

Unsupervised Image-to-Image Translation With Self-Attention and Relativistic Discriminator Adversarial Networks
-
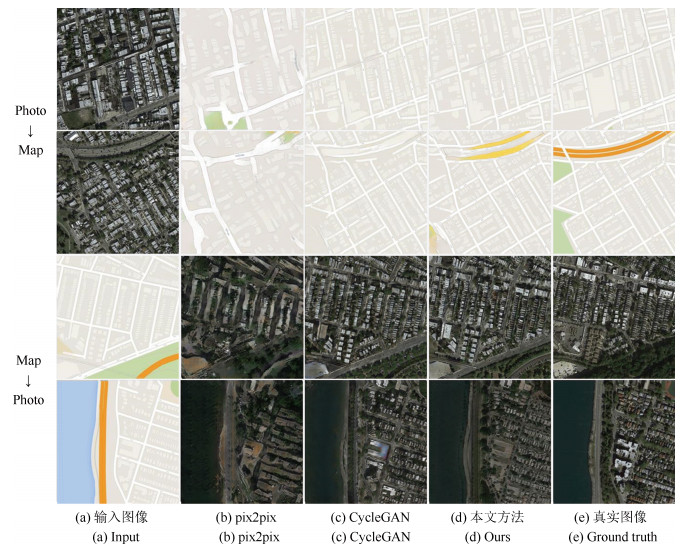
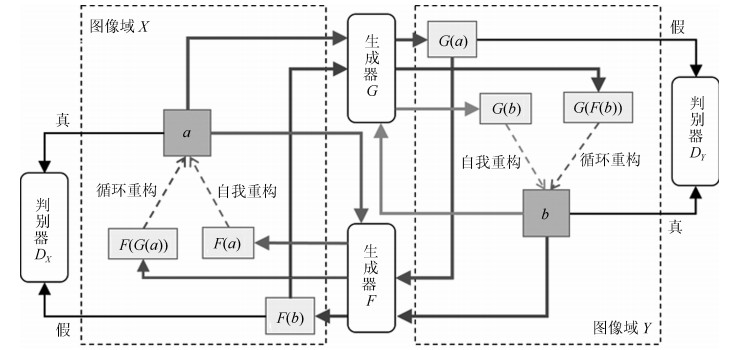
摘要: 无监督图像翻译使用非配对训练数据能够完成图像中对象变换、季节转移、卫星与路网图相互转换等多种图像翻译任务.针对基于生成对抗网络(Generative adversarial network, GAN)的无监督图像翻译中训练过程不稳定、无关域改变较大而导致翻译图像细节模糊、真实性低的问题, 本文基于对偶学习提出一种融合自注意力机制和相对鉴别的无监督图像翻译方法.首先, 生成器引入自注意力机制加强图像生成过程中像素间远近距离的关联关系, 在低、高卷积层间增加跳跃连接, 降低无关图像域特征信息损失.其次, 判别器使用谱规范化防止因鉴别能力突变造成的梯度消失, 增强训练过程中整体模型的稳定性.最后, 在损失函数中基于循环重构增加自我重构一致性约束条件, 专注目标域的转变, 设计相对鉴别对抗损失指导生成器和判别器之间的零和博弈, 完成无监督的图像翻译.在Horse & Zebra、Summer & Winter以及AerialPhoto & Map数据集上的实验结果表明:相较于现有GAN的图像翻译方法, 本文能够建立更真实的图像域映射关系, 提高了生成图像的翻译质量.Abstract: Unsupervised image-to-image translation using unpaired training data can accomplish a variety of image translation tasks such as object transformation, seasonal transfer, and satellite and map transformation. The image-to-image translation method based on generative adversarial network (GAN) has not been satisfying due to the following reasons, the training process is unstable and the irrelevant domain changes greatly, the output images are blurred in detail and low in authenticity. This paper proposes an unsupervised image-to-image translation method with self-attention and relativistic discriminator adversarial networks based on dual learning. Firstly, in the generator, self-attention mechanism is designed to build long-short-range dependency for image generation tasks. Skip-connection between low and high convolution layers help reduce the loss of feature information in irrelevant image domain. Then, in the discriminator, spectral normalization is used to prevent the gradient disappearing caused by the mutation of the discrimination ability to enhance training stability. Finally, in the loss function, the self-reconstruction consistency is added on the basis of loop reconstruction to focus on target image domain change. The relativistic adversarial loss is designed to guide the zero-sum game between generator and discriminator. The experimental results from the Horse & Zebra, Summer & Winter, and AerialPhoto & Map datasets demonstrate that compared with the current image translation methods, our method can establish a more realistic image domain mapping relationship and improve the translation quality of the generated image.
-
Key words:
- Image-to-image translation /
- dual learning /
- generative adversarial networks (GAN) /
- self-attention /
- relativistic discriminator /
- unsupervised learning
-
人体运动估计旨在通过分析和理解人体动作, 从输入传感器数据中提取出有关人体姿态、运动轨迹和动作意图等信息. 传统人体运动估计方法通常基于视觉传感器(如摄像头或深度相机)获取图像或点云数据来检测人体的姿态和运动. 然而, 该方法在遮挡、光照变化和复杂背景等情形下往往表现不佳, 这限制了其应用范围. 为了克服视觉传感器的应用局限性, 近年来, 基于表面肌电信号 (Surface electromyography, sEMG)、惯性等可穿戴式传感器的人体运动估计引起了广泛关注[1]. 特别地, 表面肌电信号是一种通过肌肉收缩状态反映肢体运动的电信号, 可用于识别手势、肢体运动和人类意图等[1]. 由于采集方式的无创性和便携性, sEMG被广泛应用于助力机器人、康复机器人、智能假肢[2-6], 以及人机协作等领域[7-10].
尽管现有sEMG采集技术已经比较成熟, 但由于sEMG自身非平稳、微弱等特性, 采集的信号中往往包含复杂噪声干扰[1, 6]. 为此, 不少研究人员开始融合惯性传感器信息, 来获取更多的姿态信息, 从而弥补sEMG感知的不足[1, 11-14]. 例如, Stival等集成sEMG和惯性测量单元(Inertial measurement unit, IMU)信息, 来提高人体运动估计的性能[15]. Sakamoto等构建了长短期记忆(Long short-term memory, LSTM)网络以sEMG和IMU信息作为输入, 来实现下肢力和力矩的估计[16]. Hollinger等将多个sEMG和IMU的特征作为网络输入, 利用Bi-LSTM网络实现了超前100 ms的关节角度预测[17]. 上述方法大多以深度学习为主, 通过挖掘各传感器数据的高维特征, 对高维特征向量进行拼接来实现人体运动的融合估计. 尽管这类方法有助于提高人体运动估计的性能, 但由于深度学习网络存在可解释性欠缺的问题, 这限制了网络模型估计性能的进一步提升[1, 12, 18].
卡尔曼滤波(Kalman filtering, KF)是一种能够有效地降低由传感器噪声以及其他外部因素引起的不确定性的滤波算法, 已被广泛用于多传感器信息融合领域. Han等利用Hill模型结合前向动力学构建了状态空间模型, 并利用无迹卡尔曼滤波(Unscented Kalman filtering, UKF)实现了基于sEMG的肢体运动估计[19]. 然而, Hill模型是一种生理现象学模型[1, 11], 其内部结构复杂, 需要专业的人体肌肉知识来进行人体运动模型的构建和分析, 存在较大的应用局限性[12-14]. 为了克服这些限制, 学者们尝试利用神经网络学习卡尔曼滤波参数和模型. Coskun等首先提出了LSTM-KF框架, 将三个LSTM模块集成到KF中, 来学习姿态估计任务中的观测模型和噪声模型[20]. Revach等提出了一种KalmanNet网络, 在传统KF的基础上, 利用深度神经网络(Deep neural networks, DNN)学习KF中的增益[21]. Bao等利用LSTM模块学习KF的所有参数, 实现了基于sEMG的腕部和指部关节角度估计[22]. 但这种LSTM-KF的结构较为简单, 线性量测框架对肌电和运动状态之间的非线性关系描述并不充分. 在LSTM-KF的基础上, 文献[23]提出了一种渐进无迹卡尔曼滤波网络(Progressive unscented Kalman filter network, PUKF-net), 设计了三个LSTM模块学习量测模型和噪声统计特性, 利用UT变换(Unscented transformation)和渐进量测来减小线性化误差, 实现了端到端的估计. 然而, 该方法在网络端到端的训练中, 缺乏多传感器互补性信息, 这限制了线性化误差的补偿性能以及估计效果的提升.
针对以上问题, 本文提出一种序贯渐进高斯滤波网络 (Sequential progressive Gaussian filtering network, SPGF-net)来融合多通道表面肌电和惯性信息, 以增强人体运动估计的性能. 首先, 利用卷积神经网络对观测数据进行特征提取, 挖掘深层次观测特征. 其次, 针对异构传感器融合问题, 采用了序贯融合的方式融合肌电和惯性量测特征. 特别地, 通过序贯渐进量测更新的方法对观测网络特征的不确定性进行补偿, 来提高人体上肢关节运动估计的精度和抗干扰能力.
