

A Blind Watermark Decoder in DT CWT Domain Using Weibull Distribution-Based Vector HMT Model
-
摘要: 本文以双树复数小波变换(Dual-tree complex wavelet transform, DT CWT)及隐马尔科夫树(Hidden Markov tree, HMT)理论为基础, 提出了一种基于Weibull向量HMT模型的DT CWT域数字音频盲水印算法. 原始数字音频首先进行DT CWT, 然后利用局部信息熵刻画音频内容特征并据此确定出重要DT CWT系数段, 进而将水印信息乘性嵌入到重要DT CWT高频系数幅值内. 水印检测时, 首先根据DT CWT系数幅值的边缘分布及系数间的多种相关性(包括子带内、尺度间、分解树间等相关性), 构造出Weibull混合向量HMT统计模型, 并估计出其统计模型参数; 然后, 利用局部最大势能(Locally most powerful, LMP)检验理论构造出局部最优检测器(Locally optimum decoder, LOD)以盲提取水印信息. 仿真实验结果表明, 本文算法可以较好地获得不可感知性、鲁棒性、水印容量之间的良好平衡, 其总体性能优于现有同类音频水印算法.Abstract: In this paper, we propose a blind audio watermark decoder in dual-tree complex wavelet transform (DT CWT) domain, wherein the Weibull distribution-based vector hidden Markov tree (HMT) model is used. In the proposed watermarking approach, the DT CWT is firstly performed on the original host audio, then the significant DT CWT coefficient segments are determined according to local information entropy, and finally the watermark data is embedded into the significant high-frequency coefficient amplitudes in the DT CWT domain. At the watermark receiver, DT CWT highpass coefficient amplitudes are firstly modeled by employing the Weibull distribution-based vector HMT Model, where both the local statistical properties and various dependencies of the DT CWT coefficients are captured. Then the parameters of the Weibull distribution-based vector HMT model are estimated on the highpass coefficients of digital audio using the maximum likelihood estimation (MLE). And finally, by employing locally most powerful test and the Weibull distribution-based vector HMT model, a blind local optimum decoder (LOD) is developed. We conduct extensive experiments to evaluate the performance of the proposed blind watermark decoder, in which encouraging results validate the effectiveness of the proposed technique.1) 收稿日期 2019-01-30 录用日期 2019-08-08 