

-
摘要: 主成分分析(Principal component analysis, PCA) 是处理高维数据的重要方法. 近年来, 基于各种范数的PCA模型得到广泛研究, 用以提高PCA对噪声的鲁棒性. 但是这些算法一方面没有考虑重建误差和投影数据描述方差之间的关系; 另一方面也缺少确定样本点可靠性(不确定性)的度量机制. 针对这些问题, 本文提出一种新的鲁棒PCA模型. 首先采用$L_{2, p}$模来度量重建误差和投影数据的描述方差. 基于重建误差和描述方差之间的关系建立自适应概率误差极小化模型, 据此计算主成分对于数据描述的不确定性, 进而提出了鲁棒自适应概率加权PCA模型(RPCA-PW). 此外, 本文还设计了对应的求解优化方案. 对人工数据集、UCI数据集和人脸数据库的实验结果表明, RPCA-PW在整体上优于其他PCA算法.Abstract: Principal component analysis (PCA) is an important method for processing high-dimensional data. In recent years, PCA models based on various norms have been extensively studied to improve the robustness. However, on the one hand, these algorithms do not consider the relationship between reconstruction error and covariance; on the other hand, they lack the uncertainty of considering the principal component to the data description. Aiming at these problems, this paper proposes a new robust PCA algorithm. Firstly, the $L_{2, p}$-norm is used to measure the reconstruction error and the description variance of the projection data. Based on the reconstruction error and the description variance, the adaptive probability error minimization model is established to calculate the uncertainty of the principal component's description of the data. Based on the uncertainty, the adaptive probability weighting PCA is established. The corresponding optimization method is designed. The experimental results of artificial data sets, UCI data sets and face databases show that RPCA-PW is superior than other PCA algorithms.
-
Key words:
- Principle component analysis (PCA) /
- weighted principal component analysis (WPCA) /
- dimensionality reduction /
- robustness
-
多目标跟踪中传感器控制的核心是根据一定的优化准则, 选择传感器的工作状态或运行参数, 进而控制量测过程以达到优化多目标跟踪性能的目的. 本质上, 它是一个最优非线性控制问题. 这类问题的解决通常是在部分可观测马尔科夫决策过程~(Partially observable Markov decision process, POMDP)~的理论框架下[1-4]进行. POMDP一般包括表征状态信息的多目标概率密度函数, 一个可允许的传感器控制集合和评价函数. 然而, 多目标传感器控制问题一般处理高度复杂的多目标随机系统, 其目标的数量不仅随时间变化, 而且其量测也会受到漏检和虚警的影响. 这些复杂的不确定性因素都使得多目标传感器控制策略的求解变得非常困难.
近些年来, 基于随机有限集~(Random finite set, RFS)的多目标跟踪方法备受关注. 该方法将多目标状态和多目标量测建模为有限集值. 同时通过引入有限集统计~(Finite set statistics, FISST)[5-6]理论, 将杂波环境下的多目标状态估计问题描述为贝叶斯滤波问题, 从而避免了传统跟踪算法中较难处理的数据关联问题. 基于~RFS~的多目标跟踪方法可在贝叶斯滤波框架下根据每个时刻接收的集值量测递推更新多目标状态的概率密度函数. 为简化在多目标状态空间上直接求解多目标贝叶斯滤波器的复杂度, ~Mahler~和~Vo~提出了一系列最优近似多目标滤波器[7-14], 包括矩递推滤波器和形式多样的~(有标签和无标签)~多伯努利滤波器. 这些方法目前已应用在多目标传感器控制问题[15-19]中. 值得注意的是, 这些传统的量测模型通常用量测噪声来表征量测模型的不确定性, 称为统计不确定性. 然而, 在许多实际应用中, 这种标准的量测建模方式是不够准确的. 例如, 复杂的监控系统通常会遭遇未知的同步偏差和系统延迟. 由此产生的量测通常会受到典型未知分布和偏差的边界误差的影响. 此时, 这种带有边界误差的量测可以用一个"区间量测"而不是点值量测来描述. 区间量测表示一种不确定性, 称为集论不确定性[20-21]. 文献[22]结合序贯蒙特卡罗方法和区间分析技术, 在目标跟踪背景下首次提出箱粒子的概念, 其核心思想是利用状态空间内的多维区间或者体积非零的矩形区域代替传统的点粒子, 同时用误差界限模型代替传统的误差统计模型. 作为一种"广义粒子滤波"算法, 箱粒子滤波仍然在贝叶斯滤波框架下进行[23], 并通过一组带有权值的箱粒子来表征多目标后验概率密度函数. 由于箱粒子可以被解释为一种由大量点粒子组成的集总形式, 因此, 用箱粒子滤波器进行状态估计时相当于箱粒子所覆盖的空间中的所有点粒子都参与估计, 这就在很大程度上减少了所需粒子的数量, 降低了算法的复杂度, 节省了计算资源, 提高了算法的运行速度. 鉴于箱粒子滤波器估计效果较好, 运行速度更快的优点, 近几年, 已有一些学者相继提出了箱粒子概率假设密度滤波器[24], 箱粒子~(多)~伯努利滤波器[25-28]等.
箱粒子滤波器运行速度快的优点使得其与传感器管理的结合更具优势. 遗憾的是, 截至目前基于箱粒子滤波器的传感器管理并没有引起太多学者的关注, 而且在我们现有的知识背景中, 也并未查阅到有相关研究成果的发表. 实际上, 基于箱粒子滤波器进行传感器控制策略的求解, 最大的难题在于如何用表征多目标概率密度的箱粒子直接求解以信息散度为代表的评价函数. 这与利用点粒子求解评价函数大不相同. 由于德尔塔粒子的正交特性和易于求解积分的特点, 点粒子求解评价函数是方便和容易的. 但箱粒子作为体积非零的矩形区域, 其并没有正交消除冗余项的便利, 因此直接利用箱粒子求解评价函数是极其困难的.
鉴于此, 本文基于区间不确定性推理, 利用箱粒子多伯努利滤波器提出了一种基于信息测度的传感器控制策略. 首先, 利用箱粒子实现多伯努利滤波器, 并通过一组带有权值的箱粒子来表征多目标后验概率密度函数. 其次, 利用箱粒子的高斯分布假设, 将多伯努利密度近似为高斯混合. 显然, 这不但避免了利用箱粒子直接求取评价函数的难题, 而且将其转化为利用高斯混合求解评价函数的问题. 随后, 针对高斯混合分布间的信息增益大都不存在闭式解的问题, 本文基于高斯混合多伯努利滤波器, 研究并推导了两个高斯混合之间的柯西施瓦兹~(Cauchy-Schwarz, CS)~散度求解公式, 并以此为基础提出相应的传感器控制策略. 为了对比说明所提方案的合理性和有效性, 基于蒙特卡罗方法, 本文也给出了通过混合均匀采样近似箱粒子, 进而利用点粒子求解~CS~散度的递推公式, 并给出了相应的传感器控制策略. 最后, 仿真实验验证了所提算法的有效性.
1. 问题描述
1.1 多目标随机有限集建模
对于一个单目标系统, 目标状态和量测一般由不同维数的随机矢量构成. 这些矢量在随时间演变的过程中, 其维数是恒定的. 而多目标系统显然并非如此, 其状态和量测一般由各自包含多个状态和量测的集合构成, 且维数随时间而变化. 假定$ k-1 $时刻在目标状态空间$ \mathcal{X}\subseteq {{\bf R}^{{n_x}}} $中存在$ N_x(k-1) $个目标, 状态分别为$ {\pmb x}_{1, k-1}, \cdots, {\pmb x}_{N_x(k-1), k-1} $, 目标状态维数为$ {n_x} $. 随着时间的演化, 这些目标可能会消亡, 或以新的状态继续存活, 而新的目标也有可能出现. 此时, $ k $时刻$ N_x(k) $个目标的状态可记为$ {{x\mathit{\boldsymbol{}}}}_{1, k}, \cdots, {\pmb x}_{N_x(k), k} $, 且状态顺序和目标顺序无关. 同时, $ k $时刻传感器接收到$ M_z(k) $个量测在量测空间$ \mathcal Z \subseteq {\bf R}^{{n_z}} $中取值分别为$ \pmb {z}_{1, k}, \cdots, {\pmb z}_{M_z(k), k} $, 量测维数为$ {n_z} $. 这些量测既可能来自于目标, 也可能来自于杂波, 并且量测顺序和目标顺序无关. 那么, $ k $时刻多目标状态$ {{X}_{k}} = \{{\pmb x}_{1, k}, \cdots, {\pmb x}_{N_x(k), k}\} \in \mathcal{F}(\mathcal{X}) $和多目标量测$ {{Z}_{k}} = \{{\pmb z}_{1, k}, \cdots, {\pmb z}_{M_z(k), k}\} \in \mathcal{F}(\mathcal{Z}) $都分别构成一个无序的RFS. 其中, $ \mathcal{F}(\mathcal{X}) $表示$ \mathcal{X} $所有有限子集的并集, $ \mathcal{F}(\mathcal{Z}) $表示$ \mathcal{Z} $所有有限子集的并集. 在区间不确定性分析中, 量测一般表示为区间量测, 此时多目标量测为$ {{Z}_{k}} = \{{\left[\pmb z\right]}_{1, k}, \cdots, {\left[\pmb z\right]}_{M_z(k), k}\} \in \mathcal{F}(\mathcal{IZ}) $, 其中$ \mathcal{IZ} $为区间量测空间, $ \mathcal{F}(\mathcal{IZ}) $表示$ \mathcal{IZ} $所有有限子集的并集. 对于$ k-1 $时刻给定的多目标状态$ X_{k-1} $, 假设目标$ \pmb x_{k-1} \in X_{k-1} $以存活概率$ p_{S, k}(\pmb x_{k-1}) $继续存活在$ k $时刻. 若不考虑衍生目标, 则多目标状态集$ X_{k} $可建模为
$$ \begin{equation} {X_k} = \left[ {\bigcup\limits_{{{\pmb x}_{k - 1}} \in {X_{k - 1}}} {{S_{k|k - 1}}({{\pmb x}_{k - 1}})} } \right] \cup {\Gamma _k} \end{equation} $$ (1) 其中, $ {{S_{k|k - 1}}({\pmb x_{k - 1}})} $是从$ k-1 $时刻到$ k $时刻存活目标状态的RFS. $ {\Gamma _k} $为$ k $时刻新生目标状态的RFS.
假设目标状态转移方程为
$$ \begin{equation} {\pmb x}_{k+1} = {f}_{k}\cdot {\pmb x}_{k}+ {\pmb w}_{k} \end{equation} $$ (2) 其中, $ {{f}_{k}} $是系统的状态转移矩阵, $ {\pmb w}_{k}\sim\mathcal{N}(0, Q_k) $为过程噪声.
此外, 假设$ k $时刻传感器以检测概率$ {{p}_{D, k}}({\pmb x_k}) $检测到目标$ \pmb x_{k} \in X_{k} $, 且被检测目标以式(3) 产生量测$ {\pmb {z}_{k}}\in Z_k $.
$$ \begin{equation} {\pmb z _{k}} = h({\pmb x}_{k}, {\pmb x}_{s, k}({\nu})) + {\pmb v_k} \end{equation} $$ (3) 其中, $ {{\pmb v}_{k}} $为量测噪声. 在本文的实际仿真场景中, $ p_{\pmb v} $描述为零均值高斯白噪声. $ k $时刻的传感器位置$ {\pmb x}_{s, k}({\nu}) = [x_{s, k}({\nu}), y_{s, k}({\nu})]^{\rm T} $由传感器控制方案$ {\nu} $所决定. 考虑传感器检测不确定性, 此时传感器对应目标量测是一个RFS, 可表示为$ \Theta _k({\pmb x_k}) $. 若考虑杂波的影响, 则$ k $时刻传感器接收到的多目标量测集$ Z_{k} $可建模为
$$ \begin{equation} {Z_k} = \left[ {\bigcup\limits_{{\pmb x_k} \in {X_k}} {{\Theta _k}({\pmb x_k})} } \right] \cup {K_k^C} \end{equation} $$ (4) 其中, $ K_{k}^C $表示$ k $时刻的杂波过程, 它是一个泊松RFS, 其强度函数为$ {\kappa_k}{(\cdot)} $.
1.2 多目标跟踪中基于信息论的传感器控制方法
多目标跟踪中基于信息论的传感器控制通常是在POMDP框架下进行的. 实际上, POMDP是马尔科夫决策过程的推广形式, 其通常包括三个要素: 表征多目标状态信息的概率密度函数, 一个可允许的传感器控制集合和评价函数. 具体来讲, FISST理论框架下的多目标状态信息可用$ k $时刻多目标后验概率密度$ p_{k|k}{(X_{k|k}|Z_{1:k})} $来描述. 用$ {U}_k $表示$ k $时刻可允许的传感器控制集合, 每一个传感器控制$ {{\nu}}\in {U}_k $决定下一时刻传感器的位置. 对于每一个传感器控制$ {\nu} $给定一个对应的评价函数$ \mathcal{R}({\nu}) $. 则最优控制序列$ u_k $可按以下准则确定
$$ \begin{align} u_k = \mathop {\rm{argmax} }\limits_{{\ \ \ \ {\nu} \in {U}_k}} {\rm E}\{\mathcal{\mathcal{R}}({\nu}, p_{k|k-1}(X|Z_{1:k-1}), Z_{k}({\nu}))\} \end{align} $$ (5) 其中, $ p_{k|k-1}(X|Z_{1:k-1}) $表示$ k $时刻多目标先验概率密度, $ {\mathcal{R}}({\nu}, p, Z) $是与传感器控制$ {\nu} $相关的评价函数, 由未来量测集$ Z_{k}({\nu}) $所决定. 通常未来量测集可由式(3) 和(4) 获得. 但这种方法通常会给传感器的求解带来极大的计算负担. 比较常用且实际的做法是在不考虑杂波、噪声且检测概率$ {{p}_{D, k} = 1} $的情况下, 对每一个控制$ {\nu} $产生一个预测理想量测集(Predicted ideal measurement set, PIMS)[29-30], 进而用PIMS代替实际量测来进行传感器控制的求解.
