

-
摘要: 深度信念网络(Deep belief network, DBN)是一种基于深度学习的生成模型, 克服了传统梯度类学习算法在处理深层结构所面临的梯度消失问题, 近几年来已成为深度学习领域的研究热点之一.基于分阶段学习的思想, 人们设计了不同结构和学习算法的深度信念网络模型.本文在回顾总结深度信念网络的研究现状基础上, 给出了其发展趋势.首先, 给出深度信念网络的基本模型结构以及其标准的学习框架, 并分析了深度信念网络与其他深度结构的关系与区别; 其次, 回顾总结深度信念网络研究现状, 基于标准模型分析不同深度信念网络结构的性能; 第三, 给出深度信念网络的不同无监督预训练和有监督调优算法, 并分析其性能; 最后, 给出深度信念网络今后的发展趋势以及未来值得研究的方向.Abstract: Deep belief network (DBN) is a generative model basedon deep learning and overcomes vanishing gradient problem resultedfrom traditional gradient-based algorithm when it comes to deeparchitecture, and it is one of hot issues in the field of deeplearning. Based on the idea of learning in stages, DBN models withdifferent structures and learning algorithms have been proposed.The aim of this paper is to summarize the current research on DBNand gives some views about its development trends in the future.First, the basic structure and standard learning framework of DBNare introduced, the relationship and difference between DBN andother deep structures are analyzed. Second, the current researchon DBN is given, the performances of DBN with different structuresare analyzed based on standard the model. Thirdly, the differentunsupervised pre-training and supervised fine-tuning of DBN aregiven, and their performances are also analyzed. Finally, someviews about DBN's development trends in the future arepresented.
-
Key words:
- Deep belief network (DBN) /
- deep learning /
- unsupervised pre-training /
- supervised fine-tuning /
- structure design
1) 本文责任编委 张敏灵 -
表 1 不同DBN结构的性能对比
Table 1 Performance comparison of different DBN structures
结构 训练RMSE 训练时间(s) 测试时间(s) 均值 方差 稀疏DBN 0.0468 0.0009 6.91 5.13 自组织DBN 0.0308 0.0085 6.50 5.06 增量式DBN 0.0173 0.0012 4.27 3.14 递归DBN 0.0149 0.0126 6.67 5.11  下载: 导出CSV
下载: 导出CSV
表 2 不同DBN算法的性能对比
Table 2 Performance comparison of different DBN algorithms
算法 训练RMSE 训练时间(s) 测试时间(s) 均值 方差 梯度下降 0.0835 0.0116 12.38 10.09 自适应学习率 0.0225 0.0102 2.97 1.39 半监督学习 0.0507 0.0130 8.68 6.17 偏最小二乘回归 0.0193 0.0091 3.62 2.28
下载: 导出CSV
附表 1 文中用到的主要数学符号
附表 1 Main mathematical notations in this paper
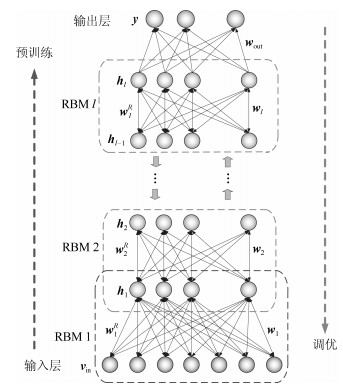
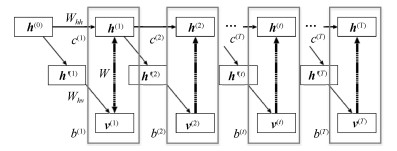
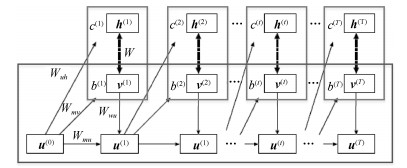
主要数学符号说明 ${\mathit{\boldsymbol{v}}}$——可视层神经元组成的状态向量 ${\mathit{\boldsymbol{h}}}$——隐含层神经元组成的状态向量 ${\mathit{\boldsymbol{b}}}_v$——可视层神经元偏置状态向量 ${\mathit{\boldsymbol{b}}}_h$——隐含层神经元偏置状态向量 ${\mathit{\boldsymbol{c}}}_u$——监督层神经元偏置状态向量 ${\mathit{\boldsymbol{w}}}^R$——标准受限玻尔兹曼机权值矩阵 ${\mathit{\boldsymbol{p}}}$——监督层与隐含层之间的权值矩阵 ${\mathit{\boldsymbol{w}}}_{\rm out}$——最后一个隐含层与输出层之间的权值矩阵 ${\mathit{\boldsymbol{W}}}^R$——整个网络的初始化权值矩阵 ${\mathit{\boldsymbol{W}}}$——整个网络的最终权值矩阵
下载: 导出CSV
-
