

Distributed Event-triggered Fixed-time Scaled Consensus Control for Second-order Multi-agent Systems
-
摘要: 研究了在无向拓扑下, 由多个子群组成的二阶多智能体系统的固定时间比例一致性问题, 采用反推法设计了一种基于事件触发的固定时间非线性比例一致控制策略, 该策略包含分段式事件触发函数: 当智能体在追踪虚拟速度时, 给出了基于速度信息的触发条件; 当智能体速度与虚拟速度达到一致时, 切换至基于位置信息的触发条件, 可有效减少系统能量耗散及控制器更新频次. 通过在位置和速度状态上设置比例参数, 在固定时间内可实现不同子群智能体之间的比例一致. 利用代数图论、线性矩阵不等式以及Lyapunov稳定性理论, 证明在该控制策略下, 二阶多智能体系统能实现固定时间比例一致性, 且不存在Zeno行为. 最后, 仿真实例进一步验证了理论结果的有效性.Abstract: The problem of fixed-time proportional consensus of second-order multi-agent systems composed of multiple subgroups under undirected topology is studied. A fixed-time non-linear proportional consensus control strategy based on event triggering is designed by using backstepping method. The strategy includes a piecewise event-triggering function. When an agent tracks virtual speed, a trigger bar based on velocity information is given. When the agent achieves the same virtual speed, switching to the event trigger condition based on location information can efiectively reduce the energy dissipation of the system and the update frequency of the controller. By setting proportional parameters in the position and speed state, the proportional consensus among different sub-group agents can be achieved in a fixed time. The Lyapunov stability theory, linear matrix inequality and algebraic graph theory are used to prove the control strategy. Second-order multi-agent systems can achieve fixed-time scaled consensus without the Zeno behavior. The simulation results further verify the validity of the theoretical results.
-
近些年来, 由于多智能体系统的分布式协同控制在编队控制[1-2]、蜂拥[3-4]等多领域的应用, 现受到许多学者广泛关注. 目前为止, 多智能体系统的一致性研究已经由一阶[5]、二阶[6]逐步发展到高阶[7-8]. 一致性的基本思想是每个智能体通过自身和邻居信息来更新自身信息, 从而使得所有个体最终收敛于同一状态.
在实际的工程应用中, 智能体自身能量和通讯信道带宽往往都是有限的, 因此, 在设计控制协议时需要考虑智能体能量的损耗, 让其能有更长的运作时间. 由此, 将事件触发机制引入到多智能体系统具有很大意义. 文献[9]将事件触发策略引入多智能体系统的研究, 控制器不再连续更新控制输入, 而是依赖于与测量误差相关的事件触发函数, 当测量误差达到某一临界状态才更新控制输入. 文献[10]给出了一阶多智能体系统的事件触发控制协议, 设计了与智能体系统状态有关的触发条件. 文献[11]研究了在有向拓扑下, 带有扰动多智能体系统的均方一致性问题, 智能体最终收敛到系统初始状态的平均值, 并且进一步分析了切换拓扑的一致性. 在大多数已有的成果中, 对于触发条件的设计, 不仅与自身的触发时间有关, 还与其邻居的触发时间有关. 这样将会增加通讯负担和控制器的更新频率. 为了解决这个问题, 文献[12]提出了联合测量误差, 能减少智能体之间的通信次数. 为了进一步的减小通讯负担和控制器的更新频次, 文献[13]将事件触发机制引入到间歇控制, 给出了集中式和分布式两种事件触发控制策略.
值得注意的是, 大部分已有的基于事件触发控制策略只是基于渐近收敛. 然而, 在一些实际的工程应用中, 尤其在一些要求较高精度和较高收敛速度的控制问题中, 经常需要达到有限时间收敛. 因此, 基于事件触发的有限时间一致性问题有很大研究价值. 文献[14]研究了在无向拓扑下, 针对有领导者和无领导者两种情形, 通过将有限时间一致性控制器与事件触发相结合, 设计了两种控制协议, 然而, 并没有排除Zeno行为. 文献[15]在此基础上, 设计了新的事件触发条件, 给出了排除Zeno行为的证明和数值仿真. 文献[16]在文献[14]基础上, 研究了在有向拓扑下的有限时间一致性问题, 给出了两种事件触发条件. 尽管上述文献很好地解决了基于事件触发的有限时间一致性, 但是设置的收敛时间都与智能体的初始状态有关, 当系统初始状态很大时, 系统收敛时间会受较大影响. 为了排除这一影响, 文献[17]设计了两种控制协议: 1)通过引入符号函数来抑制外部扰动的固定时间一致性协议; 2)为消除前者符号函数所带来的抖振现象, 引入饱和函数, 并给出事件触发的条件.
上述文献大部分都是关于普通一致性问题, 文献[18]研究了比例一致性问题, 即各个智能体最终的状态能够趋于指定的比例, 而不是同一定值. 文献[19]研究了切换拓扑下带有通信时延的比例一致性问题. 文献[20]研究了一阶和二阶分组比例一致性问题, 设计了两种分布式控制协议. 文献[21]研究了带有外部扰动的比例一致性问题, 给出了基于渐近收敛、有限时间收敛和固定时间收敛三种控制策略.
本文研究了基于事件触发二阶多智能体系统的固定时间比例一致性问题, 提出了一种新的基于事件触发的比例一致性控制协议, 该控制协议包含基于状态信息和速度信息的分段式触发条件: 当智能体在追踪虚拟速度时, 采用与系统速度有关的触发条件; 当完成虚拟速度追踪后, 切换为基于状态信息的触发条件, 能有效的减小系统能量耗散及控制器更新频次. 基于Lyapunov稳定性理论、线性矩阵不等式和代数图论证明了所提事件触发控制策略能有效地实现二阶多智能体系统的固定时间比例一致性, 并且不存在Zeno行为. 相较于文献[14]、[16], 本文所给出的收敛时间不再依赖于系统的初始状态. 在文献[17]的基础上, 本文进一步拓展, 对二阶多智能体系统进行了研究, 同时多智能体不再收敛于同一状态, 而是按照既定的比例, 收敛到不同状态. 相较于文献[18]、[20], 本文采用事件触发的策略来设计控制协议, 能在达到比例一致性的同时有效节约系统资源.
1. 预备知识及问题描述
1.1 图论
$ N $ 个智能体可视为$ N $ 个节点, 可以用无向图$ G = $ $ (V,E,A) $ 表示,$V = \{ {v_1},\cdots,{v_N}\}$ 表示节点集合,$ E \subseteq $ $ V \times V $ 表示边集.$A = [{a_{ij}}] \in {{\bf R}^{n \times n}}$ 是具有元素$ {a_{ij}} $ 的加权矩阵, 其对角线元素$ {a_{ii}} = 0 .$ 如果$ ({v_i},{v_j}) \notin $ $ E $ ,$ {a_{ij}} = 0 $ , 否则$ {a_{ij}} > 0 . $ 若$ ({v_i},{v_j}) \in E = ({v_j},{v_i}) \in $ $ E $ ,$ {e_{ij}} = ({v_i},{v_j}) $ 表示第$ i $ 个智能体与第$ j $ 个智能体之间互相传输信息, 则图$ G $ 为无向图; 若$({v_i},{v_j}) \in $ $ E \ne ({v_j},{v_i}) \in E$ ,$ {e_{ij}} = ({v_i},{v_j}) $ 表示第$ i $ 个智能体向第$ j $ 个智能体传输信息, 则图$ G $ 为有向图, 从节点$ i $ 到节点$ j $ 的有向路径被称为有向边. 度矩阵$D \in $ $ {{{\bf R} ^{N \times N}}}$ 定义为$ D = {\rm diag}\{ {d_i}\} $ , 其中$ {d_i} = \sum\nolimits_{{v_j} \in V} {{a_{ij}}} . $ Laplacian矩阵$L \in {{{\bf R}^{N \times N}}}$ 被定义为$ L = [{l_{ij}}] $ ,$ L =$ $ D - A $ , 其中,$ {l_{ii}} = \sum\nolimits_{p \ne i}^n {a{}_{ip}} $ ,$ {l_{ij}} = - {a_{ij}},\forall i \ne j $ .1.2 相关引理
引理1[22].
1)无向图
$ G $ 的Laplacian矩阵$ L $ 为半正定, 有一个特征值为0. 如果无向图$ G $ 是连通的, 则除0以外的特征值均正定;2)无向图
$ G $ 的Laplacian矩阵$ L $ 的第二小特征值$ {\lambda _2}(L) $ 满足:$$ {\lambda _2}(L) = \mathop {\min }\limits_{||x|| \ne 0,\sum\limits_{i = 1}^N {{x_i} = 0} } \frac{{{x^{\rm{T}}}Lx}}{{||x|{|^2}}} > 0 $$ 当
$\sum_{i = 1}^n {x_i} = 0$ 时, 有:$${x^{\rm T}}Lx \ge {\lambda _2}(L){x^{\rm{T}}}x $;$ 3)对于任意
$x = {({x_1},{x_2},\cdots,{x_N})^{\rm{T}}} \in {{{\bf R}^N}}$ 有:$$ {x^{\rm{T}}}Lx = \frac{1}{2}\sum_{i = 1}^N {\sum_{j = 1}^N {{a_{ij}}{{({x_j} - {x_i})}^2}} } $.$ 引理2[23]. 如果存在一个连续的径向无界函数
$ V:{{{\bf R}^N}} \to {{{\bf R}_ + }} \cup \{ 0\} $ 满足:1)
$ V(x) = 0 \Leftrightarrow x = 0 $ ;2)系统任意的解
$ x(t) $ 满足:$$ {{D}^*}V(x(t)) \le - \alpha {V^p}(x(t)) - \beta ({V^q}(x(t)) $$ 其中,
$ \alpha ,\beta > 0 $ ,$ p = 1 - \dfrac{1}{{2\kappa }} $ ,$ q = 1 + \dfrac{1}{{2\kappa }} $ ,$ \kappa > 1 $ , 则系统在固定时间达到全局稳定, 且收敛时间$ T $ 满足$ T \le {T_{\max }} = \dfrac{{ {\text{π}} \kappa }}{{\sqrt {\alpha \beta } }} $ .引理3[24]. 假设
