

-
摘要:
针对一类带有多源异质干扰和输入饱和的随机系统, 研究了其精细抗干扰控制问题. 系统中的多源异质干扰同时包含白噪声,
\begin{document}$H_{2}$\end{document} 范数有界干扰以及外源系统生成的带有状态与干扰耦合的部分信息已知干扰. 针对部分信息已知的干扰, 构建随机干扰观测器对其进行估计. 基于干扰估计, 结合
$H_{\infty}$ 控制方法, 提出基于干扰观测器的精细抗干扰控制策略, 从而实现高精度抗干扰控制. 最后, 仿真结果验证了所提策略的正确性与有效性.
Abstract:The problem of elegant anti-disturbance control are discussed for a class of stochastic systems with multiple heterogeneous disturbances and input saturation. The multiple heterogeneous disturbances simultaneously include white noise,
\begin{document}$H_{2}$\end{document} -norm bounded disturbance and the disturbance with partially-known information which with the coupling of the disturbance and state. To estimate the disturbance with partially-known information, a stochastic disturbance observer (SDO) is constructed. Based on the SDO, a disturbance observer-based elegant anti-disturbance control scheme is proposed by combining disturbance observer based control (DOBC) with
$H_{\infty}$ control, such that higher control accuracy can be achieved. Finally, a simulation example is given to illustrate the effectiveness of the proposed method.
-
硅是最重要的半导体材料. 据统计, 全球95 %以上的半导体器件和99 %以上的集成电路采用硅单晶作为衬底材料, 因此稳定、高效、高品质的硅单晶生产对信息产业安全可靠发展以及持续技术创新起到至关重要的支撑作用. 直拉法(Czochralski法, Cz法)晶体生长工艺是目前生产大尺寸、电子级硅单晶的主要方法[1-3]. 其原理是将石英坩埚中的多晶硅原料熔化, 并经过引晶、放肩、等径和收尾等一系列步骤, 最终从硅熔体中提拉出圆柱形的硅单晶, 生长工艺流程如图1所示.
Cz法硅单晶生长的主要目的是提拉出的硅单晶具有等直径、杂质少、低缺陷等优点[4-5]. 晶体直径是硅单晶生长过程中一个重要的控制目标, 精准的直径控制不但可以避免晶体内部位错缺陷生成的可能性, 而且能够提高后续加工的晶体利用率. 为此, 研究人员提出了多种晶体直径控制方法并应用于实际生产[6-8]. Zheng等根据Cz法硅单晶生长过程中能量、质量平衡、流体力学和几何方程建立了晶体半径和晶体生长速率的集总参数模型, 并利用工业运行数据验证了模型的有效性[9]. Abdollahi和Dubljevic针对晶体半径和温度提出了分布式参数模型, 该模型能够准确地描述系统动力学行为和晶体内部温度分布状态[10]. Winkler等基于弯月面处晶体半径变化与晶体倾斜角之间的关系, 建立了晶体生长过程的流体力学和几何模型, 避免了热动力学建模的复杂性. 同时, 设计了晶体半径和生长速率的双PID控制系统, 并获得了比较接近实际过程的控制效果[11-12]. Rahmanpour等针对Cz法硅单晶生长过程的非线性和大滞后特性, 设计了基于模型的提拉速度和加热器功率两个协同工作的模型预测控制器(Model predictive control, MPC), 用于控制晶体半径和熔体温度, 并获得了良好的控制性能[13]. 然而, 传统基于模型的控制器设计策略很难应用于实际硅单晶生长过程控制, 且晶体提拉速度的不断变化容易导致硅单晶品质降低. 通常, 影响晶体直径变化的主要操纵变量是加热器功率和晶体提拉速度[14]. 其中, 晶体提拉速度优化调节范围窄, 而且频繁的变化会导致生长界面波动剧烈, 容易产生断晶和缺陷生成的可能性, 而加热器功率对晶体直径的调节是一个缓慢的时延过程, 具有调节范围大、不易导致生长界面波动的优点[3, 15]. 因此, 如何建立加热器功率与晶体直径之间的硅单晶生长过程模型和设计良好的直径控制器是实现硅单晶高品质生长的关键性问题.
机理模型和数据驱动模型是晶体直径控制的两种常用模型. Cz法硅单晶生长过程处于高温、高压、多场耦合的环境中, 机理不明, 且是一个具有大滞后的非线性慢时变动态过程[1], 所以机理模型难以建立且很难实际应用于硅单晶生产过程控制. 然而, 数据驱动控制可以直接利用数据实现复杂工业过程建模和控制, 且已受到学术界的广泛关注[16-17]. 因此, 针对Cz法硅单晶生长过程中复杂的动态特性, 基于数据驱动的晶体直径建模与控制是一种可行途径. 近年来, 随着人工智能技术的迅速发展和普及, 许多机器学习方法和深度学习模型被广泛应用于工业过程建模. 然而, 单一的模型往往难以达到预期的预测效果, 所以研究人员基于“分而治之”原理提出了混合集成建模方法. 相比单一模型, 混合集成建模方法综合了不同模型的优点, 具有令人满意的预测效果[18-20]. 实际硅单晶生长过程中的数据(加热器功率、晶体直径等)包含了大量反映硅单晶生产运行和产品质量等关键参数的潜在信息, 所以采用混合集成建模方法建立硅单晶生长过程的预测模型, 具有无需显式建模晶体生长系统内部状态以及减少建模成本和提高建模精度的优点. 预测控制是工业实践中先进控制的主导技术, 具有处理大滞后、非线性、不确定性的良好能力[21-22]. 因此, 针对具有大滞后、非线性、慢时变动态特性的Cz法硅单晶生长过程, 预测控制方法可以作为晶体直径控制的首选方法. 然而, 复杂的硅单晶生长过程使得优化晶体直径目标函数的求解变得十分困难, 常用的非线性优化方法, 如最速下降法、牛顿法等很难方便实施应用, 且这些方法要求解空间具有凸性, 有的算法还要求目标函数具有二阶或高阶导数. 相比之下, 启发式优化算法对所求解问题的数学模型要求不高, 常被用于复杂目标函数的优化求解[23-24], 如遗传算法(GA)和蚁狮优化(ALO)等. ALO算法是一种无梯度的优化算法[25], 具有可调参数少、求解灵活且易于实现等优点, 非常适合求解目标函数复杂的硅单晶直径预测控制问题.
本文在不依赖Cz法硅单晶生长过程的任何数学模型信息的情况下, 根据“分而治之”原理和工业运行数据提出了一种基于混合集成建模的晶体直径自适应非线性预测控制方法(自适应 Nonlinear model predictive control, 自适应NMPC), 该方法由晶体直径混合集成建模和晶体直径预测控制组成. 其中, 晶体直径混合集成预测模型包括三个模块: 数据分解模块, 预测模型模块, 数据集成模块. 数据分解模块采用WPD将原始的硅单晶生长实验数据分解为若干子序列, 目的在于减少数据中的非平稳性和随机噪声; 预测模型模块通过ELM和LSTM网络分别对近似(低频)子序列和细节(高频)子序列进行晶体直径离线建模; 数据集成模块则利用WPD重构各个子序列晶体直径预测模型的预测结果, 以得到晶体直径的整体预测输出. 另外, 在基于混合集成预测模型的晶体直径自适应NMPC中, 考虑到晶体直径混合集成模型可能存在模型失配问题以及目标函数求解难的问题, 采用了ALO算法在线更新预测模型参数并获取满足约束的最优加热器功率控制量. 最后, 通过工程实验数据仿真验证了所提方法在硅单晶直径预测建模和控制方面的可行性和先进性.
1. 数据驱动晶体直径预测建模
Cz法硅单晶生长过程是一个非线性、大滞后的慢时变动态过程, 单晶炉内的高温、多相、多场耦合环境使得内部反应状态难以检测, 因此晶体生长机理不清, 基于机理模型的硅单晶直径控制难以实施. 为此, 本文以单晶炉制备硅单晶的历史实验数据为基础, 采用如下非线性自回归滑动平均(Nonlinear autoregressive moving average with eXogenous inputs, NARMAX)模型来描述加热器功率与晶体直径之间的关系:
$$\begin{split} y(k) =& {f_{NARMAX}}(u(k - d), \cdots ,u(k - d - {n_u}),\\ &y(k - 1), \cdots ,y(k - {n_y})) \end{split}$$ (1) 其中,
${f_{NARMAX}}( \cdot )$ 为未知的非线性映射函数;$d$ 为加热器功率与晶体直径之间的时滞阶次,${n_u}$ 和${n_y}$ 分别是模型输入输出阶次,$y(k)$ 和$u(k)$ 分别表示$k$ 时刻系统的晶体直径输出和加热器功率控制输入.对于式(1)所表述的Cz法硅单晶生长系统, 本文采用混合集成建模方法建立其模型. 考虑到混合集成建模方法是基于“分而治之”原理, 同时为了综合不同模型的优点, 基于历史加热器功率输入数据和晶体直径输出数据, 我们采用机器学习方法ELM和深度学习方法LSTM建立晶体直径预测模型. 其中, ELM方法具有快速的训练和预测速度[26-27], 能够节省晶体直径建模成本, 而LSTM方法可以学习长期依赖的信息, 能够抓取数据序列中的时间特征, 非常适合处理具有非线性特征的数据序列回归问题[28-29]. 具体的晶体直径混合集成建模流程将在第1.2节给出.
