

A Butterfly Detection Algorithm Based on Transfer Learning and Deformable Convolution Deep Learning
-
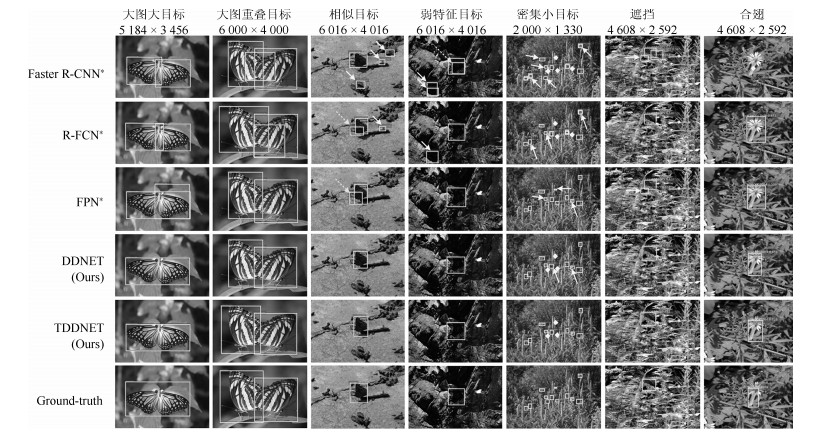
摘要: 针对自然生态蝴蝶多种特征检测的实际需求,以及生态环境下蝴蝶检测效率低、精度差问题,本文提出了一种基于迁移学习和可变形卷积深度神经网络的蝴蝶检测算法(Transfer learning and deformable convolution deep learning network,TDDNET).该算法首先使用可变形卷积模型重建ResNet-101卷积层,强化特征提取网络对蝴蝶特征的学习,并以此结合区域建议网络(Region proposal network,RPN)构建二分类蝴蝶检测网络,以下简称DNET-base;然后在DNET-base的模型上,构建RPN网络来指导可变形的敏感位置兴趣区域池化层,以便获得多尺度目标的评分特征图和更准确的位置,再由弱化非极大值抑制(Soft non-maximum suppression,Soft-NMS)精准分类形成TDDNET模型.随后通过模型迁移,将DNET-base训练参数迁移至TDDNET,有效降低数据分布不均造成的训练困难与检测性能差的影响,再由Fine-tuning方式快速训练TDDNET多分类网络,最终实现了对蝴蝶的精确检测.所提算法在854张蝴蝶测试集上对蝴蝶检测结果的mAP0.5为0.9414、mAP0.7为0.9235、检出率DR为0.9082以及分类准确率ACC为0.9370,均高于在同等硬件配置环境下的对比算法.对比实验表明,所提算法对生态照蝴蝶可实现较高精度的检测.Abstract: Aiming at the demand of butterfly multi-features recognition, and the problems of low precision and efficiency of butterfly detection in ecological environment, a butterfly detection with deformable convolution depth neural network based transfer learning is proposed (TDDNET). Firstly, the ResNet-101 convolutional layer is reconstructed by using the deformable convolutional model, which can reinforce the learning of feature extraction network for butterfly features. At the same time, this algorithm is combined with the region proposal network (RPN) to construct a two-classes detection network named DNET-base. Next, on the DNET-base to build TDDNET, the subnetwork RPN is used to guide the deformable sensitive position RoI pooling layer, which can obtain the scores feature map and the multi-scale object location. Then, we use the Soft-nms to obtain better detection results. Finally, the model after DNET-base training is transferred to the TDDNET, and fine-tuning the TDDNET multi-classification parameters. In testing datasets which have 854 images, the butterfly mAP0.5 of the proposed algorithm is 0.9414, mAP0.7 is 0.9235, the detection rate (DR) is 0.9082 and the classification accuracy (ACC) is 0.9370. The experiments demonstrate that the proposed algorithm outperforms the state-of-the-art model in the same hardware environment. The results show that the proposed algorithm can detect butterflies with high accuracy.1) 本文责任编委 金连文
-
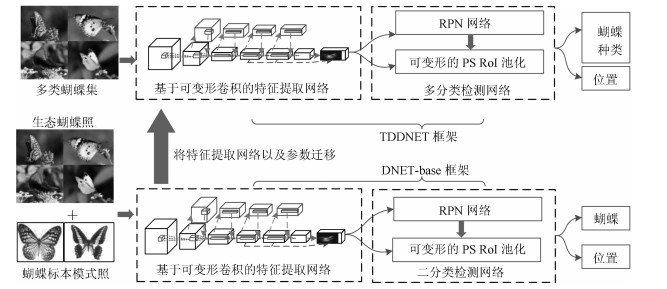
图 2 本文所提算法TDDNET的原理框架示意图
Fig. 2 Schematic diagram of TDDNET's principle framework proposed in this paper
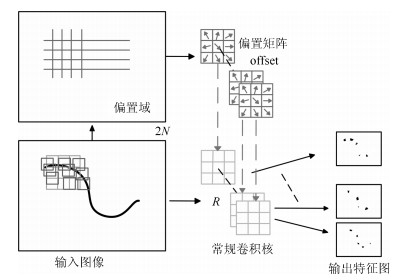
图 4 $3 \times 3$可变形卷积特征计算过程示例
Fig. 4 An example of deformable convolution feature calculation process ($3 \times 3$)
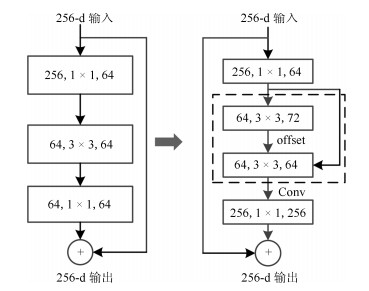
