

Virtual Machine Power Prediction Using Incremental Extreme Learning Machine Based on Compression Driving Amount
-
摘要: 在基于基础设施即服务(Infrastructure as a service,IaaS)的云服务模式下,精准的虚拟机能耗预测,对于在众多物理服务器之间进行虚拟机调度策略的制定具有十分重要的意义.针对基于传统的增量型极限学习机(Incremental extreme learning machine,I-ELM)的预测模型存在许多降低虚拟机能耗预测准确性和效率的冗余节点,在现有I-ELM模型中加入压缩动量项将网络训练误差反馈到隐含层的输出中使预测结果更逼近输出样本,能够减少I-ELM的冗余隐含层节点,从而加快I-ELM的网络收敛速度,提高I-ELM的泛化性能.Abstract: In cloud service models which is based on infrastructure as a service (IaaS), how to accurately predict power of virtual machine is very important for making scheduling strategy of virtual machines among many physical servers. However, the traditional incremental extreme learning machine (I-ELM) includes too many redundant hidden nodes, resulting in decreased efficiency and accuracy of virtual machine power prediction. Connecting compression driving amount to I-ELM, the paper builds the intelligent prediction model of I-ELM based on the compression driving amount (CDAI-ELM), and uses the model for predicting virtual machine power.1) 本文责任编委 程龙
-

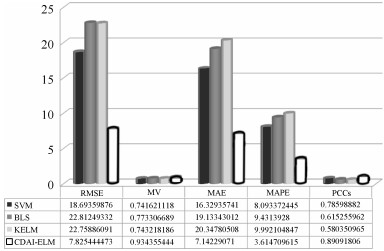
图 3 基于SVM、KELM、BLS和CDAI-ELM的虚拟机能耗预测曲线
Fig. 3 Predicted curve for power of virtual machine based on SVM、KELM、BLS和CDAI-ELM
表 1 回归数据集
Table 1 Datasets of regression
回归数据集 属性 训练数据 测试数据 Auto MPG 4 853 850 Automobile 16 8 795 8 774 BlogFeedback 281 530 500 Housing 77 153 150 NoisyOffice 128 468 300 Facebook metrics 19 300 200 SML2010 68 336 200 wiki4HE 26 2 898 2 000 UJIIndoorLoc 529 2 100 2 077 YearPredictionMSD 90 2 800 3 075  下载: 导出CSV
下载: 导出CSV
表 2 相同期望误差下4种算法隐含层节点数方差的比较
Table 2 Variance of number of hidden layer node for four algorithms under same expected error
回归数据集 期望误差 I-ELM CI-ELM EM-ELM CDAI-ELM Auto MPG 0.11 49.46 5.21 2.76 1.82 Automobile 0.15 8.82 33.08 3.55 1.95 BlogFeedback 0.2 28.56 24.87 2.50 1.58 Housing 0.12 35.95 9.98 2.51 2.26 NoisyOffice 0.08 46.81 6.28 2.18 1.72 Facebook metrics 0.06 28.87 10.02 2.28 1.46 SML2010 0.21 36.89 17.79 2.82 2.31 wiki4HE 0.13 32.81 8.19 2.88 2.14 UJIIndoorLoc 0.09 50.71 9.67 3.07 2.51 YearPredictionMSD 0.08 51.21 12.13 3.51 2.87
下载: 导出CSV
表 3 4种算法的测试误差和方差比较
Table 3 Comparison result of testing error and variance for four algorithms
回归数据集 I-ELM CI-ELM EM-ELM CDAI-ELM 误差 方差 误差 方差 误差 方差 误差 方差 Auto MPG 0.1021 0.0051 0.0952 0.0041 0.0953 0.0052 0.0811 0.0040 Automobile 0.1323 0.0149 0.1302 0.0129 0.1301 0.0118 0.1257 0.0107 BlogFeedback 0.1896 0.0121 0.1882 0.0123 0.1712 0.0108 0.1822 0.0109 Housing 0.1017 0.0064 0.1008 0.0061 0.0985 0.0051 0.0973 0.0061 NoisyOffice 0.0511 0.0039 0.0481 0.0034 0.0401 0.0029 0.0392 0.0023 Facebook metrics 0.0642 0.0058 0.0581 0.0041 0.0581 0.0018 0.0585 0.0023 SML2010 0.1555 0.0158 0.1502 0.0129 0.1461 0.0078 0.1452 0.0074 wiki4HE 0.1592 0.0311 0.1522 0.0302 0.1468 0.0031 0.1511 0.0051 UJIIndoorLoc 0.1315 0.0102 0.1291 0.0091 0.1278 0.0072 0.1116 0.0059 YearPredictionMSD 0.0912 0.0041 0.0902 0.0039 0.0903 0.0040 0.0868 0.0031
下载: 导出CSV
表 4 4种算法训练时间的比较(s)
Table 4 Comparison result of training time for four algorithms (s)
回归数据集 I-ELM CI-ELM EM-ELM CDAI-ELM Auto MPG 0.0124 0.0073 0.0061 0.0052 Automobile 0.0272 0.0171 0.0182 0.0088 BlogFeedback 0.0469 0.0391 0.0236 0.0151 Housing 0.0391 0.0119 0.0182 0.0120 NoisyOffice 0.0411 0.0051 0.0083 0.0071 Facebook metrics 0.481 0.0179 0.0171 0.0159 SML2010 0.0218 0.0107 0.0081 0.0059 wiki4HE 0.0089 0.0081 0.0298 0.0297 UJIIndoorLoc 0.0471 0.0091 0.0288 0.0272 YearPredictionMSD 0.0301 0.0297 0.0271 0.0197