1.1 晶体直径预测模型结构辨识
在硅单晶生长过程控制中, 建立准确的晶体直径预测模型是实现其控制的基础[3]. 为了准确辨识式(1)中的时滞
$d,$ 本文提出了一种基于互相关函数的时滞优化估计方法, 其中互相关系数的估计如下式:$${\hat \phi _{uy}}(d) = \frac{1}{n}\sum\limits_{i = 1}^n {\left| {\dfrac{({u_{i - d}} - {\mu _u})({y_i} - {\mu _y})}{{s_u}{s_y}}} \right|} $$ (2) 其中,
$u$ 和$y$ 可以分别表示历史的加热器功率数据序列和晶体直径数据序列,${\mu _u}$ 、${\mu _y}$ 和${s_u}$ 、${s_y}$ 分别是加热器功率和晶体直径数据的均值和标准差.根据互相关系数式(2), 可以将时滞估计问题转化为如下的优化问题:
$$\left\{ {\begin{array}{*{20}{l}} \mathop {\max }\limits_d g(y,u) = f(y,u(i - d))\\ {\rm s.t}.\;{\rm{ }}{d_{\min }} \le d \le {d_{\max }} \end{array}} \right.$$ (3) 其中,
$f( \cdot )$ 表示互相关系数${\hat \phi _{uy}}(d).$ ${d_{\min }}$ 为时滞阶次的下界,${d_{\max }}$ 为时滞阶次的上界.基于上述时滞优化问题式(3), 本文采用ALO算法进行时滞阶次寻优, 并将式(3)作为待优化的适应度函数, 从而确定式(1)中的时滞阶次
$d$ .在辨识获得时滞阶次
$d$ 的前提下, 本文提出了一种基于Lipschitz商准则[30]和模型拟合优度[31]的晶体直径模型阶次辨识方法. 所提辨识方法不仅可以保证模型估计精度, 而且无需模型阶次的先验知识, 不需要经历复杂优化过程且容易实现. 针对式(1), 将其写成更一般的形式, 如下$$y = {f_{NARMAX}}({x_1},{x_2}, \cdots ,{x_m})$$ (4) 其中,
$m$ 是变量个数且$m = {n_u} + {n_{y }}+ 1.$ $ X = [ {x_1},$ ${x_2}, \cdots ,{x_m} ] \rm ^T$ 表示${f_{NARMAX}}( \cdot )$ 的输入向量, 即历史的加热器功率与晶体直径数据.定义Lipschitz商如下
$${q_{i,j}} = \frac{{\left| {y(i) - y(j)} \right|}}{{\left| {x(i) - x(j)} \right|}},i \ne j$$ (5) 其中,
$\left| {x(i) - x(j)} \right|$ 表示两个输入向量之间的距离, 而$\left| {y(i) - y(j)} \right|$ 则表示晶体直径输出${f_{NARMAX}}(x(i))$ 与${f_{NARMAX}}(x(j))$ 之间的距离. 将Lipschitz商式(5)展开可得$$q_{i,j}^{(m)} = \frac{{\left| {y(i) - y(j)} \right|}}{{\sqrt {{{({x_1}(i) - {x_1}(j))}^2} + \cdots + {{({x_m}(i) - {x_m}(j))}^2}} }}$$ (6) 其中,
$q_{i,j}^{(m)}$ 的上标$m$ 表示式(3)中的变量个数. 根据参考文献[32]可知,$q_{i,j}^{(m)}$ 可以被用来表示非线性系统的输入是否遗漏了必要变量或者加入了多余变量. 当一个必要的输入变量${x_m}$ 被遗漏时, Lipschitz商$q_{i,j}^{(m - 1)}$ 将会远远大于$q_{i,j}^{(m)},$ 甚至表现为无穷大. 相反地, 当一个多余变量${x_{m + 1}}$ 被加入时, Lipschitz商$q_{i,j}^{(m{\rm{ + }}1)}$ 将会略小于或者大于$q_{i,j}^{(m)},$ 差别不会很明显. 为了减小噪声对辨识结果的影响, 本文采用指标式(7)来选择晶体直径模型${f_{NARMAX}}( \cdot )$ 中的变量个数, 即$${q^{(m)}} = {\left( {\prod\limits_{i = 1}^p {\sqrt m {q^m}(i)} } \right)^{\frac{1}{p}}}$$ (7) 其中,
${q^m}(i)$ 是所有的Lipschitz商$q_{i,j}^{(m)}$ 中第$i{\rm{ - }}th$ 的最大值, 而$p$ 是一个正数, 通常满足$p \in \left[ {0.01N,0.02N} \right].$ 然后, 定义停止准则评价指标$\Gamma (m + 1,m)$ 如下:$$\Gamma (m + 1,m) = \frac{{\left| {{q^{(m + 1)}} - {q^{(m)}}} \right|}}{{\max (1,\left| {{q^{(m)}}} \right|)}} < \varepsilon $$ (8) 其中, 本文将阈值
$\varepsilon $ 取为0.01. 通过Lipschitz商准则, 可以很准确地得到最佳变量个数$m$ , 再结合晶体直径模型拟合优度式(9), 将拟合优度最高值确定为最优晶体直径模型阶次组合, 从而实现对晶体直径系统式(1)的输入输出阶次辨识.$${\rm{Fit}} = 100\; {\text{%}} \times \left( {1 - \frac{{\left\| {y - \hat y} \right\|}}{{\left\| y \right\|}}} \right)$$ (9) 其中,
$y$ 是晶体直径实际值,$\hat y$ 是ELM网络的晶体直径预测值.1.2 基于WPD-ELM-LSTM的混合集成预测模型
针对硅单晶生长过程机理建模难问题, 采用数据驱动建模方法可以直接使用传感器获取的测量数据, 而无需显式建模晶体生长系统内部的状态, 减少了晶体直径建模成本和时间. 混合集成建模方法是基于“分而治之”原理, 利用多个子模型进行预测建模, 从而在预测中产生协同效应, 克服了单一模型预测性能不佳的缺点. 因此, 本文提出了一种新颖的WPD-ELM-LSTM混合集成建模方法, 并将其应用于硅单晶直径建模, 整体的建模框架, 如图2所示.
 图 2 基于WPD-ELM-LSTM的混合集成建模框架Fig. 2 Hybrid integrated modeling framework based on WPD-ELM-LSTM
图 2 基于WPD-ELM-LSTM的混合集成建模框架Fig. 2 Hybrid integrated modeling framework based on WPD-ELM-LSTM晶体直径混合集成建模过程主要包括两个阶段. 在第一阶段, 由于单晶炉内复杂的生长环境, 各种不确定性因素导致采集的晶体直径数据呈现出非平稳、非线性的特征, 所以本文选用应用广泛且可靠的WPD信号分解方法, 将原始晶体直径数据序列分解成不同的低频和高频平稳信号, 目的在于减少非平稳性、非线性特征以及满足基于“分而治之”原理对不同频率信号进行预测建模的需求. 通常, 低频子序列和高频子序列分别被称为近似子序列和细节子序列. 与低频分量相比, 高频分量具有较大的随机性, 包含了不确定性的随机噪声, 因此本文去除了最高频子序列, 从而减少了随机噪声对预测性能的影响. 在第二阶段, 首先将获得的子序列划分为训练集和测试集; 其次, 由于近似子序列包含了原始晶体直径数据固有的本征信息, 所以我们采用建模速度快和泛化能力强的ELM进行预测建模; 细节子序列是一个高频的非线性信号序列, 为了更准确地捕获晶体直径数据序列中的时间特征信息, 我们使用了具有时间记忆功能的LSTM网络进行预测建模. 然而, ELM和LSTM网络的隐含节点个数对预测性能有较大的影响, 为了得到最佳的晶体直径预测效果, 采用ALO算法进行隐含节点个数寻优, 并将晶体直径预测值与实际值之间的均方根误差作为待优化的适应度函数, 从而获取最优节点个数. 最后, 通过WPD重构所有子序列预测模型的预测结果, 以得到晶体直径的整体预测输出. 与传统单一预测建模方法相比, 混合集成建模方法能够捕捉原始数据的内在特征, 学习历史数据之间的相互依赖关系, 从而有效地提高整体预测能力.
2. 晶体直径自适应非线性预测控制
等径阶段的晶体直径控制是Cz法硅单晶生长过程的核心, 精准的直径控制, 一方面有利于减小生长界面的热应力波动, 避免位错缺陷生成的可能性, 另一方面可以提高后续晶体加工利用率[33]. 目前, 在Cz法硅单晶实际生产线上, 普遍采用的是PID控制. 然而, 非线性、时变性和大滞后特性的存在, 不但使得传统的PID控制难以实现精确的直径跟踪控制和约束处理, 而且容易降低晶体生长系统的可靠性. 因此, 为了提高硅单晶直径控制性能, 所提自适应非线性预测控制方法能够很好地解决这些潜在的问题.
2.1 晶体直径预测控制结构
晶体直径预测控制的控制性能依赖于所建混合集成预测模型的预测性能, 当被控晶体生长系统参数发生变化时, 会存在模型失配问题, 此时如果仍采用原始晶体直径预测模型的非线性预测控制器, 会导致晶体直径控制性能变差甚至不稳定, 甚至引发晶体生长失败. 因此, 为了使晶体直径预测控制系统仍能达到控制目标要求, 本文提出了一种基于ALO算法优化求解的自适应NMPC方法, 并通过ALO算法调整晶体直径混合集成预测模型的参数, 使其与晶体生长过程保持一致. 基于WPD-ELM-LSTM的晶体直径自适应NMPC结构, 如图3所示, 主要包括: 期望晶体直径参考轨迹、晶体直径WPD-ELM-LSTM预测模型、模型参数自适应更新、基于ALO算法的滚动优化、反馈校正等几个部分.
