

Short-text Sentiment Enhanced Achievement Prediction Method for Online Learners
-
摘要: 当前利用短文本情感信息进行在线学习成绩预测的研究存在以下问题: 1)当前情感分类模型无法有效适应在线学习社区的短文本特征, 分类效果较差; 2)利用短文本情感信息定量预测在线学习成绩的研究在准确性上还有较大的提升空间. 针对以上问题, 本文提出了一种短文本情感增强的成绩预测方法. 首先, 从单词和句子层面建模短文本语义, 并提出基于学习者特征的注意力机制以识别不同学习者的语言表达特点, 得到情感概率分布向量; 其次, 将情感信息与统计、学习行为信息相融合, 并基于长短时记忆网络建模学习者的学习状态; 最后, 基于学习状态预测学习者成绩. 在三种不同类别课程组成的真实数据集上进行了实验, 结果表明本文方法能有效对学习社区短文本进行情感分类, 且能够提升在线学习者成绩预测的准确性. 同时, 结合实例分析说明了情感信息、学习状态与成绩之间的关联.Abstract: Research of online learning achievement prediction based on short text sentiment information has the following problems: 1) Current sentiment classification model cannot effectively adapt to short text features of online learning community, and classification effect is poor; 2) Prediction accuracy of online learning achievements using short text sentiment information has a lot of room for improvement. In view of above problems, this paper proposes a short text sentiment enhanced achievement prediction method. Firstly, short text semantics are modeled from the word and sentence level, and attention mechanism based on learner characteristics is proposed to identify the expression characteristics of different learners. Secondly, sentiment information is fused with statistics and learning behavior information, and use long-short term memory network to model learning state of learner. Finally, learner's grade is predicted based on learning state. Experiments were carried out on real data set composed of three types courses. The results show that our method can effectively classify short texts of the learning community and improve the accuracy of online learners' achievement predictions. At the same time, combined with case analysis, relationship between emotional information, learning status and achievement is explained.