此外, 评价函数依据控制决策评价体系的不同可分为两大类: 基于任务驱动和基于信息驱动. 基于任务驱动的传感器控制策略旨在某个单一准则下基于某个特殊任务进行优化. 而基于信息驱动的传感器控制策略由于能够兼顾多任务指标的竞争优化而备受关注, 其评价函数通常反映了多目标概率密度间的信息增益$ D_I(\cdot, \cdot) $, 即$ {\mathcal{R}}({\nu}) $选择为信息测度
$$ \begin{align} {\mathcal{R}}({\nu}) = D_I({p_{k|k-1}}(X|{Z_{1:k-1}}), {p_{k|k}}(X|{Z_{1:k}}, {Z_k}({\nu}))) \end{align} $$ (6) 1.3 区间分析
区间分析又称区间数学, 是一门用区间变量代替点变量进行运算的数学分支. 通常, 由于测量误差的存在, 滤波会产生不精确结果, 而区间分析技术却能精确给出误差界限. 因此利用区间分析技术进行运算, 其运算结果相对于传统数学方法具有更高的置信度.
区间通常定义在实数域$ \bf {R} $内, 是一个连续且封闭的实数子集, 表示为$ \left[ x \right] = \left[ {\underline { x} , \overline { x }} \right] \in \bf {R} $. 其中, $ \underline { x} \in \bf {R} $表示区间下界, $ \overline { x} \in \bf {R} $表示区间上界. 一般地, 一个$ d $维区间或者箱体$ \left[ \pmb x \right] \in {\bf R}^{d} $是$ d $个一维区间的笛卡尔乘积, 表示为$ \left[ \pmb x \right] = \left[ { {x_1}} \right] \times \cdots \times \left[ { {x_d}} \right] $. 箱体的体积定义为$ \left| {\left[ \pmb x \right]} \right| $.
值得注意的是, 对于一个非线性系统, 箱体$ {\left[ \pmb x \right]} $在经过非线性转移函数$ f $传递后一般会得到不规则的非箱体形状. 为了保证转移后得到规则形状, 以便于分析计算, 区间分析技术引入了包含函数(Inclusion functions) 的概念, 其目的是通过包含函数快速的找到包围这种不规则形状的最小箱体. 若有函数$ f $, 其包含函数可定义为: 已知函数$ f $: $ { {\bf R}^n} \to { {\bf R}^m} $, 如果$ \forall \left[ \pmb x \right] \in {\bf{IR}} $, $ \left[ f \right]\left( {\left[ \pmb x \right]} \right) \supseteq f\left( {\left[ \pmb x \right]} \right) $, 那么区间函数$ \left[ f \right] $: $ {{\bf {IR}}^n} \to {{\bf {IR}}^m} $是包含函数. 收缩算法是区间分析技术中的另一个重要概念, 实现箱粒子收缩首先要解决的问题就是"约束满足问题(Constraint satisfaction problems, CSP)". 它的实质是在约束集$ H:{(f(x) = 0, x \in {\left[x \right]})} $中寻找一个满足约束函数$ f(x) = f(x_1, x_2, \cdots, x_n) = 0 $的最小约束集$ S $, 即找到一个包含$ {\left[ \pmb x \right]} $中所有$ \pmb x $且满足约束函数$ f $的最小体积$ \left[ \pmb x \right] $. 本文采用一种被广泛应用的约束传播方法(Constraints propagation, CP)[25], 又称为前向后向法.
2. Box-CBMeMBer滤波器
2.1 SMC-CBMeMBer的本质
CBMeMBer作为MeMBer的改进版本, 在概念上完全不同于PHD和CPHD. 它并没有"压缩"状态信息, 进而用统计特性去近似多目标密度, 而是通过传递一组相互独立且数量固定的伯努利参数来直接近似多目标密度. 显然, CBMeMBer的这种优势为多目标跟踪问题的递推求解和执行效率提供了极大的方便和提高. SMC-CBMeMBer作为多伯努利滤波器的具体实现形式之一, 本质上是随时间传递和更新一组德尔塔粒子和对应的权值, 并最终由这组带有权值的德尔塔粒子的加权和近似表征多伯努利密度.
2.2 点粒子到箱粒子
在SMC-CBMeMBer中, 假设多目标多伯努利密度可以表示为$ {\pi } = \{ (r^{(i)}, p^{(i)}{(\pmb x)})\} _{i = 1}^{{M}} $, 其中$ r^{(i)} $表示第$ i $个伯努利过程的存在概率, $ p^{(i)}{(\pmb x)} $表示该伯努利过程的概率分布, $ M $为伯努利过程个数. $ p^{(i)}{(\pmb x)} $一般有如下形式
$$ \begin{equation} p^{(i)}{(\pmb x)} = \sum\limits_{j = 1}^{{L^{(i)}}}w^{(i, j)}\delta _{\pmb x^{(i, j)}}{(\pmb x)} \end{equation} $$ (7) 其中, $ {L^{(i)}} $表示该概率分布的粒子个数, $ w^{(i, j)} $是其对应的粒子权值, $ \delta _{\pmb x^{(i, j)}}{(\pmb x)} $为狄拉克德尔塔函数. 当$ {L^{(i)}} \to \infty $时, 式(7) 收敛于$ p^{(i)}{(\pmb x)} $. 一般地, 粒子个数通常会对滤波器的性能产生极大影响. 粒子数越多, 滤波器整体性能越优异, 这显而易见. 但与此同时, 大量的粒子参与滤波过程会极大地提高算法的计算复杂度. 文献[22]结合粒子滤波技术和区间分析技术, 提出了一种利用箱粒子代替点粒子, 进而减少粒子个数的处理方法. 此外, 文献[22$ - $26]将每个"箱体"刻画成一个以箱粒子为支撑集的概率密度函数, 每个均匀函数都充分反映了对应箱粒子的特性. 因此, 若箱粒子$ \left[ \pmb x \right] $作为支撑集, 令$ U_{\left[ \pmb x \right]} $表示该箱粒子的均匀概率密度函数, 则式(7) 可以表示为
$$ \begin{equation} p^{(i)}{(\pmb x)} = \sum\limits_{j = 1}^{{L^{(i)}}}w^{(i, j)}U_{\left[ \pmb x^{(i, j)} \right]}{(\pmb x)} \end{equation} $$ (8) 事实上, Box-CBMeMBer滤波器在形式上可以看成是用箱粒子代替点粒子的SMC-CBMeMBer滤波器, 以下将给出具体递推公式.
2.3 Box-CBMeMBer 递推
1) 预测步
假设$ k-1 $时刻后验多目标多伯努利密度表示为$ {\pi _{k - 1}} = \{ (r_{k - 1}^{(i)}, p_{k - 1}^{(i)})\} _{i = 1}^{{M_{k - 1}}} $, 且每一个概率密度具有以下形式
$$ \begin{equation} p_{k - 1}^{(i)}{(\pmb x)} = \sum\limits_{j = 1}^{{L_{k-1}^{(i)}}}w_{k-1}^{(i, j)}U_{\left[ \pmb x_{k-1}^{(i, j)} \right]}{(\pmb x)} \end{equation} $$ (9) 则$ k $时刻预测多伯努利密度可表示为
$$ \begin{align} {\pi _{k|k - 1}} = \, &\{(r_{P, k|k - 1}^{(i)}, p_{P, k|k - 1}^{(i)})\}_{i = 1}^{{M_{k - 1}}}\cup\\&{\{(r_{\Gamma , k}^{(i)}, p_{\Gamma , k}^{(i)})\}_{i = 1}^{{M_{\Gamma , k}}}} \end{align} $$ (10) 其中, $ \{(r_{P, k|k - 1}^{(i)}, p_{P, k|k - 1}^{(i)})\}_{i = 1}^{{M_{k - 1}}} $表示$ k $时刻存活目标多伯努利密度.
$$ \begin{align} & r_{P, k|k - 1}^{(i)} = r_{k - 1}^{(i)}\sum\limits_{j = 1}^{{L_{k-1}^{(i)}}}w_{k-1}^{(i, j)}p_{S, k}{(\pmb x_{k-1}^{(i, j)})} \end{align} $$ (11) $$ \begin{align} & p_{P, k|k-1}^{(i)}{(\pmb x)} = \sum\limits_{j = 1}^{{L_{k-1}^{(i)}}} \tilde w_{P, k|k-1}^{(i, j)}U _{\left[ \pmb x_{P, k|k-1}^{(i, j)}\right]}{(\pmb x)} \end{align} $$ (12) $$ \begin{align} & \tilde w_{P, k|k-1}^{(i, j)} = \frac {{w_{P, k|k-1}^{(i, j)}}}{{\sum\nolimits_{j = 1}^{{L_{k-1}^{(i)}}}w_{P, k|k-1}^{(i, j)}}} \end{align} $$ (13) $$ \begin{align} & w_{P, k|k-1}^{(i, j)} = {{w_{k-1}^{(i, j)}}{p_{S, k}{(\pmb x_{k-1}^{(i, j)})}}} \end{align} $$ (14) $ \{(r_{\Gamma, k}^{(i)}, p_{\Gamma , k}^{(i)})\} _{i = 1}^{{M_{\Gamma , k}}} $表示$ k $时刻新生多伯努利密度.
$$ r_{\Gamma, k}^{(i)} = \rm{新生目标模型给定参数} $$ (15) $$ \begin{equation} p_{\Gamma , k}^{(i)}{(\pmb x)} = \sum\limits_{{{j}} = 1}^{L_{\Gamma , k}^{\left( i \right)}} {\tilde w_{\Gamma , k}^{\left( {i, j} \right)}} {U_{\left[ {\pmb x_{\Gamma , k}^{\left( {i, j} \right)}} \right]}}\left( {\pmb {x}} \right) \end{equation} $$ (16) 其中, $ {U_{\left[ {\pmb x_{\Gamma , k}^{\left( {i, j} \right)}} \right]}}\left( {\pmb {x}} \right) $由$ p_{\Gamma , k}^{(i)}{(\pmb x)} $所决定.
$$ \begin{equation} {\tilde w_{\Gamma , k}^{\left( {i, j} \right)}} = \frac{1}{{n}_{B}} \end{equation} $$ (17) $ n_{_B} $为新生箱粒子个数.