${w_1},{w_2},\cdots,{w_N} \ge 0$ ,$ 0 < p \le 1 $ ,$ q > 1 $ , 有:$$ \sum\limits_{i = 1}^N {w_i^p} \ge \left(\sum\limits_{i = 1}^N {w_i}\right){^p} ,\sum\limits_{i = 1}^N {w_i^q} \ge {N^{1 - q}}\left(\sum\limits_{i = 1}^N {w_i}\right){^q} $.$ 1.3 问题陈述
考虑到二阶多智能体系统由
$ N $ 个智能体组成, 智能体$ i $ 的动力学方程可写为:$$ \left\{ {\begin{aligned} &{{{\dot x}_i}(t) = {v_i}(t)}\\ &{{{\dot v}_i}(t) = {u_i}(t)} \end{aligned}} \right.,\quad i = 1,\cdots,N $$ (1) 上式中,
$ {x_i}(t) \in {\bf R} $ 表示为智能体$ i $ 的状态变量,$ {v_i}(t) \in {\bf R} $ 表示为智能体$ i $ 的速度变量,$ {u_i}(t) \in {\bf R} $ 表示为系统的控制输入,$x(t) = [{x_1}(t),{x_2}(t),\cdots,$ $ {x_N}(t)]^{\rm{T}} $ .定义1[20]. 对于给定的控制器
${u_i},i = 1,2,\cdots,N$ , 如果对于给定的任何初始值${x_i}(0),i = 1,2,\cdots,N$ , 存在一个与初始值有关的正数$ T $ 以及固定的常数$ {T_{\max }} > $ $ 0 $ ,$ T < {T_{\max }} $ , 于任意的$i,j = 1,2,\cdots,N$ 有:$$ \mathop {\lim }\limits_{t \to T} |{s_i}{x_i}(t) - {s_j}{x_j}(t)| = 0 $$ $$ \mathop {\lim }\limits_{t \to T} {v_i}(t) = 0 $$ $$ {s_i}{x_i}(t) = {s_j}{x_j}(t),v{}_i(t) = {v_j}(t),\quad\forall t \ge T $$ (2) 则称闭环系统达到固定时间比例一致性, 其中
$ {s_i}, $ $i = 1,2,\cdots,N$ , 为比例系数.2. 基于事件触发的固定时间比例一致性
受文献[7]、[25]的启发, 采用反推法来设计控制器, 引入虚拟速度:
$$ \begin{split} v_i^* =\;& - {c_1}{\rm sign}({s_i})sig{\left[ {\sum\limits_{j = 1}^N {{a_{ij}}({s_i}{x_i} - {s_j}{x_j})} } \right]^\alpha } - \\ &{c_2}{\rm sign}({s_i})sig{\left[ {\sum\limits_{j = 1}^N {{a_{ij}}({s_i}{x_i} - {s_j}{x_j})} } \right]^\beta } \end{split} $$ (3) 定义
$ sig{[m]^k} = {\rm sign}(m)|m{|^k} $ ,${\rm sign}(\cdot)$ 为符号函数. 其中,$i = 1,2,\cdots,N$ ,$ {c_1} > 0 $ ,$ {c_2} > 0 $ ,$ \alpha \in (0,1) $ ,$ \beta > 1 $ .定义速度跟踪误差:
$$ {\bar v_i} = {v_i} - v_i^* $$ (4) 令
$\bar v = {({\bar v_1},{\bar v_2},\cdots,{\bar v_N})^{\rm{T}}}$ , 式(3)、(4)求导得:$$ \begin{split} {{{\dot {\bar v}_i}}} =\;& {u_i} + {c_1}\alpha {\rm sign}({s_i})|\sum\limits_{j = 1}^N {{a_{ij}}} ({s_i}{x_i} - \\ &{s_j}{x_j}){|^{\alpha - 1}}\sum\limits_{j = 1}^N {{a_{ij}}({s_i}{v_i} - {s_j}{v_j})} + \\ &{c_{\rm{2}}}\beta {\rm sign}({s_i})|\sum\limits_{j = 1}^N {{a_{ij}}} ({s_i}{x_i} - \\ &{s_i}{x_j}){|^{\beta - 1}}\sum\limits_{j = 1}^N {{a_{ij}}({s_i}{v_i}} - {s_j}{v_j}) \end{split} $$ (5) 为设计智能体的事件触发策略, 对于每一个智能体
$ i $ 定义,$$ {\hat x_i}(t) = {s_i}{x_i}(t_i^k) $$ (6) $$ {\hat v_i}(t) = {s_i}{v_i}(t_i^k) $$ (7) 其中,
$ t_i^k $ 表示智能体$ i $ 第$ k $ 次事件触发时刻. 当$t \in $ $ [t_i^k, t_i^{k + 1}) $ 时, 定义:$$ \begin{split} \hat v_i^*(t) = \;&- {c_1}{\rm sign}({s_i})sig{\left[ {\sum\limits_{j = 1}^N {{a_{ij}}({{\hat x}_i}(t) - {{\hat x}_j}(t))} } \right]^\alpha } - \\ &{c_2}{\rm sign}({s_i})sig{\left[ {\sum\limits_{j = 1}^N {{a_{ij}}({{\hat x}_i}(t) - {{\hat x}_j}(t))} } \right]^\beta }\\[-15pt] \end{split} $$ (8) $$ {{\hat {\bar v}_i}}(t) = \frac{1}{{{s_i}}}{\hat v_i}(t) - \hat v_i^*(t) $$ (9) 经过以上分析, 给出基于事件触发的控制协议如下:
$$ \begin{split} &{u_i} = - {c_3}sig{\left[ {{{{\hat {\bar v}_i}}}} \right]^p} - {c_4} sig{\left[ {{{{\hat {\bar v}_i}}}} \right]^q} - \\ &\;\;\quad{c_1}\alpha {\rm sign}({s_i}){\left| {\sum\limits_{j = 1}^N {{a_{ij}}({{\hat x}_i} - {{\hat x}_j})} } \right|^{\alpha - 1}}\sum\limits_{j = 1}^N {{a_{ij}}({{\hat v}_i} - {{\hat v}_j})} - \\ &\;\;\quad{c_2}\beta {\rm sign}({s_i}){\left| {\sum\limits_{j = 1}^N {{a_{ij}}({{\hat x}_i} - {{\hat x}_j})} } \right|^{\beta - 1}}\sum\limits_{j = 1}^N {{a_{ij}}({{\hat v}_i} - {{\hat v}_j})} \end{split} $$ (10) 其中,
$ {c_3} $ 、$ {c_4} $ 为正常数, 且$ p \in (0,1),q > 1 $ . 定义$ x = $ ${({x_1},{x_2},\cdots,{x_N})^{\rm{T}}}$ . 为书写方便, 令$$ \begin{split} {\rho _i} = \;&{c_1}\alpha {\rm sign}({s_i})|\sum\limits_{j = 1}^N {{a_{ij}}({{\hat x}_i} - } \\ &{{\hat x}_j}){|^{\alpha - 1}}\sum\limits_{j = 1}^N {{a_{ij}}({{\hat v}_i}} - {{\hat v}_j}) + \\ &{c_2}\beta {\rm sign}({s_i})|\sum\limits_{j = 1}^N {{a_{ij}}({{\hat x}_i} - } \\ &{{\hat x}_j}){|^{\beta - 1}}\sum\limits_{j = 1}^N {{a_{ij}}({{\hat v}_i}} - {{\hat v}_j}) \end{split} $$ $$ \begin{split} {\varsigma _i} =\;& {c_1}\alpha {\rm sign}({s_i})|\sum\limits_{j = 1}^N {{a_{ij}}({s_i}{x_i} - } \\ & {s_j}{x_j}){|^{\alpha - 1}}\sum\limits_{j = 1}^N {{a_{ij}}({s_i}{v_i}} - {s_j}{v_j}) + \\ & {c_2}\beta {\rm sign}({s_i})|\sum\limits_{j = 1}^N {{a_{ij}}({s_i}{x_i} - } \\ & {s_j}{x_j}){|^{\beta - 1}}\sum\limits_{j = 1}^N {{a_{ij}}({s_i}{v_i} - {s_j}{v_j})} \end{split} $$ 当
$ t \in [0,{T_1}] $ 时, 定义测量误差为:$$ \begin{split} {e_i} =\;& {c_3}sig{\left[ {{{{\hat {\bar v}_i}}}} \right]^p} + {c_4}sig{\left[ {{{{\hat {\bar v}_i}}}} \right]^q} + {\rho _i} - \\ &{c_3}sig{\left[ {{{\bar v}_i}} \right]^p} - {c_4}sig{\left[ {{{\bar v}_i}} \right]^q} - {\varsigma _i} \end{split} $$ (11) 令
$e = {({e_1},{e_2},\cdots,{e_N})^{\rm{T}}}$ .定理1. 假设多智能体系统的固定通信拓扑图
$ G $ 为无向图, 考虑到多智能体系统(1)在控制器(10)的作用下, 给出如下触发函数:$$ \begin{split} {f_i}(t) =\;& {\rm sign}\left( {\left| {{v_i} - v_i^*} \right|} \right)\left(\left\| {{e_i}} \right\| - {\mu _i}{c_4}{N^{\frac{{1 - q}}{{\rm{2}}}}}{\left\| {{{\bar v}_i}} \right\|^q}\right) + \\ &\left[ {1 - {\rm sign}\left( {\left| {{v_i} - v_i^*} \right|} \right)} \right]\Bigg(\left\| {{E_i}} \right\| - \\ &{\varepsilon _i}{c_2}{\left\| {\sum\limits_{j = 1}^N {{a_{ij}}\left( {{x_i} - {x_j}} \right)} } \right\|^\beta }\Bigg) \\[-15pt]\end{split} $$ (12) 其中,
