

Domain Integrated-Entity Links Based on Relationship Indices andRepresentation Learning
-
摘要: 本文针对现有方法不能很好结合文本信息和知识库信息的问题, 提出一种基于关系指数和表示学习的领域集成实体链接方法.首先, 本文构建了特定领域知识库; 其次, 运用表示学习从文本信息中得到的向量表示计算实体指称项的上下文、主题关键词、扩展词三个特征的相似度; 然后, 利用知识库中的关系信息计算候选实体的关系指数; 最后, 将这三种相似度及关系指数相融合, 用于实体链接. 实验结果表明, 相较于现有方法, 本文方法能够有效地提高F1值, 并且该方法不需要标注语料, 更加简单高效, 适应于缺少标注语料的特定领域.Abstract: Aiming at the problem that the existing methods can′t combine text information and knowledge base information well, this paper proposes a domain integrated-entity links based on relationship indices and representation learning. Firstly, this paper builds a domain-specific knowledge base; Secondly, using the vector representation of learning representation from the text information to calculate the similarity of the three features of the context, topic keywords and extension words of the entity referential item; Then using the relationship information in the knowledge base to calculate the relationship index of the candidate entities; Finally, these three similarities and relationship indices are combined for physical links; The experimental results show that compared with the existing methods, the proposed method can effectively improve the F1 value, and the method does not need to label the corpus, which is simpler and more efficient, and is suitable for the specific field lacking the labeled corpus.
-
Key words:
- Integrated-entity link /
- specific field /
- representation learning /
- relationship index
-
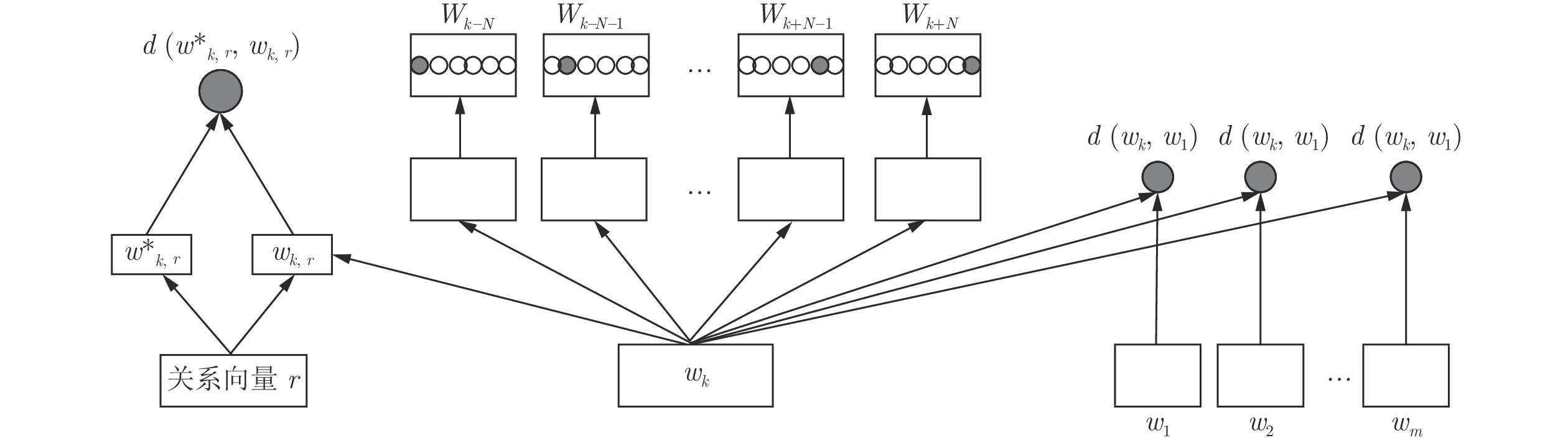
图 2 融合知识和主题信息的词向量表示模型
Fig. 2 Word vector representation model that fuses knowledge and subject information
表 1 不同特征组合实验结果统计
Table 1 Statistics of experimental results of different feature combinations
特征组合 P(%) R(%) F1 上下文 64.8 61.7 63.2 上下文+主题关键词 79.3 80.9 80.1 上下文+主题关键词+扩展词 87.7 86.5 87.1 上下文+主题关键词+扩展词+关系指数 92.6 90.4 91.5  下载: 导出CSV
下载: 导出CSV
表 2 不同v值实验结果统计
Table 2 Statistical results of different v values
v P(%) R(%) F1 1 84.4 81.8 83.1 2 89.6 87.1 88.3 3 92.6 90.4 91.5 4 90.3 89.4 89.8
下载: 导出CSV
表 3 不同w值实验结果统计
Table 3 Statistical results of different w values
w P(%) R(%) F1 1 86.4 83.5 84.9 2 89.8 87.6 88.7 3 90.5 89.2 89.8 4 92.6 90.4 91.5 5 89.7 88.6 89.1
下载: 导出CSV
表 4 各个关系子属性的实验结果统计
Table 4 Statistical results of experimental results for each relationship sub-attribute
关系属性 P(%) R(%) F1 直接关系 89.3 87.2 88.2 直接关系+垂直间接关系 91.8 88.7 90.2 直接关系+水平间接关系 91.1 87.6 89.3 直接关系+两个间接关系 92.6 90.4 91.5
下载: 导出CSV
表 6 不同领域的实验结果统计
Table 6 Statistics of experimental results in different fields
领域名称 P(%) R(%) F1 旅游领域 92.6 90.4 91.5 少数民族领域 91.8 89.6 90.7 药材领域 90.3 91.4 90.8
下载: 导出CSV
-
