

A Constrained Multi-objective Online Operation Optimization Method of Collaborative Distillation and Heat Exchanger Network
-
摘要: 针对蒸馏装置与换热网络间缺乏协同优化导致的分馏精度差和能耗高的问题,提出了一种基于代理模型的约束多目标在线协同操作优化方法.为了解决蒸馏装置与换热网络操作参数协同优化时存在的计算耗时和约束的问题,构建Kriging代理模型来近似目标函数和约束条件,提出了基于随机欠采样和Adaboost的分类代理模型(RUSBoost)来解决类别不平衡的收敛判定预测问题.提出了基于多阶段自适应约束处理的代理模型的模型管理方法,该方法采用基于参考向量激活状态的最大化改善期望准则和可行概率准则更新机制来平衡优化初始阶段种群的多样性和可行性,采用支配参考点的置信下限准则更新机制加快收敛速度.通过不断与机理模型交互来在线更新代理模型,实现在线操作优化.通过测试函数和仿真实例验证了本文方法的有效性.Abstract: To solve low separation precision and high energy-consuming caused by lacking of collaborative operation optimization between atmospheric distillation unit and heat exchanger network, this paper presents a constrained multi-objective online collaborative operation optimization method based on surrogates model. To solve the problems of time-consuming and constraints in operating parameters collaborative optimization of distillation unit and heat exchanger network, the Kriging surrogate models are built to approximate each objective function and constraint, a classification surrogate model based on random undersampling and Adaboost is presented to solve the class imbalance of convergence prediction problem. A model management method of surrogate models based on multi-stage adaptive constraint handling is proposed. The method uses the maximization expected improvement and probability of feasibility criterion updating mechanism based on the reference vector activation state to balance the diversity and feasibility of the population at the early stage of evolution. The convergence rate is accelerated by using lower confidence bound criterion update mechanism dominating the reference point. By constantly interacting with the mechanism model to online update the surrogate model, the online operation optimization is realized. The efficiency of the proposed algorithm is validated by the results of benchmark functions and simulation example.
-
常减压蒸馏过程是炼油企业原油加工生产的第一道工序, 是原油深度加工的基础, 其运行效果不仅影响本装置的产品收率和质量, 并且直接影响到下游二次装置深加工工艺和油品质量.同时, 常减压蒸馏过程属于典型的能量密集型热加工过程, 耗能量约占炼厂总能耗的10%~30%, 其能耗水平的高低直接关系到整个炼油企业的节能减排、经济效益.因此, 对常减压蒸馏装置的运行和能耗的优化具有非常重要的意义[1-3].分馏塔是常减压蒸馏过程的核心设备.原油在分馏塔中进行传热、传质, 从而将原油分离成沸点范围不同的馏分.分馏塔的运行性能直接影响常减压蒸馏过程中产品的质量和油品收率[4].换热网络是常减压蒸馏过程节能降耗的主要装置.为了充分回收装置中各冷热物流含有的热量, 常减压蒸馏过程中各冷热物流通过换热网络进行热量交换以满足各自温度要求[5].
当前, 常减压蒸馏过程普遍存在分馏精度差、能耗高的问题, 主要原因是忽略了分馏塔与换热网络间的耦合关系, 只考虑了单装置优化, 从而导致分馏塔与换热网络间的不匹配.换热网络与分馏塔紧密相关且相互制约.例如, 当换热网络运行超出规定范围, 不仅会增加系统能耗, 还会导致分馏塔内部热量不平衡, 直接影响各侧线产品质量和收率.当分馏塔内的取热分配不合理时, 会严重限制换热网络的能量回收率, 降低了热源利用率.因此, 解决上述问题的关键是考虑分馏塔和换热网络间的协同关系, 在满足产品质量的约束下, 通过调整装置的操作参数, 实现分馏塔与换热网络的优化集成.
由于炼油生产过程中各装置机理模型结构复杂, 并且进化算法在优化过程中需要多次调用模型进行评估, 直接采用机理模型进行优化会导致计算复杂度高, 难以满足系统实时性的需要.因此, 如何建立高效准确的分馏塔与换热网络的集成模型是解决常减压蒸馏过程协同操作优化问题的难点.代理模型的出现为求解计算代价昂贵的优化问题提供了有效途径[6-7].文献[8-10]解析实际炼油生产过程的操作工况数据, 建立人工神经网络代理模型对常压蒸馏塔进行模拟, 并采用进化算法对常压塔进行操作优化.文献[11-12]采用基于流程模拟软件的常压塔机理模型产生的数据建立代理模型, 考虑了原油物性对产品收率的影响.文献[13]采用二阶多项式函数建立分馏塔数据模型, 考虑了每个换热器的质量和能量守恒, 通过优化原油调和比率和操作条件, 实现了分馏塔与换热网络的优化集成.文献[14-15]提出了一种集成常减压精馏系统与能量系统的单目标优化框架, 建立了支持向量机分类代理模型来预测精馏系统是否收敛, 减少了计算时间.虽然上述研究采用基于代理模型的建模方法有效地解决了优化过程计算耗时问题, 但是上述建模方法没有考虑优化过程中代理模型的在线更新, 导致模型的泛化能力差, 从而影响了模型精度与优化效果.针对这一问题, 本文提出了基于代理模型的蒸馏与换热在线协同操作优化方法, 该方法采用多阶段自适应约束处理的模型更新管理机制来选择新样本点, 通过不断调用机理模型评估新样本点, 实现代理模型的在线更新, 确保代理模型能快速地提供更加精确的函数评估值.
1. 常压蒸馏塔与换热网络协同操作优化问题描述
1.1 问题分析
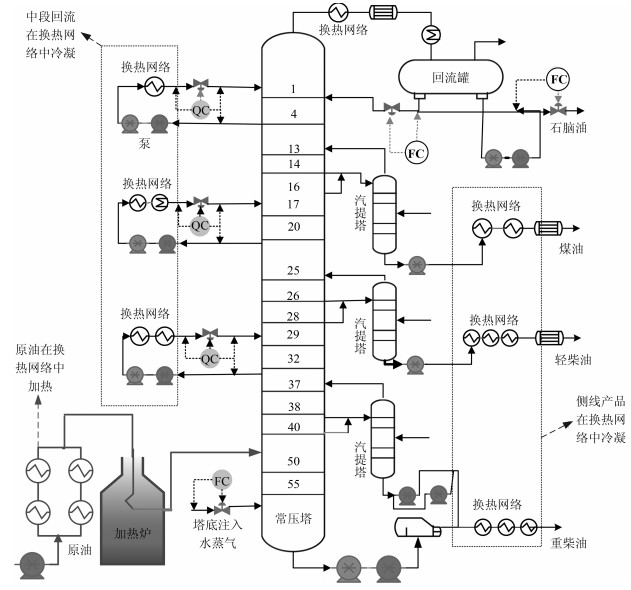
典型常压蒸馏系统工艺流程如图 1所示, 该系统包括加热炉、换热网络以及常压蒸馏塔.温度较低的原油首先进入换热网络中与温度较高的中段循环回流和各侧线产品流进行热交换.换热后的原油在加热炉中继续加热至340℃~380℃进入到常压蒸馏塔底部进行精馏, 从塔顶分离出石脑油馏分, 从塔的三个侧线依次采出煤油、轻柴油、重柴油等馏分.在常压蒸馏塔侧线处设有汽提塔和中段回流.汽提塔的作用是将塔底或侧线产品中的轻馏分蒸出, 从而调整各侧线产品的闪点和馏程范围, 提高产品拔出率.设置中段循环回流的目的是回收常压塔的余热, 增加装置的热量利用率.常压蒸馏塔的侧线产品、中段回流和进料原油通过换热网络进行各物料间的热量交换.因此, 常压蒸馏塔的设计和操作会直接影响到换热网络的热量回收效果.
