

Human Action Recognition Combined With Object Detection
-
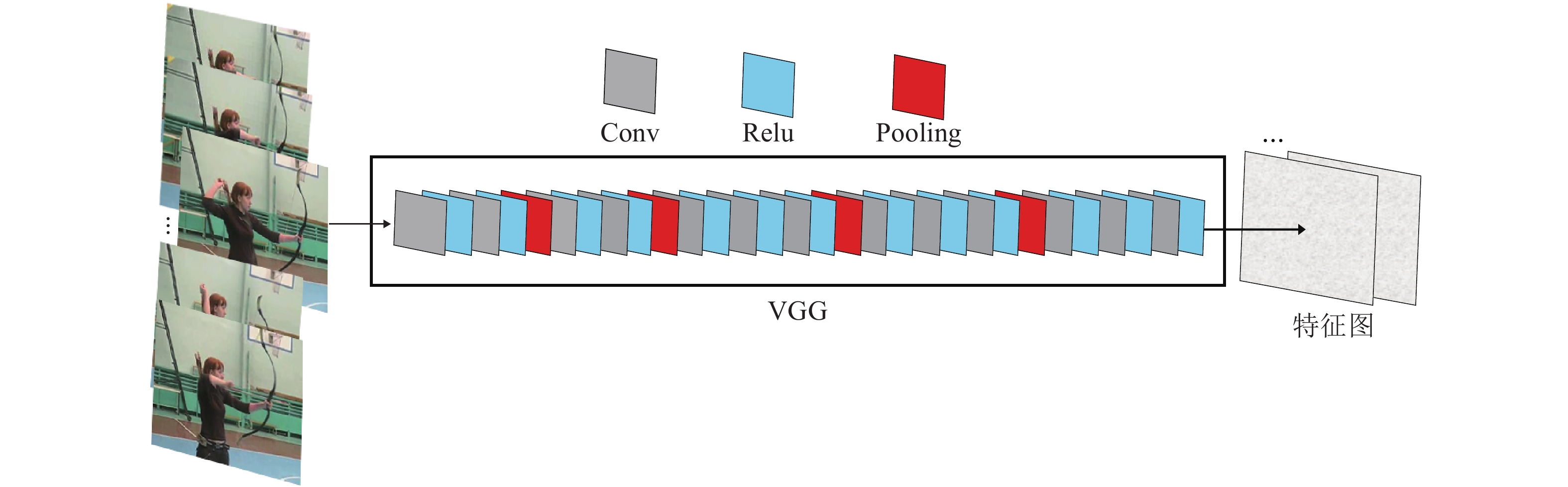
摘要: 人体行为识别领域的研究方法大多数是从原始视频帧中提取相关特征, 这些方法或多或少地引入了多余的背景信息, 从而给神经网络带来了较大的噪声. 为了解决背景信息干扰、视频帧存在的大量冗余信息、样本分类不均衡及个别类分类难的问题, 本文提出一种新的结合目标检测的人体行为识别的算法. 首先, 在人体行为识别的过程中增加目标检测机制, 使神经网络有侧重地学习人体的动作信息; 其次, 对视频进行分段随机采样, 建立跨越整个视频段的长时时域建模; 最后, 通过改进的神经网络损失函数再进行行为识别. 本文方法在常见的人体行为识别数据集UCF101和HMDB51上进行了大量的实验分析, 人体行为识别的准确率(仅RGB图像)分别可达96.0%和75.3%, 明显高于当今主流人体行为识别算法.Abstract: Most of the research methods in the field of human action recognition extract relevant features from the original video frames. These methods introduce more or less redundant background information, which brings more noise to the neural network. In order to solve the problem of background information interference, large amount of redundant information in video frames, unbalanced sample classification and difficult classification of individual classes, this paper proposes a new algorithm for human action recognition combined with object detection. Firstly, the object detection mechanism is added in the process of human action recognition, so that the neural network has a focus on learning the motion information of the human body. Secondly, the video is segmentally and randomly sampled to establish long-term time domain modeling across the entire video segment. Finally, action recognition is performed through an improved neural network loss function. In this work, a large number of experimental analyses are performed on the popular human action recognition datasets UCF101 and HDBM51. The accuracy of human action recognition (RGB images only) is 96.0% and 75.3%, respectively, which is significantly higher than the state-of-the-art human action recognition algorithms.
