

Adapted Expectation Maximization Algorithm for Gaussian Mixture Clustering With Censored Data
-
摘要: 针对聚类问题中的非随机性缺失数据, 本文基于高斯混合聚类模型, 分析了删失型数据期望最大化算法的有效性, 并揭示了删失数据似然函数对模型算法的作用机制. 从赤池弘次信息准则、信息散度等指标, 比较了所提出方法与标准的期望最大化算法的优劣性. 通过删失数据划分及指示变量, 推导了聚类模型参数后验概率及似然函数, 调整了参数截尾正态函数的一阶和二阶估计量. 并根据估计算法的有效性理论, 通过关于得分向量期望的方程得出算法估计的最优参数. 对于同一删失数据集, 所提出的聚类算法对数据聚类中心估计更精准. 实验结果证实了所提出算法在高斯混合聚类的性能上优于标准的随机性缺失数据期望最大化算法.Abstract: To provide a solution for clustering with data of missing not at random, this paper provided the efficiency analysis on the adapted expectation-maximization (EM) algorithm for Gaussian mixture clustering model with censored data. We also revealed the impact mechanism of the likelihood function of censored data on the clustering model and its estimation algorithm. With Akaike´s information criterion and Kullback-Leibler divergence, the performance of the proposed algorithm was compared with the standard EM algorithm. Based on data partition and the indicating variables of the censored data set, the paper proposed derived the posterior and likelihood function of the parameters, and adjusted its first and second moments of the truncated normal functions. According to the principles of efficient influence function, the optimal parameters of the algorithm are obtained by the equation of the expectation of the score vector. For the censored data, the proposed clustering algorithm is more accurate in estimating its centroids. The experimental results demonstrated that the proposed algorithm in Gaussian mixture clustering outperformed the standard EM algorithm, which was designed for the data of missing at random.
-
水下信息物理融合系统是集控制、通信和计算于一体的水下智能系统, 包括探测与采集、传播与组网、控制与融合等过程.为构建水下信息物理融合系统, 需要在特定水域部署静态传感器和动态潜器, 其中潜器不仅可作为移动锚节点对传感器数据进行中继转发, 也可根据任务需要动态调整姿态以达到网络灵活性的提升.为确保潜器上述功能的实现, 需通过传感器的协同来确定潜器的精确位置.
现有定位技术大致分为距离相关技术和距离无关技术两类[1-2].前者定位精度较高、受制因素较少, 是本文着力研究的定位技术.目前, 一些学者已经对距离相关定位技术进行了研究, 并从不同角度设计了协同定位算法.这些算法大多利用到达时间[3]、到达时间差[4]、到达角度[5]和接收信号强度[6]进行距离测量.例如Liu等[7]基于到达时间差设计了多潜器协作的定位算法, 实现了移动潜器群的精确定位. Zhou等[8]考虑时空相关性, 提出了基于移动预测和到达时间的协同定位算法. Luo等[9]对传感器节点的被动移动进行分析, 提出了混合网络下的协同定位算法.贺华成等[10]研究了钻井平台在工作海况下的定位精度和功率消耗.文献[11]考虑区域无解问题, 设计了两类传感器节点协作的水下定位算法.文献[12]考虑传感器不能直接获取潜器距离信息约束, 设计了直接与间接测量下的融合定位算法.上述定位算法假设节点间的时钟是同步传播的.然而, 相比于陆地无线电波通信, 声波仍是水下通信最主要的载体[13-14].水声通信具有典型的弱通信特性, 例如北斗与全球定位系统并不能直接应用于水下, 且受高噪声以及多径干扰等不稳定因素影响, 水下节点间的时钟同步难以精确实现.上述异步时钟等弱通信特性使得陆地良好通信条件下的定位算法并不能直接应用于水下.此外, 潜器的动力学模型相对于陆地机器人更加复杂.
针对异步时钟下的定位问题, Carroll等[15]提出了基于穷举法的水下请求式异步定位算法.上述算法虽能消除时钟偏移的影响, 但是在定位过程中需要不断穷举, 使得算法复杂度较高.此外, Liu等[16]设计了水下移动环境下的同步定位算法. Mortazavi等[17-18]对时钟同步与定位进行联合求解, 提出了多阶段协同定位算法.同时, 文献[19]采用移动预测的方式, 设计了异步时钟下的定位算法.根据对象的不同, 文献[15-19]分别构建了定位优化问题, 为求解上述优化问题, 需对非线性测量方程进行近似线性化处理.然而, 这种近似线性化易引入模型误差, 使其定位精度受限.
本文提出一种基于信息物理融合的水下潜器协同定位算法.设计基于传感器与潜器交互通信的异步定位策略, 并分别提出基于扩展卡尔曼滤波(Extended Kalman filter, EKF)与无迹卡尔曼滤波(Unscented Kalman filter, UKF)的协同定位算法.与文献[15, 19]类似, 本文忽略时钟漂移的影响, 仅考虑时钟偏移对定位的影响.主要创新点如下: 1)在异步时钟下, 建立通信时延与位置的关系, 进而定义了潜器协同定位问题; 与文献[7-11]不同, 本文所提的异步定位策略可以有效消除异步时钟对水下定位的影响. 2)提出基于扩展卡尔曼与无迹卡尔曼滤波的协同定位算法.同时, 对上述定位算法的有界性以及克拉美罗下界(Cramér-Rao lower bound, CRLB)进行了分析.与文献[15]中的穷举算法相比, 本文所提算法复杂度更低, 同时与文献[15-19]相比, 基于无迹卡尔曼滤波的协同定位算法, 不需要将非线性测量方程进行近似线性化处理, 其定位精度更高.
1. 系统架构与定位策略概述
1.1 水下信息物理融合系统架构
考虑如图 1所示的系统架构, 其各部分功能如下:
1) 浮标.漂浮在水面, 可通过北斗导航或全球定位系统获取自身位置及时钟同步信息, 主要作用是协助水下传感器节点进行自定位.
2) 传感器.悬浮于水下, 可通过浮标的协助获取自身位置, 但受噪声等因素影响, 时钟并不同步, 主要作用是通过信息物理融合获取水下潜器的位置信息.
3) 潜器.可看作是合作目标, 可通过向传感器广播请求来启动整个定位过程.假设水下潜器配备压力传感器, 以直接获取自身深度(即z轴)信息.
1.2 定位策略概述
文献[20]指出, 潜器在滚动和俯仰自由度上较稳定.为此, 将动力学简化为4自由度方程, 其中u, v, w和r分别表示潜器进退、横移、潜浮、偏航角的速度.潜器动力学模型[14]表示如下:
$ \begin{align} &u(k +1) = u(k)~+\nonumber\\& \dfrac{ρ _{1}}{m_{u}}(F_{u}+m_{v}vr% -k_{u}u -k_{u}^{* }u|u|) \nonumber\\ &v(k +1) =v(k) ~+\nonumber\\& \dfrac{ρ _{1}}{m_{v}}(F_{v}+% m_{u}ur-k_{v}v-k_{v}^{* }v|v|) \nonumber\\ &w(k +1) = w(k) ~+\nonumber\\& \dfrac{ρ _{1}}{m_{w}}(F_{w} % +W-k_{w}w-k_{w}^{* }w|w|) \nonumber\\ &r(k +1) = r(k) ~+\nonumber\\& \dfrac{ρ _{1}}{I_{r}}(T_{r} % -(m_{v}-m_{u})uv- k_{r}r-k_{r}^{* }r|r|)% \end{align} $
(1) 其中, mu, mv, mw分别表示潜器进退、横移、潜浮的质量; Tr表示偏航的惯性力; Fu, Fv, Fw分别表示进退、横移、潜浮作用在潜器上的外力; Ir表示潜器偏航的力矩; W表示潜浮的浮力; ku, ku*, kv, kv*, kw, kw*, kr, kr*为相关系数.
水下潜器的运动轨迹可表示为$\pmb{X}_{1, k}=[x(k)$, $y(k)$, $z(k)$, $\varphi (k)]$, 其运动学方程描述如下:
$ \begin{align} x(k+1) =\, & x(k)+\rho _{1} (u\cos \varphi (k)-v\sin \varphi (k)) \notag \\ y(k+1) =\, & y(k)+\rho _{1} (u\sin \varphi (k)+v\cos \varphi (k)) \notag \\ z(k+1) =\, & z(k)+\rho _{1} w \notag \\ \varphi (k+1)=\, & \varphi (k)+\rho _{1}r \label{z2} \end{align} $
(2) 其中, $x$, $y$和$z$分别表示潜器在惯性坐标系北、东和下三个方位的位置; $\varphi$表示偏航旋转角度; $\rho _{1}\in \bf{R}^{+}$为更新步长; 惯性坐标系和载体坐标系之间的映射关系可通过欧拉角变换进行转换.定义$\pmb{X}_{k}=[\pmb{X}_{1, k}$, $\pmb{X}_{2, k}]^{\rm T}$, 其中$\pmb{X}_{2, k}=[u(k), v(k), w(k), r (k)]$.进一步, 结合式(1)和式(2), 可得潜器的整体模型.