Manuscript received January 30, 2019; accepted August 8, 2019 国家自然科学基金 (61472171, 61701212), 中国博士后科学基金(2018T110220), 辽宁省教育厅科学研究经费项目 (面上项目) (LJKZ0985), 辽宁省自然科学基金 (2019-ZD-0468) 资助 Supported by National Natural Science Foundation of China (61472171, 61701212), Project Funded by China Postdoctoral Science Foundation (2018T110220), Scientific Research Project of Liaoning Provincial Education Department (LJKZ0985), and Natural Science Foundation of Liaoning Province (2019-ZD-0468) 本文责任编委 刘成林 Recommended by Associate Editor LIU Cheng-Lin 1. 辽宁师范大学计算机与信息技术学院 大连 116029 1. School of Computer and Information Technology, Liaoning2) Normal University, Dalian 116029
-
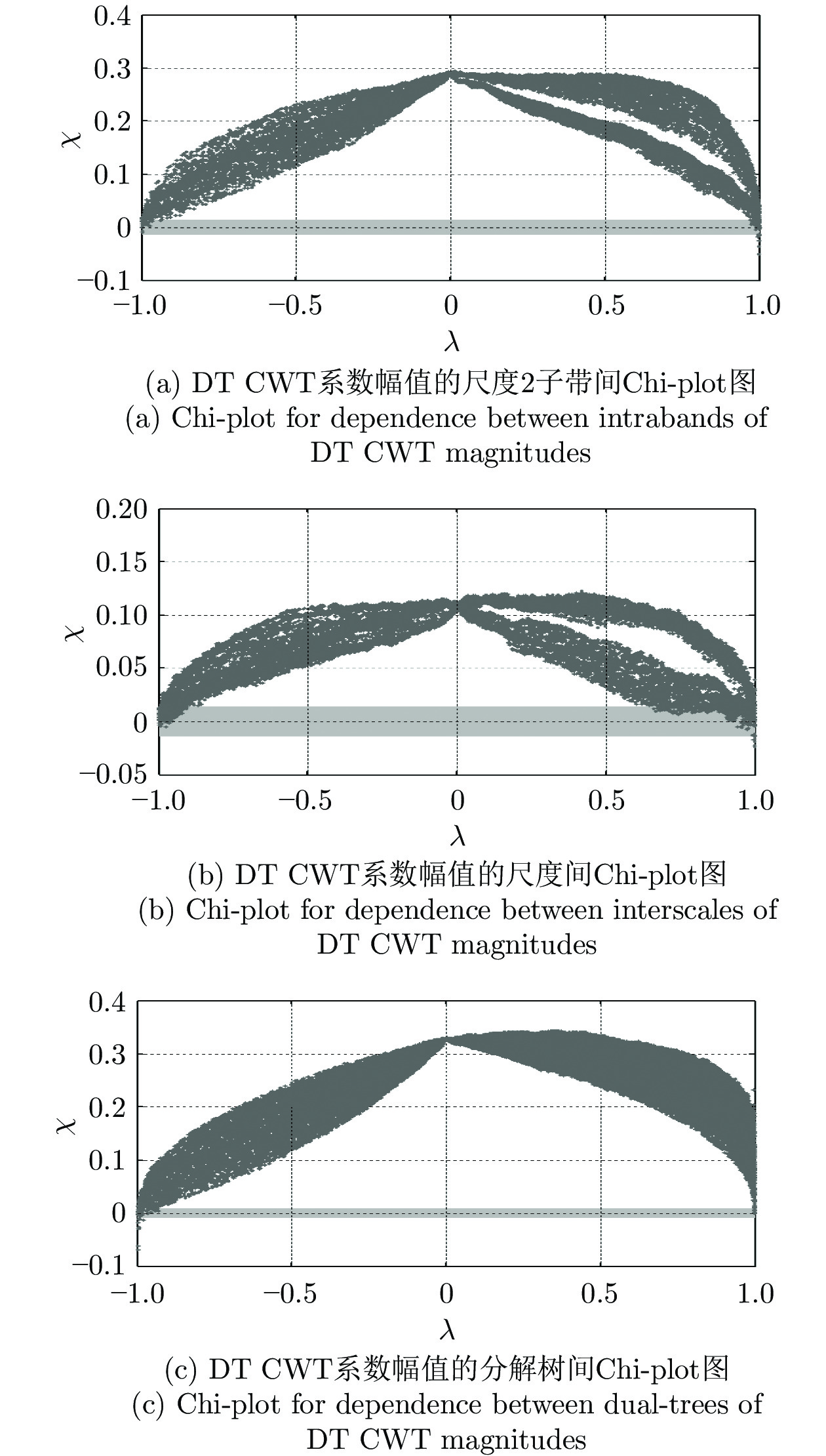
图 1 DT CWT域系数幅值的子带内、尺度间、分解树间Chi-plot图
Fig. 1 Chi-plot to illustrate the different degrees of dependence between intraband, interscale and dual-tree, DT CWT coefficient pairs

图 3 两种数字水印检测器(LOD和ML)的检测响应结果
Fig. 3 The test results of LOD watermark detector and ML watermark detector under various attacks
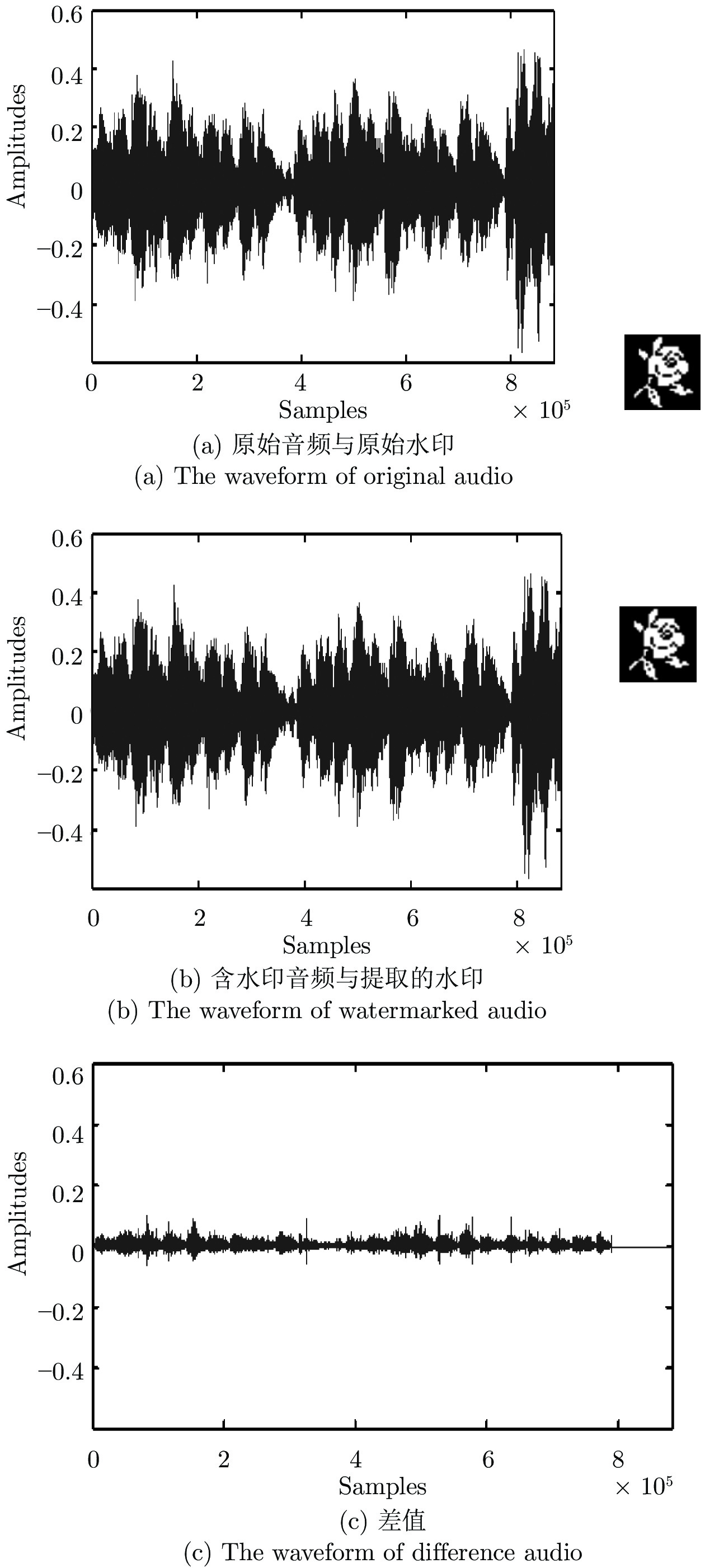
图 4 原始音频、含水印音频和差值音频波形图
Fig. 4 The waveform of original audio, watermarked audio, and difference audio
表 1 不同系数段长度下整个水印系统的工作性能 (水印容量为1 024位)
Table 1 Performance of the watermarking system in different coefficient lengths (watermark capacity is 1 024 bits)
DT CWT系数段长度 平均PSNR (dB) 平均BER (%) 平均水印嵌入时间 (s) 平均水印提取时间 (s) 40 48.45 0.29 0.45 8.42 50 47.96 0.09 0.62 9.57 60 47.28 0.00 0.71 10.67 70 46.34 0.00 1.21 11.53  下载: 导出CSV
下载: 导出CSV
表 2 不同水印容量下整个水印系统的工作性能(局部重要系数段长度为60)
Table 2 Performance of the watermarking system in different watermark capacities (coefficient length is 60)
水印容量 (bit) PSNR (dB) BER (%) 水印嵌入时间 (s) 水印提取时间 (s) 8 × 8 49.23 0.00 0.47 9.53 16 × 16 48.16 0.00 0.68 10.24 32 × 32 47.28 0.00 0.71 10.67 64 × 64 44.34 0.78 1.35 15.46
下载: 导出CSV
表 3 客观听觉测试区分度ODG
Table 3 Objective difference grades
等级 ODG 描述 5.0 0.0 不可感觉 4.0 −1.0 可感觉但不刺耳 3.0 −2.0 轻微刺耳 2.0 −3.0 刺耳 1.0 −4.0 非常刺耳
