启发, MFLF机制效仿其实现过程, 改进逐层流向结构, 以减少计算资源开支. MFLF机制让高层网络输出特征流向低层网络输出特征, 以实现在低层特征图中加权有效的语义信息. 本文将此过程称为语义流, 其实现过程如图2中虚线子图框所示. 经几次语义流向过程后, 最底层特征图完成了全部有效语义信息的加权. 为使模型有效利用语义加权优化后低层特征图中的有效几何信息, MFLF机制设计了从低层特征流向高层的网络结构, 以实现在高层特征图中加权有效几何信息的目的. 此过程称为几何流, 其实现过程如图2中实线子图框所示. 需要注意的是, 几何流的初始特征是经语义信息加权后的, 故可削弱冗杂信息的比重. 由图2可知, 语义流和几何流构成了闭合回路, 组成了多尺度特征环路融合(MFLF)机制.
ResNet-152网络可分为4个Block, 第1个Block层的网络层数较少, 其特征图含有较多冗杂信息[22]. 因此在构建MFLF机制时, 仅考虑后3个Block的输出特征, 即图2中所示的C2、C3和C4. 此外, 语义流和几何流的组合具有多种可能. 本文将在消融实验部分阐述如何选择语义流分支和几何流分支. 本文确定的最佳组合为语义流分支选择C3-C2和C4-C2, 几何流分支选择C2-C4, 其中C3-C2表示C3层特征信息流向C2 层, 以此类推.
如图2所示, 单条语义流分支实现过程为: 1)将两个不同尺度的特征图送入1×1卷积层, 以保留原有平面结构, 达到通道数统一; 2)通过上采样将高层特征表示映射到低层特征表示空间; 3)将上采样后的高层特征与低层特征进行元素级相加操作, 得到融合特征; 4)将融合特征送入1×1卷积层完成通道数调整. 实际操作中, 若残差网络Block层输出特征通道数统一, 则不需要完成步骤1)和步骤4). 本文为提高MFLF机制的健壮性和可迁移性, 特意增加这两个步骤. 单条几何流分支实现过程同单条语义流分支, 仅将其中的上采样操作更改为下采样操作即可. 最终, MFLF机制将语义流分支和几何流分支融合形成一组多尺度视觉特征. 随着训练过程中网络参数的逐步优化, 各Block层的输出视觉特征也随之优化, 使MFLF机制动态调整几何信息和语义信息在输出特征中的比例, 为解码器提供了可动态优化的多尺度融合特征, 从而使模型能够准确生成含有丰富细节的文本描述.
1.3 多分支空间分步注意力解码器
1.3.1 空间分步注意力模块
注意力机制在各个研究领域中得到广泛应用[23-25]. 本文引入注意力机制获取目标位置信息, 并借鉴卷积块注意模块(Convolutional block attention module, CBAM)[26] 模型方法, 同时考虑通道和空间两个维度, 以获得更好的注意效果. 如图3所示, 空间分步注意力模块(SSA)的类通道注意力模块(Channel-like attention module, CLAM)由维度变换操作和通道注意力模块[27]共同组成, 且通道注意与空间注意交叉进行.
给定视觉特征
$ F \in {\mathbf R ^{H \times W \times C}} $ 和预测单词$ {\boldsymbol w} \in {\mathbf R ^ {C}} $ , 其中$ H,W,C $ 分别表示特征图的高、宽和通道. 首先扩充预测单词的空间维度$ S \in {\mathbf R ^ {H \times W \times C}} $ , 并与视觉特征进行元素级加和及非线性$ {\rm ReLu} $ 函数激活, 得到携带预测单词信息的加和特征图$ F_S \in {\mathbf R ^ {H \times W \times C}} $ :$$ \begin{equation} F_S = {\rm ReLu}(F + S) \end{equation} $$ (1) 由图3可知, SSA模块包含上下两支路, 其作用过程类似. 以上支路为例, 先考虑预测单词在特征图height维度的加权, 后考虑width维度. SSA模块将加和特征
$ F_S $ 输入CLAM中, 得到预测单词在特征图height维度的注意力权重图$ A^{H} $ :$$ \begin{equation} \begin{split} A^{H} = \;&{\rm CLAM}(F_S) = \\ &\sigma({\rm Maxpool}({f^{\rm T}}(F_S)) + {\rm Avgpool}({f^{\rm T}}(F_S))) \end{split} \end{equation} $$ (2) 其中,
$ {f^{\rm T}} $ 是维度变换函数, 目的是将特征图空间维度中的height维度信息映射到通道维度所在空间. 利用式(3)将注意力权重图$ A^{H} $ 与视觉特征$ F $ 相乘进行自适应特征优化, 得到经预测单词加权height维度后的特征矩阵向量$ F^{H} $ :$$ \begin{equation} F^{H} = {\rm Matmul}(F,A^{H}) \end{equation} $$ (3) 其中,
$ {\rm Matmul} $ 函数表示两个矩阵的乘积.接下来介绍上支路中第二步空间注意, 即考虑预测单词在特征图width维度的加权. 将经预测单词加权height维度后的特征矩阵
$ F^{H} $ 送入式(2), 得到预测单词在width维度各向量上的注意权重分布图$ A^{H \& W} $ ($ H \& W $ 表示先考虑height维度, 后考虑width维度). 特别注意, 此次$ {f^ {\rm T}} $ 函数是将特征图中的width维度信息映射到通道维度所在空间. 由此得到基于预测单词加权特征空间height, width两维度的特征图表示:$$ \begin{equation} F^{H \& W} = {\rm Matmul}(F, A^{H \& W}) \end{equation} $$ (4) 图3中下支路的作用流程与上支路类似, 加和特征
$ F_{S} $ 经式(2) ~ 式(4)操作后, 可得到基于预测单词加权特征空间width, height两维度的特征图$ F^{W \& H} $ . 最后, SSA模块将优化后的上、下两分支特征图进行元素级加和, 得到预测单词调整后的视觉特征:$$ \begin{equation} F = F^{H \& W} + F^{W \& H} \end{equation} $$ (5) 综上, SSA模块通过结合解码器上一时刻的预测单词, 实现了在空间维度和通道维度的交叉注意, 以加权视觉特征中的位置信息, 并将其用于指导解码器下一时刻的单词预测. 在解码器序列建模过程中, 模型可根据当前单词的预测结果, 完成有选择性地关注视觉特征中的空间位置关系.