[1] Liu Q S, Dang C Y, Huang T W. A one-layer recurrent neural network for real-time portfolio optimization with probability criterion. IEEE Transactions on Cybernetics, 2013, 43(1): 14-23 doi: 10.1109/TSMCB.2012.2198812 [2] Lin Y Y, Chang J Y, Lin C T. Identification and prediction of dynamic systems using an interactively recurrent self-evolving fuzzy neural network. IEEE Transactions on Neural Networks and Learning Systems, 2013, 24(2): 310-321 doi: 10.1109/TNNLS.2012.2231436 [3] Lian J, Wang J. Passivity of switched recurrent neural networks with time-varying delays. IEEE Transactions on Neural Networks and Learning Systems, 2015, 26(2): 357-366 doi: 10.1109/TNNLS.2014.2379920 [4] 吴玉香, 王聪.基于确定学习的机器人任务空间自适应神经网络控制.自动化学报, 2013, 39(6): 806-815 doi: 10.3724/SP.J.1004.2013.00806Wu Yu-Xiang, Wang Cong. Deterministic learning based adaptive network control of robot in task space. Acta Automatica Sinica, 2013, 39(6): 806-815 doi: 10.3724/SP.J.1004.2013.00806 [5] Chandrasekar A, Rakkiyappan R, Cao J D, Lakshmanan S. Synchronization of memristor-based recurrent neural networks with two delay components based on second-order reciprocally convex approach. Neural Networks, 2014, 57: 79-93 doi: 10.1016/j.neunet.2014.06.001 [6] Alhamdoosh M, Wang D H. Fast decorrelated neural network ensembles with random weights. Information Sciences, 2014, 264: 104-117 doi: 10.1016/j.ins.2013.12.016 [7] Lee Y, Oh S H, Kim M W. An analysis of premature saturation in back propagation learning. Neural Networks, 1993, 6(5): 719-728 doi: 10.1016/S0893-6080(05)80116-9 [8] Burse K, Yadav R N, Shrivastava S C. Channel equalization using neural networks: A review. IEEE Transactions on Systems, Man, and Cybernetics, Part C (Applications and Reviews), 2010, 40(3): 352-357 doi: 10.1109/TSMCC.2009.2038279 [9] Pfeifer R, Lungarella M, Iida F. Self-organization, embodiment, and biologically inspired robotics. Science, 2007, 318(5853): 1088-1093 doi: 10.1126/science.1145803 [10] Schmidhuber J. Deep learning in neural networks: An overview. Neural Networks, 2015, 61: 85-117 [11] Kriegeskorte N. Deep neural networks: A new framework for modeling biological vision and brain information processing. Annual Review of Vision Science, 2015, 1: 417-446 doi: 10.1146/annurev-vision-082114-035447 [12] Hinton G E, Salakhutdinov R R. Reducing the dimensionality of data with neural networks. Science, 2006, 313(5786): 504-507 doi: 10.1126/science.1127647 [13] LeCun Y, Bengio Y, Hinton G. Deep learning. Nature, 2015, 521(7553): 436-444 doi: 10.1038/nature14539 [14] Wang G, Qiao J, Bi J, Jia Q, Zhou M. An Adaptive Deep Belief Network With Sparse Restricted Boltzmann Machines. IEEE Transactions on Neural Networks and Learning Systems, 2020, 31(10): 4217-4228 doi: 10.1109/TNNLS.2019.2952864 [15] 乔俊飞, 王功明, 李晓理, 韩红桂, 柴伟.基于自适应学习率的深度信念网设计与应用.