

-
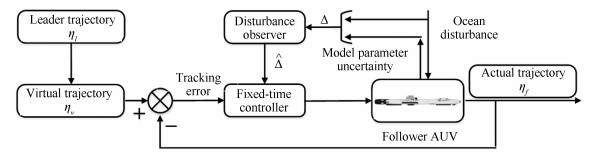
摘要: 考虑含有模型参数不确定及未知海洋扰动的多AUVs协同编队问题,本文提出一种新的控制方法,该方法可保证编队在固定时间内实现.首先,将模型参数不确定及海洋扰动看作复合扰动,设计扰动观测器,实现固定时间内对扰动的精确估计.基于扰动观测器,指令滤波技术、固定时间理论及虚拟轨迹概念,设计编队控制律,实现编队目标,并保证闭环系统中的所有信号是全局固定时间稳定的.最后通过两艘AUV的编队仿真验证了所提算法的有效性.Abstract: The paper is concerned with formation control of autonomous underwater vehicles (AUVs) subject to model parameter uncertainties and unknown ocean disturbances, a novel control scheme is developed, by which the formation can be achieved within a fixed time. The ocean disturbance is combined with the model parameter uncertainties as a compound disturbance. Then a disturbance observer (DO) is constructed to estimate the compound disturbance, which can be achieved within the settling time with zero estimation errors. Based on the DO, command filter technique, fixed-time control and virtual trajectory, a formation control law is designed, by which the formation control can be achieved with all the states globally stabilized in a given fixed time. The effectiveness of the proposed control scheme is demonstrated by numerical simulations.
-
Key words:
- Disturbance observer /
- formation control /
- multi-AUVs /
- fixed-time control /
- virtual trajectory
-
随着计算机网络、物联网和智能技术的发展, 科技社会获得的数据呈爆炸式增长.数据量巨大性给数据的处理和转移应用分析带来了诸多挑战.云计算能按需分配计算资源, 是一种很好的大数据解决方案, 同时云计算是推动信息技术能力实现按需供给、促进信息技术和数据资源充分利用的全新业态, 是信息化发展的重大变革和必然趋势[1-2].虚拟化技术是云计算的关键使能技术, 利用虚拟化技术将大量的物理服务器资源转换为可灵活按需分配的虚拟资源.精准的估计与预测虚拟机能耗不但可以优化云计算计费方式, 而且可改善虚拟机迁移调度策略, 提高云计算能耗效率, 进一步降低云服务提供商的能耗花费[3].云服务提供商可根据准确的虚拟机能耗预测设计高效的定价策略与计费方法, 为消费者提供更多的优惠措施, 避免了因定价高而致使消费者流失, 促使云计算的服务模式获得长足的发展.
虚拟机能耗模型具有非线性、强耦合和时变性的特征, 物理服务器的负载、CPU利用率和内存利用率都会对虚拟机能耗预测产生重要影响, 因此, 它的预测模型难以通过机理法用简单的数学公式或传递函数进行描述[4-5].当前伴随人工智能技术的快速发展, 研究人员利用人工智能技术解决虚拟机能耗预测的相关问题, 其中基于神经网络的机器学习方法在虚拟机能耗预测中的应用尤其突出.神经网络能加快计算速度, 可利用有限的参数描述较为复杂的系统.神经网络建模相对于机理建模方法的主要优点是无需具体的数学公式[6], 更适用于长期预测, 它能更灵活地获取虚拟机能耗参数和非线性特性, 使得神经网络对虚拟机能耗建模更具有吸引力.鉴于神经网络在建模中的优势, 其在虚拟机能耗建模中的应用越来越广泛.
唐轶轩等[7]首先利用支持向量机(Support vector machine, SVM)建立虚拟机能耗与内存利用率、CPU利用率之间的模型, 在结合待部署虚拟机的资源需求的基础上, 利用所建立的模型进行虚拟机能耗预测, 降低了数据中心能耗. Xu等[8]在深入研究多个虚拟机环境中物理服务器负载对虚拟机负载的影响分析基础上, 提出了基于RBF (Radial basis function)神经网络的虚拟机能耗预测模型, 根据实验结果可知, 基于RBF神经网络的虚拟机能耗预测模型的性能优于分段线性回归等预测模型.赵雅倩[9]利用模糊神经网络构建虚拟机能耗预测模型, 可有效避免硬阈值分区间模拟所产生的误差, 同时可以更好模拟虚拟机能耗与各相关参数之间的非线性关系.为了有效地降低云资源浪费和提高云计算系统利用率, 贾炅昊等[10]提出利用马尔科夫模型对虚拟机能耗进行建模.但支持向量机(SVM)、BP神经网络、RBF神经网络等传统神经网络需人为设定许多的神经网络训练参数, 以迭代的方式更新参数, 容易陷入局部优化, 导致网络训练误差较大.
近年来, 增量型极限学习机(Incremental Extreme Learning Machine, I-ELM)[11]在机器学习中备受青睐, 其原因在于增量型极限学习机的算法步骤少, 不需要迭代更新一些神经网络参数, 学习速度非常快, 并且不会产生局部最优解, 具有良好的泛化性能, 有效地克服了传统神经网络所存在的诸多缺陷, 充分发挥了其在机器学习中的巨大优势, 也促进了人工智能的进一步发展[12-13]. I-ELM采用增量式算法自适应地选取隐含层节点, 在算法迭代过程中随机产生隐含层节点参数, 利用最小二乘法计算其所对应的输出权值.尽管算法实现简单, 但是增量型极限学习机中存在输出权值较小的隐含层节点, 导致许多隐含层节点对最终网络输出起到的作用很小[14].大量冗余的隐含层节点只能增加网络结构的复杂性, 降低学习效率; 同时, 由于收敛速率较低, 增量型极限学习机通常需要更多的隐含层节点, 有时甚至超过学习样本的数量[15-16], 因此研究高效的预测方法对虚拟机能耗预测具有十分重要的意义.
