

Trajectory Control of Quadrotor With Cable-Suspended Load via Dynamic Feedback Linearization
-
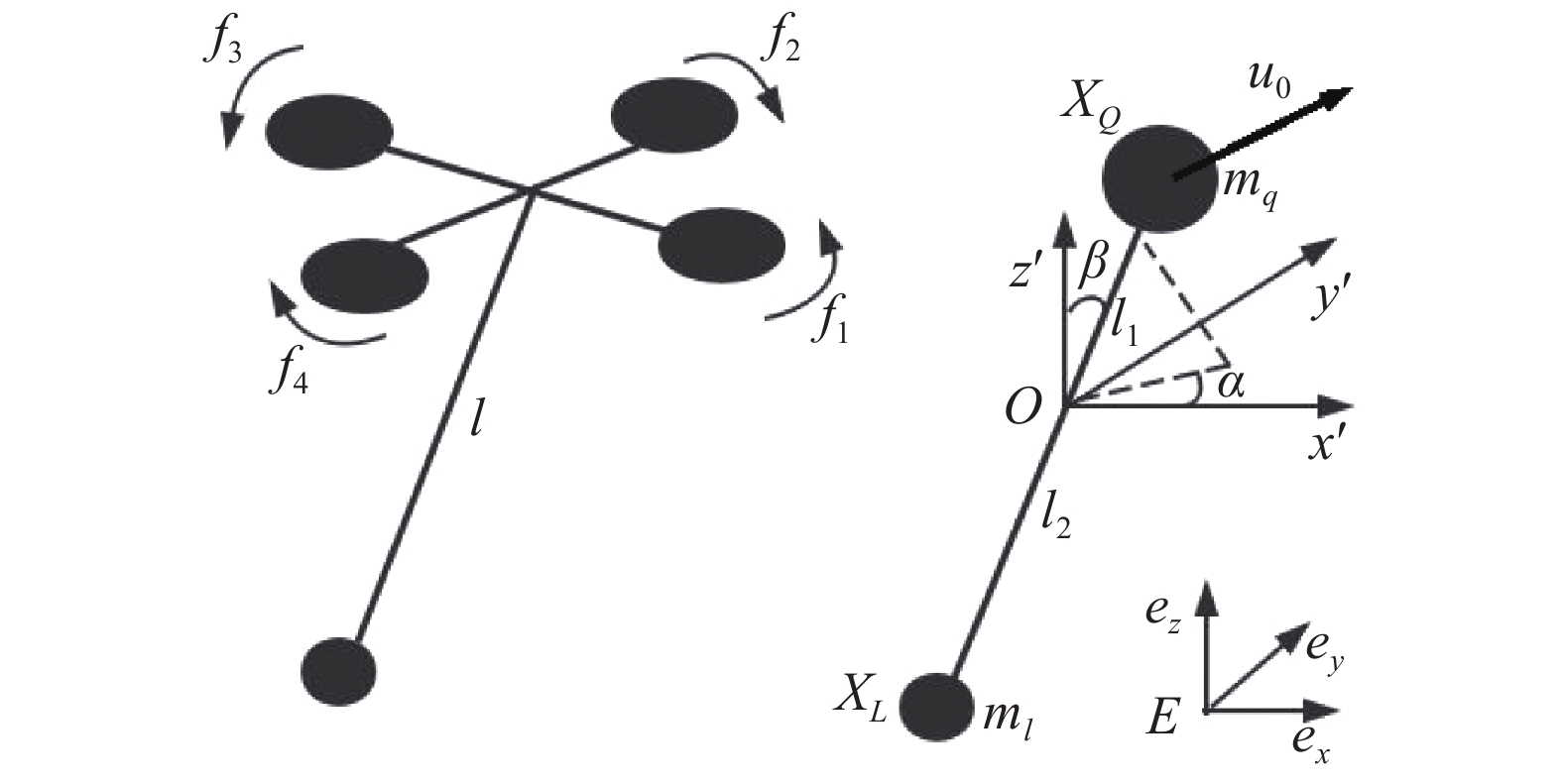
摘要: 三维空间下的四旋翼吊挂运输系统是一种欠驱动、强耦合、多变量的非线性系统. 根据系统的动力学特点, 将系统分解为双质点系绳连接子系统和四旋翼姿态控制子系统. 选择与系统自由度维数相同的广义坐标并基于虚位移原理计算对应的广义力, 从而建立系统的拉格朗日动力学方程. 利用微分平滑特性证明了运输系统存在平凡零动态, 因此可通过动态反馈转化为线性和能控系统. 经过2次动态扩展和变量代换, 原系统扩展为总相对阶等于系统状态维度的线性能控系统. 基于赫尔维茨稳定性判据, 设计了跟踪误差指数收敛的动态反馈控制律. 该方法可作为一类非线性系统控制器设计的标准方法. 最后以三维空间的螺旋曲线及水平面内频率变化的圆周曲线为参考轨迹进行仿真, 仿真结果验证了控制系统的有效性.Abstract: A quadrotor with cable-suspended load in 3-D space is considered, which is underactuated, strongly coupling and nonlinear. According to the dynamic feature, the system is decoupled into quadrotor attitude control subsystem and double points link subsystem. The generalized coordinate with the same dimension of the system freedom is selected and the generalized force is calculated based on the principle of virtual displacement, then the Lagrange dynamic equation of the system is established. The quadrotor-load system is proved to have ordinary zero dynamics based on differentially flat property, so it can be transformed into linear and controllable system by dynamic feedback. After 2 dynamic expansions and variable substitutions, the original system is extended to a linear controllable system whose total relative orders are equal to the system state dimensions. Based on Hurwitz stability criterion, a dynamic feedback controller with exponential convergence of position error is designed. This method can be used as a standard method for a class of nonlinear systems. Finally, the spiral curve in 3-D space and the circular curve in the horizontal plane with varying frequency are taken as the reference trajectory for simulation. Simulation results demonstrate the effectiveness of the proposed method.