-
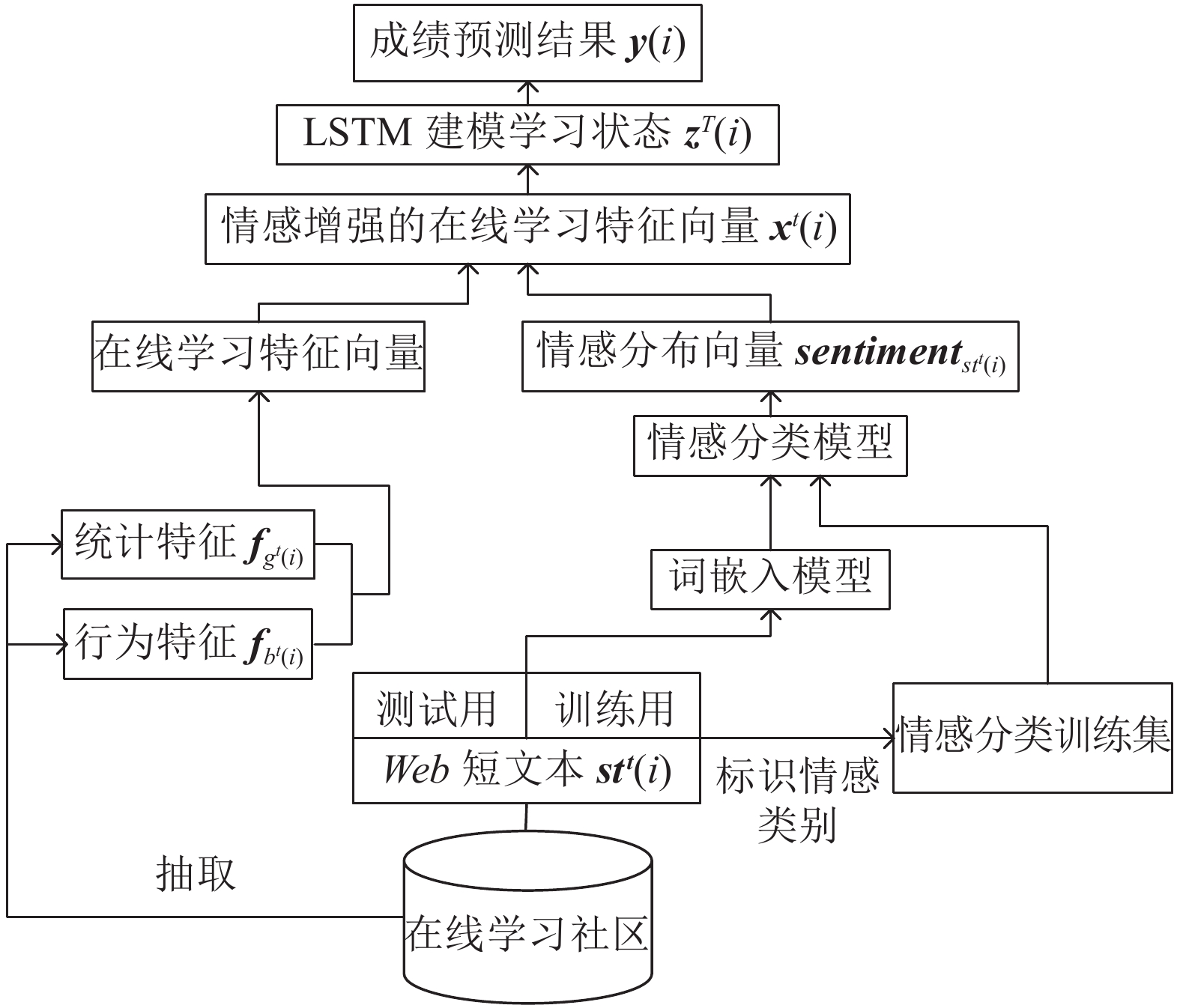
图 1 基于短文本情感增强的在线学习行为预测方法框架
Fig. 1 Short-text sentiment enhanced achievement prediction method for online learners framework
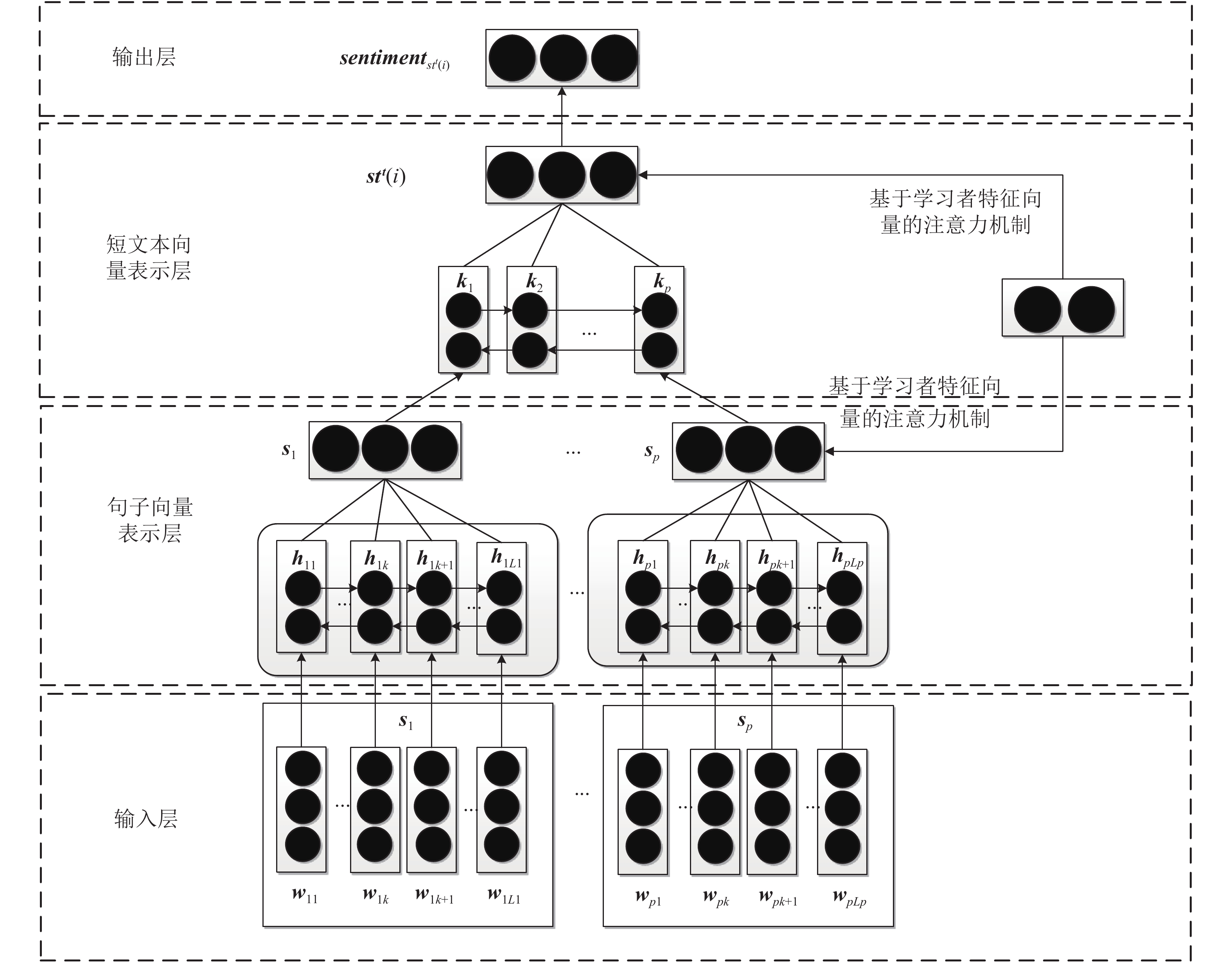
图 2 在线学习社区短文本表示模型
Fig. 2 Sentiment classification model for online learning community short text
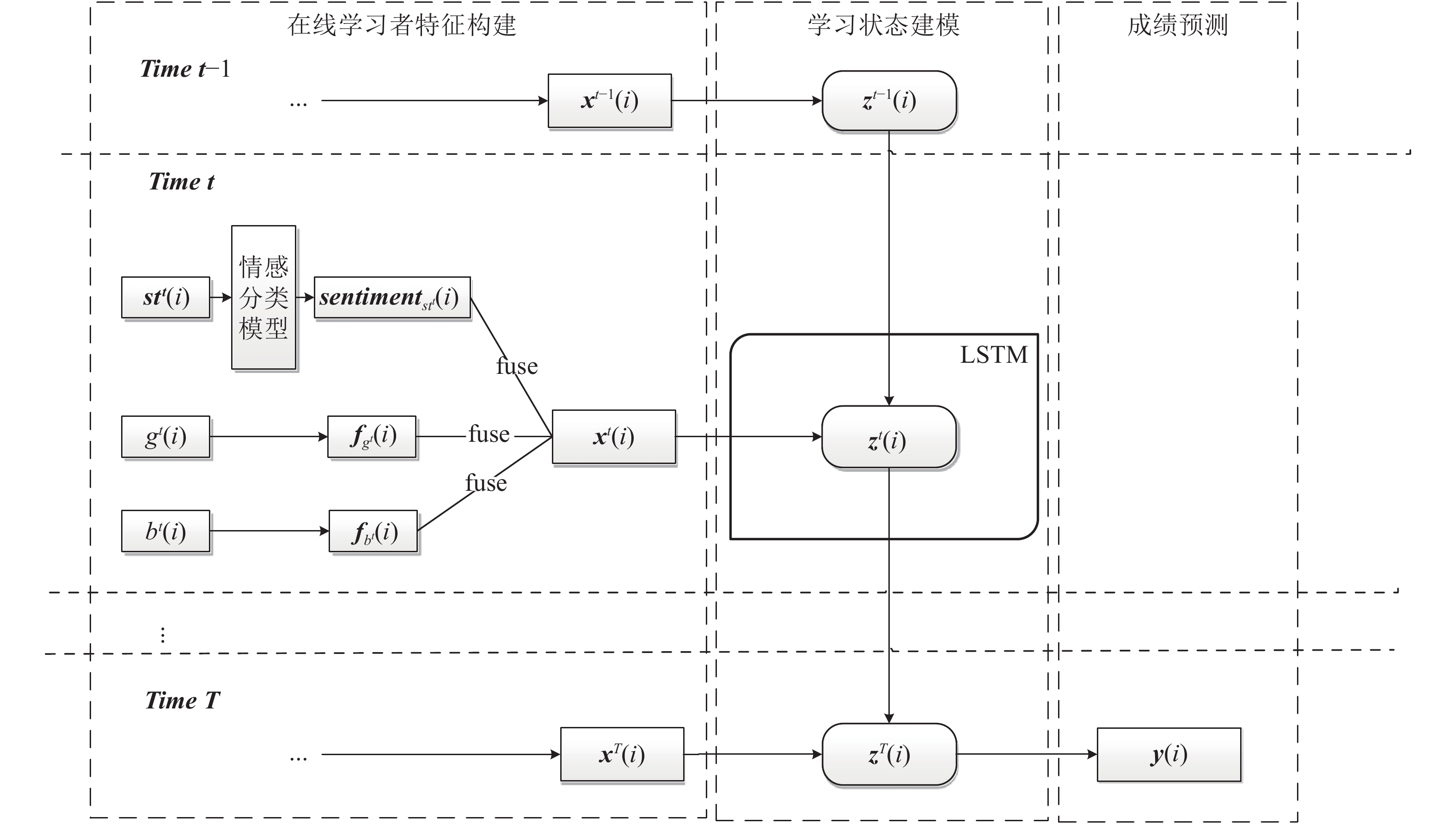
图 3 学习状态建模与成绩预测过程
Fig. 3 Learning state modeling and achievement prediction process framework
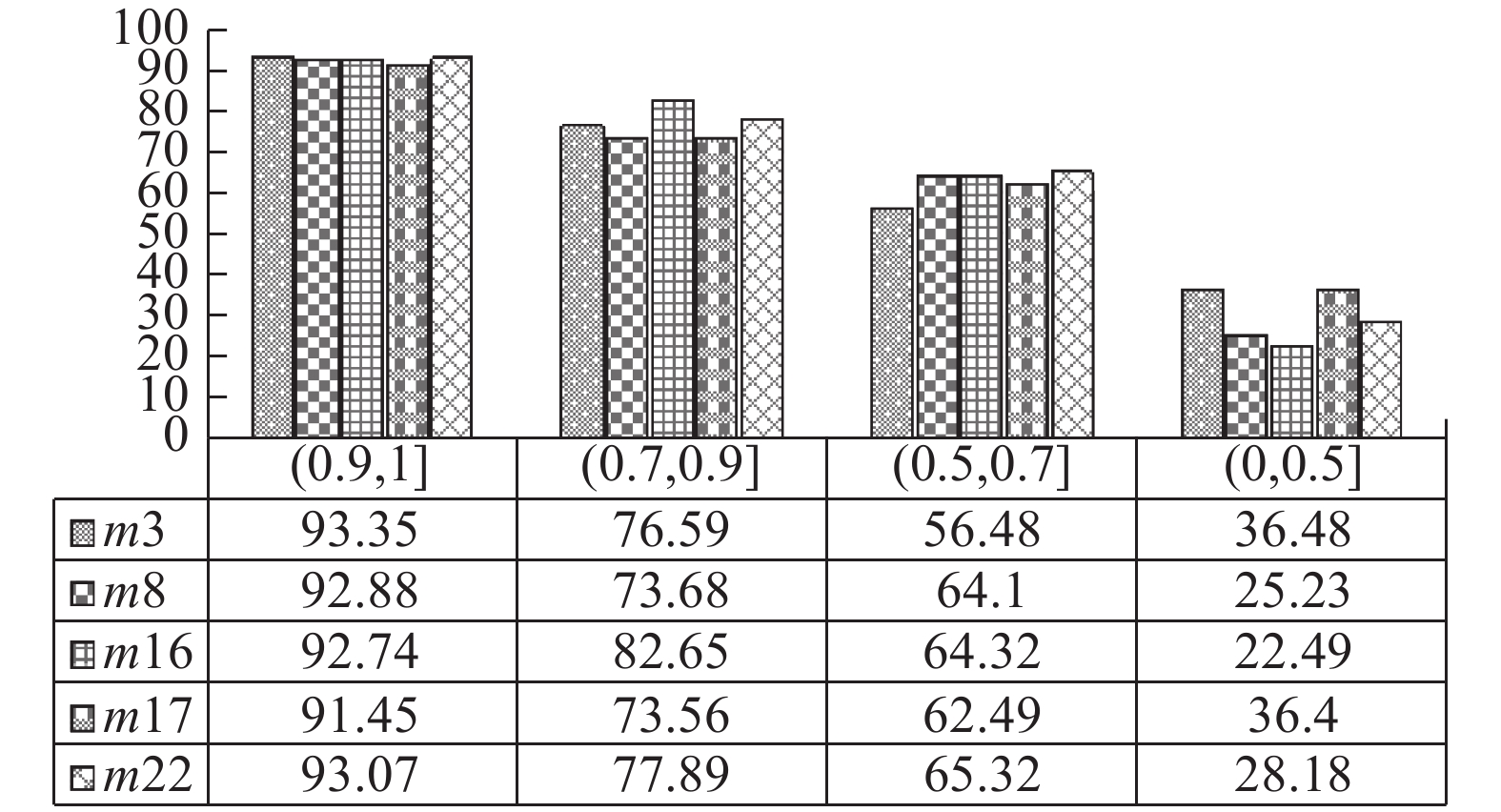
图 7 学习状态呈现正向变化的学习者占区间总学习者的比率(积极情感)
Fig. 7 The ratio of learners who have a positive change in learning status to the total learner in the interval (positive emotions)
表 1 不同类别课程的数量
Table 1 Number of different types of courses
课程类别 课程 合计课程数量数量 (门) 工科 计算机科学, 电子工程 5 理科 物理 2 文科及其他 历史,体育 4  下载: 导出CSV
下载: 导出CSV
表 4 模型部分使用的特征
Table 4 Part features used in the model
特征类别 特征个数 部分特征 统计特征 8+ 性别、年龄、教育层次、相关先行课成绩等 学习行为特征 16+ 发帖次数、被回帖次数、观看教学视频时间、知识点测验成绩等
下载: 导出CSV
表 2 不同类别课程的人数及发帖数量
Table 2 Number of people and post in different type courses
课程类别 平均学习者人数 (人) 每个知识点下的发/回帖数量 (个) 工科 2 326 3 200 理科 2 681 1 520 文科及其他 2 170 1 060
下载: 导出CSV
表 3 不同类别课程的情感类别分布
Table 3 Distribution of sentiment categories in different type courses
课程类别 情感类别分布 (约简为整数), 积极/消极/疑惑/正常情绪 (%) 工科 16/14/37/33 理科 21/19/27/33 文科及其他 29/12/22/37
下载: 导出CSV
表 5 工程类课程的情感分类结果
Table 5 Sentiment classification results of engineering courses
方法 ACC RMSE Trigram 0.373 1.754 TextFeature 0.415 1.789 SSWE 0.353 1.976 RNN + RNN 0.432 1.673 Paragraph Vector 0.379 1.834 DMGRNN 0.506 1.394 HAN 0.532 1.281 本文方法 0.573 1.185