-

图 8 不同Focal loss参数条件下实验精度直方图
Fig. 8 Experimental precision histogram under different focal loss parameters

图 10 不同的输入图像下I3D网络测试精度对比
Fig. 10 Comparison of I3D network test accuracy under different inputs
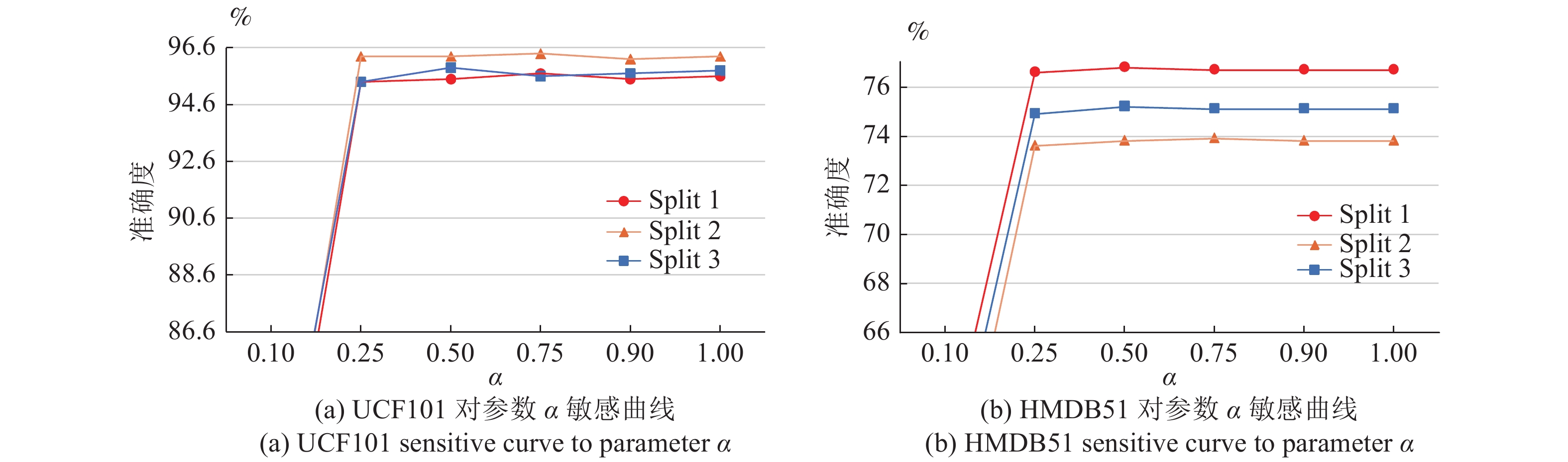
表 1 HMDB51与UCF101数据集在不同
$ \alpha $ 值下的实验结果$(\gamma = 1)$ (%)Table 1 Experimental results of HMDB51 and UCF101 data sets at different
$ \alpha $ values$(\gamma = 1)$ (%)HMDB51-FL- $\alpha$ Split1 Split2 Split3 Average UCF101-FL- $\alpha$ Split1 Split2 Split3 Average 0.10 60.6 56.5 58.7 58.6 0.1 76.8 77.4 78.4 77.5 0.25 76.6 73.6 74.9 75.0 0.25 95.4 96.3 95.4 95.7 0.50 76.8 73.8 75.2 75.3 0.5 95.5 96.3 95.9 95.9 0.75 76.7 73.9 75.1 75.2 0.75 95.7 96.4 95.6 95.9 0.90 76.7 73.8 75.1 75.2 0.9 95.5 96.2 95.7 95.8 1.00 76.7 73.8 75.1 75.2 1 95.6 96.3 95.8 95.9  下载: 导出CSV
下载: 导出CSV
表 2 在 Focal loss 的不同参数值条件下的实验精度对比(%)
Table 2 Comparison of experimental precision under different parameter values of focal loss (%)
HMDB51 Split 1 Split 2 Split 3 Average UCF101 Split 1 Split 2 Split 3 Average $\alpha$ = 0.50,$\gamma$ = 0.5065.3 62.8 63.5 63.9 $\alpha$ = 0.50,$\gamma$ = 0.5078.3 78.9 77.4 78.2 $\alpha$ = 0.50,$\gamma$ = 0.7570.8 67.5 69.2 69.2 $\alpha$ = 0.50,$\gamma$ = 0.7586.8 88.4 87.4 87.5 $\alpha$ = 0.50,$\gamma$ = 2.0076.6 73.7 75.1 75.1 $\alpha$ = 0.50,$\gamma$ = 2.0095.4 96.3 96 95.9 $\alpha$ = 0.50,$\gamma$ = 5.0076.9 73.8 75.3 75.3 $\alpha$ = 0.50,$\gamma$ = 5.0095.6 96.3 95.8 95.9 $\alpha$ = 0.75,$\gamma$ = 3.0076.7 73.7 75.2 75.2 $\alpha$ = 0.75,$\gamma$ = 3.0095.5 96.2 95.7 95.8 $\alpha$ = 0.75,$\gamma$ = 5.0076.7 73.7 75.1 75.2 $\alpha$ = 0.75,$\gamma$ = 5.0095.7 96.4 95.9 96 $\alpha$ = 0.90,$\gamma$ = 10.076.3 73.4 74.7 74.8 $\alpha$ = 0.90,$\gamma$ = 10.095 95.9 95.5 95.5
下载: 导出CSV
表 3 UCF101与HMDB51数据集实验结果(%)
Table 3 Experimental results of UCF101 and HMDB51 (%)
UCF101-Input Split 1 Split 2 Split 3 Average HMDB51-Input Split 1 Split 2 Split 3 Average CI 87.6 91.7 90.9 90.1 CI 71.3 67.1 68.8 69.7 WI 90.4 92.2 92.5 91.7 WI 74.1 70.2 70.6 71.6 RI 95.2 95.8 95.4 95.5 RI 75.9 73.1 75.0 74.7 CI+RI 91.7 92.7 92.9 92.4 CI+RI 73.3 71.8 72.0 72.4 WI+RI 95.7 96.4 96.0 96.0 WI+RI 76.8 73.9 75.3 75.3
下载: 导出CSV
表 4 不同算法在UCF101和HMDB51数据集上识别准确率对比(%)
Table 4 Comparison with the state-of-the-art on UCF101 and HMDB51 (%)
算法 Pre-training UCF101 HMDB51 LTC[28] Sports-1M 82.4 48.7 C3D[23] Sports-1M 85.8 54.9 TSN[24] ImageNet 86.4 53.7 DTPP[29] ImageNet 89.7 61.1 C3D[5] Kinetics 89.8 62.1 T3D[30] Kinetics 91.7 61.1 ARTNet[31] Kinetics 94.3 70.9 TSN[24] ImageNet+Kinetics 91.1 − I3D[2] ImageNet+Kinetics 95.6 74.8 PM without TS & FL ImageNet+Kinetics 95.8 95.1 PM without FL ImageNet+Kinetics 95.9 75.1 PM without TS ImageNet+Kinetics 95.9 75.2 Proposed method (all) ImageNet+Kinetics 96.0 75.3
下载: 导出CSV
-