下载: 导出CSV
表 4 感知透明性与鲁棒性客观评价
Table 4 Objective evaluation of perceived transparency and robustness
音频类型 ODG BER (%) Popular −0.61 0.00 Jazz −0.48 0.03 Rock −0.68 0.16 Speech −0.35 0.01 Classical −0.79 0.08
下载: 导出CSV
表 5 不同算法的平均检测性能对比(本文算法和文献[8])
Table 5 Comparison of average detection performance of different schemes (our scheme and [8])
攻击类型 本文算法 文献 [8] DWT-RDM-W+DC DWT-RDM-W DWT-ROM DWT-LQIM DWT-norm Resampling (22 050 Hz) 0.000 0.000 0.000 0.000 0.000 0.000 Requantization (16 bit - 8 bit - 16 bit) 0.000 0.000 0.000 0.000 0.001 0.000 Amplitude scaling down to 0.85 0.000 0.000 0.000 0.000 0.000 73.723 Additive of Gaussian noise 0.000 0.002 0.006 0.003 0.006 0.000 Lowpass filtering (4 kHz) 0.000 0.219 0.262 0.290 0.376 0.184 Echo addition (50 ms delay, 5 % decay) 0.021 0.026 0.041 0.041 0.187 0.142 MP3 compression (128 kbps) 0.000 0.000 0.000 0.000 0.000 0.002 MP3 compression (64 ps) 0.000 0.152 0.169 0.211 0.256 0.258
下载: 导出CSV
表 6 不同算法的平均检测性能对比(本文算法和文献[5])
Table 6 Comparison of average detection performance of different schemes (our scheme and [5])
攻击类型 本文算法 文献 [5] Classical Popular Classical N=8 Popular N=4 Classical N=8 Popular N=4 Resampling (22 050 Hz) 0.00 0.00 0.00 0.29 0.00 0.71 Resampling (11 025 Hz) 0.00 0.00 0.00 1.22 0.00 1.06 Resampling (8 000 Hz) 0.02 0.02 0.01 1.25 0.02 1.20 Lowpass filtering (3 kHz) 0.00 0.35 24.03 27.32 26.06 23.85 MP3 compression (128 kbps) 0.00 0.00 0.11 0.13 0.08 0.08 MP3 compression (112 kbps) 0.00 0.00 0.13 0.11 0.06 0.12 MP3 compression (96 kbps) 0.00 0.00 1.01 2.07 1.06 1.40 MP3 compression (80 kbps) 0.01 0.00 1.57 3.65 1.16 2.50
下载: 导出CSV
表 7 不同算法的平均检测性能对比(本文算法和文献[7])
Table 7 Comparison of average detection performance of different schemes (our scheme and [7])