下载: 导出CSV
表 7 文科及其他类课程的情感分类结果
Table 7 Sentiment classification results of no-science courses
方法 ACC RMSE Trigram 0.549 0.814 TextFeature 0.562 0.811 SSWE 0.568 0.864 RNN + RNN 0.585 0.806 Paragraph Vector 0.578 0.772 DMGRNN 0.650 0.685 HAN 0.677 0.633 本文方法 0.706 0.584
下载: 导出CSV
表 6 理科类课程的情感分类结果
Table 6 Sentiment classification results of science courses
方法 ACC RMSE Trigram 0.543 0.822 TextFeature 0.556 0.850 SSWE 0.550 0.851 RNN + RNN 0.580 0.786 Paragraph Vector 0.556 0.821 DMGRNN 0.644 0.696 HAN 0.674 0.652 本文方法 0.693 0.628
下载: 导出CSV
表 8 工科类课程的成绩预测结果
Table 8 Achievements prediction results of engineering courses
方法 Accuracy RMSE MR− 0.566 0.479 MR+ 0.590 0.452 MLP− 0.583 0.464 MLP+ 0.603 0.437 XGBoost− 0.679 0.335 XGBoost+ 0.697 0.284 FM 0.674 0.326 LadFG 0.818 0.226 SEAP 0.874 0.095
下载: 导出CSV
表 10 文科及其他类课程的成绩预测结果
Table 10 Achievements prediction results of no-science courses
方法 Accuracy RMSE MR− 0.648 0.409 MR+ 0.664 0.336 MLP− 0.652 0.340 MLP+ 0.688 0.307 XGBoost− 0.701 0.281 XGBoost+ 0.743 0.269 FM 0.726 0.222 LadFG 0.874 0.154 SEAP 0.924 0.051
下载: 导出CSV
表 9 理科类课程的成绩预测结果
Table 9 Achievements prediction results of science courses
方法 Accuracy RMSE MR− 0.598 0.430 MR+ 0.612 0.419 MLP− 0.618 0.408 MLP+ 0.643 0.372 XGBoost− 0.689 0.295 XGBoost+ 0.709 0.278 FM 0.687 0.295 LadFG 0.803 0.203 SEAP 0.902 0.084
下载: 导出CSV
-
[1] Seaton D T, Bergner Y, Chuang I, Mitros P, Pritchard D E. Who does what in a massive open online course? Communications of the ACM, 2014, 44(4): 58−65 [2] Kizilcec R F, Piech C, Schneider E. Deconstructing disengagement: Analyzing learner subpopulations in massive open online courses. In: Proceedings of the 3rd International Conference on Learning Analytics and Knowledge. Leuven, Belgium: ACM, 2013. 