自动化学报, 2017, 43(8): 1339-1349 doi: 10.16383/j.aas.2017.c160389Qiao Jun-Fei, Wang Gong-Ming, Li Xiao-Li, Han Hong-Gui, Chai Wei. Design and application of deep belief network with adaptive learning rate. Acta Automatica Sinica, 2017, 43(8): 1339-1349 doi: 10.16383/j.aas.2017.c160389 [16] Wang G, Jia Q, Qiao J, Bi J, Liu C. A sparse deep belief network with efficient fuzzy learning framework. Neural Networks, 2020, 121: 430-440 doi: 10.1016/j.neunet.2019.09.035 [17] Baldi P, Sadowski P, Whiteson D. Searching for exotic particles in high-energy physics with deep learning. Nature Communications, 2014, 5: 4308 doi: 10.1038/ncomms5308 [18] Lv Y S, Duan Y J, Kang W W, Li Z X, Wang F Y. Traffic flow prediction with big data: A deep learning approach. IEEE Transactions on Intelligent Transportation Systems, 2015, 16(2): 865-873 [19] Chan T H, Jia K, Gao S H, Lu J W, Zeng Z, Ma Y. PCANet: A simple deep learning baseline for image classification? IEEE Transactions on Image Processing, 2015, 24(12): 5017-5032 doi: 10.1109/TIP.2015.2475625 [20] Hinton G E, Osindero S, Teh Y W. A fast learning algorithm for deep belief nets. Neural Computation, 2006, 18(7): 1527-1554 doi: 10.1162/neco.2006.18.7.1527 [21] Sutskever I, Hinton G E. Deep, narrow sigmoid belief networks are universal approximators. Neural Computation, 2008, 20(11): 2629-2636 doi: 10.1162/neco.2008.12-07-661 [22] Qin Y, Wang X, Zou J Q. The optimized deep belief networks with improved logistic Sigmoid units and their application in fault diagnosis for planetary gearboxes of wind turbines. IEEE Transactions on Industrial Electronics, 2019, 66(5): 3814-3824 doi: 10.1109/TIE.2018.2856205 [23] Qiao J F, Wang G M, Li W J, Chen M. An adaptive deep Q-learning strategy for handwritten digit recognition. Neural Networks, 2018, 107: 61-71 doi: 10.1016/j.neunet.2018.02.010 [24] Abdel-Zaher A M, Eldeib A M. Breast cancer classification using deep belief networks. Expert Systems with Applications, 2016, 46: 139-144 doi: 10.1016/j.eswa.2015.10.015 [25] Qiao J F, Wang G M, Li W J, Li X L. A deep belief network with PLSR for nonlinear system modeling. Neural Networks, 2018, 104: 68-79 doi: 10.1016/j.neunet.2017.10.006 [26] Qiao J F, Wang G M, Li X L, Li W J. A self-organizing deep belief network for nonlinear system modeling. Applied Soft Computing, 2018, 65: 170-183 doi: 10.1016/j.asoc.2018.01.019 [27] Wang G M, Qiao J F, Bi J, Li W J, Zhou M C. TL-GDBN: Growing deep belief network with transfer learning. IEEE Transactions on Automation Science and Engineering, 2019, 16(2): 874-885 doi: 10.1109/TASE.2018.2865663 [28] Chen Z Y, Li W H. Multisensor feature fusion for bearing fault diagnosis using sparse autoencoder and deep belief network. IEEE Transactions on Instrumentation and Measurement, 2017, 66(7): 1693-1702 doi: 10.1109/TIM.2017.2669947 [29] Ranzato M A, Boureau Y L, LeCun Y. Sparse feature learning for deep belief networks. In: Proceedings of the 20th International Conference on Neural Information Processing Systems. Vancouver, British Columbia, Canada: Curran Associates, Inc., 2018. 1185-1192 [30] Ichimura T, Kamada S. Adaptive learning method of recurrent temporal deep belief network to analyze time series data. In: Proceedings of the 2017 International Joint Conference on Neural Networks. Anchorage, AK, USA: IEEE, 2017. 