常压蒸馏塔与换热网络协同优化是同时优化常压塔侧线产品收益和系统能耗.通过分析和优化常压蒸馏系统中关键的操作变量, 使产品收益达到最大化.同时, 更新现有换热网络结构中各冷热物流的初温、终温、热容流率和焓变值, 基于热力学原理的夹点分析模型根据改变的物流信息对换热网络进行物流匹配, 最大化原油换热终温, 从而计算出最小系统能耗.此外, 产品收益和系统能耗之间相互冲突, 例如提高常压塔的中段回流负荷会增加换热网络的热量回收, 使系统的能耗量减小, 但较高的中段回流负荷会使上升到塔顶的轻馏分减少, 使高价值塔顶产品收率降低, 减少产品收益.由于常压塔与换热网络协同操作优化问题是一个典型的多目标、强约束、评估代价高昂的复杂优化问题, 因此, 如何设计代理模型辅助的约束多目标优化算法, 在产品质量和仿真模型收敛的约束下, 通过优化操作参数, 实现产品收益最大化及能耗最小化是本文要解决的问题.
1.2 常压蒸馏塔与换热网络协同操作优化模型
常压蒸馏塔与换热网络协同操作优化问题的优化目标为产品收益$ Q ({\pmb X}) $和能耗成本$ C ({\pmb X}). $由下式表示:
$ \begin{equation} J\sim\left\{ \max Q({\pmb X}), \min C({\pmb X}) \right\} \end{equation} $
(1) 其中, $ {\pmb X} = (F_{prod}, F_{steam}, F_{PA}, Q_{PA}, T_{f}) $为14个决策变量, 分别是各侧线产品产出量$ F_{prod} $, 蒸汽注入量$ F_{steam} $, 各中段回流流量$ F_{PA} $, 各中段回流负荷$ Q_{PA} $和进料温度$ T_{f} $. $ Q({\pmb X}) $与$ C({\pmb X}) $可由式(2)~(6)计算得到:
$ \begin{align} Q({\pmb X}) = & \sum\limits_{i = 1}^4P_{prod, i}F_{prod, i}-P_{crude}F_{crude}-{}\\ & {}P_{stm}\sum\limits_{j = 1}^3F_{stm, j} \end{align} $
(2) $ \begin{equation} C({\pmb X}) = P_{fuel}U_{fuel}+P_{cw}U_{cw} \end{equation} $
(3) $ \begin{equation} U_{fuel} = GCC(TS_m, TT_m, \Delta H_m) \end{equation} $
(4) $ \begin{equation} U_{cw} = GCC(TS_m, TT_m, \Delta H_m) \end{equation} $
(5) $ \begin{equation} [TS_m, TT_m, \Delta H_m] = h({\pmb X}) \end{equation} $
(6) 其中, $ P $为价格, $ F $为流量, 下标$ prod $, $ crude $, $ stm $, $ fuel $, $ cw $分别表示产品、原油、水蒸汽、燃料油以及冷凝水. $ U_{fuel} $和$ U_{cw} $分别表示燃料油和冷凝水的最小消耗量. $ GCC $为夹点分析技术.该技术通过输入常压塔内各冷热物流(即常压蒸馏塔的各中段循环回流、产品流以及原油)的初始温度$ TS_m $、终端温度$ TT_m $和焓变值$ \Delta H_m $, 对换热网络的最大能量回收量、最小冷热公用工程量进行热分析, 最终可以确定燃料油和冷凝水公用工程的最小消耗量. $ h(\cdot) $为基于流程模拟技术的常压蒸馏塔仿真模型, 该模型是典型的黑箱模型.决策变量$ {\pmb X} = (F_{prod}, F_{steam}, F_{PA}, Q_{PA}, T_{f}) $的取值为该仿真模型的输入.常压塔仿真模型进行迭代计算后, 可以得到各冷热流股初始温度$ TS_m $、终端温度$ TT_m $和焓变值$ \Delta H_m $.
仿真模型收敛约束表达式如下:
$ \begin{equation} cov = h({\pmb X}) = 1 \end{equation} $
(7) $ h(\cdot) $为基于流程模拟技术ASPEN HYSYS的常压蒸馏塔仿真模型, 该建模方法采用序贯模块法进行流程模拟计算.当输入决策变量数值时, 需要不断迭代, 直至收敛, 即满足质量、相、能量平衡关系, 不收敛的解为不可行解.因此, 优化过程中需要保证常压蒸馏塔机理模型处于收敛状态, 而是否收敛则由决策变量的取值决定. $ cov $表示常压蒸馏塔机理模型是否处于收敛状态. $ cov $值为1时, 表示常压塔处于收敛状态; $ cov $值为0时, 常压塔处于不收敛状态.
常压蒸馏塔各侧线产品的质量约束如下:
$ \begin{equation} T95_{i}^{L}\le T{{95}_{i}}\le T95_{i}^{H}, \quad i = 1, 2, 3, 4 \end{equation} $
(8) 其中, $ i(i = 1, 2, 3, 4) $表示第$ i $种产品. $ T95_i $为第$ i $种产品的实沸点95%蒸馏温度(True boiling point 95% TBP 95%).产品的TBP 95%温度不仅与产品的性质有关, 还与常压蒸馏塔内产品的物料平衡有着密切的联系.因此, 该指标被广泛地用于炼厂中来评价产品质量是否满足要求.产品的质量要求规定在一个温度区间内, 当侧线产品的TBP 95%温度在对应目标温度区间内, 则表示为合格产品.上角标$ (L, H) $表示常压塔各侧线产品的产品质量规定区间的上下限.
2. 基于Kriging代理模型的参考向量引导的约束多目标优化算法
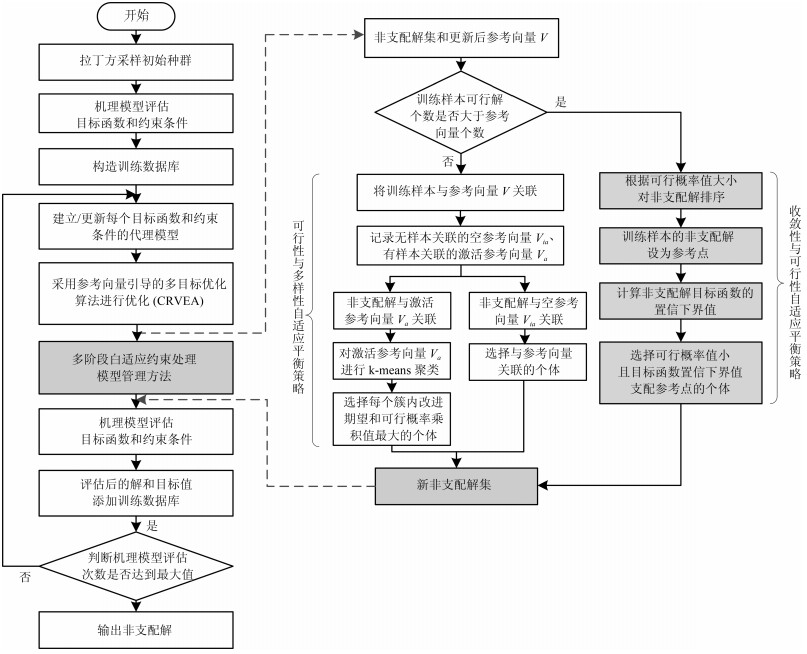
本文针对计算代价昂贵的约束优化问题, 提出了基于Kriging代理模型的参考向量引导的约束多目标优化算法, 其算法流程如图 2所示.