-
Key words:
- Quadrotor /
- transport /
- zero dynamics /
- dynamic feedback
-
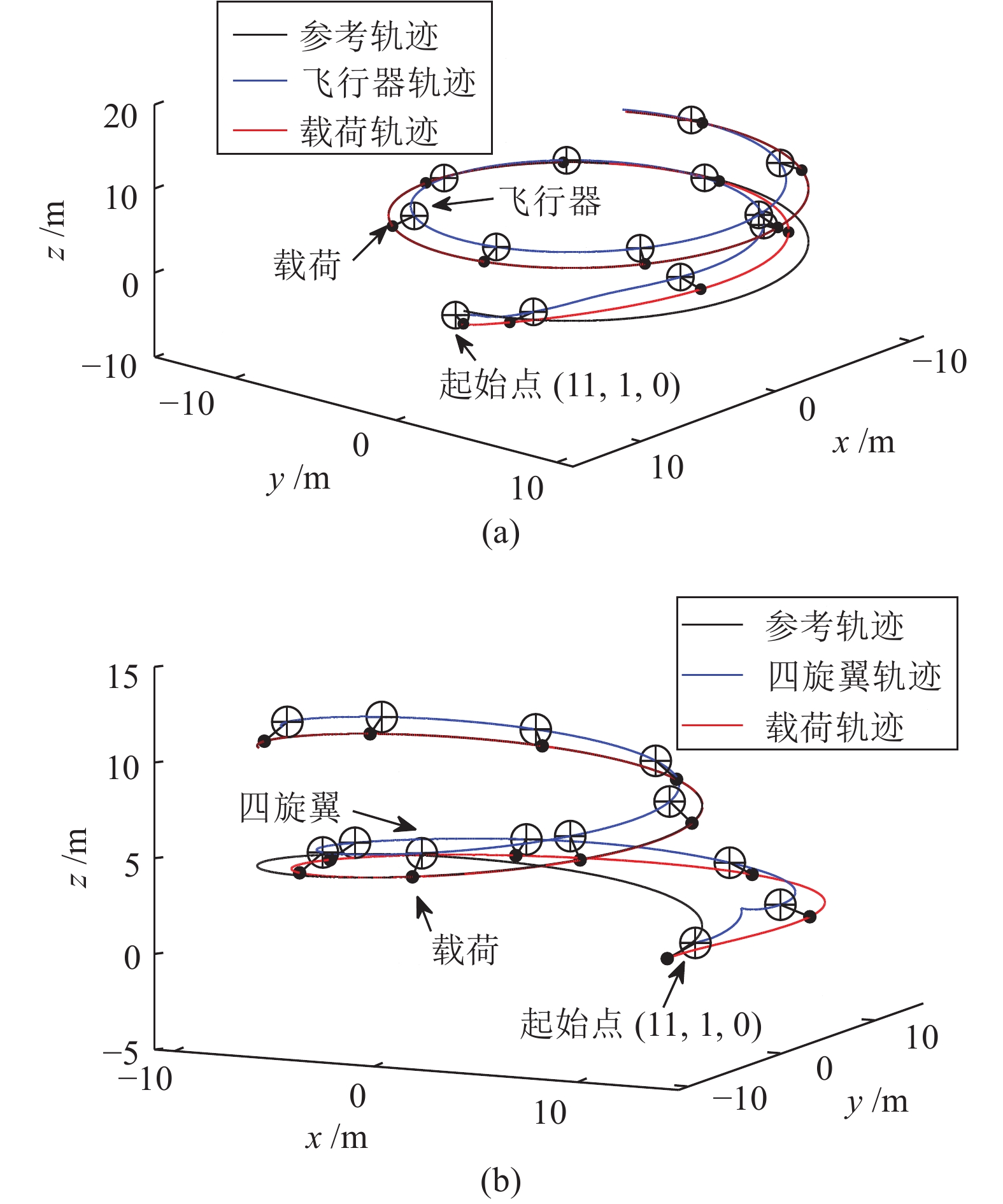
图 3 两种控制方法下螺旋曲线跟踪轨迹对比((a)动态反馈控制方法; (b)几何控制方法)
Fig. 3 Track a spiral curve via two control methods. ((a) Dynamic feedback control; (b) Geometry control)
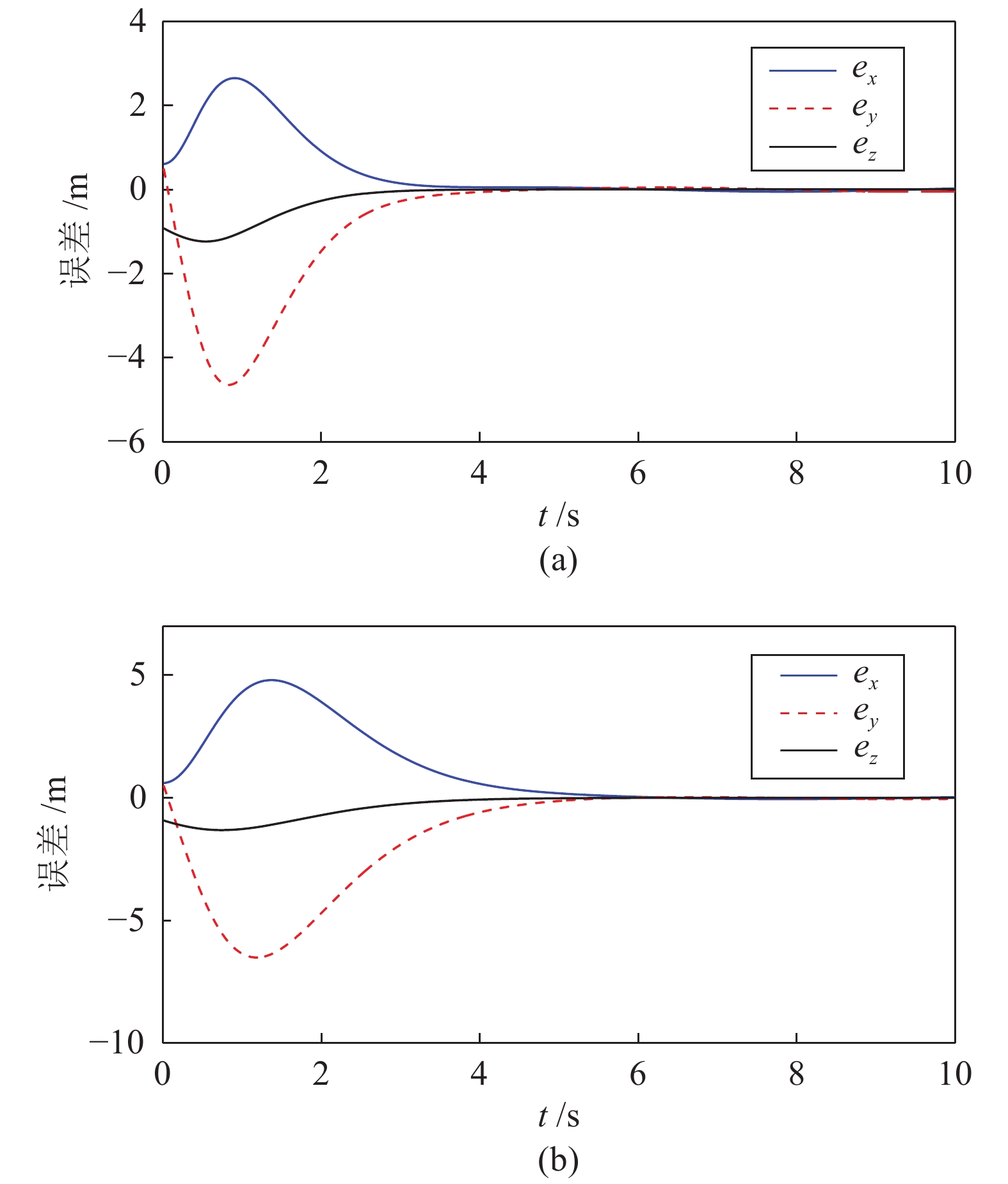
图 4 两种控制方法下跟踪螺旋曲线误差收敛情况对比((a)动态反馈控制方法; (b)几何控制方法)
Fig. 4 Position errors convergence when tracking a spiral curve via two control methods. ((a) Dynamic feedback control; (b) Geometry control)
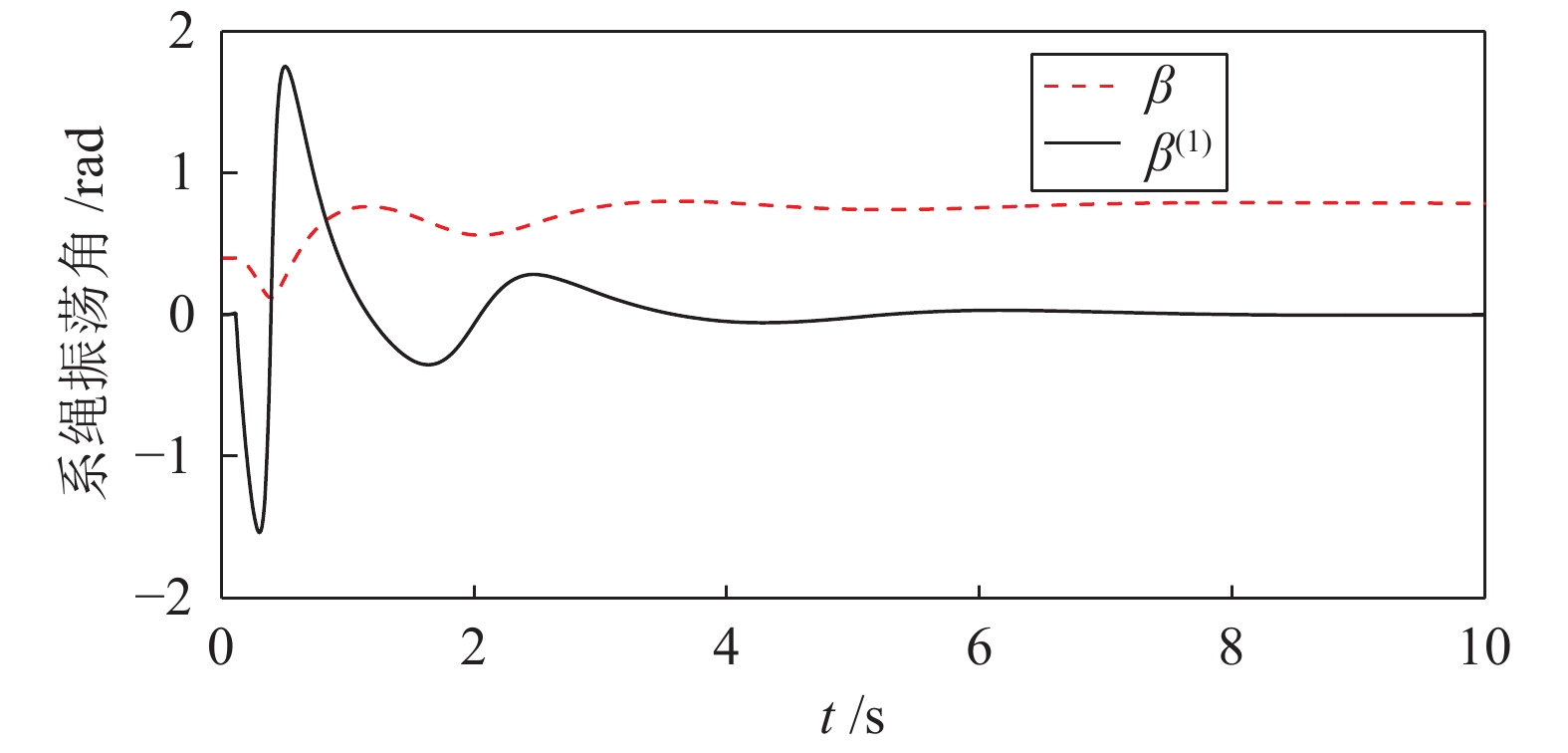
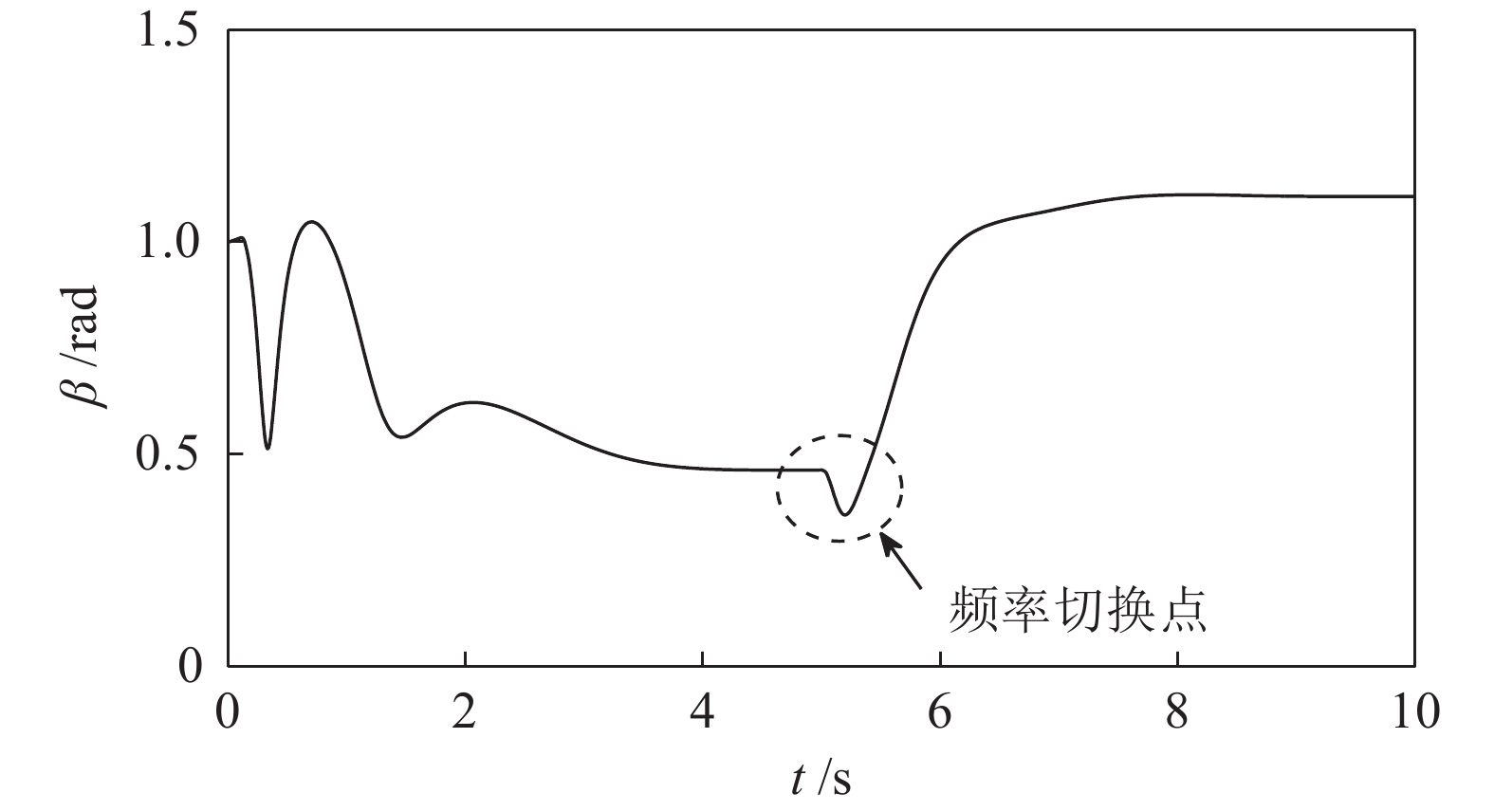
图 8 螺旋曲线跟踪过程中系绳振荡角曲线
Fig. 8 Curve of swing angel on the cable when tracking a spiral curve
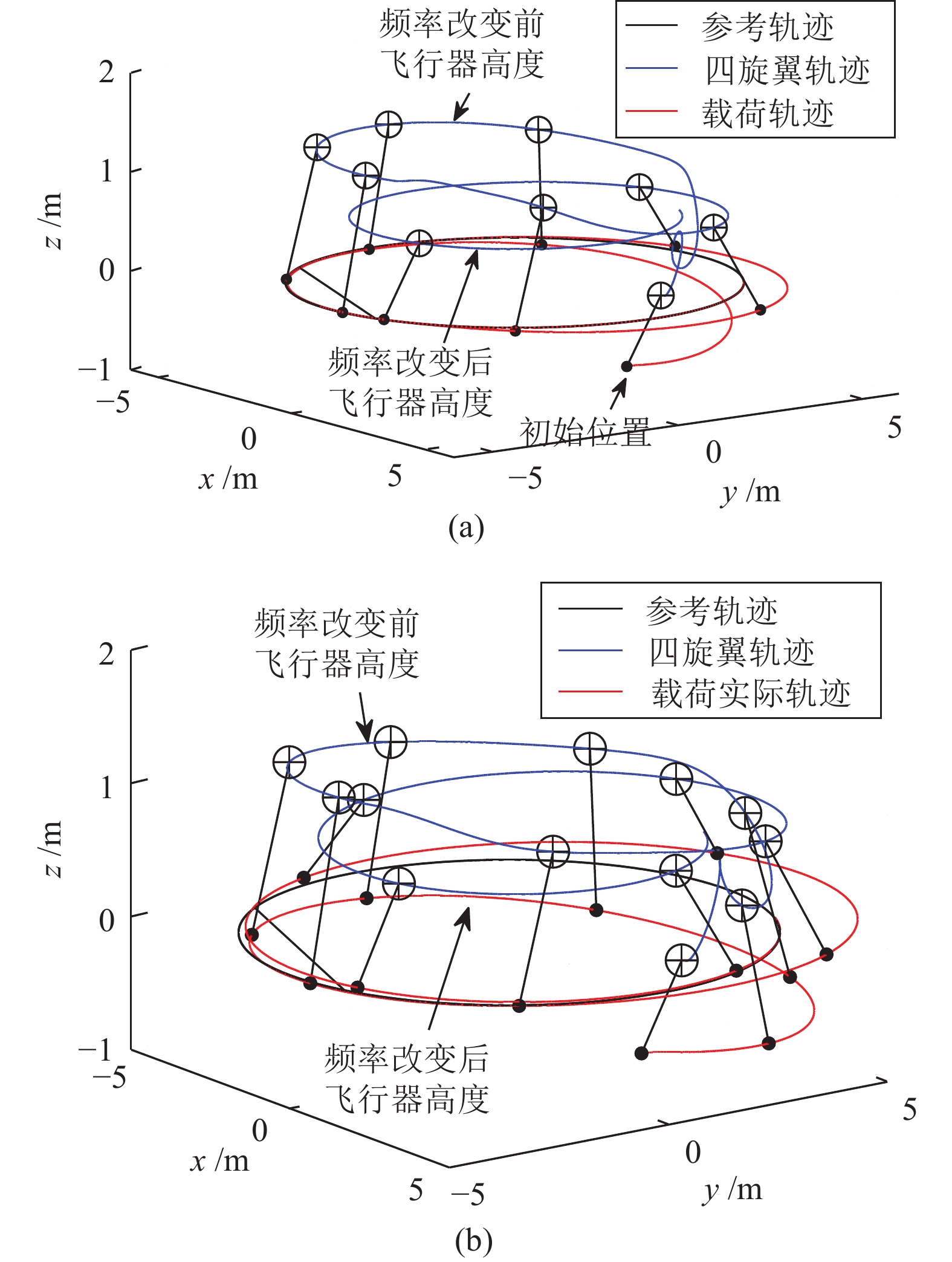
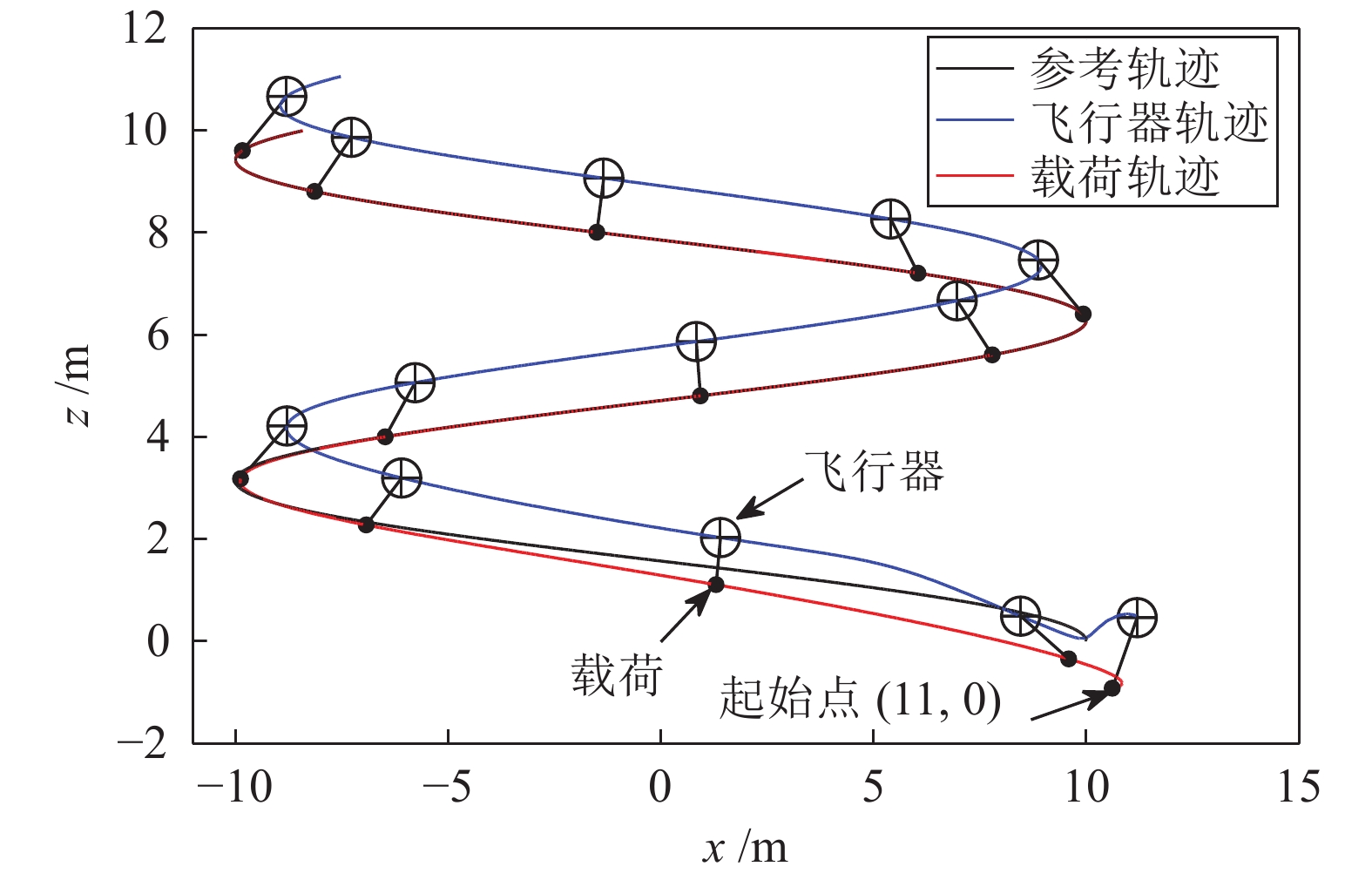
图 9 两种控制方法跟踪圆周曲线轨迹对比(a)动态反馈控制方法; (b)分段控制方法