1.3.2 多分支解码器
一般来说, 若只将单一LSTM网络作为语言模型, 则在本时刻的单词预测仅可根据前几个时刻的信息来推断. 然而, 随着时间轴的不断延长, 解码器较大概率会出现错误累积现象[16]. 因此在当前时刻采用纠正手段来缓解错误累积, 可在一定程度上提高密集描述的准确率. 由第1.3.1节可知, SSA模块可结合解码器上一时刻的预测单词, 来指导下一时刻的单词预测. 基于此, 本文设计如图4所示的多分支解码器结构以实现在当前时刻对预测单词的及时纠正. 多分支解码器结构由两个SSA模块、一个L-LSTM网络和两个A-LSTM网络组成. 三个LSTM网络的输入构成级联以实现同一时刻的错误纠正, 其输出构成并联以完成本时刻预测单词的反复验证.
三个LSTM网络的初始化向量均为局部特征、全局特征及上下文特征的串行连接向量
$ F_{\rm concat} $ . 在密集描述文本生成前, 网络初始化过程为:$$ \begin{equation} F_{\rm concat} = {\rm concat}(F_{\rm local},F_{\rm global},F_{\rm context}) \end{equation} $$ (6) $$ \begin{equation} \left\{ \begin{aligned} &h_1^{L} = {\rm{ L}} \text{-} {\rm{LSTM}}(F_{\rm concat},h_0^{L}) \\ &h_1^{A1} = {\rm{ A}} \text{-} {\rm{LSTM}}(F_{\rm concat},h_0^{A1}) \\ &h_1^{A2} = {\rm{ A}} \text{-} {\rm{LSTM}}(F_{\rm concat},h_0^{A2}) \end{aligned} \right. \end{equation} $$ (7) 其中,
$ F_{\rm local} $ ,$ F_{\rm global} $ 和$ F_{\rm context} $ 分别表示描述区域特征, 全局信息特征和上下文信息特征;$ F_{\rm concat} $ 表示特征向量的拼接. 在$ t $ 时刻下, 为生成预测单词$ y_t $ , 解码器${\rm{ L}} \text{-} {\rm{LSTM}} $ 的向量转化如下:$$ \begin{equation} h_t^{L} = {\rm{ L}} \text{-} {\rm{LSTM}}(F_{\rm concat},y_{t-1},h_{t-1}^{L}) \end{equation} $$ (8) 其中,
$ h_{t}^{L} $ 代表${\rm{ L}} \text{-} {\rm{LSTM}} $ 网络在$ t $ 时刻预测的单词向量. 为避免错误累积, 多分支解码器采用两个${\rm{ A}} \text{-} {\rm{LSTM}} $ 网络对单词向量进行纠正:$$ \begin{equation} \left\{ \begin{aligned} &F_1 = {\rm SSA}(F,h_t^{L}) \\ &h_t^{A1} = {\rm{ A}} \text{-} {\rm{LSTM}}(F_1,y_{t-1},h_{t-1}^{A1}) \\ &F_2 = {\rm SSA}(F,h_t^{A1}) \\ &h_t^{A2} = {\rm{ A}} \text{-} {\rm{LSTM}}(F_2,y_{t-1},h_{t-1}^{A2}) \end{aligned} \right. \end{equation} $$ (9) 其中,
$ h_{t}^{A1} $ 和$ h_{t}^{A2} $ 表示经过${\rm{ L}} \text{-} {\rm{LSTM}} $ 解码器一次纠正和二次纠正后的预测单词向量,$ F_{1} $ 和$ F_{2} $ 表示经SSA模块优化后的多尺度环路融合特征. 由此可知, 多分支解码器不仅可实现当前时刻预测单词的及时纠正, 还为单词预测过程引入了几何信息和空间位置信息, 从而使模型生成的描述文本更为精细. 最后, 多分支解码器更新当前隐藏状态$ h_{t} $ :$$ \begin{equation} h_t = {\rm Add}(h_{t}^{L} + h_{t}^{A1} + h_{t}^{A2}) \end{equation} $$ (10) 1.4 算法复杂度分析
MAS-ED方法主要包括多尺度特征环路融合、空间位置注意权重获取和多分支解码器建模几个步骤. 在多尺度特征环路融合中, 由于本文模型无需调整特征图通道数, 因此可去除MFLF机制的1×1卷积层, 故MFLF机制共有3次加法运算、3次上采样和2次下采样. 实验中上采样和下采样由双线性插值函数来完成, 因此每个像素点坐标需完成8次乘法和11次加法运算. 因此MFLF机制的乘法运算次数为
$ 40 \times (w \times h) $ , 加法运算次数为$ 55 \times (w \times h) + 3 $ . 新增8个输出特征图, 故空间、时间复杂度分别为$ {\rm O}(8 \times (w \times h \times C)) $ 、$ {\rm O}(95 \times (w \times h) + 3) $ . 而将同等$ w \times h $ 分辨率的高维特征图送入单个卷积层后, 其时间和空间复杂度可达到${\rm O}(k^{2} \times w \times h \times C_{\rm in} \times C_{\rm out})$ 和$ {\rm O}(k^{2} \times C_{\rm in} \times C_{\rm out}) $ . 由此可知, MFLF机制增加的计算量和参数量尚不如一个卷积操作.用SSA模块获取空间位置注意权重时, 模型需要完成3次加法运算、4次矩阵乘法运算、2次
$ {\rm ReLu} $ 非线性变换和4次CLAM模块. 每个CLAM模块包含2次池化、2次$ {\rm ReLu} $ 变换、4 次卷积和1次Sigmoid变换. 其中, 仅卷积操作和中间新增特征图涉及空间复杂度计算, 故SSA模块增加的参数量为$ {\rm O}(k^{2} \times C_{\rm in} \times C_{\rm out} + w \times h \times C) $ , 增加的计算量为$ {\rm O}(k^{2} \times w \times h \times C_{\rm in} \times C_{\rm out} + C + C^{2}) $ . 此外, 构建多分支解码器建模时, 模型仅增加了1 次加法运算, 可以忽略.基于编码器−解码器框架下, CAG-Net[18]方法采用VGG16网络进行特征提取, 并将3个LSTM网络用于文本序列解码; 而MAS-ED则采用ResNet-152网络, 同样使用3个LSTM网络用于解码. VGG16和ResNet-152的计算复杂度大致等同[23], 但前者参数量超出后者约21 MB. 暂不考虑CAG-Net所提出的CFE和CCI这两个模块, 仅基础架构模型的参数量就已超MAS-ED所有参数量; 而且两者计算复杂度基本持平. TDC (Transformer-based dense captioner)[20]模型同样采用参数量较少的ResNet-152网络, 但其后端解码网络使用了Transformer[28]. 与3个LSTM网络相比, Transformer网络增加的计算量和参数量相对较大. 综上可知, 相对于CAG-Net和TDC, MAS-ED虽然增加了MFLF机制和MSSA解码器两个模块, 但是增加的计算量和参数量均很小.