首先, 采用拉丁超立方体采样方法选取初始样本点, 并调用机理模型评估样本的目标函数值和约束违背值.建立Kriging代理模型来近似每个目标函数和约束条件总违背值.然后, 采用参考向量引导的约束进化算法进行优化.优化过程中, 调用Kriging模型评估个体的适应值.迭代寻优一定的代数后, 会产生一组近似Pareto的非支配解集.由于这些非支配解是基于Kriging代理模型评估产生的, 存在一定程度的预测误差.因此, 提出了多阶段自适应约束处理模型管理方法从非支配解集中选择代表性个体来进行机理模型评估, 用于更新代理模型训练数据库, 从而不断更新代理模型.该方法根据进化过程中种群可行解比例的变化, 动态调整更新点的选择策略.
综上, 基于Kriging代理模型的参考向量引导的约束多目标优化算法主要包括三个部分: Kriging代理模型的建立、参考向量引导的约束多目标进化算法进行优化以及多阶段自适应约束处理模型管理方法.
2.1 Kriging代理模型
Kriging模型又称高斯过程模型, 是一种常用的非参数模型, 被广泛地用于代理模型辅助的进化算法中.该建模方法不仅能预测出未知点处的函数值, 而且能提供模型在该点处函数值的不确定度.该不确定度信息在代理模型的管理中起着关键性作用.
对于任意一点$ x $, Kriging模型在该点处的预测值为:
$ \begin{equation} y(x) = \mu(x)+\varepsilon(x) \end{equation} $
(9) 其中, $ \mu(x) $为回归模型$ F(\beta, x) $的预测值. $ \varepsilon(x) $是服从均值为0、方差为$ {\sigma }^{2} $的随机过程.对于任意两个输入样本$ {{x}^{i}} $和$ {{x}^{j}} $, 随机过程$ \varepsilon ({{x}^{i}}) $和$ \varepsilon ({{x}^{j}}) $间的协方差定义如下:
$ \begin{equation} \operatorname{cov}[\varepsilon ({{x}^{i}}), \varepsilon ({{x}^{j}})] = {{\sigma }^{2}}R({{x}^{i}}, {{x}^{j}})\ \end{equation} $
(10) 其中, $ R({{x}^{i}}, {{x}^{j}}) $为$ \varepsilon ({{x}^{i}}) $和$ \varepsilon ({{x}^{j}}) $的相关函数,
$ \begin{equation} R({{x}^{i}}, {{x}^{j}}) = \exp\left(-\sum\limits_{k = 1}^{n}{{{\theta }_{k}}{{\left| x_{k}^{i}-x_{k}^{j} \right|}^{2}}}\right)\ \end{equation} $
(11) 式中, $ n $表示决策变量个数, $ \theta $表示超参数.
Kriging模型在未知样本点$ \tilde{x} $的预测值和不确定度可由下式计算得到:
$ \begin{equation} \tilde{y} = \beta +{{\pmb r}^{\rm T}}(\tilde{x}){{{ R}}^{-1}}(y-F\beta ) \end{equation} $
(12) $ \begin{align} {{\tilde{s}}^{2}}(\tilde{x}) = &{{\tilde{\sigma} }^{2}} \Bigg({\bf 1}-{\pmb r}^{\rm T}{{(\tilde{x})}}{{{R}}^{-1}}{\pmb r}(\tilde{x})+\\&\frac{{{({\bf 1}-{{{\bf 1}}^{\rm T}}{{{{ R}}}^{-1}}{\pmb r}(\tilde{x}))}^{2}}}{{{{\bf 1}}^{\rm T}}{{{R}}^{-1}}{\bf 1}}\Bigg) \end{align} $
(13) 其中, $ {\pmb r}(\tilde{x}) $为未知点$ \tilde{x} $和训练样本$ \left[ {{x}^{1}}, \cdots , {{x}^{{{N}_{I}}}} \right] $之间的相关函数, 矩阵$ R $由所有训练样本点之间的协方差函数值组成.通过最大化似然函数, 可以确定未知参数$ \beta $、$ \theta $和$ \tilde{\sigma} $的取值.
2.2 参考向量引导的约束多目标进化算法(CRVEA)
本文采用参考向量引导的进化算法(Constrained reference vector-guided EA, CRVEA)[16]进行优化求解.不同于其他基于分解的多目标进化算法, 该算法设计了一种有效的个体选择机制.该机制通过角度惩罚距离(Angle penalized distance, APD)来平衡种群的收敛性和多样性. CRVEA主要包括3个部分:参考向量的生成, 个体与参考向量关联和个体选择机制.首先, 在目标空间中生成一组均匀分布的参考向量.通过个体与参考向量进行关联, 目标空间被划分为若干个子种群.为了求解约束优化问题, 在个体选择机制中添加了约束处理技术.每个子种群中优先选择约束违背值小的个体, 如果子种群中个体均为可行解, 则优先选择APD值最小的个体作为父代个体. APD指标定义如下:
$ \begin{equation} d_{t, i, j} = (1+P(\theta_{t, i, j}))\cdot \left \| f_{t, i}{'} \right \| \end{equation} $
(14) 其中, $ \theta_{t, i, j} $为个体目标函数与参考向量间的夹角, $ f_{t, i}{'} $表示个体的目标函数值, $ P(\theta_{t, i, j}) $是计算多样性的性能指标,
$ \begin{equation} P(\theta_{t, i, j}) = M \cdot \nonumber\left(\frac {t}{t_{\max}}\right)^{\alpha}\cdot \left(\frac {\theta_{t, i, j}}{\gamma_{v_{t, j}}}\right) \end{equation} $
其中, $ M $表示目标函数的个数, $ t_{max} $是最大进化代数, $ t $是当前进化代数, $ \alpha $用于控制$ P(\theta_{t, i, j}) $变化速率, $ \gamma_{v_{t, j}} $表示子空间中的参考向量$ v_{t, j} $与当前代中其他参考向量之间的最小夹角.
2.3 多阶段自适应约束处理模型管理方法
由于常压塔与换热网络协同优化问题包含等式约束和不等式约束, 极大地缩小了可行区域的范围, 导致可行域极难搜索.因此, 求解此类约束优化问题不仅要保持种群的多样性来防止种群陷入局部最优, 还需要同时勘测可行域与不可行域的变化.如何较好地平衡目标函数和约束条件来选择有潜力的更新样本点, 使代理模型在快速逼近可行域的同时加强对不可行域的搜索是代理辅助约束优化算法的关键.本文提出了一种约束处理模型管理方法, 该方法利用参考向量和种群个体关联策略保证种群的多样性, 根据进化时期不同阶段的可行解比例, 自适应平衡目标函数和约束条件来选择更新点.该模型管理机制主要包括两个策略:进化初期阶段可行性与多样性自适应平衡策略以及进化后期阶段收敛性与可行性自适应平衡策略.
