

Pareto-based Multi-objective Optimization of Energy Management for Fuel Cell Tramway
-
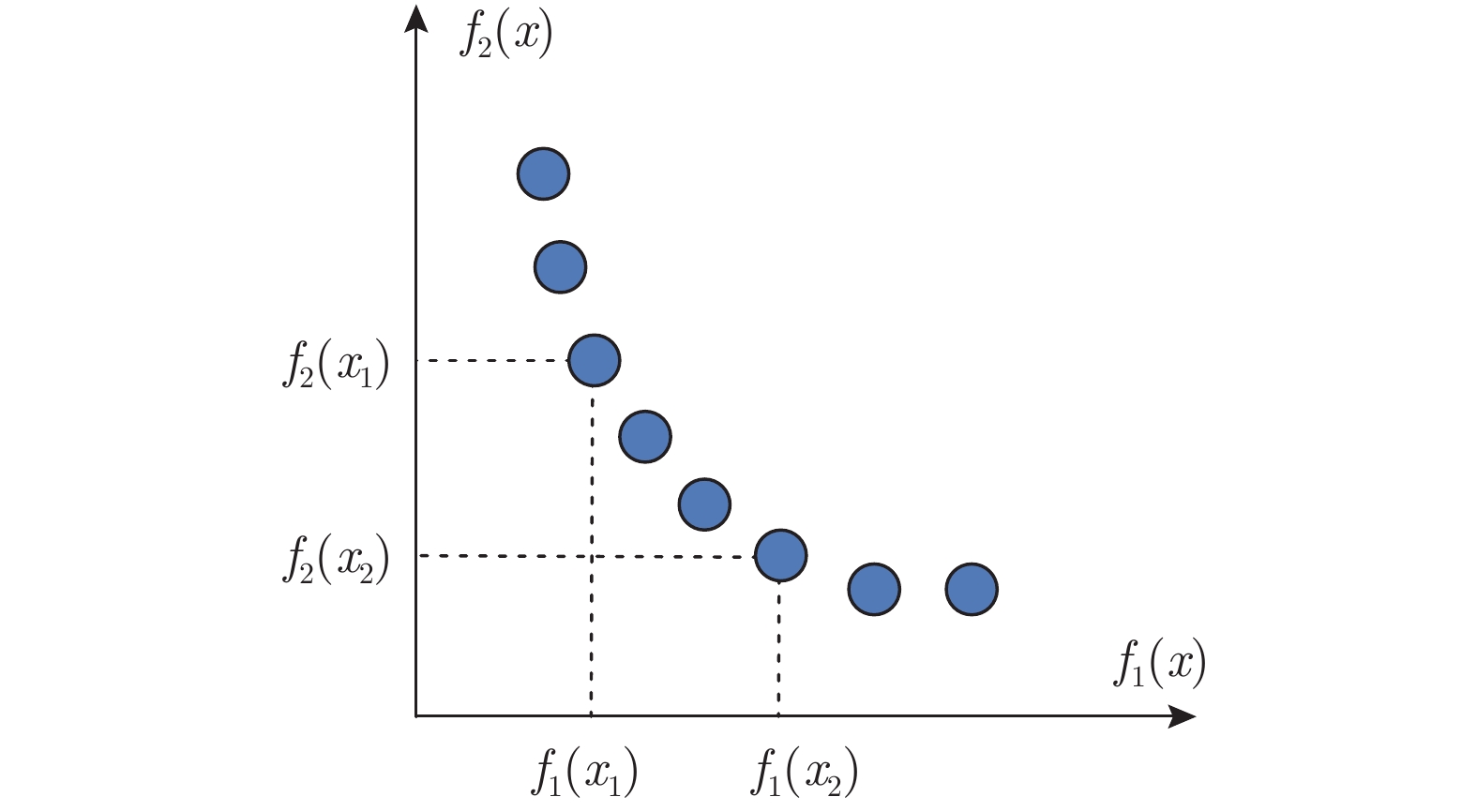
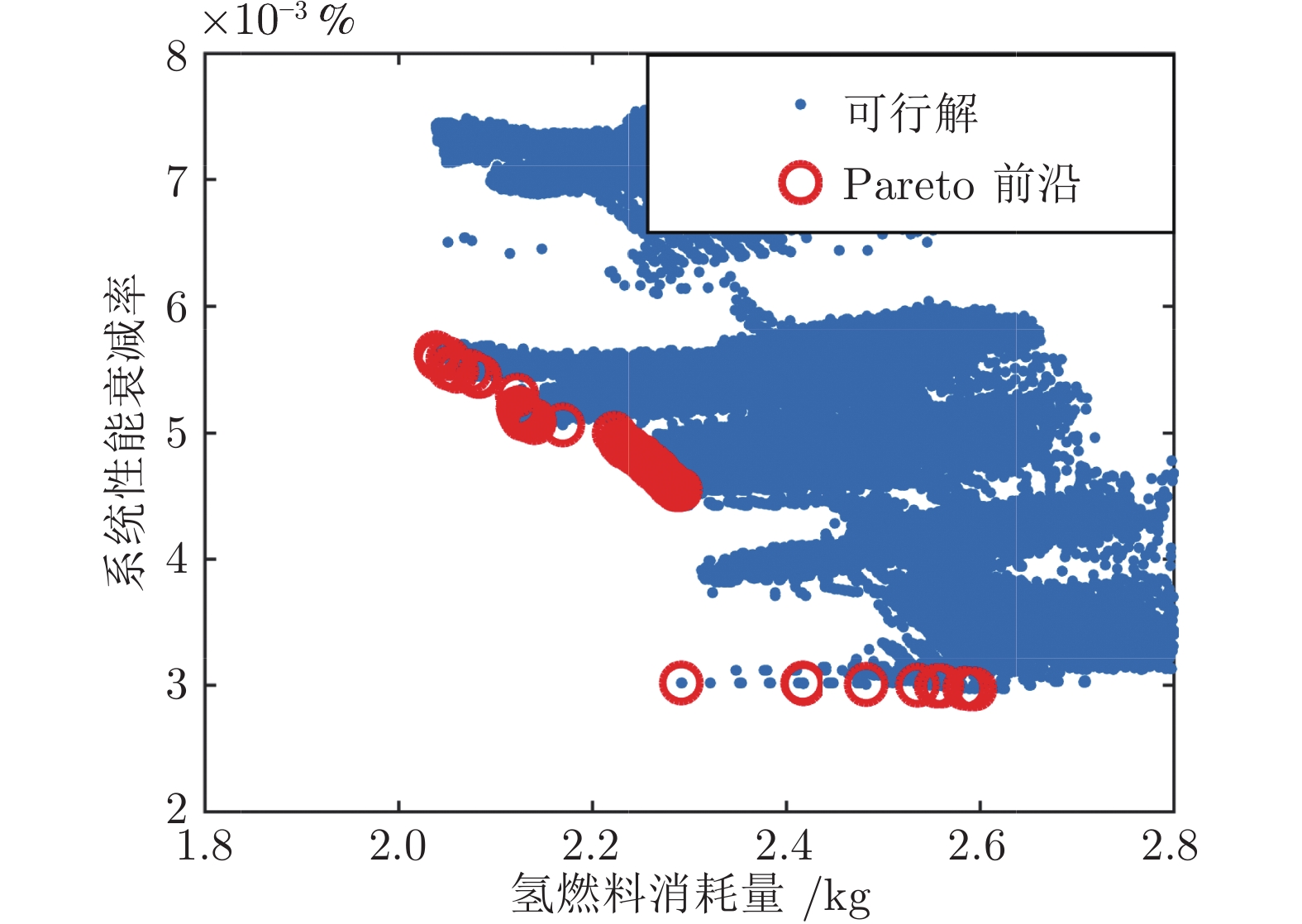
摘要: 节能环保的出行方式得到政府的大力推广, 其中燃料电池混合动力有轨电车由于可无网运行且节能环保而备受关注.为了改善燃料电池/超级电容/动力电池大功率有轨电车的燃料经济性与系统耐久性, 提出一种有轨电车能量管理策略(Energy management strategy, EMS)的多目标优化方法. 首先以氢燃料消耗量和能量源性能衰减率作为评价指标, 建立多目标成本函数. 由于两个指标很难在同一个等式中评价, 设计了基于状态机与非支配排序的能量管理Pareto多目标优化方法, 获得了有轨电车能量管理策略Pareto非劣解集, 并分析了能量管理策略的目标功率参数对性能指标的影响规律, 进而遴选出兼顾燃料经济性与系统耐久性的综合最优解. 结果表明, 与功率跟随策略和基于遗传算法优化策略相比, 该能量管理优化方法的燃料经济性分别提高了29.4 %和2.4 %.Abstract: The environment-friendly transportation has been greatly promoted by governments. Because of non-polluting and being operated without nets, fuel cell hybrid tramway has attracted much attention. In order to improve the fuel economy and system durability of fuel cell/supercapacitor/power battery high-power hybrid electric vehicles, a multi-objective optimization method of energy management strategy for tramway is proposed. Firstly, the multi-objective cost function is established by using the hydrogen fuel consumption and the performance degradation rate of each energy source as performance indices. These two performance indeces are difficult to evaluate in one equation, so a Pareto multi-objective optimization method based on the state machine and non-dominated sorting is designed. The Pareto non-inferior solution set of the energy management strategy is obtained, and the influence law of the target power parameters of the energy management strategy on the performance index is revealed, and then the comprehensive optimal solution considering both fuel economy and system durability is selected. The results show that the fuel economy of the energy management optimization method is improved by 29.4 % and 2.4 % respectively, compared with the power following strategy and the genetic algorithm based optimization strategy.