2. 实验与分析
2.1 数据集和评估指标
本文使用标准数据集Visual Genome对MAS-ED方法进行测试. 该数据集有V1.0和V1.2两个版本, V1.2比V1.0标注重复率更低, 标注语句也更符合人类习惯. 对数据集的处理同文献[15], 将出现次数少于15的单词换为 <UNK> 标记, 得到一个包含10 497个单词的词汇表; 将超过10个单词的注释语句去除, 来提高运行效率. 本文的数据划分方式同基线方法, 77 398张图片用于训练, 5 000张图片用于验证和测试. 本文基于V1.0和V1.2两个版本的数据集来验证方法的有效性.
与目标检测任务的平均准确均值(Mean average precision, mAP)指标不同, 本文所用的mAP指标专门用来评估图像密集描述任务, 由文献[15]首次提出. 该指标的计算过程为: 首先, 利用交并比函数(IoU), 将区域间重叠分值处于
$\{0.2, 0.3, 0.4, 0.5, 0.6\}$ 的几种精度均值(Average precision, AP) 作为预测区域性定位的准确性度量; 之后, 使用METEOR指标[29]将语义相似度处于$\{0, 0.05, 0.10, 0.15, 0.20, 0.25\}$ 的几种精度均值(AP), 作为预测文本和真值标注间的语义相似度度量; 最后, 计算这几组AP的平均值作为最终的mAP分值.2.2 实验设置
本文采用文献[17]的近似联合训练方法来实现模型的端到端训练, 并使用随机梯度下降来优化模型, 其学习率和迭代数的设置均与基线方法相同. 训练过程中, 图像批大小设为1, 且每次前向训练中为单个图像生成256个感兴趣区域. 实验使用具有512个隐藏节点的LSTM单元, 并将单词序列长度设为12. 对于测试评估, 将高度重叠的框合并为具有多个参考标题的单个框, 来预处理验证/测试集中的真值标注区域. 具体地, 对于每个图像, 迭代选择具有最多重叠框的框(基于阈值为0.7的IoU), 将它们合并在具有多个标注的单个框中. 之后排除该组, 并重复以上过程.
2.3 MAS-ED评估
为验证MAS-ED方法的有效性和可靠性, 本文选取几种典型的基线方法来完成对比实验. 基线方法根据网络框架分为两组: 基于LSTM解码网络框架和基于Transformer解码网络框架. 其中, 仅TDC[20]模型为基于Transformer解码网络框架. 密集描述模型性能由mAP分值来评估.
基于LSTM解码网络框架下的各模型性能如表1所示. 针对V1.0数据集, 与FCLN相比, MAS-ED的mAP分值提高了98.01%, 性能提升明显; 与T-LSTM和COCG相比, MAS-ED的mAP分别提升了14.64%和8.76%. 由于T-LSTM和COCG模型仅致力于上下文信息的改进, 而MAS-ED不仅考虑到上下文关系, 还有效利用浅层特征和空间位置关系, 所以本文mAP性能得到有效提升. 与最先进的CAG-Net方法相比, 为公平起见, MAS-ED未使用ResNet-152网络而使用VGG16网络, 其mAP性能仍提升1.55%. 这表明, MAS-ED优于CAG-Net. 针对V1.2数据集, MAS-ED性能同样优于基线方法, 与最先进的COCG相比, MAS-ED获得了6.26%的性能优势.
表 1 基于LSTM解码网络密集描述算法mAP性能Table 1 mAP performance of dense caption algorithms based on LSTM decoding network表2所示为基于Transformer解码网络框架下的模型性能. 由表2可见, MAS-ED方法的mAP分值优于TDC方法, 在V1.2数据集上mAP分值达到了11.04; 而与TDC + ROCSU模型相比, MAS-ED性能稍差. 但TDC + ROCSU模型算法复杂度远高于MAS-ED. 具体来说, TDC + ROCSU模型选用Transformer作为序列解码器, 而本文选用LSTM网络, 前者所增加的计算量和参数量远远大于后者; 其次, TDC + ROCSU模型在使用ROCSU模块获取上下文时, 部分网络不能进行on-line训练, 无法实现整个网络的端到端训练, 而MAS-ED却可实现端到端的网络优化; 最后, TDC + ROCSU致力于获取准确的文本描述, 而MAS-ED不仅考虑文本描述的准确性, 还试图为文本增加几何细节和空间位置关系, 在一定程度上增加了文本的丰富度. 所以相比于TDC + ROCSU模型, 本文方法MAS-ED算法复杂度低, 可端到端优化且能提高文本丰富性.
表 2 基于非LSTM解码网络密集描述算法mAP性能Table 2 mAP performance of dense caption algorithms based on non-LSTM decoding network模型 V1.0 V1.2 TDC 10.64 10.33 TDC + ROCSU 11.49 11.90 MAS-ED 10.68 11.04 2.4 消融实验
本文共实现了三种基于注意结构的密集描述模型: 1)多尺度特征环路融合模型(MFLF-ED), 使用深、浅层网络的融合特征作为视觉信息, 由标准三层LSTM解码; 2)多分支空间分步注意力模型(MSSA-ED), 仅使用深层网络特征作为视觉信息, 由多分支空间分步注意力解码器解码; 3)多重注意结构模型(MAS-ED), 使用深、浅层网络的融合特征作为视觉信息, 由多分支空间分步注意力解码器解码. 为验证两个模块的有效性, 在相同实验条件下, 本文设置了如表3所示的对比实验.
