

Stroke Segmentation of Calligraphy Based on Conditional Generative Adversarial Network
-
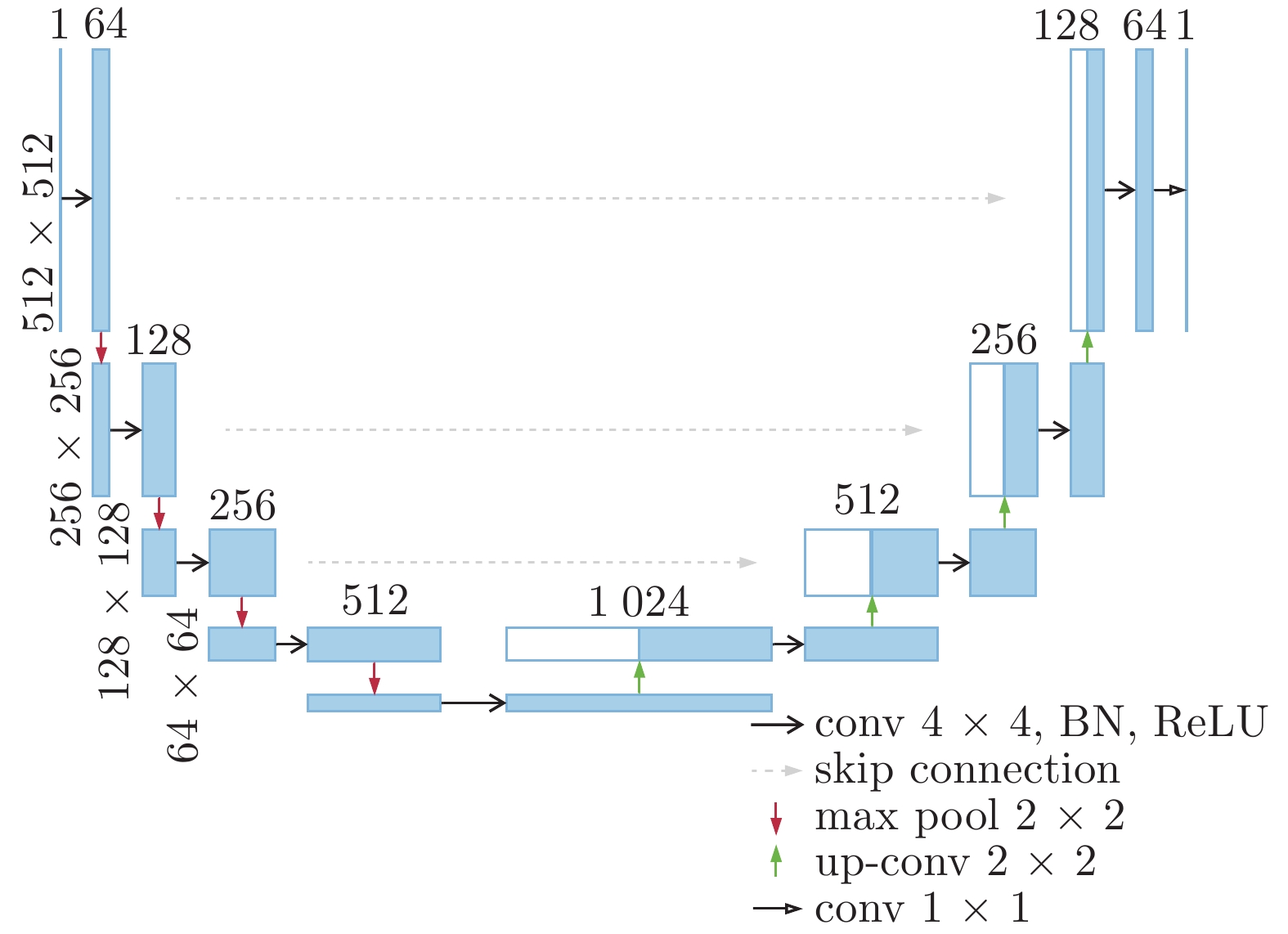
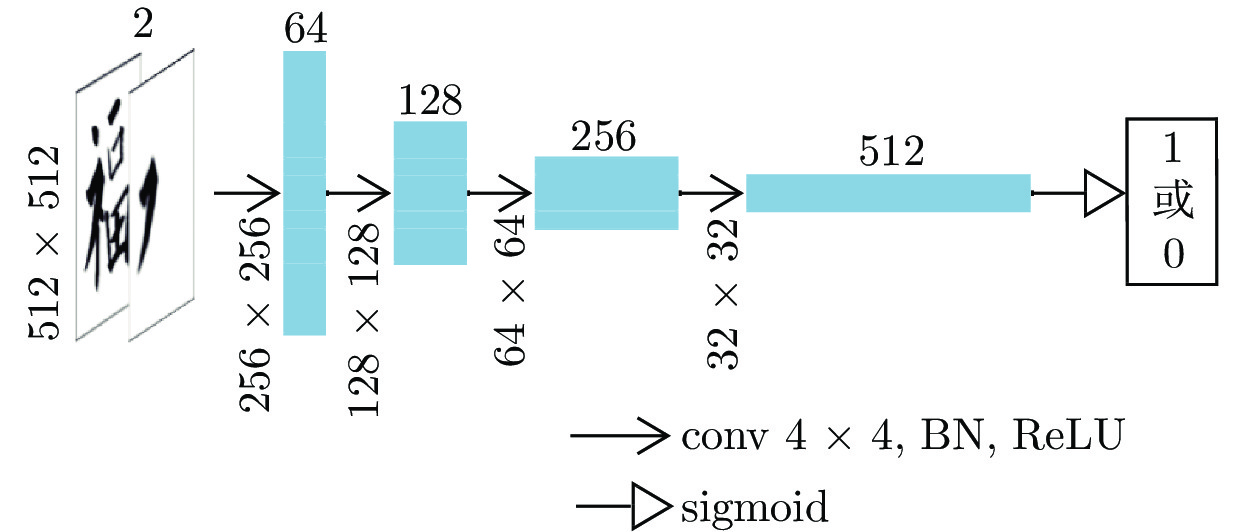
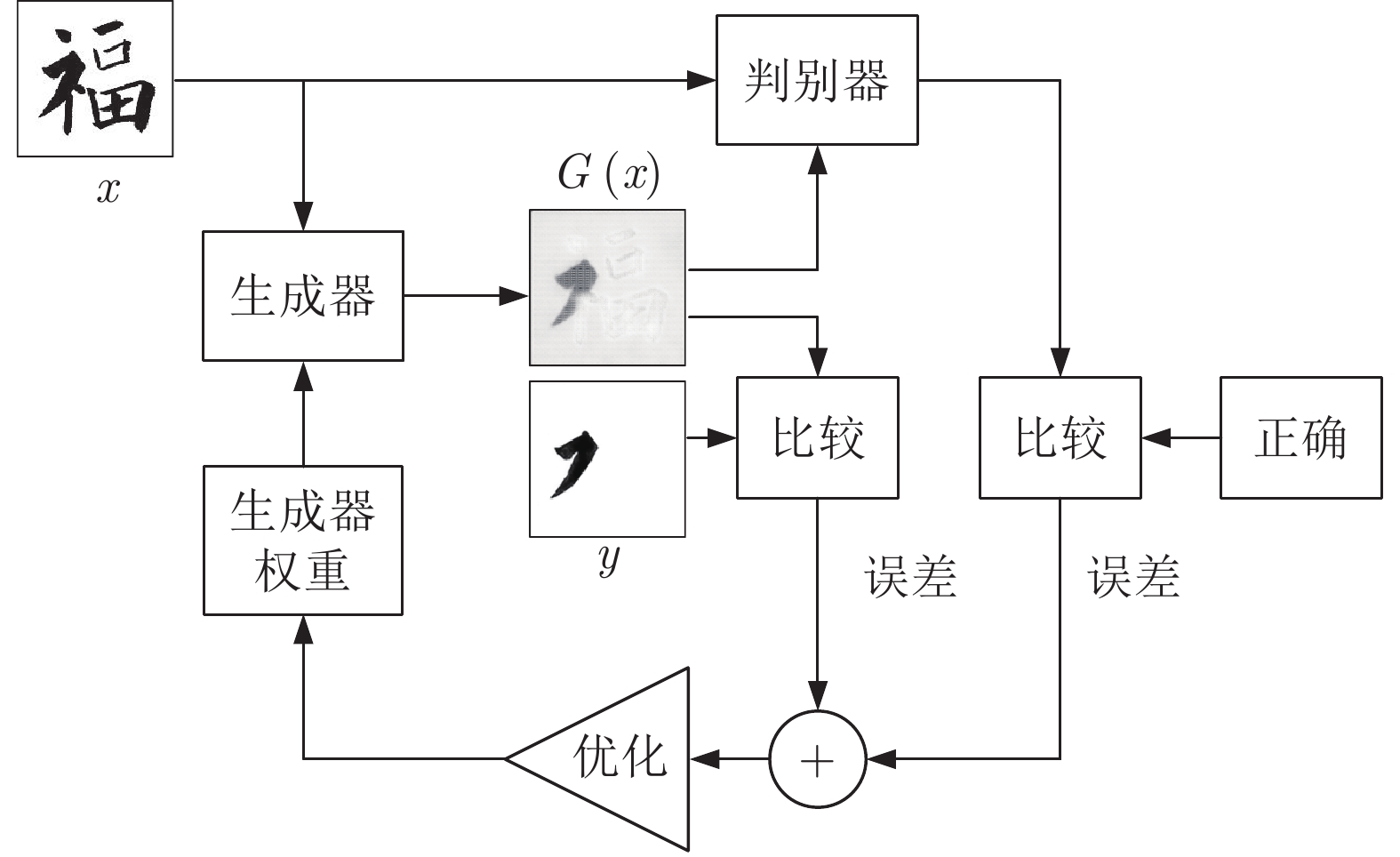
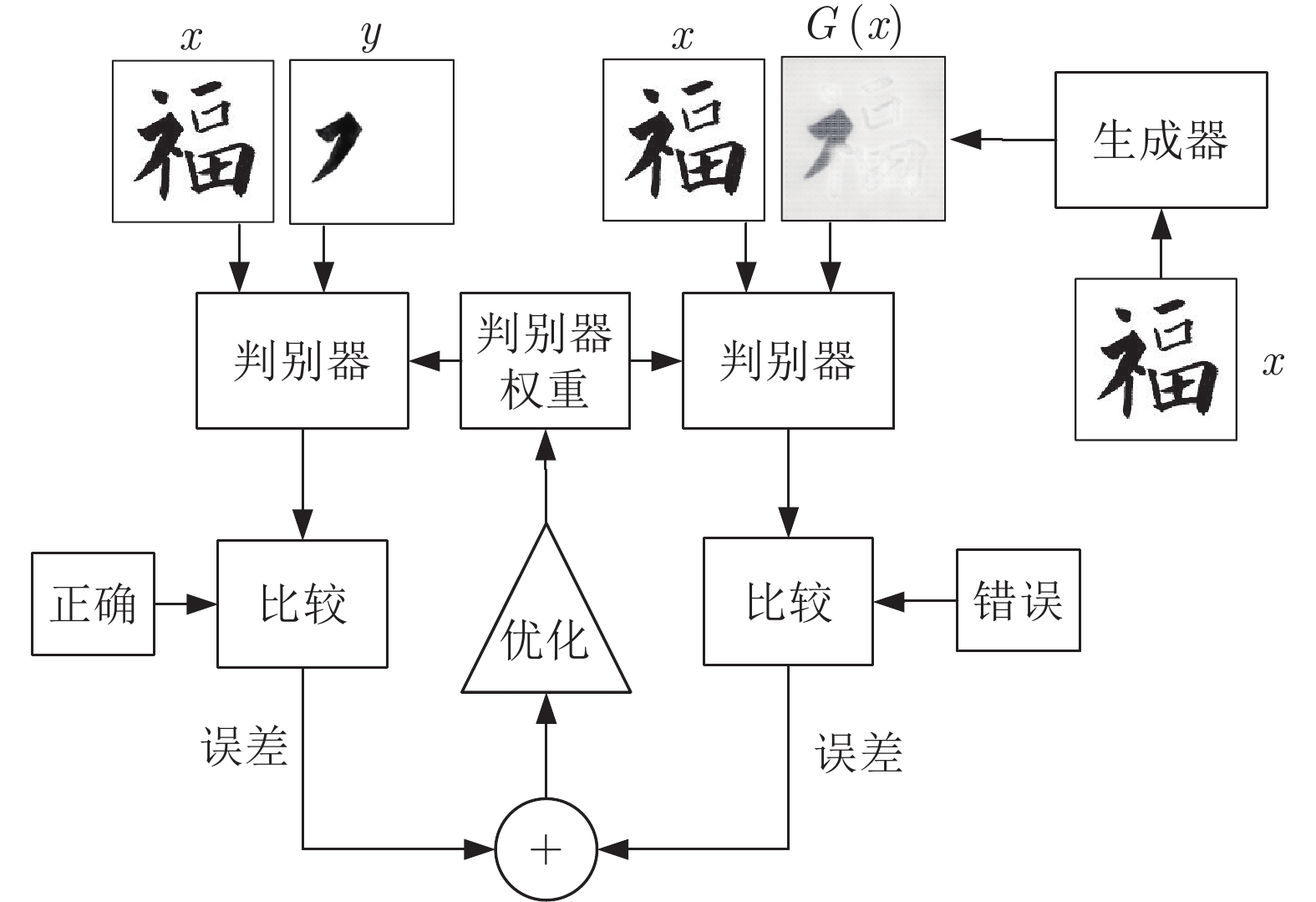
摘要: 毛笔书法作为中华传统艺术的精华, 需要在新的时代背景下继续传承和发扬. 书法字是以笔画为基本单元组成的复杂图形, 如果要分析书法结构, 笔画分割是首要的步骤. 传统的笔画分割方法主要利用细化法从汉字骨架上提取特征点, 分析交叉区域的子笔画拓扑结构关系来分割笔画. 本文分析了传统笔画分割基于底层特征拆分笔画的局限性, 利用条件生成对抗网络(Conditional generative adversarial network, CGAN)的对抗学习机制直接分割笔画, 使提取笔画从先细化再分割改进为直接分割. 该方法能有效提取出精确的笔画, 得到的高层语义特征和保留完整信息的单个笔画利于后续对书法轮廓和结构的评价.Abstract: As the essence of Chinese traditional art, brush calligraphy needs to continue to inherit and carry forward in the new era. Calligraphy is a complex figure composed of strokes as the basic unit. If you want to analyze the structure of calligraphy, stroke segmentation is the first step. The traditional stroke segmentation method mainly uses the refinement method to extract feature points from the Chinese character skeleton, and analyzes the sub-stroke topology relationship of the intersection region to segment the strokes. This paper analyzes the limitations of traditional stroke segmentation based on the underlying feature splitting strokes, and the strokes are directly segmented by using the adversarial learning mechanism of conditional generative adversarial network (CGAN). Improve the method of extracting strokes from first refinement and then segmentation to direct segmentation. This method can effectively extract accurate strokes. The resulting high-level semantic features and individual strokes that retain complete information are helpful for the subsequent evaluation of the outline and structure of calligraphy.