2) 更新步
结合存活目标多伯努利密度和新生多伯努利密度, 可令$ k $时刻预测多伯努利密度$ {\pi _{k|k - 1}} $为
$$ \begin{equation} {\pi _{k|k - 1}} = \{ (r_{k|k - 1}^{(i)}, p_{k|k - 1}^{(i)})\} _{i = 1}^{{M_{{k|k - 1}}}} \end{equation} $$ (18) 其中
$$ \begin{equation} p_{k|k - 1}^{(i)} = \sum\limits_{j = 1}^{{L_{k|k-1}^{(i)}}}w_{k|k-1}^{(i, j)}U_{\left[\pmb x_{k|k-1}^{(i, j)}\right]}{( \pmb x)} \end{equation} $$ (19) 则后验多伯努利密度$ {\pi _{k|k}} $可表示为
$$ \begin{align} {\pi _{k|k}} \approx \, &{\{ (r_{L, k}^{(i)}, p_{L, k}^{(i)})\} }_{i = 1}^{{M_{k|k - 1}}}\cup \\&{{{\{ ({r_{U, k}}(\left[\pmb z\right]), {p_{U, k}}(\pmb x;\left[\pmb z\right]))\} }_{\left[\pmb z\right] \in {Z_k}}}} \end{align} $$ (20) 其中, 继承航迹(漏检) 部分的多伯努利参数$ \{ (r_{L, k}^{(i)}, p_{L, k}^{(i)})\} _{i = 1}^{{M_{k|k - 1}}} $为
$$ \begin{equation} r_{L, k}^{(i)} = r_{k|k - 1}^{(i)}\frac{1 - \rho_{L, k}^{(i)}}{1 - r_{k|k - 1}^{(i)}\rho_{L, k}^{(i)}} \end{equation} $$ (21) $$ \begin{equation} p_{L, k}^{(i)}{(\pmb x)} = \sum\limits_{j = 1}^{{L_{k|k-1}^{(i)}}}\tilde w_{L, k}^{(i, j)}U_{\left[\pmb x_{k|k-1}^{(i, j)}\right]}{(\pmb x)} \end{equation} $$ (22) $$ \begin{equation} {\rho_{L, k}^{(i)}{(\pmb x)}} = \sum\limits_{j = 1}^{{L_{k|k-1}^{(i)}}}w_{k|k-1}^{(i, j)}p_{D, k}{(\pmb x_{k|k-1}^{(i, j)})} \end{equation} $$ (23) $$ \begin{equation} \tilde w_{L, k}^{(i, j)} = \frac {{w_{L, k}^{(i, j)}}}{{\sum\nolimits_{j = 1}^{{L_{k|k-1}^{(i)}}}w_{L, k}^{(i, j)}}} \end{equation} $$ (24) $$ \begin{equation} w_{L, k}^{(i, j)} = w_{k|k-1}^{(i, j)}{(1-p_{D, k}{(\pmb x_{k|k-1}^{(i, j)})})} \end{equation} $$ (25) 量测更新的多伯努利密度$ \{ ({r_{U, k}}(\left[\pmb z\right]), {p_{U, k}}(\pmb x $; $ \left[\pmb z\right]))\} _{\left[\pmb z\right] \in {Z_k}} $的参数为
$$ \begin{align} {r_{U, k}}(\left[\pmb {z}\right]) = & \frac{{\sum\nolimits_{i = 1}^{{M_{k|k - 1}}} {\frac{{r_{k|k - 1}^{(i)}(1 - r_{k|k - 1}^{(i)})\rho_{U, k}^{(i)}{(\left[\pmb z\right])}}}{{{{(1 - r_{k|k - 1}^{(i)}\rho_{L, k}^{(i)}{(\pmb x)})}^2}}}} }}{{{\kappa _k}(\left[\pmb {z}\right]) + \sum\nolimits_{i = 1}^{{M_{k|k - 1}}} {\frac{{r_{k|k - 1}^{(i)}\rho_{U, k}^{(i)}{(\left[\pmb z\right])}}}{{1 - r_{k|k - 1}^{(i)}\rho_{L, k}^{(i)}{(\pmb x)}}}} }} \end{align} $$ (26) $$ \begin{align} {p_{U, k}}(\pmb {x};\left[\pmb {z}\right]) = \sum\limits_{i = 1}^{{M_{k|k - 1}}}\sum\limits_{j = 1}^{{L_{k|k - 1}^{(i)}}}\tilde w_{U, k}^{*(i, j)}{(\left[\pmb z\right])}U_{\left[\pmb x_{k|k}^{(i, j)}\right]}{(\pmb x)} \end{align} $$ (27) $$ \begin{equation} \rho_{U, k}^{(i)}{\left(\left[\pmb z\right]\right)} = \sum\limits_{j = 1}^{{L_{k|k - 1}^{(i)}}}w_{k|k-1}^{(i, j)}\psi_{k, \left[{z\mathit{\boldsymbol{}}}\right]}\left(\left[\pmb x_{k|k-1}^{(i, j)}\right]\right) \end{equation} $$ (28) $$ \begin{equation} \tilde w_{U, k}^{*(i, j)}{\left(\left[\pmb z\right]\right)} = \frac {{ w_{U, k}^{*(i, j)}{\left(\left[\pmb z\right]\right)}}}{{\sum\nolimits_{i = 1}^{{M_{k|k - 1}}}\sum\nolimits_{j = 1}^{{L_{k|k - 1}^{(i)}}} w_{U, k}^{*(i, j)}{\left(\left[\pmb z\right]\right)}}} \end{equation} $$ (29) $$ \begin{equation} w_{U, k}^{*(i, j)}{\left(\left[\pmb z\right]\right)} = w_{k|k-1}^{(i, j)}\frac {{r_{k|k-1}^{(i)}}}{{1-r_{k|k-1}^{(i)}}}\psi_{k, \left[{z\mathit{\boldsymbol{}}}\right]}\left(\left[\pmb x_{k|k-1}^{(i, j)}\right]\right) \end{equation} $$ (30) $$ \begin{align} \psi_{k, \left[{z\mathit{\boldsymbol{}}}\right]}\left(\left[\pmb x_{k|k-1}^{(i, j)}\right]\right) = g_{k}{\left(\left[\pmb z\right]\Big|\left[\pmb x_{k|k-1}^{(i, j)}\right]\right)}p_{D, k}(\pmb x_{k|k-1}^{(i, j)}) \end{align} $$ (31) 其中, $ g_{k}{(\left[\pmb z\right]|\left[\pmb x_{k|k-1}^{(i, j)}\right])} = \frac{{\left| {\left[ \pmb z \right] \cap \left( {{h_k}\left( {\left[ {{\pmb x_{k|k-1}^{(i, j)}}} \right]} \right) + \left[ \pmb v \right]} \right)} \right|}}{{\left| {\left[ {\pmb v} \right]} \right|}} $为广义似然函数[25], 当$ {{{\left[ \pmb z \right] \cap \left( {{h_k}\left( {\left[ {{\pmb x_{k|k-1}^{(i, j)}}} \right]} \right) + \left[ \pmb v \right]} \right)} }}\neq\varnothing $时, $ g_{k}{(\left[\pmb z\right]|\left[\pmb x_{k|k-1}^{(i, j)}\right])} = \prod\nolimits_{l = 1}^{{n_x}} {\frac{{\left| \left[{\pmb x_{k|k}^{(i, j)}(l)}\right] \right|}}{{\left| \left[{\pmb x_{k|k - 1}^{(i, j)}(l)}\right] \right|}}} $, $ {\left[\pmb x_{k|k}^{(i, j)}\right]} $为收缩后的箱粒子, $ \left[{\pmb x_{k|k}^{(i, j)}(l)}\right] $表示$ \left[{\pmb x_{k|k}^{(i, j)}}\right] $第$ l $维区间的长度. $ { {\pmb v} } $为加性量测噪声, $ {h_k}(\cdot ) $为量测函数.
3) 重采样和状态估计
和传统的点粒子滤波器一样, 箱粒子滤波器仍然需要进行重采样. 但具体的采样方法却显著不同, 箱粒子滤波器通常采用随机子划分法进行重采样, 即可以将权重大的箱粒子用一组区间更小的箱粒子去替代. 此外, 目标状态是所对应箱粒子质心状态的加权和.
3. Box-CBMeMBer中基于箱粒子高斯分布近似的传感器控制方法
尽管Box-CBMeMBer也类似地通过一组带有权值的箱粒子来逼近多伯努利密度. 但相比于SMC-CBMeMBer, 基于Box-CBMeMBer进行传感器求解显然要困难许多. 利用点粒子求解信息散度是极具优势的, 这主要是因为狄拉克德尔塔函数(Dirac delta function) 的正交特性和便于求解积分的特性. 而对于箱粒子, 这一体积非零的矩形区域, 显然并没有正交消除冗余项的便利. 因此, 利用箱粒子直接求解信息测度是相当困难的.
文献[25]利用服从高斯分布的量测噪声来构造服从均匀分布的区间量测噪声, 即给出了一种由统计不确定性转化为区间不确定性的有效方法. 该方法给本文以启发式的思考. 特别是该方法用严格的等式给出了计算过程. 由于不存在等式成立的限定条件, 因此该等式合理的给出了一个高斯分布和区间箱体相互转化的方法. 换而言之, 利用区间噪声近似代替服从高斯分布的噪声, 这显然是一个可逆过程. 假设任一箱粒子$ \left[\pmb x \right] $, 其质心状态$ {{\pmb m}_{\pmb x}} = {\rm mid}\left( \left[x \right]\right) = {\left[ {x, x', y, y'} \right]^{\rm T}} $, 其区间中心到边界的长度$ \Delta = [\Delta _{x}, \Delta _{x'}, \Delta _{y}, \Delta _{y'}]^{\rm T} $. 则可通过构造高斯分布来逼近服从混合均匀分布的箱粒子, 即
$$ \begin{align} p\left( \pmb x \right) = {U_{\left[\pmb x \right]}}{(\pmb x)} = {\cal N}(\pmb x; \pmb m_{\pmb x}, P) \end{align} $$ (32) 其中, $ P = {\rm diag}\{(\frac{1}{3}{\Delta _{ x}}, \frac{1}{3}{\Delta _{{{x'}}}}, \frac{1}{3}{\Delta _{y}}, \frac{1}{3}{\Delta _{{{y'}}}} )^2\} $. 进一步, 根据式(32), 式(19) 可近似表达为
$$ \begin{align} p_{k|k-1}^{(i)} = \sum\limits_{j = 1}^{L_{k|k-1}^{(i)}}w_{k|k-1}^{(i)} {\cal N}(\pmb x;\pmb m_{k|k-1}^{(i)}, P_{k|k-1}^{(i)}) \end{align} $$ (33) 式(33) 的重要意义就在于代替式(19) 来近似多伯努利密度, 如此不但避免了直接利用箱粒子求解评价函数的难题, 而且进一步将基于Box-CBMeMBer的传感器控制求解问题转化为利用高斯混合求解评价函数的问题.
利用高斯混合求解评价函数即便在以点目标滤波器为基础的传感器控制策略中也不多见, 究其原因主要在于高斯混合分布间的信息散度大都不存在闭式解. 尽管如此, 相比于点粒子求解评价函数, 高斯混合求解仍有其无法比拟的执行效率上的优势, 这对于传感器的实时管理具有很重要的价值和意义. 有鉴于此, 本文基于GM-CBMeMBer滤波器, 研究了两个高斯混合之间的CS散度的求取, 并以此为基础提出相应的传感器控制策略.
假设$ p_0 $和$ p_1 $分别表示两个概率密度函数, 则它们之间的CS散度可表示为
$$ \begin{align} D_I(p_0, p_1) = -\ln\left(\frac{\int p_0(\pmb x)p_1(\pmb x){\rm d} \pmb x}{\sqrt{\int (p_0(\pmb x))^2{\rm d} \pmb x\int (p_1(\pmb x))^2{\rm d} \pmb x}}\right) \end{align} $$ (34) 根据式(6) 和(34), 评价函数可以表示为
$$ \begin{align} \mathcal{R}({\nu}) = \, &-{\rm ln}\int p_{k|k-1}(\pmb{x})p_{k|k} (\pmb{x};{\nu}){\rm d}\pmb{x}+\\ &\frac{1}{2}{\rm ln}\int (p_{k|k}(\pmb{x};{\nu}))^2{\rm d} \pmb{x}+\\ &\frac{1}{2}{\rm ln}\int (p_{k|k-1}(\pmb{x}))^2{\rm d}\pmb{x} \end{align} $$ (35) GM-CBMeMBer滤波器通过传递一组带有权值的高斯分量来逼近多目标密度. 显而易见, 每个伯努利过程对应的高斯分量对于整体的多目标密度的逼近程度是不同的. 出于简化计算的考虑, 本文提取存在概率$ r $较大的伯努利过程($ r>r_m $), 从而利用这些伯努利过程去联合近似空间多目标概率密度, 进而研究相应评价函数的求解.
首先, 从预测多伯努利参数$ \{ (r_{k|k - 1}^{(i)}, $ $ p_{k|k - 1}^{(i)})\} _{i = 1}^{{M_{{k|k - 1}}}} $中提取存在概率$ r_{k|k - 1}^{(i)}>r_m $的伯努利过程, 因为这些伯努利过程事实上几乎涵盖了所有的多目标信息. 此外, 对于已提取的每个伯努利过程, 可确定其权值$ w_{k|k-1}^{(i)}>w_m $的高斯分量去近似该过程状态空间的分布. 此时, 预测多目标密度可由这些带有权值的高斯分量近似, 即
$$ \begin{align} &\pi_{k|k-1}(\pmb x)\approx \\ &\quad \sum\limits_{i = 1}^{M'_{k|k - 1}}w_{m, k|k-1}^{(i)} {\cal N}(\pmb x;\pmb m_{m, k|k-1}^{(i)}, P_{m, k|k-1}^{(i)}) \end{align} $$ (36) $$ \begin{align} w_{m, k|k-1}^{(i)} = \frac{r_{m', k|k-1}^{(i)}{{w_{m', k|k-1}^{(i)}}} }{\sum\nolimits_{i = 1}^{M'_{k|k-1}}r_{m', k|k-1}^{(i)}{{w_{m', k|k-1}^{(i)}}}} \end{align} $$ (37) 其中, $ M'_{k|k-1} $为提取的多伯努利过程数, $ r_{m', k|k-1}^{(i)} $和$ w_{m', k|k-1}^{(i)} $分别代表第$ i $个伯努利过程中的存在概率和所提取的高斯分量的权值.
其次, 对于每种控制方案$ {{\nu}}\in {U}_k $确定传感器的位置$ {\pmb x}_{s, k}({\nu}) $. 随后对每一个控制$ {{\nu}} $仅产生一个相应的PIMS, 可表示为
$$ \begin{align} {Z_k}({\nu}) = \bigcup\limits_{\hat {\pmb x} \in {{\hat{X}}_{k|k - 1}}} {{\rm{\{ }}h(\hat {\pmb x}, {{\pmb x}_{s, k}}({\nu})){\rm{\} }}} \end{align} $$ (38) 其中, $ {\hat{X}}_{k|k - 1} $是$ k $时刻的多目标预测状态.