170−179 [3] Fujita H. Neural-fuzzy with representative sets for prediction of student performance. Applied Intelligence, 2019, 49(1): 172−187 doi: 10.1007/s10489-018-1262-7 [4] Guay F, Bureau J S. Motivation at school: Difierentiation between and within school subjects matters in the prediction of academic achievement. Contemporary Educational Psychology, 2018, 54(1): 42−54 [5] Bergold S, Steinmayr R. Personality and intelligence interact in the prediction of academic achievement. Journal of Intelligence, 2018, 6(2): 27−27 doi: 10.3390/jintelligence6020027 [6] Gardner J, Brooks C. Student success prediction in MOOCs. User Modeling and User-Adapted Interaction, 2018, 28(2): 127−203 doi: 10.1007/s11257-018-9203-z [7] Fujita H. Neural-fuzzy with representative sets for prediction of student performance. Applied Intelligence, 2019, 49(1): 172−187 doi: 10.1007/s10489-018-1262-7 [8] Dalipi F, Imran A S, Kastrati Z. MOOC dropout prediction using machine learning techniques: Review and research challenges. In: Proceedings of the 2018 Global Engineering Education Conference. Albuquerque, USA: IEEE, 2018. 1007−1014 [9] Conijn R, Van den Beemt A, Cuijpers P. Predicting student performance in a blended MOOC. Journal of Computer Assisted Learning, 2018, 34(5): 612−628 [10] Corbett A T, Anderson J R. Knowledge tracing: Modeling the acquisition of procedural knowledge. User Modeling and User-Adapted Interaction, 1994, 4(4): 235−278 [11] Piech C, Bassen J, Huang J, Ganguli S, Sahami