2346-2353 [31] Hinton G E. Training products of experts by minimizing contrastive divergence. Neural Computation, 2002, 14(8): 1771-1800 doi: 10.1162/089976602760128018 [32] 王功明, 乔俊飞, 王磊.一种能量函数意义下的生成式对抗网络.自动化学报, 2018, 44(5): 793-803 doi: 10.16383/j.aas.2018.c170600Wang Gong-Ming, Qiao Jun-Fei, Wang Lei. A generative adversarial network based on energy function. Acta Automatica Sinica, 2018, 44(5): 793-803 doi: 10.16383/j.aas.2018.c170600 [33] Goodfellow I J, Pouget-Abadie J, Mirza M, Xu B, Warde-Farley D, Ozair S, et al. Generative adversarial nets. In: Proceedings of the 27th International Conference on Neural Information Processing Systems. Montreal, Canada: NIPS, 2014. 2672-2680 [34] Schirrmeister R T, Springenberg J T, Fiederer L D J, Glasstetter M, Eggensperger K, Tangermann M, et al. Deep learning with convolutional neural networks for EEG decoding and visualization. Human Brain Mapping, 2017, 38(11): 5391-5420 doi: 10.1002/hbm.23730 [35] Nguyen A T, Xu J, Luu D K, Zhao Q, Yang Z. Advancing system performance with redundancy: From biological to artificial designs. Neural Computation, 2019, 31(3): 555-573 doi: 10.1162/neco_a_01166 [36] Bengio Y. Learning deep architectures for AI. Foundations and Trends® in Machine Learning, 2009, 2(1): 1-127 doi: 10.1561/2200000006 [37] Glorot X, Bordes A, Bengio Y. Deep sparse rectifier neural networks. In: Proceedings of the 14th International Conference on Artificial Intelligence and Statistics. Fort Lauderdale, USA: JMLR.org, 2011. 315-323 [38] Ali M B. Use of Dropouts and Sparsity for Regularization of Autoencoders in Deep Neural Networks.[Master dissertation], Bilkent University, Bilkent, 2015 [39] Wright J, Yang A Y, Ganesh A, Sastry S, Ma Y. Robust face recognition via sparse representation. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2009, 31(2): 210-227 doi: 10.1109/TPAMI.2008.79 [40] Lee H, Ekanadham C, Ng A Y. Sparse deep belief net model for visual area V2. In: Proceedings of the 20th International Conference on Neural Information Processing Systems. Vancouver, British Columbia, Canada: Curran Associates, Inc., 2007. 873-880 [41] Keyvanrad M A, Homayounpour M M. Normal sparse deep belief network. In: Proceedings of the 2015 International Joint Conference on Neural Networks. Killarney, Ireland: IEEE, 2015. 1-7 [42] Lian R J. Adaptive self-organizing fuzzy sliding-mode radial basis-function neural-network controller for robotic systems. IEEE Transactions on Industrial Electronics, 2014, 61(3): 1493-1503 doi: 10.1109/TIE.2013.2258299 [43] Li F J, Qiao J F, Han H G, Yang C L. A self-organizing cascade neural network with random weights for nonlinear system modeling. Applied Soft Computing, 2016, 42: 184-193 doi: 10.1016/j.asoc.2016.01.028 [44] Sarinnapakorn K, Kubat M. Combining