针对上述问题, 本文对增量型极限学习机进行改进, 通过计算每一个隐含层节点的网络输出误差, 构造合适的压缩动量项, 构建基于压缩动量项的增量型极限学习机模型, 实现对虚拟机能耗的精确预测, 能够有效提高预测精度和效率.
1. 基于核函数的极限学习机
2012年, 在深入研究支持向量机的基础上, Huang等将核函数引入到极限学习机中(Kernel ELM, KELM)[17], 获取最小平方优化解, 使得极限学习机具有更稳定的泛化性能.该算法适用于当研究人员无法了解隐含层与输入层之间映射关系的时候, 研究人员仅需了解一个核函数便可构造一个极限学习机. KELM的计算步骤可归纳为:给定一个含有$ N $个样本的训练集合$ {\{({\pmb x}_{i}, {\pmb t}_{k})\mid {\pmb x}_{i}\in {\bf R}^{n}, {\pmb t}_{k}\in {\bf R}^{m}, i, k = 1, 2, \cdots, N\}} $, 确定核函数$ K({\pmb x}_{i}, {\pmb x}_{j}) $, 计算输出方程:
$ \begin{align} &f(\pmb{x}) = \pmb{K}\left(\frac{\pmb{I}}{C}+\Omega_{\rm ELM}\right)^{-1}\pmb{T} \end{align} $
(1) $ \begin{align} \Omega_{\rm ELM} = \, &\pmb{H}\pmb{H}^{\rm T}: \Omega_{{\rm ELM}i, j} = \\&h(\pmb{x}_{i})\cdot h(\pmb{x}_{j}) = K(\pmb{x}_{i}, \pmb{x}_{j}) \end{align} $
(2) $ \begin{align} &\pmb{K} = [K(\pmb{x}_{i}, \pmb{x}_{1}), K(\pmb{x}_{i}, \pmb{x}_{2}), \cdots, K(\pmb{x}_{i}, \pmb{x}_{N})]^{\rm{T}} \end{align} $
(3) 式中, $ C $为正则化系数.
2. 宽度学习系统
针对深度学习算法存在的训练时间长、难以收敛等问题, Chen等提出了宽度学习系统(Broad learning system, BLS)[18]. BLS方法利用稀疏自动编码器产生最优的输入权值矩阵, 对输入样本进行线性变换后形成特征节点, 再对特征节点经过激励函数非线性变换后获得增强节点.通过合并增强节点输出与特征节点输出形成BLS的输出矩阵, 利用岭回归广义逆直接计算输出权值矩阵. BLS的计算步骤可归纳为:给定一个含有$ N $个样本的训练集合$ \{ (\pmb{X}, \pmb{Y})| \pmb{X}\in {\bf R}^{N\times M}, \pmb{Y}\in {\bf R}^{N\times Q}\} $, 其中$ \pmb{X} $为输入样本, $ \pmb{Y} $为输出样本, $ N $为样本个数, $ M $为每一个输入样本的特征维数, $ Q $为每一个输出样本的特征维数.假设BLS网络结构中包含$ s $个特征节点和$ z $个增强节点, 则特征节点输出与增强节点输出分别表示为式(4)和式(5):
$ \begin{align} &\pmb{G}^{N\times s} = \pmb{X}^{N\times M}\cdot \pmb{U}^{M\times s}_{e} \end{align} $
(4) $ \begin{align} &\pmb{J}^{N\times z} = \psi(\pmb{G}^{N\times s}\cdot \pmb{U}^{s\times z}_{h}+ v^{N\times z}_{h}) \end{align} $
(5) $ \begin{align} &\pmb{A}^{N\times (s+z)} = [\pmb{G}^{N\times s}| \pmb{J}^{N\times z}] \end{align} $
(6) 式中, $ \pmb{U}^{M\times s}_{e} $为利用稀疏自动编码器产生最优的输入权值矩阵, $ \pmb{U}^{s\times z}_{h} $为特征节点到增强节点之间的随机输入权值矩阵, $ v^{N\times z}_{h} $为增强节点的随机偏置, $ \psi(\cdot) $为非线性激励函数. $ \pmb{A}^{N\times (s+z)} $表示特征节点和增强节点相连得到的合并矩阵, 即为宽度学习模型的节点输出矩阵.通过岭回归广义逆直接计算输出权值矩阵$ \pmb{W}^{(s+z)\times N} $, 具体求解如下:
$ \begin{align} &\pmb{W}^{(s+z)\times N} = (\lambda \pmb{I}+\pmb{A}\pmb{A}^{\rm{T}})^{-1}\pmb{A}^{\rm{T}}\pmb{Y} \end{align} $
(7) 式中, $ \lambda $为正则化系数.
3. 增量型极限学习机
增量型极限学习机通常是从一个规模比较小的神经网络开始, 根据误差大小向网络中逐个增加隐含层节点, 利用最小二乘法计算所增加的隐含层节点的输出权值, 进而计算网络训练误差, 直至达到最大隐含层节点数或者网络的期望误差时停止增加隐含层节点.
I-ELM算法的迭代公式可表示为:
$ \begin{align} &\pmb{f}_{n}(\pmb{x}) = \pmb{f}_{n-1}(\pmb{x})+\beta_{n}\pmb{g}_{n}(\pmb{x}), \end{align} $
(8) 式中, $ \pmb{g}_{n}(\pmb{x}) $表示在第$ n $步神经网络新增加的隐含层节点输出, 连接第$ n $个新增隐含层节点与输出层的权值可表示为:
$ \begin{align} &\beta_{n} = \frac{\langle \pmb{e}_{n-1}, \pmb{g}_{n}(\pmb{x})\rangle}{\parallel \pmb{g}_{n}(\pmb{x})\parallel^{2}}. \end{align} $
(9) I-ELM算法流程:
给定神经网络的训练样本$ \boldsymbol{\phi} = {(\pmb{x}_i, \pmb{t}_i)_{i = 1}^{N}}\in{\bf R}^m\times{\bf R}^n $, 隐含层节点的激励函数$ \pmb{g}:{\bf R}\rightarrow{\bf R} $, 最大隐含层节点数$ L_{\max} $, 期望精度为$ \epsilon $.