2.3.1 可行性与多样性自适应平衡策略
在初期更新阶段, 代理模型的训练样本中通常包含极少的可行解, 甚至没有可行解.因此, 该阶段更新点的选择策略是提高种群多样性的同时增加种群可行解数量, 目的是避免陷入局部最优.将训练样本与参考向量进行关联, 没有个体关联的参考向量为空参考向量, 有个体关联的参考向量则为激活参考向量.根据参考向量激活状态, 代理模型更新机制按下面方式确定:
1) 无个体关联的参考向量:将优化过程中得到的非支配解集与空参考向量进行关联.选择与空参考向量关联的个体作为代理模型更新点, 目的是增加种群多样性, 使种群尽可能探索可行区域.
2) 处于激活状态的参考向量:提出了目标函数改善期望准则(Generalized expected improvement, GEI)[17]与约束违背值的可行概率准则(Probability of feasibility, PoF)[18]相结合的机制进行代理模型更新, 有效地利用了目标函数和约束条件提供的信息.该更新机制首先将优化过程中得到的非支配解集与激活参考向量进行关联.然后, 采用k-means聚类方法将参考向量划分成若干个簇, 从每个簇中选择GEI与PoF乘积值$ \gamma $最大的样本作为更新点. $ \gamma $计算公式如下:
$ \begin{equation} \gamma = P({{F}_{i}}(\tilde{x})>g_{\min }^{i})\cdot {\rm GEI}(\tilde{x}) \end{equation} $
(15) 其中, $ g_{\min }^{i} $为约束条件的边界范围取值, $ P({{F}_{i}}(\tilde{x})>g_{\min }^{i}) $计算未知点$ \tilde{x} $满足约束的概率, 即PoF值. PoF定义如下:
$ \begin{equation} {\rm PoF}(\tilde{x}) = P({{F}_{i}}(\tilde{x})>g_{\min }^{i}) = \Phi \left(\frac{{{F}_{i}}-{{{\hat{g}}}^{i}}(\tilde{x})}{{{s}_{i}} (\tilde{x})}\right) \end{equation} $
(16) 其中, $ \Phi (\cdot ) $表示标准正态累积分布函数, $ {{\hat{g}}^{i}}(\tilde{x}) $表示Kriging模型对第$ i $个约束条件的预测值, $ {{s}_{i}}(\tilde{x}) $表示预测值的不确定度.上述PoF概率值越大表明个体满足约束条件的可能性越大.
式(16)中的GEI$ (\tilde{x}) $表示未知点$ \tilde{x} $处的GEI值. GEI准则主要思想是每个目标函数的改善期望准则值(Expected improvement, EI)进行归一化并求和, 用于衡量未知点处每个目标函数值比当前函数最小值提高的概率. GEI值最大的点被认为是真实函数评估最有价值的点.定义如下:
$ \begin{equation} {\rm GEI}(\tilde{x}) = \sum\limits_{i = 1}^{M}{\overline{EI}_{i}(\tilde{x})} \end{equation} $
(17) $ \begin{equation} \overline{EI}_{i}(\tilde{x}) = \frac{E{{I}_{i}}(\tilde{x})-\min (E{{I}_{i}})}{\max (E{{I}_{i}})-\min (EI_i)} \end{equation} $
(18) 其中, $ i(i = 1, 2, \cdots, M) $表示第$ i $个目标函数, $ \min(EI_{i}) $和$ \max({EI}_{i}) $分别表示种群个体中第$ i $个目标函数的最小EI值和最大EI值, $ \overline{EI}(\tilde{x}) $表示所有归一化后的目标函数EI值.综上, GEI准则会优先选择目标预测值比当前最优值小或预测的不确定度较大的点作为更新样本点.
2.3.2 可行性与收敛性自适应平衡策略
进化后期阶段中可行解的个数逐渐增多且分布较为集中, 因此需要增强算法的收敛性, 从而快速地搜索到全局最优解.为了保证代理模型向可行区域逼近的同时加快收敛速度, 提出了自适应平衡可行性与收敛性的模型管理策略.首先, 计算优化过程中得到的非支配解集中每个个体的PoF值和目标函数的置信下界值(Lower confidence bound, LCB)[19].根据PoF值大小对个体进行比较排序.个体的PoF值越大表明该个体优先选择级别越高.然后, 选择代理模型训练样本中非支配解作为参考点.由于LCB准则是函数的预测值减去不确定度, 当个体目标函数的LCB值小于参考点目标函数值时, 表明该个体的真实函数值可能会优于参考点的函数值.因此, 选择PoF值小且目标函数LCB值支配参考点的个体作为代理模型的更新样本. LCB函数定义如下:
$ \begin{equation} {\rm LCB}(x) = \hat{y}(x)-\omega s(x) \end{equation} $
(19) 其中, $ \hat{y}(x) $为Kriging模型对个体目标函数预测值; $ s(x) $为Kriging模型提供该预测值的不确定度, 即标准差; $ \omega $为自定义常数, 用于约束条件的预测值与不确定度的折衷.
3. 常压蒸馏塔与换热网络协同操作优化方法
3.1 协同优化框架
本文通过对炼油过程常压蒸馏塔和换热网络间的耦合关系进行分析研究, 根据第2节所论述的基于代理模型的参考向量引导的约束优化算法构建了蒸馏与换热协同的在线操作优化方法, 其优化框架如图 3所示.由于本文蒸馏与换热协同操作优化问题中包含仿真模型收敛约束, 优化过程中需要保证输入样本使常压塔仿真模型处于收敛状态, 不收敛样本为不可行解.此外, 模型不收敛时, 基于流程模拟技术的常压塔仿真模型需要层层迭代来确定是否为不收敛的状态, 计算耗时极长.因此, 建立准确高效的分类模型来近似仿真模型收敛约束, 对优化过程向可行设计域搜索和计算效率起到关键性的作用.本文所提的协同操作优化方法首先调用常压塔仿真模型来评估样本的收敛性、目标函数值和约束违背值, 采用夹点分析技术来评估样本的能耗.所有样本(收敛样本和不收敛样本)及对应的收敛状态用于建立基于RUSBoost的收敛判定分类代理模型, 所有收敛样本及对应的目标函数和约束违背值用于建立基于Kriging的性能指标和约束代理模型.然后采用CRVEA算法进行优化.优化过程中, 调用分类代理模型筛除不收敛解.调用Kriging代理模型评估收敛样本的性能指标和约束违背值.采用多阶段自适应约束处理模型管理策略选出最有潜力的样本点并在线调用机理模型进行评估, 将评估后的样本添加至代理模型训练样本库, 重新训练代理模型, 从而实现代理模型的在线更新.