Fig. 9 Track a circle via two control methods. (a) Dynamic feedback control; (b) Two-time-scale control

图 10 两种控制方法跟踪圆周曲线误差收敛情况对比((a)动态反馈方法; (b)分段控制方法)
Fig. 10 Position errors convergence when tracking a circle curve via two control methods. ((a) Dynamic feedback control; (b) Two-time-scale control)
表 1 仿真中使用的模型参数
Table 1 Model parameters in the simulations
变量 参数 单位 mq 0.4 kg ml 0.1 kg l1 0.8 m l2 0.2 m g −9.8 m·s−2  下载: 导出CSV
下载: 导出CSV
-
[1] 梁潇, 方勇纯, 孙宁. 平面四旋翼无人飞行器运送系统的轨迹规划与跟踪控制器设计. 控制理论与应用, 2015, 32(11): 1430−1438Liang Xiao, Fang Yong-Chun, Sun Ning. Trajectory planning and tracking controller design for a planar quadrotor unmanned aerial vehicle transportation system. Control Theory and Applications, 2015, 32(11): 1430−1438 [2] Alothman Y, Gu D B. Quadrotor transporting cablesuspended load using iterative Linear Quadratic regulator (iLQR) optimal control. In: Proceedings of the 8th IEEE Conference on Computer Science and Electronic Engineering. Colchester, UK: IEEE, 2017. 168−173 [3] Qian L H, Liu H H T. Dynamics and control of a quadrotor with a cable suspended payload. In: Proceedings of the 30th IEEE Canadian Conference on Electrical and Computer Engineering. Windsor, Canada: IEEE, 2017. 1−4 [4] 王诗章, 鲜斌, 杨森. 无人机吊挂飞行系统的减摆控制设计. 自动化学报, 2018, 44(10): 45−54Wang Shi-Zhang, Xian Bin, Yang Sen. Anti-swing controller design for an unmanned aerial vehicle with a slung-load. Acta Automatica Sinica, 2018, 44(10): 45−54 [5] Cruz P J, Oishi M, Fierro R. Lift of a cable-suspended load by a quadrotor: A hybrid system approach. In: Proceedings of the 2015 IEEE American Control Conference. Chicago, IL, USA: IEEE, 2015. 