-
Key words:
- Hybrid tram /
- fuel cell /
- energy management /
- Pareto /
- multi-objective optimization
1) tong University, Chengdu 610031 2. School of Information Science and Technology, Southwest Jiaotong University, Chengdu 611756 3. School of Automobile and Transportation, Xihua University, Chengdu 610039 4. College of Electrical and Information Engineering, Southwest Minzu University, Chengdu 6100412) 收稿日期 2019-01-18 录用日期 2019-07-30 Manuscript received January 18, 2019; accepted July 30, 2019 国家自然科学基金 (11572264), 四川省科技厅重大科技专项 (2019ZDZX0002), 流体机械及工程四川省重点实验室开放基金 (szjj2019-015) 资助 Supported by National Natural Science Foundation of China (11572264), Science and Technology Major Project of Sichuan Province (2019ZDZX0002), and the Open Research Subject of Key Laboratory of Fluid and Power Machinery (szjj2019-015) 本文责任编委 董海荣 Recommended by Associate Editor DONG Hai-Rong 1. 西南交通大学牵引动力国家重点实验室 成都 610031 2. 西南交通大学信息科学与技术学院 成都 611756 3. 西华大学汽车与交通学院 成都 610039 4. 西南民族大学电气信息工程学院 成都 610041 1. State Key Laboratory of Traction Power, Southwest Jiao- -
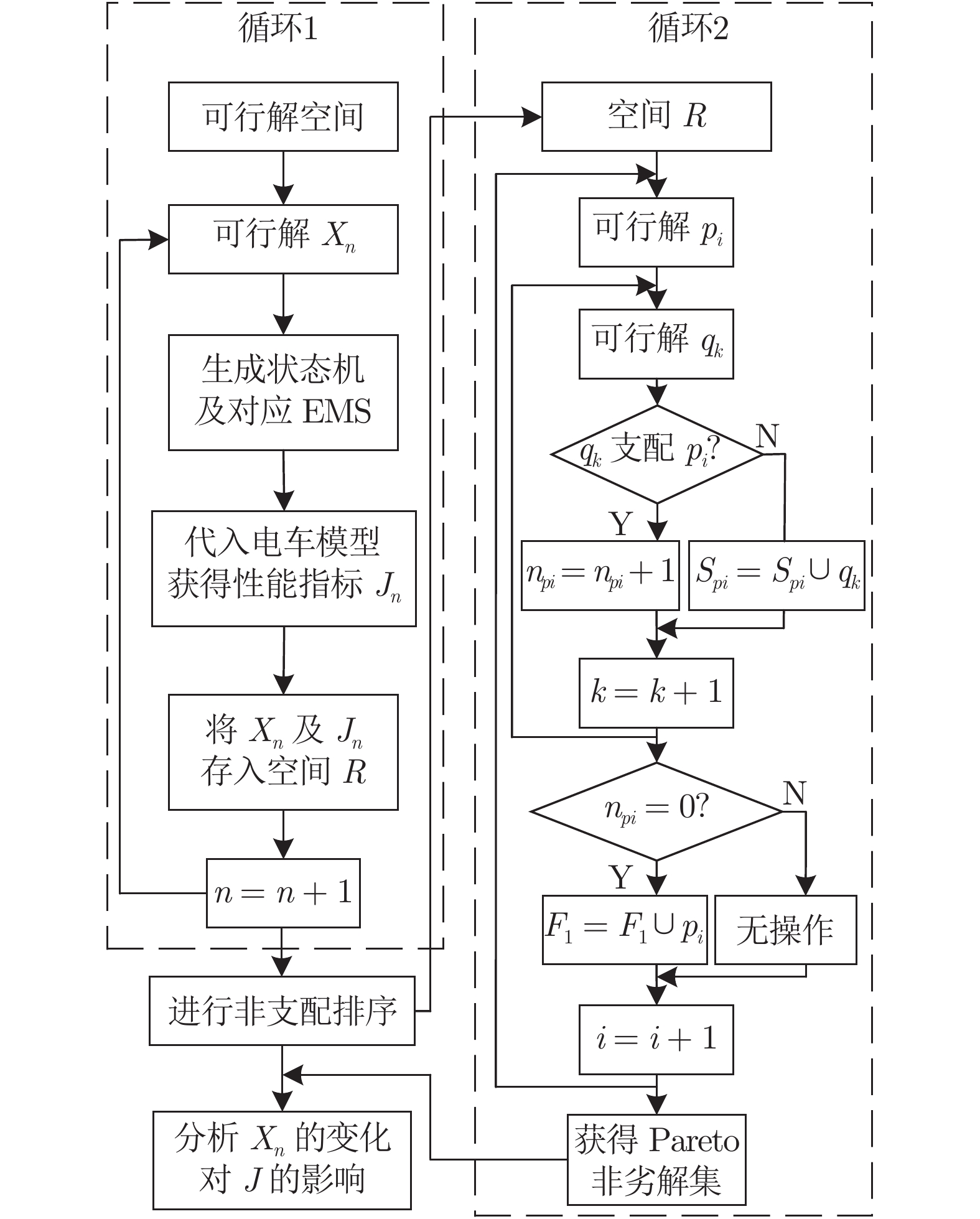
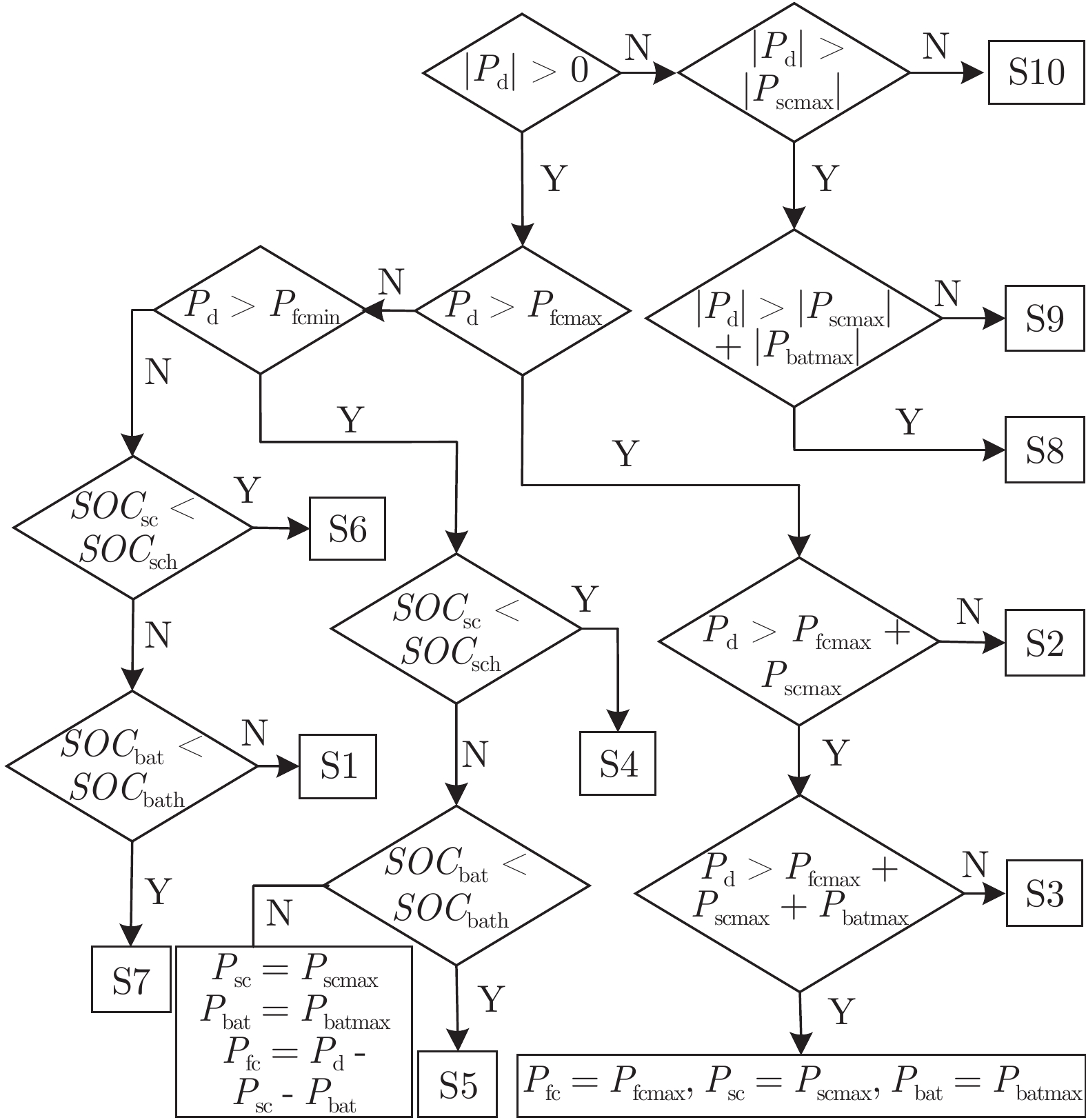
图 6 基于状态机与非支配排序的Pareto优化方法
Fig. 6 Pareto optimization based on state machine and non-dominated sorting
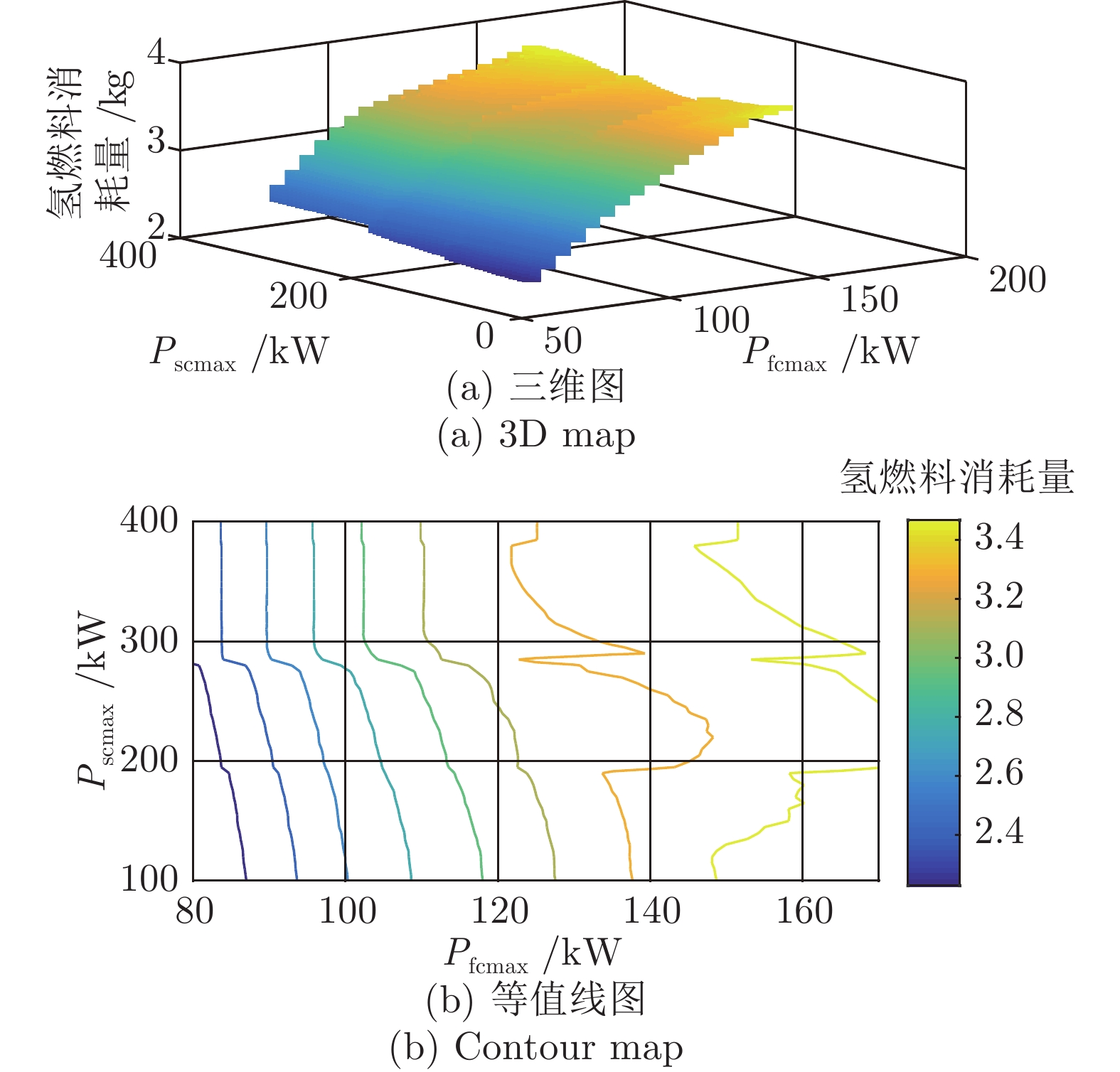
图 9 Pfcmax与Pscmax变化对燃料消耗的影响(Pbatmax = 150 kW)
Fig. 9 The effect of Pfcmax and Pscmax change on fuelconsumption (Pbatmax = 150 kW)
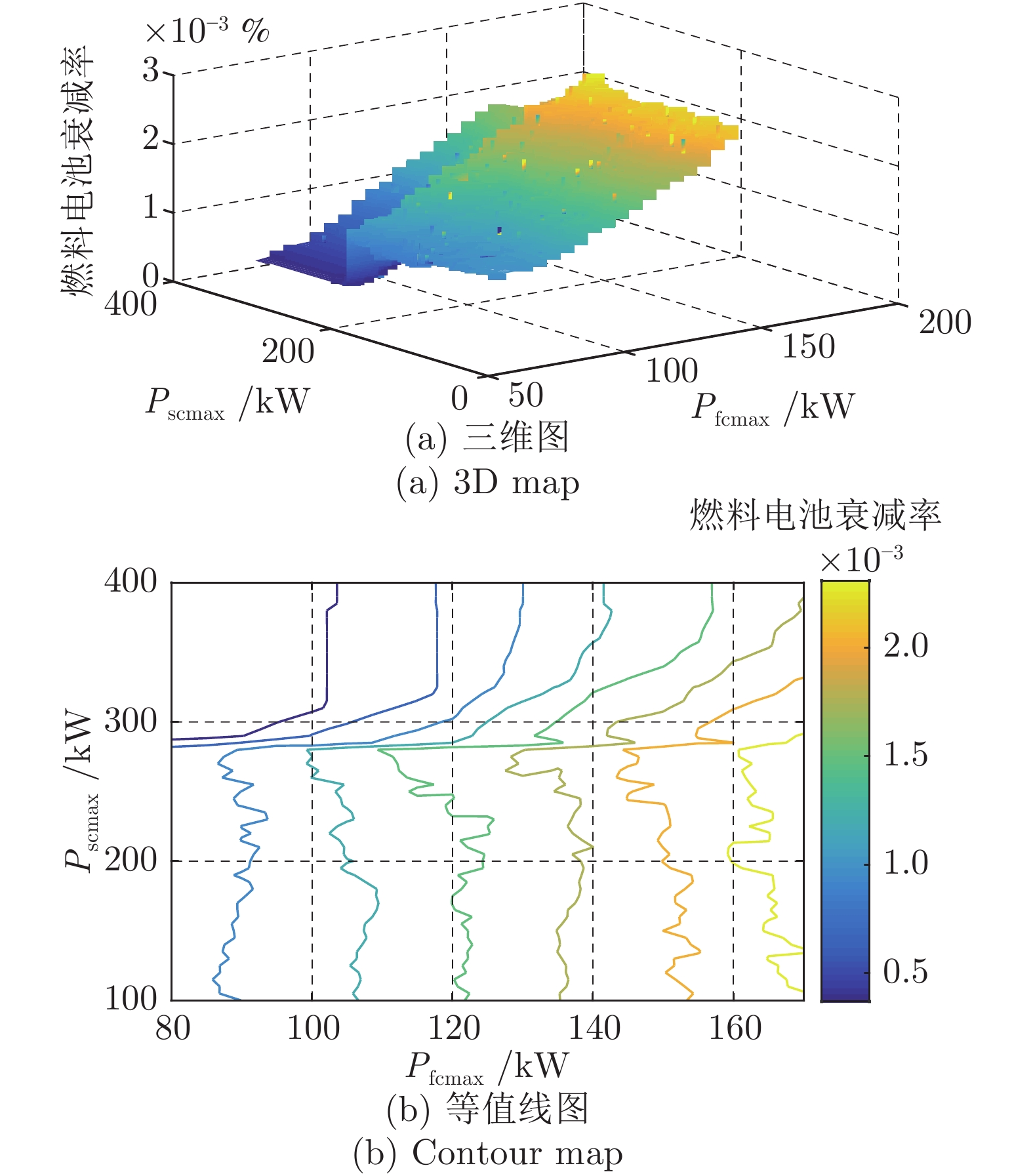
图 10 Pfcmax与Pscmax变化对燃料电池耐久性的影响(Pbatmax = 150 kW)
Fig. 10 The effect of Pfcmax and Pscmax change on fuel cell durability (Pbatmax = 150 kW)

图 11 Pfcmax与Pscmax变化对超级电容耐久性的影响(Pbatmax = 150 kW)
Fig. 11 The effect of Pfcmax and Pscmax change on SCdurability (Pbatmax = 150 kW)
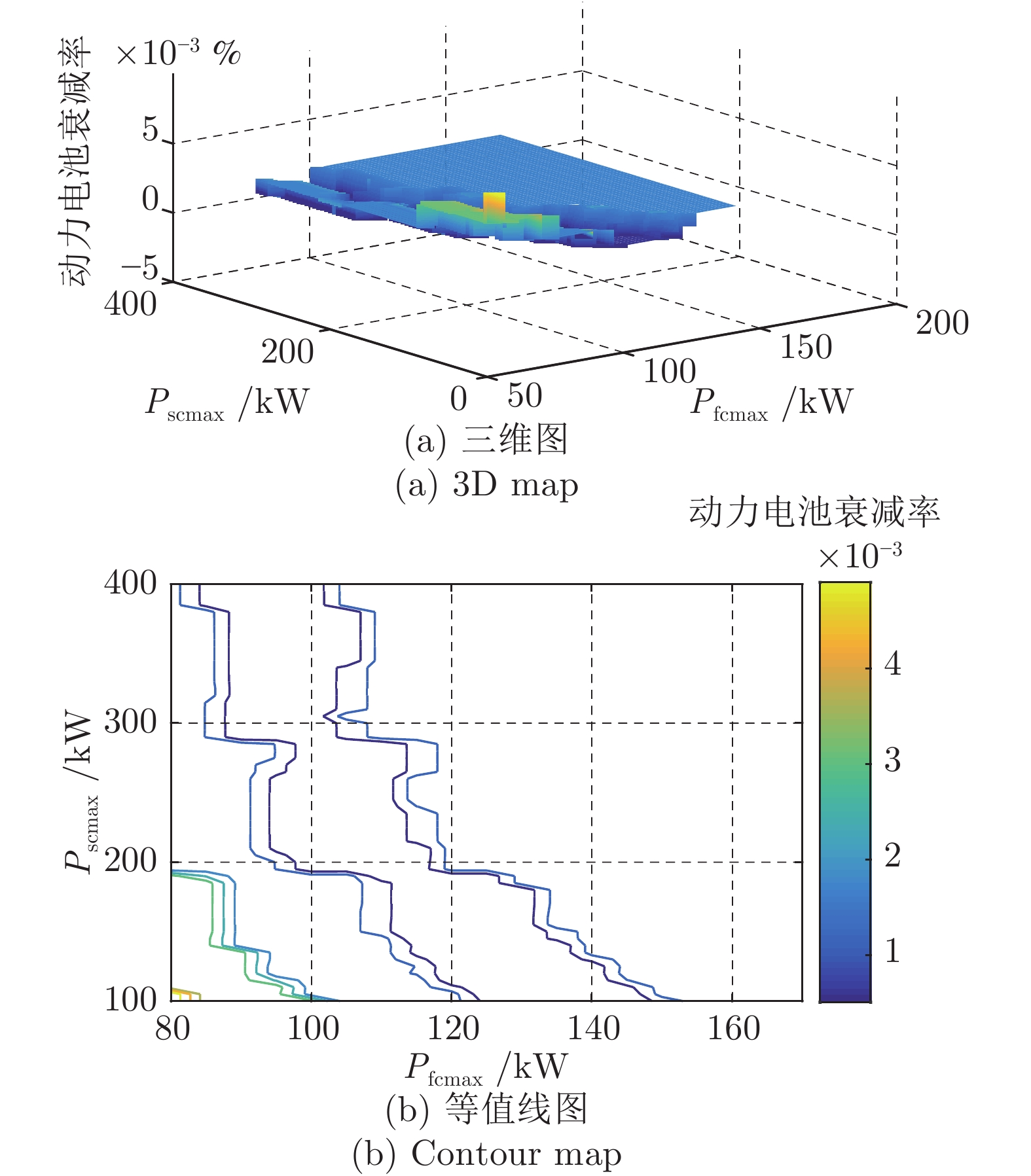
图 12 Pfcmax与Pscmax变化对动力电池耐久性的影响(Pbatmax = 150 kW)
