

-
摘要: 讨论现有基于模型的故障诊断与容错控制方法的局限性, 并由此提出一个基于$\nu$- 间隙度量来处理故障诊断与容错控制的新框架. 并且, 讨论了如何在此框架下对故障进行分类和分级以及提出如何进行容错控制的一般性控制结构.
-
关键词:
- 故障诊断 /
- 容错控制 /
- $\nu$- 间隙度量 /
- 鲁棒控制 /
- 系统辨识
Abstract: This paper discusses the limitations of existing model-based fault diagnosis and fault-tolerant control methods, and proposes a new framework for fault diagnosis and fault-tolerant control based on $\nu$-gap metric. The paper discusses further how to classify faults under this framework and proposes a general control structure for fault-tolerant control.-
Key words:
- Fault diagnosis /
- fault-tolerant control /
- $\nu$-gap metric /
- robust control /
- system identification
1) 本文责任编委 杨浩 -
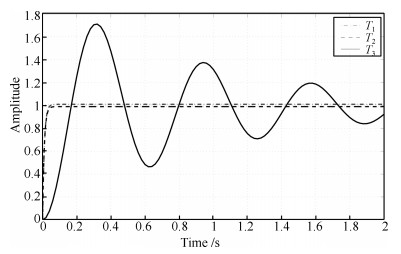
图 7 闭环系统$T_1$, $T_2$和$T_3$阶跃响应
Fig. 7 Step responses of the closed-loop systems $T_1$, $T_2$ and $T_3$
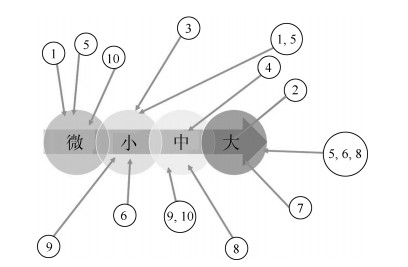
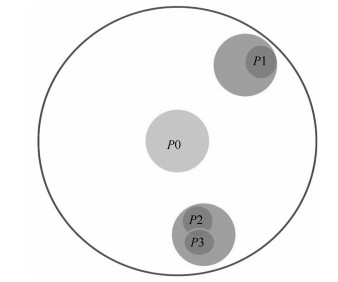
图 9 故障按照对系统性能影响程度分级示意图
Fig. 9 Illustrative diagram for fault classification according to its impact on system performance
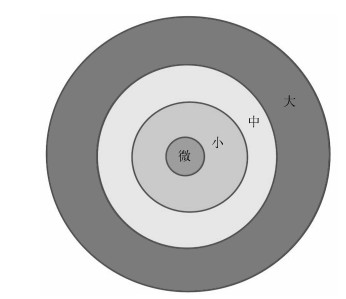
图 10 按$\nu$- 间隙度量分成故障等级示意图
Fig. 10 Illustrative diagram for fault classification according to $\nu$-gap metric
-
[1] Chen J, Patton R. Robust Model-Based Fault Diagnosis for Dynamic Systems. Springer, 1999. [2] Ding S X. Model-Based Fault Diagnosis Techniques -Design Schemes, Algorithms and Tools. 2nd Edition, Springer-Verlag, London, 2013. [3] Ding S X. Data-Driven Design of Fault Diagnosis and Fault-Tolerant Control Systems. Springer-Verlag, London, 2014. [4] Zhou K. Essentials of Robust Contro. Prentice-Hall, Englewood Cliffs, NJ, 1998. [5] Liu N, Zhou K. Optimal robust fault detection for linear discrete time systems. Journal of Control Science and Engineering, 2008, 2008(7): 1-16 http://ieeexplore.ieee.org/document/4434125/citations [6] Li X, Zhou K. A time domain approach to robust fault detection of linear time-varying systems. Automatica, 2009, 45(1): 94-102 doi: 10.1016/j.automatica.2008.07.017 [7] Vinnicombe G. Uncertainty and Feedback: Hinf Loop-Shaping and the V-Gap Metric. World Scientific, 2000. [8] Zhou K, Ren Z. A new controller architecture for high performance, robust, adaptive, and fault tolerant control. IEEE Transactions on Automatic Control, 2001, 46(10): 1613-1618 doi: 10.1109/9.956059 [9] Zhou K. A new approach to robust and fault tolerant control. Acta Automatica Sinca, 2005, 31(1): 43-55 [10] 周克敏. 鲁棒控制: 回顾与展望(黄琳院士主编《中国学科发展战略: 控制科学》第十二章). 科学出版社, 2015.Zhou K M. Robust control: Retrospect and prospect, (Huang Lin as Editor-in-Chief of the Chinese Discipline Development Strategy: Control Science, Chapter 12), Science Press, 2015. [11] Ding S X, Yang, Y, Zhang Y, Li L. Data-driven realization of kernel and image representations and their application to fault detection and control system design. Automatica, 2014, 50: 2615-2623 doi: 10.1016/j.automatica.2014.08.022 [12] Ding S X. Application of factorization and gap metric techniques to fault detection and isolation, Part Ⅰ and Part 2. IFAC Conference Paper Archive, 2015, 48(21): 113-124 http://www.sciencedirect.com/science/article/pii/S2405896315016420 [13] Georgiou T T. On the computation of the gap metric. Systems and Control Letters, 1988, 11: 253-257 doi: 10.1016/0167-6911(88)90067-9 [14] Georgiou T T, Smith M C. Optimal robustness in the gap metric. IEEE Transactions on Automatic Control, 1990, 35: 673-686 doi: 10.1109/9.53546 [15] Koenings T, Krueger M, Luo H, Ding S X. A data-driven computation method for the gap metric and the optimal stability margin. IEEE Transactions on Automatic Control, 2018, 63(3): 805-810 doi: 10.1109/TAC.2017.2735023 -

 下载:
下载:
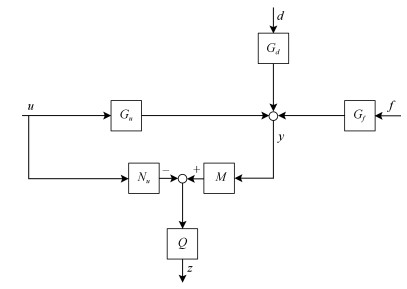








图(13)
计量
- 文章访问数: 1602
- HTML全文浏览量: 1322
- PDF下载量: 716
- 被引次数: 0
