

-
摘要:
主流的目标跟踪算法以矩形模板的形式建立被跟踪物体的视觉表征, 无法有效区分目标与背景像素, 在背景复杂、目标非刚体形变、复杂运动等挑战性因素影响下容易出现模型偏移的问题, 导致跟踪失败. 与此同时, 像素级的显著性信息与运动先验信息作为人类视觉系统有效区分目标与背景、识别运动物体的重要信号, 并没有在主流目标跟踪算法中得到有效的集成利用. 针对上述问题, 提出目标的像素级概率性表征模型, 并且建立与之对应的像素级目标概率推断方法, 能够有效利用像素级的显著性与运动观测信息, 实现与主流的相关滤波跟踪算法的融合; 提出基于显著性的观测模型, 通过背景先验与提出的背景距离模型, 能够在背景复杂的情况下得到高辨识度的像素级图像观测; 利用目标与相机运动的连续性来计算目标和背景的运动模式, 并以此为基础建立基于运动估计的图像观测模型. 实验结果表明, 提出的目标表征模型与融合方法能够有效集成上述像素级图像观测信息, 提出的跟踪方法总体跟踪精度优于多种当下最先进的跟踪器, 对跟踪场景中的背景复杂、目标形变、平面内旋转等挑战性因素具有更好的鲁棒性.
Abstract:Rectangle template is a popular target representation adopted by mainstream visual tracking methods. However, by including some background clutter as part of the target representation, the model is likely to drift away from the target gradually and result in tracking failure, especially in challenging situations such as background clutter, target deformation and complex motions. Meanwhile, motion and saliency cues, which play important roles in distinguishing targets from the background and identifying moving objects in the human vision system, have not been modeled into existing tracking methods. To solve these problems, we propose a foreground probabilistic inference formulation that collects pixel-level observations from different sources, and a unified framework integrating the pixel-level model with a widely used correlation filter based method. A saliency-based observation model is proposed by introducing background prior and a distance-based model, which provides reliable evidence to resolve confusion caused by appearance similarity between targets and the background. By taking advantage of continuity and inertia of both target and camera motion, we discover motion patterns in the spatial domain to distinguish targets from the background, and introduce a pixel-level motion-based observation model. Experiments demonstrate that the proposed method outperforms some of the state-of-the-art methods, and shows better robustness in challenging situations such as background clutter, target deformation and in-plane rotation.
1) 收稿日期 2019-03-03 录用日期 2019-07-30 Manuscript received March 3, 2019; accepted July 30, 2019 国家重点研发计划 (2016YFF0101502) 资助 Supported by the National Key Research and Development Program of China (2016YFF0101502) 本文责任编委 赖建煌 Recommended by Associate Editor LAI Jian-Huang 1. 华中科技大学人工智能与自动化学院 武汉 430074 中国 2. 华中科技大学多谱信息处理技术国家级重点实验室 武汉 430074 中国 3. 美国西北大学电子工程与计算机系 埃文斯顿 伊利诺伊州 60208 美国 1. School of Artificial Intelligence and Automation, Huazhong University of Science and Technology, Wuhan 430074, China 2. Na-tional Key Laboratory of Science and Technology on MultiSpectral Information Processing, Huazhong University of Science and Technology, Wuhan 430074, China 3. Department of Elec-2) trical Engineering and Computer Science, Northwestern University, Evanston, IL 60208, USA -