M, Guibas L, Sohl-Dickstein J. Deep knowledge tracing. Computer Science, 2015, 3(3): 19−23 [12] Zhang J N, Shi X J, King I, Yeung D Y. Dynamic key-value memory network for knowledge tracing. In: Proceedings of the 26th International Conference on World Wide Web Conferences, Perth, Western Australia: ACM, 2017. 765−774 [13] Embretson S E, Reise S P. Item response theory for psychologists. Quality of Life Research, 2004, 13(3): 715−716 doi: 10.1023/B:QURE.0000021503.45367.f2 [14] Torre J D L. DINA model and parameter estimation: A didactic. Journal of Educational and Behavioral Statistics, 2009, 34(1): 115−130 [15] Liu Q, Wu R Z, Chen E H, Xu G D, Su Y, Chen Z G, Hu G P. Fuzzy cognitive diagnosis for modelling examinee performance. ACM Transactions on Intelligent Systems and Technology, 2018, 9(4): 1−26 [16] Anderson A, Huttenlocher D, Kleinberg J, Leskovec J. Engaging with massive online courses. In: Proceedings of the 23rd International Conference on World Wide Web. New York, USA: ACM, 2014. 687−698 [17] Ramesh A, Goldwasser D, Huang B, Daumé H, Getoor L. Learning latent engagement patterns of students in online courses. In: Proceedings of the 28th AAAI Conference on Artiflcial Intelligence. Québec, Canada: AAAI, 2014.1272−1278 [18] Bayer J, Bydžovská H, Géryk J, Obšívač T, Popelínský L. Predicting drop-out from social behaviour students. In: Proceedings of the 4th International Conference on Educational Data Mining. Eindhoven, Netherlands: IEDM 2012. 103−109 [19] Sweeney M, Rangwala H, Lester J, Johri A. Next-term student performance prediction: A recommender systems approach. In: Proceedings of the 8th International Conference on Educational Data Mining. Madrid, Spain: IEDM. 2016. 