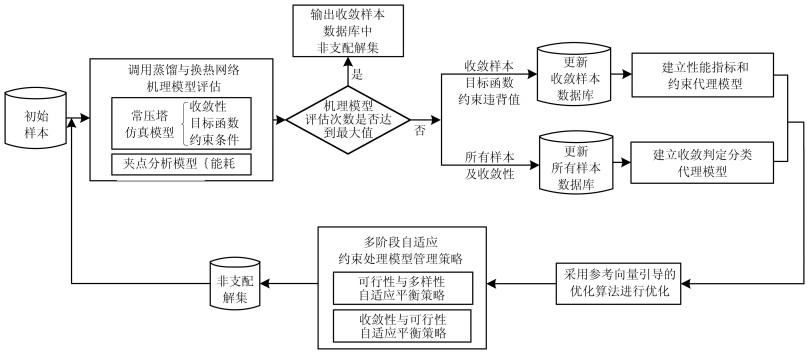 图 3 常压蒸馏塔与换热网络协同操作优化框架Fig. 3 Collaborative operation optimization framework of atmospheric distillation column and heat exchanger network
图 3 常压蒸馏塔与换热网络协同操作优化框架Fig. 3 Collaborative operation optimization framework of atmospheric distillation column and heat exchanger network3.2 RUSBoost代理模型
常压塔蒸馏模型是否收敛预测问题是一个典型的类别不平衡分类问题, 且不同类别间的样本在特征空间中存在相互交叠情况, 难以被传统的分类器正确分类.针对该问题特性, 本文采用随机欠采样方法(Random undersampling, RUS)来重构训练样本集.通过改变样本类别分布, 使其降低类别不平衡比例.采用Adaboost集成学习方法对平衡后的数据集建立分类模型. RUSBoost (Random undersampling boosting)[20]的具体构建步骤在算法1中给出.该方法的主要思想为: 1)采用随机欠采样技术对训练样本进行预处理, 保持少数类样本数量不变, 减少多数类样本的数目来平衡数据集, 从而减少训练代理模型的计算代价. 2)根据每一轮迭代训练的弱分类器预测错误率来调整每个样本的权重.如果样本预测正确, 则降低此样本权重; 反之, 如果预测错误, 则增加该样本权重, 从而使下次迭代训练的分类器更多关注误分类样本.
算法1.RUSBoost代理模型的建立
输入.训练数据集$ (x_1, y_1), \cdots, (x_m, y_m) $, 类别数$ \left| Y \right| = 2 $, 迭代次数$ T $.
输出.预测值$ H(x) = {\rm arg max}_{y \in Y}\sum\nolimits_{t = 1}^T h_t(x, y) \cdot $$ \log{\frac{1}{\alpha_t}} $
1) 初始化训练样本权值, $ D_1(i) = \frac{1}{m} $
2) for $ t = 1, 2, \cdots, T $ do
3) 随机欠采样对初始训练数据集进行数据预处理, 平衡后的数据集为$ S_{t}{'} $, 分布为$ D_{t}{'} $
4) 调用弱分类器决策树进行训练, 输入训练样本$ S_{t}{'} $和权值$ D_{t}{'} $
5) 输出假设函数$ h_t $: $ X\times Y\rightarrow[0, 1] $
6) 基于样本$ S $和分布$ D_t $计算损失函数值:
$ \varepsilon_t = \sum\nolimits_{(i, y):{y_i\neq y}}D_t(i)\cdot(1-h_t(x_i, y_i)+h_t(x_i, y)) $
7) 更新权值:$ \alpha_t = {\varepsilon_t}/{(1-\varepsilon_t)} $
8) 更新样本分布:
$ D_{t+1}(i)\leftarrow D_t(i)\cdot \alpha_t^{\frac{1}{2}(1+h_t(x_i, y_i)-h_t(x_i, y:y\neq y_i))} $
9) 归一化:
$ D_{t+1}(i)\leftarrow {D_{t+1}(i)}/{Z_t} $, $ Z_t = \sum_{i}D_{t+1}(i) $
10) end for
4. 实验验证
本文将从标准测试函数和常压蒸馏塔与换热网络协同优化两个方面, 验证所提基于代理模型的参考向量引导的约束优化算法(RK-CRVEA)的性能.
4.1 标准测试函数实验
本文选取CF系列约束优化标准测试问题[21]中的CF1~CF5进行仿真实验.对于CF系列问题, 目标函数个数均为2, 决策变量维度均为10.该约束测试集较为全面地包含了不同特性的约束问题, 如可行域不连续、不规则, 可行域极小, 全局最优解位于可行边界等特性.选择CRVEA[16]和EI-PoF[18]作为对比算法来验证本文方法的有效性.其中, CRVEA算法不包含代理模型, 优化过程中采用真实函数评估个体的性能.算法EI-PoF是基于Kriging代理模型的约束优化算法, 采用最大化期望提高机制和可行概率准则相结合的代理模型更新机制来处理约束条件.
4.1.1 参数设置
1) RK-CRVEA和CRVEA控制参数设置:分布指数$ \eta_{c} = 20 $, 交叉概率$ p_{c} = 1 $, 控制惩罚函数变化速率的参数$ \alpha = 2 $, 参考向量自适应频率$ {{f}_{r}} = 0.1 $, 种群大小设为50, 参考向量个数设为49.
2) RK-CRVEA和EI-PoF代理模型参数设置:初始训练样本采样数为$ {{K}_{I}} = 11n-1 $, 其中$ n $为决策变量维度, 代理模型训练样本数最大值设为105.
3) RK-CRVEA参数设置: CRVEA对代理模型优化求解迭代次数设为20, k-means算法聚类簇数设为5.
4) 终止条件:真实函数评估次数为300次.
4.1.2 评价指标
本文采用反世代距离(Inverse generation distance, IGD)[22]指标来评估所提算法的收敛性和分布性.算法的IGD值越小, 表明该算法求得的Pareto前沿面与真实前沿面拟合度越高. IGD定义如下:
$ \begin{equation} {\rm IGD}({{P}^{*}}, \Omega ) = \frac{\sum\limits_{x\in {{P}^{*}}}{dis(x, \Omega)}}{\left| {{P}^{*}} \right|} \end{equation} $
(20) 其中, $ {P}^{*} $是真实Pareto前沿面上均匀分布的参考点, $ \Omega $是算法求解得到的近似Pareto最优解集, $ dis(x, \Omega) $表示真实Pareto前沿面的点$ x $到近似Pareto最优解集$ \Omega $中所有个体的最小欧氏距离.
4.1.3 实验结果及分析
对本文提出算法RK-CRVEA、EI-PoF和CRVEA三种算法分别独立运行20次进行实验研究.性能评价指标IGD的统计均值和方差如表 1所示.表中加粗部分表示算法的IGD值相对最小, 说明对应算法具有较好的收敛性和多样性.从表 1可以看出, RK-CRVEA和EI-PoF的IGD值相对较小, 其原因是两种算法采用高斯过程代理模型来辅助优化算法搜索方向, 并选择最有潜力的样本点来更新代理模型, 在有限次真实函数评估下可以得到均匀分布的最优解.本文算法RK-CRVEA求得的IGD指标值是最小的, 表明本文所提算法得到的最优解更接近Pareto真实前沿面, 所得解集的收敛性和分布性均明显优于对比算法.
