

Model Predict Control Method Based on Higher-order Observer and Disturbance Compensation Control
-
摘要: 针对状态不可测、外部干扰未知, 并且状态和输入受限的离散时间线性系统, 将高阶观测器、干扰补偿控制与标准模型预测控制(Model predictive control, MPC)相结合, 提出了一种新的MPC方法. 首先利用高阶观测器同步观测未知状态和干扰, 使得观测误差一致有界收敛;然后基于该干扰估计值设计新的干扰补偿控制方法, 并将该方法与基于状态估计的标准MPC相结合, 实现上述系统的优化控制. 所提出的MPC方法克服了利用现有MPC方法求解具有外部干扰和状态约束的优化控制问题时存在无可行解的局限, 能够保证系统状态在每一时刻都满足约束条件, 并且使系统的输出响应接近采用标准MPC方法控制线性标称系统时得到的输出响应. 最后, 将所提控制方法应用到船舶航向控制系统中, 仿真结果表明了所提方法的有效性和优越性.Abstract: By combining a higher-order observer with disturbance compensation control and standard model predictive control (MPC), a novel MPC method is proposed for a discrete-time linear system with unmeasurable states, unknown external disturbances and constraints of states and inputs. Firstly, a higher-order observer is used to simultaneously observe unknown states and disturbances, such that the observation errors are uniformly bounded. Then a new disturbance compensation control method is designed based on the disturbance estimation, and the proposed method is obtained by combining the disturbance compensation control with the standard MPC based on the state estimation. The proposed method overcomes the limitation that there is no feasible solution when using the existing MPC methods to solve the optimization control problem with external disturbances and state constraints, which can also assure the system states satisfying their constraint conditions at each time instant, and make the output responses of the system close to those of the linear nominal system controlled by the standard MPC method. Finally, the proposed control method is applied to a ship heading control system, and the simulation results show its effectiveness and superiority.
-
信息物理系统(Cyber-physical systems, CPSs)是一个综合了计算、网络和物理环境的多维智能化复杂系统, 它借助有线或无线通信网络将各个关键设施整合在一起, 使得人机和物理进程的交互更加便捷. 随着网络通信、嵌入式系统、计算机控制及相关硬件技术的不断发展, 信息物理系统已引起了工业界的广泛关注[1-3]. 然而在此框架下, 原有系统的封闭性被打破, 使其面临着来自网络攻击的安全威胁. 例如: 2010年, 伊朗的首座核电站−布什核电站被震网病毒攻击, 使得伊朗的第一座核设施推迟发电, 严重损害了伊朗的工业设施[4]; 2011年美国伊利诺伊州一处水利控制系统遭到网络攻击, 险些造成大面积的供水中断. 当信息物理系统遭受网络攻击时, 准确、及时地监测到攻击信号对于监测中心采取高效的防御策略是至关重要的[5].
从控制角度来看, 信息物理系统是传统数字控制系统融合通信技术的下一代网络化控制系统[6]. 信息物理系统中被控对象的量测信号和控制信号均通过网络进行传输, 因此无论是传感器到控制器端, 还是控制器到执行器端, 均有受到恶意网络攻击的可能, 从而影响系统的稳定性, 甚至引发系统崩溃, 造成严重的生产事故与经济损失[7-8]. 典型的网络攻击有三种, 分别是拒绝服务攻击(Denial of service, DoS)、欺骗攻击和重放攻击. 针对拒绝服务攻击, 文献[9]将DoS攻击建模为一类能量约束问题, 针对攻击者与防御者设计递归分布式卡尔曼估计器进行双边优化; 文献[10]假定DoS攻击有界的情况下, 通过构建嵌套切换模型得到了CPS在基于包控制方法下的稳定性条件. 针对重放攻击, 文献[11]从防御者的角度提出一种带补偿策略的数学模型来描述重放攻击和带宽约束, 并在线性最小方差意义下设计了递归分布式卡尔曼融合估计器. 欺骗攻击又称为假数据注入(False data injection, FDI)攻击, 它通过向系统注入错误的控制信号或测量信号影响信号数据的准确性. 注意到FDI攻击可以通过欺骗攻击检测机制来影响信息物理系统, 从而造成攻击检测器的漏报或虚警[12]. 文献[13]中研究了电力系统中针对FDI攻击的状态估计问题, 揭示了现有错误测量检测算法中存在的脆弱性. 该研究表明,即使攻击者的资源受限, 依旧可以改变状态估计的结果; 而在假定攻击者可以获取系统参数及所有数据流的基础上, 此类攻击则可以对系统产生一定影响的同时却不被检测到. 目前信息物理系统中的FDI攻击主要采用异常信号检测方法进行检测[14], 如基于二元假设的贝叶斯检测[15-18]、基于卡尔曼滤波器的
$ \chi^2 $ 检测[19-21]和加权最小平方检测[22-24]. 后两种方法均是利用观测值构造新息残差, 然后通过与一个给定的阈值比较来判决是否受到攻击. 攻击检测的阈值对检测精度起着重要作用, 然而阈值通常在检测前根据已有经验进行选择, 这无疑会降低检测精度. 而且对于CPSs而言, 特别是电力、医疗系统, 仅仅检测或识别到攻击是不够的, 因为这些基础设施系统无法快速对其关闭、重启、恢复, 以对抗攻击. 为此, 不同于文献[15-24]中基于阈值的FDI攻击信号检测方法, 本文将对CPSs中控制器与执行器间的通信网络遭受的FDI攻击信号进行实时估计, 不仅可以检测攻击信号是否存在, 而且还可以掌握攻击信号的基本特征, 从而使防御方采取简单有效的补救措施以降低系统性能的损失程度.为了对FDI攻击信号进行实时估计, 本文将攻击信号建模为状态动态方程中的一个未知参数, 然后在每个传感器端利用自适应卡尔曼滤波设计FDI攻击信号的局部估计. 由于基于递归最小二乘的自适应Kalman滤波方法适应于被估计的参数是时不变或者变化缓慢的, 而恶意的攻击信号往往是时变的. 因此, 本文充分利用多传感器融合所提供的冗余信息, 通过引入补偿因子和设计分布式融合准则, 来提高时变攻击信号的估计精度. 注意到补偿因子是通过影响局部互协方差的信息来提高估计性能, 而局部互协方差矩阵存在于分布式融合结构中. 最后, 通过两个仿真验证所设计的融合算法对FDI攻击信号估计的有效性. 特别地, 当攻击信号是时变时, 仿真结果表明所引入的补偿因子可以明显提高攻击信号的融合估计性能.
符号说明.
${\rm{E}}$ 表示数学期望,$ {\rm diag}\{N_1,\cdots,N_n\} $ 表示由$ N_1,\cdots,N_n $ 组成的块对角矩阵,$ I $ 表示单位矩阵,$ \perp $ 表示正交.1. 问题描述与分析
考虑如下离散线性时变状态空间模型
$$ {\boldsymbol x}(k) = A(k){\boldsymbol x}(k-1)+B(k){\boldsymbol u}(k-1)+{\boldsymbol w}(k)$$ (1) 其中,
$ {\boldsymbol x}(k)\in{\bf { R}}^n $ 为系统状态,$ {\boldsymbol u}(k)\in{\bf { R}}^l $ 为控制输入;$ A(k) $ 与$ B(k) $ 分别为系统状态转移矩阵和控制输入矩阵. 当控制输入信号$ {\boldsymbol u}(k) $ 受到FDI攻击时, 被攻击后的控制输入信号描述为$$ {\boldsymbol u}_a(k) = {\boldsymbol u}(k)+{\boldsymbol \theta}(k) $$ (2) 其中,
$ {\boldsymbol \theta}(k)\in{\bf { R}}^l $ 表示FDI攻击信号. 因此, 控制信号遭受攻击后的系统(1)建模为$$ {\boldsymbol x}(k) = A(k){\boldsymbol x}(k-1)+B(k)({\boldsymbol u}(k-1)+{\boldsymbol \theta}(k-1))+{\boldsymbol w}(k) $$ (3) 然后, 利用
$ L $ 个传感器对系统(3)的状态进行实时监测, 且每个传感器的量测$ {\boldsymbol y}_i(k) $ 建模为$$ {\boldsymbol y}_i(k) = C_i(k){\boldsymbol x}(k)+{\boldsymbol v}_i(k),\;\; i = 1,2,\cdots,L $$ (4) 其中,
$ C_i(k) $ 为量测矩阵.$ {\boldsymbol w}(k)\in{\bf { R}}^n $ ,$ {\boldsymbol v}_i(k)\in{\bf { R}}^{m_i} $ 是相互独立的零均值高斯白噪声, 且满足$$\begin{split} &{ {\rm{E}}}\left\{\left[ \begin{aligned} {\boldsymbol w}(k)\\ {\boldsymbol v}_i(k)\\ {\boldsymbol v}_j(k) \end{aligned}\right]\left[ \begin{aligned} {\boldsymbol w}(k)\\ {\boldsymbol v}_i(k)\\ {\boldsymbol v}_j(k) \end{aligned}\right]^{\rm T}\right\} = \\ &\qquad{\rm diag}\{Q(k), R_i(k),R_j(k)\},\;\;i\ne j \end{split}$$ (5) 本文要解决的问题是: 针对控制信号遭受FDI攻击篡改的信息物理系统(3), 根据各个传感器的量测信息, 计算得到FDI攻击信号的局部估计
$ \hat{{\boldsymbol \theta}}_i(k);$ 然后, 基于局部估计$\hat{{\boldsymbol \theta}}_i(k),\;i = 1,2,\cdots,L,$ 设计满足$\sum\nolimits^L_{i = 1}W^\theta_i(k) = I$ 最优加权融合矩阵$ W^\theta_1(k),\cdots,W^\theta_L(k) ,$ 使得攻击信号的分布式融合估计器$$ \hat{{\boldsymbol \theta}}_0(k) = \sum\limits_{i = 1}^L W^\theta_i(k)\hat{{\boldsymbol \theta}}_i(k) $$ (6) 在线性最小方差意义下是最优的.