图 7 构建ResNet单元为可变形ResNet结构
Fig. 7 Construct the ResNet unit as a deformable ResNet structure RoI

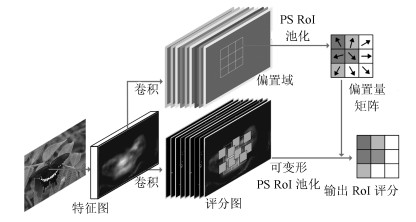
图 8 本文所提算法的网络模型与参数说明(TDDNET)
Fig. 8 Network model and parameter description of the algorithm proposed in this paper (TDDNET)
表 1 针对所提算法网络结构自身差异对比
Table 1 Contrast the differences of the network structure of the proposed algorithm
网络结构差异 mAP0.5 mAP0.7 DR ACC TDDNET (Soft-NMS) 0.9415 0.9235 0.9082 0.9370 TDDNET (NMS) 0.9358 0.9208 0.9004 0.9274 DDNET (NMS, 无迁移) 0.9137 0.9009 0.8503 0.9180 TDDNET(无可变形卷积) 0.8827 0.8506 0.8532 0.8728  下载: 导出CSV
下载: 导出CSV
表 2 针对所提算法中在不同层使用可变形卷积模型的差异
Table 2 Aiming at the difference of using deformable convolution network in different layers of the proposed algorithm
可变形卷积网络层 mAP0.5 mAP0.7 DR ACC TDDNET完整框架 0.9415 0.9235 0.9082 0.9370 TDDNET框架(除Res2c) 0.9402 0.9174 0.9004 0.9304 Res5 $(a, b, c)+$ PS RoI 0.9258 0.9076 0.8939 0.9186 PS RoI 0.9106 0.8902 0.8899 0.8960 Res5 $(a, b, c)$ 0.8802 0.8609 0.8693 0.8901
下载: 导出CSV
表 3 所提算法与其他目标检测算法的实验结果
Table 3 Experimental results of the proposed algorithm and other target detection algorithms
对比算法 mAP0.5 mAP0.7 DR ACC Faster R-CNN [12] 0.7879 0.7418 0.8308 0.7845 Faster R-CNN* 0.8207 0.7932 0.8554 0.8144 R-FCN [22] 0.8650 0.8405 0.8650 0.8911 R-FCN* 0.8957 0.8594 0.8747 0.9087 FPN [24] 0.8926 0.8644 0.8994 0.9057 FPN* 0.9288 0.9261 0.8982 0.9206 SSD [25] 0.7794 0.7013 0.8648 0.7564 YOLO-v3 [17] (ResNet50) 0.7787 0.7785 0.8751 0.7956 YOLO-v3 [17] (DarkNet) 0.7889 0.7822 0.8746 0.8050 TDDNET 0.9415 0.9235 0.9082 0.9370
下载: 导出CSV
-
[1] 寿建新, 周尧, 李宇飞.世界蝴蝶分类名录.陕西:陕西科学技术出版社, 2006Shou Jian-Xin, Zhou Yao, Li Yu-Fei. Systematic butterffly names of the world. Shaanxi:Shaanxi Science and Technology Press, 2006 [2] 马方舟, 徐海根, 陈萌萌.全国蝴蝶多样性观测网络(China BON-Butterflies)建设进展.生态与农村环境学报, 2018, 34(1):27-36 http://d.old.wanfangdata.com.cn/Periodical/ncsthj201801004Ma Fang-Zhou, Xu Hai-Geng, Chen Meng-Meng. Progress in construction of china butterfly diversity observation network (China BON-Butterflies). Journal of Ecology and Rural Environment, 2018, 34(1):27-36 http://d.old.wanfangdata.com.cn/Periodical/ncsthj201801004 [3] Kang S H, Cho J H, Lee S H. Identification of butterfly based on their shapes when viewed from different angles using an artificial neural network. Journal of Asia-Pacific Entomology, 2014, 17(2):143-149 doi: 10.1016/j.aspen.2013.12.004 [4] Kaya Y, Kayci L, Uyar M. Automatic identification of butterfly species based on local binary patterns and artificial neural network. Applied Soft Computing, 2015, 28:132-137 doi: 10.1016/j.asoc.2014.11.046 [5] 李凡.