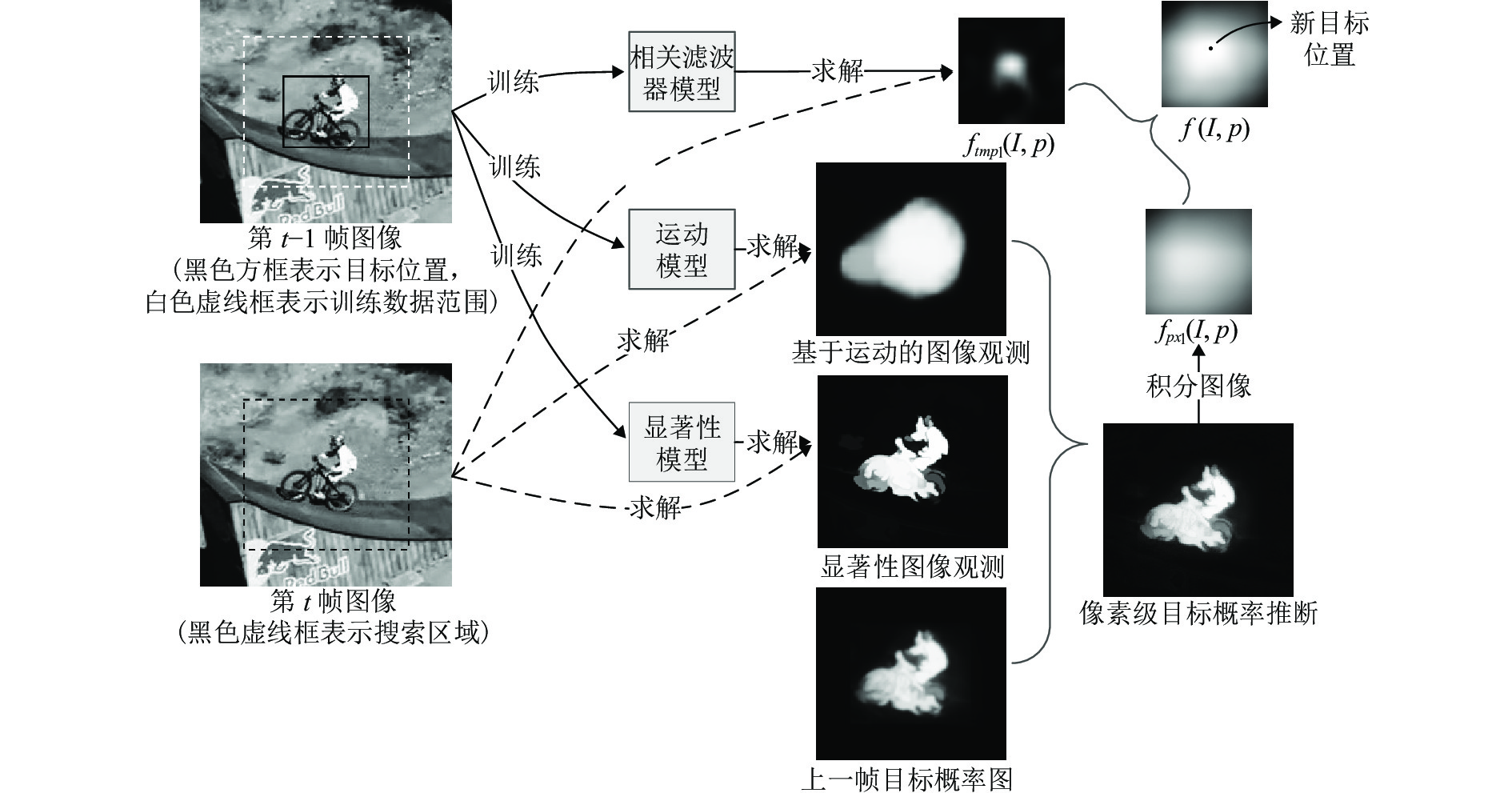
图 2 像素级目标概率推断模型的贝叶斯网络示意图
Fig. 2 Bayesian network representation of pixel-level target probabilistic inference model

图 3 基于颜色与基于显著性的目标似然概率估计结果对比
Fig. 3 Results of color-based and saliency-based target likelihood estimation

图 4 基于目标与背景运动模型的似然概率估计示意图
Fig. 4 Demonstration of likelihood estimation based on motion models of target and background

图 5 本文提出的跟踪算法和 DSST[23]、SRDCF[24]、ACFN[18]、CFNet[17]在 8 个典型 OTB 序列上的跟踪结果 (从上往下分别是 David、Singer2、Doll、Bolt、Soccer、Panda、Diving 和 MotorRolling 序列)
Fig. 5 Tracking results using our proposed method compared with DSST, SRDCF, ACFN and CFNet on 8 OTB image sequences (From top to down: David, Singer2, Doll, Bolt, Soccer, Panda, Diving and MotorRolling
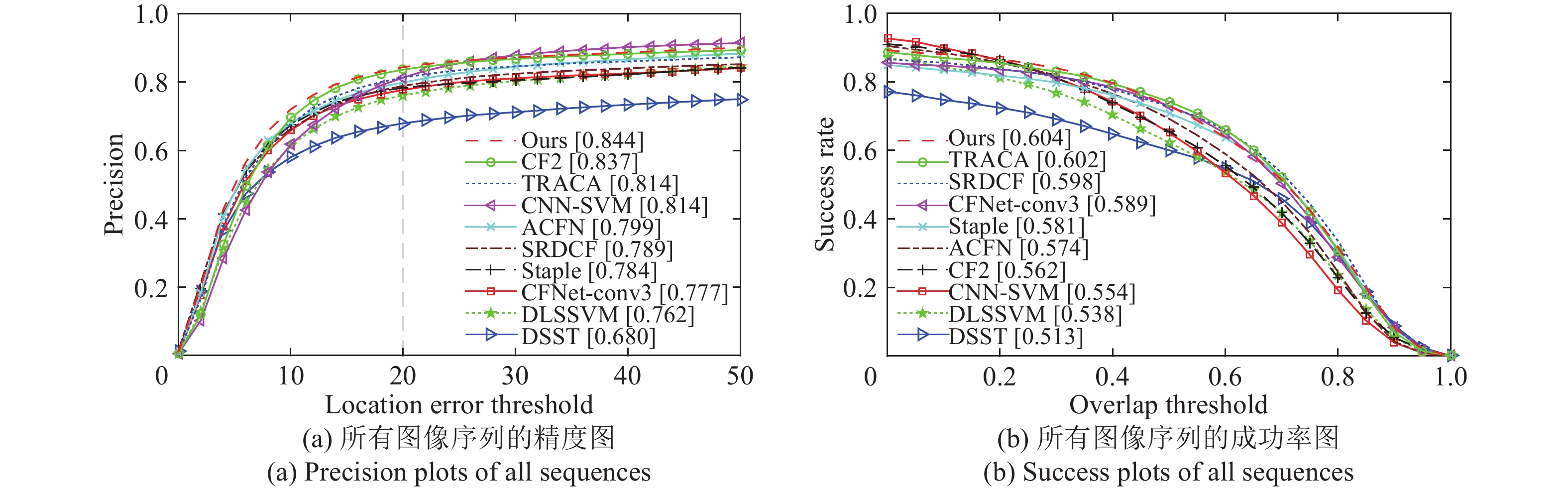
图 6 在 OTB-100 数据集上的一次通过估计曲线
Fig. 6 One-pass-evaluation (OPE) curves on OTB-100 dataset

图 7 在 OTB-100 数据集不同挑战性因素影响下的成功率图
Fig. 7 Success plots on sequences with different challenging attributes on OTB-100 dataset
-
[1] 孟琭, 杨旭. 目标跟踪算法综述. 自动化学报, 2019, 45(7): 1244−1260Meng Lu, Yang Xu. A survey of object tracking algorithms. Acta Automatica Sinica, 2019, 45(7): 1244−1260 [2] Li P X, Wang D, Wang L J, Lu H C. Deep visual tracking: Review and experimental comparison. Pattern Recognition, 2018, 76: 323−338 doi: 10.1016/j.patcog.2017.11.007 [3] Mabrouk A B, Zagrouba E. Abnormal behavior recognition for intelligent video surveillance systems: A review. Expert Systems with Applications, 2018, 91: 480−491 doi: 10.1016/j.eswa.2017.09.029 [4] Li P L, Qin T, Shen S J. Stereo vision-based semantic 3D object and ego-motion tracking for autonomous driving. In: Proceedings of the 2018 European Conference on Computer Vision. Munich, Germany: Springer, 2018. 664−679 [5] Singha J, Roy A, Laskar R H. Dynamic hand gesture recognition using vision-based approach for human — Computer interaction. Neural Computing and Applications, 2018, 29(4): 1129−1141 doi: 10.1007/s00521-016-2525-z [6] Singh P, Agrawal P, Karki H, Shukla A, Verma N K, Behera L. Vision-based guidance and switching-based sliding mode controller for a mobile robot in the cyber physical framework. IEEE Transactions on Industrial Informatics, 2019, 15(4): 1985−1997 doi: 10.1109/TII.2018.2869622 [7] Gupta V, Lantz J, Henriksson L, Engvall J, Karlsson M, Persson A, et al. Automated three-dimensional tracking of the left ventricular myocardium in time-resolved and dose-modulated cardiac CT images using deformable image registration. Journal of Cardiovascular Computed Tomography, 2018, 12(2): 139−148 doi: 10.1016/j.jcct.2018.01.005 [8] 张芷君, 钟胜, 吴郢, 王建辉. 