$ \begin{align} \label{b1} \pmb{X}_{k}=f(\pmb{X}_{k-1})+\bar{\pmb{\omega}}_{k-1} \end{align} $
(3) 其中, $f$表示$k-1$与$k$时刻状态的非线性关系; $\bar{\omega}$为高斯白噪声, 噪声协方差为.
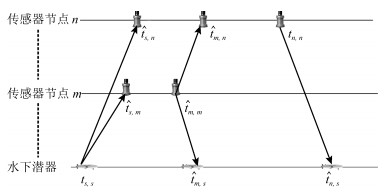
在定位过程中, 每个传感器节点有对应的ID号, 且彼此知道感知范围内节点的ID.传感器节点可编号为$1, 2, \cdots, N$, 且第$n$个传感器节点的位置可表示为$(x_{n}, y_{n}, z_{n})$, 其中潜器的位置可表示为$(x$, $y$, $z)$.为此, 定位过程(见图 2)可以归纳为如下4步:
步骤1. 在初始时刻$t_{s, s}$, 潜器向传感器节点发送定位请求, 其中发起消息包含传感器节点的发送顺序, 由$n=1, 2, \cdots, N$表示.随后, 潜器进入监听模式, 等待来自传感器节点的消息有序传回.
步骤2. 在$\hat{t}_{s, n}$时刻, 传感器节点$n$接收到潜器消息后, 节点$n$进入监听模式并对来自节点, $\cdots$, $n-1$的所有消息进行解码.记录到达时间为$\hat{t}_{m, n}$, 其中$m=1, 2, \cdots, n-1$.当节点$n$接收完节点$n-1$的消息后, 进入发送模式并在时间$t_{n, n}$发出它自己的消息.节点$n$发出的时间戳信息包含$\hat{t}_{s, n}$, $\{\hat{t}_{m, n}\}_{\forall m}$以及$t_{n, n}$.
步骤3. 潜器在时刻$\hat{t}_{n, s}$接收到来自传感器节点$n$的回复, 其中$n=1, 2, \cdots, N$.在接收到传感器节点$N$消息后, 潜器完成本次定位交互过程, 其中收集到的时间戳可表示为$\{\hat{t}_{s, n}, t_{n, n}, \hat{t}_{n, s}\}_{n=1}^{N}$, $\{\hat{t}_{m, n}\}_{n=2, m=1}^{N, n-1}$.
步骤4. 基于上述时间戳测量, 潜器结合水下声速, 将时间戳信息转化为距离信息, 进而利用协同定位算法确定水平位置$(x, y)$.最后, 将水下水平位置与深度位置进行结合, 确定潜器的位置$(x, y, z)$, 整个定位过程结束.
考虑如下的异步时钟模型[15]: $T=t+a$, 其中$T$表示测量时间, $t$表示真实时间, $a$为时钟偏移.
算法目的:构建传播时延与位置之间的交互关联; 定义潜器协同定位问题, 并根据潜器整体模型(3), 提出基于扩展卡尔曼与无迹卡尔曼滤波的协同定位算法, 以实现潜器$(x, y)$位置的准确获取.
2. 水下潜器协同定位
2.1 传播时间与位置关系构建
为抵消时钟异步的影响, 获取时间差如下:
$ \begin{align} &T_{s, n} =(\hat{t}_{n, s}-t_{s, s})-(t_{n, n}-\hat{t}_{s, n}) \label{a4} \\%, \text{ \ }% %n=1, \cdots, N \\ \end{align} $
(4) $ \begin{align} &T_{m, n} =(\hat{t}_{m, n}-\hat{t}_{s, n})-(t_{m, m}-\hat{t}_{s, m}) \label{z4}%, \text{ \ }% %m=1, \cdots, n-1, \forall n \end{align} $
(5) 其中, $n=1, 2, \cdots, N$, $m=1, 2, \cdots , n-1$.可看出上述时间戳差值都是在相同的节点时钟上做差的, 因此上述计算可以消去时钟偏差的影响.
水下潜器与传感器节点$n$、传感器节点$n$与传感器节点$m$之间的距离可分别表示为
$ \begin{align} \label{a3} &l_{s, n} =\sqrt{(x-x_{n})^{2} +(y-y_{n})^{2} +% (z-z_{n})^{2}} \notag \\[1mm] &l_{m, n} =\sqrt{(x_{m}-x_{n})^{2} +(y_{m}-y_{n})^{2} +(z_{m}-z_{n})^{2}}% \end{align} $
(6) 假设测量值具有相同精度, 且方差为$\delta _{\rm mea}^{2}$.为此, 结合式(4) ~(6)可获得相应的定位位置与时间测量值的关系.
$ \begin{align}\label{b5} &T_{s, n} = 2\gamma _{s, n}+v_{s, n}\\ \end{align} $
(7) $ \begin{align} &T_{m, n} = \gamma _{s, m}+\gamma _{m, n}-\gamma _{s, n}+v_{m, n} \end{align} $
(8) 其中, $\gamma _{s, n}={l_{s, n}}/{c}$, $\gamma _{m, n}={l_{m, n}}/{c}$, $c$为水声传播速度. $v_{s, n}$和$v_{m, n}$为测量噪声.根据图 2, 在定位过程中获取的对应时间戳的传播次数及式(4)和式(5)可以推导出$v_{s, n}$与$v_{m, n}$的协方差可以分别为与$3\delta _{\rm mea}^{2}$.
水下潜器异步时钟定位问题可以表示为
$ \begin{align*} (\hat{x}, \hat{y})=&\ \arg \min\limits_{(x, y)}\Bigg\{ \dfrac{1}{4\delta _{\rm mea}^{2}}% \sum\limits_{n=1}^{N}(T_{s, n}-2\gamma _{s, n})^{2}\, +\\ &\ \dfrac{1}{% 6\delta _{\rm mea}^{2}} \sum\limits_{n=2}^{N}\sum% \limits_{m=1}^{n-1}[T_{k, n}\, -\\ &\ (\gamma _{s, m}+\gamma _{m, n}-% \gamma _{s, n})]^{2}\Bigg\} \end{align*} $
注1. 相比于超短基线定位方法, 本文的定位方法有如下不同:在超短基线定位中, 潜器与传感器(或浮标)直接交互, 没有考虑传感器间的信息交互, 在上述思想下定位问题可定义为, 而本文给出的定位问题也考虑了锚节点间的协作, 可通过锚节点的协作增加定位的可靠性与精度.
2.2 协同定位算法设计
2.2.1 基于扩展卡尔曼滤波的协同定位算法
基于式(4)~(6), 定位时间差可转化为如下距离测量: $\pmb{Z}_{k}=\{cT_{s, n}, cT_{m, n}|n=1, \cdots , N.$ $m=1, $ $\cdots$, $n-1\}$.由于$\pmb{Z}_{k}$与潜器的位置$(x , y, z)^{\rm T}$有关, 再根据式(6)~ (8)将位置与距离测量构建关联如下:
$ \begin{align} \label{a6} \pmb{Z}_{k}=h(\pmb{X_{k})}+\pmb{v}_{k} \end{align} $
(9) 其中, $+$ ; 假设$\pmb{v}_{k}$是方差为$R_{k}$的零均值测量噪声.
考虑到穷举法在求解水下时钟异步协同定位时存在算法复杂度较高的问题, 本部分用扩展卡尔曼滤波, [21]进行定位迭代, 进而估计出优化问题的最优解, 其中$k$时刻潜器的位置估计可由$\hat{\pmb{X}}_{e, k}$表示.
步骤1. 在$k=1$时进行初始化, 得, .
步骤2. 基于式(3)对潜器位置进行状态预测\begin{align}\label{a21} \hat{\pmb{X}}_{e, k|k-1}=f({\hat{\pmb{X}}_{e, k-1}}) \end{align}
步骤3. 基于式(6)和式(9), 可知在$k$时刻测量方程$h(\hat{\pmb{X}}_{e, k|k-1})$关于状态位置$\pmb{X}_{k}$的雅克比矩阵为.与其类似, 状态方程$f$关于$\pmb{X}_{k-1}$的雅克比矩阵可定义为.进而, 在$k$时刻估计协方差矩阵表示为$P_{e, k}$, 同时状态预测协方差矩阵$P_{e, k|k-1}$更新为
$ \begin{align} \label{c21} P_{e, k|k-1}=F_{e, k-1}P_{e, k-1}F_{e, k-1}^{\rm T}+Q_{k-1} \end{align}% $
(11) 步骤4. 估计协方差更新为
$ \begin{align} P_{e, k} =[I-K_{e, k}H_{e, k}]P_{e, k|k-1} \label{d21} \end{align}% $
(12) 卡尔曼增益$K_{e, k}$为
$ \begin{align}\label{f21} K_{e, k}=P_{e, k|k-1}H_{e, k}^{\rm T}S_{k}^{-1} \end{align}% $
(13) 状态更新方程为
$ \begin{align}\label{g21} \hat{\pmb{X}}_{e, k}=\hat{\pmb{X}}_{e, k|k-1}+K_{e, k}[\pmb{Z}_{k}-h(\hat{\pmb{X}}_{e, k|k-1})] \end{align}% $
(14) 其中, $S_{k}=H_{e, k}P_{e, k|k-1}H_{e, k}^{\rm T}+R_{k}$.