基于数字图像的蝴蝶种类自动识别研究[硕士学位论文], 北京林业大学, 中国, 2015Li Fan. The research on automatic identification of butterfly species based on the digital image[Master dithesis], Beijing Forestry University, China, 2015 [6] 孙晓, 潘汀, 任福继.基于ROI-KNN卷积神经网络的面部表情识别.自动化学报, 2016, 42(6):883-891 http://www.aas.net.cn/CN/abstract/abstract18879.shtmlSun Xiao, Pan Ting, Ren Fu-Ji. Facial expression recognition using ROI-KNN deep convolutional neural networks. Acta Automatica Sinica, 2016, 42(6):883-891 http://www.aas.net.cn/CN/abstract/abstract18879.shtml [7] 张慧, 王坤峰, 王飞跃.深度学习在目标视觉检测中的应用进展与展望.自动化学报, 2017, 43(8):1289-1305 http://www.aas.net.cn/CN/abstract/abstract19104.shtmlZhang Hui, Wang Kun-Feng, Wang Fei-Yue. Advances and perspectives on applications of deep learning in visual object detection. Acta Automatica Sinica, 2017, 43(8):1289-1305 http://www.aas.net.cn/CN/abstract/abstract19104.shtml [8] 常亮, 邓小明, 周明全, 武仲科, 袁野, 等.图像理解中的卷积神经网络.自动化学报, 2016, 42(9):1300-1312 http://www.aas.net.cn/CN/abstract/abstract18919.shtmlChang Liang, Deng Xiao-Ming, Zhou Ming-Quan Wu Zhong-Ke, Yuan Ye, et al. Convolutional neural networks in image understanding. Acta Automatica Sinica, 2016, 42(9):1300-1312 http://www.aas.net.cn/CN/abstract/abstract18919.shtml [9] Liu Z Y, Gao J F, Yang G G. Localization and classification of paddy field pests using a saliency map and deep convolutional neural network. Scientific Reports, 2016, 6:204-210 [10] 周爱明, 马鹏鹏, 席天宇, 王江宁, 冯晋, 邵泽中, 等.基于深度学习的蝴蝶科级标本图像自动识别.昆虫学报, 2017, 60(11):1339-1348 http://d.old.wanfangdata.com.cn/Periodical/kcxb201711012Zhou Ai-Ming, Ma Peng-Peng, Xi Tian-Yu, Wang Jiang-Ning, Feng Jin, Shao Ze-Zhong, et al. Automatic identification of butterfly specimen images at the family level based on deep learning method. Acta Entomologica Sinica, 2017, 60(11):1339-1348 http://d.old.wanfangdata.com.cn/Periodical/kcxb201711012 [11] 谢娟英, 侯琦, 史颖欢, 吕鹏, 景丽萍, 庄福振, 等.蝴蝶种类自动识别研究.计算机研究与发展, 2018, 55(8):1609-1618 http://d.old.wanfangdata.com.cn/Periodical/jsjyjyfz201808002Xie Juan-Ying, Hou Qi, Shi Ying-Huan, Lv Peng, Jing Li-Ping, Zhuan Fu-Zhen, et al. The automatic identification of butterfly species. Journal of Computer Research and Development, 2018, 55(8):1609-1618 http://d.old.wanfangdata.com.cn/Periodical/jsjyjyfz201808002 [12] Ren S Q, He Kai-Ming, Gitshick R. Faster R-CNN:Towards real-time object detection with region proposal networks. IEEE Transactions on Pattern Analysis & Machine Intelligence, 2017, 39(6):1137-1149 [13] Zeiler M D, Fergus R. Visualizing and understanding convolutional networks. In: Proceedings of the 13th European Conference on Computer Vision, Zurich, Switzerland: Springer Verlag, 2014. 