注1. 本文的主要思想是将攻击信号
$ {\boldsymbol \theta}(k) $ 建模为系统(3)中的未知输入, 然后在信息融合框架下利用多组传感器的冗余量测信息, 实现对$ {\boldsymbol \theta}(k) $ 的实时估计. 特别地, 分布式信息融合不仅可以保证所设计估计器的鲁棒性, 而且也能够提高对攻击信号的估计精度. 注意到攻击信号的融合估计器与原闭环系统(1)中的控制信号设计是相互独立的, 即: 本文的控制信号是原有闭环控制系统根据未被攻击情况下的期望性能而提前设计给出的, 不依赖于融合中心的状态估计结果. 此外, 由于文中所给出的局部估计算法是以递推形式给出, 所以实现局部的状态估计不需要局部可观性条件. 但是, 为了保证局部估计器可以提供较好的估计性能, 则需要$ (A(k),C_i(k)) $ 是可观的.2. 攻击信号的估计 − 分布式融合策略
在分布式融合结构下, 首先基于每个传感器量测信息
$ \{{\boldsymbol y}_i(1),\cdots,{\boldsymbol y}_i(k)\} $ , 结合Kalman滤波和带有遗忘因子的递归最小二乘估计方法导出攻击信号的局部估计$ \hat{{\boldsymbol \theta}}_i(k) $ , 主要结果由定理1给出.定理 1. 给定初始值
$P_i(0\vert 0) = P_0$ ,$\Upsilon_i(0) = 0$ ,$ S_i(0) =$ $ \omega I_p $ ,$ \hat{{\boldsymbol \theta}}_i(0) = {\boldsymbol \theta}_0, $ $ \hat{{\boldsymbol x}}_i(0\vert 0) = {\boldsymbol x}_0 $ 和遗忘因子$ 0 < {\lambda _i} \le 1 $ , 则局部估计$ \hat{{\boldsymbol \theta}}_i(k) $ 由以下递推公式计算$$ \left\{ \begin{aligned} &\widetilde{{\boldsymbol y}}_i(k) = {\boldsymbol y}_i(k)-C_i(k)[A(k)\hat{{\boldsymbol x}}_i(k-1\vert k-1)\;+ \\ &\qquad \quad\;\; B(k)({\boldsymbol u}(k-1)+\hat{{\boldsymbol \theta}}_i(k-1))] \\ &\hat{{\boldsymbol \theta}}_i(k) = \hat{{\boldsymbol \theta}}_i(k-1)+\Gamma_i(k)\widetilde{{\boldsymbol y}}_i(k) \\ &\hat{{\boldsymbol x}}_i(k\vert k) = A(k)\hat{{\boldsymbol x}}_i(k-1\vert k-1)\;+ \\ &\qquad \;\;\;\;\quad B(k)({\boldsymbol u}(k-1)+\hat{{\boldsymbol \theta}}_i(k-1))\;+\\ &\qquad \;\;\;\;\quad K_i(k)\widetilde{{\boldsymbol y}}_i(k)+ \Upsilon_i(k)[\hat{{\boldsymbol \theta}}_i(k)\;-\\ &\qquad \;\;\;\;\quad\hat{{\boldsymbol \theta}}_i(k-1)] \end{aligned}\right. $$ (7) $$ \left\{ \begin{aligned} &P_i(k\vert k-1) = A(k)P_i(k-1\vert k-1)A^{\rm T}(k)+Q(k) \\&\Sigma_i(k) = C_i(k)P_i(k\vert k-1)C_i^{\rm T}(k)+R_i(k) \\&K_i(k) = P_i(k\vert k-1)C_i^{\rm T}(k)\Sigma_i^{-1}(k) \\&P_i(k\vert k) = [I_n-K_i(k)C_i(k)]P_i(k\vert k-1) \end{aligned}\right. $$ (8) $$ \left\{ \begin{aligned} &\Upsilon_i(k) = [I_n-K_i(k)C_i(k)]A(k)\Upsilon_i(k-1)\;+ \\&\qquad \;\;\;\quad[I_n-K_i(k)C_i(k)]B(k) \\&\Omega_i(k) = C_i(k)A(k)\Upsilon_i(k-1)+C_i(k)B(k) \\&\Lambda_i(k) = [\lambda_i\Sigma_i(k)+\Omega_i(k)S_i(k-1)\Omega_i^{\rm T}(k)]^{-1} \\&\Gamma_i(k) = S_i(k-1)\Omega_i^{\rm T}(k)\Lambda_i(k) \\&S_i(k) = \frac{1}{\lambda_i}S_i(k-1)-\frac{1}{\lambda_i}\Gamma_i(k)\Omega_i(k)S_i(k-1) \end{aligned}\right.\;\;\; $$ (9) 证明. FDI攻击信号
$ {\boldsymbol \theta}(k) $ 的局部估计器的推导类似于文献[25]与文献[26]的推导过程, 故在此省略. □注 2. 局部FDI攻击信号估计
$ \hat{{\boldsymbol \theta}}_i(k) $ 和局部状态估计$ \hat{{\boldsymbol x}}_i(k\vert k) $ 由递推式(7)计算, 其中, 未知输入$ {\boldsymbol \theta}(k-1) $ 的真实值由$ \hat{{\boldsymbol \theta}}_i(k-1) $ 给出. 当$ {\boldsymbol \theta}(k-1) = \hat{{\boldsymbol \theta}}_i(k-1) $ 时, 则$$ \widetilde{{\boldsymbol y}}_i(k) = C_i(k)A(k)\widetilde{{\boldsymbol x}}_i(k-1\vert k-1)+C_i(k){\boldsymbol w}(k)+{\boldsymbol v}_i(k) $$ (10) 其中,
$ \widetilde{{\boldsymbol x}}_i(k-1\vert k-1) = {\boldsymbol x}(k-1)-\hat{{\boldsymbol x}}_i(k-1\vert k-1) .$ 显然新息(10)与标准Kalman滤波的新息相同, 此时将$ B(k)\hat{{\boldsymbol \theta}}_i(k-1) $ 作为局部状态估计器的输入信号, 则可直接由Kalman滤波得到状态的估计值; 当${\boldsymbol \theta}(k-1)\ne $ $ \hat{{\boldsymbol \theta}}_i(k-1)$ 时, 将无法避免攻击信号的估计误差, 此时则用$ \Upsilon_i(k)[\hat{{\boldsymbol \theta}}_i(k)-\hat{{\boldsymbol \theta}}_i(k-1)] $ 补偿这一误差. 另一方面, 遗忘因子$ \lambda_i\;(0 < {\lambda _i} \le 1) $ 是用来控制过去量测信息被遗忘的速度, 以体现新近数据的作用, 即: 小的遗忘因子$ \lambda_i $ 代表过去的量测信息将被快速遗忘. 根据递归最小二乘法的核心思想, 当$ {\boldsymbol \theta}(k) $ 是缓慢变化时, 式(7)中的局部估计器$ \hat{{\boldsymbol \theta}}_i(k) $ 的性能随着$ \lambda_i $ 的减小而提高; 而当$ {\boldsymbol \theta}(k) $ 是时不变参数时, 则式(7)中的局部估计器$ \hat{{\boldsymbol \theta}}_i(k) $ 的性能随着$ \lambda_i $ 的减小而降低[26]. 特别地, 当$ {\boldsymbol \theta}(k) $ 是变化速率快时, 不能通过调节遗忘因子保证局部估计器的收敛性.定义
$$ \left\{ \begin{aligned} & \widetilde{{\boldsymbol \theta}}_i(k) = {\boldsymbol \theta}(k)-\hat{{\boldsymbol \theta}}_i(k) \\ & P^\theta_{ij}(k) = {\rm E}(\widetilde{{\boldsymbol \theta}}_i(k)\tilde{{\boldsymbol \theta}}^{\rm T}_j(k),\;\;\forall i,j \end{aligned} \right. $$ (11) 当在
$ k $ 时刻$ L $ 个局部估计$ \hat{{\boldsymbol \theta}}_i(k) $ 由定理1给出时, 根据文献[27]的结论可以导出满足式(6)最优融合估计$\hat{{\boldsymbol \theta}}_0(k) = $ $ \sum^L_{i = 1}W^\theta_i(k)\hat{{\boldsymbol \theta}}_i(k) $ 的权重$W^\theta_i(k),\;i = 1,2,\cdots,L,$ 由下式计算得到$$ W^\theta(k) = \Sigma_\theta^{-1}(k)e_\theta\left(e_\theta^{\rm T}\Sigma_\theta^{-1}(k)e_\theta\right)^{-1} $$ (12) 其中,
$W^\theta(k) = [W^\theta_1(k),W^\theta_2(k),\cdots,W^\theta_L(k)]^{\rm T}$ 与$e_\theta = $ $ [I_p,\cdots, I_p]^{\rm T}$ 均为$ pL\times p $ 的矩阵;$ \Sigma_\theta(k) = (P^\theta_{ij}(k)) $ 为$ pL\times pL $ 的对称正定矩阵. 在此情形下, 最优分布式融合估计器$ \hat{{\boldsymbol \theta}}_0(k) $ 的协方差矩阵为$$ P^\theta_0(k) = (e_\theta^{\rm T}\Sigma_\theta^{-1}(k)e_\theta)^{-1} $$ (13) 且满足
${\rm tr}(P^\theta_{ii}(k))\ge{\rm tr}(P^\theta_0(k))$ .由式(11)可知, 最优加权矩阵
$W^\theta_i(k)\;(i = 1,2,\cdots, $ $ L)$ 的计算需要求解每个协方差矩阵$P^\theta_{ij}(k)\;(\forall i,j)$ . 因此, 定理2将给出$ P^\theta_{ij}(k) $ 的递推形式. 在给出主要结果之前, 需要定义如下变量$$ \left\{ \begin{aligned} &\widetilde{{\boldsymbol x}}_i(k\vert k) = {\boldsymbol x}(k)-\hat{{\boldsymbol x}}_i(k\vert k) \\&P^x_{ij}(k) = { {\rm{E}}}(\widetilde{{\boldsymbol x}}_i(k\vert k)\tilde{{\boldsymbol x}}^{\rm T}_j(k\vert k)) \\&\Psi_{ij}(k) = { {\rm{E}}}(\widetilde{{\boldsymbol x}}_i(k\vert k)\tilde{{\boldsymbol \theta}}^{\rm T}_j(k)) \end{aligned}\right. $$ (14) 定理 2. 给定补偿因子