由上述迭代过程, 最终可得出水下潜器的位置估计$\hat{\pmb{X}}_{e, k}$, 即$(\hat{x}, \hat{y})$.具体定位过程见算法1.
算法1.扩展卡尔曼协同定位算法
1:初始化: 迭代次数$\hat{M}$、状态初始估计$\hat{\pmb{X}}_{e, 0}$和状态估计初始协方差$P_{e, 0}$.
2:输出: 位置估计$\hat{\pmb{X}}_{e, k}$和相应的$P_{e, k}$.
3:for $k=1:\hat{M}$ do
4: 根据式(10)计算得到状态预测$\hat{\pmb{X}}_{e, k|k-1}$, 从式(11)得到协方差矩阵$P_{e, k|k-1}$;
5: 根据式(9)得到预测距离表示为$h(\hat{\pmb{X}}_{e, k|k-1})$;
6: 由式(12)更新协方差矩阵$P_{e, k}$, 由式(13)更新卡尔曼系数$K_{e, k}$, 再根据式(14)更新状态信息$\hat{\pmb{X}}_{e, k}$;
7: end for
2.2.2 基于无迹卡尔曼滤波的协同定位算法
上述算法需求解雅克比矩阵, 易引入模型误差且求解繁琐.为此, 采用无迹卡尔曼滤波[22]进行协同定位, 其中$k$时刻潜器的位置估计可由$\hat{\pmb{X}}_{u, k}$表示.
步骤1. 在$k=1$时, 进行如下初始化: $\hat{\pmb{X}}_{u, 0}=\mathbb{E}[X_{0}]$, .
步骤2. 基于状态估计$X_{u, k-1}$和误差协方差矩阵$P_{u, k-1}$, 选择Sigma点如下:
$ \begin{align} \label{b22} \chi _{_{j, k-1}}=\left[\hat{\pmb{X}}_{u, k-1}, {\hat{\pmb{X}}_{u, k-1}}\pm \left(\tau \sqrt{\hat{P}_{u, k-1}}% \right)_{\hat{m}}\right] \end{align}% $
(15) 其中, $\chi _{_{j, k-1}}$是$\pmb{X}_{u, k-1}$的第$j+1$列, ; $\tau$ $ =$ $\sqrt{L+\lambda}$; 其中$L=8$; $\hat{m}$表示矩阵的第$\hat{m}$列.
步骤3 .根据状态方程(3)预测下一时刻状态 $=f(\chi _{_{j, k-1}})$, 并加权处理后得
$ \begin{align}\label{d22} \hat{\pmb{X}}_{u, k|k-1}=\sum\limits_{j=0}^{2L}W_{j}^{(\hat{m})}\chi _{_{j, k|k-1}} \end{align}% $
(16) 协方差矩阵更新为
$ \begin{align} \hat{P}_{u, k|k-1}=&\ \sum\limits_{j=0}^{2L}W_{j}^{(c)}\left[\chi _{_{j, k|k-1}}-% \hat{\pmb{X}}_{u, k|k-1}\right] \, \times \notag\\ &\ \left\lbrack \chi _{_{j, k|k-1}}-\hat{\pmb{X}}_{u, k|k-1}\right]^{\rm T} \label{e22} \end{align}% $
(17) 其中, $W_{0}^{(\hat{m})}=\lambda /(L+\lambda )$, $W_{0}^{(c)}=\lambda /(L+\lambda )+(1$ $-$ $\alpha ^{2}$ $+$ , $W_{j}^{(\hat{m})}=W_{j}^{(c)}=1/(2(L+\lambda ))$, 和$\beta =2$.由式(15), 对状态进行第二次Sigma取点.
$ \begin{align*} \chi _{_{j, k|k-1}}= \left[\hat{\pmb{X}}_{u, k|k-1}, \hat{\pmb{X}}_{u, k|k-1}\pm (\tau \sqrt{\hat{P% }_{u, k|k-1}})_{\hat{m}}\right] \end{align*}% $
然后由式(9)计算自身位置测量值的无迹变换.
$ \begin{align} &\pmb{Z}_{j, k|k-1} =h(\chi _{_{j, k|k-1}})+\pmb{v}_{k} \notag\\ &\hat{\pmb{Z}}_{u, k|k-1} =\sum\limits_{j=0}^{2L}W_{j}^{(\hat{m})}\pmb{Z}_{j, k|k-1} \label{f22} \end{align}% $
(18) 步骤4 .测量协方差矩阵和状态值测量交互协方差矩阵更新为
$ \begin{align*} P_{\hat{Z}_{u, k}\hat{Z}_{u, k}} =&\, \sum\limits_{j=0}^{2L}W_{j}^{(c)}\left[\pmb{Z}_{j, k|k-1}-\hat{\pmb{Z}}_{u, k|k-1}\right] \, \times\\ &\ \left[\pmb{Z}_{j, k|k-1}-\hat{\pmb{Z}}_{u, k|k-1}\right]^{\rm T}\\[2mm] P_{\hat{X}_{u, k}\hat{Z}_{u, k}} =&\, \sum\limits_{j=0}^{2L}W_{j}^{(c)}\left[\chi _{_{j, k|k-1}}-\hat{\pmb{X}}_{u, k|k-1}\right]\times\\ &\ \left[\pmb{Z}_{j, k|k-1}-\hat{\pmb{Z}}_{u, k|k-1}\right]^{\rm T}\end{align*} $
步骤5 .通过以下更新规则来更新卡尔曼增益、协方差和估计状态.
$ \begin{align} &K_{u, k} =P_{\hat{X}_{u, k}\hat{Z}_{u, k}}P_{\hat{Z}_{u, k}\hat{Z}% _{u, k}}^{-1} \label{g22} \\ \end{align} $
(19) $ \begin{align} &\hat{P}_{u, k} =\hat{P}_{u, k|k-1}\, -\notag\\ &\qquad\quad P_{\hat{X}_{u, k}\hat{Z}% _{u, k}}P_{\hat{Z}_{u, k}\hat{Z}_{u, k}}^{-1}P_{\hat{X}_{u, k}\hat{Z}_{u, k}}^{\rm T} \label{i22} \\ \end{align} $
(20) $ \begin{align} &\hat{\pmb{X}}_{u, k} =\hat{\pmb{X}}_{u, k|k-1} +K_{u, k}(\pmb{Z}_{k}-% \hat{\pmb{Z}}_{u, k|k-1}) \label{h22} \end{align} $
(21) 由上述过程, 也可以得出水下潜器的位置估计${\hat{\pmb X}_{u, k}}$, 即$(\hat{x}, \hat{y})$.具体定位过程如算法2所示.
算法2.无迹卡尔曼协同定位算法
1: 初始化: 迭代次数$\overline{M}$, 状态初始估计$\hat{\pmb{X}}_{u, 0}$和状态估计初始协方差$\hat{P}_{u, 0}$.
2: 输出: 位置估计$\hat{\pmb{X}}_{u, k}$和相应的$\hat{P}_{u, k}$.
3: for $k=1:\overline{M}$ do
4: 根据式(15)选取sigma点;
5: 根据式(16)计算$\chi _{_{j, k|k-1}}$, 从式(17)得$\hat{P}_{u, k|k-1}$;
6: 二次选取sigma点, 更新;
7: 根据式(18)得到预测距离$\hat{\pmb{Z}}_{u, k|k-1}$;
8: 由式(20)更新协方差矩阵$\hat{P}_{u, k}$, 由式(19)更新卡尔曼系数$K_{u, k}$, 由式(21)更新状态信息$\hat{\pmb{X}}_{u, k}$;
9:end for
3. 性能分析
3.1 算法有界性分析
虽然一般卡尔曼估计均方误差(Mean squared error, MSE)已被证明有界[23], 但在对水下异步时钟定位进行稳定性分析上有所不同.由文献[24]可知, 滤波算法有界性分析需要在线性化后的系统矩阵$F_{e, k-1}$和测量矩阵$H_{e, k}$的基础上进行.基于此, 可导出伪系统矩阵$F_{u, k-1}$和测量矩阵$H_{u, k}$.考虑到扩展卡尔曼滤波与无迹卡尔曼滤波的证明类似, 下文以无迹卡尔曼滤波为例证明. $H_{u, k}$可以直接计算得到, .进一步, 伪系统矩阵$F_{u, k-1}$可定义为, 其中, .