Fig. 12 The effect of Pfcmax and Pscmax change on battery durability (Pbatmax = 150 kW)
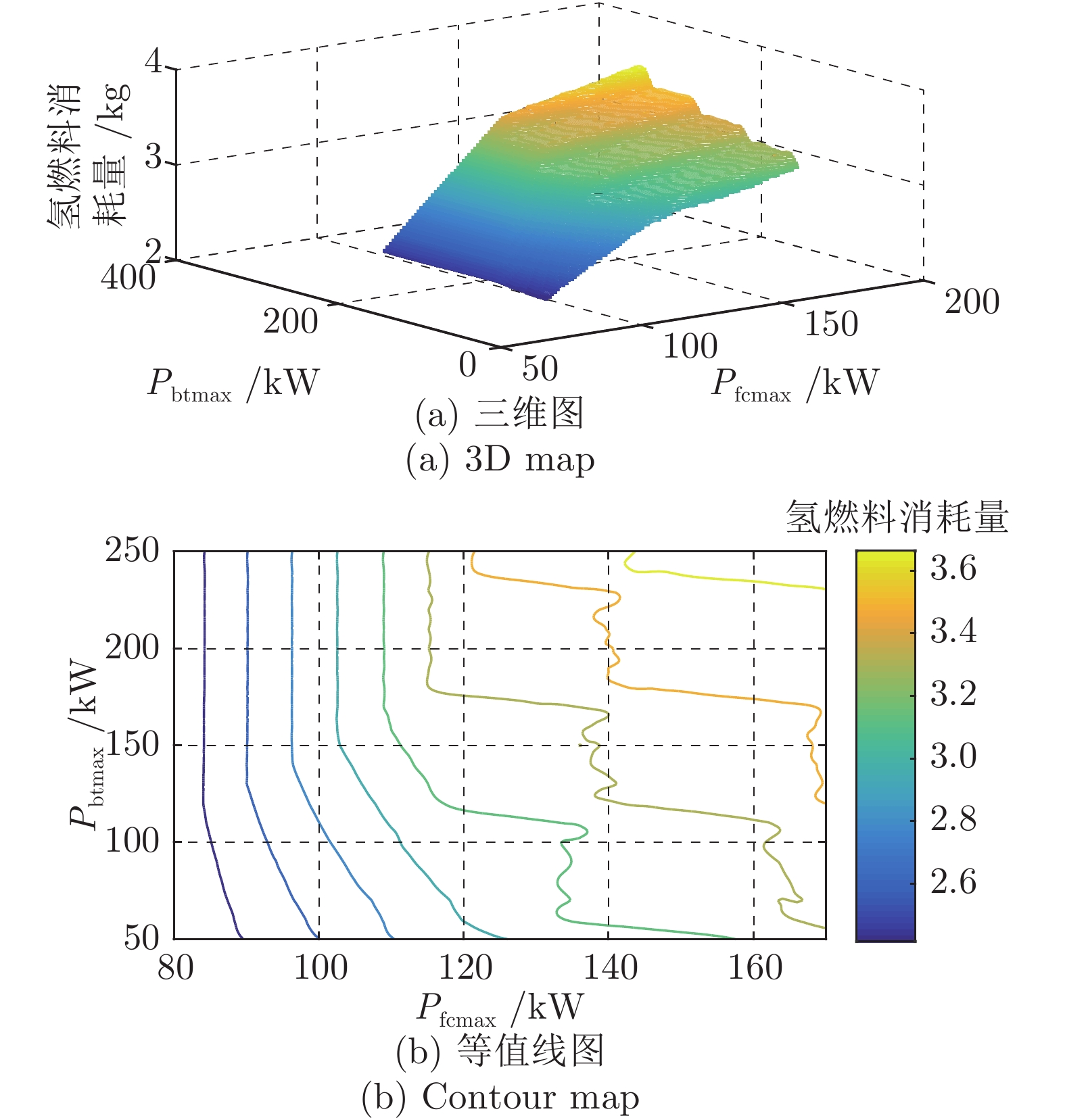
图 13 Pfcmax与Pbatmax变化对燃料经济性的影响(Pscmax = 300 kW)
Fig. 13 The effect of Pfcmax and Pbatmax change on fuelconsumption (Pscmax = 300 kW)
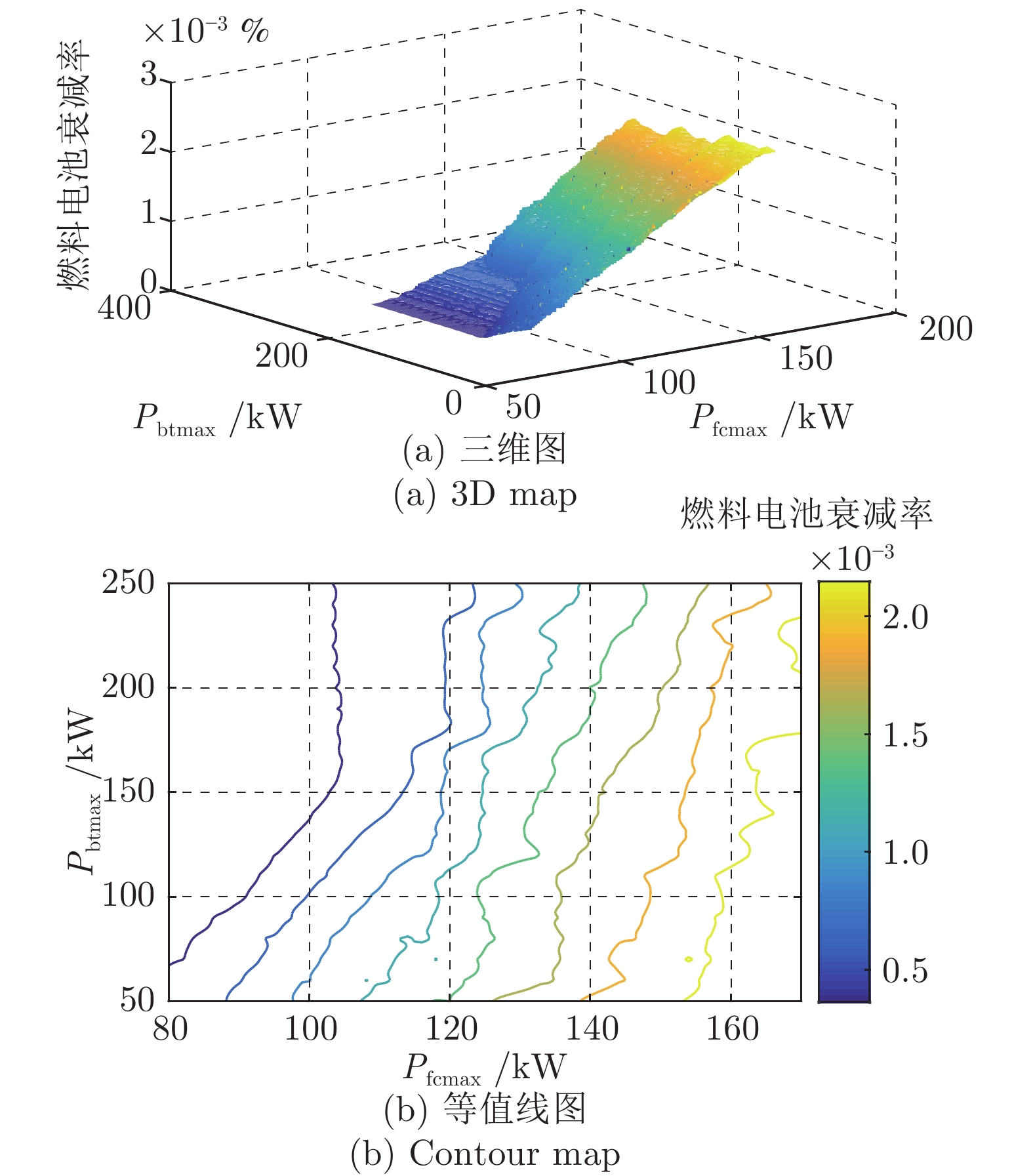
图 14 Pfcmax与Pbatmax变化对燃料电池耐久性的影响(Pscmax = 300 kW)
Fig. 14 The effect of Pfcmax and Pbatmax change on fuel cell durability (Pscmax = 300 kW)
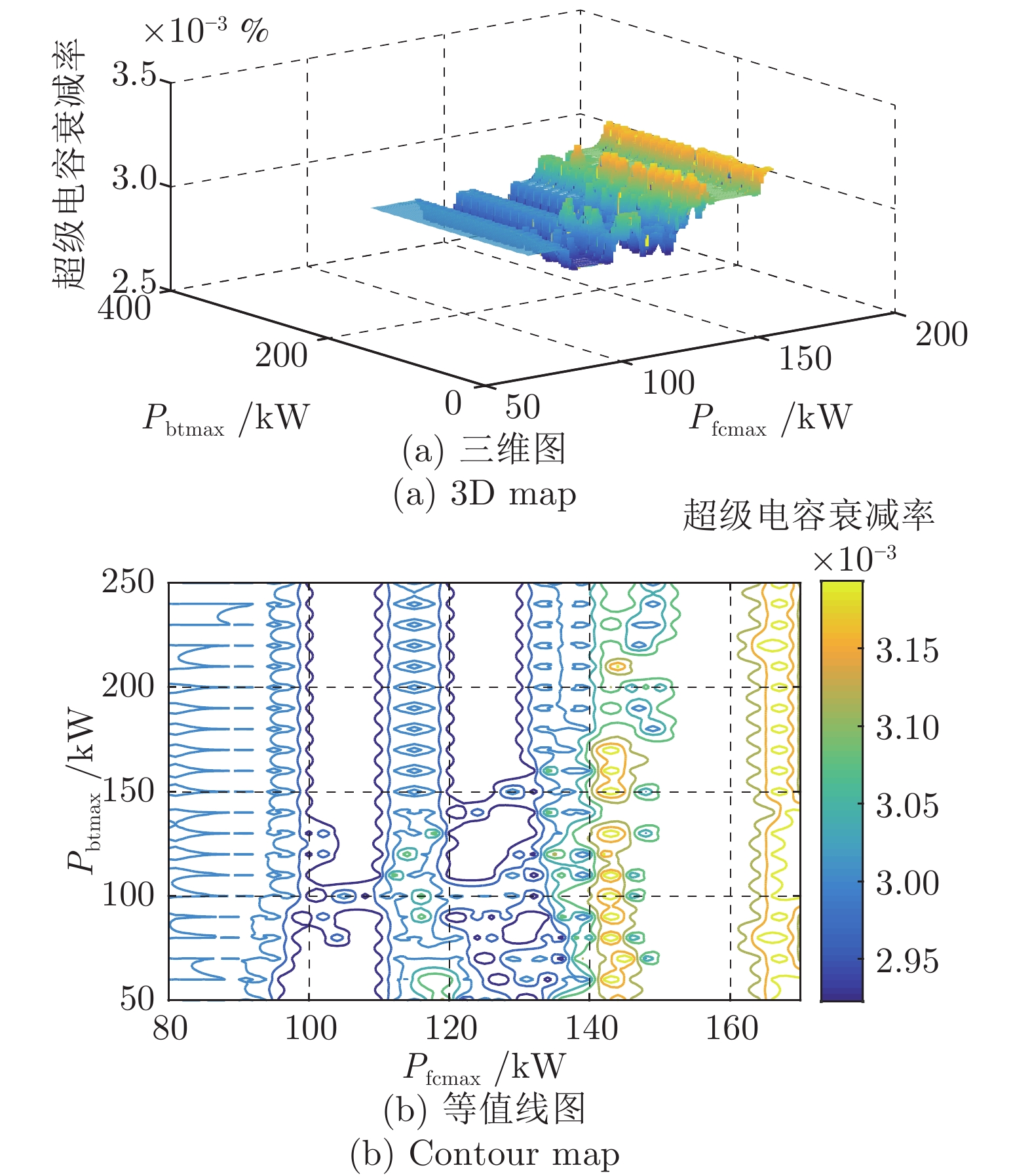
图 15 Pfcmax与Pbatmax变化对超级电容耐久性的影响(Pscmax = 300 kW)
Fig. 15 The effect of Pfcmax and Pbatmax change on SCdurability (Pscmax = 300 kW)

图 16 Pfcmax与Pbatmax变化对动力电池耐久性的影响(Pscmax = 300 kW)
Fig. 16 The effect of Pfcmax and Pbatmax change on battery durability (Pscmax = 300 kW)
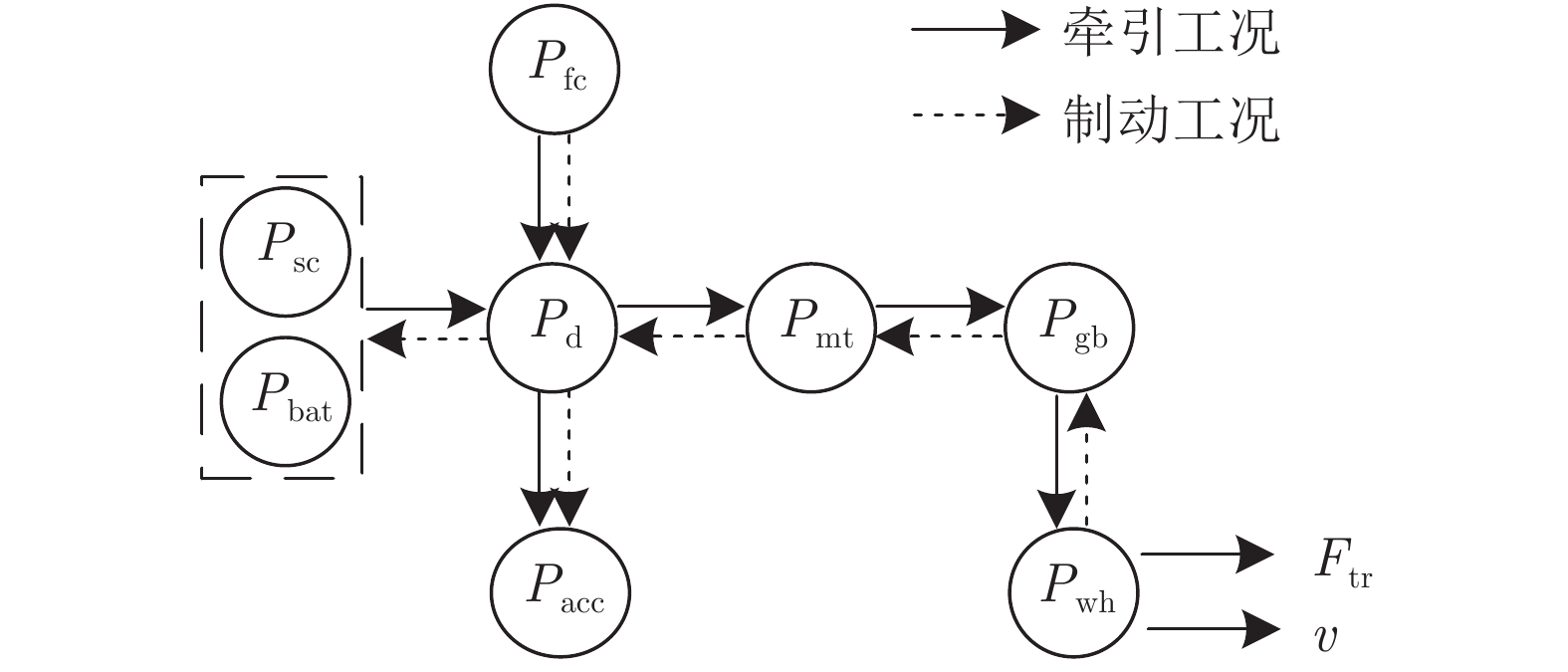
表 1 电车运行状态和对应策略
Table 1 Operating state and strategy of tramway
运行状态 策略 S1: FC 牵引 ${P_{\rm{d}}}= {P_{\rm{fc} }}$ S2: FC + SC 牵引 ${P_{\rm{d}}}= {P_{\rm{fc} }} + {P_{\rm{sc}}}$ S3: FC + SC + BT 牵引 ${P_{\rm{d}}} = {P_{\rm{fc} }} + {P_{\rm{sc}}} + {P_{\rm{bat}}}$ S4: 低功率 SC 充电 ${P_{\rm{d}}}= {P_{\rm{fc} }} - \left| {{P_{\rm{sc}}}} \right|$ S5: 低功率 BT 充电 ${P_{\rm{d}}}= {P_{\rm{fc} }} - \left| {{P_{\rm{bat}}}} \right|$ S6: 惰行/停车 SC 充电 ${P_{\rm{d}}}= {P_{\rm{fc} }} - \left| {{P_{\rm{sc}}}} \right|$ S7: 惰行/停车 BT 充电 ${P_{\rm{d}}} = {P_{\rm{fc} }} - \left| {{P_{\rm{bat}}}} \right|$ S8: 再生制动 + 机械制动 $\left| {{P_{\rm{d}} }} \right|{\rm{ + }}{P_{\rm{fc}}}= \left| {{P_{\rm{sc}}}} \right| + \left| {{P_{\rm{bat}}}} \right| + \left| {{P_{\rm{mb}}}} \right|$ S9: 高功率再生制动 $\left| {{P_{\rm{d}}}} \right| + {P_{\rm{fc}}}= \left| {{P_{\rm{sc}}}} \right| + \left| {{P_{\rm{bat}}}} \right|$ S10: 低功率再生制动 $\left| {{P_{\rm{d}}}} \right|{\rm{ + }}{P_{\rm{fc}}} = \left| {{P_{\rm{sc}}}} \right|$  下载: 导出CSV
下载: 导出CSV
表 2 燃料电池电压衰减值
Table 2 Fuel cell voltage degradation rates