表 3 VG数据集上密集描述模型mAP性能Table 3 mAP performance of dense caption models on VG dataset模型 VGG16 ResNet-152 Baseline[17] 9.31 9.96 MFLF-ED 10.29 10.65 MSSA-ED 10.42 11.87 MAS-ED 10.68 11.04 由表3可知, 在两种不同网络框架下, MSSA-ED模型和MFLF-ED模型的性能表现均优于基线模型, 这表明浅层细节信息和空间位置信息都利于图像的密集描述. 此外, MSSA-ED模型要比MFLF-ED模型表现更优. 这是因为在MSSA解码器中, SSA模块通过上一解码器的预测单词指导下一解码器的单词生成时, 模块有额外视觉特征输入, 所以MSSA-ED模型除了可获取物体的空间位置信息, 还在一定程度上利用了视觉特征中区域目标的相关信息. 而MFLF-ED模型仅使用MFLF机制来融合多尺度特征, 增加几何信息, 以此提升小目标的检测精度和增加大目标的描述细节. 因此相对而言, MSSA-ED模型的改进方法较为多元, 实验效果较好.
此外, MAS-ED模型性能优于两个单独模型. 这是因为在MAS-ED模型训练过程中, MSSA解码器通过反向传播机制, 促使MFLF机制不断调整视觉融合特征中语义信息和几何信息的参与比例; 同时, MFLF机制通过提供优质融合特征, 来辅助MSSA解码器尽最大可能地获取区域实体间的空间位置关系. 最后, 由表3可知, 基于ResNet-152的三个消融模型性能比基于VGG16更优越. 说明密集描述模型不仅需要具有几何细节的浅层特征, 也需要包含丰富语义的深层特征, 从而也证明本文将深层残差网络ResNet-152作为特征提取网络的正确性.
2.4.1 MFLF-ED
为探索MFLF机制的最佳实现方式, 本文设计了不同语义流和几何流支路组合的性能对比实验, 实验结果如表4所示. 由MFLF机理可知, 语义流的源特征层应为最高的C4层, 以保证最优的语义信息可流向低层特征图; 其目的特征层应为最低的C2层, 以确保较完整的几何细节可流向高层特征图. 而几何流的源特征层和目的特征层应与语义流相反, 从而几何流和语义流构成环路融合. 语义流有4种情况: C4-C2, C4-C3 & C3-C2, C4-C2+(C3-C2), C4-C2+(C4-C3 & C3-C2), 同样几何流有C2-C4, C2-C3 & C3-C4, C2-C4+(C3-C4)和C2-C4+(C2-C3 & C3-C4). 本文将从源特征层直接流向目的特征层的分支(如C4-C2)称为直接流向分支, 而将途经其他特征层的分支(如C4-C3 & C3-C2)称为逐层流向分支.
表 4 不同分支组合模型的mAP性能比较Table 4 Comparison of mAP performance of different branch combination models语义流 几何流 C2-C4 C2-C3 & C3-C4 C2-C4 + (C3-C4) C2-C4 + (C2-C3 & C3-C4) C3-C2 9.924 10.245 10.268 7.122 C4-C2 10.530 10.371 9.727 8.305 C4-C3 & C3-C2 10.125 10.349 10.474 10.299 C4-C2+(C3-C2) 10.654 10.420 10.504 10.230 C4-C2+(C4-C3&C3-C2) 10.159 10.242 10.094 7.704 由表4可知, 当语义流和几何流均采用单条直接流向分支[C4-C2]+[C2-C4]时, 其性能(10.530)优于两者均采用单条逐层流向分支[C4-C3 & C3-C2]+ [C2-C3 & C3-C4](10.349), 更优于两者均采用逐层流向分支和直接流向分支[C4-C2+(C4-C3 & C3-C2)]+[C2-C4+(C2-C3 & C3-C4)](7.704). 这是由于直接流向结构可确保源特征图信息完整地融入目的特征图, 而逐层流向结构会造成信息丢失. 此外, 若同时使用两种结构进行信息传播, 由于信息含量过多且较为冗杂, 会造成显著性信息缺失, 从而性能表现最差.
当语义流和几何流均选用单条直接流向分支和部分逐层流向分支[C4-C2+(C3-C2)]+[C2-C4+(C3-C4)] 时, 其模型性能(10.504)虽优于逐层流向结构模型(10.349), 但劣于直接流向结构模型(10.530). 为进一步提高模型性能, 本文选择分开考虑语义流和几何流配置. 当语义流选用直接流向分支, 而几何流选用直接流向分支和部分逐层流向分支[C4-C2]+[C2-C4+(C3-C4)]时, 其模型性能较差(9.727). 而当语义流选用直接流向分支和部分逐层流向分支, 几何流选用直接流向分支[C4-C2+(C3-C2)]+[C2-C4]时, 其模型性能(10.654)要优于直接流向结构模型(10.530).
除此之外, 由表4中前2行数据可知, C4层中的优质语义信息多于C3层, C2层中的几何细节信息也比C3层多, 从而进一步证明了MFLF机制将C4层和C2层作为源特征层和目的特征层的正确性.
综上, [C4-C2+(C3-C2)]+[C2-C4]是MFLF机制的最优组合方式. 为了更加直观, 本文将各模型的描述结果可视化如图5所示. 当语义流和几何流均采用直接流向和逐层流向的双通路实现时, 由于信息冗杂, 语句中含有的信息量少, 甚至出现错误信息, 如“A shelf of a shelf”. 当单独采用直接流向或逐层流向时, 语句中含有的语义和几何信息有所提升, 如“wood”和“yellow”. 随着网络结构不断优化, 生成语句中的语义信息更抽象, 如“kitchen room”, 几何信息也更加具体, 如“many items”.