1887−1892 [6] Cruz P J, Fierro R. Cable-suspended load lifting by a quadrotor UAV: Hybrid model, trajectory generation, and control. Autonomous Robots, 2017, 41(8): 1629−1643 doi: 10.1007/s10514-017-9632-2 [7] de Angelis E L, Giulietti F, Pipeleers G. Two-time-scale control of a multirotor aircraft for suspended load transportation. Aerospace Science and Technology, 2019, 84(2019): 193−203 [8] Isidori A, Wang B, Zhuang S X. Nonlinear Control System I. Beijing: Electronics Industry Press, 2012. [9] 梁晓, 胡欲立. 基于微分平滑的四旋翼运输系统轨迹跟踪控制. 控制理论与应用, 2019, 36(4): 525−532Liang Xiao, Hu Yu-Li. Trajectory control of a quadrotor with a cable-suspended load based on differential Flatness. Control Theory and Applications, 2019, 36(4): 525−532 [10] Lee T, Leok M, McClamroch N H. Geometric tracking control of a quadrotor UAV on SE(3). In: Proceedings of the 49th IEEE Conference on Decision and Control (CDC). Atlanta, GA, USA: IEEE, 2010. 5420−5425 [11] 王宁, 王永. 基于模糊不确定观测器的四旋翼飞行器自适应动态面轨 迹跟踪控制. 自动化学报, 2018, 44(4): 685−695Wang Ning, Wang Yong. Fuzzy uncertainty observer based adaptive dynamic surface control for trajectory tracking of a quadrotor. Acta Automatica Sinica, 2018, 44(4): 685−695 [12] 陈乐生, 王以伦. 多刚体动力学基础. 哈尔滨: 哈尔滨工程大学出版社, 1995.Chen Le-Sheng, Wang Yi-Lun. Multi-body System Dynamics. Harbin: Harbin Engineering University Press, 1995. [13] 赵杰梅, 胡忠辉. 基于动态反馈的AUV水平面路径跟踪控制. 浙江大学学报(工学版), 2018, 52(18): 1467−1481Zhao Jie-Mei, Hu Zhong-Hui. Path following control of AUV in horizontal plane based on dynamic feedback control. Journal of Zhejiang University (Engineering Science), 2018, 52(18): 1467−1481 [14] 苏善伟, 朱波, 向锦武, 林岩. 