运行状态 符号 衰减值 启停 $V_1'$ 23.91 μV·周期−1 空转 $U_1'$ 10.17 μV·h−1 负载变化 $V_2'$ 0.0441 μV·ΔkW−1 高功率运行 $U_2'$ 11.74 μV·h−1
下载: 导出CSV
表 3 不同DOD范围下允许消耗的循环次数
Table 3 DOD ranges and lifespan cycles
DODi 范围 LCbati LCsci DOD1 (10 %) 70 000 106 DOD2 (20 %) 31 000 106 DOD3 (30 %) 18 100 106 DOD4 (40 %) 11 800 106 DOD5 (50 %) 8 100 106 DOD6 (60 %) 5 800 106 DOD7 (70 %) 4 300 106 DOD8 (80 %) 3 300 106 DOD9 (90 %) 2 500 106
下载: 导出CSV
表 4 列车主要仿真参数
Table 4 The main simulation parameters of tramway
参数 取值 参数 取值 列车质量 (t) 66 最高车速 (km·h−1) 50 机械传动比 6.28 最大加速度 (m·s−1) 1 惯性质量系数 0.09 最大减速度 (m·s−1) 1 基本阻力系数 A0 2.59 整车辅助功耗 (kWh) 30 基本阻力系数 B0 0.0917 DC/DC 效率 92 % 基本阻力系数 C0 0.000775 DC/AC 效率 90 %
下载: 导出CSV
表 5 PEMFC系统参数
Table 5 The PEMFC system parameters
参数 取值 额定电压 (V) 540 额定功率 (kW) 150 最大功率 (kW) 170 单电池数量 (个) 735 最大电流 (A) 320
下载: 导出CSV
表 6 辅助能量源单体参数
Table 6 The parameters of auxiliary power units
动力电池参数 取值 超级电容参数 取值 额定电压 (V) 3.2 额定电压 (V) 2.7 额定容量 (Ah) 40 额定容量 (F) 3 000 工作温度 (℃) −20$\sim $45 工作温度 (℃) −40$\sim $60 内阻 (mΩ) $ \le 2$ 内阻 (mΩ) 0.29
下载: 导出CSV
表 8 不同策略下的性能指标对比
Table 8 The performance index of different EMS
性能指标 功率跟随
策略基于 GA
优化基于Pareto
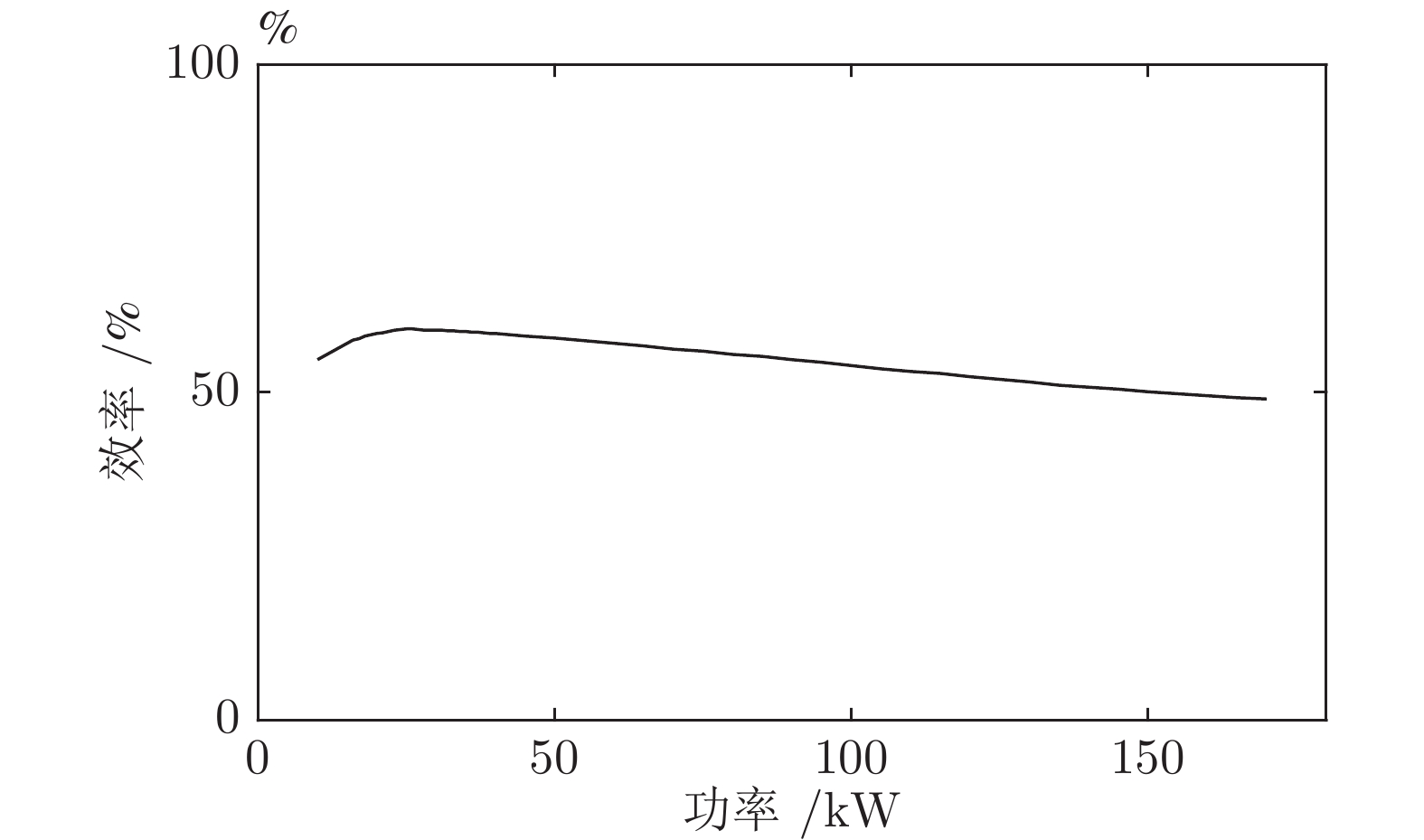
多目标优化燃料消耗量 (kg) 3.43 2.48 2.42 燃料电池性能衰减率 (%) 2.42 × 10−3 1.18 × 10−3 1.15 × 10−4 超级电容性能衰减率 (%) 3.2 × 10−3 3.3 × 10−3 2.9 × 10−3 动力电池性能衰减率 (%) 1.43 × 10−3 3.23 × 10−3 1.43 × 10−3 燃料电池系统效率 (%) 53.3 55.6 55.7
下载: 导出CSV
-
[1] 1 Kasimalla V K R, G N S, Velisala V. A review on energy allocation of fuel cell/battery/ultracapacitor for hybrid electric vehicles. International Journal of Energy Research, 2018, 42: 4263−4283 doi: 10.1002/er.4166 [2] 2 Scheepmaker G M, Goverde R M P, Kroon L G. Review of energy-efficient train control and timetabling. European Journal of Operational Research, 2017, 257(2): 355−376 doi: 10.1016/j.ejor.2016.09.044 [3] 吴铁洲, 王越洋, 许玉姗, 郭林鑫, 石肖, 何淑婷. 基于 PMP 算法的 HEV 能量优化控制策略. 