[1] 朱红蕾, 朱昶胜, 徐志刚. 人体行为识别数据集研究进展. 自动化学报, 2018, 44(6): 978−1004Zhu Hong-Lei, Zhu Chang-Sheng, Xu Zhi-Gang. Research advances on human activity recognition datasets. Acta Automatica Sinica, 2018, 44(6): 978−1004 [2] Carreira J, Zisserman A. Quo vadis, action recognition? A new model and the kinetics dataset. In: Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). Honolulu, HI, USA: IEEE, 2017. 4724−4733 [3] Ng Y H, Hausknecht M, Vijayanarasimhan S, Vinyals O, Monga R, Toderici G. Beyond short snippets: Deep networks for video classification. In: Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). Boston, MA, USA: IEEE, 2015. 4694−4702 [4] Hara K, Kataoka H, Satoh Y. Can spatiotemporal 3d CNNs retrace the history of 2d CNNs and imagenet? In: Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Salt Lake City, UT, USA: IEEE, 2018. 6546−6555 [5] Tran D, Ray J, Shou Z, Chang S F, Paluri M. Convnet architecture search for spatiotemporal feature learning. arXiv: 1708.05038, 2017. [6] Wang H, Schmid C. Action recognition with improved trajectories. In: Proceedings of the 2013 IEEE International Conference on Computer Vision (ICCV). Sydney, Australia: IEEE, 2013. 3551−3558 [7] Dalal N. Triggs B. Histograms of oriented gradients for human detection. In: Proceedings of the 2005 IEEE Conference on Computer Vision and Pattern Recognition. San Diego, CA, USA: IEEE, 2005. 886−893 [8] Chaudhry R. Ravichandran A. Hager G. Vidal R. Histograms of oriented optical flow and Binet-Cauchy kernels on nonlinear dynamical systems for the recognition of human actions. In: Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA: IEEE, 2009. 1932−1939 [9] Knopp J, Prasad M, Willems G, Timofte R, VanGool L. Hough transformand 3D SURF for robust threedimensional classification. In: Proceedings of the 11th European Conference on Computer Vision (ECCV2010). Berlin Heidelberg, Germany: Springer. 2010. 589−602 [10] Sánchez J, Perronnin F, Mensink T, Verbeek J. Image classification with the fisher vector: Theory and practice. International Journal of Computer Vision, 2013, 105(3): 222−245 doi: 10.1007/s11263-013-0636-x [11] Yang Y H, Deng C, Gao S L, Liu W, Tao D P, Gao X B. Discriminative multi-instance multi-task learning for 3d action recognition. IEEE Transactions on Multimedia, 2017, 19(3): 519−529 doi: 10.1109/TMM.2016.2626959 [12] Yang Y H, Deng C, Tao D P, Zhang S T, Liu W, Gao X B. Latent max-margin multi-task learning with skelets for 3d action recognition. IEEE Transactions on Cybernetics, 2017, 47(2): 439−448 [13] Kim T S, Reiter A. Interpretable 3d human action analysis with temporal convolutional networks. In: Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition Workshops (CVPRW). Honolulu, HI, USA: IEEE, 2017. 1623−1631 [14] Yang Y, Liu R S, Deng C, Gao X B. Multi-task human action recognition via exploring super-category. Signal Process, 2016, 124: 36−44 doi: 10.1016/j.sigpro.2015.10.035 [15] 朱煜, 赵江坤, 王逸宁, 郑兵兵. 基于深度学习的人体行为识别算法综述. 自动化学报, 2016, 42(6): 848−857Zhu Yu, Zhao Jiang-Kun, Wang Yi-Ning, Zheng Bing-Bing. A review of human action recognition based on deep learning. Acta Automatica Sinica, 2016, 42(6): 848−857 [16] Karpathy A, Toderici G, Shetty S, Leung T, Sukthankar R, Li F F. Large-scale video classification with convolutional neural networks. In: Proceedings of the 2014 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). Columbus, OH, USA: IEEE, 2014. 