-

图 12 传统算法(上)与本文算法(下)骨架对比
Fig. 12 Traditional algorithm (top) and the algorithm of this paper (bottom) extract skeleton comparison
表 1 笔画分割的性能
Table 1 Performance of stroke segmentation
笔画 1 2 3 4 5 6 7 8 9 10 11 12 13 AC 0.9996 0.9976 0.9988 0.9994 0.9996 0.9996 0.9986 0.9991 0.9991 0.9967 0.9992 0.9986 0.9983 F1 0.9592 0.9435 0.9604 0.9397 0.9710 0.9663 0.9519 0.9312 0.9610 0.9583 0.9483 0.9307 0.9572  下载: 导出CSV
下载: 导出CSV
-
[1] 郭晨. 基于图像处理技术的手写体汉字特征分析的研究 [硕士学位论文]. 天津科技大学, 中国, 2010.Guo Chen. Research on Character Analysis of Handwritten Chinese Characters Based on Image Processing Technology [Master thesis]. Tianjin University of Science and Technology, China, 2010. [2] 李凡. 基于改进K段主曲线算法的图像骨架提取 [硕士学位论文]. 大连海事大学, 中国, 2016.Li Fan. Image Skeleton Extraction Based on Improved K-segment Main Curve Algorithm [Master thesis]. Dalian Maritime University, China, 2016. [3] 阳平, 娄海涛, 胡正坤. 一种基于骨架的篆字笔划分割方法. 计算机科学, 2013, 40(2):297-300 doi: 10.3969/j.issn.1002-137X.2013.02.066Yang Ping, Yan Haitao, Hu Zhengkun. A Skeleton-based Segmentation Method for Scratch Strokes. Computer Science, 2013, 40(2): 297-300(in Chinese) doi: 10.3969/j.issn.1002-137X.2013.02.066 [4] 苗晋诚. 基于骨架化、骨架划分获取书法汉字结构特征的方法. 昆明理工大学学报:理工版, 2008, 33(3):53-61Miao Jincheng. A method for obtaining the structural features of Chinese characters based on skeletonization and skeleton division. Journal of Kunming University of Science and Technology: Science and Engineering Edition, 2008, 33(3): 53-61(in Chinese) [5] 章夏芬, 刘佳岩. 用爬虫法提取书法笔画. 计算机辅助设计与图形学学报, 2016, 28(02):301-309. doi: 10.3969/j.issn.1003-9775.2016.02.013Zhang Xiafen, Liu Jiayan. Extraction of Calligraphy Strokes by Reptile Method. Journal of Computer-Aided Design and Computer Graphics, 2016, 28(02):301-309.(in Chinese) doi: 10.3969/j.issn.1003-9775.2016.02.013 [6] 程立, 王江晴, 李波, 田微, 朱宗晓, 魏红昀, 刘赛. 基于轮廓的汉字笔画分离算法. 计算机科学, 2013, 40(07):307-311. doi: 10.3969/j.issn.1002-137X.2013.07.069Cheng Li, Wang Jiangqing, Li Bo, Tian Wei, Zhu Zongxiao, Wei Hongwei, Liu Sai. Algorithm for Separation of Chinese Character Strokes Based on Contours. Computer Science, 2013, 40(07): 307-311.(in Chinese) doi: 10.3969/j.issn.1002-137X.2013.07.069 [7] 曹忠升, 苏哲文, 王元珍, 熊鹏. 基于模糊区域检测的手写汉字笔画提取方法. 中国图象图形学报, 2009, 14(11):2341-2348. doi: 10.11834/jig.20091124Cao Zhongsheng, Su Zhewen, Wang Yuanzhen, Xiong Peng. A method for extracting handwritten Chinese characters based on fuzzy region detection. Chinese Journal of Image and Graphics, 2009, 14(11): 2341-2348.(in Chinese) doi: 10.11834/jig.20091124 [8] 陈睿, 唐雁, 邱玉辉. 基于笔画段分割和组合的汉字笔画提取模型. 计算机科学, 2003(10):74-77. doi: 10.3969/j.issn.1002-137X.2003.10.020Chen Rui, Tang Yan, Qiu Yuhui. Extraction model of Chinese strokes based on segmentation and combination of stroke segments. Computer Science, 2003(10):74-77.(in Chinese) doi: 10.3969/j.issn.1002-137X.2003.10.020 [9] Goodfellow I, Pouget-Abadie J, Mirza M, et al. Generative adversarial nets. In: Proceedings of the 27th Annual Conference on Advances in Neural Information Processing Systems (NeurIPS), Montreal, Canada: NIPS, 2014. 2672−2680 [10] 王坤峰, 苟超, 段艳杰, 林懿伦, 郑心湖, 王飞跃. 生成式对抗网络GAN的研究进展与展望. 