subclassifiers in text categorization: A DST-based solution and a case study. IEEE Transactions on Knowledge and Data Engineering, 2007, 19(2): 1638-1651 [45] Van Opbroek A, Achterberg H C, Vernooij M W, De Bruijne M. Transfer learning for image segmentation by combining image weighting and kernel learning. IEEE Transactions on Medical Imaging, 2019, 38(1): 213-224 doi: 10.1109/TMI.2018.2859478 [46] Shin H C, Roth H R, Gao M C, Lu L, Xu Z Y, Nogues I, et al. Deep convolutional neural networks for computer-aided detection: CNN architectures, dataset characteristics and transfer learning. IEEE Transactions on Medical Imaging, 2016, 35(5): 1285-1298 doi: 10.1109/TMI.2016.2528162 [47] Long M S, Wang J M, Ding G G, Pan S J, Yu P S. Adaptation regularization: A general framework for transfer learning. IEEE Transactions on Knowledge and Data Engineering, 2014, 26(5): 1076-1089 doi: 10.1109/TKDE.2013.111 [48] Afridi M J, Ross A, Shapiro E M. On automated source selection for transfer learning in convolutional neural networks. Pattern Recognition, 2018, 73: 65-75 doi: 10.1016/j.patcog.2017.07.019 [49] Taylor M E, Stone P. Transfer learning for reinforcement learning domains: A survey. The Journal of Machine Learning Research, 2009, 10: 1633-1685 [50] Lu J, Behbood V, Hao P, Zuo H, Xue S, Zhang G Q. Transfer learning using computational intelligence: A survey. Knowledge-Based Systems, 2015, 80: 14-23 doi: 10.1016/j.knosys.2015.01.010 [51] Shao L, Zhu F, Li X L. Transfer learning for visual categorization: A survey. IEEE Transactions on Neural Networks and Learning Systems, 2015, 26(5): 1019-1034 doi: 10.1109/TNNLS.2014.2330900 [52] Sutskever I, Hinton G E, Taylor G W. The recurrent temporal restricted Boltzmann machine. In: Proceedings of the 21st International Conference on Neural Information Processing Systems. Vancouver, British Columbia, Canada: Curran Associates, Inc., 2008. 1601-1608 [53] Fischer A, Igel C. An introduction to restricted Boltzmann machines. In: Proceedings of the 17th Iberoamerican Congress on Pattern Recognition. Buenos Aires, Argentina: Springer, 2012. 14-36 [54] Srivastava N, Salakhutdinov R R. Multimodal learning with deep Boltzmann machines. In: Proceedings of the 25th International Conference on Neural Information Processing Systems. Lake Tahoe, Nevada, USA: NIPS, 2012. 2222-2230 [55] Fischer A, Igel C. Training restricted Boltzmann machines: An introduction. Pattern Recognition, 2014, 47(1): 25-39 doi: 10.1016/j.patcog.2013.05.025 [56] Boulanger-Lewandowski N, Bengio Y, Vincent P. Modeling temporal dependencies in high-dimensional sequences: Application to polyphonic music generation and transcription. In: Proceedings of the 29th International Conference on Machine Learning. Edinburgh, Scotland, UK: Icml.cc/Omnipress, 2012. 1881-1888 [57] Hermans M, Schrauwen B. Training and analyzing deep recurrent neural networks. In: Proceedings of the 26th International Conference on Neural Information Processing Systems. Lake Tahoe, Nevada, USA: NIPS, 2013. 