1725−1732 [17] Ji S W, Xu W, Yang M, Yu K. 3D convolutional neural networks for human action recognition. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2013, 35(1): 221−231 doi: 10.1109/TPAMI.2012.59 [18] Donahue J, Hendricks L A, Rohrbach M, Venugopalan S, Guadarrama S, Saenko K. Long-term recurrent convolutional networks for visual recognition and description. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2014, 39(4): 677−691 [19] Cho K, Van Merrienboer B, Bahdanau D, Bengio Y. On the properties of neural machine translation: Encoder-decoder approaches. arXiv: 1409.1259, 2014. [20] Zolfaghari M, Singh K, Brox T. ECO: Efficient convolutional network for online video understanding. arXiv: 1804.09066, 2018. [21] Simonyan K, Zisserman A. Two-stream convolutional networks for action recognition in videos. Advance in Neural Information Processing Systems, 2014, 1(4): 568−576 [22] Sevilla-Lara L, Liao Y Y, Guney F, Jampani V, Geiger A, Black M J. On the integration of optical flow and action recognition. arXiv: 1712.08416, 2017. [23] Tran D, Bourdev L, Fergus R, Torresani L, Paluri M. Learning spatiotemporal features with 3d convolutional networks. In: Proceedings of the 2015 IEEE International Conference on Computer Vision (ICCV). Santiago, Chile: IEEE, 2015. 4489−4497. [24] Wang L M, Xiong Y J, Wang Z, Qiao Y, Lin D H, Tang X O, Van Gool L. Temporal segment networks: Towards good practices for deep action recognition. In: Proceedings of the 14th European Conference on Computer Vision (ECCV). Amsterdam, the Netherlands: Springer, 2016. 20−36 [25] He D L, Li F, Zhao Q J, Long X, Fu Y, Wen S L. Exploiting spatial-temporal modelling and multi-modal fusion for human action recognition. arXiv: 1806.10319, 2018. [26] Lin T Y, Goyal P, Girshick R, He K M, Dollár P. Focal loss for dense object detection. In: Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV). Venice, Italy: IEEE, 2017. 2999−3007 [27] Ren S Q, He K M, Girshick R, Sun J. Faster R-CNN: Towards real-time object detection with region proposal networks. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2015, 39(6): 1137−1149 [28] Varol G, Laptev I, Schmid C. Long-term temporal convolutions for action recognition. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2017, 40(6): 1510−1517 [29] Zhu J G, Zou W, Zhu Z. End-to-end video-level representation learning for action recognition. In: Proceedings of the 24th International Conference on Pattern Recognition (ICPR). Beijing, China, 2018. 645−650 [30] Diba A, Fayyaz M, Sharma V, Karami A H, Arzani M M, Yousefzadeh R, et al. Temporal 3d convnets: New architecture and transfer learning for video classification. arXiv: 1711.08200, 2017. [31] Wang L M, Li W, Li W, Van Gool L. Appearance-and-relation networks for video classification. In: Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Salt Lake City, UT, USA: IEEE, 2018. 1430−1439 -

 下载:
下载:







































计量
- 文章访问数: 3065
- HTML全文浏览量: 483
- PDF下载量: 567
- 被引次数: 0