自动化学报, 2018, 44(11): 2092−21023 Wu Tie-Zhou, Wang Yue-Yang, Xu Yu-Shan, Guo Lin-Xin, Shi Xiao, He Shu-Ting. Energy optimal control strategy of HEV with PMP algorithm. Acta Automatica Sinica, 2018, 44(11): 2092−2102 [4] 叶佩军, 吕宜生, 吉竟初. 基于社会网络视角的交通仿真和计算实验研究分析. 自动化学报, 2013, 39(9): 1402−14124 Ye Pei-Jun, Lv Yi-Sheng, Ji Jing-Chu. Literature analysis for traffic simulation and computational experiments based on social networks. Acta Automatica Sinica, 2013, 39(9): 1402−1412 [5] 5 Han Y, Li Q, Wang T H, Chen W R, Ma L. Multi-source coordination energy management strategy based on SOC consensus for a PEMFC–Battery–Supercapacitor hybrid tramway. IEEE Transactions on Vehicular Technology, 2018, 67(1): 296−305 doi: 10.1109/TVT.2017.2747135 [6] 6 Zhang W B, Li J Q, Xu L F, Ouyang M G. Optimization for a fuel cell/battery/capacity tram with equivalent consumption minimization strategy. Energy Conversion and Management, 2017, 134: 59−69 doi: 10.1016/j.enconman.2016.11.007 [7] 7 Dong H R, Zhu H N, Gao S G. An approach for energy-efficient and punctual train operation via driver advisory system. IEEE Intelligent Transportation Systems Magazine, 2018, 10(3): 57−67 doi: 10.1109/MITS.2018.2842030 [8] 8 Olatomiwa L, Mekhilef S, Ismail M S, Moghavvemi M. Energy management strategies in hybrid renewable energy systems: a review. Renewable and Sustainable Energy Reviews, 2016, 62: 821−835 doi: 10.1016/j.rser.2016.05.040 [9] 林泓涛, 姜久春, 贾志东, 程龙, 齐洪峰, 韦绍远. 权重系数自适应调整的混合储能系统多目标模型预测控制. 中国电机工程学报, 2018, 38(18): 5538−55479 Lin Hong-Tao, Jiang Jiu-Chun, Jia Zhi-Dong, Cheng Long, Qi Hong-Feng, Wei Shao-Yuan. Multi-objective model predictive control for hybrid energy storage system with adaptive adjustment of weight coefficients. Proceedings of the Chinese Society for Electrical Engineering, 2018, 38(18): 5538−5547 [10] 10 Zhang P, Yan F, Du C Q. A