与文献[23]类似, 引入对角矩阵和 $\cdots $, $\beta_{n, k})$对状态和观测进行补偿, 则式(3)和式(9)可更新为
$ \begin{align} &\hat{\pmb{X}}_{u, k} = \alpha _{k-1}F_{u, k-1}\hat{\pmb{X}}_{u, k-1}+\bar{\pmb{\omega}}_{k-1} \label{m4} \\ \end{align} $
(22) $ \begin{align} &\hat{\pmb{Z}}_{u, k} = \beta _{k}H_{u, k}\hat{\pmb{X}}_{u, k}+\pmb{v}_{k} \label{m5} \end{align} $
(23) 进而, 可得出预测误差协方差、更新误差协方差和无迹卡尔曼滤波增益如下:
$ \begin{align} &\hat{P}_{u, k|k-1} =\, \alpha _{k-1}F_{u, k-1}\hat{P}_{u, k-1}\, \times \notag\\ &\qquad\quad\ (\alpha _{k-1}F_{u, k-1})^{\rm T}+Q_{k-1} \label{m6}\\ \end{align} $
(24) $ \begin{align} &\hat{P}_{u, k} =\, (I-K_{u, k}\beta _{k}H_{u, k})\hat{P}_{u, k|k-1} \label{m7}\\ \end{align} $
(25) $ \begin{align} &K_{u, k} =\, \hat{P}_{u, k|k-1}(\beta _{k}H_{u, k})^{\rm T}\, \times \notag\\ &\qquad\quad\ \left[\beta _{k}H_{u, k}\hat{P}% _{u, k|k-1}(\beta _{k}H_{u, k})^{\rm T}+R_{k}\right]^{-1}\label{m8} \end{align} $
(26) 为给出估计有界性证明, 参考如下引理, [25].
引理1. 假设$\zeta _{k}$是随机过程, 且存在和正实数$v_{\min}, v_{\max}$且$0 <\lambda \leq 1$, 这样对于$\forall k$, 有
$ \begin{align*} &v_{\min }\left\Vert \zeta _{k}\right\Vert ^{2}\leq V(\zeta _{k})\leq v_{\max }\left\Vert \zeta _{k}\right\Vert ^{2} \\[2mm] &\mathbb{E}[V(\zeta _{k})|\zeta _{k-1}]-V(\zeta _{k-1})\leq \mu -\lambda V(\zeta _{k-1}) \end{align*} $
若满足上式则该随机过程以均方为界表示为
$ \begin{align*} \mathbb{E}\{\left\Vert \zeta _{k}\right\Vert ^{2}\}\leq &\ \frac{v_{\max }}{v_{\min }}% \mathbb{E}\{\left\Vert \zeta _{0}\right\Vert ^{2}\}(1-\lambda )^{k}\, +\\&\ \frac{\mu }{% v_{\min }}\sum\limits_{i=1}^{k-1}(1-\lambda )^{i} \end{align*} $
引理2. 如果矩阵$A>0$且$C>0$, 可知$A^{-1}$ $>$ $B(B^{\rm T}AB+C)^{-1}B^{\rm T}$.
基于上述引理, 给出如下有界性定理.
定理1 .基于状态方程(3)和测量方程(9), 并结合算法2, 可得出结论如下:
1) 存在不为零的实数$\alpha _{\min }$, $\beta _{\min}$, $f_{\min }$, $h_{\min }$, $\alpha _{\max }$, $\beta _{\max }$, $f_{\max}$和$h_{\max }$, 使得对于任何$k\geq0$满足如下关系: $f_{\min }^{2}I\leq F_{u, k}F_{u, k}^{\rm T}\leq f_{\max }^{2}I, $ $H_{u, k}H_{u, k}^{\rm T}\leq h_{\max }^{2}I, $ 以及$\beta _{\min }^{2}I$ ;
2) 存在正实数$p_{\min}$, $p_{\max}$, $q_{\min}$, $q_{\max}$, $r_{\min}$和$r_{\max}$, 使满足如下关系: $r_{\min }I$ $\leq R_{k}\leq r_{\max }I$以及.
证明. 由文献[26]得, 预测和估计误差分别定义为$\tilde{\pmb{X}}_{u, k}=\pmb{X}_{k}-\hat{\pmb{X}}_{u, k}$和$\tilde{\pmb{X}}_{u, k+1|k}=\pmb{X}_{k+1}-\hat{\pmb{X}}_{u, k+1|k}$.进而, 预选李亚普洛夫函数如下:
$ \begin{align}\label{m9} V_{k+1}(\tilde{\pmb{X}}_{u, k+1|k})=\tilde{\pmb{X}}_{u, k+1|k}^{\rm T}\hat{P}_{u, k+1|k}^{-1}% \tilde{\pmb{X}}_{u, k+1|k} \end{align} $
(27) 从定理中的两个条件可知, $\hat{P}_{u, k+1|k}^{-1}$满足
$ \begin{align*} & (p_{\max }\alpha _{\max }^{2}f_{\max }^{2}+q_{\max })^{-1}I \leq \\ &\qquad \hat{P}_{u, k+1|k}^{-1}\leq (p_{\min }\alpha _{\min }^{2}f_{\min}^{2}+q_{\min })^{-1}I \end{align*} $
其中, $\tilde{\pmb{X}}_{u, k+1|k}$可表示为
$ \begin{align} \tilde{\pmb{X}}_{u, k+1|k}=&\ \alpha _{k-1}F_{u, k-1}[(I-K_{u, k}\beta _{k}H_{u, k})\, \times \notag\\ &\ (\pmb{X}_{k}-\hat{\pmb{X}}% _{u, k|k-1})-K_{u, k}\pmb{v}_{k}]+\bar{\pmb{\omega}}_{k} \label{m11} \end{align} $
(28) 综合式(27)和式(28)得到
$ \begin{align*} \mathbb{E}[V_{k+1}(\tilde{\pmb{X}}_{u, k+1|k})|\tilde{\pmb{X}}_{u, k|k-1}]=\Phi _{k+1}^{x}+\Phi _{k+1}^{v}+\Phi _{k+1}^{w} \end{align*} $
其中
$ \begin{align*} \Phi _{k+1}^{x} =&\ {\mathbb{E}}\{[\alpha _{k-1}F_{u, k-1}(I-% K_{u, k}\beta _{k}H_{u, k})\, \times \notag\\ &\ \tilde{\pmb{X}}_{u, k|k-1}]^{\rm T}\hat{P}_{u, k+1|k}^{-1}[\alpha _{k-1}F_{u, k-1}\, \times \notag\\ &\ (I-K_{u, k}\beta _{k}H_{u, k})\tilde{\pmb{X}}_{u, k|k-1}]|\tilde{\pmb{X}% }_{u, k|k-1}\} \notag\\ \Phi _{k+1}^{v} =&\ {\mathbb{E}}\{(-\alpha _{k-1}F_{u, k-1}K_{u, k} {\pmb{v}}_{k})^{\rm T}\hat{% P}_{u, k+1|k}^{-1} \, \times\notag\\ & \ (-\alpha _{k-1}F_{u, k-1}K_{u, k}\pmb{v}_{k})|\tilde{\pmb{X}}_{u, k|k-1}\} \notag\\ \Phi _{k+1}^{w} =&\ {\mathbb{E}}\{\bar{\pmb{\omega}}_{k}^{\rm T}\hat{P}_{u, k+1|k}^{-1}% \bar{\pmb{\omega}}_{k}|\tilde{\pmb{X}}_{u, k|k-1}\} \end{align*}% $
由式(24)知,
$ $$P_{u, k+1|k}^{-1}=[\alpha _{k}F_{u, k}\hat{P}_{u, k}(\alpha_{k}F_{u, k})^{\rm T}+Q_{k}]^{-1}$$ $
结合引理2, $P_{u, k+1|k}^{-1}$可放缩为
$ P_{u, k+1|k}^{-1}\leq (\alpha_{k}F_{u, k})^{-\rm T}\hat{P}_{u, k}^{-1}(\alpha _{k}F_{u, k})^{-1} $
由定理的两个条件可将式(24)代入$\Phi _{k+1}^{x}$中, 并综合式(25)以及文献[26], 可知
$ \begin{align} \Phi _{k+1}^{x}\leq&\ \mathbb{E}\{[(I-K_{u, k}\beta _{k}H_{u, k})\tilde{\pmb{X}}_{u, k|k-1}]^{\rm T}\hat{P}_{u, k}^{-1}~\times \notag\\ &\ (I-K_{u, k}\beta _{k}H_{u, k})\tilde{\pmb{X}}_{u, k|k-1}|\tilde{\pmb{X}}_{u, k|k-1}\}= \notag\\ &\ \mathbb{E}\{\tilde{\pmb{X}}_{u, k|k-1}^{\rm T}\hat{P}_{u, k|k-1}^{-\rm T}\tilde{\pmb{X}}_{u, k|k-1}|% \tilde{\pmb{X}}_{u, k|k-1}\}\, + \notag\\ &\ \mathbb{E}\{\tilde{\pmb{X}}_{u, k|k-1}^{\rm T}\hat{P}_{u, k|k-1}^{-\rm T}(K_{u, k}\beta _{k}H_{u, k}) \, \times\notag\\% &\ \tilde{\pmb{X}}_{u, k|k-1}|\tilde{\pmb{X}}_{u, k|k-1}\} \label{m112} \end{align} $
(29) 结合式(26), (27), (29), 可得