[1] Hoffart J, Yosef M A, Bordino I, et al. Robust disambiguation of named entities in text. In: Proceedings of Conference on Empirical Methods in Natural Language Processing. Association for Computational Linguistics, 2011. 782−792 [2] Burdick D, Fagin R, Kolaitis P G, et al. Expressive power of entity-linking frameworks. Journal of Computer and System Sciences, 2019, 100: 44-69 doi: 10.1016/j.jcss.2018.09.001 [3] Saeedi A, Peukert E, Rahm E. Using link features for entity clustering in knowledge graphs. In: Proceedings of European Semantic Web Conference. Springer, Cham, 2018. 576−592 [4] Dubey M, Banerjee D, Chaudhuri D, et al. Earl: Joint entity and relation linking for question answering over knowledge graphs. In: Proceedings of International Semantic Web Conference. Springer, Cham, 2018. 108−126 [5] Bunescu R C. Using encyclopedic knowledge for named entity disambiguation. In: Proceedings of Conference of the European Chapter of the Association for Computational Linguistics, 2006. 9−16 [6] Ganea O E, Ganea M, Lucchi A, et al. Probabilistic bag-of-hyperlinks model for entity linking. In: Proceedings of the 25th International Conference on World Wide Web. International World Wide Web Conferences Steering Committee, 2016. 927−938 [7] Cucerzan S. Large-scale named entity disambiguation based on Wikipedia data. In: Proceedings of the 2007 Joint Conference on Empirical Methods in Natural Language Processing and Computational Natural Language Learning, 2007. 708−716 [8] Nguyen H T, Cao T H. Exploring wikipedia and text features for named entity disambiguation. In: Proceedings of Asian Conference on Intelligent Information and Database Systems. Springer, Berlin, Heidelberg, 2010. 11−20 [9] Zeng Y, Wang D, Zhang T, et al. Linking entities in short texts based on a Chinese semantic knowledge base. Natural Language Processing and Chinese Computing. Springer, Berlin, Heidelberg, 2013. 266−276 [10] Han X, Sun L, Zhao J. Collective entity linking in web text: A graph-based method. In: Proceedings of the 34th international ACM SIGIR conference on Research and development in Information Retrieval. ACM, 2011. 765−774 [11] Liu Q, Zhong Y, Li Y, et al. Graph-based collective Chinese entity linking algorithm. Comput. Res. Develop, 2016, 53(2): 270-283 [12] Ferragina P, Scaiella U. Tagme: On-the-fly annotation of short text fragments. In: Proceedings of the 19th ACM international conference on Information and knowledge management. ACM, 2010. 1625−1628 [13] Francis-Landau M, Durrett G, Klein D. Capturing semantic similarity for entity linking with convolutional neural networks. In: Proceedings of the North American Chapter of the Association for Computational Linguistics, 2016. 1256−1261 [14] Wang W, Arora R, Livescu K, et al. On deep multi-view representation learning: Objectives and optimization. In: Proceedings of International Conference on Machine Learning 2015, 2016. 