1. 问题描述与建模
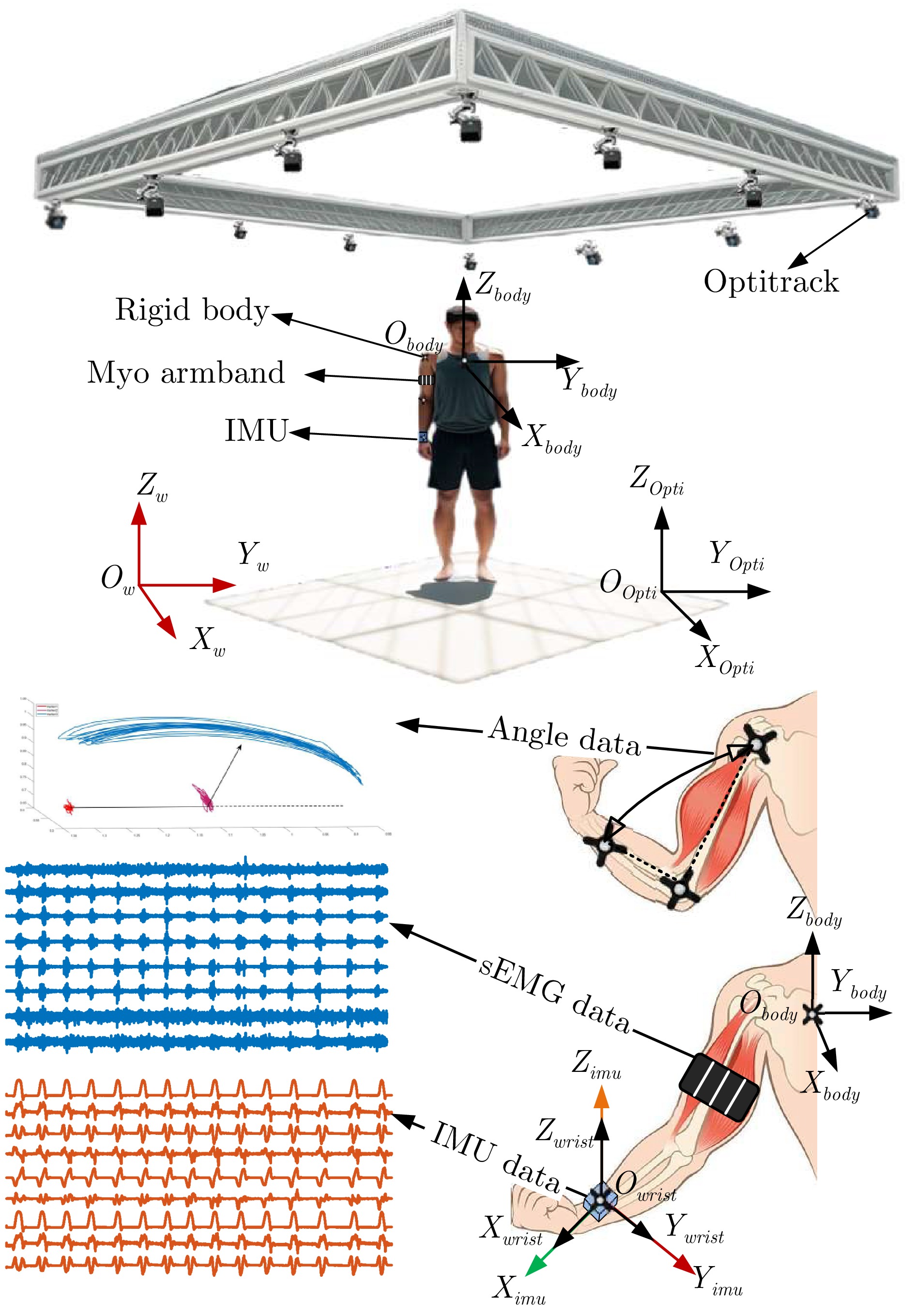
本文考虑了一类基于多通道表面肌电和惯性融合的人体运动估计问题. 如图1所示, 本文以人体上肢运动估计为例, 将八通道肌电传感器穿戴于大臂来检测上肢肌肉的状态, 同时将一个惯性传感器(由加速度计、陀螺仪和磁力计组成)固定在手腕处来估计小臂的运动状态. $ O_{w}\text{-}X_{w}Y_{w}Z_{w} $为全局坐标系({G}系), $ O_{Opti}\text{-}X_{Opti}Y_{Opti}Z_{Opti} $为光捕全局坐标系({O}系), $ O_{body}\text{-}X_{body}Y_{body}Z_{body} $为躯体坐标系({B}系), $ O_{wrist}\text{-}X_{wrist}Y_{wrist}Z_{wrist} $为手腕坐标系({W}系), $ O_{imu}\text{-}X_{imu}Y_{imu}Z_{imu} $为惯性传感器坐标系({S}系). 在运动过程中惯性传感器的坐标系会随手腕运动而变化, 而且肢体运动姿态与身体朝向密切相关, 为此, 需要建立坐标转换来描述肢体在躯体坐标系中的姿态. 为了便于坐标系转换, 简化实验, 在光捕系统进行标定时, 令光捕全局坐标系({O}系)与全局坐标系({G}系)指向相同, 即转换矩阵$ R^G_O $为单位阵. 同时, 令腕部坐标系与惯性坐标系重合, 即转换矩阵$ R^S_W $也为单位阵. 根据光捕系统中躯体的刚体坐标系可以求得{O}系与{B}系之间转换矩阵$ R^B_O $, 同时利用IMU静止时, 测到的重力加速度和磁感应强度两个矢量计算出{G}系与{S}系之间旋转矩阵$ R^G_S $, 那么, 通过惯性传感器相对于躯体的转换矩阵$ R^B_S=R^G_SR^O_GR^B_O $, 可以得到肢体在躯体坐标系中的姿态信息$ {{o}^{imu}_{k, B}}= R^B_SR^S_W $.
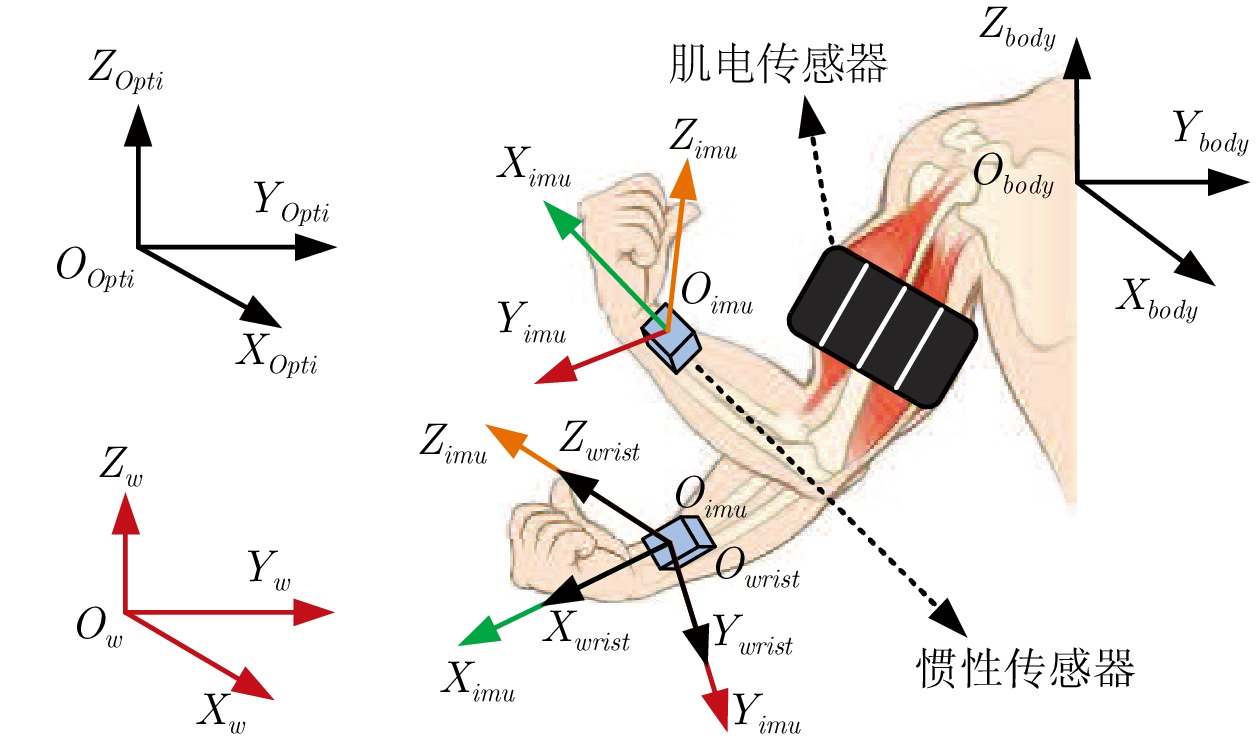 图 1 多传感器融合的人体肢体估计示意图Fig. 1 Multi-sensor fusion human body limb estimation schematic diagram
图 1 多传感器融合的人体肢体估计示意图Fig. 1 Multi-sensor fusion human body limb estimation schematic diagram为了挖掘原始观测数据的深层次特征, 利用卷积神经网络(Convolutional neural networks, CNN)将原始观测数据$ {{o}_k} $提炼为观测特征$ {z_k} $, 并将$ {z_k} $作为观测信号建模如下:
$$ {z_k} = {g^\theta }({{o}_k}) $$ (1) 其中, $ {g^\theta }\left( \cdot \right) $为观测网络. 由于观测网络的引入以及多维观测的复杂性, 往往难以描述准确的观测模型. 在此, 利用LSTM网络去学习各量测和运动状态之间的关系, 并建立观测模型如下:
$$ z_k^{emg} = {\rm{LSTM}}_h^{emg}({x_k}) + v_k^{emg} $$ (2) $$ z_k^{imu} = {\rm{LSTM}}_h^{imu}({x_k}) + v_k^{imu} $$ (3) $ {\rm{LST}}{{\rm{M}}_h} $表示用于学习观测函数的网络模块, ${x_k} = [ {{{( {{\theta _k}} )}{}^{\rm{T}}}}\;\;{{{( {{{\dot \theta }_k}} )}{}^{\rm{T}}}} ]^{\rm{T}}$表示$ k $时刻上肢关节状态向量, $ {z_k^{emg}={g^\theta }({o^{emg}_k})} $表示$ k $时刻肌电特征向量, $ {o^{emg}_k} $为整流后的肌电幅值, $ {z_k^{imu}={g^\theta }({o^{imu}_{k, B}})} $表示$ k $时刻姿态特征向量, $ {o^{imu}_{k, B}} $为肢体相对于躯体的姿态角(roll、pitch、yaw), $ {v_k} $为$ k $时刻观测噪声. 同时, 对人体运动建模如下:
$$ {x_k} = f({x_{k - 1}, a_{k-1}}) + {w_k} $$ (4) 其中, $f( {x_{k}, a_{k}}) = \left[ {\begin{aligned} {{\theta _k} + {{\dot \theta }_k} \cdot {T_s}}\;\;\;\;\;\;\;\;\\ {{{\dot \theta }_k} + (\tfrac{{{a_k} + g\sin\theta }}{l}) \cdot {T_s}} \end{aligned}} \right]$为系统非线性状态方程, $ a_{k} $为惯性传感器测得的加速度, $ g $为重力加速度, $ l $ 为小臂长度, $ T_s $为采样时间, $ {w_k} $为$ k $时刻系统噪声, 且$ {w_k} $和$ v_k $为互不相关的零均值高斯白噪声.