$ \eta>0 $ , FDI攻击信号的协方差矩阵$ P^\theta_{ij}(k) $ 由以下的递推公式计算$$ \begin{split} P^\theta_{ij}(k) =\;& [I_p-\Gamma_i(k)C_i(k)B(k)]P^\theta_{ij}(k-1)\;\times \\ &[I_p-\Gamma_j(k)C_j(k)B(k)]^{\rm T}\;+\\ &\Gamma_i(k)C_i(k)A(k)P^x_{ij}(k-1)\;\times \\ &A^{\rm T}(k)C^{\rm T}_j(k)\Gamma^{\rm T}_j(k)-[I_p-\Gamma_i(k)C_i(k)B(k)]\;\times \\ &\Psi^{\rm T}_{ji}(k-1)A^{\rm T}(k)C^{\rm T}_j(k)\Gamma^{\rm T}_j(k)\;-\\ &\Gamma_i(k)C_i(k)A(k)\Psi_{ij}(k-1)\;\times \\ &[I_p-\Gamma_j(k)C_j(k)B(k)]^{\rm T}\;+\\ &\Gamma_i(k)C_i(k)Q(k)C^{\rm T}_j(k)\Gamma^{\rm T}_j(k)\;+ \\ &\Gamma_i(k)\delta_{ij}R_i\Gamma^{\rm T}_j(k)+\eta I\\[-10pt] \end{split} $$ (15) 其中,
$$ \begin{split} P^x_{ij}(k) =\;& [I_n-(K_i(k)+\Upsilon_i(k)\Gamma_i(k))C_i(k)]\;\times \\ &[A(k)P^x_{ij}(k-1)A^{\rm T}(k)+B(k)P^\theta_{ij}(k-1)\;\times\\ &B^{\rm T}(k)+ A(k)\Psi_{ij}(k-1)B^{\rm T}(k)\;+\\ &B(k)\Psi^{\rm T}_{ji}(k-1)A^{\rm T}(k)\;+ \\ &Q(k)][I_n-(K_j(k)+\Upsilon_j(k)\Gamma_j(k))C_j(k)]^{\rm T}\;+ \\ &[K_i(k)+\Upsilon_i(k)\Gamma_i(k)]\delta_{ij}R_i[K_j(k)\;+\\ &\Upsilon_j(k)\Gamma_j(k)]^{\rm T} \\[-10pt]\end{split} $$ (16) $$ \begin{split} {\Psi}_{ij}(k) =\;& [I_n-(K_i(k)+\Upsilon_i(k)\Gamma_i(k))C_i(k)]\;\times \\&[A(k)\Psi_{ij}(k-1)+B(k)P^\theta_{ij}(k-1)]\;\times \\&[I_p-\Gamma_j(k)C_j(k)B(k)]^{\rm T}\;- \\&[I_n-(K_i(k)+\Upsilon_i(k)\Gamma_i(k))C_i(k)]\;\times \\&[A(k)P^x_{ij}(k-1)A^{\rm T}(k)\;+ \\ &B(k)\Psi^{\rm T}_{ji}(k-1)A^{\rm T}(k)+Q(k)]C^{\rm T}_j(k)\Gamma^{\rm T}_j(k)\;+ \\&[K_i(k)+\Upsilon_i(k)\Gamma_i(k)]\delta_{ij}R_i\Gamma^{\rm T}_j(k)\\[-10pt] \end{split} $$ (17) 其中,
$\delta_{ii} = 1,\delta_{ij} = 0,\;i\ne j$ .证明. 定义
$ {\boldsymbol \phi}(k) = {\boldsymbol \theta}(k)-{\boldsymbol \theta}(k-1) $ , 则由式(7)可导出攻击信号$ {\boldsymbol \theta}(k) $ 的局部估计误差为$$ \begin{split} \widetilde{{\boldsymbol \theta}}_i(k) = \;&{\boldsymbol \phi}(k)+{\boldsymbol \theta}(k-1)-[\hat{{\boldsymbol \theta}}_i(k-1)+\Gamma_i(k)\widetilde{{\boldsymbol y}}_i(k)] = \\ &\widetilde{{\boldsymbol \theta}}_i(k-1)-\Gamma_i(k)C_i(k)\;\times \\ &[A(k)\widetilde{{\boldsymbol x}}_i(k-1\vert k-1)+B(k)\widetilde{{\boldsymbol \theta}}_i(k-1)]\;- \\ &\Gamma_i(k)C_i(k){\boldsymbol w}(k)-\Gamma_i(k){\boldsymbol v}_i(k)+{\boldsymbol \phi}(k) = \\ &[I_p-\Gamma_i(k)C_i(k)B(k)]\widetilde{{\boldsymbol \theta}}_i(k-1)\;- \\ &\Gamma_i(k)C_i(k)A(k)\widetilde{{\boldsymbol x}}_i(k-1\vert k-1)\;- \\ &\Gamma_i(k)C_i(k){\boldsymbol w}(k)-\Gamma_i(k){\boldsymbol v}_i(k)+{\boldsymbol \phi}(k)\\[-10pt] \end{split} $$ (18) 由式(3)和式(7)可得状态估计误差为
$$ \begin{split} \widetilde{{\boldsymbol x}}_i(k\vert k) =\;& [I_n-K_i(k)C_i(k)][A(k)\widetilde{{\boldsymbol x}}_i(k-1\vert k-1)\;+ \\ &B(k)\widetilde{{\boldsymbol \theta}}_i(k-1)]-\Upsilon_i(k)[\hat{{\boldsymbol \theta}}_i(k)-\hat{{\boldsymbol \theta}}_i(k-1)]\;+ \\ &[I_n-K_i(k)C_i(k)]{\boldsymbol w}(k)-K_i(k){\boldsymbol v}_i(k) = \\ &[I_n-K_i(k)C_i(k)][A(k)\widetilde{{\boldsymbol x}}_i(k-1\vert k-1)\;+ \\ &B(k)\widetilde{{\boldsymbol \theta}}_i(k-1)]+\Upsilon_i(k)[\widetilde{{\boldsymbol \theta}}_i(k)\;-\\ &\widetilde{{\boldsymbol \theta}}_i(k-1)-{\boldsymbol \phi}(k)]\;+ \\ &[I_n-K_i(k)C_i(k)]{\boldsymbol w}(k)-K_i(k){\boldsymbol v}_i(k) \\[-10pt]\end{split} $$ (19) 将式(18)代入式(19), 导出
$$ \begin{split} \widetilde{{\boldsymbol x}}_i(k\vert k) =\;& [I_n-(K_i(k)+\Upsilon_i(k)\Gamma_i(k))C_i(k)]\;\times \\ &[A(k)\widetilde{{\boldsymbol x}}_i(k-1\vert k-1)+B(k)\widetilde{{\boldsymbol \theta}}_i(k-1)]\;+ \\ &[I_n-(K_i(k)+\Upsilon_i(k)\Gamma_i(k))C_i(k)]{\boldsymbol w}(k)\;- \\ &[K_i(k)+\Upsilon_i(k)\Gamma_i(k)]{\boldsymbol v}_i(k) \\[-10pt]\end{split}$$ (20) 注意到
$ {\boldsymbol \phi}(k) $ 是未知变量, 在此假设它与其他统计变量无关, 且它的协方差为$\eta I = { {\rm{E}}}({\boldsymbol \phi}(k){\boldsymbol \phi}^{\rm T}(k))$ . 在此情况下, 调整参数$ \eta $ 可以改变所设计融合估计器对攻击信号$ {\boldsymbol \theta}(k) $ 的估计性能, 即通过$ \eta $ 实现对估计误差$ \widetilde{{\boldsymbol \theta}}_i(k) $ 的协方差进行补偿, 因而$ \eta $ 称为补偿因子. 根据${\boldsymbol w}(k)\perp\widetilde{{\boldsymbol x}}_j(k- $ $ 1\vert k-1),$ ${\boldsymbol v}_i(k)\;\perp$ $\widetilde{{\boldsymbol x}}_j\;(k-1\vert k-1),$ ${\boldsymbol \phi}_i(k)\;\perp\;\widetilde{{\boldsymbol x}}_j(k- $ $ 1\vert k- 1),$ $ {\boldsymbol w}(k)\perp\widetilde{{\boldsymbol \theta}}_i(k-1) ,$ $ {\boldsymbol v}_i(k)\perp\widetilde{{\boldsymbol \theta}}_i(k-1) ,$ ${\boldsymbol \phi}_i(k)\perp $ $ \widetilde{{\boldsymbol \theta}}_i(k-1),$ 由式(18)可得$P ^\theta_{ij}(k)$ 由下式计算$$ \begin{split} P^\theta_{ij}(k) =\;& [I_p-\Gamma_i(k)C_i(k)B(k)]P^\theta_{ij}(k-1)\;\times \\ &[I_p-\Gamma_j(k)C_j(k)B(k)]^{\rm T}\;+ \\ &\Gamma_i(k)C_i(k)A(k)P^x_{ij}(k-1)A^{\rm T}(k)C^{\rm T}_j(k)\Gamma^{\rm T}_j(k)\;+ \\ &\Gamma_i(k)C_i(k){\rm E}({\boldsymbol w}(k){\boldsymbol w}^{\rm T}(k))C^{\rm T}_j(k)\Gamma^{\rm T}_j(k)\;+ \\ &\Gamma_i(k){\rm E}({\boldsymbol v}_i(k){\boldsymbol v}_j^{\rm T}(k))\Gamma^{\rm T}_j(k)+{\rm E}({\boldsymbol \phi}(k){\boldsymbol \phi}^{\rm T}(k))\;- \\ &[I_p-\Gamma_i(k)C_i(k)B(k)]\Psi^{\rm T}_{ji}(k-1)\;\times \\ &A^{\rm T}(k)C^{\rm T}_j(k)\Gamma^{\rm T}_j(k)-\Gamma_i(k)C_i(k)A(k)\;\times \\ &\Psi_{ij}(k-1)[I_p-\Gamma_j(k)C_j(k)B(k)]^{\rm T}\;+ \\ &\Gamma_i(k)C_i(k){\rm E}({\boldsymbol w}(k){\boldsymbol v}^{\rm T}_j(k))\Gamma^{\rm T}_j(k)\;+ \\ &\Gamma_i(k){\rm E}({\boldsymbol v}_i(k){\boldsymbol w}^{\rm T}(k))C^{\rm T}_j(k)\Gamma^{\rm T}_j(k) \\[-10pt]\end{split} $$ (21) 根据式(5), 式(21)简化为