自动化学报, 2017, 43(03):321-332.Wang Kunfeng, Yan Chao, Duan Yanjie, Lin Yulun, Zheng Xinhu, Wang Feiyue. Research progress and prospects of generatival adversarial network GAN. Acta Automatica Sinica, 2017, 43(03): 321-332.(in Chinese) [11] Isola P, Zhu J Y, Zhou T H, Efros A A. Image-to-image translation with conditional adversarial networks. In: Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA: IEEE, 2017. 1125−1134 [12] Yu J H, Lin Z, Yang J M, Shen X H, Lu Xin, Huang T S. Generative image inpainting with contextual attention. In: Proceedings of the 2018 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, USA: IEEE, 2018. 5505−5514 [13] 张毅锋, 刘袁, 蒋程, 程旭. 用于超分辨率重建的深度网络递进学习方法. 自动化学报, 2020, 46(2): 274−282Zhang Yi-Feng, Liu Yuan, Jiang Cheng, Cheng Xu. A deep network progressive learning method for super-resolution reconstruction. Acta Automatica Sinica, 2020, 46(2): 274−282 [14] Al-Amri S S, Kalyankar N V. Image segmentation by using threshold techniques. arXiv preprint arXiv: 1005.4020, 2010. [15] Kang J, Kim S, Oh T J, Chung M J. Moving region segmentation using sparse motion cue from a moving camera. Intelligent Autonomous Systems 12, 2013, 193: 257−264 [16] Gaur P, Tiwari S. Recognition of 2D barcode images using edge detection and morphological operation. International Journal of Computer Science and Mobile Computing, 2014, 3(4): 1277-1282. [17] 刘松涛, 殷福亮. 基于图割的图像分割方法及其新进展. 自动化学报, 2012, 38(06):911-922. doi: 10.3724/SP.J.1004.2012.00911Liu Songtao, Yin Fuliang. Image segmentation method based on graph cut and its new progress. Acta Automatica Sinica, 2012, 38(06): 911-922.(in Chinese) doi: 10.3724/SP.J.1004.2012.00911 [18] Mirza M, Osindero S. Conditional generative adversarial nets. arXiv preprint arXiv: 1411.1784, 2014. [19] 蒋芸, 谭宁. 基于条件深度卷积生成对抗网络的视网膜血管分割. 自动化学报, 2021, 47(1): 136−147Jiang Yun, Tan Ning. Retinal vascular segmentation based on conditional deep convolution to generatival adversarial network. Acta Automatica Sinica, 2021, 47(1): 136−147 [20] Ronneberger O, Fischer P, Brox T. U-Net: Convolutional networks for biomedical image segmentation. In: Proceedings of the 2015 International Conference on Medical image computing and computer-assisted intervention. Springer, Cham, 2015. 234−241 [21] 杜雪莹. 中国书法 AI 的研究与应用 [硕士学位论文]. 浙江大学, 中国, 2018.Du Xue-Ying. Research and Application of Chinese Calligraphy AI [Master thesis]. Zhejiang University, China, 2018. [22] Hu M K. Visual pattern recognition by moment invariants. IRE transactions on information theory, 1962, 8(2): 179-187. doi: 10.1109/TIT.1962.1057692 [23] Zhang Junsong, Yu Jinhui, Mao Guohong, Ye Xiuzi. Denoising of Chinese calligraphy tablet images based on run-length statistics and structure characteristic of character strokes. Journal of Zhejiang University-Science A, 2006, 7(7): 1178-1186. doi: 10.1631/jzus.2006.A1178 [24] Xu Songhua, Lau F C M, Cheung W K, et al. Automatic generation of artistic Chinese calligraphy. IEEE Intelligent Systems, 2005, 20(3): 32-39. doi: 10.1109/MIS.2005.41 [25] 张福成. 基于卷积神经网络的书法风格识别的研究 [硕士学位论文]. 西安理工大学, 中国, 2018.Zhang Fu-Cheng. Research on Calligraphy Style Recognition Based on Convolutional Neural Network [Master thesis]. Xi'an University of Technology, China, 2018. -

 下载:
下载:







图(14) / 表(1)
计量
- 文章访问数: 999
- HTML全文浏览量: 726
- PDF下载量: 273
- 被引次数: 0