7−7 [20] Ren Z, Xia N, Rangwala H. Grade prediction with temporal course-wise influence. arXiv:1709.05433, 2017. [21] Qiu J Z, Tang J, Liu T X, Gong J, Zhang C H, Zhang Q, Xue Y F. Modeling and predicting learning behavior in MOOCs. In: Proceedings of the 2016 ACM International Conference on Web Search and Data Mining. San Francisco, USA: ACM, 2016. 93−102 [22] Yang H, Cheung L P. Implicit heterogeneous features embedding in deep knowledge tracing. Cognitive Computation, 2018, 10(1): 3−14 doi: 10.1007/s12559-017-9522-0 [23] Zhang L, Xiong X L, Zhao S Y, Botelho A F, Heffernan N T. Incorporating rich features into deep knowledge tracing. In: Proceedings of the 4th ACM Conference on Learning Scale. Cambridge, USA: ACM, 2017. 169−172 [24] Huang Y. Deeper knowledge tracing by modeling skill application context for better personalized learning. In: Proceedings of the 2016 Conference on User Modeling Adaptation and Personalization. Halifax, Canada: ACM, 2016. 325−328 [25] Su Y, Liu Q W, Liu Q, Huang Z Y, Yin Y, Chen E H, Ding C, Wei S, Hu G P. Exercise-enhanced sequential modeling for student performance prediction. In: Proceedings of the 32nd AAAI Conference on Artiflcial Intelligence. New Orleans, USA: AAAI, 2018. 2435−2443 [26] Feng W Z, Tang J, Liu T X. Understanding dropouts in MOOCs. In: Proceedings of the 32nd AAAI Conference on Artiflcial Intelligence, Hawaii, USA: AAAI, 2019. [27] Wen M M, Yang D Y, Rosé C P. Sentiment analysis in MOOC discussion forums: What does it tell us? In: Proceedings of the 6th International Conference on Educational Data Mining. London, UK: IEDM, 2014. 