$$ \begin{split} P^\theta_{ij}(k) = \;&[I_p-\Gamma_i(k)C_i(k)B(k)]P^\theta_{ij}(k-1)\;\times \\ &[I_p-\Gamma_j(k)C_j(k)B(k)]^{\rm T}+\Gamma_i(k)C_i(k)A(k)\;\times \\ &P^x_{ij}(k-1)A^{\rm T}(k)C^{\rm T}_j(k)\Gamma^{\rm T}_j(k)\;- \\ &[I_p-\Gamma_i(k)C_i(k)B(k)]\Psi^{\rm T}_{ji}(k-1)\;\times \\ &A^{\rm T}(k)C^{\rm T}_j(k)\Gamma^{\rm T}_j(k)-\Gamma_i(k)C_i(k)A(k)\;\times \\ &\Psi_{ij}(k-1)[I_p-\Gamma_j(k)C_j(k)B(k)]^{\rm T}\;+ \\ &\Gamma_i(k)C_i(k)Q(k)C^{\rm T}_j(k)\Gamma^{\rm T}_j(k)\;+ \\ &\Gamma_i(k){\rm E}({\boldsymbol v}_i(k){\boldsymbol v}_j^{\rm T}(k))\Gamma^{\rm T}_j(k)+\eta I\\[-10pt] \end{split} $$ (22) 从而导出式(15)成立. 另一方面, 由式(20)可得
$ P^x_{ij}(k) $ 由下式计算$$ \begin{split} P^x_{ij}(k) = \;&[I_n-(K_i(k)+\Upsilon_i(k)\Gamma_i(k))C_i(k)]\;\times \\ &[A(k)P^x_{ij}(k-1)A^{\rm T}(k)\;+\\ &B(k)P^\theta_{ij}(k-1)B^{\rm T}(k)\;+ \\ &A(k)\Psi_{ij}(k-1)B^{\rm T}(k)\;+\\ &B(k)\Psi^{\rm T}_{ji}(k-1)A^{\rm T}(k)+ \\&{\rm E}({\boldsymbol w}(k){\boldsymbol w}^{\rm T}(k))]\;\times \\ &[I_n-(K_j(k)+\Upsilon_j(k)\Gamma_j(k))C_j(k)]^{\rm T}\;+ \\ &[K_i(k)+\Upsilon_i(k)\Gamma_i(k)]{\rm E}({\boldsymbol v}_i(k){\boldsymbol v}_j^{\rm T}(k))\;\times \\ &[K_i(k)+\Upsilon_i(k)\Gamma_i(k)]^{\rm T}\;+ \\ &[I_n-(K_i(k)+\Upsilon_i(k)\Gamma_i(k))C_i(k)]\;\times \\ &{\rm E}({\boldsymbol w}(k){\boldsymbol v}_j^{\rm T}(k))[K_j(k)+\Upsilon_j(k)\Gamma_j(k)]^{\rm T}\;+ \\ &[K_i(k)+\Upsilon_i(k)\Gamma_i(k)]{\rm E}({\boldsymbol v}_i(k){\boldsymbol w}^{\rm T}(k))\;\times \\ &[I_n-(K_j(k)+\Upsilon_j(k)\Gamma_j(k))C_j(k)]^{\rm T} \\[-10pt]\end{split} $$ (23) 根据式(5), 式(23)转换为
$$ \begin{split} P^x_{ij}(k) =\;& [I_n-(K_i(k)+\Upsilon_i(k)\Gamma_i(k))C_i(k)]\;\times \\ &[A(k)P^x_{ij}(k-1)A^{\rm T}(k)\;+\\ &B(k)P^\theta_{ij}(k-1)B^{\rm T}(k)\;+ \\ &A(k)\Psi_{ij}(k-1)B^{\rm T}(k)\;+ \\ &B(k)\Psi^{\rm T}_{ji}(k-1)A^{\rm T}(k)+Q(k)]\;\times \\ &[I_n-(K_j(k)+\Upsilon_j(k)\Gamma_j(k))C_j(k)]^{\rm T}\;+ \\ &[K_i(k)+\Upsilon_i(k)\Gamma_i(k)]{\rm E}({\boldsymbol v}_i(k){\boldsymbol v}_j^{\rm T}(k))\;\times \\ &[K_j(k)+\Upsilon_j(k)\Gamma_j(k)]^{\rm T} \end{split} $$ (24) 故式(16)成立. 进一步, 根据式(18)和式(20)导出
$ \Psi_{ij}(k) $ 由下式计算$$ \begin{split} \Psi_{ij}(k) =\;& [I_n-(K_i(k)+\Upsilon_i(k)\Gamma_i(k))C_i(k)]\;\times \\ &[A(k)\Psi_{ij}(k-1)+B(k)P^\theta_{ij}(k-1)]\;\times \\ &[I_p-\Gamma_j(k)C_j(k)B(k)]^{\rm T}\;- \\ &[I_n-(K_i(k)+\Upsilon_i(k)\Gamma_i(k))C_i(k)]\;\times \\ &[A(k)P^x_{ij}(k-1)A^{\rm T}(k)\;+\\ &B(k)\Psi^{\rm T}_{ji}(k-1)A^{\rm T}(k)]\;\times \\ &C^{\rm T}_j(k)\Gamma^{\rm T}_j(k)+[I_n-(K_i(k)\;+\\ &\Upsilon_i(k)\Gamma_i(k))C_i(k)]{\rm E}({\boldsymbol w}(k)\;\times \\ &{\boldsymbol w}^{\rm T}(k))C^{\rm T}_j(k)\Gamma^{\rm T}_j(k)+[I_n-(K_i(k)+ \Upsilon_i(k)\;\times \\ &\Gamma_i(k))C_i(k)]{\rm E}({\boldsymbol w}(k){\boldsymbol v}^{\rm T}_j(k))\Gamma^{\rm T}_j(k)+ [K_i(k)\;+\\ &\Upsilon_i(k)\Gamma_i(k)]{\rm E}({\boldsymbol v}_i(k){\boldsymbol w}^{\rm T}(k))C^{\rm T}_j(k)\Gamma^{\rm T}_j(k)\;+ \\ &[K_i(k)+\Upsilon_i(k)\Gamma_i(k)]{\rm E}({\boldsymbol v}_i(k){\boldsymbol v}^{\rm T}_j(k))\Gamma^{\rm T}_j(k) \end{split} $$ (25) 由式(5)和式(25)导出
$$ \begin{split} \Psi_{ij}(k) =\;& [I_n-(K_i(k)+\Upsilon_i(k)\Gamma_i(k))C_i(k)]\;\times \\ &[A(k)\Psi_{ij}(k-1)+B(k)P^\theta_{ij}(k-1)]\;\times \\ &[I_p-\Gamma_j(k)C_j(k)B(k)]^{\rm T}\;- \\ &[I_n-(K_i(k)+\Upsilon_i(k)\Gamma_i(k))C_i(k)][A(k)\;\times \\ &P^x_{ij}(k-1)A^{\rm T}(k)+B(k)\Psi^{\rm T}_{ji}(k-1)A^{\rm T}(k)]\;\times \\ &C^{\rm T}_j(k)\Gamma^{\rm T}_j(k)+[I_n-(K_i(k)+\Upsilon_i(k)\Gamma_i(k))\;\times \\ &C_i(k)]{\rm E}({\boldsymbol w}(k){\boldsymbol w}^{\rm T}(k))C^{\rm T}_j(k)\Gamma^{\rm T}_j(k)\;+ \\ &[K_i(k)+\Upsilon_i(k)\Gamma_i(k)]{\rm E}({\boldsymbol v}_i(k){\boldsymbol v}^{\rm T}_j(k))\Gamma^{\rm T}_j(k) \end{split} $$ (26) 故式(17)成立. □
注 3. 当补偿因子
$ \eta = 0 $ 时, 意味着$ \widetilde{{\boldsymbol \theta}}_i(k) $ 的协方差信息无法得到补偿. 在此情况下, 如果攻击信号$ {\boldsymbol \theta}(k) $ 恒等于一个常值, 则所设计的融合估计器将提供满意的估计性能; 但是如果攻击信号$ {\boldsymbol \theta}(k) $ 是时变的, 则$ \eta $ 取$ 0 $ 时相应的融合估计性能将会因为无法得到协方差的补偿信息而变差. 由于$ {\boldsymbol \theta}(k) $ 是未知的, 所以补偿因子$ \eta $ 作为一个可调参数可以提高对攻击信号的估计精度. 但是如何设计补偿因子的选取准则以保证满意的融合性能非常具有挑战性, 将作为今后在攻击信号实时估计方面的重要研究方向之一.注 4. 当获得FDI攻击信号的估计值时, 攻击对系统性能的破环仍然存在. 为此, 可以采取在系统(1)中直接减去攻击信号融合估计值的方法来尽可能地降低攻击所带来的损失, 即带有补偿策略的系统(1)由如下动态方程描述
$$ \begin{split} {\boldsymbol x}(k) =\;& A(k){\boldsymbol x}(k-1)+B(k){\boldsymbol u_a}(k-1)\;+ \\&{\boldsymbol w}(k)-B(k)\hat\theta_0(k-1) = \\&A(k){\boldsymbol x}(k-1)+B(k){\boldsymbol u}(k-1)\;+ \\&{\boldsymbol w}(k)+B(k)(\theta(k-1)-\hat\theta_0(k-1)) \end{split} $$ (27) 其中,
$ \hat\theta_0(k-1) $ 是攻击信号的融合估计值. 由式(27)可知, 融合估计器精度越高, 系统所受到的破坏就越小.根据定理1和定理2, 给定遗忘因子
$\lambda_1,\cdots,\lambda_L$ 和补偿因子$ \eta $ , 则攻击信号的融合估计$ \hat{{\boldsymbol \theta}}_0(k) $ 实现的算法如下:算法1. 最优融合估计算法
步骤1. 根据式(8), 计算卡尔曼增益
$ K_i(k) $ , 然后根据式(9), 计算参数估计增益$ \Gamma_i(k) $ ;步骤2. 将步骤1计算的结果代入式(7), 得到攻击信号的局部估计
$ \hat{{\boldsymbol \theta}}_i(k) $ 和局部状态估计$ \hat{{\boldsymbol x}}_i(k\vert k) $ ;步骤3. 根据式(15)计算协方差矩阵
$ P^\theta_{ii}(k) $ 和互协方差矩阵$ P^\theta_{ij}(k) $ ;步骤4. 将步骤3计算的结果代入式(12)得到融合权重
$ W^\theta_i(k) $ ;步骤5. 将步骤2和步骤4的结果代入式(6), 计算得到融合估计
$ \hat{{\boldsymbol \theta}}_0(k) $ ;步骤6. 重复步骤1 ~ 5, 得到
$k+1 $ 时刻的最优融合估计$ \hat{{\boldsymbol \theta}}_0(k+1) $ .3. 仿真算例
算例 1. 考虑一个IEEE四路配电线路的电网系统. 本文采用互连的分布式发电器 (Distributed energy generator, DEG)模型, 4个DEG被建模为电压源. 4个DEG通过对应的公共耦合点(Point of common coupling, PCC)与主电网连接, PCC的电压为