表 1 IGD指标比较结果Table 1 The comparison result of IGD测试函数 RK-CRVEA EI-PoF RVEA CF1 0.0169(0.0016) 0.0231(0.0027) 0.0338(0.0021) CF2 0.0131(0.0032) 0.0305(0.0102) 0.0473(0.0095) CF3 0.1322(0.0128) 0.3909(0.0764) 0.4351(0.0856) CF4 0.0382(0.0290) 0.1445(0.0325) 0.1622(0.0413) CF5 0.1754(0.0457) 0.3517(0.0824) 0.7395(0.0881) 以CF1测试函数为例, 图 4为三种算法获得的Pareto解的分布.从图中可以发现, 相同函数评估次数下, 由于CRVEA缺少了高斯过程代理模型的辅助搜索, 只能获得有限个远离真实Pareto前沿面的个体.由于EI-PoF在整个优化搜索阶段, 只选择目标函数较小和约束违背值较小的个体作为代理模型的更新样本, 忽略了对不可行域的搜索, 导致该算法难以找到一些位于可行边界的非支配解, 收敛性差于RK-CRVEA.本文所提算法RK-CRVEA获得的最优解分布更加均匀, 收敛性更好, 更接近真实Pareto前沿面, 原因在于提出的基于参考向量的多阶段自适应约束处理模型管理策略有效地利用了可行解与不可行解的信息, 保证了种群的多样性, 使其快速逼近可行域的同时找到全局最优解.
4.2 常压蒸馏塔与换热网络协同操作优化实验
本文采用ASPEN HYSYS流程模拟软件建立常压蒸馏装置仿真模型, 采用基于热力学原理的夹点分析技术来建立换热网络数学模型, 并编写MATLAB与HYSYS接口工具箱, 保证两个装置模型间的实时通讯, 从而实现在MATLAB中直接调用、采集和操作常压塔仿真模型的数据.
4.2.1 实验参数
在常压蒸馏塔与换热网络协同操作优化实验中, 拉丁超立方体采样的初始样本点个数为153.其中, 收敛样本的个数为124, 不收敛样本的个数为29.机理模型评估次数设置为400次.各决策变量的取值范围设置见表 2.各物料的价格如表 3所示.根据生产经验, 各产品TBP 95%温度区间上下限设定值见表 4.其余参数设置均与标准测试函数的实验参数设置相同.
表 2 决策变量的取值范围Table 2 The range limit of decision variables序号 变量 单位 下限 上限 实际值 1 $F_{prod-1}$, 石脑油流量 bbl/h 430 600 450 2 $F_{prod-2}$, 煤油流量 bbl/h 315.5 500 351.5 3 $F_{prod-3}$, 轻柴油流量 bbl/h 550.1 802.1 789 4 $F_{prod-4}$, 重柴油流量 bbl/h 180.5 387.5 200 5 $F_{stm-1}$, 塔底蒸汽注入量 kg/h 3 000 4 000 3 400 6 $F_{stm-2}$, 第一汽提塔蒸汽注入量 kg/h 1 000 2 000 1 350 7 $F_{stm-3}$, 第二汽提塔蒸汽注入量 kg/h 1 000 2 000 1 150 8 $F_{PA-1}$, 常顶循环回流量 bbl/h 1 883 2 483 2 000 9 $F_{PA-2}$, 常一中循环回流量 bbl/h 950 1 550 1 258 10 $F_{PA-3}$, 常二中循环回流量 bbl/h 950 1 550 1 258 11 $Q_{PA-1}$, 常顶循环回流负荷 MW 10 20 12.5 12 $Q_{PA-2}$, 常一中循环回流负荷 MW 6 16 10.8 13 $Q_{PA-3}$, 常二中循环回流负荷 MW 6 16 10.8 14 $T_{f}$, 常压炉出口温度 ℃ 330 370 350 表 3 原油、产品及公用工程的价格Table 3 Prices of crude oil, distillation product and utilities参数 原油$P_{crude}$ 水蒸气$P_{stm}$ 燃料油$P_{fuel}$ 冷凝水$P_{cw}$ 石脑油$F_{prod-1}$ 煤油$F_{prod-2}$ 轻柴油$F_{prod-3}$ 重柴油$F_{prod-4}$ 价格 79.6 0.0055 0.017 $4.74\times10^{-3}$ 103.5 92.7 99 96.6 单位 $/bbl $/kg $/MJ $/MJ $/bbl $/bbl $/bbl $/bbl 表 4 产品TBP 95 %规定范围(℃)Table 4 The value range of product TBP 95 % (℃)产品 石脑油$T95_1$ 煤油$T95_2$ 轻柴油$T95_3$ 重柴油$T95_4$ 上限($T95^L$) 95 175 285 345 下限($T95^H$) 120 200 310 370 4.2.2 评价指标
由于在炼油过程蒸馏与换热系统协同操作优化问题中, 真实的Pareto前沿面未知, 无法使用IGD指标作为算法的评价指标, 因此选择超体积(Hypervolume, HV)[23]作为算法评价指标. HV值越大代表算法性能越好. HV定义如下:
$ \begin{equation} \text{HV} = \lambda \left(\bigcup _{i = 1}^{\left| S \right|}{{v}_{i}}\right) \end{equation} $
(21) 式中, $ S $表示算法求得的最优解集, $ v_i $表示参考点和最优解集构成的超体积.
4.2.3 实验结果与分析
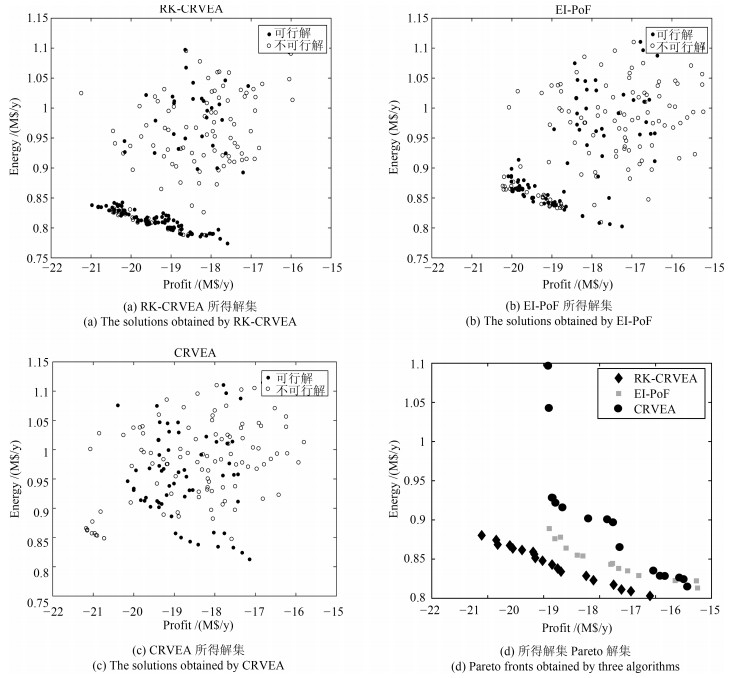
本文采用RK-CRVEA、CRVEA和EI-PoF三种算法对常压蒸馏塔与换热网络协同操作优化问题进行求解, 图 5为三种算法获得的机理模型评估解的分布图.图中的横坐标为产品净收益, 纵坐标为能耗成本, 两个目标单位均为百万美元/每年(M$/y).从图中可以看出, 与算法EI-PoF和CRVEA相比, RK-CRVEA算法所得解集集中分布在可行域内, 且Pareto解集的收敛性和分布性均明显优于对比算法.表明RK-CRVEA算法通过代理模型的辅助搜索, 在有限的机理模型评估次数下, 可以快速地搜索到可行区域, 且具有较好的收敛性.