comprehensive analysis of energy management strategies for hybrid electric vehicles based on bibliometrics. Renewable and Sustainable Energy Reviews, 2015, 48: 88−104 doi: 10.1016/j.rser.2015.03.093 [11] 11 Zhang H, Yang J B, Zhang J Y, Song P Y, Xu X H. A firefly algorithm optimization-based equivalent consumption minimization strategy for fuel cell hybrid light rail vehicle. Energies, 2019, 12(14): 2665 doi: 10.3390/en12142665 [12] 12 Garcia P, Fernandez L M, Torreglosa J P, Jurado F. Comparative study of four control systems for a 400-kW fuel cell battery–powered tramway with two dc/dc converters. International Transactions on Electrical Energy System, 2013, 23: 1028−1048 doi: 10.1002/etep.1636 [13] 杨继斌, 宋鹏云, 张继业, 陈彦秋, 王国梁. 燃料电池混合动力列车建模与运行控制研究. 铁道学报, 2017, 39(9): 40−47 doi: 10.3969/j.issn.1001-8360.2017.09.00613 Yang Ji-Bin, Song Peng-Yun, Zhang Ji-Ye, Chen Yan-Qiu, Wang Guo-Liang. Research on modeling and operation Control of fuel cell hybrid power train. Journal of the China Railway Society, 2017, 39(9): 40−47 doi: 10.3969/j.issn.1001-8360.2017.09.006 [14] 王钦普, 游思雄, 李亮, 杨超. 插电式混合动力汽车能量管理策略研究综述. 机械工程学报, 2017, 53(16): 1−1914 Wang Qin-Pu, You Si-Xiong, Li Liang, Yang Chao. Survey on energy management strategy for plug-in hybrid electric vehicles. Journal of Mechanical Engineering, 2017, 53(16): 1−19 [15] Xu L F, Ouyang M G, Li J Q, Yang F Y. Dynamic programming algorithm for minimizing operating cost of a PEM fuel cell vehicle. In: Proceedings of the 21st IEEE International Symposium on Industrial Electronics. Hangzhou, China: IEEE, 2012. 28−31 [16] 杨继斌, 徐晓惠, 张继业, 宋鹏云. 燃料电池有轨电车能量管理策略多目标优化. 