虽然观测网络的引入能提取原始数据中深层次的特征, 但其依赖于训练数据, 而肌电和惯性传感器信号具有时变性[24-27], 在一定程度上增加了信息提取的难度. 为此, 设计了一种基于多通道表面肌电和惯性融合的高斯滤波网络, 利用序贯融合的方式实现互补性传感器观测融合, 同时, 采用渐进量测更新对量测特征的不确定性进行补偿.
2. 运动估计方法
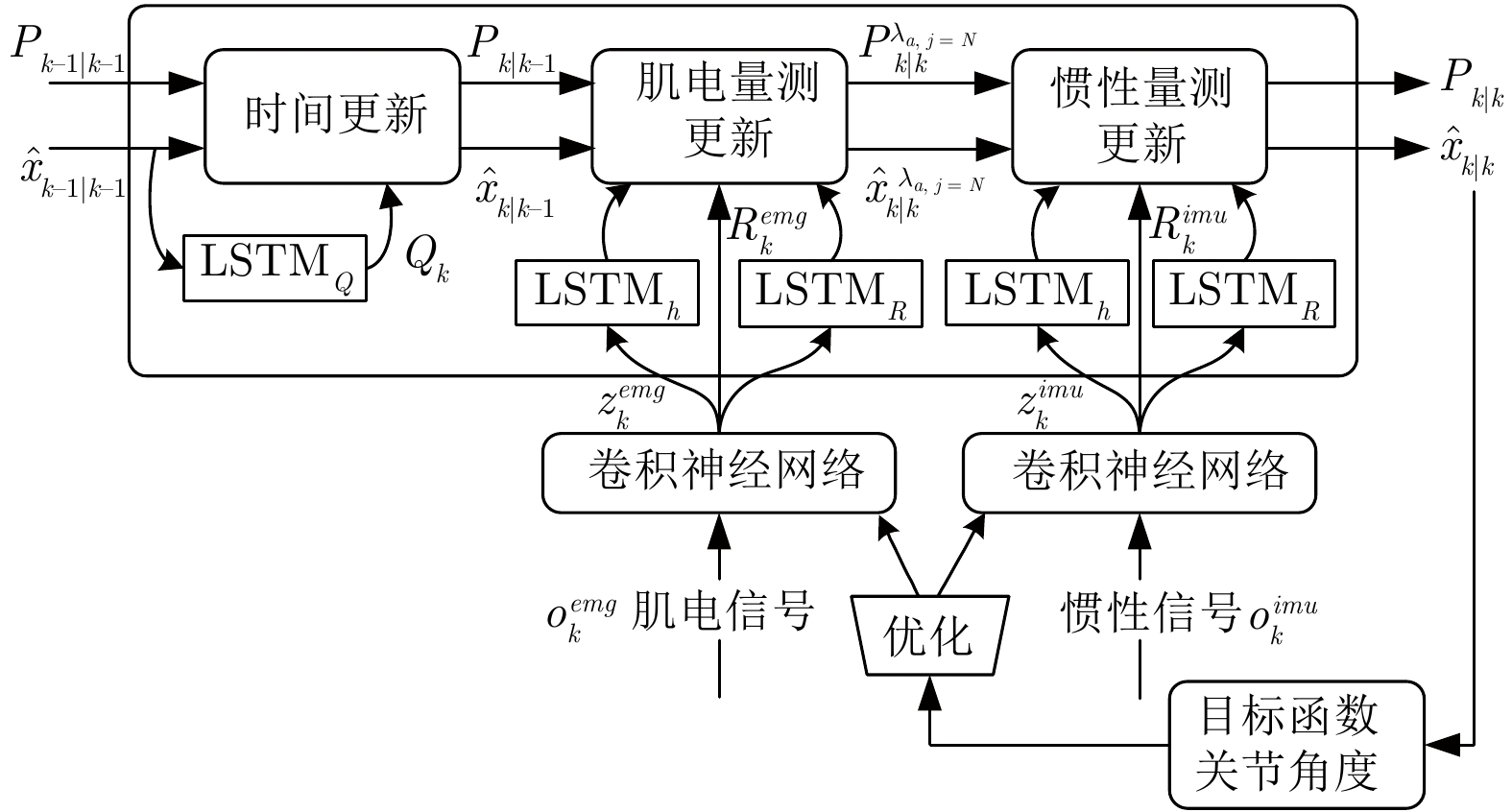
如图2所示, 利用卷积神经网络分别提取肌电和惯性信号的量测特征$ z_k^{emg} $和$ z_k^{imu} $. 同时, 设计了${\rm{LSTM}} _{Q} $和${\rm{LSTM}} _R $模块来学习噪声统计特性$ {Q_{k}} $和$ {R_{k}} $. 其次, 利用UT变换将用于学习量测函数的$ {\rm{LSTM}}_h $模块输出线性化. 考虑到肌电信号具有超前性, 通常在肢体运动之前产生[1], 因此, 采用序贯渐进量测更新方法灵活地融合肌电和惯性传感器量测特征, 以逐步更新状态估计, 从而减小线性化误差. 最后, 利用真值与估计值 $ \hat{x}_{k|k} $的偏差优化滤波网络的权重参数, 以此学习合适的状态转移过程.
2.1 序贯渐进高斯滤波网络
贝叶斯滤波是一种常见的用于递归估计未知概率密度函数的概率方法, 它包括两个阶段:
预测:
$$ \begin{split} &p(x_{k}|Z_{1:k-1})=\\ &\qquad\int p\left(x_{k}|x_{k-1}\right)p(x_{k-1}|Z_{1:k-1}){\rm d}x_{k-1} \end{split} $$ (5) 量测更新:
$$ p(x_k|Z_{1:k})=\frac{p(z_k|x_k)p(x_k|Z_{1:k-1})}{\int p(z_k|x_k)p(x_k|Z_{1:k-1}){\rm d}x_k}$$ (6) 式中, $ p(\cdot) $表示概率密度函数, $ Z_{1:k-1} $=$ \{z_{1} $, $ z_{2}, {\cdots} $, $ z_{k-1}\} $为1到$ {k-1} $ 时刻所有量测. 对于系统(4), 结合UT变换, 可以计算系统先验均值$ \hat x_{k|k-1} $和协方差$ P_{k|k-1} $为:
$$ \begin{split} &\hat x_{k|k-1} =\int x_{k}p(x_{k-1}|Z_{1:k-1}){\rm d}x_{k-1}=\\ &\qquad\int f({x}_{k-1}){\rm N}\left(x_{k};\hat{x}_{k-1|k-1}, P_{k-1|k-1}\right){\rm d}x_{k-1}\approx\\ &\qquad\sum_{i=0}^{2n}W_{i}^{m}f({\chi_{k-1|k-1}^{i}})\\[-15pt] \end{split} $$ (7) $$ \begin{split} &P_{k|k-1}=\int\left(x_{k}-\hat{x}_{k|k-1}\right)\left(x_{k}-\hat{x}_{k|k-1}\right)^{\rm{T}}\;\times\\ &\quad p(x_{k-1}|Z_{1:k-1}){\rm d}x_{k-1}=\int f({x}_{k-1})f^{\rm{T}}({x}_{k-1})\;\times \\ &\quad{\rm N}(x_k;\hat{x}_{k-1|k-1}, P_{k-1|k-1}){\rm d}x_{k-1}-\hat{x}_{k|k-1}\hat{x}_{k|k-1}^{\rm{T}}\;+\\ &\quad{Q}_{k-1}\approx\sum\limits_{i = 0}^{2n} {W_i^c} f(\chi _{k - 1|k - 1}^i){f^{\rm{T}}}(\chi _{k - 1|k - 1}^i)\;- \\&\quad{{\hat x}_{k|k - 1}}\hat x_{k|k - 1}^{\rm{T}} + {Q_{k-1}}\\[-15pt] \end{split} $$ (8) $N(\cdot) $为高斯分布, $ {W_i^m} $ 和$ {W_i^c} $, $ i=0, \; 1, \; \cdots, \; 2n $是均值和协方差计算中的权值, $ {\chi _{k-1|k-1}^{i}} $为生成的sigma点, $ {Q_k} $为系统噪声协方差. 考虑到噪声统计特性通常隐藏在时序数据中, 而LSTM能够充分捕获时序数据之间的关联性, 为此直接利用LSTM模块从系统状态向量中学习$ {Q_k} $.