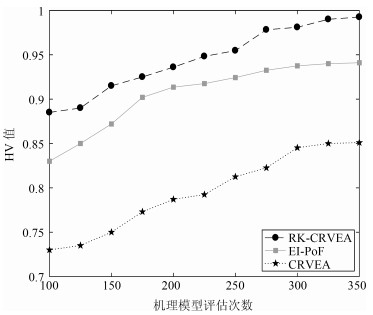
统计三种算法独立运行5次的HV性能指标的均值.三种算法的HV均值随机理模型评估次数的变化曲线如图 6所示.从图中可以看出, 所提算法RK-CRVEA的HV值最大且上升较快, 较少的机理函数评估次数就可以获得最优解, 而其他两种算法计算得到的HV均值相对较小.
图 7为夹点分析方法得到的总复合曲线, 该曲线可以表征不同操作条件下对应的能耗.图中横坐标表示冷凝水消耗量, 纵坐标表示燃料油的消耗量.实线表示优化前能耗, 虚曲线表示采用RK-CRVEA算法优化后的能耗.从图中可以看出, 与优化前相比, 优化后燃料油与冷凝水消耗量分别降低了2.75MW和3.32MW.
表 5为相同机理模型评估次数下, 基于代理模型的约束优化算法(RK-CRVEA)和基于机理模型的约束优化算法(CRVEA)的最终优化结果.与基于机理模型优化相比, 代理模型辅助的优化方法有效地降低了常减压蒸馏过程的能耗成本, 提高了常压塔侧线产品净收益.
表 5 相同机理模型评估次数下优化结果的比较Table 5 The comparison results under the same mechanism model evaluation times优化前 机理模型优化 代理模型辅助优化 燃料油消耗量(MW) 49.21 48.20 (-2.0%) 45.12 (-8.3%) 冷凝水消耗量(MW) 41.01 39.23 (-4.4%) 36.52 (-10.9%) 能耗成本(M$/y) 1.12 0.96 (-14.2%) 0.85 (-24.0%) 产品净收益(M$/y) 18.51 19.33 (4.3%) 19.92 (7.5%) 5. 结论
蒸馏装置与换热网络协同操作优化问题是一个典型的计算昂贵的约束优化问题.针对这一问题, 本文提出了基于代理模型的蒸馏与换热协同的在线操作优化方法.建立RUSBoost分类代理模型近似常压塔仿真模型收敛约束, 优化过程中通过调用收敛判定RUSBoost分类模型来删除不收敛的样本, 从而使优化过程不断地向可行设计域搜索.设计了基于参考向量的多阶段自适应约束处理模型管理方法.根据优化过程中参考向量的激活状态, 通过自适应平衡可行性、收敛性与多样性来选择代理模型的更新样本.该代理模型更新机制有效地利用了可行解与不可行解的信息, 保证了种群的多样性, 使其快速逼近可行域的同时找到全局最优解, 可以有效地解决可行域小且不连续的约束优化问题.上述方法实现了在线调用机理模型来不断地更新校正代理模型, 使代理模型快速逼近计算耗时的机理模型.通过标准测试函数和常压蒸馏塔与换热网络协同操作优化实验验证, 实验结果表明本文所提算法很大程度地提高了复杂过程系统进化优化的效率.实际应用中普遍存在可行域极难搜索的计算代价昂贵的约束优化问题, 本文所提方法可以有效地解决该类问题, 在有限次的函数评估下, 快速找到最优解.
-
图 3 常压蒸馏塔与换热网络协同操作优化框架
Fig. 3 Collaborative operation optimization framework of atmospheric distillation column and heat exchanger network
表 1 IGD指标比较结果
Table 1 The comparison result of IGD
测试函数 RK-CRVEA EI-PoF RVEA CF1 0.0169(0.0016) 0.0231(0.0027) 0.0338(0.0021) CF2 0.0131(0.0032) 0.0305(0.0102) 0.0473(0.0095) CF3 0.1322(0.0128) 0.3909(0.0764) 0.4351(0.0856) CF4 0.0382(0.0290) 0.1445(0.0325) 0.1622(0.0413) CF5 0.1754(0.0457) 0.3517(0.0824) 0.7395(0.0881)  下载: 导出CSV
下载: 导出CSV
表 2 决策变量的取值范围
Table 2 The range limit of decision variables
序号 变量 单位 下限 上限 实际值 1 $F_{prod-1}$, 石脑油流量 bbl/h 430 600 450 2 $F_{prod-2}$, 煤油流量 bbl/h 315.5 500 351.5 3 $F_{prod-3}$, 轻柴油流量 bbl/h 550.1 802.1 789 4 $F_{prod-4}$, 重柴油流量 bbl/h 180.5 387.5 200 5 $F_{stm-1}$, 塔底蒸汽注入量 kg/h 3 000 4 000 3 400 6 $F_{stm-2}$, 第一汽提塔蒸汽注入量 kg/h 1 000 2 000 1 350 7 $F_{stm-3}$, 第二汽提塔蒸汽注入量 kg/h 1 000 2 000 1 150 8 $F_{PA-1}$, 常顶循环回流量 bbl/h 1 883 2 483 2 000 9 $F_{PA-2}$, 常一中循环回流量 bbl/h 950 1 550 1 258 10 $F_{PA-3}$, 常二中循环回流量 bbl/h 950 1 550 1 258 11 $Q_{PA-1}$, 常顶循环回流负荷 MW 10 20 12.5 12 $Q_{PA-2}$, 常一中循环回流负荷 MW 6 16 10.8 13 $Q_{PA-3}$, 常二中循环回流负荷 MW 6 16 10.8 14 $T_{f}$, 常压炉出口温度 ℃ 330 370 350
下载: 导出CSV
表 3 原油、产品及公用工程的价格
Table 3 Prices of crude oil, distillation product and utilities
参数 原油$P_{crude}$ 水蒸气$P_{stm}$ 燃料油$P_{fuel}$ 冷凝水$P_{cw}$ 石脑油$F_{prod-1}$ 煤油$F_{prod-2}$ 轻柴油$F_{prod-3}$ 重柴油$F_{prod-4}$ 价格 79.6 0.0055 0.017 $4.74\times10^{-3}$ 103.5 92.7 99 96.6 单位 $/bbl $/kg $/MJ $/MJ $/bbl $/bbl $/bbl $/bbl
下载: 导出CSV
表 4 产品TBP 95 %规定范围(℃)
Table 4 The value range of product TBP 95 % (℃)
产品 石脑油$T95_1$ 煤油$T95_2$ 轻柴油$T95_3$ 重柴油$T95_4$ 上限($T95^L$) 95 175 285 345 下限($T95^H$) 120 200 310 370
下载: 导出CSV
表 5 相同机理模型评估次数下优化结果的比较
Table 5 The comparison results under the same mechanism model evaluation times
优化前 机理模型优化 代理模型辅助优化 燃料油消耗量(MW) 49.21 48.20 (-2.0%) 45.12 (-8.3%) 冷凝水消耗量(MW) 41.01 39.23 (-4.4%) 36.52 (-10.9%) 能耗成本(M$/y) 1.12 0.96 (-14.2%) 0.85 (-24.0%) 产品净收益(M$/y) 18.51 19.33 (4.3%) 19.92 (7.5%)
下载: 导出CSV
-
[1] Inamdar S V, Gupta K S, Saraf D N. Multi-objective optimization of an industrial crude distillation unit using the elitist non-dominated sorting genetic algorithm. Chemical Engineering Research and Design, 2004, 82(5):611-623 doi: 10.1205/026387604323142667 [2] 丁进良, 杨翠娥, 陈远东, 柴天佑.复杂工业过程智能优化决策系统的现状与展望.自动化学报, 2018, 44(11):1931-1943 http://www.aas.net.cn/CN/abstract/abstract19377.shtmlDing Jin-Liang, Yang Cui-E, Chen Yuan-Dong, Chai Tian-You. Research progress and prospects of intelligent optimization decision making in complex industrial process. Acta Automatica Sinica, 2018, 44(11):1931-1943 http://www.aas.net.cn/CN/abstract/abstract19377.shtml [3] Yang S L, Wang J M, Shi L Y, Tan Y J, Qiao F. Engineering management for high-end equipment intelligent manufacturing. Frontiers of Engineering Management, 2018, 5(4):420-450 doi: 10.15302/J-FEM-2018050 [4] Ochoa-Estopier L M, Jobson M, Smith R. The use of reduced models for design and optimisation of heat-integrated crude oil distillation systems. Energy, 2014, 75(5):5-13 http://www.wanfangdata.com.cn/details/detail.do?_type=perio&id=ad5c0a3e0c9aa507611554b3b641568d [5] Liebmann K, Dhole V R, Jobson M. Integrated design of a conventional crude Oil distillation tower using pinch analysis. Chemical Engineering Research and Design, 1998, 76(3):335-347 doi: 10.1205/026387698524767 [6] Ding J L, Yang C E, Jin Y C, Chai T Y. Generalized multi-tasking for evolutionary optimization of expensive problems. IEEE Transactions on Evolutionary Computation, 2019, 23(1):44-58 doi: 10.1109/TEVC.2017.2785351 [7] 丁进良, 杨翠娥, 陈立鹏, 柴天佑.