攻击类型 −30 dB WSR −25 dB WSR −20 dB WSR 文献 [7] 本文算法 文献 [7] 本文算法 文献 [7] 本文算法 No Attack 0.14 0.00 0.04 0.00 0.00 0.00 MP3 compression (64 kbps) 32.12 10.35 25.12 0.83 17.11 0.04 MP3 compression (128 kbps) 24.22 0.33 19.54 0.04 12.01 0.01 Resampling (24 kHz) 0.21 0.00 0.12 0.00 0.01 0.00 Resampling (16 kHz) 8.17 0.03 6.35 0.02 3.23 0.00 Additive of Gaussian noise (30 dB) 13.07 0.10 11.06 0.09 9.04 0.01 Lowpass filtering (12 kHz) 0.41 0.13 0.22 0.00 0.04 0.00 Amplitude scaling down to 0.7 0.43 0.41 0.31 0.01 0.05 0.00
下载: 导出CSV
表 8 不同算法的平均检测性能对比(本文算法和文献[17])
Table 8 Comparison of average detection performance of different schemes (our scheme and [17])
攻击类型 本文算法 文献 [17] Classical Popular Speech Classical Popular Speech Additive of Gaussian noise (22 dB) 0.00 0.00 0.00 0.00 0.00 0.14 Lowpass filtering (8 kHz) 0.00 0.00 0.00 1.23 0.72 0.54 Highpass filtering (50 Hz) 0.00 0.00 0.00 0.00 0.05 0.45 Echo addition (50 ms delay, 40 % decay) 0.21 0.34 0.41 1.56 0.70 3.23 Requantization (16 bit-8 bit-16 bit) 0.00 0.00 0.00 0.00 0.00 0.00 Resampling (11 025 Hz) 0.00 0.00 0.00 0.00 0.00 0.06 Resampling (6 000 Hz) 0.00 0.00 0.00 0.00 0.00 0.15 Amplitude scaling up to 1.3 0.00 0.00 0.00 0.00 0.00 0.00 Amplitude scaling down to 0.7 0.00 0.00 0.00 0.00 0.00 0.00 MP3 compression (64 kbps) 0.00 0.00 0.00 0.02 0.00 0.06 MP3 compression (48 kbps) 0.11 0.01 0.54 0.13 0.00 1.25
下载: 导出CSV
-
[1] Liu X L, Lin C C, Yuan S M. Blind dual watermarking for color images’ authentication and copyright protection. IEEE Trans. on Circuits and Systems for Video Technology, 2018, 28(5): 1047−1055 doi: 10.1109/TCSVT.2016.2633878 [2] 熊祥光. 空域强鲁棒零水印方案. 自动化学报, 2018, 44(1): 160−175XIONG Xiang-Guang. A zero watermarking scheme with strong robustness in spatial domain. Acta Automatica Sinica, 2018, 44(1): 160−175 [3] Asikuzzaman M, Pickering M R. An overview of digital video watermarking. IEEE Trans. on Circuits and Systems for Video Technologya, 2018, 28(9): 2131−2153 doi: 10.1109/TCSVT.2017.2712162 [4] Shih F Y. Digital Watermarking and Steganography: Fundamentals and Techniques. Boca Raton: CRC Press, 2017. [5] Chen S T, Huang H N. Optimization-based audio watermarking with integrated quantization embedding. Multimedia Tools and Applications, 2016, 75(8): 4735−4751 doi: 10.1007/s11042-015-2500-1 [6] 姜传贤, 杨铁军, 董明刚, 程小辉, 李智. 