第1步, 神经网络初始化阶段:令$ L = 0 $, 初始网络误差为$ \pmb{E} = \pmb{T} $, 其中$ \pmb{T} = [\pmb{t}_{1}, \pmb{t}_{2}, \cdots, \pmb{t}_{N}]^T $;
第2步, 神经网络训练阶段:
当$ L<L_{\max} $且$ \parallel \pmb{E}\parallel>\epsilon $时,
1) 增加一个隐含层节点: $ L\leftarrow L+1 $;
2) 随机产生新增隐含层节点的输入权值和阈值$ (\pmb{a}_{L}, b_L) $;
3) 根据最小二乘法计算新增隐含层节点的输出权值: $ \beta_{L} = \frac{{\pmb E}\cdot\pmb{g}_{L}^{\rm{T}}}{\pmb{g}_{L}\cdot\pmb{g}_{L}^{\rm{T}}} $;
4) 计算神经网络在增加了第$ L $个隐含层节点后的误差: $ {\pmb E}\leftarrow{\pmb E}-\beta_{L}\cdot\pmb{g}_{L} $;
结束.
4. 基于压缩动量项的增量型极限学习机
4.1 基于压缩动量项的增量型极限学习机的拓扑结构
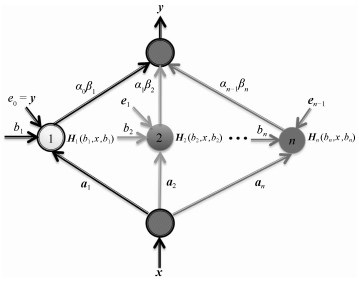
如图 1所示, 为了改进增量型极限学习机的收敛速度和泛化性能, 在原拓扑结构的的基础上引入压缩动量项, 优化网络结构, 提高网络学习效率.
图 1中, $ \pmb{x} $为输入变量, $ \pmb{y} $为目标输出变量, $ {\pmb{a}_n} $和$ {b _n} $分别表示第$ n $个隐含层节点的输入权值和阈值, $ {\beta _n} $表示第$ n $个隐含层节点的输出权值, $ \pmb{g}_{n}({\pmb{a}_n}, \pmb{x}, {b_n}) $表示第$ n $个加法型或RBF型隐含层节点的输出, $ {\pmb{f}_{n-1}} $表示当前包含$ n-1 $个隐含层节点的网络输出, $ {\pmb{e}_{n-1}} = \pmb{y} - {\pmb{f}_{n-1}} $表示当前包含$ n-1 $个隐含层节点的网络训练误差, $ \alpha_{n-1} $为第$ n $个隐含层节点的压缩因子.
4.2 基于压缩动量项的增量型极限学习机的收敛性分析和证明
定理1. 若一个递增型单隐含层前馈神经网络, 以任意分段连续的函数作为隐含层激励函数, 随机产生隐含层节点输出矩阵$ \pmb{g}_{n}(\pmb{a}_{n}, \pmb{x}, b_{n}), n\in\pmb{Z}^{+} $. $ \lambda_{n} $为常数且满足$ \lambda_{1} = 0, 0<\lambda_{n}<{1}/{2}, n>1 $, $ 0<B<1 $且满足$ \|\pmb{g}_{n}(\pmb{a}_{n}, \pmb{x}, b_{n})+\pmb{e}_{n-1}\|<B $.对于任意连续非常值的目标函数$ \pmb{f} $, 有$ \|\pmb{e}_{n}\| = \|\pmb{f}-\pmb{f}_{n}\|<B(1+\sum_{i = 1}^n\lambda_{i}^{2})^{-\frac{1}{2}} $, 若压缩因子[19] $ \alpha_{n-1} $和输出权值$ \beta_{n} $由如下公式计算获取:
$ \begin{align} &\alpha_{n-1} = \frac{\|\pmb{e}_{n-1}\|}{1+\|\pmb{e}_{n-1}\|^{2}} \end{align} $
(10) $ \begin{align} &\beta_{n} = \frac{\langle \pmb{e}_{n-1}, \pmb{g}_{n}+\pmb{e}_{n-1}\rangle}{\alpha_{n-1}\|\pmb{g}_{n}+\pmb{e}_{n-1}\|^{2}} \end{align} $
(11) 式中, $ \pmb{e}_{n} $为在训练中由于增加了第$ n $个隐含层节点而引入的网络训练误差, 其表达了当网络中仅有$ n $个隐含层节点时, 网络产生的输出$ \pmb{f}_{n} $与样本给定的理想输出之间的差值.