130−138 [28] Tucker C, Pursel B K, Divinsky A. Mining studentgenerated textual data in MOOCs and quantifying their effects on student performance and learning outcomes. The ASEE Computers in Education Journal, 2014, 5(4): 84−84 [29] Chaplot D S, Rhim E, Kim J. Predicting student attrition in MOOCs using sentiment analysis and neural networks. In: Proceedings of the 2015 Workshops at the 17th International Conference on Artiflcial Intelligence in Education. Madrid, Spain: CEUR-WS.org, 2015. 7−12 [30] 冯冲, 康丽琪, 石戈, 黄河燕. 融合对抗学习的因果关系抽取. 自动化学报, 2018, 44(5): 811−818Feng Chong, Kang Li-Qi, Shi Ge, Huang He-Yan. Causality extraction with GAN. Acta Automatica Sinica, 2018, 44(5): 811−818 [31] 郝洺, 徐博, 殷绪成, 王方圆. 基于n-gram频率的语种识别改进方法. 自动化学报, 2018, 44(3): 453−460Hao Ming, Xu Bo, Yin Xu-Cheng, Wang Fang-Yuan. Improve language identiflflcation method by means of n-gram frequency. Acta Automatica Sinica, 2018, 44(3): 453−460 [32] 侯丽微, 胡珀, 曹雯琳. 主题关键词信息融合的中文生成式自动摘要研究. 自动化学报, 2019, 45(3): 530−539Hou Li-Wei, Hu Po, Cao Wen-Lin. Automatic Chinese abstractive summarization with topical keywords fusion. Acta Automatica Sinica, 2019, 45(3): 530−539 [33] Wu Z, Dai X Y, Yin C Y, Huang S J, Chen J J. Improving review representations with user attention and product attention for sentiment classiflcation. In: Proceedings of the 32nd AAAI Conference on Artiflcial Intelligence. New Orleans, USA: AAAI, 2018. 