基于线性空间隐藏模型的 可逆图像水印算法. 自动化学报, 2014, 40(10): 2324−2333JIANG Chuan-Xian, YANG Tie-Jun, DONG Ming-Gang, CHENG Xiao-Hui, LI Zhi. A reversible image watermarking algorithm using linear space hiding model. Acta Automatica Sinica, 2014, 40(10): 2324−2333 [7] Hwang M J, Lee J S, Lee M S, Kang H G. SVD-based adaptive QIM watermarking on stereo audio signals. IEEE Trans. on Multimedia, 2018, 20(1): 45−54 doi: 10.1109/TMM.2017.2721642 [8] Hu H T, Chang J R, Hsu L Y. Windowed and distortioncompensated vector modulation for blind audio watermarking in DWT domain. Multimedia Tools and Applications, 2017, 76(24): 26723−26743 doi: 10.1007/s11042-016-4202-8 [9] Barni M, Bartolini F, DeRosa A, Piva A. Optimum decoding and detection of multiplicative watermarks. IEEE Trans. on Signal Processing, 2003, 51(4): 1118−1123 doi: 10.1109/TSP.2003.809371 [10] 崔汉国, 刘健鑫, 李正民. 基于金字塔技术的STL模型数字水印算 法. 自动化学报, 2013, 39(6): 852−806CUI Han-Guo, LIU Jian-Xin, LI Zheng-Min. STL model watermarking algorithm bsed on pyramid technique. Acta Automatica Sinica, 2013, 39(6): 852−806 [11] Etemad S, Amirmazlaghani M. A new multiplicative watermark detector in the contourlet domain using t locationscale distribution. Pattern Recognition, 2018, 77: 99−112 doi: 10.1016/j.patcog.2017.12.006 [12] Amini M, Sadreazami H, Ahmad M O, Swamy M N S. A channel-dependent statistical watermark detector for color images. IEEE Trans. on Multimedia, 2019, 21(1): 65−73 doi: 10.1109/TMM.2018.2851447 [13] Hua G, Huang J, Shi Y Q. Twenty years of digital audio watermarking-a comprehensive review. Signal Processing, 2016, 128: 222−242 doi: 10.1016/j.sigpro.2016.04.005 [14] Akhaee M A, Kalantari N K, Marvasti F. Robust audio and speech