证明. 根据定理1的假设条件可知, 当$ n = 1 $时, 可得:
$ \begin{align} \|\pmb{e}_{1}\| = \, &\|\pmb{f}-\pmb{f}_{1}\|<\|\pmb{f}\|<\|\pmb{f}+\pmb{g}_{1}\| = \\&\|\pmb{e}_{0}+\pmb{g}_{1}\|<B \end{align} $
(12) 根据数学归纳法[20]可知, 假设$ \|\pmb{e}_{n-1}\| = \|\pmb{f}-\pmb{f}_{n-1}\|<B(1+\sum_{i = 1}^n\lambda_{i}^{2})^{-\frac{1}{2}} $成立, 则
$ \begin{align} \|\pmb{e}_{n}\|^{2} = \, &\|\pmb{e}_{n-1}-\alpha_{n-1}\beta_{n}(\pmb{g}_{n}+\pmb{e}_{n-1})\|^{2} = \\ &\|\pmb{e}_{n-1}\|^{2}+\alpha_{n-1}^{2}\beta_{n}^{2}\|\pmb{g}_{n}+\pmb{e}_{n-1}\|^{2}- \\ &2\alpha_{n-1}\beta_{n}\langle \pmb{e}_{n-1}, \pmb{g}_{n}+\pmb{e}_{n-1}\rangle = \\ &\|\pmb{e}_{n-1}\|^{2}+\frac{\langle \pmb{e}_{n-1}, \pmb{g}_{n}+\pmb{e}_{n-1}\rangle^{2}}{\|\pmb{g}_{n}+\pmb{e}_{n-1}\|^{2}} - \\ &2\frac{\langle \pmb{e}_{n-1}, \pmb{g}_{n}+\pmb{e}_{n-1}\rangle^{2}}{\|\pmb{g}_{n}+\pmb{e}_{n-1}\|^{2}} = \\ &\|\pmb{e}_{n-1}\|^{2}-\frac{\langle \pmb{e}_{n-1}, \pmb{g}_{n}+\pmb{e}_{n-1}\rangle^{2}}{\|\pmb{g}_{n}+\pmb{e}_{n-1}\|^{2}}< \\ &\|\pmb{e}_{n-1}\|^{2}-\frac{\lambda^{2}_{n}\|\pmb{e}_{n-1}\|^{4}}{\|\pmb{g}_{n}+\pmb{e}_{n-1}\|^{2}}< \\ &\|\pmb{e}_{n-1}\|^{2}\left(1-\frac{\lambda^{2}_{n}\|\pmb{e}_{n-1}\|^{2}}{B^{2}}\right) < \\ &\|\pmb{e}_{n-1}\|^{2}\left(1+\frac{\lambda^{2}_{n}\|\pmb{e}_{n-1}\|^{2}}{B^{2}}\right)^{-1} = \\ &\frac{1}{\dfrac{1}{\|\pmb{e}_{n-1}\|^{2}}+\dfrac{\lambda^{2}_{n}}{B^{2}}} < \\ &\frac{1}{\dfrac{1}{B^{2}}\left(1+\sum\limits_{i = 1}^{n-1}\lambda_{i}^{2}\right)+\dfrac{\lambda^{2}_{n}}{B^{2}}} = \\ &B^{2}\left(1+\sum\limits_{i = 1}^{n}\lambda_{i}^{2}\right)^{-\frac{1}{2}} \end{align} $
(13) 故可得$ \|\pmb{e}_{n}\| = \|\pmb{f}-\pmb{f}_{n}\|<B\left(1+\sum_{i = 1}^n\lambda_{i}^{2}\right)^{-\frac{1}{2}}. $
4.3 基于压缩动量项的增量型极限学习机的学习步骤
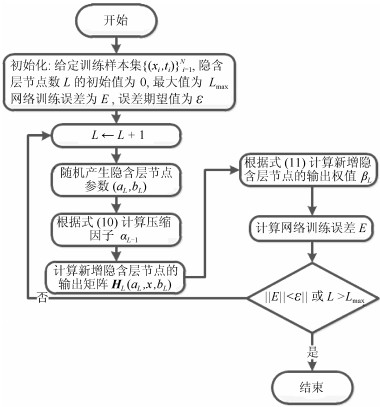
如图 2所示, 基于压缩动量项的增量型极限学习机与其他增量型极限学习机算法的区别在于在其模型和训练过程中引入压缩动量项, 进一步加快网络的收敛速度, 提高网络的泛化性能, 训练步骤如图 2所示.
5. 实验分析
5.1 基于压缩动量项的增量型极限学习机的收敛速度和泛化性能分析
通过10个回归问题对CDAI-ELM、I-ELM、CI-ELM和EM-ELM等4种算法从神经网络训练时间、隐含层节点数和测试精度等方面进行比较分析. 4种算法均选择Sigmoid函数作为其隐含层节点的激励函数, 即$ \pmb{g}(\pmb{a}\text{, }b\text{, }\pmb{x}) = \frac{1}{1+{\rm exp}(-(\pmb{a}\cdot\pmb{x}+b))} $.
针对每一个回归问题, 每一种测试算法均取相同的期望精度, 所有测试算法中最大隐含层节点数为300, EM-ELM算法中初始隐含层节点数是1, 且在迭代运算过程中每次仅增加1个隐含层节点.所有回归问题的测试数据均来自于KDD数据库[21], 相关测试数据的信息如表 1所示.所有测试实验均在Matlab 2014a环境中运行, 最后的测试结果取200次实验结果的平均值.最好的实验结果均用粗体标注, 相近的实验结果均用下划线标明.
表 1 回归数据集Table 1 Datasets of regression回归数据集 属性 训练数据 测试数据 Auto MPG 4 853 850 Automobile 16 8 795 8 774 BlogFeedback 281 530 500 Housing 77 153 150 NoisyOffice 128 468 300 Facebook metrics 19 300 200 SML2010 68 336 200 wiki4HE 26 2 898 2 000 UJIIndoorLoc 529 2 100 2 077 YearPredictionMSD 90 2 800 3 075 在表 2中, 在相同期望精度的情况下, 当训练精度提高时, 所需要的隐含层节点数也随之增多, 神经网络的泛化性能也随之提升, 但是当隐含层节点数到达一定程度后, 神经网络结构变得复杂, 其泛化性能并未提升, 将当前的精度作为期望精度.从表 2可知, 对所有的回归问题, CDAI-ELM算法所需要的隐含层节点数方差均为最小的, 但I-ELM算法所需要的隐含层节点数方差均为最多的.在不同的回归问题中, I-ELM算法所需要的隐含层节点数方差是CDAI-ELM算法的数十倍, CDAI-ELM算法所需要的隐含层节点数方差均小于CI-ELM算法和EM-ELM算法, 在表 2中由粗体标注, 这也说明了CDAI-ELM算法可获得更稳定且更紧凑的神经网络结构.