由于不考虑杂波和噪声, 且$ {{p}_{D, k} = 1} $, 因此不存在继承航迹(漏检) 的伯努利RFS, 而对于每个PIMS更新的伯努利RFS, 其存在概率恒为1. 因此, 我们只需要结合GM-CBMeMBer滤波算法, 利用PIMS对式(36) 中的每个高斯分量参数进行更新, 则更新后的多目标概率密度也具有高斯混合的形式, 即
$$ \begin{align} \pi_{k|k}(\pmb x;{\nu})\approx& \sum\limits_{\pmb z\in {Z_k} ({\nu})}\sum\limits_{j = 1}^{M'_{k|k}}{{w_{m, k|k}^{(j)}(\pmb z;{\nu})}} \times\\ &{\cal N}(\pmb x;{\pmb m}_{m, k|k}^{(j)}(\pmb z;{\nu}), {{ P}_{m, k|k}^{(j)}({\nu})}) \end{align} $$ (39) 其中, 每个高斯分量对应权值为
$$ \begin{align} w_{m, k|k}^{(j)}(\pmb z;{\nu}) = \frac{{{w_{m', k|k}^{(j)}(\pmb z;{\nu})}} }{\sum\nolimits_{j = 1}^{M'_{k|k}}{{w_{m', k|k}^{(j)}(\pmb z;{\nu})}}} \end{align} $$ (40) $$ \begin{align} w_{m', k|k}^{(j)}(\pmb z;{\nu}) = \frac{r_{m', k|k-1}^{(j)}}{1-r_{m', k|k-1}^{(j)}}w_{m, k|k-1}^{(j)}q_{k}^{(j)}(\pmb z) \end{align} $$ (41) 式(41)中, 似然函数$ q_{k}^{(j)}(\pmb z) $可表示为
$$ \begin{align} q_{k}^{(j)}(\pmb z) = {\cal N}(\pmb z;H_{k}{\pmb m_{k|k-1}^{(i, j)}}, P_{mzz, k|k-1}^{(j)}) \end{align} $$ (42) 其中, 新息协方差矩阵$ P_{mzz, k|k - 1}^{(j)} $为
$$ \begin{align} P_{mzz, k|k - 1}^{(j)} = {H_{k}{P_{m, k|k - 1}^{(i, j)}}H_{k}^{\rm T}+R_{k}} \end{align} $$ (43) $$ \begin{align} P_{mxz, k|k - 1}^{(j)} = {P_{m, k|k - 1}^{(i, j)}}H_{k}^{\rm T} \end{align} $$ (44) $ k $时刻目标状态估计、估计误差协方差分别为
$$ \begin{align} \pmb m_{m, k|k}^{(j)}(\pmb z;{\nu}) = \pmb m_{m, k|k-1}^{(j)}+K_{m, k}^{(j)}(\pmb z-H_{k}{\pmb m_{k|k-1}^{(i, j)}}) \end{align} $$ (45) $$ \begin{align} {{P}}_{m, k|k}^{(j)}({\nu}) = P_{m, k|k - 1}^{(j)} - K_{m, k}^{(j)}P_{mzz, k|k -1}^{(j)}{(K_{m, k}^{(j)})^{\rm T}} \end{align} $$ (46) 滤波增益矩阵$ K_{m, k}^{(j)} $为
$$ \begin{align} K_{m, k}^{(j)} = P_{mxz, k|k - 1}^{(j)}{(P_{mzz, k|k - 1}^{(j)})^{ - 1}} \end{align} $$ (47) 其中, $ H_{k} $表示$ k $时刻非线性量测函数的雅克比矩阵. 更新后的多目标概率密度可近似表示为
$$ \begin{align} \pi_{k|k}(\pmb x;{\nu})\approx\, &\sum\limits_{j = 1}^{M'_{k|k}}{{w_{m, k|k}^{(j)}(\pmb z;{\nu})}} \\ & {\cal N}(\pmb x;{\pmb m}_{m, k|k}^{(j)}(\pmb z;{\nu}), {{P}_{m, k|k}^{(j)}({\nu})}) \end{align} $$ (48) 值得注意的是, 为了计算式(35), 本文需要借助两个高斯分布之间的乘积公式, 即
$$ \begin{align} {\cal N}({\pmb x};\mu_1, A_1^{-1}){\cal N}({\pmb x};\mu_2, A_2^{-1}) = z_{12}({\pmb x};\mu_{12}, A_{12}^{-1}) \end{align} $$ (49) 其中, $ A_{12} = {A_1} + {A_2} $, $ \mu_{12} = A_{12}^{-1}(A_1\mu_{1}+ {A_2}\mu_{2}) $, $ {z_{12}} = {\cal N}({\mu _1};{\mu _2}, (A_1^{ - 1} + A_2^{ - 1})) $.
根据式(36) 和(48), 式(35) 第一项可推导如下
$$ \begin{align} &\ln \Big(\int {\sum\limits_{i = 1}^{M'_{k|k-1}} {\sum\limits_{j = 1}^ {M'_{k|k}}{w_{m, k|k-1}^{(i)}} } } {w_{m, k|k}^{(j)}(\pmb z;{\nu})}\cdot\\& \qquad {\cal N}(\pmb x;{\pmb m}_{m, k|k-1}^{(i)}, { P}_{m, k|k-1}^{(i)}) \times\\& \qquad {\cal N}(\pmb x;{\pmb m}_{m, k|k}^{(j)}(\pmb z ;{\nu}), { P}_{m, k|k}^{(j)}({\nu}))d{\pmb x}\Big) = \\& \qquad \ln \Big(\sum\limits_{i = 1}^{M'_{k|k-1}} {\sum\limits_{j = 1}^{M'_{k|k}}{w_{m, k|k-1}^{(i)}} } {w_{m, k|k}^{(j)}(\pmb z;{\nu})}\\& \qquad \int {\cal N}(\pmb x;{\pmb m}_{m, k|k-1}^{(i)}, { P}_{m, k|k-1}^{(i)}) \times\\& \qquad {\cal N}(\pmb x;{\pmb m}_{m, k|k}^{(j)}(\pmb z;{\nu}), {P}_{m, k|k}^{(j)}({\nu}))d{\pmb x}\Big) = \\& \qquad \ln \Big(\sum\limits_{i = 1}^{M'_{k|k-1}} {\sum\limits_{j = 1}^{M'_{k|k}} {w_{m, k|k-1}^{(i)}} } {w_{m, k|k}^{(j)}(\pmb z;{\nu})}{ z_{ij}}\Big) \end{align} $$ (50) 其中
$$ \begin{align} {z_{ij}} = \, &{\cal N}({\pmb m_{m, k|k-1}^{(i)}};{\pmb m_{m, k|k}^{(j)} (\pmb z;{\nu})}, \\ &(P_{m, k|k-1}^{(i)} + P_{m, k|k}^{(j)} ({\nu}))) \end{align} $$ (51) 式(35) 中的第二项和第三项类似于第一项的推导方法, 不再赘述. 则最后评价函数可写成如下形式
$$ \begin{align} \mathcal{R}({\nu}) \approx\, & - \ln (\sum\limits_{i = 1}^{M'_{k|k-1}} {\sum\limits_{j = 1}^{M'_{k|k}} { {w_{m, k|k-1}^{(i)}} {w_{m, k|k}^{(j)}(\pmb z;{\nu})}{z_{ij}})} } + \\& \frac{1}{2}\ln (\sum\limits_{i = 1}^{M'_{k|k-1}} \frac{{(w_{m, k|k-1}^{(i)})^2|{P}_{m, k|k-1}^{(i)} {|^{1/2}}}}{{(2\pi )}^2}+\\& 2\sum\limits_{i = 1}^{M'_{k|k-1}} \sum\limits_{i' < i}^{} w_{m, k|k-1}^{(i)}{w_{m, k|k-1}^{(i')}} { z_{ii'}} )+\\& \frac{1}{2}\ln (\sum\limits_{j = 1}^{M'_{k|k}} \frac{{(w_{m, k|k}^{(j)}(\pmb z;{\nu}))^2|{P}_{m, k|k}^{(j)} ({\nu}){|^{1/2}}}}{{(2\pi )}^2}+\\& 2\sum\limits_{j = 1}^{M'_{k|k}} \sum\limits_{j' < j}^{} w_{m, k|k}^{(j)}(\pmb z;{\nu}) {w_{m, k|k}^{(j')}(\pmb z;{\nu})}{ z_{jj'}}) \end{align} $$ (52) 其中
$$ \begin{align} {z_{ii'}} = \, &{\cal N}({\pmb m_{m, k|k-1}^{(i)}}; \\ &{\pmb m_{m, k|k-1}^{(i')}}, (P_{m, k|k-1}^{(i)} + P_{m, k|k-1}^{(i')})) \end{align} $$ (53) $$ \begin{align} {z_{jj'}} = \, &{\cal N}({\pmb m_{m, k|k}^{(j)}(\pmb z;{\nu})};{\pmb m_{m, k|k}^{(j')}(\pmb z;{\nu})}, \\ &( P_{m, k|k}^{(j)}({\nu})+P_{m, k|k}^{(j')}({\nu}))) \end{align} $$ (54) 为了直观地说明本节所提方案的求解步骤, 以下给出算法1实现伪码.
输入: 预测多伯努利密度$ \{r_{k|k - 1}^{(i)}, $ $ p_{k|k - 1}^{(i)} \}_{i = 1}^{{M_{k|k - 1}}} $, 其中, $ p_{k|k - 1}^{(i)}{(\pmb x)} = \sum\nolimits_{j = 1}^{{L_{k|k-1}^ {(i)}}}w_{k|k-1}^{(i, j)} $ $ U_{\left[ \pmb x_{k|k-1}^{(i, j)} \right]}{(\pmb x)} $, 传感器控制位置$ \pmb x_{s, k-1} $.
依式(18)和(19)提取多目标状态$ {\hat X_{k|k - 1}} = \left\{ {{{{\rm{\hat {\pmb x}}}}_{k|k - 1}}} \right\}_{i = 1}^N $.
利用箱粒子高斯分布近似, 通过式(33) 代替式(19) 来近似预测多伯努利密度. 利用提取的高斯分量近似预测多目标密度.
令$ {U}_k = \{\nu^{(l)}\}_{l = 1}^{N} $.
for $ l = 1:N $
根据$ {\hat X_{k|k - 1}} $和$ \nu $生成一个PIMS $ Z_k(\nu) $.
利用$ Z_k(\nu) $更新预测多目标密度, 得到式(48).
for $ j = 1:{M'_{k|k}} $
$ w_{m', k|k}^{(j)}(\pmb z;{\nu}) = \frac{r_{m', k|k-1}^{(j)}} {1-r_{m', k|k-1}^{(j)}}w_{m, k|k-1}^{(j)}q_{k}^{(j)}(\pmb z) $.
$ q_{k}^{(j)}(\pmb z) = {\cal N}(\pmb z;H_{k} {\pmb m_{k|k-1}^{(i, j)}}, P_{mzz, k|k-1}^{(j)}) $.
end for
$ w_{m, k|k}^{(j)}(\pmb z;{\nu}) = \frac{{{w_{m', k|k}^{(j)} (\pmb z;{\nu})}} }{\sum\nolimits_{j = 1}^{M'_{k|k}} {{w_{m', k|k}^{(j)}(\pmb z;{\nu})}}} $.
for $ i = 1:{M'_{k|k-1}} $
for $ j = 1:{M'_{k|k}} $
$ {z_{ij}} = {\cal N}({\pmb m_{m, k|k-1}^{(i)}};{\pmb m_{m, k|k}^{(j)}(\pmb z;{\nu})}, (P_{m, k|k-1}^{(i)} + P_{m, k|k}^{(j)}({\nu}))) $ $ { u}_{1}^{ij} = w_{m, k|k}^{(j)}(\pmb z;{\nu})\times{ z_{ij}} $.
end for
$ {u}_{1}^{i} = {w_{m, k|k-1}^{(i)}}\times{\rm {sum}}{({ u}_1^{ij})} $.
end for
$ \mathcal{R}_{c1}({\nu}) = - {\rm {ln}}({\rm {sum}} {({ u}_{1}^{(i)})}) $.
for $ i = 1:{M'_{k|k-1}} $
$ { u}_{21}^{i} = \frac{{(w_{m, k|k-1}^{(i)})^2|{P}_{m, k|k-1}^{(i)} {|^{1/2}}}}{{(2\pi )}^2} $.
end for
$ {u}_3 = 0.5\times{\rm {ln}}{({\rm {sum}}{({u}_{21}^{i})})} $.
for $ i = 1:{M'_{k|k-1}} $}
if $ {i' < i} $
$ { z_{ii'}} = {\cal N}({\pmb m_{m, k|k-1}^{(i)}}; {\pmb m_{m, k|k-1}^{(i')}}, (P_{m, k|k-1}^{(i)} + P_{m, k|k-1}^{(i')})) $.
$ { u}_{22}^{ii'} = {w_{m, k|k-1}^{(i')}}{z_{ii'}} $.
end if
$ {u}_{23}^{i} = w_{m, k|k-1}^{(i)}\times{\rm {sum}}({{ u}_{22}^{ii'}}) $.
end for
$ { u}_4 = {\rm {ln}}{({\rm {sum}}{({ u}_{23}^{i})})} $.
$ \mathcal{R}_{c2}({\nu}) = {u}_3+{ u}_4 $.
for $ j = 1:{M'_{k|k}} $
$ {u}_{31}^{j} = \frac{{(w_{m, k|k}^{(j)} (\pmb z;{\nu}))^2|{P}_{m, k|k}^{(j)}({\nu}){|^{1/2}}}}{{(2\pi )}^2} $.
if $ {j' < j} $
$ {z_{jj'}} = {\cal N}\Big({\pmb m_{m, k|k}^{(j)}(\pmb z;{\nu})}; {\pmb m_{m, k|k}^{(j')}(\pmb z;{\nu})} $,
$ \Big(P_{m, k|k}^{(j)}({\nu})+ P_{m, k|k}^{(j')}({\nu})\Big)\Big) $.
$ { u}_{32}^{j'} = w_{m, k|k}^{(j)}(\pmb z;{\nu}) {w_{m, k|k}^{(j')}(\pmb z;{\nu})}{z_{jj'}} $.
end if
end for
$ \mathcal{R}_{c3}({\nu}) = 0.5\times{\rm {ln}} {({\rm {sum}}{({ u}_{31}^{j})})}+{\rm {ln}} {({\rm {sum}}{({u}_{32}^{j})})} $.
$ \mathcal{R}_{c}({\nu}) = \mathcal{R}_{c1}({\nu})+ \mathcal{R}_{c2}({\nu})+\mathcal{R}_{c3}({\nu}) $.
end for
输出: $ { u_k} = \mathop {{\rm{argmax}}}\nolimits_{\nu \in {{U}_k}} {\rm E}{\left[ {R(\nu)} \right]} $.