机械工程学报, 2018, 54(22): 153−15916 Yang Ji-Bin, Xu Xiao-Hui, Zhang Ji-Ye, Song Peng-Yun. Multi-objective optimization of energy management strategy for fuel cell tram. Journal of Mechanical Engineering, 2018, 54(22): 153−159 [17] 17 Li M G, Li M, Han G P, Liu N, Zhang Q M, Wang Y O. Optimization analysis of the energy management strategy of the new energy hybrid 100% low-floor tramcar using a genetic algorithm. Applied Sciences, 2018, 8(7): 1144 doi: 10.3390/app8071144 [18] 苏兆品, 张国富, 蒋建国, 岳峰, 张婷. 基于非支配排序差异演化的应急资源多目标分配算法. 自动化学报, 2017, 43(2): 195−21418 Su Zhao-Pin, Zhang Guo-Fu, Jiang Jian-Guo, Yue Feng, Zhang Ting. Multi-objective approach to emergency resource allocation using none-dominated sorting based differential evolution. Acta Automatica Sinica, 2017, 43(2): 195−214 [19] Jain M, Desai C, Kharma N, Williamson S S. Optimal powertrain component sizing of a fuel cell plug-in hybrid electric vehicle using multi-objective genetic algorithm. In: Proceedings of the 35th Annual Conference of IEEE. Porto, Portugal: IEEE, 2009. 3741–3746 [20] 李连升, 邓楼楼, 梅志武, 吕政欣, 刘继红. 聚焦型X 射线脉冲星望远镜Pareto多目标优化与多场耦合分析. 机械工程学报, 2018, 54(23): 174−18420 Li Lian-Sheng, Deng Lou-Lou, Mei Zhi-Wu, Lv Zheng-Xin, Liu Ji-Hong. Pareto-based multi-objective optimization of focusing X-ray pulsar telescope and multi-physics coupling analysis. Journal of Mechanical Engineering, 2018, 54(23): 174−184 [21] 21 Yang J B, Xu X H, Peng Y Q, Zhang J Y, Song P Y. Modeling and optimal energy management strategy for a catenary-battery-ultracapacitor based hybrid tramway. Energy, 2019, 183: 1123−1135 doi: 10.1016/j.energy.2019.07.010 [22] 杨继斌, 宋鹏云, 张继业, 王国梁, 张晗. 混合动力现代有轨电车仿真系统研究. 机械工程学报, 2017, 53(18): 161−16822 Yang Ji-Bin, Song Peng-Yun, Zhang Ji-Ye, Wang Guo-Liang, Zhang Han. Research on simulation system of hybrid modern tramway. Journal of Mechanical Engineering, 2017, 53(18): 161−168 [23] Spiegel C. PEM Fuel Cell Modeling and Simulation Using MATLAB. NewYork: Academic Press, 2008. 