watermarking using Gaussian and Laplacian modeling. Signal processing, 2010, 90(8): 2487−2497 doi: 10.1016/j.sigpro.2010.02.013 [15] Majoul T, Raouafl F, Jaidane M. An improved scheme of audio watermarking based on turbo codes and channel efiect modeling. In: Proceedings of the 2011 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). Prague, Czech Republic: 2011. 353−356 [16] 唐鑫, 马兆丰, 钮心忻, 杨义先. 基于变分贝叶斯学习的音频水印盲 检测方法. 通信学报, 2015, 36(1): 121−128TANG Xin, MA Zhao-Feng, NIU Xin-Xin, YANG YiXian. Blind audio watermarking mechanism based on variational Bayesian learning. Journal on Communications, 2015, 36(1): 121−128 [17] Akhaee M A, Sahraeian S M E. Scaling-based watermarking with universally optimum decoder. Multimedia Tools and Applications, 2015, 74(15): 5995−6018 doi: 10.1007/s11042-014-1904-7 [18] Kingsbury N G. The dual-tree complex wavelet transform: A new technique for shift invariance and directional fllters. In: Proceedings of the 8th IEEE Digital Signal Processing Workshop, Bryce Canyon, USA: 1998. 120−131 [19] Selesnick I W, Baraniuk R G, Kingsbury N C. The dual-tree complex wavelet transform. IEEE Signal Processing Magazine, 2005, 22(6): 123−151 doi: 10.1109/MSP.2005.1550194 [20] Kwitt R, Uhl A. Lightweight probabilistic texture retrieval. IEEE Trans. on Image Processing, 2010, 19(1): 241−253 doi: 10.1109/TIP.2009.2032313 [21] Fisher N I, Switzer P. Chi-plots for assessing dependence. Biometrica, 1985, 72: 253−265 doi: 10.1093/biomet/72.2.253 [22] Crouse M S, Nowak R D, Baraniuk R G. Wavelet-based statistical signal processing using hidden Markov models. IEEE Trans. on Signal Processing, 1998, 46(4): 886−902 doi: 10.1109/78.668544 [23] Bian Y, Liang S. Locally optimal detection of image watermarks in the wavelet domain using Bessel K form distribution. IEEE Trans. on Image Processing, 2013, 22(2): 2372−2384 -

 下载:
下载:



计量
- 文章访问数: 1051
- HTML全文浏览量: 451
- PDF下载量: 137
- 被引次数: 0