表 2 相同期望误差下4种算法隐含层节点数方差的比较Table 2 Variance of number of hidden layer node for four algorithms under same expected error回归数据集 期望误差 I-ELM CI-ELM EM-ELM CDAI-ELM Auto MPG 0.11 49.46 5.21 2.76 1.82 Automobile 0.15 8.82 33.08 3.55 1.95 BlogFeedback 0.2 28.56 24.87 2.50 1.58 Housing 0.12 35.95 9.98 2.51 2.26 NoisyOffice 0.08 46.81 6.28 2.18 1.72 Facebook metrics 0.06 28.87 10.02 2.28 1.46 SML2010 0.21 36.89 17.79 2.82 2.31 wiki4HE 0.13 32.81 8.19 2.88 2.14 UJIIndoorLoc 0.09 50.71 9.67 3.07 2.51 YearPredictionMSD 0.08 51.21 12.13 3.51 2.87 如表 3所示, 在10个回归问题中, 除了BlogFeedback和wiki4HE两个例子中EM-ELM算法的测试误差比CDAI-ELM算法小, Housing、NoisyOffice、SML2010和Facebook metrics 4个例子中CDAI-ELM算法与EM-ELM算法的测试误差比较接近外, 其余例子中CDAI-ELM算法的测试误差均为最小, 这也说明了CDAI-ELM算法具有较好的泛化性能.
表 3 4种算法的测试误差和方差比较Table 3 Comparison result of testing error and variance for four algorithms回归数据集 I-ELM CI-ELM EM-ELM CDAI-ELM 误差 方差 误差 方差 误差 方差 误差 方差 Auto MPG 0.1021 0.0051 0.0952 0.0041 0.0953 0.0052 0.0811 0.0040 Automobile 0.1323 0.0149 0.1302 0.0129 0.1301 0.0118 0.1257 0.0107 BlogFeedback 0.1896 0.0121 0.1882 0.0123 0.1712 0.0108 0.1822 0.0109 Housing 0.1017 0.0064 0.1008 0.0061 0.0985 0.0051 0.0973 0.0061 NoisyOffice 0.0511 0.0039 0.0481 0.0034 0.0401 0.0029 0.0392 0.0023 Facebook metrics 0.0642 0.0058 0.0581 0.0041 0.0581 0.0018 0.0585 0.0023 SML2010 0.1555 0.0158 0.1502 0.0129 0.1461 0.0078 0.1452 0.0074 wiki4HE 0.1592 0.0311 0.1522 0.0302 0.1468 0.0031 0.1511 0.0051 UJIIndoorLoc 0.1315 0.0102 0.1291 0.0091 0.1278 0.0072 0.1116 0.0059 YearPredictionMSD 0.0912 0.0041 0.0902 0.0039 0.0903 0.0040 0.0868 0.0031 如表 4所示, 在10个回归问题中, 除NoisyOffice, wiki4HE和UJIIndoorLoc三个例子中CI-ELM算法的训练时间比CDAI-ELM算法短, Housing在CDAI-ELM算法与CI-ELM算法所用训练时间接近, 其余例子中CDAI-ELM算法的训练时间均为最小, 这也说明了CDAI-ELM算法可更快地确定最优的神经网络结构.
表 4 4种算法训练时间的比较(s)Table 4 Comparison result of training time for four algorithms (s)回归数据集 I-ELM CI-ELM EM-ELM CDAI-ELM Auto MPG 0.0124 0.0073 0.0061 0.0052 Automobile 0.0272 0.0171 0.0182 0.0088 BlogFeedback 0.0469 0.0391 0.0236 0.0151 Housing 0.0391 0.0119 0.0182 0.0120 NoisyOffice 0.0411 0.0051 0.0083 0.0071 Facebook metrics 0.481 0.0179 0.0171 0.0159 SML2010 0.0218 0.0107 0.0081 0.0059 wiki4HE 0.0089 0.0081 0.0298 0.0297 UJIIndoorLoc 0.0471 0.0091 0.0288 0.0272 YearPredictionMSD 0.0301 0.0297 0.0271 0.0197 5.2 虚拟机能耗预测实验分析
本文使用一台戴尔PowerEdge T640塔式服务器进行实验仿真.该服务器包含2个Xeon Silver 4114的标配CPU, 64GB内存和120TB硬盘空间, 服务器的操作系统为CentOS 7.5.利用KVM虚拟化技术在服务器上创建了具有相同配置的5台虚拟机, 具体配置为单核Xeon Silver 4114 CPU, 8GB内存和100GB硬盘空间.
实验采集了30天的虚拟机的运行参数和能耗数据, 记录每天从0时到24时虚拟机的运行参数和能耗值, 并计算出当天的虚拟机的运行参数和能耗值的平均值作为当天的数据, 一共记录30天的数据, 形成数据集$ \phi = (\pmb{x}_{j}, y_{j})^{M}_{j = 1} $, 其中, $ y_{j} $为第$ j $天的虚拟机能耗值; 对应的第$ j $天的输入样本表达为$ \pmb{x}_{j} = [x_{1j}, x_{2j}, x_{3j}, x_{4j}] $, 其中$ x_{1j} $表示为第$ j $天的虚拟机CPU利用率, $ x_{2j} $表示为第$ j $天的内存利用率, $ x_{3j} $表示为第$ j $天的执行指令数, $ x_{4j} $表示为第$ j $天的丢失的Cache数.因为是短期预测, 故以前20组数据作为训练样本, 后10组数据作为测试样本.
5.3 评价指标
本文选取模型有效性MV、均方根误差(Root mean square error, RMSE)、平均绝对误差(Mean absolute error, MAE)、相对百分误差(Mean absolution percent error, MAPE)和皮尔逊相关系数(Pearson correlation coefficients, PCCs)作为衡量预测模型的泛化性能与精度的评价指标[22-24].