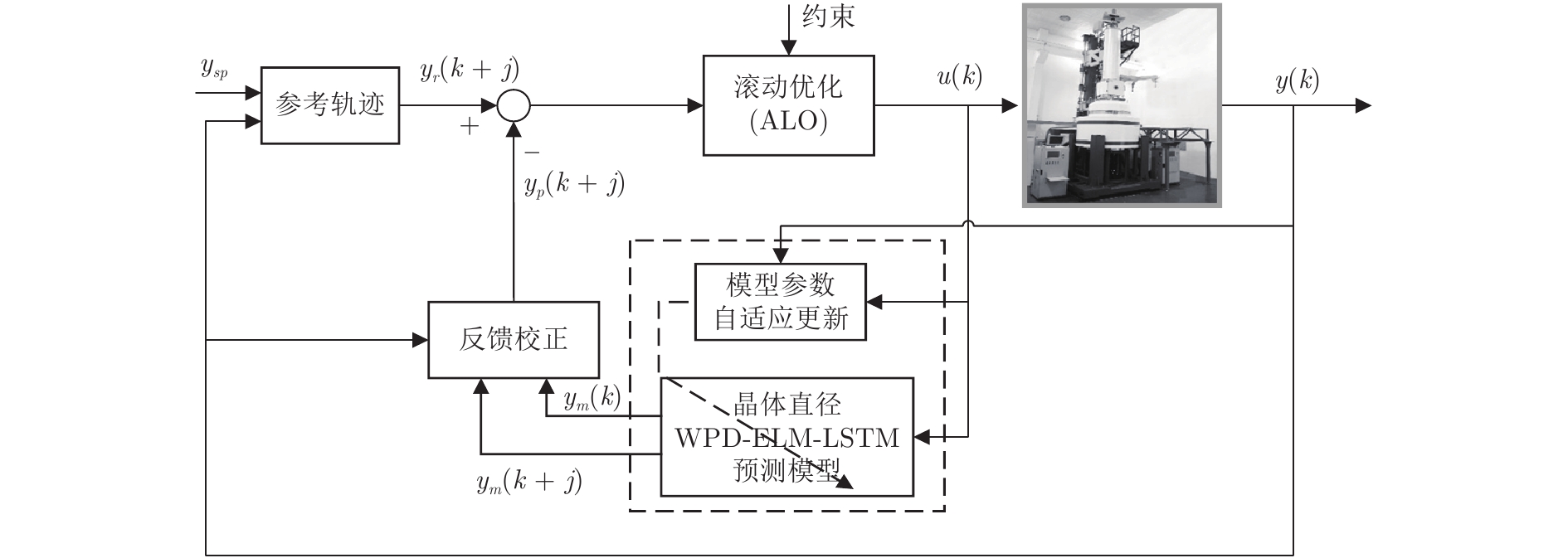 图 3 基于WPD-ELM-LSTM的晶体直径自适应NMPC结构Fig. 3 Crystal diameter adaptive NMPC structure based on WPD-ELM-LSTM
图 3 基于WPD-ELM-LSTM的晶体直径自适应NMPC结构Fig. 3 Crystal diameter adaptive NMPC structure based on WPD-ELM-LSTM晶体直径WPD-ELM-LSTM预测模型: 根据式(1)所描述的晶体直径非线性系统, 建立其相应的WPD-ELM-LSTM混合集成预测模型. 预测模型的训练输入数据集由历史加热器功率和晶体直径数据组成, 即
$X = \{ u(k - d), \cdots ,u(k - d - {n_u}),$ $y(k), \cdots , y(k - {n_y})\},$ 输出数据集为历史晶体直径$Y = \left\{ {y(k)} \right\},$ 晶体直径系统的时滞阶次$d$ 、模型阶次${n_u}$ 和${n_y}$ 可由第1.1节所提模型辨识方法确定. 晶体直径WPD-ELM-LSTM预测模型可由第1.2节所提的建模方法建立. 所建立的晶体直径混合集成预测模型的目的是为求解晶体直径预测控制优化问题提供可靠的基础.根据建立的晶体直径混合集成预测模型, 从
$k$ 时刻起利用系统的当前信息和未来的加热器功率控制输入, 可以预测出未来的晶体直径预测值${y_m}$ , 然后经过在线反馈校正为滚动优化问题提供所需的未来晶体直径控制预测输出${y_p}$ .基于ALO算法的滚动优化: 本文所设计的晶体直径非线性预测控制是一种有限时域内的滚动优化过程. 定义
$k$ 时刻的加热器功率控制输入信号为$U = {\left[ {u(k),u(k + 1), \cdots ,u(k + N - 1)} \right]\rm^T}.$ 在采样时刻$k,$ 优化式(10)所示的性能指标.$$\left\{ \begin{array}{*{20}{l}} \min {\rm{ }}J(u) = \displaystyle\sum\limits_{j = 1}^{{N_p}} {{{\left[ {{y_r}(k + j) - {y_p}(k + j)} \right]}^2} + } \\ \qquad\qquad {\rm{ }}\displaystyle\sum\limits_{j = 1}^{{N_c}} {r{{\left[ {\Delta u(k + j - 1)} \right]}^2}} \\ {\rm{s}}{\rm{.t}}{\rm{. }}\;\Delta {u_{\min }} \le \Delta u \le \Delta {u_{\max }},\\ \qquad{u_{\min }} \le u \le {u_{\max }} \end{array} \right.$$ (10) 其中,
${N_p}$ 为预测时域,${N_c}$ 为控制时域,${N_p} \geqslant {N_c}$ ,$r$ 为控制权系数.$\Delta u(k) = u(k) - u(k - 1)$ ;${y_p}(k + j)$ 是第$j$ 步晶体直径混合集成预测模型的预测输出;${y_r}(k + j)$ 是第$j$ 步晶体直径参考输出, 其由式(11)所示的参考轨迹给出.晶体直径自适应NMPC的核心是式(10)所示非线性约束优化问题, 由于建立的WPD-ELM-LSTM混合集成预测模型相对复杂, 难以采用传统优化算法进行求解. 而ALO算法是一种模拟蚁狮与蚂蚁之间狩猎行为及相互作用机制的全局优化搜索方法, 具有潜在的并行性和鲁棒性. 此外, ALO算法是一种无梯度的算法, 它把优化问题看作一个黑盒, 很容易应用于实际复杂工业优化问题的求解, 算法的具体实现过程, 可以参考文献[25]. 本文正是基于ALO算法的优点, 通过求解晶体直径预测控制性能指标函数式(10), 获得一组最优的加热器功率控制序列U, 但仅对硅单晶生长系统施加第一个控制量
${u^ * }(k).$ 参考轨迹: 针对上述晶体直径自适应非线性预测控制过程, 为了把当前晶体生长系统输出的晶体直径
$y(k)$ 平滑地过渡到真实设定值$y_{sp},$ 定义${y_r}(k + j)$ 为第 j 步的晶体直径参考输出, 即$$\left\{ {\begin{array}{*{20}{l}} {{y_r}(k) = y(k)}\\ {{y_r}(k + j) = \eta {y_r}(k + j - 1) + (1 - \eta ){y_{{{sp}}}}} \end{array}} \right.$$ (11) 其中,
$ \eta \; (0 < \eta < 1)$ 为柔化系数, 用以调整系统的鲁棒性和收敛性.反馈校正: 为了克服所建立的晶体直径混合集成预测模型与晶体生长被控系统之间的模型失配和外部干扰对控制系统的影响, 通过反馈校正对晶体直径预测输出补偿, 即
$$\left\{ {\begin{array}{*{20}{l}} e(k) = y(k) - {y_m}(k)\\ {y_p}(k + j) = {y_m}(k + j) + h \times e(k) \end{array}} \right.$$ (12) 其中,
$h$ 为补偿系数,${y_m}$ 是晶体直径混合集成预测模型WPD-ELM-LSTM的预测输出,${y_p}$ 是经过反馈校正的晶体直径预测输出.2.2 模型参数自适应更新
Cz法硅单晶生长过程存在各种不确定性因素(熔体对流、氩气流动等), 使得所建立的晶体直径混合集成预测模型难免与实际系统存在偏差. 另外, 当实际晶体生长过程的结构参数发生变化造成模型失配时, 会导致晶体直径预测模型的输出和实际输出之间的误差增大, 因而难以获得满意的晶体直径预测控制性能. 为此, 进一步引入模型参数自适应估计方法[34], 通过最小化晶体直径混合预测模型输出和实际输出之间的误差, 在线调整预测模型WPD-ELM-LSTM的参数集. 考虑到近似子序列的ELM预测模型包含着晶体直径固有的本征信息, 且方便在线实施模型参数估计, 所以本文主要调整ELM网络的输入权值
$W$ 和偏置 b, 以保证晶体直径混合集成预测模型的准确性. WPD–ELM–LSTM模型参数估计的性能指标, 如式(13)所示:$$\left\{ {\begin{array}{*{20}{l}} {\mathop {\min {\rm{ }}}\limits_\theta {J_\theta } = {{\left[ {y(k) - {{\hat y}_\theta }(k)} \right]}^2} + \psi \displaystyle\sum\limits_{m = 1}^{{n_\theta }} {{{\left( {\Delta {\theta _m}(k)} \right)}^2}} }\\ {\rm{s}}{\rm{.t}}{\rm{. }}\;{{\hat y}_\theta }(k) = {{\hat y}_{{\theta _{ELM}}}}(k) + {{\hat y}_{LSTM}}(k)\\ \quad\;\; {\rm{ }}\Delta {\theta _m}(k) = {\theta _m}(k) - {\theta _m}(k - 1) \end{array}} \right.$$ (13) 其中,
$\theta $ 为ELM网络中的参数$\left\{ {W,b} \right\},$ $y(k)$ 和${\hat y_\theta }(k)$ 分别表示$k$ 时刻晶体直径系统的实际输出值和晶体直径预测模型WPD–ELM–LSTM的预测值;$\psi\; (\psi > 0)$ 为参数变量权系数,${n_\theta }$ 表示模型参数个数;${\hat y_{{\theta _{ELM}}}}(k)$ 和${\hat y_{LSTM}}(k)$ 分别表示晶体直径近似子序列和细节子序列的预测值.针对上述混合集成预测模型参数估计问题, 本文将模型参数估计性能指标函数式(13)作为ALO算法优化的适应度函数, 当满足迭代终止条件时, 即可求得当前
$k$ 时刻自适应调整后的WPD-ELM-LSTM预测模型参数值.2.3 实现步骤
基于WPD-ELM-LSTM混合集成预测模型的晶体直径自适应NMPC算法的实现步骤如下:
1) 设定合适的控制参数包括预测时域
${N_p}$ 、控制时域${N_c}$ 、柔化系数$\eta $ 、补偿系数$h$ 、控制加权系数$r$ 、参数变量权系数$\psi $ 以及ALO算法的种群个数$Num,$ 最大迭代次数$Ma{x_{iter}};$ 2) 离线训练晶体直径混合集成预测模型WPD-ELM-LSTM;
3) 设定晶体直径的期望值
${y_{sp}},$ 并按式(11)得到晶体直径参考轨迹${y_r};$ 4) 计算晶体直径混合集成预测模型的预测输出值
${y_m}(k)$ 以及实际系统直径输出值$y(k);$ 5) 根据ALO算法求解式(13) 非线性优化问题, 以得到最优参数集
$\hat \theta ,$ 从而更新晶体直径预测模型WPD–ELM–LSTM;6) 利用当前时刻晶体直径预测误差
$e(k)$ 和未来时刻晶体直径预测值${y_m}(k + j),$ 经在线反馈校正式(12)得到晶体直径预测输出${y_p}(k + j);$ 7) 基于ALO算法滚动优化求解晶体直径预测控制性能指标式(10), 并获得一组最优的加热器功率控制量序列
$U(k);$ 8) 将最优加热器功率控制序列的第1个控制量
${u^ * }(k)$ 作用于当前硅单晶生长系统;9) 返回步骤4), 不断进行迭代求解.