$ {\boldsymbol v}_s = (v_1,v_2,v_3, $ $ v_4)^{\rm T} ,$ 其中$ v_i $ 为第$ i $ 个PCC电压. 为了保持DEG的正常工作, 这些PCC电压需要保持在一定的参考值. 在每个DEG和其余的电力网络之间存在耦合电感. 然后, 节点电压方程可以用下述线性状态空间模型表示为[3]$$ \dot{{\boldsymbol x}}(t) = \left[\begin{array}{cccc} \;175.9&\;\,176.8&\;511.0&\;1\;036.0 \\ \,-350.0\;\,&\;\,0&\;\,0&\;\,\;\;\,0 \\ -544.2&-474.8&-408.8&\;\;-828.8 \\ -119.7&-554.6&-968.8&-1\;077.5 \end{array}\right]{\boldsymbol x}(t) $$ (28) 其中,
$ {\boldsymbol x}(t) = {\boldsymbol v}_s(t)-{\boldsymbol v}_{\rm ref}(t) $ 为PCC状态电压偏差,$ {\boldsymbol v}_{\rm ref}(t) $ 为PCC参考电压; 针对系统(28), 当采样周期取$T_0 = $ $ 0.001\;{\rm{s}}$ 时, 则离散化系统的状态转移矩阵为$$ A_d = \left[\begin{array}{cccc} \;\;\,1.0779&-0.0691&\;\;\,0.1412&\;\;\,0.6022 \\ -0.3665&\;\;\,1.0012&-0.0417&-0.1247 \\ -0.4245&-0.2761&\;\;\,0.8447&-0.6105 \\ \;\;\,0.1515&-0.2261&-0.5207&\;\;\,0.5588 \end{array}\right] $$ 考虑到系统中存在的噪声, 得到如下离散系统方程:
$$ {\boldsymbol x}(k) = A_d{\boldsymbol x}(k-1)+{\boldsymbol w}(k) $$ (29) 注意到在没有控制信号输入的情况下, 系统(29)无法稳定. 因此, 将设计控制器以确保系统稳定. 考虑到控制输入信号受到FDI攻击, 利用两组传感器对系统进行量测, 得到如下动态方程
$$ \begin{split} {\boldsymbol x}(k) =\;& A_d{\boldsymbol x}(k-1)+B_d({\boldsymbol u}(k-1)+\\ &{\boldsymbol \theta}(k-1))+{\boldsymbol w}(k) \end{split}$$ (30) $$ {\boldsymbol y}_i(k) = C_i{\boldsymbol x}(k)+{\boldsymbol v}_i(k),\;\;i = 1,2\;\;\;\;\;$$ (31) 其中,
$B_d \;=\; [2.6890,\;-4.3035,\;-8.3410,\;-7.0725]^{\rm T},$ ${\boldsymbol u}(k) = -[5.7495,3.4187,-7.3869,8.3114]{\boldsymbol x}(k)$ 是通过极点配置设计的稳定控制器. 系统过程噪声$ {\boldsymbol w}(k) $ 的方差取$ Q = {\rm diag}\{0.1,0.2,0.2,0.1\} $ . 量测矩阵为$$ C_1 = \left[\begin{array}{ccccccc} 0&0&0&0 \\ 0&1&0&0 \\ 0&0&1&0 \\ 0&1&1&0 \end{array}\right] $$ $$ C_2 = \left[ \begin{array}{ccccccccc} 0 & 1 & 0 & 0 \\ 0 & 0 & 1 & 0 \\ 0 & 1 & 0 & 1 \\ 0 & 0 & 0 & 1 \end{array}\right] $$ 量测噪声的协方差矩阵分别取
$R_1 = {\rm diag}\{0.5,0.6, 0.3, $ $ 0.2\}$ ,$ R_2 = {\rm diag}\{0.8,0.3,0.5,0.9\} $ . 在仿真中考虑以下两种情况:情况 1. 攻击信号保持常值不变, 取
$$ {\boldsymbol \theta}(k)\equiv1 $$ (32) 令补偿因子
$ \eta = 0 $ 及遗忘因子$ \lambda = 0.95 $ . 执行算法1, 仿真结果如图1和图2所示.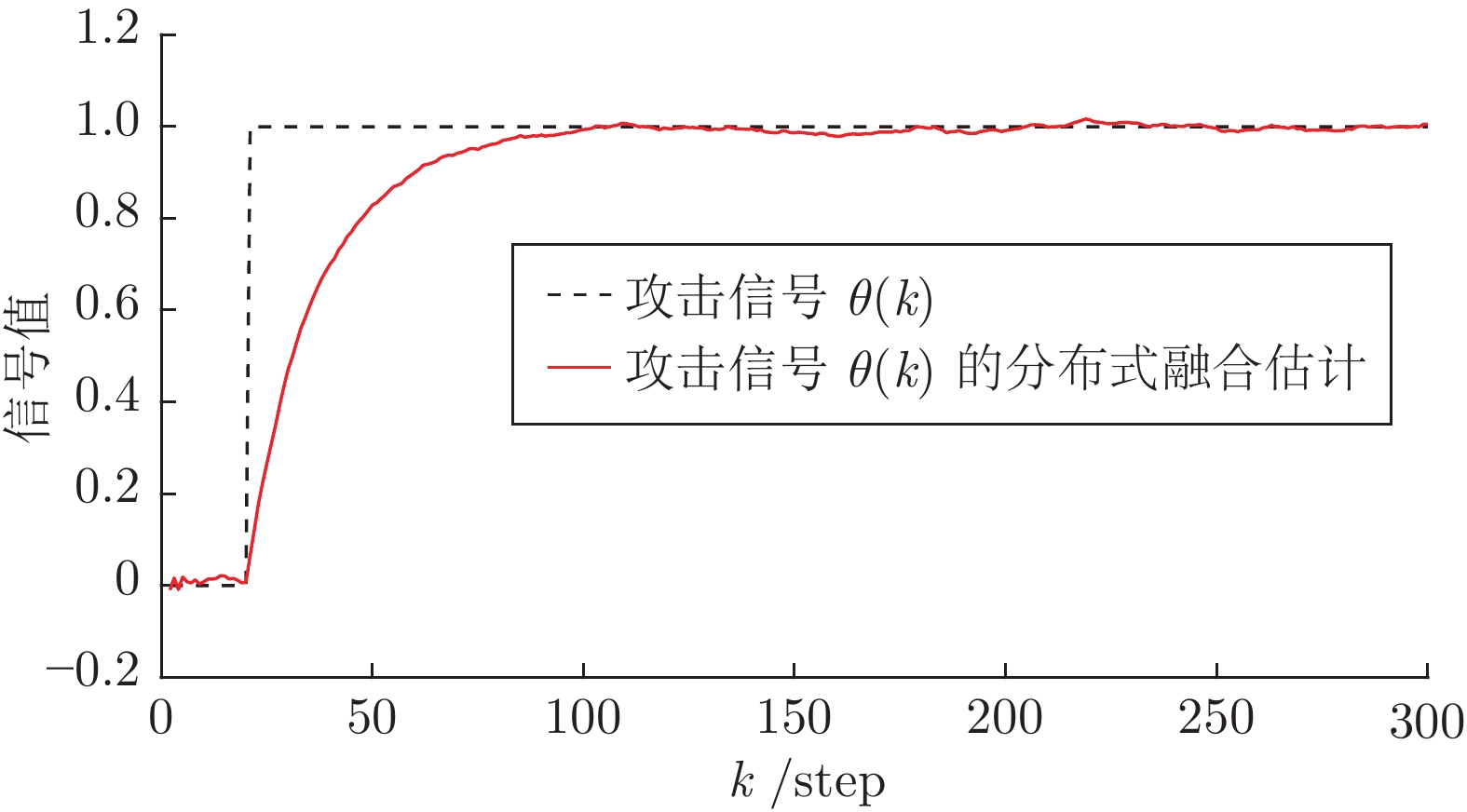 图 1 算例1: 情况1中攻击信号和融合估计的轨迹Fig. 1 Example 1: The trajectories of attack signal and its fusion estimation under Case 1
图 1 算例1: 情况1中攻击信号和融合估计的轨迹Fig. 1 Example 1: The trajectories of attack signal and its fusion estimation under Case 1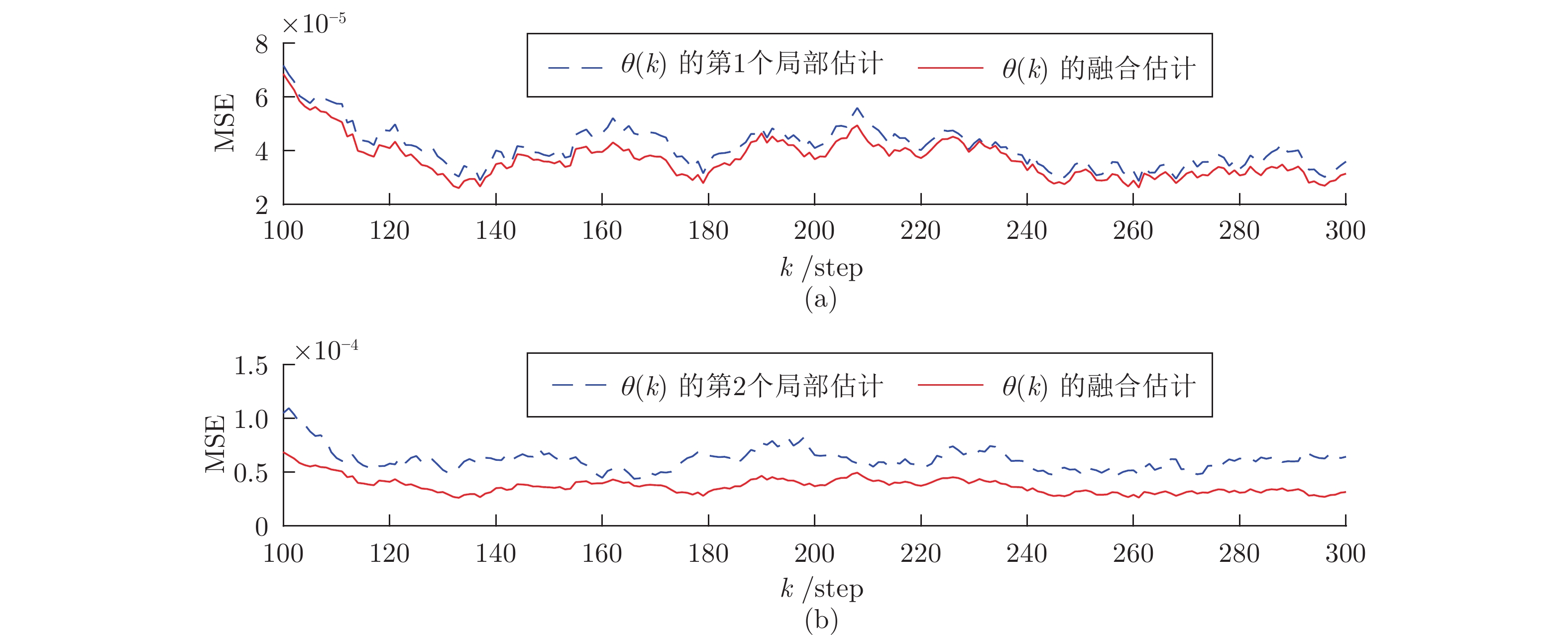 图 2 算例1: 情况1中攻击信号的局部估计器与融合估计器之间的性能比较Fig. 2 Example 1: The performance comparison between local estimators and fusion estimators under Case 1
图 2 算例1: 情况1中攻击信号的局部估计器与融合估计器之间的性能比较Fig. 2 Example 1: The performance comparison between local estimators and fusion estimators under Case 1由图1可知, 当遭受的攻击信号保持常值不变时, 所提出的融合算法可以很好地估计到攻击信号. 图2给出了300次Monte Carlo实验的局部估计器和融合估计器的均方误差(Mean square errors, MSEs)曲线. 由此图可以看到融合估计器的性能优于局部估计器的性能, 从而验证了基于多传感器信息融合的攻击信号估计方法优于基于单一传感器的估计方法.
情况 2. 攻击信号
$ {\boldsymbol \theta}(k) $ 是时变的, 这里假设$ {\boldsymbol \theta}(k) $ 按如下正弦函数变化$$ {\boldsymbol \theta}(k) = {\rm sin}(0.3k) $$ (33) 令补偿因子
$ \eta = 0.2 $ 和遗忘因子$ \lambda = 0.7 $ . 执行算法1, 仿真结果如图3 ~ 6所示.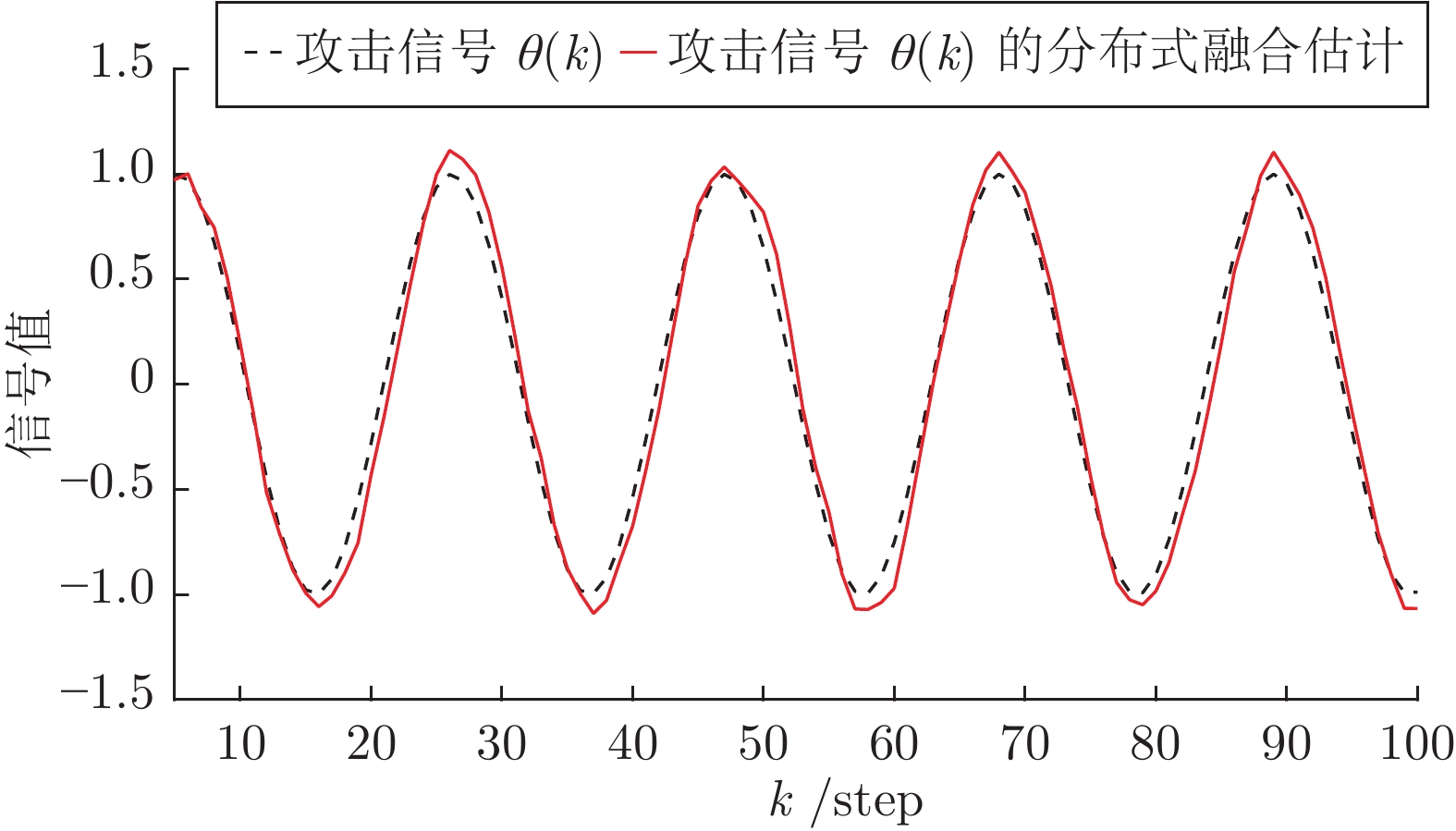 图 3 算例1: 情况2中攻击信号和融合估计轨迹Fig. 3 Example 1: The trajectories of attack signal and its fusion estimation under Case 2
图 3 算例1: 情况2中攻击信号和融合估计轨迹Fig. 3 Example 1: The trajectories of attack signal and its fusion estimation under Case 2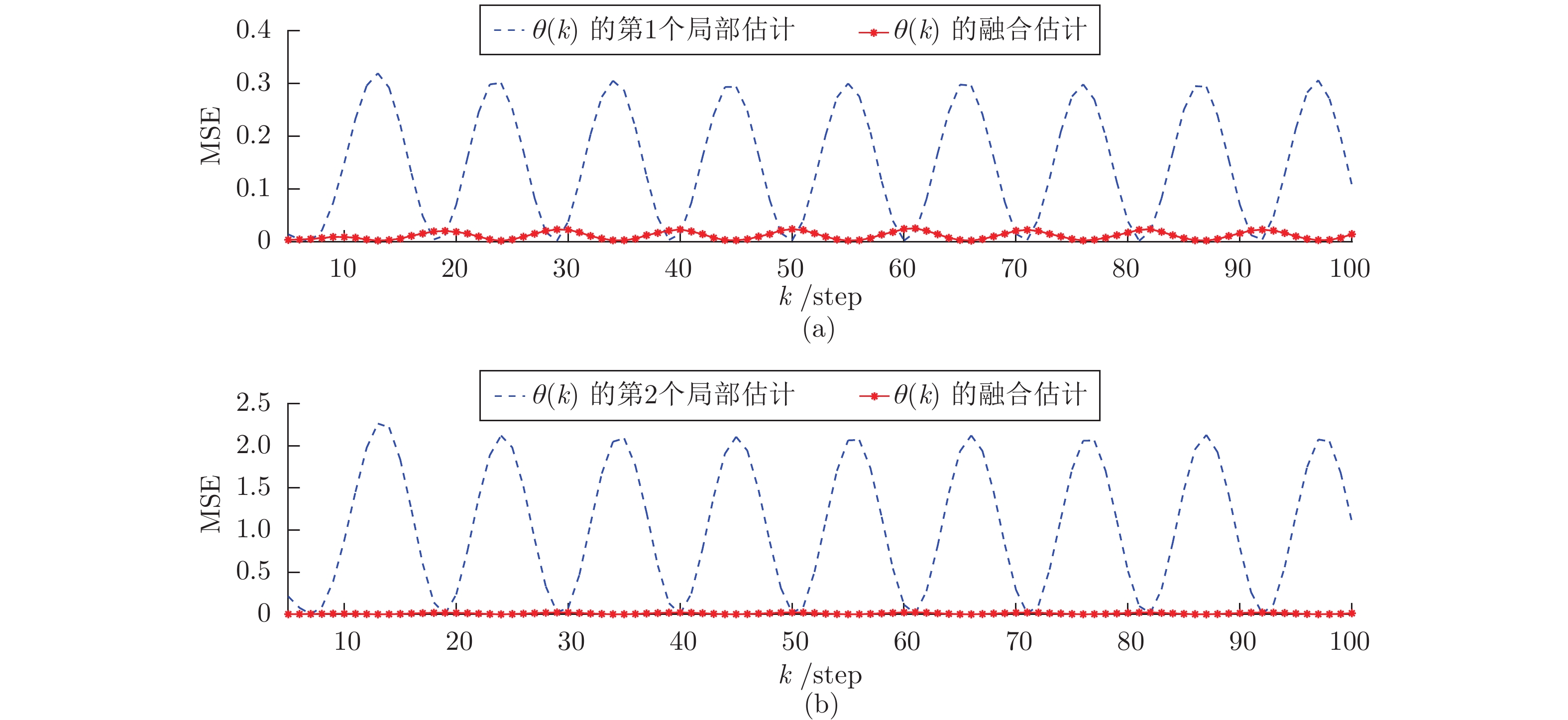 图 4 算例1: 情况2中攻击信号的局部估计器与融合估计器之间的性能比较Fig. 4 Example 1: The performance comparison between local estimators and fusion estimators under Case 2
图 4 算例1: 情况2中攻击信号的局部估计器与融合估计器之间的性能比较Fig. 4 Example 1: The performance comparison between local estimators and fusion estimators under Case 2 图 5 算例1: 情况2中不同补偿因子下攻击信号融合估计性能的比较Fig. 5 Example 1: The comparison of fusion estimation performance of attack signal under different compensation factors under Case 2
图 5 算例1: 情况2中不同补偿因子下攻击信号融合估计性能的比较Fig. 5 Example 1: The comparison of fusion estimation performance of attack signal under different compensation factors under Case 2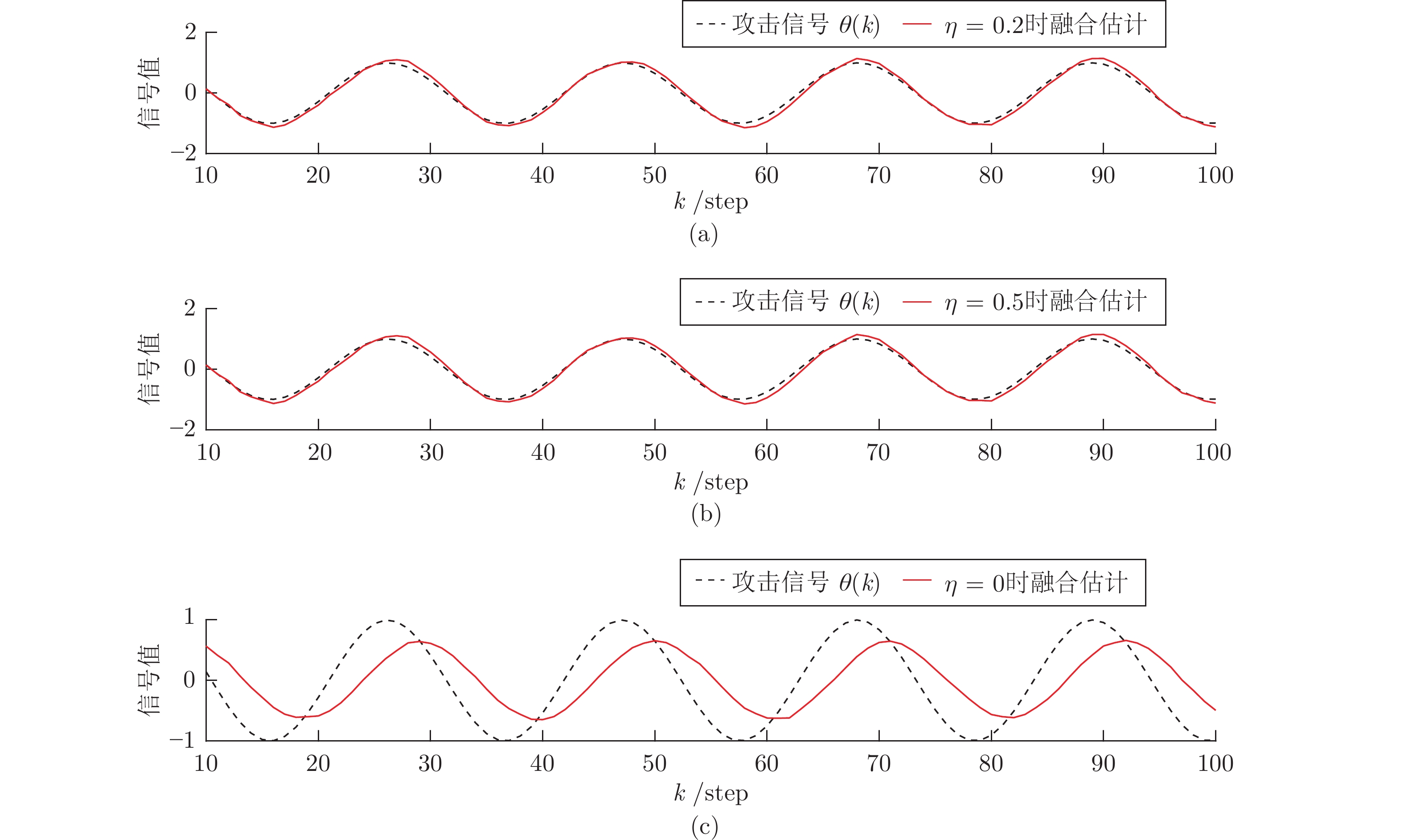 图 6 算例1: 情况2中不同补偿因子下攻击信号融合估计的轨迹Fig. 6 Example 1: The trajectories of fusion estimation of attack signal under different compensation factors under Case 2
图 6 算例1: 情况2中不同补偿因子下攻击信号融合估计的轨迹Fig. 6 Example 1: The trajectories of fusion estimation of attack signal under different compensation factors under Case 2由图3可知, 当攻击信号是时变的情况时, 所设计的分布式融合器仍可以准确地估计攻击信号. 图4给出了100次Monte Carlo实验的局部估计器和融合估计器的MSE曲线. 由此图可知, 融合估计性能明显优于局部估计性能, 进一步说明了融合策略可以提高攻击信号的估计精度. 另一方面, 当取不同的补偿因子
$ \eta $ 时, 相应的融合估计性能如图5和图6所示, 即$ \eta = 0.2 $ 和$ \eta = 0.5 $ 的融合性能明显优于$ \eta = 0 $ 时的融合估计器, 说明了当FDI攻击信号是时变的情形时, 补偿因子$ \eta $ 对融合估计性能发挥着重要的作用, 即: 不考虑补偿策略的融合方法, 相应的估计性能会变得很差.算例 2. 考虑一个由两个传感器监控的机动目标, 其运动可以由它的位置和速度矢量来描述. 定义状态向量
${\boldsymbol{x}}(k) = $ $ {\rm col}\{X_s(k), \dot X_s(k), Y_s(k), \dot Y_s(k)\}$ , 其中,$(X_s(k), Y_s(k))$ 分别为X与Y轴的位置坐标, 同时$ (\dot X_s(k), \dot Y_s(k)) $ 是对应的速度. 引入控制信号改变机动目标的速度以控制移动目标的运动, 考虑控制信号遭受FDI攻击, 机动目标的运动轨迹可由如下时变状态空间模型描述[28]:$$ \boldsymbol{x}(k)= \left[ \begin{array}{ccccccc} 1&f(k)&0&0\\ 0&1&0&0\\ 0&0&1&f(k)\\ 0&0&0&1 \end{array}\right]\boldsymbol{x}(k-1)+\boldsymbol{w}(k)\;+ $$ $$ \left[ \begin{array}{ccc} 0\\ 10f(k)\\ 0 \\ 10f(k) \end{array}\right](\boldsymbol{u}(k-1)+\boldsymbol{\theta}(k-1))\\[-20pt] $$ (34) $$ {\boldsymbol y}_i(k) = C_i{\boldsymbol x}(k)+{\boldsymbol v}_i(k),\;\;i = 1,2 \;\;\qquad\qquad\quad $$ (35) 其中,