$ {E_i} $ 定义为$ t \in ({T_1},T] $ 时的测量误差,$ {T_1} $ 表示智能体速度与虚拟速度达到一致的时间,$ T $ 表示多智能体系统收敛所需时间.$ {\mu _i} \in (0,1),{\varepsilon _i} \in (0,1) $ . 多智能体系统(1)在任意初始条件下均能实现固定时间比例一致性, 且收敛时间满足:$$ \begin{split} T =\;& {T_1} + {T_2} \le {T_{1\max }} + {T_{2\max }}=\\ &\frac{{2{\text{π}} }}{{(q - p)\sqrt {(1 - {\mu _i}){c_3}{c_4}{N^{{{(1 - q)} / 2}}}{2^{\frac{{p + q + 2}}{2}}}} }} + \\ &\frac{{2{\text{π}} }}{{(\beta - \alpha )\sqrt {(1 - {\varepsilon _i}){c_1}{c_2}{N^{{{(1 - \beta )} / 2}}}{{(2{\lambda _2}(L))}^{\frac{{\alpha + \beta + 2}}{2}}}} }} \end{split} $$ (13) $ {T_2} $ 表示智能体达到虚拟速度之后整个系统实现一致性的时间.证明. 由式(5)、(10)、(11)可得:
$$ {{{\dot {\bar v}_i}}} = - {c_3}sig{\left[ {{{\bar v}_i}} \right]^p} - {c_4}sig{\left[ {{{\bar v}_i}} \right]^q} - {e_i} $$ 当
$ t \in [0,{T_1}] $ 时, 选定Lyapunov函数为:$$ {V_1} = \frac{1}{2}{\bar v^{\rm{T}}}\bar v $$ 求导得
$$ \begin{split} {{\dot V}_1} =\;& \sum\limits_{i = 1}^N {{{\bar v}_i}} {{{\dot {\bar v}_i}}}=\\ &\sum\limits_{i = 1}^N {{{\bar v}_i}} ( - {c_3} sig{\left[ {{{\bar v}_i}} \right]^p} - {c_4}sig{\left[ {{{\bar v}_i}} \right]^q} - {e_i})=\\ &- {c_3}\sum\limits_{i = 1}^N {|{{\bar v}_i}{|^{p + 1}} - {c_4}\sum\limits_{i = 1}^N {|{{\bar v}_i}{|^{q + 1}}} } - \sum\limits_{i = 1}^N {{{\bar v}_i}{e_i}} =\\ &- {c_3}\sum\limits_{i = 1}^N {{{(\bar v_i^2)}^{\frac{{p + 1}}{2}}} - {c_4}\sum\limits_{i = 1}^N {{{(\bar v_i^2)}^{\frac{{q + 1}}{2}}}} } - \sum\limits_{i = 1}^N {{{\bar v}_i}{e_i}} \le\\ &- {c_3}{\left(\sum\limits_{i = 1}^N {\bar v_i^2} \right)^{\frac{{p + 1}}{2}}} - {c_4}{N^{\frac{{1 - q}}{2}}}{\left(\sum\limits_{i = 1}^N {\bar v_i^2} \right)^{\frac{{q + 1}}{2}}} - \\ &\sum\limits_{i = 1}^N {{{\bar v}_i}{e_i}}\\[-15pt] \end{split} $$ (14) 上式中
$$ \begin{split} \sum\limits_{i = 1}^N {{{\bar v}_i}{e_i}} =\;& {{\bar v}^{\rm{T}}}e \le \parallel \bar v\parallel \parallel e\parallel =\\ &\dfrac{{\parallel \bar v\parallel \parallel e\parallel {V_1}^{\frac{{1 + q}}{2}}}}{{{V_1}^{\dfrac{{1 + q}}{2}}}}=\\ &\dfrac{{{2^{\frac{{1 + q}}{2}}}\parallel \bar v\parallel \parallel e\parallel {V_1}^{\frac{{1 + q}}{2}}}}{{\parallel \bar v{\parallel ^{1 + q}}}}=\\& {2^{\dfrac{{1 + q}}{2}}}\parallel \bar v{\parallel ^{ - q}}\parallel e\parallel {V_1}^{\frac{{1 + q}}{2}} \end{split} $$ (15) 结合式(14)、(15)有:
$$ \begin{split} {{\dot V}_1} \le \;& - {c_3}{\left(\sum\limits_{i = 1}^N {\bar v_i^2} \right)^{\frac{{p + 1}}{2}}} - {c_4}{N^{\frac{{1 - q}}{2}}}{\left(\sum\limits_{i = 1}^N {\bar v_i^2} \right)^{\frac{{q + 1}}{2}}} + \\ &{2^{\frac{{1 + q}}{2}}}\parallel \bar v{\parallel ^{ - q}}\parallel e\parallel {V_1}^{\frac{{1 + q}}{2}}=\\ &- {2^{\frac{{p + 1}}{2}}}{c_3}V_1^{\frac{{p + 1}}{2}} - {2^{\frac{{q + 1}}{2}}}{N^{\frac{{1 - q}}{2}}}{c_4}V_1^{\frac{{q + 1}}{2}} + \\ &{2^{\frac{{1 + q}}{2}}}\parallel \bar v{\parallel ^{ - q}}\parallel e\parallel {V_1}^{\frac{{1 + q}}{2}}\\[-10pt] \end{split} $$ (16) 由引理2得, 事件触发条件为:
$$ \parallel {e_i}\parallel \le {\mu _i}{c_4}{N^{\frac{{1 - q}}{2}}}\parallel {\bar v_i}{\parallel ^q} $$ (17) 结合式(16)、(17)得:
$$ {\dot V_1} \le - {2^{\tfrac{{p + 1}}{2}}}{c_3}V_1^{\tfrac{{p + 1}}{2}} - (1 - {\mu _i}){2^{\tfrac{{q + 1}}{2}}}{c_4}{N^{\tfrac{{1 - q}}{2}}}V_1^{\tfrac{{q + 1}}{2}} $$ (18) 令
$ \dfrac{{p + 1}}{2} = 1 - \dfrac{1}{{2{\kappa _1}}} $ ,$ \dfrac{{q + 1}}{2} = 1 + \dfrac{1}{{2{\kappa _1}}} $ ,${\kappa _1} = $ $ \dfrac{2}{{q - p}}$ , 由引理2,在时间$ {T_1} $ 时, 虚拟速度的追踪误差$ {\bar v_i} $ 收敛于0, 意味着在固定时间内, 智能体系统能实现对虚拟速度$ v_i^* $ 的追踪, 且收敛时间$ {T_1} $ 满足:$$ \begin{split} {T_1} \le \;&{T_{1\max }}=\\ &\frac{2 \text{π} }{(q - p)\sqrt {(1 - {\mu _i}){c_3}{c_4}{N^{\frac{1 - q}{2}}2^{\frac{p + q + 2}{2}}} }} \end{split} $$ (19) 另一方面, 当
$ t \in [0,{T_1}] $ 时, 由式(18)及引理2知$ {\bar v_i} $ 有界, 再由式(1)、(3)、(4)得:$$ \begin{split} {{\dot x}_i} =\;& - {c_1}{\rm sign}({s_i})sig{\left[ {\sum\limits_{j = 1}^N {{a_{ij}}({s_i}{x_i} - {s_j}{x_j})} } \right]^\alpha } - \\ &{c_2}{\rm sign}({s_i})sig{\left[ {\sum\limits_{j = 1}^N {{a_{ij}}({s_i}{x_i} - {s_j}{x_j})} } \right]^\beta } + {{\bar v}_i} \end{split} $$ (20) 根据式(20),由于
$ {\bar v_i} $ 有界, 当$ t \in [0,{T_1}] $ , 要初始状态有界, 则$ {x_i} $ 有界. 同时, 由于$ {x_i} $ 有界, 由式(3)、(4)不难得出$ {v_i} $ 有界.注意到, 当
$ {\bar v_i} = 0 $ 时, 由式(4)得:$$ \begin{split} {v_i} = \;&- {c_1}{\rm sign}({s_i})sig{\left[ {\sum\limits_{j = 1}^N {{a_{ij}}({s_i}{x_i} - {s_j}{x_j})} } \right]^\alpha } - \\ &{c_2}{\rm sign}({s_i})sig{\left[ {\sum\limits_{j = 1}^N {{a_{ij}}({s_i}{x_i} - {s_j}{x_j})} } \right]^\beta } \end{split} $$ (21) 考虑到控制器
$ {u_i} $ 是不连续更新控制输入的, 故有:$$ \begin{split} {{\dot x}_i} = \;&- {c_1}{\rm sign}({s_i})sig{\left[ {\sum\limits_{j = 1}^N {{a_{ij}}({{\hat x}_i} - {{\hat x}_j})} } \right]^\alpha } - \\ &{c_2}{\rm sign}({s_i})sig{\left[ {\sum\limits_{j = 1}^N {{a_{ij}}({{\hat x}_i} - {{\hat x}_j})} } \right]^\beta } \end{split} $$ (22) 当
$ t \in ({T_1},T] $ 时, 定义测量误差:$$ \begin{split} {E_i} =\;& {c_1}{\rm sign}({s_i})sig{\left[ {\sum\limits_{j = 1}^N {{a_{ij}}({{\hat x}_i} - {{\hat x}_j})} } \right]^\alpha } + \\ &{c_2}{\rm sign}({s_i})sig{\left[ {\sum\limits_{j = 1}^N {{a_{ij}}({{\hat x}_i} - {{\hat x}_j})} } \right]^\beta } - \\ &{c_1}{\rm sign}({s_i})sig{\left[ {\sum\limits_{j = 1}^N {{a_{ij}}({s_i}{x_i} - {s_j}{x_j})} } \right]^\alpha } - \\ &{c_2}{\rm sign}({s_i})sig{\left[ {\sum\limits_{j = 1}^N {{a_{ij}}({s_i}{x_i} - {s_j}{x_j})} } \right]^\beta } \end{split} $$ (23) 选取Lyapunov函数为:
$$ {V_2} = \frac{1}{2}{x^{\rm{T}}}{S^{\rm{T}}}LSx $$ 其中,
$S = {\rm diag}\{{s_i}{\rm sign}({s_i})\}$ , 导有:$$ {\dot V_2} = {x^{\rm{T}}}{S^{\rm{T}}}LS\dot x = \sum\limits_{i = 1}^N {\sum\limits_{j = 1}^N {{a_{ij}}({s_i}{x_i} - {s_j}{x_j}){{\dot x}_i}} } $$ 令
${y_i} = \sum\nolimits_{j = 1}^N {{a_{ij}}({s_i}{x_i} - {s_j}{x_j})},$ $y = ({y_1},{y_2},\cdots, $ $ {y_N})^{\rm{T}}$ .$$ \begin{split} {{\dot V}_2} =\;& \sum\limits_{i = 1}^N {\sum\limits_{j = 1}^N {{a_{ij}}({s_i}{x_i} - {s_j}{x_j})( - {c_1}{\rm sign}({s_i})sig{{\left[ y \right]}^\alpha }} } - \\ &{c_2}{\rm sign}({s_i})sig{\left[ y \right]^\beta } - {E_i}) \le \\ &- {c_1}\sum\limits_{i = 1}^N {\parallel {y_i}{\parallel ^{\alpha + 1}}} - {c_2}\sum\limits_{i = 1}^N {\parallel {y_i}{\parallel ^{\beta + 1}}} + \\ &\sum\limits_{i = 1}^N {\parallel {E_i}\parallel \parallel {y_i}\parallel }\\[-15pt] \end{split} $$ (24) 于是, 可以得到事件触发条件:
$$ \parallel {E_i}\parallel \le {\varepsilon _i}{c_2}\parallel {y_i}{\parallel ^\beta } $$ (25) 由引理3, 式(24)可以写成:
$$ {\dot V_2} \le - {c_1}{\left[ {\sum\limits_{i = 1}^N {y_i^2} } \right]^{\frac{{\alpha + 1}}{2}}} - (1 - {\varepsilon _i}){c_2}{N^{\frac{{1 - \beta }}{2}}}{\left[ {\sum\limits_{i = 1}^N {y_i^2} } \right]^{\frac{{\beta + 1}}{2}}} $$ (26) 由引理1,
$$ \begin{split} \sum\limits_{i = 1}^N {y_i^2} =\;& {({L^{\frac{1}{2}}}Sx)^{\rm T}}L({L^{\frac{1}{2}}}Sx)\ge\\ &{\lambda _2}(L){x^{\rm T}}SLSx = 2{\lambda _2}(L){V_2} \end{split} $$ 于是式子(26)可以写成:
$$ \begin{split} {{\dot V}_2} \le\;& - {c_1}{\left[ {2{\lambda _2}(L){V_2}} \right]^{\frac{{\alpha + 1}}{2}}} - \\ &(1 - {\varepsilon _i}){c_2}{N^{\frac{{1 - \beta }}{2}}}{\left[ {2{\lambda _2}(L){V_2}} \right]^{\frac{{\beta + 1}}{2}}} \end{split} $$ (27) 其中,
$ {\lambda _2}(L) $ 为矩阵$ L $ 的第二小特征值. 令$\dfrac{{\alpha + 1}}{2} = 1 -$ $ \dfrac{1}{{2{\kappa _2}}} $ ,$ \dfrac{{\beta + 1}}{2} = 1 + \dfrac{1}{{2{\kappa _2}}} $ ,$ {\kappa _2} = \dfrac{2}{{\beta - \alpha }} $ , 由引理2, 当$ {\bar v_i} $ 收敛后,$ {x_i} $ 可以实现固定时间一致性, 且收敛时间$ {T_2} $ 满足:$$ \begin{split} {T_2} \le\;& {T_{2\max }}=\\ &\frac{{2 {\text{π}} }}{{(\beta - \alpha )\sqrt {(1 - {\varepsilon _i}){c_1}{c_2}{N^{{{(1 - \beta )} / 2}}}{{(2{\lambda _2}(L))}^{\frac{{\alpha + \beta + 2}}{2}}}} }} \end{split} $$ (28) 结合式(19)、(28),可得多智能体系统(1)在控制输入(10)及触发条件(12)的作用下, 可以实现固定时间一致性, 且收敛时间T满足:
$$ \begin{split} T =\;& {T_1} + {T_2} \le {T_{1\max }} + {T_{2\max }} = \\ &\dfrac{{2 {\text{π}} }}{{(q - p)\sqrt {(1 - {\mu _i}){c_3}{c_4}{N^{{{(1 - q)} / 2}}}{2^{\frac{{p + q + 2}}{2}}}} }} + \\ &\dfrac{{2 {\text{π}} }}{{(\beta - \alpha )\sqrt {(1 - {\varepsilon _i}){c_1}{c_2}{N^{{{(1 - \beta )} / 2}}}{{(2{\lambda _2}(L))}^{\frac{{\alpha + \beta + 2}}{2}}}} }} \end{split} $$ 考虑到时间
$ {T_1} $ 是不确定的, 对两个事件触发条件进行合并. 由式(29)可以看出, 当$ t \in [0,{T_1}] $ 时, 智能体处于追踪虚拟速度的状态,$ {\rm sign}\left( {\left| {{v_i} - v_i^*} \right|} \right)=$ $ 1 $ , 此时事件触发条件为式(17);当$ t \in ({T_1},T] $ 时, 触发条件为式(25).$$ \begin{split} {f_i}(t) =\;& {\rm sign}\left( {\left| {{v_i} - v_i^*} \right|} \right)\left( {\left\| {{e_i}} \right\| - {\mu _i}{c_4}{N^{\frac{{1 - q}}{2}}}{{\left\| {{{\bar v}_i}} \right\|}^q}} \right) + \\ &\left[ {1 - {\rm sign}\left( {\left| {{v_i} - v_i^*} \right|} \right)} \right]\left( {\left\| {{E_i}} \right\| - {\varepsilon _i}{c_2}{{\left\| {{y_i}} \right\|}^\beta }} \right) \end{split} $$ (29) 定理2. 假设固定通信拓扑图
$ G $ 是无向连通的, 考虑多智能体系统(1)在控制器(10)和触发条件(12)的作用下, 系统能实现一致且不存在Zeno行为.证明. 当
$ t \in [0,{T_1}] $ 时, 定义$ \gamma = \parallel e\parallel /\parallel {\bar v^q}\parallel $ , 每个时间段$ [t_k^i,t_{k + 1}^i)) $ 内有:$$ \begin{split} \dot \gamma =\;& \dfrac{{{{(e)}^{\rm{T}}}(e)'}}{{\parallel e\parallel \parallel {{\bar v}^q}\parallel }} - \dfrac{{\parallel e\parallel }}{{\parallel {{\bar v}^q}\parallel }}\frac{{{{({{\bar v}^q})}^{\rm{T}}}({{\bar v}^q})'}}{{\parallel {{\bar v}^q}{\parallel ^2}}}=\\ &- \dfrac{{{{(e)}^{\rm{T}}}(U)'}}{{\parallel e\parallel \parallel {{\bar v}^q}\parallel }} - \dfrac{{\parallel e\parallel }}{{\parallel {{\bar v}^q}\parallel }}\frac{{{{({{\bar v}^q})}^{\rm{T}}}({{\bar v}^q})'}}{{\parallel {{\bar v}^q}{\parallel ^2}}} \end{split} $$ 其中,
$ U $ 表示控制器(10)不采用事件触发机制时的控制协议. 定理1中给出了事件触发条件, 并在其后证明了在控制器(10)的作用下多智能体系统的稳定性. 控制器$ U $ 实时更新控制输入, 也就是说, 控制器$ U $ 比控制器(10)更为保守. 不难证明, 在控制器$ U $ 的作用下, 依然能实现多智能体系统的固定时间一致性, 因此$ U' $ 必定是有界的. 假定$ U' $ 绝对值的最大值为$ {G_{\max }} $ ,则有:$$ \begin{split} \dot \gamma \le \;&\dfrac{{{G_{\max }}}}{{\parallel {{\bar v}^q}\parallel }} + \gamma \dfrac{{\parallel ({{\bar v}^q})'\parallel }}{{\parallel {{\bar v}^q}\parallel }}\le\\ &(1 + \gamma )\dfrac{{{G_{\max }}}}{{\parallel {{\bar v}^q}\parallel }} + (1 + \gamma )\dfrac{{\parallel ({{\bar v}^q})'\parallel }}{{\parallel {{\bar v}^q}\parallel }}=\\ &(1 + \gamma )\left( {\dfrac{{{G_{\max }}}}{{\parallel {{\bar v}^q}\parallel }} + \dfrac{{\parallel ({{\bar v}^q})'\parallel }}{{\parallel {{\bar v}^q}\parallel }}} \right)=\\ &(1 + \gamma )\left( {\dfrac{{{G_{\max }}}}{{\parallel {{\bar v}^q}\parallel }} + \dfrac{{q\parallel {\bar v}{\parallel ^{q - 1}}\parallel \dot {\bar v}\parallel }}{{\parallel {{\bar v}^q}\parallel }}} \right)=\\ &(1 + \gamma )\left( {\dfrac{{{G_{\max }}}}{{\parallel {{\bar v}^q}\parallel }} + } \right.