1083−1092 [15] Bengio Y, Courville A, Vincent P. Representation Learning: A Review and New Perspectives. IEEE Transactions on Pattern Analysis & Machine Intelligence, 2013, 35(8): 1789-1828 [16] ZENG Qi, ZHOU Gang, LAN Ming-jing, et al. Polysemous Word Multi-embedding Calculation. Journal of Chinese Computer Systems, 2016, 37(5): 1417-1421 [17] Raiman J R, Raiman O M. DeepType: Multilingual entity linking by neural type system evolution. In: Proceedings of 32nd AAAI Conference on Artificial Intelligence, 2018. 5406-5413 [18] Mikolov T, Chen K, Corrado G, et al. Efficient estimation of word representations in vector space. In: Proceedings of the International Conference on Learning Representations, 2013. 1−12 [19] Goldberg Y, Levy O. Word2vec Explained: Deriving Mikolov et al.′s negative-sampling word-embedding method. CoRR abs/1402.3722, 2014, 1−5 [20] Kar R, Reddy S, Bhattacharya S, et al. Task-specific representation learning for web-scale entity disambiguation. In: Proceedings of Thirty-Second AAAI Conference on Artificial Intelligence, 2018. 5812−5819 [21] Moreno J G, Besancon R, Beaumont R, et al. Combining Word and Entity Embeddings for Entity Linking. In: Proceedings of European Semantic Web Conference. Springer, Cham, 2017. 337−352 [22] You M, Yang H, Lin Z, et al. BTM Topic Modeling Approach to Named Entity Linking. Journal of Physics: Conference Series. IOP Publishing, 2018, 1060(1): 012-027 [23] Gao Y, Li A, Duan L. Entity disambiguation method based on multi-feature fusion graph model for entity linking. Application Research of Computers,, 2017: 2909-2914 [24] Sakor A, Mulang I O, Singh K, et al. Old is gold: Linguistic driven approach for entity and relation linking of short text. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, 2019. 2336−2346 [25] Xu C, Bai Y, Bian J, et al. Rc-net: A general framework for incorporating knowledge into word representations. In: Proceedings of the 23rd ACM international conference on conference on information and knowledge management. ACM, 2014. 1219−1228 [26] Ganea O E, Ganea M, Lucchi A, et al. Bordes A, Usunier N, Garcia-Duran A, et al. Translating embeddings for modeling multi-relational data. In: Proceedings of Advances in Neural Information Processing Systems, 2013. 2787−2795 [27] Bao-Xing H, Bao T F, Zhu H S, et al. Topic modeling approach to named entity linking. Journal of Software, 2014, (9): 2076-2087 [28] WU Yunbing, ZHU Danhong, LIAO Xiangwen, et al. Knowledge Graph Reasoning Based on Paths of Tensor Factorization. Pattern Recognition and Artificial Intelligence, 2017, 30(5): 473-480 [29] Kundu G, Sil A, Florian R, et al. Neural cross-lingual coreference resolution and its application to entity linking. In: Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics, 2018. 395−400 -

 下载:
下载:


计量
- 文章访问数: 921
- HTML全文浏览量: 193
- PDF下载量: 147
- 被引次数: 0