$ \begin{align} &\Phi _{k+1}^{x}-V_{k}(\tilde{\pmb{X}}_{u, k|k-1})= \notag\\ &\qquad \mathbb{E}\{\tilde{\pmb{X}}^{\rm T}_{u, k|k-1}\hat{P}_{u, k|k-1}^{-\rm T}\hat{P}_{u, k|k-1}\, \times \notag\\ &\qquad (\beta _{k}H_{u, k})^{\rm T}[\beta _{k}H_{u, k}\hat{P}% _{u, k|k-1}(\beta _{k}H_{u, k})^{\rm T}\, + \notag\\ &\qquad R_{k}]^{-1}\beta _{k}H_{u, k}\tilde{\pmb{X}}_{u, k|k-1}|\tilde{\pmb{X}}_{u, k|k-1}\} \label{m16} \end{align} $
(30) 由引理2可知,
$ \begin{align*} &\hat{P}_{u, k|k-1}^{-1}>(\beta _{k}H_{u, k})^{\rm T}\, \times\\ &\qquad\left[\beta _{k}H_{u, k}\hat{P}% _{u, k|k-1}(\beta _{k}H_{u, k})^{\rm T} +R_{k}\right]^{-1}\beta _{k}H_{u, k}\end{align*} $
两边同时乘以$\tilde{\pmb{X}}_{u, k|k-1}^{\rm T}$和$\tilde{\pmb{X}}_{u, k|k-1}$, 其中$\tilde{\pmb{X}}_{u, k|k-1}$ $\neq$ $0$, 令
$ \begin{align} \lambda =&\ \tilde{X}_{u, k|k-1}^{\rm T}(\beta _{k}H_{u, k})^{\rm T}[\beta _{k}H_{u, k}\hat{P}_{u, k|k-1}\, \times \notag \\ &\ (\beta _{k}H_{u, k})^{\rm T}+R_{k}]^{-1}\beta _{k}H_{u, k}\tilde{\pmb{X}}_{u, k|k-1}\, \times \notag\\ &\ (\tilde{\pmb{X}}_{u, k|k-1}^{\rm T}\hat{P}_{u, k|k-1}^{-1}\tilde{\pmb{X}}_{u, k|k-1}) \label{m17} \end{align} $
(31) 从式(31)可知, $0 <\lambda <1$, 根据定理的两个条件可得
$ \begin{align*} \lambda \geq &\ p_{\min }(h_{\min }\beta _{\min })^{2}\, \times\\ & \left[p_{\max }(h_{\max}\beta _{\max })^{2}+r_{\max }\right]^{-1}= \lambda _{\min }>0\end{align*} $
则式(30)可改写为
$ \begin{align} &\Phi _{k+1}^{x}-\mathbb{E}\{V_{k}(\tilde{\pmb{X}}_{u, k|k-1})\} \leq \notag\\ &\quad-\lambda _{\min }\mathbb{E}\{\tilde{\pmb{X}}_{u, k|k-1}^{\rm T}\hat{P}_{u, k|k-1}^{-\rm T}% \tilde{\pmb{X}}_{u, k|k-1}|\tilde{\pmb{X}}_{u, k|k-1}\}= \notag \\ &\quad-\lambda _{\min }\mathbb{E}\{V_{k}(\tilde{\pmb{X}}_{u, k|k-1})\} \label{m18} \end{align} $
(32) $\Phi _{k+1}^{v}$和$\Phi _{k+1}^{w}$的分析与上述过程类似, 进而可得
$ \begin{align*} & \Phi _{k+1}^{v}+\Phi _{k+1}^{w}\leq(p_{\min }\alpha _{\min }^{2}f_{\min }^{2}+q_{\min })^{-1}\, \times \\ &\qquad \left(\alpha _{\max }^{2}f_{\max }^{2}k_{\max }^{2}+q_{\max }\right)=\mu \end{align*} $
最终可知
$ \begin{align} &\mathbb{E}\{V_{k+1}(\tilde{\pmb{X}}_{u, k+1|k})|\tilde{\pmb{X}}_{u, k|k-1}\}-V_{k}(\tilde{\pmb{X}}_{u, k|k-1})\leq \notag \\ &\qquad \mu -\lambda _{\min }V_{k}(\tilde{\pmb{X}}_{u, k|k-1}) \label{m20} \end{align} $
(33) 由式(33)推导, 根据引理1, 可知$\pmb{X}_{u, k+1|k}$均方根有界, 根据式(22)可变形为
$ $$\tilde{\pmb{X}}_{u, k+1|k}=\alpha _{k}F_{u, k}(\pmb{X}_{k}- \hat{\pmb{X}}_{u, k})+\bar{\pmb{\omega}}_{k}$$ $
两边同时求期望, 可得
$ \begin{align*} &\mathbb{E}\{\|\tilde{\pmb{X}}_{u, k}\|^{2}\}\leq\\&\qquad \alpha _{\min }^{-2}f_{\min }^{-2}\left\{\mathbb{E}\{\|% \tilde{\pmb{X}}_{u, k+1|k}\|^{2}\}-\mathbb{E}[\|\bar{\pmb{\omega}}_{k}\|^{2}]\right\} \end{align*} $
遵循与前面相同的规律, $\bar{\pmb{\omega}}_{k}$在均方中也是指数有界的.因此, 可知估计误差$\tilde{\pmb{X}}_{u, k}$均方有界.
3.2 克拉美罗下界(CRLB)
令$M^{k}=\{\pmb{X}_{0}, \pmb{X}_{1}, \cdots, \pmb{X}_{k}\}$, $N^{k}=\{\pmb{Z}_{0}, \pmb{Z}_{1}$, $\cdots$, $\pmb{Z}_{k}\}$. $P(M^{k}, N^{k})$对应的联合概率密度为$(M^{k}$, $N^{k})$, 则克拉美罗估计误差的形式为
$ \begin{align} P_{k}:= \mathbb{E}\left\{[\hat{\pmb{X}}_{k}-\pmb{X}_{k}][\hat{\pmb{X}}_{k}-\pmb{X}_{k}]^{\rm T}\right\}\geq J_{k}^{-1} \label{n1} \end{align} $
(34) 其中, 为Fisher信息矩阵.
进一步, $J_{k}$可定义为
$ \begin{align} J_{k}=D_{k}^{22}-D_{k}^{21}(J_{k-1}+D_{k}^{11})^{-1}D_{k}^{12} \label{n3} \end{align} $
(35) 其中,
$ \begin{align*} &D_{k}^{11}=\mathbb{E}\left\{ -\frac{\partial ^{2}\ln \hat{P}_{k|k-1}}{\partial \pmb{X}_{k-1}^{2}} \right\}\\ &D_{k}^{12}=\mathbb{E} \left\{ -\frac{\partial ^{2}\ln \hat{P}_{k|k-1}}{\partial \pmb{X}_{k}{\rm \partial}\pmb{X}_{k-1}} \right\}\\ &D_{k}^{21}=\mathbb{E}\left\{ -\frac{\partial ^{2}\ln \hat{P}_{k|k-1}}{\partial\pmb{X}_{k-1}\partial \pmb{X}_{k}} \right\}\\ &D_{k}^{22}=\mathbb{E}\left\{ -\frac{\partial ^{2}\ln \hat{P}_{k|k-1}}{\partial\pmb{X}_{k}^{2}}\right\} +\mathbb{E}\left\{ -\frac{\partial ^{2}\ln P_{Z_{k}|X_{k}}}{\partial \pmb{X}_{k}^{2}}\right\}\end{align*} $
在高斯白噪声假设下, 由式(3)和式(9)可知
$ \begin{align*} { \hat{P}}_{k|k-1} =&\ \frac{1}{\sqrt{2\pi \left\vert Q_{k}\right\vert }}\, \times\\ &\ { \rm e}^{% \{-\frac{1}{2}[\pmb{X}_{k}-f(\pmb{X}_{k-1})]^{\rm T}Q_{k}^{-1}[\pmb{X}_{k}-f(\pmb{X}_{k-1})]\}}\notag \\ { P}_{Z_{k}|X_{k}} =&\ \frac{1}{\sqrt{2\pi \left\vert R_{k}\right\vert }}\, \times\\ &\ { \rm e}^{% \{-\frac{1}{2}[Z_{k}-h(\pmb{X}_{k})]^{\rm T}R_{k}^{-1}[Z_{k}-h(\pmb{X}_{k})]\}}% \label{n5} \end{align*} $
进而可得
$ \begin{align*} &D_{k}^{11}=-F_{e, k}^{\rm T}Q_{k}^{-1}F_{e, k}\\ &D_{k}^{12} =-F_{e, k}^{\rm T}Q_{k}^{-1}\\ &D_{k}^{21} =-Q_{k}^{-1}F_{e, k}\\ &D_{k}^{22} =-Q_{k}^{-1}+H_{e, k}^{\rm T}R_{k}^{-1}H_{e, k}\end{align*} $
综上, 式(35)可更新为
$ \begin{align*} J_{k} =&\ Q_{k}^{-1}+H_{e, k}^{\rm T}R_{k}^{-1}H_{e, k}-Q_{k}^{-1}F_{e, k}\, \times \\&\ (J_{k-1}+F_{e, k}^{\rm T}Q_{k}^{-1}F_{e, k})^{-1}F_{e, k}^{\rm T}Q_{k}^{-1} \end{align*} $
4. 仿真分析
使用4个传感器对潜器定位.设定状态方差为Q =0.01I, 初始协方差矩阵为P=0.2I, 测量方差为R= diag(3, 3, 3, 3, 4.5, 4.5, 4.5, 4.5, 4.5, 4.5).潜器初始位置为(500 m, 200 m, -100 m).传感器位置分别为(600 m, 100 m, -100 m), (400 m, 300 m, -110 m), (600 m, 300 m, -90 m)以及(550 m, 150 m, -100 m).