下载: 导出CSV
表 5 4种模型训练时间(s)
Table 5 Training time of four models (s)
预测模型 训练时间(s) SVM 3.4788 BLS 0.9828 KELM 1.06 CDAI-ELM 0.5772
下载: 导出CSV
-
[1] 武志学.云计算虚拟化技术的发展与趋势.计算机应用, 2017, 37(4):915-923 http://d.old.wanfangdata.com.cn/Periodical/jsjyy201704001Wu Zhi-Xue. Advances on virtualization technology of cloud computing. Journal of Computer Applications, 2017, 37(4):915-923 http://d.old.wanfangdata.com.cn/Periodical/jsjyy201704001 [2] 崔勇, 宋健, 缪葱葱, 唐俊.移动云计算研究进展与趋势.计算机学报, 2017, 37(4):915-923 http://d.old.wanfangdata.com.cn/Periodical/jsjxb201702001Cui Yong, Song Jian, Miao Cong-Cong, Tang Jun. Mobile cloud computing research progress and trends. Chinese Journal of Computers, 2017, 40(2):273-295 http://d.old.wanfangdata.com.cn/Periodical/jsjxb201702001 [3] 夏元清, 闫策, 王笑京, 宋向辉.智能交通信息物理融合云控制系统.自动化学报, 2019, 45(1):132-142 doi: 10.3969/j.issn.1003-8930.2019.01.021Xia Yuan-Qing, Yan Ce, Wang Xiao-Jing, Song Xiang-Hui. Intelligent transportation cyber-physical cloud control systems. Acta Automatica Sinica, 2019, 45(1):132-142 doi: 10.3969/j.issn.1003-8930.2019.01.021 [4] 金顺福, 郝闪闪, 王宝帅.融合双速率和工作休眠的虚拟机调度策略及参数优化.通信学报, 2017, 38(12):10-20 doi: 10.11959/j.issn.1000-436x.2017298Jin Shun-Fu, Hao Shan-Shan, Wang Bao-Shuai. Virtual machine scheduling strategy based on dual-speed and work vacation mode and its parameter optimization. Journal on Communications, 2017, 38(12):10-20 doi: 10.11959/j.issn.1000-436x.2017298 [5] 赵春, 闫连山, 崔允贺, 邢焕来, 冯斌.基于动态调整阈值的虚拟机迁移算法.计算机应用, 2017, 37(9):2547-2550 http://d.old.wanfangdata.com.cn/Periodical/jsjyy201709022Zhao Chun, Yan Lian-Shan, Cui Yun-He, Xing Huan-Lai, Feng Bin. Dynamic adjusting threshold algorithm for virtual machine migration. Journal of Computer Applications, 2017, 37(9):2547-2550 http://d.old.wanfangdata.com.cn/Periodical/jsjyy201709022 [6] 周平, 张丽, 李温鹏, 戴鹏, 柴天佑.集成自编码与PCA的高炉多元铁水质量随机权神经网络建模.自动化学报, 2018, 44(10):1799-1811 http://www.aas.net.cn/CN/abstract/abstract19362.shtmlZhou Ping, Zhang Li, Li Wen-Peng, Dai Peng, Chai Tian-You. Autoencoder and PCA based RVFLNs modeling for multivariate molten iron quality in blast furnace ironmaking. Acta Automatica Sinica, 2018, 44(10):1799-1811 http://www.aas.net.cn/CN/abstract/abstract19362.shtml [7] 唐轶轩, 薛晓茹, 姚振, 徐敏, 张永梅, 张禾良, 徐道磊.电力信息系统资源池的能耗感知虚拟机部署策略.电力信息与通信技术, 2017, 15(6):95-100 http://www.wanfangdata.com.cn/details/detail.do?_type=perio&id=dlxxh201706017Tang Yi-Xuan, Xue Xiao-Ru, Yao Zhen, Xu Min, Zhang Yong-Mei, Zhang He-Liang, Xu Dao-Lei. An energy-aware VM deployment strategy for the resource pool of power information system. Electric Power Information and Communication Technology, 2017, 15(6):95-100 http://www.wanfangdata.com.cn/details/detail.do?_type=perio&id=dlxxh201706017 [8] Xu H. Research on neural network based on virtual machine power prediction model[Master thesis], Beijing University of Posts and Telecommunications, 2015. [9] 赵雅倩.一种基于模糊神经网络的虚拟机能耗预测方法及系统, 中国专利CN105975385A, 2016.09.28. [10] 贾炅昊, 陈宁江, 李湘, 黄汝维.基于可用能力建模的云虚拟机动态调整策略.