3. 工业数据实验与分析
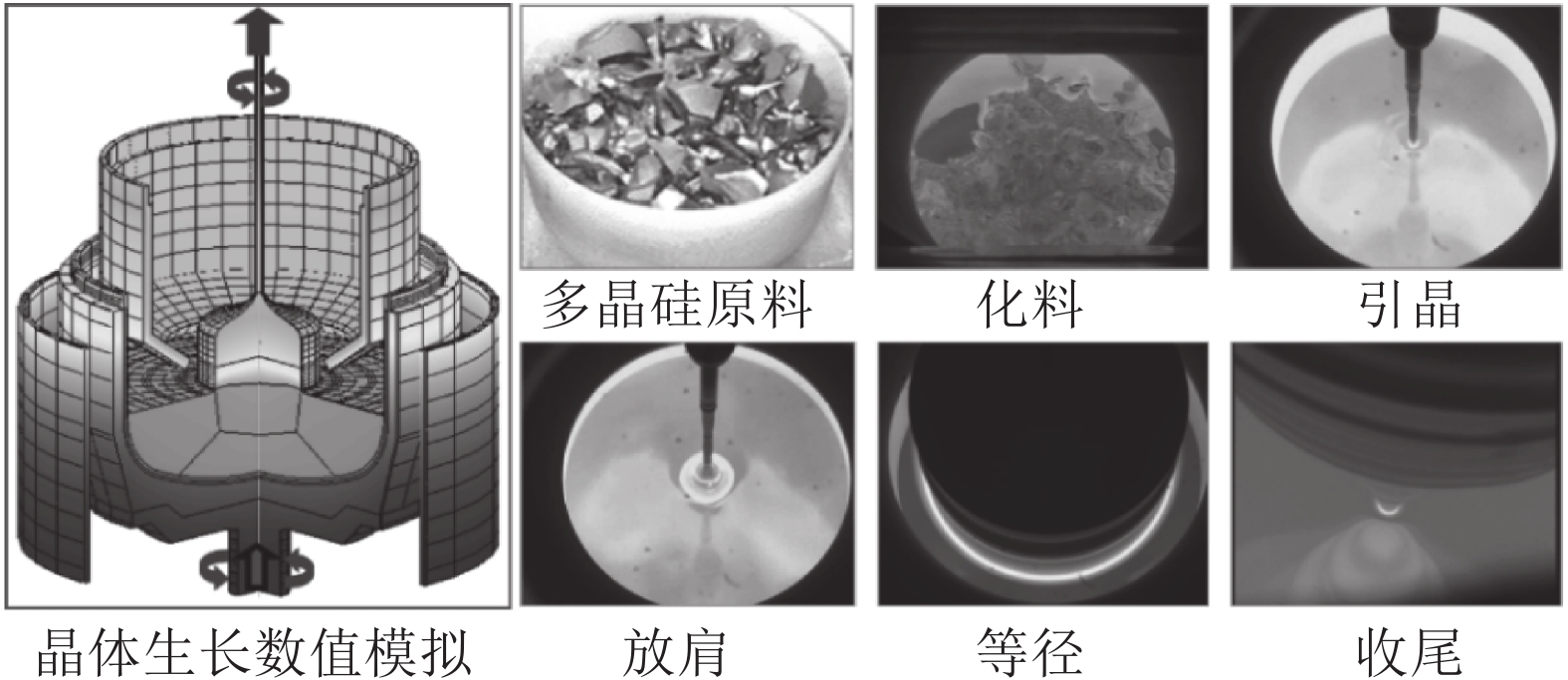
为了验证本文所提方法在实际Cz法硅单晶生长控制过程中的有效性, 本文以晶体生长设备及系统集成国家地方联合工程研究中心的TDR-150型号的单晶炉为实验平台, 图4是Cz法单晶炉生长设备及直径测量系统[35]. 从图4可知, 硅单晶是由多晶硅原料在高温、磁场等作用下经过一系列晶体生长工艺步骤所获得. 晶体直径的动态变化是通过CCD相机进行实时监测. 实验数据采集过程来源于8英寸硅单晶生长实验, 实验条件分别为: 多晶硅原料为180 kg, 炉压为20 Torr, 磁场强度为2 000高斯, 晶体旋转速度为10 r/min, 坩埚旋转速度为10 r/min, 氩气流速为100 L/min.
 图 4 Cz法硅单晶生长过程和晶体直径测量系统Fig. 4 Cz silicon single crystal growth process and crystal diameter measurement system
图 4 Cz法硅单晶生长过程和晶体直径测量系统Fig. 4 Cz silicon single crystal growth process and crystal diameter measurement system3.1 模型建立
基于上述TDR-150单晶炉拉制8英寸硅单晶现场数据库收集到的2017年2月26日至2017年3月2日的历史实验数据进行预测建模和直径控制. 由于硅单晶等径阶段的晶体生长控制不仅影响后期晶体加工的利用率, 还决定了硅单晶品质的好坏, 所以本文主要利用硅单晶等径阶段的晶体直径和加热器功率的历史测量数据, 整个硅单晶等径阶段总共历时27小时左右, 采样时间为2 s. 考虑到后续晶体直径建模的计算量, 我们从等径阶段某个时刻起间隔5个数据点连续选取5 000组实验数据, 该数据集的数据记录时间间隔为10 s, 原始实验数据如图5所示. 选取前3 800组作为训练数据集, 后1 200组作为测试数据集, 用于验证模型拟合效果. 表1是实验数据集的统计描述, 包括总样本数, 平均值(Mean), 最大值(Max), 最小值(Min)和标准差(Std).
表 1 原始实验数据集的统计特性Table 1 Statistical characteristics of the raw experimental data set数据集 数量 Mean Max Min Std 晶体直径 (mm) 总样本 5 000 208.92 212.57 206.16 0.66 训练集 3 800 208.92 212.57 206.16 0.72 测试集 1 200 208.92 209.83 208.06 0.41 加热器功率 (kW) 总样本 5 000 70.52 72.51 68.37 0.80 训练集 3 800 70.20 72.32 68.37 0.59 测试集 1 200 71.56 72.51 70.44 0.40 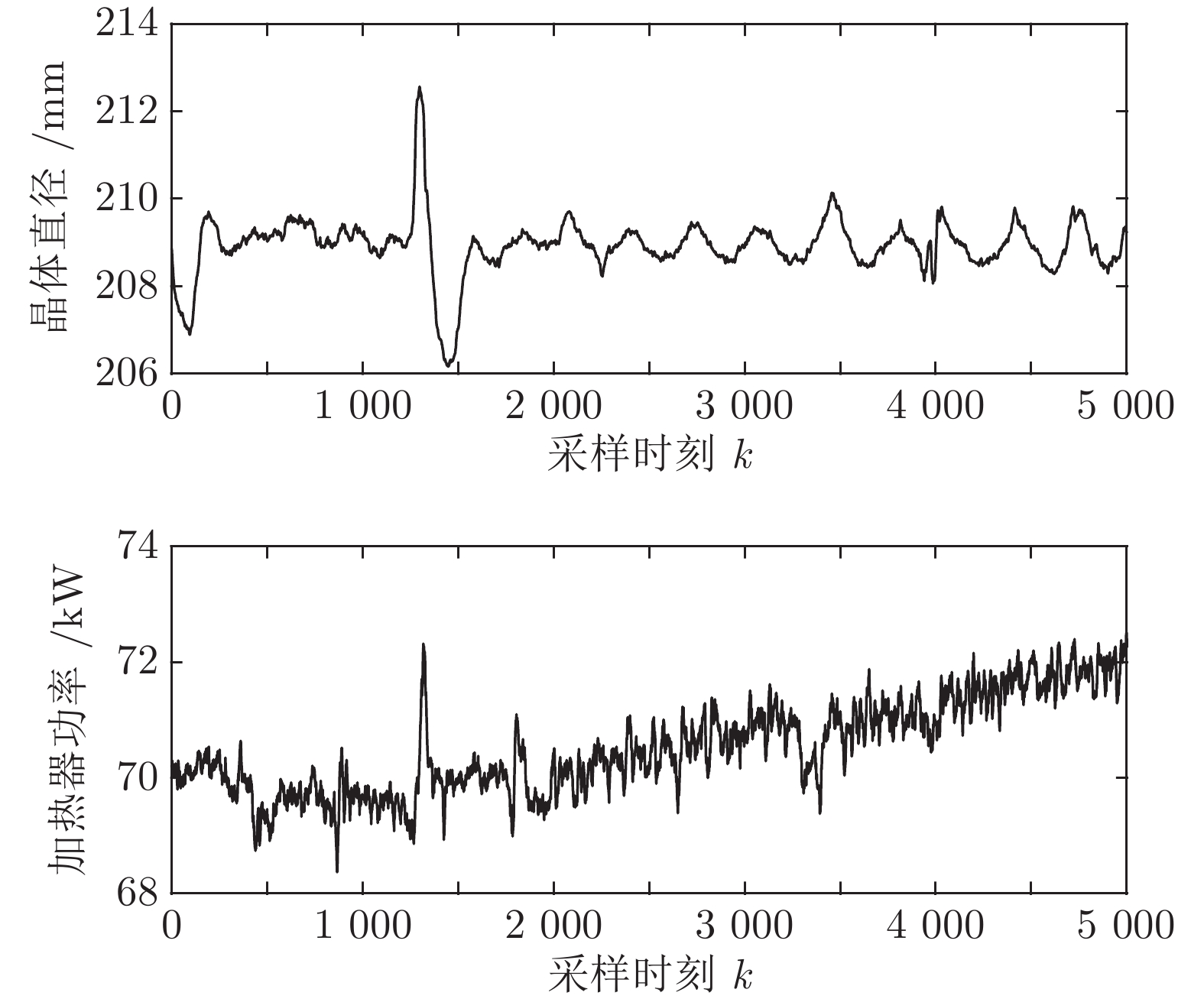 图 5 原始晶体直径与加热器功率实验数据Fig. 5 Experimental data of raw crystal diameter and heater power
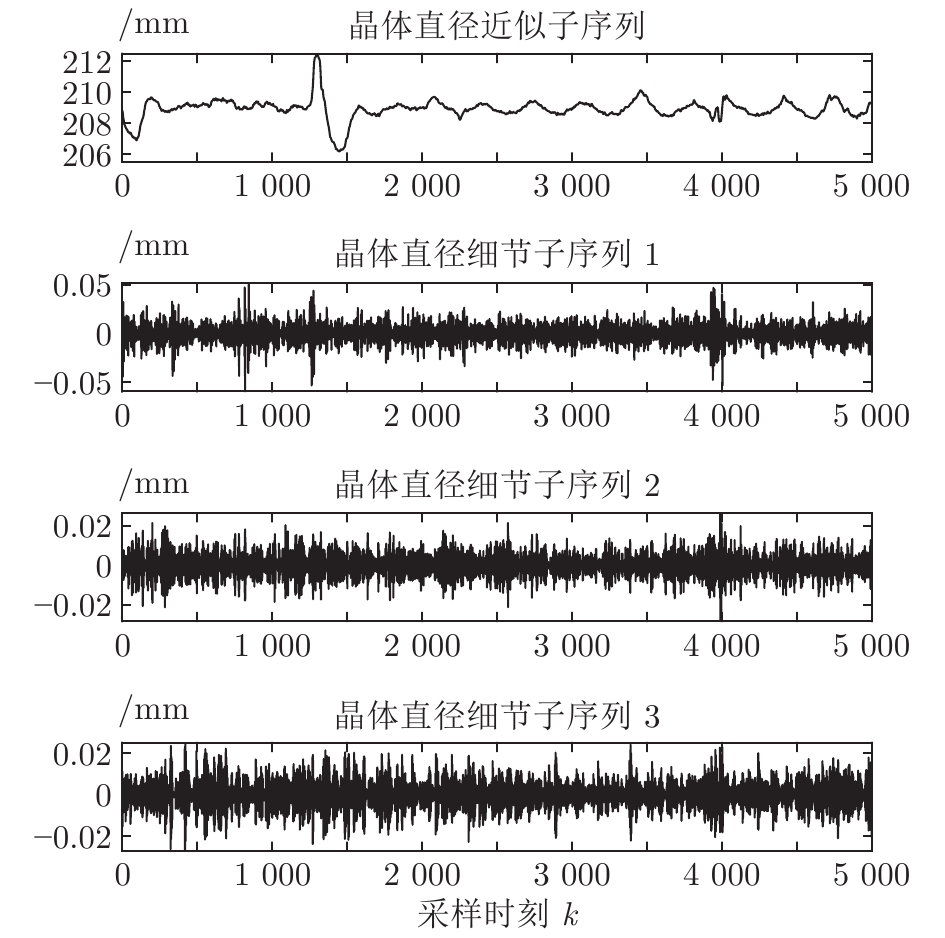
图 5 原始晶体直径与加热器功率实验数据Fig. 5 Experimental data of raw crystal diameter and heater power基于上述等径阶段的历史实验数据, 并考虑到所提混合集成模型的复杂度和计算量, 采用WPD信号分解方法对晶体直径原始数据进行2层分解, 图6是分解之后的不同子序列结果.