1) 传感器与潜器信息物理交互过程分析
图 3给出了同步测量(文献[7-8, 11])与异步测量(本文)方式下的距离比较.为更加直观显示距离精度, 图 4给出了同步与异步测量下的距离误差.从图 3和图 4可以看出, 本文所提的异步定位策略可以有效消除异步时钟对水下定位的影响.
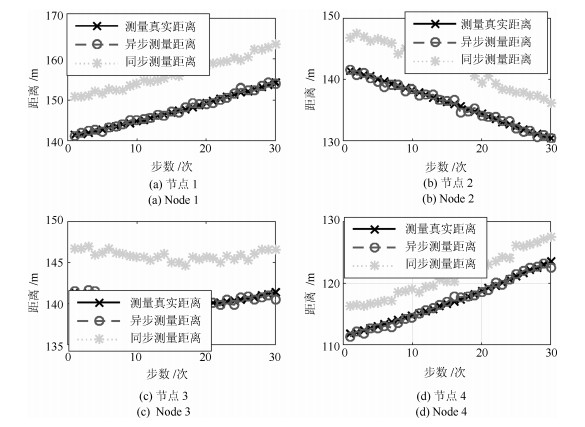 图 3 同步测量与异步测量距离比较Fig. 3 Distance comparison with synchronous and asynchronous measurements
图 3 同步测量与异步测量距离比较Fig. 3 Distance comparison with synchronous and asynchronous measurements 图 4 同步测量与异步测量距离误差比较Fig. 4 Distance error comparison with synchronous and asynchronous measurements
图 4 同步测量与异步测量距离误差比较Fig. 4 Distance error comparison with synchronous and asynchronous measurements2) 协同定位算法精度比较
从图 5可以看出, 基于无迹卡尔曼滤波的定位算法精度更高.为更清晰地表述上述判断, 图 6给出了上述3种定位算法下的均方误差(MSE), 可以看出扩展卡尔曼与无迹卡尔曼滤波下的定位精度比穷举法下定位精度高, 基于扩展卡尔曼滤波的定位算法精度没有无迹卡尔曼滤波下定位精度高. 图 7给出了两种滤波下的MSE, 可看出无迹卡尔曼滤波更接近CRLB, 其定位精度更高.
 图 5 穷举法、扩展卡尔曼和无迹卡尔曼定位轨迹Fig. 5 Trajectories with exhaustive, EKF-based and UKF-based methods
图 5 穷举法、扩展卡尔曼和无迹卡尔曼定位轨迹Fig. 5 Trajectories with exhaustive, EKF-based and UKF-based methods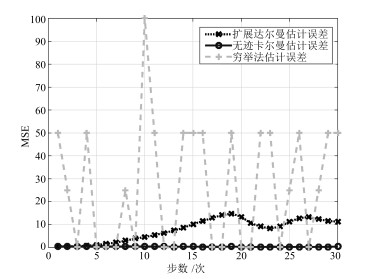 图 6 穷举法、扩展卡尔曼与无迹卡尔曼MSE比较Fig. 6 Comparison of MSE for exhaustive, EKF and UKF based methods
图 6 穷举法、扩展卡尔曼与无迹卡尔曼MSE比较Fig. 6 Comparison of MSE for exhaustive, EKF and UKF based methods 图 7 扩展卡尔曼与无迹卡尔曼MSE与CRLB比较Fig. 7 Comparison of MSE and CRLB for UKF and EKF-based methods
图 7 扩展卡尔曼与无迹卡尔曼MSE与CRLB比较Fig. 7 Comparison of MSE and CRLB for UKF and EKF-based methods3) 协同定位算法仿真时间比较
图 8给出了三种方法下的定位过程持续时间.可以看出, 相比于扩展卡尔曼与无迹卡尔曼滤波算法, 基于穷举法的定位算法需要更长的时间达到所需要的定位精度.同时, 基于扩展卡尔曼与无迹卡尔曼滤波的定位算法仿真时间相差不大, 但是基于无迹卡尔曼滤波的定位算法定位精度更高(见图 6和图 7).
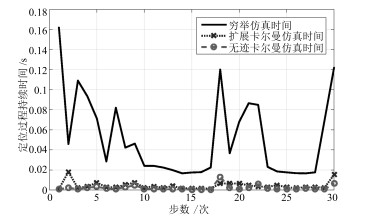 图 8 算法仿真定位用时比较Fig. 8 Localized trajectories of underwater vehicle different interference intensities
图 8 算法仿真定位用时比较Fig. 8 Localized trajectories of underwater vehicle different interference intensities4) 误差统计分析
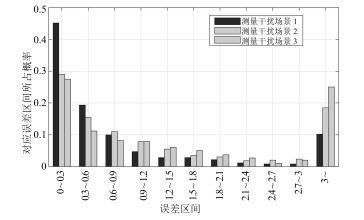
以无迹卡尔曼滤波定位算法为例, 设定三种干扰场景.场景2下的干扰强度大于场景1下的干扰强度, 而场景3下的干扰强度大于场景2下的干扰强度.考虑上述场景, 图 9和图 10分别给出了潜器的定位轨迹与定位误差.可以看出, 在上述场景下潜器尽管可以完成定位任务, 然而场景1下的定位精度最高, 而场景3下的定位精度最差, 即干扰强度的增大降低了定位的精度. 图 11给出了测量距离误差的统计特性, 可以看出干扰越小距离误差分布越接近于零.
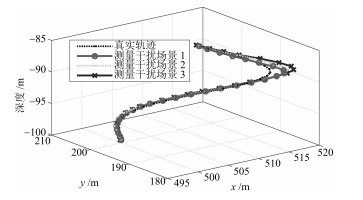 图 9 不同干扰强度下潜器定位轨迹Fig. 9 Positioning trajectories of submersible under different interference intensities
图 9 不同干扰强度下潜器定位轨迹Fig. 9 Positioning trajectories of submersible under different interference intensities 图 10 不同干扰强度下潜器定位误差Fig. 10 Positioning errors of underwater vehicle under different interference intensities
图 10 不同干扰强度下潜器定位误差Fig. 10 Positioning errors of underwater vehicle under different interference intensities5. 结论
针对异步时钟下的潜器定位问题, 提出了一种基于信息物理融合的水下潜器协同定位算法.建立了通信时延与位置的关系, 并定义了潜器协同定位问题.为求解上述优化问题, 提出了基于扩展卡尔曼与无迹卡尔曼滤波的协同定位算法, 并对上述定位算法的有界性以及克拉美罗下界进行了分析.最后, 通过仿真对比验证了本文所提方法的有效性.