广西大学学报(自然科学版), 41(3):796-803 http://d.old.wanfangdata.com.cn/Periodical/gxdxxb201603023Jia Jiong-Hao, Chen Ning-Jiang, Li Xiang, Huang Ru-Wei. A dynamic adjustment strategy for virtual machines in cloud based on availability capability. Journal of Guangxi University (Nat Sci Ed), 2016, 41(3):796-803 http://d.old.wanfangdata.com.cn/Periodical/gxdxxb201603023 [11] Huang G B, Chen L, Siew C K. Universal approximation using incremental constructive feedforward networks with random hidden nodes. IEEE Transactions on Neural Networks, 2006, 17(4):879-892 doi: 10.1109/TNN.2006.875977 [12] Tian Z D, Li S J, Wang Y H, Sha Y. Short-term wind power prediction based on empirical mode decomposition and improved extreme learning machine. Journal of Electrical Engineering and Technology, 2018, 13(5):1841-1851 http://www.wanfangdata.com.cn/details/detail.do?_type=perio&id=zgdjgcxb201325006 [13] Tian Z D, Li S J, Wang Y H, Sha Y. An adaptive online sequential extreme learning machine for short-term wind speed prediction based on improved artificial bee colony algorithm. Neural Network World, 2018, 28(3):191-212 doi: 10.14311/NNW.2018.28.012 [14] Tian Z D, Li S J, Wang Y H, Sha Y. Network traffic prediction method based on improved ABC algorithm optimized EM-ELM. Journal of China Universities of Posts and Telecommunications, 2018, 25(3):33-44 http://www.wanfangdata.com.cn/details/detail.do?_type=perio&id=zgydgxxb-e201803005 [15] Tang X L, Han M. Partial Lanczos extreme learning machine for single output regression problems. Neurocomputing, 2009, 13(72):3066-3076 http://www.wanfangdata.com.cn/details/detail.do?_type=perio&id=cedd039eebe8b7c3695d63c452506b22 [16] 韩敏, 李德才.基于替代函数及贝叶斯框架的1范数ELM算法.自动化学报, 2011, 37(11):1344-1350 http://www.aas.net.cn/CN/abstract/abstract17624.shtmlHan Min, Li De-Cai. An norm 1 regularization term ELM algorithm based on surrogate function and Bayesian framework. Acta Automatica Sinica, 2011, 37(11):1344-1350 http://www.aas.net.cn/CN/abstract/abstract17624.shtml [17] Huang G B, Zhou H, Ding X, Zhang R. Extreme learning machine for regression and multiclass classification. IEEE Transactions on Systems, Man and Cybernetics, Part B (Cybernetics), 2012, 2(42):513-529 [18] Chen C L P, Liu Z L. Broad learning system:An effective and efficient incremental learning system without the need for deep architecture. IEEE Transactions on Neural Networks and Learning Systems, 2018, 29(1):10-24 doi: 10.1109/TNNLS.2017.2716952 [19] Sara S, Nicholas F, Geoffrey E H. Dynamic routing between capsules. In: Proceedings of the 31st Conference on Neural Information Processing Systems. California, USA, 2017. arXiv: 1710.09829 [20] Wang B. The approximation order of convex incremental extreme learning machine[Master thesis], Northwest University, 2015 [21] Knowledge discovery in databases, http://www.kdd.org.htm [22] 田中大, 李树江, 王艳红, 王向东.高斯过程回归补偿ARIMA的网络流量预测.北京邮电大学学报, 2017, 40(6):65-73 http://d.old.wanfangdata.com.cn/Periodical/bjyddx201706010Tian Zhong-Da, Li Shu-Jiang, Wang Yan-Hong, Wang Xiang-Dong. Network traffic prediction based on ARIMA with Gaussian process regression compensation. Journal of Beijing University of Posts and Telecommunications, 2017, 40(6):65-73 http://d.old.wanfangdata.com.cn/Periodical/bjyddx201706010 [23] Tian Z D, Li S J, Wang Y H, Sha Y. A prediction method based on wavelet transform and multiple models fusion for chaotic time series. Chaos, Solitons and Fractals, 2017, 98:158-172 doi: 10.1016/j.chaos.2017.03.018 [24] Tian Z D, Li S J, Wang Y H, Sha Y. Short-term wind speed prediction based on improved PSO algorithm optimized EM-ELM. Energy Sources, Part A:Recovery, Utilization, and Environmental Effects, 2019, 41(1):26-46 doi: 10.1080/15567036.2018.1495782 -

 下载:
下载:

计量
- 文章访问数: 2545
- HTML全文浏览量: 387
- PDF下载量: 460
- 被引次数: 0