818-833 [14] Chatfield, Ken. Return of the devil in the details: Delving deep into convolutional nets. arXiv preprint, arXiv: 1405.3531, 2014 [15] Simonyan K, Zisserman A. Very deep convolutional networks for large-scale image recognition. arXiv preprint, arXiv: 1409.1556, 2015 [16] Redmon J, Farhadi A. YOLO9000: better, faster, stronger. In: Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, Hawaii, USA: IEEE, 2017. 6517-6525 [17] Redmon J, Farhadi A. YOLO-v3: An incremental improvement. arXiv preprint, arXiv: 1804.02767, 2018 [18] He Kai-Ming, Zhang Xiang-Yu, Ren Shao-Ping. Deep residual learning for image recognition. In: Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, Nevada, USA: IEEE, 2016. 770-778 [19] Bodla N, Singh B, Chellappa R. Soft-NMS: Improving object detection with one line of code. In: Proceedings of the 2017 IEEE International Conference on Computer Vision, Venice, Italy: IEEE, 2017. 5562-5570 [20] Dai J F, Qi H Z, Xiong Y W. Deformable convolutional networks. In: Proceedings of the 2017 IEEE International Conference on Computer Vision, Venice, Italy: IEEE, 2017. 764-773 [21] Jadergarg M, Simonyan K, Zisserman A. Spatial transformer networks. In: Proceedings of the 30th Annual Conference on Neural Information Processing Systems, Barcelona, Spain: Curran Associates, Inc. 2016. 2017-2025 [22] Dai J F, Li Y, He K M. R-FCN: Object detection via region-based fully convolutional networks. In: Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition. Las Vegas, NV, USA: IEEE, 2016. 379-387 [23] Shrivastava A, Gupta A, Girshick R. Training region-based object detectors with online hard example mining. In: Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, Nevada, USA: IEEE, 2016. 761-769 [24] Lin T Y, Dollar P, Girshick R B. Feature pyramid networks for object detection. In: Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, Hawaii, USA: IEEE, 2017. 936-944 [25] Liu W, Anguelov D, Erhan D. SSD: Single shot multibox detector. In: Proceedings of the 13th European conference on computer vision, Amsterdam, the Netherlands: Springer Verlag, 2016. 21-37 [26] 刘丽, 赵凌君, 郭承玉, 王亮, 汤俊.图像纹理分类方法研究进展和展望.自动化学报, 2018, 44(4):584-607 http://www.aas.net.cn/CN/abstract/abstract19252.shtmlLiu Li, Zhao Ling-Jun, Guo Cheng-Yu, Wang Liang, Tang Jun. Texture classification:state-of-the-art methods and prospects. Acta Automatica Sinica, 2018, 44(4):584-607 http://www.aas.net.cn/CN/abstract/abstract19252.shtml [27] 罗建豪, 吴建鑫.基于深度卷积特征的细粒度图像分类研究综述.