 图 5 不同分支组合模型结果可视化(图中每行上面“[·]”表示语义流, 下面“[·]”表示几何流)Fig. 5 Visualization of results of different semantic flow branching models (The upper “[·]” of each line in the figure represents the semantic flow, and the lower “[·]” represents the geometric flow)
图 5 不同分支组合模型结果可视化(图中每行上面“[·]”表示语义流, 下面“[·]”表示几何流)Fig. 5 Visualization of results of different semantic flow branching models (The upper “[·]” of each line in the figure represents the semantic flow, and the lower “[·]” represents the geometric flow)2.4.2 MSSA-ED
1) SSA模块. 基于相同实验条件下, 本文在模型MSSA-ED上对SSA模块中上下两分支进行冗余性分析, 实验结果如表5所示. 表中Up-ED表示仅使用SSA模块上支路, 即先考虑预测单词在特征图height维度的加权, 后考虑width维度; Down-ED则仅使用SSA模块下支路, 维度加权顺序与上支路相反. 由表5可知, 两个单支路模型的性能相差不大, 而采用双支路的MSSA-ED性能优于两个单支路模型. 这是因为每个支路对两个空间维度(height维度和width维度)都进行加权考虑, 加权先后顺序对模型性能影响并不大, 若将上下两支路所得到的加权信息融合, 模型便可获得更加准确的空间位置信息.
表 5 SSA模块支路模型的mAP性能Table 5 mAP performance of SSA module branch model模型 Up-ED Down-ED MSSA-ED mAP 10.751 10.779 10.867 各模型的可视化效果如图6所示. Up-ED能检测出“sign”与“wall”的左右关系, Down-ED则捕捉到目标物体与“refrigerator”的高低关系, 而MSSA-ED则通过融合两个位置信息得出最符合真值标注的预测语句.
2)多分支解码器. 本文通过设计对比实验来确定多分支解码器的支路数, 实验结果见表6. 其中单支路表示仅添加一条A-LSTM通路, 依此类推两支路与三支路表示. 由表6可知, 基于三种不同SSA模块, 两支路模型的性能都优于单支路模型和三支路模型. 这是因为采用A-LSTM对预测单词进行实时纠正时, 过少支路的模型不能在复杂特征信息中准确定位描述目标; 而过多支路的模型, 虽对单目标区域十分友好, 但在多目标区域描述时, 会过度关注每个目标, 导致模型忽略目标间的语义关系.
表 6 不同支路数对多分支解码器性能的影响Table 6 Effects of different branch numbers on the performance of multi-branch decoders模型 单支路 两支路 三支路 Up-ED 10.043 10.751 10.571 Down-ED 10.168 10.779 10.686 MSSA-ED 10.347 10.867 10.638 为了更加直观, 图7将基于MSSA-ED的三种不同支路模型的注意权重可视化. 图中从左到右依次为原图、单支路注意图、两支路注意图和三支路注意图, 图下方为各模型的预测语句. 其中单支路模型的注意权重分布较分散, 无法准确捕捉到目标; 三支路对单目标注意相对集中, 但对多目标注意权重图成点簇状; 而两支路不仅能突出描述区域内的目标, 并且可关注到区域内目标间的空间位置关系.
2.5 可视化分析
为进一步直观表明各个模块实验效果, 图8给出了多个密集描述模型的定性表现. 由图中的描述语句可得, MFLF-ED模型可以描述出灌木丛“bush”的“small”和“green”, 建筑物“building”和公交车“bus”的颜色“red”等细节信息, 说明MFLF机制能为密集描述增加有效几何信息, 但描述语句均为简单句, 较少体现物体间的逻辑关系; MSSA-ED模型能够捕捉到建筑物“building”与植物“plants”、树“trees”与大象“elephant”间的空间位置关系, 证明MSSA解码器能为密集描述获取有效位置关系, 但因缺乏几何细节, 左子图中“bush”的信息表述模糊, 采用了广泛的“plant”来表述; 而MAS-ED模型不仅可检测出灌木丛“bush”、建筑物“building”以及公交车“bus”的颜色、大小细节, 而且还在一定程度上能够表达出各物体间的空间位置关系, 如“side”, “behind”等.
值得注意的是, MAS-ED模型的预测语句沿用了MSSA-ED中的“growing on”词组, 这表明“bush”的一种生长状态, 是基准描述语句中未体现的. 类似地, 右子图中的“beard man”也没有存在于基准语句中, 这些都体现了MAS-ED方法可为密集描述增加丰富度, 能够生成灵活多样的描述语句.
特殊地, 对于大目标物体的细节信息, 如“build-ing”, MAS-ED模型指出了该物体的颜色“red”和组成“brick”. 但GT和MFLF-ED模型的语句中仅体现了颜色这一细节, 因此“brick” 是MAS-ED模型自适应添加的几何细节, 且该几何细节完全符合图中物体. 此外, MAS-ED还一定程度上增加了小目标物体的精确检测, 如GT语句中未体现“beard man”. 该目标是MAS-ED模型在描述语句中自适应增加的, 并且由图8可知当前描述区域中的确含有这一目标. 此外, 图8中间子图的密集描述语句体现了MAS-ED模型可自适应加入位置信息. 在该子图中, MSSA-ED模型捕捉到了“tress”与“elephant”间的位置关系, 但MAS-ED模型中却未体现, 而是指出了“building”与“elephant”间的关系. 这是由于MAS-ED模型经训练后, 有选择地筛选出了最为突出的目标间位置信息.
3. 结论
本文提出了一种基于多重注意结构的图像密集描述生成方法, 该方法通过构建一个多尺度特征环路融合机制, 为文本描述增加了较为细节的几何信息; 并设计了多分支空间分步注意力解码器, 以加强描述目标间的空间位置关系. 实验结果表明, 基于LSTM解码网络框架, 本文MAS-ED方法的性能优于其他图像密集描述方法.