从图6中可以明显看出, 近似子序列具有晶体直径原始数据的固有本征信息特征, 代表了晶体直径数据序列的整体趋势, 而细节子序列具有高频的非线性特征反映了晶体直径数据局部波动趋势. 由于高频分量具有较大的随机性, 通常包含了不确定性的测量噪声, 所以为了保证晶体直径预测模型的准确性, 本文将具有最高频的细节子序列3移除, 利用剩余的子序列进行预测建模.
根据晶体生长过程的先验知识, 滞后时间
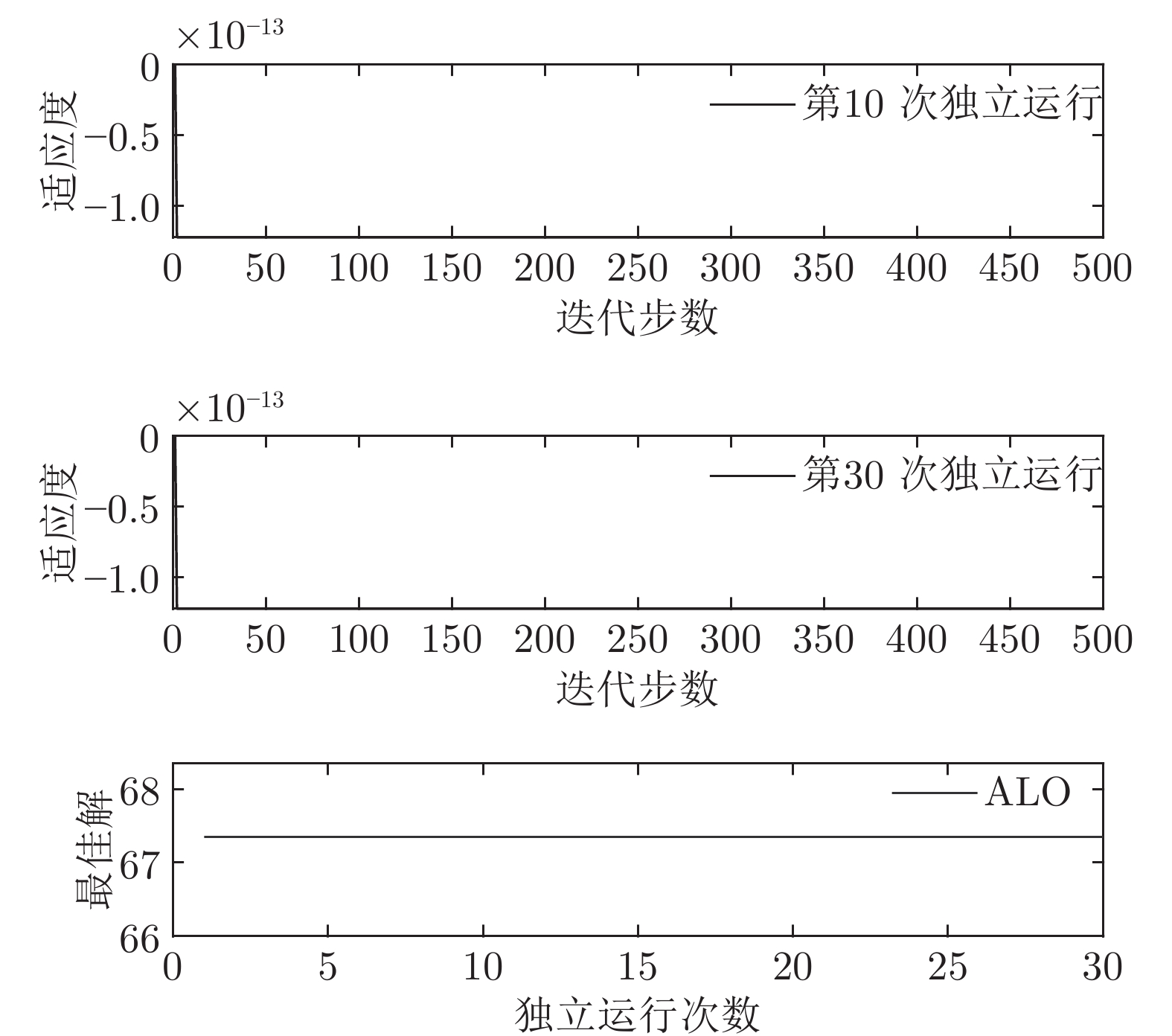
$t$ 一般在5 min ~ 25 min. 采用本文所提出的模型结构辨识方法, 首先对晶体直径模型式(1)中的时滞阶次进行辨识. ALO算法的参数设置为: 种群数$Num = 30,$ 最大迭代次数$Ma{x_{iter}} = 500,$ 时滞阶次$d$ 范围为$30\sim 150. $ 由于ALO算法的初始种群位置是随机生成的, 为了说明所提时滞辨识方法的准确性和可靠性, 图7是30次独立运行后的时滞阶次寻优结果. 可知, 30次独立寻优的时滞阶次未发生明显变化, 说明了所辨识的时滞是准确且可靠的, 同时也说明了ALO算法具有很强的全局搜索能力. 通过四舍五入原则确定时滞
$d = 67,$ 即滞后时间$t = 670\;\rm s,$ 约为11.17 min.然后, 针对式(1)中的模型输入输出阶次, 假设最高阶次为5, 采用所提模型阶次辨识方法, 初步得到表2中基于Lipschitz商准则的不同输入变量个数的评价指标值
$\Gamma $ . 根据停止准则评价指标$\Gamma (m + $ $1,m),$ 可以确定最佳的输入变量个数为$m = {n_u} + $ $ {n_y} + 1 = 5,$ 即${n_u} + {n_y} = 4.$ 最后, 根据模型拟合优度方法可以得到不同阶次组合下的拟合优度值, 如表3所示. 依据最优拟合优度值可以确定输入阶次${n_u} = 1,$ 输出阶次${n_y} = 3.$ 表 2 基于Lipschitz商准则的输入变量个数辨识结果Table 2 Identification results of the number of input variables based on Lipschitz quotient criterion$\Gamma (m + 1,m)$ $\Gamma (4,3)$ $\Gamma (5,4)$ $\Gamma (6,5)$ $\Gamma (7,6)$ $\Gamma (8,7)$ $\Gamma (9,8)$ $\Gamma (10,9)$ $\Gamma (11,10)$ 指标值 0.0145 0.0105 0.0088 0.0071 0.0141 0.0071 0.0033 0.0003 表 3 不同阶次组合的模型拟合优度结果Table 3 Goodness-of-fit of the models with different order combinations不同阶次组合$({n_u},{n_y})$ (1,3) (2,2) (3,1) 模型拟合优度值Fit 99.9132 99.9085 99.9090 3.2 预测性能
为了验证本文所提的晶体直径混合集成预测模型WPD-ELM-LSTM的有效性, 采用三种常用的统计标准来评估直径预测性能, 如表4所示.
表 4 模型性能评价指标Table 4 Model performance evaluation index指标 定义 公式 MAE 平均绝对值误差 ${\rm MAE} = \dfrac{1}{N}\displaystyle\sum\limits_{i = 1}^N {\left| {f(i) - \hat f(i)} \right|} $ MAPE 平均绝对百分
比误差${\rm MAPE} = \dfrac{1}{N}\displaystyle\sum\limits_{i = 1}^N {\left| {\frac{ {f(i) - \hat f(i)} }{ {f(i)} } } \right|} \times 100{\rm{\% } }$ RMSE 均方根误差 ${\rm RMSE} = \sqrt {\dfrac{1}{N}\displaystyle\sum\limits_{i = 1}^N { { {(f(i) - \hat f(i))}^2} } } $ 表5是不同晶体直径预测方法的参数设置. 图8是所提建模方法与ELM、LSTM、WPD-ELM和WPD-LSTM方法的晶体直径预测效果以及相应的预测性能评价指标对比. 为了准确评价所提预测建模方法的有效性, 表6中比较了不同预测模型的预测性能指标. 本文所有的仿真环境配置如下: 系统Windows 10, 内存16 GB, 处理器Intel(R) Core(TM) i5-4590, 仿真软件MATLAB 2018b.
表 5 不同预测方法的参数设置Table 5 Parameter setting of different prediction methods预测方法 参数设置 ELM 20 个隐含节点数, 激活函数 sigmoid LSTM 200 个隐含节点数, 学习率 0.005, 训练轮次 200 WPD-ELM 20 个隐含节点数, 激活函数 sigmoid WPD-LSTM 200 个隐含节点数, 学习率 0.005, 训练轮次 200 WPD-ELM-LSTM ELM: 27 个隐含节点数, 激活函数 sigmoid; LSTM: 185 个隐含节点数, 学习率 0.005, 训练轮次 200 表 6 不同预测模型的晶体直径预测指标Table 6 Prediction index of crystal diameter based on different prediction models模型 MAE (mm) MAPE (%) RMSE (mm) ELM 0.0197 0.0094 0.0258 LSTM 0.0878 0.0420 0.1131 WPD-ELM 0.0172 0.0082 0.0228 WPD-LSTM 0.0431 0.0206 0.0627 WPD-ELM-LSTM 0.0096 0.0046 0.0125  图 8 不同建模方法的晶体直径预测效果及评价指标对比Fig. 8 Comparison of prediction effect and evaluation index of crystal diameter by different modeling methods
图 8 不同建模方法的晶体直径预测效果及评价指标对比Fig. 8 Comparison of prediction effect and evaluation index of crystal diameter by different modeling methods根据图8所示, 所提的混合集成预测模型WPD-ELM-LSTM的晶体直径预测准确性优于其他预测模型(ELM、LSTM、WPD-ELM和WPD-LSTM). 在表6中, 与其他预测模型相比, 所提晶体直径预测模型的MAE指标分别降低了51.27 %, 89.07 %, 44.19 %和77.73 %; MAPE指标下降了51.06 %, 89.05 %, 43.90 %和77.67 %; RMSE指标减少了51.55 %, 88.95 %, 45.18 %和80.06 %. 此外, 所提混合集成预测模型WPD-ELM-LSTM的晶体直径预测值与实际值有更多的相似性, 这是因为混合集成预测模型在预测过程中产生了协同效应, 提高了整体预测结果的准确性. 总之, 所提晶体直径混合集成预测模型WPD-ELM-LSTM提高了单一ELM或LSTM模型的晶体直径预测性能, 从而显示了强大的“分解–集成”框架的学习预测能力.