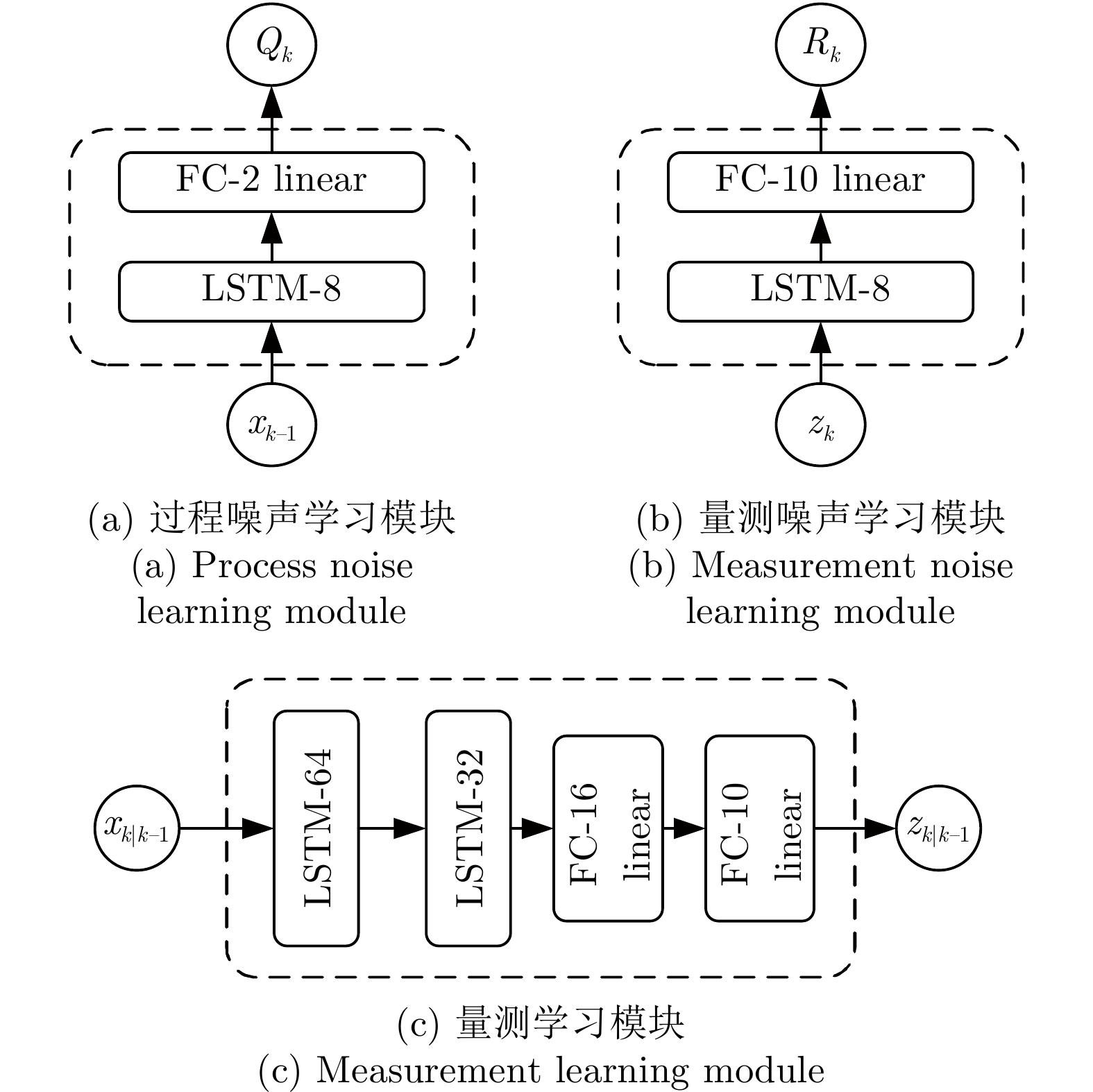
$$ {Q_k} = {\rm{LST}}{{\rm{M}}_Q}({x_{k - 1}}, c_{k - 1}^Q) $$ (9) $ {\rm{LSTM}}_Q $表示用于学习系统中$ Q_{k} $的LSTM模块, $ c_{k-1}^Q $是上一时刻$ {\rm{LSTM}}_Q $的隐藏单元. $ {\rm{LSTM}}_{Q} $结构如图3(a)所示, 由1层LSTM和1个全连接层组成, LSTM层由8个隐藏单元, 1个归一化层和1个LeakyReLU激活函数组成, 全连接层有2个隐藏单元.
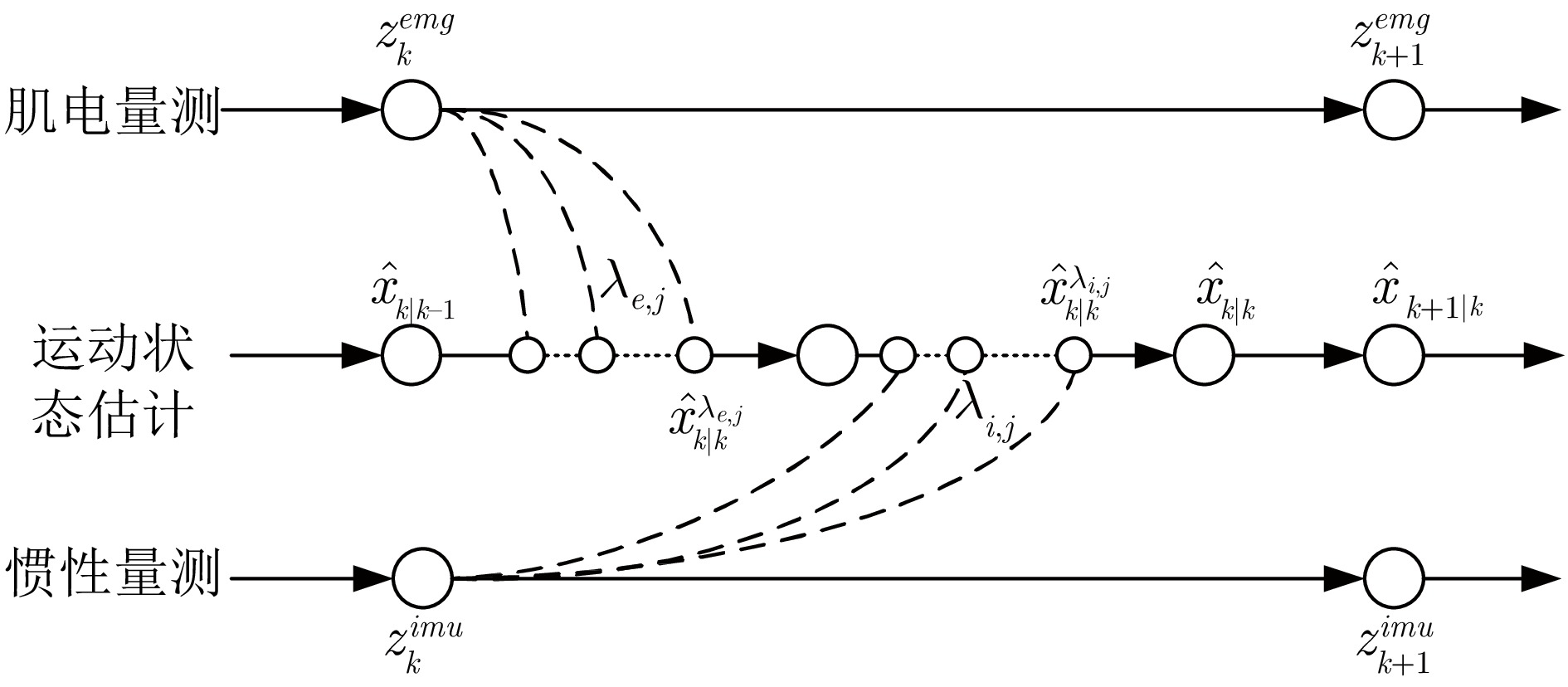
如图4所示, 在序贯渐进高斯滤波网络中, 量测更新由几个子过程组成, 在每个子过程中, 采集到的传感器测量将依次用于更新状态估计.
注1. 在卡尔曼滤波中, 当量测测量向量的维数很大时, 求解增益阵$ K $时求逆的阶数将很高(通常, 求逆的计算量与矩阵阶数的三次方近似成正比). 特别地, 在高维矩阵运算时, 可能会出现发生数值溢出近似、奇异矩阵等问题, 从而导致估计系统不稳定. 而在序贯渐进高斯滤波中, 将传感器测量分解为多个分量, 使得对高阶矩阵的求逆转变为对低阶矩阵求逆, 同时利用传感器的互补优势逐一渐进地引入信息, 来降低线性化误差以及提高滤波的稳定性. 这就改善了高维量测引发的模型融合估计效率降低以及系统不稳定等问题.