-

图 9 测试集图像在不同网络结构中的检测准确率
Fig. 9 The detection accuracy of test images in different network structures
表 1 不同
$k$ 值对应的先验框宽高Table 1 The width and height of priori boxes corresponding to different
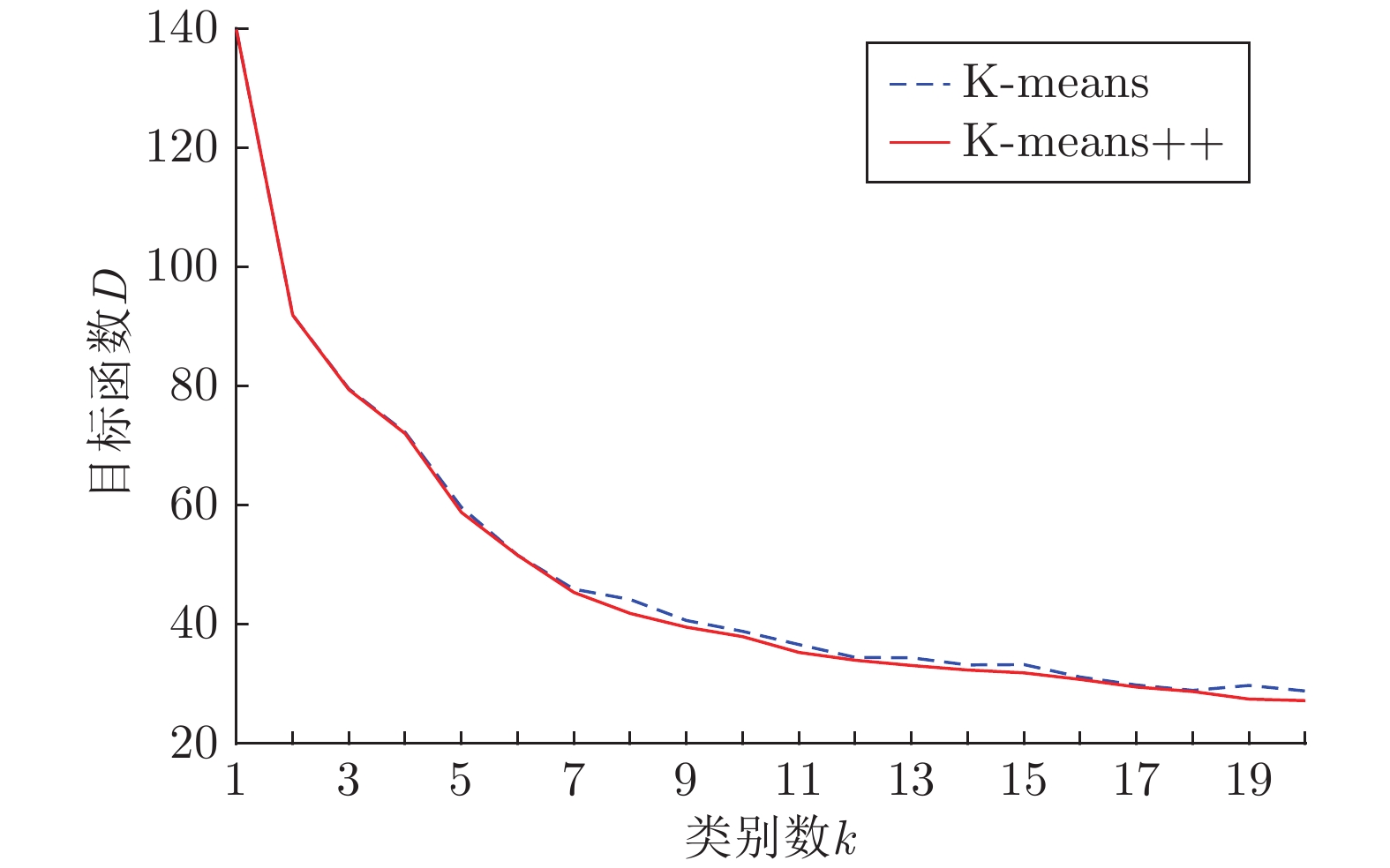
$k$ values$k$ = 7 $k$ = 8 $k$ = 9 $k$ = 10 $k$ = 11 (6, 9) (6, 9) (6, 9) (5, 12) (5, 7) (10, 15) (8, 12) (9, 14) (5, 17) (7, 11) (13, 21) (11, 17) (12, 18) (7, 11) (10, 14) (19, 30) (15, 24) (15, 24) (10, 14) (10, 18) (27, 44) (20, 32) (20, 32) (11, 18) (13, 20) (36, 60) (26, 43) (26, 43) (15, 24) (16, 25) (141, 10) (36, 69) (32, 51) (20, 32) (21, 32) — (141, 10) (40, 69) (27, 44) (26, 43) — — (141, 10) (36, 60) (32, 51) — — — (141, 10) (40, 70) — — — — (141, 10)  下载: 导出CSV
下载: 导出CSV
-
[1] 张慧, 王坤峰, 王飞跃. 深度学习在目标视觉检测中的应用进展与展望. 自动化学报, 2017, 43(08): 1289-1305Zhang Hui, Wang Kun-Feng, Wang Fei-Yue. Advances and perspectives on applications of deep learning in visual object detection. Acta Automatica Sinica, 2017, 43(08): 1289-1305 [2] 尹宏鹏, 陈波, 柴毅, 刘兆栋. 基于视觉的目标检测与跟踪综述. 自动化学报, 2016, 42(10): 1466-1489Yin Hong-Peng, Chen Bo, Chai Yi, Liu Zhao-Dong. Vision-based object detection and tracking: a review. Acta Automatica Sinica, 2016, 42(10): 1466-1489 [3] 《中国公路学报》编辑部. 中国汽车工程学术研究综述. 中国公路学报, 2017, 30(06): 1-197 doi: 10.3969/j.issn.1001-7372.2017.06.001Editorial department of china journal of highway and transport. Review on China's automotive engineering research progress. China Journal of Highway and Transport, 2017, 30(06): 1-197 doi: 10.3969/j.issn.1001-7372.2017.06.001 [4] 田娟秀, 刘国才, 谷珊珊, 鞠忠建, 刘劲光, 顾冬冬. 医学图像分析深度学习方法研究与挑战. 自动化学报, 2018, 44(03): 401-424Tian Juan-Xiu, Liu Guo-Cai, Gu Shan-Shan, Ju Zhong-Jian, Liu Jin-Guang, Gu Dong-Dong. Deep learning in medical image analysis and its challenges. Acta Automatica Sinica, 2018, 44(03): 401-424 [5] 李文英, 曹斌, 曹春水, 黄永祯. 一种基于深度学习的青铜器铭文识别方法. 自动化学报, 2018, 44(11): 2023-2030Li Wen-Ying, Cao Bing, Cao Chun-Shui, Huang Yong-Zhen. A deep learning based method for bronze inscription recognition. Acta Automatica Sinica, 2018, 44(11): 2023-2030 [6] 唐智威. 基于视觉的无人驾驶汽车研究综述. 制造业自动化, 2016, 38(8): 134-136 doi: 10.3969/j.issn.1009-0134.2016.08.032Tang Zhi-Wei. A review of driverless cars based on vision. Manufacturing Automation, 2016, 38(8): 134-136 doi: 10.3969/j.issn.1009-0134.2016.08.032 [7] He B, Ai R, Yan Y. Accurate and robust lane detection based on dual-view convolution neutral network. In: Proceedings of the 2016 Intelligent Vehicles Symposium. Gothen, Sweden: IEEE, 2016. 1041−1046 [8] Li J, Mei X, Prokhorov D, Tao D. Deep neural network for structural prediction and lane detection in traffic scene. Neural Networks and Learning Systems, 2017, 28(3): 690-703 doi: 10.1109/TNNLS.2016.2522428 [9] 陈无畏, 胡振国, 汪洪波, 魏振亚, 谢有浩. 基于可拓决策和人工势场法的车道偏离辅助系统研究. 机械工程学报, 2018, 54(16): 134-143 doi: 10.3901/JME.2018.16.134Chen Wu-Wei, Hu Zhen-Guo, Wang Hong-Bo, Wei Zhen-Ya, Xie You-Hao. Study on extension decision and artificial potential field based lane departure assistance system. Journal of Mechanical Engineering, 2018, 54(16): 134-143 doi: 10.3901/JME.2018.16.134 [10] 冯学强, 张良旭, 刘志宗. 无人驾驶汽车的发展综述. 山东工业技术, 2015, 2015(05): 51Feng Xue-Qiang, Zhang Liang-Xu, Liu Zhi-Zong. Overview of the development of driverless cars. Shandong Industrial Technology, 2015, 2015(05): 51 [11] 余天洪, 王荣本, 顾柏园, 郭烈. 基于机器视觉的智能车辆前方道路边界及车道标识识别方法综述. 公路交通科技, 2006, 2006(01): 139-142+158 doi: 10.3969/j.issn.1002-0268.2006.01.034Yu Tian-Hong, Wang Rong-Ben, Gu Bai Yuan, Guo Lie. Survey on the vision-based recognition methods of intelligent vehicle road boundaries and lane markings. Journal of Highway and Transportation, 2006, 2006(01): 139-142+158 doi: 10.3969/j.issn.1002-0268.2006.01.034 [12] Aly M. Real time detection of lane markers in urban streets. In: Proceedings of the 2008 Intelligent Vehicles Symposium. Eindhoven, the Netherlands: IEEE, 2008. 