5989−5996 [34] Pennington J, Socher R, Manning C. Glove: Global vectors for word representation. In: Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing. Doha, Qatar: ACL, 2014: 1532−1543 [35] Ramesh A, Kumar S H, Foulds J, Getoor L. Weakly supervised models of aspect-sentiment for online course discussion forums. In: Proceedings of the 53rd Annual Meeting of the Association for Computational Linguistics and the 7th International Joint Conference on Natural Language Processing. Beijing, China: ACL, 2015. 74−83 [36] Fan R E, Chang K W, Hsieh C J, Wang X R, Lin C J. LIBLINEAR: A library for large linear classiflcation. Journal of Machine Learning Research, 2008, 9(9): 1871−1874 [37] Kiritchenko S, Zhu X D, Mohammad S M. Sentiment analysis of short informal text. Journal of Artiflcial Intelligence Research, 2014, 50(1): 723−762 [38] Socher R, Perelygin A, Wu J Y, Chuang J, Manning C D, Ng A, Potts C. Recursive deep models for semantic compositionality over a sentiment treebank. In: Proceedings of the 2013 Conference on Empirical Methods in Natural Language Processing. Seattle, USA: ACL, 2013. 1631−1642 [39] Le Q V, Mikolov T. Distributed representations of sentences and documents. In: Proceedings of the 2013 Conference on Empirical Methods in Natural Language Processing. Seattle, USA: ACL. 2013: 1631−1642 [40] Tang D Y, Qin B, Liu T. Document modeling with gated recurrent neural network for sentiment classiflcation. In: Proceedings of the 2015 Conference on Empirical Methods in Natural Language Processing. Lisbon, Portuga: ACL. 2015: 1422−1432 [41] Yang Z C, Yang D Y, Dyer C, He X D, Smola A, Hovy E. Hierarchical attention networks for document classiflcation. In: Proceedings of the 2016 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies. San Diego, USA: ACL, 2016: 1480−1489 -

 下载:
下载:




计量
- 文章访问数: 1947
- HTML全文浏览量: 390
- PDF下载量: 245
- 被引次数: 0