为了描述上述不同晶体直径预测模型在模型训练阶段的计算量, 表7是不同晶体直径预测模型的训练计算时间, 即离线建模时间. 可以看出集成模型WPD-ELM和WPD-LSTM的训练计算时间分别高于各自单一模型ELM和LSTM, 而在单一模型中ELM的训练计算时间小于LSTM, 从而说明了ELM具有快速训练模型的优点. 正是基于ELM的建模优点, 所以所提WPD-ELM-LSTM的训练计算时间有所减少. 总之, 由于集成模型是由多个子模型进行建模, 必然会牺牲一定的建模时间. 然而在实际应用中晶体直径离线建模的计算量很少被优先考虑. 另一方面, 随着硬件计算能力的提高以及并行计算技术的应用, 所提混合集成建模方法的计算量将会有所减少.
表 7 不同晶体直径预测模型的训练计算时间Table 7 Training calculation time of different crystal diameter prediction models预测模型 训练计算时间 (s) ELM 0.0828 LSTM 304.4786 WPD-ELM 0.2752 WPD-LSTM 972.6920 WPD-ELM-LSTM 601.1670 3.3 控制测试
为了验证本文所提晶体直径混合集成预测模型WPD-ELM-LSTM和ALO优化求解方法在晶体直径自适应NMPC过程中的有效性. 选取预测时域
${N_p}$ 为5, 控制时域${N_c}$ 为3, 柔化系数$\eta $ 为0.2, 控制加权系数$r$ 为0.3, 补偿系数$h$ 为0.5, 控制量约束$\Delta {u_{\min }} = - 2,$ $\Delta {u_{\max }} = - 2,$ ${u_{\min }} = 69,$ ${u_{\max }} = 73,$ 控制量$u$ 的单位是kW. WPD-ELM-LSTM模型参数估计器的优化参数变量权系数$\psi = 0.03.$ ALO的参数设置为种群个数$Num = 30,$ 最大迭代次数$Ma{x_{iter}} = 300.$ 根据晶体生长工艺要求, 晶体生长控制目标为: 晶体直径$y$ 变化范围207 mm ~ 210 mm 加热器功率$u$ 变化范围69 kW ~ 73 kW. 由于实际硅单晶生长过程中会存在很多不确定性干扰因素, 为了模拟检测系统在测量过程中所产生的随机误差, 同时为了验证所提控制方法的鲁棒性, 所以本文在单晶炉系统的输出中加入均值为0, 方差0.01的高斯随机噪声, 用以模拟传感器数据采集混入的高斯噪声.首先, 测试所提混合集成建模方法下晶体直径自适应NMPC的跟踪性能, 选取晶体直径的初始设定值
${y_{sp}}$ 为208.5 mm, 在采样时刻150时改变晶体直径设定值${y_{sp}}$ 为209 mm, 得到晶体直径的设定值跟踪曲线, 如图9所示. 在外部干扰的情况下, 所提自适应NMPC方法和常规NMPC方法的晶体直径控制输出均在直径设定点附近轻微波动、超调较小, 且各自的加热器功率控制变量也在约束的范围之内. 然而, 在直径跟踪精度和快速性方面, 所提基于混合集成预测模型WPD-ELM-LSTM的晶体直径自适应NMPC控制性能优于常规NMPC, 而且加热器功率控制变量的抖动幅度相对较小. 因此, 自适应NMPC方法更适合硅单晶生长过程中的晶体直径控制.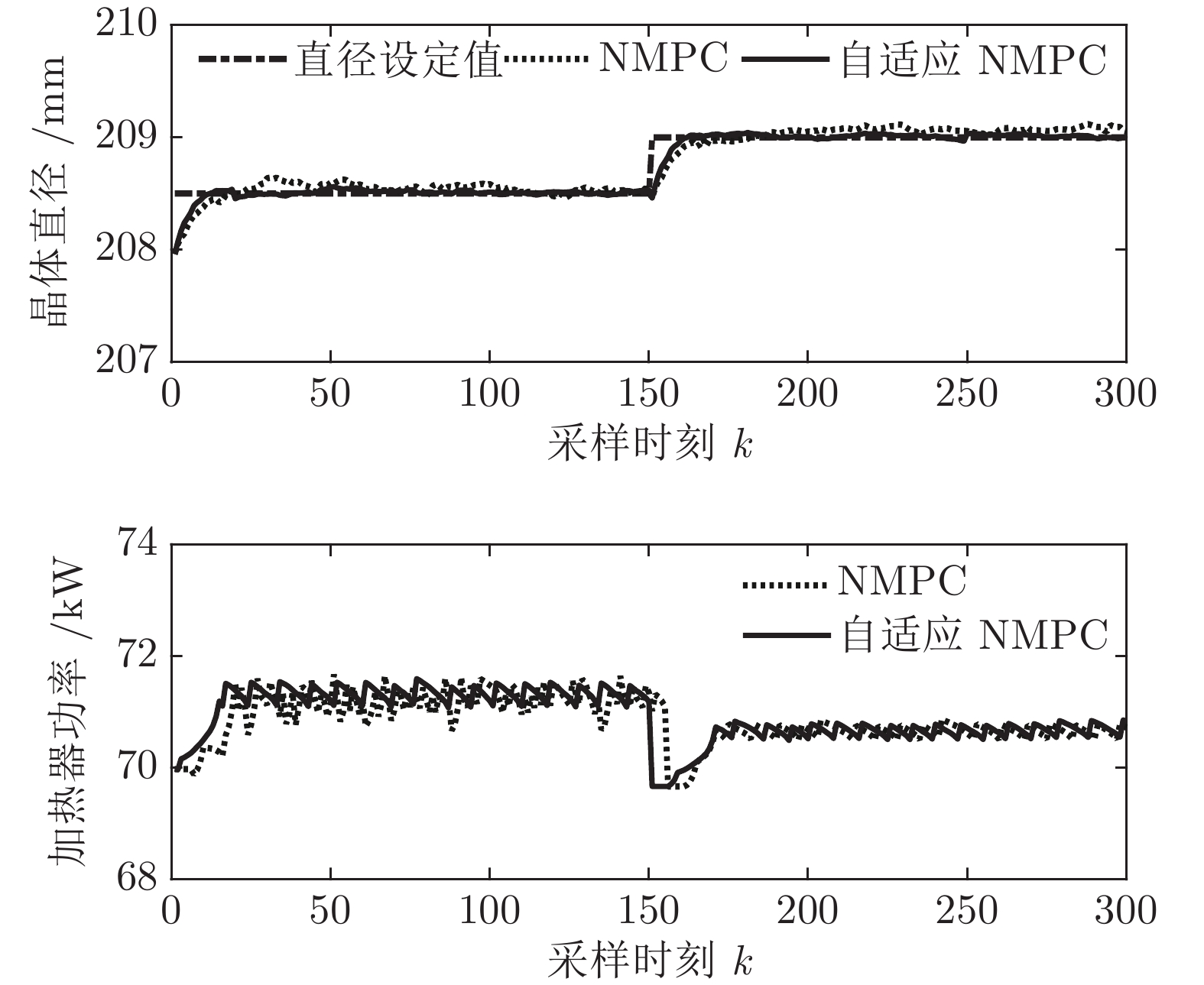 图 9 自适应NMPC和常规NMPC的晶体直径设定值跟踪效果Fig. 9 Crystal diameter setpoint tracking effect of adaptive NMPC and conventional NMPC
图 9 自适应NMPC和常规NMPC的晶体直径设定值跟踪效果Fig. 9 Crystal diameter setpoint tracking effect of adaptive NMPC and conventional NMPC然后, 验证所提晶体直径自适应NMPC在ALO优化求解下的晶体直径控制性能指标
$J$ 收敛性、WPD-ELM-LSTM预测模型参数估计性能指标${J_\theta }$ 收敛性以及晶体直径预测控制的实时性. 根据上述图9晶体直径设定值跟踪仿真结果, 可以得到晶体直径自适应NMPC在单步计算过程中的控制性能指标$J$ 和模型参数估计的性能指标${J_\theta }$ 收敛曲线, 如图10所示. 从中可以看出, 晶体直径控制性能指标$J$ 基本在160次迭代以后, 进入稳定收敛状态, 而晶体直径预测模型参数估计的性能指标${J_\theta }$ 在第150次迭代以后, 也能够满足稳定收敛. 因此, 采用ALO算法求解自适应NMPC可以实现晶体直径的有效控制. 此外, 为了比较晶体直径自适应NMPC在直径设定值跟踪控制中的实时性, 表8是不同预测模型下晶体直径预测控制计算时间, 即平均控制量更新时间. 从表8中可以看出, 所提混合集成预测模型WPD-ELM-LSTM的自适应NMPC计算时间高于单一模型的计算时间, 这主要是由所建混合集成模型的复杂性导致. 另外, 基于混合集成预测模型WPD-ELM-LSTM的自适应NMPC计算时间高于常规NMPC, 这主要是因为模型参数自适应更新过程比较耗时. 然而, 硅单晶生长是一个缓慢的时变动态过程, 通过加热器功率调节晶体直径存在较大的滞后时间(5 min ~ 25 min), 且实际应用中对控制系统的实时性要求不高, 所以7.3113 s的平均控制量更新时间是可以接受的. 另外, 随着硬件计算能力的提高, 所提控制方法的计算时间将会有所减少.表 8 基于不同预测模型的晶体直径预测控制计算时间Table 8 Calculation time of crystal diameter predictive control based on different prediction models预测模型 平均控制量更新时间 (s) ELM (常规NMPC) 0.4512 LSTM (常规NMPC) 0.4899 WPD-ELM-LSTM (常规NMPC) 0.6841 WPD-ELM-LSTM (自适应NMPC) 7.3113 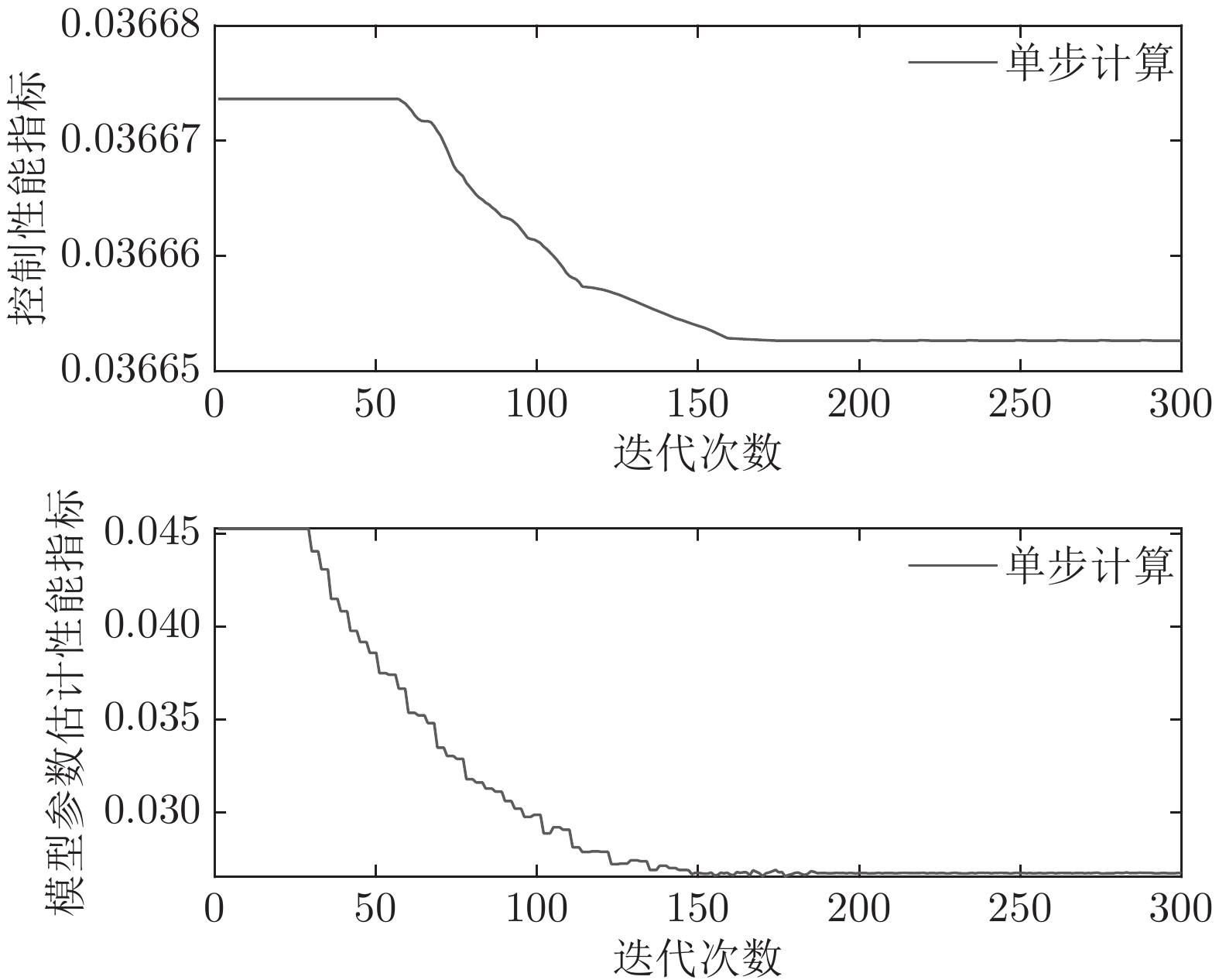 图 10 晶体直径控制性能指标和模型参数估计性能指标收敛曲线Fig. 10 Convergence curve of crystal diameter control performance index and model parameter estimation performance index
图 10 晶体直径控制性能指标和模型参数估计性能指标收敛曲线Fig. 10 Convergence curve of crystal diameter control performance index and model parameter estimation performance index最后, 由于硅单晶生长系统是一个慢时变动态过程, 且具有大滞后特点, 因此为了进一步验证所提控制方法的应用性能以及在时滞变化情况下的稳定性, 本文将晶体生长工业中常规PID控制方法与本文方法进行对比. 设置晶体直径的期望指标
${y_{sp}}$ 为209 mm, 补偿系数$h$ 为0.3, WPD-ELM-LSTM模型参数估计器的优化参数变量的权系数$\psi = 0.01,$ 其他晶体直径控制参数与上述设置相同; PID控制参数设置为${k_p} = 0.26,$ ${k_i} = 0.01,$ ${k_d} = 0.1.$ 图11是原始时滞阶次下的所提控制方法与常规PID晶体直径控制结果对比. 图12是时滞阶次$d$ 增大20 %和时滞阶次减少20 %的晶体直径控制结果.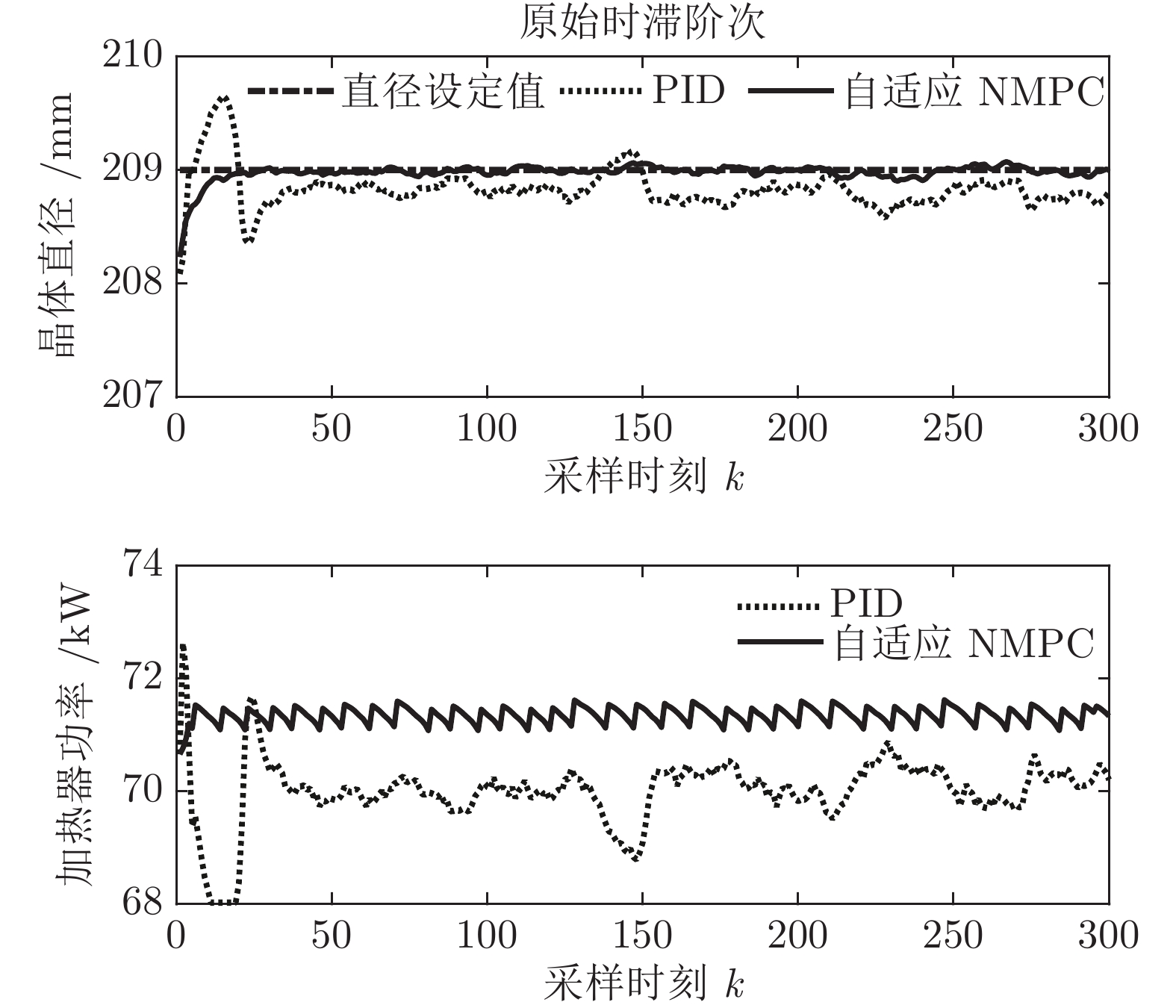 图 11 所提自适应NMPC与常规PID的晶体直径控制结果Fig. 11 The crystal diameter control results of the proposed adaptive NMPC and conventional PID
图 11 所提自适应NMPC与常规PID的晶体直径控制结果Fig. 11 The crystal diameter control results of the proposed adaptive NMPC and conventional PID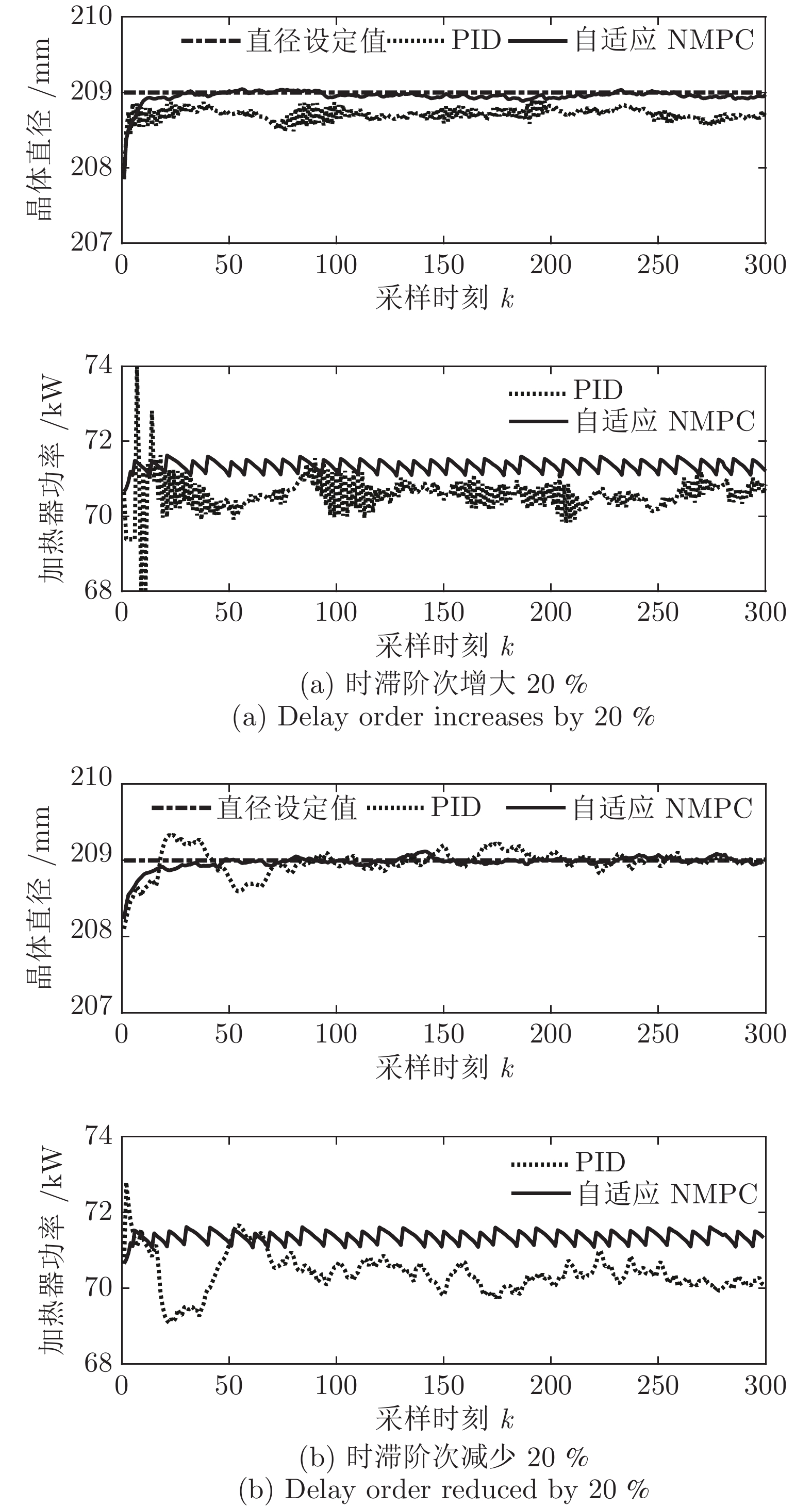 图 12 时滞阶次变化时所提自适应NMPC与常规PID的晶体直径控制结果Fig. 12 Crystal diameter control results of adaptive NMPC and conventional PID for delay order variation
图 12 时滞阶次变化时所提自适应NMPC与常规PID的晶体直径控制结果Fig. 12 Crystal diameter control results of adaptive NMPC and conventional PID for delay order variation从图11可知, 所提控制方法和PID控制均能获得有效的晶体直径控制效果. 然而, 与常规PID方法相比, 所提控制方法的直径设定值跟踪和干扰抑制性能更好, 并且具有更好的动态跟踪和稳态性能. 另外, 在图12中, 当时滞阶次