\\ &\left. {q\parallel \bar v\parallel ^{q - 1}\dfrac{{\parallel e\parallel + {c_3}\parallel {\bar v}{\parallel ^p} + {c_4}\parallel {\bar v}\parallel ^q}}{{\parallel {{\bar v}^q}\parallel }}} \right) \le\\ &q\parallel {\bar v}\parallel ^{q - 1}(1 + \gamma )\left( {\dfrac{{{G_{\max }}}}{{q{N^{1 - q}}\parallel {\bar v}{\parallel ^{2q - 1}}}} + } \right.\\ &\left. {\dfrac{{{c_3}}}{{{N^{1 - q}}}}\parallel {\bar v}\parallel ^{p - q} + \dfrac{{{c_4}}}{{{N^{1 - q}}}} + \gamma } \right) \le\\ &q\parallel {\bar v}\parallel ^{q - 1}\left( {1 + \dfrac{{{G_{\max }}}}{{q{N^{1 - q}}\parallel \bar v{\parallel ^{2q - 1}}}} + } \right.\\ &{\left. {\dfrac{{{c_3}}}{{{N^{1 - q}}}}\parallel {\bar v}\parallel ^{p - q} + \dfrac{{{c_4}}}{{{N^{1 - q}}}} + \gamma } \right)^2} \end{split} $$ 考虑到
$\parallel \bar v\parallel = \sqrt {{{\bar v}^T}\bar v} = \sqrt {2{V_1}} \le \sqrt {2{V_1}(0)}$ , 因此$ 1 + $ $ \dfrac{{{G_{\max }}}}{{q{N^{1 - q}}\parallel \bar v{\parallel ^{2q - 1}}}} + \dfrac{{{c_3}}}{{{N^{1 - q}}}}\parallel \bar v{\parallel ^{p - q}} + \dfrac{{{c_4}}}{{{N^{1 - q}}}} $ 必定存在最大值, 假定其最大值为$ {\omega _2} $ , 上式可以写成:$$ \dot \gamma \le {\omega _1}{({\omega _2} + \gamma )^2} $$ (30) 其中,
$ {\omega _1} = q{(2{V_1}(0))^{{{(q - 1)} / 2}}} $ , 此$ {\dot \gamma _i}(t) $ 满足:$$ {\dot \gamma _i}(t) \le {\phi _i}(t,\phi _0^i) $$ (31) 其中,
$ {\phi _i}(t,\phi _0^i) $ 为下式的解:$$ {\dot \phi _i} = {\omega _1}{({\omega _2} + {\phi _i})^2},{\phi _i}(0,\phi _0^i) = \phi _0^i $$ (32) 上述等式的解为:
$$ {\phi _i}({\tau _i},0) = \frac{{{\tau _i}{\omega _1}\omega _2^2}}{{1 - {\tau _i}{\omega _1}{\omega _2}}} $$ (33) 由事件触发条件(17)得:
$$ \frac{{\parallel e\parallel }}{{\parallel \bar v\parallel ^q}} \le {\mu _{\min }}{c_4}{N^{\frac{{1 - q}}{2}}} $$ (34) 其中,
${\mu _{\min }} = \min \left\{ {{\mu _1},{\mu _2},\cdots,{\mu _N}} \right\}$ . 由引理3得:$$ \frac{{\parallel e\parallel }}{{\parallel {{\bar v}^q}\parallel }} \le \frac{1}{{{N^{1 - q}}}}\frac{{\parallel e\parallel }}{{\parallel \bar v{\parallel ^q}}} $$ (35) 于是式(33)可以写成:
$$ \frac{{\parallel e\parallel }}{{\parallel {{\bar v}^q}\parallel }} \le {\mu _{\min }}{c_4}{N^{\frac{{q - 1}}{2}}} $$ (36) 于是在时间间隔
$ [t_k^i,t_{k + 1}^i) $ 内, 有:$$ {\phi _i}({\tau _i},0) = {\mu _{\min }}{c_4}{N^{\frac{{q - 1}}{2}}} $$ (37) 结合等式(32)、(36),可得最小触发时间间隔:
$$ {\tau _i} = \frac{{{\mu _{\min }}{c_4}{N^{\frac{{q - 1}}{2}}}}}{{{\omega _1}\omega _2^2 + {\mu _i}{N^{\frac{{q - 1}}{2}}}{c_4}{\omega _1}{\omega _2}}} $$ (38) 当
$ t \in ({T_1},T] $ 时, 定义$ \ell = {{{\parallel E\parallel } / {\parallel y}}^\beta }\parallel $ , 每个时间段$ [t_h^i,t_{h + 1}^i) $ 内有:$$ \begin{split} \dot \ell =\;& \dfrac{{{{(E)}^{\rm{T}}}(E)'}}{{\parallel E\parallel \parallel {y^\beta }\parallel }} - \dfrac{{\parallel E\parallel }}{{\parallel {y^\beta }\parallel }}\dfrac{{{{({y^\beta })}^{\rm{T}}}({y^\beta })'}}{{\parallel {y^\beta }{\parallel ^2}}}\le\\ & \dfrac{1}{{\parallel {y^\beta }\parallel }}\left[ {{c_1}({y^\alpha })' + {c_2}({y^\beta })'} \right] + \dfrac{{\parallel E\parallel ({y^\beta })'}}{{\parallel {y^\beta }{\parallel ^2}}}=\\ &\dfrac{{{c_1}({y^\alpha })' + {c_2}({y^\beta })'}}{{\parallel {y^\beta }\parallel }} + \ell \dfrac{{({y^\beta })'}}{{\parallel {y^\beta }\parallel }}\le \\ &(1 + \ell )\dfrac{{{ c_1}({y^\alpha })' + (1 + {c_2})({y^\beta })'}}{{\parallel {y^\beta }\parallel }}=\\ &(1 + \ell )\dfrac{{{\alpha c_1}{y^{\alpha - 1}}y' + \beta(1 + {c_2}){y^{\beta - 1}}y'}}{{\parallel {y^\beta }\parallel }}\le\\ & \beta{\rm sign} (y')(1 + \ell )\left[ {{c_1}\parallel {y^{\alpha - 1}}\parallel + (1 + {c_2})\parallel {y^{\beta - 1}}\parallel } \right]\times\\ &\dfrac{{y'}}{{\parallel {y^\beta }\parallel }}\le\beta(1 + \ell )\parallel L\parallel \parallel S\parallel \bigg[ {\dfrac{{{c_1}}}{{\parallel y{\parallel ^{1 - \alpha }}}} + } \\ & {(1 + {c_2}){N^{2 - \beta }}\parallel y{\parallel ^{\beta - 1}}} \bigg]\bigg( {\ell + \dfrac{{{c_1}}}{{{N^{1 - \beta }}\parallel y{\parallel ^{\beta - \alpha }}}} + } \\ & {\dfrac{{{c_2}}}{{{N^{1 - \beta }}}}} \bigg)\le\beta\parallel L\parallel \parallel S\parallel \bigg[ {\dfrac{{{c_1}}}{{\parallel y{\parallel ^{1 - \alpha }}}} + } \\ & {(1 + {c_2}){N^{2 - \beta }}\parallel y{\parallel ^{\beta - 1}}} \bigg]\bigg( {\ell + \dfrac{{{c_1}}}{{{N^{1 - \beta }}\parallel y{\parallel ^{\beta - \alpha }}}} + } \\ &{ {\dfrac{{{c_2}}}{{{N^{1 - \beta }}}} + 1} \bigg)^2} \\[-15pt]\end{split} $$ (39) 由引理1,
$ \sum\nolimits_{i = 1}^N {y_i^2} = {({L^{{1/ 2}}}Sx)^{\rm{T}}}L({L^{{1 / 2}}}Sx) \le \\ {\lambda _{\max }}(L){x^{\rm{T}}}SLSx \le 2{\lambda _{\max }}(L){V_2} \le 2{\lambda _{\max }}(L){V_2}(0) $ 于是不难得到:
$$ \parallel y\parallel \le \sqrt {2{\lambda _{\max }}(L){V_2}(0)} $$ (40) 因此, 式子
$$ \beta\parallel L\parallel \parallel S\parallel \left[ {\frac{{{c_1}}}{{\parallel y{\parallel ^{1 - \alpha }}}} + (1 + {c_2}){N^{2 - \beta }}\parallel y{\parallel ^{\beta - 1}}} \right] $$ 以及
$ \dfrac{{{c_1}}}{{{N^{1 - \beta }}\parallel y{\parallel ^{\beta - \alpha }}}} + \dfrac{{{c_2}}}{{{N^{1 - \beta }}}} + 1 $ 必定存在最大值, 分别假定其最大值为$ {\chi _1},{\chi _2} $ , 结合式(39)、(40),可以得到:$$ \dot \ell \le {\chi _1}{(\ell + {\chi _2})^2} $$ (41) 以下证明类似于
$ t \in [0,{T_1}] $ 的情况, 可得最小触发时间间隔为:$$ {\tau '_i} = \frac{{{\varepsilon _{\min }}{c_2}}}{{{N^{1 - \beta }}{\chi _1}\chi _2^2 + {\varepsilon _i}{c_2}{\chi _1}{\chi _2}}} $$ (42) 其中,