基于协同重排序的手势识别方法. 计算机辅助设计与图形学学报, 2018, 30(11): 2182−2192Zhang Zhi-Jun, Zhong Sheng, Wu Ying, Wang Jian-Hui. Collaborative reranking: A novel approach for hand pose estimation. Journal of Computer-Aided Design & Computer Graphics, 2018, 30(11): 2182−2192 [9] Xiao B, Wu H P, Wei Y C. Simple baselines for human pose estimation and tracking. In: Proceedings of the 2018 European Conference on Computer Vision. Munich, Germany: Springer, 2018. 472−487 [10] Wu Y, Lim J, Yang M H. Object tracking benchmark. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2015, 37(9): 1834−1848 doi: 10.1109/TPAMI.2014.2388226 [11] Kristan M, Leonardis A, Matas J, Felsberg M, Pflugfelder R, Zajc L C, et al. The sixth visual object tracking vot2018 challenge results. In: Proceedings of the 2018 European Conference on Computer Vision. Munich, Germany: Springer, 2018. 3−53 [12] Ross D A, Lim J, Lin R S, Yang M H. Incremental learning for robust visual tracking. International Journal of Computer Vision, 2008, 77(1): 125−141 [13] Zhang T Z, Ghanem B, Liu S, Ahuja N. Low-rank sparse learning for robust visual tracking. In: Proceedings of the 2012 European Conference on Computer Vision. Florence, Italy: Springer, 2012. 470−484 [14] Henriques J F, Caseiro R, Martins P, Batista J. High-speed tracking with kernelized correlation filters. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2015, 37(3): 583−596 doi: 10.1109/TPAMI.2014.2345390 [15] Ning J F, Yang J M, Jiang S J, Zhang L, Yang M H. Object tracking via dual linear structured SVM and explicit feature map. In: Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). Las Vegas, NV, USA: IEEE, 2016. 4266−4274 [16] Bertinetto L, Valmadre J, Henriques J F, Vedaldi A, Torr P H S. Fully-convolutional siamese networks for object tracking. In: Proceedings of the 2016 European Conference on Computer Vision. Amsterdam, The Netherlands: Springer, 2016. 850−865 [17] Valmadre J, Bertinetto L, Henriques J, Vedaldi A, Torr P H S. End-to-end representation learning for correlation filter based tracking. In: Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). Honolulu, HI, USA: IEEE, 2017. 5000−5008 [18] Choi J, Chang H J, Yun S, Fischer T, Demiris Y, Choi J Y. Attentional correlation filter network for adaptive visual tracking. In: Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition. Honolulu, HI, USA: IEEE, 2017. 4828−4837 [19] Itti L, Koch C. Computational modelling of visual attention. Nature Reviews Neuroscience, 2001, 2(3): 194−203 doi: 10.1038/35058500 [20] 于明, 李博昭, 于洋, 刘依. 基于多图流形排序的图像显著性检测. 