自动化学报, 2017, 43(8):1306-1318 http://www.aas.net.cn/CN/abstract/abstract19105.shtmlLuo Jian-Hao, Wu Jian-Xin. A survey on fine-grained image categorization using deep convolutional features. Acta Automatica Sinica, 2017, 43(8):1306-1318 http://www.aas.net.cn/CN/abstract/abstract19105.shtml [28] Yu Fisher, Vladlen Koltun, Thomas Funkhouser. Dilated residual networks. In: Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, Hawaii, USA: IEEE, 2017. 636-644 [29] Zhou Y Z, Ye Q X, Qiu Q, Jiao J B. Oriented response networks. In: Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, Hawaii, USA: IEEE, 2017. 4961-4970 [30] Jeon Y, Kim J. Active convolution: Learning the shape of convolution for image classification. In: Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, Hawaii, USA: IEEE, 2017. 1846-1854 [31] He K M, Gkioxari G, Dollar P. Mask r-cnn. In: Proceedings of the 2017 IEEE International Conference on Computer Vision, Venice, Italy: IEEE, 2017. 2980-2988 [32] 李策, 张亚超, 蓝天, 杜少毅.一种高分辨率遥感图像视感知目标检测算法.西安交通大学学报, 2018, 6(52):9-16 http://d.old.wanfangdata.com.cn/Periodical/xajtdxxb201806002Li Ce, Zhang Ya-Chao, Lan Tian, Du Shao-Yi. An object detection algorithm with visual perception for high-resolution remote sensing images. Journal of Xi'an Jiaotong University, 2018, 6(52):9-16 http://d.old.wanfangdata.com.cn/Periodical/xajtdxxb201806002 [33] Kim S W, Kook H K. Parallel feature pyramid network for object detection. In: Proceedings of the 15th European Conference on Computer Vision, Munich, Germany: Springer Verlag, 2018. 234-250 [34] Cai Z W, Nuno V. Cascade R-CNN: Delving into high quality object detection. In: Proceedings of the 2018 IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake, USA: IEEE, 2018. 6154-6162 [35] Szegedy C, Ioffe S, Vanhoucke V. Inception-v4, inception-resnet and the impact of residual connections on learning. In: Proceedings of the 31st AAAI Conference on Artificial Intelligence, San Francisco, California, USA: AAAI, 2017. 4278-4284 [36] Xie S N, Girxhick R, Dollar P. Aggregated residual transformations for deep neural networks. In: Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, Hawaii, USA: IEEE, 2017. 5987-5995 [37] Zhou P, Ni B B. Scale-transferrable object detection. In: Proceedings of the 2018 IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake, USA: IEEE, 2018. 528-537 [38] Bharat Singh, Larry S. Davis. An Analysis of Scale Invariance in Object Detection SNIP. In: Proceedings of the 2018 IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake, USA: IEEE, 2018. 3578-3587 -

 下载:
下载:




计量
- 文章访问数: 2541
- HTML全文浏览量: 604
- PDF下载量: 294
- 被引次数: 0