均方根误差RMSE可表示为:
$ {\rm{RMSE}} = \sqrt {\frac{{\sum\limits_{j = 1}^K {{{({{\hat \alpha }_j} - {y_j})}^2}} }}{K}} $
(14) 模型有效性MV可表示为:
$ \begin{align} {\rm MV} = 1-\frac{\sum\limits_{j = 1}^K(\hat{\alpha}_{j}-y_{j})^{2}}{\sum\limits_{j = 1}^K(\bar{\alpha}-y_{j})^{2}} \end{align} $
(15) 平均绝对误差MAE可表示为:
$ \begin{align} {\rm MAE} = \frac{1}{K}\sum\limits_{j = 1}^K|\hat{\alpha}_{j} - y_{j}| \end{align} $
(16) 相对百分误差MAPE可表示为:
$ \begin{align} {\rm MAPE} = \frac{1}{K}\sum\limits_{j = 1}^K\frac{|\hat{\alpha}_{j} - y_{j}|}{\hat{\alpha}_{j}}\times 100\% \end{align} $
(17) 皮尔逊相关系数PCCs可表示为:
$ \begin{align} {\rm PCCs} = \frac{\sum\limits_{j = 1}^K(y_{j}-\bar{y})(\hat{\alpha}_{j}-\bar{\alpha})}{\sqrt{\sum\limits_{j = 1}^K(y_{j}-\bar{y})^{2}}\sqrt{\sum\limits_{j = 1}^K(\hat{\alpha}_{j}-\bar{\alpha})^{2}}} \end{align} $
(18) 式中, $ y_{j} $为预测模型输出值, $ \bar{y} $为预测模型输出值的平均值, $ \hat{\alpha}_{j} $为真实值, $ \bar{\alpha} $为真实值的平均值, $ K $为样本数.均方根误差RMSE、平均绝对误差MAE和相对百分误差MAPE的大小反应了预测模型输出曲线在真实曲线上的波动情况, 模型有效性MV和皮尔逊相关系数PCCs反应了预测模型输出与真实值的误差相对于真实值的离散程度.
5.4 预测结果分析
为了验证本文所提算法的有效性, 采用支持向量机(SVM)、基于核函数的极限学习机(KELM)、宽度学习系统(BLS)和基于压缩动量项的增量型极限学习机(CDAI-ELM)分别对虚拟机能耗数据进行建模预测. CDAI-ELM算法选用Sigmoid函数作为隐含层激励函数, 隐含层节点参数$ (\pmb{a}, b) $服从一致分布, 从$ [-1, 1]^{d}\times[-1, 1] $中随机选取, 最大隐含层节点数为300.选取RBF函数作为SVM和KELM的核函数, 即$ \pmb{K}(\pmb{x}_{i}, \pmb{x}_{j}) = {\rm e}^{-\gamma \parallel \pmb{x}_{i}-\pmb{x}_{j}\parallel^{2}} $, 核函数参数和误差惩罚参数分别取值为$ \gamma_{\rm SVM} = 2^{-0.3} $、$ C_{\rm SVM} = 2^{1.1} $、$ \gamma_{\rm KELM} = 2^{3} $、$ C_{\rm KELM} = 2^{5} $.宽度学习算法选用双曲正切函数作为增强节点的激励函数, 特征节点数和增强节点数分别为50和10, 收敛系数和正则化系数分别为0.1和0.02.
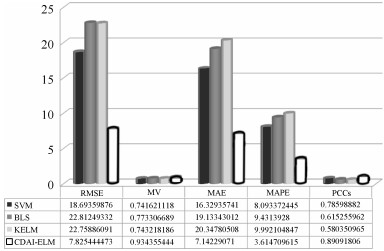
从图 3和4可知, 基于CDAI-ELM的能耗预测模型精度与其他模型相比有较大的改进.与BLS、SVM和KELM相比之下, 基于CDAI-ELM的能耗预测模型的均方根误差分别减小了14.987、10.8682、14.9334, 模型有效性分别提高了0.161049、0.192734、0.191137, 平均绝对误差分别减少了11.99114、9.187067、13.20551, 相对百分误差分别减少了5.816683%、4.478663%、6.377395%, 皮尔逊相关系数分别提高了0.275662、0.104929、0.310567.根据表 5可知, SVM模型的训练时间均大于其他模型, KELM模型训练时间与BLS模型接近, 而CDAI-ELM模型训练时间仅需0.5772s, 均优于其他模型, 其原因在于输入数据经过隐含层的特征映射后, 根据每一个隐含层节点的网络输出误差构造合适的压缩动量项, 隐含层输出矩阵的规模均小于其他算法, 致使算法的计算复杂度降低, 网络训练时间变短.根据图 3和4及表 5可知, BLS模型、SVM模型和KELM模型训练时间均大于CDAI-ELM模型, 且对虚拟机能耗数据进行预测时效果较差, 预测误差较大, 而CDAI-ELM模型对虚拟机能耗数据进行预测准确度较高, 预测误差小, 收敛速度快, 说明CDAI-ELM模型对虚拟机能耗进行模拟预测是行之有效的.
 图 3 基于SVM、KELM、BLS和CDAI-ELM的虚拟机能耗预测曲线Fig. 3 Predicted curve for power of virtual machine based on SVM、KELM、BLS和CDAI-ELM表 5 4种模型训练时间(s)Table 5 Training time of four models (s)
图 3 基于SVM、KELM、BLS和CDAI-ELM的虚拟机能耗预测曲线Fig. 3 Predicted curve for power of virtual machine based on SVM、KELM、BLS和CDAI-ELM表 5 4种模型训练时间(s)Table 5 Training time of four models (s)预测模型 训练时间(s) SVM 3.4788 BLS 0.9828 KELM 1.06 CDAI-ELM 0.5772 6. 结论
本文分析了国内外虚拟机能耗预测和增量型极限学习机的研究进展, 针对增量型极限学习机因存在大量冗余节点, 致使网络结构复杂, 降低网络收敛速度, 通过引入压缩动量项优化增量型极限学习机网络结构, 提出了基于压缩动量项的增量型ELM虚拟机能耗预测方法, 实现了对虚拟机能耗的高效精准预测.然而本文仅针对5个虚拟机进行预测建模, 如何对大规模的虚拟机集群进行预测建模, 仍需进一步进行实验验证.