自动化学报, 2019, 45(3): 577−592Yu Ming, Li Bo-Zhao, Yu Yang, Liu Yi. Image saliency detection with multi-graph model and manifold ranking. Acta Automatica Sinica, 2019, 45(3): 577−592 [21] Spelke E S, Katz G, Purcell S E, Ehrlich S M, Breinlinger K. Early knowledge of object motion: Continuity and inertia. Cognition, 1994, 51(2): 131−176 doi: 10.1016/0010-0277(94)90013-2 [22] Johnson S P, Aslin R N. Perception of object unity in young infants: The roles of motion, depth, and orientation. Cognitive Development, 1996, 11(2): 161−180 doi: 10.1016/S0885-2014(96)90001-5 [23] Danelljan M, Hager G, Khan F S, Felsberg M. Accurate scale estimation for robust visual tracking. In: Proceedings of the 2014 British Machine Vision Conference. Nottingham, UK: BMVA Press, 2014. 1−11 [24] Danelljan M, Hager G, Khan F S, Felsberg M. Learning spatially regularized correlation filters for visual tracking. In: Proceedings of the 2015 IEEE International Conference on Computer Vision. Santiago, Chile: IEEE, 2015. 4310−4318 [25] Bertinetto L, Valmadre J, Golodetz S, Miksik O, Torr P H S. Staple: Complementary learners for real-time tracking. In: Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). Las Vegas, NV, USA: IEEE, 2016. 1401−1409 [26] Kwon J, Lee K M. Tracking of a non-rigid object via patch-based dynamic appearance modeling and adaptive Basin Hopping Monte Carlo sampling. In: Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition. Miami, FL, USA: IEEE, 2009. 1208−1215 [27] 刘大千, 刘万军, 费博雯, 曲海成. 前景约束下的抗干扰匹配目标跟踪方法. 自动化学报, 2018, 44(6): 1138−1152Liu Da-Qian, Liu Wan-Jun, Fei Bo-Wen, Qu Hai-Cheng. A new method of anti-interference matching under foreground constraint for target tracking. Acta Automatica Sinica, 2018, 44(6): 1138−1152 [28] Fan J L, Shen X H, Wu Y. Scribble tracker: A matting-based approach for robust tracking. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2012, 34(8): 1633−1644 doi: 10.1109/TPAMI.2011.257 [29] Godec M, Roth P M, Bischof H. Hough-based tracking of non-rigid objects. Computer Vision and Image Understanding, 2013, 117(10): 1245−1256 doi: 10.1016/j.cviu.2012.11.005 [30] Bibby C, Reid I. Robust real-time visual tracking using pixel-wise posteriors. In: Proceedings of the 2008 European Conference on Computer Vision. Marseille, France: Springer, 2008. 831−844 [31] Oron S, Bar-Hille A, Avidan S. Extended lucas-kanade tracking. In: Proceedings of the 2014 European Conference on Computer Vision. Zurich, Switzerland: Springer, 2014. 142−156 [32] Possegger H, Mauthner T, Bischof H. In defense of color-based model-free tracking. In: Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). Boston, MA, USA: IEEE, 2015. 