

-
摘要: 本文提出了一种注意力胶囊网络的新框架利用录音识别家庭活动.胶囊网络可以通过动态路由算法来选择基于每个声音事件的代表性频带.为了进一步提高其能力,我们在胶囊网络中加入注意力机制,它通过加权来增加对重要时间帧的关注.为了评估我们的方法,我们在声学场景和事件的检测和分类(Detection and Classification of Acoustic Scenes and Events,DCASE)2018挑战任务5数据集上进行测试.结果表明,F1平均得分可达92.1%,优于几个基线方法的F1得分.
-
关键词:
- DCASE 2018挑战 /
- 声音事件分类 /
- 家庭活动识别 /
- 胶囊网络 /
- 注意力
Abstract: In this paper, a novel framework of attention capsule network is proposed, which uses sound recordings to identify domestic activities. The capsule network can select a representative frequency band based on each sound event by the dynamic routing algorithm. To further improve its ability, we add attention mechanism to the capsule network. It can increase the focus on significant time frames by weighting. To evaluate our approach, we test it on the dataset of task 5 of the Detection and Classification of Acoustic Scenes and Events (DCASE) 2018 Challenge. The results show that the average F1 score can reach 92.1%, outperforming several baselines.-
Key words:
- DCASE 2018 challenge /
- sound event classification /
- domestic activity recognition /
- capsule network /
- attention
1) 本文责任编委 吴建鑫 -
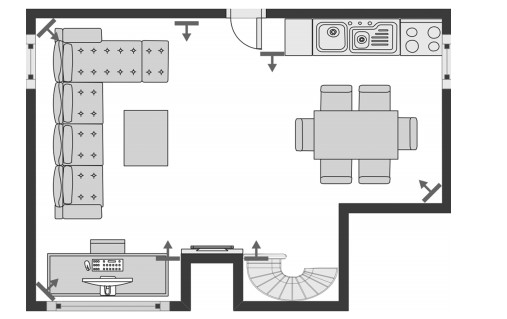
图 3 具有传感器节点的厨房和客厅混合的2D平面布置图
Fig. 3 2D floorplan of the combined kitchen and living room with the used sensor nodes
表 1 开发集和评估集音频数量
Table 1 Development set and evaluation set audio quantity
活动 开发集样本数 评估集样本数 缺席 18 860 21 112 烹饪 5 124 4 221 洗碗 1 424 1 477 吃饭 2 308 2 100 其他 2 060 1 960 社会活动 4 944 3 815 真空吸尘 972 868 看电视 18 648 21 116 工作 18 644 16 302 总计 72 984 71 971  下载: 导出CSV
下载: 导出CSV
表 2 开发集上各模型的F1得分
Table 2 F1 scores of each model on development dataset
活动 基线系统 GCRNN GCRNN-att Caps Caps-att 缺席 85.4 % 85.8 % 86.9 % 87.5 % 91.3 % 烹饪 95.1 % 93.7 % 96.9 % 93.8 % 95.8 % 洗碗 76.7 % 78.3 % 81.1 % 67.3 % 82.7 % 吃饭 83.6 % 83.3 % 87.8 % 82.8 % 90.5 % 其他 44.8 % 39.1 % 41.5 % 38.0 % 55.4 % 社会活动 93.9 % 84.7 % 98.8 % 89.8 % 96.8 % 真空吸尘 99.3 % 99.9 % 100.0 % 99.5 % 99.6 % 看电视 99.6 % 98.7 % 99.8 % 100.0 % 99.9 % 工作 82.0 % 84.1 % 84.4 % 84.3 % 87.6 % 平均值 84.5 % 86.9 % 87.8 % 87.3 % 92.1 %
下载: 导出CSV
表 3 评估集上各模型F1得分
Table 3 F1 scores of each model on evaluation dataset
模型 F1得分 基线系统 85.0 % GCRNN 86.5 % GCRNN-att 86.9 % Caps 86.6 % Caps-att 88.8 %
下载: 导出CSV
-
[1] Rafferty J, Nugent C D, Liu J, Chen L. From activity recognition to intention recognition for assisted living within smart homes. IEEE Transactions on Human-Machine Systems, 2017, 47(3):368-379 doi: 10.1109/THMS.2016.2641388 [2] Erden F, Velipasalar S, Alkar A Z, Cetin A E. Sensors in assisted living:a survey of signal and image processing methods. IEEE Signal Processing Magazine, 2016, 33(2):36-44 doi: 10.1109/MSP.2015.2489978 [3] Phan H, Hertel L, Maass M, Koch P, Mazur R, Mertins A. Improved audio scene classification based on label-tree embeddings and convolutional neural networks. IEEE/ACM Transactions on Audio, Speech, and Language Processing, 2017, 25(6):1278-1290 doi: 10.1109/TASLP.2017.2690564 [4] 朱煜, 赵江坤, 王逸宁, 郑兵兵.基于深度学习的人体行为识别算法综述.自动化学报, 2016, 42(6):848-857 http://www.aas.net.cn/CN/abstract/abstract18875.shtmlZhu Yu, Zhao Jiang-Kun, Wang Yi-Ning, Zheng Bing-Bing. A review of human action recognition based on deep learning. Acta Automatica Sinica, 2016, 42(6):848-857 http://www.aas.net.cn/CN/abstract/abstract18875.shtml [5] Fonseca E, Gong R, Serra X. A simple fusion of deep and shallow learning for acoustic scene classification. In: Proceedings of the 15th Sound and Music Computing Conference. Limassol, Cyprus, 2018 http://www.researchgate.net/publication/325893998_A_Simple_Fusion_of_Deep_and_Shallow_Learning_for_Acoustic_Scene_Classification [6] Hershey S, Chaudhuri S, Ellis D P W, Gemmeke J F, Jansen A, Moore R C, et al. CNN architectures for large-scale audio classification. In: Proceedings of the 2017 IEEE International Conference on Acoustics, Speech and Signal Processing. Seoul, South Korea: IEEE, 2017. 