-
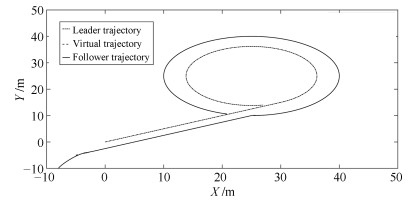
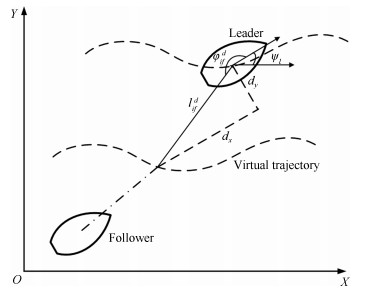
图 4 领航AUV轨迹、虚拟轨迹及跟随AUV轨迹
Fig. 4 Trajectory of leader, virtual trajectory and trajectory of follower
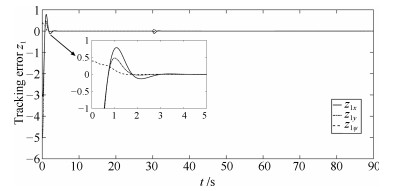
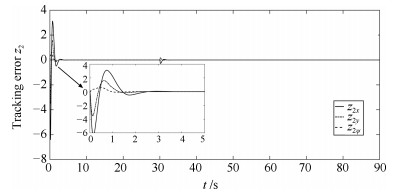
图 5 跟随AUV轨迹与虚拟轨迹跟踪误差$z_1$
Fig. 5 Tracking error $z_1$ between follower trajectory and virtual trajectory
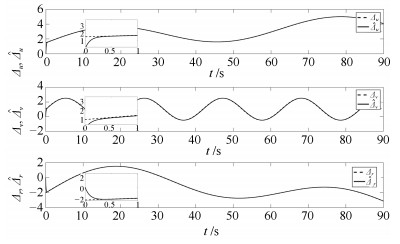
图 9 复合干扰$\varDelta$及其观测值$\hat{\varDelta}$
Fig. 9 Compound disturbance $\varDelta$ and its estimate $\hat{\varDelta}$
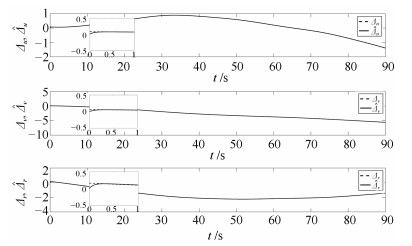
图 10 复合扰动$\varDelta$及其观测值$\hat{\varDelta}$
Fig. 10 Compound disturbance $\varDelta$ and its estimate $\hat{\varDelta}$
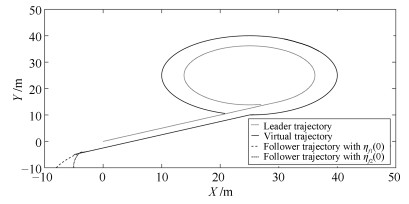
图 11 领航AUV轨迹、虚拟轨迹及不同初始状态下跟随AUV轨迹
Fig. 11 Trajectory of leader, virtual trajectory and trajectory of follower under different initial states
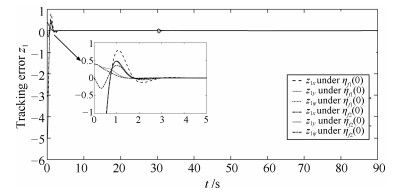
图 12 不同初始状态下跟随AUV轨迹与虚拟轨迹位置及航向跟踪误差$z_1$
Fig. 12 Tracking error $z_1$ between follower trajectory and virtual trajectory with different initial states
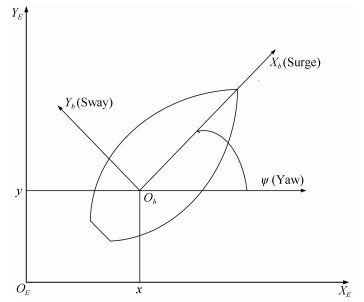
表 1 AUV模型参数
Table 1 Parameters of AUV
Symbol Value Unit $m$ 185 kg $X_u$ $-$70 kg/s $Y_v$ $-$100 kg/s $N_r$ $-$50 $\text{kgm}^2$ $X_{\dot{u}}$ $-$30 kg $Y_{\dot{v}}$ $-$80 kg $N_{\dot{r}}$ $-$30 $\text{kgm}^2$ $X_{u|u|}$ $-$100 kg/m $Y_{|v|v}$ $-$200 kg/m $N_{|r|r}$ $-$100 $\text{kgm}^2$ $I_z$ 50 $\text{kgm}^2$  下载: 导出CSV
下载: 导出CSV
-
[1] 王宏健, 陈子印, 贾鹤鸣, 李娟, 陈兴华.基于滤波反步法的欠驱动AUV三维路径跟踪控制.自动化学报, 2015, 41(3): 631-645 http://www.aas.net.cn/CN/abstract/abstract18640.shtmlWang Hong-Jian, Chen Zi-Yin, Jia He-Ming, Li Juan, Chen Xing-Hua. Three-dimensional path-following control of underactuated autonomous underwater vehicle with command filtered backstepping. Acta Automatica Sinica, 2015, 41(3): 631-645 http://www.aas.net.cn/CN/abstract/abstract18640.shtml [2] Peng Z, Wang D, Wang H, Wang W. Distributed coordinated tracking of multiple autonomous underwater vehicles. Nonlinear Dynamics, 2014, 78(2): 1261-1276 doi: 10.1007/s11071-014-1513-z [3] Ali F, Kim E K, Kim Y G. Type-2 fuzzy ontology-based semantic knowledge for collision avoidance of autonomous underwater vehicles. Information Sciences, 2015, 295: 441-464 doi: 10.1016/j.ins.2014.10.013 [4] Rizzini D L, Kallasi F, Aleotti J, Oleari F, Caselli S. Integration of a stereo vision system into an autonomous underwater vehicle for pipe manipulation tasks. Computers & Electrical Engineering, 2017, 58: 560-571 http://www.wanfangdata.com.cn/details/detail.do?_type=perio&id=c20d9bd1b72535e40b984ab3ac93b6e1 [5] Elhaki O, Shojaei K. Neural network-based target tracking control of underactuated autonomous underwater vehicles with a prescribed performance. Ocean Engineering, 2018, 167: 239-256 doi: 10.1016/j.oceaneng.2018.08.007 [6] Sun P, Boukerche A. Modelling and analysis of coverage degree and target detection for autonomous underwater vehicle-based system. IEEE Transactions on Vehicular Technology, 2018, 67(10): 9959-9971 doi: 10.1109/TVT.2018.2864141 [7] Hu Z, Ma C, Zhang L. Formation control of impulsive networked autonomous underwater vehicles under fixed and switching topologies. Neurocomputing, 2015, 147: 291-298 doi: 10.1016/j.neucom.2014.06.060 [8] Gao Z, Guo G. Adaptive formation control of autonomous underwater vehicles with model uncertainties. International Journal of Adaptive Control and Signal Processing, 2018, 32(7): 1067-1080 doi: 10.1002/acs.v32.7 [9] Gao Z, Guo