在渐进高斯滤波中[28-29], 通过引入伪时间长度$ {\lambda_j}={\lambda_{j-1}}+{\Delta_j} $ ($ {\Delta_j} $为渐进步长, $ {\lambda_{0}}=0) $, 对观测中的不确定性进行补偿. 其中, 似然函数可以写成如下形式:
$$ \begin{split} p(z_k|x_k)=\;&\frac{1}{\sqrt{2\pi\left|R_k\right|}}\exp\{-\frac{1}{2}[z_k-h(x_k)]^{{\rm{T}}}\;\times \\ &\big(R_{k}\big)^{-1}\big[z_{k}-h(x_{k})\big]\}\;= \\ &C_{N}\prod_{j=1}^{N}\frac{1}{\sqrt{\left|\frac{2\pi R_k}{\Delta_{j}}\right|}}\exp\{-\frac{1}{2}[z_k-h(x_k)]^{{\rm{T}}}\;\times \\ &\left(\frac{R_{k}}{\Delta_{j}}\right)^{-1}\left[\left.z_{k}-h\left(x_{k}\right)\right]\right\}\;= \\ &C_{N}\prod_{j=1}^{N}p(z_k, \Delta_{j}|x_k)\\[-15pt] \end{split} $$ (10) $ {p ({z_k}, {\Delta _j}|{x_k})} $为渐进似然函数. $ {C_N} $为归一化常量, $ C_N=\left(1/\sqrt{2\pi R_k}\right)^{N-1}\prod_{j=1}^N\sqrt{\Delta_j} $, $ {\Delta _j}=\frac{1}{N} $为渐进步长. $ {N} $为渐进步数, 理论上, 较大的$ {N} $可以提供更精确的状态估计, 较小的$ {N} $能降低计算复杂度, 但可能无法充分捕捉系统的非线性行为, 导致滤波估计不准确. 在实际应用中, 通常需要进行实验和调整, 以找到最佳的$ N $值. 在本文中, 经过权衡, $ {N} $的取值为20. 根据贝叶斯准则, 伪时间$ {\lambda_{j+1}} $对应的渐进后验概率密度函数为:
$$ \begin{split} p( {x_k}|&{\lambda _{j + 1}}, {z_k}, {Z_{1:k - 1}})=\\ &p({x_k}|{\lambda _j} + {\Delta _j}, {z_k}, {Z_{1:k - 1}})=\\ &\frac{{p({z_k}, {\Delta _j}|{x_k})p({x_k}|{\lambda _j}, {Z_{1:k - 1}})}}{{\int {p({z_k}, {\Delta _j}|{x_k})p({x_k}, {\lambda _j}|{Z_{1:k - 1}}){\rm d}{x_k}} }} \end{split} $$ (11) 对于系统(2), 假设$ {p(z_k^{emg}, \Delta_j|x_k)} $服从零均值协方差为$ {R_k^{emg}/\Delta_j} $的高斯分布, 即
$$ \begin{split} &p(z_k^{emg}, {\Delta _j}|{x_k})= \\ &\qquad\frac{1}{{\sqrt {\left| {\frac{{2\pi R_k^{emg}}}{{{\Delta _j}}}} \right|} }}\exp \Bigg\{ { - \frac{1}{2}}{\left[ {z_k^{emg} - {\rm{LSTM}}_{{h}}^{{{emg}}}\left( {{x_k}} \right)} \right]^{\rm{T}}}\;\times \\ &\qquad {{{\left( {\frac{{R_k^{emg}}}{{{\Delta _j}}}} \right)}^{ - 1}}\left[ {z_k^{emg} - {\rm{LSTM}}_{{h}}^{{{emg}}}\left( {{x_k}} \right)} \right]} \Bigg\}\\[-20pt] \end{split} $$ (12) $ {\rm{LSTM}}^{emg}_{h} $为学习的肌电观测函数, $ {R^{emg}_k} $由LSTM模块直接从系统状态向量中学习得到, 结构分别如图3(b)、3(c)所示. 其中, $ {\rm{LSTM}}^{emg}_{h} $由2个LSTM层和2个全连接层组成, 每层LSTM由1个归一化层和1个LeakyReLU激活函数组成. 第1层LSTM中有64个隐藏单元, 第2层LSTM中有32个隐藏单元. 第1个全连接层有16个隐藏单元, 第2个全连接层有10个隐藏单元. $ {\rm{LSTM}}_{R} $ 由1层LSTM和1个全连接层组成, LSTM层由8个隐藏单元、1个归一化层和1个LeakyReLU激活函数组成, 全连接层有10个隐藏单元.
假设渐进联合概率密度函数为高斯分布:
$$ \begin{split} &p({x_k}, z_k^{emg}, {\lambda _{e, j + 1}}|{Z_{1:k - 1}}) = {\rm N} \Biggr( {\left[ {\begin{array}{*{20}{l}} {{x_k}}\\ {{z_k}} \end{array}} \right];} \\ &\qquad {\left[ {\begin{array}{*{20}{l}} {\hat x_{k|k}^{{\lambda _{e, j}}}}\\ {\hat z_{k|k}^{emg, {\lambda _{e, j + 1}}}} \end{array}} \right], \left[ {\begin{array}{*{20}{l}} {P_{xx, k|k}^{{\lambda _{e, j}}}}&{P_{xz, k|k}^{{\lambda _{e, j + 1}}}}\\ {P_{zx, k|k}^{{\lambda _{e, j + 1}}}}&{P_{zz, k|k }^{{\lambda _{e, j + 1}}}} \end{array}} \right]} \Biggr) \end{split} $$ (13) 则渐进后验概率密度函数为:
$$ \begin{split} p( & x_{k}|\lambda_{{e}, j+1}, z_{k}^{emg}, Z_{1:k-1})=\\ &\qquad{\rm N}\left(x_k; \hat{x}_{k|k}^{\lambda_{e, j+1}}, P_{k|k}^{\lambda_{e, j+1}}\right) \end{split} $$ (14) 结合UT变换计算量测预测值及其协方差:
$$ \begin{split} &\hat z_{k|k}^{{{emg}, \lambda _{e, j}}} =\\ &\quad\int\int{{z_{k}^{emg}}p({x_k}, z_k^e, {\lambda _{e, j }}|{Z_{1:k - 1}}){\rm d}{z_k}{\rm d}{x_k}}\;=\\ &\quad\int {\left\{ {\int {{z_{k}^{emg}}p(z_k^{emg}, {\Delta _j}|{x_k}){\rm d}{z_k}} } \right\}}\; \times \\ &\quad p(x_{k}|\lambda_{e, j-1}, z_{k}^{emg}, Z_{1:k-1}){\rm d}{x_k}\;\approx \\ &\quad\int {{\rm{LSTM}}^{emg}_{h}({x_k})}{\rm N}\left(x_k; \hat{x}_{k|k}^{\lambda_{e, j-1}}, P_{k|k}^{\lambda_{e, j-1}}\right){\rm d}{x_k}\;\approx \\ &\quad\sum\limits_{i = 0}^{2n} W_i^m{{\rm{LSTM}}^{emg}_{h}}(\chi _{i, k|k}^{{\lambda _{e, j - 1}}}) \\[-15pt]\end{split} $$ (15) $$ \begin{split} &P_{zz, k|k}^{{\lambda _{e, j}}} = \\ &\;\;\int {\int {(z_k^{emg} - \hat z_{k|k}^{emg, {\lambda _{e, j}}})} } {(z_k^{emg} - \hat z_{k|k}^{emg, {\lambda _{e, j}}})^{\rm{T}}} \;\times \\ &\;\;p({x_k}, z_k^{emg}, {\lambda _{e, j}}|{Z_{1:k - 1}}){\rm{d}}{z_k}{\rm{d}}{x_k} \;= \\ &\;\;\int {\left( {\int {z_k^{emg}} {{(z_k^{emg})}^{\rm{T}}}p(z_k^{emg}, {\Delta _j}|{x_k}){\rm{d}}{z_k}} \right)}\; \times \\ &\;\;p({x_k}, {\lambda _{e, j - 1}}|{Z_{1:k - 1}}){\rm{d}}{x_k} - \hat z_{k\mid k}^{emg, {\lambda _{e, j}}}{\left( {\hat z_{k\mid k}^{emg, {\lambda _{e, j}}}} \right)^{\rm{T}}} \approx \\ &\;\;\frac{{R_k^{emg}}}{{{\Delta _j}}} - \hat z_{k\mid k}^{emg, {\lambda _{e, j}}}{(\hat z_{k\mid k}^{emg, {\lambda _{e, j}}})^{\rm{T}}} + \int {{\rm{LSTM}}_h^{emg}\left( {{x_k}} \right)} \; \times \\ &\;\;{\left[ {{\rm{LSTM}}_h^{emg}\left( {{x_k}} \right)} \right]^{\rm{T}}}{\rm N}\left( {{x_k};\hat x_{k|k}^{{\lambda _{e, j - 1}}}, P_{k|k}^{{\lambda _{e, j - 1}}}} \right){\rm{d}}{x_k} \;= \\ &\;\;\sum\limits_{i = 0}^{2n}{W_i^c}{\rm{LSTM}}_h^{emg} \left( {\chi _{i, k|k}^{{\lambda _{e, j - 1}}}} \right) {\left[ {{\rm{LSTM}}_h^{emg} \left( {\chi _{i, k|k}^{{\lambda _{e, j - 1}}}} \right)} \right]^{\rm{T}}}+\\ &\;\;\frac{{R_k^{emg}}}{{{\Delta _j}}} - \hat z_{k|k}^{emg, {\lambda _{e, j}}}{\left( {\hat z_{k|k}^{emg, {\lambda _{e, j}}}} \right)^{\rm{T}}} \\[-15pt]\end{split} $$ (16) 计算先验状态估计值与观测预测值间的互协方差:
$$ \begin{split} &P_{xz, k|k}^{{\lambda _{e, j}}} = \int {\int {\left( {{x_k} - \hat x_{k|k}^{{\lambda _{e, j - 1}}}} \right)} } {\left( {z_k^{emg} - \hat z_{k|k}^{{emg}, {\lambda _{e, j}}}} \right)^{\rm{T}}}\;\times\\ &\qquad p({x_k}, z_k^{emg}, {\lambda _{e, j }}|{Z_{1:k - 1}}){\rm d}{z_k}{\rm d}{x_k}\;-\\ &\qquad \hat x_{k|k}^{{\lambda _{e, j - 1}}}{\left( {\hat z_{k|k}^{{emg}, {\lambda _{e, j}}}} \right)^{\rm{T}}}\approx\int {{x_k}{{\left[ {{\rm{LSTM}}_{{h}}^{{{emg}}}\left( {{x_k}} \right)} \right]}^{\rm{T}}}}\;\times\\ &\qquad {\rm N}\left( {{x_k};\hat x_{k|k}^{{\lambda _{e, j - 1}}}, P_{k|k}^{{\lambda _{e, j - 1}}}} \right){\rm d}{x_k}\; - \\ &\qquad \hat x_{k\mid k}^{{emg}, {\lambda _{e, j - 1}}}{(\hat z_{k\mid k}^{{emg}, {\lambda _{e, j}}})^{\rm{T}}}\;\approx \\ &\qquad \sum\limits_{i = 0}^{2n} {W_i^c} \chi _{i, k|k}^{{\lambda _{e, j - 1}}}{\left[ {{\rm{LSTM}}_{{h}}^{{{emg}}}\left( {\chi _{i, k|k}^{{\lambda _{e, j - 1}}}} \right)}\right]^{\rm{T}}}\; -\\ &\qquad \hat x_{k\mid k}^{{emg}, {\lambda _{e, j - 1}}}{(\hat z_{k\mid k}^{{emg}, {\lambda _{e, j}}})^{\rm{T}}}\\[-15pt] \end{split} $$ (17) 其中, $ \chi_{i, k|k}^{{\lambda_{e, j}}} $和$ {W_i^c} $为对应的sigma点与权值. 由式(15) ~ (17)可得状态估计和估计方差为:
$$ \hat x_{k|k}^{{\lambda _{e, j}}} = \hat x_{k|k}^{{\lambda _{e, j - 1}}} + K_{k|k}^{{\lambda _{e, j}}}({z_{k}^{emg}} - \hat z_{k|k}^{{{emg}, \lambda _{e, j}}}) $$ (18) $$ P_{k|k}^{{\lambda _{e, j}}} = P_{k|k}^{{\lambda _{e, j - 1}}} - K_{k|k}^{{\lambda _{e, j}}}P_{zz, k|k}^{{\lambda _{e, j}}}{(K_{k|k}^{{\lambda _{e, j}}})^{\rm{T}}} $$ (19) 其中, 渐进卡尔曼增益为:
$$ K_{k|k}^{{\lambda _{e, j}}} = P_{xz, k|k}^{{\lambda _{e, j}}}{(P_{zz, k|k}^{{\lambda _{e, j}}})^{ - 1}} $$ (20) 伪时间$ {\lambda _{e, j}} $从0走向1的过程也即从先验走向后验的过程, 对应的观测噪声协方差间接趋向 $ {R^{emg}_k} $. 从而将观测不确定性补偿问题转换为了伪时间长度的控制问题.
同理, 融合惯性量测$ {z_k^{imu}} $, 更新状态估计值和协方差:
$$ \hat x_{k|k}^{{\lambda _{i, j}}} = \hat x_{k|k}^{{\lambda _{i, j - 1}}} + K_{k|k}^{{\lambda _{i, j}}}({z_{k}^{imu}} - \hat z_{k|k}^{{{imu}, \lambda _{i, j}}}) $$ (21) $$ P_{k|k}^{{\lambda _{i, j}}} = P_{k|k}^{{\lambda _{i, j - 1}}} - K_{k|k}^{{\lambda _{i, j}}}P_{zz, k|k}^{{\lambda _{i, j}}}{(K_{k|k}^{{\lambda _{i, j}}})^{\rm{T}}} $$ (22) 且满足:
$$ \left\{ {\begin{aligned} &{\hat x_{k|k}^{{\lambda _{i, j = 0}}} = \hat x_{k|k}^{{\lambda _{e, j=N}}}}\\ &{ P_{k|k}^{{\lambda _{i, j = 0}}} = P_{k|k}^{{\lambda _{e, j=N}}}} \end{aligned}} \right. $$ (23) 其中, 渐进卡尔曼增益矩阵为:
$$ K_{k|k}^{{\lambda _{i, j}}} = P_{xz, k|k}^{{\lambda _{i, j}}}{( P_{zz, k|k}^{{\lambda _{i, j}}})^{ - 1}} $$ (24) 状态和观测互协方差, 预测观测协方差分别为:
$$ \begin{split} P_{xz, k|k}^{{\lambda _{i, j}}} \approx \;&\sum\limits_{l = 0}^{2n} {W_l^c} \left[ {\chi _{l, k|k}^{{\lambda _{i, j-1}}} - x_{k|k}^{{\lambda _{i, j - 1}}}} \right]\;\times\\ &{\left[ {{{{\rm{LSTM}}^{{{imu}}}_{h}}}(\chi _{l, k|k}^{{\lambda _{i, j-1}}}) - \hat z_{k|k}^{{imu}, {\lambda _{i, j}}}} \right]^{\rm{T}}} \end{split} $$ (25) $$ \begin{split} &P_{zz, k|k}^{{\lambda _{i, j}}}\approx\sum\limits_{l = 0}^{2n} {W_l^c} \left[ {{{\rm{LSTM}}^{{{imu}}}_{h}}(\chi _{l, k|k}^{{\lambda _{i, j-1}}}) - \hat z_{k|k}^{{{{imu}}}, {\lambda _{i, j}}}} \right]\;\times\\ &\qquad{\left[ {{{{\rm{LSTM}}^{{{imu}}}_{h}}}(\chi _{l, k|k}^{{\lambda _{i, j-1}}}) - \hat z_{k|k}^{{imu}, {\lambda _{i, j}}}} \right]^{\rm{T}}} + \frac{{R_k^{imu}}}{\Delta_j } \end{split} $$ (26) 为了保证各观测模块和噪声统计模块学习到合理的映射, 将真值与估计值的偏差作为序贯高斯滤波网络的损失:
$$ \begin{split} L\left( \theta \right) =\;& \frac{1}{T}\sum\limits_{k = 1}^T {\left( {{{\left\| {{x_k} - \hat x_{k|k - 1}^{}} \right\|}^2} \;+ } \right.} \\ &\left. {{{\left\| {{x_k} - \hat x_{k|k}^{{\lambda _{e, j = N}}}} \right\|}^2} + {{\left\| {{x_k} - \hat x_{k|k}^{{\lambda _{i, j = N}}}} \right\|}^2}} \right) \end{split} $$ (27) 其中, $ T $表示单个训练样本的时间步长, $ {x_k} $表示真值, $ {\hat x}_{k|k - 1} $表示状态预测值, $ \hat x_{k|k}^{{\lambda _{e, j=N}}} $和$ \hat x_{k|k}^{{\lambda _{i, j=N}}} $分别为$ {N} $步时肌电和惯性信号的观测更新值.
算法 1. 深度序贯渐进高斯滤波算法
1: 初始化;
2: while
3: 利用卷积网络提取观测特征;
4: 利用式(7) ~ (9)进行时间更新;
5: for $ j = 1:N $ do
6: 利用式(10) ~ (20)融合肌电观测;
7: end for
8: for $ j = 1:N $ do
9: 利用式(21) ~ (26)融合惯性观测;
10: end for
11: end while
3. 实验
为了验证该融合算法的可行性, 本文以人体上肢肘关节为例, 对$12 $名健康受试者的左右手肘关节进行了实验, 其中男性8名, 女性4名, 平均年龄为25.3 ± 4.8岁; 平均身高为165.3 ± 13.6厘米; 平均体重为68.5 ± 10.2千克. 实验前, 获得了每位受试者的书面同意.
3.1 数据采集
如图5所示, 实验采用Myo臂环作为表面肌电信号的采集系统, 其信号采样频率为100 Hz, 能采集8通道数据. 同时利用1个9轴IMU对受试者小臂的惯性信号进行采集, 采样频率100 Hz. 对于关节角度采集部分, 采用Optitrack视觉捕捉系统获取上肢关节运动特性, 分别用4个刚体描述腕部、肘部、肩部和躯体坐标, 采样频率100 Hz. 在数据采集过程中, 受试者站在Optitrack工作区间, 手臂自然下垂, 进行屈肘运动, 弯曲至最大角度位置. 在短暂停顿后进行伸展, 最后恢复到初始位置. 每次实验进行15组肘关节屈伸运动. 每个测试者进行5组重复实验, 为了防止肌肉疲劳, 每组实验之间设置5分钟的休息时间, 实验持续约35分钟.