4. Box-CBMeMBer中基于箱粒子混合均匀采样的传感器控制方法
事实上, 除了上文中给出的通过构造高斯分布近似箱粒子的方法以外, 一个自然的选择是基于蒙塔卡罗方法, 利用采样粒子集去代替箱粒子. 如前所述, 箱体是一个均匀分布函数, 因此本文利用混合均匀采样的思想, 对每个箱粒子进行均匀采样, 用得到的点粒子来近似代替箱粒子, 从而将传感器策略求解问题转化为更一般的利用点粒子求解评价函数的问题. 以下将给出利用点粒子求解CS散度的递推公式.
一般地, CS散度除了有式(34) 的表示方法外. Hoang等[31]也推导了两个泊松点过程之间的CS散度, 表达如下
$$ \begin{align} {D_{CS}}\left( {{{\pi}_1}, {{\pi}_2}} \right) = \frac{K}{2}{\left\| {{u_1} - {u_2}} \right\|^2} \end{align} $$ (55) 其中, $ {\pi}_1 $和$ {\pi}_2 $表示泊松点过程, $ {u_1} $和$ {u_2} $分别是其强度函数, $ K $表示目标状态的量测测度. 此外, 值得注意的是, 对任一多目标概率分布最有效的泊松近似是多目标分布的一阶矩. 基于这种思想, 文献[19]结合式(55) 给出了两个多伯努利分布间的CS散度. 本文进一步给出了传感器控制中CS散度的粒子求解方法.
假设$ k $时刻预测多目标多伯努利密度表示为$ {\pi _{k|k - 1}} = \{ (r_{k|k - 1}^{(i)}, p_{k|k - 1}^{(i)})\} _{i = 1}^{{M_{k|k - 1}}} $, 且每一个概率密度$ p_{k|k - 1}^{(i)} $被一组带有权值的粒子近似
$$ \begin{equation} \left\{ {w_{k|k-1}^{(i, j)} {\pmb x_{k|k-1}^{(i, j)} }{(\pmb x)}} \right\}_{j = 1}^{L_{k|k-1}^{(i)}} \end{equation} $$ (56) 则预测多伯努利密度的强度函数为
$$ \begin{equation} u_{k|k-1}{(\pmb x)} = \sum\limits_{i = 1}^{M_{k|k-1}} {\sum\limits_{j = 1}^{L_{k|k-1}^{(i)}} \left[{r_{k|k - 1}^{(i)}}{w_{k|k-1}^{(i, j)}} \right]{\delta_{\pmb x_{k|k-1}^{(i, j)}} { (\pmb x)} }} \end{equation} $$ (57) 此外, 由于不考虑杂波和噪声, 且$ {{p}_{D, k} = 1} $, 因此不存在继承航迹(漏检) 的伯努利RFS. 此时利用PIMS更新后的后验多伯努利密度可表示为
$$ \begin{equation} {\pi _{k|k}} \approx {{{\{ ({r_{U, k}}(\pmb z), {p_{U, k}}(\pmb x;\pmb z))\} }_{\pmb z \in {Z_k}}}} \end{equation} $$ (58) 类似地, 后验多伯努利密度的强度函数为
$$ \begin{align} u_{k|k}{(\pmb x)} = \, &\sum\limits_{\pmb z \in {Z_k}}\sum\limits_{i = 1}^{M_{k|k-1}} \sum\limits_{j = 1}^{L_{k|k-1}^{(i)}} \left[{r_{U, k}^{(i)}{(\pmb z)}}{w_{U, k}^{(i, j)}{(\pmb z)}} \right]\times\\&{\delta_{\pmb x_{k|k-1}^{(i, j)}} { (\pmb x)} } \end{align} $$ (59) 将式(57) 和(59) 代入式(55) 可得
$$ \begin{align} &{D_{CS}}\left( {{{\pi}_{k|k-1}}, {{\pi}_{k|k}}} \right) = \frac{K}{2} \int {\sum\limits_{i = 1}^{M_{k|k-1}} {\sum\limits_{j = 1}^{L_{k|k-1}^{(i)}}}}\\ &\qquad\Bigg(\sum\limits_{\pmb z \in {Z_k}}{r_{U, k}^{(i)}{(\pmb z)}}{w_{U, k}^{(i, j)}{(\pmb z)}}-\\ &\qquad {r_{k|k - 1}^{(i)}}{w_{k|k-1}^{(i, j)}}\Bigg)^2{\delta_{\pmb x_{k|k-1}^{(i, j)}} { (\pmb x)} } \end{align} $$ (60) 利用德尔塔函数积分特性, 则基于CS散度的传感器评价函数为
$$ \begin{align} \mathcal{R}_{cs}({\nu})& = \frac{K}{2} {\sum\limits_{i = 1}^{M_{k|k-1}} {\sum\limits_{j = 1}^{L_{k|k-1}^{(i)}}}}\\ &{\left({\sum\limits_{\pmb z \in {Z_k}}{r_{U, k}^{(i)}{(\pmb z;{\nu})}}{w_{U, k}^{(i, j)}{(\pmb z;{\nu})}}-{r_{k|k - 1}^{(i)}}{w_{k|k-1}^{(i, j)}}}\right)^2} \end{align} $$ (61) 为了直观地说明本方案的求解步骤, 以下给出算法2实现伪码.
输入: 预测多伯努利密度$ \{r_{k|k - 1}^{(i)}, $ $ p_{k|k - 1}^{(i)} \}_{i = 1}^{{M_{k|k - 1}}} $, 其中, $ p_{k|k - 1}^{(i)}{(\pmb x)} = \sum\nolimits_{j = 1}^{{L_{k|k-1}^ {(i)}}}w_{k|k-1}^{(i, j)} $ $ U_{\left[ \pmb x_{k|k-1}^{(i, j)} \right]} {(\pmb x)} $, 传感器控制位置$ \pmb x_{s, k-1} $.
依式(18)和(19)提取多目标状态$ {\hat X_{k|k - 1}} = \left\{ {{{{\hat{ \pmb x}}}_{k|k - 1}}} \right\}_{i = 1}^N $.
for $ i = 1:M_{k|k-1} $
for $ j = 1:L_{k|k-1}^{(i)} $
对每个$ U_{\left[ \pmb x_{k|k-1}^{(i, j)} \right]} $进行混合均匀采样.
end for
end for
利用箱粒子混合均匀采样后的一组带有权值的点粒子来近似预测多伯努利密度, 如式(56).
通过式(57) 求取预测多伯努利密度的强度函数.
令$ {U}_k = \{\nu^{(l)}\}_{l = 1}^{N} $.
for $ l = 1:N $
根据$ {\hat X_{k|k - 1}} $和$ \nu $生成一个PIMS $ Z_k(\nu) $.
利用$ Z_k(\nu) $更新式(57), 得到式(59).
for $ i = 1:{M_{k|k-1}} $
for $ j = 1:{L_{k|k-1}^{(i)}} $
for each $ \pmb z \in {Z_{k}} $
$ {s}^{ij} = {r_{U, k}^{(i)}{(\pmb z;{\nu})}}{w_{U, k}^{(i, j)}} $.
end for
$ {s}_{1}^{ij} = ({\rm {sum}}{({s}^{ij})}- {r_{k|k - 1}^{(i)}}{w_{k|k-1}^{(i, j)}})^2 $.
end for $ {s}_{2}^{i} = {\rm {sum}}{({s}_{1}^{ij})} $.
end for
$ \mathcal{R}_{cs}({\nu}) = \frac {{K}}{2}\times{\rm {sum}} {({\rm s}_{2}^{i})} $.
end for
输出: $ {u_k} = \mathop {{\rm{argmax}}}\limits_{\nu \in {{U}_k}} {{\rm E}}{\left[ {R(\nu)} \right]} $.
5. 算法程序的伪码
为了说明基于Box-CBMeMBer传感器控制策略的整体算法流程, 列出算法伪码如下:
输入: 多伯努利密度$ \{ r_{k - 1}^{(i)}, p_{k - 1}^{(i)} \}_{i = 1}^{{M_{k - 1}}} $, 其中, $ p_{k - 1}^{(i)}{(\pmb x)} = \sum\nolimits_{j = 1}^{{L_{k-1}^ {(i)}}}w_{k-1}^{(i, j)}U_{\left[ \pmb x_{k-1}^{(i, j)} \right]}{(\pmb x)} $, 传感器控制位置$ \pmb x_{s, k-1} $.
步骤1. 预测和新生
for $ i = 1:M_{k-1} $
for $ j = 1:L^{(i)}_{k-1} $
依式(11) 计算$ r_{P, k|k - 1}^{(i)} $, 式(12) 计算$ p_{P, k|k-1}^{(i)}{(\pmb x)} $, 式(13)和(14) 计算$ \tilde w_{P, k|k-1}^{(i, j)}. $
end for
end for
通过(15) $ \sim $ (17) 计算新生目标多伯努利密度, 结合预测和新生得到如式(18) 的预测多伯努利密度.
步骤2. 传感器控制
箱粒子高斯分布近似传感器控制的步骤可见算法1. (箱粒子混合均匀采样传感器控制的步骤可见算法2.)
步骤3. 更新
在新的传感器位置, 得到区间量测后, 根据式(21) $ \sim $ (31) 更新得到后验多伯努利密度(20).
步骤4. 重采样
利用随机子划分进行重采样.
步骤5. 状态提取
$ {\rm target\_index = find}(r_{k}^{(i)}>0.5) $.
求目标个数, 即$ \hat{N_k} = {\rm length(target\_index)} $.
通过质心点加权求和得到目标状态集合$ \hat{X}_k $.
输出: 传感器控制位置$ \pmb x_{s, k} $, 目标状态集合$ \hat{X}_k $, 目标数$ \hat{N_k} $.
6. 仿真分析
6.1 场景参数
本文考虑距离方位跟踪(Range-bearing tracking, RBT). 设置监控区域为$ [-{\pi}, \rm \pi] \times $ $ [0, 2 000\sqrt 2\; m] $. 场景中目标轨迹均为近常速运动模型(Nearly constant velocity model, NCVM)[32], 共计出现4个目标, 其状态转移密度为
$$ \begin{equation} \pi\left({\pmb x_k}|{\pmb x_{k-1}}\right) = {\cal N}\left({\pmb x_k};{F_k\pmb x_{k-1}}, Q_k\right) \end{equation} $$ (62) 其中[25],
$$ \begin{equation} {F_k} = \left[ {\begin{array}{*{20}{c}} 1&T&0&0\\ 0&1&0&0\\ 0&0&1&T\\ 0&0&0&1 \end{array}} \right] \end{equation} $$ (63) $$ \begin{equation} Q_k = {I_2} \otimes \left[ {\begin{array}{*{20}{c}} \frac{T^3}{3}&\frac{T^2}{2}\\ \frac{T^2}{2}&T \end{array}} \right] \cdot \varpi \end{equation} $$ (64) 其中, $ T = 1 $ s为采样周期, 总共采样50次. $ Q_k $为过程噪声协方差, $ I_2 $为2阶单位矩阵, $ \otimes $为克罗内克积, $ \varpi = 0.05 $为过程噪声强度. 本文借鉴文献[25] (如式(32)) 将服从高斯分布的$ Q_k $转化为服从均匀分布的区间过程噪声.
在本文仿真中, 设置检测概率$ p_{D, k} = 0.98 $. 杂波强度$ {\kappa_k}{({\pmb z})} = \lambda_cVu{({\pmb z})} $, 其中每周期杂波平均数$ \lambda_c = 5 $, $ V $为监控区域体积, $ u{({\pmb z})} $表示监控区域内的杂波均匀分布. 目标存活概率$ p_{S, k} = 0.99 $. 目标新生过程是一个多伯努利RFS, 其密度为$ \pi_{\Gamma } = {\{(r_{\Gamma }^{(i)}, p_{\Gamma }^{(i)})\}_{i = 1}^{{4}}} $, 其中$ r_{\Gamma, k}^{(i)} = 0.01 $. $ p_{\Gamma }^{(i)}{(\pmb x)} = {\mathcal N}(\pmb x;\pmb m_{\gamma}^{(i)}, P_{\gamma}) $, $ \pmb m_{\gamma}^{(1)} = [-800, -8, -600, 7]^{\rm T} $, $ \pmb m_{\gamma}^{(2)} = [-900, 10, 800, -12]^{\rm T} $, $ \pmb m_{\gamma}^{(3)} = [1 000, $ $ -20, -400, -10]^{\rm T}, \; \pmb m_{\gamma}^{(4)} = [700, -7, -800, 16]^{\rm T} $, $ P_{\gamma} = {\rm diag}\{[10, 5, 10, 5]^{\rm T}\} $. 新生箱粒子可通过采样$ p_{\Gamma }^{(i)}{(\pmb x)} $得到. 假设轨迹删减阈值为$ r_{T} = 10^{-3} $, 伯努利过程存在概率提取阈值为$ r_{m} = 0.5 $, 对应高斯混合分量权值提取阈值为$ w_m = 0.2 $, 箱粒子个数$ L_{box} = 40 $, 每个箱体(箱粒子) 均匀采样粒子数$ L_{sam} = 30 $.