2113−2120 [33] Son J, Jung I, Park K, Han B. Tracking-by-segmentation with online gradient boosting decision tree. In: Proceedings of the 2015 IEEE International Conference on Computer Vision (ICCV). Santiago, Chile: IEEE, 2015. 3056−3064 [34] Duffner S, Garcia C. Fast pixelwise adaptive visual tracking of non-rigid objects. IEEE Transactions on Image Processing, 2017, 26(5): 2368−2380 doi: 10.1109/TIP.2017.2676346 [35] Aeschliman C, Park J, Kak A C. A probabilistic framework for joint segmentation and tracking. In: Proceedings of the 2010 IEEE Computer Society Conference on Computer Vision and Pattern Recognition. San Francisco, CA, USA: IEEE, 2010. 1371−1378 [36] Papoutsakis K E, Argyros A A. Integrating tracking with fine object segmentation. Image and Vision Computing, 2013, 31(10): 771−785 doi: 10.1016/j.imavis.2013.07.008 [37] Vo B T, Vo B N. Labeled random finite sets and multi-object conjugate priors. IEEE Transactions on Signal Processing, 2013, 61(13): 3460−3475 doi: 10.1109/TSP.2013.2259822 [38] Wong S C, Stamatescu V, Gatt A, Kearney D, Lee I, McDonnell M D. Track everything: Limiting prior knowledge in online multi-object recognition. IEEE Transactions on Image Processing, 2017, 26(10): 4669−4683 doi: 10.1109/TIP.2017.2696744 [39] Punchihewa Y G, Vo B T, Vo B N, Kim D Y. Multiple object tracking in unknown backgrounds with labeled random finite sets. IEEE Transactions on Signal Processing, 2018, 66(11): 3040−3055 doi: 10.1109/TSP.2018.2821650 [40] Itti L, Koch C, Niebur E. A model of saliency-based visual attention for rapid scene analysis. IEEE Transactions on Pattern Analysis and Machine Intelligence, 1998, 20(11): 1254−1259 doi: 10.1109/34.730558 [41] Hou X D, Zhang L Q. Saliency detection: A spectral residual approach. In: Proceedings of the 2007 IEEE Conference on Computer Vision and Pattern Recognition. Minneapolis, Minnesota, USA: IEEE, 2007. 1−8 [42] Wei Y C, Wen F, Zhu W J, Sun J. Geodesic saliency using background priors. In: Proceedings of the 2012 European Conference on Computer Vision. Florence, Italy: Springer, 2012. 29−42 [43] Ciesielski K C, Strand R, Malmberg F, Saha P K. Efficient algorithm for finding the exact minimum barrier distance. Computer Vision and Image Understanding, 2014, 123: 53−64 doi: 10.1016/j.cviu.2014.03.007 [44] Zhang J M, Sclaroff S, Lin Z, Shen X H, Price B, Mech R. Minimum barrier salient object detection at 80 FPS. In: Proceedings of the 2015 IEEE International Conference on Computer Vision (ICCV). Santiago, Chile: IEEE, 2015. 