基于参考点预测的动态多目标优化算法.自动化学报, 2017, 43(2):313-320 http://www.aas.net.cn/CN/abstract/abstract19009.shtmlDing Jin-Liang, Yang Cui-E, Chen Li-Peng, Chai Tian-You. Dynamic multi-objective optimization algorithm based on reference point prediction. Acta Automatica Sinica, 2017, 43(2):313-320 http://www.aas.net.cn/CN/abstract/abstract19009.shtml [8] Ochoa-Estopier L M, Jobson M. Optimization of heat-integrated crude oil distillation systems. Part I:The Distillation Model. Industrial & Engineering Chemistry Research, 2015, 54(18):4988-5000 http://cn.bing.com/academic/profile?id=3fc6aa9e00cdc136b2d7c0587bc51a70&encoded=0&v=paper_preview&mkt=zh-cn [9] Ochoa-Estopier L M, Jobson M, Chen L, Rodr-guez-Forero C A, Smith R. Optimization of heat-integrated crude oil distillation systems. Part Ⅱ:Heat exchanger network retrofit model. Industrial & Engineering Chemistry Research, 2015, 54(18):5001-5017 http://cn.bing.com/academic/profile?id=73b74f4f04c094c1b2ea88d07a388664&encoded=0&v=paper_preview&mkt=zh-cn [10] Ochoa-Estopier L M, Jobson M. Optimization of heat-integrated crude oil distillation systems. Part Ⅲ:Optimization Framework. Industrial & Engineering Chemistry Research, 2015, 54(18):5018-5036 http://cn.bing.com/academic/profile?id=b625acd749d31e770c36c08f14430946&encoded=0&v=paper_preview&mkt=zh-cn [11] Al-Mayyahi M A, Hoadley A F A, Smith N E, Rangaiah G P. Investigating the trade-off between operating revenue and CO2 emissions from crude oil distillation using a blend of two crudes. Fuel, 2011, 90(12):3577-3585 doi: 10.1016/j.fuel.2010.12.043 [12] Ji S, Bagajewicz M. Design of crude distillation plants with vacuum units. I. targeting. Industrial & Engineering Chemistry Research, 2002, 54(24):6094-6099 http://cn.bing.com/academic/profile?id=cd8338396883c39aa0ba3ba3017ae8c6&encoded=0&v=paper_preview&mkt=zh-cn [13] Lopez C D C, Hoyos L J, Mahecha C A, Arellano-Garcia H, Wozny G. Optimization model of crude oil distillation units for optimal crude oil blending and operating conditions. Industrial & Engineering Chemistry Research, 2013, 52(36):12993-13005 http://www.wanfangdata.com.cn/details/detail.do?_type=perio&id=1d2d8046aaf44c1aaae574764daad9e9 [14] Ibrahim D, Jobson M, Li J, Guillén-Gosálbez G. Optimization-based design of crude oil distillation units using surrogate column models and a support vector machine. Chemical Engineering Research and Design, 2018, 134:212-225 doi: 10.1016/j.cherd.2018.03.006 [15] Yao H H, Chu J Z. Operational optimization of a simulated atmospheric distillation column using support vector regression models and information analysis. Chemical Engineering Research and Design, 2012, 90(12):2247-2261 doi: 10.1016/j.cherd.2012.06.001 [16] Cheng R, Jin Y C, Olhofer M, Sendhoff B. A reference vector guided evolutionary algorithm for many-objective optimization. IEEE Transactions on Evolutionary Computation, 2016, 40(5):773-791 http://cn.bing.com/academic/profile?id=a78f88991f475d68f269707178b2f22e&encoded=0&v=paper_preview&mkt=zh-cn [17] Jones D R, Schonlau M, Welch W J. Efficient global optimization of expensive black-box functions. Journal of Global Optimization, 1998, 13(4):455-492 doi: 10.1023/A:1008306431147 [18] Martínez-Frutos J, Herrero-Pérez D. Kriging based infill sampling criterion for constraint handling in multi-objective optimization. Journal of Global Optimization, 2016, 64(1):1-19 doi: 10.1007/s10898-015-0328-x [19] Guo D, Jin Y C, Ding J L, Chai T Y. Heterogeneous ensemble based infill criterion for evolutionary multi-objective optimization of expensive problems. IEEE Transactions on Cybernetics, 2019, 49(3):1012-1025 doi: 10.1109/TCYB.6221036 [20] Seiffert C, Khoshgoftaar T M, Van Hulse J, Napolitano A. RUSBoost:a hybrid approach to alleviating class imbalance. IEEE Transactions on Systems, Man, and Cybernetics-Part A:Systems and Humans, 2010, 40(1):185-197 doi: 10.1109/TSMCA.2009.2029559 [21] Wang J H, Liang G X, Zhang J. Cooperative differential evolution framework for constrained multiobjective optimization. IEEE Transactions on Cybernetics, 2019, 49(6):2060-2072 doi: 10.1109/TCYB.2018.2819208 [22] Zhang Q F, Zhou A M, Jin Y C. RM-MEDA:A regularity model-based multi-objective estimation of distribution algorithm. IEEE Transactions on Evolutionary Computation, 2008, 12(1):41-63 doi: 10.1109/TEVC.2007.894202 [23] Zitzler E, Thiele L, Laumanns M, Fonseca C M, Fonseca V G D. Performance assessment of multiobjective optimizers:an analysis and review. IEEE Transactions on Evolutionary Computation, 2003, 7(2):117-132 doi: 10.1109/TEVC.2003.810758 -

 下载:
下载:


计量
- 文章访问数: 2019
- HTML全文浏览量: 375
- PDF下载量: 140
- 被引次数: 0