非线性非最小相位系统的控制研究综 述. 自动化学报, 2015, 41(1): 9−21Su Shan-Wei, Zhu Bo, Xiang Jin-Wu, Lin Yan. A survey on the control of nonlinear non-minimum phase systems. Acta Automatica Sinica, 2015, 41(1): 9−21 [15] 易国, 毛建旭, 王耀南, 郭斯羽, 缪志强. 非完整移动机器人目标环绕动态反馈 线性化控制. 控制理论与应用, 2017, 34(7): 895−902 doi: 10.7641/CTA.2017.60962Yi Guo, Mao Jian-Xu, Wang Yao-Nan, Guo Si-Yu, Miao Zhi-Qiang. Circumnavigation of a target with nonholonomic mobile robots via dynamic feedback linearization. Control Theory and Applications, 2017, 34(7): 895−902 doi: 10.7641/CTA.2017.60962 [16] Fliess M. Flatness and defect of non-linear systems: Introductory theory and examples. International Journal of Control, 1995, 61(6): 1327−1361 doi: 10.1080/00207179508921959 [17] Taniguchi T, Eciolaza L, Sugeno M. Quadrotor control using dynamic feedback linearization based on piecewise bilinear models. In: Proceedings of the 2014 IEEE Symposium on Computational Intelligence in Control and Automation (CICA). Orlando, USA: IEEE, 2014. 1−7 [18] Choi I H, Bang H C. Quadrotor-tracking controller design using adaptive dynamic feedback-linearization method. Proceedings of the Institution of Mechanical Engineers, Part G: Journal of Aerospace Engineering, 2013, 228(12): 2329−2342 [19] Rego B S, Raffo G V. Suspended load path tracking control based on zonotopic state estimation using a tilt-rotor UAV. In: Proceedings of the 19th IEEE International Conference on Intelligent Transportation Systems (ITSC). Rio de Janeiro, Brazil: IEEE, 2016. 1445−1451 -

 下载:
下载:






计量
- 文章访问数: 1989
- HTML全文浏览量: 194
- PDF下载量: 247
- 被引次数: 0