1404−1412 [45] Zhao D W, Xiao L, Fu H, Wu T, Xu X, Dai B. Augmenting cascaded correlation filters with spatial — temporal saliency for visual tracking. Information Sciences, 2019, 470: 78−93 doi: 10.1016/j.ins.2018.08.053 [46] Hong S, You T, Kwak S, Han B. Online tracking by learning discriminative saliency map with convolutional neural network. In: Proceedings of the 32nd International Conference on Machine Learning. Lille, France: JMLR, 2015. 597−606 [47] Ma C, Huang J B, Yang X K, Yang M H. Hierarchical convolutional features for visual tracking. In: Proceedings of the 2015 IEEE International Conference on Computer Vision (ICCV). Santiago, Chile: IEEE, 2015. 3074−3082 [48] Choi J, Chang H J, Fischer T, Yun S, Lee K, Jeong J, et al. Context-aware deep feature compression for high-speed visual tracking. In: Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Salt Lake City, UT, USA: IEEE, 2018. 479−488 [49] Gladh S, Danelljan M, Khan F S, Felsberg M. Deep motion features for visual tracking. In: Proceedings of the 23rd International Conference on Pattern Recognition (ICPR). Cancun, Mexico: IEEE, 2016. 1243−1248 [50] Viola P, Jones M. Rapid object detection using a boosted cascade of simple features. In: Proceedings of the 2001 IEEE Computer Society Conference on Computer Vision and Pattern Recognition. Kauai, HI, USA: IEEE, 2001. I-511−I-518 [51] Danelljan M, Hager G, Khan F S, Felsberg M. Discriminative scale space tracking. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2017, 39(8): 1561−1575 doi: 10.1109/TPAMI.2016.2609928 [52] Kroeger T, Timofte R, Dai D, van Gool L. Fast optical flow using dense inverse search. In: Proceedings of the 2016 European Conference on Computer Vision. Amsterdam, The Netherlands: Springer, 2016. 471−488 [53] Torr P H S, Zisserman A. MLESAC: A new robust estimator with application to estimating image geometry. Computer Vision and Image Understanding, 2000, 78(1): 138−156 doi: 10.1006/cviu.1999.0832 [54] Bhat G, Johnander J, Danelljan M, Khan F A, Felsberg M. Unveiling the power of deep tracking. In: Proceedings of the 2018 European Conference on Computer Vision. Munich, Germany: Springer, 2018. 493−509 [55] Lee H, Kim D. Salient region-based online object tracking. In: Proceedings of the 2018 IEEE Winter Conference on Applications of Computer Vision (WACV). Lake Tahoe, NV, USA: IEEE, 2018. 1170−1177 [56] Wang N, Zhou W G, Tian Q, Hong R C, Wang M, Li H Q. Multi-cue correlation filters for robust visual tracking. In: Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Salt Lake City, UT, USA: IEEE, 2018. 4844−4853 [57] Lukezic A, Vojir T, Zajc L C, Matas J, Kristan M. Discriminative correlation filter with channel and spatial reliability. In: Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). Honolulu, HI, USA: IEEE, 2017. 4847−4856 -

 下载:
下载:


计量
- 文章访问数: 1227
- HTML全文浏览量: 494
- PDF下载量: 243
- 被引次数: 0