7−12 [13] Turchetto R, Manduchi R. Visual curb localization for autonomous navigation. In: Proceedings of the 2003 International Conference on Intelligent Robots and Systems. Las Vegas, USA: IEEE, 2003. 1336−1342 [14] Dang H S, Guo C J. Structure lane detection based on saliency feature of color and direction. In: Proceedings of the 2014 International Conference on Advances in Materials Science and Information Technologies in Industry. Xi'an, China: Science, 2014. 2876−2879 [15] Du X X, Tan K K, Htet K K K. Vision-based lane line detection for autonomous vehicle navigation and guidance. In: Proceedings of the 10th Asian Control Conference. Kota Kinabalu, Malaysia: IEEE, 2015. 1−5 [16] 李彦冬, 郝宗波, 雷航. 卷积神经网络研究综述. 计算机应用, 2016, 36(09): 2508-2515Li Yan-Dong, Hao Zong-Bo, Lei Hang. Survey of convolutional neural network. Journal of Computer Applications, 2016, 36(09): 2508-2515 [17] 李茂晖, 吴传平, 鲍艳, 房卓群. 论YOLO算法在机器视觉中应用原理. 教育现代化, 2018, 5(41): 174-176Li Mao-Hui, Wu Chuan-Ping, Bao Yan, Fang Zhuo-Qun. On the application principle of YOLO algorithm in machine vision. Journal of Computer Applications, 2018, 5(41): 174-176 [18] Girshick R, Donahue J, Darrell T, Malik J. Rich feature hierarchies for accurate object detection and semantic segmentation. In: Proceedings of the 2014 Conference on Computer Vision and Pattern Recognition. Columbus, OH, USA: IEEE, 2014. 580−587 [19] Girshick R. Fast R-CNN. In: Proceedings of the 2015 International Conference on Computer Vision. Santiago, Chile: IEEE, 2015. 1440−1448 [20] Ren S, He K, Girshick R, Sun J. Faster R-CNN: towards real-time object detection with region proposal networks. Pattern Analysis and Machine Intelligence, 2017, 39(60): 1137-1149 [21] Kim J, Lee M. Robust lane detection based on convolutional neural network and random sample consensus. In: Proceedings of the 2014 International Conference on Neural Information Progressing. Springer, Cham: 2014. 454−461 [22] Redmon J, Divvala S, Girshick R, Farhadi A. You only look once: Unified, real-time object detection. In: Proceedings of the 2016 Conference on Computer Vision and Pattern Recognition. Las Vegas, NV, USA: IEEE, 2016. 779−788 [23] Redmon J, Farhadi A. YOLO9000: Better, faster, stronger. In: Proceedings of the 2017 Conference on Computer Vision and Pattern Recognition. Honolulu, HI, USA: IEEE, 2017. 6517−6525 [24] 魏湧明, 全吉成, 侯宇青阳. 基于YOLO v2的无人机航拍图像定位研究. 激光与光电子学进展, 2017, 54(11): 101-110Wei Yong-Ming, Quan Ji-Cheng, Hou Yu-Qing-Yang. Aerial image location of unmanned aerial vehicle based on YOLO v2. Laser and Optoelectronics Progress, 2017, 54(11): 101-110 [25] Lee S, Kim J, Yoon J S, Shin S, Bailo O, Kim N, et al. VPGNet: Vanishing point guide network for lane and road marking detection and recognition. In: Proceedings of the 2017 International Conference on Computer Vision. Venice, Italy: IEEE, 2017. 1965−1973 [26] Redmon J, Farhadi A. YOLOv3: An incremental improvement. In: Proceedings of the 2018 Conference on Computer Vision and Pattern Recognition. Salt Lake City, USA: 2018. 1−4 期刊类型引用(24)
1. 方虹苏,常城,石鑫雨,熊润莲,贺门涛. 自动驾驶场景中YOLO目标检测算法的应用研究. 汽车实用技术. 2025(06): 65-74 .  百度学术