${\varepsilon _{\min }} = \min \left\{ {{\varepsilon _1},{\varepsilon _2},\cdots,{\varepsilon _N}} \right\}$ . 综合上述论证, 在两个时间段内, 事件触发间隔都存在正下界. □3. 实例仿真
实例1. 考虑到多智能体系统由5个智能体组成, 5个智能体互连构成的连通拓扑图如图1所示.
由通信拓扑图不难得到Laplacian矩阵
$ L $ :$$ L = \left[ {\begin{array}{*{20}{c}} 2&{ - 1}&{ - 1}&0&0\\ { - 1}&3&{ - 1}&0&{ - 1}\\ { - 1}&{ - 1}&3&{ - 1}&0\\ 0&0&{ - 1}&2&{ - 1}\\ 0&{ - 1}&0&{ - 1}&2 \end{array}} \right] $$ 其中,
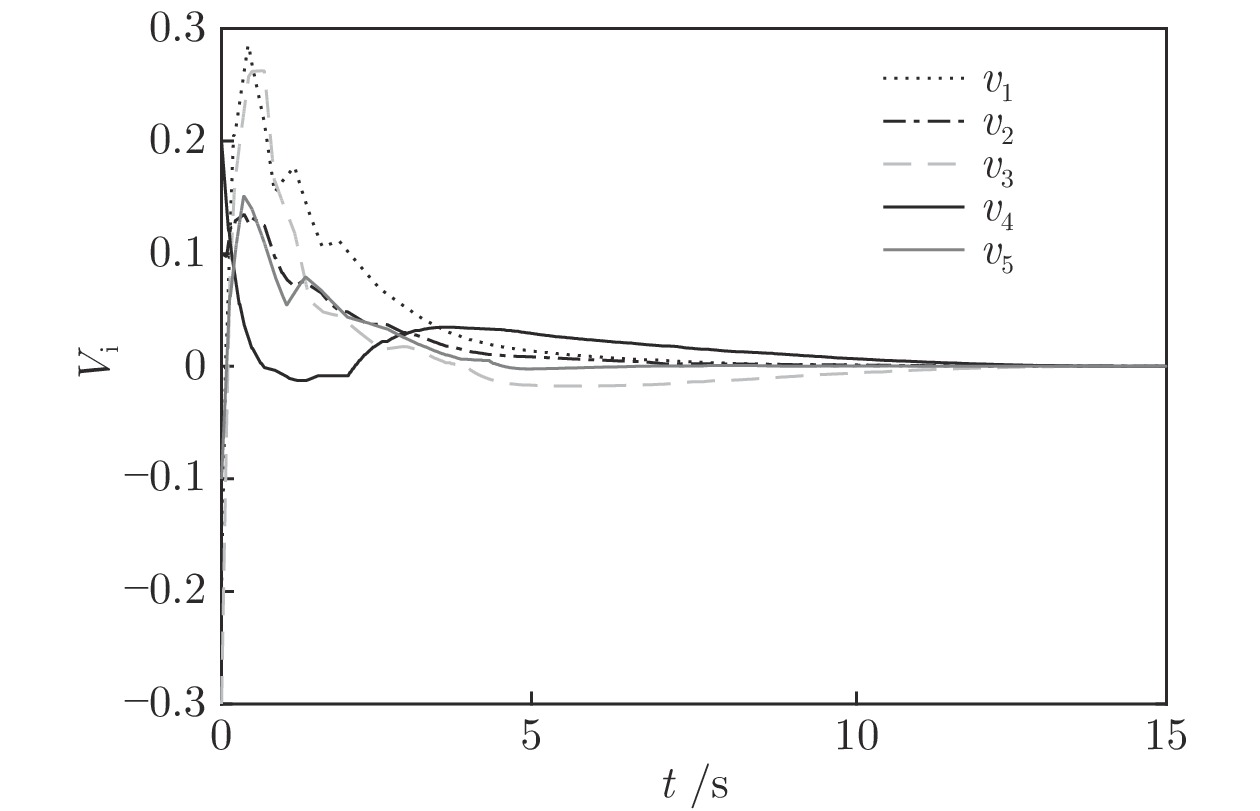
$ {\lambda _2}(L) = 1.38. $ 选定初始的状态为$ x(0) =[ - 0.5,$ $ - 0.3,0.1,0.2, - 0.1], $ 初始速度为$v(0) = [ - 0.2,0.1,$ $- 0.3, 0.2, - 0.1].$ 设定控制增益分别为:$ {c_1} = 0.22, $ ${c_2} = $ $ 1.2,$ $ {c_3} = 0.85 $ ,$ {c_4} = 0.4 $ . 比例参数设置为:$ {s_1} = - 1.3, $ $ {s_2} = - 1.3, $ $ {s_3} = 0.3, $ $ {s_4} = 0.3, $ $ {s_5} = 1. $ 其他需要设定的参数分别为:$ \alpha = 0.6, $ $ \beta = 1.8, $ $ p = 0.8, $ $ q = 1.1, $ $ {\mu _i} = 0.5, $ $ {\varepsilon _i} = 0.95. $ 由等式(19)不难得出${T_{1\max }} = $ $ 26.9\;{\rm{s}},$ 由等式(26)得$ {T_{2\max }} = 20.9\;{\rm{s}} . $ 系统总的收敛时间满足:$ T = {T_1} + {T_2} \le {T_{1\max }} +{T_{2\max }} =$ $ 47.8\;{\rm{s}}. $ 图2表明每个智能体最后收敛到不同状态. 由图2和图3知, 系统总体的收敛时间在10 s左右, 显然小于47.8 s. 由图4知, 当各个智能体追踪虚拟速度的误差趋近于零时, 所需要的时间小于5 s, 显然小于
${T_{1\max }}.$ 图5和图6表示智能体1在事件触发控制协议(10)及事件触发函数(12)下, 其误差范数的演化过程. 图5表示的是在
$ t \in [0,{T_1}] $ , 用基于速度信息的事件触发条件时, 智能体1误差范数的演化过程. 图6表示在$ t \in ({T_1},T] $ , 当多智能体系统完成虚拟速度追踪时, 切换为基于状态信息的事件触发条件, 智能体1的误差范数演化过程.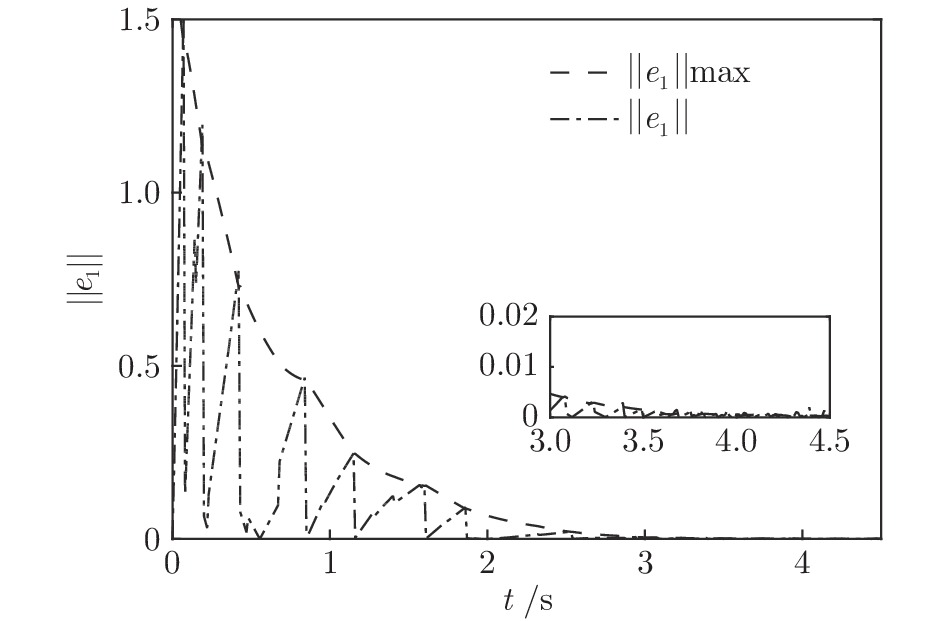 图 5 智能体1在触发条件(17)下的测量误差及阈值变化趋势Fig. 5 The evolution of the error norm and the threshold of agent 1 with trigger function (17)
图 5 智能体1在触发条件(17)下的测量误差及阈值变化趋势Fig. 5 The evolution of the error norm and the threshold of agent 1 with trigger function (17)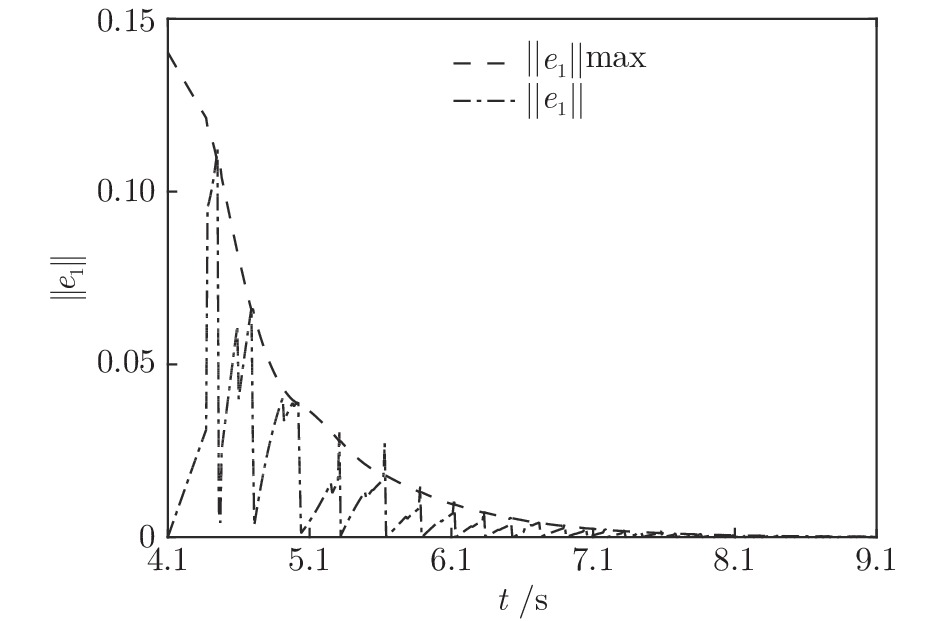 图 6 智能体1在触发条件(25)下的测量误差及阈值变化趋势Fig. 6 The evolution of the error norm and the threshold of agent 1 with trigger function (25)
图 6 智能体1在触发条件(25)下的测量误差及阈值变化趋势Fig. 6 The evolution of the error norm and the threshold of agent 1 with trigger function (25)图7中
$ i = 1,2, \cdots ,5 $ 为在控制策略(10)下, 各个智能体触发间隔;$ i = 6 $ 为在时间触发下, 每个智能体触发间隔. 图7表明本文所提出的事件触发控制策略在减小系统的能量耗散和控制器的更新频次的优越性. 图 7 各智能体在控制策略(10)下的触发间隔及在时间触发控制策略下的触发间隔Fig. 7 The triggered interval of each agent undercontrol scheme (10) and the trigger interval underthe time trigger control strategy
图 7 各智能体在控制策略(10)下的触发间隔及在时间触发控制策略下的触发间隔Fig. 7 The triggered interval of each agent undercontrol scheme (10) and the trigger interval underthe time trigger control strategy图8给出了智能体1在控制协议(10)下, 与其它智能体之间的状态误差. 当系统达到稳定状态时, 各个智能体收敛于不同的值, 且满足既定的比例关系.
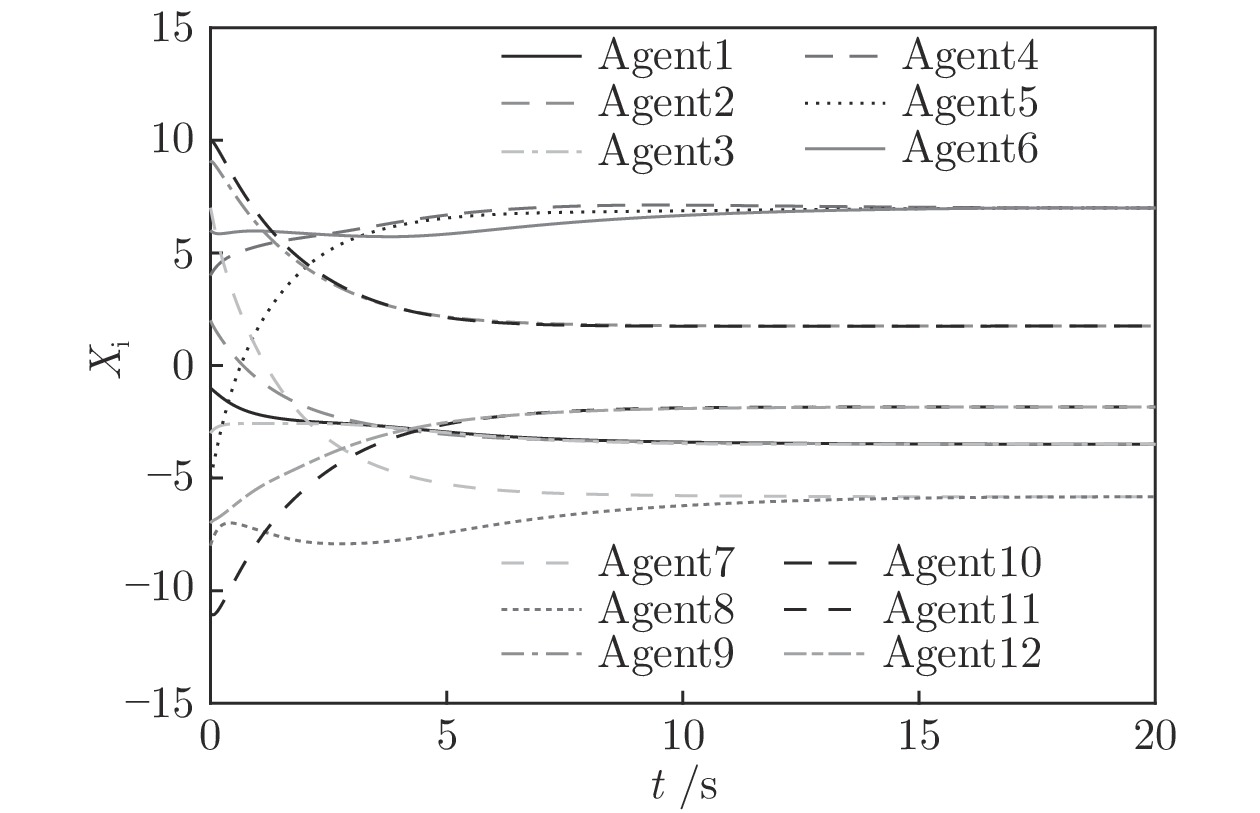
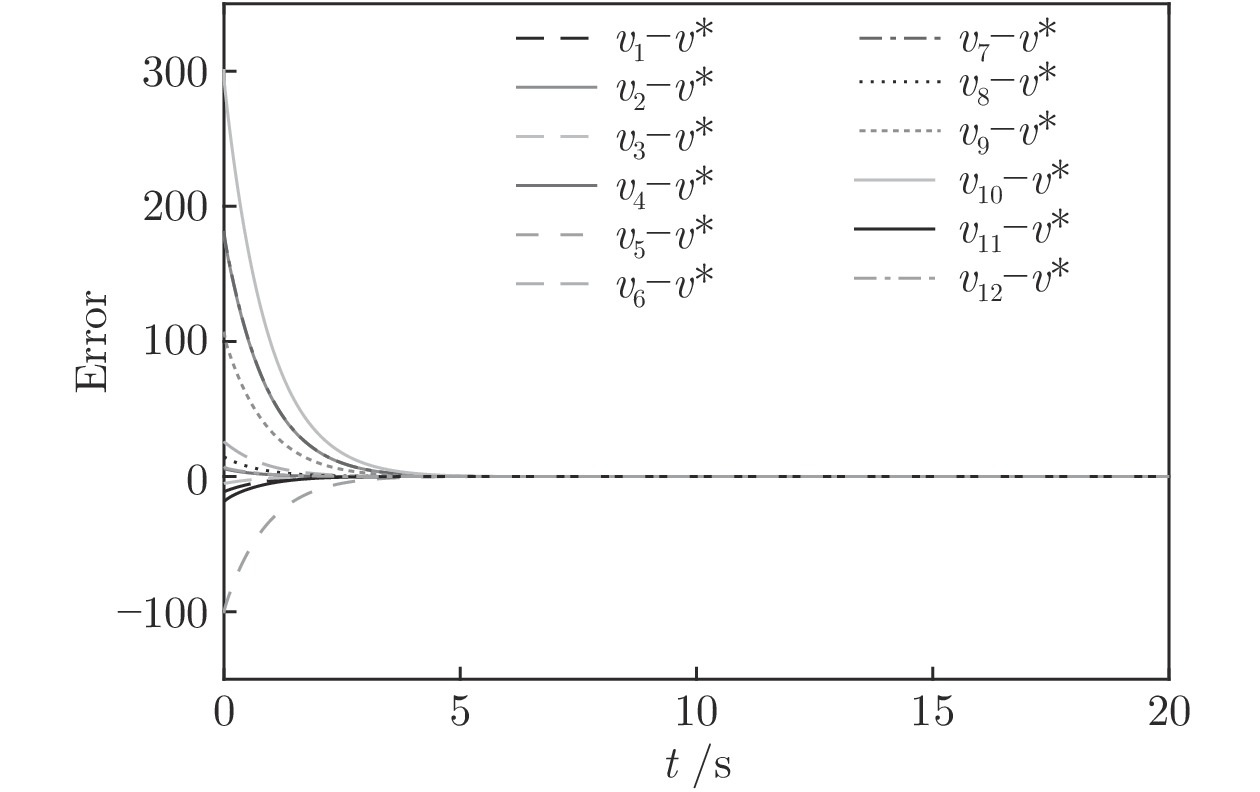
实例2. 为了证明本文给出的结果能够适应更为复杂的多智能体系统, 选用12个智能体组成的复杂多智能体系统, 12个智能体互连构成的连通拓扑图如图9所示. 其中, 取多智能体系统的初始状态、初始速度分别为
$x(0) = [ - 1,2, - 3,4, - 5,6,7, - 8, $ $ 9,10, - 11, - 7], $ $ v(0) = [ - 2, - 1,3,4, - 2, - 6,7,8,9, - 3,$ $ 3.5] $ . 设定控制增益分别为:$ {c_1} = 0.2 $ ,$ {c_2} = 0.3 $ ,${c_3} = $ $ 1.2 $ ,$ {c_4} = 0.4 $ .$ {\lambda _2}(L) = 0.558 $ . 其他需要设定的参数分别为:$ \alpha = 0.4 $ ,$ \beta = 1.8 $ ,$ p = 0.8 $ ,$ q = 1.1 $ ,$ {\mu _i} = 0.5 $ ,$ {\varepsilon _i} = 0.66 $ .由等式(19)不难得出
$ {T_{1\max }} = 32.7\;{\rm{s}} $ , 由等式(26)得$ {T_{2\max }} = 26.2\;{\rm{s}} . $ 系统总的收敛时间满足:$ T = {T_1} + {T_2} \le {T_{1\max }} + {T_{2\max }} = 58.9\;{\rm{s}} $ . 图10表明在控制策略(10)下, 多智能体系统能收敛至5个不同的子群. 图11表示各个智能体速度状态轨迹图. 而图12则表明智能体追踪虚拟速度的误差. 从图中可以看出, 智能体大约在4 s左右实现虚拟速度的追踪, 系统总体的收敛时间在10 s左右, 显然小于58.9 s.4. 结论
本文研究了基于事件触发二阶多智能体系统的固定时间比例一致性. 为使得系统状态收敛到不同状态, 设计了一种基于事件触发的固定时间非线性比例一致控制策略, 该控制协议包含一种基于状态信息和速度信息的分段式触发条件: 当多智能体系统处于追踪虚拟速度的状态时, 采用基于速度信息的事件触发条件; 当完成虚拟速度的追踪时, 采用基于状态信息的事件触发条件, 能有效的减小系统的能量耗散和控制器的更新频次. 利用Lyapunov稳定性理论、线性矩阵不等式和代数图论, 证明在该控制策略下, 二阶多智能体系统能实现固定时间比例一致性, 且不存在Zeno行为.
-
图 5 智能体1在触发条件(17)下的测量误差及阈值变化趋势
Fig. 5 The evolution of the error norm and the threshold of agent 1 with trigger function (17)
图 6 智能体1在触发条件(25)下的测量误差及阈值变化趋势
Fig. 6 The evolution of the error norm and the threshold of agent 1 with trigger function (25)
图 7 各智能体在控制策略(10)下的触发间隔及在时间触发控制策略下的触发间隔
Fig. 7 The triggered interval of each agent undercontrol scheme (10) and the trigger interval underthe time trigger control strategy
-
[1] Thunberg J, Goncalves J, Hu X. Consensus and formation control on SE(3) for switching topologies[J]. Automatica, 2016, 66(5): 63-82. [2] Xiao F, Wang L, Chen J, Gao Y P. Finite-time formation control for multi-agent systems[J]. Automatica, 2009, 45(11): 2605-2611. doi: 10.1016/j.automatica.2009.07.012 [3] Martin S. Multi-agent flocking under topological interactions[J]. Systems & Control Letters, 2014, 69(1): 53-61. [4] 陈世明, 化俞新, 祝振敏, 赖强. 邻域交互结构优化的多智能体快速蜂拥控制算法[J]. 