$ f(k) $ 表示采样周期取$ f(k) = 0.9+0.1{\rm sin}(k) $ ; 控制信号$ {\boldsymbol u}(k) $ 取$ {\boldsymbol u}(k) = -[0,0.01,0,0.01]x(k-1) ,$ 表示改变机动目标的速度;$ {\boldsymbol \theta}(k) $ 表示未知的FDI攻击信号, 且取$$ {\boldsymbol \theta}(k) = {\boldsymbol \theta}(k-1)+c(k) $$ (36) 其中,
$ c(k) $ 为方差为1的零均值高斯随机信号. 系统过程噪声$ {\boldsymbol w}(k) $ 和量测噪声$ {\boldsymbol v}_1(k) $ ,$ {\boldsymbol v}_2(k) $ 的方差分别取$Q = $ $ {\rm diag}\{0.1,\;0.2,\;0.3,\;0.2\},$ $R_1 = {\rm diag}\{0.3,\;0.2\},$ $R_2 = $ ${\rm diag}\{0.2,\;0.5\}.$ 量测矩阵取[28]$$ C_1 = \left[\begin{array}{ccccccc} 0.5&1&0&0 \\ 0&1&0.9&0.6 \end{array}\right] $$ $$ C_2 = \left[\begin{array}{ccccccc} 0.9&0.8&0&0 \\ 0&1&0.5&0.1 \end{array}\right] $$ 最后, 令遗忘因子
$ \lambda = 0.6 $ , 补偿因子$ \eta_1 = 1, \eta_2 = 0 $ . 执行算法1, 仿真结果如图7 ~ 9所示.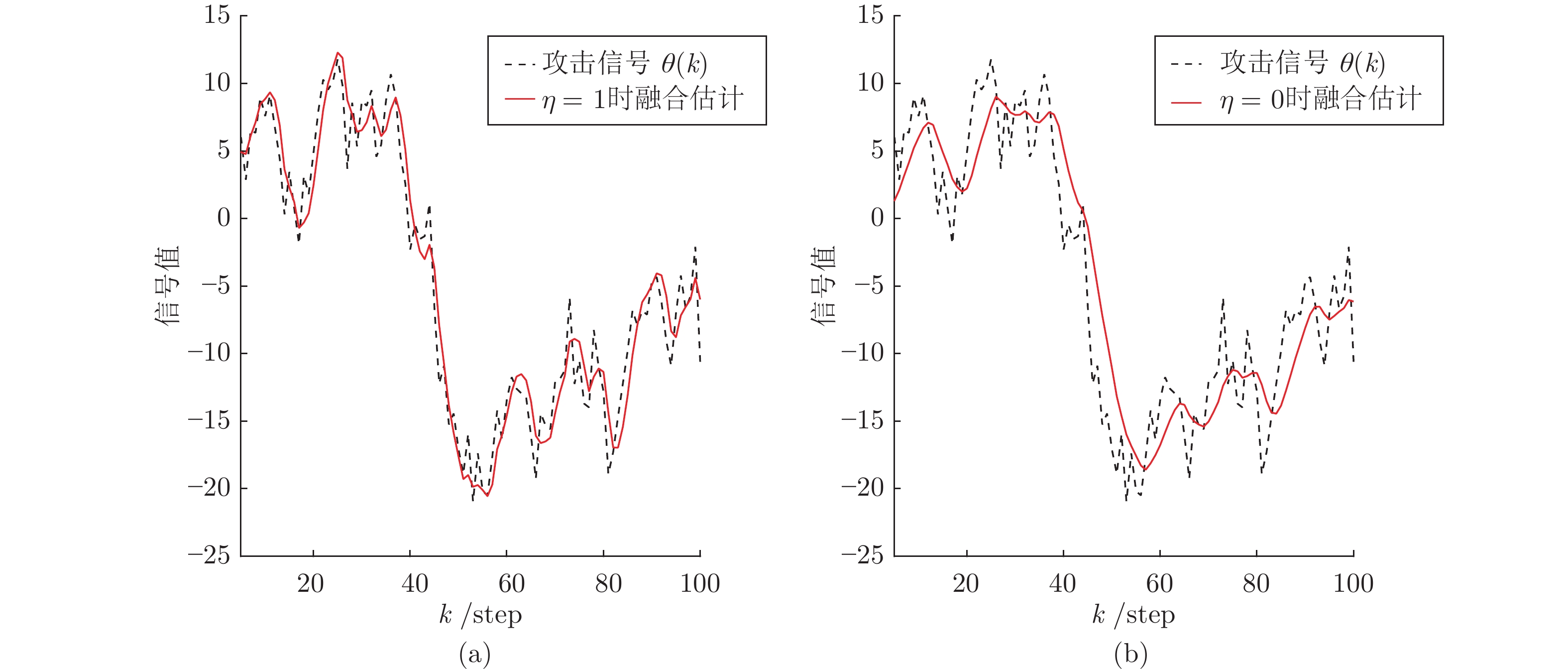 图 7 算例2: 不同补偿因子下攻击信号融合估计的轨迹Fig. 7 Example 2: The trajectories of fusion estimation of attack signal under different compensation factors
图 7 算例2: 不同补偿因子下攻击信号融合估计的轨迹Fig. 7 Example 2: The trajectories of fusion estimation of attack signal under different compensation factors 图 8 算例2: 不同补偿因子下攻击信号融合估计性能的比较Fig. 8 Example 2: The comparison of fusion estimation performance of attack signal under different compensation factors
图 8 算例2: 不同补偿因子下攻击信号融合估计性能的比较Fig. 8 Example 2: The comparison of fusion estimation performance of attack signal under different compensation factors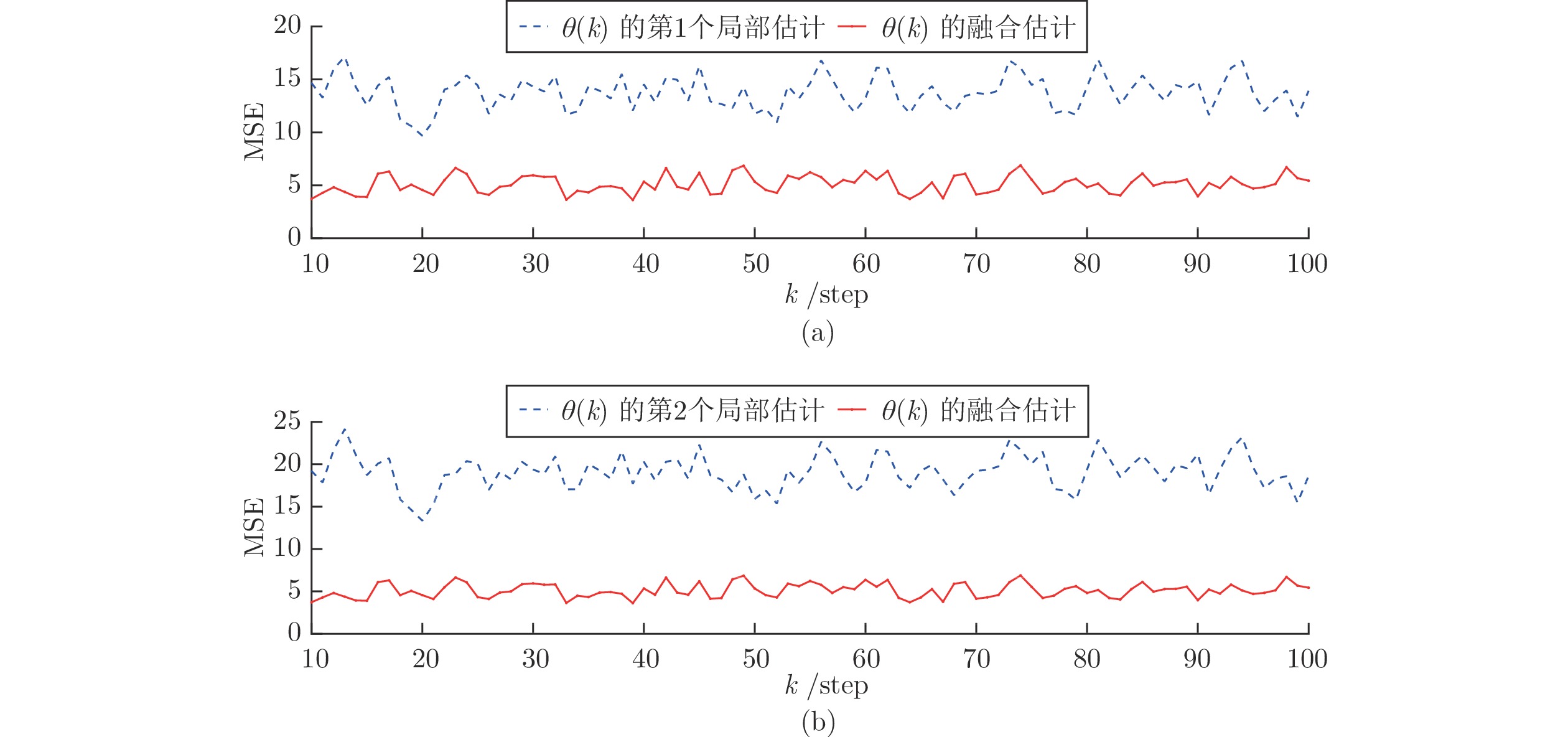 图 9 算例2: 攻击信号的局部估计器与融合估计器之间的性能比较Fig. 9 Example 2: The performance comparison of attack signal between local estimators and fusion estimators
图 9 算例2: 攻击信号的局部估计器与融合估计器之间的性能比较Fig. 9 Example 2: The performance comparison of attack signal between local estimators and fusion estimators由图7可知, 系统参数时变的情况时, 所设计的估计算法仍可以很好地估计攻击信号. 图8基于Monte Carlo实验给出了不同补偿因子下融合估计器的MSE曲线. 图7和图8表明, 补偿因子
$ \eta = 1 $ 的情况下, 算法的性能优于$ \eta = 0 $ 的情况(无补偿的情况). 图9基于Monte Carlo实验给出了局部估计器和融合估计器的MSE曲线. 图9表明融合性能明显优于局部估计器. 仿真结果验证了算法的有效性.4. 结束语
本文研究了信息物理系统中遭受的FDI攻击信号的分布式融合估计问题. 首先, 根据FDI攻击策略对系统的影响, 将攻击信号建模为系统状态方程中的一个未知输入, 然后基于自适应卡尔曼滤波, 利用量测信息对系统状态和攻击参数进行联合估计, 从而得到攻击参数的局部变化轨迹. 在此基础上, 在分布式融合结构下, 引入补偿因子并设计了最优融合估计方法, 提高了攻击信号估计的精度. 最后, 通过例子验证了所提算法的有效性. 今后的研究方向包括如下几点: 首先, 选择合适的补偿因子对本文算法估计精度的提高有着显著的影响, 如何选择补偿因子将是未来研究的重要方向之一; 此外, 许多实际系统无法简单地利用线性模型描述, 因此将该算法推广至非线性情况的攻击信号估计具有重要的意义; 最后, 研究控制器与攻击信号融合估计器及攻击信号实时补偿策略的协同设计, 以降低攻击所带来的损失是另一个重要的研究方向.
-
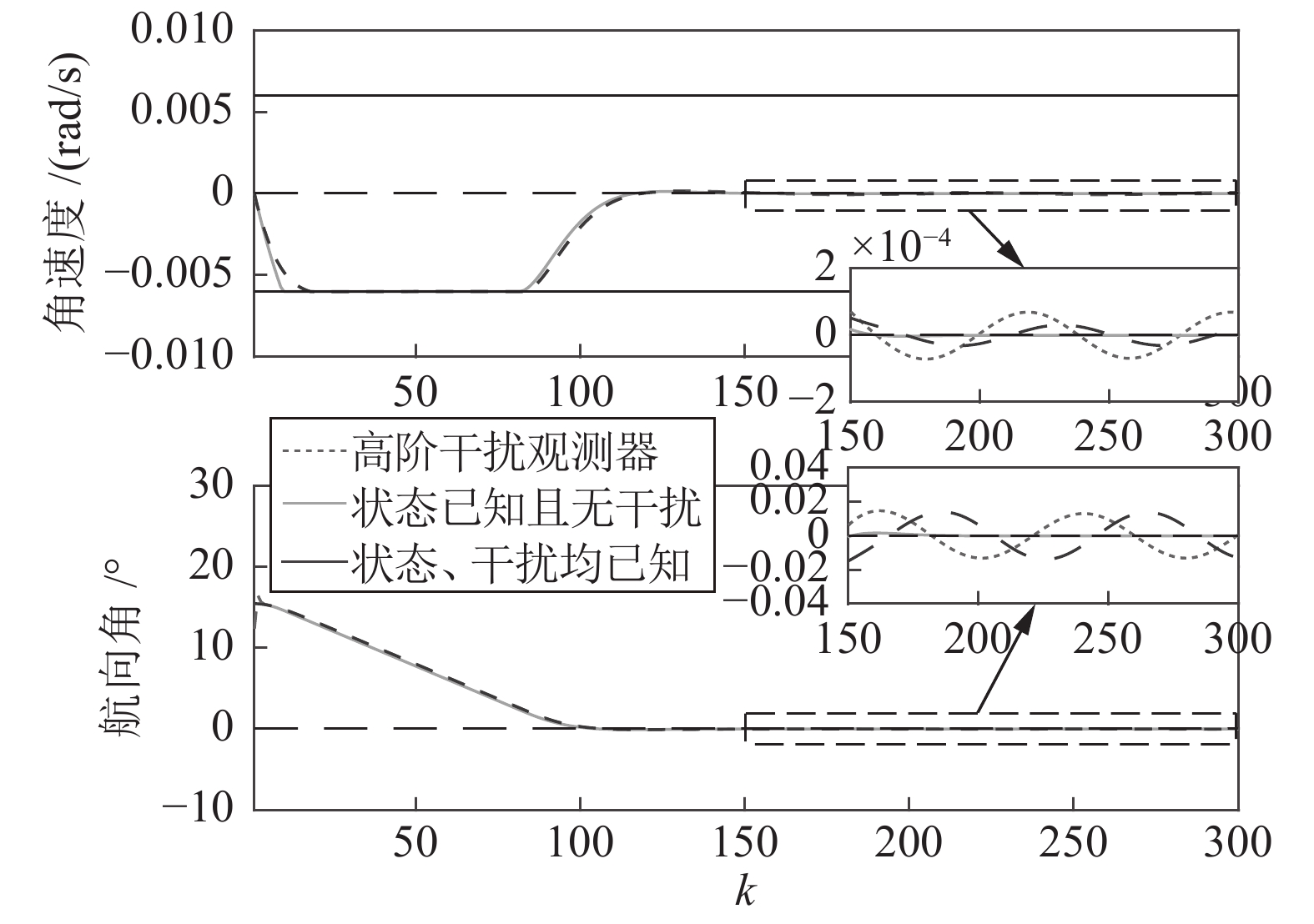
图 1 角速度
$\gamma$ 及高阶观测器观测的结果Fig. 1 Yaw velocity
$\gamma$ and the observed result of higher-order observer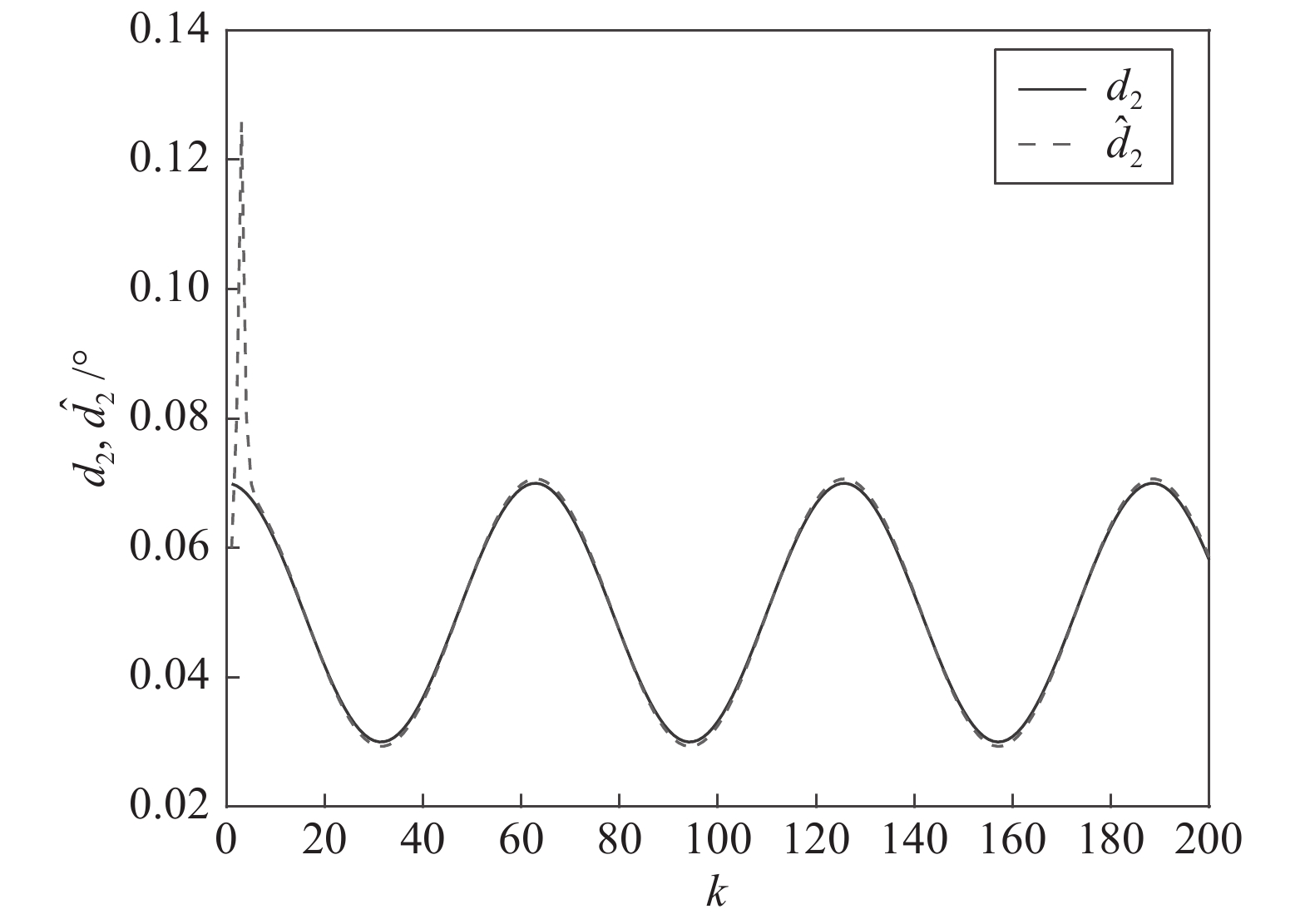
图 4 干扰
$d_{2}$ 及高阶观测器观测的结果Fig. 4 Disturbance
$d_{2}$ and observed result of higher-order observer
图 2 航向角
$\psi$ 及高阶观测器观测的结果Fig. 2 Heading angle
$\psi$ and the observed result of higher-order observer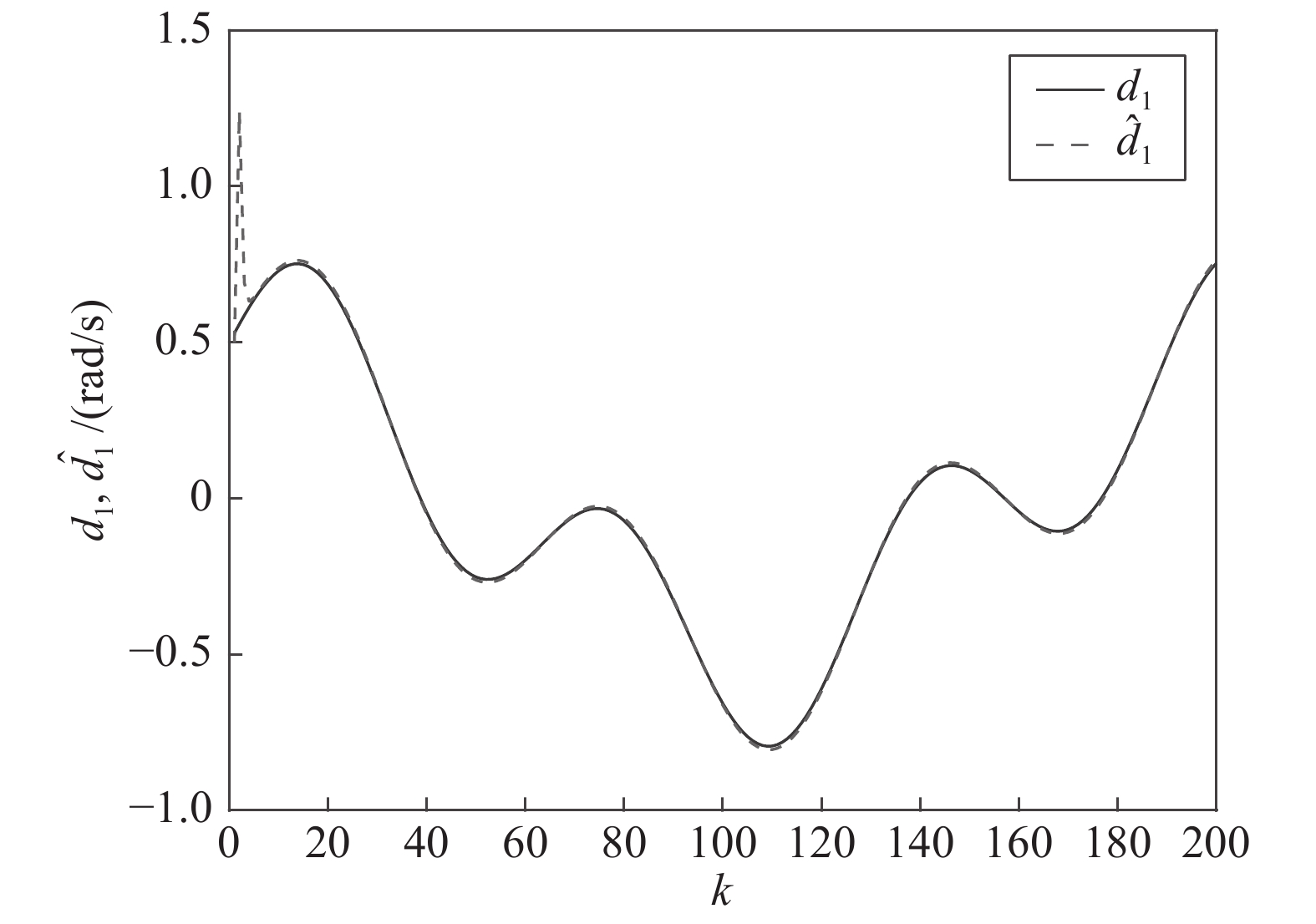
图 3 干扰
$ d_{1}$ 及高阶观测器观测的结果Fig. 3 Disturbance
$ d_{1}$ and observed result of higher-order observer
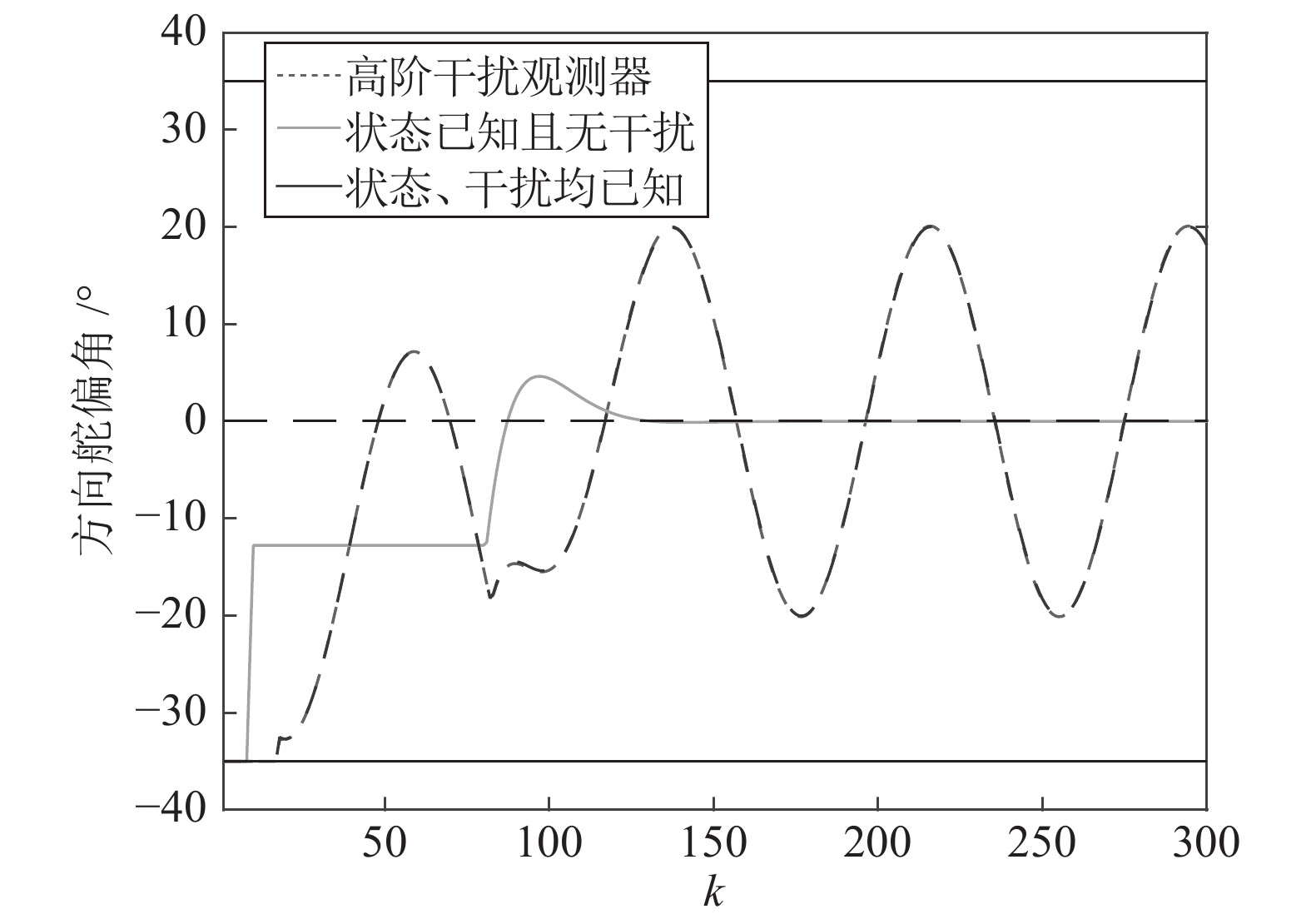
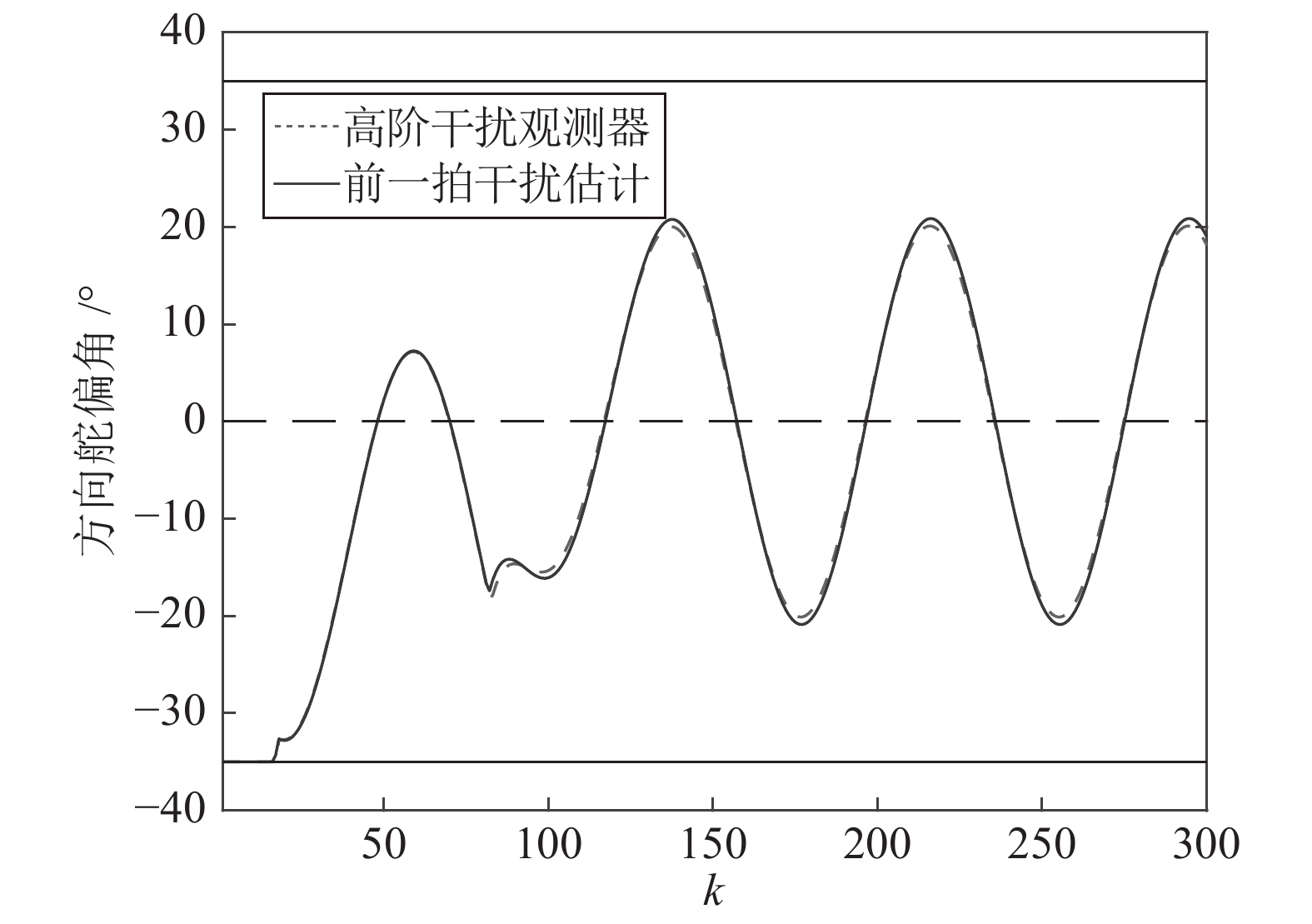
图 7 两种观测方法下系统的输出响应曲线
Fig. 7 Output response curves of the system under two observation methods
-
[1] Qin S J, Badgwell T A. A survey of industrial model predictive control technology. Control Engineering Practice, 2003, 11(7): 733−764 doi: 10.1016/S0967-0661(02)00186-7 [2] 陈虹. 模型预测控制. 北京: 科学出版社, 2013, 1–12Chen Hong. Model Predictive Control. Beijing: Science Press, 2013. 1–12 [3] Kouro S, Cortes P, Vargas R, Ammann U, Rodriguez J. Model predictive control — a simple and powerful method to control power converters. IEEE Transactions on Industrial Electronics, 2009, 56(6): 1826−1838 doi: 10.1109/TIE.2008.2008349 [4] 席裕庚, 李德伟, 林姝. 模型预测控制 — 现状与挑战. 自动化学报, 2013, 39(3): 222−236Xi Yu-Geng, Li De-Wei, Lin Shu. Model predictive control — status and challenges. Acta Automatica Sinica, 2013, 39(3): 222−236 [5] Mayne D Q, Seron M M, Rakovic S V. Robust model predictive control of constrained linear systems with bounded disturbances. Automatica, 2005, 41(2): 245−250 [6] 牛宏, 张向帅, 张思远. 连续搅拌釜的非线性模型预测控制方法. 控制工程, 2017, 24(4): 752−755Niu Hong, Zhang Xiang-Shuai, Zhang Si-Yuan. Nonlinear model predictive control method for continuous stirred tank reactor. Control Engineering, 2017, 24(4): 752−755 [7] Zeilinger M N, Raimondo D M, Domahidi A, Morari M, Jones C N. On real-time robust model predictive control. Automatica, 2014, 50(3): 683−694 doi: 10.1016/j.automatica.2013.11.019 [8] Huang H, Li D W, Xi Y G. The improved robust model predictive control with mixed H2/H∞ control approach. Acta Automatica Sinica, 2012, 38(6): 944−949 [9] Villanueva M E, Quirynen R, Diehl M, Chachuat B, Houska B. Robust MPC via min-max differential inequalities. Automatica, 2017, 77: 311−321 doi: 10.1016/j.automatica.2016.11.022 [10] Li Z, Sun J. Disturbance compensating model predictive control with application to ship heading control. IEEE Transactions on Control Systems Technology, 2012, 20(1): 257−265 [11] Chen W H, Yang J, Guo L, Li S H. Disturbance-observe-based control and related methods — an overview. IEEE Transactions on Industrial Electronics, 2016, 63(2): 1083−1095 doi: 10.1109/TIE.2015.2478397 [12] Kim S K, Park C R, Yoon T W, Lee Y II. Disturbance-observer-based model predictive control for output voltage regulation of three-phase inverter for unint-erruptible-power-supply applications. European Journal of Control, 2015, 23(3): 71−83 [13] Purnawan H, Asfihani T, Adzkiya D, Subchan. Disturbance compensating model predictive control for warship heading control in missile firing mission. Journal of Physics: Conference Series, 2018, 1108(1): 1−6 [14] Liang L H, Wen Y. Integrated rudder/fin control with disturbance compensation distributed model predictive control. IEEE Access, 2018, 44: 72925−72938 [15] Wu C, Yang Y, Li S H, Li Q, Guo L. Disturbance observer based model predictive control for accurate atmospheric entry of spacecraft. Advances in Space Research, 2018, 61(9): 2457−2471 doi: 10.1016/j.asr.2018.02.010 [16] Zhang F, Zhang Y, Wu X, Shen J, Lee K Y. Control of ultra-supercritical once-through boiler-turbine unit using MPC and ESO approaches. In: Proceedings of the 2017 IEEE Conference on Control Technology and Applications (CCTA). Mauna Lani, USA: IEEE, 2017. 