3.2 特征提取
本文采用CNN提取原始数据的深层特征. 具体而言, 采用滑动窗口法分别获得大小为$ {{L}}\times{{C_1}} $的表面肌电信号矩阵和大小为$ {{L}}\times{C_2} $的惯性信息矩阵. 其中, $ {{L}} $表示窗口长度, $ {{C_1}} $和$ {C_2} $ 分别表示肌电传感器和惯性传感器通道数. 本文的CNN由4个卷积块和2个全连接块组成. 每个卷积块由1个卷积层、1个批归一化层、1个ReLU激活函数层、1个最大池化层和1个丢弃层组成. 卷积层内核大小为3, 步幅为1. 第1和第2个卷积块有16个核, 而第3和第4卷积块有32个核. 每个全连接块都由批归一化层、ReLU激活函数层和丢失层组成. 第1个全连接块有100个隐藏单元, 第2个全连接块有10个隐藏单元. 第2个全连接块的输出将被用作观测特征.
3.3 模型参数设置
实验中的所有网络模型都基于Python语言实现, 由Pytorch1.10库搭建, 在英特尔i7*10750H处理器以及英伟达RTX 2070显卡上完成训练和测试. 网络模型训练总轮次设置为60, 训练的批次设置为32, 选用Adam作为实验训练的优化器, CNN特征提取模块训练阶段初始学习率为0.001, 且学习率每隔10轮降为原来的一半, 所有LSTM模块均使用初始化权重, 初始学习率为0.001, 每隔5轮对学习率进行一次调整, 衰减率为0.8. 数据集前60%用于训练, 剩余40%用于测试. 为确保实验的可靠性, 在对比模型上都设置相同的超参数.
4. 实验结果与分析
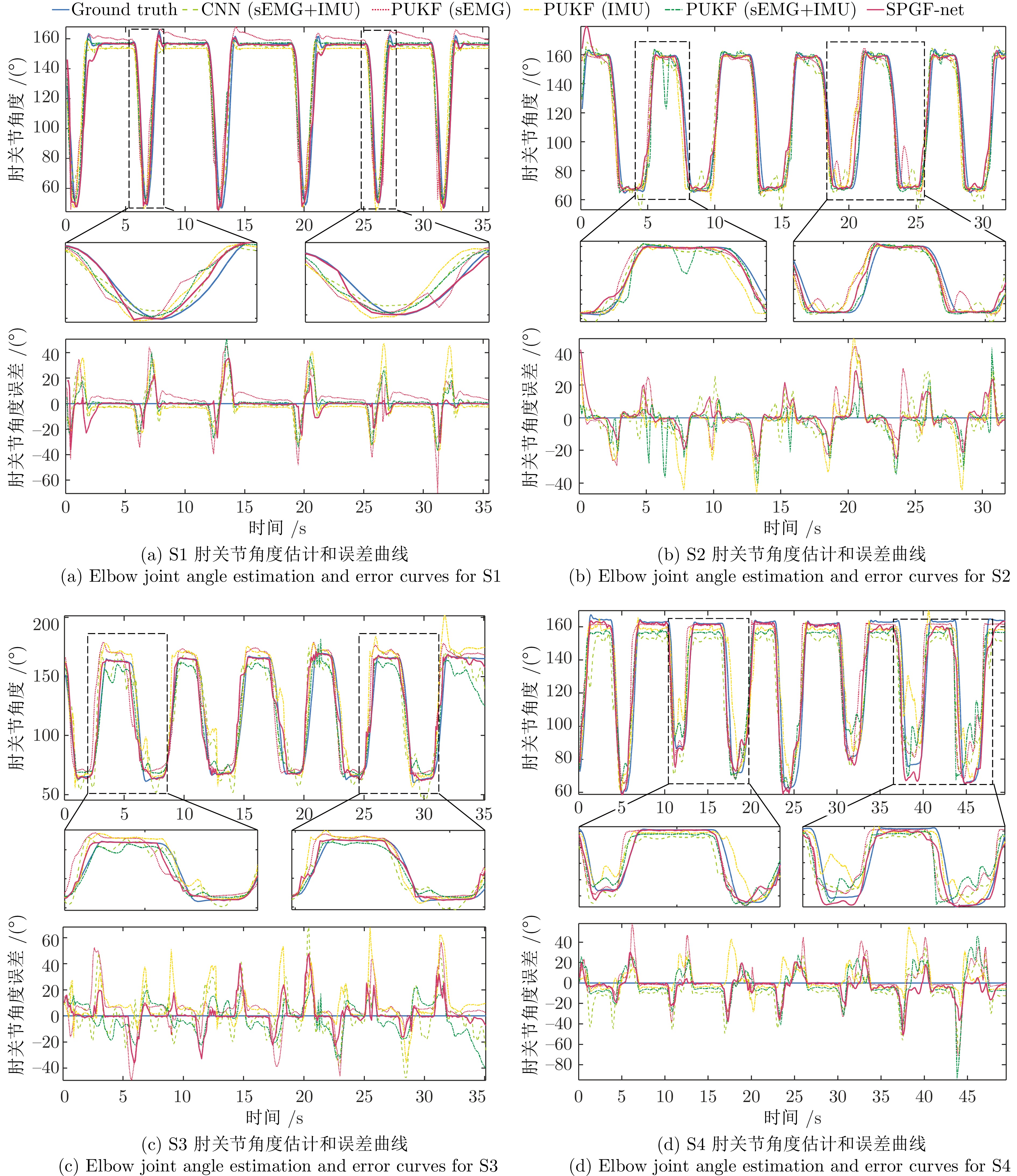
本文将相关系数(R2)和均方根误差(RMSE)作为性能指标对融合模型进行评估, 并统计了各网络模型的浮点运算数 (FLOPs)和参数数量(Params). 其中, R2表明估计的曲线与测量的关节运动的相关程度, 而RMSE计算估计值与测量值之间的幅值差异. 本文选择卷积神经网络(sEMG和IMU信号为输入, 对高维特征进行拼接) 和渐进无迹卡尔曼滤波网络(分别以sEMG和IMU信号为输入, 对提取的特征向量进行建模; 将sEMG和IMU信号作为输入, 对特征融合后的特征向量进行建模)作为模型比较的基线方法. 以S1 ~ S4四名测试者右手的估计结果为例, 图6展示了四名受试者在五种模型下的肘关节角度估计和误差曲线. 五种方法都可以从表面肌电信号中有效地重建肘关节运动.
由于传感器布局、个数等因素, 基于sEMG的人体运动估计结果总体上略高于基于IMU的人体运动估计结果. PUKF-net通过利用先验知识和渐进量测对卷积神经网络提取的特征向量进行校正和不确定性补偿取得了相对光滑的估计曲线, 但由于单一信号有效信息有限, PUKF (sEMG)和PUKF(IMU)的估计结果在整体上还是低于CNN (sEMG+IMU). PUKF (sEMG+IMU)在CNN特征融合的基础上利用卡尔曼滤波框架提高了网络的估计性能和稳定性, SPGF-net在PUKF的基础上通过序贯融合肌电和惯性量测特征向量, 发挥了肌电和惯性信号的互补优势, 得到了相对光滑的曲线. 如图6(b)所示, 在18 s至26 s, CNN (sEMG+IMU)、PUKF (sEMG)和PUKF (IMU)估计测试者2的关节角度曲线都出现了不同程度的波动, 而SPGF-net的估计曲线(紫色实线)相对光滑且整体上更接近Optitrack真实值(蓝色实线). 为了定量比较几种方法的估计性能, 表1总结了CNN (sEMG+IMU)、PUKF (sEMG)、PUKF (IMU)、PUKF (sEMG+IMU)和SPGF-net五种方法的平均性能(平均值 ± 标准差). 其中, R2分别为0.854 ± 0.093、0.847 ± 0.080、0.838 ± 0.080、0.865 ± 0.080、0.884 ± 0.060, RMSE分别为14.52 ± 4.21、15.07 ± 3.54、15.64 ± 3.46、13.99 ± 3.96、12.99 ± 3.51. 与其他四种方法相比, SPGF-net通过序贯融合的方式提高了模型的精度和稳定性. 相较于PUKF (sEMG)模型而言, 在肘关节角度估计中的RMSE平均下降了13.8%, 相关系数平均提高了4.36%.
表 1 五种模型性能评价Table 1 The performance evaluation of five models测试者 均方根误差 (RMSE) 相关系数(R2) CNN
(sEMG+IMU)PUKF
(sEMG)PUKF
(IMU)PUKF
(sEMG+IMU)SPGF-net CNN
(sEMG+IMU)PUKF
(sEMG)PUKF
(IMU)PUKF
(sEMG+IMU)SPGF-net S1 9.75 11.91 12.48 9.56 9.27 0.922 0.884 0.872 0.925 0.930 S2 11.65 12.18 13.25 10.89 9.78 0.917 0.913 0.893 0.923 0.941 S3 16.18 15.90 16.42 15.63 14.15 0.864 0.868 0.859 0.876 0.896 S4 15.66 16.18 16.95 14.57 13.45 0.825 0.822 0.816 0.832 0.847 S5 24.24 23.30 23.79 22.74 18.98 0.594 0.624 0.609 0.651 0.751 S6 10.15 11.43 11.65 9.96 8.91 0.937 0.920 0.917 0.941 0.949 S7 16.31 16.62 17.19 16.13 15.90 0.856 0.851 0.847 0.860 0.869 S8 16.84 16.37 16.53 16.30 16.23 0.807 0.809 0.805 0.813 0.821 S9 9.23 9.95 10.86 8.82 7.73 0.930 0.918 0.903 0.938 0.951 S10 14.97 15.74 16.17 14.53 14.00 0.849 0.831 0.821 0.853 0.866 S11 16.86 17.19 17.66 16.62 15.78 0.852 0.846 0.838 0.857 0.864 S12 12.46 14.09 14.83 12.13 11.74 0.905 0.885 0.870 0.909 0.924 均值 14.52 15.07 15.64 13.99 12.99 0.854 0.847 0.838 0.865 0.884 标准差 4.21 3.54 3.46 3.96 3.51 0.093 0.080 0.080 0.080 0.060 为了评估各网络模型的复杂度, 本文统计了各网络模型浮点运算数(FLOPs)和网络模型参数数量(Params), 如表2所示. 由于观测网络模型的增加, 整个网络模型的计算量和参数总量也有一定程度的增加, 相较于提升的性能而言, 模型复杂度的增加在接受范围之内.