-
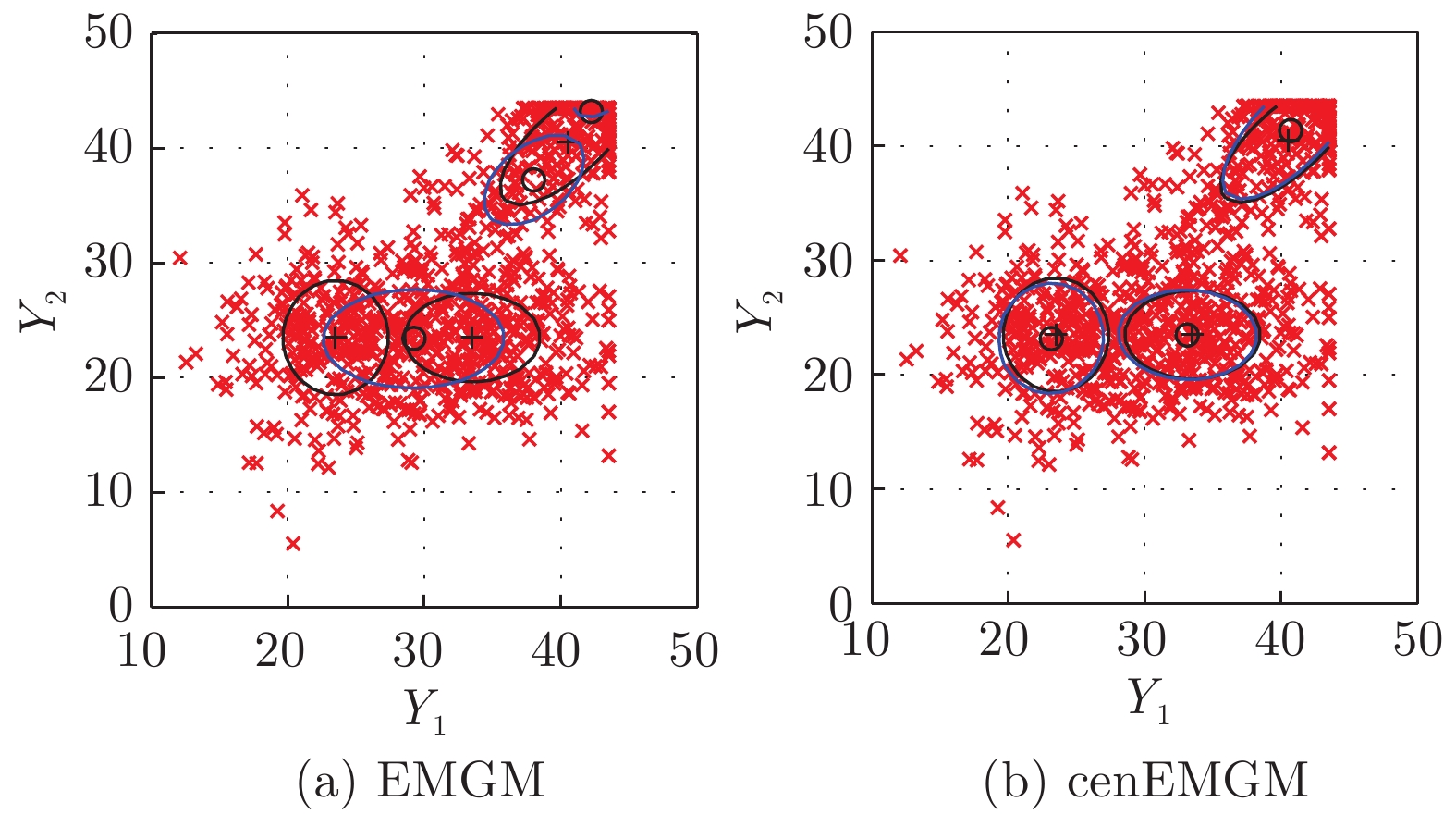
图 1 在数据集DS-a右删失上的两种算法比较
Fig. 1 Comparison of the two algorithms on the dataset DS-a with right censoring
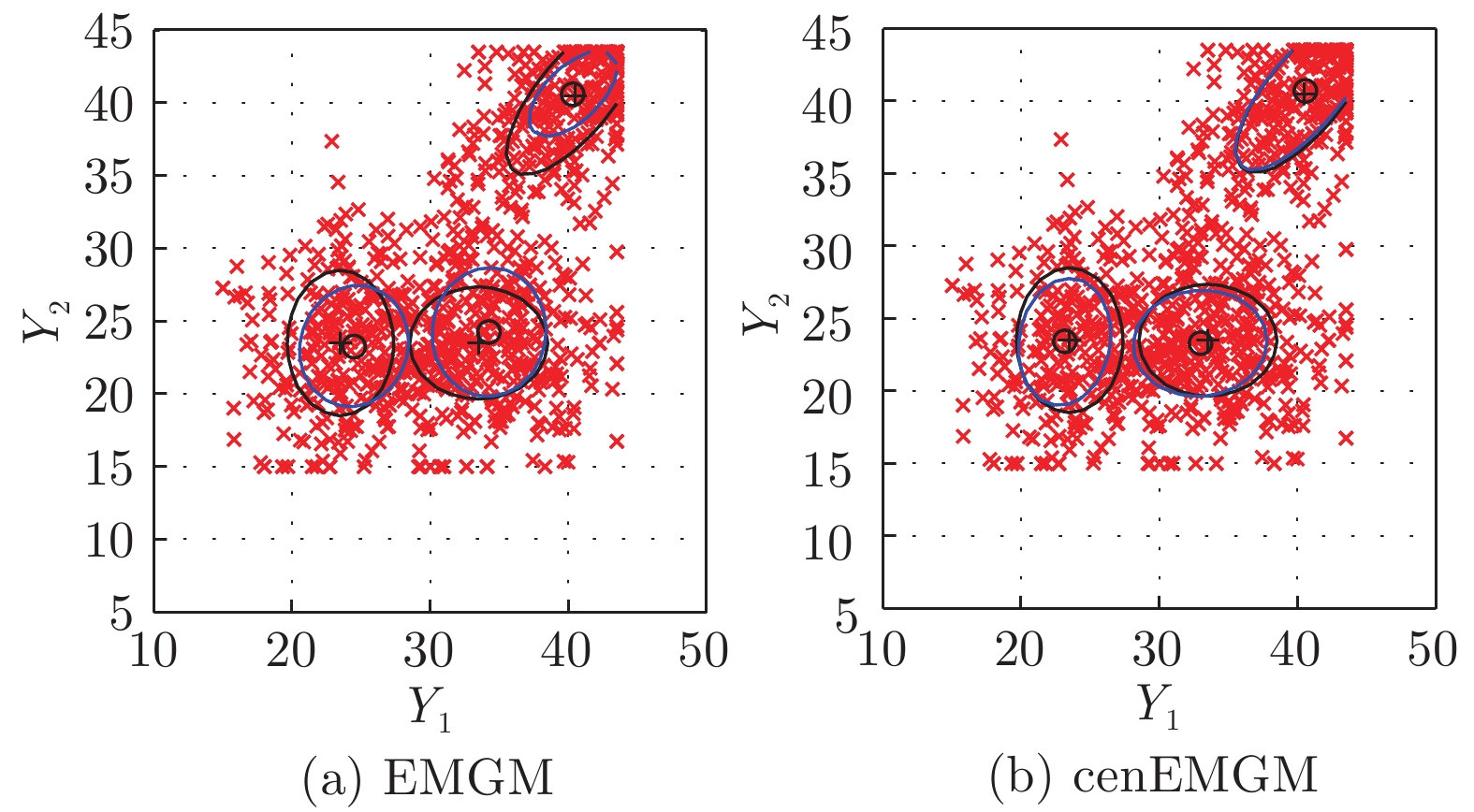
图 2 在数据集DS-a双边删失上的两种算法比较
Fig. 2 Comparison of the two algorithms on the dataset DS-a with double-side censoring

图 3 在数据集DS-b左删失上的两种算法比较
Fig. 3 Comparison of the two algorithms on the dataset DS-b with left censoring
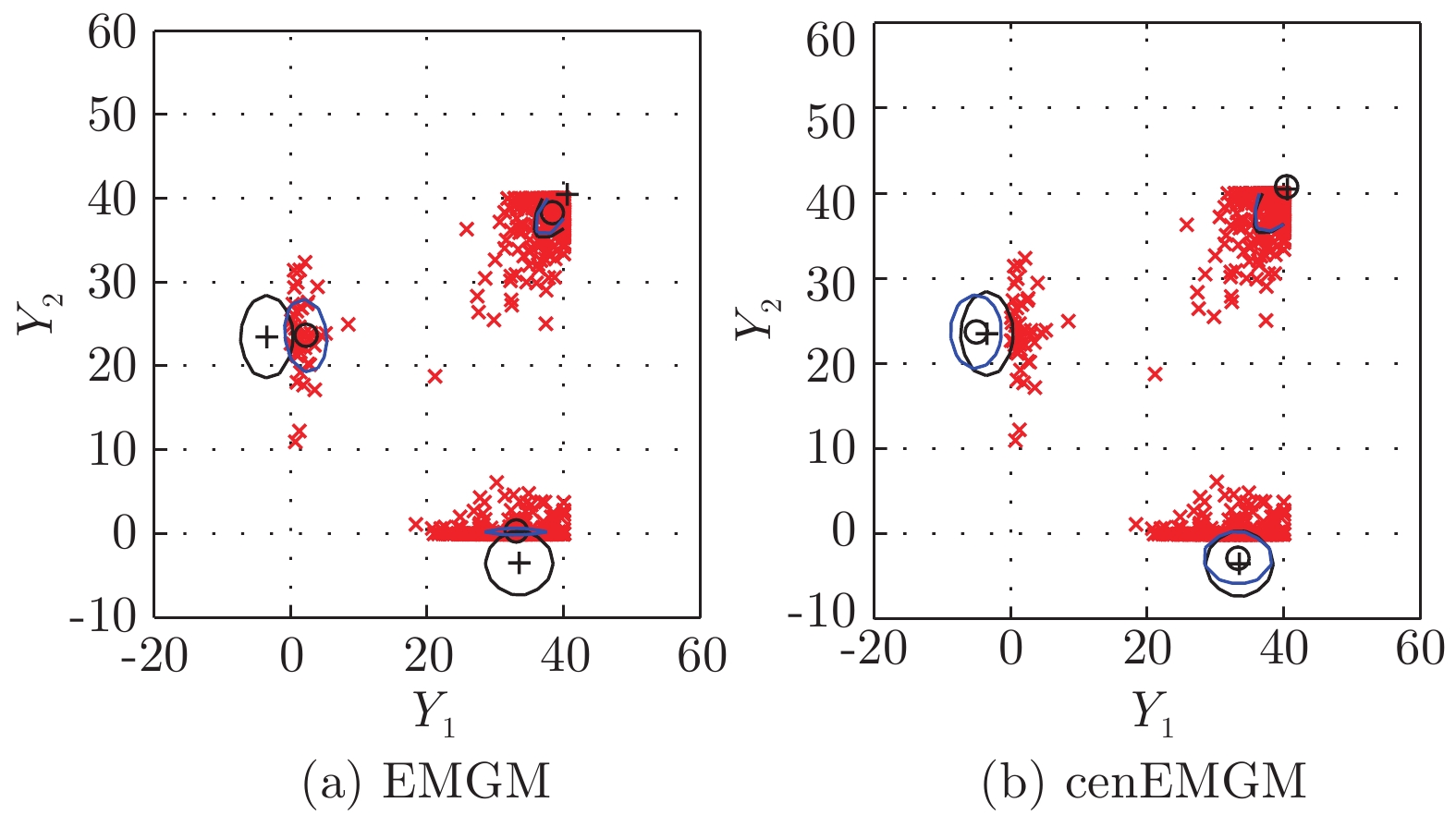
图 4 在数据集DS-b双边删失上的两种算法比较
Fig. 4 Comparison of the two algorithms on the dataset DS-b with double-side censoring

图 5 在血糖测试数据右删失上两种算法比较
Fig. 5 Comparison of the two algorithms on the dataset of blood sugar tests with right-side censoring
表 1 实验合成数据集真实分布和估计分布之间的KLD值
Table 1 Kullback-Leibler divergence (KLD) between the true densities and the estimated densities of the synthetic data set
数据集 观测值 (删失) EMGM cenEMGM DS-a 右删失 0.072 ± 0.011 0.261 ± 0.016 0.051 ± 0.003 DS-a 双边删失 0.226 ± 0.017 10.602 ± 1.966 0.028 ± 0.009 DS-b 左删失 4.362 ± 0.393 32.263 ± 4.193 22.583 ± 3.392 DS-b 双边删失 4.219 ± 0.381 30.321 ± 4.128 29.655 ± 3.938  下载: 导出CSV
下载: 导出CSV
表 2 实验合成数据集参数估计的两种算法AIC比较
Table 2 AIC comparison of the two estimation algorithms on the synthetic data set
数据集 EMGM cenEMGM DS-a 右删失 12852 ± 594 12349 ± 481 DS-a 双边删失 12782 ± 436 12323 ± 417 DS-b 左删失 9435 ± 317 8815 ± 305 DS-b 双边删失 8759 ± 293 7152 ± 264
下载: 导出CSV
表 3 真实数据及其拓展数据的两种算法比较
Table 3 Comparison of the two algorithms with the real data and its extended data
EMGM 算法 cenEMGM 算法 右边删失率 8.51 % 聚类中心 (4.50, 7.22) (4.53, 7.54) (4.94, 9.55) (6.01, 10.51) KLD 12.7 9.1 AIC 4366 4263 右边删失率 11.67 % 聚类中心 (4.50, 7.20) (4.53, 7.54) (4.81, 9.70) (6.08, 9.85) KLD 11.35 9.08 AIC 4 290 4 209 双边删失率 15.05 %: 右边删失 8.51 %,
左边删失 6.54 %聚类中心 (5.10, 7.43) (5.10, 7.48) (5.48, 8.56) (5.48, 8.94) KLD 173.7 158.6 AIC 2226 −24327
下载: 导出CSV
-
[1] Scrucca L, Raftery A E. Clustvarsel: A package implementing variable selection for Gaussian model-based clustering in R. Journal of Statistical Software, 2018: 84 [2] O´Hagan A, Murphy TB, Gormley IC, McNicholas PD, Karlis D. Clustering with the multivariate normal inverse Gaussian distribution. Computational Statistics & Data Analysis, 2016, 93: 18−30 [3] Xu M, Yu H Y, and Shen J. New approach to eliminate structural redundancy in case resource pools usingαmutual information. Journal of Systems Engineering and Electronics, 2013, 24(4): 625−633 doi: 10.1109/JSEE.2013.00073 [4] Qiu H, Yu H Y, Wang L Y, Yao Q, Wu S N, Yin C, Deng J. Electronic health record driven prediction for gestational diabetes mellitus in early pregnancy. Scientific Reports, 2017, 7(1): 16417 doi: 10.1038/s41598-017-16665-y [5] 李晓庆, 唐昊, 司加胜, 苗刚中. 面向混合属性数据集的改进半监督FCM聚类方法. 自动化学报, 2018, 44(12): 2259−2268Li Xiao-Qing, Tang Hao, Si Jia-Sheng, Miao Gang-Zhong. An improved semi-supervised FCM clustering method for mixed attribute datasets. Acta Automatica Sinica, 2018, 44(12): 2259−2268 [6] Xu M, Yu H Y, and Shen J. New algorithm for CBR-RBR fusion with robust thresholds. Chinese Journal of Mechanical Engineering, 2012, 25: 1255−1263 doi: 10.3901/CJME.2012.06.1255 [7] 沈江, 余海燕, 徐曼. 实体异构性下证据链融合推理的多属性群决策. 自动化学报, 2015, 41: 832−842Shen Jiang, Yu Hai-Yan, Xu Man. Heterogeneous evidence chains based fusion reasoning for multi-attribute group decision making. Acta Automatica Sinica, 2015, 41: 832−842 [8] 余海燕, 沈江, 徐曼. 类别误标下证据链推理的群决策分类方法. 