在RBT中, 量测函数$ h_k{(\pmb x)} $有如下形式
$$ \begin{equation} h_k{(\pmb x)} = \left[ {\begin{array}{*{20}{c}} {\arctan{(\frac {y_{k}-y_{s, k}}{x_{k}-x_{s, k}})}}\\ {\sqrt {(x_{k}-x_{s, k})^2+(y_{k}-y_{s, k})^2}} \end{array}} \right] \end{equation} $$ (65) 其中, $ x_{k} $和$ y_{k} $表示$ k $时刻目标的位置, $ x_{s, k} $和$ y_{s, k} $表示$ k $时刻传感器的位置. 量测噪声$ \pmb v $是零均值高斯白噪声, 其协方差为$ \Sigma_{v} = {\rm diag}\{ {\sigma _\theta ^2, \sigma _r^2}\} $, 其中$ \sigma _\theta = {0.25^ \circ } $, $ \sigma _r = 2.5 $ m. 此外, 传感器返回的是区间量测, 其区间长度为$ \Delta = {\left[ {{\Delta_\theta}, \Delta_r} \right]^{\rm T}} $, 其中$ \Delta_\theta = 4^ \circ $, $ \Delta_r = 70 $ m分别是区间量测的角度长度和距离长度. 值得注意的是, 传感器通常有偏差(系统误差), 此时$ h_k{{(\pmb x)}}+{\pmb v_k} $并不在区间量测的中心位置. 因此, 结合RBT量测方程, 传感器区间量测可构造如下
$$ \begin{equation} \left[ {\pmb z}_{k} \right] = \left[h_k{{(\pmb x)}}+{\pmb v_k}-0.75\Delta, h_k{{(\pmb x)}}+{\pmb v_k}+0.25\Delta \right] \end{equation} $$ (66) 6.2 多目标跟踪性能评价
本文采用OSPA (Optimal subpattern assignment) 距离[33]来评估多目标跟踪的性能. 其定义如下: 设真实的和估计的多目标状态集合分别为$ X = \{\pmb{x}_1, \cdots, \pmb{x}_m\} $和$ \hat X = \{\hat{\pmb x}_1, \cdots, \hat {\pmb x}_n\} $, 若$ m\leq n $, 则OSPA距离为
$$ \begin{align} &\bar d_p^{(c)}(X, \hat X) = \\ &\quad{\left( {\frac{1}{n}(\mathop {\min }\limits_{\pi \in {\Pi _n}} \sum\limits_{i = 1}^m {{d^{(c)}}{{({\pmb x_i}, {\hat{\pmb x}_{\pi (i)}})}^p} + {c^p}(n - m)} )} \right)^{\frac{1}{p}}} \end{align} $$ (67) 其中, $ {d^{(c)}}(\pmb x, \hat{ \pmb x}) = $ min$ (c, \left\|{\pmb x - \hat{\pmb x}} \right\|) $, $ {\prod _k} $表示所有$ \{1, \cdots, k\} $的排列构成的集合, 距离阶次$ p \ge 1 $, 截断系数$ c > 0 $. 如果$ m>n $, 则$ {\bar d_p^{(c)}}(X, \hat X) = {\bar d_p^{(c)}}(\hat X, X) $. 本次仿真中选取$ c = 50 $ m, $ p = 1 $. 实验软硬件条件为: MATLAB 2010b, Windows 7, Inter Core i5-4590 CPU 3.30 GHz, RAM 8 GB.
6.3 传感器控制集合
若$ k $时刻传感器实际位置为$ {\pmb x}_{s, k} = [{{x}_{s, k}}, {{y}_{s, k}}]^{\rm T} $, 则下一时刻传感器所有可允许控制的位置集合$ {U}_{k+1} $可表示为
$$ \begin{align} {U}_{k+1} = \, &\Bigg\{\Big({x}_{s, k} + j\frac{v_{s, c}\cdot T}{N_R} \cos\Big(\ell \frac{2{\rm \pi}}{N_{\theta}}\Big); \\ & {y}_{s, k} + j \frac{v_{s, c}\cdot T}{N_R}\sin\Big(\ell \frac{2{\rm \pi}}{N_{\theta}}\Big)\Big) ;\\ &j = 1, \cdots, N_R;\ell = 1, \cdots, N_{\theta} \Bigg\} \end{align} $$ (68) 其中$ {N_{\theta}} = 8 $, $ {N_R} = 2 $, 则$ {U}_{k+1} $总共包括17种控制方案(包含传感器处于静默状态). $ v_{s, c} $是传感器自身的容许控制速度, 设为20 m/s.
6.4 实验仿真
本文设计的RBT仿真场景中, 共计出现四个目标, 其运动参数如表 1所示.
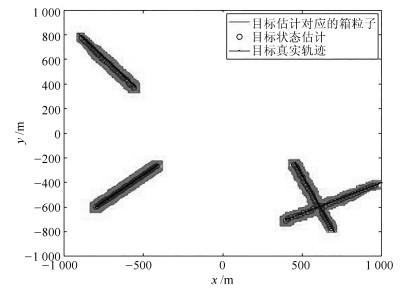
表 1 多目标参数Table 1 Parameters of multi-target新生时刻(s) 消亡时刻(s) 初始位置(m) 速度(m/s) 目标1 1 50 [-800, -600] [8, 7] 目标2 5 40 [-900, 800] [10, -12] 目标3 10 40 [1 000, -400] [-20, -10] 目标4 15 50 [700, -800] [-7, 16] 首先基于Box-CBMeMBer滤波器对RBT场景中的多目标进行单次跟踪仿真, 如图 1所示. 显然, 即便在杂波较多的环境下, Box-CBMeMBer仍能克服目标新生和消亡带来的不确定性, 排除杂波干扰, 最终得到良好的跟踪估计效果.
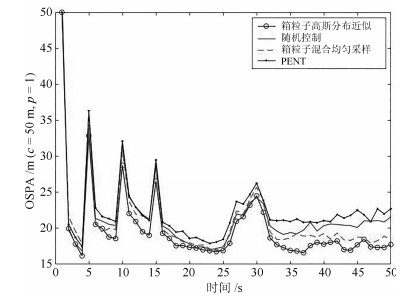
为了对比说明所提控制方案的合理性和有效性. 本文在如图 1所示同样的场景条件下, 构造了四种控制方案并进行了200次蒙特卡罗(Monte Carlo, MC) 实验. 其中, 方案一是"箱粒子高斯分布近似", 即本文所提控制方案. 该方案通过构造高斯分布来近似表示箱粒子, 进而利用高斯混合加权和来逼近多目标状态空间分布, 最终在求解本文所给出的高斯混合CS散度的基础上得到传感器最优控制方案. 方案二是"箱粒子混合均匀采样" 即通过混合均匀采样得到点粒子进而代替箱粒子, 利用加权粒子集近似表达多目标空间分布, 并求其强度函数. 该方案借鉴了传统粒子滤波的思想, 利用德尔塔粒子的正交特性和易于求解积分的特点, 计算CS散度并最终得到传感器最优控制方案. 方案三是"随机控制", 代表每个时刻的传感器控制方案在可允许的控制集合中随机选取. 这种随机选取看似简单, 但该方案往往会获得比较良好的控制效果, 因此经常作为典型的控制方案被加以比较. 方案四是"ENT" 作为一种经典的控制方案[34], 其仍然利用箱粒子混合均匀采样得到的点粒子来求取相应的评价函数, 其目的旨在一套可允许的传感器控制集合中决策出相应的控制方案, 以使得传感器检测到目标势的后验期望值(PENT) 达到最大.
图 2给出了四种控制方案在200次MC实验中对多目标状态估计的OSPA距离统计对比结果. 可以看出, 四种控制方案都有较好的跟踪估计效果, 这说明了四种控制方案的有效性. 具体地, OSPA距离分别在5 s, 10 s, 15 s呈现出明显的波动, 这是因为随着目标的新生, 多目标状态空间分布发生了较大变化, 但随着传感器有目的的机动, 相对于其他传感器控制方案, Box-CBMeMBer滤波器显然很快应对了这种变化, 因此OSPA距离在短暂波动后又回到理想的平稳状态. 这种快速收敛性说明在目标势摄动的情况下, 本文所提算法具有相对较好的鲁棒性. 另外, 多目标状态OSPA在30 s左右也发生了较为明显的波动, 究其原因主要在于在25 s到32 s之间, 目标3和目标4在空间中非常接近(如图 1所示), 两个目标运动过程中的"汇集"影响了彼此的状态估计. 此外, 比较四种方案可以看出, 方案一显然比其余三种方案的跟踪估计效果要好. 尤其是相比于方案二, 方案一通过构造高斯分布显然更能表征箱粒子, 更能逼近多目标状态空间分布, 从而通过CS散度指导传感器得到最优的控制方案. 而最优的控制方案能够提供更加精确的量测, 进而得到更好的估计效果. 方案四跟踪估计效果较差, 这是因为该控制方案是以目标势后验期望值(PENT) 最大化为评价准则, 并没有以多目标跟踪精度达到最优作为评价指标.
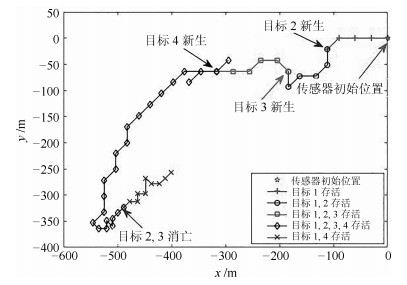
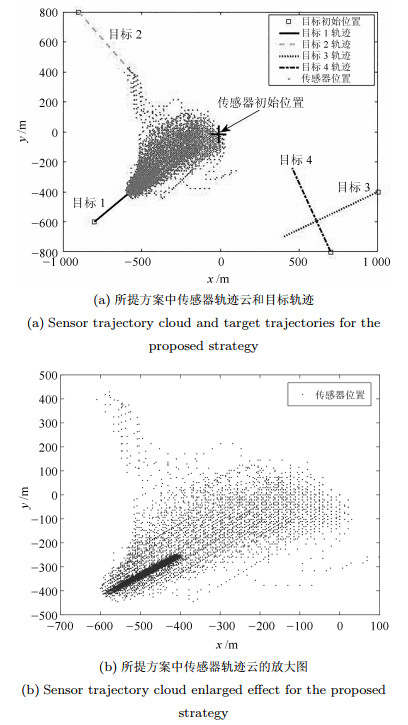
图 3给出了方案一, 即本文所提控制方案在单次实验中对传感器的最优控制轨迹. 可以看出, 在整个控制过程中, 传感器会始终依据当前的滤波结果不断地对自身的位置进行自适应调节, 即基于最优评价准则求解出当前时刻传感器相对于所有目标的最佳观测位置. 特别是随着目标的出生和消亡, 传感器总是会产生明显的机动来适应这种变化, 进而适应总体多目标概率密度函数的变化, 以保证自身能在最优的位置最大化地接收多目标信息.
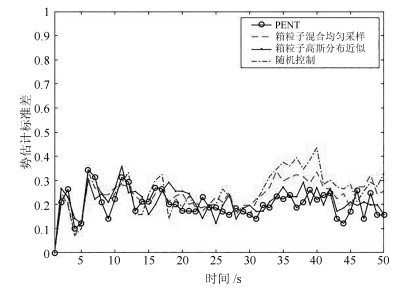
目标势估计如图 4所示. 显然, 四种控制方案的势估计均值都很接近真实目标数. 但通过统计目标势估计标准差(如图 5, 表 2), 仍能发现方案一有相对较好的估计效果. 尤其是相比于方案二, 方案一由于更能真实地反映多目标状态空间分布, 从而能够为CS散度的求解乃至于最优传感器位置的决策提供更加精确的多目标信息, 这使得方案一在估计效果上要优于方案二. 方案四对目标势的估计效果最好, 这毫不奇怪, 因为该方案是以目标势的后验期望值最大化为评价准则, 只是针对目标势优化的单一任务进行决策, 虽然在这种情况下, 并不能使多目标整体定位的性能得到提升, 但却可以提升滤波器对于多目标的检测性能.
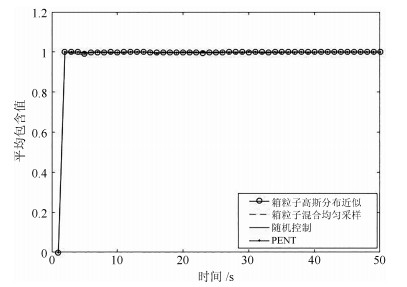
表 2 四种控制方案势估计误差均值的绝对值Table 2 Absolute value of cardinality error for four control strategies方案 势误差Ne 方案一(箱粒子高斯分布近似) 0.21338 方案二(箱粒子混合均匀采样) 0.23839 方案三(随机控制) 0.24979 方案四(PENT) 0.19987 此外, 图 6给出了四种控制方案在200次MC实验中的平均包含值. 可以看出, 四种方案下的平均包含值都非常接近1, 这说明多目标的估计状态几乎都被包含在相应箱粒子内, 这同时也说明了基于四种控制方案的Box-CBMeMBer滤波器都具有良好的跟踪估计性能.
四种方案在同样的场景参数下均运行50步, 其单步平均运行时间如表 3所示. 可以看出, 方案一在执行效率上要优于方案二, 这种差别主要来自于传感器评价函数的求解所花的时间. 而利用高斯混合求解评价函数, 在执行效率上具有天然的优势. 从这点来看, 显然方案一, 即本文所提控制方案更适合作为Box-CBMeMBer的传感器控制策略, 因为两者的结合更能保留Box-CBMeMBer滤波器执行速度快的优点. 方案三运行速度最快, 这是因为其在传感器求解上的时间花费几近于无, 时间成本主要来源于滤波过程. 方案四运行较慢, 这是因为在求解评价函数的过程中需要对所有预测箱粒子混合均匀采样后的所有点粒子进行更新.