百度学术2. 郭心悦,韩星宇,习超,王辉,范自柱. 基于非对称卷积的多车道线检测方法. 计算机工程与设计. 2024(02): 428-435 . 百度学术3. 苏盈盈,何亚平,邓圆圆,刘兴华,阎垒,斯洪云. 基于改进YOLOv5s轻量化带钢表面缺陷检测方法. 光电子·激光. 2024(07): 723-730 . 百度学术4. 张云佐,郑宇鑫,武存宇,张天. 基于双特征提取网络的复杂环境车道线精准检测. 吉林大学学报(工学版). 2024(07): 1894-1902 . 百度学术5. 刘德儿,李雨晴. 激光点云特征与知识规则协同的车道线提取. 激光与红外. 2024(07): 1069-1075 . 百度学术6. 蒋源,张欢,朱高峰,朱凤华,熊刚. 融合多尺度特征的残差车道线检测网络. 测绘通报. 2024(10): 71-76 . 百度学术7. 杨威,杨俊,许聪源. 基于改进YOLOv5的带钢表面缺陷检测. 计量学报. 2024(11): 1671-1680 . 百度学术8. 陈涵露,宋小军. 变光照下基于改进的deeplabv3+的车道线检测方法. 计算机仿真. 2024(11): 178-181+452 . 百度学术9. 廖龙杰,吕文涛,叶冬,郭庆,鲁竞,刘志伟. 基于深度学习的小目标检测算法研究进展. 浙江理工大学学报(自然科学). 2023(03): 331-343 . 百度学术10. 石金鹏,张旭. 基于空间语义分割的多车道线检测跟踪网络. 光学精密工程. 2023(09): 1357-1365 . 百度学术11. 王晓云,夏杰,刘凤丽,郭金玉. 交通标志识别综述. 长江信息通信. 2023(08): 76-78 . 百度学术12. 王燕妮,贾瑞英. 基于改进YOLOv3的轻量级目标检测算法. 探测与控制学报. 2023(05): 98-105 . 百度学术13. 徐治国. 数字信息化技术在市政道路运维管理中的实践探索. 中国建设信息化. 2023(20): 108-111 . 百度学术14. 杨飞帆,李军. 面向自动驾驶的YOLO目标检测算法研究综述. 汽车工程师. 2023(11): 1-11 . 百度学术15. 杨静,郎璐红,马书香,徐慧. 基于优化ERFNet的智能车辆车道线精确检测算法. 黑龙江工业学院学报(综合版). 2023(10): 109-114 . 百度学术16. 张林,谢刚,谢新林,张涛源. 融合MobileNetv3与Transformer的钢板缺陷实时检测算法. 计算机集成制造系统. 2023(12): 3951-3963 . 百度学术17. 赵世达,王树才,郝广钊,张一驰,杨华建. 基于单阶段目标检测算法的羊肉多分体实时分类检测. 农业机械学报. 2022(03): 400-411 . 百度学术18. 李春明,杨姗,远松灵. 结合帧差法与窗口搜索的车道线跟踪方法. 太赫兹科学与电子信息学报. 2022(04): 372-377 . 百度学术19. 韩逸,舒小华,杨明俊. 一种基于改进YOLOv5s的车道线检测方法. 湖南工业大学学报. 2022(03): 51-58 . 百度学术20. 茅智慧,朱佳利,吴鑫,李君. 基于YOLO的自动驾驶目标检测研究综述. 计算机工程与应用. 2022(15): 68-77 . 百度学术21. 黄志强,李军,张世义. 基于轻量级神经网络的目标检测研究. 计算机工程与科学. 2022(07): 1265-1272 . 百度学术22. 江漫,徐艳,吕义付,张乾. 基于计算机视觉的车道线检测技术研究进展. 信息技术与信息化. 2022(11): 21-24 . 百度学术23. 张琰,梁莉娟. 基于轻量化卷积神经网络的车道线检测. 信息与电脑(理论版). 2022(20): 87-90 . 百度学术24. 刘丹萍. 基于ROI自适应定位的复杂场景车道线检测. 长春师范大学学报. 2020(10): 66-70 . 百度学术其他类型引用(31)
-

 下载:
下载:

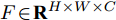
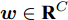
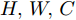
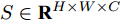
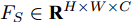
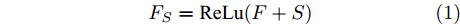
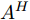
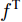
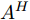
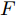
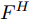


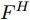
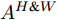
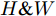
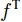

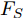
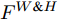
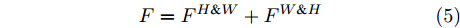
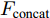
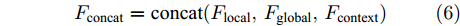
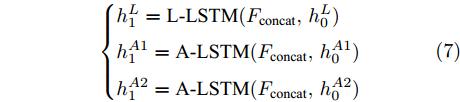
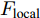
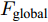
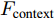
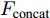
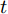
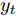
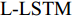
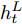
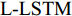
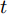
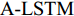
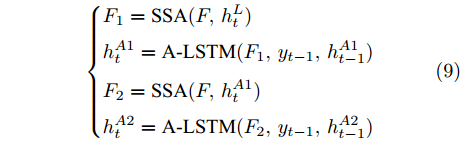
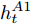
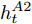
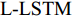

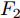
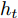
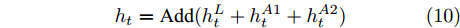
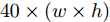
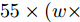
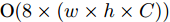
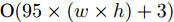

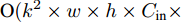
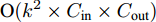
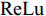
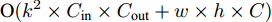
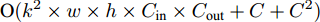
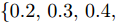
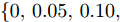









计量
- 文章访问数: 1810
- HTML全文浏览量: 1128
- PDF下载量: 615
- 被引次数: 55