994–999 [17] Zhang F, Wu X, Shen J. Extended state observer based fuzzy model predictive control for ultra-supercritical boiler-turbine unit. Applied Thermal Engineering, 2017, 118: 90−100 doi: 10.1016/j.applthermaleng.2017.01.111 [18] Li W H, Sun Y Q, Chen H Q, Wang G. Model predictive controller design for ship dynamic positioning system based on state-space equations. Journal of Marine Science and Technology, 2016, 22(3): 426−431 [19] Simkoff J M, Wang S Y, Baldea M, Chiang L H, Castillo I, Bindlish R, Stanley D B. Plant-model mismatch evaluation for unconstrained MPC with state estimation. In: Proceedings of the 56th IEEE Annual Conference on Decision and Control (CDC). Melbourne, Australia: IEEE, 2017. 6177–6188 [20] Simkoff J M, Wang S Y, Baldea M, Chiang L H, Castillo I, Bindlish R, Stanley D B. Plant-model mismatch estimation in unconstrained state-space MPC. In: Proceedings of the 2017 American Control Conference (ACC). Seattle, USA: IEEE, 2017. 3078–3083 [21] Ohhira T, Shimada A. Movement control based on model predictive control with disturbance suppression using kalman filter including disturbance estimation. IEEJ Journal of Industry Applications, 2018, 7(5): 387−395 doi: 10.1541/ieejjia.7.387 [22] Scokaert P O M, Rawlings J B. Feasibility issues in linear model predictive control. Aiche Journal, 2010, 8(45): 1649−1659 [23] Gautam A, Soh Y C. Soft-constrained model predictive control based on off-line-computed feasible sets. In: Proceedings of the 52nd IEEE Conference on Decision and Control. Florence, Italy: IEEE, 2013. 5777–5782 [24] Zeilinger M N, Morari M, Jones C N. Soft constrained model predictive control with robust stability guarantees. IEEE Transactions on Automatic Control, 2014, 59(5): 1190−1202 doi: 10.1109/TAC.2014.2304371 [25] Abidi K, Xu J X. Advanced Discrete-Time Control Designs and Applications: Discrete-Time Sliding Mode Control. Singapur-Verlag: Springer, 2015. [26] Chang J L. Applying discrete-time proportional integral observers for state and disturbance estimations. IEEE Transactions on Automatic Control, 2006, 51(5): 814−818 doi: 10.1109/TAC.2006.875019 [27] Goodwin G C, Ramadge P J, Caines P E. Discrete-time multivariable adaptive control. IEEE Transactions on Automatic Control, 1980, 25(3): 449−456 doi: 10.1109/TAC.1980.1102363 期刊类型引用(11)
1. 董颖慧,陈健,吕成兴,张子叶,余继恒. 基于扰动观测器的水面无人船自适应模糊控制器设计. 控制理论与应用. 2024(02): 261-272 .  百度学术
百度学术2. 葛静,张传林,董鑫,冒建亮,曹忠昆. 一类输出受限非线性系统的降维非递归预设性能控制策略. 控制理论与应用. 2024(07): 1225-1234 . 百度学术3. 韩春松,曹冉,魏瑶. 基于模型预测的事件触发多智能体系统设计. 齐齐哈尔大学学报(自然科学版). 2024(04): 1-4 . 百度学术4. 肖振飞,刘宁,张亚军,柴天佑. 基于参数优化和补偿信号的非线性广义预测控制方法. 中国科学:信息科学. 2024(09): 2240-2262 . 百度学术5. 张振,郭一楠,巩敦卫,朱松,田滨. 基于改进扩展状态观测器的液压锚杆钻机滑模摆角控制. 自动化学报. 2023(06): 1256-1271 . 本站查看6. 朱可嘉,周子天,王友清. 网络环境下无人艇定位系统的主动容错控制. 控制工程. 2023(06): 969-980 . 百度学术7. 储瑞婷,刘志全. 基于FTESO和漂角补偿的船舶航向滑模控制. 中国舰船研究. 2022(01): 71-79 . 百度学术8. 李亨博,何发胜. 基于观测器的线性重复控制系统干扰抑制. 现代工业经济和信息化. 2022(06): 50-53+59 . 百度学术9. 章沪淦,卜仁祥,李宗宣. 带状态观测器的船舶路径跟踪预测滑模控制. 计算机仿真. 2021(09): 262-266+271 . 百度学术10. 李繁飙,黄培铭,阳春华,廖力清,桂卫华. 基于非线性干扰观测器的飞机全电刹车系统滑模控制设计. 自动化学报. 2021(11): 2557-2569 . 本站查看11. 吴陶然. 模型预测算法结合灰色预测的自适应巡航控制. 农业装备与车辆工程. 2020(12): 80-84 . 百度学术其他类型引用(14)
-

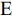
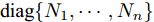
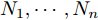
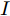

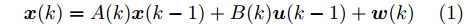
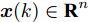
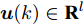
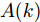
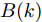
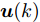
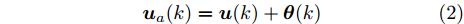
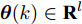
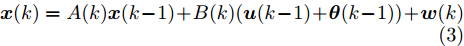
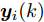
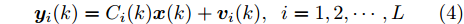
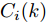
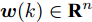
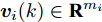
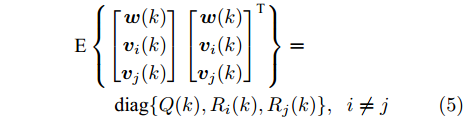
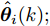
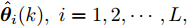
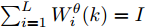
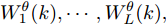
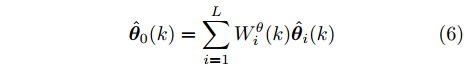
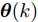
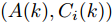
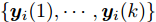
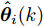
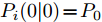
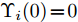
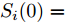
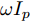
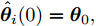