表 3 四种控制方案单步平均运行时间对比Table 3 The average execution time for four control strategies方案 单步平均运行时间(s) 方案一(箱粒子高斯分布近似) 2.54639 方案二(箱粒子混合均匀采样) 3.71813 方案三(随机控制) 1.88743 方案四(PENT) 5.55129 为了验证过程噪声变化对所提算法性能的影响, 本文结合式(64), 通过改变过程噪声强度$ \varpi $的大小, 在同样的场景条件下运行MC仿真并统计OSPA均值加以比较. 如图 7所示, 随着过程噪声强度$ \varpi $的不断变大($ \varpi = 0.05, 0.5, 1, 5, 10 $), 多目标估计精度在不断下降. 但就总体趋势而言, 多目标估计精度仅是有限度小范围的变化, 整体变化趋势比较平稳. 这说明了在参数摄动(过程噪声)的情况下, 本文所提传感器控制方法具备良好的鲁棒性.
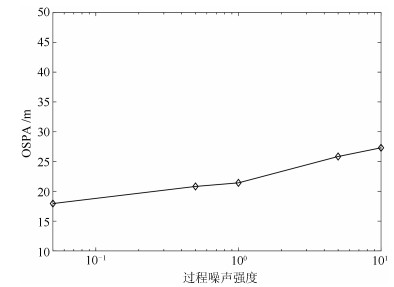 图 7 所提方案中不同过程噪声强度对估计性能的影响Fig. 7 Tracking performance of different process noise intensities for the proposed strategy
图 7 所提方案中不同过程噪声强度对估计性能的影响Fig. 7 Tracking performance of different process noise intensities for the proposed strategy以下讨论量测噪声的变化对本文算法的影响. 本文仍然在相同的仿真场景下通过改变量测噪声协方差系数$ \varsigma $ ($ \Sigma_{v} = \varsigma \cdot{ \rm diag}\{ {\sigma _\theta ^2, \sigma _r^2} \} $来控制量测噪声协方差的大小, 进而对比说明其对滤波器性能的影响. 如图 8所示, 随着$ \varsigma $的不断增大, 多目标状态的OSPA在不断增大, 估计精度在不断降低, 这反应了量测不确定性程度对滤波器精度的影响. 此外, 尽管噪声协方差的增大如预期的那样引起了多目标跟踪估计效果的变差, 但总体而言, 多目标整体滤波效果呈现了一个相对平稳的过程, 在参数摄动的范围内, 多目标状态估计OSPA均值的最大变化(最大值和最小值)小于15 m, 这说明了所提算法在不同的量测噪声水平下有着较好的鲁棒性.
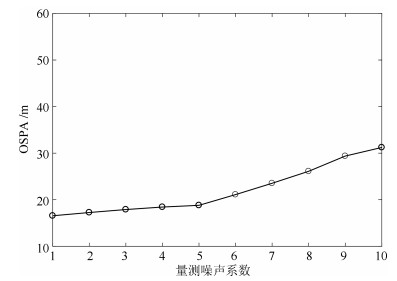 图 8 所提方案中不同量测噪声系数对估计性能的影响Fig. 8 Tracking performance of different measure noise factors for the proposed strategy
图 8 所提方案中不同量测噪声系数对估计性能的影响Fig. 8 Tracking performance of different measure noise factors for the proposed strategy事实上, 箱粒子滤波同样适用于解决非线性非高斯跟踪问题. 本文选择具有普遍意义的闪烁噪声[35-36]模拟非高斯噪声, 闪烁噪声与高斯噪声的主要差别在于尾部较长. 一般地, 闪烁噪声可以分解为高斯噪声和具有"厚尾"特性的噪声之加权和[35-36], 即$ f(g) = (1-\xi ){{f}_{N}}(g)+\xi {{f}_{I}}(g) $, 其中, $ f(g) $为闪烁噪声, $ {{f}_{N}} $和$ {{f}_{I}} $分别为高斯和大方差高斯分布, 其协方差分别为$ {{\Sigma }_{N}} $和$ {{\Sigma }_{I}} $, $ \xi $为闪烁噪声概率, $ 0<\xi <1 $. 本文基于以上非高斯模型, 设定$ {{\Sigma }_{N}} = \rm{diag}\{\begin{matrix}\sigma _{\theta }^{2} , \sigma _{r}^{2} \\ \end{matrix}\} $, $ {{\sigma }_{\theta }} = {{0.25}^{\circ }}, {{\sigma }_{r}} = 2.5 $ m, 闪烁噪声概率$ \xi = 0.2 $, $ {{{\Sigma }_{I}}} = K \cdot {{{\Sigma }_{N}}} $, 并在$ K $分别取值为5, 10, 20, 50, 100的条件下进行MC仿真, 进而对多目标状态估计的OSPA均值进行统计分析. 如图 9所示, 随着$ K $的不断增大, 厚尾程度越严重, 相应的多目标状态的估计精度不断下降. 但从OSPA所呈现出的总体趋势来看, 面对不同厚尾程度的非高斯噪声, 所提算法仍能以较好的精度跟踪多目标, 这也证明了本文所提方法对典型的非高斯噪声具有较好的适应性.
 图 9 所提方案中不同K值对估计性能的影响Fig. 9 Tracking performance of difierent K values for the proposed strategy
图 9 所提方案中不同K值对估计性能的影响Fig. 9 Tracking performance of difierent K values for the proposed strategy在本文所提算法中, 传感器速度也会在一定程度上影响多目标状态的估计精度. 本文结合实际的场景设置, 分别在设定不同的传感器速度的基础上进行MC仿真, 并统计多目标跟踪估计的OSPA均值. 如图 10所示, 可以看出, 传感器速度的不同设定会对多目标跟踪精度产生影响, 而速度为20 m/s时, 多目标估计精度较好. 总体而言, 随着传感器速度的增大, 多目标估计精度似乎在一定范围内进行有限的优化. 可以理解的是, 传感器的速度越大将会使传感器越快到达"最佳"观测区域. 但也不是传感器速度越快就越好, 因为在离散时间动态系统中, 传感器每周期内的控制距离过大, 也可能会使传感器"错过"最优观测位置.
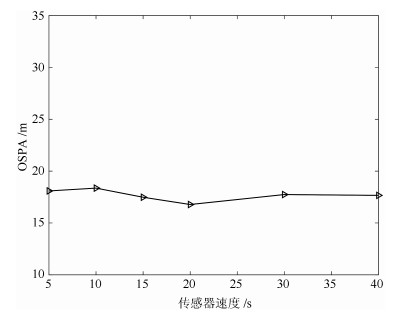 图 10 所提方案中不同的传感器速度对估计性能的影响Fig. 10 Tracking performance of different sensor speeds for the proposed strategy
图 10 所提方案中不同的传感器速度对估计性能的影响Fig. 10 Tracking performance of different sensor speeds for the proposed strategy为了详细说明由于分量删减所产生的不同的高斯混合分量个数对多目标状态估计精度和计算复杂度的影响, 本文分别在$ r_m $和$ w_m $不同取值的情况下进行MC仿真, 并在表 4中对多目标状态估计的OSPA和对应运行时间进行对比分析. 可以看出, 随着$ r_m $和$ w_m $的不断减小, 越多的高斯分量参与近似多目标密度. 多目标密度的近似程度越高, 所提出的多目标概率密度间的信息增益的计算也就越精确, 传感器控制的效果也就越好, 这最终反映在多目标状态的OSPA上. 很显然, 随着阈值的不断减小, 多目标的跟踪效果也在不断优化. 但这种优化是有限度的, 阈值小到一定程度并继续减小, 跟踪精度并没有得到显著的提高, 算法的计算花销却在显著提高, 这严重影响了多目标跟踪中传感器管理的计算效率. 因此, 当进行传感器控制时, 需要控制高斯分量个数来平衡多目估计精度和计算复杂度. 本文中设定$ r_m = 0.5 $, $ w_m = 0.2 $, 此时被提取的高斯混合分量在事实上几乎涵盖了所有的多目标信息, 在保证估计精度的同时, 也有着不错的运行速率.
表 4 不同高斯分量个数的性能比较Table 4 Tracking performance comparison of different Gaussian componentswm 0.3 0.2 0.1 0.01 rm = 0.5 OSPA(m) 18.04 17.62 17.38 16.88 时间(s) 2.49 2.61 2.87 3.59 rm = 0.3 OSPA(m) 17.57 17.19 16.95 16.48 时间(s) 2.62 2.76 3.01 3.83 rm = 0.1 OSPA(m) 17.27 17.01 16.53 15.98 时间(s) 2.89 3.12 3.64 4.37 图 11 (a)给出了RBT在200次MC仿真中, 方案一所遍历的所有传感器控制位置及与目标的相对位置. 可以看出, 随着多目标的不断变化(新生、消亡及状态的变化), 传感器总会及时调整自身的位置以适应目标的不确定性所带来的多目标状态空间分布的变化. 如图 11 (b) (传感器轨迹云放大效果图), 尽管跟踪场景中存在诸多随机因素, 导致每次MC仿真中的传感器运动轨迹都不大可能一致, 但该轨迹云仍能够充分展示传感器轨迹控制的总体趋势.
7. 结论与展望
本文的主要工作是基于区间不确定性推理, 利用Box-CBMeMBer滤波器提出了基于信息测度的传感器控制策略. 文中首先利用箱粒子实现Box-CBMeMBer滤波器, 并通过一组带有权值的箱粒子来表征多目标后验概率密度函数. 其次, 利用箱粒子的高斯分布假设, 将多伯努利密度近似为高斯混合. 随后, 选择CS散度作为评价函数, 并详细推导了两个高斯混合之间的CS散度的求解公式, 以此为基础提出相应的传感器控制策略. 该方法也是本文提出的最为核心的基于区间不确定性推理的传感器控制方案. 此外, 作为一种对比方案, 本文利用蒙特卡罗方法, 即通过对箱粒子进行混合均匀采样, 进而利用点粒子求解CS散度提出了相应的控制策略. 后一种方案符合粒子滤波解决传感器控制问题的传统思路, 但它的计算效率还是要明显低于所提出的箱粒子高斯近似的传感器控制策略. 最后, 通过几种经典方案的对比, 验证了所提算法的有效性. 所提方法的意义在于, 通过对传感器控制策略合理近似求解, 成功将Box-CBMeMBer滤波器与现代传感器管理系统相结合. 这对于广泛存在着区间不确定性的现实多目标跟踪系统的管理与控制具有重要的理论价值. 显然, 所提方法可以进一步推广到基于现代高分辨率传感器的多扩展目标跟踪问题中, 未来对利用区间不确定性推理解决多传感器管理也具有重要的参考价值.