$d$ 发生变化时, 所提控制方法均能达到满意的晶体直径控制性能, 更好地显示了其具有更强的鲁棒性. 然而, 对于常规PID控制方法而言, 当时滞阶次d增大20 %时, 晶体直径控制难以较好地跟踪直径设定值, 始终存在较大的控制误差, 出现晶体直径控制效果抖振现象; 当时滞阶次d减小20 %时, 晶体直径跟踪控制能够逐渐收敛到直径设定值附近, 且受时滞阶次变化影响较小. 因此, 对于此类具有大滞后、慢时变动态特性的Cz法硅单晶生长过程, 常规PID控制难免有其局限性, 而所提控制方法具有明显的晶体直径控制优点, 即准确、稳定的在线控制性能.4. 结论
Cz法硅单晶生长过程的晶体直径控制一直是晶体生长领域研究的热点和难点. 针对这一问题, 本文提出了一种基于混合集成预测模型WPD-ELM-LSTM的晶体直径自适应NMPC方法. 通过基于互相关函数的时滞优化估计方法和基于Lipschitz商准则与模型拟合优度的模型阶次辨识方法, 准确的辨识了晶体直径模型结构, 并在“分而治之”原理下构建了数据驱动的晶体直径混合集成模型, 为晶体直径预测控制提供了精确的预测模型. 同时, 为了解决晶体直径混合集成模型失配问题以及目标函数难以求解问题, 采用ALO算法设计了晶体直径自适应NMPC求解策略. 基于实际硅单晶生长实验数据的晶体直径建模与控制仿真实验表明, 所提混合集成预测模型WPD-ELM-LSTM比常规ELM、LSTM、WPD-ELM和WPD-LSTM模型表现出更好的晶体直径预测性能和泛化能力. 另外, 基于混合集成模型的硅单晶直径自适应NMPC算法不仅可以实现晶体直径的精准控制, 而且能够有效抑制外部扰动和时滞变化的影响, 具有良好的控制性能以及工程应用前景.
-
[1] Wei X J, Wu Z J, Hamid R K. Disturbance observerbased disturbance attenuation control for a class of stochastic systems. Automatica, 2016, 63: 21−25 doi: 10.1016/j.automatica.2015.10.019 [2] 魏新江, 孙式香, 张慧凤. 随机多源干扰系统的复合DOBC和容错 控制. 控制与决策, 2019, 34(3): 668−672Wei Xin-Jiang, Sun Shi-Xiang, Zhang Hui-Feng. Faulttolerant control based on disturbance observer for stochastic systems with multiple disturbances. Control and Decision, 2019, 34(3): 668−672 [3] Li Y K, Chen M, Cai L, Wu Q X. Resilient control based on disturbance observer for nonlinear singular stochastic hybrid system with partly unknown Markovian jump parameters. Journal of the Franklin Institute, 2018, 355(5): 2243−2265 doi: 10.1016/j.jfranklin.2017.12.038 [4] Wei X J, Sun S X. Elegant anti-disturbance control for discrete-time stochastic systems with nonlinearity and multiple disturbances. International Journal of Control, 2017, 91(3): 706−714 [5] Wei X J, Zhang H F, Sun S X, Hamid R K. Composite hierarchical anti-disturbance control for a class of discretetime stochastic systems. International Journal of Robust and Nonlinear Control, 2018, 28(9): 3292−3302 doi: 10.1002/rnc.4080 [6] Zong G D, Li Y, Sun H B. Composite anti-disturbance resilient control for Markovian jump nonlinear systems with general uncertain transition rate. Science China Information Sciences, 2019, 62(2): 101−118 [7] 司文杰, 董训德, 王聪. 输入饱和的一类切换系统神经网络跟踪控 制. 自动化学报, 2017, 43(8): 1383−1392Si Wen-Jie, Dong Xun-De, Wang Cong. Adaptive neural tracking control design for a class of uncertain switched nonlinear systems with input saturation. Acta Automatica Sinica, 2017, 43(8): 1383−1392 [8] 林安辉, 蒋德松, 曾建平. 具有输入饱和的欠驱动船舶编队控制. 自 动化学报, 2018, 44(8): 1496−1504Lin An-Hui, Jiang De-Song, Zeng Jian-Ping. Underactuated ship formation control with input saturation. Acta Automatica Sinica, 2018, 44(8): 1496−1504 [9] 王萌, 孙雷, 尹伟, 等. 面向交互应用的串联弹性驱动器力矩控制方 法. 自动化学报, 2017, 43(8): 1319−1328Wang Meng, Sun Lei, Yin Wei, et al. Series elastic actuator torque control approach for interaction application. Acta Automatica Sinica, 2017, 43(8): 1319−1328 [10] Sui S, Tong S, Li Y. Observer-based fuzzy adaptive prescribed performance tracking control for nonlinear stochastic systems with input saturation. Neurocomputing, 2015, 158: 100−108 doi: 10.1016/j.neucom.2015.01.063 [11] Si W, Dong X, Si W, et al. Adaptive neural control for MIMO stochastic nonlinear purefeedback systems with input saturation and full-state constraints. Neurocomputing, 2018, 275(31):298−307 [12] Dong L W, Wei X J, Zhang H F. Anti-disturbance control based on nonlinear disturbance observer for a class of stochastic systems. Transactions of the Institute of Measurement and Control, 2019, 41(6): 1665−1675 doi: 10.1177/0142331218787608 [13] Bernt K O. Stochastic Differential Equations: An Introduction with Applications, Berlin: Springer-Verlag, 2002. [14] Kozin F. A survey of stability of stochastic systems. Automatica, 1969, 5(1): 95−112 doi: 10.1016/0005-1098(69)90060-0 [15] Mao X R, Yuan C G. Stochastic Differential Equations with Markovian Switching. London: Imperial College Press, 2006, 157−158 期刊类型引用(4)
1. 乔宏霞,杜杭威,李元可,杨安. 氯氧镁水泥混凝土中涂层钢筋的锈蚀劣化模型研究. 建筑结构. 2024(03): 65-70 .  百度学术
百度学术2. 康守强,邢颖怡,王玉静,王庆岩,谢金宝,MIKULOVICH Vladimir Ivanovich. 基于无监督深度模型迁移的滚动轴承寿命预测方法. 自动化学报. 2023(12): 2627-2638 . 本站查看3. 严帅,熊新. 基于KPCA和TCN-Attention的滚动轴承退化趋势预测. 电子测量技术. 2022(15): 28-34 . 百度学术4. 张伟涛,纪晓凡,黄菊,楼顺天. 航发轴承复合故障诊断的循环维纳滤波方法. 西安电子科技大学学报. 2022(06): 139-151 . 百度学术其他类型引用(12)