G. Fixed-time leader-follower formation control of autonomous underwater vehicles with event-triggered intermittent communications. IEEE Access, 2018, 6: 27902-27911 doi: 10.1109/ACCESS.2018.2838121 [10] Park B S. Adaptive formation control of underactuated autonomous underwater vehicles. Ocean Engineering, 2015, 96: 1-7 doi: 10.1016/j.oceaneng.2014.12.016 [11] Shojaei, K. Neural network formation control of underactuated autonomous underwater vehicles with saturating actuators. Neurocomputing, 2016, 194: 372-384 doi: 10.1016/j.neucom.2016.02.041 [12] 李乐强, 王银涛.模型参数不确定条件下的自主水下航行器(AUV)自适应编队控制研究.舰船电子工程, 2015, 1: 154-157 http://www.wanfangdata.com.cn/details/detail.do?_type=perio&id=jcdzgc201501040Li Le-Qiang, Wang Yin-Tao. Adaptive formation control of AUVs in the presence of parametric model uncertainty. Ship Electronic Engineering, 2015, 1: 154-157 http://www.wanfangdata.com.cn/details/detail.do?_type=perio&id=jcdzgc201501040 [13] Yang Y, Du J, Liu H, Guo C, Abraham A. A trajectory tracking robust controller of surface vessels with disturbance uncertainties. IEEE Transactions on Control Systems Technology, 2014, 22(4): 1511-1518 doi: 10.1109/TCST.2013.2281936 [14] Wang N, Qian C, Sun J C, Liu Y C. Adaptive robust finite-time trajectory tracking control of fully actuated marine surface vehicles. IEEE Transactions on Control Systems Technology, 2016, 24(4): 1454-1462 doi: 10.1109/TCST.2015.2496585 [15] 张国庆, 黄晨峰, 吴晓雪, 张显库.考虑伺服系统增益不确定的船舶动力定位自适应有限时间控制.自动化学报, 2018, 44(10): 1907-1912 http://www.aas.net.cn/CN/abstract/abstract19372.shtmlZhang Guo-Qing, Huang Chen-Feng, Wu Xiao-Xue, Zhang Xian-Ku. Adaptive finite time dynamic positioning control of fully-actuated ship with servo system uncertainties. Acta Automatica Sinica, 2018, 44(10): 1907-1912 http://www.aas.net.cn/CN/abstract/abstract19372.shtml [16] Ye H, Li M, Yang C, Gui W. Finite-time stabilization of the double integrator subject to input saturation and input delay. IEEE/CAA Journal of Automatica Sinica, 2018, 5(5): 1017-1024 doi: 10.1109/JAS.2018.7511177 [17] Tian B, Zuo Z, Yan X, Wang H. A fixed-time output feedback control scheme for double integrator systems. Automatica, 2017, 80: 17-24 doi: 10.1016/j.automatica.2017.01.007 [18] Polyakov A. Nonlinear feedback design for fixed-time stabilization of linear control systems. IEEE Transactions on Automatic Control, 2012, 57(8): 2106-2110 doi: 10.1109/TAC.2011.2179869 [19] Farrell J A, Polycarpou M, Sharma M. Command filtered backstepping. IEEE Transactions on Automatic Control, 2009, 54(6): 1391-1395 doi: 10.1109/TAC.2009.2015562 期刊类型引用(11)
1. 任姗. 基于动态手势识别算法的VSTi系统研究. 自动化与仪器仪表. 2025(01): 214-217+222 .  百度学术
百度学术2. 李婷婷,王靖,骆亚丽,刘红梅. 基于Leap Motion传感器的弹琴触键手势自动控制系统设计. 自动化与仪器仪表. 2025(02): 223-227 . 百度学术3. 许燕,王维兰. 基于RFID技术的动态手势指令识别方法仿真. 计算机仿真. 2025(02): 248-251+487 . 百度学术4. 范文婧,孙剑锋,霍成欣,高阳,李毅彪. 基于坐标动态转换算法的专变采集终端ALB算法. 太赫兹科学与电子信息学报. 2025(03): 288-294+301 . 百度学术5. 邹灵果,张美花. 基于数理统计特征的人机交互图像手势识别. 黑龙江工业学院学报(综合版). 2024(01): 97-104 . 百度学术6. 边宝丽. 基于手势识别的幼儿游戏机器系统设计. 自动化与仪器仪表. 2024(03): 171-174+179 . 百度学术7. 闫颢月,王伟,田泽. 复杂环境下基于改进YOLOv5的手势识别方法. 计算机工程与应用. 2023(04): 224-234 . 百度学术8. 张琳钦. 基于支持向量机的人机交互媒体播放界面手势识别方法. 西安航空学院学报. 2023(03): 83-88 . 百度学术9. 盛博莹,侯进,李嘉新,党辉. 面向复杂交通场景的道路目标检测方法. 计算机工程与应用. 2023(15): 87-96 . 百度学术10. 李俊文,张红英,韩宾. 深层特征聚合引导的轻量级显著性目标检测. 计算机工程与应用. 2023(19): 122-129 . 百度学术11. 王鹏飞,黄汉明,王梦琪. 改进YOLOv5的复杂道路目标检测算法. 计算机工程与应用. 2022(17): 81-92 . 百度学术其他类型引用(4)
-

 下载:
下载:

计量
- 文章访问数: 2762
- HTML全文浏览量: 452
- PDF下载量: 698
- 被引次数: 15