-
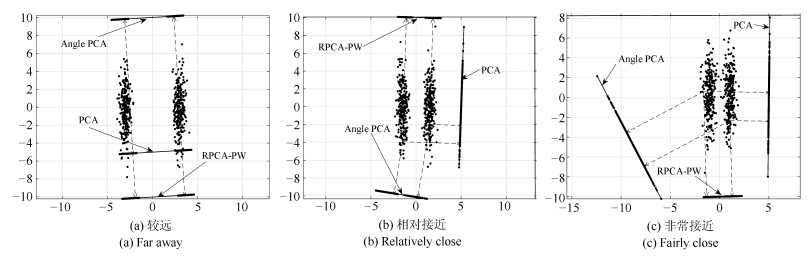
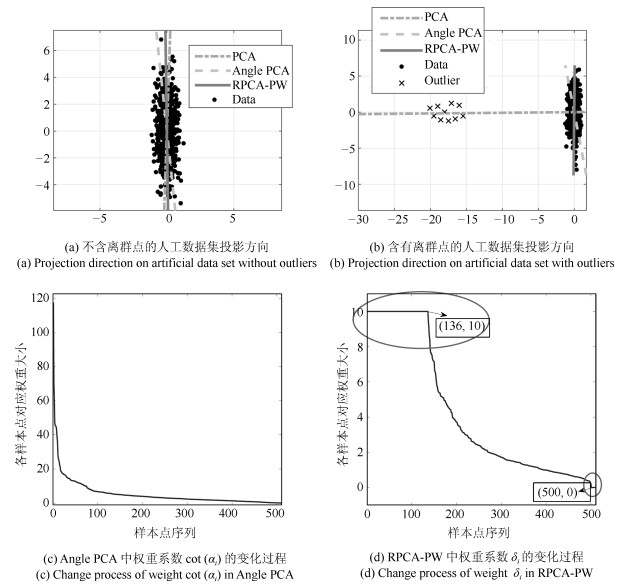
图 3 三种算法在双高斯人工数据集上的投影结果
Fig. 3 Projection result of three algorithms on two-Gaussian artificial dataset

图 4 Extended Yale B和AR人脸数据库原始图像与加入三种不同噪声后对应的图像(从上至下分别为黑白噪声块、高斯噪声和椒盐噪声
Fig. 4 Original images in Extended Yale B and AR face database and the corresponding images with three different noise types (top to bottom are noise block, Gaussian noise and salt-and-pepper noise respectively)

图 6 人脸重构效果图, 每一列从左到右依次是原图、PCA、PCA-L21、RPCA-OM、Angle PCA、HQ-PCA、$L{_{2, p}}$-PCA $p=0.5$、$L_{2, p}$-PCA $p=1$、RPCA-PW $p=0.5$、RPCA-PW $p=1$
Fig. 6 Face reconstruction pictures, each column represents original image, PCA, PCA-L21, RPCA-OM, Angle PCA, HQ-PCA, $L_{2, p}$-PCA $p=0.5$, $L_{2, p}$-PCA $p=1$, RPCA-PW $p=0.5$ and RPCA-PW $p=1$ from left to right

图 7 各算法对不同数据集的平均时间比较结果
Fig. 7 Comparison of average iteration time for different data sets by different algorithms
表 1 实验中使用的UCI数据集
Table 1 UCI data sets used in the experiment
数据集 维数 类别数 样本数 Australian 14 2 690 Cars 8 3 392 Cleve 13 8 303 Solar 12 6 323 Zoo 19 7 101 Control 60 6 600 Crx 15 2 690 Glass 9 6 214 Iris 4 3 150 Wine 13 3 178  下载: 导出CSV
下载: 导出CSV
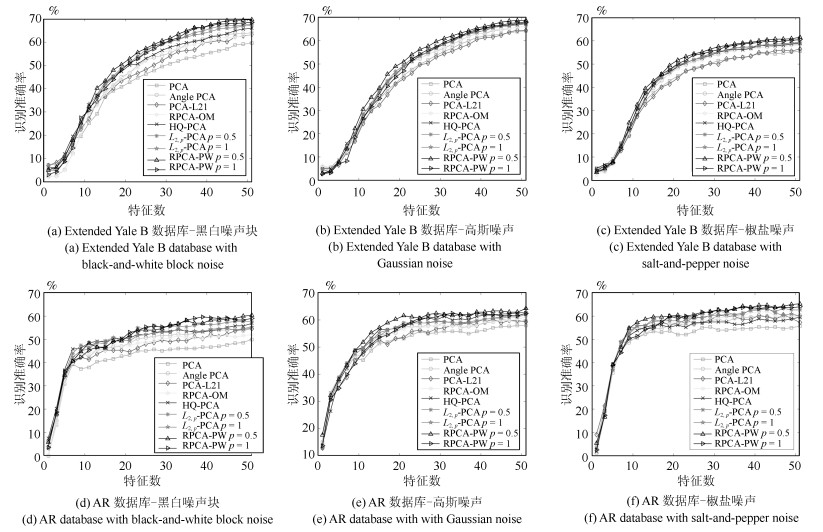
表 2 UCI数据集上各算法的平均分类正确率(%)
Table 2 Average classification accuracy of each algorithm on UCI data sets (%)
数据集 Australian Cars Cleve Solar Zoo Control Crx Glass Iris Wine PCA 57.32 69.27 52.16 64.11 96.00 91.83 54.93 74.35 96.00 73.04 PCA-$L$21 62.41 69.17 52.74 64.44 95.60 92.50 53.39 75.33 97.33 74.13 RPCA-OM 63.04 69.93 52.16 65.27 95.00 92.83 56.96 74.35 96.00 74.15 Angle PCA 60.39 69.43 52.16 65.60 94.00 84.28 59.59 73.94 95.53 74.15 MaxEnt-PCA 60.14 69.17 52.45 64.76 95.10 92.15 59.32 74.42 95.33 73.59 HQ-PCA 60.77 69.27 52.46 65.46 95.80 91.50 60.87 76.16 92.00 75.55 $L{_{2, p}}$-PCA $p=0.5$ 60.68 69.60 52.84 65.42 93.40 92.10 60.29 73.56 96.47 73.59 $p=1$ 62.39 69.58 52.16 64.51 94.90 92.50 59.43 73.73 96.67 73.59 $p=1.5$ 62.81 69.43 52.16 65.28 95.00 92.50 58.20 75.57 96.33 73.04 $p=2$ 62.32 69.43 52.16 64.11 96.00 91.83 54.93 75.82 96.00 73.59 RPCA-PW $p=0.5 $ 63.77 71.21 53.76 66.85 95.00 92.50 58.84 74.35 95.33 74.15 $p=1 $ 63.04 69.43 52.49 65.94 95.00 91.67 60.14 73.94 96.00 74.15 $p=1.5$ 62.17 69.43 52.16 64.72 95.00 97.83 61.16 76.28 96.67 74.15 $p=2$ 62.32 69.43 52.16 64.11 96.00 92.33 54.93 75.82 96.00 73.59
下载: 导出CSV
表 3 UCI数据集上各算法的重建误差
Table 3 Reconstruction error of each algorithm on UCI data sets
数据集 Australian Cars Cleve Solar Zoo Control Crx Glass Iris Wine PCA 197.53 1 979.82 5.47 2.97 1.43 115.06 6 265.42 37.91 0.67 24.49 PCA-$L$21 197.21 1 979.16 6.90 2.90 1.56 132.84 6 545.72 38.59 1.56 34.44 RPCA-OM 193.23 1 977.98 5.61 2.65 1.51 108.13 5 684.38 38.64 0.64 24.85 Angle PCA 197.96 1 981.34 13.27 2.95 2.04 123.62 6 583.82 38.42 0.59 25.85 MaxEnt-PCA 203.82 1 976.70 6.24 2.61 1.44 113.01 6 805.98 38.12 0.58 25.01 HQ-PCA 195.79 1 929.26 5.92 2.37 1.39 131.35 6 987.68 36.38 4.31 25.85 $L_{2, p}$-PCA $p=0.5$ 193.29 1 978.76 9.22 2.93 2.05 106.69 6 601.74 38.33 1.04 26.14 $p=1$ 193.71 1 978.33 5.60 2.75 1.72 108.06 6 588.17 38.37 0.84 25.44 $p=1.5 $ 193.50 1 977.93 5.50 2.69 1.44 109.69 6 807.38 37.82 0.72 25.05 $ p=2$ 193.53 1 977.82 5.47 2.97 1.43 115.06 5 865.42 37.91 0.67 24.49 RPCA-PW $p=0.5$ 192.93 1 976.94 5.75 2.95 1.57 106.11 6 467.83 38.43 0.52 24.12 $p=1$ 193.27 1 979.96 6.84 2.84 1.83 110.46 6491.19 38.17 0.70 24.36 $p=1.5$ 193.36 1 977.82 5.06 2.83 1.46 110.45 6 073.11 37.91 0.71 25.26 $p=2$ 193.53 1 977.82 5.47 2.97 1.43 115.06 5 865.42 37.91 0.67 24.49
下载: 导出CSV
-
[1] Jolliffe I. Principal Component Analysis. New York: Springer-Verlag, 1986. 115-128 [2] 高全学, 潘泉, 梁彦, 张洪才, 程咏梅. 基于描述特征的人脸识别研究. 自动化学报, 2006, 32(3): 386-392 http://www.aas.net.cn/article/id/15824Gao Quan-Xue, Pan Quan, Liang Yan, Zhang Hong-Cai, Cheng Yong-Mei. Face recognition based on expressive features. Acta Automatica Sinica, 2006, 32(3): 386-392 http://www.aas.net.cn/article/id/15824 [3] 张先鹏, 陈帆, 红杰. 结合多种特征的高分辨率遥感影像阴影检测. 自动化学报, 2016, 42(2): 290-298 doi: 10.16383/j.aas.2016.c150196Zhang Xian-Peng, Chen Fan, He Hong-Jie. Shadow detection in high resolution remote sensing images using multiple features. Acta Automatica Sinica, 2016, 42(2): 290-298 doi: 10.16383/j.aas.2016.c150196 [4] Gao Q X, Ma L, Liu Y, Gao X B, Nie F P. Angle 2DPCA: A new formulation for 2DPCA. IEEE Transactions on Cybernetics, 2018, 48(5): 1672-1678 doi: 10.1109/TCYB.2017.2712740 [5] Koren Y, Carmel L. Robust linear dimensionality reduction. IEEE Transactions on Visualization & Computer Graphics, 2004, 10(4): 459-470 doi: 10.1109/TVCG.2004.17 [6] Schölkopf B, Smola A, Müller K R. Nonlinear component analysis as a kernel eigenvalue problem. MIT Press, 1998, 10(5): 1299-1319 http://icesjms.oxfordjournals.org/external-ref?access_num=10.1162/089976698300017467&link_type=DOI [7] 李春娜, 陈伟杰, 邵元海. 鲁棒的稀疏$L_{p}$模主成分分析. 自动化学报, 2017, 43(1): 142-151 https://www.cnki.com.cn/Article/CJFDTOTAL-MOTO201306024.htmLi Chun-Na, Chen Wei-Jie, Shao Yuan-Hai. Robust sparse $L_{p}$-norm principal component analysis. Acta Automatica Sinica, 2017, 43(1): 142-151 https://www.cnki.com.cn/Article/CJFDTOTAL-MOTO201306024.htm [8] Xu L, Yuille A L. Robust principal component analysis by self-organizing rules based on statistical physics approach. IEEE Transactions on Neural Networks, 1995, 6(1): 131-143 doi: 10.1109/72.363442 [9] Ke Q, Kanade T. Robust ${\rm{L}}_1$-norm factorization in the presence of outliers and missing data by alternative convex Programming. In: Proceedings of the 2005 IEEE Computer Society Conference on Computer Vision and Pattern Recognition. San Diego, CA, USA: IEEE, 2005, 1: 739-746 [10] Kwak N. Principal component analysis based on L1-norm maximization. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2008, 30(9): 1672-1680 doi: 10.1109/TPAMI.2008.114 [11] Nie F, Huang H, Ding C, Luo D, Wang H. Robust principal component analysis with non-greedy L1-norm maximization. In: Proceedings of IJCAI International Joint Conference on Artificial Intelligence. Barcelona, Catalonia, Spain: AAAI, 2011, 22(1): 1433 [12] Ng A Y. Feature selection, L1 vs. L2 regularization, and rotational invariance. In: Proceedings of the 21st international conference on Machine learning. Banff, Canada: ACM, 2004, 78 [13] He R, Hu B, et al. Principal component analysis based on non-parametric maximum entropy. Neurocomputing, 2010, 73(10): 1840-1852 http://www.sciencedirect.com/science/article/pii/S092523121000144X [14] He R, Hu B, et al. Robust principal component analysis based on maximum correntropy criterion. IEEE Transactions on Image Processing, 2011, 20(6): 1485-1494 doi: 10.1109/TIP.2010.2103949 [15] He R, Tan T, Wang L. Robust recovery of corrupted low-rank matrix by implicit regularizers. IEEE Transactions on Patteren Analysis and Machine Intelligence, 2014, 36(4): 770-783 doi: 10.1109/TPAMI.2013.188 [16] Ding C, Zhou D, He X F, Zha H Y. R1-PCA: Rotational invariant L1-norm principal component analysis for robust subspace factorization. In: Proceedings of the 23rd International Conference on Machine Learning. Pittsburgh, USA: ACM, 2006. 281-288 [17] Nie F, Yuan J, Huang H. Optimal mean robust principal component analysis. In: Proceedings of 31st International Conference on Machine Learning. Beijing, China: ACM 2014. 2755-2763 [18] Nie, F, Huang, H. Non-greedy L21-norm maximization for principal component analysis. arXiv 2016, arXiv: 1603.08293 [19] Wang Q, Gao Q, Gao X, Nie F. ${{\rm{L}}_{2, p}}$-norm based PCA for image recognition. IEEE Transactions on Image Processing, 2018, 27(3): 1336-1346 doi: 10.1109/TIP.2017.2777184 [20] Wang Q, Gao Q, Gao X, Nie F. Angle principal component analysis. In: Proceedings of the 26th International Joint Conference on Artificial Intelligence. Melbourne, Australia: AAAI, 2017. 2936-2942 [21] Liu Y, Gao Q, Miao S, et al. A non-greedy algorithm for L1-norm LDA. IEEE Transactions on Image Processing, 2016, 1-1 http://ieeexplore.ieee.org/document/7707468 [22] Guo Y F, Li S J, Yang J Y, Shu T T, Wu L D. A generalized Foley--Sammon transform based on generalized fisher discriminant criterion and its application to face recognition. Pattern Recognition Letters, 2003, 24(1-3): 147-158 doi: 10.1016/S0167-8655(02)00207-6 [23] Cover T, Hart P. Nearest neighbor pattern classification. IEEE Transactions on Information Theory, 1967, 13(1): 21-27 doi: 10.1109/TIT.1967.1053964 期刊类型引用(7)
1. 杨可馨,李永强,侯忠生,冯宇. 基于多李雅普诺夫函数的一般非线性系统渐近镇定. 自动化学报. 2025(01): 197-209 .  本站查看
本站查看2. 陈辉,王秋菊,彭天曙,赵永红. 基于非中心逆威沙特分布的非线性扩展目标跟踪方法. 兰州理工大学学报. 2025(01): 100-107 . 百度学术3. 张永权,李志彬,张文博,苏镇镇. 多源传感器箱粒子LMB滤波算法. 西安电子科技大学学报. 2024(04): 51-66 . 百度学术4. 陈辉,王荆宇,张文旭,赵永红,席磊. 基于蒙特卡罗策略梯度的雷达观测器轨迹规划. 兰州理工大学学报. 2024(05): 77-85 . 百度学术5. 张文旭,王晓晴,陈辉,赵永红. 基于智能优化决策的目标跟踪传感器路径规划. 兰州理工大学学报. 2024(06): 92-98 . 百度学术6. 陈辉,魏凤旗,韩崇昭. 多扩展目标跟踪中基于多特征优化的传感器控制方法. 电子与信息学报. 2023(01): 191-199 . 百度学术7. 张君,鲍明,赵静,陈志菲,杨建华. 基于单声矢量传声器虚拟扩展的多机动声目标跟踪算法. 自动化学报. 2023(02): 383-398 . 本站查看其他类型引用(4)
-

 下载:
下载:


计量
- 文章访问数: 1559
- HTML全文浏览量: 305
- PDF下载量: 254
- 被引次数: 11