131-135 [7] Parascandolo G, Huttunen H, Virtanen T. Recurrent neural networks for polyphonic sound event detection in real life recordings. In: Proceedings of the 2016 IEEE International Conference on Acoustics, Speech and Signal Processing. Shanghai, China: IEEE, 2016. 6440-6444 [8] Cakir E, Parascandolo G, Heittola T, Huttunen H, Virtanen T. Convolutional recurrent neural networks for polyphonic sound event detection. IEEE Transactions on Audio, Speech, and Language Processing, 2017, 25(6):1291-1303 doi: 10.1109/TASLP.2017.2690575 [9] Xu Y, Kong Q Q, Huang Q, Wang W W, Plumbley M. D. Attention and localization based on a deep convolutional recurrent model for weakly supervised audio tagging. In: Proceedings of Interspeech 2017. Stockholm, Sweden: ISCA, 2017. 3083-3087 [10] Xu Y, Kong Q Q, Wang W, Plumbley M D. Large-scale weakly supervised audio classification using gated convolutional neural network. In: Proceedings of the 2018 IEEE International Conference on Acoustics, Speech and Signal Processing. Calgary, Alberta, Canada: IEEE, 2018. 121-125 http://www.researchgate.net/publication/322797180_LARGE-SCALE_WEAKLY_SUPERVISED_AUDIO_CLASSIFICATION_USING_GATED_CONVOLUTIONAL_NEURAL_NETWORK [11] Barker J, Marxer R, Vincent E, Watanabe S. Multi-microphone speech recognition in everyday environments. Computer Speech & Language, 2017, 26:386-387 http://www.sciencedirect.com/science/article/pii/S0885230817300475 [12] Dekkers G, Vuegen L, Waterschoot T V, Vanrumste B, Karsmakers P. Dcase 2018 challenge-task 5: monitoring of domestic activities based on multi-channel acoustics.[Online], available: https://arxiv.org/pdf/1807.11246.pdf, August 1, 2018 [13] Kong Q Q, Iqbal T, Xu Y, Wang W W, Plumbley M D. Dcase 2018 challenge surrey cross-task convolutional neural network baseline.[Online], available: https://arxiv.org/pdf/1808.00773.pdf, September 29, 2018 [14] Tanabe R, Endo T, Nikaido Y, Ichige T, Nguyen P, Kawaguchi Y, et al.[Online], available: http://dcase.community/documents/challenge2018/technical_reports/DCASE2018_Tanabe_55.pdf, September 15, 2018 [15] Inoue T, Vinayavekhin P, Wang S, Wood D, Greco N, Tachibana R.[Online], available: http://dcase.community/documents/challenge2018/technical_reports/DCASE2018_Inoue_14.pdf, September 15, 2018 [16] Sabour S, Frosst N, Hinton G E. Dynamic routing between capsules. In: Proceedings of the 2017 Neural Information Processing Systems. Long Beach, CA, USA: NIPS, 2017. 3856-3866 [17] Dauphin Y N, Fan A, Auli M, Grangier D. Language modeling with gated convolutional networks. In: Proceedings of the 2016 International Conference on Machine Learning. New York, USA: ACM, 2016. 933-941 http://www.researchgate.net/publication/311900760_Language_Modeling_with_Gated_Convolutional_Networks [18] Dekkers G, Lauwereins S, Thoen B, Adhana M W, Brouckxon H, Waterschoot T V, et al. The sins database for detection of daily activities in a home environment using an acoustic sensor network. In: Proceedings of the Detection and Classification of Acoustic Scenes and Events 2017 Workshop. Munich, Germany: DCASE, 2017. 32-36 [19] Kong Q Q, Xu Y, Wang W W, Plumbley M D. A joint separation-classification model for sound event detection of weakly labelled data. In: Proceedings of the 2018 IEEE International Conference on Acoustics, Speech and Signal Processing. Calgary, Alberta, Canada: IEEE, 2018. 321-325 [20] Kong Q Q, Xu Y, Sobieraj I, Wang W W, Plumbley M D (2019). Sound Event Detection and Time-Frequency Segmentation from Weakly Labelled Data. IEEE/ACM Transactions on Audio, Speech, and Language Processing, 2019, 27(4):777-787 doi: 10.1109/TASLP.2019.2895254 -

 下载:
下载:

计量
- 文章访问数: 1915
- HTML全文浏览量: 693
- PDF下载量: 242
- 被引次数: 0