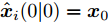

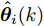
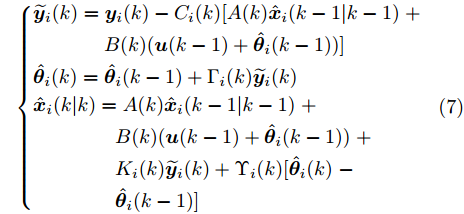
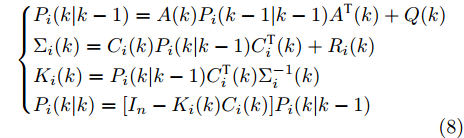
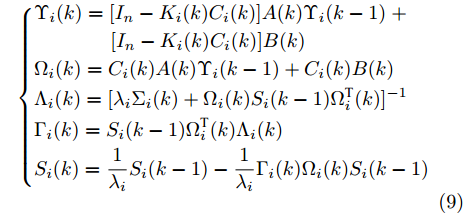
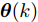
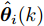
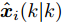
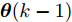

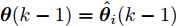
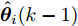
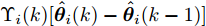
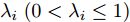
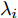
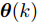
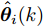
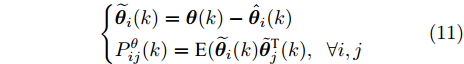
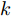
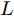
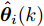
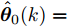
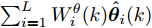
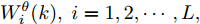
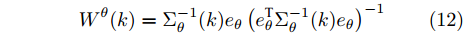
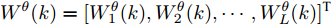
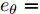
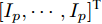
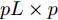
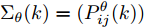
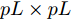
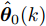
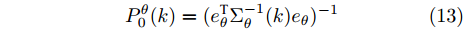
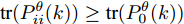
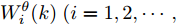
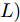
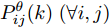
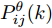
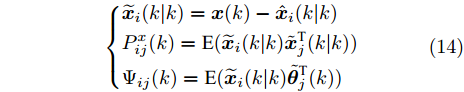
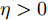
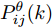
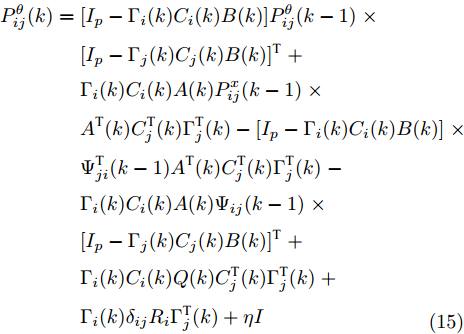
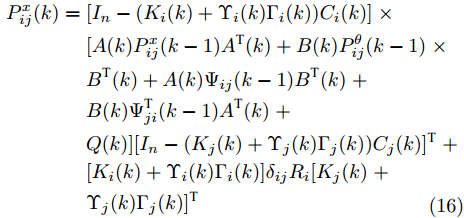
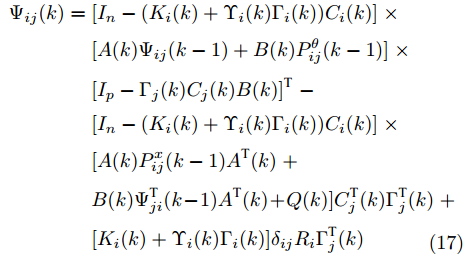
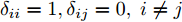
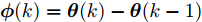
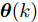
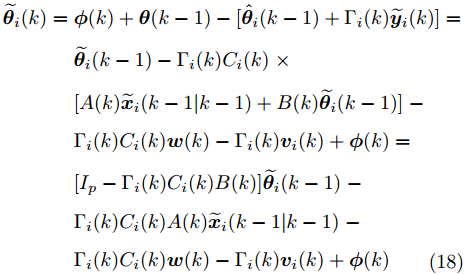
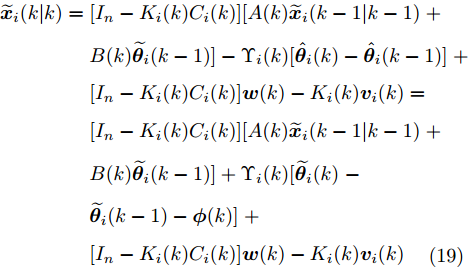
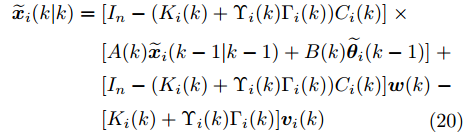
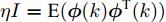
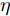
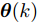
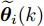
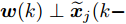
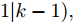
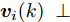
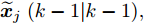
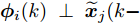
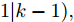
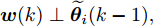
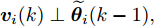
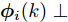
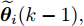
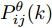
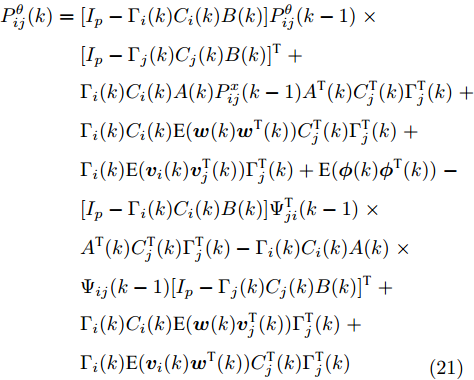
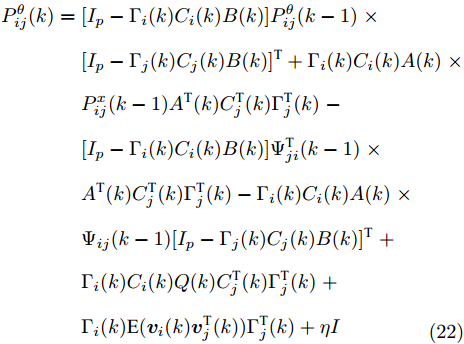
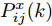

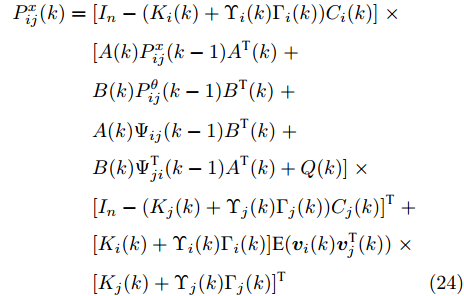
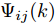

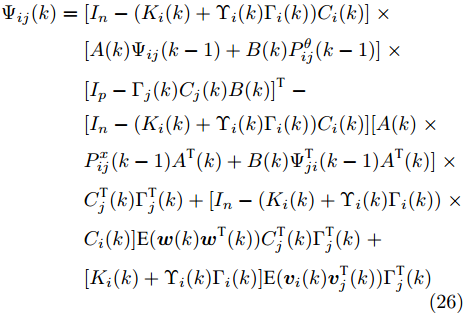
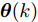
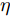
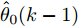
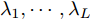
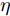
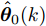
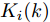
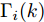
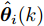
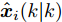
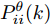
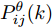
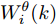
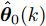
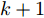

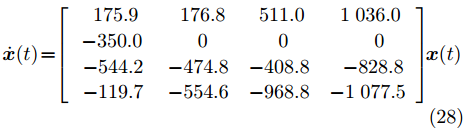
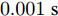
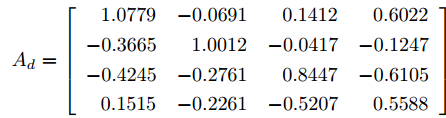
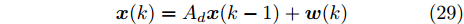
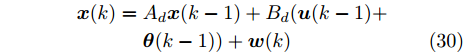
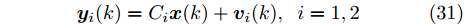
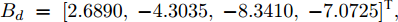
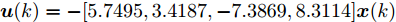
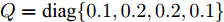
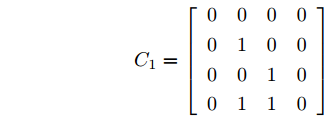
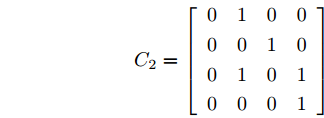
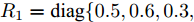
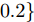
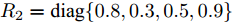
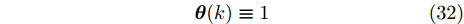
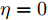
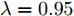
 下载:
下载:
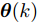
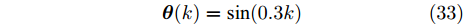
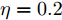
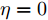
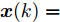
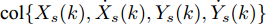
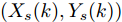

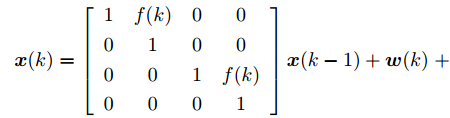
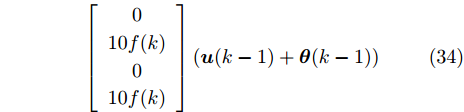
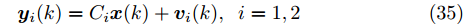
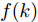

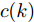
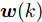
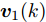
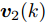
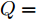
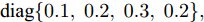
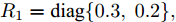
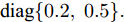
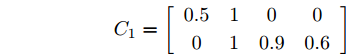
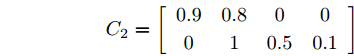
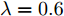
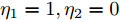
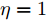
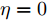


 下载:
下载:






计量
- 文章访问数: 2133
- HTML全文浏览量: 225
- PDF下载量: 527
- 被引次数: 25