系统工程与电子技术, 2015, (11): 2546−2553 doi: 10.3969/j.issn.1001-506X.2015.11.19Yu Hai-Yan, Shen Jiang, Xu Man. ECs-based reasoning for group decision analysis in the mislabeled classification context. Systems Engineering and Electronic Technology, 2015, (11): 2546−2553 doi: 10.3969/j.issn.1001-506X.2015.11.19 [9] Yu H Y, Shen J, Xu M. Temporal case matching with information value maximization for predicting physiological states. Information Sciences, 2016, 367: 766−782 [10] Yu H Y, Shen J, Xu M. Resilient parallel similarity-based reasoning for classifying heterogeneous medical cases in mapreduce. Digital Communications & Networks, 2016, 2(3): 145−150 [11] Lee G, Scott C. EM algorithms for multivariate Gaussian mixture models with truncated and censored data. Computational Statistics & Data Analysis, 2012, 56(9): 2816−2829 [12] Little R J, and Donald B R. Statistical Analysis with Missing Data. John Wiley & Sons, 2019. [13] Linero A R, Daniels M J. Bayesian approaches for missing not at random outcome data: The role of identifying restrictions. Statistical Science, 2018, 33: 198−213 doi: 10.1214/17-STS630 [14] Fang F, Shao J. Model selection with nonignorable nonresponse. Biometrika, 2016, 103(4): asw039 [15] Wu Y J, Fang W Q, Cheng L H, et al. A flexible Bayesian non-parametric approach for fitting the odds to case II interval-censored data. Journal of Statistical Computation and Simulation, 2018, 88(16): 3132−3150 doi: 10.1080/00949655.2018.1504944 [16] Leão J, Leiva V, Saulo H, et al. A survival model with Birnbaum – Saunders frailty for uncensored and censored cancer data. Brazilian Journal of Probability and Statistics, 2018, 32(4): 707−729 doi: 10.1214/17-BJPS360 [17] Goldberg Y, Kosorok M R. Support vector regression for right censored data. Electronic Journal of Statistics, 2017, 11(1): 532−69 doi: 10.1214/17-EJS1231 [18] 荀立, 周勇. 左截断右删失数据分位差估计及其渐近性质. 数学学报, 2017, 60(3): 451−464Xun Li, Zhou Yong. Estimators and their asymptotic properties for quantile difference with left truncated and right censored data. Acta Mathematica Sinica (Chinese Series), 2017, 60(3): 451−464 [19] Ma Y, Wang Y. Estimating disease onset distribution functions in mutation carriers with censored mixture data. Journal of the Royal Statistical Society: Series C (Applied Statistics), 2014, 63(1): 1−23 [20] 周志华. 机器学习. 北京: 清华大学出版社, 2016.Zhou Zhi-Hua. Machine Learning, Beijing: Tsinghua University Press, 2016. [21] Cai T T, Ma J, Zhang L. CHIME: Clustering of highdimensional Gaussian mixtures with EM algorithm and its optimality. The Annals of Statistics, 2019, 47: 1234−1267 doi: 10.1214/18-AOS1711 [22] Chauveau D. A stochastic EM algorithm for mixtures with censored data. Journal of Statistical Planning & Inference, 1995, 46(1): 1−25 [23] Dempster A P, Laird N M, Rubin D B. Maximum likelihood from incomplete data via the EM algorithm. Series B (Methodological), 1977: 1−38 [24] Tsiatis A. Semiparametric Theory and Missing Data. Springer Science & Business Media, 2007. [25] Wang Yong, et al. A hybrid user similarity model for collaborative filtering. Information Sciences, 2017, 418: 102−118 [26] Yu H, Chen J, Wang J N, Chiu Y L, Qiu H, Wang L Y. Identification of the differential effect of city-level on the Gini coefficient of healthcare service delivery in online health community. International Journal of Environmental Research and Public Health, 2019, 16: 2314 doi: 10.3390/ijerph16132314 [27] Luers B, Klasnja P, Murphy S. Standardized effect sizes for preventive mobile health interventions in micro-randomized trials. Prevention Science, 2019, 20: 100−109 doi: 10.1007/s11121-017-0862-5 [28] McIntyre H D, Catalano P, Zhang C, Desoye G, Mathiesen E R, Damm P. Gestational diabetes mellitus. Nature Reviews Disease Primers, 2019, 5: 47 doi: 10.1038/s41572-019-0098-8 -


 下载:
下载:
计量
- 文章访问数: 1346
- HTML全文浏览量: 277
- PDF下载量: 165
- 被引次数: 0