190-198 [58] Chaturvedi I, Ong Y S, Tsang I W, Welsch R E, Cambria E. Learning word dependencies in text by means of a deep recurrent belief network. Knowledge-Based Systems, 2016, 108: 144-154 doi: 10.1016/j.knosys.2016.07.019 [59] Pascanu R, Ģülçehre C, Cho K, Bengio Y. How to construct deep recurrent neural networks. In: Proceedings of the 2nd International Conference on Learning Representations. Banff, AB, Canada: ICLR, 2014. [60] Mohamed A R, Dahl G E, Hinton G E. Acoustic modeling using deep belief networks. IEEE Transactions on Audio, Speech, and Language Processing, 2012, 20(1): 14-22 doi: 10.1109/TASL.2011.2109382 [61] Wang G M, Qiao J F, Li X L, Wang L, Qian X L. Improved classification with semi-supervised deep belief network. IFAC-PapersOnLine, 2017, 50(1): 4174-4179 doi: 10.1016/j.ifacol.2017.08.807 [62] Lopes N, Ribeiro B. Improving convergence of restricted Boltzmann machines via a learning adaptive step size. In: Proceedings of the 17th Iberoamerican Congress on Pattern Recognition. Buenos Aires, Argentina: Springer, 2012. 511-518 [63] Raina R, Madhavan A, Ng A Y. Large-scale deep unsupervised learning using graphics processors. In: Proceedings of the 26th Annual International Conference on Machine Learning. Montreal, Quebec, Canada: ACM, 2009. 873-880 [64] Sierra-Sosa D, Garcia-Zapirain B, Castillo C, Oleagordia I, Nu?o-Solinis R, Urtaran-Laresgoiti M, Elmaghraby A. Scalable Healthcare Assessment for Diabetic Patients Using Deep Learning on Multiple GPUs. IEEE Transactions on Industrial Informatics, 2019, 15(10): 5682-5689 doi: 10.1109/TII.2019.2919168 [65] Lopes N, Ribeiro B. Towards adaptive learning with improved convergence of deep belief networks on graphics processing units. Pattern recognition, 2014, 47(1): 114-127 doi: 10.1016/j.patcog.2013.06.029 [66] 王功明, 李文静, 乔俊飞.基于PLSR自适应深度信念网络的出水总磷预测.化工学报, 2017, 68(5): 1987-1997Wang Gong-Ming, Li Wen-Jing, Qiao Jun-Fei. Prediction of effluent total phosphorus using PLSR-based adaptive deep belief network. CIESC Journal, 2017, 68(5): 1987-1997 [67] Belkin M, Niyogi P. Laplacian eigenmaps for dimensionality reduction and data representation. Neural Computation, 2003, 15(6): 1373-1396 doi: 10.1162/089976603321780317 [68] Chapelle O, Weston J, Schölkopf B. Cluster kernels for semi-supervised learning. In: Proceedings of the 15th International Conference on Neural Information Processing Systems. Vancouver, British Columbia, Canada: MIT Press, 2003. 601-608 [69] Larochelle H, Bengio Y. Classification using discriminative restricted Boltzmann machines. In: Proceedings of the 25th International Conference on Machine Learning. Helsinki, Finland: ACM, 2008. 536-543 [70] Lasserre J A, Bishop C M, Minka T P. Principled hybrids of generative and discriminative models. In: Proceedings of the 2006 IEEE Computer Society Conference on Computer Vision and Pattern Recognition. New York, NY, USA: IEEE, 2006. 