表 2 五种模型的复杂度Table 2 The complexity of five modelsCNN (sEMG+
IMU)PUKF (sEMG) PUKF (IMU) PUKF (sEMG+
IMU)SPGF-net FLOPs 1 237 714 719 448 619 828 1 328 864 1 419 176 Params 442 337 256 511 255 971 473 970 505 614 5. 结束语
本文设计了一种面向多通道表面肌电和惯性融合的序贯渐进高斯滤波网络, 实现了人体上肢运动估计. 利用卷积神经网络提取观测特征向量, 与常见的特征拼接不同, SPGF-net采用序贯融合的方式, 融合异构传感器量测. 特别地, 通过渐进量测更新的方法, 对观测网络的不确定性进行补偿. 实验结果表明所提出的融合方法可有效提高人体上肢关节角度估计的精度和稳定性. 本文仅对单个肘关节运动进行了估计, 然而多关节协同对模型要求更高. 在未来工作中, 将考虑多关节的协同和更复杂场景下的运动估计, 来评估我们的模型, 并进一步提高高斯滤波网络的自适应性, 同时将充分发挥深度学习在自适应滤波中的优势, 研究更为智能且泛用的自适应滤波策略.
-
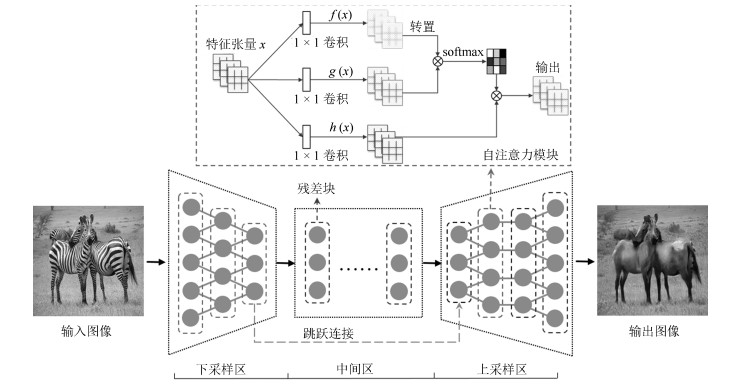
表 1 生成器网络结构参数设置
Table 1 The parameter setting of generator
序号 区域划分 层类型 卷积核 步长 深度 归一化 激活函数 0 下采样 Convolution $ 7 \times 7 $ 1 64 IN ReLU 1 下采样 Convolution $ 3 \times 3 $ 2 128 IN ReLU 2 下采样 Convolution $ 3 \times 3 $ 2 256 IN ReLU 3 中间区 Residual Block $ 3 \times 3 $ 1 256 IN ReLU 4 中间区 Residual Block $ 3 \times 3 $ 1 256 IN ReLU 5 中间区 Residual Block $ 3 \times 3 $ 1 256 IN ReLU 6 中间区 Residual Block $ 3 \times 3 $ 1 256 IN ReLU 7 中间区 Residual Block $ 3 \times 3 $ 1 256 IN ReLU 8 中间区 Residual Block $ 3 \times 3 $ 1 256 IN ReLU 9 上采样 Deconvlution $ 3 \times 3 $ 2 128 IN ReLU 10 上采样 Self-Attention – – – – – 11 上采样 Deconvlution $ 3 \times 3 $ 2 64 IN ReLU 12 上采样 Convolution $ 7 \times 7 $ 1 3 – Tanh  下载: 导出CSV
下载: 导出CSV
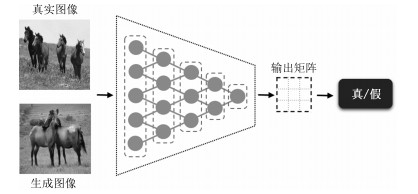
表 2 判别器网络结构参数设置
Table 2 The parameter setting of discriminator
序号 层类型 卷积核 步长 深度 归一化 激活函数 0 Convolution $ 4 \times 4 $ 2 64 – LeakyReLU 1 Convolution $ 4 \times 4 $ 2 128 SN LeakyReLU 2 Convolution $ 4 \times 4 $ 2 256 SN LeakyReLU 3 Convolution $ 4 \times 4 $ 2 512 SN LeakyReLU 4 Convolution $ 4 \times 4 $ 1 1 – –
下载: 导出CSV
表 3 本文不同条件分类准确率
Table 3 CA under different conditions
数据集 真实图像 相对对抗 自注意力 自注意力+相对对抗 Horse&Zebra 0.985 0.849 0.862 0.873 Summer&Winter 0.827 0.665 0.714 0.752
下载: 导出CSV
-
[1] Isola P, Zhu J Y, Zhou T H, Efros A A. Image-to-image translation with conditional adversarial networks. In: Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition. Honolulu, Hawaii, USA: IEEE, 2017. 1125-1134 [2] Xu F R, Ma B P, Chang H, Shan S G, Chen X L. Style transfer with adversarial learning for cross-dataset person re-identification. In: Proceedings of the 2018 Asian Conference on Computer Vision. Perth, Australia: Springer, 2018. [3] Goodfellow I J, Pouget-Abadie J, Mirza M, Xu B, WardeFarley D, Ozair S, et al. Generative adversarial nets. In: Proceedings of the 27th International Conference on Neural Information Processing Systems. Montreal, Canada: MIT Press, 2014. 2672-2680 [4] Huang H, Yu P S, Wang C. An introduction to image synthesis with generative adversarial nets. arXiv Preprint arXiv: 1803.04469, 2018. [5] Mirza M, Osindero S. Conditional generative adversarial nets. arXiv preprint arXiv: 1411.1784, 2014. [6] Ronneberger O, Fischer P, Brox T. U-net: Convolutional networks for biomedical image segmentation. In: Proceedings of the 18th International Conference on Medical Image Computing and Computer-assisted Intervention. Munich, Germany: Springer, 2015. 234-241 [7] Zhu J Y, Park T, Isola P, Efros A A. Unpaired image-toimage translation using cycle-consistent adversarial networks. In: Proceedings of the 2017 IEEE International Conference on Computer Vision. Venice, Italy: IEEE, 2017. 2223 -2232 [8] Liu M Y, Breuel T, Kautz J. Unsupervised image-to-image translation networks. In: Proceedings of the 31st Conference on Neural Information Processing Systems. Long Beach, California, USA: MIT Press, 2017. 700-708 [9] Miyato T, Kataoka T, Koyama M, Yoshida Y. Spectral normalization for generative adversarial networks. arXiv Preprint arXiv: 1802.05957, 2018. [10] He D, Xia Y C, Qin T, Wang L W, Yu N H, Liu T Y, et al. Dual learning for machine translation. In: Proceedings of the 30th Conference on Neural Information Processing Systems. Barcelona, Spain: NIPS, 2016. 820-828 [11] Johnson J, Alahi A, Li F F. Perceptual losses for real-time style transfer and super-resolution. In: Proceedings of the 2016 European Conference on Computer Vision. Amsterdam, The Netherlands: Springer, 2016. 694-711 [12] He K M, Zhang X Y, Ren S Q, Sun J. Deep residual learning for image recognition. In: Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition. Las Vegas, NV, USA: IEEE, 2016. 770-778 [13] Ulyanov D, Vedaldi A, Lempitsky V. Instance normalization: The missing ingredient for fast stylization. arXiv Preprint arXiv: 1607.08022, 2016. [14] Jolicoeur-Martineau A. The relativistic discriminator: A key element missing from standard GAN. arXiv Preprint arXiv: 1807.00734, 2018. [15] Mao X D, Li Q, Xie H R, Lau R Y, Wang Z, Smolley S P. Least squares generative adversarial networks. In: Proceedings of the 2017 IEEE International Conference on Computer Vision. Venice, Italy: IEEE, 2017. 2794-2802 [16] Russakovsky O, Deng J, Su H, Krause J, Satheesh S, Ma S, et al. Imagenet large scale visual recognition challenge. International Journal of Computer Vision, 2015, 115(3): 211-252 [17] Heusel M, Ramsauer H, Unterthiner T, Nessler B, Hochreiter S. Gans trained by a two time-scale update rule converge to a local nash equilibrium. In: Proceedings of the 31st Conference on Neural Information Processing Systems. Long Beach, California, USA: MIT Press, 2017. 6626-6637 [18] Kingma D P, Ba J. Adam: A method for stochastic optimization. arXiv Preprint arXiv: 1412.6980, 2014. [19] Chollet F. Xception: Deep learning with depthwise separable convolutions. In: Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition. Honolulu, Hawaii, USA: IEEE, 2017. 1251-1258 [20] Simonyan K, Zisserman A. Very deep convolutional networks for large-scale image recognition. arXiv Preprint arXiv: 1409.1556, 2014. -

 下载:
下载:



计量
- 文章访问数: 844
- HTML全文浏览量: 739
- PDF下载量: 194
- 被引次数: 0