-



 下载:
下载:
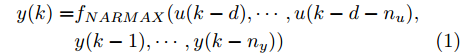
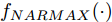
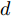
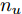
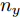
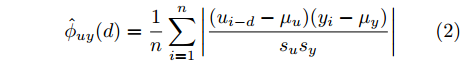
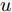
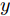
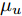
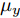
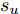
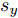
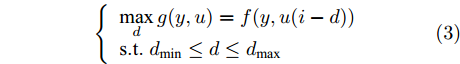
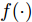
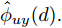


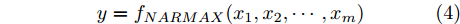

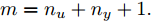
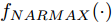
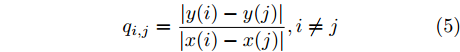
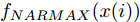
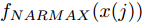
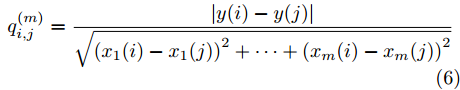
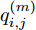

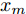
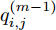
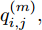
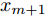
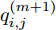
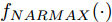
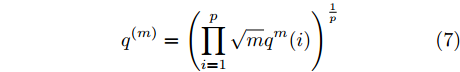
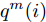
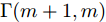
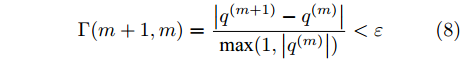


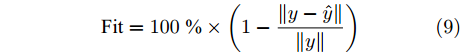
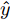
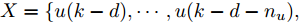
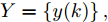
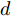
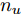
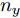
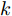
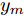
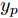
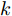
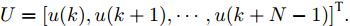
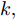
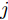
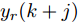
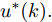
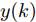
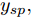
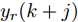
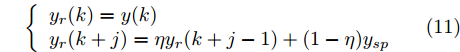
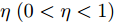
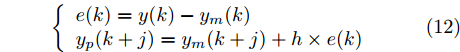
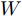
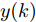
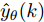
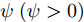
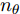
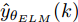
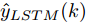
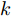
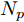
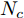
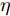
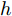
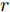
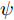
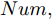
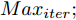
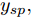
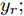
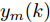
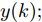
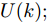
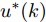
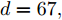
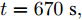
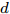
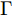
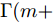
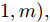
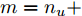
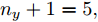
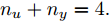
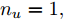
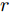
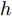
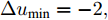
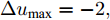
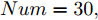



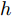
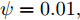
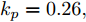
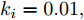
 下载:
下载:

计量
- 文章访问数: 1256
- HTML全文浏览量: 288
- PDF下载量: 286
- 被引次数: 16