335−364 [24] 24 Tremblay O, Dessaint L A. Experimental validation of a battery dynamic model for EV applications. World Electric Vehicle Journal, 2009, 3(2): 289−298 doi: 10.3390/wevj3020289 [25] Ehsani M, Gao Y, Longo S, Ebrahimi K. Modern Electric, Hybrid Electric, and Fuel Cell Vehicles: Fundamentals, Theory, and Design (Second Edition). Boca Raton: CRC Press, 2018. 337−370 [26] 26 Herrera V I, Gaztanaga H, Milo A, Saez-de-Ibarra A, Etxeberria-Otadui I, Nieva Txomin. Optimal energy management and sizing of a battery-supercapacitor-based light rail vehicle with a multiobjective approach. IEEE Transactions on Industry Applications, 2016, 52(4): 3367−3377 doi: 10.1109/TIA.2016.2555790 [27] 27 Fang L C, Qin S Y, Xu G, Li T L, Zhu K M. Simultaneous optimization for hybrid electric vehicle parameters based on multi-objective genetic algorithms. Energies, 2011, 4(3): 532−544 doi: 10.3390/en4030532 [28] 28 Chen H C, Pei P C, Song M C. Lifetime prediction and the economic lifetime of proton exchange membrane fuel cells. Applied Energy, 2015, 142: 154−163 doi: 10.1016/j.apenergy.2014.12.062 [29] 29 Fletcher T, Thring R, Watkinson M. An energy management strategy to concurrently optimise fuel consumption & PEM fuel cell lifetime in a hybrid vehicle. International Journal of Hydrogen Energy, 2016, 41(46): 21503−21515 doi: 10.1016/j.ijhydene.2016.08.157 [30] 瞿凯平, 李昊飞, 余涛. 临近邻近均分轴线法及其在电 − 气互联系统帕累托优化运行中的应用. 中国电机工程学报, 2018, 38(7): 1990−200030 Qu Kai-Ping, Li Hao-Fei, Yu Tao. Adjoin uniform axes method and its application to the Pareto optimal operation of electric and natural gas combined systems. Proceedings of the Chinese Society for Electrical Engineering, 2018, 38(7): 1990−2000 [31] 31 Deb K. Multiobjective genetic algorithms: problem difficulties and construction of test functions. Evolutionary Computation, 1999, 7(3): 205−230 doi: 10.1162/evco.1999.7.3.205 -

 下载:
下载:



计量
- 文章访问数: 3105
- HTML全文浏览量: 879
- PDF下载量: 261
- 被引次数: 0