自动化学报, 2015, 41(12): 2092-2099.CHEN Shi-Ming, HUA Yu-Xin, ZHU Zhen-Min, LAI Qiang. Fast flocking algorithm for multi-agent systems by opti-mizing local interactive topology[J]. Acta Automatica Sinica, 2015, 41(12): 2092-2099. [5] Huang N, Duan Z, Zhao Y. Consensus of multi-agent systems via delayed and intermittent communications[J]. IET Control Theory and Applications, 2015, 9(1): 62-73. doi: 10.1049/iet-cta.2014.0729 [6] Zhao M, Peng C, He W L, Song Y. Event-triggered communication for leader-following consensus of second-order multiagent systems[J]. IEEE Transactions on Cybernetics, 2018, 48(6): 1888-1897. doi: 10.1109/TCYB.2017.2716970 [7] Li J P, Yang Y N, Hua C C, Guan X P. Fixed-time backstepping control design for high-order strict-feedback non-linear systems via terminal sliding mode[J]. IET Control Theory and Applications, 2017, 11(8): 1184-1193. doi: 10.1049/iet-cta.2016.1143 [8] Wang H H, Chen B, Lin C, Sun Y M, Wang F. Adaptive flnite-time control for a class of uncertain high-order nonlinear systems based on fuzzy approximation[J]. IET Control Theory and Applications, 2017, 11(5): 677-684. doi: 10.1049/iet-cta.2016.0947 [9] Paulo T. Event-triggered real-time scheduling of stabilizing control tasks[J]. IEEE Transactions on Automatic Control, 2007, 52(9): 2680-1685. [10] Dimos V D, Emilio F, Karl H J. Distributed event-triggered control for multi-agent systems[J]. IEEE Transactions on Automatic Control, 2012, 57(5): 1291-1297. doi: 10.1109/TAC.2011.2174666 [11] Hu A H, Cao J, Hu M F, Guo L X. Event-triggered consensus of multi-agent systems with noises[J]. Journal of the Franklin Institute, 2015, 352(9): 3489-3503. doi: 10.1016/j.jfranklin.2014.08.005 [12] Fan Y, Feng G, Wang Y, Song C. Distributed eventtriggered control of multi-agent systems with combinational measurements[J]. Automatica, 2013, 49(2): 671-675. doi: 10.1016/j.automatica.2012.11.010 [13] Hu A H, Cao J. Consensus of multi-agent systems via intermittent event-triggered control[J]. International Journal of Systems Science, 2017, 48(2): 280-287. doi: 10.1080/00207721.2016.1179817 [14] Zhu Y K, Guan X P, Luo X Y, Li S B. Finite-time consensus of multi-agent system via nonlinear event-triggered control strategy[J]. IET Control Theory and Applications, 2015, 9(17): 2548-2552. doi: 10.1049/iet-cta.2014.0533 [15] Yu S H, Wang Y L, Jin L N. Comments on ’Finite-time consensus of multi-agent system via non-linear event-triggered control strategy’[J]. IET Control Theory and Applications, 2017, 11(10): 1658-1661. doi: 10.1049/iet-cta.2016.0955 [16] Dong Y, Xian J G. Finite-time event-triggered consensus for non-linear multi-agent networks under directed network topology[J]. IET Control Theory and Applications, 2017, 11(15): 2458-2464. doi: 10.1049/iet-cta.2017.0085 [17] Liu J, Yu Y, Sun J, Sun C Y. Distributed event-triggered fixed-time consensus for leader-follower multiagent systems with nonlinear dynamics and uncertain disturbances[J]. International Journal of Robust and Nonlinear Control, 2018, 28(11): 3543-3559 doi: 10.1002/rnc.4098 [18] Roy S. Scaled consensus[J]. Automatica, 2015, 51 : 259-262. doi: 10.1016/j.automatica.2014.10.073 [19] Meng D, Jia Y. Scaled consensus problems on switching networks[J]. IEEE Transactions on Automatic Control, 2016, 61(6): 1664-1669. doi: 10.1109/TAC.2015.2479119 [20] Yu J, Shi Y. Scaled group consensus in multiagent systems with flrst/second-order continuous dynamics[J]. IEEE Transactions on Cybernetics, 2018, 48(8): 2259-2271. doi: 10.1109/TCYB.2017.2731601 [21] Meng D, Jia Y. Robust consensus algorithms for multiscale coordination control of multi-vehicle systems with disturbances[J]. IEEE Transactions on Industrial Electronics, 2016, 63(2): 1107-1119. doi: 10.1109/TIE.2015.2478740 [22] Olfatisaber R, Murray R M. Consensus problems in networks of agents with switching topology and timedelays[J]. IEEE Transactions on Automatic Control 2004, 49(9): 1520-1533. doi: 10.1109/TAC.2004.834113 [23] Ning B, Jin J, Zheng J C, Man Z H. Finite-time and fixed-time leader-following consensus for multi-agent systems with discontinuous inherent dynamics[J]. International Journal of Control, 2017, 91(6): 1259-1270. [24] Zuo Z, Lin T. A new class of flnite-time nonlinear consensus protocols for multi-agent systems[J]. International Journal of Control, 2014, 87(2): 363-370. doi: 10.1080/00207179.2013.834484 [25] Wei X Y, Yu W W, Wang H, Yao Y Y, Mei F. An observer based fixed-time consensus control for second-order multi-agent systems with disturbances[J]. IEEE Transactions on Circuits and Systems Ⅱ Express Briefs, 2019, 66(2): 247-251. doi: 10.1109/TCSII.2018.2831922 期刊类型引用(14)
1. 杨自钦,夏长清,刘玉奇,金曦,许驰. 通信时延约束下的多智能体系统动态事件触发编队方法. 控制工程. 2025(01): 126-134 .  百度学术
百度学术2. 陈世明,叶舒康,马旭阳,邹钰彬,刘江. 基于事件触发的不确定多智能体系统自适应一致性. 控制理论与应用. 2025(01): 33-40 . 百度学术3. 邓甲 ,王付永 ,刘忠信 ,陈增强 . 动态事件触发机制下二阶多智能体系统完全分布式控制. 控制理论与应用. 2024(01): 11-20 . 百度学术4. 高林庆,王超,哈登喆,耿华,侯帅. 领导-跟随混合阶异质多智能体系统的一致性. 河北大学学报(自然科学版). 2024(01): 104-112 . 百度学术5. 赵华荣,彭力,吴治海,谢林柏,于洪年. 随机时延下多输入多输出多智能体系统事件触发双向编队. 控制与决策. 2024(04): 1251-1259 . 百度学术6. 郭宏达,娄静涛,徐友春,叶鹏,李永乐,陈晋生. 基于MADDPG的多无人车协同事件触发通信. 系统工程与电子技术. 2024(07): 2525-2533 . 百度学术7. 宁君,彭周华,李铁山,陈俊龙. 带有输入量化的分布式多无人船舶自适应模糊编队控制. 控制与决策. 2024(08): 2588-2596 . 百度学术8. 石井龙,刘志杰,郭皓晨,刘剑. 动态事件触发下的一阶非线性多智能体系统设定时间一致性. 工程科学学报. 2024(09): 1604-1612 . 百度学术9. 邓甲,王付永,刘忠信,陈增强. 基于自适应动态时钟通信的二阶多智能体系统完全分布式一致性. 中国科学:信息科学. 2023(01): 97-110 . 百度学术10. 李猛,付兴建. 事件触发的时滞二阶多UAV系统一致性控制. 火力与指挥控制. 2023(05): 25-32 . 百度学术11. 孙梦薇,任璐,刘剑,孙长银. 切换拓扑下动态事件触发多智能体系统固定时间一致性. 自动化学报. 2023(06): 1295-1305 . 本站查看12. 刘青松,习晓苗,柴利. 具有类万有引力的有界置信观点动力学分析与应用. 自动化学报. 2023(09): 1967-1975 . 本站查看13. 张云清,冯江涛,范晓宇,谢云飞. 随机多智能体系统的多率协同控制. 计算机测量与控制. 2023(11): 151-158 . 百度学术14. 陈侠,周琦轩. 延时和切换拓扑下多智能体系统动态事件触发一致性. 火力与指挥控制. 2022(01): 43-49 . 百度学术其他类型引用(35)
-