87-94 [71] Larochelle H, Erhan D, Bengio Y. Zero-data learning of new tasks. In: Proceedings of the 23rd AAAI Conference on Artificial Intelligence. Chicago, Illinois, USA: AAAI Press, 2008. 646-651 [72] Sun X C, Li T, Li Q, Huang Y, Li Y Q. Deep belief echo-state network and its application to time series prediction. Knowledge-Based Systems, 2017, 130: 17-29 doi: 10.1016/j.knosys.2017.05.022 [73] Deng Y, Ren Z Q, Kong Y Y, Bao F, Dai Q H. A hierarchical fused fuzzy deep neural network for data classification. IEEE Transactions on Fuzzy Systems, 2017, 25(4): 1006-1012 doi: 10.1109/TFUZZ.2016.2574915 [74] Janik L J, Forrester S T, Rawson A. The prediction of soil chemical and physical properties from mid-infrared spectroscopy and combined partial least-squares regression and neural networks (PLS-NN) analysis. Chemometrics and Intelligent Laboratory Systems, 2009, 97(2): 179-188 doi: 10.1016/j.chemolab.2009.04.005 [75] He Y L, Geng Z Q, Xu Y, Zhu Q X. A robust hybrid model integrating enhanced inputs based extreme learning machine with PLSR (PLSR-EIELM) and its application to intelligent measurement. ISA Transactions, 2015, 58: 533-542 doi: 10.1016/j.isatra.2015.06.007 [76] Furber S B, Lester D R, Plana L A, Garside J D, Painkras E, Temple S, et al. Overview of the spinnaker system architecture. IEEE Transactions on Computers, 2013, 62(12): 2454-2467 doi: 10.1109/TC.2012.142 [77] Erhan D, Bengio Y, Courville A, Manzagol P A, Vincent P, Bengio S. Why does unsupervised pre-training help deep learning? The Journal of Machine Learning Research, 2010, 11: 625-660 [78] Angermueller C, PĠrnamaa T, Parts L, Stegle O. Deep learning for computational biology. Molecular Systems Biology, 2016, 12(7): 878 doi: 10.15252/msb.20156651 [79] Min S, Lee B, Yoon S. Deep learning in bioinformatics. Briefings in Bioinformatics, 2017, 18(5): 851-869 [80] Gharehbaghi A, Lindén M. A Deep Machine Learning Method for Classifying Cyclic Time Series of Biological Signals Using Time-Growing Neural Network. IEEE Transactions on Neural Networks and Learning Systems, 2018, 29(9): 4102-4115 doi: 10.1109/TNNLS.2017.2754294 [81] Denil M, Shakibi B, Dinh L, Ranzato M, de Freitas N. Predicting parameters in deep learning. In: Proceedings of the 26th International Conference on Neural Information Processing Systems. Lake Tahoe, Nevada, USA: NIPS, 2013. 2148-2156 [82] Lenz I, Knepper R, Saxena A. DeepMPC: Learning deep latent features for model predictive control. In: Proceedings of the Robotics: Science and Systems XI. Rome, Italy: 2015. -

 下载:
下载:



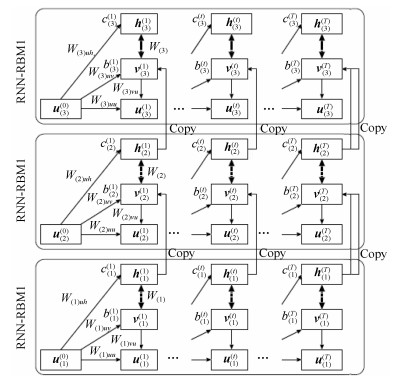
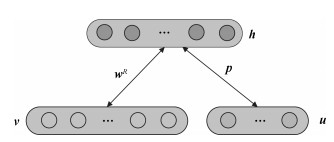
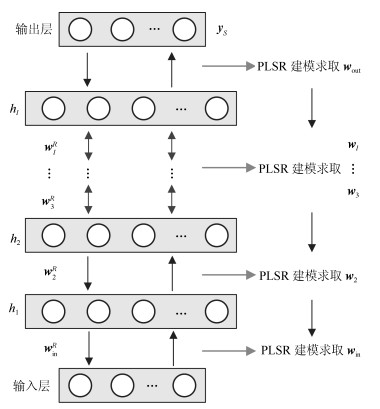


图(11) / 表(3)
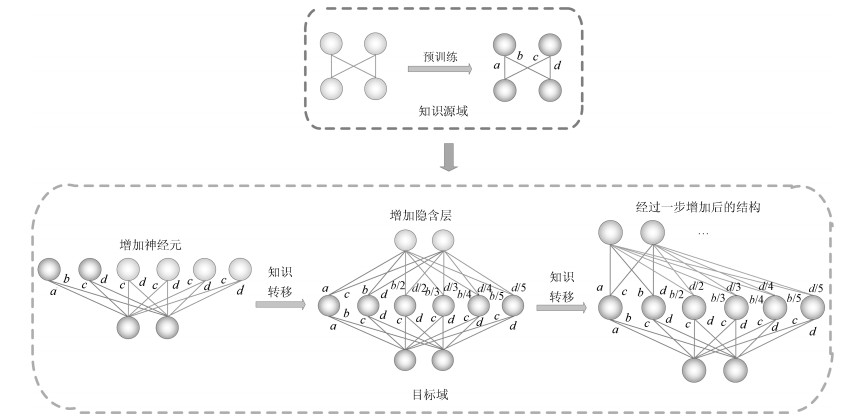
计量
- 文章访问数: 3372
- HTML全文浏览量: 2073
- PDF下载量: 926
- 被引次数: 0