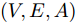
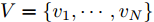
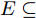
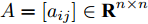
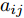
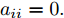
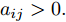
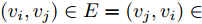

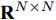

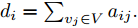
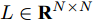
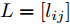
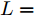

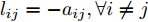
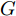
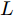
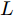
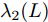
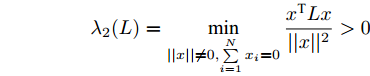
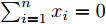
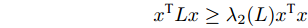
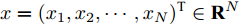
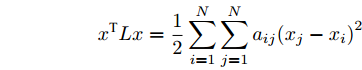
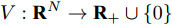
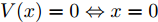
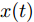
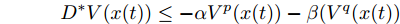
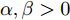
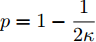
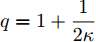
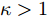
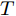
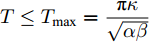
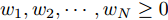
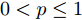
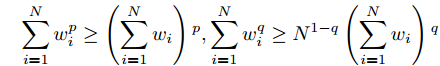
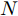


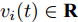
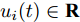
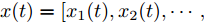
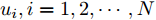
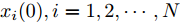
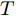
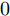
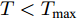
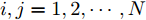
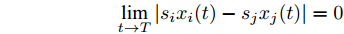

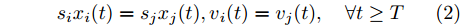
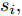
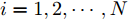
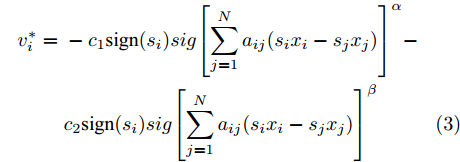
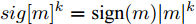
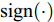
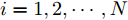
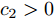
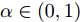
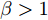
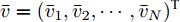
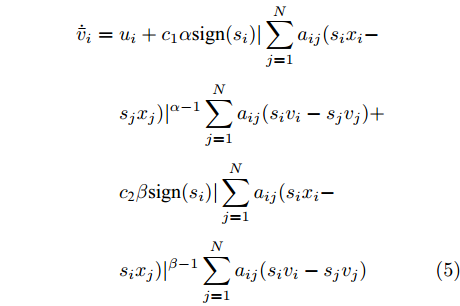

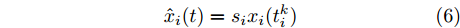
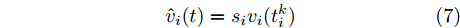
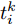

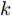
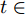
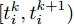
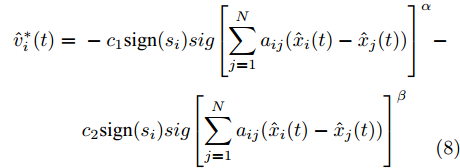
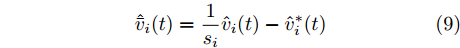
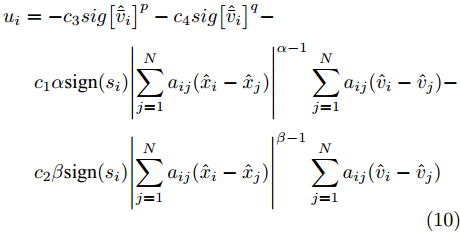
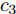
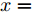
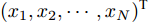
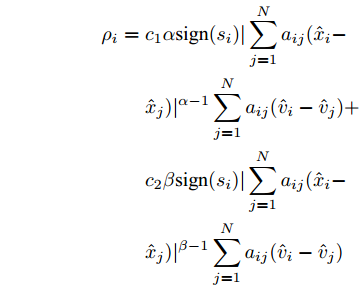
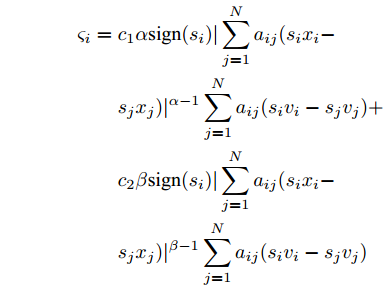
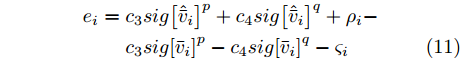
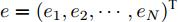
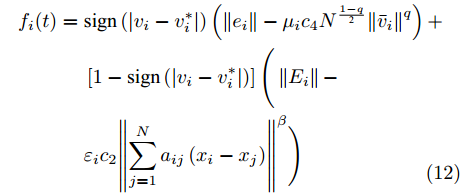
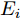
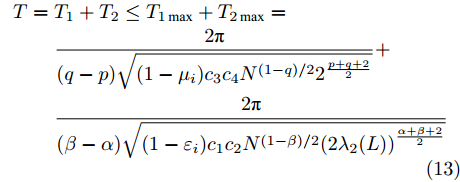
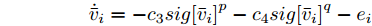

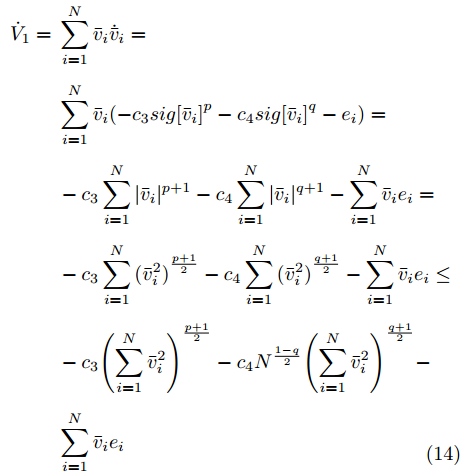
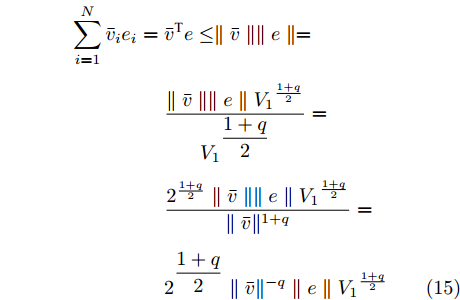
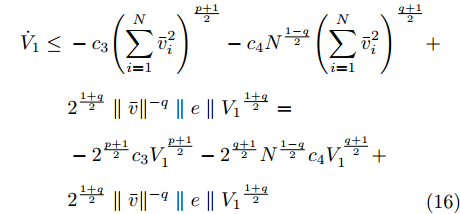
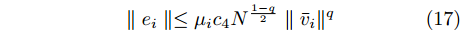
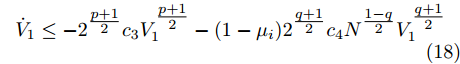
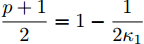
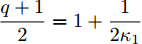
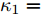
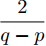
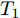
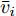
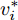
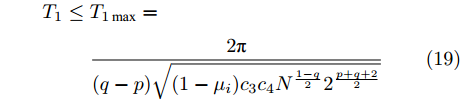
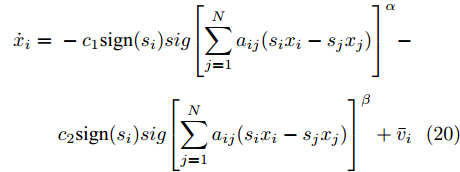
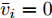
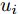
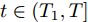
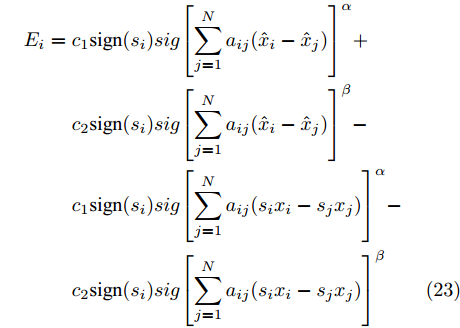
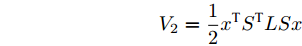
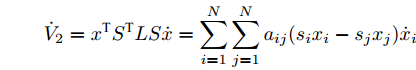
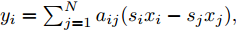
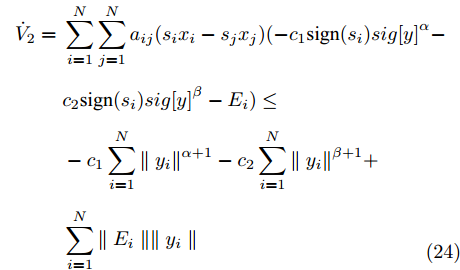
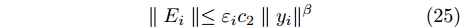
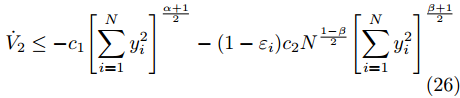
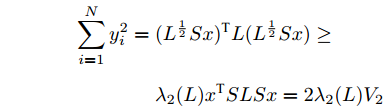
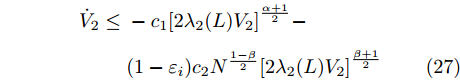
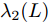
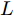
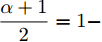
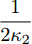
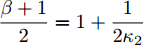
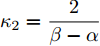
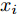
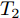
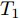
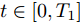
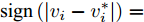
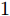
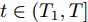
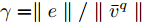
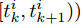
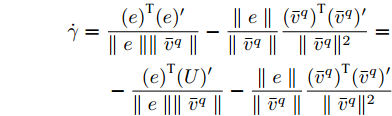
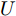
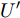
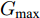
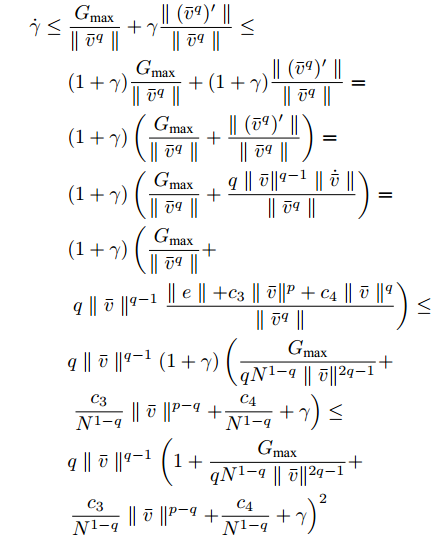
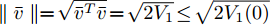
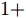
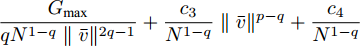
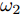
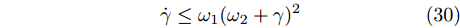
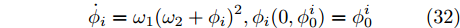
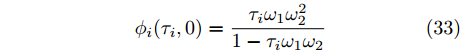
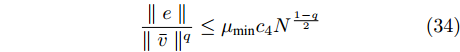
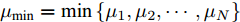
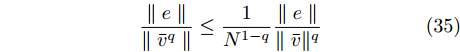
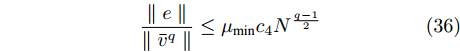
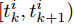
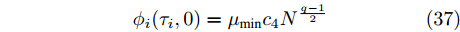
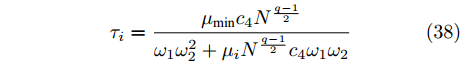
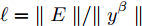
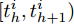
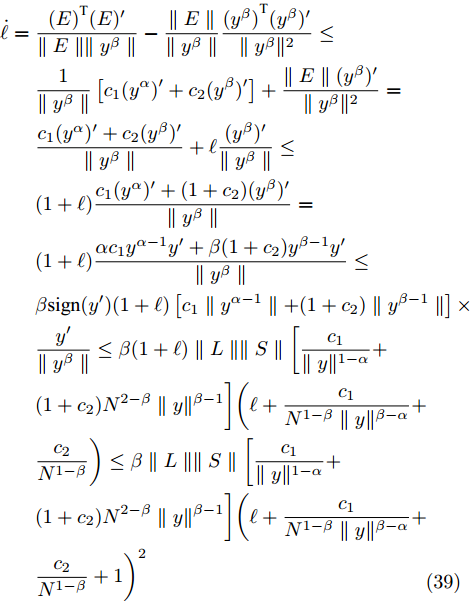
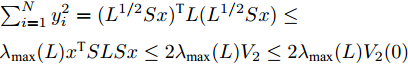
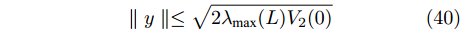
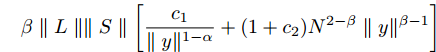
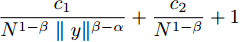
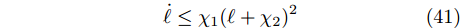
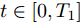
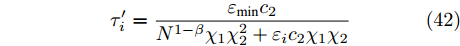

 下载:
下载:
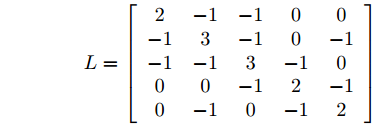
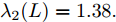

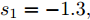
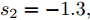
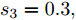
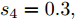
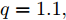
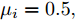
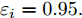

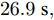


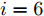
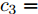
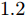
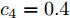
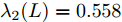

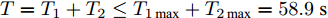

 下载:
下载:

计量
- 文章访问数: 1035
- HTML全文浏览量: 259
- PDF下载量: 342
- 被引次数: 49
